《高质量的C/C++编程规范》学习
目录
一、编程规范基础知识
1、头文件
2、程序的板式风格
3、命名规则
二、表达式和基本语句
1、运算符的优先级
2、复合表达式
3、if语句
4、循环语句的效率
5、for循环语句
6、switch语句
三、常量
1、#define和const比较
2、常量定义规则
四、函数设计
1、参数规则
2、返回值规则
3、函数内部实现规则
4、断言
五、内存管理
1、内存分配
2、指针与数组
3、free和delete
4、动态内存释放
5、内存耗尽
6、malloc和free使用
一、编程规范基础知识
1、头文件
(1)防止头文件被重复包含
首先,和大家聊一聊头文件为什么会被被重复包含呢。这一错误操作主要是因为include嵌套造成的。举个例子,在a.h文件中#include "c.h",而在b.c文件中#include "a.h"和#include "c.h"。此时,就造成了c.h重复包含。
头文件被重复引用会引起哪些后果呢?有些头文件重复引用,只是增加了编译工作的工作量,不会引起太大的问题,仅仅是编译效率低一些,但是对于大工程而言编译效率就是很重要的了;有些头文件重复包含,会引起编译错误,比如在头文件中定义了全局变量或写了函数的实现而不是声明(虽然这种方式不被推荐,但确实是C规范允许的),这种会引起重复定义。
那,么如何避免头文件被重复包含呢?我们可以使用#ifndef/#define/#endif方式,下面我们给出该用法如何来使用:
#ifndef __XXX_H__ //意思是 "if not define __XXX_H__" 也就是没包含XXX.h#define __XXX_H__ //就定义__XXX_H__... //此处放头文件中本来应该写的代码#endif //否则不需要定义 (2)引用头文件
- < >头文件:引用标准库的头文件,编译器将,从标准目录开始搜索。
- " "头文件:引用非标准库的头文件,将从用户的工作目录开始搜索,用户自己创建的头文件。
2、程序的板式风格
清晰、美观,是程序风格的重要构成因素。
(1)空行
我们在编程时可以使用空行(起着分隔程序段落的作用)。关于空行,和大家聊一下以下三点规则:空行不会浪费内存;在每个类声明之后、每个函数定义结束之后都要加空行;在一个函数体内,逻揖上密切相关的语句之间不加空行,其它地方应加空行分隔。
(2)代码行
一行代码只做一件事情,如只定义一个变量,或只写一条语句。这样的代码容易阅读,并且方便于写注释。关于代码行,主要是以下几点规则:
规则一:if、for、while、do等语句独自占一行,执行语句不得紧跟其后。不论执行语句有多少后面都要加{}。这样可以防止书写失误。
规则二:关键字之后要留空格。像 const、virtual、inline、case 等关键字之后至少要留一个空格,否则无法辨析关键字。像 if、for、while 等关键字之后应留一个空格再跟左括号‘(’,以突出关键字。
规则三:如果‘;’不是一行的结束符号,其后要留空格,如for(initialization; condition; update)。
规则四:赋值操作符、比较操作符、算术操作符、逻辑操作符、位域操作符,如“=”、“+=” “>=”、“<=”、“+”、“”、“%”、“&&”、“||”、“<<”,“^”等二元操作符的前后应当加空格。
(3)对齐
关于对齐讲两点规则:
规则一:程序的分界符‘{’和‘}’应独占一行并且位于同一列,同时与引用它们的语句左对齐。
规则二:{ }之内的代码块在‘{’右边数格处左对齐。

(4)长行拆分
每条代码行不要过长,不利于观看和打印。长表达式要在低优先级操作符处拆分成新行,操作符放在新行之首(以便突出操作符)。拆分出的新行要进行适当的缩进,使排版整齐,语句可读。

(5)修饰符
修饰符位置: * 和 & 紧靠变量名。
int* x, y; // 这样写,y容易被误解为指针变量。应该修改为int *x, y,这样y就不会再被误解成指针了。
(6)注释
如果代码本来就是清楚的,则不必加注释。否则多此一举,令人厌烦。注释的花样要少 。注释的位置应与描述的代码相邻,可以放在代码的上方或有方,不可放在下方。当代码比较长,特别是有多重循环,应当在一些段落的结束处加注释,便于阅读。
3、命名规则
Windows应用程序的标识符通常采用“大小写”混排的方式,如 AddChild。而 Unix 应用程序的标识符通常采用“小写加下划线”的方式,如 add_child。接下来讲几点常见规则:
规则一:类名和函数名用大写字母开头的单词组成。
规则二:变量和参数用小写字母开头的单词组成。
规则三:常量全用大写字母,用下划线分割单词。
规则四:静态变量加前缀s_(表示static)。
规则五:如果使用全局变量,则使全局变量加前缀g_(表示global)。
二、表达式和基本语句
1、运算符的优先级
如果代码行中的运算符比较多,用括号确定表达式的操作顺序,避免使用运算符默认的优先级。
比如:if ((a | b) && (a & c)) 2、复合表达式
关于复合表达式,在这里讲解以下三点规则:
规则一:不要编写太复杂的复合表达式。
规则二:不要有多用途的复合表达式。例如:d = (a = b + c) + r , 该表达式既求 a 值又求 d 值。应该拆分为两个独立的语句。
规则三:不要把程序中的复合表达式与“真正的数学表达式”混淆。 例如: if (a < b < c) 。在这条语句里a < b < c 是数学表达式而不是程序表达式,所以该语句并不表示 if ((a<b) && (b<c)) ;而是成了令人费解的 if ( (a<b)<c )。
3、if语句
(1)布尔变量与零值比较
不可将布尔变量直接与 TRUE、FALSE 或者 1、0 进行比较。根据布尔类型的语义,零值为“假”(记为 FALSE),任何非零值都是“真”(记为TRUE)。
假设布尔变量名字为 flag,它与零值比较的标准 if 语句如下:
- if (flag) 表示 flag 为真
- if (!flag) 表示 flag 为假
(2)整型变量与零值比较
应当将整型变量用“==”或“!=”直接与 0 比较。假设整型变量的名字为 value,它与零值比较的标准 if 语句如下:
if (value == 0)
if (value != 0)
(3)浮点变量与零值比较
不可将浮点变量用“==”或“!=”与任何数字比较。无论是 float 还是 double 类型的变量,都有精度限制。一定要避免将浮点变量用“==”或“!=”与数字比较,应该设法转化成“>=”或“<=”形式。
假设浮点变量的名字为 x,应当将if (x == 0.0)隐含错误的比较,转化为if ((x>=-EPSINON) && (x<=EPSINON)) //其中 EPSINON 是允许的误差(即精度)。EPSINON是e的负10次方,该数表示接近于0的小正数。
(4)指针变量与零值比较
应当将指针变量用“==”或“!=”与 NULL 比较。指针变量的零值是“空”(记为 NULL)。尽管NULL 的值与 0 相同但是两者意义不同。假设指针变量的名字为 p,它与零值比较的标准 if 语句如下:
if (p == NULL) // p 与 NULL 显式比较,强调 p 是指针变量 if (p != NULL)
4、循环语句的效率
本块重点讲述循环体的效率。提高循环体效率的基本办法是降低循环体的复杂性。接下来讲解两种主要规则:
规则一:在多重循环,如果有可能,应当将最长的循环放在最内层,最短的循环放在最外层,以减少cpu跨切循环层的次数。如下图所示:
for (i=0; i<5; i++ )
{for (j=0; j<100; j++) { sum = sum + a[j][i]; }
}
规则二:如果循环体内存在逻辑判断,并且循环次数很大,宜将逻辑判断移到循环体外面。如下图所示:
for (i=0; i<N; i++)
{ if (condition) DoSomething(); else DoOtherthing();
} 转化为
if (condition)
{ for (i=0; i<N; i++) DoSomething();
}
else
{ for (i=0; i<N; i++) DoOtherthing();
}
5、for循环语句
不可在for循环内修改循环变量,防止for循环失去控制。建议for循环控制变量的取值采用"半开半闭区间的写法"。如图:

6、switch语句
switch是多分支语句,格式如下:
switch (variable)
{ case value1:break; case value2: break; default:break;
}
规则一:每个case语句的结尾不要忘了加break,否则将导致多个分支重叠(除非有意使用多个分支重叠)。
规则二:不要忘记最后那个default分支。即使程序真的不需要default处理,也应该保留语句default:break;那样做并非多此一举,而是为了防止别人误以为你忘了default处理。
三、常量
1、#define和const比较
(1) const常量有数据类型,而宏常量没有类型。编译器可以对前者进行类型安全检查。而对后者只进行字符替换,没有类型安全检查,并且字符替换可能会产生意料不到的错误(边际效应)。
(2) 有些集成化的调试工具可以对const常量进行调试,但是不能对宏常量进行调试。
(3) 在c++程序中只使用const常量而不使用宏常量,即const常量完全替代宏常量。
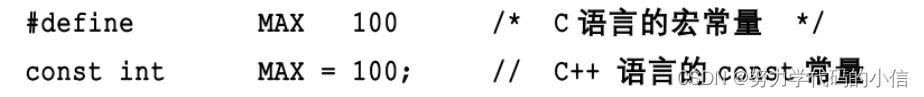
2、常量定义规则
规则一:需要对外公开的常量放在头文件中,不需要对外公开的常量在定义文件的头部。为便于管理,可以把不同模块的常量集中存放在一个公共的头文件中。
规则二:如果某一常量与其它常量密切相关,应在定义中包含这种关系,而不应给出一些孤立的值。例如:
const float RADIUS = 100;
const float DIAMETER = RADIUS * 2;
四、函数设计
函数接口的两个要素是参数和返回值。C语言中,函数的参数和返回值的传递方式有两种:值传递和指针传递。C++语言中多了引用传递(引用传递的性质像指针传递,而使用方式却像值传递)。
1、参数规则
规则一:参数的书写要完整。如果函数没有参数,则用 void 填充。
规则二:参数命名要恰当,顺序要合理。一般应将目的参数放在前面,源参数放在后面。
规则三:如果参数是指针,且仅作输入用,则应在类型前加 const,以防止该指针在函数体内被意外修改。
void StringCopy(char *strDestination,const char *strSource);
规则四:如果输入参数以值传递的方式传递对象,则宜用"const &" 方式来传递,这样可以省去临时对象的构造和分析过程,从而提高效率。
2、返回值规则
(1)不要省略返回值的类型
C语言中,凡不加类型说明的函数,一律自动按整型处理。这样做易被误认为是 void类型。C++语言有严格的类型安全检查,不允许上述情况发生。由于C++可以调用C函数,为了避免混乱,规定任何c/c++函数都必须有类型。如果函数没有返回值,那么应声明为void类型。
(2)函数名字与返回值类型在语义上不可冲突

(3) 不要将正常值和错误标志混在一起返回。正常值用输出参数获得,而错误标志用return语句返回
在正常情况下,getchar的确返回单个字符。但如果getchar碰到文件结束标志或发生读错误,它必须返回一个标志EOF。为了区别于正常的字符,只好将EOF定义为负数(通常为-1)。因此函数getchar就成了int类型。
3、函数内部实现规则
(1) 在函数的"入口处",对参数的有效性进行检查
很多程序错误是由非法参数引起的,应当充分理解并正确使用断言"assert" 来防止此类错误。
(2) 在函数的"出口处",对return语句的正确性和效率进行检查。
return语句不可返回指向"栈内存"的"指针"或者"引用",因为该内存在函数体结束时被自动销毁。强行使用,会造成非法访问(等于访问了一块不再属于你的空间)。
4、断言
程序一般分为Debug版本和Release版本,Debug版本用于内部调试,Release版本发行给用户使用。
断言assert是仅在Debug版本起作用的宏,他用于检查"不应该"发生的情况。在运行过程中assert的参数为假,那么程序就会终止。
如果程序在assert处终止了,并不是说含有该assert的函数有错误,而是调用者出了差错,assert可以帮助我们找到发生错误的原因。
(1) 使用断言捕捉不应该发生的非法情况。不要混淆非法情况与错误情况之间的区别,错误情况是必然存在的并且一定要做出处理。
(2) 在函数的入口处,使用断言检查参数的有效性(合法性)。
(3) 在编写函数时要进行反复考察,如果不可能的事情的确发生了,则要用断言进行报警。

