架构设计:流式处理与实时计算
引言
随着大数据技术的不断发展,流式处理和实时计算在各行各业中变得越来越重要。那么什么是流式处理呢?我们又该怎么使用它?流式处理允许我们对数据流进行实时分析和处理,而实时计算则使我们能够以低延迟和高吞吐量处理数据。本文将介绍流式处理和实时计算的架构设计,包括使用场景、Java代码示例以及在使用过程中需要注意的问题。
1. 概述
1.1 概念定义
-
流式处理:
- 流式处理是一种连续处理数据流的方式,数据以流的形式持续进入系统,系统对数据流进行实时处理和分析,并产生实时结果或输出。
- 流式处理通常涉及对无限数据集合进行处理,不断地处理新的数据输入,而不是一次性地处理静态数据集合。
-
实时计算:
- 实时计算是一种即时处理数据的方式,数据进入系统后立即进行计算和分析,并产生实时结果或输出。
- 实时计算通常要求在非常短的时间内完成计算和处理,以满足对数据及时性的要求。
1.2 特点
-
流式处理的特点:
- 数据持续不断地进入系统,需要对数据流进行实时处理。
- 数据处理通常是有状态的,需要维护和更新状态信息。
- 数据处理结果通常是实时的,要求低延迟和高吞吐量。
-
实时计算的特点:
- 数据需要立即进行处理和计算,以满足对数据的及时性要求。
- 计算和处理通常需要在非常短的时间内完成,要求低延迟和高性能。
- 结果通常是实时的,可以立即应用于业务场景中。
2. 流式处理架构设计
2.1 使用场景
流式处理和实时计算适用于许多不同的应用场景,下面是比较常用的场景:
- 实时监控与警报:监控系统日志、网络流量等,及时发现异常并触发警报。
- 实时分析:对实时数据进行分析,如实时推荐系统、广告点击率分析等。
- 实时数据处理:实时处理传感器数据、交易数据等,支持实时决策和操作。
- 实时数据聚合:将大量的实时数据聚合为汇总报表或统计信息。
2.2 Java代码示例
Flink流式处理代码示例
Apache Flink 是一个流式处理框架,提供了丰富的流式处理功能和API。以下是一个使用 Apache Flink 进行流式处理的简单 Java 代码示例:
添加maven依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.12</artifactId><version>${flink.version}</version>
</dependency>
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class FlinkStreamProcessingExample {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> text = env.socketTextStream("localhost", 9999);DataStream<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer()).keyBy(0).sum(1);counts.print();env.execute("Flink Stream Processing Example");}public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) {String[] words = value.split(" ");for (String word : words) {out.collect(new Tuple2<>(word, 1));}}}
}
Spark批处理代码示例
Apache Spark 是一个快速、通用、可扩展的大数据处理引擎,Spark 提供了丰富的功能和 API,包括批处理、交互式查询、流式处理和机器学习等。它的核心特性包括内存计算、容错性和高效的数据抽象等。下面用java代码演示如何使用 Spark 进行单词计数。
<dependencies><!-- Spark 核心依赖 --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.2.0</version></dependency><!-- Spark SQL 依赖(如果需要使用 SQL 功能)--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.2.0</version></dependency>
</dependencies>
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;import java.util.Arrays;public class WordCount {public static void main(String[] args) {// 创建 Spark 配置对象SparkConf conf = new SparkConf().setAppName("WordCount").setMaster("local");// 创建 Spark 上下文对象JavaSparkContext sc = new JavaSparkContext(conf);// 读取文本文件并创建 RDDJavaRDD<String> lines = sc.textFile("input.txt");// 将每行文本拆分为单词JavaRDD<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());// 将单词转换为键值对,键为单词,值为1JavaRDD<String> pairs = words.mapToPair(word -> new Tuple2<>(word, 1));// 对键值对进行聚合操作,统计单词出现的次数JavaRDD<String> wordCounts = pairs.reduceByKey((x, y) -> x + y);// 打印结果wordCounts.foreach(wordCount -> System.out.println(wordCount._1 + ": " + wordCount._2));// 关闭 Spark 上下文对象sc.close();}
