Linux性能学习(2.2):内存_进程线程内存分配机制探究
文章目录
- 1 进程内存分配探究
- 1.1 代码
- 1.2 试验过程
- 2 线程内存分配探究
- 2.1 代码
- 2.2 试验过程
- 3 总结
参考资料:
1. 嵌入式软件开发杂谈(3):Linux下内存与虚拟内存
2. 嵌入式软件开发杂谈(1):Linux下最大能创建多少线程?
在链接1中,我们可以了解到系统为每一个进程分配了4GB的虚拟内存空间,其中3GB为用户空间,是每个进程独有的,1GB为内核空间,所有的进程以及内核共同享有。
在链接2中,我们了解到系统为每个线程分配独立的堆栈,不同的系统有不同的大小,在32位linux系统上默认为8MB。
在上篇文章中介绍了系统以及进程相关的内存指标,但是有个疑问,当进程运行时候,系统是如何来分配内存的,是直接分配3GB给到内存,还是按需分配,最大3GB,通过下面代码来探究一番。
PS:下面测试环境为Ubuntu 64位系统。
1 进程内存分配探究
1.1 代码
#include <stdio.h>
#include <stdlib.h>int main()
{int ch = 0;int s32Size = 1024;char* s8Ptr = NULL;int s32Cnt = 0;while ((ch = getchar()) != EOF){printf("get char,malloc %d mem\n", s32Size);s8Ptr = NULL;s8Ptr = (char*)malloc(s32Size);if (NULL == s8Ptr){printf("malloc err\n");}else{printf("malloc success, cnt:%d, addr:%p\n", ++s32Cnt, s8Ptr);}}return 0;
}
上面代码,每当我们在终端输入一个字符,程序就申请1KB的内存,并且打印申请内存的地址。
1.2 试验过程
我们知道,堆是负责动态内存的分配,因此可以通过 # cat /proc/$(pid)/maps | grep heap
来查看进程的内存分配情况。
运行程序,然后使用top查看虚拟内存的使用情况以及使用上面指令来查看堆的使用情况。

# cat /proc/11031/maps | grep heap
00ae2000-00b03000 rw-p 00000000 00:00 0
从上面可以可以看到这个进程的虚拟内存使用量为4352KiB,堆的地址为00ae2000-00b03000,换算一下堆的大小为132KB。但是此时程序并没有申请内存,怎么回事?
我们第一次申请内存,打印如下:
get char,malloc 1024 mem
malloc success, cnt:1, addr:0xae2830
然后查看虚拟内存VIRT使用量,还是4352KiB,并没有增加,堆的使用地址还是00ae2000-00b03000,也没有改变。
继续申请内存:
get char,malloc 1024 mem
malloc success, cnt:2, addr:0xae2c40
get char,malloc 1024 mem
malloc success, cnt:3, addr:0xae3050
第二次和第三次申请内存,VIRT和堆的信息仍然维持原状,没有改变,继续申请:
get char,malloc 1024 mem
malloc success, cnt:128, addr:0xb02c20
直到第128次申请内存时候,VIRT的使用量为4484KiB,比4352增加了132KB,而堆的使用量为264KB,比上次增加了132KB,信息如下:

cat /proc/11031/maps | grep heap
00ae2000-00b24000 rw-p 00000000 00:00 0 [heap]
继续申请内存,直到第258次申请内存,VIRT变为4616K,比4484增加了132KB,而堆的使用量为396KB,比上次增加了132KB,信息如下:
get char,malloc 1024 mem
malloc success, cnt:258, addr:0xb23c40

# cat /proc/11031/maps | grep heap
00ae2000-00b45000 rw-p 00000000 00:00 0 [heap]
从上面的测试中,我们看到第二次申请内存的地址为0xae2c40,而第一次申请内存的地址为0xae2830,两者相减,为1040,但是我们只申请了1024个字节,为什么会多16个字节?
第一个问题:为什么系统分配的内存比实际申请的内存大16个字节?
然后,我们可以看到,当程序运行时候,系统已经先为程序分配了132KB的内存,在随后我们申请内存时候,一直使用的是系统预先申请的132KB内存,直到我们申请的内存超过132KB,然后系统再次申请132KB,而不是我们需要多少就申请多少?
第二个问题:为什么系统会给进程申请132KB的内存,而不是我们真正需要的内存?
2 线程内存分配探究
2.1 代码
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
#include <sys/prctl.h>void *fun(void *arg)
{printf("----->thread_test\n");prctl(PR_SET_NAME, "thread_test");int ch = 0;int s32Size = 1024;char* s8Ptr = NULL;int s32Cnt = 0;while ((ch = getchar()) != EOF){printf("get char,malloc %d mem\n", s32Size);s8Ptr = NULL;s8Ptr = (char*)malloc(s32Size);if (NULL == s8Ptr){printf("malloc err\n");}else{printf("malloc success, cnt:%d, addr:%p\n", ++s32Cnt, s8Ptr);}}
}int main()
{int s32Ret = 0;pthread_t thread;if (getchar() != EOF){s32Ret = pthread_create(&thread, NULL, fun, NULL); printf("pthread_create, ret:%d\n", s32Ret);}while(1) sleep(10);return 0;
}
上面代码,当我们第一次输入一个字符,则创建线程,随后再次输入字符则是分配内存
2.2 试验过程
运行程序,查看VIRT为6520KB,如下:

maps信息如下:

然后我们创建线程,查看VIRT和maps信息如下:


可以看到,VIRT由6520增加到14716,即增加了8MB,这个8MB是系统为每个线程创建时分配的。
然后开始第一次分配内存,VIRT和maps信息如下:


可以看到,当我们第一次申请内存的时候,VIRT由14716增加到80252,即系统为线程申请了64MB内存,而不是给进程分配的132KB内存。
第三个问题:为什么系统会给线程申请64MB的内存,而不是我们真正需要的内存?
开始第二次申请内存,VIRT和maps数据均没有变化,和进程中的分配机制一样,先从已经分配的内存中使用,当超过已经分配的内存时,才会重新分配新的内存。
get char,malloc 1024 mem
malloc success, cnt:1, addr:0x7f9bac0008c0get char,malloc 1024 mem
malloc success, cnt:2, addr:0x7f9bac000cd0
上面是程序的打印信息,可以看到我们申请了1024字节的内存,但是系统还是分配了1040个字节的内存,即多分配了16字节的内存,和问题1一致。
3 总结
通过上面的测试,我们得出了三个问题:
- 第一个问题:64位系统,为什么系统分配的内存比实际申请的内存大16个字节?
- 第二个问题:64位系统,为什么系统会给进程申请132KB的内存,而不是我们真正需要的内存?
- 第三个问题:64位系统,为什么系统会给线程申请64MB的内存,而不是我们真正需要的内存?
后面章节将解决这几个问题。
相关文章:
Linux性能学习(2.2):内存_进程线程内存分配机制探究
文章目录1 进程内存分配探究1.1 代码1.2 试验过程2 线程内存分配探究2.1 代码2.2 试验过程3 总结参考资料:1. 嵌入式软件开发杂谈(3):Linux下内存与虚拟内存2. 嵌入式软件开发杂谈(1):Linux下最…...
BPMN2.0规范及流程引擎选型方案
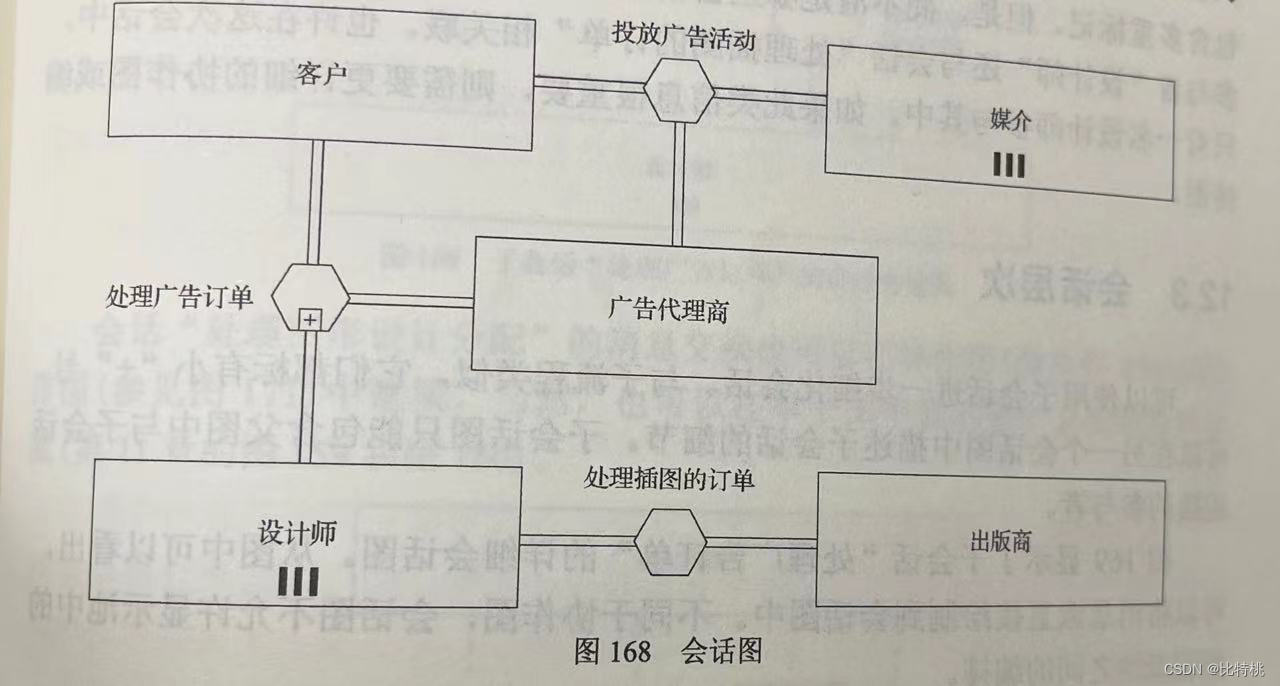
BPMN2.0规范及流程引擎选型方案一、基本概念二、BPMN意义三、主要元素3.1 活动任务子流程调用活动事件子流程事务3.2 网关排他网关包容网关并行网关事件网关3.3 事件开始事件结束事件中间事件3.4 辅助泳道图注释与组数据存储四、图类型4.1 编排图4.2 会话图五、技术选型5.1 前端…...