五、内存管理
1、内存分配
内存分配方式有三种:
(1)从静态存储区域分配
内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static 变量。
(2)在栈上创建
在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
(3)从堆上分配,亦称动态内存分配
程序在运行的时候用 malloc 或 new 申请任意多少的内存,程序员自己负责在何时用 free 或 delete 释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也最多。
在这里关于内存分配不过多赘述了,对这里不熟悉的同学,推荐看这篇文章---《C语言内存空间布局》,讲解十分详细。
在简单总结一下内存分配的几种常见错误吧!
(1)内存分配未成功,却使用了它。
(2)内存分配成功,但尚未初始化就引用它。
(3)内存分配成功并且已初始化,但操作越过了内存的边界。
(4)忘了释放内存。动态内存的申请与释放必须配对,程序中malloc与free的次数一定要相同,否则肯定有错误(new与delete同理)。
(5)内存释放了却继续使用它。
2、指针与数组
(1)对比
数组在静态存储区(全局数组)或者在栈上被创建。数组名对应着(而不是指向)一块内存,其地址与容量在生命期内保持不变,只有数组的内容可以改变。
指针可以随时指向任意类型的内存块,它的特征是"可变",常用指针来操作动态内存。指针远比数组灵活,但也更危险。
(2)内容的复制与比较
不能对数组名进行直接复制与比较。若想把数组a的内容复制给数组b,应该用标准库函数strcpy进行复制。比较a与b的内容是否相等,应该也用标准库函数strcmp进行比较。
若要复制数组a的内容,应用malloc申请strlen(a)+1个字节的内存空间,再用strcpy进行字符串复制。
(3)内存容量
用运算符sizeof可以计算出数组的容量(字节数)。
C/C++没有办法知道指针所指的内存容量,除非在申请内存时记住它。
3、free和delete
free和delete只是把指针所指向的空间释放掉,但并没有把指针本身干掉。

切记要初始化指针,释放指针后要置成空指针。要么将指针设置为 NULL,要么让它指向合法的内存。例如:
char *p = NULL; *char *str = (char *) malloc(100);
4、动态内存释放

