Java文档搜索引擎总结
Java文档搜索引擎总结
- 项目介绍
- 项目使用的技术栈
- 前端页面展示
- 后端逻辑部分
- 索引部分
- 搜索模块部分
- Web模块部分
项目介绍
Java文档搜索引擎项目是一个SSM项目,该项目的前端界面部分是由搜索页面和展示页面组成,后端部分索引模块(ScanAnalysis、index)、搜索模块(Searcher)、Web模块(SearcherController)。该项使用ansj第三方分词库进行分词,该项目并没有使用爬虫程序来获取Java文档,而是直接将Java文档下载下来,将Java文档里面的内容进行分词保存到正排索引文件和倒排索引文件中。
项目使用的技术栈
HTML、CSS、JS、Ajax、SpringBoot、SpringMVC
前端页面展示
搜索页面:

显示页面:

后端逻辑部分
索引部分
索引部分底层实现了两个类:ScanAnalysis类、Index类
***ScanAnalysis类:***用来扫描Java文档中的所有HTML文件,将HTML文件的标题、url路径、正文保存到正排索引文件和倒排索引文件中。
***Index类:***底层实现了正排索引结构和倒排索引结构,Index类是配合ScanAnalysis类一起使用的,Index将HTML文件内容保存到正排索引和倒排索引结构中,最终保存到正排索引文件和倒排索引文件中。
ScanAnalysis类的底层代码:
public class ScanAnalysis {//要扫描的根路径private static final String PATH_ROOT = "D:\\知识复习思维导图(Java)和Java笔记\\project-warehouse\\jdk-8u351-docs-all\\docs\\api";//Java文档的网络地址 不同部分private static final String JAVA_PATN = "https://docs.oracle.com/javase/8/docs/api/";//索引对象private static Index index = new Index();/*** 启动方法* 我们在进行扫描的时候,我们会发现在进行扫描的时候效率是比较低的。* 该方法使用的是单线程的方式* 我们可以使用多线程的方式来提高效率*/public void run() {long ben1 = System.currentTimeMillis();//保存每一个文档的路径ArrayList<String> arrayList = new ArrayList<>();//1.获取每一个文档的路径scanPath(PATH_ROOT,arrayList);long ben = System.currentTimeMillis();//2.对每一个html文件进行解析for (String pathChild:arrayList) {analysis(pathChild);}long end = System.currentTimeMillis();System.out.println("解析所花费的时间:"+(end - ben)+"ms");//3.将索引保存的索引文档中index.saveFile();long end1 = System.currentTimeMillis();System.out.println("整个程序的时间:"+(end1 - ben1) +"ms");}/*** 启动方法2:我们对解析这个步骤使用多线程的方式来提高效率**/public void run2() {long ben1 = System.currentTimeMillis();//保存每一个文档的路径ArrayList<String> arrayList = new ArrayList<>();//1.获取每一个文档的路径scanPath(PATH_ROOT,arrayList);long ben = System.currentTimeMillis();//2.对每一个html文件进行解析//我们创建一个有时光线程的线程池ExecutorService executorService = Executors.newFixedThreadPool(15);//这个CountDownLatch对象,是用来表明需要等待多少个任务才结束//因为我们要等到解析这个过程完成了在执行下一步CountDownLatch countDownLatch = new CountDownLatch(arrayList.size());for (String pathChild:arrayList) {//将解析的工作提交倒线程池中executorService.submit(new Runnable() {@Overridepublic void run() {analysis(pathChild);//完成一次解析任务就减一countDownLatch.countDown();}});}try {//等待任务结束,如果没结束,就阻塞等待countDownLatch.await();//关闭线程池executorService.shutdown();} catch (InterruptedException e) {e.printStackTrace();}long end = System.currentTimeMillis();System.out.println("解析所花费的时间:"+(end - ben)+"ms");//3.将索引保存的索引文档中index.saveFile();long end1 = System.currentTimeMillis();System.out.println("整个程序的时间:"+(end1 - ben1) +"ms");}/*** 对 HTML文件进行解析* 获取到题目、正文、url* @param pathChild*/private void analysis(String pathChild) {File file = new File(pathChild);//1.获取标题String title = getTitle(file);
// System.out.println(title);//2.获取正文String content = getContents(file);//3.获取urlString url = getUrl(file);System.out.println(url);//4.将标题、正文、url保存到索引中index.saveIndex(title,content,url);}/*** 获取url* @param file* @return*/private String getUrl(File file) {StringBuilder stringBuilder = new StringBuilder();String str = file.getAbsolutePath().substring(PATH_ROOT.length()+1);for (int i = 0; i < str.length(); i++) {char ch = str.charAt(i);if (ch != '\\') {stringBuilder.append(ch);} else {stringBuilder.append('/');}}return JAVA_PATN+stringBuilder.toString();}/*** 获取正文,这个比较麻烦,我们需要去除标签,和<script></script>里面的内容* 这里我们需要使用正则表达式* @param file* @return*/public String getContents(File file) {//获取到HTML里面的内容String content = getcontentHtml(file);//使用正则表达式,将<script></script>标签和里面的内容都替换掉//字符串中的replaceAll方法是支持正则表达式的content = content.replaceAll("<script.*?>(.*?)</script>"," ");//使用正则表达式,去除其他标签content = content.replaceAll("<.*?