VMware虚拟机安装Linux教程
前言 本文小新为大家带来 VMware虚拟机安装Linux教程 ,后边将为大家分享Linux系统的相关知识与操作,在此之前的第一步我们需要在我们的电脑上搭建好一个Linux系统的环境,本文的具体内容包括VMware虚拟机软件安装与Linux系统安装~ 不积跬步&a…...
多人协作|RecyclerView列表模块新架构设计
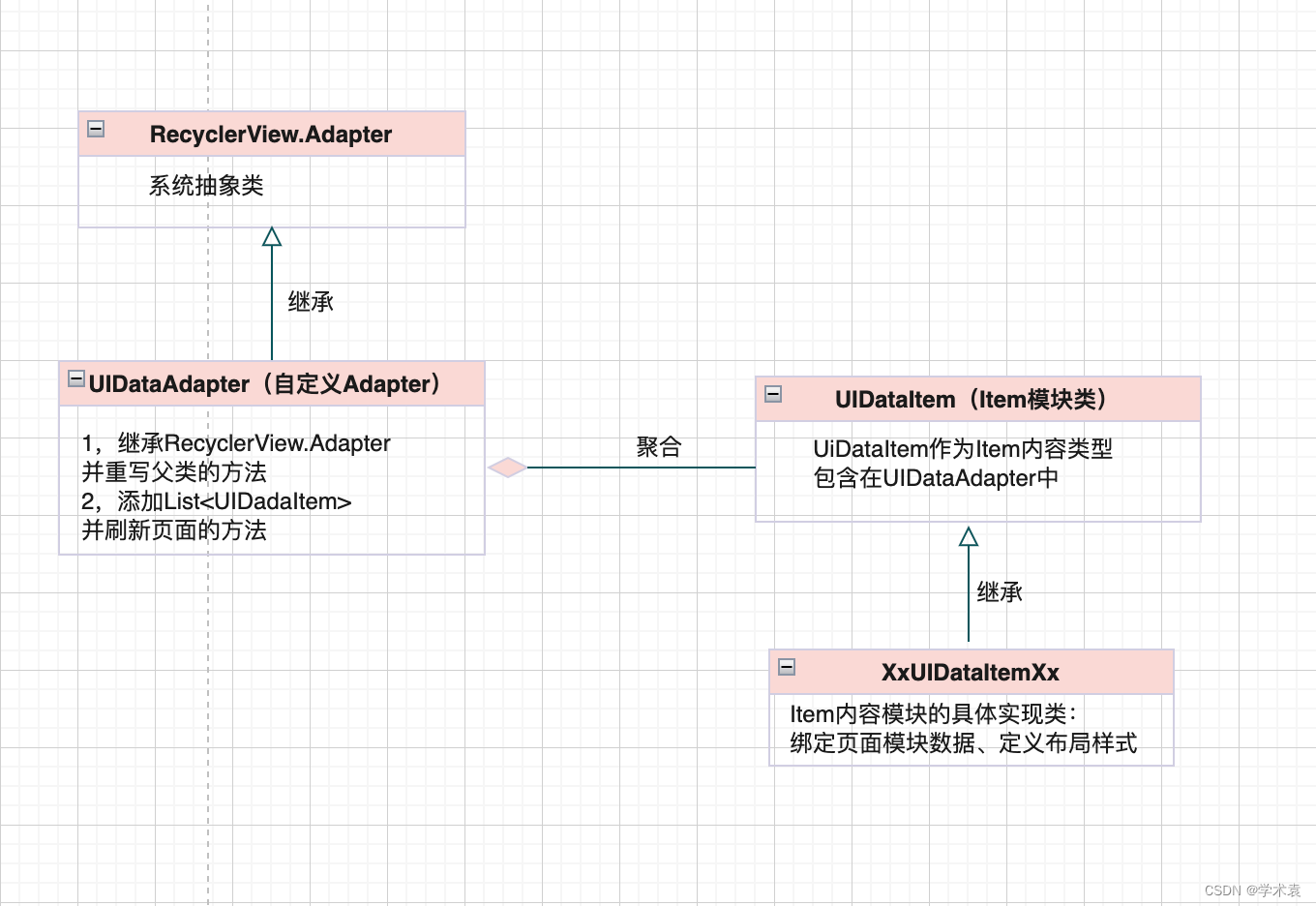
多人协作|RecyclerView列表模块新架构设计多人协作设计图新架构设计与实现设计背景与新需求新架构设计多人协作设计图 根据产品设计,将首页列表即将展示内容区域,以模块划分成多个。令团队开发成员分别承接不同模块进行开发,且互不影响任务开…...
 整合配置文件 @Value、ConfigurationProperties)
SpringBoot (六) 整合配置文件 @Value、ConfigurationProperties
哈喽,大家好,我是有勇气的牛排(全网同名)🐮🐮🐮 有问题的小伙伴欢迎在文末评论,点赞、收藏是对我最大的支持!!!。 1 使用 Value 注解 /** Auth…...
docker 入门篇
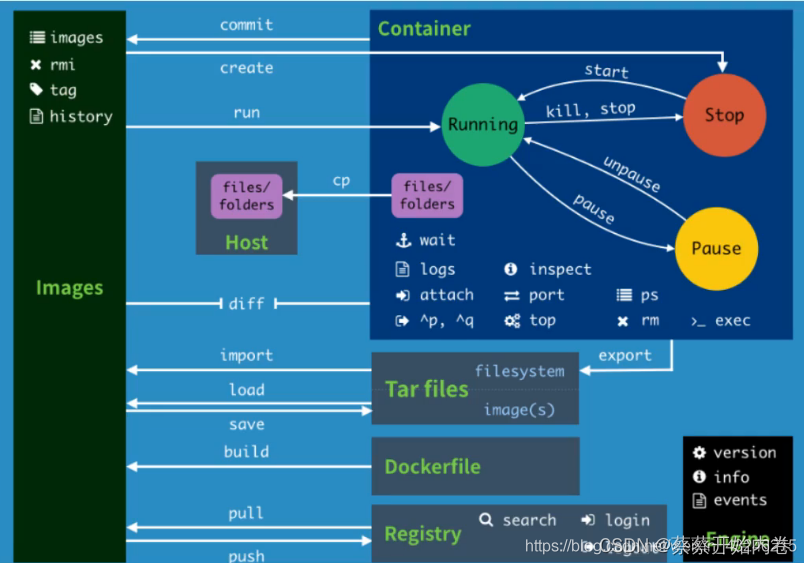
docker为什么会出现? 一款产品:开发---->运维,两套环境!应用环境,应用配置! 常见问题:我的电脑可以运行,版本更新,导致服务不可用。 环境配置十分的麻烦,…...