}
3. 框架介绍及对比
3.1. Apache Kafka Streams
-
简介:Apache Kafka Streams 是一个用于构建实时流处理应用程序的库,它直接构建在 Apache Kafka 之上,并与 Kafka 集成紧密。特点:
- 轻量级,易于使用,直接与 Kafka 集成。
- 提供了丰富的 API,支持状态管理、窗口操作等功能。
- 可以与 Apache Kafka Connect、Kafka Producer 和 Kafka Consumer 无缝集成。
3.2. Apache Flink
-
简介:Apache Flink 是一个分布式流处理框架,提供了高吞吐量、低延迟的流处理能力,同时支持批处理。
-
特点:
- 支持事件时间处理、状态管理、容错性等特性。
- 提供了丰富的算子和 API,支持丰富的流处理和批处理操作。
- 支持灵活的窗口操作、流与表的集成等功能。
3.3. Apache Storm
-
简介:Apache Storm 是一个分布式实时计算系统,用于处理大规模实时数据流。
-
特点:
- 提供了高吞吐量、低延迟的实时数据处理能力。
- 支持容错性、可扩展性等特性。
- 提供了丰富的拓扑结构和可编程 API,支持复杂的实时数据处理流程。
3.4. Spark Streaming
-
简介:Spark Streaming 是 Apache Spark 生态系统中的一个组件,提供了高级别的流处理抽象,使得用户可以使用 Spark 引擎来处理实时数据流。
-
特点:
- 提供了与 Spark 集成的流处理 API,支持类似于批处理的编程模型。
- 可以利用 Spark 引擎的内存计算和优化技术,实现高吞吐量和低延迟的流处理。
3.5. Apache Hadoop MapReduce
-
简介:Apache Hadoop MapReduce 是一个分布式批处理框架,用于处理大规模数据集。虽然它不是专门用于流式处理和实时计算的框架,但也可以用于批处理的实时数据分析。
-
特点:
- 支持分布式批处理任务的并行执行。
- 可以处理大规模数据集,适用于离线数据分析和处理。
- 对于实时计算场景,可能存在较高的延迟和较低的吞吐量。
下面是一个简单的表格,对这几个流式处理和实时计算框架进行了对比:
| 框架 | 特点 | 优点 | 缺点 |
|---|---|---|---|
| Apache Kafka Streams | 直接构建在 Kafka 之上,易于集成 | 与 Kafka 集成紧密,提供了丰富的 API 和状态管理功能 | 功能相对较简单,不如 Flink 灵活 |
| Apache Flink | 高吞吐量、低延迟,支持事件时间处理等特性 | 提供了丰富的 API 和算子,支持流处理和批处理操作 | 部署和维护相对复杂,学习曲线较陡 |
| Apache Storm | 高吞吐量、低延迟,支持复杂的实时处理流程 | 可以处理大规模实时数据流,提供了丰富的可编程 API 和拓扑结构 | 相对于 Flink 和 Spark Streaming 功能较为有限 |
| Spark Streaming | 利用 Spark 引擎的内存计算和优化技术 | 与 Spark 集成紧密,提供了高级别的流处理抽象,易于使用和集成 | 延迟较高,不如 Flink 那样支持低延迟处理 |
| Apache Hadoop MapReduce | 分布式批处理框架,适用于离线数据分析 | 可以处理大规模数据集,适用于离线数据分析和处理 | 不适用于流式处理和实时计算场景 |
各个框架都有其独特的特点和适用场景,选择合适的框架应根据具体业务需求、技术栈和团队实际情况进行评估和选择。
4. 注意事项
在设计实时计算架构时,需要考虑以下几个关键的注意事项:
-
性能与延迟:
- 实时计算的一个重要指标是性能和延迟。需要确保实时计算系统能够在较短的时间内处理数据,以满足实时性的要求。为了达到较低的延迟,可以采用并行计算、内存计算等技术手段来优化性能。
-
容错与可靠性:
- 实时计算系统需要具备良好的容错性和可靠性,以应对可能发生的故障或异常情况。为了保证数据处理的准确性,需要实现数据的持久化和恢复机制,并在系统崩溃时能够自动恢复工作状态。
-
数据一致性:
- 实时计算系统需要保证处理的数据具有一致性,避免数据丢失或重复处理。在数据处理过程中,需要考虑如何处理数据的并发访问和并行计算,以确保数据的一致性和准确性。
-
负载均衡:
- 实时计算系统需要能够有效地处理大量的数据流,并确保各个计算节点之间的负载均衡。需要考虑如何分配和调度任务,以最大化系统的吞吐量和性能。
-
监控与调试:
- 实时计算系统需要建立完善的监控和调试机制,及时发现和解决问题。可以通过监控系统性能指标、日志记录和异常处理等方式来实现对系统运行状态的监控和分析,以及对异常情况的处理和调试。
-
扩展性与灵活性:
- 实时计算系统需要具备良好的扩展性和灵活性,以应对不断增长的数据规模和变化的业务需求。需要考虑如何设计可扩展的架构和组件,以便随着业务的发展和数据量的增长进行水平扩展和垂直扩展。
-
安全性:
- 实时计算系统需要具备良好的安全性,保护系统和数据免受恶意攻击和未经授权的访问。需要考虑如何实现数据加密、身份验证、访问控制等安全机制,以确保数据的保密性和完整性。
5. 结语
在大数据领域,流式处理和实时计算是处理实时数据的关键技术,不同的框架则提供了各自独特的特点和优势。在选择合适的框架时,需要综合考虑业务需求、技术栈、团队技术水平以及系统规模等因素。无论选择哪种框架,都需要根据实际情况进行灵活应用,不断优化和改进,以实现更高效、更可靠的实时数据处理系统。
相关参考:
Flink vs. Spark:特点、区别和使用场景_spark和flink应用场景区别-CSDN博客
Kafka快速实战与基本原理详解-CSDN博客
相关文章:

架构设计:流式处理与实时计算
引言 随着大数据技术的不断发展,流式处理和实时计算在各行各业中变得越来越重要。那么什么是流式处理呢?我们又该怎么使用它?流式处理允许我们对数据流进行实时分析和处理,而实时计算则使我们能够以低延迟和高吞吐量处理数据。本…...

Linux系统安装zookeeper
Linux安装zookeeper 安装zookeeper之前需要安装jdk,确认jdk环境没问题之后再开始安装zookeeper 下载zookeeper压缩包,官方下载地址:Apache Download Mirrors 将zookeeper压缩包拷贝到Linux并解压 # (-C 路径)可以解压到指定路径 tar -zxv…...

【前端素材】推荐优质后台管理系统Modernize平台模板(附源码)
一、需求分析 后台管理系统是一种用于管理和控制网站、应用程序或系统后台操作的软件工具,通常由授权用户(如管理员、编辑人员等)使用。它提供了一种用户友好的方式来管理网站或应用程序的内容、用户、数据等方面的操作,并且通常…...
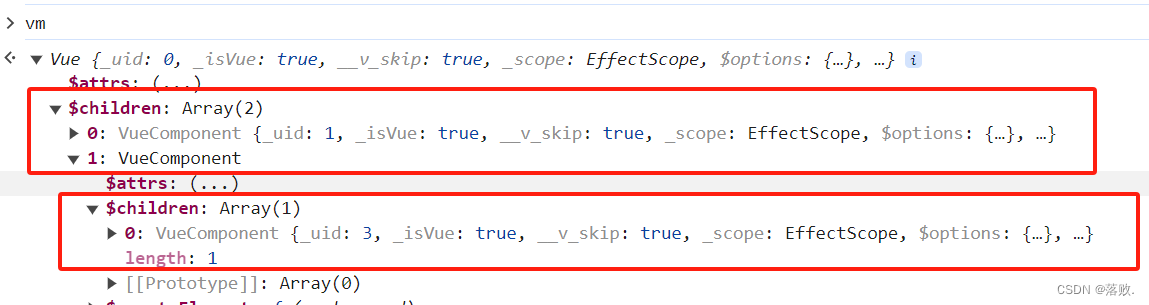
二、Vue组件化编程
2、Vue组件化编程 2.1 非单文件组件 <div id"root"><school></school><hr><student></student> </div> <script type"text/javascript">//创建 school 组件const school Vue.extend({template: <div&…...
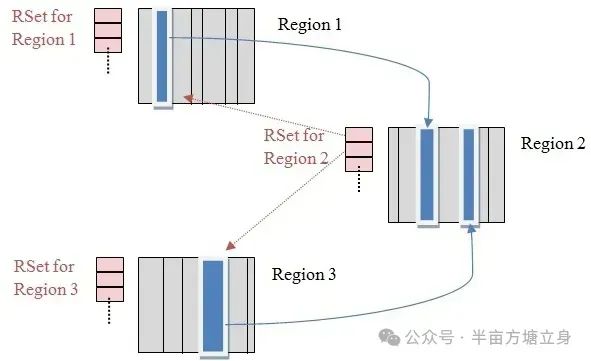
JVM跨代引用垃圾回收
1. 跨代引用概述 在Java堆内存中,年轻代和老年代之间存在的对象相互引用,假设现在要进行一次新生代的YGC,但新生代中的对象可能被老年代所引用的,为了找到新生代中的存活对象,不得不遍历整个老年代。这样明显效率很低…...
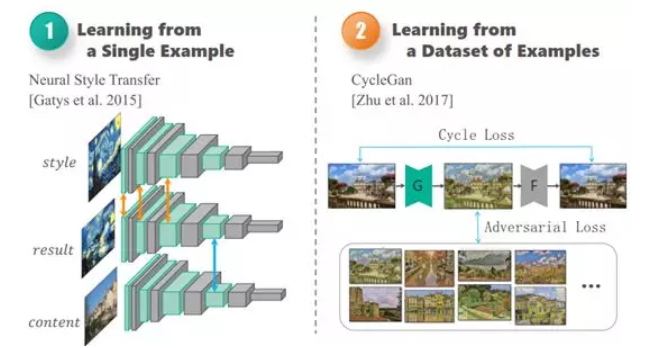
AI:135-基于卷积神经网络的艺术品瑕疵检测与修复
🚀点击这里跳转到本专栏,可查阅专栏顶置最新的指南宝典~ 🎉🎊🎉 你的技术旅程将在这里启航! 从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。 ✨✨✨ 每一个案例都附带关键代码,详细讲解供大家学习,希望…...

