Redis主从、哨兵、Redis Cluster集群架构
Redis主从、哨兵、Redis Cluster集群架构
Redis主从架构
Redis主从架构搭建
主从搭建的问题- 如果同步数据失败,查看log日志
- 报错无法连接,检查是否端口未开放
- 出现”
Error reply to PING from master:...“日志,修改参数protected-mode no
Redis主从复制原理
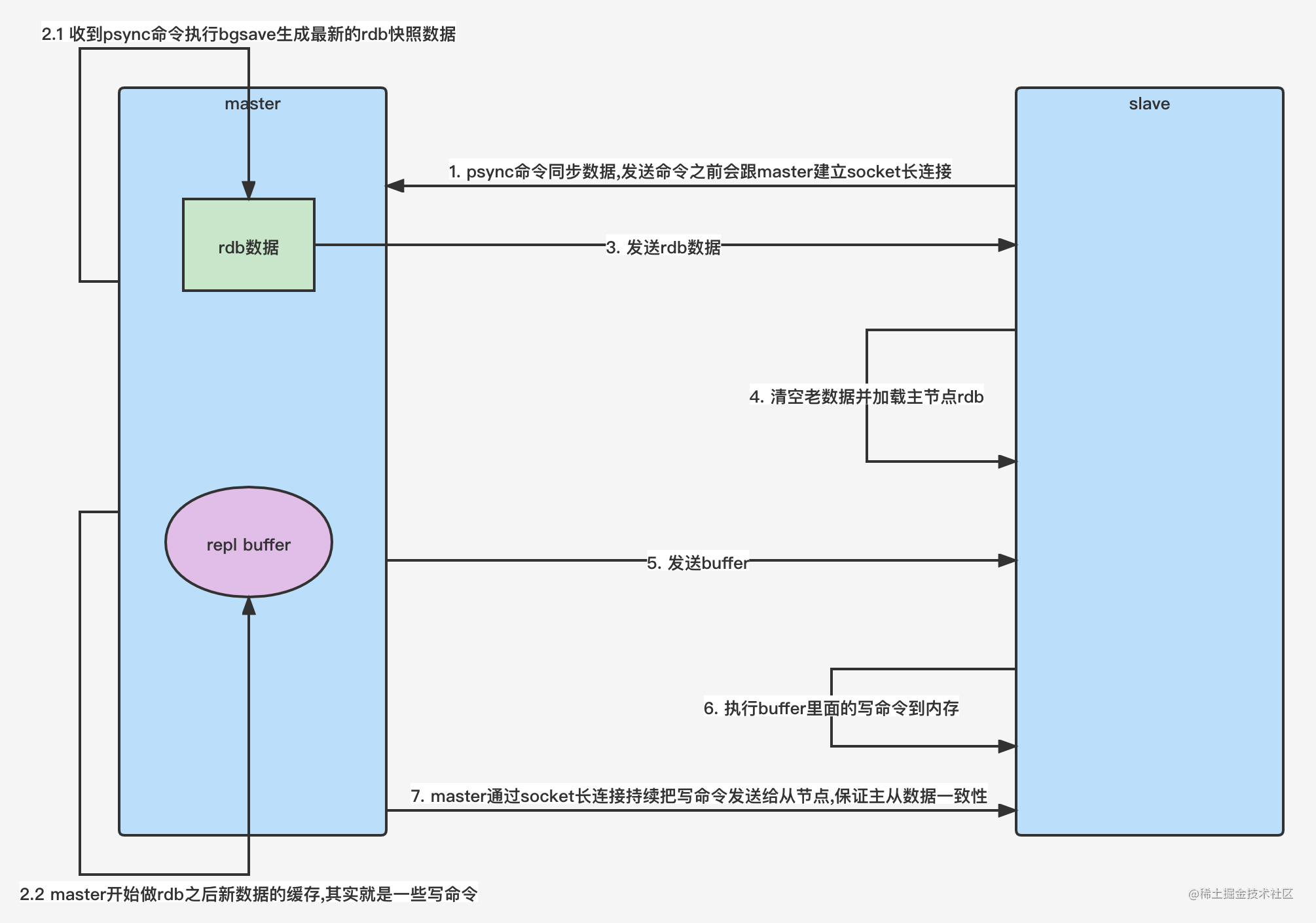
详细流程- 如果你为master配置了一个slave,不管这个slave是否是第一次连接上master,它都会发送一个
psync指令给master请求复制数据 - master收到
psync指令之后,会在后台进行数据持久化通过bgsave生成最新的rdb文件 - 持久化期间,master会继续接收客户端的请求,它会把这些可能修改数据集的请求缓存在内存中
- 当持久化完毕之后,master会把这份rdb文件数据集发送给slave,slave会把接收到的数据进行持久化生成rdb,然后再加载到内存中
- 然后master再将之前缓存在内存中的命令发送给slave
- 当master与slave之间的连接由于某些原因而断开的时候,slave能够自动重连master
- 如果master收到了多个slave并发连接请求,它只会进行一次持久化,而不是一个连接一次,然后再把一份持久化的数据发送给多个并发连接的slave
- 如果你为master配置了一个slave,不管这个slave是否是第一次连接上master,它都会发送一个
简概- 从节点每次都会向主节点发送psync同步指令,如果是首次连接,主节点会开启bgsave子线程进行全量数据复制并且生成rdb文件,并且在持久化期间会将从节点新的写命令缓存下来,当持久化结束后,主节点将rdb文件同步给从节点进行持久化,如果同步期间存在网络波动,从节点会进行重连,恢复连接后,主节点会将部分缺失的数据同步给从节点
数据部分复制(断点续传)
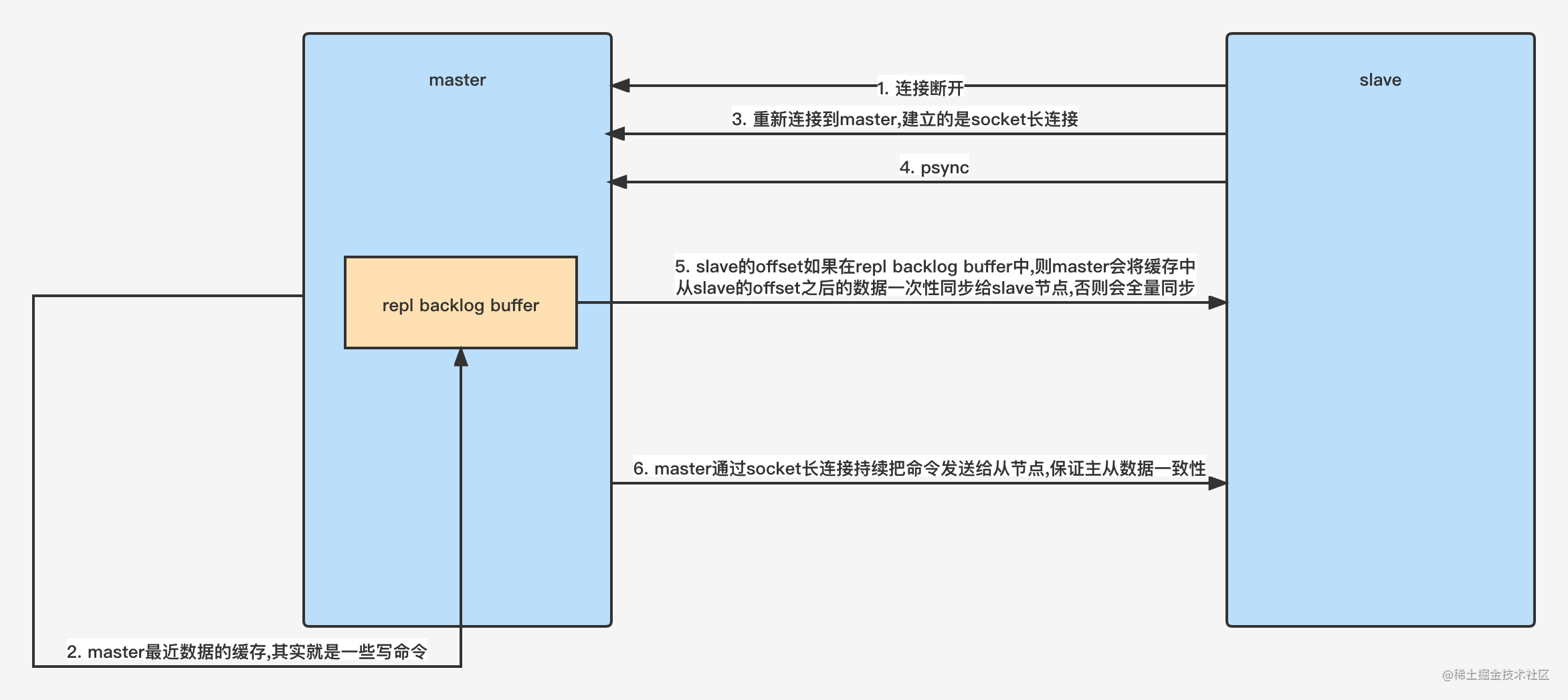
- 当master和slave断开重连后,一般都会对整份数据进行复制。但从Redis 2.8之后,Redis开始改用支持部分数据复制的命令psync去master同步数据,slave和master能够在网络连接断开重连之后只进行部分数据复制(断点续传)
- master会在其内存中创建一个复制数据用的缓存队列,缓存最近一段时间的数据,master和它所有的slave都维护了复制的数据下标offset和master的进程id,因此当网络连接断开后,slave会请求master继续进行未完成的复制,从所记录的数据下标开始。如果master进程id变化了,或者从节点数据下标offset太旧,已经不在master的缓存队列里了,那么将会进行一次全量数据的复杂
主从复制风暴
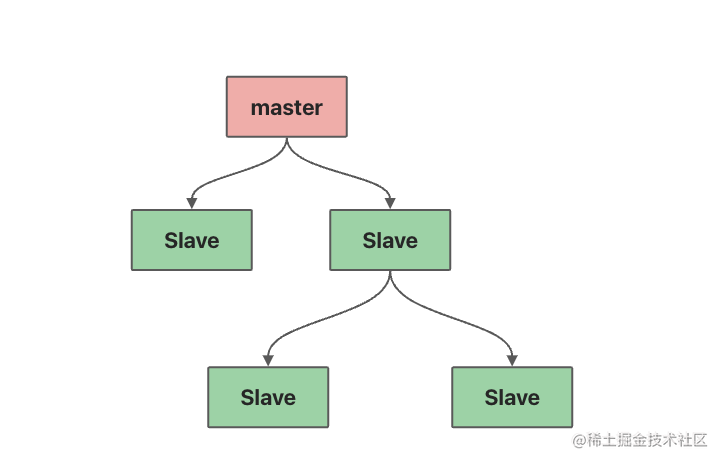
- 如果有很多从节点,为了缓解主从
复制风暴(多个节点同时复制主节点导致主节点压力过大),我们可以让部分从节点与从节点(与主节点同步)同步数据,也就是分层结构
Redis哨兵架构
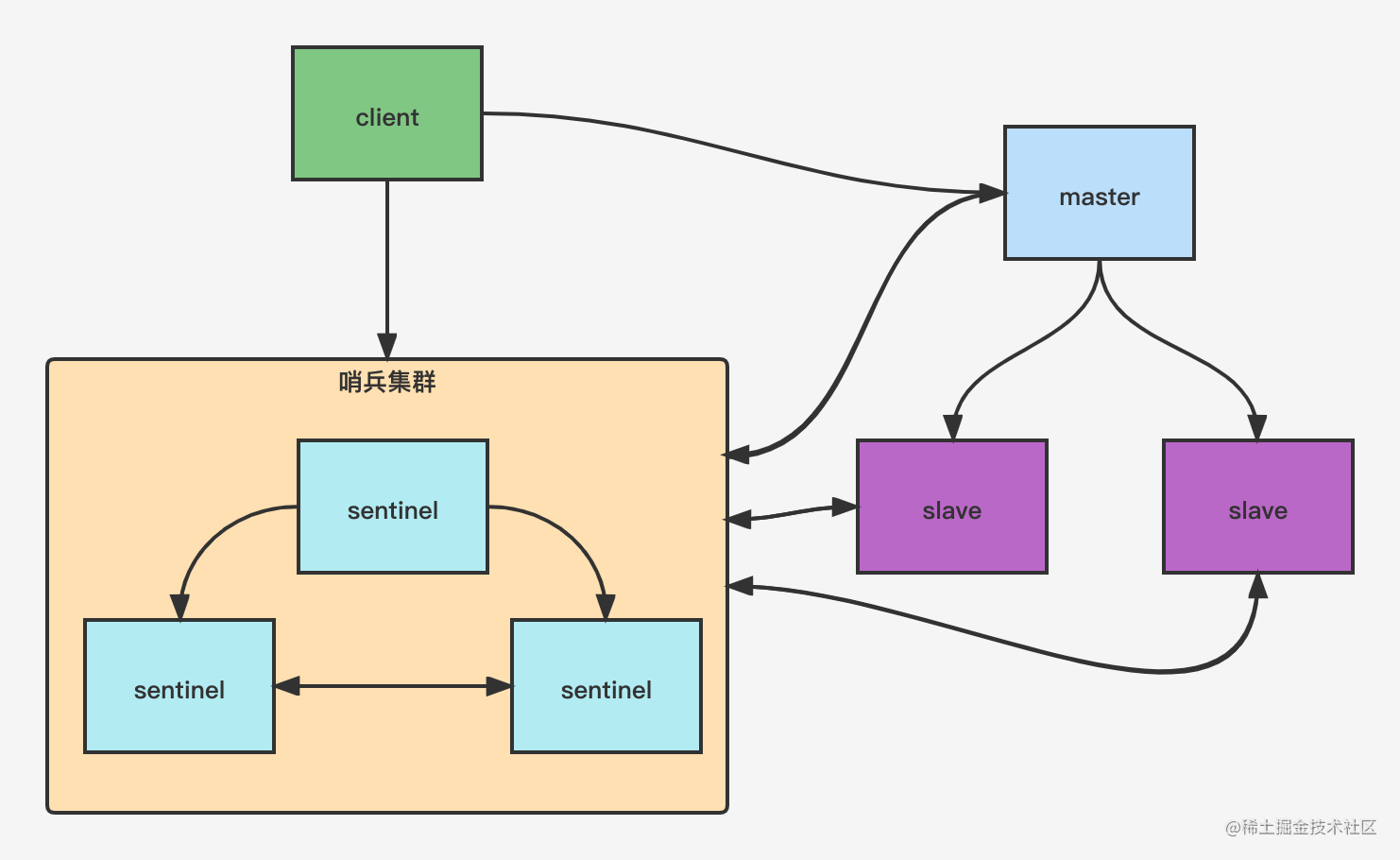
哨兵模式
主从复制存在不能自动故障转移、达不到高可用的功能,哨兵模式解决了这些问题,通过哨兵机制可以自动切换主从节点,客户端连接Redis的时候,先连接哨兵,哨兵会告诉客户端Redis主节点的地址,然后客户端连接上Redis进行后续的操作,当主节点宕机的时候,哨兵监测到主节点宕机,会重新推选出过半选举后的从节点作为新的主节点,然后通过发布订阅模式通知其他从节点,让它们切换主机- 哨兵是特殊的Redis服务,不提供读写服务,主要是用来
监控Redis实例节点
哨兵集群选举流程
-
每个sentinel每秒钟向master节点进行ping,当master回复时间超过指定值会被标记为主观下线,如果master节点被标记为主观下线,那么正在监视这个master节点的所有sentinel都会ping去确认是否真的主观下线,当有足够数量的sentinel确认master节点主观下线,那么master会被标记为客观下线,反之解除标记
-
每个发现
