onnx 1.16 doc学习笔记七:python API一览
onnx作为一个通用格式,很少有中文教程,因此开一篇文章对onnx 1.16文档进行翻译与进一步解释,
onnx 1.16官方文档:https://onnx.ai/onnx/intro/index.html](https://onnx.ai/onnx/intro/index.html),
如果觉得有收获,麻烦点赞收藏关注,目前仅在CSDN发布,本博客会分为多个章节,目前尚在连载中,详见专栏链接:
https://blog.csdn.net/qq_33345365/category_12581965.html
开始编辑时间:2024/2/27;最后编辑时间:2024/2/27。
这是本教程的第七篇,其余内容见上述专栏链接。
ONNX with Python
本教程的第一篇:介绍了ONNX的基本概念。
在本教程的第二篇,介绍了ONNX关于Python的API,具体涉及一个简单的线性回归例子和序列化。
本教程的第三篇,包括python API的三个部分:初始化器Initializer;属性Attributes;算子集和元数据Opset和Metadata
本教程的第四篇,包括子图的两个内容,使用If和Scan算子实现子图的选择和循环。
本教程的第五篇,包括函数,模型解析域形状推理。
本教程的第六篇:包括求值:即实现模型的计算与其他的一些实现细节。
在本教程,会简单的一览ONNX现有的API。
Python API一览
完整的的API描述见API Reference,后续的教程可能会进一步的进行介绍。
01 加载ONNX模型
import onnxonnx_model = onnx.load("path/to/the/model.onnx")
02 带有外部数据时加载ONNX模型
如果外部数据在模型的相同目录,则简单的使用onnx.load即可.
import onnxonnx_model = onnx.load("path/to/the/model.onnx")
如果外部数据在其他目录,使用load_external_data_for_model()来指定目录路径,并在onnx.load之后加载。
import onnx
from onnx.external_data_helper import load_external_data_for_modelonnx_model = onnx.load("path/to/the/model.onnx", load_external_data=False)
load_external_data_for_model(onnx_model, "data/directory/path/")
03 将ONNX模型转换为外部数据
from onnx.external_data_helper import convert_model_to_external_data# onnx_model是一个内存中的ModelProto
onnx_model = ...
convert_model_to_external_data(onnx_model, all_tensors_to_one_file=True, location="filename", size_threshold=1024, convert_attribute=False)
# 然后onnx_model已经将原始数据转换为外部数据;# 必须在后面保存模型
04 存储ONNX模型
import onnx# onnx_model是一个内存中的ModelProto
onnx_model = ...# 保存ONNX模型
onnx.save(onnx_model, "path/to/the/model.onnx")
05 转换并保存ONNX模型到一个外部数据
import onnx# onnx_model是一个内存中的ModelProto
onnx_model = ...
onnx.save_model(onnx_model, "path/to/save/the/model.onnx", save_as_external_data=True, all_tensors_to_one_file=True, location="filename", size_threshold=1024, convert_attribute=False)
# 然后onnx_model将原始数据转换为外部数据并保存到特定目录
06 操作TensorProto和Numpy数组
import numpy
import onnx
from onnx import numpy_helper# 预处理: 创建一个Numpy数组
numpy_array = numpy.array([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]], dtype=float)
print(f"Original Numpy array:\n{numpy_array}\n")# 将Numpy数组转换成一个TensorProto
tensor = numpy_helper.from_array(numpy_array)
print(f"TensorProto:\n{tensor}")# 转换TensorProto成一个Numpy数组
new_array = numpy_helper.to_array(tensor)
print(f"After round trip, Numpy array:\n{new_array}\n")# 保存TensorProto
with open("tensor.pb", "wb") as f:f.write(tensor.SerializeToString())# 加载TensorProto
new_tensor = onnx.TensorProto()
with open("tensor.pb", "rb") as f:new_tensor.ParseFromString(f.read())
print(f"After saving and loading, new TensorProto:\n{new_tensor}")from onnx import TensorProto, helper# ONNX IR上映射属性的实用格式转换技巧;以下函数在ONNX 1.13之后可用
np_dtype = helper.tensor_dtype_to_np_dtype(TensorProto.FLOAT)
print(f"The converted numpy dtype for {helper.tensor_dtype_to_string(TensorProto.FLOAT)} is {np_dtype}.")
storage_dtype = helper.tensor_dtype_to_storage_tensor_dtype(TensorProto.FLOAT)
print(f"The storage dtype for {helper.tensor_dtype_to_string(TensorProto.FLOAT)} is {helper.tensor_dtype_to_string(storage_dtype)}.")
field_name = helper.tensor_dtype_to_field(TensorProto.FLOAT)
print(f"The field name for {helper.tensor_dtype_to_string(TensorProto.FLOAT)} is {field_name}.")
tensor_dtype = helper.np_dtype_to_tensor_dtype(np_dtype)
print(f"The tensor data type for numpy dtype: {np_dtype} is {helper.tensor_dtype_to_string(tensor_dtype)}.")for tensor_dtype in helper.get_all_tensor_dtypes():print(helper.tensor_dtype_to_string(tensor_dtype))
输出:
Original Numpy array:
[[1. 2. 3.][4. 5. 6.]]TensorProto:
dims: 2
dims: 3
data_type: 11
raw_data: "\000\000\000\000\000\000\360?\000\000\000\000\000\000\000@\000\000\000\000\000\000\010@\000\000\000\000\000\000\020@\000\000\000\000\000\000\024@\000\000\000\000\000\000\030@"After round trip, Numpy array:
[[1. 2. 3.][4. 5. 6.]]After saving and loading, new TensorProto:
dims: 2
dims: 3
data_type: 11
raw_data: "\000\000\000\000\000\000\360?\000\000\000\000\000\000\000@\000\000\000\000\000\000\010@\000\000\000\000\000\000\020@\000\000\000\000\000\000\024@\000\000\000\000\000\000\030@"The converted numpy dtype for TensorProto.FLOAT is float32.
The storage dtype for TensorProto.FLOAT is TensorProto.FLOAT.
The field name for TensorProto.FLOAT is float_data.
The tensor data type for numpy dtype: float32 is TensorProto.FLOAT.
TensorProto.FLOAT
TensorProto.UINT8