(1) 指针消亡了,并不表示他所指的内存会被自动释放。
(2) 内存被释放了,并不表示指针会消亡或者成了NULL指针。
(3)程序终止运行,一切指针都会消亡,动态内存会被操作系统回收。
5、内存耗尽
如果在申请动态内存时找不到足够大的内存块,malloc 和 new 将返回 NULL 指针,宣告内存申请失败。通常有三种方式处理“内存耗尽”问题。
(1) 判断指针是否为NULL,如果是则马上用return语句终止本函数。
(2) 判断指针是否为NUL,如果是则马上用exit(1)终止整个程序的运行。
(3) 为new和malloc设置异常处理函数。
对于 32 位以上的应用程序而言,无论怎样使用malloc 与 new,几乎不可能导致“内存耗尽”。
6、malloc和free使用
malloc函数原型如下:
int *p = (int *) malloc(sizeof(int) * length);
(1)malloc返回值是void* ,在调用malloc时要显式地进行类型转换,将void*转换成所需要的指针类型。
(2)malloc函数本身不识别要申请的内存是什么类型,他只关心内存的总字节数。
(3)在malloc的"()"中使用sizeof运算符是良好的风格。
free函数原型如下:
void free(void *memblock);为什么free函数不像malloc函数那样复杂呢?这是因为指针的类型以及它所指向的内存的容量事先都是知道的,语句free()能正确地释放内存。如果该指针是NULL指针,那么free对指针无论操作多少次都不会出现问题。如果该指针不是NULL指针,那么free连续操作两次就会导致程序运行错误。