C++标准头文件汇总及功能说明
文章目录 algorithmbitsetcctypecerrnoclocalecmathcstdioctimedequeiostreamexceptionfstreamfunctionallimitslistmapiosiosfwdsetsstreamstackstdexceptstreambufcstringutilityvectorcwcharcwctype algorithm algorithm头文件是C的标准算法库,它主要用在容器上。…...
)
glTF 添加数据属性(extras)
使用3D 模型作为可视化界面的一个关键是要能够在3D模型中添加额外的数据属性,利用这些数据属性能够与后台的信息模型建立对应关系,例如后台信息模型是opcua 信息模型的话,在3D模型中要能够包含OPC UA 的NodeId,BrowserName 等基本…...
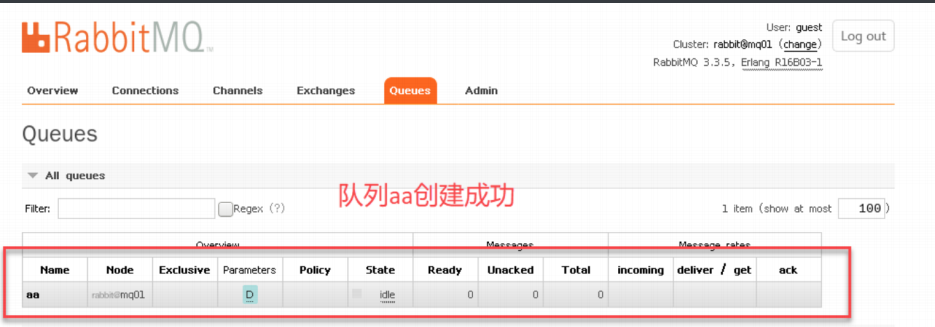
linux系统消息中间件rabbitmq普通集群的部署
rabbitmq普通集群的部署 普通集群准备环境查询版本对应安装rabbitmq软件启动创建登录用户开启用户远程登录查看端口 部署集群创建数据存放目录和日志存放目录:拷⻉erlang.cookie将其他两台服务器作为节点加⼊节点集群中查看集群状态创建新的队列 普通集群准备环境 配置hosts⽂件…...

TextCNN:文本分类卷积神经网络
模型原理 1、前言2、模型结构3、示例3.1、词向量层3.2、卷积层3.3、最大池化层3.4、Fully Connected层 4、总结 1、前言 TextCNN 来源于《Convolutional Neural Networks for Sentence Classification》发表于2014年,是一个经典的模型,Yoon Kim将卷积神…...

欧几里得和《几何原本》
欧几里得和《几何原本》 欧几里得(Euclid),公元前约300年生于古希腊,被认为是几何学的奠基人之一。他的主要成就是编写了一本名为《几何原本》(Elements)的著作,这本书成为了几何学的经典教材&a…...

linux c++ 开发 tensorrt 安装
tensorrt 官方下载地址(需要注册账号登录):Log in | NVIDIA Developer 根据系统发行版和CUDA版本 (nvcc -V) 选择合适的安装包 EA(early access)版本代表抢先体验。 GA(general availability)代…...
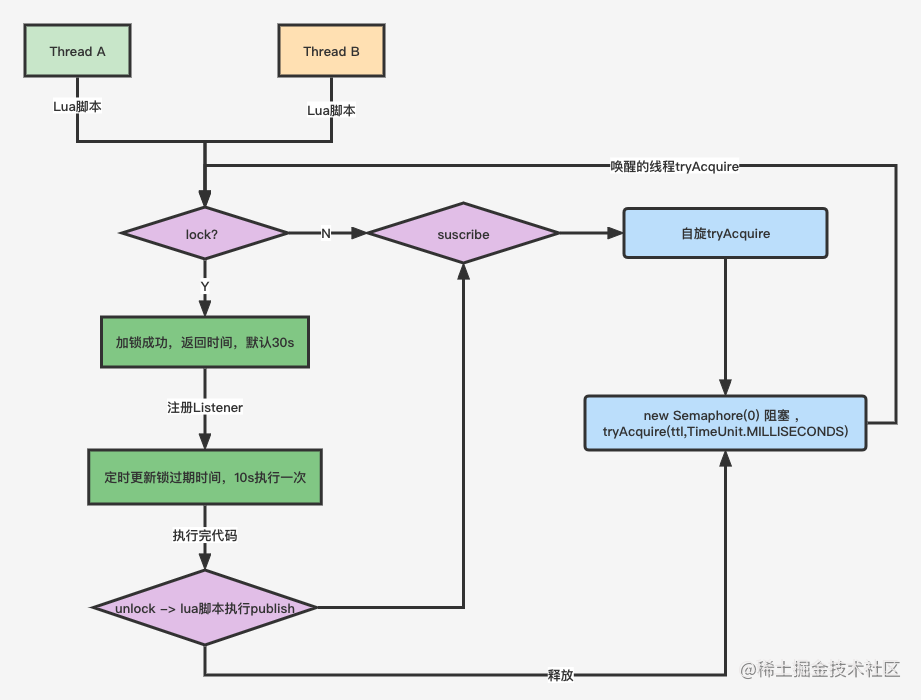
Redis高并发分布锁实战
Redis高并发分布锁实战 问题场景 场景一: 没有捕获异常 // 仅仅加锁 // 读取 stock15 Boolean ret stringRedisTemplate.opsForValue().setIfAbsent("lock_key", "1"); // jedis.setnx(k,v) // TODO 业务代码 stock-- stringRedisTemplate.delete(&quo…...