TensorProto.INT8
TensorProto.UINT16
TensorProto.INT16
TensorProto.INT32
TensorProto.INT64
TensorProto.BOOL
TensorProto.FLOAT16
TensorProto.BFLOAT16
TensorProto.DOUBLE
TensorProto.COMPLEX64
TensorProto.COMPLEX128
TensorProto.UINT32
TensorProto.UINT64
TensorProto.STRING
TensorProto.FLOAT8E4M3FN
TensorProto.FLOAT8E4M3FNUZ
TensorProto.FLOAT8E5M2
TensorProto.FLOAT8E5M2FNUZ
07 使用Helper函数创建ONNX模型
import onnx
from onnx import helper
from onnx import AttributeProto, TensorProto, GraphProto# 创建输入(ValueInfoProto)
X = helper.make_tensor_value_info("X", TensorProto.FLOAT, [3, 2])
pads = helper.make_tensor_value_info("pads", TensorProto.FLOAT, [1, 4])
value = helper.make_tensor_value_info("value", AttributeProto.FLOAT, [1])# 创建输出(ValueInfoProto)
Y = helper.make_tensor_value_info("Y", TensorProto.FLOAT, [3, 4])# 创建节点(NodeProto)
node_def = helper.make_node("Pad", # name["X", "pads", "value"], # inputs["Y"], # outputsmode="constant", # attributes
)# 创建图(GraphProto)
graph_def = helper.make_graph([node_def], # nodes"test-model", # name[X, pads, value], # inputs[Y], # outputs
)# 创建模型(ModelProto)
model_def = helper.make_model(graph_def, producer_name="onnx-example")# 检查模型
onnx.checker.check_model(model_def)
print("The model is checked!")
08 ONNX IR上映射属性的转换实用技术
from onnx import TensorProto, helpernp_dtype = helper.tensor_dtype_to_np_dtype(TensorProto.FLOAT)
print(f"The converted numpy dtype for {helper.tensor_dtype_to_string(TensorProto.FLOAT)} is {np_dtype}.")field_name = helper.tensor_dtype_to_field(TensorProto.FLOAT)
print(f"The field name for {helper.tensor_dtype_to_string(TensorProto.FLOAT)} is {field_name}.")
# 在helper中还有其它转换函数
输出是:
The converted numpy dtype for TensorProto.FLOAT is float32.
The field name for TensorProto.FLOAT is float_data.
09 检查ONNX模型
Onnx提供了一个函数来检查模型是否有效。当它检测到不一致时,它会检查输入类型或形状。
import onnx# 预处理: 加载ONNX模型
model_path = "path/to/the/model.onnx"
onnx_model = onnx.load(model_path)print(f"The model is:\n{onnx_model}")# 检查模型
try:onnx.checker.check_model(onnx_model)
except onnx.checker.ValidationError as e:print(f"The model is invalid: {e}")
else:print("The model is valid!")
10 检查大于2GB的ONNX模型
当前检查器支持使用外部数据检查模型,但对于那些大于2GB的模型,请使用onnx的模型路径,而不是内存中的模型。Checker和外部数据需要在同一个目录下。
import onnxonnx.checker.check_model("path/to/the/model.onnx")
# onnx.checker.check_model(loaded_onnx_model)在模型大于2GB时会出错
11 在一个ONNX模型上执行形状推理
import onnx
from onnx import helper, shape_inference
from onnx import TensorProto# 预处理: 创建一个有两个节点的模型, Y的形状未知
node1 = helper.make_node("Transpose", ["X"], ["Y"], perm=[1, 0, 2])
node2 = helper.make_node("Transpose", ["Y"], ["Z"], perm=[1, 0, 2])graph = helper.make_graph([node1, node2],"two-transposes",[helper.make_tensor_value_info("X", TensorProto.FLOAT, (2, 3, 4))],[helper.make_tensor_value_info("Z", TensorProto.FLOAT, (2, 3, 4))],
)original_model = helper.make_model(graph, producer_name="onnx-examples")# 检查模型并打印出Y的形状信息
onnx.checker.check_model(original_model)
print(f"Before shape inference, the shape info of Y is:\n{original_model.graph.value_info}")# 在模型上应用形状推理
inferred_model = shape_inference.infer_shapes(original_model)# 检查模型并打印出Y的形状信息
onnx.checker.check_model(inferred_model)
print(f"After shape inference, the shape info of Y is:\n{inferred_model.graph.value_info}")
输出是:
Before shape inference, the shape info of Y is:
[]
After shape inference, the shape info of Y is:
[name: "Y"
type {tensor_type {elem_type: 1shape {dim {dim_value: 3}dim {dim_value: 2}dim {dim_value: 4}}}
}
]
12 对一个大于2GB模型进行形状推理
当前的shape_inference支持具有外部数据的模型,但对于那些大于2GB的模型,请使用onnx.shape_inference的模型路径。Infer_shapes_path和外部数据需要位于同一目录下。你可以指定保存推断出的模型的输出路径;否则,默认输出路径与原始模型路径相同。
import onnx# 将推断出的模型输出到原始模型路径
onnx.shape_inference.infer_shapes_path("path/to/the/model.onnx")# 将推断出的模型输出到指定的模型路径
onnx.shape_inference.infer_shapes_path("path/to/the/model.onnx", "output/inferred/model.onnx")# inferred_model = onnx.shape_inference.infer_shapes(loaded_onnx_model) # 在模型大于2GB会报错
13 在ONNX函数上执行类型推断
import onnx
import onnx.helper
import onnx.parser
import onnx.shape_inferencefunction_text = """<opset_import: [ "" : 18 ], domain: "local">CastTo <dtype> (x) => (y) {y = Cast <to : int = @dtype> (x)}
"""
function = onnx.parser.parse_function(function_text)# 上面的函数有一个输入参数x和一个属性参数dtype。
# 要对该函数应用“类型与形状推断”,必须提供输入参数的类型和属性参数的属性值,如下所示:
float_type_ = onnx.helper.make_tensor_type_proto(1, None)
dtype_6 = onnx.helper.make_attribute("dtype", 6)