>"," ");//使用正则表达式,去除连续的空格content = content.replaceAll("\\s+"," ");return content ;}/*** 获取到HTML文件的内容,这人进行文件读取操作,* 使用字符流,进行读取* @param f* @return*/private String getcontentHtml(File f) {try(BufferedReader bufferedReader = new BufferedReader(new FileReader(f),1024*1024)) {StringBuilder content = new StringBuilder();while (true) {int ret = bufferedReader.read();if (ret == -1) {break;}char ch = (char) ret;//去除换行if(ch == '\n' || ch == '\r') {ch = ' ';}content.append(ch);}return content.toString();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}return null;}/*** 获取标题* @param file* @return*/private String getTitle(File file) {return file.getName().replace(".html","");}/*** 扫描根路径,获取该目录下的索引HTML文件的路径* 这里要使用的递归 和 文件操作* @param pathRoot* @param arrayList*/private void scanPath(String pathRoot, ArrayList<String> arrayList) {File file = new File(pathRoot);//获取到该目录的以及文件对象File[] files = file.listFiles();//遍历for (File file1:files) {if (file1.isFile()) {//是普通文件//我们要的是html文件,所以还要进行处理if (file1.getAbsolutePath().endsWith("html")) {arrayList.add(file1.getAbsolutePath());System.out.println(file1.getAbsolutePath());}} else {//是目录,进行递归scanPath(file1.getAbsolutePath(),arrayList);}}}public static void main(String[] args) {ScanAnalysis scanAnalysis = new ScanAnalysis();//程序的入口scanAnalysis.run2();}
}Index类的底层代码:
public class Index {//正排索引的底层,使用顺序表public ArrayList<JavaDocModel> arrayList = new ArrayList<>();//倒排索引的底层,使用HashMappublic HashMap<String,ArrayList<Weight>> map = new HashMap<>();//创建两个锁private Object lock1 = new Object();private Object lock2 = new Object();//正排索引文件 和倒排索引文件保存的 根目录private static final String INDEX_SAVE_PATH ="D:\\知识复习思维导图(Java)和Java笔记\\project-warehouse\\jdk-8u351-docs-all\\";//线上环境 正排索引文件 和倒排索引文件保存的 根目录
// private static final String INDEX_SAVE_PATH =
// "/project/java_doc_searcher_ssm/";//进行JSON格式化的 对象private ObjectMapper objectMapper = new ObjectMapper();/*** 1.正排索引:通过文档Id来获取文档对象* @param docId* @return*/public JavaDocModel getForwardIndex(Integer docId) {return arrayList.get(docId);}/*** 2.通过分词来获取相对应的一组文档的id,这里不仅仅获取到了id,还有权重,有利于进行排序* @param terim* @return*/public ArrayList<Weight> getReverseIndex(String terim) {return map.get(terim);}/*** 3.将标题,正文,url* 保存到正排索引,和倒排索引中*/public void saveIndex(String title,String content,String url){JavaDocModel javaDocModel = new JavaDocModel();javaDocModel.setContent(content);javaDocModel.setTitle(title);javaDocModel.setUrl(url);//1.建立正排索引buildForwardIndex(javaDocModel);//2.建立倒排索引buildReverseIndex(javaDocModel);}/*** 建立倒排索引* 我们需要对文档的标题,正文 进行分词* @param javaDocModel*/private void buildReverseIndex(JavaDocModel javaDocModel) {//统计一个分词在标题和内容中出现多少次class Count{public Integer titleCount;public Integer contentCount;}//1.对文档标题 进行分词List<Term> terms = ToAnalysis.parse(javaDocModel.getTitle()).getTerms();//用来统计词频HashMap<String,Count> hashMap = new HashMap<>();//记录总的分词synchronized (lock1) {//遍历分词termsfor (Term term:terms) {//获取到分词结果String termName = term.getName();Count myCount = hashMap.get(termName);if (myCount == null) {//没有Count newCount = new Count();newCount.titleCount = 1;newCount.contentCount = 0;hashMap.put(termName,newCount);} else {//有,titleCount加一myCount.titleCount += 1;}}//2.对文档对象的正文进行分词terms = ToAnalysis.parse(javaDocModel.getContent()).getTerms();//遍历分词termsfor (Term term:terms) {//获取到分词结果String termName = term.getName();Count myCount = hashMap.get(termName);if (myCount == null) {//没有Count newCount = new Count();newCount.contentCount = 1;newCount.titleCount = 0;hashMap.put(termName,newCount);} else {//有,contentCount加一myCount.contentCount += 1;}}//3.将hashMap 里的数据整合到 map 里面//遍历hashMapfor (Map.Entry<String,Count> entry:hashMap.entrySet()) {String key = entry.getKey();Count val = entry.getValue();//从倒排索引中获取value值ArrayList<Weight> weights = map.get(key);if (weights == null) {//没有,创建新的ArrayList<Weight> newWeights = new ArrayList<>();Weight weight = new Weight();//设置文档Idweight.setDocId(javaDocModel.getDocId());//设置权重,titleCount*20+contentCountweight.setWeight(val.contentCount + val.titleCount*20);newWeights.add(weight);map.put(key,newWeights);} else {//有的话,直接添加Weight weight = new Weight();//设置文档Idweight.setDocId(javaDocModel.getDocId());//设置权重,titleCount*20+contentCountweight.setWeight(val.contentCount + val.titleCount*20);weights.add(weight);}}}}/*** 建立正排索引,以顺序表的下标作为文档ID* 直接插入顺序表就行* @param javaDocModel*/private void buildForwardIndex(JavaDocModel javaDocModel) {synchronized (lock2) {//插入docIdjavaDocModel.setDocId(arrayList.size());//直接插入顺序表尾部arrayList.add(javaDocModel);}}/*** 4.