【Python从入门到进阶】49、当当网Scrapy项目实战(二)
接上篇《48、当当网Scrapy项目实战(一)》
上一篇我们正式开启了一个Scrapy爬虫项目的实战,对当当网进行剖析和抓取。本篇我们继续编写该当当网的项目,讲解刚刚编写的Spider与item之间的关系,以及如何使用item,以及使用pipelines管道进行数据下载的操作。
一、使用item封装数据
在上一篇我们通过编写的爬虫文件,获取到当当网“一般管理类”书籍的第一页的明细列表信息。但是我们仅仅是将爬取到的目标信息print打印到控制台了,没有保存下来,这里我们就需要item先进行数据的封装。在“dang.py”爬虫文件里,我们获取到了目标数据,这些数据是我们之前通过item定义过这些数据的数据结构,但是没有使用过:
import scrapyclass ScrapyDangdang01Item(scrapy.Item):# 书籍图片src = scrapy.Field()# 书籍名称title = scrapy.Field()# 书籍作者search_book_author = scrapy.Field()# 书籍价格price = scrapy.Field()# 书籍简介detail = scrapy.Field()那么,我们如何使用item定义好的数据结构呢?我们在爬虫文件中,首先通过from引用上面的class的名称:
from scrapy_dangdang_01.items import ScrapyDangdang01Item注:可能编译器会报错,这是编译器版本的问题,不影响后面的执行,可以忽略。
导入完毕之后,我们创建一个book对象,这个对象就是把上面那些零散的信息全部都组装起来的集合体,然后在构造函数中,将所有抓取到的属性,挨个赋值到item文件中的各个属性中去:
book = ScrapyDangdang01Item(src=src, title=title, search_book_author=search_book_author, price=price, detail=detail)然后这个book对象,就要交给pipelines进行下载。
二、设置yield返回目标对象
这里我们需要使用到Python中的yield指令,它的作用如下:
yield是Python中的一个关键字,主要用于定义生成器(generator)。生成器是一种特殊的迭代器,可以逐个地生成并返回一系列的值,而不是一次性地生成所有的值。这可以节省大量的内存,尤其是在处理大量数据时。
yield的工作原理类似于return,但它不仅仅返回一个值,还可以保存生成器的状态,使得函数在下次调用时可以从上次离开的地方继续执行。
下面是一个简单的生成器函数的例子:def simple_generator(): n = 1 while n <= 5: yield n n += 1 for i in simple_generator(): print(i)在这个例子中,simple_generator 是一个生成器函数,它使用 yield 来生成一系列的数字。当我们对这个生成器进行迭代(例如,在 for 循环中)时,它会逐个生成数字 1 到 5,并打印出来。
所以我们这里使用yield是用来将上面for循环中的每一个book交给pipelines处理,循环一个处理一个。编写代码如下:
# 将数据封装到item对象中
book = ScrapyDangdang01Item(src=src, title=title, search_book_author=search_book_author, price=price, detail=detail)# 获取一个book对象,就将该对象交给pipelines
yield book此时for循环每执行一次,爬虫函数就会返回一个封装好的book对象。完整的爬虫文件代码如下(scrapy_dangdang_01/scrapy_dangdang_01/spiders/dang.py):