result = onnx.shape_inference.infer_function_output_types(function, [float_type_], [dtype_6]
)
print(result) # a list containing the (single) output type
输出:
[tensor_type {elem_type: 6
}
]
14 转换默认域("“或"ai.onnx”)上ONNX模型的opset版本
import onnx
from onnx import version_converter, helper# 预处理: 加载待转换的模型
model_path = "path/to/the/model.onnx"
original_model = onnx.load(model_path)print(f"The model before conversion:\n{original_model}")# 进行版本转换
converted_model = version_converter.convert_version(original_model, <int target_version>)print(f"The model after conversion:\n{converted_model}")
15 实用函数:使用输入张量名称和输出张量名称提取子模型
函数extract_model()可以从一个ONNX模型中提取子模型,可以使用输入张量名称和输出张量名称提取子模型。
import onnxinput_path = "path/to/the/original/model.onnx"
output_path = "path/to/save/the/extracted/model.onnx" # 提取模型保存到的路径
input_names = ["input_0", "input_1", "input_2"]
output_names = ["output_0", "output_1"]onnx.utils.extract_model(input_path, output_path, input_names, output_names)
注意:对于控制流操作,例如 If 和 Loop,子模型的边界,即由输入和输出张量定义的边界,不应穿过作为这些操作符属性连接到主图的子图。
16 实用函数:onnx.compose
onnx.compose 模块提供工具来创建结合的模型。
onnx.compose.merge_models可以用于合并两个模型,方法是将第一个模型的某些输出连接到第二个模型的输入。默认情况下,io_map参数中不存在的输入/输出将保留为合并模型的输入/输出。
在这个例子中,我们通过将第一个模型的每个输出连接到第二个模型中的一个输入来合并两个模型。得到的模型将具有与第一个模型相同的输入和与第二个模型相同的输出。
import onnxmodel1 = onnx.load("path/to/model1.onnx")
# agraph (float[N] A, float[N] B) => (float[N] C, float[N] D)
# {
# C = Add(A, B)
# D = Sub(A, B)
# }model2 = onnx.load("path/to/model2.onnx")
# agraph (float[N] X, float[N] Y) => (float[N] Z)
# {
# Z = Mul(X, Y)
# }combined_model = onnx.compose.merge_models(model1, model2,io_map=[("C", "X"), ("D", "Y")] # c->x; d ->y
)
此外,用户可以指定一个输入/输出列表,以包含在组合模型中,有效地舍弃了对组合模型输出没有贡献的图的部分。在下面的示例中,我们只将第一个模型中的两个输出中的一个连接到第二个模型中的两个输入。通过显式指定组合模型的输出,我们从第一个模型中丢弃了未使用的输出,以及图的相关部分。
import onnx# 默认例子. 在结合后的模型上包括所有输出
combined_model = onnx.compose.merge_models(model1, model2,io_map=[("C", "X"), ("C", "Y")],
) # outputs: "D", "Z"# 显式输出. “Y”输出和子节点在组合模型中不存在
combined_model = onnx.compose.merge_models(model1, model2,io_map=[("C", "X"), ("C", "Y")],outputs=["Z"],
) # outputs: "Z"
onnx.compose.add_prefix允许您向模型中的名称添加前缀,以避免在合并它们时发生名称冲突。默认情况下,它会重命名图中的所有名称:输入、输出、边、节点、初始化器、稀疏初始化器和值信息。
import onnxmodel = onnx.load("path/to/the/model.onnx")
# model - outputs: ["out0", "out1"], inputs: ["in0", "in1"]new_model = onnx.compose.add_prefix(model, prefix="m1/")
# new_model - outputs: ["m1/out0", "m1/out1"], inputs: ["m1/in0", "m1/in1"]# 也可以就地运行
onnx.compose.add_prefix(model, prefix="m1/", inplace=True)
onnx.compose.expand_out_dim 可以用来连接那些期望不同维度数量的模型,通过插入范围为一的维度。当结合一个产生样本的模型与一个处理样本批次的模型时,这会很有用。
import onnx# outputs: "out0", shape=[200, 200, 3]
model1 = onnx.load("path/to/the/model1.onnx")# outputs: "in0", shape=[N, 200, 200, 3]
model2 = onnx.load("path/to/the/model2.onnx")# outputs: "out0", shape=[1, 200, 200, 3]
new_model1 = onnx.compose.expand_out_dims(model1, dim_idx=0)# 模型现在可以合并了
combined_model = onnx.compose.merge_models(new_model1, model2, io_map=[("out0", "in0")]
)# 也可以就地执行
onnx.compose.expand_out_dims(model1, dim_idx=0, inplace=True)
17 更行模型的输入/输出维度大小
函数 update_inputs_outputs_dims 更新模型的输入和输出的维度,将其更新为参数中提供的值。可以通过使用 dim_param 提供静态和动态维度大小。在更新输入/输出大小之后,该函数运行模型检查器。
import onnx
from onnx.tools import update_model_dimsmodel = onnx.load("path/to/the/model.onnx")
# Here both "seq", "batch" and -1 are dynamic using dim_param.
variable_length_model = update_model_dims.update_inputs_outputs_dims(model, {"input_name": ["seq", "batch", 3, -1]}, {"output_name": ["seq", "batch", 1, -1]})
18 ONNX解析器
函数 onnx.parser.parse_model 和 onnx.parser.parse_graph 可以用来从文本表示中创建一个 ONNX 模型或图,如下所示。有关语言语法的更多详细信息,请参阅Language Syntax。
input = """agraph (float[N, 128] X, float[128, 10] W, float[10] B) => (float[N, 10] C){T = MatMul(X, W)S = Add(T, B)C = Softmax(S)}
"""
graph = onnx.parser.parse_graph(input)input = """<ir_version: 7,opset_import: ["" : 10]>agraph (float[N, 128] X, float[128, 10] W, float[10] B) => (float[N, 10] C){T = MatMul(X, W)S = Add(T, B)C = Softmax(S)}
"""
model = onnx.parser.parse_model(input)
19 ONNX Inliner
函数 onnx.inliner.inline_local_functions 和 inline_selected_functions 可用于在 ONNX 模型中内联模型本地函数。特别地,inline_local_functions 可用于生成一个无函数的模型(适用于不处理或不支持函数的后端)。另一方面,inline_selected_functions 可用于内联选定的函数。目前尚不支持内联 ONNX 标准操作中的函数(也称为模式定义(schema-defined)的函数)。
import onnx
import onnx.inlinermodel = onnx.load("path/to/the/model.onnx")
inlined = onnx.inliner.inline_local_functions(model)
onnx.save("path/to/the/inlinedmodel.onnx")
相关文章:

onnx 1.16 doc学习笔记七:python API一览
onnx作为一个通用格式,很少有中文教程,因此开一篇文章对onnx 1.16文档进行翻译与进一步解释, onnx 1.16官方文档:https://onnx.ai/onnx/intro/index.html](https://onnx.ai/onnx/intro/index.html), 如果觉得有收获&am…...
LACP——链路聚合控制协议
LACP——链路聚合控制协议 什么是LACP? LACP(Link Aggregation Control Protocol,链路聚合控制协议)是一种基于IEEE802.3ad标准的实现链路动态聚合与解聚合的协议,它是链路聚合中常用的一种协议。 链路聚合组中启用了…...

终端启动jupyter notebook更换端口
一、问题描述 如果尝试在端口 8889 上启动 Jupyter Notebook 但最终启动在了 8890 端口,这通常意味着 8889 端口已经被占用。要解决这个问题,可以尝试以下几种方法来关闭占用 8889 端口的进程。 1. 查找并终止占用端口的进程 首先,需要找出…...

IT发布管理,轻松部署软件
我们带来了一项令人振奋的好消息,可有效缓解构建的质量相对劣质和发布的速度相对缓慢。 ManageEngine卓豪推出了ServiceDesk Plus MSP中的IT发布管理,配备了可视化的工作流程,这是PSA-ITSM解决方案的一部分。有了这个新功能,您可以…...

