ELK日志系统

一、规划
| 服务名 | 所在服务器 |
|---|---|
| kafka1—2.13-2.4.1 | 192.168.76.10 |
| kafka2—2.13-2.4.1 | 192.168.76.11 |
| kafka3—2.13-2.4.1 | 192.168.76.12 |
| zookeeper1—3.6.3 | 192.168.76.10 |
| zookeeper2—3.6.3 | 192.168.76.11 |
| zookeeper3—3.6.3 | 192.168.76.12 |
| elasticsearch1—7.12.1 | 192.168.76.10 |
| elasticsearch2—7.12.1 | 192.168.76.11 |
| elasticsearch3—7.12.1 | 192.168.76.12 |
| kibana—7.12.1 | 192.168.76.13 |
| logstash—7.12.1 | 192.168.76.14 |
| JDK—11.0.21 | ------ |
二、JDK
# 官网下载JDK11的安装包,并上传到服务器解压/home/java
tar -zxvf jdk-11.0.21_linux-x64_bin.tar.gz# 编辑文件并加入以下内容
vim /etc.profile
# JAVA_11
export PATH=/home/java/jdk-11.0.21/bin:$PATH# 使环境变量生效
source /etc/profilejava -version
java version "11.0.21" 2023-10-17 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.21+9-LTS-193)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.21+9-LTS-193, mixed mode)
三、kafka
# 以下操作在3个节点执行
# zookeeper集群
mkdir /apps
cd /appswget https://downloads.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz# 三个zookeeper节点执行:解压安装包并做软链接
tar xvf apache-zookeeper-3.6.3-bin.tar.gz
ln -sv /apps/apache-zookeeper-3.6.3-bin /apps/zookeeper# zookeeper配置
cd /apps/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfgtickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181server.1=192.168.76.10:2888:3888
server.2=192.168.76.11:2888:3888
server.3=192.168.76.12:2888:3888# 创建数据目录
mkdir -p /data/zookeeper# 配置zookeeper节点id(注意,zookeeper集群每个节点的id都不一样)
在zookeeper1节点192.168.76.10上执行:
echo 1 > /data/zookeeper/myid
在zookeeper2节点192.168.76.11上执行:
echo 2 > /data/zookeeper/myid
在zookeeper3节点192.168.76.12上执行:
echo 3 > /data/zookeeper/myid# 运行zookeeper集群.
# 注意:zookeeper配置的初始化时间为10*2000ms,即20s,因此三个节点服务拉起时间不能超过20s,超过20s将会集群初始化失败查看集群各节点角色
/apps/zookeeper/bin/zkServer.sh start
/apps/zookeeper/bin/zkServer.sh status #当前集群zookeeper2为leader角色。# kafka集群
wget https://archive.apache.org/dist/kafka/2.4.1/kafka_2.13-2.4.1.tgz
tar xvf kafka_2.13-2.4.1.tgz
ln -sv /apps/kafka_2.13-2.4.1 /apps/kafka# 修改kafka配置文件
# kafka1节点192.168.76.10配置
cd /apps/kafka/config
vim server.properties
broker.id=10 #指定borkerid,每个节点都不一样,这里以节点ip最后一位作为brokerid
listeners=PLAINTEXT://192.168.76.10:9092 #指定监听地址和端口,指定监听本地地址
log.dirs=/data/kafka-logs #指定日志目录
log.retention.hours=168 #指定日志保存时长
