python中字典(dict)原理及其操作
原理
Python中的字典(Dictionary)是一种基于哈希表(Hash Table)的实现,提供了高效的键值对(Key-Value Pair)存储和访问机制。了解字典的工作原理有助于更好地理解其性能特性以及为什么在某些情况下使用字典会非常高效。
哈希表的基本原理
-
哈希函数:哈希表依赖于哈希函数来将键(Key)转换为存储位置的索引。理想情况下,哈希函数应该将不同的键均匀分布到哈希表的地址空间中,以减少冲突(两个键映射到同一位置)的可能性。
-
键的唯一性:在字典中,键必须是唯一的。如果尝试使用已存在的键来存储新的值,旧的值将被新的值覆盖。
-
冲突解决:当两个键映射到同一个位置时,会发生冲突。Python字典使用开放寻址法(Open Addressing)和二次探测(Quadratic Probing)等技术来解决冲突。
字典的性能特性
-
时间复杂度:对于大多数操作(包括查找、插入和删除),Python字典的平均时间复杂度为O(1)。然而,在最坏的情况下(例如,当哈希函数导致大量冲突时),这些操作的时间复杂度可能会恶化到O(n)。但是,通过使用良好的哈希函数和动态调整哈希表的大小,Python尽量保证字典操作的高效性。
-
动态调整大小:当字典中的元素数量增加,导致装载因子(存储的元素数量与哈希表大小的比值)超过某个阈值时,Python会增加哈希表的大小并重新哈希所有的键。这个过程称为“重新哈希”(Rehashing),虽然会暂时增加操作的开销,但可以保持字典操作的长期效率。
字典的特性
-
无序:在Python 3.6中,字典的有序性首次作为CPython实现的一个细节被引入,虽然它在实践中确实是有序的,但当时官方并不保证所有Python实现都会有这个特性。从3.7版本开始,这一特性成为了Python语言的官方规范的一部分,因此在所有遵循该规范的Python实现中,字典都是有序的。
这一变化使得在需要维护元素顺序的情况下,开发者不再需要使用
collections.OrderedDict,因为普通的dict已经可以满足需求。这不仅简化了代码,也改善了性能,因为标准的dict类型在Python 3.7及更高版本中被优化以更高效地存储和访问元素。-
验证
# 创建一个空字典 ordered_dict = {}# 向字典中添加一些键值对 ordered_dict['banana'] = 1 ordered_dict['apple'] = 2 ordered_dict['pear'] = 3 ordered_dict['orange'] = 4# 打印字典中的项,查看是否按插入顺序输出 for key in ordered_dict:print(key, ordered_dict[key])# 创建两个具有相同键值对但插入顺序不同的字典 dict1 = {'a': 1, 'b': 2, 'c': 3} dict2 = {'b': 2, 'a': 1, 'c': 3}# 比较字典 print(dict1) print(dict2) print(dict1 == dict2) # 输出: True -
尽管
dict1和dict2的插入顺序不同,但它们被认为是相等的,因为它们包含相同的键值对。这证明了字典的比较不考虑键值对的插入顺序,但字典本身在内部是维护了插入顺序的。
-
-
键的数据类型:作为键的对象必须是不可变的,比如整数、浮点数、字符串、元组。这是因为只有不可变对象才能保证在整个生命周期中哈希值不变,从而保持字典的完整性。
了解这些原理有助于开发者更有效地使用Python字典,尤其是在处理大量数据和对性能有较高要求的场景中。
操作
Python 中的字典(dict)是一种可变容器模型,可以存储任意类型对象,如字符串、数字、元组等。字典中的每个元素都是一个键值对。这里介绍一些基本的字典操作:
创建字典
# 空字典
my_dict = {}# 带有数据的字典
my_dict = {'name': 'John', 'age': 30, 'city': 'New York'}
访问元素
print(my_dict['name']) # 输出: John# 使用 get 方法,如果键不存在返回 None 而不是抛出异常
print(my_dict.get('age')) # 输出: 30
添加或修改元素
# 添加新键值对
my_dict['email'] = 'john@example.com'# 修改已有键的值
my_dict['age'] = 31
删除元素
# 删除特定的键值对,使用 del 关键词:
del my_dict['city']# 使用 pop 方法删除并返回被删除值:
removed_value = my_dict.pop('email')