import scrapyfrom scrapy_dangdang_01.items import ScrapyDangdang01Itemclass DangSpider(scrapy.Spider):name = "dang"allowed_domains = ["category.dangdang.com"]start_urls = ["http://category.dangdang.com/cp01.22.01.00.00.00.html"]def parse(self, response):# 获取所有的图书列表对象li_list = response.xpath('//ul[@id="component_59"]/li')# 遍历li列表,获取每一个li元素的几个值for li in li_list:# 书籍图片src = li.xpath('.//img/@data-original').extract_first()# 第一张图片没有@data-original属性,所以会获取到控制,此时需要获取src属性值if src:src = srcelse:src = li.xpath('.//img/@src').extract_first()# 书籍名称title = li.xpath('.//img/@alt').extract_first()# 书籍作者search_book_author = li.xpath('./p[@class="search_book_author"]//span[1]//a[1]/@title').extract_first()# 书籍价格price = li.xpath('./p[@class="price"]//span[@class="search_now_price"]/text()').extract_first()# 书籍简介detail = li.xpath('./p[@class="detail"]/text()').extract_first()# print("======================")# print("【图片地址】", src)# print("【书籍标题】", title)# print("【书籍作者】", search_book_author)# print("【书籍价格】", price)# print("【书籍简介】", detail)# 将数据封装到item对象中book = ScrapyDangdang01Item(src=src, title=title, search_book_author=search_book_author, price=price, detail=detail)# 获取一个book对象,就将该对象交给pipelinesyield book三、编写pipelines保存数据至本地
首先我们进入setting.py中,设置“ITEM_PIPELINES”参数,在其中添加我们设置的pipelines管道文件的路径地址:
# 管道可以有很多个,前面是管道名后面是管道优先级,优先级的范围是1到1000,值越小优先级越高
ITEM_PIPELINES = {"scrapy_dangdang_01.pipelines.ScrapyDangdang01Pipeline": 300,
}此时我们进入pipelines.py中编写管道逻辑:
from itemadapter import ItemAdapter# 如果需要使用管道,要在setting.py中打开ITEM_PIPELINES参数
class ScrapyDangdang01Pipeline:# process_item函数中的item,就是爬虫文件yield的book对象def process_item(self, item, spider):# 这里写入文件需要用'a'追加模式,而不是'w'写入模式,因为写入模式会覆盖之前写的with open('book.json', 'a', encoding='utf-8') as fp:# write方法必须写一个字符串,而不能是其他的对象fp.write(str(item))return item此时我们执行爬虫函数,可以看到执行成功:
然后我们打开生成的book.json文件,“Ctrl+Alt+l”排版之后,可以看到我们爬取的数据已经生成了: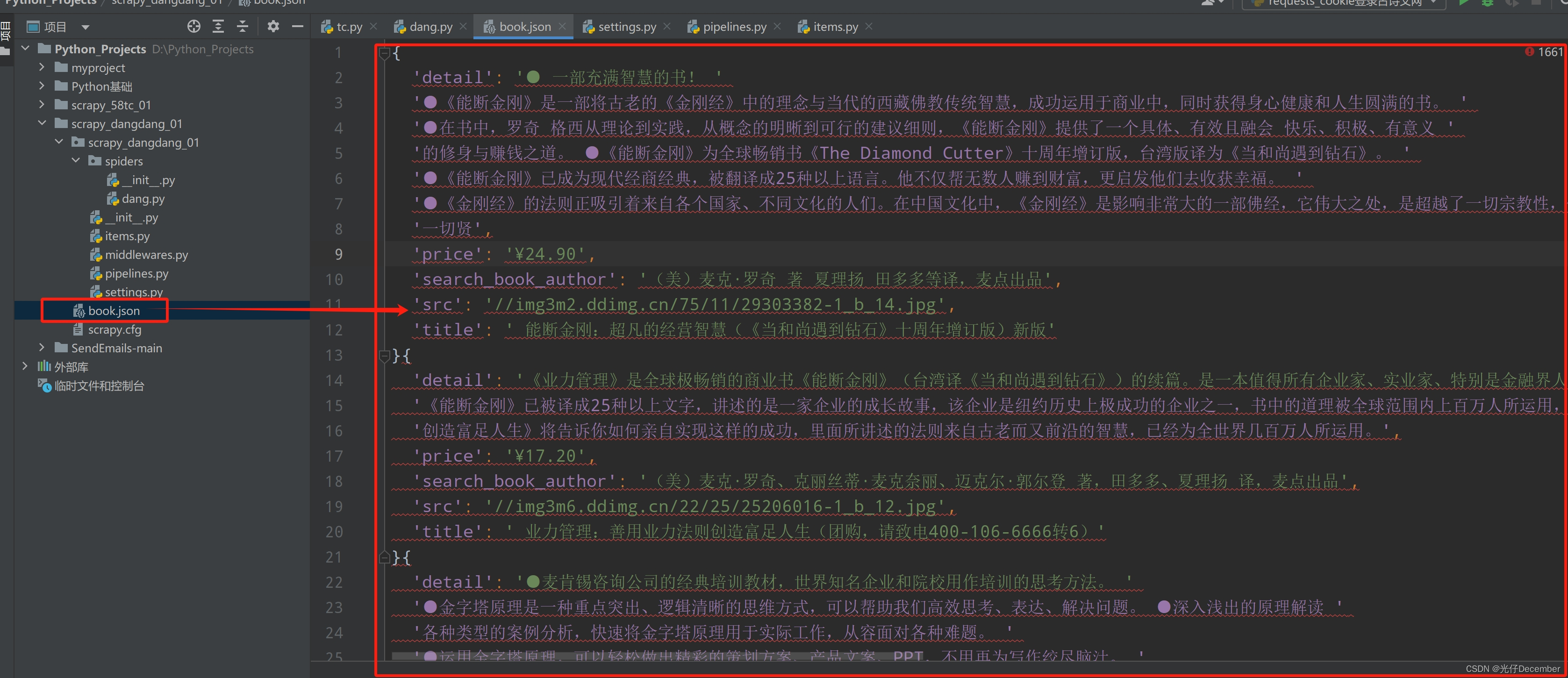
上面就是管道+爬虫+item的综合使用模式。
四、进行必要的优化
在上面的pipelines管道函数中,我们每一次获取到爬虫for循环yield的book对象时,都需要打开一次文件进行写入,比较耗费读写资源,对文件的操作过于频繁。
优化方案:在爬虫执行开始的时候就打开文件,爬虫执行结束之后再关闭文件。此时我们就需要了解pipelines的生命周期函数。分别为以下几个方法:
(1)open_spider(self, spider): 当爬虫开始时,这个方法会被调用。你可以在这里进行一些初始化的操作,比如打开文件、建立数据库连接等。
(2)close_spider(self, spider): 当爬虫结束时,这个方法会被调用。你可以在这里进行清理操作,比如关闭文件、断开数据库连接等。