MapReduce的shuffle过程详解
shuffle流程概括 因为频繁的磁盘I/O操作会严重的降低效率,因此“中间结果”不会立马写入磁盘,而是优先存储到Map节点的“环形内存缓冲区”,在写入的过程中进行分区(partition),也就是对于每个键值对来说&a…...
【软件使用】MarkText下载安装与汉化设置 (markdown快捷键收藏)
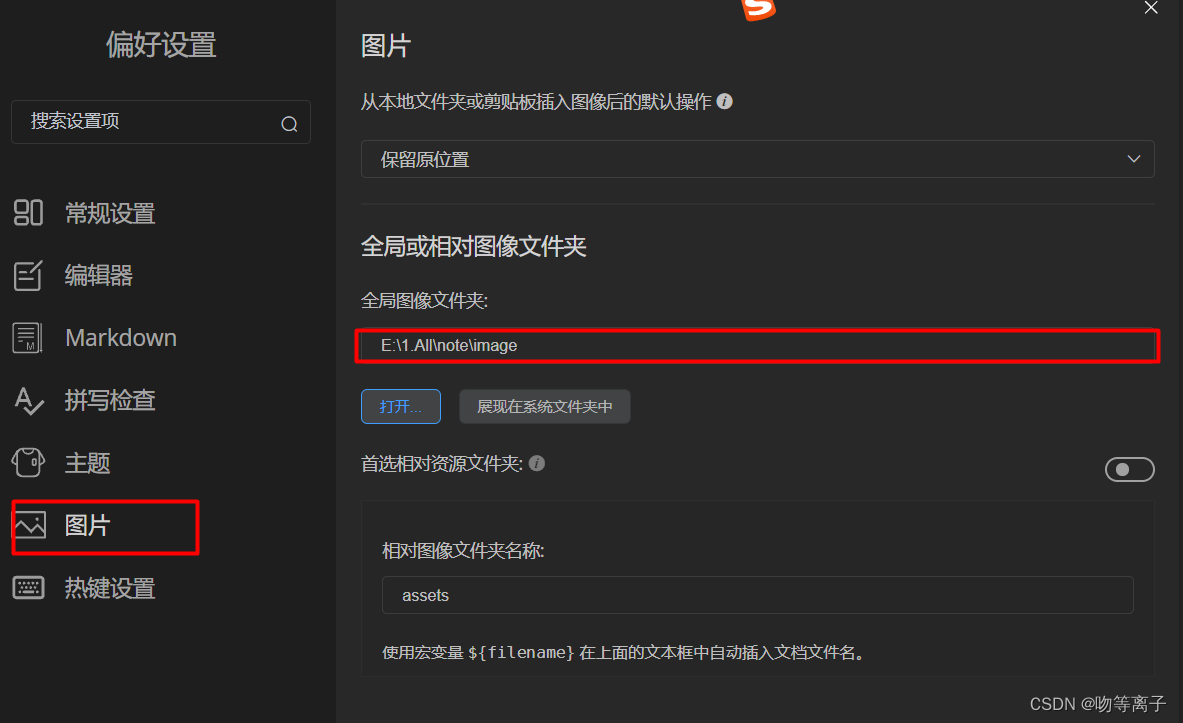
一、安装与汉化 对版本没要求的可以直接选择 3、免安装的汉化包 1、下载安装MarkText MaxText win64 https://github.com/marktext/marktext/releases/download/v0.17.1/marktext-setup.exe 使用迅雷可以快速下载 2. 配置中文语言包 中文包下载地址:GitHub - chi…...