本篇文章是我在学习林锐博士的《高质量的C/C++编程》及一些其他网络资料之后进行的一篇自我学习总结。由于对C++还不是很熟悉,所以本篇文章主要总结了C语言部分,在日后深入学习C++时,在进行详细补充。如果本篇文章哪里出现问题,感谢大家能够指正。
相关文章:
《高质量的C/C++编程规范》学习
目录 一、编程规范基础知识 1、头文件 2、程序的板式风格 3、命名规则 二、表达式和基本语句 1、运算符的优先级 2、复合表达式 3、if语句 4、循环语句的效率 5、for循环语句 6、switch语句 三、常量 1、#define和const比较 2、常量定义规则 四、函数设计 1、参…...
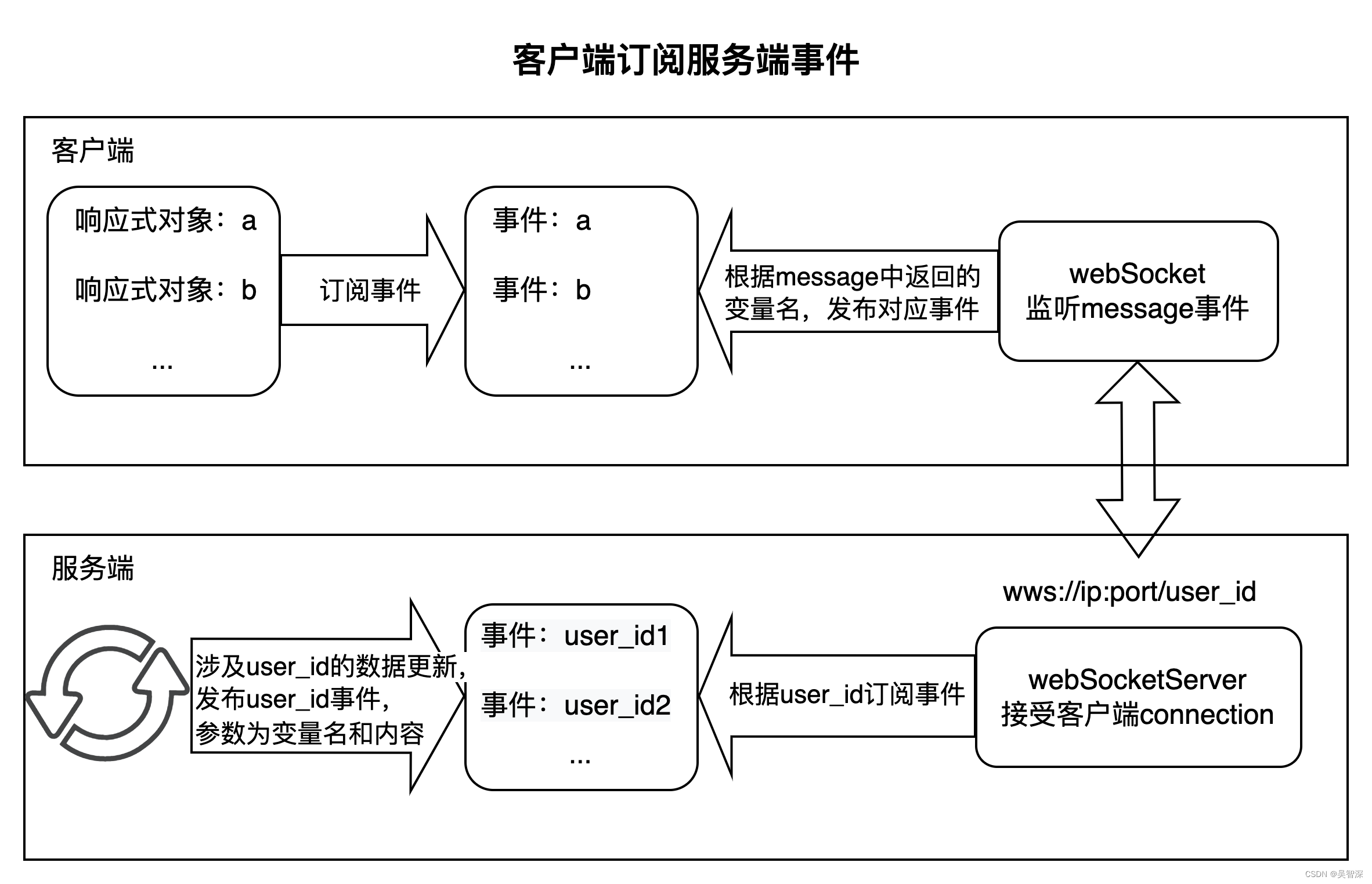
客户端订阅服务端事件的机制
一、场景描述 产业大脑平台是一个典型的审核系统,用户发布到平台的信息需要经过审核员审核后生效。 用户发布信息->审核员审核信息->用户信息生效,这一流程可能发生在用户的同一次登录周期内。为了使客户端能实时响应信息的状态变化,…...
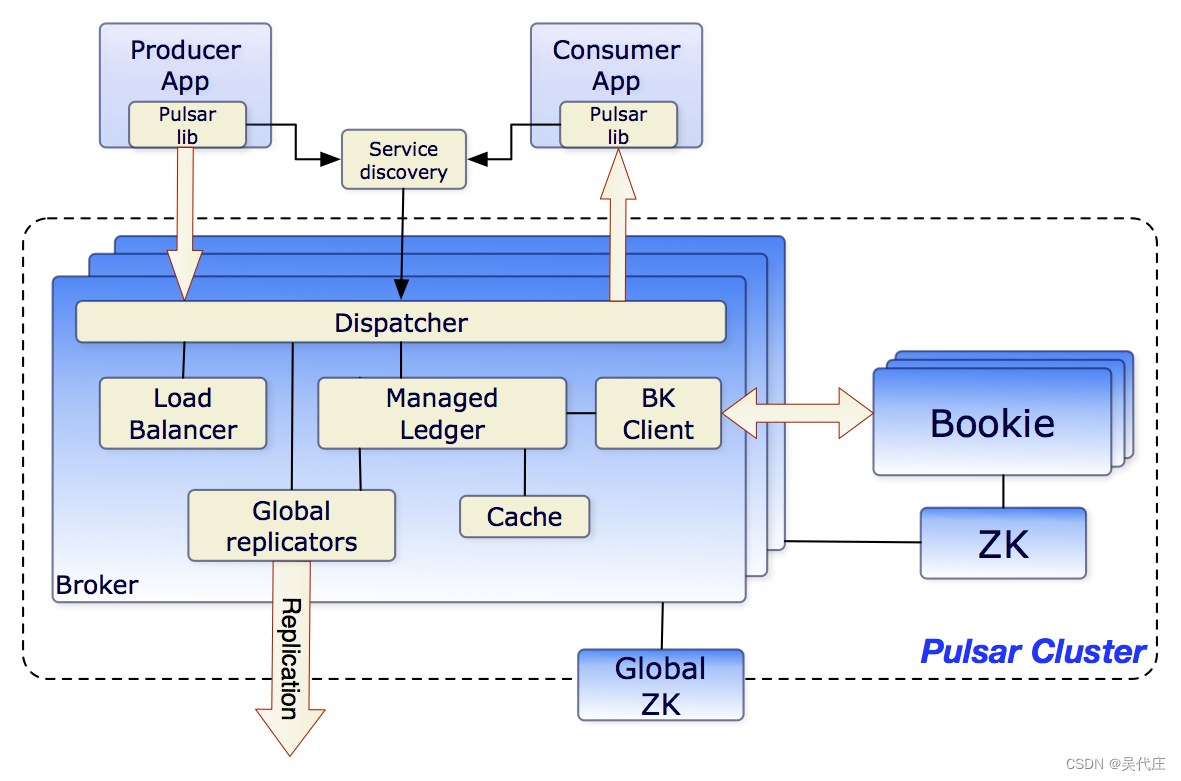
pulsar入门介绍
概述 Pulsar 是一个多租户、高性能的服务器到服务器消息传递解决方案。Pulsar 最初由 Yahoo 开发,由 Apache 软件基金会管理。 特点 Pulsar 的主要功能如下: 原生支持 Pulsar 实例中的多个集群,可跨集群无缝地复制消息。非常低的发布和端…...