master节点进入客观下线的sentinel都会要求其他sentinel将自己设置为局部leader,选举是先到先得的,同时每个sentinel每次选举都会自增epoch,而每个纪元只会选择出一个sentinel作为局部leader,如果所有超过一半的sentinel选举某个sentinel作为局部leader,之后这个sentinel会进行故障转移,从存活的slave节点中选举出新的master节点,这个选举过程跟集群的master选举很类似的 -
如果哨兵集群只有一个sentinel节点,Redis的主从节点也能正常运行以及选举master,如果master挂了,那唯一的sentinel节点就是局部leader
-
注意情况- 哨兵集群虽然也是可以选举leader,但是哨兵架构配置复杂,只会提供一个master节点进行对外服务,还是不能解决线上并发问题,而且哨兵模式还会出现
访问瞬断问题,基于以上情况,我们可以选择Redis集群架构,集群架构也能进行选举,而且是配置多主多从的,配置简单,性能上远远高于哨兵模式
- 哨兵集群虽然也是可以选举leader,但是哨兵架构配置复杂,只会提供一个master节点进行对外服务,还是不能解决线上并发问题,而且哨兵模式还会出现
Redis Cluster集群架构
哨兵模式的缺陷
- 在Redis 3以前的版本要实现集群一般是借助哨兵SentInel工具来监控master节点的状态,如果master节点异常,就会做主从切换,将某一台slave作为master,哨兵的配置略微复杂,并且性能和高可用等各方面表现一般,特别是在
主从切换的瞬间存在访问瞬断的情况,而且哨兵模式只有一个主节点对外提供服务,没法支持很高的并发,并且单个主节点内存页不适合设置得过大,否则会导致持久化文件过大,影响数据恢复或主从同步的效率Sentinel模式的主从切换出现访问瞬断的问题,该怎么解决呢?- 集群架构已经包括了Sentinel模式
Redis Cluster集群模式
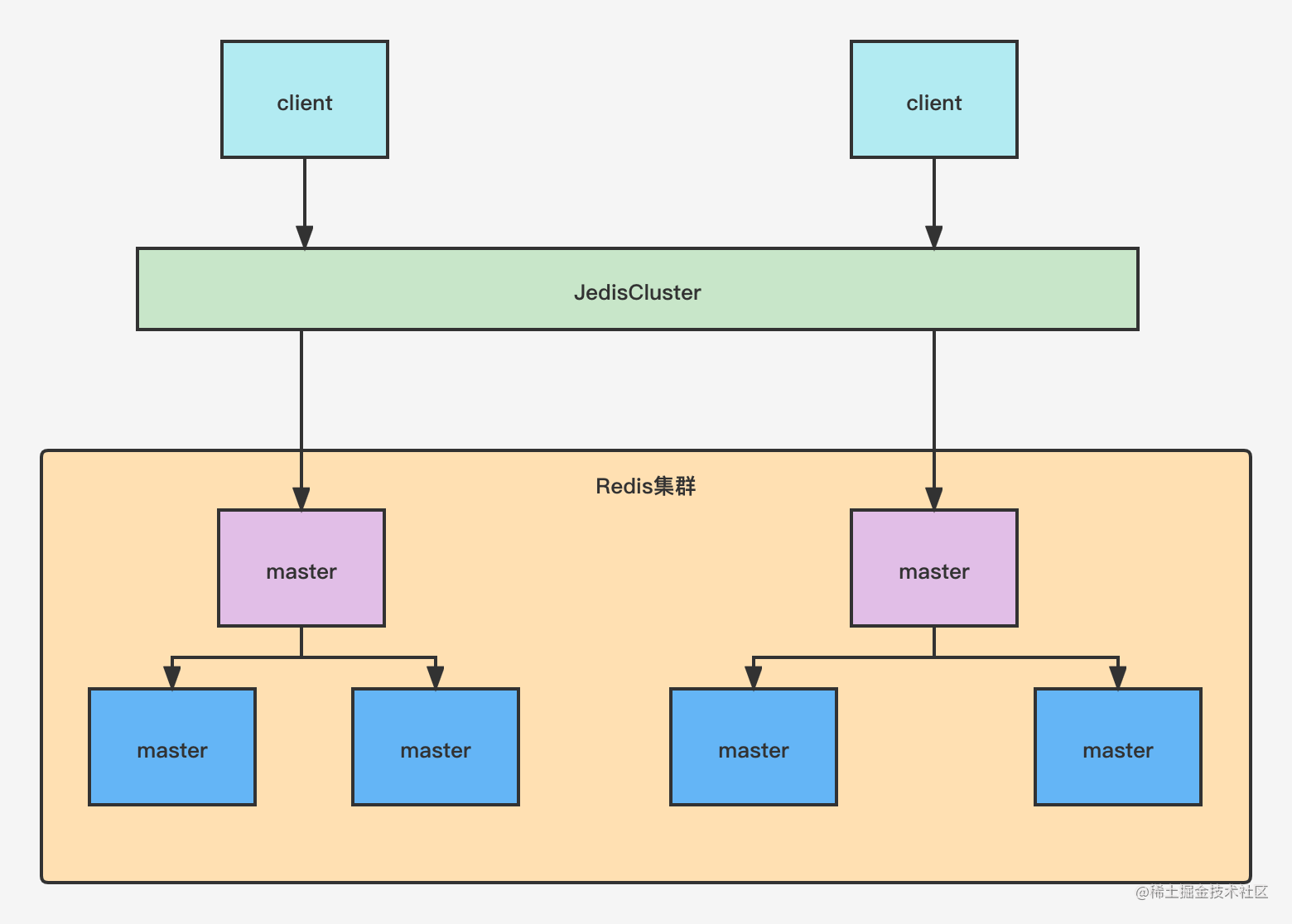
- Redis集群是一个由
多个主从节点群组成的分布式服务器群,它具有复制、高可用和分片特性 - Redis集群不需要Sentinel哨兵,也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展,据官方文档称可以线性扩展到上万个节点,
官方推荐不超过1k节点) - Redis集群的性能和高可用性均优于之前版本的哨兵模式,并且集群配置非常简单
Redis集群原理分析
Redis Cluster将所有数据划分为16384个slots(Redis集群没有使用一致性hash),每个节点负责其中一部分slots,slots的信息存储于每个节点中槽位定位算法- Redis集群默认会对key值使用CRC16算法进行hash得到一个整数值,然后用这个整数值
对16384进行取模来得到具体槽位 HASH_SLOT = CRC16(key) mod 16384
- Redis集群默认会对key值使用CRC16算法进行hash得到一个整数值,然后用这个整数值
- 当
Redis Cluster的客户端来连接集群时,它也会得到一份集群的slots配置信息并且将其缓存在客户端本地,这样当客户端要查找某个key的时候,可以直接定位到目标节点,同时因为slots的信息可能会存在客户端与服务器不一致的问题,还需要纠正机制来实现槽位信息的校验调整跳转重定位- 当客户端
向一个错误的节点发出了指令,该节点会发现指令的key所在的槽位并不归自己管理,这时它会向客户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去连这个节点去获取数据 - 客户端收到指令后除了跳转到正确的节点上去操作,还会同步
更新纠正本地的槽位映射表缓存,后续所有key将使用新的槽位映射表
- 当客户端
Redis集群节点间的通信机制
-
集中式(如zookeeper)
- 优点在于元数据的更新和读取,时效性非常好,一旦数据出现变更立即就会更新到集中式的存储中吗,其他节点读取的时候立即就能感知到
- 不足在于所有的元数据的更新压力全部集中在一个地方,可能导致元数据的存储压力
- 很多中间件都会借助zookeeper集中式存储数据
-