将正排索引结构 和 倒排索引结构 保存到 正排索引文件 和倒排索引文件中* 序列化的方法:以JSON的格式保存*/public void saveFile() {//正排索引 和 倒排索引保存的目录File filePath = new File(INDEX_SAVE_PATH);if (!filePath.exists()) {//创建目录filePath.mkdirs();}//正排索引文件对象File fileForwardIndex = new File(INDEX_SAVE_PATH+"forward.txt");//倒排索引文件对象File fileReverseIndex = new File(INDEX_SAVE_PATH+"reverse.txt");if (!fileForwardIndex.exists()) {//不存在,创建正排索引文件try {fileForwardIndex.createNewFile();} catch (IOException e) {e.printStackTrace();}}if (!fileReverseIndex.exists()) {//不存在,创建倒排索引文件try {fileReverseIndex.createNewFile();} catch (IOException e) {e.printStackTrace();}}try {//将正排索引结构转成JSON格式,保存到正排索引文件中objectMapper.writeValue(fileForwardIndex,arrayList);//将倒排索引结构转成JSON格式,保存到倒排索引文件中objectMapper.writeValue(fileReverseIndex,map);} catch (IOException e) {e.printStackTrace();}}/*** 5.加载正排 和 倒排 文件 ,将内容加载倒内存中* 反序列*/public void load() {long ben = System.currentTimeMillis();//正排索引文件对象File fileForwardIndex = new File(INDEX_SAVE_PATH+"forward.txt");//倒排索引文件对象File fileReverseIndex = new File(INDEX_SAVE_PATH+"reverse.txt");try {//这里的 readValue方法用法要注意// 第二个参数是一个匿名内部类,实现了TypeReference,目的就是 我们想要把JSON格式的字符串转成什么类型 告诉了 readValue方法//正排arrayList = objectMapper.readValue(fileForwardIndex, new TypeReference<ArrayList<JavaDocModel>>() {});//倒排map = objectMapper.readValue(fileReverseIndex, new TypeReference<HashMap<String,ArrayList<Weight>>>() {});} catch (IOException e) {e.printStackTrace();}long end = System.currentTimeMillis();System.out.println("加载文档的时间:"+(end - ben) +"ms");}
}搜索模块部分
搜索模块部分底层实现了Searcher类,提供了searcher方法来搜索相关的文档。
Searcher类的底层代码:
public class Searcher {//索引类private Index index = new Index();//保存停用词表的数据结构private Set<String> stopWordsSet = new HashSet<>();//停用词表的存放路径private static final String STOP_WORDS ="D:\\知识复习思维导图(Java)和Java笔记\\project-warehouse\\jdk-8u351-docs-all\\stop_words.txt";//线上环境 停用词表的存放路径
// private static final String STOP_WORDS =
// "/project/java_doc_searcher_ssm/stop_words.txt";public Searcher() {//1.创建该类的时候,加载一些索引文档index.load();//2.创建该类的时候,加载停用词表loadStopWords();}/*** 加载停用词表*/private void loadStopWords() {long ben = System.currentTimeMillis();//进行读操作try(BufferedReader bufferedReader = new BufferedReader(new FileReader(STOP_WORDS)) ){while (true) {String str = bufferedReader.readLine();if (str == null) {break;}stopWordsSet.add(str);}} catch (IOException e) {e.printStackTrace();}long end = System.currentTimeMillis();System.out.println("加载停用词表的时间:"+(end - ben) + "ms");}public List<ResultReturnModenl> searcher(String word) {//将查询词进行分词、List<Term> terms = ToAnalysis.parse(word).getTerms();//我们通过分词结果可以得出,有些分词是不合理的//我们要排除一些不合理的分词结果//这里我们使用停用词表进行过滤List<Term> newTerms = new ArrayList<>();//保存过滤后的termfor (Term term:terms) {//分词内容String wordName = term.getName();if (!stopWordsSet.contains(wordName)) {//不是停用词newTerms.add(term);}}//遍历newTerms,获取要返回的数据List<ArrayList<Weight>> listList = new ArrayList<>();for (Term term:newTerms) {//获取倒分词的内容String wordName = term.getName();//通过倒排索引,来获取倒相对应的文档对象ArrayList<Weight> reverseIndex = index.getReverseIndex(wordName);//判断是否拿到if (reverseIndex == null) {//没有拿到continue;}//将reverseIndex保存到 listList中listList.add(reverseIndex);}//合并listList中的数组,并且进行去重//类似于合并多个有序数组,并且最后的结果要有序List<Weight> list = sortArray(listList);//对list进行排序,按照权重的大小由高到低排序Collections.sort(list, new Comparator<Weight>() {@Overridepublic int compare(Weight o1, Weight o2) {//降序return o2.getWeight() - o1.getWeight();}});//保存返回的数据List<ResultReturnModenl> results = new ArrayList<>();//将数据进行封装for (Weight weight:list) {//通过正排索引找到文档对象JavaDocModel forwardIndex = index.getForwardIndex(weight.getDocId());ResultReturnModenl resultReturnModenl = new ResultReturnModenl();//设置标题resultReturnModenl.setTitle(forwardIndex.getTitle());//设置urlresultReturnModenl.setUrl(forwardIndex.getUrl());//设置摘要resultReturnModenl.setDesc(getDesc(forwardIndex.getContent(),newTerms));results.add(resultReturnModenl);}return results;}/**生成正文摘要* 由于docInfo对象里面是正文,所以还要做一些处理* 摘要要包含 查询词 或者 查询词的一部分* 生成摘要的思路:可以遍历查询词的分词,找到对应位置* 就针对这个位置,往前截取60个字符,作为描述的开始,然后从描述开始在截取160个字符* @param content* @param newTerms* @return*/public String getDesc(String content, List<Term> terms) {//记录分词出现的位置int termIndex = -1;for (Term term:terms) {//获取到分词内容String wordName = term.getName();//将正文转成小写 使用toLowerCase()//此处需要的是全词匹配,在word前后都加一个空 在进行查找//这里的匹配不严谨,更严谨的方法是使用 正则表达式//indexOf不支持正则表达式//Java提供了 Pattern 和 Matcher 这两个类 来实现正则表达式,自己学习一下//Pattern : 描述一个匹配规则//Matcher 负责进行具体的匹配工作//这里的做法:把不是空格的转成空格content = content.toLowerCase().replaceAll("\\b"+wordName+"\\b"," " + wordName + " ");termIndex = content.toLowerCase().indexOf(" "+wordName+" ");if (termIndex != -1 ) {//存在break;}}if (termIndex == -1) {//所有的分词结果都不存在//返回正文的前160个字符if (content.length() <=160) {return content;}return content.substring(0,160)+"...";}//程序如果到这里,说明正文中有分词结果//判断是否要往前60个字符termIndex = termIndex - 60 >=0?termIndex-60:0;String desc = "";//保存正文摘要if (termIndex+160 >= content.length()) {//从termIndex这个位置截到尾desc = content.substring(termIndex);} else {desc = content.substring(termIndex,160+termIndex)+"...";}//在此处加上替换操作,把描述中的 和 分词结果相同的部分,//加上依次<i>标签,可以使用 replaceAll 的方法来实现//者样在前端显示的时候,可以标红//遍历分词结果for (Term term:terms) {//获取到结果String word = term.getName();//注意此处要进行全字匹配,不区分大小写替换desc = desc.replaceAll("(?i) "+word +" ","<i> "+word+" </i>");}return desc;}/*** 合并listList中的数组,并且进行去重* 类似于合并多个有序数组,并且最后的结果要有序* @param listList* @return*/private List<Weight> sortArray(List<ArrayList<Weight>> listList) {class Pos{public Integer row = 0;//行public Integer col = 0;//列public Pos(Integer row, Integer col) {this.row = row;this.col = col;}}//使用优先级队列,来解决该问题//创建优先级队列PriorityQueue<Pos> pos = new PriorityQueue<>(new Comparator<Pos>() {@Overridepublic int compare(Pos o1, Pos o2) {//小根堆return listList.get(o1.row).get(o1.col).getDocId() - listList.get(o2.row).get(o2.col).getDocId();}});//将每一个数组,按docId的大小,升序排序for (ArrayList<Weight> weights:listList) {Collections.sort(weights, new Comparator<Weight>() {@Overridepublic int compare(Weight o1, Weight o2) {return o1.getDocId() - o2.getDocId();}});}//将每一个数组的第一个元素的位置放进来for (int i = 0; i < listList.size(); i++) {pos.offer(new Pos(i,0));}List<Weight> listResult = new ArrayList<>();//保存最后返回的结果while (!pos.isEmpty()) {//从优先级队列出来的队首元素Pos pos1 = pos.poll();if (listResult.size() == 0) {//插入第一个元素listResult.add(listList.get(pos1.row).get(pos1.col));} else {//不是第一个,要判断是否于前一个相同,相同权重相加if (listResult.get(listResult.size() - 1).getDocId() == listList.get(pos1.row).get(pos1.col).getDocId()) {//文档相同,权重相加listResult.get(listResult.size() - 1).setWeight(listResult.get(listResult.size() - 1).getWeight()+listList.get(pos1.row).get(pos1.col).getWeight());} else {//不相同,添加到listResult中listResult.add(listList.get(pos1.row).get(pos1.col));}}if (pos1.col + 1 >= listList.get(pos1.row).size()) {//这一行处理完了continue;}pos.offer(new Pos(pos1.row, pos1.col+1));}return listResult;}public static void main(String[] args) {Searcher searcher = new Searcher();}
}Web模块部分
Web模块部分实现前后端的交互。
Web模块的代码:
@RestController
public class SearcherController {@AutowiredSearcher searcher ;@RequestMapping("/searcher")public Object searcher(String word) {if (word == null || word.trim().equals("")) {return -1;}return searcher.searcher(word);}@RequestMapping("/getword")public String getWord(String word) {System.out.println(word);return word;}
}
相关文章:
Java文档搜索引擎总结
Java文档搜索引擎总结项目介绍项目使用的技术栈前端页面展示后端逻辑部分索引部分搜索模块部分Web模块部分项目介绍 Java文档搜索引擎项目是一个SSM项目,该项目的前端界面部分是由搜索页面和展示页面组成,后端部分索引模块(ScanAnalysis、in…...
Linux内核学习笔记——页表的那些事。
目录页表什么时候创建内核页表变化什么时候更新到用户页表源码分析常见问题解答问题一:页表到底是保存在内核空间中还是用户空间中?问题2:页表访问,软件是不是会频繁陷入内核?问题3:内存申请,软…...