Kotlin基础——DSL
DSL(领域特定语言) 常见的DSL就是SQL和正则表达式,用于操作数据库和文本字符串,Kotlin DSL通常为嵌套的Lambda表达式或链式方法,如 https://github.com/gradle/gradle-script-kotlin 用于构建Gradle脚本https://gith…...

《Docker 简易速速上手小册》第4章 Docker 容器管理(2024 最新版)
文章目录 4.1 容器生命周期管理4.1.1 重点基础知识4.1.2 重点案例:启动并管理 Python Flask 应用容器4.1.3 拓展案例 1:调试运行中的容器4.1.4 拓展案例 2:优雅地停止和清理容器 4.2 容器数据管理与持久化4.2.1 重点基础知识4.2.2 重点案例&a…...
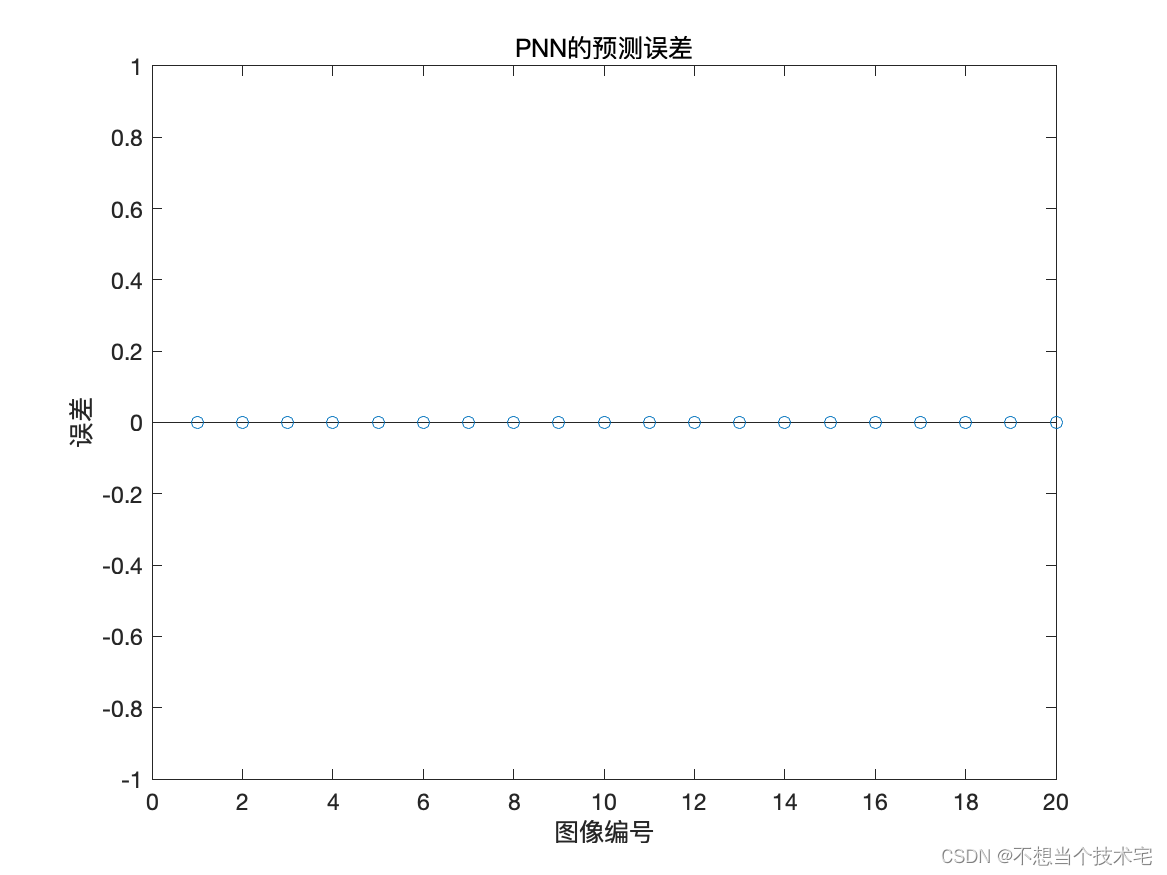
【人脸朝向识别与分类预测】基于PNN神经网络
课题名称:基于PNN神经网络的人脸朝向识别分类 版本日期:2024-02-20 运行方式:直接运行PNN0503.m文件 代码获取方式:私信博主或 QQ:491052175 模型描述: 采集到一组人脸朝向不同角度时的图像,图像来自不…...
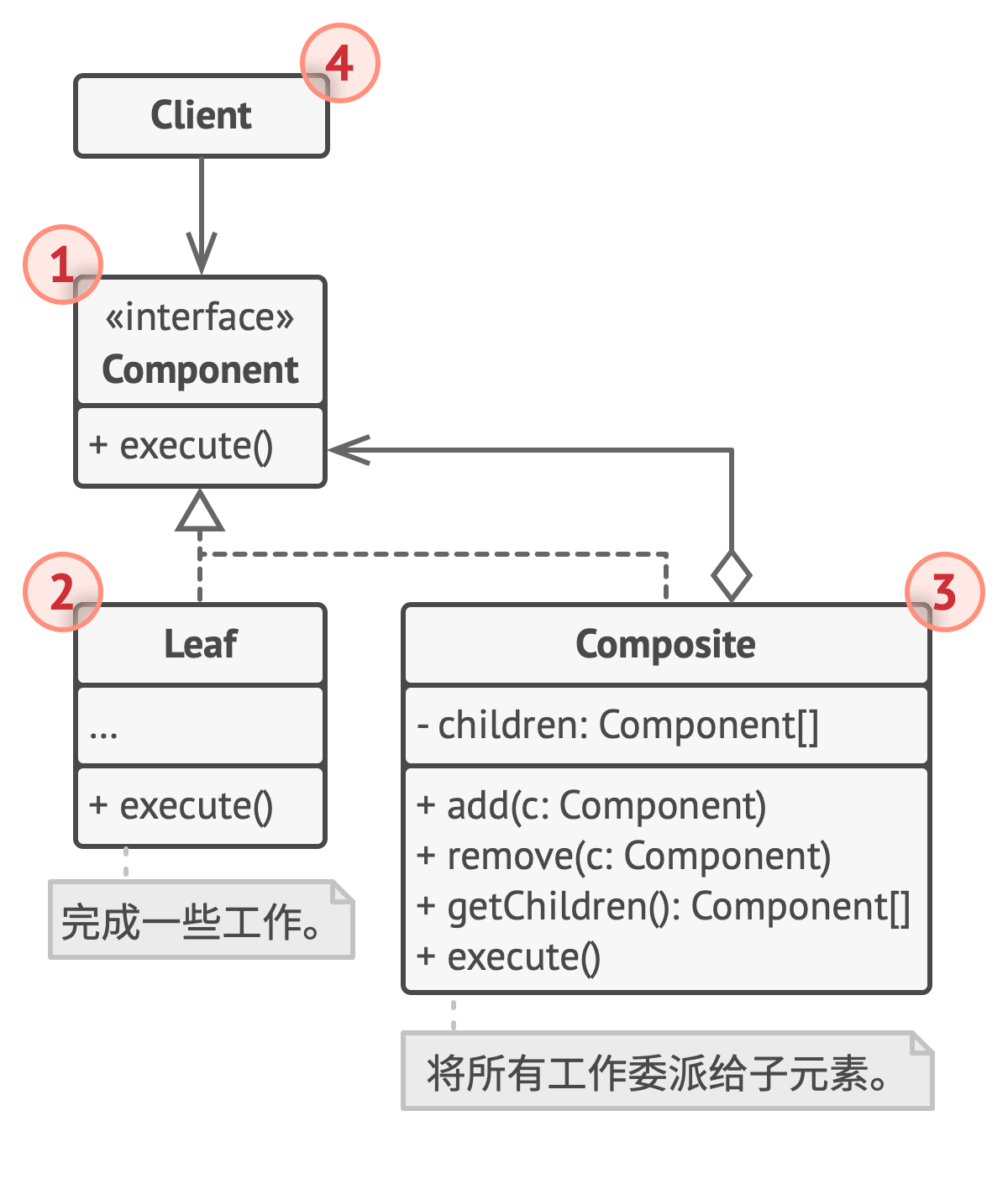
【Python笔记-设计模式】组合模式
一、说明 组合模式是一种结构型设计模式, 你可以使用它将对象组合成树状结构, 并且能像使用独立对象一样使用它们。 (一) 解决问题 处理树形结构:可以很好地处理树形结构的数据,使得用户可以统一对待单个对象和对象组合。统一接…...