zookeeper.connect=192.168.76.10:2181,192.168.76.11:2181,192.168.76.12:2181 #指定zk地址和端口
# 创建日志目录
mkdir -p /data/kafka-logs# kafka2节点192.168.76.11配置
cd /apps/kafka/config
vim server.properties
broker.id=11 #指定borkerid,每个节点都不一样,这里以节点ip最后一位作为brokerid
listeners=PLAINTEXT://192.168.76.11:9092 #指定监听地址和端口,指定监听本地地址
log.dirs=/data/kafka-logs #指定日志目录
log.retention.hours=168 #指定日志保存时长
zookeeper.connect=192.168.76.10:2181,192.168.76.11:2181,192.168.76.12:2181 #指定zk地址和端口
# 创建日志目录
mkdir -p /data/kafka-logs# kafka3节点192.168.76.12配置
cd /apps/kafka/config
vim server.properties
broker.id=12 #指定borkerid,每个节点都不一样,这里以节点ip最后一位作为brokerid
listeners=PLAINTEXT://192.168.76.12:9092 #指定监听地址和端口,指定监听本地地址
log.dirs=/data/kafka-logs #指定日志目录
log.retention.hours=168 #指定日志保存时长
zookeeper.connect=192.168.76.10:2181,192.168.76.11:2181,192.168.76.12:2181 #指定zk地址和端口
# 创建日志目录
mkdir -p /data/kafka-logs# 启动kafka
/apps/kafka/bin/kafka-server-start.sh -daemon /apps/kafka/config/server.properties# 验证端口是否起来
netstat -antp | grep 9092
tcp 0 0 192.168.76.10:9092 0.0.0.0:* LISTEN 69836/java
四、elasticsearch
# 以下操作在3个节点执行
cd /apps
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.1-x86_64.rpm
rpm -ivh elasticsearch-7.12.1-x86_64.rpm# 修改配置文件并启动服务
# elasticsearch01节点192.168.76.10上执行:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: es-yaya #指定集群名称,三个节点集群名称配置一样
node.name: master-10 #指定node名称,每个节点配置不能一样,这里将主机名配置文件node name
path.data: /var/lib/elasticsearch #指定数据目录,如果要保存数据,可以挂载存储到该目录
path.logs: /var/log/elasticsearch #指定日志目录,如果要保存数据,可以挂载存储到该目录
#bootstrap.memory_lock: true #是否开启内存锁定,即当elasticsearch启动时为其分配多大内存,通过修改vim /etc/elasticsearch/jvm.options文件来配置,这里暂不开启。
network.host: 192.168.76.10 #指定监听地址,这里写本机地址
http.port: 9200 #客户端监听端口,9200是给客户端使用的端口
discovery.seed_hosts: ["192.168.76.10", "192.168.76.11","192.168.76.12"] #发现配置,发现消息后通告给目标主机,这里填写集群内各节点ip地址或主机名
cluster.initial_master_nodes: ["192.168.76.10", "192.168.76.11","192.168.76.12"] #集群内哪些节点可以被选举为master,一般会将集群内各节点都加上
action.destructive_requires_name: true #通过严格匹配删除索引,防止误删除索引
配置完成后启动elasticsearch服务
systemctl start elasticsearch.service# elasticsearch02节点192.168.76.11上执行:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: es-yaya #指定集群名称,三个节点集群名称配置一样
node.name: node1-11 #指定node名称,每个节点配置不能一样,这里将主机名配置文件node name