C++,Qt分别读写xml文件
XML语法 第一行是XML文档声明,<>内的代表是元素,基本语法如以下所示。C常见的是使用tiny库读写,Qt使用自带的库读写; <?xml version"1.0" encoding"utf-8" standalone"yes" ?> <根元素>…...
WebStorm安装教程【2023年最新版图解】一文教会你安装
文章目录引言一、下载WebStorm三、WebStorm激活配置及创建项目Active Code安装完成尝试新建一个项目引言 今天发现了一个专注前端开发的软件,相比VSCode的话,这个好像也不错,为了后续做个API接口项目做准备。 对于入门JavaScript 开发的者&am…...

用户态和内核态,系统调用
特权指令:具有特殊权限的指令,比如清内存,重置时钟,分配系统资源,修改用户的访问权限 由于这类指令的权限最大,所以使用不当会导致整个系统崩溃 系统调用:是操作系统提供给应用程序的接口(供应…...

Java 包装类
Java 中有些类只能操作对象,因此 Java 的基本数据类型都有一个对应的包装类。 byte:Byteshort:Shortint:Integerlong:Longfloat:Floatdouble:Doublechar:Characterbooleanÿ…...

Raspberry Pi GPIO入门指南
如果您想使用 Raspberry Pi 进行数字输入/输出操作,那么您需要使用 GPIO(通用输入/输出)引脚。在这篇文章中,我们将为您提供 Raspberry Pi GPIO 的基础知识,包括如何访问和操作 GPIO 引脚。 0.认识GPIO 树莓派上的那…...

汇编语言程序设计(三)之汇编程序
系列文章 汇编语言程序设计(一) 汇编语言程序设计(二)之寄存器 汇编程序 经过上述课程的学习,我们可以编写一个完整的程序了。这章开始我们将开始编写完整的汇编语言程序,用编译和连接程序将它们连接成可…...

用二极管和电容过滤电源波动,实现简单的稳压 - 小水泵升压改装方案
简而言之,就是类似采样保持电路,当电源电压因为电机启动而骤降时,用二极管避免电容电压跟着降低,从而让电容上连接的低功耗芯片有一个比较稳定的供电电压。没什么特别的用处,省个LDO 吧,电压跌幅太大的时候…...

