5.2 Ajax 数据爬取实战
目录
1. 实战内容
2、Ajax 分析
3、爬取内容
4、存入MySQL 数据库
4.1 创建相关表
4.2 数据插入表中
5、总代码与结果
1. 实战内容
爬取Scrape | Movie的所有电影详情页的电影名、类别、时长、上映地及时间、简介、评分,并将这些内容存入MySQL数据库中。
2、Ajax 分析
根据上一篇文章5.1 Ajax数据爬取之初介绍-CSDN博客,找到详情页的数据包,如下:
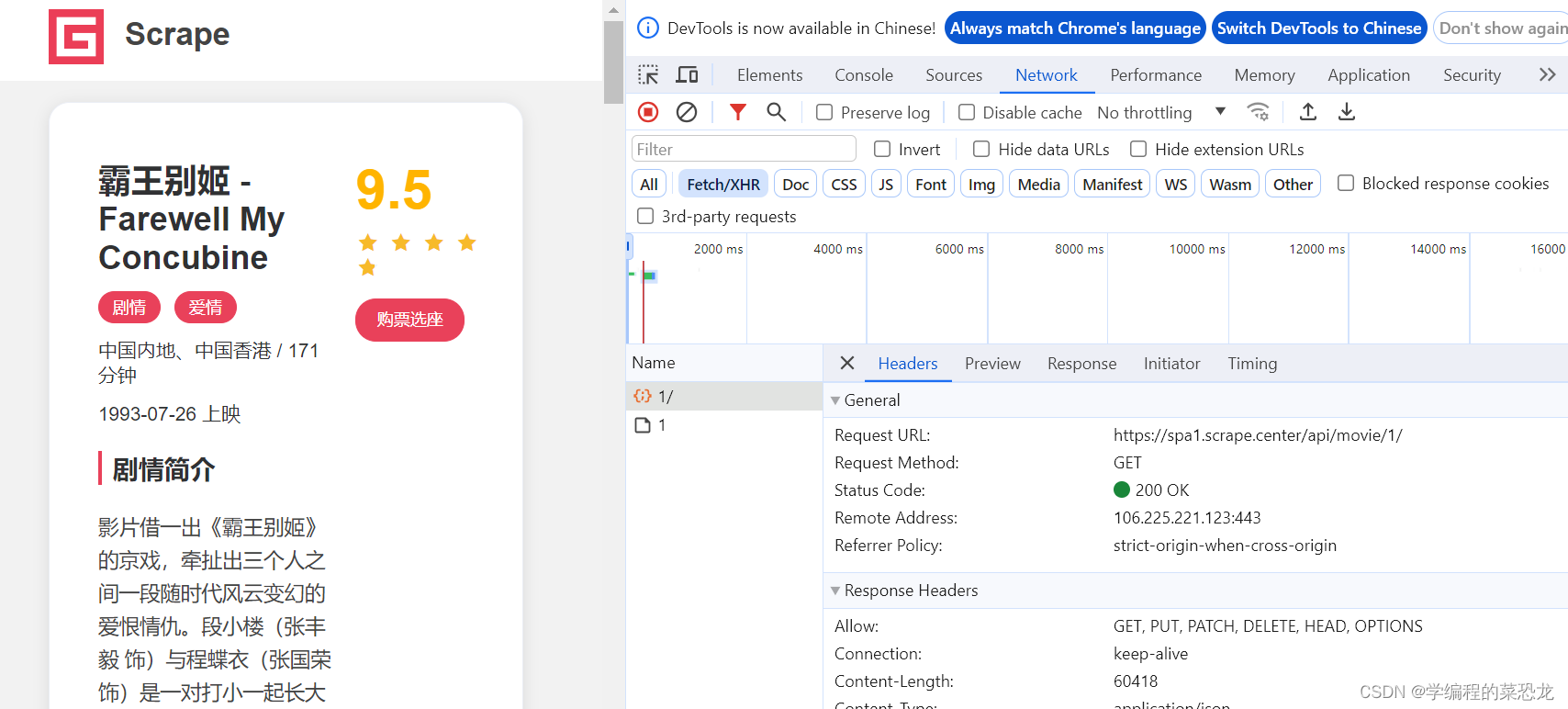
根据数据包,会发现其中 Response中有我们想要的内容。查看其及其他页的Request URL,发现其规律,只需改变后面的数字,构造链接,即可一一爬取信息。
Response中想要的内容如下(为Response部分内容截图):