2024国际生物发酵展览会独家解读-力诺天晟科技
参展企业介绍 北京力诺天晟科技有限公司,专业致力于智能仪器仪表制造,工业自动控制系统用传感器、变送器的研发、设计、销售和服务。 公司坐落于首都北京行政副中心-通州区,下设生产子公司位于河北香河经济开发区,厂房面积 300…...

YOLOv9尝鲜测试五分钟极简配置
pip安装python包: pip install yolov9pip在https://github.com/WongKinYiu/yolov9/tree/main中下载好权重文件yolov9-c.pt。 运行下面代码: import yolov9model yolov9.load("yolov9-c.pt", device"cpu") # load pretrained or c…...
消息中间件篇之Kafka-消息不丢失
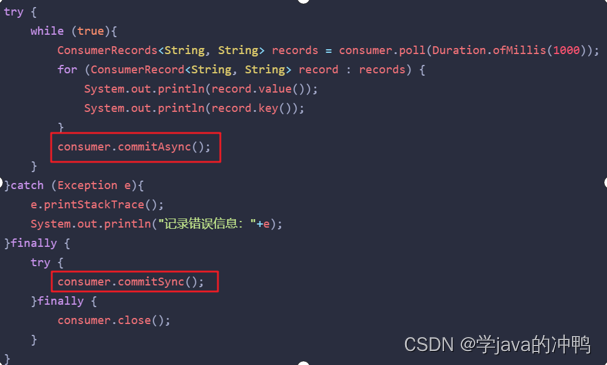
一、 正常工作流程 生产者发送消息到kafka集群,然后由集群发送到消费者。 但是可能中途会出现消息的丢失。下面是解决方案。 二、 生产者发送消息到Brocker丢失 1. 设置异步发送 //同步发送RecordMetadata recordMetadata kafkaProducer.send(record).get();//异…...

