Kafka入门介绍一
介绍
Kafka是一个分布式系统,由服务器和客户端组成,通过高性能TCP网络协议进行通信。它可以部署在本地和云中的裸机硬件、虚拟机和容器上环境。
服务器:Kafka作为一个或多个服务器的群集运行,这些服务器可以跨越多个数据中心或云区域。其中一些服务器构成了存储层,称为代理。其他服务器运行KafkaConnect以持续导入和导出数据作为事件流,用于将Kafka与现有系统(如关系数据库)集成,以及其他Kafka集群。为了让您实现任务关键型用例,Kafka集群具有高度可扩展性容错:如果其任何服务器发生故障,其他服务器将接管其工作以确保连续操作,不会丢失任何数据。
客户端:它们允许您编写可读、写、并并行、大规模和容错的方式处理事件流,即使在网络的情况下也是如此问题或机器故障。Kafka附带了一些这样的客户端,Kafka提供了数十个客户端社区:客户端可用于Java和Scala,包括更高级别的KafkaStreams库、Go、Python、C/C++和许多其他编程语言以及RESTAPI。
主要概念
生产者和消费者
生产者
Kafka生产者发送数据时会直接与分区领导者(leader) broker进行交互。
Kafka生产者在发送数据到Kafka集群时,会利用Kafka的分区机制来组织消息。以下是详细过程:
-
元数据请求:Kafka生产者在初始化或定期检查更新时会从Kafka集群中的任意节点获取元数据信息,包括哪些服务器是活动的以及每个主题分区的领导者在哪里。
-
序列化与分区选择:在发送消息之前,生产者会将消息键和值序列化成字节数组。然后,生产者根据ProducerRecord对象指定的信息来决定消息应该发送到哪个分区。如果指定了分区,则消息会被发送到该分区;如果没有指定分区但提供了键,则会使用键的哈希值与分区数取余的方式来确定分区;如果只存在值而没有键和分区指定,Kafka内部会采用Sticky partition策略随机选择一个分区。
-
发送消息:Kafka生产者将创建的ProducerRecord对象包装好的消息发送给对应的分区领导者broker。这个过程是异步的,由一个独立线程负责管理批次并将它们发送到相应的broker上。
-
领导者负责:由于Kafka采用领导者复制机制,生产者只需将数据发送至分区的领导者副本,领导者副本负责处理消息的存储和复制到跟随者副本(follower)。
消费者
Kafka消费者的工作方式是通过向Kafka broker发送“fetch”请求来拉取(pull)数据,不是推送(push)模式。以下是Kafka消费者的工作机制和特点:
-
拉取数据:消费者主动从broker拉取数据,即采用pull模式。这种方式允许消费者以自己的速度处理数据,避免了因为broker推送消息过快而导致消费者处理不过来的问题。
-
指定偏移量:在拉取数据时,消费者可以在请求中指定从哪个偏移量开始消费日志。这给了消费者很大的灵活性,它可以选择从当前偏移量开始消费,也可以选择从之前的某个偏移量开始重新消费数据。
-
分区分配策略:Kafka中的数据被分成多个分区,消费者可以消费多个分区的数据,但每个分区的数据只能被消费者组中的一个消费者消费。Kafka提供了不同的分区分配策略,如Range分配策略、RoundRobin分配策略和Sticky分配策略等。
-
消费者组:当一个主题的数据量很大时,可以通过消费者组来实现横向扩展。消费者组中的每个消费者可以消费不同分区的数据,从而实现负载均衡。在同一个消费者组中,每个分区只能被一个消费者消费,以避免重复处理数据。
-
位移提交和存储:消费者在消费数据时会维护一个偏移量(offset),表示它在分区中消费到了哪个位置。这个偏移量需要定期提交给Kafka,以便在服务重启或故障恢复时能够从准确的位置继续消费。
-
再均衡机制:当消费者组中的消费者数量发生变化时,Kafka会自动进行分区的重新分配,这个过程称为再均衡(rebalance)。再均衡确保了每个分区都有消费者负责,且每个消费者都能公平地分担负载。
-
拦截器和反序列化:Kafka消费者提供了拦截器(Interceptor)机制,允许开发者在数据处理过程中插入自定义逻辑。此外,消费者还需要对从Kafka接收到的消息进行反序列化,将其转换为应用程序可以理解的数据格式。
-
消费进度监控:为了确保数据处理的稳定性和可靠性,监控系统通常会跟踪消费者的消费进度,包括当前的偏移量、消费速率等信息。
主题(Topic)与分区(Partition)
,Kafka 通过主题(Topic)来组织消息,每个主题可以看作是一个独立的消息队列。为了提高系统的可伸缩性和性能,Kafka 采用了分区(Partition)机制。
在 Kafka 中,每个主题被分割成多个分区。