【数据结构与算法】数据结构有哪些?算法有哪些?
1. 算法与数据结构总览图 2.常用的数据结构 2.1.数组(Array) 数组是一种聚合数据类型,它是将具有相同类型的若干变量有序地组织在一起的集合。数组可以说是最基本的数据结构,在各种编程语言中都有对应。一个数组可以分解为多个数…...
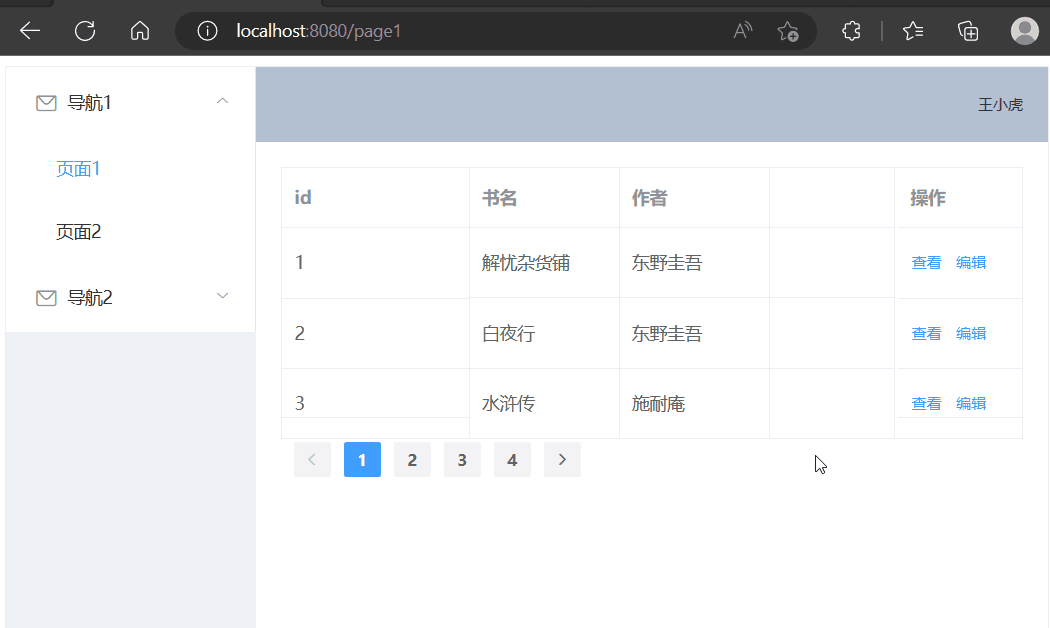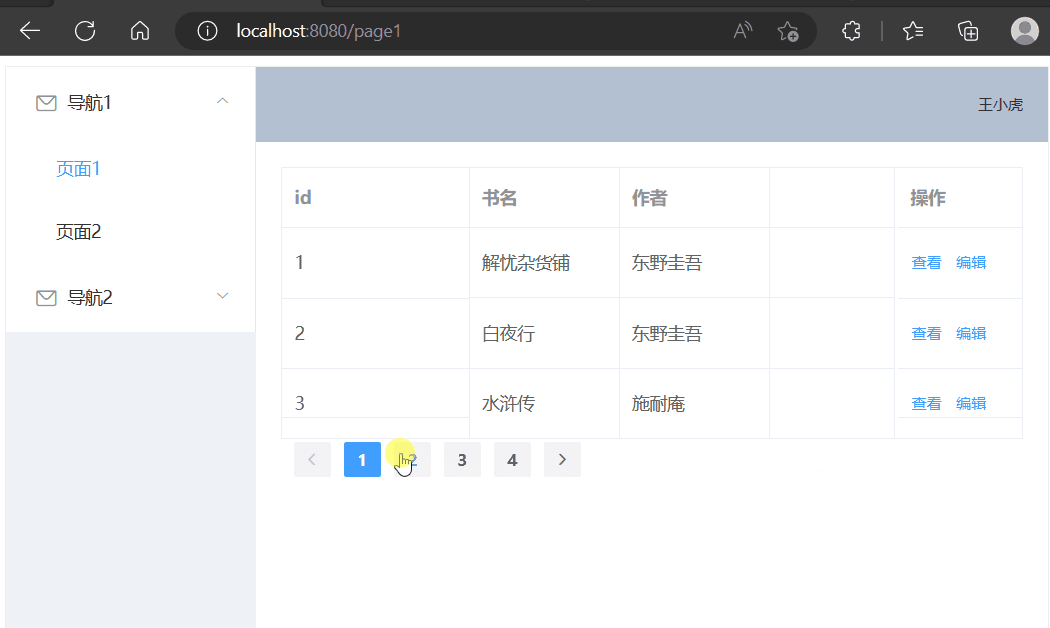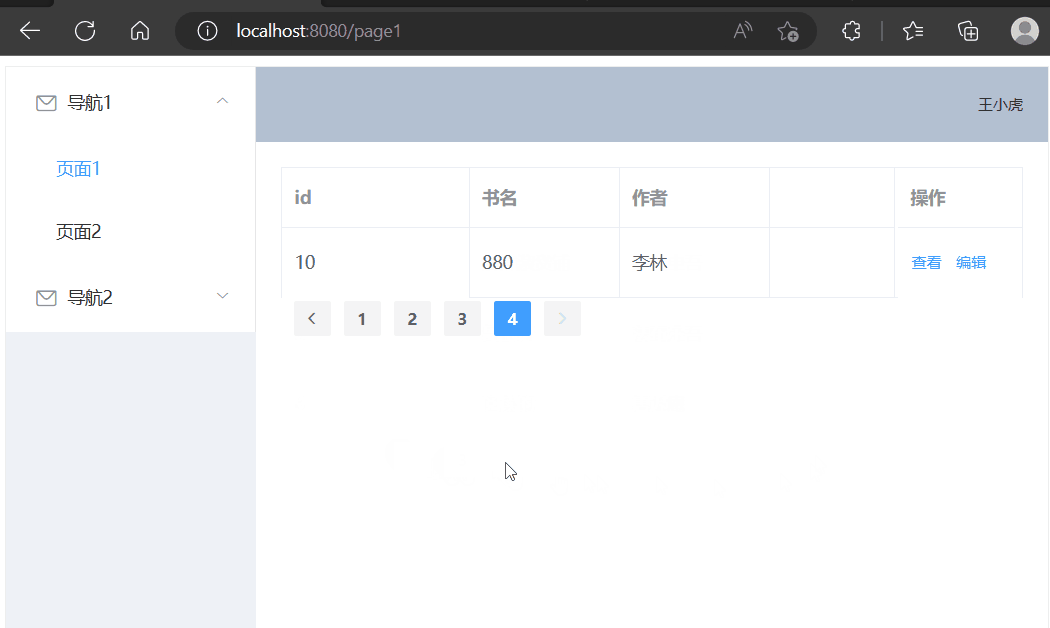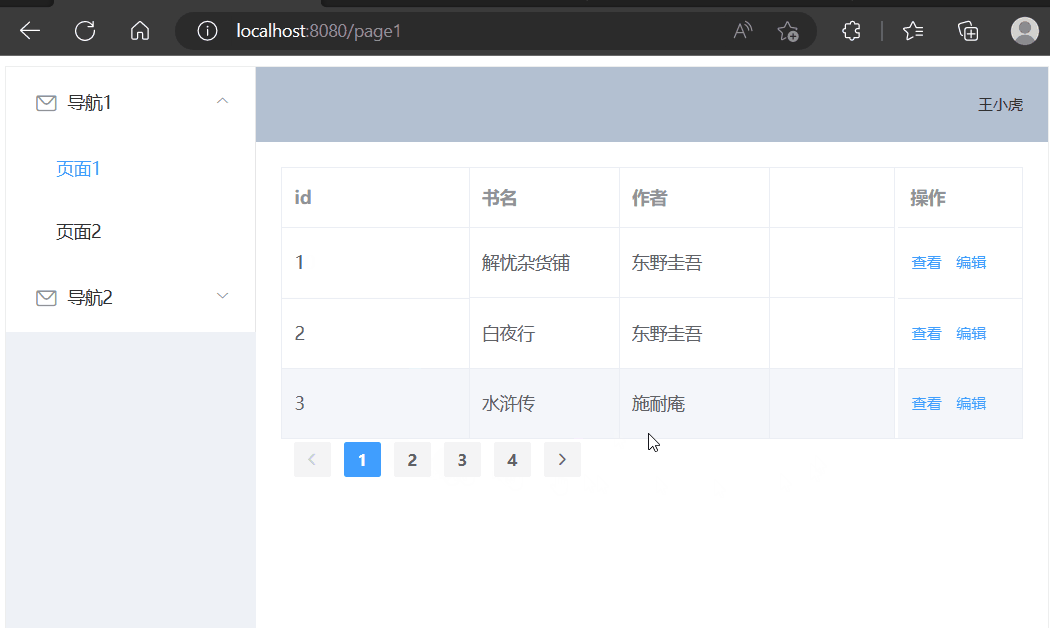
使用Element-UI展示数据(动态查询)
学习内容来源:视频P4 本篇文章进度接着之前的文章进行续写 精简前后端分离项目搭建 Vue基础容器使用 目录选择组件修改表格组件修改分页组件增加后端接口前端请求数据接口页面初始化请求数据点击页码请求数据选择组件 在官方文档中选择现成的组件,放在页…...

lamda 表达式例子全集
1、List 转 map 1.1、key(Model属性) value Model Map<String, Model> modeMap List.stream().collect(Collectors.toMap(Model1::属性get方法, v -> v, (p1, p2) -> p1)); 1.2、key(Model1属性) value Model2 Map<String, Model1> model2Map List.stream…...

