13.云原生之常用研发中间件部署
云原生专栏大纲
文章目录
- mysql主从集群部署
- mysql高可用集群
- 高可用互为主从架构
- 互为主从架构
- 如何实现
- 主主复制中若是两台master上同时出现写操作可能会出现的问题
- 该架构是否存在问题?
- heml部署mysql高可用集群
- nacos集群部署
- 官网文档部署nacos
- helm部署nacos
- redis集群部署
- 主从哨兵部署
- redis cluster部署
- 安装reids客户端redisinsight
- zk集群部署
- kafka集群部署
- kafka可视化控制台
- es集群部署
- rocketmq集群部署
- minio集群部署
- SkyWalking部署
- 使用 Docker Helm 存储库 (>= 4.3.0) 安装已发布的版本
- 使用 master 分支安装 SkyWalking 的开发版本
- MongoDB部署
该章节主要讲述helm安装研发常用环境,目前很多厂商都提供组件的helm安装支持,使用helm能大大降低部署难度。
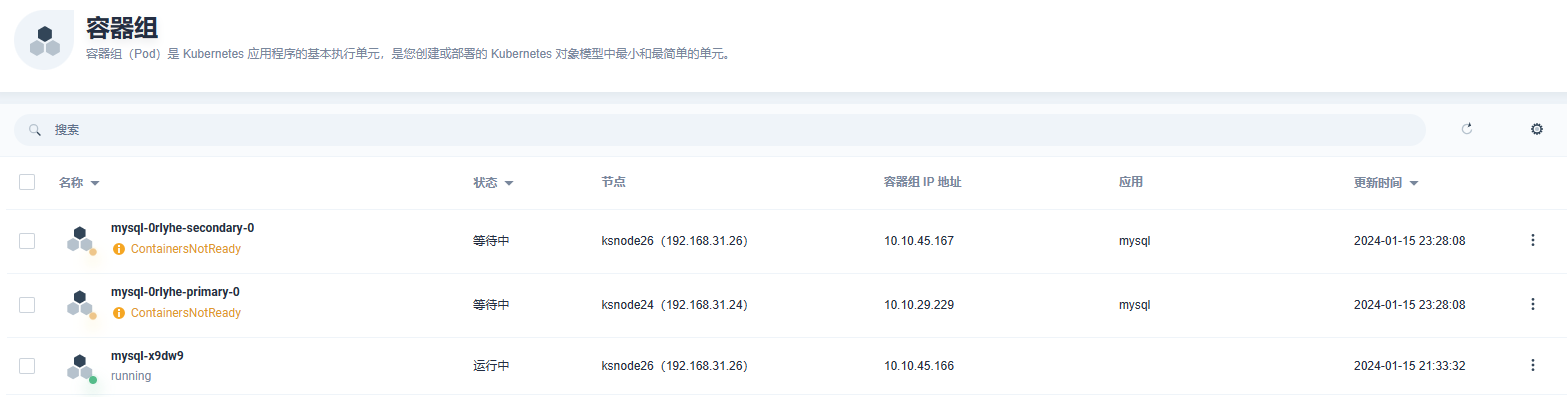
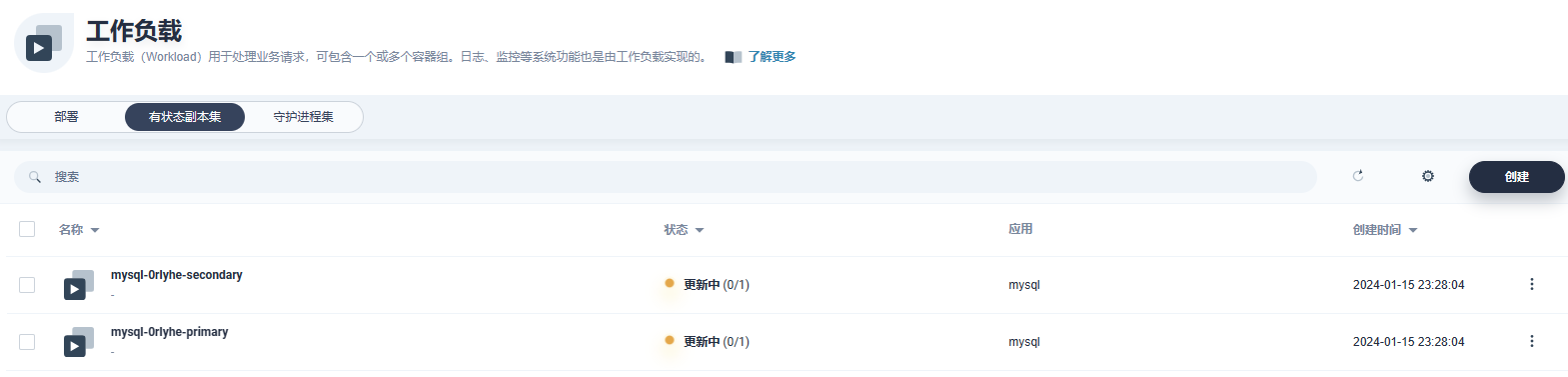
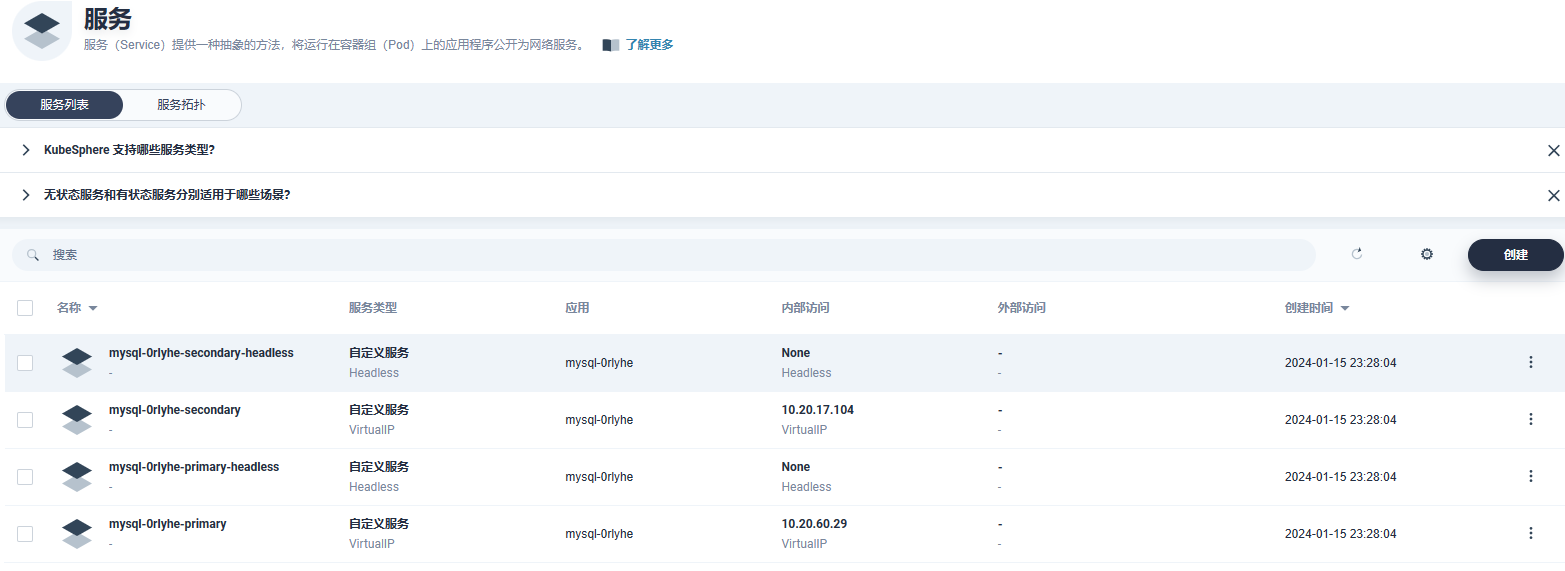
mysql主从集群部署
- 添加应用仓库:https://charts.bitnami.com/bitnami
- 搜索mysql部署,配置参考
- 查看部署情况
mysql高可用集群
高可用互为主从架构
互为主从架构
mysql基于主从复制可以实现互为主从,若是两个mysql都对外提供写服务可能出现数据冲突问题。为避免写冲突,master只会有一个对外提供写服务,采用keepalived+mysql实现互为主从架构。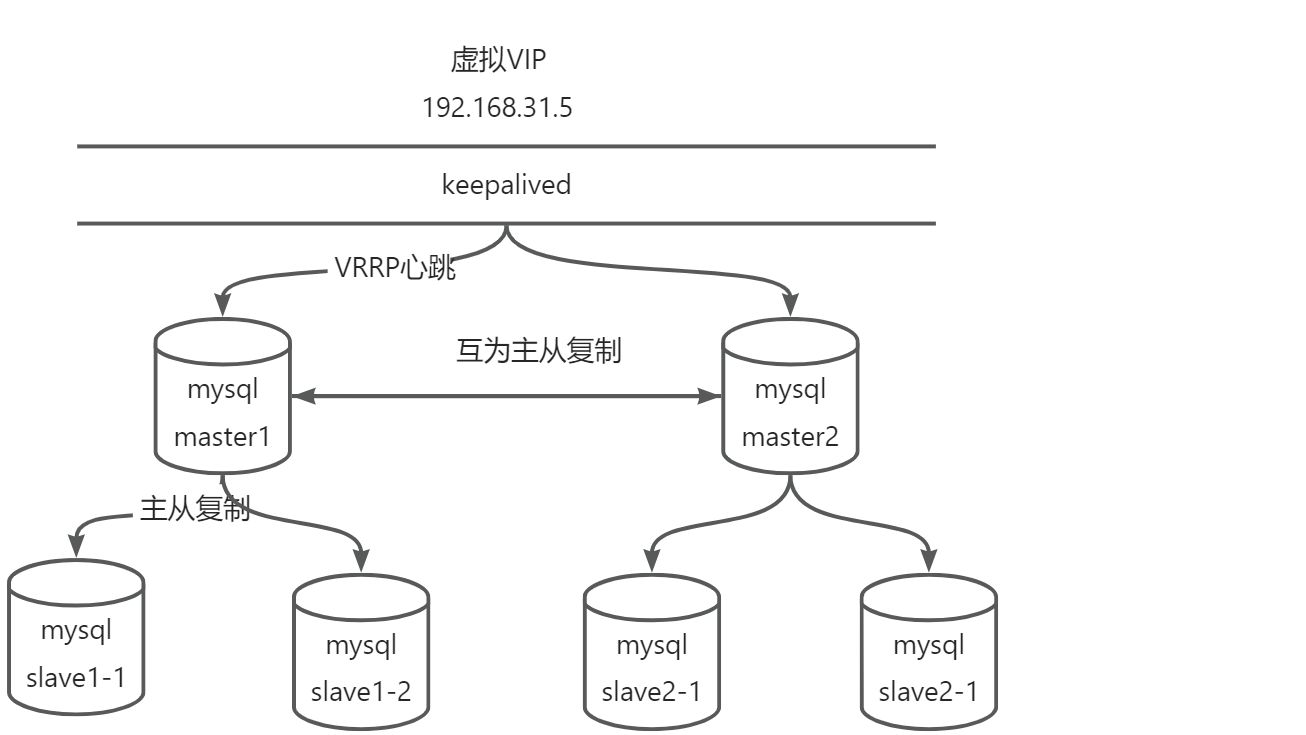
互为主从的架构通常称为主主复制(Master-Master Replication)或双主复制(Dual-Master Replication)。在这种架构中,两个或多个 MySQL 实例充当主服务器,并且彼此互为对方的从服务器。
以下是主主复制的基本工作原理:
- 双向复制:每个主服务器都可以接收写操作,并将这些写操作记录到自己的二进制日志中。同时,它也会将二进制日志事件发送给其他主服务器,以便它们可以复制这些写操作到自己的数据库中。
- 数据同步:每个主服务器都会将其他主服务器发送的二进制日志事件应用到自己的数据库中,从而保持数据的同步。这样,每个主服务器都包含了完整的数据集,并且可以独立地处理读和写操作。
- 冲突解决:在主主复制中,由于每个主服务器都可以接收写操作,可能会发生冲突。例如,如果两个主服务器同时接收到对同一行数据的更新操作,那么就会发生冲突。解决冲突的方法可以通过配置冲突检测和解决策略,例如使用时间戳或自定义逻辑来确定哪个写操作应该优先。
主主复制的优点包括:
- 冗余备份:每个主服务器都具有完整的数据集,可以作为其他主服务器的冗余备份,提供高可用性和数据冗余。
- 读写负载均衡:由于每个主服务器都可以处理读和写操作,可以将读操作分发到不同的主服务器,实现读写负载均衡,提高系统的性能和扩展性。
- 故障切换:如果一个主服务器发生故障,可以将应用程序的写操作切换到其他主服务器,从而实现故障切换,减少停机时间。
但是,主主复制也有一些注意事项和限制:
- 冲突处理:需要仔细处理冲突,确保数据的一致性。冲突的解决策略需要根据具体的应用程序需求进行配置。
- 网络延迟:由于主服务器之间需要相互复制数据,网络延迟可能会对性能产生影响。
- 数据一致性:在主主复制架构中,需要确保应用程序的写操作只发送到其中一个主服务器,以避免数据不一致的情况发生。
总的来说,主主复制架构提供了更高的可用性、冗余备份和读写负载均衡。但是,它也需要仔细的配置和管理,以确保数据的一致性和冲突的解决。
如何实现
在Kubernetes(K8s)中实现Keepalived和MySQL的互为主从架构可以提供高可用性和故障转移的能力。下面是一个基本的步骤概述:
- 创建Kubernetes集群:首先,您需要创建一个Kubernetes集群,确保有足够的节点和资源来部署Keepalived和MySQL实例。
- 部署Keepalived:使用Kubernetes的Deployment或StatefulSet对象,部署Keepalived实例。Keepalived是一个开源的高可用性解决方案,可以用于实现虚拟IP(VIP)的故障转移和健康检查。您可以配置两个Keepalived实例,一个作为主节点,另一个作为备份节点。
- 配置Keepalived:在Keepalived配置中,指定VIP和健康检查的目标。Keepalived将定期检查MySQL实例的健康状态,并在主节点故障时将VIP转移到备份节点。
- 部署MySQL实例:使用Kubernetes的Deployment或StatefulSet对象,部署两个MySQL实例,一个作为主服务器,另一个作为从服务器。在配置MySQL实例时,确保主服务器和从服务器的复制配置正确,并且它们能够连接到正确的数据库。
- 配置MySQL主从复制:在MySQL实例中,配置主服务器和从服务器之间的主从复制关系。确保主服务器和从服务器之间的网络连接正常,并且复制配置正确。这样,主服务器上的写操作将被异步地复制到从服务器上,实现数据的复制和同步。
- 测试和监控:完成部署后,进行测试以确保Keepalived和MySQL实例的故障转移和复制功能正常工作。监控Keepalived和MySQL实例的健康状态,并及时处理任何故障或问题。
主主复制中若是两台master上同时出现写操作可能会出现的问题
在主主复制中,如果两台主服务器同时接收到对同一行数据的写操作,可能会出现以下问题:
- 冲突数据:由于两台主服务器同时接收到写操作,它们可能会在同一行数据上进行不同的修改,导致数据冲突。这可能会导致数据不一致的情况发生,因为每个主服务器都会复制自己接收到的写操作到其他主服务器。
- 数据丢失:如果两台主服务器同时进行写操作,而没有进行冲突检测和解决策略,可能会导致其中一台主服务器的写操作被覆盖或丢失。这可能会导致数据的不完整性或丢失。
- 数据一致性问题:由于两台主服务器之间的数据复制是异步的,复制的延迟可能导致数据在两台主服务器之间不一致。如果一个主服务器上的写操作在另一个主服务器上复制之前被读取,可能会导致读取到不一致的数据。
为了解决这些问题,可以采取以下策略:
- 冲突检测和解决:在主主复制中,需要配置冲突检测和解决策略。这可以通过使用时间戳、自定义逻辑或其他冲突解决算法来确定哪个写操作应该优先。例如,可以使用时间戳来判断哪个写操作更早,然后应用该操作并忽略其他写操作。
- 分区数据:可以将数据按照一定的规则分区,确保同一行数据只在一个主服务器上进行写操作。例如,可以根据数据的某个属性或哈希值将数据分配给不同的主服务器,从而避免冲突。
- 应用程序层面的冲突解决:在应用程序中处理冲突,可以通过在应用程序层面实现乐观锁或悲观锁来避免数据冲突。例如,使用乐观锁机制可以在写操作之前检查数据的版本,并在写操作时进行冲突检测和解决。
该架构是否存在问题?