这些分区有以下特点和优势:
-
并行处理:分区允许 Kafka 主题并行地处理数据。不同的分区可以在不同的服务器(Broker)上进行处理,这意味着一个主题可以扩展到多个服务器以容纳更多的数据或处理更高的吞吐量。
-
分区复制:为了保证高可用性,每个分区可以有多个副本。在这些副本中,会选出一个作为领导者(Leader),而其他的则是跟随者(Follower)。领导者负责处理所有的读写请求,跟随者则同步领导者的数据。如果领导者发生故障,跟随者中的一个会被提升为新的领导者。
-
负载均衡:分区还允许 Kafka 进行负载均衡。生产者可以将消息均匀地发送到不同的分区,消费者组内的每个消费者可以消费不同分区的数据,从而实现负载的分散。
-
有序性保证:虽然分区允许并行处理,但在单个分区内,消息是按照它们进入的顺序存储的。这意味着对于单个消费者来说,即使在并行消费的情况下,从单个分区中读取的消息也是有序的。
-
灵活的消费者偏移量管理:消费者组中的每个消费者维护着自己的偏移量(Offset),这个偏移量标记了它已经消费到了分区中的哪个位置。这使得消费者可以在服务重启或故障恢复时从准确的位置继续消费,而不是从头开始。
-
扩展性:随着系统需求的增长,可以通过增加服务器数量和合理配置分区数量来水平扩展 Kafka 集群。
Broker 和集群(Cluster)
一个 Kafka Broker 能够处理成千上万的分区和百万量级的消息。
Kafka 的设计允许单个 Broker 具有高效的数据处理能力,这得益于以下几个方面:
-
顺序磁盘I/O:Kafka 在写消息数据时,会为每个分区创建一个文件,并将数据顺序地追加到该文件对应的磁盘空间中。这种顺序写入的方式充分利用了磁盘的顺序访问性能,相比随机访问要高效得多。
-
分区和并行处理:Kafka 通过将主题分为多个分区,并在不同的 Broker 上分布这些分区,实现了应用级别的水平扩展。这样,不同的分区可以并行地在不同的 Broker 上进行处理,从而提高了整体的处理能力。
-
高效的网络通信模型:Kafka 设计了一个高效的网络通信模型来处理它与生产者(Producer)和消费者(Consumer)之间的消息传递问题。这个模型对于保持高性能至关重要。
-
监控和度量指标:为了确保 Broker 的性能和稳定性,Kafka 提供了一系列的服务端度量指标,用于监控 Broker 的状态。这些指标包括 Kafka 本身的指标和主机层面的指标,有助于及时发现并解决可能出现的问题。
-
集群的扩缩容能力:Kafka 集群可以通过增删 Broker 来简单地实现整个集群的扩缩容,这使得根据实际需求调整系统性能成为可能。
动手搭建kafka
1.下载压缩包
下载并解压,下载地址
$ tar -xzf kafka_2.13-3.6.1.tgz
$ cd kafka_2.13-3.6.1
2.启动kafka
注意:您的本地环境必须安装 Java 8+。
Apache Kafka 可以使用 ZooKeeper 或 KRaft 启动。要开始使用任一配置,请遵循以下部分之一,但不能同时执行两者。
使用 ZooKeeper 的 Kafka
1. 配置 zookeeper地址
修改config/server.properties文件,修改如下配置:
zookeeper.connect=127.0.0.1:2181
2.添加对外暴漏ip
修改config/server.properties文件,添加以下配置:
# 允许外部端口连接
listeners=PLAINTEXT://0.0.0.0:9092
# 外部代理地址
advertised.listeners=PLAINTEXT://[本机ip]:9092
运行以下命令启动kafka
$ bin/kafka-server-start.sh config/server.properties
使用 KRaft 的 Kafka
生成集群 UUID
$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
设置日志目录的格式
$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
启动 Kafka 服务器
$ bin/kafka-server-start.sh config/kraft/server.properties
相关文章:

Kafka入门介绍一
介绍 Kafka是一个分布式系统,由服务器和客户端组成,通过高性能TCP网络协议进行通信。它可以部署在本地和云中的裸机硬件、虚拟机和容器上环境。 服务器:Kafka作为一个或多个服务器的群集运行,这些服务器可以跨越多个数据中心或云…...