path.data: /var/lib/elasticsearch #指定数据目录,如果要保存数据,可以挂载存储到该目录
path.logs: /var/log/elasticsearch #指定日志目录,如果要保存数据,可以挂载存储到该目录
#bootstrap.memory_lock: true #是否开启内存锁定,即当elasticsearch启动时为其分配多大内存,通过修改vim /etc/elasticsearch/jvm.options文件来配置,这里暂不开启。
network.host: 192.168.76.11 #指定监听地址,这里写本机地址
http.port: 9200 #客户端监听端口,9200是给客户端使用的端口
discovery.seed_hosts: ["192.168.76.10", "192.168.76.11","192.168.76.12"] #发现配置,发现消息后通告给目标主机,这里填写集群内各节点ip地址或主机名
cluster.initial_master_nodes: ["192.168.76.10", "192.168.76.11","192.168.76.12"] #集群内哪些节点可以被选举为master,一般会将集群内各节点都加上
action.destructive_requires_name: true #通过严格匹配删除索引,防止误删除索引
配置完成后启动elasticsearch服务
systemctl start elasticsearch.service# elasticsearch03节点192.168.76.12上执行:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: es-yaya #指定集群名称,三个节点集群名称配置一样
node.name: node2-12 #指定node名称,每个节点配置不能一样,这里将主机名配置文件node name
path.data: /var/lib/elasticsearch #指定数据目录,如果要保存数据,可以挂载存储到该目录
path.logs: /var/log/elasticsearch #指定日志目录,如果要保存数据,可以挂载存储到该目录
#bootstrap.memory_lock: true #是否开启内存锁定,即当elasticsearch启动时为其分配多大内存,通过修改vim /etc/elasticsearch/jvm.options文件来配置,这里暂不开启。
network.host: 192.168.76.12 #指定监听地址,这里写本机地址
http.port: 9200 #客户端监听端口,9200是给客户端使用的端口
discovery.seed_hosts: ["192.168.76.10", "192.168.76.11","192.168.76.12"] #发现配置,发现消息后通告给目标主机,这里填写集群内各节点ip地址或主机名
cluster.initial_master_nodes: ["192.168.76.10", "192.168.76.11","192.168.76.12"] #集群内哪些节点可以被选举为master,一般会将集群内各节点都加上
action.destructive_requires_name: true #通过严格匹配删除索引,防止误删除索引
配置完成后启动elasticsearch服务
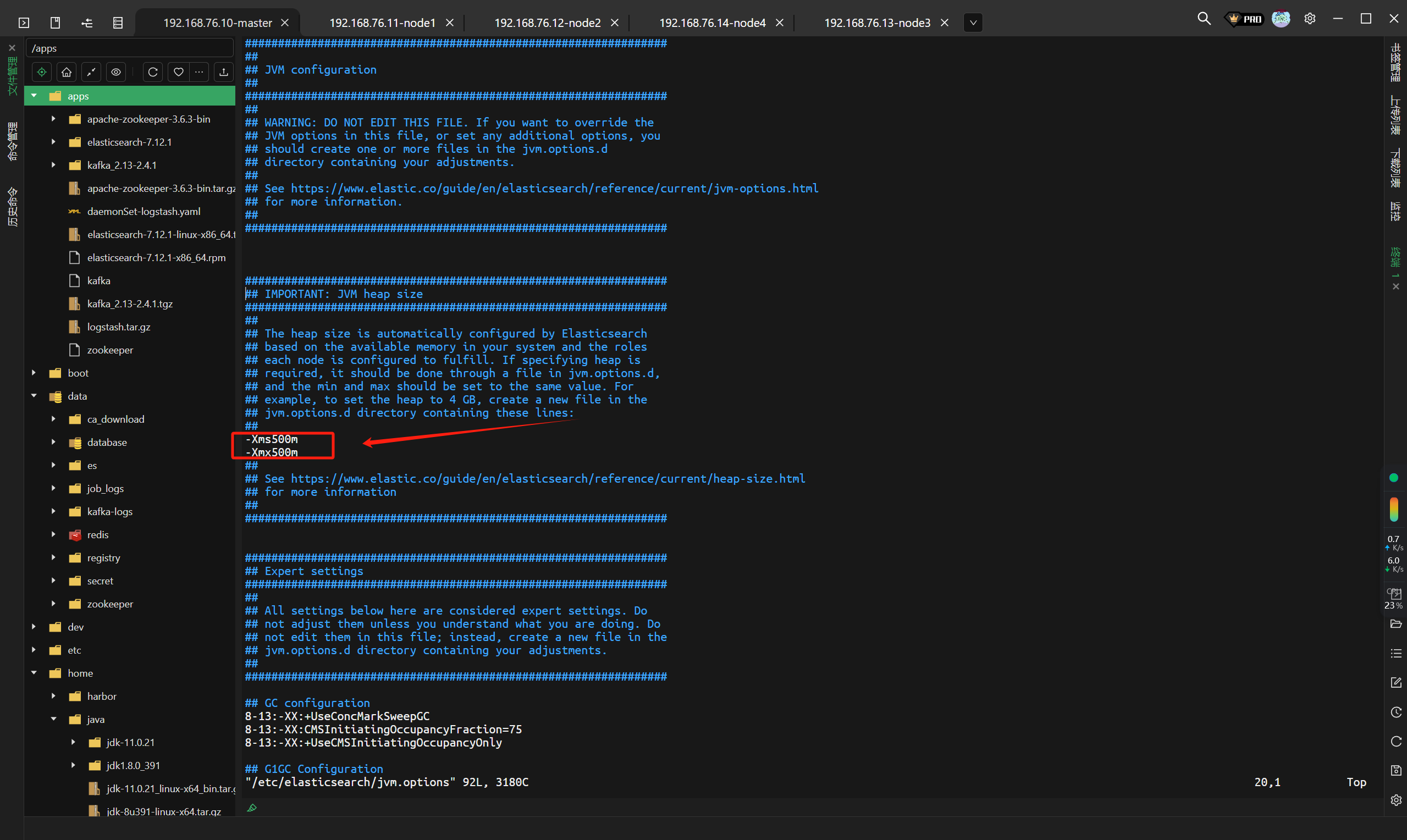
systemctl start elasticsearch.service# 如果es起不来的话,可能是资源不够,修改如下文件并重启就可以了
vim /etc/elasticsearch/jvm.options
五、kibana
# 下载
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.12.1-x86_64.rpm
rpm -ivh kibana-7.12.1-x86_64.rpmvim /etc/kibana/kibana.yml
server.port: 5601 #kibana监听端口
server.host: "192.168.76.13" #kibana地址
elasticsearch.hosts: ["http://192.168.76.10:9200"] #elasticsearch的地址和端口
i18n.locale: "zh-CN" #修改kibana页面显示语言为中文# 启动
systemctl start kibana
netstat -antp | grep 5601
访问:http://192.168.76.13:5601/
六、logstash
# 构建镜像
vim logstash.yml
http.host: "0.0.0.0"
#xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200" ] #关闭xpack功能,该功能收费,如果不关闭将无法正常使用logstash# 准备logstash日志收集的配置,通过配置input日志输入和output输出来匹配收集的容器日志