LeetCode笔记:Biweekly Contest 99
LeetCode笔记:Biweekly Contest 99 1. 题目一 1. 解题思路2. 代码实现 2. 题目二 1. 解题思路2. 代码实现 3. 题目三 1. 解题思路2. 代码实现 4. 题目四 1. 解题思路2. 代码实现 比赛链接:https://leetcode.com/contest/biweekly-contest-99 1. 题目一…...

初探富文本之CRDT协同实例
初探富文本之CRDT协同实例 在前边初探富文本之CRDT协同算法一文中我们探讨了为什么需要协同、分布式的最终一致性理论、偏序集与半格的概念、为什么需要有偏序关系、如何通过数据结构避免冲突、分布式系统如何进行同步调度等等,这些属于完成协同所需要了解的基础知…...
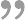
团队死气沉沉?10种玩法激活你的项目团队拥有超强凝聚力
作为项目经理和PMO,以及管理者最头疼的是团队的氛围和凝聚力,经常会发现团队死气沉沉,默不作声,你想尽办法也不能激活团队,也很难凝聚团队。这样的项目团队你很难带领大家去打胜仗,攻克堡垒。但是如何才能避…...

Spring三级缓存核心思想
spring在启动时候,会创建bean,并给bean填充属性,这事会使用到三级缓存 private final Map<String, Object> singletonObjects new ConcurrentHashMap<>(256); //一级缓存private final Map<String, Object> earlySingleto…...