(3)process_item(self, item, spider): 这是pipelines中最核心的方法。每个被抓取并返回的项目都会经过这个方法。你可以在这里对数据进行清洗、验证、转换等操作。这个方法必须返回一个项目(可以是原项目,也可以是经过处理的新项目),或者抛出一个DropItem异常,表示该项目不应被进一步处理。
此时我们就可以使用open_spider定义爬虫开始时打开文件,close_spider定义爬虫结束时关闭文件,而在爬虫运行期间的process_item方法中,只进行写的操作,完整代码如下:
from itemadapter import ItemAdapter
import json# 如果需要使用管道,要在setting.py中打开ITEM_PIPELINES参数
class ScrapyDangdang01Pipeline:# 1、在爬虫文件开始执行前执行的方法def open_spider(self,spider):print('++++++++爬虫开始++++++++')# 这里写入文件需要用'a'追加模式,而不是'w'写入模式,因为写入模式会覆盖之前写的self.fp = open('book.json', 'a', encoding='utf-8') # 打开文件写入# 2、爬虫文件执行时,返回数据时执行的方法# process_item函数中的item,就是爬虫文件yield的book对象def process_item(self, item, spider):# write方法必须写一个字符串,而不能是其他的对象self.fp.write(str(item)) # 将爬取信息写入文件return item# 在爬虫文件开始执行后执行的方法def close_spider(self, spider):print('++++++++爬虫结束++++++++')self.fp.close() # 关闭文件写入这样就能解决对文件操作频繁,耗费读写资源的问题了。
五、多管道的支持
pipelines支持设置多个管道,例如我们在原来的pipelines.py中再定义一个管道class类,用来下载每一个图书的图片:
# 下载爬取到的book对象中的图片文件
class ScrapyDangdangImagesPipeline:def process_item(self, item, spider):# 获取book的src属性,并按照地址下载图片,保存值books文件夹下url = 'http:' + item.get('src')filename = './books/' + item.get('title') + '.jpg'# 检查并创建目录if not os.path.exists('./books/'):os.makedirs('./books/')urllib.request.urlretrieve(url=url, filename=filename)return item然后我们在setting.py中的ITEM_PIPELINES参数中追加这个管道:
# 管道可以有很多个,前面是管道名后面是管道优先级,优先级的范围是1到1000,值越小优先级越高
ITEM_PIPELINES = {"scrapy_dangdang_01.pipelines.ScrapyDangdang01Pipeline": 300,"scrapy_dangdang_01.pipelines.ScrapyDangdangImagesPipeline": 301
}运行爬虫文件,可以看到相关的图片已经全部下载下来: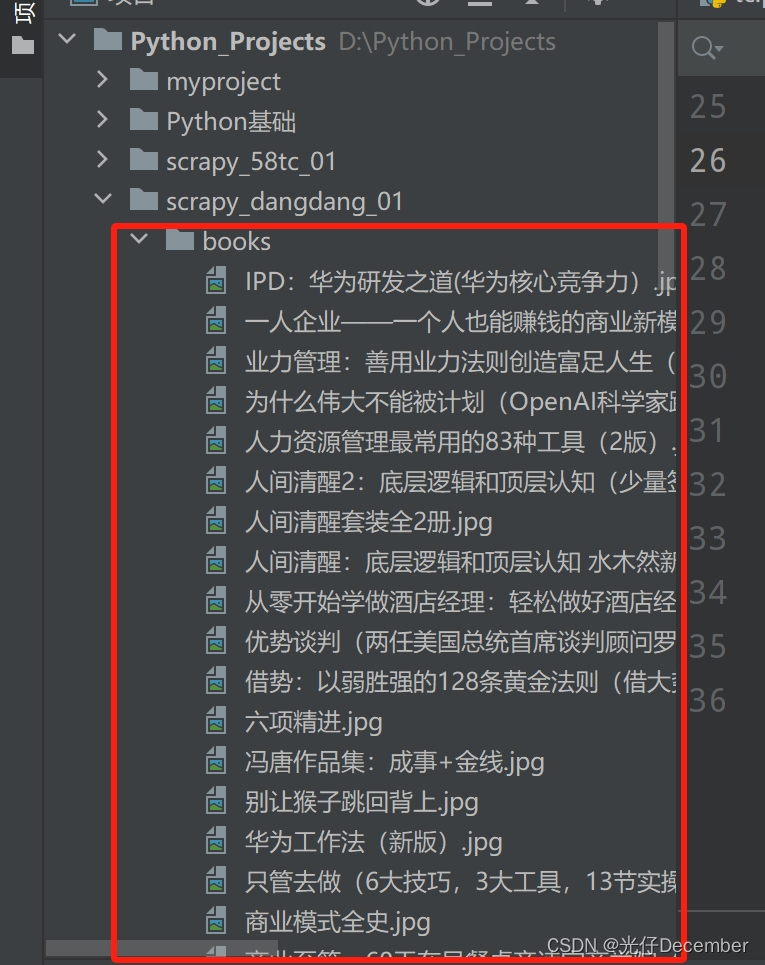
并且都是可以打开的图片: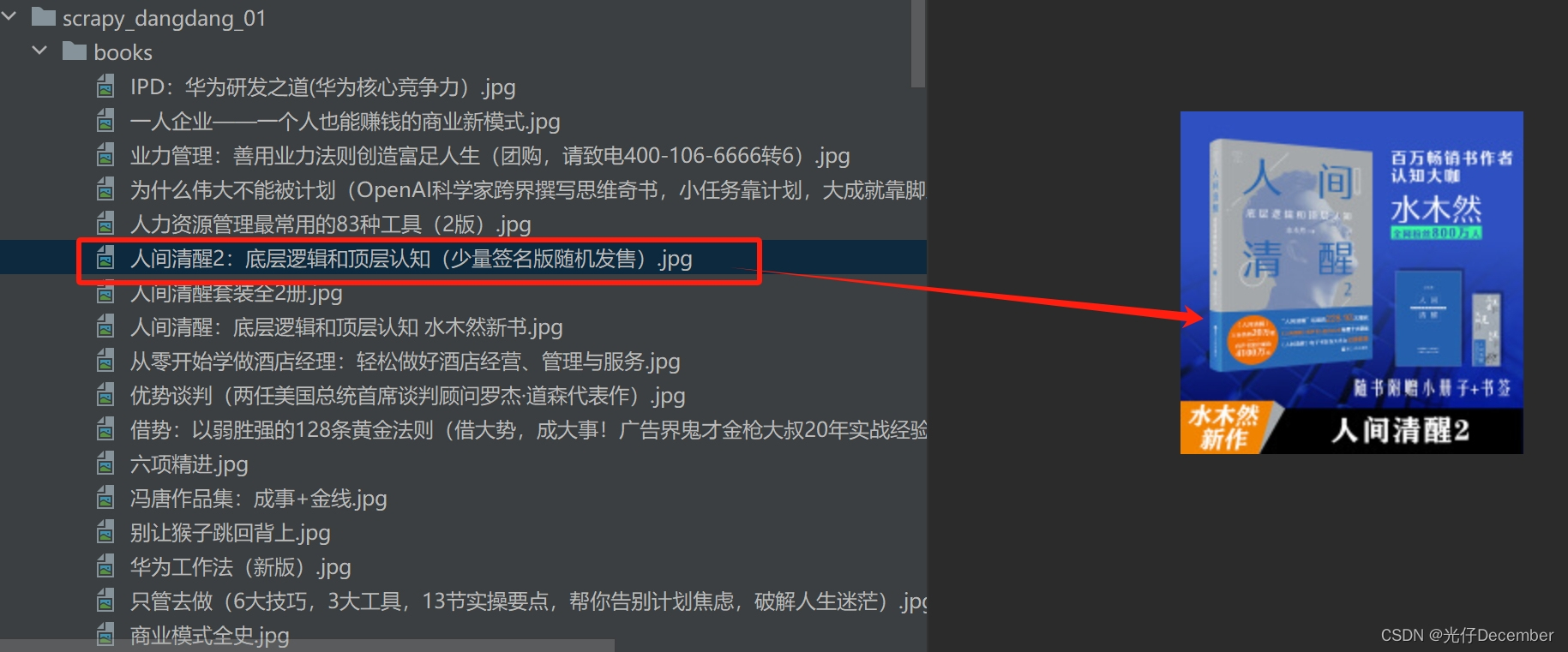
至此管道+爬虫+item的综合使用模式讲解完毕。下一篇我们来讲解Scrapy的多页面下载如何实现。
参考:尚硅谷Python爬虫教程小白零基础速通
转载请注明出处:https://guangzai.blog.csdn.net/article/details/136283532
相关文章:
【Python从入门到进阶】49、当当网Scrapy项目实战(二)
接上篇《48、当当网Scrapy项目实战(一)》 上一篇我们正式开启了一个Scrapy爬虫项目的实战,对当当网进行剖析和抓取。本篇我们继续编写该当当网的项目,讲解刚刚编写的Spider与item之间的关系,以及如何使用itemÿ…...