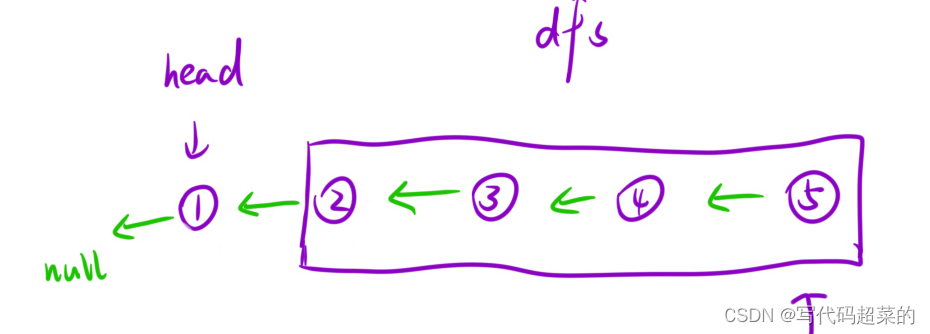
leetcode 3.反转链表;
1.题目: 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 2.用例: 3.题目解析: (1)函数头: 要求返回结点,就 ListNode* reverseList(ListNode* head)&…...

【蓝桥杯】快读|min和max值的设置|小明和完美序列|顺子日期|星期计算|山
目录 一、输入的三种方式 1.最常见的Scanner的输入方法 2.数据多的时候常用BufferedReader快读 3.较麻烦的StreamTokenizer快读(用的不多) StreamTokenizer常见错误: 二、min和max值的设置 三、妮妮的翻转游戏 四、小明和完美序列 五…...