深度学习算法训练和部署流程介绍--让初学者一篇文章彻底理解算法训练和部署流程
目录 1 什么是深度学习算法 2 算法训练 2.1 训练的原理 2.2 名词解释 3 算法C部署 3.1 嵌入式终端板子部署 3.3.1 tpu npu推理 3.3.2 cpu推理 3.2 服务器部署 3.2.1 智能推理 3.2.2 CPU推理 1 什么是深度学习算法 这里不去写复杂的概念,就用通俗的话说…...
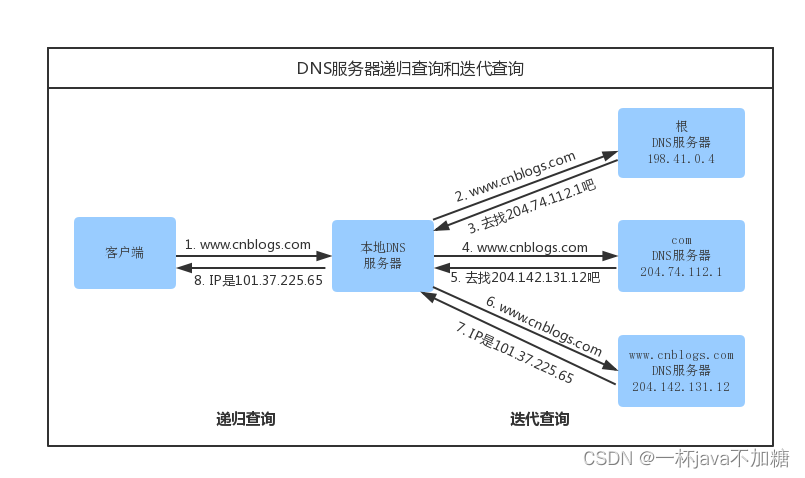
计算机网络整理
TCP与UDP 介绍 HTTP:(HyperText Transport Protocol)是超文本传输协议的缩写,它用于传送WWW方式的数据,关于HTTP协议的详细内容请参考RFC2616。HTTP协议采用了请求/响应模型。 TCP:(Transmission Contro…...
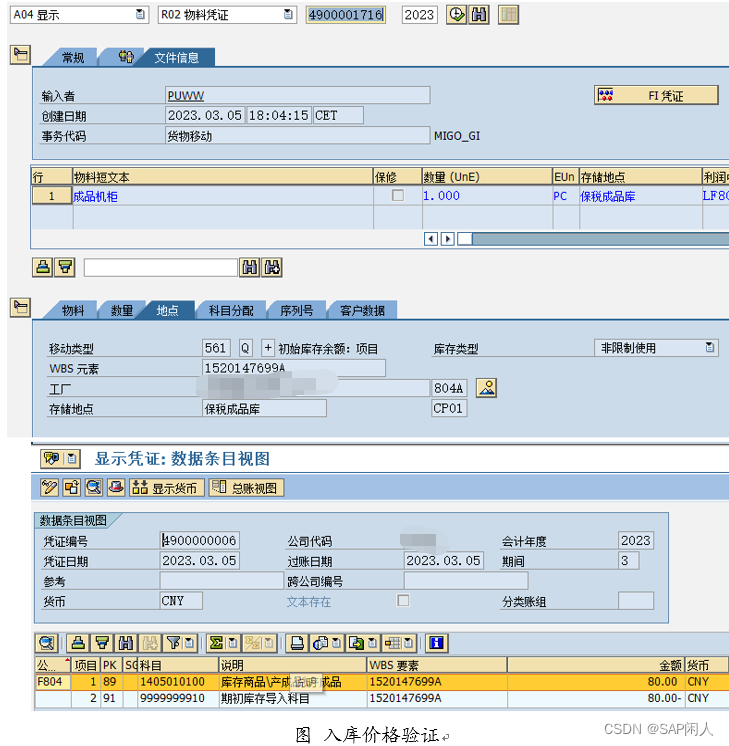
闲人闲谈PS之三十八——混合制生产下WBS-BOM价格发布增强
惯例闲话:最近中《三体》的毒很深,可能是电视剧版确实给闲人这种原著粉带来太多的感动,又一次引发了怀旧的热潮,《我的三体-罗辑传》是每天睡前必刷的视频,结尾BGM太燃了。闲人对其中一句台词感触很深——人类不感谢罗…...

Java 根类 Object
java.lang.Object 是 Java 类层次结构中的根类,所有类都直接或间接实现了此类的方法。 Object API 源码 package java.lang;public class Object {private static native void registerNatives();static {registerNatives();}public final native Class<?>…...

04_Apache Pulsar的可视化监控管理、Apache Pulsar的可视化监控部署
1.4.Apache Pulsar的可视化监控管理 1.4.1.Apache Pulsar的可视化监控部署 1.4.Apache Pulsar的可视化监控管理 1.4.1.Apache Pulsar的可视化监控部署 第一步:下载Pulsar-Manager https://archive.apache.org/dist/pulsar/pulsar-manager/pulsar-manager-0.2.0/…...