flutter build ipa 打包比 xcode archive 打出的ipa包大
为什么 flutter build ipa 打包比 xcode archive 打出的ipa包大? 如果你用Flutter构建的.ipa文件比通过Xcode Archive构建的.ipa文件要大,这可能是因为Flutter构建了一个包含了多平台的二进制文件的通用包。这意味着在Flutter构建的.ipa中包含了所有的C…...
B端系统:巧妙地容错和防错设置,减少用户操作错误
Hi,大家好,我是大美B端工场,从事8年前端开发的老司机。很多B端系统体验不好,让用户非常茫然或者容易出错,大大降低了操作体验,本文着重分析B端系统的容错机制该如何设计,欢迎老铁们关注、评论、…...
BIO实战、NIO编程与直接内存、零拷贝深入辨析
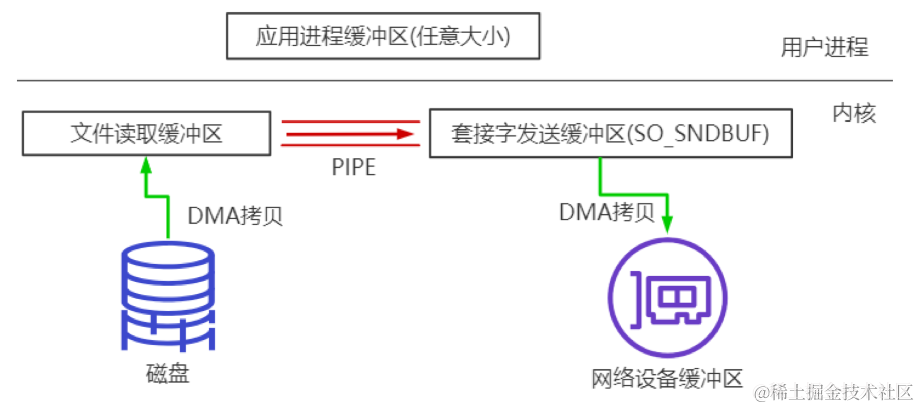
BIO实战、NIO编程与直接内存、零拷贝深入辨析 长连接、短连接 长连接 socket连接后不管是否使用都会保持连接状态多用于操作频繁,点对点的通讯,避免频繁socket创建造成资源浪费,比如TCP 短连接 socket连接后发送完数据后就断开早期的http服…...
PDF文件转换为图片
现在确实有很多线上的工具可以把pdf文件转为图片,比如smallpdf等等,都很好用。但我们有时会碰到一些敏感数据,或者要批量去转,那么需要自己写脚本来实现,以下脚本可以提供这个功能~ def pdf2img(pdf_dir, result_path…...