print(removed_value) # 输出被删除的值:john@example.com# 清空整个字典:
my_dict.clear()
检查键是否存在
if 'name' in my_dict:print("Name is present in the dictionary")
遍历字典
遍历所有键:
for key in my_dict.keys():print(key)
遍历所有值:
for value in my_dict.values():print(value)
同时遍历键和值:
for key, value in my_dict.items():print(key, value)
字典长度
获取包含多少个键值对:
len(my_dict)
复制一个字典
创建当前字典的浅拷贝:
new_mydict = my_dic.copy()或者使用 dict() 函数:
new_mydict2 = dict(my_dic)
以上就是 Python 字典中常用操作。Python 的 dict 类型提供了丰富而强大的方法来处理映射关系,并且由于其底层实现为哈希表,因此在访问和添加数据时具有非常高效率。
高级操作
Python 字典的高级操作涉及更复杂的数据处理和字典操作技巧。以下是一些有用的高级字典操作:
字典推导式
字典推导式(Dictionary Comprehension)是一种简洁地创建字典的方法,类似于列表推导式。
# 通过键值对序列创建字典
keys = ['name', 'age', 'city']
values = ['John', 30, 'New York']my_dict = {k: v for k, v in zip(keys, values)}
print(my_dict) # 输出: {'name': 'John', 'age': 30, 'city': 'New York'}
合并两个字典
在 Python 3.5+ 中,可以使用 {**d1, **d2} 的语法合并两个字典。在 Python 3.9+ 中,还可以使用 | 操作符,表达式中后出现的字典中的键值对将覆盖先前字典中的键值对。
dict1 = {'name': 'John', 'age': 30}
dict2 = {'city': 'New York', 'email': "john@example.com"}merged_dict = {**dict1, **dict2}
# 或者在 Python 3.9+
merged_dict_39 = dict1 | dict2print(merged_dict)
使用 collections.defaultdict
Python中的defaultdict和普通的dict都是字典类型,用于存储键值对。但是,它们之间有一个主要的区别:
当你试图访问dict中不存在的键时,Python会抛出一个KeyError。但是,如果你使用defaultdict,并试图访问一个不存在的键,它会首先为这个键生成一个默认值,然后返回这个默认值。这个默认值是通过传递给defaultdict的default_factory函数生成的。
from collections import defaultdictddict = defaultdict(list)# 当尝试访问不存在的键时,默认初始化为空列表,并不会抛出 KeyError 异常。
ddict['a'].append(1)
ddict['a'].append(2)
print(ddict) # 输出: defaultdict(<class ‘list’>, {'a': [1, 2]})# 创建一个默认值为int的defaultdict
d = defaultdict(int)
# 访问一个不存在的键
print(d['key']) # 输出 0
# 当我们试图访问不存在的键 'key' 时,`defaultdict`首先调用`int()`(没有任何参数)来生成一个默认值(0),然后返回这个值。
这个特性使得defaultdict在某些情况下非常有用,例如,当你需要一个字典来存储列表,且希望所有的键都默认关联一个空列表时,你可以使用defaultdict(list)。
使用fromkeys生成默认值的新字典
fromkeys() 是一个类方法,用于创建一个新字典,其中包含指定的键,每个键对应的值都是相同的初始值。这个方法通常用于初始化字典。
基本语法:
dict.fromkeys(seq[, value])
seq:键列表。value:可选参数,所有键对应的初始值,默认为 None。
示例:
# 使用 fromkeys 创建一个新字典,所有键的初始值为 None
new_dict = dict.fromkeys(['a', 'b', 'c'])