计算机网络第八版——第一章课后题答案(超详细)
第一章 该答案为博主在网络上整理,排版不易,希望大家多多点赞支持。后续将会持续更新(可以给博主点个关注~ 【1-01】计算机网络可以向用户提供哪些服务? 解答:这道题没有现成的标准答案,因为可以从不同的…...
嵌入式和Python(二):python初识及其基本使用规则
目录 一,python基本特点 二,python使用说明 ● 两种编程方式 ① 交互式编程 ② 脚本式编程 ● python中文编码 ● python行和缩进 ● python引号 ● python空行 ● python等待用户输入 ① 没有转换变量类型 ② 转换变量类型 ● python变…...

C语言详解双向链表的基本操作
目录 双链表的定义与接口函数 定义双链表 接口函数 详解接口函数的实现 创建新节点(BuyLTNode) 初始化双链表(ListInit) 双向链表打印(ListPrint) 双链表查找(ListFind) 双链…...
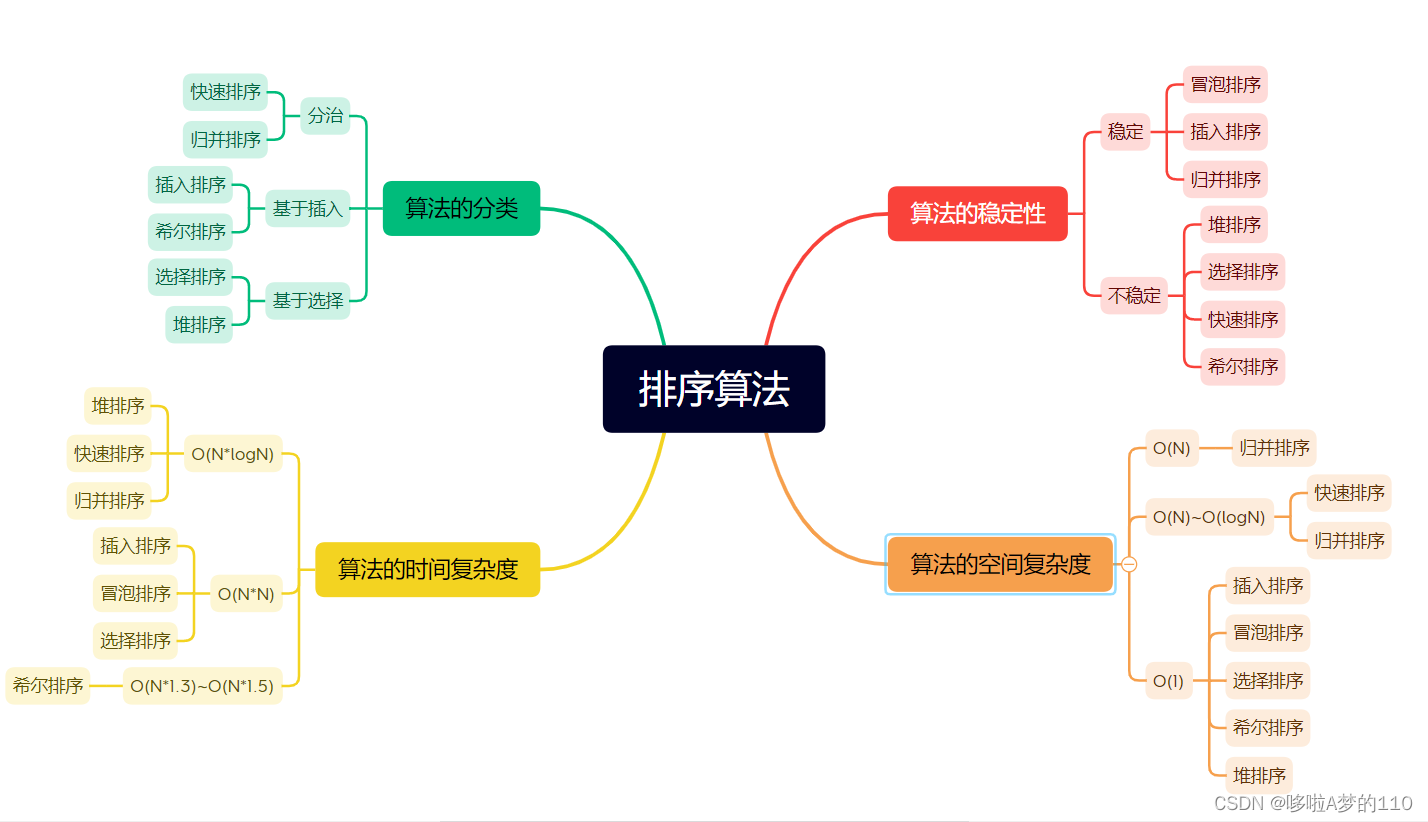
面试必须要知道的常见排序算法
以下排序均为升序 1.直接插入排序 具体思想 把待排序的数据按大小比较插入到一个已经排序好的有序序列中,直到所有的待排序数据全部插入到有序序列中为止.实际生活中,我们平常斗地主摸牌时,就用到了插入排序的思想. 当插入第n个数据时,前面n-1个数据已经有序;第n个数据依次与前…...

Kubernetes之服务发布
学了服务发现后,svc的IP只能被集群内部主机及pod才可以访问,要想集群外的主机也可以访问svc,就需要利用到服务发布。 NodePort Nodeport服务是外部访问服务的最基本方式。当我们创建一个服务的时候,把服务的端口映射到kubernete…...

【第二章】谭浩强C语言课后习题答案
1. 什么是算法?试从日常生活中找3个例子,描述它们的算法 算法:简而言之就是求解问题的步骤,对特定问题求解步骤的一种描述。 比如生活中的例子: 考大学首先填报志愿表、交报名费、拿到准考证、按时参加考试、收到录取通知书、按照日期到指定学校报到。 去北京听演唱会首先…...