【Java程序设计】【C00317】基于Springboot的智慧社区居家养老健康管理系统(有论文)
基于Springboot的智慧社区居家养老健康管理系统(有论文) 项目简介项目获取开发环境项目技术运行截图 项目简介 这是一个基于Springboot的智慧社区居家养老健康管理系统设计与实现,本系统有管理员、社区工作人员、医生以及家属四种角色权限 管…...
Vue3前端实现一个本地消息队列(MQ), 让消息延迟消费或者做缓存
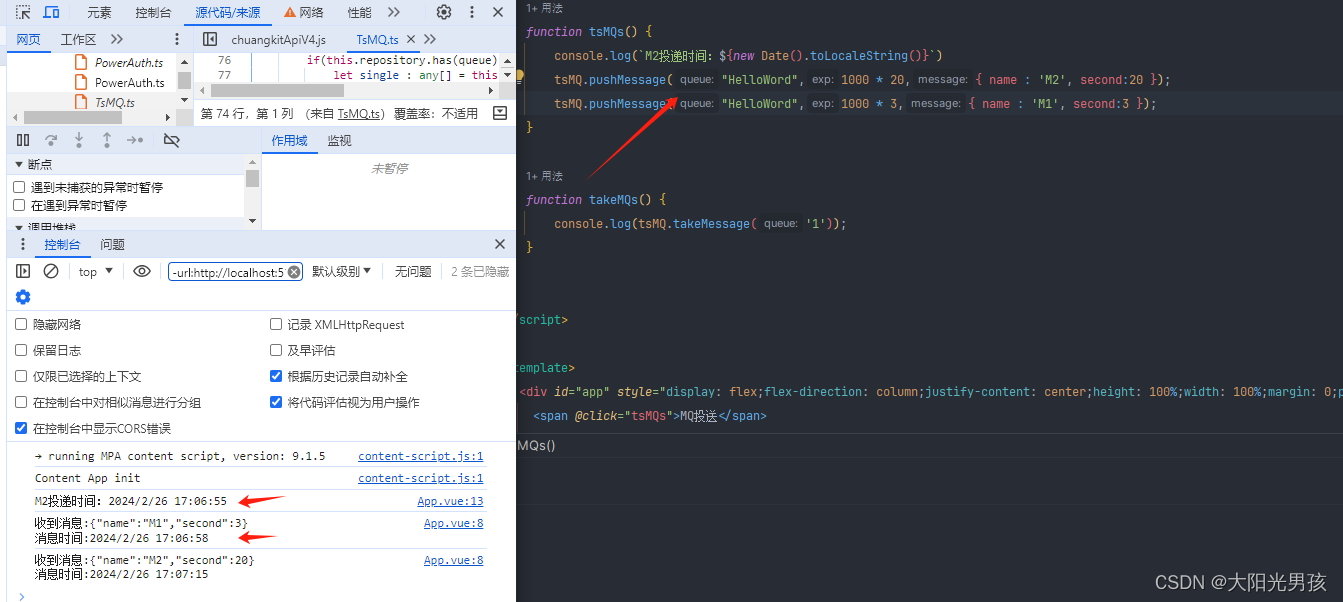
MQ功能实现的具体代码(TsMQ.ts): import { v4 as uuidx } from uuid;import emitter from /utils/mitt// 消息类 class Message {// 过期时间,0表示马上就消费exp: number;// 消费标识,避免重复消费tag : string;// 消息体body : any;constr…...
普中51单片机学习(8*8LED点阵)
8*8LED点阵 实验代码 #include "reg52.h" #include "intrins.h"typedef unsigned int u16; typedef unsigned char u8; u8 lednum0x80;sbit SHCPP3^6; sbit SERP3^4; sbit STCPP3^5;void HC595SENDBYTE(u8 dat) {u8 a;SHCP1;STCP1;for(a0;a<8;a){SERd…...
Python 实现Excel自动化办公(上)
在Python 中你要针对某个对象进行操作,是需要安装与其对应的第三方库的,这里对于Excel 也不例外,它也有对应的第三方库,即xlrd 库。 什么是xlrd库 Python 操作Excel 主要用到xlrd和xlwt这两个库,即xlrd是读Excel &am…...