Rust使用calamine读取excel文件,Rust使用rust_xlsxwriter写入excel文件
Rust使用calamine读取已存在的test.xlsx文件全部数据,还读取指定单元格数据;Rust使用rust_xlsxwriter创建新的output.xlsx文件,并写入数据到指定单元格,然后再保存工作簿。 Cargo.toml main.rs /*rust读取excel文件*/ use cala…...
)
中文文本分类(pytorch 实现)
import torch import torch.nn as nn import torchvision from torchvision import transforms, datasets import os, PIL, pathlib, warningswarnings.filterwarnings("ignore") # 忽略警告信息# win10系统 device torch.device("cuda" if torch.cuda.i…...

【每日前端面经】2023-02-27
题目来源: 牛客 CSS盒模型 CSS中的盒子包括margin|border|padding|content四个部分,对于标准盒子模型(content-box)的widthcontent,但是对于IE盒子模型(border-box)的widthcontentborder2padding2 CSS选…...

springboot + easyRules 搭建规则引擎服务
依赖 <dependency><groupId>org.jeasy</groupId><artifactId>easy-rules-core</artifactId><version>4.0.0</version></dependency><dependency><groupId>org.jeasy</groupId><artifactId>easy-rules…...

Mac电脑配置环境变量
1.打开配置文件bash_profile open -e .bash_profile 2.如果没有创建过.bash_profile,则先需要创建 touch .bash_profile 3.输入你要配置的环境变量 #Setting PATH for Android ADB Tools export ANDROID_HOME/Users/xxx/android export PATH${PATH}:${ANDROID_HOME}…...
Windows系统x86机器安装(麒麟、统信)ARM系统详细教程
本次介绍在window系统x86机器上安装国产系统 arm 系统的详细教程。 注:ubuntu 的arm系统安装是一样的流程。 1.安装环境准备。 首先,你得有台电脑,配置别太差,至少4核8G内存,安装window10或者11都行(为啥…...

消息中间件篇之RabbitMQ-高可用机制
一、怎么保证高可用性 在生产环境下,使用集群来保证高可用性,一般我们采用普通集群、镜像集群、仲裁队列。 二、普通集群 普通集群,或者叫标准集群(classic cluster),具备下列特征: 1. 会在集…...
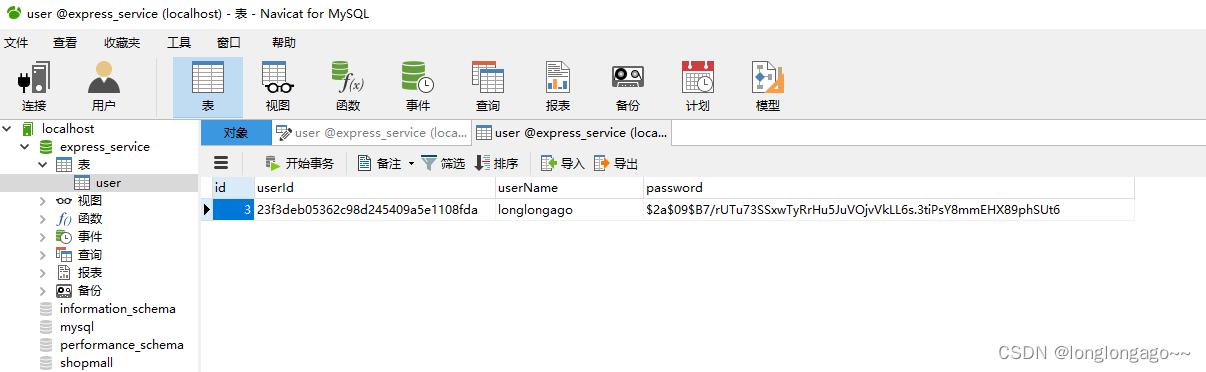
express+mysql+vue,从零搭建一个商城管理系统5--用户注册
提示:学习express,搭建管理系统 文章目录 前言一、新建user表二、安装bcryptjs、MD5、body-parser三、修改config/db.js四、新建config/bcrypt.js五、新建models文件夹和models/user.js五、index.js引入使用body-parser六、修改routes/user.js七、启动项…...

canvas水波纹效果,jquery鼠标水波纹插件
canvas水波纹效果,jquery鼠标水波纹插件 效果展示 jQuery水波纹效果,canvas水波纹插件 HTML代码片段 <div class"scroll04wrap"><h3>发展历程</h3><div class"scroll04"><p>不要回头,一…...