51单片机学习(5)-----蜂鸣器的介绍与使用
前言:感谢您的关注哦,我会持续更新编程相关知识,愿您在这里有所收获。如果有任何问题,欢迎沟通交流!期待与您在学习编程的道路上共同进步。 目录 一. 蜂鸣器的介绍 1.蜂鸣器介绍 2.压电式蜂鸣器 (无源…...

-bash: /root/.ssh/authorized_keys: Read-only file system
问题背景 由于跳板机不支持 ssh-copy-id 命令,为了配置免密登录,考虑在服务器上手动使用 cat 命令写入跳板机公钥 cat <<EOL >> ~/.ssh/authorized_keys [Your public key] EOL但却出现了以下错误 -bash: /root/.ssh/authorized_keys: Re…...
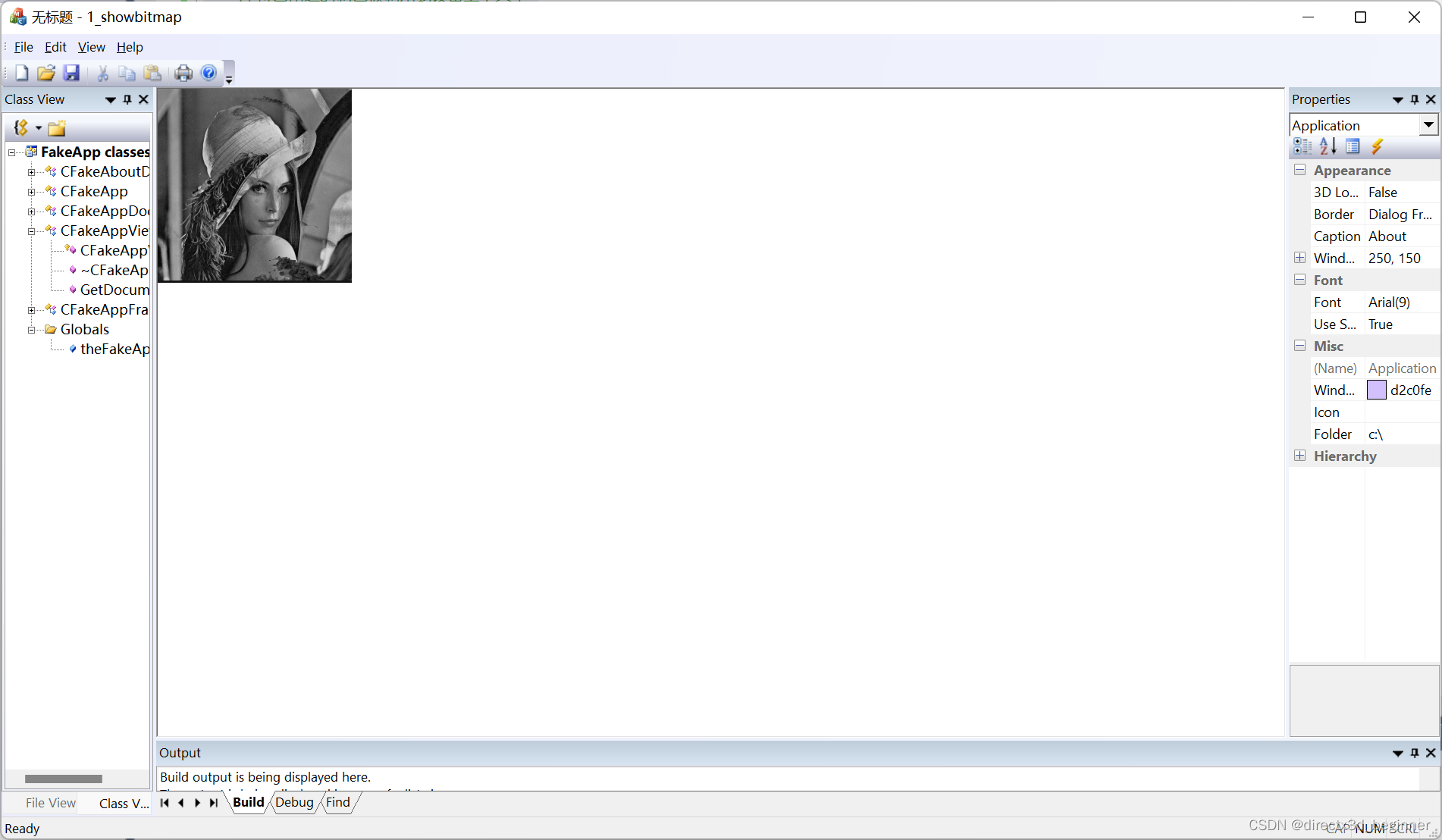
3,设备无关位图显示
建立了一个类Dib Dib.h #pragma once #include “afx.h” class CDib :public CObject { public: CDib(); ~CDib(); char* GetFileName(); BOOL IsValid(); DWORD GetSize(); UINT GetWidth(); UINT GetHeight(); UINT GetNumberOfColors(); RGBQUAD* GetRGB(); BYTE* GetDat…...