等等,不难发现此内容以字典的形式呈现在我们眼前。
3、爬取内容
所以用 eval() 将字符串形式的 content 转换为字典,方便提取信息。将提取的信息汇合成字典,便于传递、存入MySQL数据库。
在爬取的过程中,会发现一些电影数据不完整,会造成错误使得程序崩溃,所以使用try...except...去避免。
import requestsdef crawler(url):response = requests.get(url)content = response.textcontent = eval(content)name = content['name']alias = content['alias'] # 外文名categories = content['categories']cate = ','.join(categories) # 电影种类regions = content['regions']region = ','.join(regions) # 地点publish_time = content['published_at']score = content['score']minute = content['minute'] # 时长drama = content['drama']# print(name, alias, cate, region, publish_time, score, minute, drama)movie_dict = {'name': name,'alias': alias,'cate': cate,'region': region,'publish_time':publish_time,'minute': minute,'score': score,'drama': drama}print(movie_dict)if __name__ == '__main__':last = 100for i in range(1, last+1):url = f'https://spa1.scrape.center/api/movie/{i}/'try:crawler(url)except NameError:print(f'链接{url}数据不完整')
以第一个详情页为例子展现输出结果:

之后,我们可以根据结果存入MySQL数据库。
4、存入MySQL 数据库
4.1 创建相关表
要存入数据库前,要根据字典的键创建相关表,之后才能存入表中。创建表可以在爬取数据之前创建,不需要每次循环创建一次。
相关代码见 create_table() 函数,**mysql_local 用法见上一篇文章5.1 Ajax数据爬取之初介绍-CSDN博客
def creat_table():conn = pymysql.connect(**mysql_local)cursor = conn.cursor()sql = ('CREATE TABLE IF NOT EXISTS movie(id INT AUTO_INCREMENT PRIMARY KEY,''name VARCHAR(100) ,''alias VARCHAR(100) ,''cate VARCHAR(100) ,''region VARCHAR(100) ,''publish_time DATE,''minute VARCHAR(100),''score VARCHAR(100),''drama TEXT)') # 文本内容cursor.execute(sql)conn.close()sql语句创建表具体可见4.4 MySQL存储-CSDN博客
4.2 数据插入表中
使用 insert_movie() 函数插入字典数据,具体解析可见4.4 MySQL存储-CSDN博客
def insert_movie(movie_dict):conn = pymysql.connect(**mysql_local)cursor = conn.cursor()keys = ','.join(movie_dict.keys())values = ','.join(['%s'] * len(movie_dict))sql = f'INSERT INTO movie({keys}) VALUES ({values})'# print(sql)# print(tuple(movie_dict.values()))cursor.execute(sql, tuple(movie_dict.values()))conn.commit()conn.close()
5、总代码与结果
import requests
import pymysql