vim app1.conf
input {file {path => "/var/lib/docker/containers/*/*-json.log"start_position => "beginning"type => "jsonfile-daemonset-applog"}file {path => "/var/log/*.log "start_position => "beginning"type => "jsonfile-daemonset-syslog"}
}output {if [type] == "jsonfile-daemonset-applog" {kafka {bootstrap_servers => "${KAFKA_SERVER}"topic_id => "${TOPIC_ID}"batch_size => 16384 #logstash每次向ES传输的数据量大小,单位为字节codec => "${CODEC}"} }if [type] == "jsonfile-daemonset-syslog" {kafka {bootstrap_servers => "${KAFKA_SERVER}"topic_id => "${TOPIC_ID}"batch_size => 16384#codec => "${CODEC}" #系统日志不是json格式}}
}# Dockerfile
vim Dockerfile
FROM logstash:7.12.1USER root
WORKDIR /usr/share/logstash
#RUN rm -rf config/logstash-sample.conf
ADD logstash.yml /usr/share/logstash/config/logstash.yml
ADD app1.conf /usr/share/logstash/pipeline/logstash.conf# 构建镜像
docker build -t harbor.magedu.local/baseimages/logstash:v7.12.1-json-file-log-v4 .
# 准备镜像,所有节点
docker save -o logstash.tar.gz logstash:v7.12.1-json-file-log-v4
docker load -i logstash.tar.gz
scp logstash.sh#
vim daemonSet-logstash.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:name: logstash-elasticsearchnamespace: log-collectionlabels:k8s-app: logstash-logging
spec:selector:matchLabels:name: logstash-elasticsearchtemplate:metadata:labels:name: logstash-elasticsearchspec:tolerations:# this toleration is to have the daemonset runnable on master nodes# remove it if your masters can't run pods- key: node-role.kubernetes.io/masteroperator: Existseffect: NoSchedulecontainers:- name: logstash-elasticsearchimage: logstash:v7.12.1-json-file-log-v4 #使用自构建的镜像env: #设置环境变量,便于在Dockerfile中引用这些变量- name: "KAFKA_SERVER"value: "192.168.76.10:9092,192.168.76.11:9092,192.168.76.12:9092" - name: "TOPIC_ID"value: "jsonfile-log-topic"- name: "CODEC"value: "json"volumeMounts: - name: varlogmountPath: /var/log #指定宿主机系统日志在容器内的挂载路径- name: varlibdockercontainersmountPath: /var/lib/docker/containers #指定容器存储在宿主机上日志目录在容器内的挂载路径readOnly: falseterminationGracePeriodSeconds: 30volumes: #设置挂载,将宿主机系统日志路径和容器存储宿主机的日志路径挂载到logstash容器中,便于logstash收集日志- name: varloghostPath: #使用hostPath类型的存储卷path: /var/log- name: varlibdockercontainershostPath:path: /var/lib/docker/containers# 创建nomespace