print(new_dict) # 输出: {'a': None, 'b': None, 'c': None}# 使用 fromkeys 创建一个新字典,并设置所有键的初始值为 0
new_dict_with_value = dict.fromkeys(['x', 'y', 'z'], 0)
print(new_dict_with_value) # 输出: {'x': 0, 'y': 0, 'z': 0}
这种方式非常适合快速初始化具有固定或默认值的字典。
使用 collections.OrderedDict
从 Python 3.7 开始,所有普通的 dict 都保持插入顺序。但是,在早期版本中或者当需要依赖顺序相关功能时(如移动元素到末尾),可以使用 OrderedDict。
from collections import OrderedDictodict = OrderedDict([('name', 'John'), ('age', 30)])
odict['city'] = "New York" # 添加到末尾
print(odict) # 输出: OrderedDict([('name', ‘John’), ('age’, 30), ('city’, ‘New York')])
使用 zip() 合并键和值列表为字典
如果你有两个分别代表键和值的列表,你可以使用 zip() 函数轻松合并它们为一个字典。
keys_list = ["a", "b", "c"]
values_list =[1, 2, 3]combined_dict= dict(zip(keys_list , values_list))
print(combined_dict) # 输出:{'a’:1,'b’:2,'c’:3}
更新或添加多个元素
使用 .update() 方法更新或添加多个键值对。原本字典存在的值仍然保留
my_dict.update({'email':'john_new@example.com','country':'USA'})
这些高级操作使得处理复杂数据结构、合并数据以及进行各种转换变得更加简单有效。掌握这些技巧能够帮助你编写更加简洁、高效且易于维护的代码。
与json格式相似
相似
Python的字典和JSON(JavaScript Object Notation)非常相似,因为它们都是键值对的集合,这种数据结构在许多编程语言中都很常见。这种结构非常灵活,可以用来存储和表示各种复杂的数据类型。
JSON是一种数据交换格式,它的语法来源于JavaScript的对象字面量语法,但它是语言无关的,可以被许多编程语言(包括Python)读取和生成。JSON的数据格式和Python的字典非常相似,这使得在Python中处理JSON数据非常方便。
Python的json模块提供了一种简单的方式来编码和解码JSON数据。例如,你可以使用json.dumps()函数将一个Python字典转换为一个JSON字符串,或者使用json.loads()函数将一个JSON字符串解析为一个Python字典。
区别
尽管Python的字典和JSON有很多相似之处,但它们也有一些重要的区别。例如,Python的字典可以包含各种类型的键,包括不可变类型(如整数和元组)和可变类型(如列表),而JSON的键必须是字符串。此外,Python的字典可以包含任何Python对象作为值,而JSON的值只能是一种基本数据类型(如字符串、数字、布尔值、null、数组或另一个JSON对象)。
转换
在Python中,字典和JSON之间的转换可以通过json模块来实现。
将字典转换为JSON字符串(序列化):
dumps()方法用于将Python对象编码成 JSON 字符串。loads()方法用于解码 JSON 数据。该方法返回 Python 字段的数据类型。
import json# 假设dict_obj是一个Python字典
dict_obj = {'name': 'John', 'age': 30, 'city': 'New York'}# 将字典转换为JSON字符串
json_str = json.dumps(dict_obj)print(json_str) # 输出:{"name": "John", "age": 30, "city": "New York"}
将JSON字符串转换为字典(反序列化):
import json# 假设json_str是一个JSON格式的字符串
json_str = '{"name": "John", "age": 30, "city": "New York"}'# 将JSON字符串转换回Python字典
dict_obj = json.loads(json_str)print(dict_obj) # 输出:{'name': 'John', 'age': 30, 'city': 'New York'}