在Keepalived和MySQL互为主从架构中,当主服务器(Master)宕机并切换到备份服务器(Slave)时,可能会发生事务丢失的问题。这是因为MySQL的主从复制是异步的,主服务器上的事务在复制到从服务器之前可能会丢失。
以下是一些可能导致事务丢失的情况:
- 主服务器宕机期间的未提交事务:如果主服务器在宕机之前有未提交的事务,这些事务将无法被复制到备份服务器,因此会丢失。
- 主从复制延迟:即使主服务器上的事务已经提交,由于网络延迟或复制进程的延迟,从服务器可能无法立即接收到这些事务的复制。在这段延迟期间,如果主服务器宕机,那么这些已提交但尚未复制到从服务器的事务也会丢失。
为了减少事务丢失的风险,可以采取以下措施:
- 使用持久化存储引擎:选择适当的MySQL存储引擎,如InnoDB,它支持事务和持久化存储。这样,即使主服务器宕机,已提交的事务也会在数据库重新启动后恢复。
- 配置同步复制:将MySQL的主从复制配置为同步复制模式,这意味着主服务器上的事务必须在复制到从服务器之前进行确认。这样可以确保在主服务器宕机之前,已提交的事务已经复制到从服务器。
- 使用半同步复制:MySQL提供了半同步复制模式,它在主服务器上接收到事务后会等待至少一个备份服务器确认已接收该事务,然后才会提交。这可以进一步减少事务丢失的风险。
- 定期监控复制状态:实施监控和警报系统来监测主从复制的状态。如果出现复制延迟或错误,可以及时采取措施来解决问题,减少事务丢失的可能性。
需要注意的是,即使采取了上述措施,完全消除事务丢失的风险是很困难的。在高可用性和数据一致性之间需要进行权衡,根据业务需求和数据的重要性来选择适当的复制策略和措施。此外,定期备份数据并测试恢复过程也是重要的,以便在发生事务丢失或其他故障时能够快速恢复数据。
heml部署mysql高可用集群
RadonDB MySQL 是基于 MySQL 的开源、云原生、高可用集群解决方案。通过使用 Raft 协议,RadonDB MySQL 可以快速进行故障转移,且不会丢失任何事务。
参考:
在 Kubernetes 上部署 RadonDB MySQL 集群 | RadonDB 开源社区
https://github.com/radondb/radondb-mysql-kubernetes/blob/main/README_zh.md
在 KubeSphere 上部署 RadonDB MySQL 集群
kubesphere应用商店mysql兼容高可用: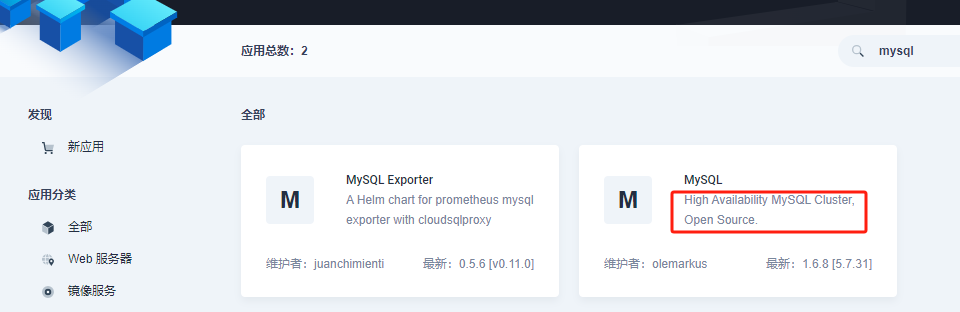
官网部署失败,参考下述文档部署成功
容器化 | 在 Kubernetes 上部署 RadonDB MySQL 集群_helm radondb-CSDN博客
nacos集群部署
官网文档部署nacos
官方部署文档:Kubernetes Nacos 官网部署文档
- 下载官网项目
git clone https://github.com/nacos-group/nacos-k8s.git
- 快速部署
./quick-startup.sh# 脚本内容如下:
# 小编修改了部署namespace为nacos,数据持久化等可查看下载项目文件进行修改
echo "mysql mysql startup"
kubectl create -f ./deploy/mysql/mysql-local.yaml -n nacosecho "nacos quick startup"
kubectl create -f ./deploy/nacos/nacos-quick-start.yaml -n nacos
- 查看部署情况
helm部署nacos
- 添加应用仓库
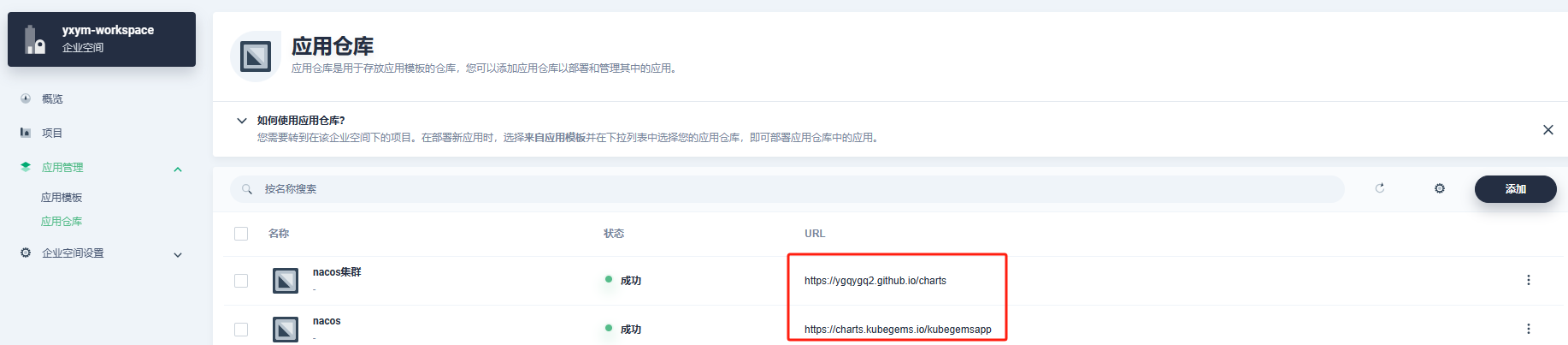
https://ygqygq2.github.io/charts
https://charts.kubegems.io/kubegemsapp
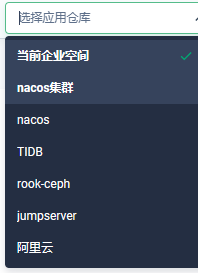
- 进入项目空间,选择应用仓库
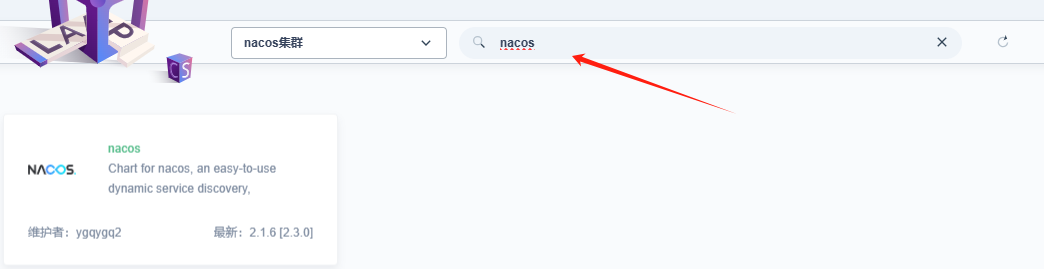
- 在应用仓库中搜索nacos,点击nacos
- 选择nacos版本,点击下一步
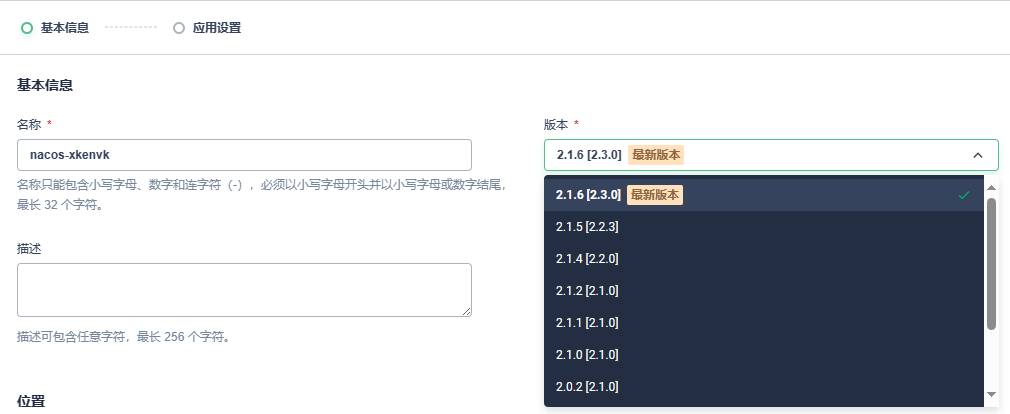
- 修改values.yaml
mysql:enabled: true # 是否启用内部mysql,false使用外部需配置externalexternal:mysqlMasterHost: "mysql_master_host"mysqlDatabase: "nacos"mysqlMasterPort: "3306"mysqlMasterUser: "nacos"mysqlMasterPassword: "nacos"mysqlSlaveHost: "mysql_slave_host"mysqlSlavePort: "3306"architecture: replicationauth: # 修改nacosrootPassword: "nacos"database: "nacos"username: "nacos"password: "nacos"replicationUser: "replicator"replicationPassword: "replicator"
- 查看部署情况
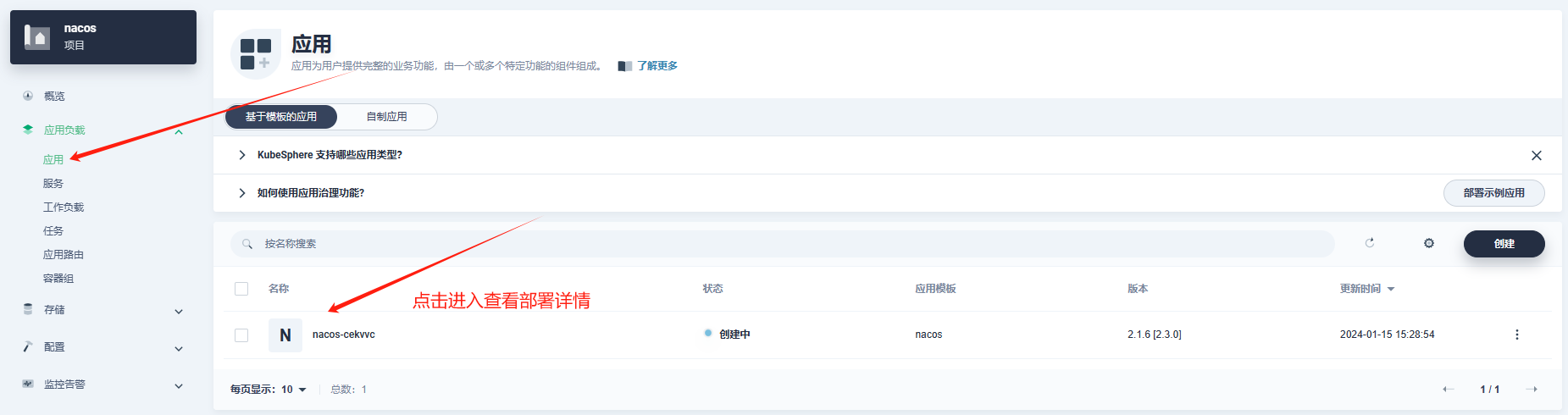