gossip协议(默认)ping:节点之间互相发送ping交换元数据信息pong:对ping和meet消息的返回,包含自己的状态和其他信息,也可以用于信息广播和更新meet: 某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信fail:某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了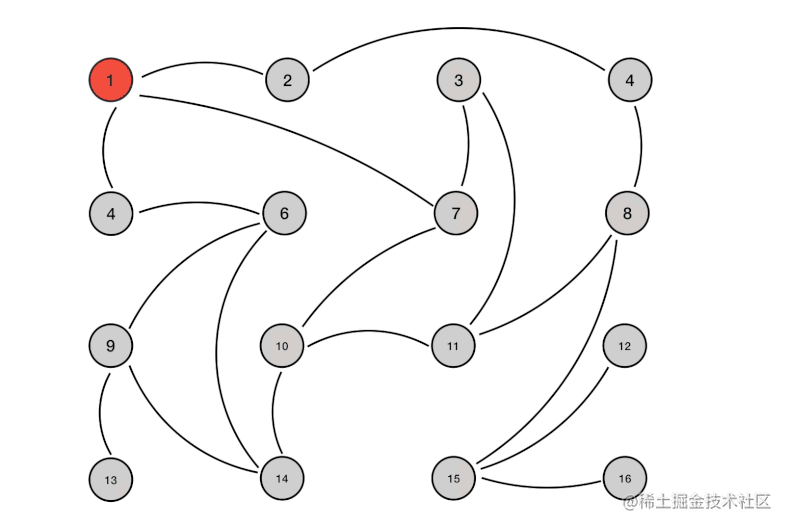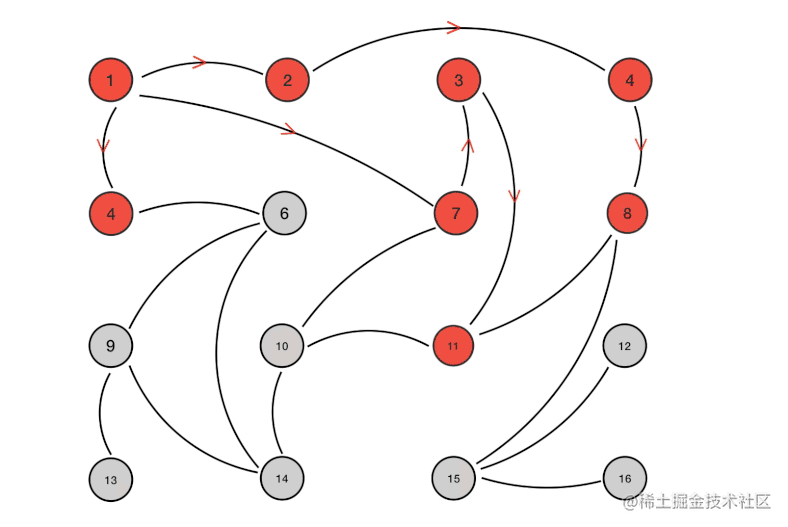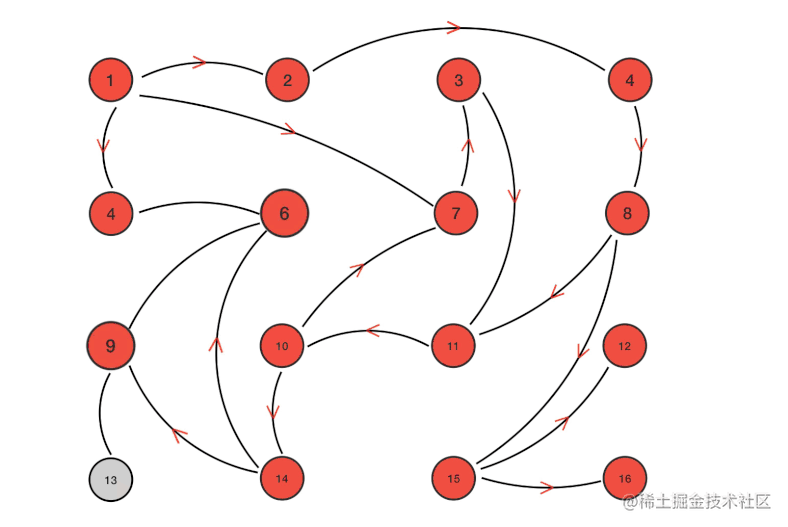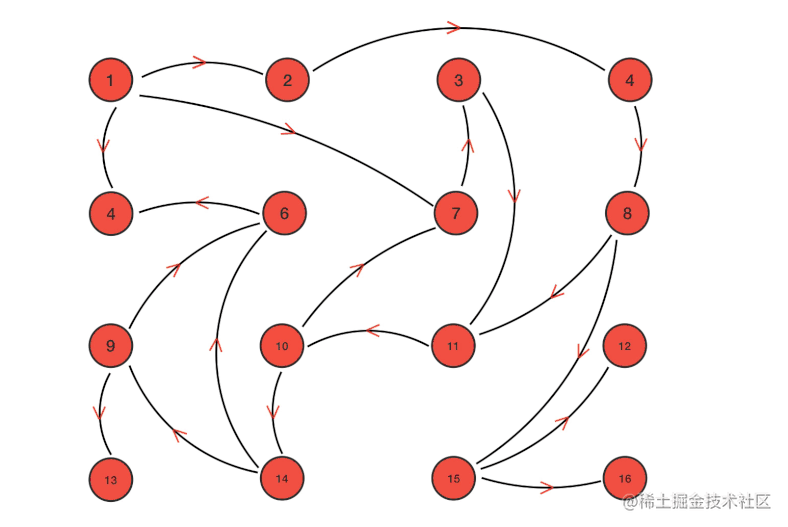
-
gossip协议优缺点
- 优点:
元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上去更新,有一定的延时,降低了压力 - 缺点:
元数据更新有延时可能导致集群的一些操作会有一些滞后
- 优点:
-
网络抖动问题:假如不同的机房网络不太好的情况下,突然节点之间访问延迟不了的情况(过几秒又连接上了),为了避免因为这种场景而导致Cluster频繁切换(数据的重新赋值)造成性能消耗,该如何解决?Redis Cluster提供cluster-node-timeout,表示如果超过这个时间,则认定节点出现故障,需要切换
Redis集群选举原理
-
当slave发现自己的master变为
FAIL状态时,便会尝试进行Failover,以期待成为新的master,由于挂掉的master可能会有多个slave,从而存在多个slave竞争成master节点的过程- slave发现自己的master变为
FAIL - 将自己记录的集群currentEpoch加1,并广播
FAILOVER_AUTH_REQUEST信息 - 其他节点收到该信息(
只有master响应),判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack - 尝试failover的slave收集master返回的
FAILOVER_AUTH_ACK - slave收到
超过半数master的ack后变为新master(这里解释了集群为什么至少需要三个主节点,如果只有两个,当其中一个节点挂了,只剩一个主节点是不能选举成功的) - slave广播pong消息通知其他集群节点
- slave发现自己的master变为
-
问题:如果重新选举时出现同一时刻多个slave发送请求给master节点进行选举,可能会出现选举失败,而且还可能会多次失败,如果避免此问题- 延迟每个节点发送重新选举的时间:
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms- SLAVE_RANK
- 表示slave已经从master复制数据的总量的rank,rank越小代表已经复制的数据越新(
理论上持有最新数据的slave将会首先发起选举)
- 表示slave已经从master复制数据的总量的rank,rank越小代表已经复制的数据越新(
- SLAVE_RANK
- 延迟每个节点发送重新选举的时间:
Redis集群脑裂数据丢失问题
-
Redis集群没有过半机制会有脑裂问题 -
网络分区导致脑裂后出现多个主节点对外提供写服务,一旦网络恢复,会将其中一个主节点变成从节点,(
因为从节点初始化或启动时会删除本地的所有数据,然后再从主节点同步数据)这时会有大量数据丢失 -
解决方案: min-replicas-to-write 1,写数据成功的前提是最少同步的slave节点数,这种机制类似zookeeper的zab机制,比如集群共三个,加上master就是2个节点,超过半数-
注意:脑裂问题的解决方案有个弊端,如果需要至少一个slave节点同步数据成功才算成功的话,就可能引发另一个问题,Redis本就是AP机制(可以看CAP机制),如果改变这样的机制,使其成为CP机制,一旦slave节点写入失败,就会造成Redis返回失败,就牺牲了可用性,这样就违背了Redis的初衷CAP含义- C表示一致性,访问所有的节点得到的数据应该是一样的
- A表示可用性,所有的节点都保持高可用性
- P表示分区容错性,这里的分区是指网络意义上的分区,由于网络是不可靠的,所有节点之间很可能出现无法通讯的情况,在节点不能通信时,要保证系统可以继续正常服务
-