from mysql_info import mysql_localdef creat_table():conn = pymysql.connect(**mysql_local)cursor = conn.cursor()sql = ('CREATE TABLE IF NOT EXISTS movie(id INT AUTO_INCREMENT PRIMARY KEY,''name VARCHAR(100) ,''alias VARCHAR(100) ,''cate VARCHAR(100) ,''region VARCHAR(100) ,''publish_time DATE,''minute VARCHAR(100),''score VARCHAR(100),''drama TEXT)')cursor.execute(sql)conn.close()def insert_movie(movie_dict):conn = pymysql.connect(**mysql_local)cursor = conn.cursor()keys = ','.join(movie_dict.keys())values = ','.join(['%s'] * len(movie_dict))sql = f'INSERT INTO movie({keys}) VALUES ({values})'# print(sql)# print(tuple(movie_dict.values()))cursor.execute(sql, tuple(movie_dict.values()))conn.commit()conn.close()def crawler(url):response = requests.get(url)content = response.textcontent = eval(content)# id = content['id']name = content['name']alias = content['alias'] # 外文名categories = content['categories']cate = ','.join(categories)regions = content['regions']region = ','.join(regions)publish_time = content['published_at']score = content['score']minute = content['minute']drama = content['drama']# print(name, alias, cate, region, publish_time, score, minute, drama)movie_dict = {# 'id': id,'name': name,'alias': alias,'cate': cate,'region': region,'publish_time':publish_time,'minute': minute,'score': score,'drama': drama}# print(movie_dict)insert_movie(movie_dict)if __name__ == '__main__':creat_table()last = 100for i in range(1, last+1):url = f'https://spa1.scrape.center/api/movie/{i}/'try:crawler(url)except NameError:print(f'链接{url}数据不完整')
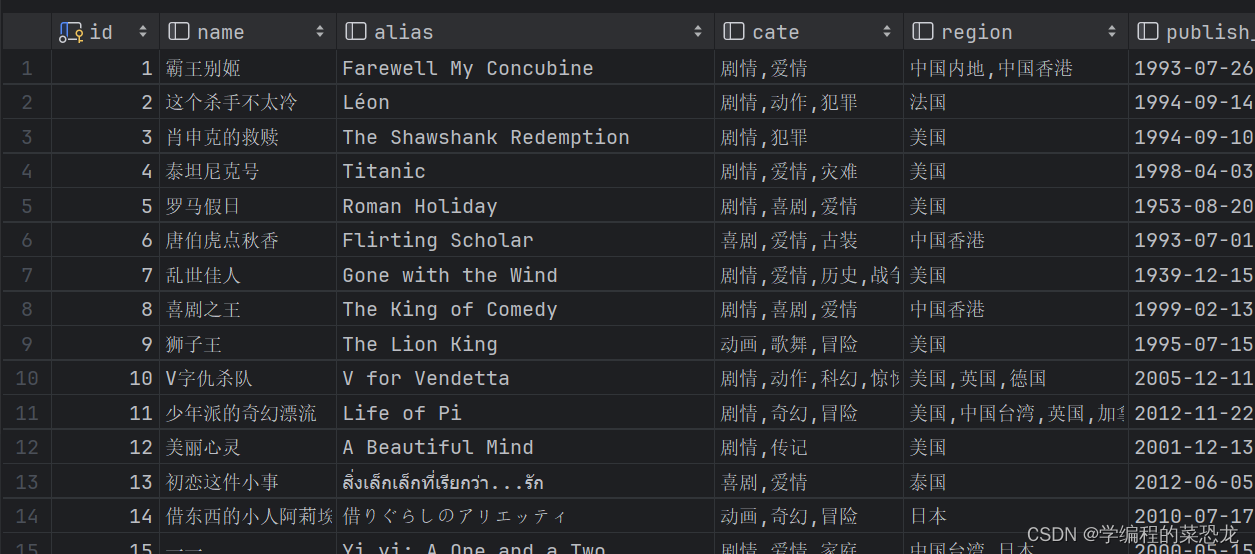
mysql数据库部分内容:
本人新手,若有错误,欢迎指正;若有疑问,欢迎讨论。若文章对你有用,点个小赞鼓励一下,谢谢,一起加油吧!
相关文章:
5.2 Ajax 数据爬取实战
目录 1. 实战内容 2、Ajax 分析 3、爬取内容 4、存入MySQL 数据库 4.1 创建相关表 4.2 数据插入表中 5、总代码与结果 1. 实战内容 爬取Scrape | Movie的所有电影详情页的电影名、类别、时长、上映地及时间、简介、评分,并将这些内容存入MySQL数据库中。 2、…...
)
276.【华为OD机试真题】矩阵匹配(二分法—JavaPythonC++JS实现)
🚀点击这里可直接跳转到本专栏,可查阅顶置最新的华为OD机试宝典~ 本专栏所有题目均包含优质解题思路,高质量解题代码(Java&Python&C++&JS分别实现),详细代码讲解,助你深入学习,深度掌握! 文章目录 一. 题目-矩阵匹配二.解题思路三.题解代码Python题解代码…...
java——多线程基础
目录 线程的概述多线程的创建方式一:继承Thread类方式二:实现Runnable接口方式三:利用Callable接口、FutureTask类来实现。Thread常用的方法 线程安全问题线程安全问题概述线程安全问题案例取钱案例描述模拟代码如下:执行结果 线程…...