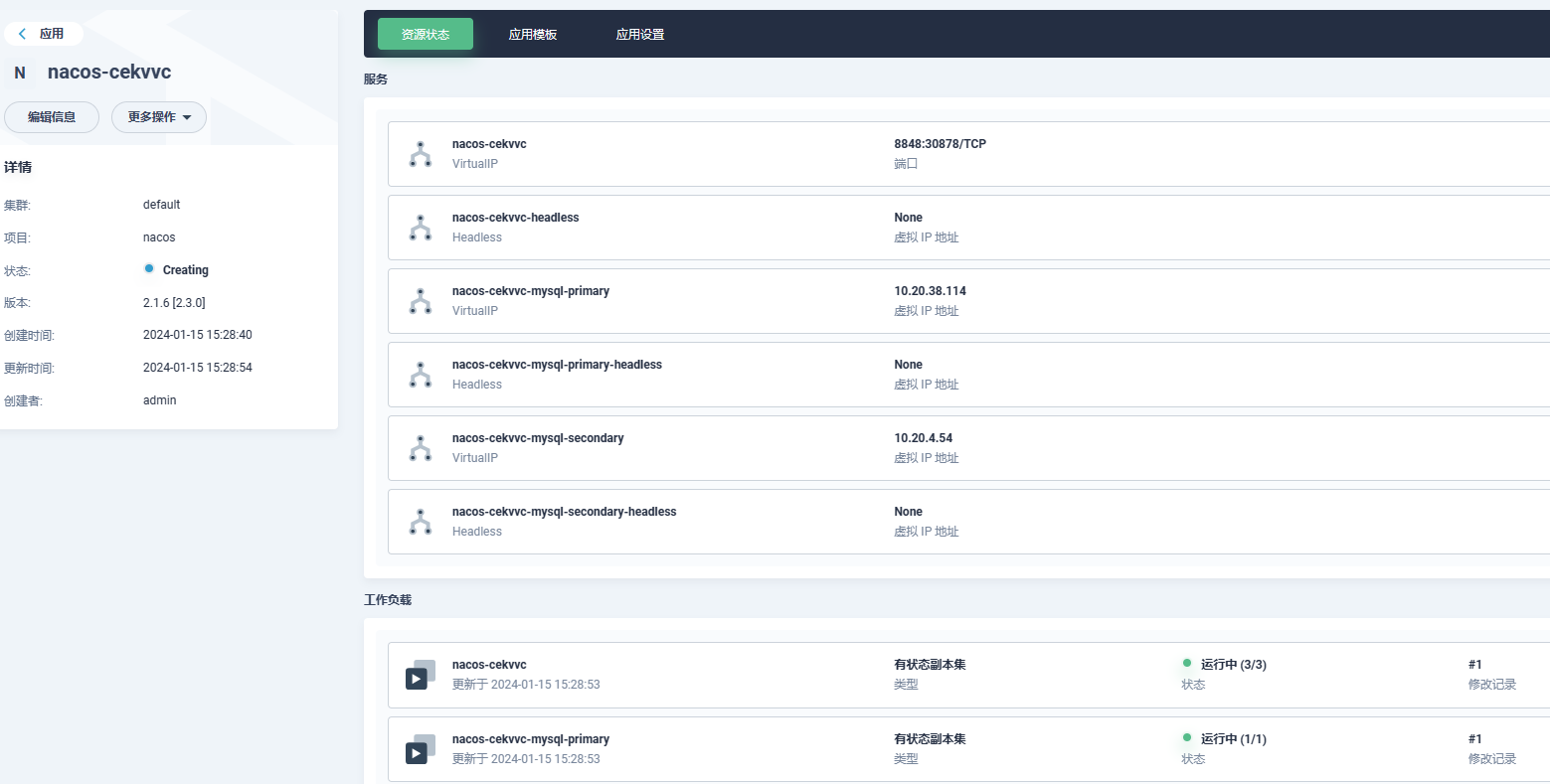
- 服务暴露
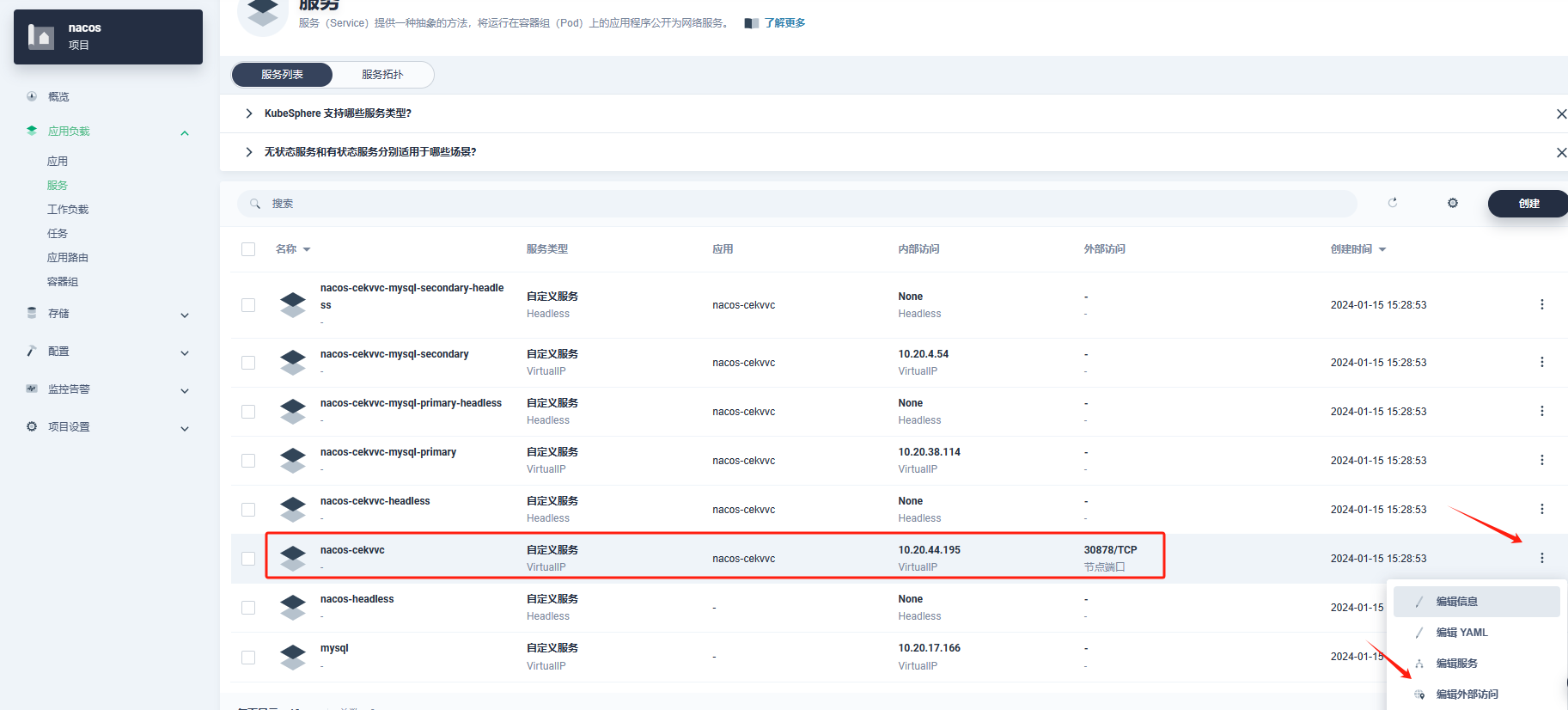
- 访问测试
redis集群部署
主从哨兵部署
- 添加应用仓库:https://charts.bitnami.com/bitnami
- 搜索redis部署
- values.yaml配置修改,配置参考,常用配置如下:
| 配置项 | 描述 | 值 |
|---|---|---|
| architecture | Redis架构。允许的值:standalone或replication | replication |
| auth.enabled | 启用密码身份验证 | true |
| auth.sentinel | 在哨兵上也启用密码身份验证 | true |
| auth.password | Redis密码 | “” |
| master.count | ||
| master.count | 要部署的 Redis 主实例数(实验性,需要额外配置) | 1 |
| replica.replicaCount | 要部署的 Redis 副本数 | 3 |
| replica.configuration | Redis副本节点的配置 | “” |
| sentinel.enabled | 在 Redis Pod 上使用 Redis Sentinel。 | false |
可视化修改配置,可在右上角点击编辑YAML切换: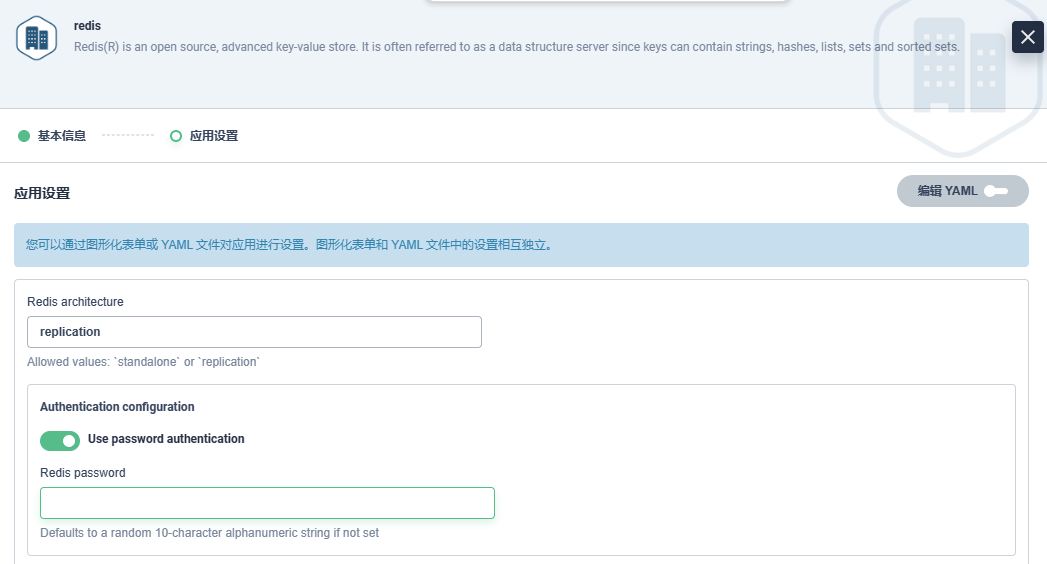
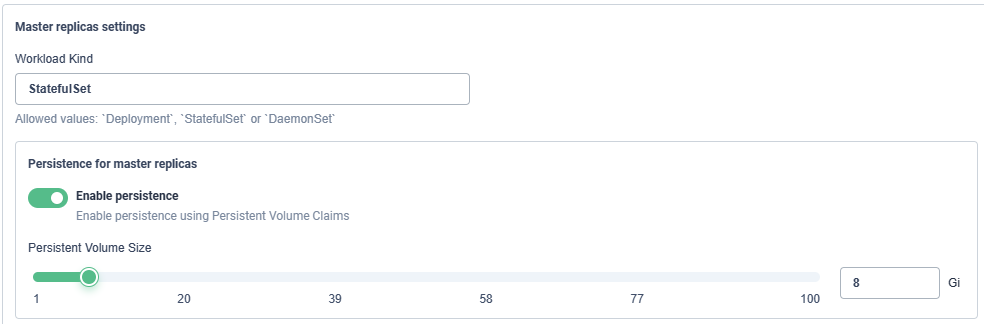
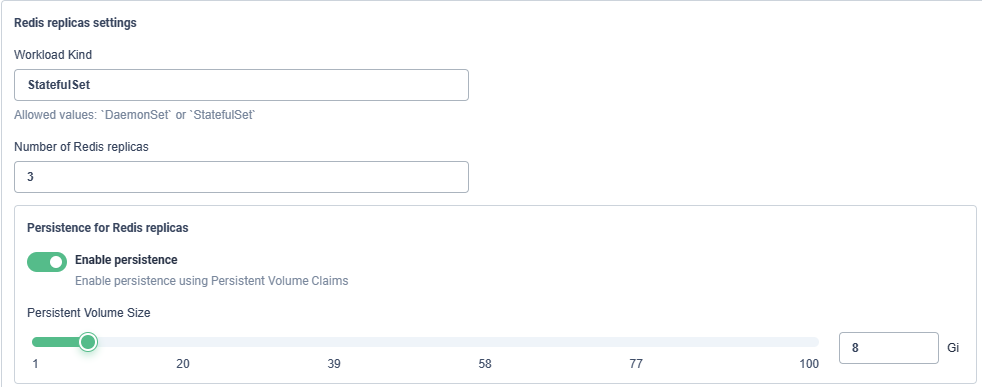
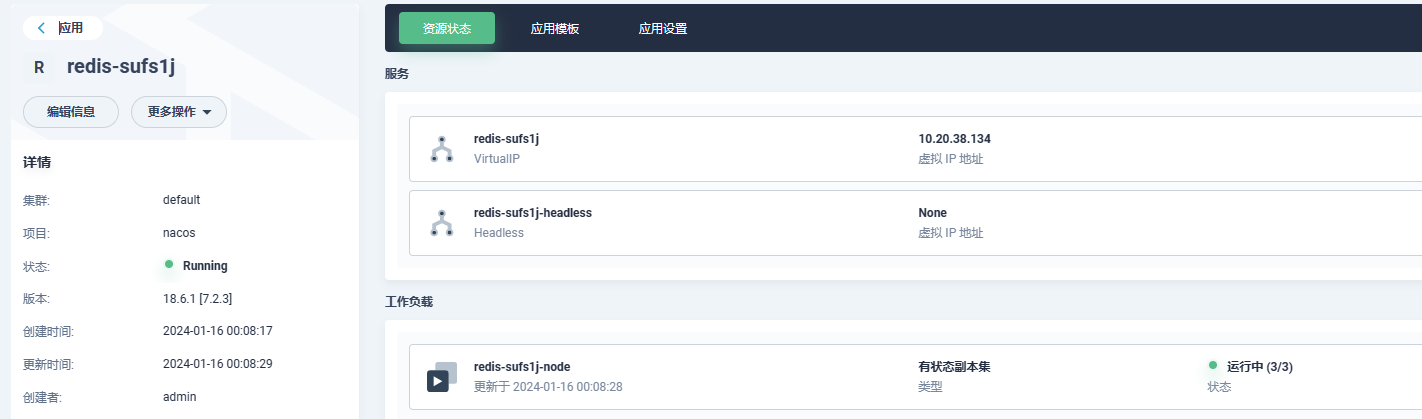
- 部署情况
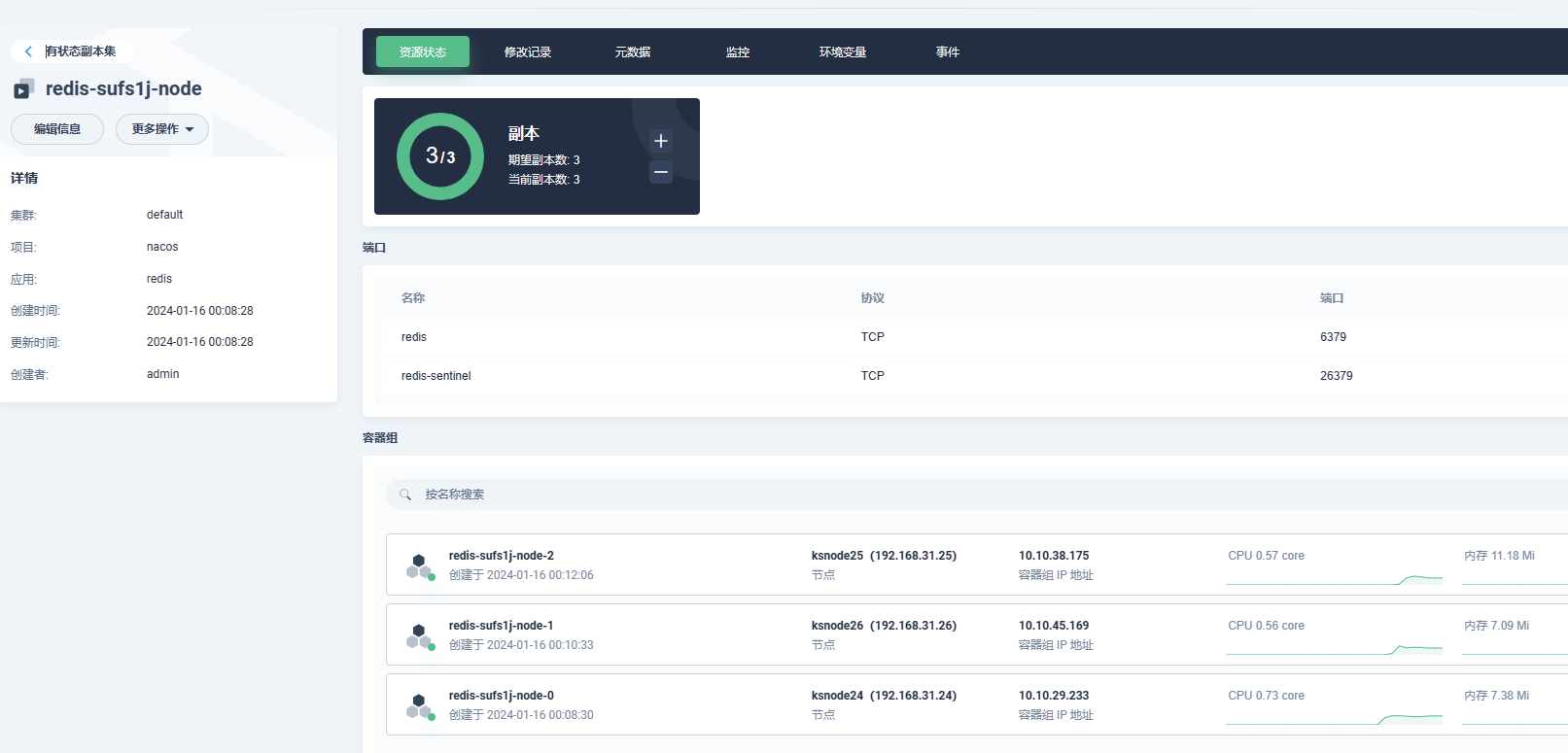
redis cluster部署
Helm(bitnami)部署zookeeper和kafka集群_helm bitnami-CSDN博客
- 添加应用仓库:https://charts.bitnami.com/bitnami
- 搜索redis-cluster
- values.yaml配置修改,配置参考,常用配置如下:
| cluster.nodes | 主节点数应始终为 >= 3,否则集群创建将失败 | 6 |
|---|---|---|
| cluster.replicas | 集群中每个主节点的副本数 | 1 |
| cluster.externalAccess.enabled | 启用对 Redis 的访问 | false |
| metrics.enabled | 启动边车 prometheus 导出器 | false |
- helm方式部署
# 添加仓库
helm repo add bitnami https://charts.bitnami.com/bitnami
# 安装
helm install -n middleware redis-cluster bitnami/redis-cluster
# 查看密码
kubectl get secret --namespace "middleware" redis-cluster -o jsonpath="{.data.redis-password}" | base64 -d
# 自定义values.yaml,https://github.com/bitnami/charts/blob/main/bitnami/redis-cluster/values.yaml# 使用自定义values.yaml更新已安装redis-cluster
helm upgrade -n middleware -f values.yaml redis-cluster

参考:
在 K8S 中快速部署 Redis Cluster & Redisinsight
https://www.cnblogs.com/hacker-linner/p/15839374.html
Helm 安装 bitnami/redis 集群模式
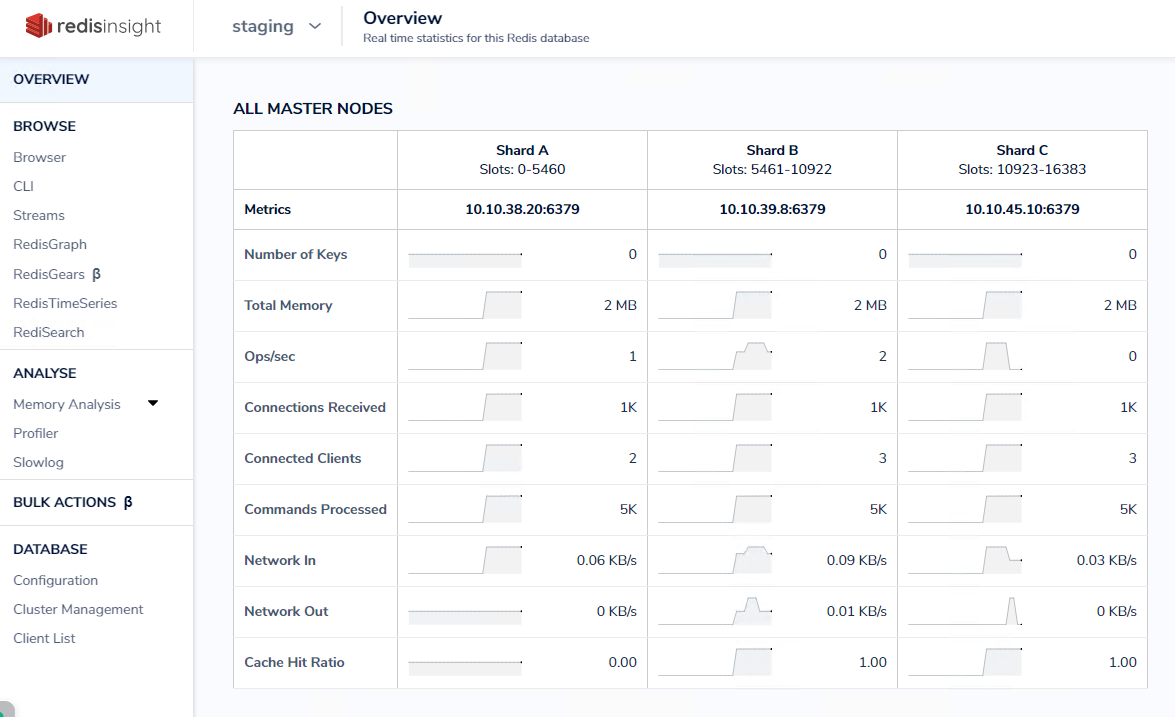
安装reids客户端redisinsight
镜像:redislabs/redisinsight:1.9.0
容器内部数据路径:/db
使用ks可视化方式安装,不过多介绍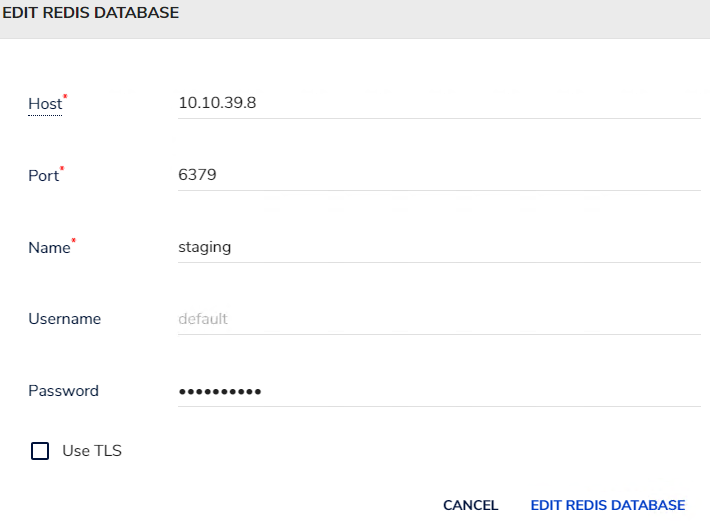
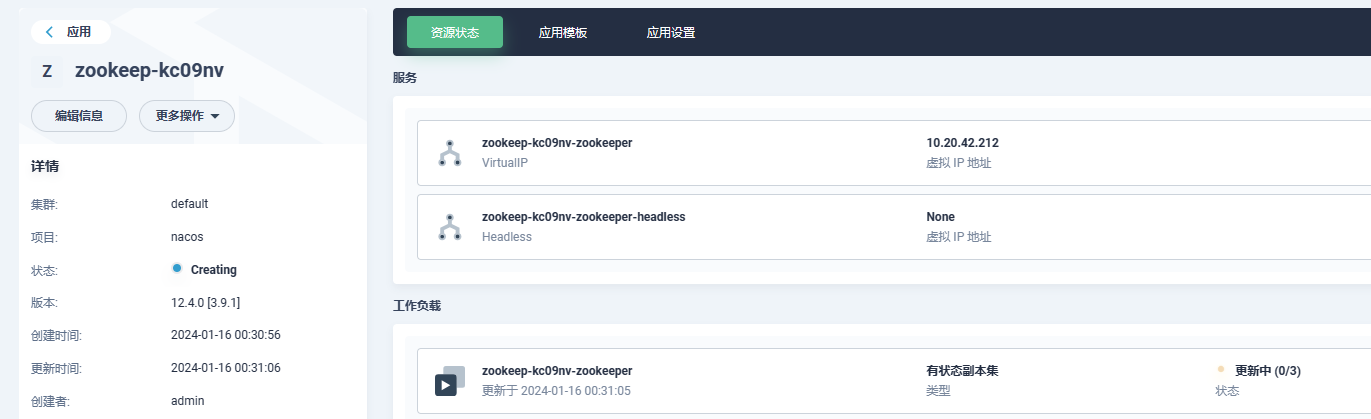
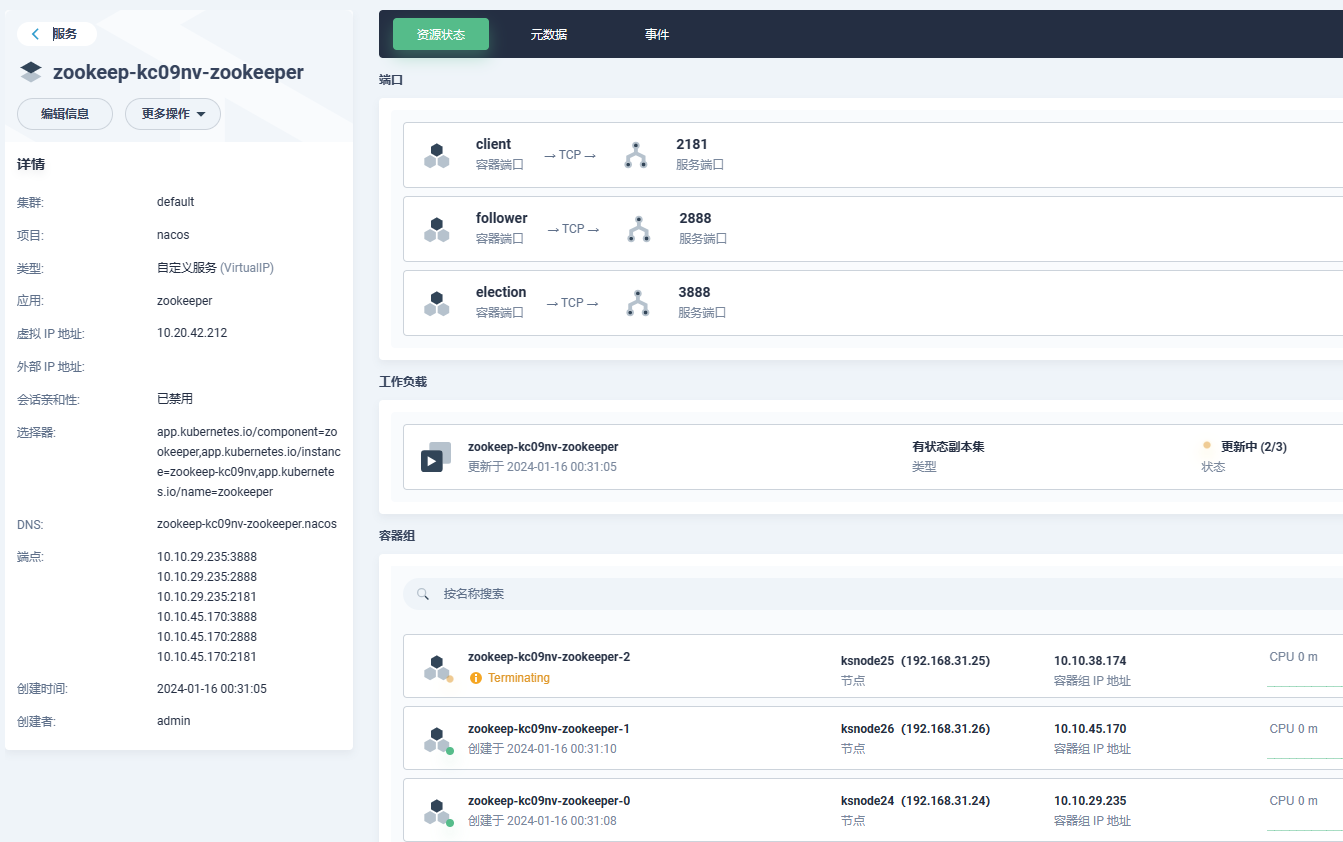
zk集群部署
-
添加应用仓库:https://charts.bitnami.com/bitnami
-
搜索zookeeper部署
-
values.yaml配置修改,配置参考,常用配置如下:
| 名字 | 描述 | 值 |
| — | — | — |
| replicaCount | ZooKeeper 节点数 | 1 |
| auth.client.enabled | 启用 ZooKeeper 客户端-服务器身份验证。它使用 SASL/Digest-MD5 | false | -
查看部署情况
kafka集群部署
- 添加应用仓库:https://charts.bitnami.com/bitnami