kubectl create ns log-collectionkubectl apply -f daemonSet-logstash.yaml# 查看pod是否运行
kubectl get po -n log-collection
NAME READY STATUS RESTARTS AGE
logstash-elasticsearch-6m8j2 1/1 Running 1 19h
logstash-elasticsearch-7n7ls 1/1 Running 1 19h
logstash-elasticsearch-9ns25 1/1 Running 1 19h
logstash-elasticsearch-csmvc 1/1 Running 1 19h
logstash-elasticsearch-vscv4 1/1 Running 1 19h
宿主机安装logstash消费kafka集群日志
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.12.1-x86_64.rpm
rpm -ivh logstash-7.12.1-x86_64.rpm# 编辑配置文件
vim /etc/logstash/conf.d/daemonset-log-to-es.conf
input {kafka {bootstrap_servers => "192.168.76.10:9092,192.168.76.11:9092,192.168.76.12:9092" # kafka三个节点地址topics => ["jsonfile-log-topic"]codec => "json"}
}output {if [type] == "jsonfile-daemonset-applog" {elasticsearch {hosts => ["192.168.76.10:9200","192.168.76.11:9200"] # es地址,写两个就好index => "jsonfile-daemonset-applog-%{+YYYY.MM.dd}"}}if [type] == "jsonfile-daemonset-syslog" {elasticsearch {hosts => ["192.168.76.10:9200","192.168.76.11:9200"] # es地址,写两个就好index => "jsonfile-daemonset-syslog-%{+YYYY.MM.dd}"}}}# 启动查看有无报错
systemctl start logstash
配置参数说明:
input配置:指定kafka集群个节点地址,指定topics,该topics就是在k8s集群中daemonset yml文件中引用的topics变量,指定编码为json
output配置:通过type过来日志,将过滤的日志发送给elasticsearch,hosts指定elasticsearch集群各节点地址,index指定索引,用日期进行区分。这里分别过滤容器日志jsonfile-daemonset-applog和系统日志jsonfile-daemonset-syslog
hosts:指定elasticsearch集群各节点地址
index:指定索引格式
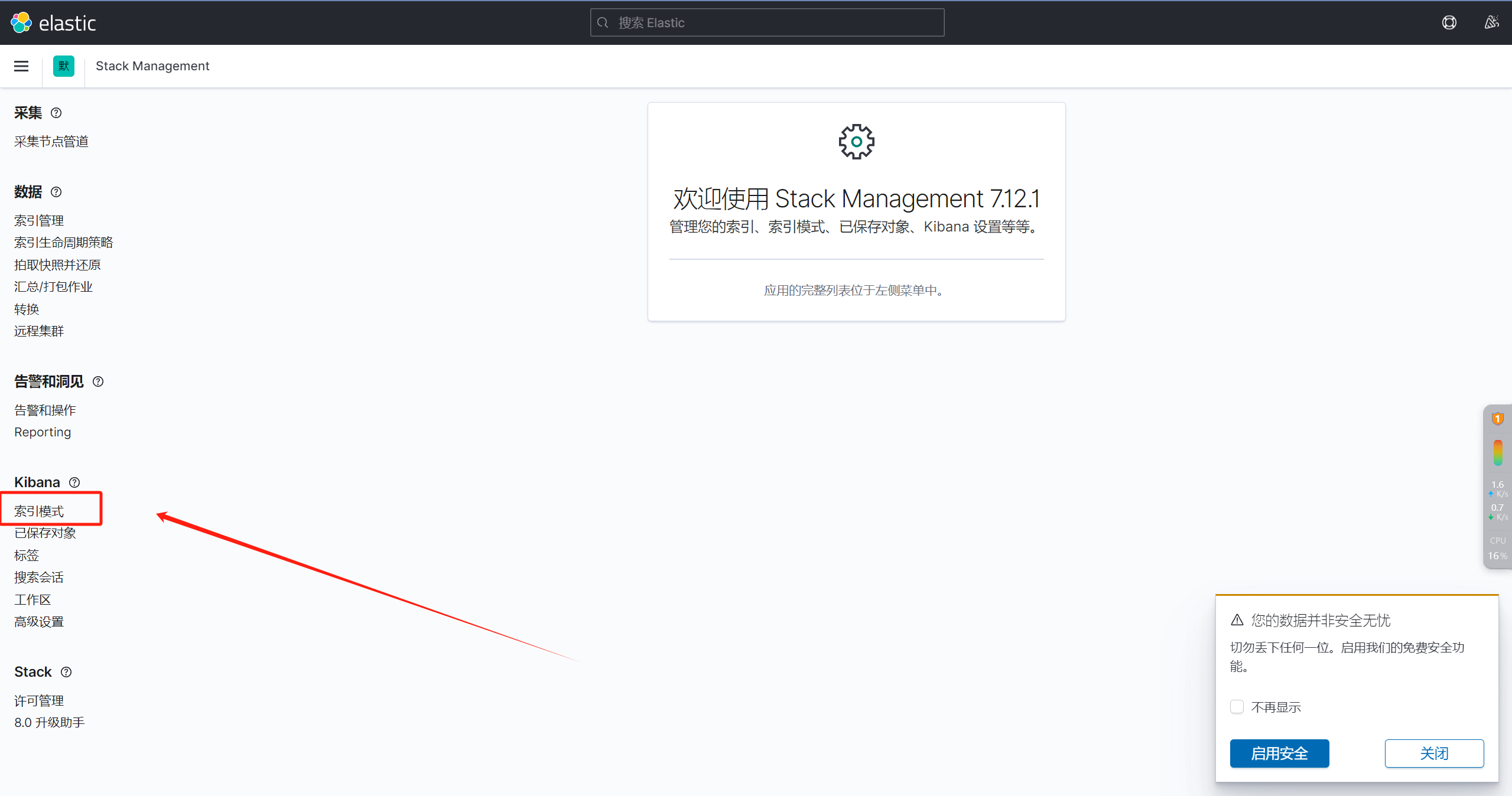
七、配置kibana
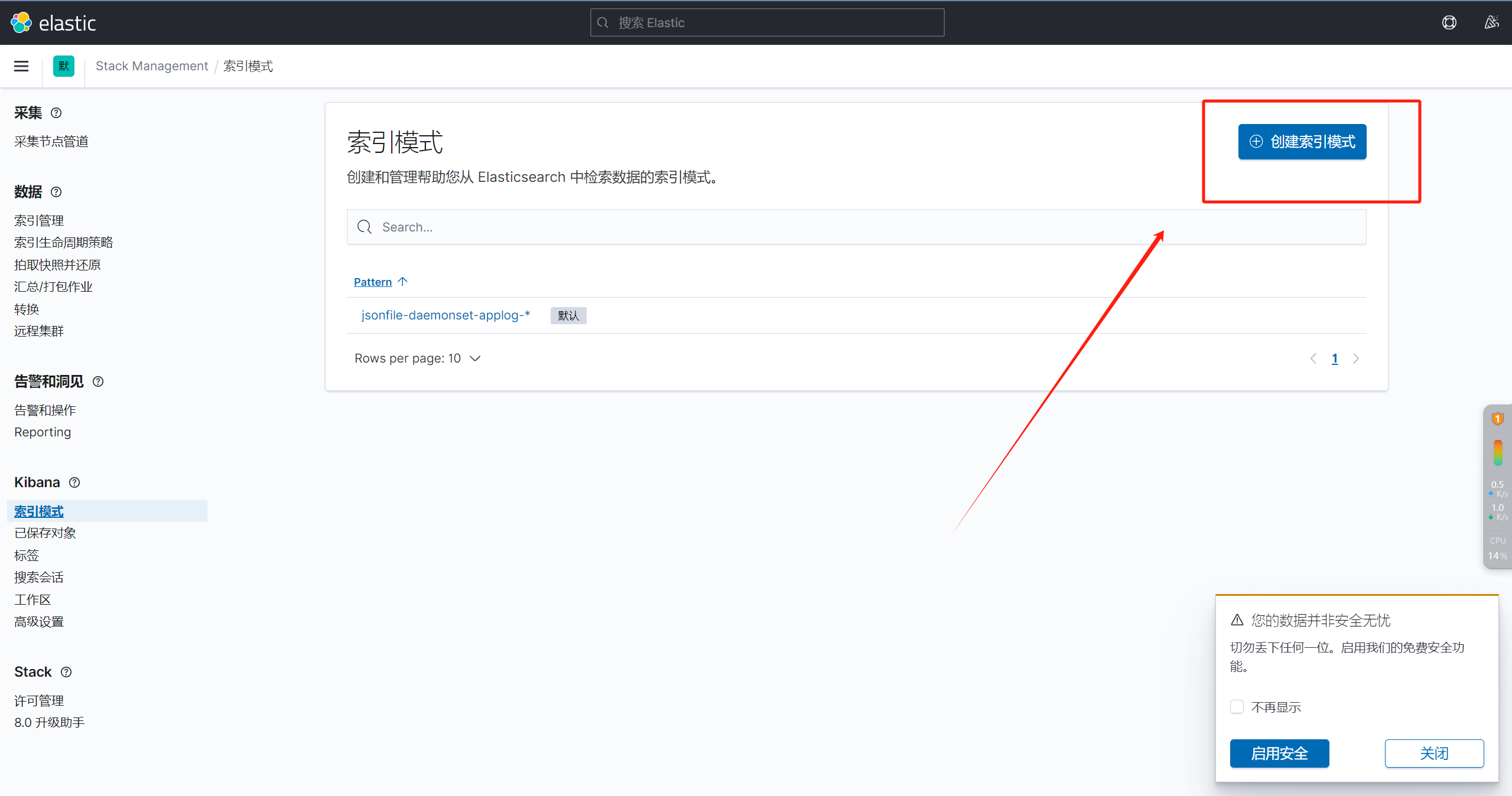
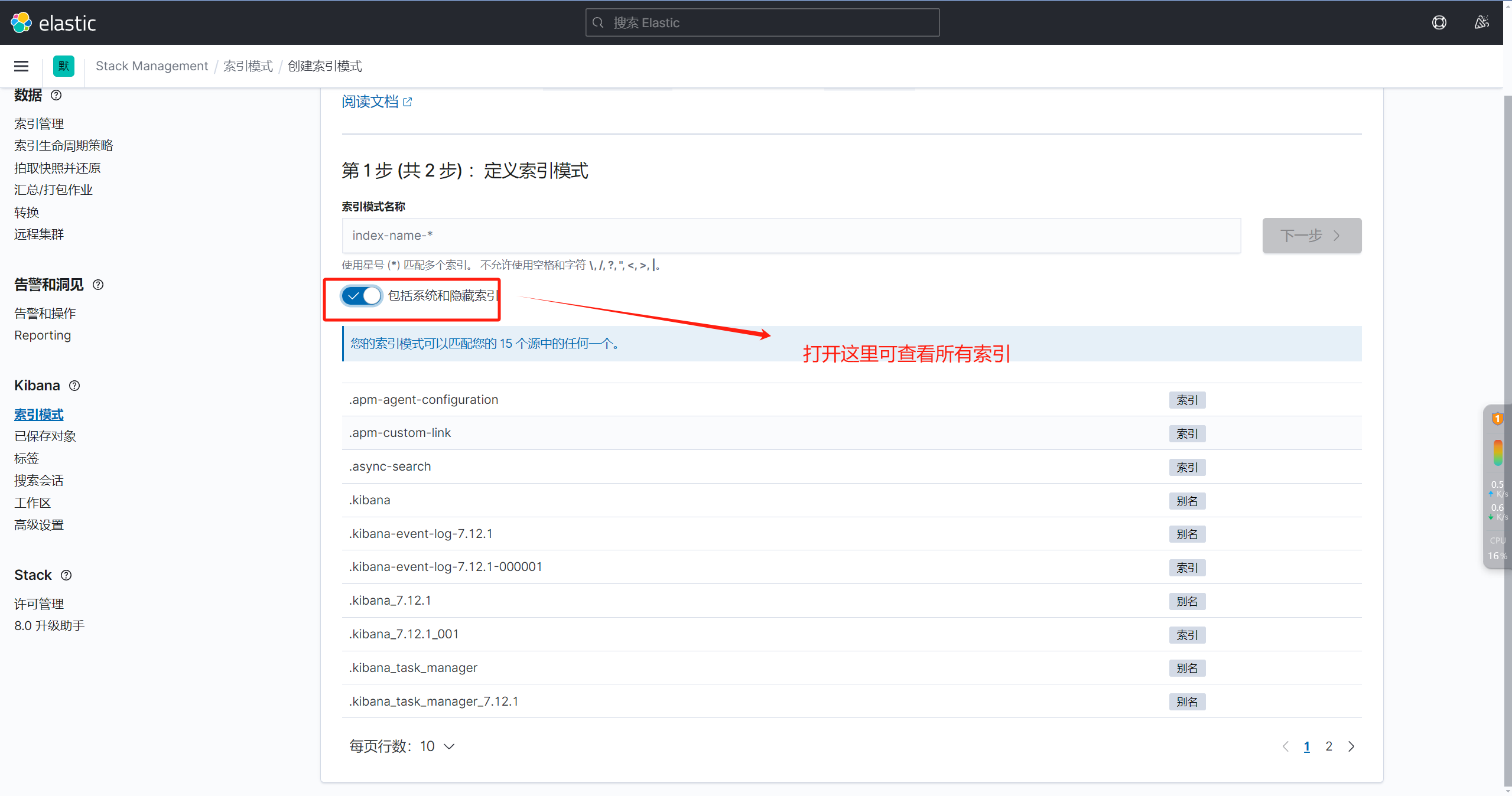
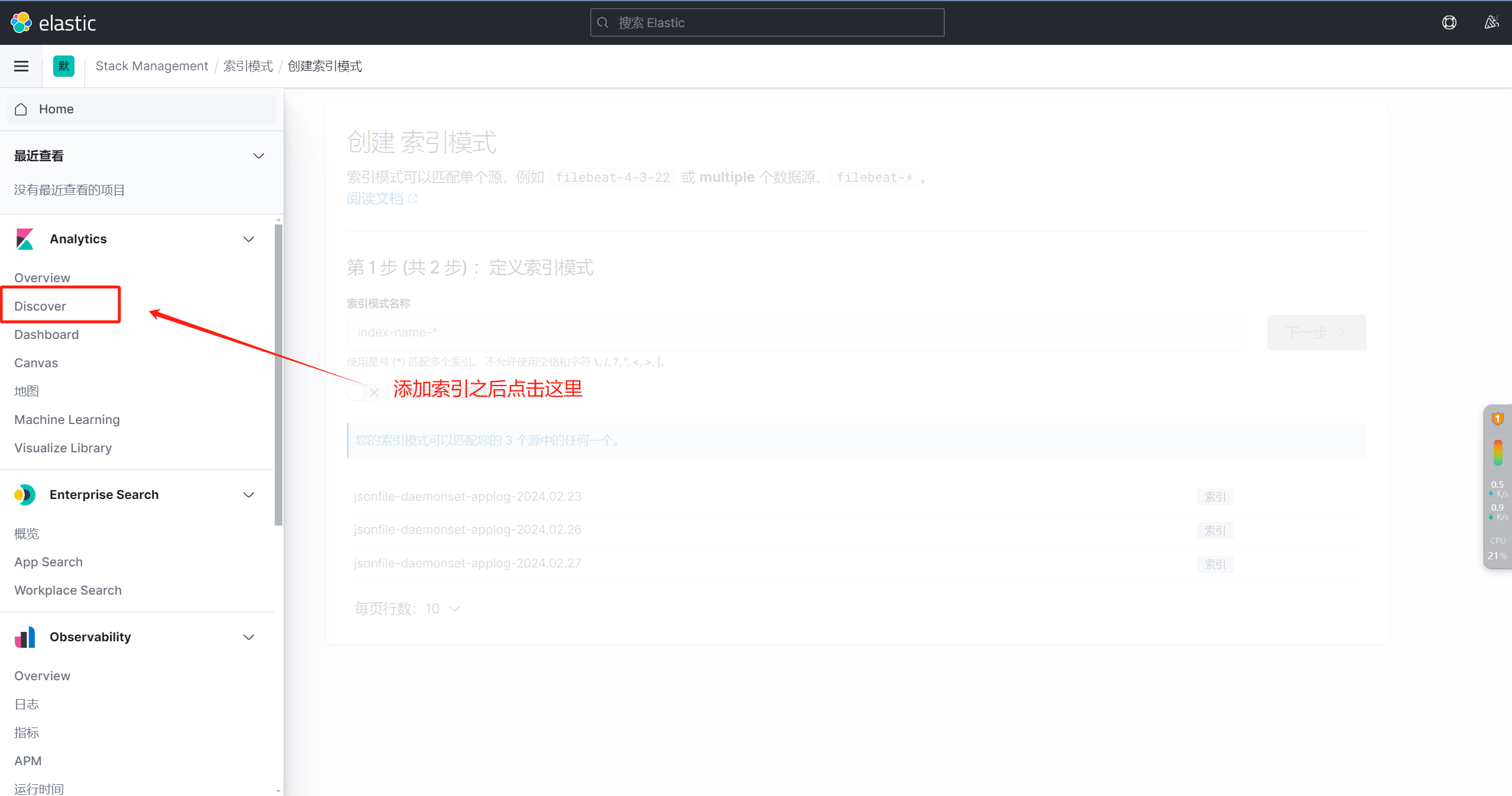
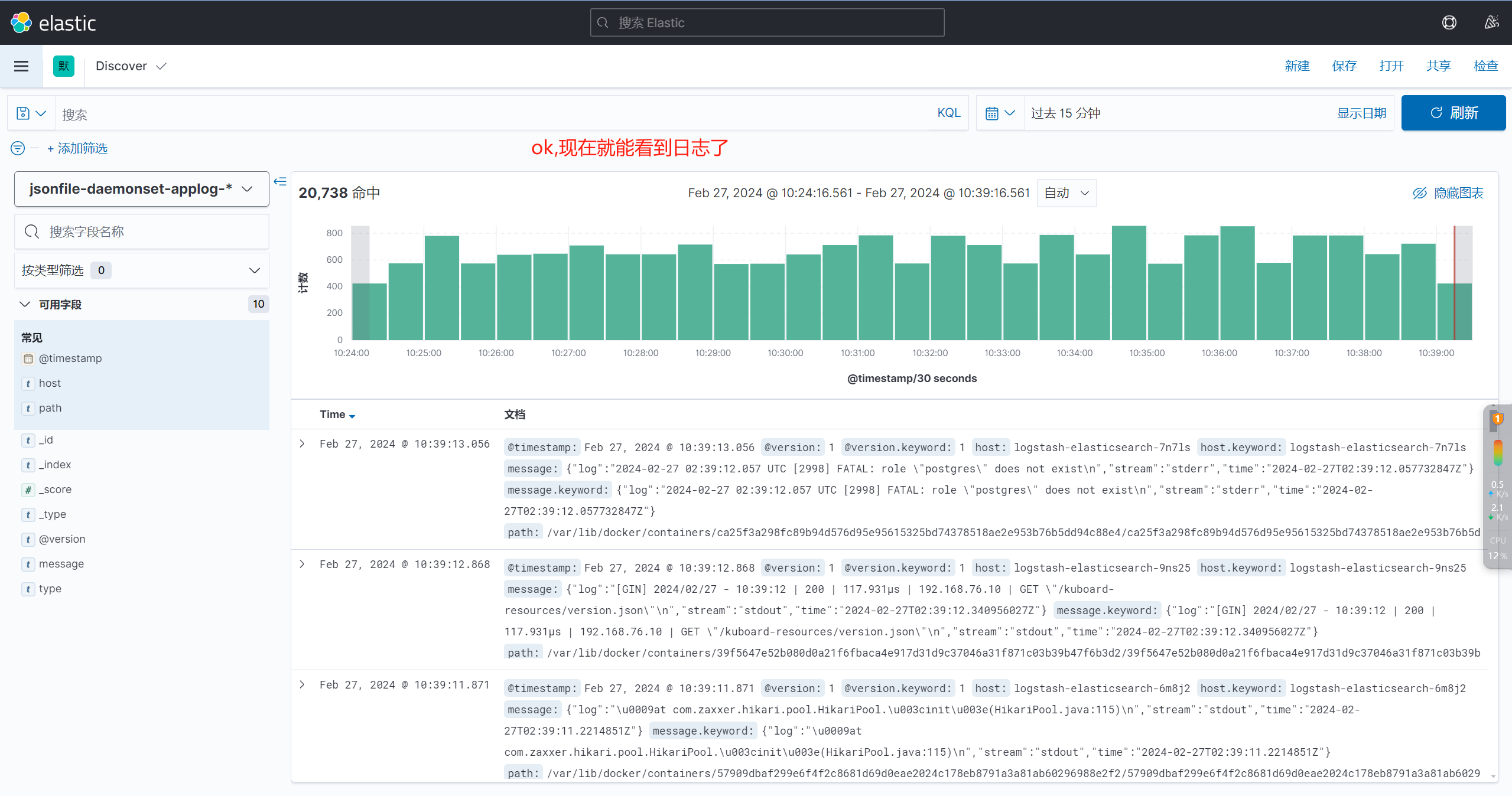
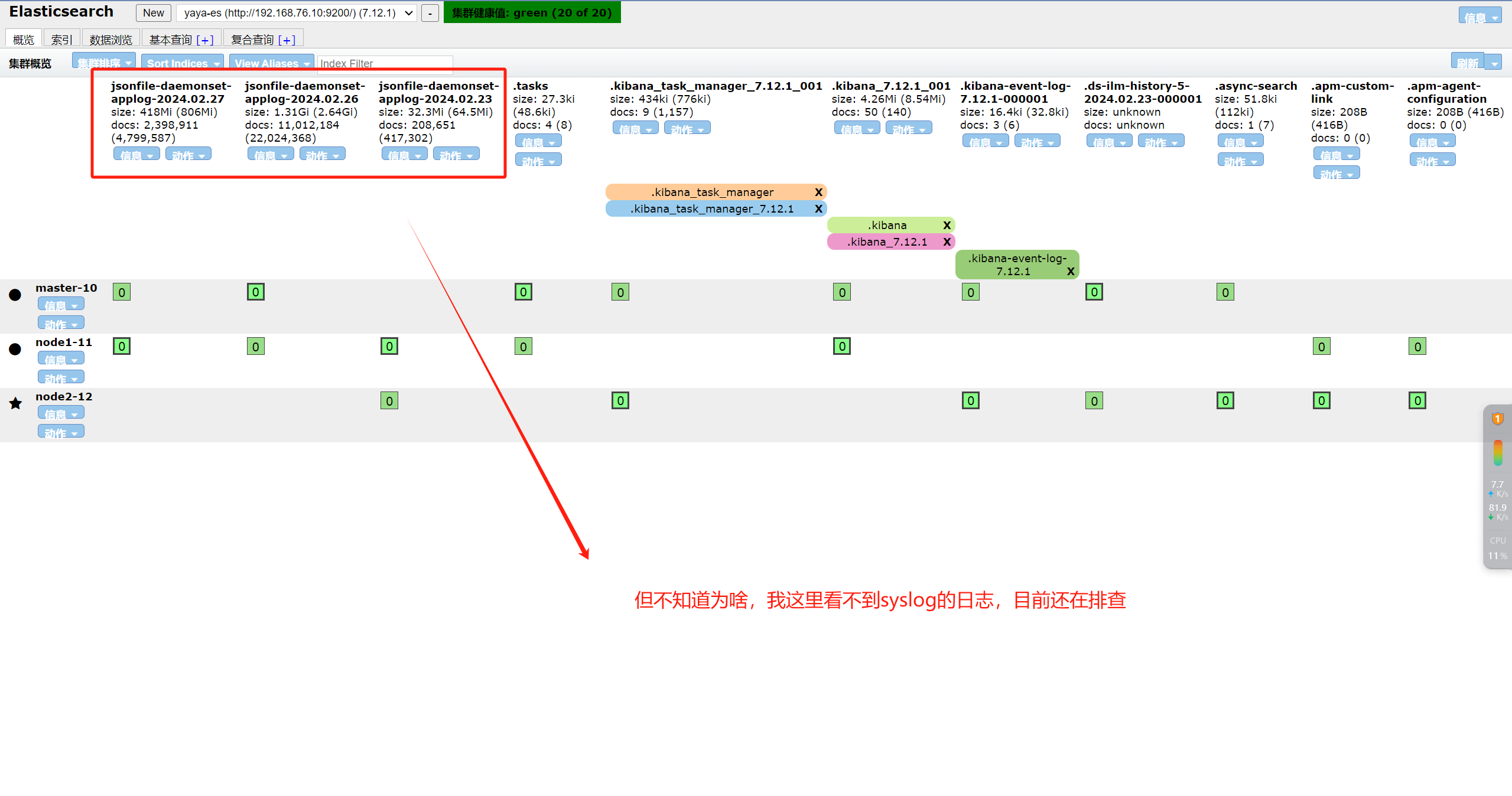
相关文章:
ELK日志系统
一、规划 服务名所在服务器kafka1—2.13-2.4.1192.168.76.10kafka2—2.13-2.4.1192.168.76.11kafka3—2.13-2.4.1192.168.76.12zookeeper1—3.6.3192.168.76.10zookeeper2—3.6.3192.168.76.11zookeeper3—3.6.3192.168.76.12elasticsearch1—7.12.1192.168.76.10elasticsearc…...
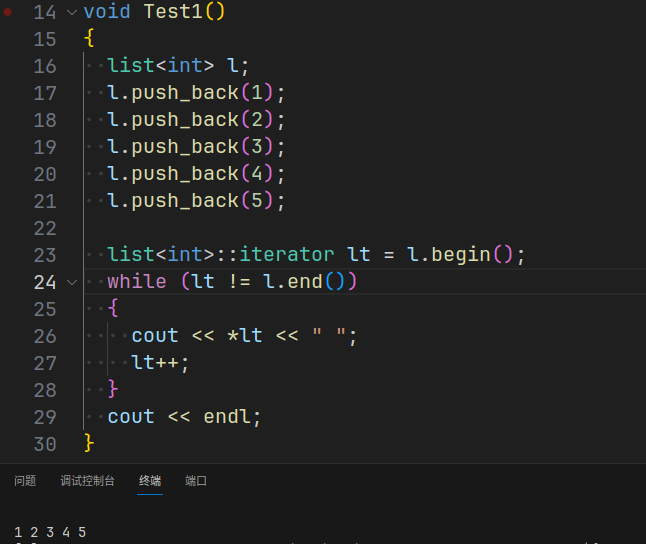
C++:list容器(非原生指针迭代器的实现)
本章是STL容器 list 的模拟实现。 之前已经使用 C语言 对带头双向循环链表 进行实现,详见数据结构: 线性表(带头双向循环链表实现), 相较于之前的实现,C 下多了对迭代器以及模板等相关语法特性。下面将着重讲解这些新知识。 文章目录 一. list 的基本框架…...
抖音视频批量下载软件|视频评论采集工具
抖音视频评论采集软件是一款基于C#开发的高效、便捷的工具,旨在为用户提供全面的数据采集和分析服务。用户可以通过关键词搜索抓取视频数据,也可以通过分享链接进行单个视频的抓取和下载,从而轻松获取抖音视频评论数据。 批量视频提取模块&a…...