Python服务器监测测试策略与工具:确保应用的高可用性!
在构建高可用性的应用程序时,服务器监测测试是至关重要的一环。Python作为一种强大的编程语言,提供了丰富的工具和库来帮助我们进行服务器监测测试。本文将介绍一些关键的策略和工具,帮助你确保应用的高可用性。 1. 监测策略的制定ÿ…...
Spring Security源码学习
Spring Security本质是一个过滤器链 过滤器链本质是责任链设计模型 1. HttpSecurity 【第五篇】深入理解HttpSecurity的设计-腾讯云开发者社区-腾讯云 在以前spring security也是采用xml配置的方式,在<http>标签中配置http请求相关的配置,如用户…...

大数据面试总结三
1、hdfs作为分布式存储系统,底层的实现的方式(可能不正确) 1、底层是一个分布式存储的,底层会将数据进行切分多个block块(128M),并存储在不同的节点上面,这种分布式方式有助于提高数…...

AI赚钱套路总结和教程
最近李一舟和Sora 很火,作为第一批使用Sora赚钱的男人,一个清华学美术的跟人讲AI,信的人太多了,钱太好赚了。3年时间,李一舟仅通过卖课就赚了1.75亿元,其中《每个人的人工智能课》收入2786万元,…...

Linux安装jdk、tomcat、MySQL离线安装与启动
一、JDK和Tomcat的安装 1.JDK安装 直接上传到Linux服务器的,上传jdk、tomcat安装包 解压JDK安装包 //解压jdk tar -zxvf jdk-8u151-linux-x64.tar.gz 置环境变量(JAVA_HOME和PATH) vim /etc/profile 在文件末尾添加以下内容: //java environment expo…...

Python爬虫-使用代理伪装IP
爬虫系列:http://t.csdnimg.cn/WfCSx 前言 我们在做爬虫的过程中经常会遇到这样的情况,最初爬虫正常运行,正常抓取数据,一切看起来都是那么的美好,然而一杯茶的功夫可能就会出现错误,比如 403 Forbidden&…...

Typora结合PicGo + 使用Github搭建个人免费图床
文章目录 一、国内图床比较二、使用Github搭建图床三、PicGo整合Github图床1、下载并安装PicGo2、设置图床3、整合jsDelivr具体配置介绍 4、测试5、附录 四、Typora整合PicGo实现自动上传 每次写博客时,我都会习惯在Typora写好,然后再复制粘贴到对应的网…...

【Redis】redis简介与安装
Redis 简介 Redis 是完全开源的,遵守 BSD 协议(Berkeley Software Distribution 意思是"伯克利软件发行版),是一个高性能的 key-value 数据库。具有以下几个比较明显的特点: 性能极高 – Redis能读的速度可以达…...

【xss跨站漏洞】xss漏洞利用工具beef的安装
安装环境 阿里云服务器,centos8.2系统,docker docker安装 前提用root用户 安装docker yum install docker 重启docker systemctl restart docker beef安装 安装beef docker pull janes/beef 绑定到3000端口 docker run --rm -p 3000:3000 janes/beef …...