- 搜索kafka部署
- values.yaml配置修改,常用配置如下,其他参考配置参考
- helm命令
helm install kafka bitnami/kafka \--namespace kafka --create-namespace \--set global.storageClass=<storageClass-name> \--set kubeVersion=<theKubeVersion> \--set image.tag=3.1.0-debian-10-r22 \--set replicaCount=3 \--set service.type=ClusterIP \--set externalAccess.enabled=true \--set externalAccess.service.type=LoadBalancer \--set externalAccess.service.ports.external=9094 \--set externalAccess.autoDiscovery.enabled=true \--set serviceAccount.create=true \--set rbac.create=true \--set persistence.enabled=true \--set logPersistence.enabled=true \--set metrics.kafka.enabled=false \--set zookeeper.enabled=true \--set zookeeper.persistence.enabled=true \--wait
- –namespace kafka --create-namespace: 安装在 kafka namespace, 如果没有该 ns 就创建;
- global.storageClass= 使用指定的 storageclass
- kubeVersion= 让 bitnami/kafka helm 判断是否满足版本需求,不满足就无法创建
- image.tag=3.1.0-debian-10-r22: 20220219 的最新镜像,使用完整的名字保证尽量减少从互联网 pull 镜像;
- replicaCount=3: kafka 副本数为 3
- service.type=ClusterIP : 创建 kafka service, 用于 k8s 集群内部,所以 ClusterIP 就可以
- –set externalAccess.enabled=true --set externalAccess.service.type=LoadBalancer --set externalAccess.service.ports.external=9094 --set externalAccess.autoDiscovery.enabled=true --set serviceAccount.create=true --set rbac.create=true 创建用于 k8s 集群外访问的 kafka-<0|1|2>-external 服务 (因为前面 kafka 副本数为 3)
- persistence.enabled=true: Kafka 数据持久化,容器中的目录为 /bitnami/kafka
- logPersistence.enabled=true: Kafka 日志持久化,容器中的目录为 /opt/bitnami/kafka/logs
- metrics.kafka.enabled=false 不启用 kafka 的监控 (Kafka 监控收集数据是通过 kafka-exporter 实现的)
- zookeeper.enabled=true: 安装 kafka 需要先安装 zookeeper
- zookeeper.persistence.enabled=true: Zookeeper 日志持久化,容器中的目录为:/bitnami/zookeeper
- –wait: helm 命令会一直等待创建的结果
- Kafka 测试验证
创建kafka-client pod:
kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:3.1.0-debian-10-r22 --namespace kafka --command -- sleep infinity
进入到 kafka-client 中,运行如下命令测试:
kafka-console-producer.sh --broker-list kafka-0.kafka-headless.kafka.svc.cluster.local:9092 --topic test
kafka-console-consumer.sh --bootstrap-server kafka-0.kafka-headless.kafka.svc.cluster.local:9092 --topic test --from-beginningkafka-console-producer.sh --broker-list 10.109.205.245:9094 --topic test
kafka-console-consumer.sh --bootstrap-server 10.109.205.245:9094 --topic test --from-beginning
kafka可视化控制台