Oracle RMAN 备份恢复
Oracle RMAN 备份恢复 1.什么是RMAN RMAN在数据库服务器的帮助下实现数据库文件、控制文件、数据库文件和控制文件的映像副本,以及归档日志文件,数据库服务器参数文件的备份。RMAN也允许使用脚本文件实现数据的备份与恢复,而且这些脚本保存…...

【MySQL】学习和总结联合查询
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:“没有罗马,那就自己创造罗马~” #mermaid-svg-OPj5g6evbkm5ol0U {font-family:"trebuchet ms",verdana,arial,sans-serif;font-siz…...
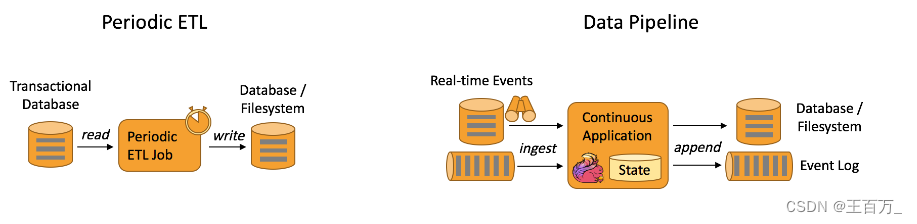
Flink应用场景
1、介绍 (1) Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink 不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架…...
产品渲染3D效果图一张多少钱,哪个平台更有性价比?
产品渲染3D效果图的价格受到多方面因素的影响,包括但不限于产品类型、渲染难度以及输出尺寸等。如果效果图需要后期处理,还有可能增加其他费用。接下来,我们来了解一下产品渲染效果图的费用情况。 1.产品渲染3D效果图一张多少钱? …...