-
分析: Redis和Zookeeper的脑裂问题以及解决方案都很类似,都是需要半数或半数以上数据同步成功才能避免脑裂问题
-
-
集群是否只有在完整的情况才能对外提供服务
- 当Redis的配置文件中
cluster-require-full-coverage no时,表示当负责一个插槽的主库下线且没有相应的从库进行故障恢复时,集群仍然可用,如果为yes则集群不可用。
- 当Redis的配置文件中
-
问题: Redis集群为什么至少需要三个master节点,并且推荐节点数为奇数-
因为新master的选举需要大于半数的集群master节点同意才能选举成功,如果只有两个master节点,其中一个挂了,是达不到选举新的master的条件的
-
3个master节点和4个master节点的场景 -
奇数master节点可以在满足选举该条件的基础上节省一个节点
- 3个或者4个master节点如果挂了一个节点,是可以重新选举新的master节点
- 3个或4个master节点如果挂了两个节点,就都无法选举出新的master节点了(
无法满足半数以及以上)
-
所以
奇数的master节点更多的是从节省机器资源角度出发的
-
-
Redis集群对大批量操作命令的支持
-
Redis集群支持将key落到同一个slots中
-
解决方案: 数据分片时,hash计算的只会是大括号里的值,确保不同的key落到同一个slots中 -
例子- **mset {user1}:1:name linc {user1}:1:age 18 **
-
-
Redis集群架构下的数据倾斜问题如何解决-
使用本地缓存
-
使用分片算法的特性,对key进行打散处理
-
big key形成集群数据倾斜,对big key进行拆分
-
总结
-
问题: Redis的主从复制原理-
从节点每次都会向主节点发送psync同步指令,如果是首次连接,主节点会开启bgsave子线程进行全量数据复制并且生成rdb文件,并且在持久化期间会将从节点新的写命令缓存下来,当持久化结束后,主节点将rdb文件同步给从节点进行持久化,如果同步期间存在网络波动,从节点会进行重连,恢复连接后,主节点会将部分缺失的数据同步给从节点
-
问题: 主从复制会有什么问题- 主从复制会带来主从复制风暴问题
- 如果有很多从节点,为了缓解主从
复制风暴(多个节点同时复制主节点导致主节点压力过大),我们可以让部分从节点与从节点(与主节点同步)同步数据,也就是分层结构
- 如果有很多从节点,为了缓解主从
- 主从复制会带来主从复制风暴问题
-
-
问题: 哨兵模式的缺陷哨兵模式不适合线上高并发场景,主从切换会导致访问瞬断,以及只是监控master节点,并不做转发,最终还是单节点master提供访问,性能并没有提升多少高可用集群模式不仅很好的弥补了哨兵模式的缺点,而且还具备了哨兵模式的选举机制,所以推荐在生产环境使用
-
问题: Redis集群的数据是怎么存储的- Redis集群的
所有数据被划分到16384个槽位中,并且每个节点管理一部分的槽位,而到客户端连接集群的时候会去缓存一份槽位信息方便定位到目标节点,但是缓存的槽位信息可能会存在数据不一致的问题,所以Redis集群提供了纠错机制,当客户端通过槽位信息去定位目标节点的时候发现异常,集群会帮忙纠错并且重定位到目标节点以及缓存一份新的槽位信息给客户端 - 定位是通过CRC算法进行位运算的
- Redis集群的
-
问题: ZK和Redis的通信机制- ZK是集中式存储数据的,时效性好,但是会有数据存储压力,Redis是gossip协议的,数据存储被分散开了,时效性稍微滞后
-
问题: Redis集群选举原理当slave发现自己的master挂掉了,就会尝试进行故障转移,期待自己成为新的master,首先会将自己记录集群的epoch进行加1,并且广播通知给其他存活的master节点,让他们来判断请求者是否合法,如果合法,就只会给每一个epoch发送一次ack,尝试故障转移的slave收到超过一半的master节点的同意的ack信息,就会成为新的master,然后广播通知其他集群的节点自己成为新的master了注意: 建议设置3个以上的奇数master节点问题: Redis集群为什么至少需要三个master节点,并且推荐节点数为奇数- 因为新master的选举需要大于半数的集群master节点同意才能选举成功,如果只有两个master节点,其中一个挂了,是达不到选举新的master的条件的
- 例子
3个master节点和4个master节点的场景- 奇数master节点可以在满足选举该条件的基础上节省一个节点
- 3个或者4个master节点如果挂了一个节点,是可以重新选举新的master节点
- 3个或4个master节点如果挂了两个节点,就都无法选举出新的master节点了(
无法满足半数以及以上)
- 所以
奇数的master节点更多的是从节省机器资源角度出发的
问题:如果重新选举时出现同一时刻多个slave发送请求给master节点进行选举,可能会出现选举失败,而且还可能会多次失败,如果避免此问题- 集群选举并不一定是一次就能成功的,假如同一时刻有多个slave节点发送信息给maste节点,master节点可能会同时发送到所有slave节点,如果slave节点收到的结果都是各自持有一票,这样就会再次重新选举,我们可以通过参数设置slave发送信息给master的时间,避免让所有slave同一时刻发送信息
-
问题: Redis集群的脑裂问题Redis集群没有过半机制会有脑裂问题网络分区导致出现多个master节点,一旦网络恢复了,会将其中一个master变成slave,而变成从节点后会将从节点本地数据清空,同步master节点的rdb快照数据- 如果变成slave节点的,服务数据是最新的,而另外一个master节点不是最新的,这样
直接从master同步数据,就会出现数据丢失问题 - Redis也有解决脑裂问题的方案,但是是牺牲性能换来的,可以通过设置参数,让半数节点数据同步成功之后才能响应客户端,避免脑裂问题,但是性能却大大降低了,这个其实就违背了Redis的AP机制
Redis和ZK的脑裂问题以及解决方案都很类似,都是需要半数或半数以上数据同步成功才能避免脑裂问题问题: CAP理论- CAP理论是分布式领域⾮常重要的⼀个理论,很多分布式中间件在实现时都需要遵守这个理论
- C表示⼀致性:指的的是分布式系统中的数据的⼀致性
- A表示可⽤性:表示分布式系统是否正常可⽤
- P表示分区容错性:表示分布式系统出现⽹络问题时的容错性
- CAP理论是指在分布式系统中不能同时保证C和A,也就是说在分布式系统中要么保证CP,要么保证 AP,也就是⼀致性和可⽤性只能取其⼀,如果想要数据的⼀致性,那么就需要损失系统的可⽤性,如果需要系统⾼可⽤,那么就要损失系统的数据⼀致性,特指强⼀致性
- CAP理论太过严格,在实际⽣产环境中更多的是使⽤BASE理论,BASE理论是指分布式系统不需要保证数据的强⼀致,只要做到最终⼀致,也不需要保证⼀直可⽤,保证基本可⽤即可
- CAP理论是分布式领域⾮常重要的⼀个理论,很多分布式中间件在实现时都需要遵守这个理论
-
问题: Redis集群架构下的数据倾斜问题如何解决-
使用本地缓存 -
使用分片算法的特性,对key进行打散处理 -
big key形成集群数据倾斜,
对big key进行拆分
-
相关文章:
Redis主从、哨兵、Redis Cluster集群架构
Redis主从、哨兵、Redis Cluster集群架构 Redis主从架构 Redis主从架构搭建 主从搭建的问题 如果同步数据失败,查看log日志报错无法连接,检查是否端口未开放出现”Error reply to PING from master:...“日志,修改参数protected-mode no …...