| 组件 | 描述 |
|---|---|
| Know Streaming | 专注于Kafka运维管控、监控告警、资源治理、多活容灾等核心场景。 Know Streaming github | Know Streaming官网 |
| Kafka Manager | Kafka Manager 是 Yahoo 开源的 Kafka 集群管理工具。它提供了一个直观的 Web 界面,用于监控和管理 Kafka 集群。Kafka Manager 可以显示集群的整体状态、主题和分区的详细信息,以及消费者组的偏移量等。您可以使用 Kafka Manager 进行主题和分区的管理、消费者组的监控和管理,以及执行一些集群维护任务。Kafka Manager官网 |
| Kafdrop | Kafdrop 是一个开源的 Kafka 可视化工具,提供了一个简单易用的 Web 界面来监控 Kafka 集群。Kafdrop 可以显示 Kafka 集群中的主题、分区和消费者组的信息,并提供了实时的消息流量监控。它还支持查看消息的详细内容和偏移量的管理。Kafdrop官网 |
| Kafka Map | Kafka Map 是一个开源的 Kafka 可视化工具,它提供了一个交互式的 Web 界面,用于可视化 Kafka 主题和分区之间的消息流。Kafka Map 使用图形化的方式展示了消息在不同分区之间的流动情况,帮助用户更好地理解和分析消息的传输路径。kafka-map官网 |
从功能的专业程度建议使用Know Streaming,关注消息分区流向建议kafka-map,轻量级的 Kafka 可视化工具建议Kafdrop
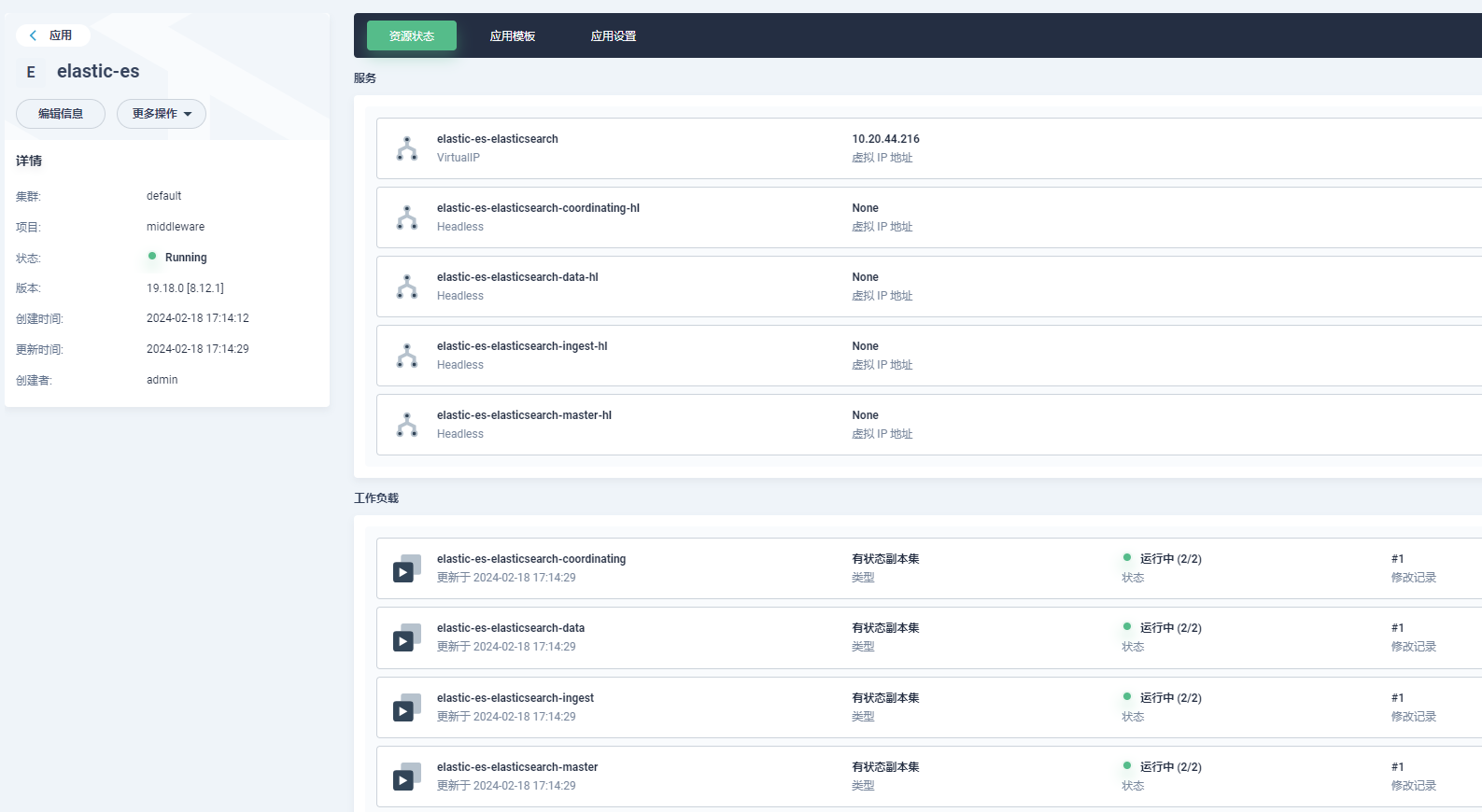
es集群部署
参考
Download Elasticsearch
Elasticsearch支持哪些插件_检索分析服务 Elasticsearch版(ES)-阿里云帮助中心
Kubernetes Helm3 部署 ElasticSearch & Kibana 7 集群-腾讯云开发者社区-腾讯云
- 添加应用仓库:https://charts.bitnami.com/bitnami
- 搜索elasticsearch部署
- values.yaml配置修改,配置参考
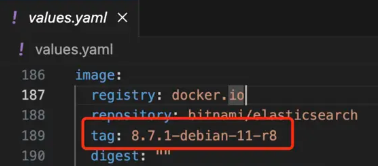
制作安装ik分词器的es可使用上述截图中镜像作为基础镜像(推荐),也可使用plugins参数初始化安装
# 查看elasticsearch安装位置
which elasticsearch# 查看当前已安装的插件
elasticsearch-plugin list# 安装插件
elasticsearch-plugin install {插件名称}# ik分词器地址https://github.com/medcl/elasticsearch-analysis-ik/releases/
# elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v8.12.0/elasticsearch-analysis-ik-8.12.0.zip
在 Elasticsearch 集群中,不同角色承担着不同的职责和功能。下面是关于 Elasticsearch 集群中各个角色的详细介绍:
- Coordinating(协调节点)角色:
- 职责:协调节点是集群中的请求入口点,它接收来自客户端的请求并将其转发到适当的节点。它不存储数据,主要用于处理搜索请求和聚合操作。
- 功能:
- 路由请求:协调节点根据请求的内容将其路由到正确的数据节点,以提高集群的性能和扩展性。
- 整合结果:协调节点将从数据节点接收到的结果进行汇总和整合,然后将结果返回给客户端。
- Data(数据节点)角色:
- 职责:数据节点存储和管理实际的索引数据。
- 功能:
- 数据存储:数据节点负责存储索引数据,并提供对数据的增删改查操作。
- 数据分片:数据节点将索引数据分成多个分片,每个分片可以分布在不同的节点上,以实现数据的分布式存储和处理。
- 数据复制:数据节点可以复制数据分片,以提供高可用性和故障容错性。
- Ingest(数据预处理节点)角色:
- 职责:Ingest 节点用于处理数据的预处理和转换,以便在索引之前进行必要的操作。
- 功能:
- 数据预处理:Ingest 节点可以执行各种数据的提取、转换和加载(ETL)操作,例如数据过滤、转换、标准化等。
- 数据修改:Ingest 节点可以在数据进入索引之前对其进行修改和处理,以满足特定的需求和要求。
- Master(主节点)角色:
- 职责:主节点管理集群的整体状态和配置。
- 功能:
- 集群管理:主节点负责协调集群中的各个节点,执行集群范围的操作,例如创建和删除索引、添加和删除节点等。
- 元数据维护:主节点维护集群的元数据,包括索引的映射、分片分配、节点状态等。
- 集群稳定性:主节点确保集群的稳定性和一致性,协调节点的选举和故障检测等操作由主节点负责。
这些角色在 Elasticsearch 集群中相互协作,共同构建一个高性能、可扩展和可靠的分布式搜索和分析平台。需要注意的是,一个节点可以同时承担多个角色,具体取决于集群的规模和配置。
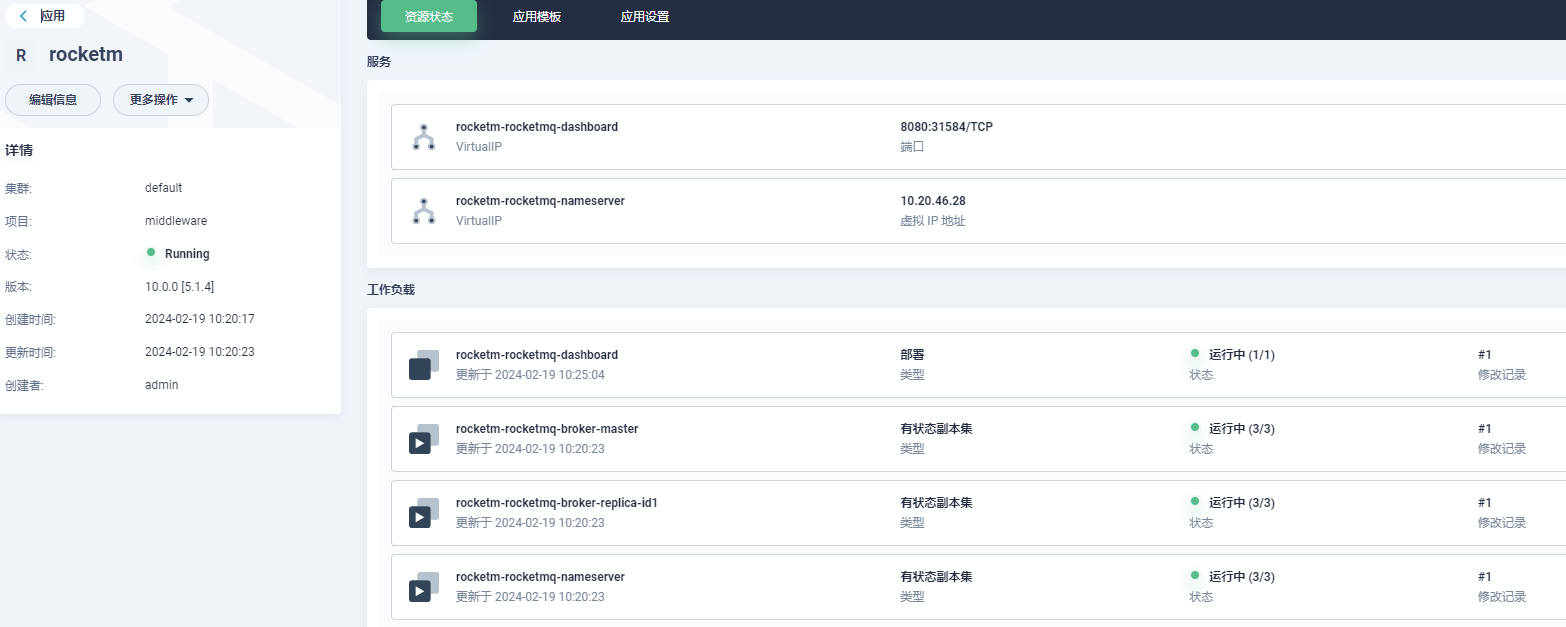
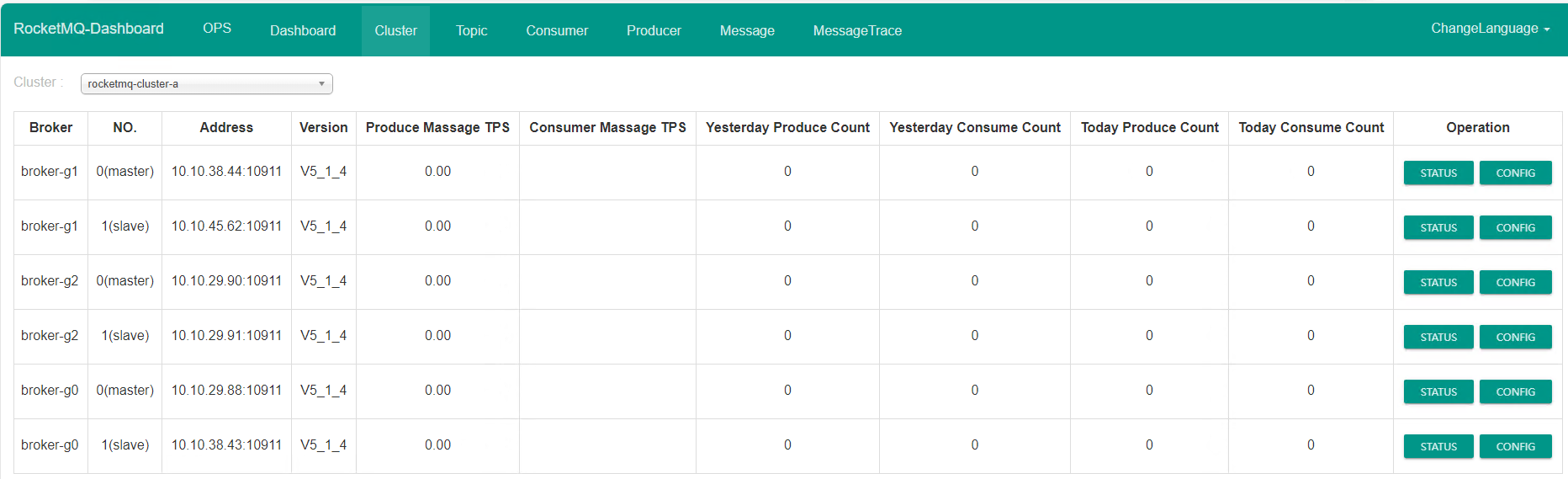
rocketmq集群部署
参考:Helm 部署 RocketMQ-腾讯云开发者社区-腾讯云