Leetcode 3047. Find the Largest Area of Square Inside Two Rectangles
Leetcode 3047. Find the Largest Area of Square Inside Two Rectangles 1. 解题思路2. 代码实现 题目链接:3047. Find the Largest Area of Square Inside Two Rectangles 1. 解题思路 这道题倒是没啥特别的思路,直接暴力求解就是了,因此…...
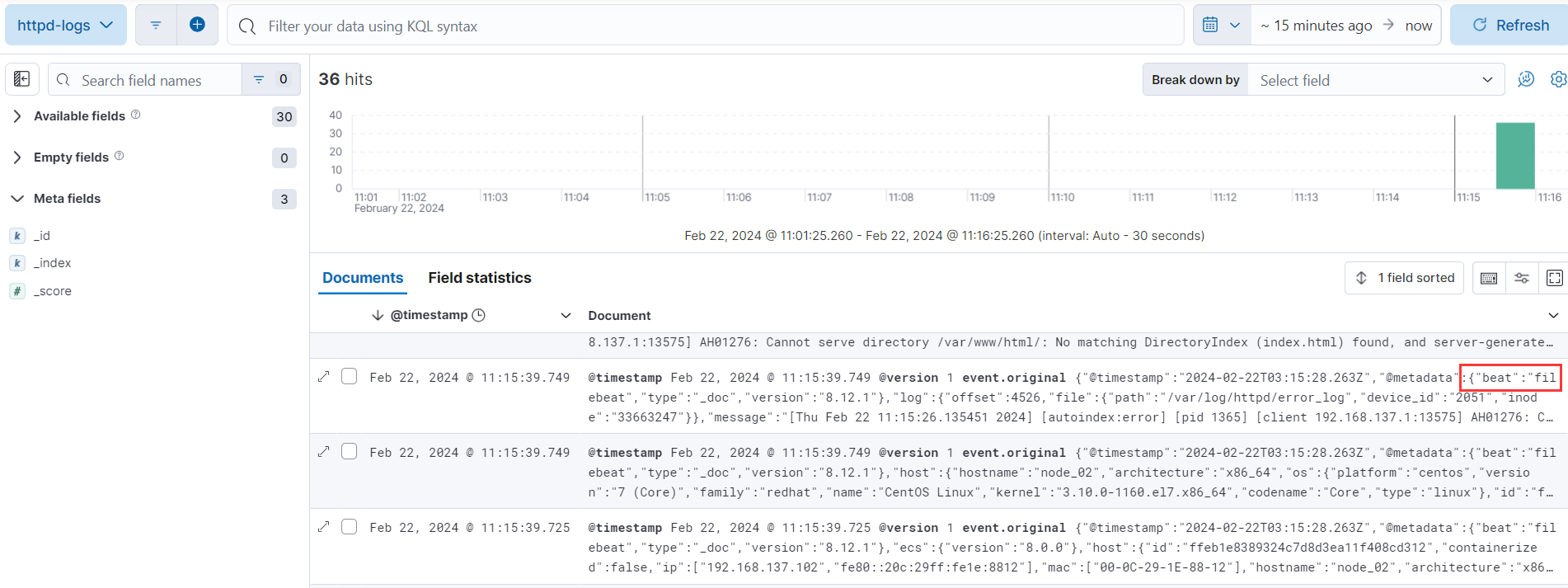
ELK 简介安装
1、概念介绍 日志介绍 日志就是程序产生的,遵循一定格式(通常包含时间戳)的文本数据。 通常日志由服务器生成,输出到不同的文件中,一般会有系统日志、 应用日志、安全日志。这些日志分散地存储在不同的机器上。 日志…...
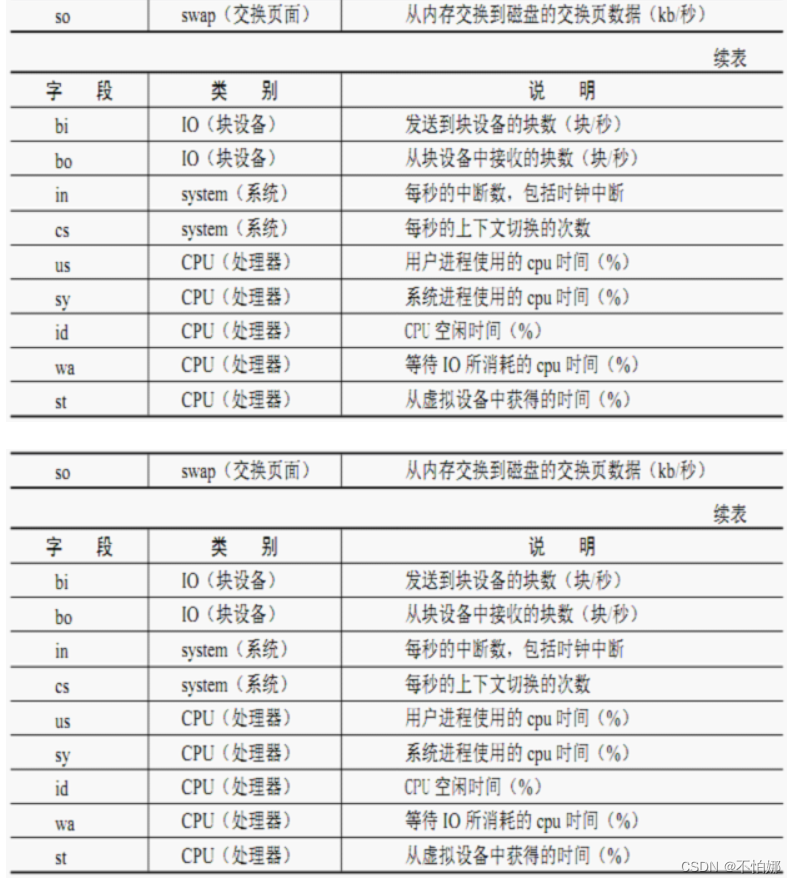
Linux 的交换空间(swap)是什么?有什么用?
目录 swap是什么?swap有什么用?swap使用典型场景如何查看你的系统是否用到交换空间呢?查看系统中swap in/out的情况 swap是什么? swap就是磁盘上的一块区域。它和Windows系统中的交换文件作用类似,但是它是一段连续的…...
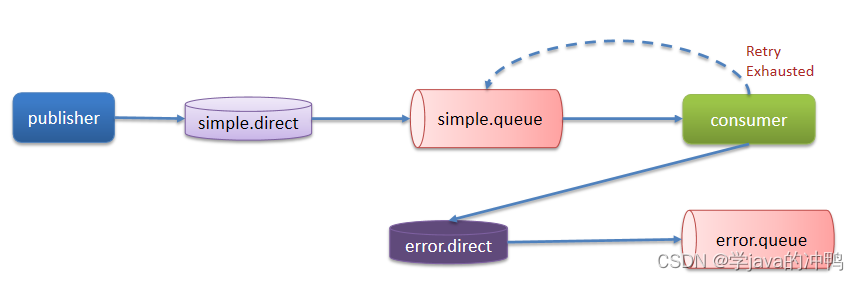
消息中间件篇之RabbitMQ-消息不丢失
一、生产者确认机制 RabbitMQ提供了publisher confirm机制来避免消息发送到MQ过程中丢失。消息发送到MQ以后,会返回一个结果给发送者,表示消息是否处理成功。 当消息没有到交换机就失败了,就会返回publish-confirm。当消息没有到达MQ时&…...