Javascript 运算符、流程控制语句和数组
【三】运算符 【1】算数运算符 (1)分类 加减乘除:*/取余:%和python不一样的点:没有取整// (2)特殊的点 只要NaN参与运算得到的结果也是NaNnull转换成0,undefined转换成NaN 【2…...

电机驱动死区时间
电机驱动死区时间 电机驱动死区时间死区时间(Dead Time)自己话补充说明 电机驱动死区时间 电机驱动死区时间一般在几纳秒到几微秒之间,具体长度取决于所使用的电子器件。 一、什么是电机驱动死区时间? 电机驱动死区时间指的是在电…...

图像的压缩感知的MATLAB实现(第3种方案)
前面介绍了两种不同的压缩感知实现: 图像压缩感知的MATLAB实现(OMP) 压缩感知的图像仿真(MATLAB源代码) 上述两种方法还存在着“速度慢、精度低”等不足。 本篇介绍一种新的方法。 压缩感知(Compressed S…...
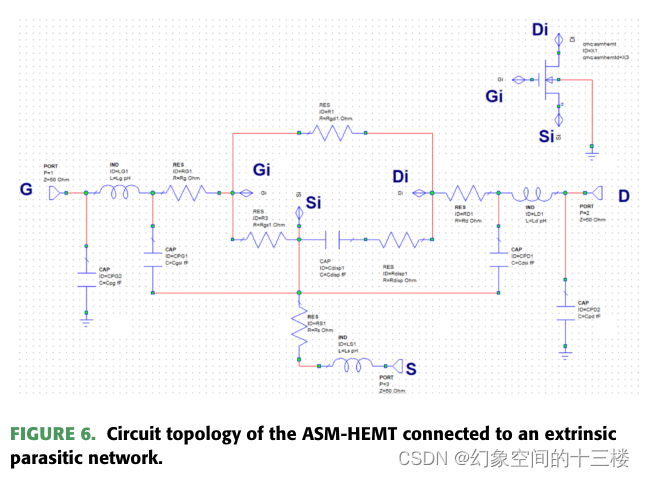
高温应用中GaN HEMT大信号建模的ASM-HEMT
来源:An ASM-HEMT for Large-Signal Modeling of GaN HEMTs in High-Temperature Applications(JEDS 23年) 摘要 本文报道了一种用于模拟高温环境下氮化镓高电子迁移率晶体管(GaN HEMT)的温度依赖性ASM-HEMT模型。我…...