云原生之容器编排实践-ruoyi-cloud项目部署到K8S:MySQL8
背景 前面搭建好了 Kubernetes 集群与私有镜像仓库,终于要进入服务编排的实践环节了。本系列拿 ruoyi-cloud 项目进行练手,按照 MySQL , Nacos , Redis , Nginx , Gateway , Auth ,…...

go interface{} 和string的转换问题
1.遇到的问题 问题来源于,我sql模版拼接遇到的问题。 首先,这样是没有问题的。 var qhx interface{} "qhx"s : qhx.(string)fmt.Println(s) 但是当我在这段代码里用:1.类型断言 var sqlStr "select * from tx_user where username %s" join…...

【Git教程】(三)提交详解 —— add、commit、status、stach命令的说明,提交散列值与历史,多次提交及忽略 ~
Git教程 提交详解 1️⃣ 访问权限与时间戳2️⃣ add命令与 commit 命令3️⃣ 提交散列值4️⃣ 提交历史5️⃣ 一种特别的提交查看方法6️⃣ 同一项目的多部不同历史6.1 部分输出:-n6.2 格式化输出:--format、--oneline6.3 统计修改信息:--st…...

vue3个人网站电子宠物
预览 具体代码 Attack.gif Attacked.gif Static.gif Walk.gif Attack.gif Static.gif Attacked.gif Walk.gif <template><div class"pet-container" ref"petContainer"><p class"pet-msg">{{ pet.msg }}</p><img re…...
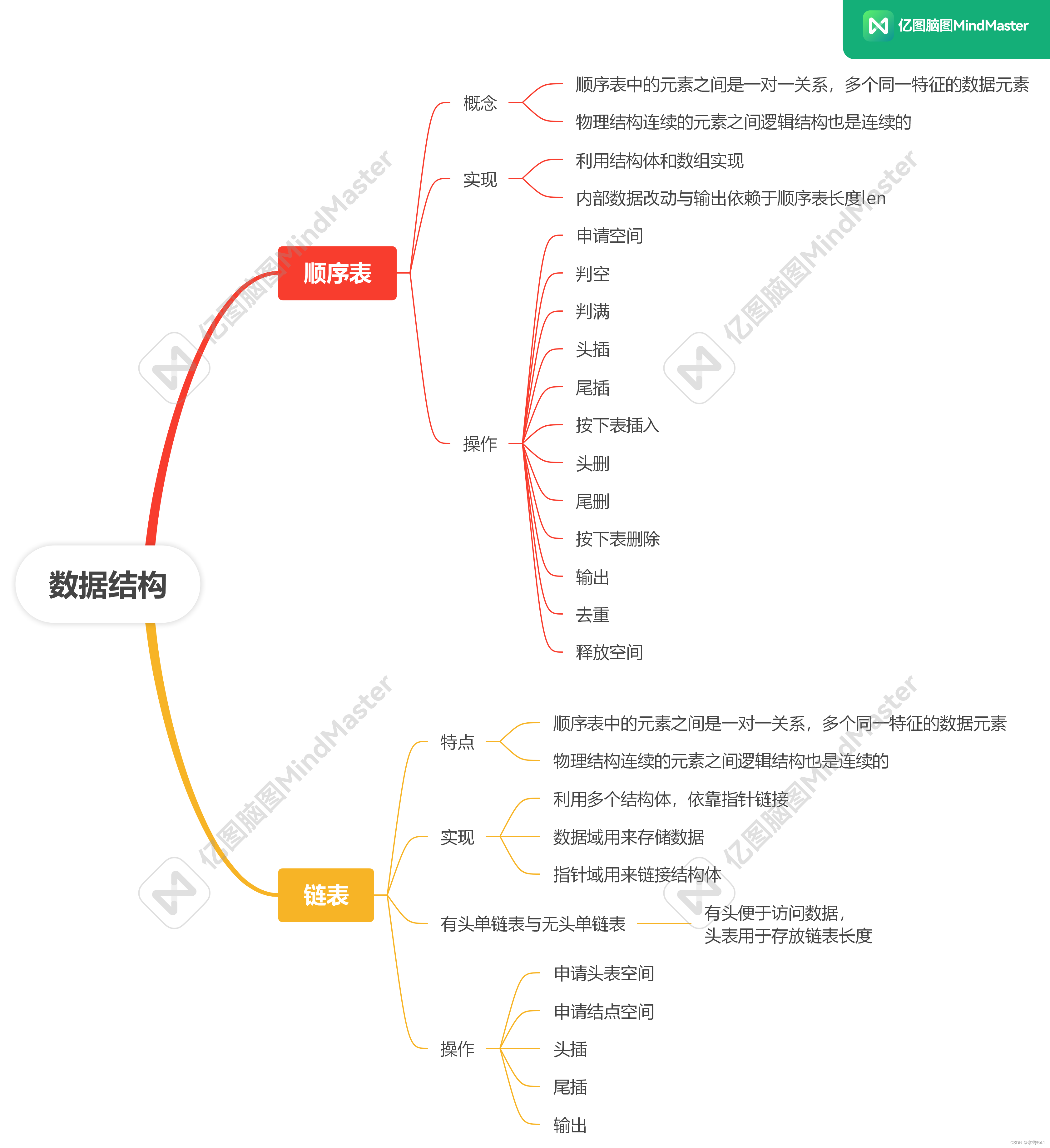
2.22 作业
顺序表 运行结果 fun.c #include "fun.h" seq_p create_seq_list() {seq_p L (seq_p)malloc(sizeof(seq_list));if(LNULL){printf("空间申请失败\n");return NULL;}L->len 0; bzero(L,sizeof(L->data)); return L; } int seq_empty(seq_p L) {i…...
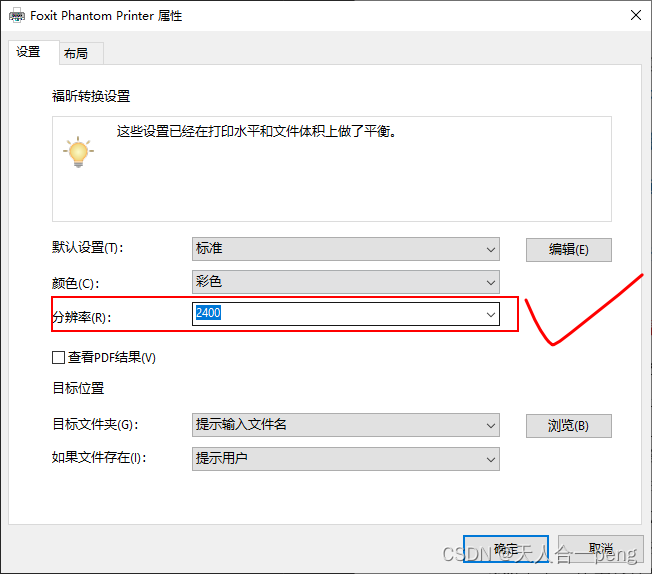
office word保存pdf高质量设置
1 采用第三方pdf功能生成 分辨率越大质量越好...
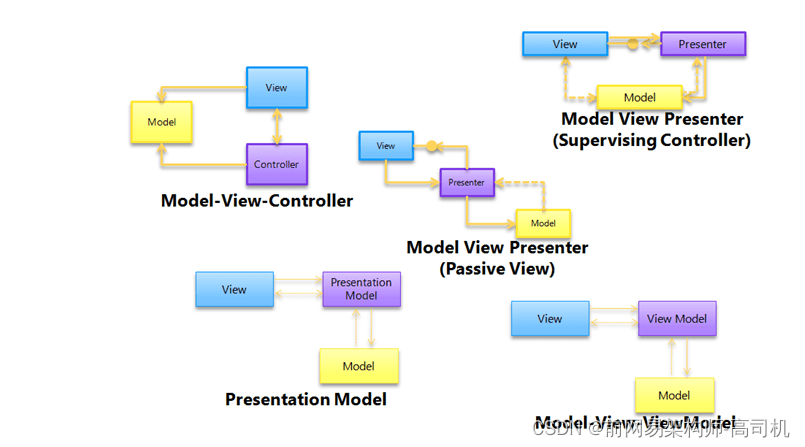
微服务设计模式
微服务在过去十年中已经发展到现在非常成熟的水平。许多模式被演变以适应不同的需求。 架构模式 分层图案 2层三层n层客户端服务器 一个服务器和多个客户端大多数在线应用程序,例如电子邮件、银行应用程序等。分开演示 模型-视图-控制器 (MVC) 模型——包含核心功能和数据查看…...

10.网络游戏逆向分析与漏洞攻防-游戏网络架构逆向分析-接管游戏发送数据的操作
内容参考于:易道云信息技术研究院VIP课 上一个内容:接管游戏连接服务器的操作 码云地址(master 分支):染指/titan 码云版本号:00820853d5492fa7b6e32407d46b5f9c01930ec6 代码下载地址,在 ti…...
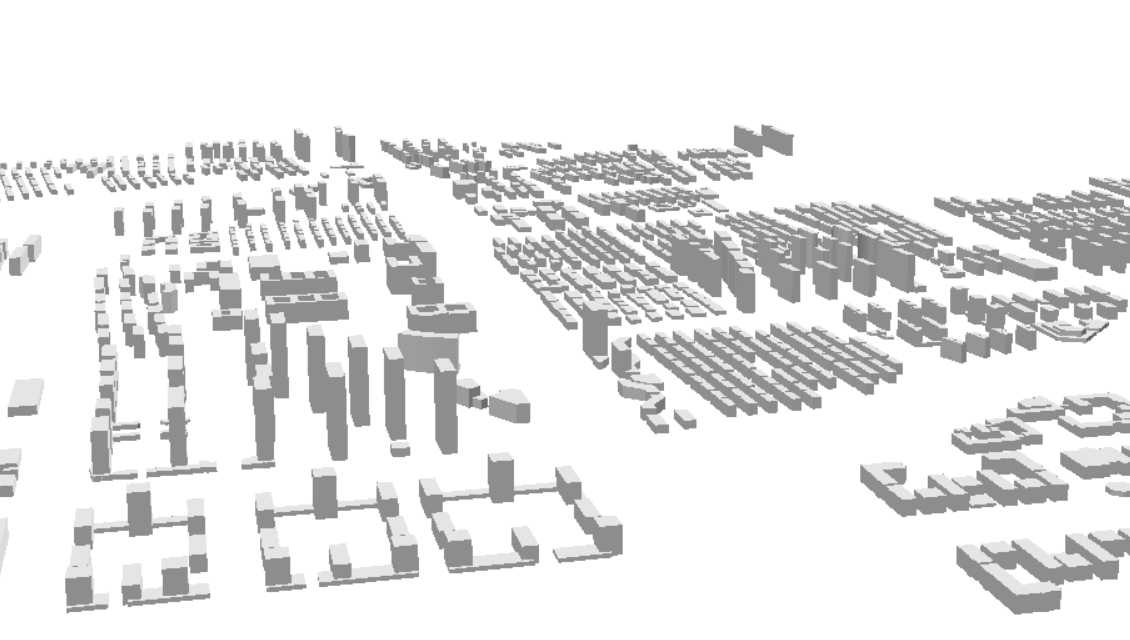
将SU模型导入ARCGIS,并获取高度信息,多面体转SHP文件(ARCMAP)
问题:将Sketchup中导出的su模型,导入arcgis并得到面shp文件,进而获取各建筑的高度、面积等信息。 思路: (1)导入arcgis得到多面体 (2)转为面shp文件 (3)计算高度/面积等 1、【3D Analyst工具】【转换】【由文件转出】【导入3D文件】(在此步骤之间,建议先建立一个…...
【电子通识】为什么单片机芯片上会有多组VDD电源?
在单片机芯片规格书中,我们经常能看到多个组VDD的设计,如下红框所示管脚都是VDD管脚。 为什么需要这样设计?只设置一个VDD管脚,把其他的VDD管脚让出来多做几个IO或是其他复用功能不好吗?接下来我们从单片机内部的电路结…...