DayDreamInGIS 之 ArcGIS Pro二次开发 图层属性中换行符等特殊字符替换
具体参考ArcMap中类似的问题,本帖开发一个ArcGISPro版的工具 1.基础库部分 插件开发,经常需要处理图层与界面的交互。基础库把常用的交互部分做了封装,方便之后的重复使用。 (1)下述类定义了数据存储结构࿰…...
RK3568平台 RTC时间框架
一.RTC时间框架概述 RTC(Real Time Clock)是一种用于计时的模块,可以是再soc内部,也可以是外部模块。对于soc内部的RTC,只需要读取寄存器即可,对于外部模块的RTC,一般需要使用到I2C接口进行读取…...

番外篇 | YOLOv5+DeepSort实现行人目标跟踪检测
前言:Hello大家好,我是小哥谈。DeepSort是一种用于目标跟踪的深度学习算法。它结合了目标检测和目标跟踪的技术,能够在视频中准确地跟踪多个目标,并为每个目标分配一个唯一的ID。DeepSort的核心思想是将目标检测和目标跟踪两个任务进行联合训练,以提高跟踪的准确性和稳定性…...

认识Sass
sass中文文档: Sass: Sass 文档 1. sass的安装步骤 1. 卸载冲突的Node.js (1) winR输入control,找到电脑上的卸载软件,找到Node.js,右键”卸载” (2) winR输入cmd,输入命令:node -v查看结果。 如果提示: node 不…...