MongoDB中的TTL索引:自动过期数据的深入解析与使用方式
目录 一、TTL索引的深入原理二、TTL索引的使用方式三、TTL索引的限制与考虑因素四、优化TTL索引的策略五、总结 一、TTL索引的深入原理 TTL(Time-To-Live)索引在MongoDB中是一种特殊的索引,用于自动删除过期的文档。其核心原理在于MongoDB会…...

IPV6地址
技术背景:对IPV4做优化,比如地址长度128,简化了报文头部---快 ipv6地址 十六进制,简写前导0忽略,连续的0写成:: IPv6地址类型 1.单播 2.组播---接口有地址后,自动加入到一个组播里 3.任播---允许地址…...
解密API关键词搜索(淘宝京东1688)商品列表数据
API关键词搜索商品列表数据:赋能电商行业的新动力 随着电子商务的蓬勃发展,API(应用程序接口)关键词搜索商品列表数据在电商行业中的重要性日益凸显。这一数据资源不仅为消费者提供了便捷的购物体验,还为电商企业带来…...
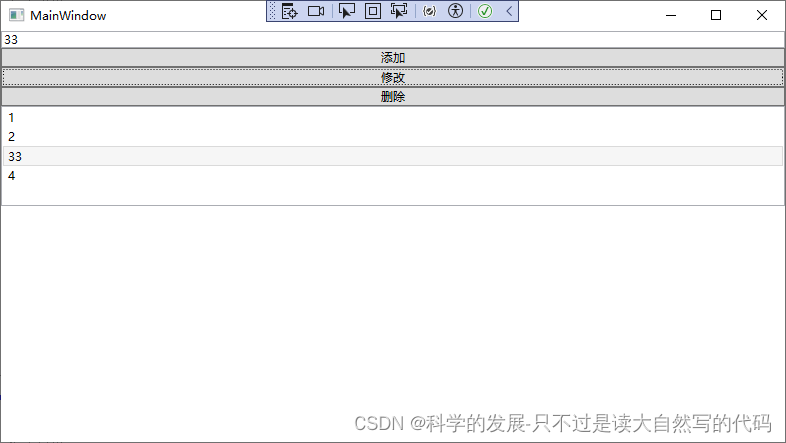
wpf 简单实验 数据更新 列表更新
1.概要 1.1 需求 一个列表提供添加修改删除的功能,添加和修改的内容都来自一个输入框 1.2 要点 DisplayMemberPath"Zhi"列表.ItemsSource datalist;(列表.SelectedItem ! null)(列表.SelectedItem as A).Zhi 内容.Text;datalist.Remove((列表.Selec…...
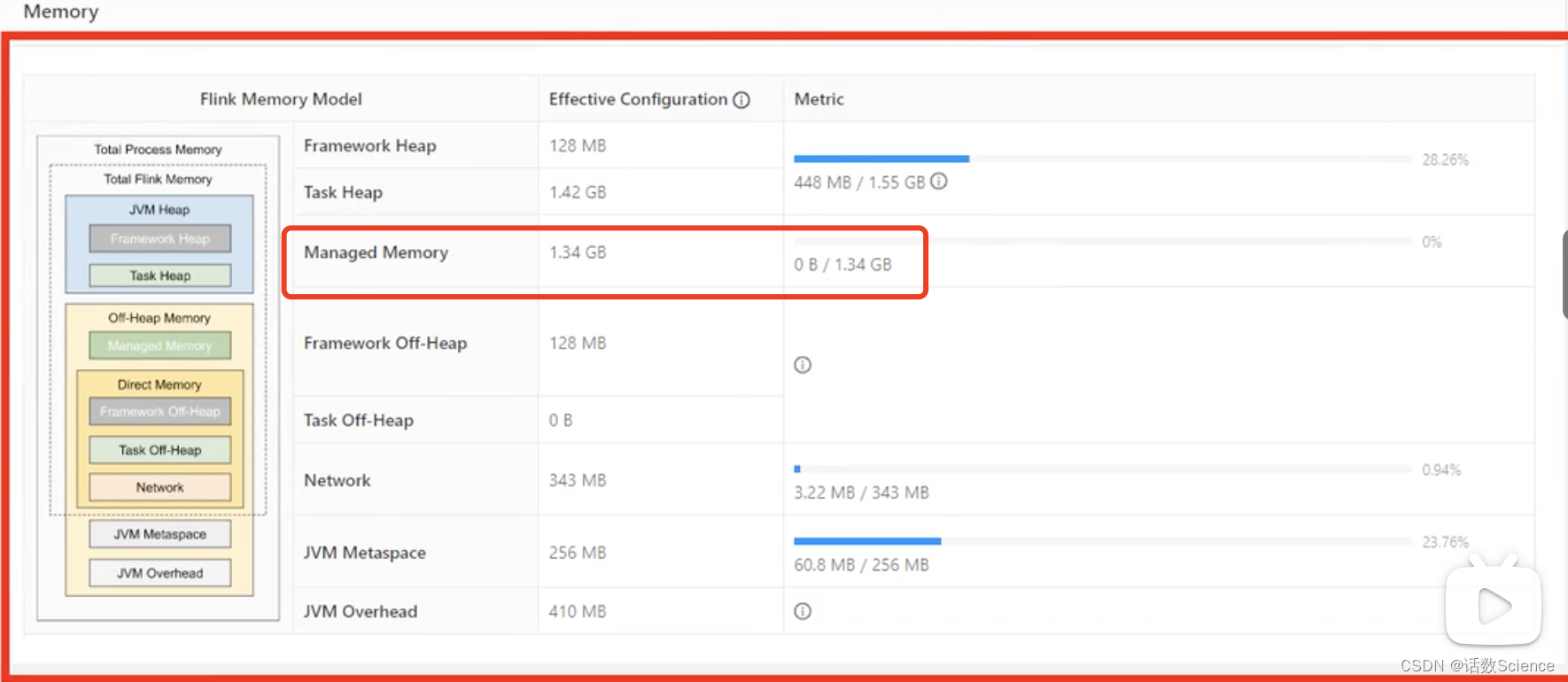
【Flink精讲】Flink性能调优:内存调优
内存调优 内存模型 JVM 特定内存 JVM 本身使用的内存,包含 JVM 的 metaspace 和 over-head 1) JVM metaspace: JVM 元空间 taskmanager.memory.jvm-metaspace.size,默认 256mb 2) JVM over-head 执行开销࿱…...
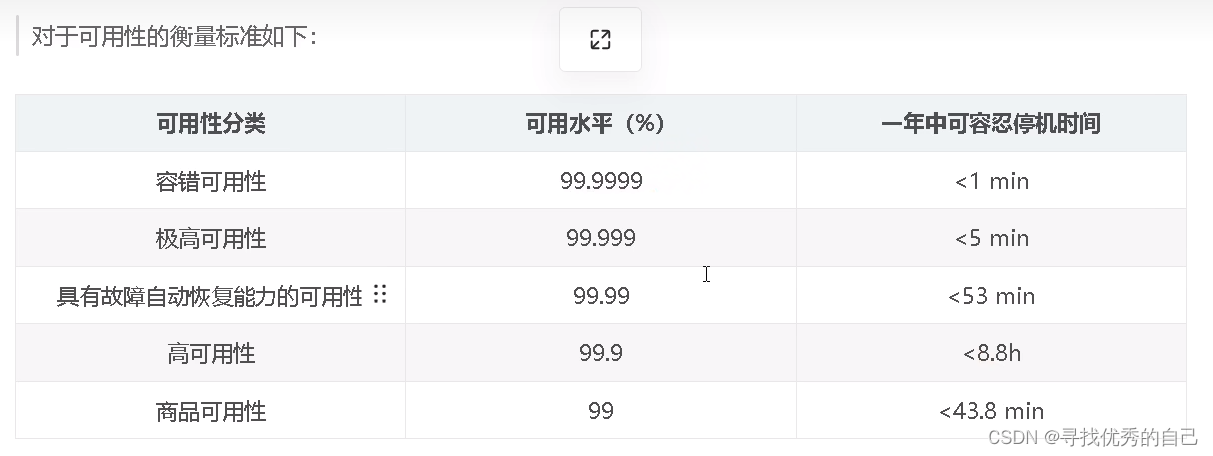
Java 中常用的数据结构类 API
目录 常用数据结构API 对应的线程安全的api 高可用衡量标准 常用数据结构API ArrayList: 实现了动态数组,允许快速随机访问元素。 import java.util.ArrayList; LinkedList: 实现了双向链表,适用于频繁插入和删除操作。 import java.util.LinkedLis…...
基本数据结构(数组,字符串))
JavaScript学习小记(1)基本数据结构(数组,字符串)
一个寒假确实过的很快,这个寒假除了调包调参突然心血来潮想学一下前端,学习过程比较平滑,我是自己找的技术文档+写代码实践来学习的,教程视频虽然详细,但是真的一点都看不动。 目录 JS如何定义变量的老旧的…...