特别注意!!!
1、别使用错方法,dumps()和dump() 是两个方法,dump()只传一个参数会报错
Traceback (most recent call last):File "/Users/fangyirui/PycharmProjects/pythonProject/11 字典.py", line 31, in <module>json.dump(dic)
TypeError: dump() missing 1 required positional argument: 'fp'
错误信息表明json.dump()函数缺少一个必需的位置参数'fp'。在Python的json模块中,dump()方法用于将Python对象编码成JSON格式并写入到一个文件中。因此,它需要两个主要参数:
- 要序列化的Python对象(例如字典)。
- 一个
.write()支持的file-like对象,即可以是打开文件进行写操作的文件句柄。
如果你想将字典保存为JSON到文件中,应该这样做:
import json# 假设dic是你想要序列化的字典
dic = {'name': 'John', 'age': 30, 'city': 'New York'}# 打开一个文件用于写入,并确保使用utf-8编码以支持多语言内容
with open('output.json', 'w', encoding='utf-8') as f:# 使用dump()方法将字典保存到刚才打开的文件里json.dump(dic, f)
这段代码会创建(或覆盖)名为"output.json" 的文件,并将 dic 字典以JSON格式写入该文件。
2、python字段的True布尔类型和"true"字符串类型转成json会导致格式错乱
dic = {'Alice': '23dsq41', True: '9102', 98.6: '3258'}
dic["true"] = "字符串"
print(dic) # {'Alice': '23dsq41', True: '9102', 98.6: '3258', 'true': '字符串'}
json_str_2 = json.dumps(dic)
print(json_str_2) # {"Alice": "23dsq41", "true": "9102", "98.6": "3258", "true": "\u5b57\u7b26\u4e32"}
因为python的布尔类型True转成json是"true",如果要确保不丢失数据,请避免使用可以导致重复关键字(经过类型强制之后) 的原始关键字。
当json解析回字典时,后面的相同的key值会覆盖前面的值,且key都是字符串类型
# 解析json
{"Alice": "23dsq41", "true": "9102", "98.6": "3258", "true": "\u5b57\u7b26\u4e32"}# 结果
dict =
{'Alice': '23dsq41', 'true': '字符串', '98.6': '3258'}
3、编码问题
在JSON中,非ASCII字符(比如中文字符)默认会被转换为Unicode转义序列。这是为了确保JSON字符串在各种环境下都能正确地被解析和显示,特别是在不同的编码系统之间传输数据时。
{"Alice": "23dsq41", "98.6": "3258", "true": "\u5b57\u7b26\u4e32"}
其中的 \u5b57\u7b26\u4e32 是“字符”两个字的Unicode编码。\u5b57 对应于“字”,\u7b26 对应于“符”。
如果你希望在使用 json.dumps() 方法将Python对象转换成JSON字符串时保持非ASCII文字(如中文)不被转义,可以通过设置 ensure_ascii=False 参数来实现:
import jsondict_obj = {'Alice': '23dsq41', '98.6': '3258', 'true': '字符串'}
json_str = json.dumps(dict_obj, ensure_ascii=False)print(json_str)
输出将会是:
{"Alice": "23dsq41", "true": "字符串", "98.6": "3258"}
相关文章:
原理及其操作)
python中字典(dict)原理及其操作
原理 Python中的字典(Dictionary)是一种基于哈希表(Hash Table)的实现,提供了高效的键值对(Key-Value Pair)存储和访问机制。了解字典的工作原理有助于更好地理解其性能特性以及为什么在某些情…...