编程笔记 html5cssjs 086 JavaScript 内置对象
编程笔记 html5&css&js 086 JavaScript 内置对象 一、Object二、Array三、String四、Number五、Math六、Date七、RegExp八、Function九、示例小结 JavaScript 内置对象是 JavaScript 语言本身定义的一系列预定义的对象,这些对象在全局作用域中可以直接使用&…...

AttributeError: ‘DataFrame‘ object has no attribute ‘set_value‘怎么修改问题的解决
在jupyternotebook中运行: def remplacement_df_keywords(df, dico_remplacement, roots False):df_new df.copy(deep True)for index, row in df_new.iterrows():chaine row[plot_keywords]if pd.isnull(chaine): continuenouvelle_liste []for s in chaine.…...
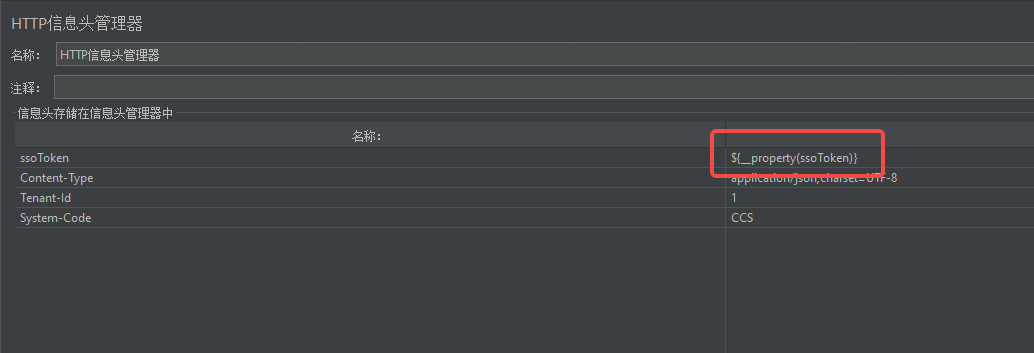
Jmeter内置变量 vars 和props的使用详解
JMeter是一个功能强大的负载测试工具,它提供了许多有用的内置变量来支持测试过程。其中最常用的变量是 vars 和 props。 vars 变量 vars 变量是线程本地变量,它们只能在同一线程组内的所有线程中使用(线程组内不同线程之间变量不共享&#…...

c#高级-正则表达式
正则表达式是由普通字符和元字符(特殊符号)组成的文字形式 应用场景 1.用于验证输入的邮箱是否合法。 2.用于验证输入的电话号码是否合法。 3.用于验证输入的身份证号码是否合法。等等 正则表达式常用的限定符总结: 几种常用的正则简写表达式…...

说说UE5中的几种字符串类
在Unreal Engine 5 (UE5) 的C中,与字符串相关的类主要包括: FString: Unreal Engine中用于处理字符串的主要类,提供了丰富的字符串操作方法和功能。 FText: 用于表示本地化文本的类,可以包含多种语言的文本…...

(done) 如何判断一个矩阵是否可逆?
参考视频:https://www.bilibili.com/video/BV15H4y1y737/?spm_id_from333.337.search-card.all.click&vd_source7a1a0bc74158c6993c7355c5490fc600 这个视频里还暗含了一些引理 1.若 AX XB 且 X 和 A,B 同阶可逆,那么 A 和 B 相似。原因࿱…...

洗眼镜用的超声波清洗机哪一家更好一点?好用超声波清洗机排名
在我们日常生活中,眼镜、首饰、手表等细小物件的清洁一直是一个让人头疼的问题。传统的清洁方法不仅耗时耗力,还可能因为不当的操作而损伤到这些精细的物品。那么,有没有一种既快捷又安全的清洁方式呢?答案就是使用超声波清洗机。…...
Flask之上下文管理第三篇【收尾—讲一讲g】)
(二十二)Flask之上下文管理第三篇【收尾—讲一讲g】
目录: 每篇前言:g到底是什么?生命周期在请求周期内保持数据需要注意的是:拓展—面向对象的私有字段深入讲解一下那句:每篇前言: 🏆🏆作者介绍:【孤寒者】—CSDN全栈领域优质创作者、HDZ核心组成员、华为云享专家Python全栈领域博主、CSDN原力计划作者🔥🔥本文已…...