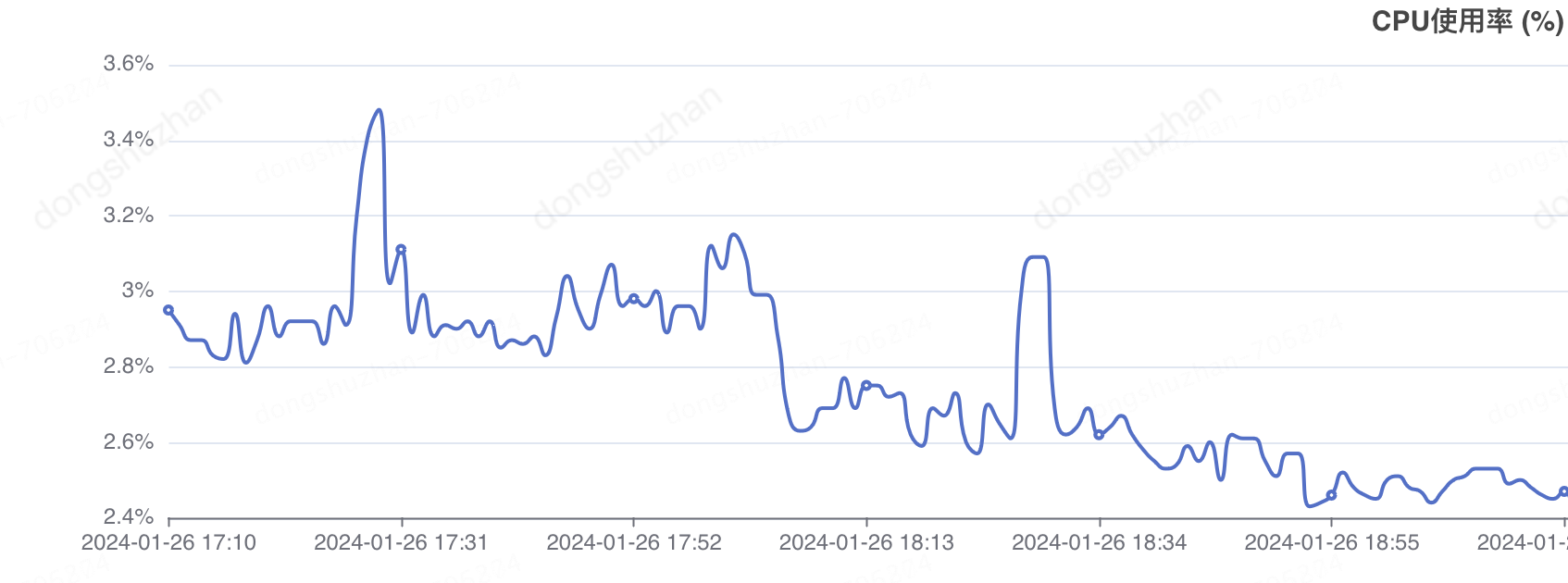
半小时到秒级,京东零售定时任务优化怎么做的?
导言: 京东零售技术团队通过真实线上案例总结了针对海量数据批处理任务的一些通用优化方法,除了供大家借鉴参考之外,也更希望通过这篇文章呼吁大家在平时开发程序时能够更加注意程序的性能和所消耗的资源,避免在流量突增时给系统…...

stm32——hal库学习笔记(ADC)
这里写目录标题 一、ADC简介(了解)1.1,什么是ADC?1.2,常见的ADC类型1.3,并联比较型工作示意图1.4,逐次逼近型工作示意图1.5,ADC的特性参数1.6,STM32各系列ADC的主要特性 …...
一周学会Django5 Python Web开发-Http请求HttpRequest请求类
锋哥原创的Python Web开发 Django5视频教程: 2024版 Django5 Python web开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili2024版 Django5 Python web开发 视频教程(无废话版) 玩命更新中~共计25条视频,包括:2024版 Django5 Python we…...

element el-date-picker 日期组件置灰指定日期范围、禁止日期范围日期选择
JS如何将当前日期或指定日期转时间戳_javascript技巧_脚本之家 小于指定日期前的日期置灰 比如这里 指定日期是 2024-02-20 10:48:15 disabledDate(time) time是一个函数提供的时间用于比较 他是一个时间戳↓ 理解为我们想要置灰的时间 time.getTime() < timeStamps- 1 *…...

202434读书笔记|《繁星·春水》——残花缀在繁枝上,鸟儿飞去了,撒得落红满地,生命也是这般的一瞥么?
202434读书笔记|《繁星春水》——残花缀在繁枝上,鸟儿飞去了,撒得落红满地,生命也是这般的一瞥么? 繁星春水 《繁星春水》冰心著,共300多首小诗,并不是惊艳,就那么平凡而朴实的看完了。 繁星 黑…...

Golang 关于 interface 接口的理解
package mainimport "fmt"// 定义一个存储器接口:支持mysql存储、redis存储 type StorageManager interface {insert(data string) int // 增加update(id int, data string) int // 更新 }// 实现一个Mysql存储器 type Mysql struct{}func (mysql…...