基于OCR与NLP的智能账单分析系统:从数据处理到消费洞察
1. 项目概述:一个AI驱动的家庭账单智能分析系统最近在GitHub上看到一个挺有意思的项目,叫ai_code_family_bill。光看名字,你大概能猜到它和家庭账单、AI分析有关。作为一个长期和代码、数据打交道的技术人,我第一反应是࿱…...

DLP Pico技术与近眼显示系统设计解析
1. DLP Pico技术解析:微镜阵列如何重塑显示未来 在2014年,德州仪器(TI)推出了一项颠覆性的显示技术——基于DLP TRP架构的Pico芯片组。这项技术的核心是一块布满微小铝镜的芯片,每个微镜尺寸仅5.4微米,比人类头发直径的十分之一还…...

NExT-GPT:从多模态对齐到任意模态生成的架构与实战
1. 项目概述:从“多模态”到“任意模态”的进化 如果你在过去一年里关注过AI领域,一定对“多模态大模型”这个词不陌生。从GPT-4V到Gemini,主流模型都在努力让AI能同时理解文本和图像。但不知道你有没有想过一个问题:为什么我们和…...

CVPR2019 Oral论文DVC复现指南:用TensorFlow搭建你的第一个端到端深度学习视频压缩模型
CVPR2019 Oral论文DVC复现实战:从零构建端到端视频压缩模型 视频压缩技术正经历从传统编码标准向深度学习范式的革命性转变。2019年CVPR Oral论文《DVC: An End-to-end Deep Video Compression Framework》首次提出了完整的端到端深度学习视频压缩框架,其…...

LLM长文本处理实战:模块化分割策略与向量化预处理指南
1. 项目概述:一个为LLM打造的文本处理中心如果你和我一样,经常和大型语言模型打交道,无论是用它来总结文档、分析代码,还是处理客服对话,那你肯定遇到过这个痛点:喂给模型的文本太长了怎么办?模…...

移动端AI智能体Operit AI:打造离线可编程的Android全能助手
1. 项目概述:在手机上构建你的全能AI副驾如果你和我一样,是个重度效率工具爱好者,同时又对AI技术充满好奇,那么你肯定也经历过这样的困境:手机上的AI助手,要么是功能单一的聊天机器人,要么就是需…...

免费素材资源终极指南:发现300+个高质量免费图片视频网站 [特殊字符]
免费素材资源终极指南:发现300个高质量免费图片视频网站 🚀 【免费下载链接】awesome-stock-resources :city_sunrise: A collection of links for free stock photography, video and Illustration websites 项目地址: https://gitcode.com/gh_mirror…...

收藏!小白程序员必看:详解7种RAG分块策略,轻松提升大模型检索效果
收藏!小白程序员必看:详解7种RAG分块策略,轻松提升大模型检索效果 本文深入解析了RAG系统中7种主流分块策略,包括固定大小、语义、递归、文档结构、智能体、句子和段落分块。强调了分块策略对检索增强生成(RAG…...

基于MCP协议构建AI知识库:解决会话失忆,实现知识持久化
1. 项目概述:让AI拥有自己的“亚历山大图书馆”如果你和我一样,长期与Claude Code、Cursor这类AI编程助手打交道,一定会遇到一个核心痛点:会话失忆。每次开启一个新对话,AI助手就像一张白纸,它对你项目的历…...

IGF-I Analog ;CYAAPLKPALSSC
一、基础信息多肽名称:IGF-I Analog 胰岛素样生长因子 I 类似物 三字母序列:Cys-Tyr-Ala-Ala-Pro-Leu-Lys-Pro-Ala-Lys-Ser-Cys 单字母序列:CYAAPLKPALSSC 氨基酸数量:12 aa 结构修饰:分子内二硫键 二硫键配对…...