PostgreSQL和PostGISWGS84和CGCS2000与GCJ02和BD09坐标系与之间互转
– 如果转换后结果为null,查看geom的srid是否为4326或者4490 WGS84转GCJ02 select geoc_wgs84togcj02(geom) from test_table GCJ02转WGS84 select geoc_gcj02towgs84(geom) from test_table WGS84转BD09 select geoc_wgs84tobd09(geom) from test_table BD09转WGS84 select …...
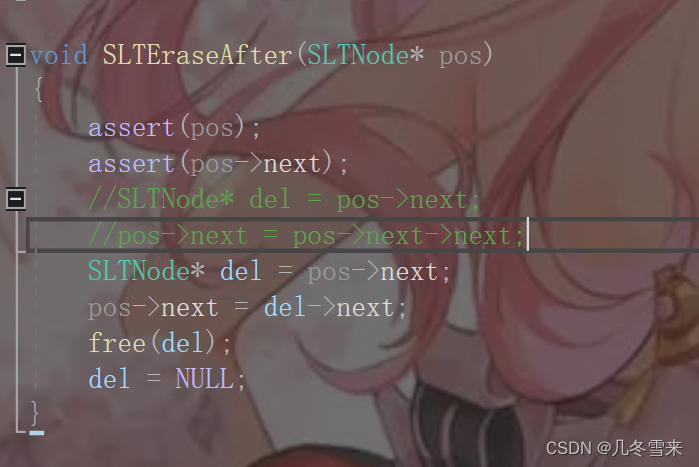
数据结构——链表讲解(2)
作者:几冬雪来 时间:2023年3月5日 内容:数据结构链表讲解 目录 前言: 剩余的链表应用: 1.查找: 2.改写数据: 3.在pos之前插入数据: 4.pos位置删除: 5.在pos的后…...

Docker 完全指南:从入门到生产级实践
一篇长文,彻底搞懂 Docker、Compose 与 Swarm容器技术已经成为现代软件交付的基石。无论是开发者、运维工程师,还是架构师,掌握 Docker 都是必备技能。本文将系统介绍 Docker 的核心概念、多容器编排、集群管理,以及从开发到生产的…...

VS2019项目重构实战:从命名空间到解决方案的全面重命名指南
1. 为什么需要全面重命名项目? 接手他人项目或者复用旧项目框架时,第一件事就是要给项目"改头换面"。这就像买二手房后的装修,不改名字总觉得住着别人的房子。我在团队协作中经常遇到这种情况:某个老项目要适配新业务&a…...
)
Linux 定时备份 MySQL 数据库(完整教程)
为了防止数据丢失,我们需要定时把数据备份起来。我们使用用 Linux crontab mysqldump 实现定时自动备份,包含备份、压缩、保留历史、自动清理旧文件。一、先准备备份脚本创建一个备份脚本 mysql_backup.sh,放在 /usr/local/bin/ 方便管理。#…...

游戏角色建模新革命:用Face3D.ai Pro快速生成高精度3D人脸资产
游戏角色建模新革命:用Face3D.ai Pro快速生成高精度3D人脸资产 1. 从一张照片到游戏角色,到底有多远? 想象一下这个场景:你是一位游戏美术师,刚刚拿到策划发来的角色设定图。图上是一位面容坚毅的东方武士࿰…...

3步实现微信聊天记录永久保存与智能分析的完整方案
3步实现微信聊天记录永久保存与智能分析的完整方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChatMsg 在数…...
)
用Python+NumPy手把手实现四足机器人腿部三维运动学(附完整代码与避坑点)
用PythonNumPy手把手实现四足机器人腿部三维运动学(附完整代码与避坑点) 四足机器人的运动控制一直是机器人学中最具挑战性的领域之一。想象一下,当你看到一只机械狗灵活地穿越复杂地形时,背后其实是数百行精密的运动学代码在实时…...

让旧电脑焕发新生:RyTuneX系统优化工具全解析
让旧电脑焕发新生:RyTuneX系统优化工具全解析 【免费下载链接】RyTuneX RyTuneX is a cutting-edge optimizer built with the WinUI 3 framework, designed to amplify the performance of Windows devices. Crafted for both Windows 10 and 11. 项目地址: http…...

NeuroKit2深度解析:Python神经生理信号处理的进阶实战指南
NeuroKit2深度解析:Python神经生理信号处理的进阶实战指南 【免费下载链接】NeuroKit NeuroKit2: The Python Toolbox for Neurophysiological Signal Processing 项目地址: https://gitcode.com/gh_mirrors/ne/NeuroKit 在当今神经科学和生物医学工程领域&a…...

Microsoft团队提出“弯曲雅各布天梯”新思路,了解量子数据如何教会AI做更好的化学
来源:ScienceAI 本文约3500字,建议阅读5分钟量子计算机生成精确数据,AI模型学习并实现百万倍加速预测。有时,一个视觉上引人注目的隐喻,足以让你传达一个复杂的观点。2001 年夏天,杜兰大学物理教授 John P.…...

从 OData 元数据到强类型前端:SAP UI5 与 TypeScript 生成服务类型定义的完整实践
在 UI5 项目里引入 TypeScript,很多团队已经能享受到编辑器补全、静态检查、重构安全这些直接收益。可一旦应用开始真正处理业务数据,一个很现实的问题就会出现:UI5 的官方类型定义覆盖了控件、模型、事件、基类 API,但你自己服务里的实体结构,像 Person、SalesOrder、Bus…...