YOLOv9-Openvino和ONNXRuntime推理【CPU】
1 环境: CPU:i5-12500 Python:3.8.18 2 安装Openvino和ONNXRuntime 2.1 Openvino简介 Openvino是由Intel开发的专门用于优化和部署人工智能推理的半开源的工具包,主要用于对深度推理做优化。 Openvino内部集成了Opencv、Tens…...
 应用可以使用 PostgreSQL 作为向量数据库组件吗?)
AIGC 架构:RAG (retrieval augumented generation) 应用可以使用 PostgreSQL 作为向量数据库组件吗?
是的,RAG(检索增强生成)应用程序可以绝对地使用 PostgreSQL 作为向量数据库!事实上,它是一个流行的选择,因为有以下几个优点: 使用 PostgreSQL 和 pgvector 的优点: 集成解决方案&…...
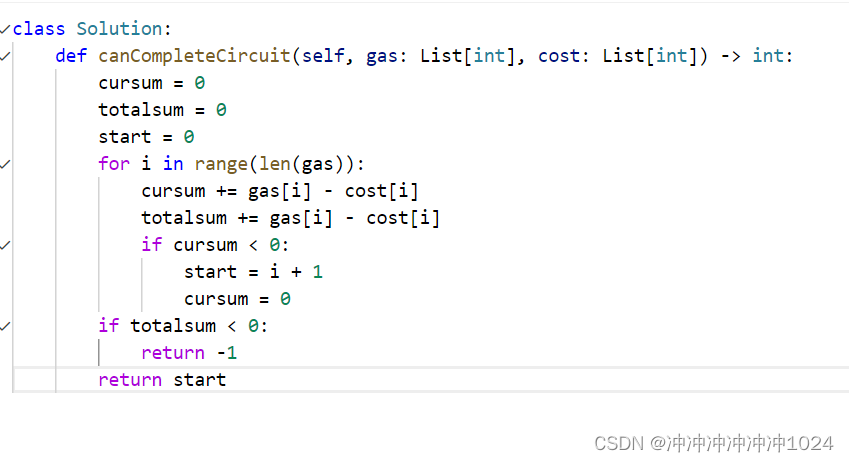
leetcode:134.加油站
解题思路:需要注意开始时的编号,有的可以走一圈,有的走不了 模拟过程:for循环主要是用来模拟线性的过程,而在这里它是环状的; 可以用暴力解法,但是在这里我用贪心来解决。 常见疑惑࿱…...
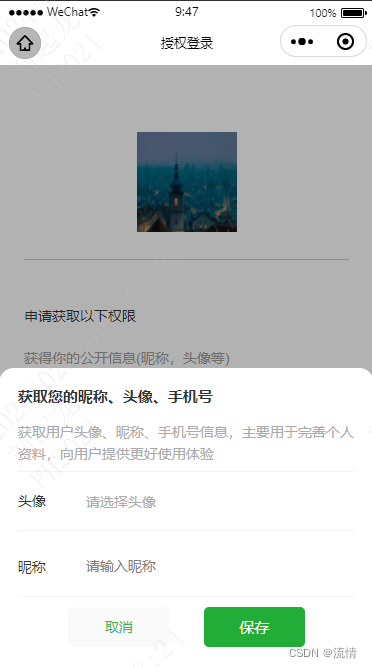
uniapp的微信小程序授权头像昵称(最新版)
前面我出过两期博客关于小程序授权登录,利用php实现一个简单的小程序授权登录并存储授权用户信息到数据库的完整流程。无奈,小程序官方又整幺蛾子了。wx.getUserInfo接口收回,wx.getUserProfile接口也不让用。导致我的个人小程序:梦缘 的授权…...
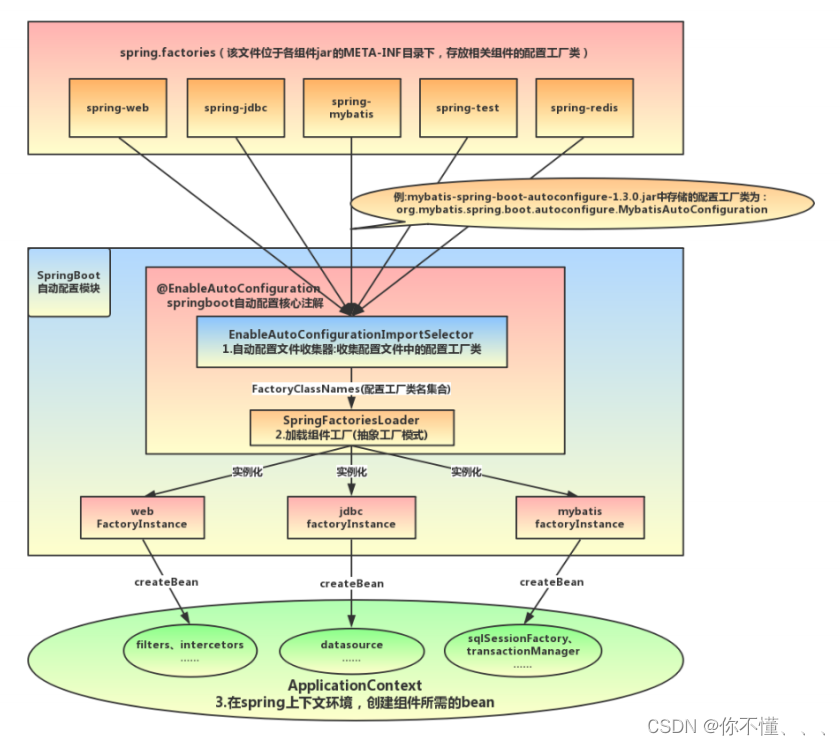
Spring Boot到底是如何进行自动配置的?
【1】从 spring.factories 配置文件中加载 EnableAutoConfiguration 自动配置类),获取的自动配 置类如图所示。 【2】若 EnableAutoConfiguration 等注解标有要 exclude 的自动配置类,那么再将这个自动配置类 排除掉; 【3】排除掉要 exclude …...
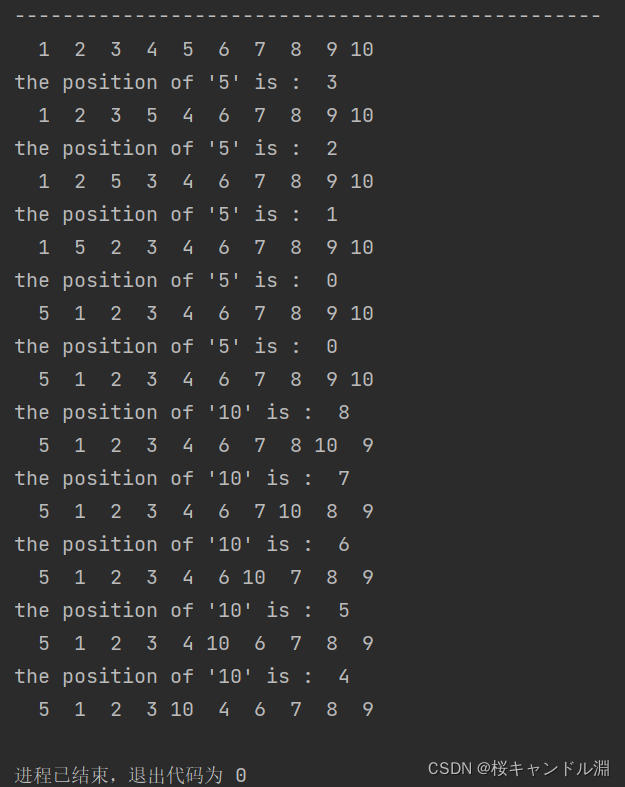
【王道数据结构】【chapter7查找】【P285t5】
线性表中各节点的检索概率不等时,可用如下策略提高顺序检索的效率;若找到指定的结点,则将该结点和其前驱结点(若存在)交换,使得经常被访问的结点尽量位于表的前端。试设计在顺序结构和链式结构的线性表盘上…...
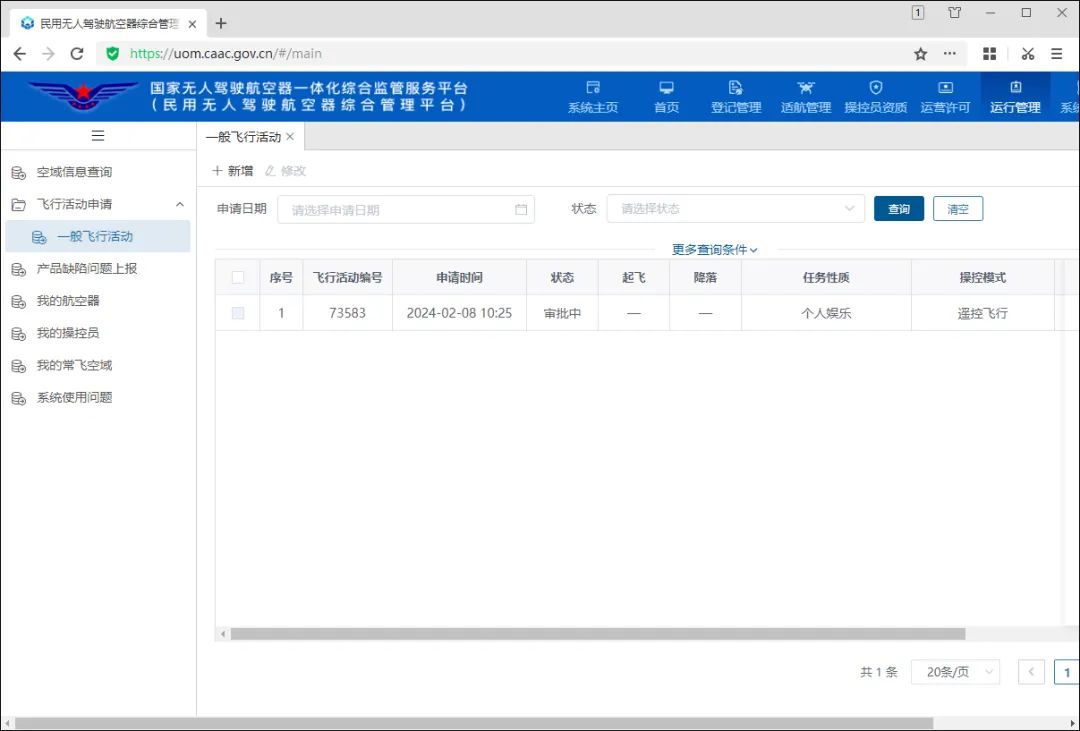
个人玩航拍,如何申请无人机空域?
我们在《年会不能停》一文中,有分享我们在西岭雪山用无人机拍摄的照片和视频,有兴趣可以去回顾。 春节的时候,趁着回老家一趟,又将无人机带了回去,计划拍一下老家的风景。 原本以为穷乡僻壤的地方可以随便飞…...