文件上传---->生僻字解析漏洞
现在的现实生活中,存在文件上传的点,基本上都是白名单判断(很少黑名单了) 对于白名单,我们有截断,图片马,二次渲染,服务器解析漏洞这些,于是今天我就来补充一种在upload…...

Ubuntu中Python3找不到_sqlite3模块
今天跑一个代码,出现了一个找不到sqlite3模块的错误,错误如下: from _sqlite3 import * ModuleNotFoundError: No module named _sqlite3 网上查资料说,因为python3没有自带sqlite3相关方面的支持,要自己先安装然后再重新编译Py…...

HarmonyOS4.0系统性深入开发37 改善布局性能
改善布局性能 Flex为采用弹性布局的容器。容器内部的所有子元素,会自动参与弹性布局。子元素默认沿主轴排列,子元素在主轴方向的尺寸称为主轴尺寸。 在单行布局场景下,容器里子组件的主轴尺寸长度总和可能存在不等于容器主轴尺寸长度的情况…...

Internet协议
文章目录 Internet协议网络层协议IPV4协议IP地址:IPv4数据报格式IP数据报的封装和分片 Internet路由协议路由信息协议RIP开放最短路径优先协议OSPF外部网关协议BGP组播协议PIM和MOSPF ARP和RARPARP协议:RARP协议: Internet控制报文协议ICMPIP…...
深度学习基础(一)神经网络基本原理
之前的章节我们初步介绍了机器学习相关基础知识,目录如下: 机器学习基础(一)理解机器学习的本质-CSDN博客 机器学习基础(二)监督与非监督学习-CSDN博客 机器学习基础(四)非监督学…...