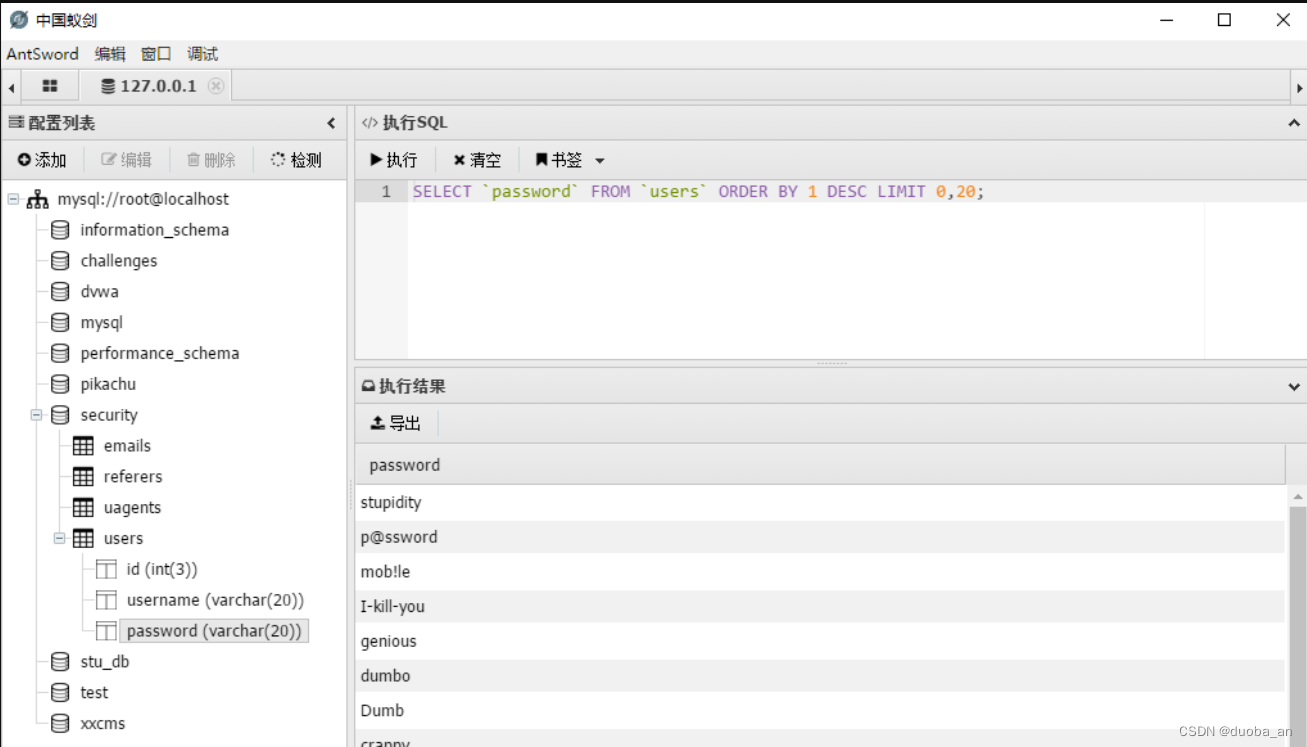
SQL注入漏洞解析--less-7
我们先看一下第七关 页面显示use outfile意思是利用文件上传来做 outfile是将检索到的数据,保存到服务器的文件内: 格式:select * into outfile "文件地址" 示例: mysql> select * into outfile f:/mysql/test/one f…...