https://github.com/itboon/rocketmq-helm
## 部署高可用集群, 多 Master 多 Slave
## 3个 master 节点,每个 master 具有1个副节点,共6个 broker 节点
helm upgrade --install rocketmq \--namespace rocketmq-demo \--create-namespace \--set broker.size.master="3" \--set broker.size.replica="1" \--set broker.master.jvmMemory="-Xms2g -Xmx2g" \--set broker.master.resources.requests.memory="4Gi" \--set nameserver.replicaCount="3" \--set dashboard.enabled="true" \--set dashboard.ingress.enabled="true" \--set dashboard.ingress.hosts[0].host="rocketmq-ha.example.com" \rocketmq-repo/rocketmq
minio集群部署
- 添加应用仓库:https://charts.bitnami.com/bitnami
- 搜索kafka部署
- values.yaml配置修改,配置参考,常用配置如下:
- helm命令
SkyWalking部署
参考:
https://github.com/apache/skywalking-helm
k8s 部署 skywalking 并将 pod 应用接入链路追踪 - 掘金
https://www.cnblogs.com/lina-2159/p/16190984.html
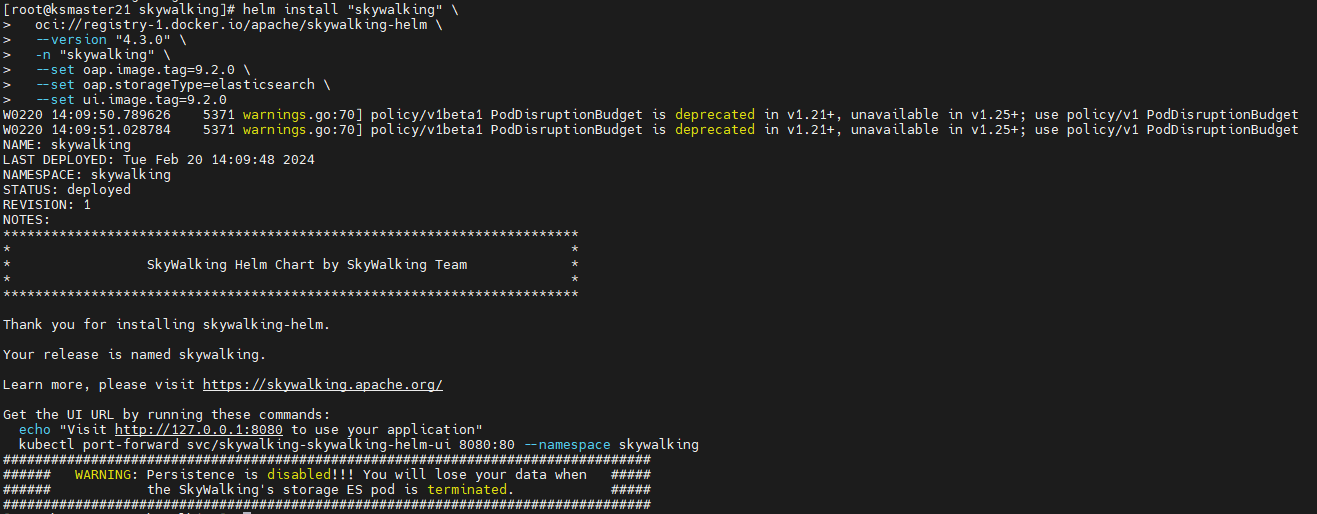
使用 Docker Helm 存储库 (>= 4.3.0) 安装已发布的版本
helm install "skywalking" \oci://registry-1.docker.io/apache/skywalking-helm \--version "4.3.0" \-n "skywalking" \--set oap.image.tag=9.2.0 \--set oap.storageType=elasticsearch \--set ui.image.tag=9.2.0
使用 master 分支安装 SkyWalking 的开发版本
git clone https://github.com/apache/skywalking-kubernetescd skywalking-kubernetes/chart
helm repo add elastic https://helm.elastic.co
helm dep up skywalking
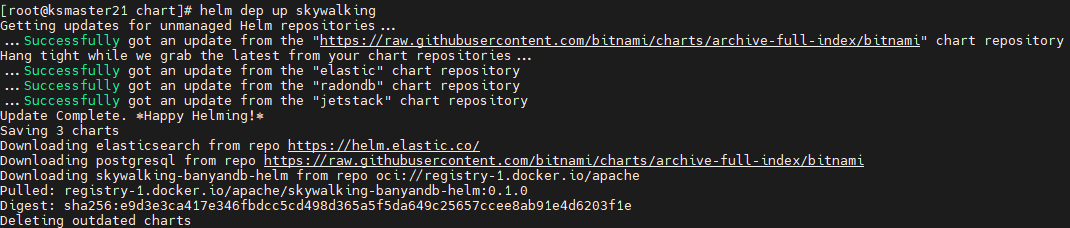
# 安装
helm install "skywalking" ./skywalking -n "skywalking" -f ./skywalking/values-my-es.yaml# 卸载
helm uninstall skywalking -n skywalking
修改values-my-es.yaml配置是否使用外部es
elasticsearch:enabled: false # 由于使用 外部的 es,所以这里需要设置为 false,因为设置为 true 会在 k8s 中部署 esconfig: # For users of an existing elasticsearch cluster,takes effect when `elasticsearch.enabled` is falsehost: your.elasticsearch.host.or.ipport:http: 9200user: "xxx" # [optional]password: "xxx" # [optional]
MongoDB部署
- 添加应用仓库:https://charts.bitnami.com/bitnami
- 搜索kafka部署
- values.yaml配置修改,配置参考,常用配置如下:
- helm命令
helm 安装 MongoDB 集群
helm pull bitnami/mongodb
tar -xzvf mongodb-14.10.1.tgz
helm -n mongodb install mongodb ./mongodb
相关文章:
13.云原生之常用研发中间件部署
云原生专栏大纲 文章目录 mysql主从集群部署mysql高可用集群高可用互为主从架构互为主从架构如何实现主主复制中若是两台master上同时出现写操作可能会出现的问题该架构是否存在问题? heml部署mysql高可用集群 nacos集群部署官网文档部署nacoshelm部署nacos redis集…...
远离远程代码执行 ,RPC 运行时中的三个漏洞是如何被发现的?
引言 MS-RPC 是 Windows 网络中广泛使用的协议,许多服务和应用程序都依赖它。 因此,MS-RPC 中的漏洞可能会导致严重后果。 Akamai 安全情报小组在过去一年中一直致力于 MS-RPC 研究。 我们发现并利用了漏洞,构建了研究工具,并编写…...