2024年2月22日 - mis
rootyy3568-alip:/sys# ls /sys/class/gpio/gpio* -F /sys/class/gpio/gpio114 /sys/class/gpio/gpiochip511 /sys/class/gpio/gpiochip0 /sys/class/gpio/gpiochip64 /sys/class/gpio/gpiochip128 /sys/class/gpio/gpiochip96 /sys/class/gpio/gpiochip32符号表示该文…...
【字符串处理】)
拼接 URL(C 语言)【字符串处理】
题目来自于博主算法大师的专栏:最新华为OD机试C卷AB卷OJ(CJavaJSPy) https://blog.csdn.net/banxia_frontend/category_12225173.html 题目 给定一个 url 前缀和 url 后缀 通过,分割 需要将其连接为一个完整的 url 如果前缀结尾和后缀开头都…...
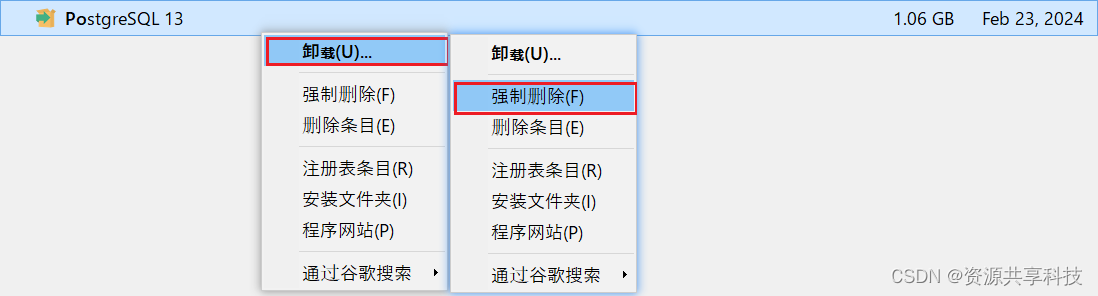
故障排除:Failed to load SQL Modules into database Cluster
PostgreSQL 安装和故障排除 重新安装前的准备工作 在重新安装 PostgreSQL 之前,确保完成以下步骤: 重新卸载 PostgreSQL 并重启电脑。 删除以下目录: C:\Program Files\PostgreSQL\13C:\Users\admin\AppData\Roaming\pgadmin 重启安装过…...
)
【超详细】HIVE 日期函数(当前日期、时间戳转换、前一天日期等)
文章目录 相关文献常量:当前日期、时间戳前一天日期、后一天日期获取日期中的年、季度、月、周、日、小时、分、秒等时间戳转换时间戳 to 日期日期 to 时间戳 日期之间月、天数差 作者:小猪快跑 基础数学&计算数学,从事优化领域5年&#…...
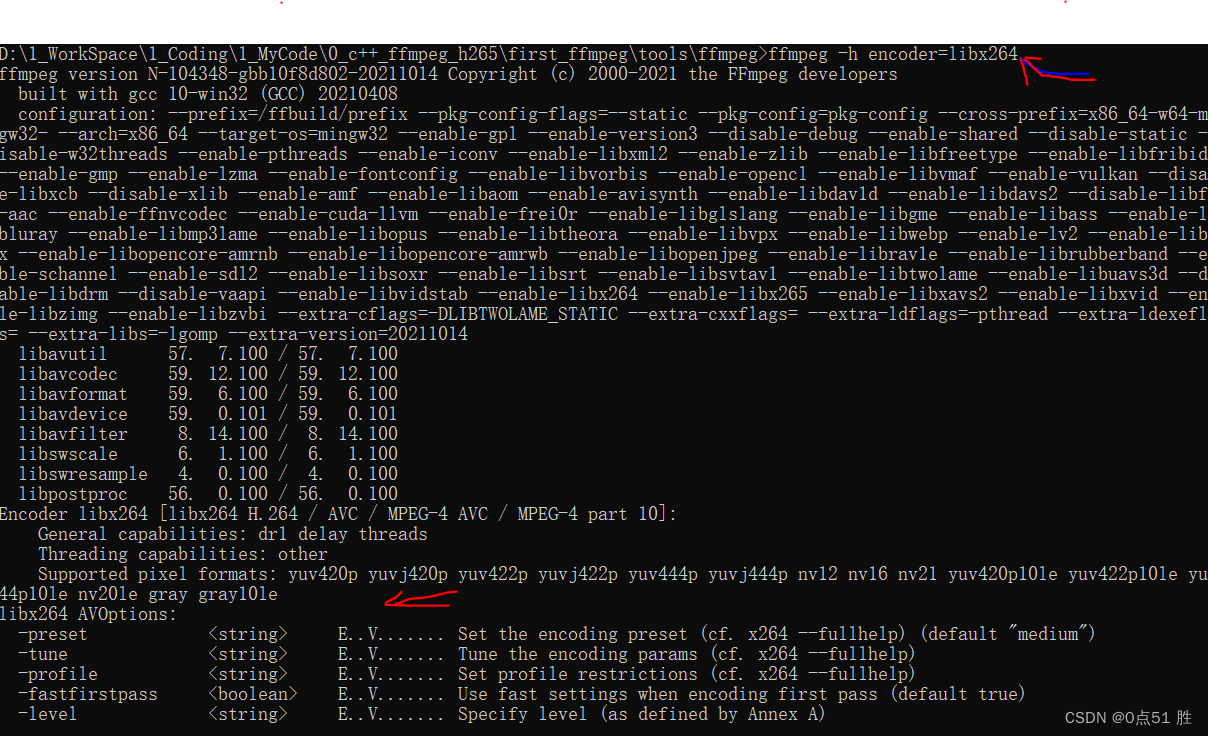
[ffmpeg] x264 配置参数解析
背景 创建 x264 编码器后,其有一组默认的编码器配置参数,也可以根据需要修改参数,来满足编码要求。 具体参数 可修改的参数,比较多,这边只列举一些常用的。 获取可以配置的参数 方式1 查看 ffmpeg源码 libx264.c…...
GO语言基础总结
多态: 定义一个父类的指针(接口),然后把指针指向子类的实例,再调用这个父类的指针,然后子类的方法被调用了,这就是多态现象。 Golang 高阶 goroutine 。。。。。 channel channel的定义 …...
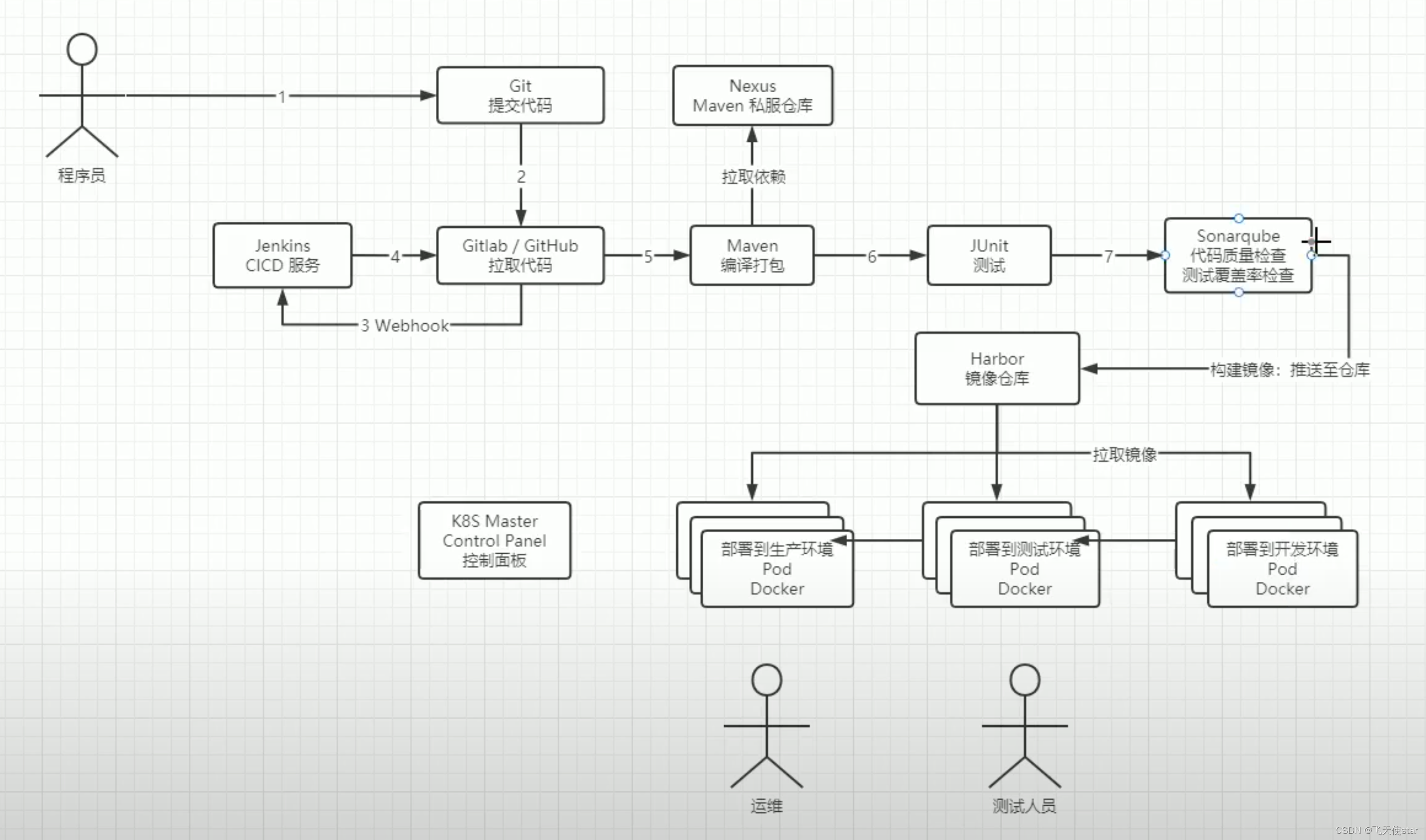
飞天使-linux操作的一些技巧与知识点7-devops
文章目录 简述devopsCICD 简述devops 让技术团队,运维,测试等团队实现一体式流程自动化 进阶版图 CICD 持续集成, 从编译,测试,发布的完成自动化流程 持续交付,包含持续集成,并且将项目部署…...