【算法】期末复盘,酒店住宿问题——勿向思想僵化前进
文章目录前言题目描述卡在哪里代码(C)前言 省流:一个人也可以住双人间,如果便宜的话。 害!尚正值青春年华,黄金岁月,小脑瓜子就已经不灵光咯。好在我在考试的最后一分钟还是成功通过了这题&am…...
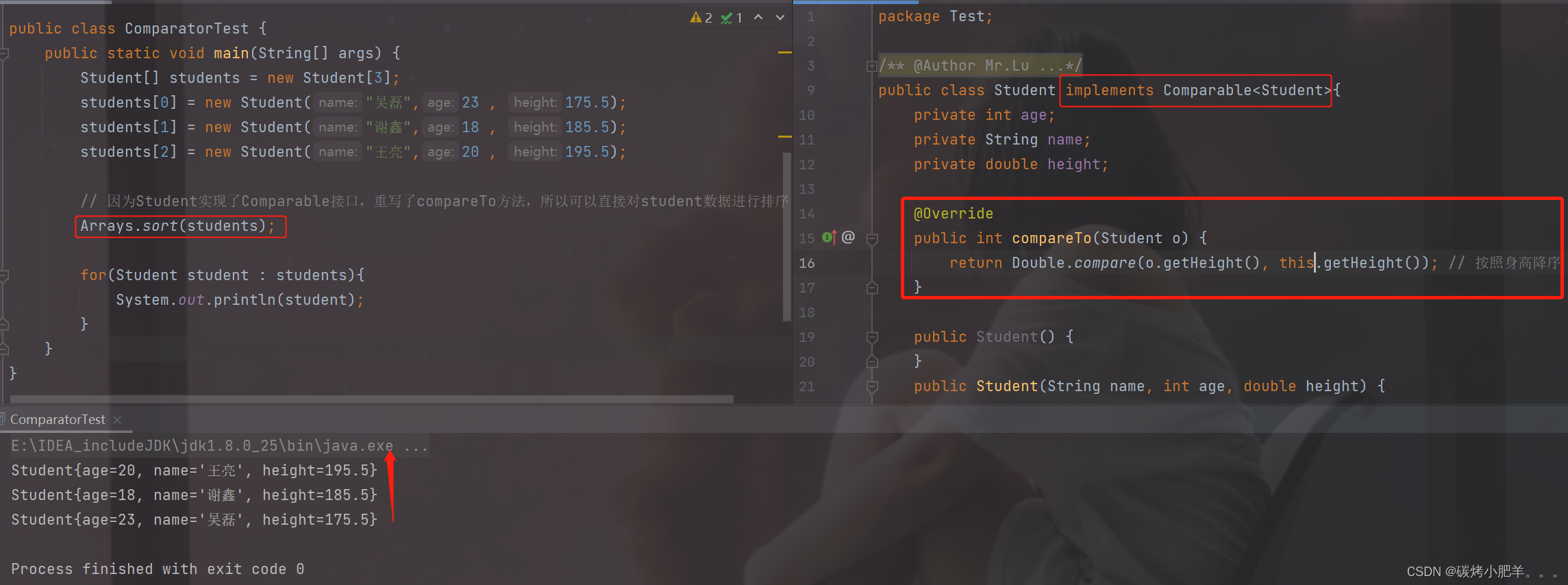
Java中的Comparator 与 Comparable详解
Comparator VS Comparable1. Comparator1.1 对一维数组进行排序1.2 对二维数组进行排序1.3 对对象数组进行排序2. Comparable3. 二者区别1. Comparator 通过源码发现Comparator是一个接口。 根据compare方法中的注释可以发现方法返回三种类型的值,正数、零、负数&a…...
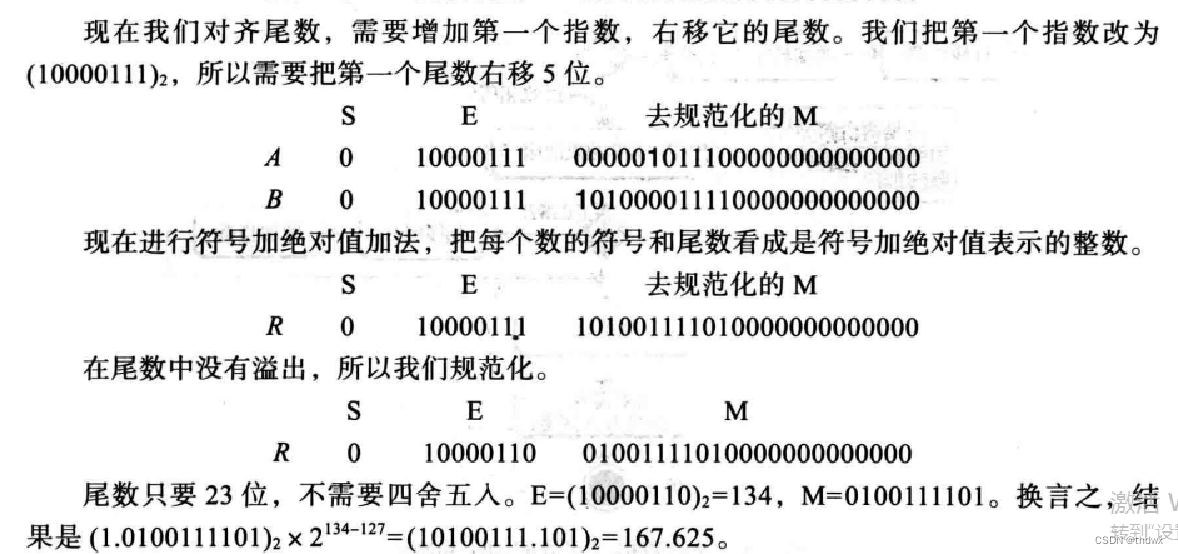
计算机科学导论笔记(二)
三、数据存储 3.1 数据类型 计算机行业中使用术语“多媒体”来定义包含数字、文本、音频、图像和视频的信息。 位:bit,binary digit的缩写,是存储在计算机中的最小单位,它是0或1. 位模式:为了表示数据的不同类型&a…...