Zookeeper客户端命令、JAVA API、监听原理、写数据原理以及案例
1. Zookeeper节点信息 指定服务端,启动客户端命令: bin/zkCli.sh -server 服务端主机名:端口号 1)ls / 查看根节点下面的子节点 ls -s / 查看根节点下面的子节点以及根节点详细信息 其中,cZxid是创建节点的事务id,…...
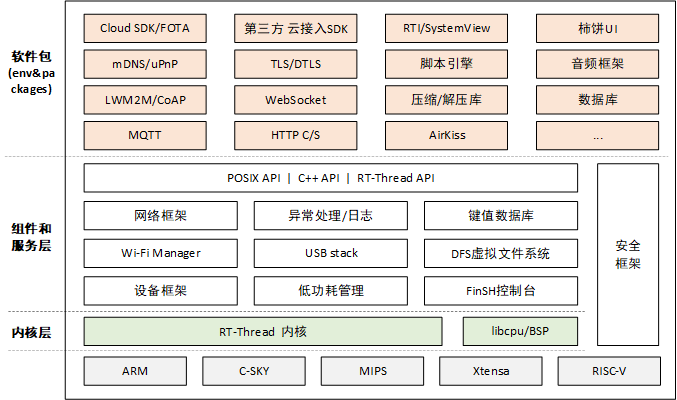
[嵌入式系统-34]:RT-Thread -19- 新手指南:RT-Thread标准版系统架构
目录 一、RT-Thread 简介 二、RT-Thread 概述 三、许可协议 四、RT-Thread 的架构 4.1 内核层: 4.2 组件与服务层: 4.3 RT-Thread 软件包: 一、RT-Thread 简介 作为一名 RTOS 的初学者,也许你对 RT-Thread 还比较陌生。然…...
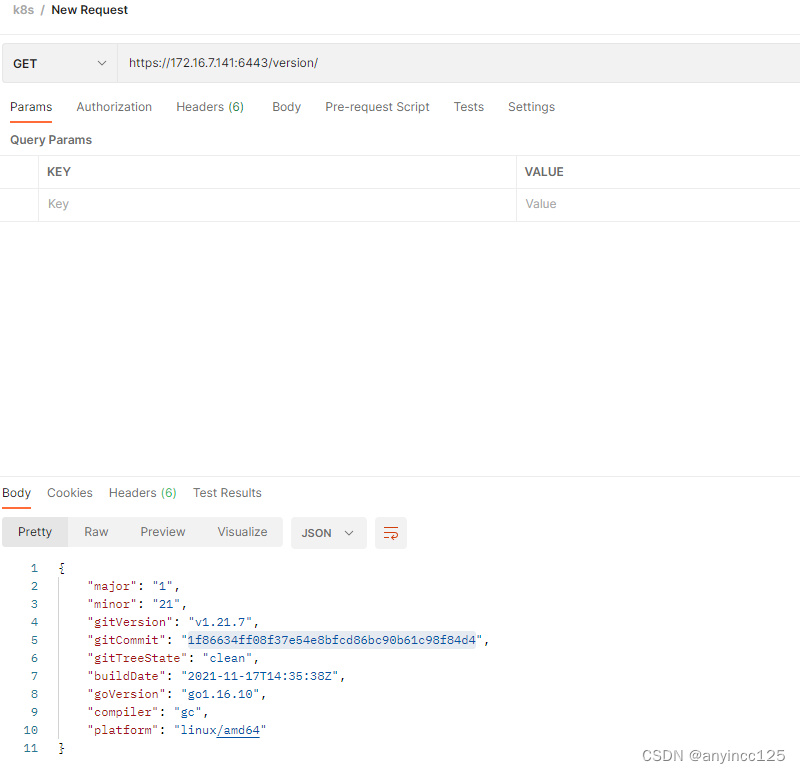
postman访问k8s api
第一种方式: kubectl -n kubesphere-system get sa kubesphere -oyaml apiVersion: v1 kind: ServiceAccount metadata:annotations:meta.helm.sh/release-name: ks-coremeta.helm.sh/release-namespace: kubesphere-systemcreationTimestamp: "2023-07-24T07…...
UE4c++ ConvertActorsToStaticMesh
UE4c ConvertActorsToStaticMesh ConvertActorsToStaticMesh UE4c ConvertActorsToStaticMesh创建Edior模块(最好是放Editor模块毕竟是编辑器代码)创建UBlueprintFunctionLibraryUTestFunctionLibrary.hUTestFunctionLibrary.cpp:.Build.cs 目标:为了大量…...