跟我学C++中级篇——单实例和静态化
一、单实例模式 在设计模式中,单实例模式几乎是所有语言中都非常常用的一种设计模式。它在实际的应用中也非常广泛,在很多的开源框架中,都可以看到单实例的影子。单实例,简单的就可以看做在整个应用周期中,只有一个对…...
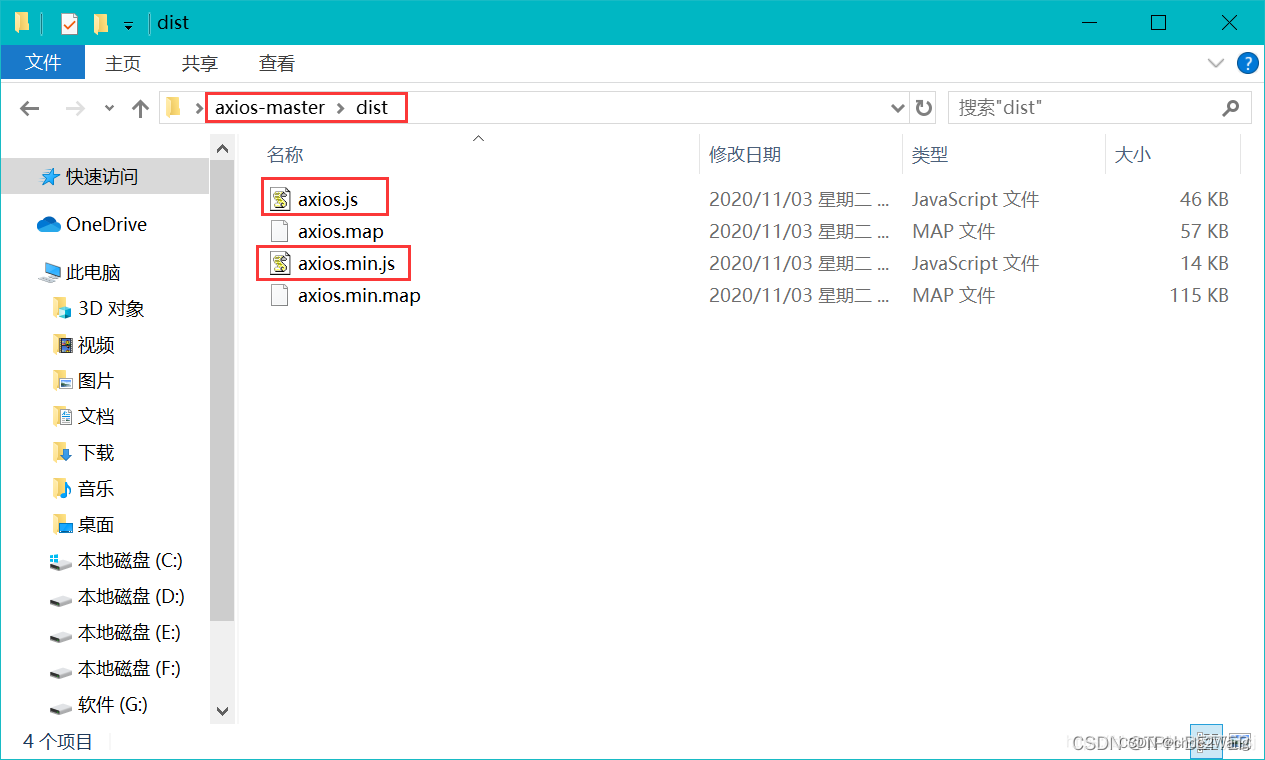
下载 axios.js 文件到本地【linux】
方式一 npm install axios在$NODE_PATH/node_modules/axios/dist路径下即可找到axios.js。 方式二 1、百度搜索 GitHub 官网:https://github.com/ 2、搜索 axios 3、点击 axios/axios 4、下载到本地 5、解压,进入到 dist 文件夹** 参考&#x…...

一些matlab的常用用法。在MATLAB中,如何实现数据的导入和导出?
一些matlab的常用用法。 MATLAB(Matrix Laboratory)是一款广泛使用的数值计算环境和编程语言,主要用于算法开发、数据可视化、数据分析以及数值计算等。以下是一些MATLAB的常用用法: 创建矩阵: 使用方括号 [] 创建矩阵…...
)
【会议征稿通知 | 台州学院主办 | IET出版 | EI 、Scopus稳定检索】第二届新能源与电力电网国际学术会议(NEPG 2026)
第二届新能源与电力电网国际学术会议(NEPG 2026) 2026 2nd International Conference on New Energy and Power Grid 2026年5月29-31日 | 中国台州 大会官网:www.ic-nepg.org 截稿时间:见官网(早投稿,早…...

避坑指南:搭建自己的GPS数据处理流水线,从原始观测值到最终坐标
GPS数据处理实战:从原始观测到高精度定位的完整流水线构建 在测绘工程、自动驾驶和地理信息系统等领域,GPS数据处理能力直接决定了最终成果的质量。与教科书式的理论讲解不同,本文将带您深入GPS数据处理的工程实践现场,揭示从原始…...

别再到处搜了!OpenSSL/GmSSL SM2国密密钥生成与签名验签,这一篇命令大全就够了
SM2国密算法实战手册:OpenSSL与GmSSL全场景命令对照 当项目文档要求"采用SM2算法实现数字签名"时,有多少开发者会陷入搜索引擎、技术论坛和碎片化笔记的循环?这份手册将终结这种低效状态。不同于网络上零散的代码片段,我…...

用PyTorch手把手实现BoTNet:把ResNet50的3x3卷积换成MHSA到底有多简单?
用PyTorch手把手实现BoTNet:把ResNet50的3x3卷积换成MHSA到底有多简单? 如果你正在寻找一种既能保留CNN局部特征提取能力,又能引入全局注意力机制的方法,BoTNet可能是最优雅的解决方案之一。这个将ResNet中3x3卷积替换为多头自注意…...

基于Teensy 4.0的可编程激光投影仪设计与实现
1. 项目概述:打造一台可编程激光投影仪去年冬天,我在工作室捣鼓老式示波器时突然萌生一个想法:能否用现代微控制器驱动激光振镜,创造一台既保留模拟设备灵魂又具备数字精度的投影仪?经过半年迭代,这台基于T…...

从富士康到华强北:一文看懂EMS电子制造服务如何重塑你的产品供应链
从富士康到华强北:EMS如何重构智能硬件供应链的底层逻辑 当一款智能手表从设计图纸变成消费者手腕上的产品,中间究竟经历了多少隐形环节?我曾亲眼见证深圳一家创业团队的首批IoT设备交付:原计划6个月的开发周期,因为元…...

终极指南:如何使用Harepacker-resurrected高效编辑MapleStory游戏资源
终极指南:如何使用Harepacker-resurrected高效编辑MapleStory游戏资源 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 你是否曾因…...
)
保姆级教程:手把手教你用ROS驱动Ouster OS1激光雷达(含编译避坑指南)
ROS实战:Ouster OS1激光雷达从驱动配置到高级应用全解析 激光雷达作为机器人感知环境的核心传感器,其性能与集成效率直接影响着SLAM、导航等关键系统的表现。Ouster OS1系列凭借出色的性价比和稳定的性能,已成为众多机器人开发团队的首选。本…...

终极科研生产力革命:如何用Obsidian模板30天构建你的个人学术知识库
终极科研生产力革命:如何用Obsidian模板30天构建你的个人学术知识库 【免费下载链接】obsidian_vault_template_for_researcher This is an vault template for researchers using obsidian. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian_vault_templat…...

Zotero插件市场终极指南:一键安装管理所有插件的完整解决方案
Zotero插件市场终极指南:一键安装管理所有插件的完整解决方案 【免费下载链接】zotero-addons Zotero Add-on Market | Zotero插件市场 | Browsing, installing, and reviewing plugins within Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-addons…...