MySQL函数及条件查询相关用法
文章目录 前言 一、函数(可跳过) 1.字符串函数 2.数值函数 3.日期和时间函数 4.聚合函数(常用) 5.控制流函数 6.加密和压缩函数 7.系统信息函数 二、条件查询(select) 1.筛选条件子句where与hav…...

网站SEO推广需要多少钱_如何选择合适的网站 SEO 推广服务商
网站SEO推广需要多少钱_如何选择合适的网站 SEO 推广服务商 一、了解网站SEO推广的基本概念 在当今的数字时代,网站SEO推广(Search Engine Optimization,搜索引擎优化)已成为任何企业在互联网上获得流量和客户的关键手段之一。S…...
)
保姆级教程:用Python 3.10和Hugging Face镜像站,10分钟搞定通义千问1.8B-Chat本地部署(CPU也能跑)
零基础CPU部署通义千问1.8B指南:从镜像加速到对话实战 在开源大模型如火如荼的今天,许多开发者都渴望亲手体验这些前沿技术的魅力,却常常被显卡门槛劝退。本文将打破这一限制,带你用普通笔记本电脑或云服务器CPU环境,…...

Zotero CitationCounts:学术引用追踪与文献影响力分析的高效工具
Zotero CitationCounts:学术引用追踪与文献影响力分析的高效工具 【免费下载链接】zotero-citationcounts Zotero plugin for auto-fetching citation counts from various sources 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-citationcounts Zote…...

深度测评|2026AI短剧出海服务商
2026 年短剧出海进入全球化传播阶段,声画同步与多语种适配成为短剧出海的基础核心能力,更是保障海外受众观剧体验的关键要素。相较于国内市场,海外受众来自不同的语言区域,对多语种配音的自然度、口型同步的精准度、台词翻译的适配…...

2026年木蜡油定做厂家大盘点,究竟哪家才是行业首选?
在当今注重环保和品质的时代,木蜡油作为一种天然环保的涂料,受到了越来越多消费者的青睐。无论是室内外木器家具、木艺制品,还是全屋定制、装饰装修等领域,木蜡油都有着广泛的应用。然而,市场上木蜡油定做厂家众多&…...

实战esp32智能门禁系统,快马平台生成完整应用代码助力项目落地
最近在做一个办公室智能门禁的小项目,用ESP32实现了完整的门禁控制功能。整个过程挺有意思的,特别是发现用InsCode(快马)平台可以快速生成项目代码框架,省去了很多重复工作。下面分享下具体实现思路和经验。 硬件选型与连接 ESP32作为主控板性…...

SEO优化有哪些快速有效的方法_自媒体如何通过SEO快速提升曝光度
SEO优化有哪些快速有效的方法 在当前数字化时代,自媒体如何通过SEO快速提升曝光度成为了许多内容创作者和网络营销人员关注的焦点。搜索引擎优化(SEO)不仅能够提升网站的自然排名,还能有效增加自媒体的曝光度。具体有哪些快速有效…...

Brax环境封装指南:无缝集成Gym和DM_Env接口
Brax环境封装指南:无缝集成Gym和DM_Env接口 【免费下载链接】brax Massively parallel rigidbody physics simulation on accelerator hardware. 项目地址: https://gitcode.com/gh_mirrors/br/brax Brax是一个基于JAX的高性能物理模拟引擎,专为强…...

从“技术迷宫“到“一键导航“:OpCore-Simplify如何让黑苹果配置变得像搭积木一样简单
从"技术迷宫"到"一键导航":OpCore-Simplify如何让黑苹果配置变得像搭积木一样简单 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-S…...