Qwen3.5-4B-Claude-Opus应用场景:游戏开发中NPC对话逻辑生成引擎
Qwen3.5-4B-Claude-Opus应用场景:游戏开发中NPC对话逻辑生成引擎 1. 游戏NPC对话系统的挑战与机遇 在游戏开发过程中,NPC(非玩家角色)的对话系统一直是开发者面临的重要挑战。传统NPC对话系统通常采用以下几种方式: …...

【Dify 2026插件开发权威指南】:零基础到生产级自定义插件的7大核心实践与避坑清单
第一章:Dify 2026插件生态全景与开发范式演进Dify 2026标志着插件架构从“能力扩展”迈向“智能协同”的关键跃迁。其插件生态不再局限于API代理或简单工具封装,而是以统一的语义契约(Semantic Contract)为基础,支持跨…...

imFile下载管理器:从零开始构建你的高效下载工作流
imFile下载管理器:从零开始构建你的高效下载工作流 【免费下载链接】imfile-desktop A full-featured download manager. 项目地址: https://gitcode.com/gh_mirrors/im/imfile-desktop 还记得那些焦急等待大文件下载的夜晚吗?当浏览器下载器卡在…...

从原理图到后仿真的完整流程:Virtuoso Layout XL + Calibre DRC/LVS/PEX保姆级避坑指南
从原理图到后仿真的完整流程:Virtuoso Layout XL Calibre DRC/LVS/PEX保姆级避坑指南 在集成电路设计领域,从原理图到最终的后仿真验证是一个环环相扣的系统工程。对于刚入行的工程师来说,这个过程往往充满了各种"坑"——从版图绘…...

PVZ Toolkit 终极指南:5分钟掌握植物大战僵尸最强修改器
PVZ Toolkit 终极指南:5分钟掌握植物大战僵尸最强修改器 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PVZ Toolkit 是一款专为经典游戏《植物大战僵尸》PC版设计的开源辅助工具&#…...

格子玻尔兹曼双分布函数液汽相变传热模拟代码功能说明
格子玻尔兹曼 LBM 多孔介质沸腾 Gongchen双分布函数模型,matlab代码,有参考文献一、代码整体概述 本代码基于格子玻尔兹曼方法(Lattice Boltzmann Method, LBM),实现了液汽相变传热过程的数值模拟,核心聚焦…...

FPGA驱动RGB屏幕时序详解:从VGA原理到480x272 TFT实战调试记录
FPGA驱动RGB屏幕时序详解:从VGA原理到480x272 TFT实战调试记录 当你在调试一块4.3寸RGB TFT屏幕时,是否遇到过这样的场景:FPGA程序烧录后,屏幕要么一片空白,要么显示错位、花屏?这往往源于对时序参数的误解…...

【微软内部未发布文档级实践】:EF Core 10 VectorSearchExtension如何规避L2缓存污染与向量维度错配灾难
第一章:EF Core 10 VectorSearchExtension 的核心定位与设计哲学EF Core 10 VectorSearchExtension 并非简单的语法糖或临时补丁,而是微软在 ORM 领域面向 AI 原生应用的一次范式跃迁。它将向量搜索能力深度内嵌于 EF Core 的查询管道中,使开…...

PowerCat在企业环境中的应用:合规使用的最佳实践指南
PowerCat在企业环境中的应用:合规使用的最佳实践指南 【免费下载链接】powercat netshell features all in version 2 powershell 项目地址: https://gitcode.com/gh_mirrors/po/powercat PowerCat作为一款功能强大的PowerShell版Netcat工具,集成…...
)
Java项目Loom化安全加固全路径(JVM层/协程调度/Reactive Stream三重防护体系深度拆解)
第一章:Java项目Loom化安全加固全路径概览Java Loom 作为 JDK 21 的正式特性,通过虚拟线程(Virtual Threads)显著提升高并发场景下的资源利用率与吞吐能力。然而,Loom 的引入也重构了传统线程模型的安全边界——线程局…...