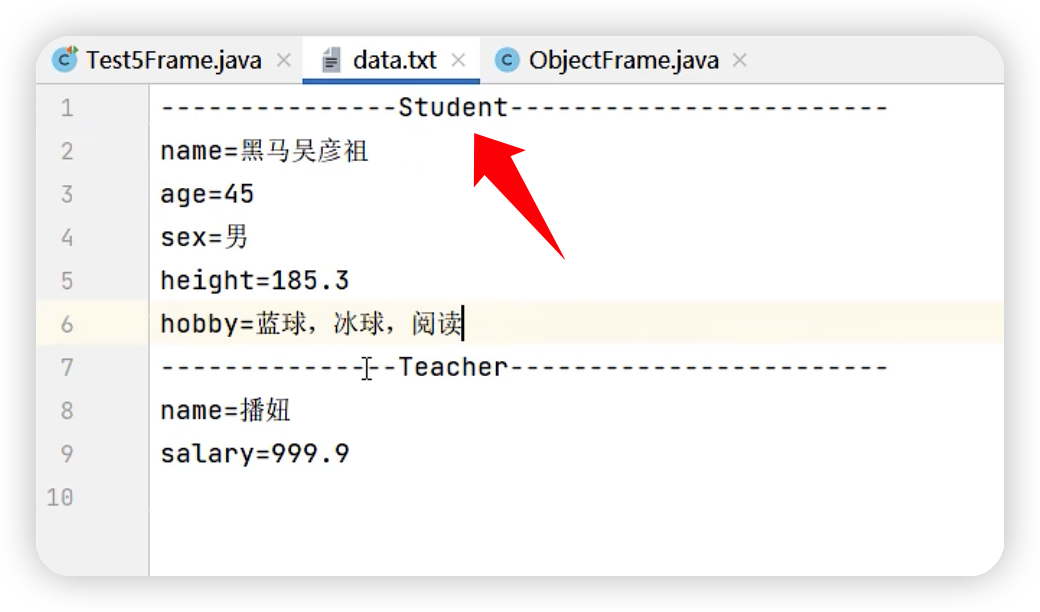
java高级——反射
目录 反射概述反射的使用获取class对象的三种方式反射获取类的构造器1. 获取类中所有的构造器2. 获取单个构造器 反射获取构造器的作用反射获取成员变量反射变量赋值、取值获取类的成员方法反射对象类方法执行 反射简易框架案例案例需求实现步骤代码如下 反射概述 什么是反射 反…...

云计算新宠:探索Apache Doris的云原生策略
文章目录 Apache Doris 特性极简架构高效自运维高并发场景支持MPP 执行引擎明细与聚合模型的统一便捷数据接入 Apache Doris 极速 1.0 时代极速列式内存布局向量化的计算框架Cache 亲和度虚函数调用SIMD 指令集 稳定多源 关于 Apache Doris 开源社区基于云原生向量数据库Milvus…...

【PHP设计模式08】装饰模式
【装饰模式】 装饰模式,又称装饰器模式 或 装饰者模式 或 油漆工模式,通过创建一个“装饰对象”,在不改变原有类和使用继承的情况下,动态地扩展一个对象的功能,比直接生成子类继承更加灵活,可以通过多个不同的具体装饰类,创建多个不同的行为组合。 结构: 抽象构件…...
寒假作业Day 01
这个项目主要是为了复习博主之前关于C语言和数据结构的寒假作业,大家也可以根据这些题目自己进行填写并检查自己的知识点是否过关 博主也会有错误,所以如果大家看到错误,也希望大家能够进行指正,谢谢大家! Day 01 一…...
)
学习JAVA的第四天(基础)
目录 方法 方法的定义 方法的调用 参数 注意事项 方法的重载 练习 面向对象 类和对象 定义类的注意事项 封装 private关键字 this关键字 构造方法 标准的Javabean类 创建一个对象时,虚拟机做了什么? 方法 方法含义:方法是程序…...

拉美巴西阿根廷媒体宣发稿墨西哥哥伦比亚新闻营销如何助推跨境出海推广?
【本篇由言同数字科技有限公司原创】拉美地区是一个巨大的市场,其中包括了许多国家,如巴西、阿根廷、智利、哥伦比亚等。这些国家的消费者对品牌的认知度和忠诚度不同,而且市场环境也存在着很大的差异。因此,品牌需要通过跨境海外…...