Sora:视频生成模型作为世界模拟器
我们探索了视频数据上生成模型的大规模训练。具体来说,我们在可变持续时间、分辨率和长宽比的视频和图像上联合训练文本条件扩散模型。我们利用了一个在视频和图像潜在码的时空块上操作的变压器架构。我们规模最大的模型 Sora 能够生成一分钟的高保真视频。我们的结…...
FairyGUI × Cocos Creator 3.x 使用方式
前言 上一篇文章 FariyGUI Cocos Creator 入门 简单介绍了FairyGUI,并且按照官方demo成功在Cocos Creator2.4.0上运行起来了。 当我今天使用Creator 3.x 再引入2.x的Lib时,发现出现了报错。 这篇文章将介绍如何在Creator 3.x上使用fgui。 引入 首先&…...

基于Java的养生健康管理系统
物质生活的丰富而使得人们已经不仅仅满足于吃饱而向着吃好、吃健康的方向阔步前进。生活方式的改变使人们在日常摄入了大量的营养却没有足够的运动进行消耗,因此而导致肥胖成为当前城市生活的主要标志,而高血压、糖尿病等慢性疾病也在偷偷吞噬着人们健康…...

2026年南京本地实测整理,值得入手的高性价比全屋定制品牌推荐
讲真,南京准备装房子、换柜子的姊妹们、老少爷们,谁没为全屋定制头大过?刚收了江北核心区的新房,还是鼓楼老破小准备翻新,跑了三五家门店就会发现:水太深了!低价套餐勾你进去,签约后…...

小微团队如何利用 Taotoken 统一管理多个 AI 模型密钥与用量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 小微团队如何利用 Taotoken 统一管理多个 AI 模型密钥与用量 对于小型开发或产品团队而言,在项目开发中集成多个大语言…...

https://github.com/langgenius/dify查看设置的apikey
现在我已经掌握了足够的信息,来做一个完整清晰的分析。好的,现在我来给出一个完整的分析。 Dify provider_model_credentials.encrypted_config 解密分析 整体加密架构 Dify 使用 PKCS1_OAEP 加密来保护 API key。每个用户(tenant)…...

完整掌握yuzu模拟器:专业级Switch游戏体验优化指南
完整掌握yuzu模拟器:专业级Switch游戏体验优化指南 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu yuzu模拟器作为目前最成熟的任天堂Switch开源模拟器,为PC玩家提供了在电脑上畅玩Switch游…...

Paperless-ngx终极指南:如何打造智能文档管理系统的完整解决方案
Paperless-ngx终极指南:如何打造智能文档管理系统的完整解决方案 【免费下载链接】paperless-ngx A community-supported supercharged document management system: scan, index and archive all your documents 项目地址: https://gitcode.com/GitHub_Trending/…...

基于Agentify框架构建AI智能体:从核心原理到实战应用
1. 项目概述:从代码仓库到智能体构建平台最近在开源社区里,一个名为harindukavishka/agentify的项目引起了我的注意。乍一看,这只是一个GitHub上的代码仓库,但当你点进去,深入其文档和代码结构,你会发现它远…...

为什么92%的开发者首次调用PlayAI翻译API会触发token溢出?3步诊断清单+4类典型错误码速查表
更多请点击: https://intelliparadigm.com 第一章:PlayAI多语种同步翻译功能详解 PlayAI 的多语种同步翻译功能基于端到端神经机器翻译(NMT)架构,支持实时语音流输入与毫秒级文本输出,覆盖中、英、日、韩…...

STFT音高迁移:C++实现音频变调不变速的核心原理与工程实践
1. 项目概述:音频处理的“时间魔法师”如果你玩过音乐制作或者做过音频分析,肯定遇到过这样的场景:一段人声录音的音调有点低,你想把它调高一点,但又不想改变它说话的速度和节奏感。或者反过来,一段背景音乐…...

Taotoken用量看板如何帮助团队清晰管理API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队清晰管理API成本 作为团队的技术负责人,在引入大模型能力支持多个业务项目时,…...

告别官网SDK的迷茫:手把手教你为MSP430f5529在CCS中搭建‘私人定制’开发环境
告别官网SDK的迷茫:手把手教你为MSP430f5529在CCS中搭建‘私人定制’开发环境 嵌入式开发者常陷入这样的困境:每次新建项目都要重复配置开发环境,不仅浪费时间,还容易因配置不一致导致各种奇怪的问题。对于MSP430f5529这样的经典型…...