.NET Core Web API实现微服务集群部署
.NET Core Web API实现微服务集群部署 在.NET Core Web API中实现微服务集群部署通常涉及多个步骤,包括服务拆分、容器化、服务注册与发现、负载均衡等。以下是一个简化的步骤指南,用于在.NET Core中构建和部署微服务集群: 服…...

网络安全与信创产业发展:构建数字时代的护城河
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua,在这里我会分享我的知识和经验。&#x…...

外包干了3个月,技术倒退1年。。。
先说情况,大专毕业,18年通过校招进入湖南某软件公司,干了接近6年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测试…...
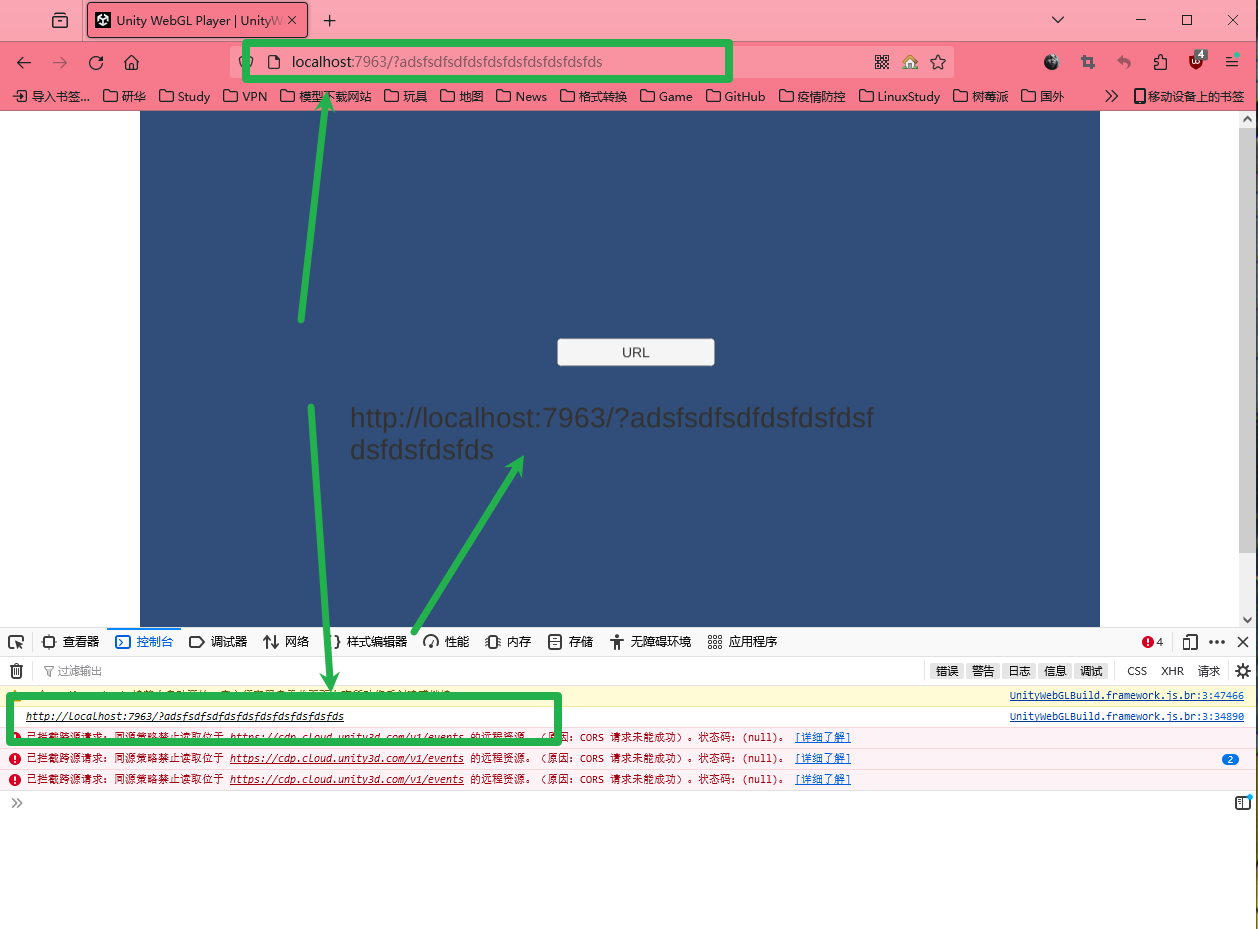
Unity发布webgl获取浏览器的URL
Unity发布webgl获取浏览器的URL Unity发布webgl之后获取浏览器的url 在unity中创建文件夹Plugins,然后添加添加文件UnityGetBrowserURL.jslib var GetUrlFunc {//获取地址栏的URLStringReturnValueFunction: function () {var returnStr window.top.location.hre…...