python opencv实现车牌识别
目录 一:实现步骤: 二:实现车牌检测 一:实现步骤: 使用Python和OpenCV实现车牌识别的步骤大致可以分为以下两部分: 车牌检测: 读取需要进行车牌识别的图片。 对图像进行灰度化处理,可能还包括高斯模糊和灰度拉伸。 进行开运算,消除图像中的噪声。 将灰度拉伸后的图…...
)
K8S节点GPU虚拟化(vGPU)
vGPU实现方案 4paradigm提供了k8s-device-plugin,该插件基于NVIDIA官方插件(NVIDIA/k8s-device-plugin),在保留官方功能的基础上,实现了对物理GPU进行切分,并对显存和计算单元进行限制,从而模拟出多张小的vGPU卡。在k8s集群中,基于这些切分后的vGPU进行调度,使不同的容器…...

NLP 使用Word2vec实现文本分类
🍨 本文为[🔗365天深度学习训练营学习记录博客 🍦 参考文章:365天深度学习训练营 🍖 原作者:[K同学啊 | 接辅导、项目定制]\n🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/…...

【Redis学习笔记03】Java客户端
1. 初识Jedis Jedis的官网地址:https://github.com/redis/jedis 1.1 快速入门 使用步骤: 注意:如果是云服务器用户使用redis需要先配置防火墙! 引入maven依赖 <dependencies><!-- 引入Jedis依赖 --><dependency&g…...
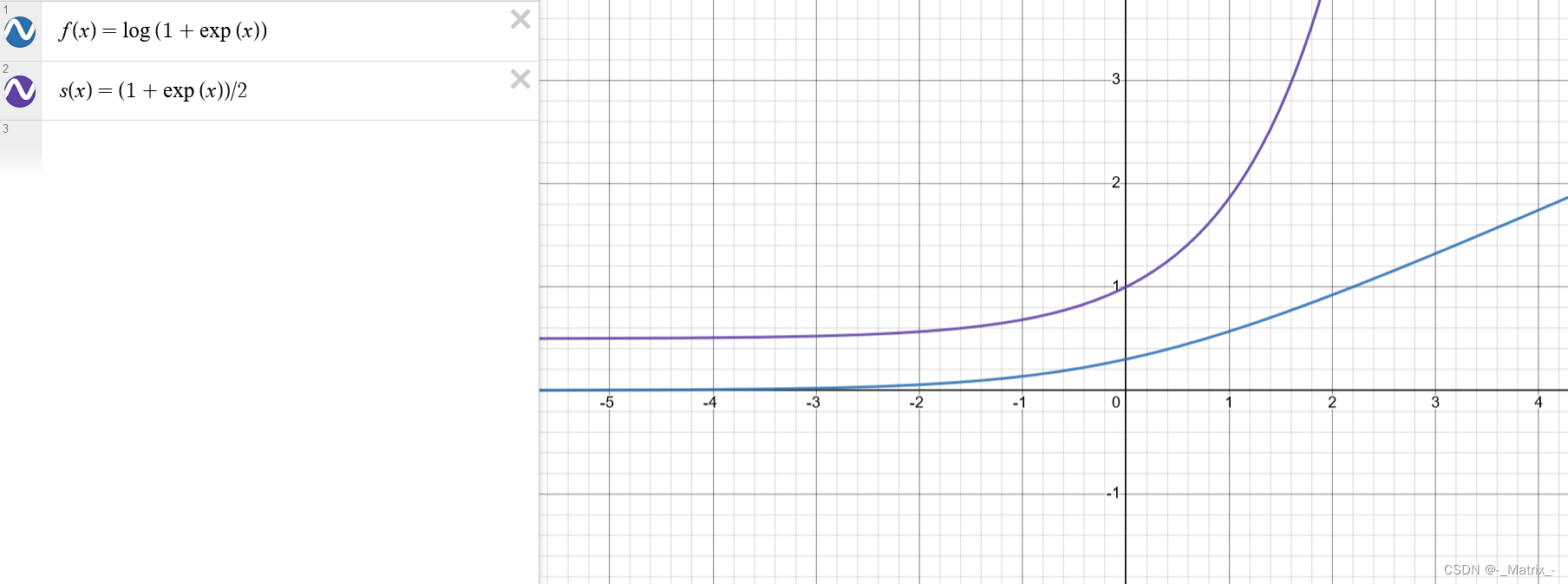
神经网络系列---激活函数
文章目录 激活函数Sigmoid 激活函数Tanh激活函数ReLU激活函数Leaky ReLU激活函数Parametric ReLU激活函数 (自适应Leaky ReLU激活函数)ELU激活函数SeLU激活函数Softmax 激活函数Swish 激活函数Maxout激活函数Softplus激活函数 激活函数 一般来说…...
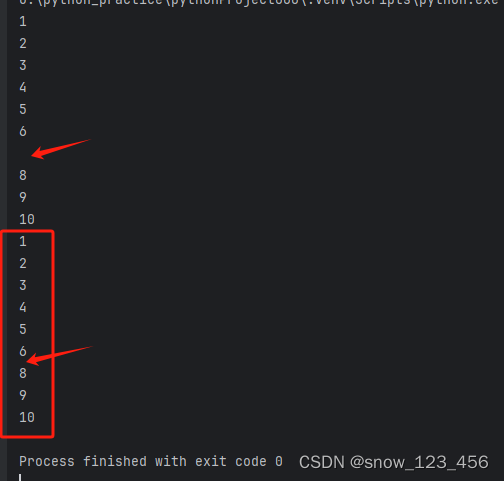
python中continue的对比理解
# 使用while循环,输入1-10之间的数字,除7之外。 以下为代码对比: # 使用while循环,输入1-10之间的数字,除7之外。 # 第一种方式 num 0 while num < 10:num num 1if num 7:print("")else:print(num)…...

芯片原型开发实战指南:从虚拟原型到FPGA的决策与调试
1. 原型决策前的核心考量:一份来自一线的深度清单在硬件和系统设计领域,原型开发是连接构想与现实的桥梁,但这座桥怎么搭、用什么材料、何时能通车,每一步都充满了抉择。很多团队在项目启动时,满腔热情地喊着“先做个原…...

Nucleus MCP:构建AI智能体标准化工具层的核心架构与实践
1. 项目概述:一个为AI智能体打造的“工具箱”中枢最近在折腾AI智能体(Agent)开发的朋友,可能都遇到过类似的困境:你有一个绝佳的想法,想让AI去调用某个API、查询数据库,或者操作一个本地工具。你…...

【NotebookLM企业级部署避坑清单】:37家技术团队踩过的12个合规/安全/集成雷区,现在不看下周就宕机
更多请点击: https://intelliparadigm.com 第一章:NotebookLM企业级部署的核心价值与适用边界 NotebookLM 作为 Google 推出的基于文档理解的 AI 助手,其企业级部署并非简单地将 Web 版本私有化,而是围绕数据主权、合规闭环与业…...

Cursor Pro破解工具:5步实现永久免费使用的完整指南
Cursor Pro破解工具:5步实现永久免费使用的完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial…...

5种智能匹配模式:Illustrator脚本replaceItems.jsx如何让设计元素替换效率提升20倍
5种智能匹配模式:Illustrator脚本replaceItems.jsx如何让设计元素替换效率提升20倍 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 在Adobe Illustrator设计工作中&…...

Windows更新修复终极指南:Script-Reset-Windows-Update-Tool完全解析
Windows更新修复终极指南:Script-Reset-Windows-Update-Tool完全解析 【免费下载链接】Script-Reset-Windows-Update-Tool This script reset the Windows Update Components. 项目地址: https://gitcode.com/gh_mirrors/sc/Script-Reset-Windows-Update-Tool …...

Hummingbot自动化交易框架:从原理到实战的量化交易指南
1. 项目概述:一个为专业交易者打造的自动化交易框架如果你在加密货币交易领域摸爬滚打过一段时间,一定会对“手动盯盘”的疲惫和“情绪化操作”的代价深有体会。市场24/7运转,机会转瞬即逝,而人的精力终究有限。这正是我最初接触并…...

从专利数量到质量:从业者深度解析专利评估与策略
1. 从“专利数量”到“专利质量”:一个从业者的深度观察 最近和几位做硬件的朋友聊天,大家不约而同地提到了一个现象:现在无论是看行业报告,还是和国内供应商、合作伙伴交流,“专利”这个词出现的频率越来越高。尤其是…...

终极模组加载器指南:如何在5分钟内安全扩展《杀戮尖塔》游戏内容
终极模组加载器指南:如何在5分钟内安全扩展《杀戮尖塔》游戏内容 【免费下载链接】ModTheSpire External mod loader for Slay The Spire 项目地址: https://gitcode.com/gh_mirrors/mo/ModTheSpire ModTheSpire是一款专为《杀戮尖塔》设计的开源模组加载器&…...

阴阳师百鬼夜行自动化脚本终极指南:3种智能模式解放你的双手
阴阳师百鬼夜行自动化脚本终极指南:3种智能模式解放你的双手 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 你是否曾在深夜为刷百鬼夜行而手指酸痛?是否…...