月薪8K到年薪80万!这个AI职位一年暴涨985%,普通人如何抓住风口?2026年最火爆的5个岗位+3条入场路径全解析!
文章讲述了AI Agent开发工程师的兴起,年薪可达80万。文章以小李的真实故事为例,展示了通过主动学习AI技术,可以实现职业的巨大转变。文章还分析了Agentic AI的特点及其对就业市场的影响,指出40%的岗位将被重新定义。文章列举了AI …...
)
硬核手搓解析!进程-内核分析:命令行参数及环境变量,重构main()
目录 命令行参数与环境变量 命令行参数 vim下的main() 环境变量 环境变量的应用举例 查询环境变量 全部查询 针对名称查询(常用的方式) 环境变量的更改 配置环境变量 进程:命令行参数及环境变量的关系 结论 获取环境变量 ①get…...

如何用DownKyi实现B站视频自由:5个实用场景与解决方案
如何用DownKyi实现B站视频自由:5个实用场景与解决方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&#…...
)
收藏 | 从零开始学大模型:6个月完整开发路线图(附免费资源)
本文提供一份从Python基础到企业级大模型应用开发的6-8个月学习路线图,涵盖API调用、提示词工程、RAG知识库问答、Agent智能体开发及模型微调部署。结合近百份招聘需求及专家建议,适合初学者快速构建AI技能体系,附有前沿拓展方向与免费学习资…...

Ollama Operator:在Kubernetes上轻松部署与管理大语言模型
1. 项目概述:在Kubernetes上轻松部署大语言模型如果你和我一样,既对本地运行大语言模型(LLM)的便捷性着迷,又对Kubernetes集群的资源调度和弹性伸缩能力有刚需,那么你很可能也面临过一个两难的选择…...
)
ChatGPT Discord机器人开发全链路拆解(含Rate Limit绕过策略与上下文记忆优化)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT与Discord机器人开发全链路概览 构建一个能调用 ChatGPT 能力的 Discord 机器人,需跨越 API 集成、身份认证、消息路由与状态管理四大核心层。该链路并非单向调用,而是一…...

模块三-数据清洗与预处理——15. 异常值检测与处理
15. 异常值检测与处理 1. 概述 异常值(Outlier)是指与其他观测值显著不同的数据点。它们可能来自测量错误、数据录入错误,也可能是真实的极端情况(如高收入人群)。正确识别和处理异常值对数据分析至关重要。 import pa…...

如何轻松下载B站4K大会员视频?这款开源工具让你三步搞定离线收藏
如何轻松下载B站4K大会员视频?这款开源工具让你三步搞定离线收藏 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 想象一下…...

如何用嘎嘎降AI处理期刊投稿论文:SCI核心期刊论文全流程降AI4.8元完整操作教程
如何用嘎嘎降AI处理期刊投稿论文:SCI核心期刊论文全流程降AI4.8元完整操作教程 第一次用降AI工具会遇到很多不确定的地方——传什么格式、选哪个模式、怎么验收效果。 这篇教程把常见问题都覆盖了,主要基于嘎嘎降AI(www.aigcleaner.com&…...

Windows进程内存操作实战:ClawMem库核心原理与应用指南
1. 项目概述:一个内存操作工具箱的诞生在软件开发和逆向工程领域,对进程内存进行安全、高效、可控的读写操作,是一个既基础又充满挑战的需求。无论是为了调试、分析程序行为,还是为了实现特定的功能扩展,直接与内存打交…...