StarRocks实战——多维分析场景与落地实践
目录 一、OLAP 系统历史背景 1.1 历史背景与痛点 1.2 组件诉求 二、StarRocks 的特点和优势 2.1 极致的查询性能 2.2 丰富的导入方式 2.3 StarRocks 的优势特点 三、多维分析的运用场景 3.1 实时计算场景 / 家长监控中心 3.2 实时更新模型选择 3.2.1 更新模型UNIQU…...

golang 函数式编程库samber/mo使用: Result
golang 函数式编程库samber/mo使用: Result 如果您不了解samber/mo库, 请先阅读上一篇 Option , 这篇讲述结构体Result的使用 Result和Option区别 samber/mo有了Option, 为什么还有Result呢? 我们先看看定义: Opt…...

Python 实现 CHO 指标计算(济坚指数):股票技术分析的利器系列(12)
Python 实现 CHO 指标计算(济坚指数):股票技术分析的利器系列(12) 介绍算法公式 代码rolling函数介绍核心代码计算 CHO 完整代码 介绍 CHO(济坚指数)是一种在金融领域中用于衡量市场波动性和风险的指数 先…...
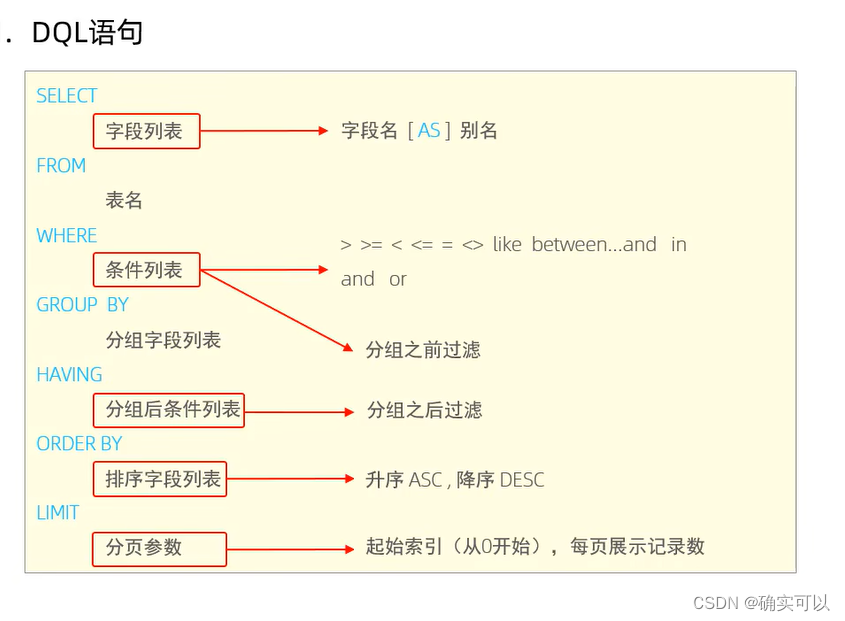
MySQL的SQL语句
1.MySQL连接 连接命令一般是这样写的 mysql -h$ip -P$port -u$user -p比如:mysql -h127.0.0.1 -P3306 -uroot -p -h 指定连接的主机地址;-P 指定连接端口号;-u 指定用户名 -p指定用户名密码 2.SQL分类 DDL(Data Definition Language) 数据定义语言&…...

ABAP 发送带EXCEL邮件
前言 没啥特殊需求,就是有个库龄报表用户想整邮件发送 实现 用的最简单的XLS文件作为excel附件发送出去 观察XLS文件的纯文本格式,每列之间用TAB制表符分隔,每行之间用回车符分隔 思路也比较明确,在SAP中实现这种格式…...
Linux Nginx SSL 证书配置正确,扔展示不安全
Nginx SSL 配置 首先我能够确定自己的Nginx SSL是配置正确的: 问题展示 通过浏览器访问自己域名,点击不安全后查看证书,展示的证书并不是自己所配置的证书,如下: 通过curl -vvv https://域名访问返回的证书是过期…...

算法沉淀——动态规划之子数组、子串系列(上)(leetcode真题剖析)
算法沉淀——动态规划之子数组、子串系列 01.最大子数组和02.环形子数组的最大和03.乘积最大子数组04.乘积为正数的最长子数组长度 01.最大子数组和 题目链接:https://leetcode.cn/problems/maximum-subarray/、 给你一个整数数组 nums ,请你找出一个具…...

Flutter GetX 之 暗黑模式
我们紧接上篇文章,今天继续讲解一下强大的 GetX 的另一个功能,就是 暗黑模式 ,在iOS 13开始苹果的应用慢慢的都开始适配 暗黑模式,andr。oid 也慢慢的 开始跟进,截止到目前,商店的大部分应用都已经完成了 暗…...

SQLlabs46关
看看源码 最终我们的id是放到order by后面了 如果我们直接用列去排序 ?sortusername/password username: passward 可以看到顺序是不同的,当然第一列第二列第三列也可以,基本上都是这个原理,那怎么去实现注入呢,我…...
【Android移动开发】Windows10平台安装Android Studio与人工智能算法模型部署案例
目录 一、Android Studio下载地址二、开发环境JDK三、开始安装Android Studio四、案例展示与搭建五、人工智能算法模型移动端部署案例参考 一、Android Studio下载地址 https://developer.android.google.cn/studio/install.html 电脑配置要求: 下载保存在指定文…...
【IDEA】java 项目启动偶现Kotlin 版本问题 error:Kotlin:module was
一、问题描述: error:Kotlin:module was compiled with an incompatible version of kotlin the binary version of its metadata is二、问题原因: jar包版本冲突 三、解决方式: 1、Rebuild Project(推荐☆) 重新构…...
Jmeter系列(2)目录介绍
目录 Jmeter目录介绍bin目录docsextrasliblicensesprintable_docs Jmeter目录介绍 在学习Jmeter之前,需要先对工具的目录有些了解,也会方便后续的学习 bin目录 examplesCSV目录中有CSV样例jmeter.batwindow 启动文件jmeter.shMac/linux的启动文件jmete…...
vue基础操作(vue基础)
想到多少写多少把,其他的想起来了在写。也写了一些css的 input框的双向数据绑定 html <input value"123456" type"text" v-model"account" input"accou" class"bottom-line bottom" placeholder"请输入…...