Java Loom响应式改造必踩的5个安全雷区:从Project Loom Beta到生产级落地的零信任实践
第一章:Java Loom响应式改造必踩的5个安全雷区:从Project Loom Beta到生产级落地的零信任实践线程局部变量(ThreadLocal)在虚拟线程中的隐式泄漏 Project Loom 的虚拟线程复用机制会导致 ThreadLocal 实例跨请求残留。若未显式清理…...

酒店信息数据集,数据量1.1万条,包含多个字段,可以用于酒店评分/价格/销量预测大数据分析毕设
酒店信息数据集,数据量1.1万条,包含多个字段,可以用于酒店评分/价格/销量预测大数据分析毕设,具体字段如下:酒店ID 酒店名称 图片URL 推荐理由 星级代码 星级描述 评分 评分描述 评论标签 评论数量 历史消费人数 原价 …...

为什么92%的Java团队卡在Loom响应式配置最后一公里?这份内部调试日志级配置清单请收好
第一章:Java 项目 Loom 响应式编程转型指南 配置步骤详解Java 项目向 Project Loom(虚拟线程)与响应式编程(如 Reactor WebFlux)协同演进,需兼顾线程模型迁移、依赖兼容性及运行时调优。本章聚焦可落地的配…...

2026年怎么搭建OpenClaw?京东云1分钟萌新教程含大模型API与Skill配置
2026年怎么搭建OpenClaw?京东云1分钟萌新教程含大模型API与Skill配置。OpenClaw(前身为Clawdbot/Moltbot)作为开源、本地优先的AI助理框架,凭借724小时在线响应、多任务自动化执行、跨平台协同等核心能力,成为个人办公…...

从《加密与解密》到实战:用OllyDbg永久Patch掉TraceMe.exe的校验逻辑
逆向工程实战:用OllyDbg永久修改TraceMe.exe的校验逻辑 在软件安全领域,逆向工程就像一把双刃剑——它既能帮助开发者发现潜在漏洞,也能被用来分析软件保护机制。今天我们要探讨的是一个经典案例:如何通过OllyDbg动态调试工具&…...

实战踩坑:在华为ENSP上配置OSPF NSSA区域时,为什么外部路由没传出去?
华为ENSP实战:OSPF NSSA区域外部路由失效的深度排查指南 当你在华为eNSP模拟器中配置OSPF NSSA区域时,是否遇到过这样的困惑:明明按照文档配置了所有参数,外部路由却像被黑洞吞噬一样无法传递?这不是个例——根据企业网…...

Claude+Obsidian 5小时速成新领域
别只抄工具!Claude+Obsidian 5小时速成新领域 目录 别只抄工具!Claude+Obsidian 5小时速成新领域 一、一步步复现:原作者的5小时知识框架搭建法 步骤1:理解核心问题 步骤2:列出已知条件 步骤3:逐步推理(以"本体论"为例) 步骤4:原方法的核心结论 二、深度反…...

Nginx upstream反向代理400错误排查:从Host头到协议版本的深度解析
1. 400错误背后的真相:从表象到本质 当你看到Nginx返回400 Bad Request错误时,第一反应可能是"请求有问题"。但作为运维老司机,我遇到这种问题时通常会先问三个问题:请求真的有问题吗?问题出在哪个环节&…...

Bebas Neue:为什么这款开源免费商用字体是现代设计的完美解决方案?
Bebas Neue:为什么这款开源免费商用字体是现代设计的完美解决方案? 【免费下载链接】Bebas-Neue Bebas Neue font 项目地址: https://gitcode.com/gh_mirrors/be/Bebas-Neue 你是否曾经在设计项目中选择字体时陷入两难境地?商业字体价…...

终极鼠标增强方案:Mac Mouse Fix让你的普通鼠标在macOS上超越苹果触控板
终极鼠标增强方案:Mac Mouse Fix让你的普通鼠标在macOS上超越苹果触控板 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 还在为macO…...