---python异常类型及其类型处理)
零基础学python之高级编程(4)---python异常类型及其类型处理
python异常类型及其类型处理 文章目录 python异常类型及其类型处理前言一、异常的概念二、异常类型1.捕获异常方法2.主动抛出异常 总结 前言 我们在日常学习中或者在开发一个项目时,一定会出现的问题就是报错,今天我们就学习错误类型的种类以及错误类型的处理方法 一、异常的概…...
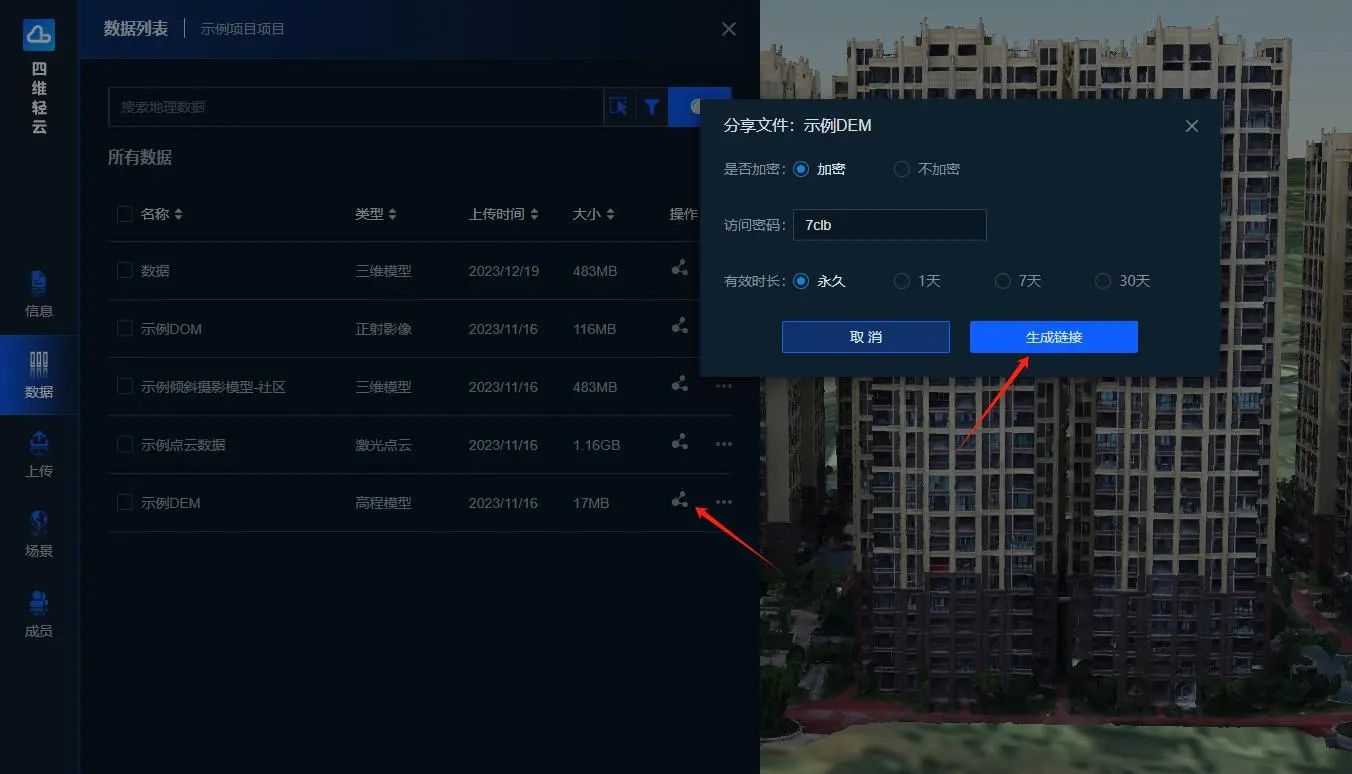
如何实现三维模型在网页/手机端/APP上的展示与分享?
在四维轻云平台中,只需要简单几步,就能轻松实现三维模型在网页/手机端/APP上的交互展示,也可分享转发给他人进行在线查看。 1、注册登录 打开四维轻云官网,完成注册并登录。 2、创建项目 在【项目管理】中点击“新建项目”按钮…...

SpringBoot项目在进行部署打包的时候,打包成jar和war有何差异?
首先给大家来讲一个我们遇到的一个奇怪的问题: 我的一个springboot项目,用mvn install打包成jar,换一台有jdk的机器就直接可以用java -jar 项目名.jar的方式运行,没任何问题,为什么这里不需要tomcat也可以运行了? 然…...
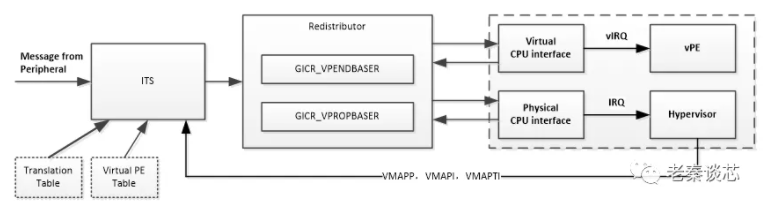
ARM系列 -- 虚拟化(四)
今天来看看虚拟中断。 在一个非虚拟化的系统中,操作系统可以直接访问GIC的寄存器,并且处理GIC的物理中断接口(physical interrupt interface)。 但是在一个虚拟化的系统中,不是这样。Guest OS并不知道它运行在虚拟系…...
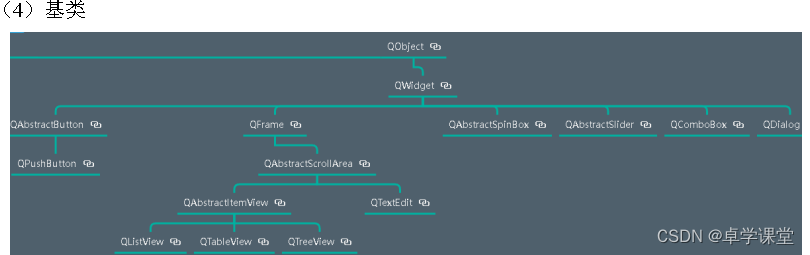
QT GUI编程常用控件学习
1 GUI编程应该学什么 2 QT常用模块结构 QtCore: 包含了核心的非GUI的功能。主要和时间、文件与文件夹、各种数据、流、URLs、mime类文件、进程与线程一起使用 QtGui: 包含了窗口系统、事件处理、2D图像、基本绘画、字体和文字类 QtWidgets: 包含了一些列创建桌面应用的UI元素…...
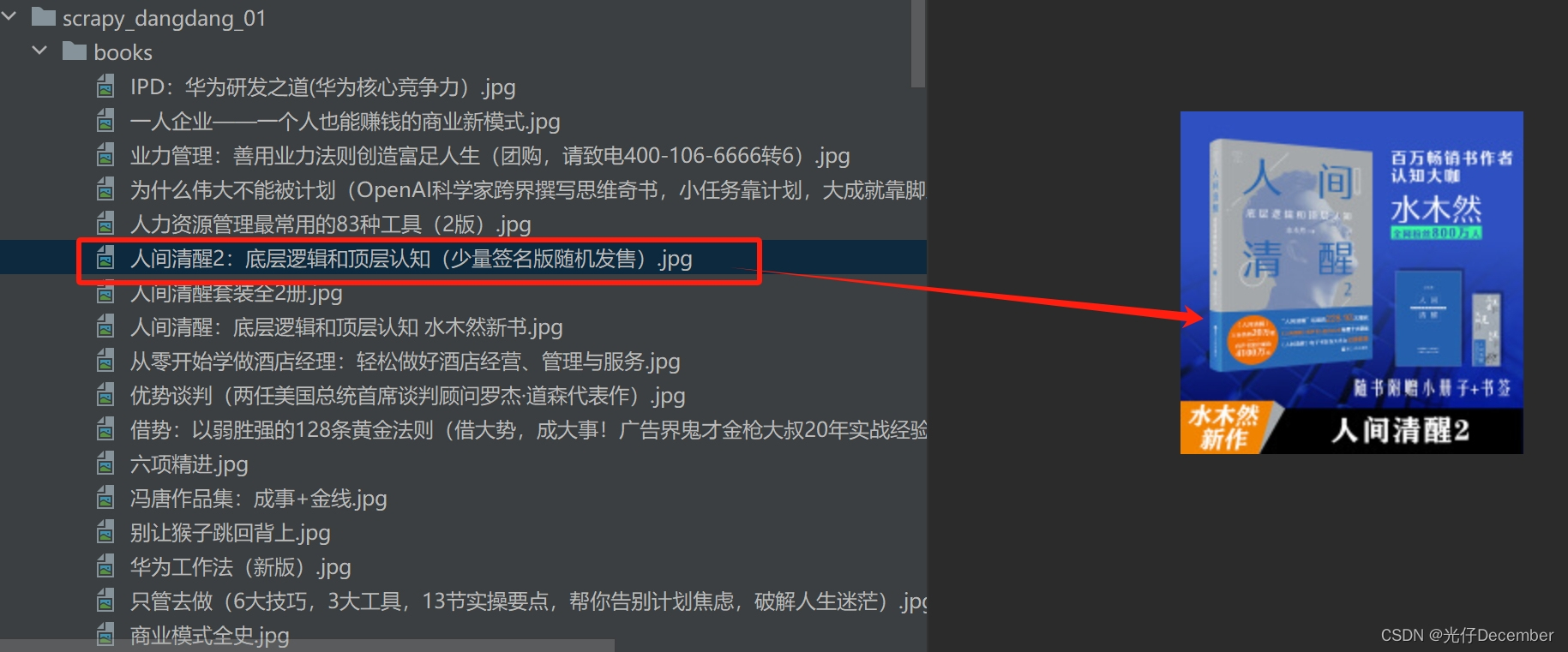
【Python从入门到进阶】49、当当网Scrapy项目实战(二)
接上篇《48、当当网Scrapy项目实战(一)》 上一篇我们正式开启了一个Scrapy爬虫项目的实战,对当当网进行剖析和抓取。本篇我们继续编写该当当网的项目,讲解刚刚编写的Spider与item之间的关系,以及如何使用itemÿ…...

flutter build ipa 打包比 xcode archive 打出的ipa包大
为什么 flutter build ipa 打包比 xcode archive 打出的ipa包大? 如果你用Flutter构建的.ipa文件比通过Xcode Archive构建的.ipa文件要大,这可能是因为Flutter构建了一个包含了多平台的二进制文件的通用包。这意味着在Flutter构建的.ipa中包含了所有的C…...
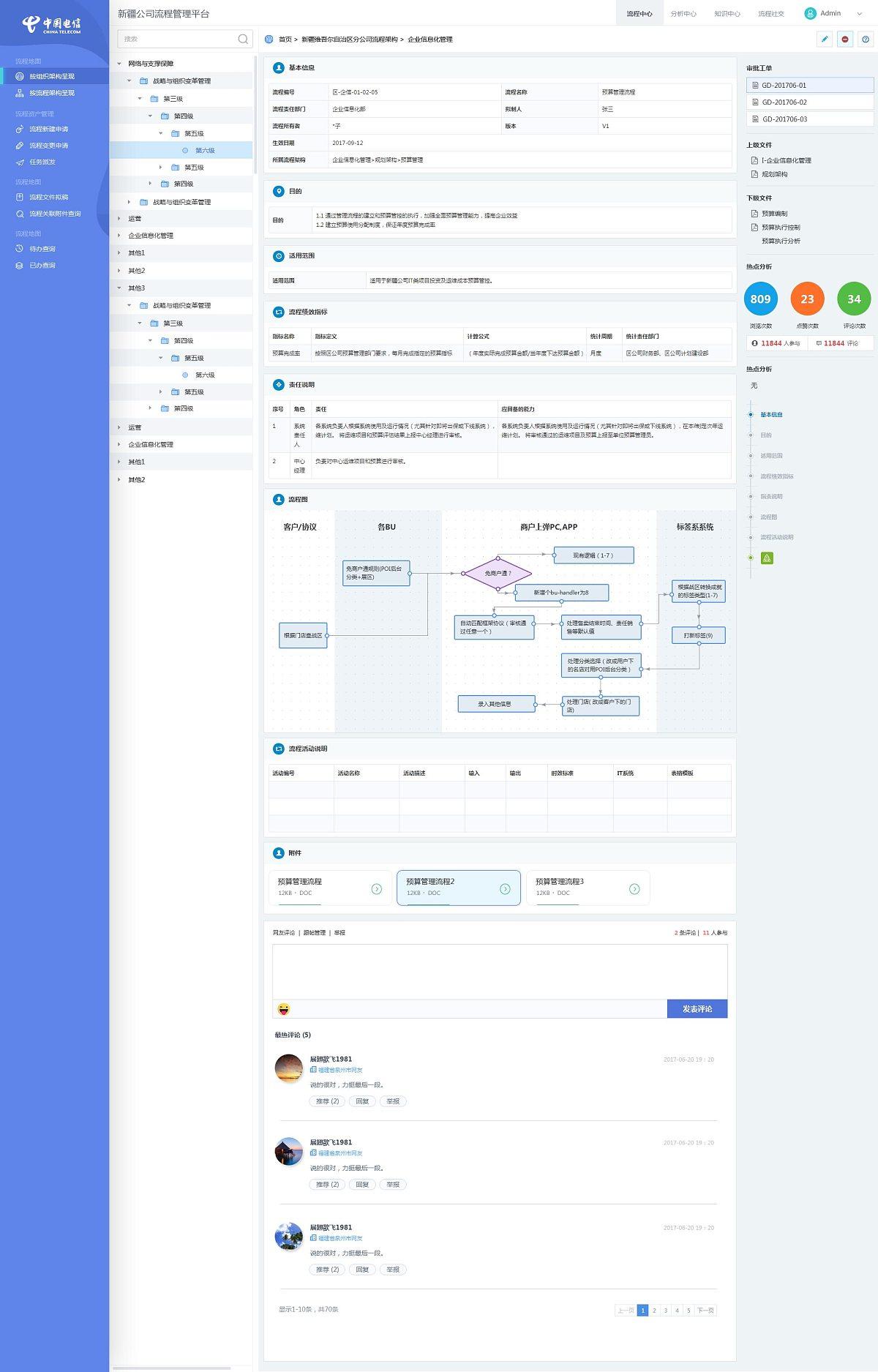
B端系统:巧妙地容错和防错设置,减少用户操作错误
Hi,大家好,我是大美B端工场,从事8年前端开发的老司机。很多B端系统体验不好,让用户非常茫然或者容易出错,大大降低了操作体验,本文着重分析B端系统的容错机制该如何设计,欢迎老铁们关注、评论、…...