EEA架构
概念 EEA(Electrical/Electronic Architecture)是一个综合性的概念,它涉及汽车电子电气系统的设计和整合。EEA是汽车上电气部件之间的相互关系,以及包含所有电气部件和电气系统所承载的逻辑功能的组织结构。它是系统的组织结构表…...

【物联网应用案例】牧场牛棚环境管理项目
众所周知,奶牛的健康和牛奶的产量在很大程度上取决于其所在的环境。对于牧场而言,牛棚内的环境更是至关重要。一个适宜的环境不仅能保证奶牛的舒适度,还能提高其产奶量,从而为牧场带来更多的经济效益。 为了更好地理解牛棚环境对…...

告别笨重模拟器:Windows系统上直接安装APK的终极方案
告别笨重模拟器:Windows系统上直接安装APK的终极方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经为了在电脑上运行一个简单的手机应用而不得…...

Anno 1800模组加载器:企业级XML智能合并与高性能游戏扩展架构实现指南
Anno 1800模组加载器:企业级XML智能合并与高性能游戏扩展架构实现指南 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com…...

3个步骤让你在Windows上轻松安装安卓应用:APK安装器完全指南
3个步骤让你在Windows上轻松安装安卓应用:APK安装器完全指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想过,如果能在Windows电…...

开源机械爪OpenClaw Max:从设计原理到实践应用全解析
1. 项目概述:从开源机械爪到OpenClaw Max的进化之路如果你和我一样,对机器人、自动化或者DIY硬件充满热情,那么“机械爪”这个组件一定不会陌生。它就像是机器人的“手”,是实现抓取、搬运、操作等复杂任务的核心执行器。市面上有…...

Adobe-GenP 3.0:三步解锁Adobe全家桶的终极指南
Adobe-GenP 3.0:三步解锁Adobe全家桶的终极指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 还在为昂贵的Adobe Creative Cloud订阅费而烦恼吗&#…...

GPT-5.5推理效率优化背后的5个核心技术突破
概要GPT-5.5是OpenAI于2026年4月23日发布的旗舰模型,代号"Spud"。最近在库拉(c.877ai.cn)AI工具聚合平台上做了集中测试,GPT-5.5的推理效率提升不是单一优化的结果,而是五个核心技术方向同时突破。从数据看&…...

利用 JiuwenClaw AgentTeam 打造自动化研发团队
利用 JiuwenClaw AgentTeam 打造自动化研发团队 本文介绍如何通过 JiuwenClaw AgentTeam 构建自动化研发团队,实现字幕软件开发、AtomGit Issue/PR 智能处理与飞书文档同步。 目录 JiuwenClaw 平台概述 系统架构预置智能体类型 什么是 AgentTeams飞书群中添加机器人…...

工业现场故障排查:从温度敏感故障到CMOS浮空输入根因分析
1. 项目概述:一个“脾气暴躁”的堆垛起重机 在工业现场,最让人头疼的往往不是那些彻底罢工的设备,而是那些“时好时坏”、“看心情工作”的间歇性故障。它们像幽灵一样,在你想复现问题时消失得无影无踪,等你一离开又悄…...

如何快速掌握WarcraftHelper:魔兽争霸III终极辅助工具完整指南
如何快速掌握WarcraftHelper:魔兽争霸III终极辅助工具完整指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸III的画面拉…...

LLamaSharp实战指南:在.NET应用中本地部署与集成大语言模型
1. 项目概述:LLamaSharp,一个让大语言模型在本地跑起来的C#利器 如果你是一名C#或.NET开发者,最近肯定被ChatGPT和各种大语言模型(LLM)刷屏了。但你是否想过,不依赖OpenAI的API,不担心网络延迟…...