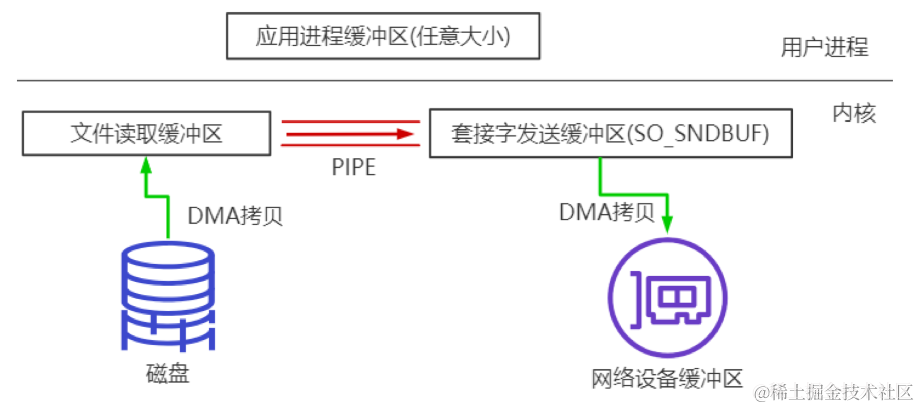
BIO实战、NIO编程与直接内存、零拷贝深入辨析
BIO实战、NIO编程与直接内存、零拷贝深入辨析 长连接、短连接 长连接 socket连接后不管是否使用都会保持连接状态多用于操作频繁,点对点的通讯,避免频繁socket创建造成资源浪费,比如TCP 短连接 socket连接后发送完数据后就断开早期的http服…...
PDF文件转换为图片
现在确实有很多线上的工具可以把pdf文件转为图片,比如smallpdf等等,都很好用。但我们有时会碰到一些敏感数据,或者要批量去转,那么需要自己写脚本来实现,以下脚本可以提供这个功能~ def pdf2img(pdf_dir, result_path…...

【Java程序设计】【C00317】基于Springboot的智慧社区居家养老健康管理系统(有论文)
基于Springboot的智慧社区居家养老健康管理系统(有论文) 项目简介项目获取开发环境项目技术运行截图 项目简介 这是一个基于Springboot的智慧社区居家养老健康管理系统设计与实现,本系统有管理员、社区工作人员、医生以及家属四种角色权限 管…...
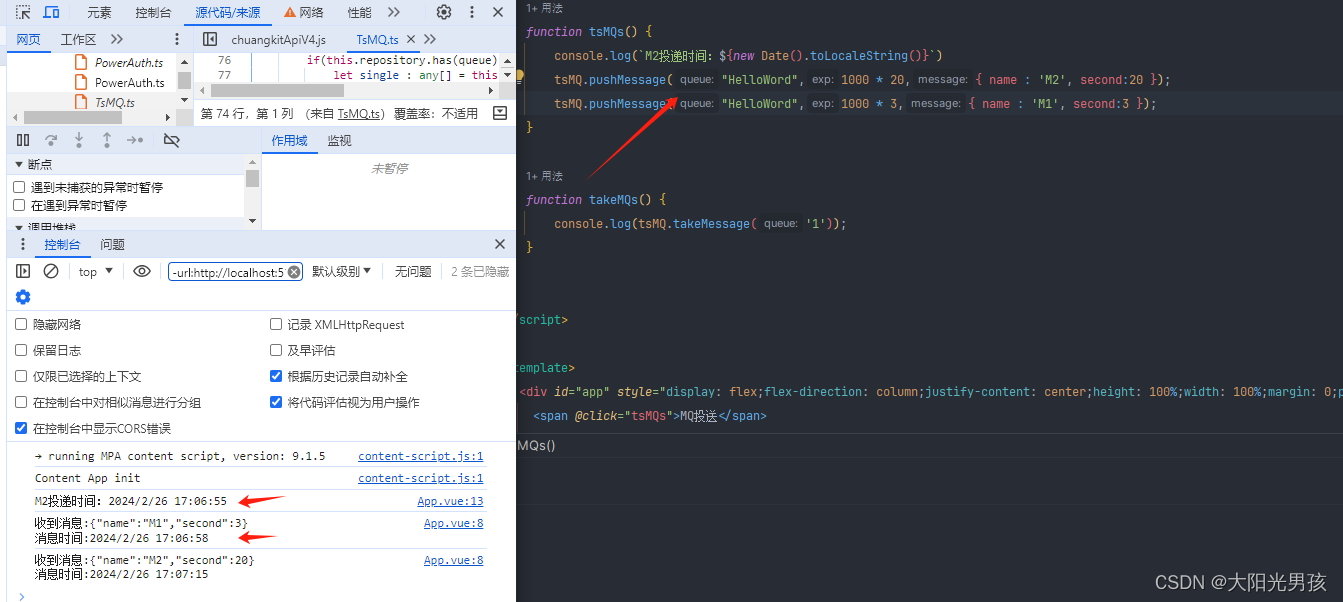
Vue3前端实现一个本地消息队列(MQ), 让消息延迟消费或者做缓存
MQ功能实现的具体代码(TsMQ.ts): import { v4 as uuidx } from uuid;import emitter from /utils/mitt// 消息类 class Message {// 过期时间,0表示马上就消费exp: number;// 消费标识,避免重复消费tag : string;// 消息体body : any;constr…...
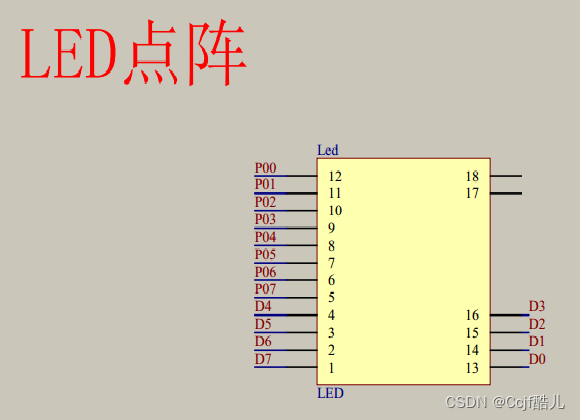
普中51单片机学习(8*8LED点阵)
8*8LED点阵 实验代码 #include "reg52.h" #include "intrins.h"typedef unsigned int u16; typedef unsigned char u8; u8 lednum0x80;sbit SHCPP3^6; sbit SERP3^4; sbit STCPP3^5;void HC595SENDBYTE(u8 dat) {u8 a;SHCP1;STCP1;for(a0;a<8;a){SERd…...
Python 实现Excel自动化办公(上)
在Python 中你要针对某个对象进行操作,是需要安装与其对应的第三方库的,这里对于Excel 也不例外,它也有对应的第三方库,即xlrd 库。 什么是xlrd库 Python 操作Excel 主要用到xlrd和xlwt这两个库,即xlrd是读Excel &am…...

DayDreamInGIS 之 ArcGIS Pro二次开发 图层属性中换行符等特殊字符替换
具体参考ArcMap中类似的问题,本帖开发一个ArcGISPro版的工具 1.基础库部分 插件开发,经常需要处理图层与界面的交互。基础库把常用的交互部分做了封装,方便之后的重复使用。 (1)下述类定义了数据存储结构࿰…...
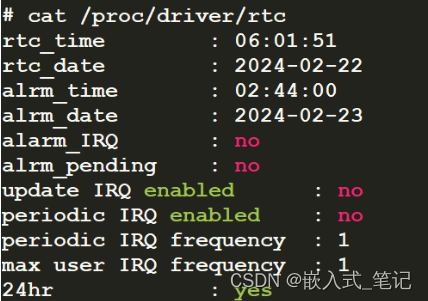
RK3568平台 RTC时间框架
一.RTC时间框架概述 RTC(Real Time Clock)是一种用于计时的模块,可以是再soc内部,也可以是外部模块。对于soc内部的RTC,只需要读取寄存器即可,对于外部模块的RTC,一般需要使用到I2C接口进行读取…...

番外篇 | YOLOv5+DeepSort实现行人目标跟踪检测
前言:Hello大家好,我是小哥谈。DeepSort是一种用于目标跟踪的深度学习算法。它结合了目标检测和目标跟踪的技术,能够在视频中准确地跟踪多个目标,并为每个目标分配一个唯一的ID。DeepSort的核心思想是将目标检测和目标跟踪两个任务进行联合训练,以提高跟踪的准确性和稳定性…...

认识Sass
sass中文文档: Sass: Sass 文档 1. sass的安装步骤 1. 卸载冲突的Node.js (1) winR输入control,找到电脑上的卸载软件,找到Node.js,右键”卸载” (2) winR输入cmd,输入命令:node -v查看结果。 如果提示: node 不…...

前端三大核心技术语言
前端开发涉及的编程语言主要可分为核心标记/样式语言、核心脚本语言及其增强/替代方案,以及辅助/全栈语言。其核心生态、优势及典型应用场景对比如下: 语言类别具体语言核心定位与优势典型应用场景核心标记/样式语言HTML (HTML5)网页内容与结构的骨架&a…...
)
别再手动拖Actor了!用UE4官方Python插件解放你的双手(附7种运行脚本方法)
用UE4 Python插件打造高效自动化工作流:7种脚本运行方式全解析 在虚幻引擎4的日常开发中,你是否经历过这样的场景:需要批量放置数百个环境装饰Actor,或者重命名一整套材质资源?传统的手动操作不仅耗时耗力,…...

告别环境报错:用Docker一键部署Pypbc + Python 3.10开发环境
告别环境报错:用Docker一键部署Pypbc Python 3.10开发环境 密码学开发者在搭建Pypbc环境时,最头疼的莫过于处理GMP、PBC等底层库的版本冲突问题。你是否经历过在Ubuntu 20.04上编译成功的代码,换到CentOS就报错?或是团队协作时&a…...
)
告别ArcGIS手动操作:用Python脚本批量处理MCD12Q2植被物候数据(附完整代码)
用Python全自动处理MODIS物候数据:从HDF到生长季分析的完整解决方案 在植被物候研究中,MCD12Q2数据集因其高时间分辨率和全球覆盖能力成为不可替代的数据源。但面对动辄数十GB的HDF文件,传统ArcGIS点选操作不仅效率低下,更难以应对…...

【MicroPython ESP32】ST7735 TFT中文显示实战:从固件烧录到多行文本渲染
1. 准备工作:硬件与固件选择 玩转MicroPython和ESP32的硬件组合,最让人头疼的往往不是代码本身,而是前期准备工作。我刚开始接触ST7735屏幕时,光是选对固件就折腾了好几天。这里分享几个关键点,帮你少走弯路。 首先说说…...

从相位缠绕到高程图:InSAR干涉测量核心原理全解析
1. InSAR技术初探:从雷达回波到三维地表 第一次接触InSAR技术时,我被它神奇的能力震撼到了——居然能用卫星拍的照片算出地面的高度变化!这就像用普通相机拍两张照片,就能测量出建筑物的精确高度一样不可思议。InSAR全称是干涉合…...

我的模型总在测试集上翻车?可能是数据增强的‘姿势’不对!避坑指南与场景化策略
模型泛化困境突围:数据增强的精准应用与场景化避坑指南 当你的模型在训练集上表现优异,却在测试集上频频"翻车"时,问题可能出在数据增强这一关键环节。数据增强本应是提升模型泛化能力的利器,但不当使用反而会成为引入噪…...

Python的__getattribute__中间件
Python的__getattribute__中间件:深入探索属性访问的魔法 在Python中,对象的属性访问看似简单,实则隐藏着强大的控制机制。__getattribute__作为属性访问的核心钩子,允许开发者拦截所有属性调用,甚至实现动态计算、权…...
)
告别拍脑袋!用Python+MindOpt搞定营销预算分配(附实战代码)
用PythonMindOpt实现营销预算智能分配的实战指南 当市场团队拿着季度预算发愁"钱该往哪儿花"时,数据科学的价值就体现在把决策从"凭感觉"升级为"看数据"。去年双十一前,我们团队接手了一个典型case:某母婴品牌…...

离散选择模型中的‘极值’秘密:为什么Gumbel分布是Logit模型的基石?
离散选择模型中的‘极值’秘密:为什么Gumbel分布是Logit模型的基石? 在交通规划中选择公交还是地铁?在市场营销中预测消费者会购买A品牌还是B品牌?这些看似简单的二选一问题背后,都隐藏着一个强大的统计学工具——离散…...