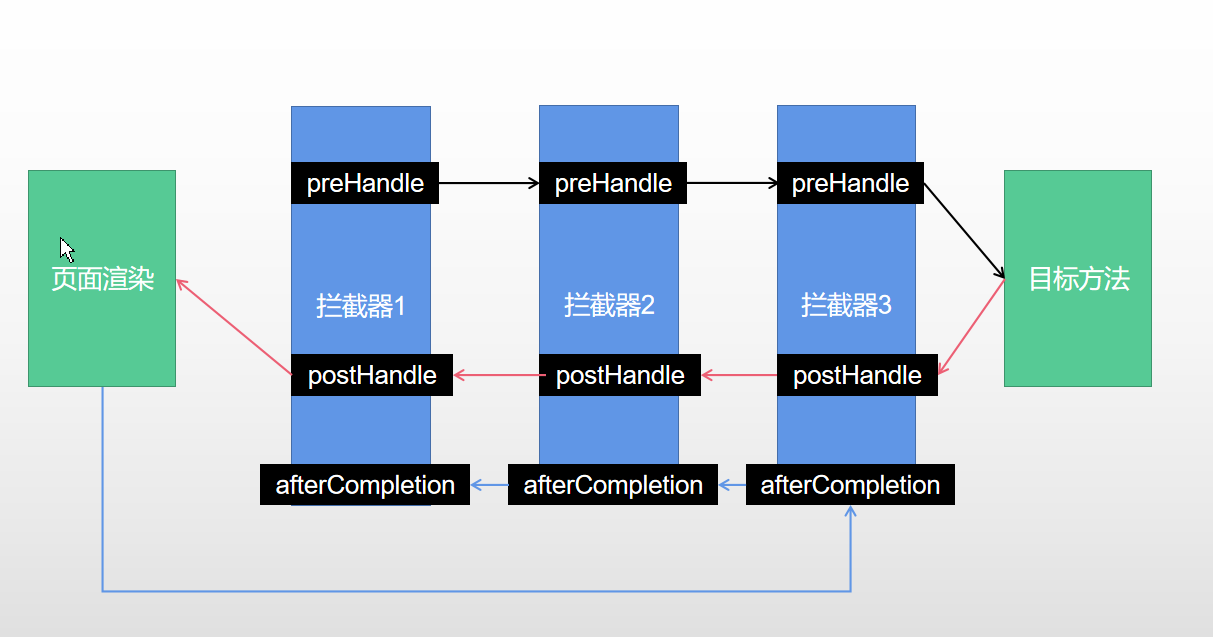
SpringMVC 学习(九)之拦截器
目录 1 拦截器介绍 2 创建一个拦截器类 3 配置拦截器 1 拦截器介绍 在 SpringMVC 中,拦截器 (Interceptor) 是一种用于拦截 HTTP 请求并在请求处理之前或之后执行自定义逻辑的组件。拦截器可以用于实现以下功能: 权限验证:在请求处理之前…...
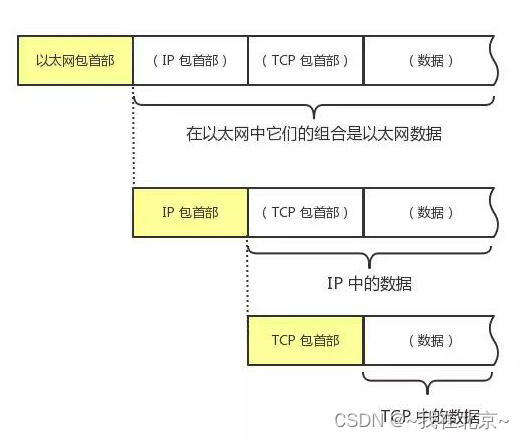
TCP/IP-常用网络协议自定义结构体
1、TCP/IP模型: 2、TCP/IP- 各层级网络协议(从下往上): 1)数据链路层: ARP: 地址解析协议,用IP地址获取MAC地址的协议,通过ip的地址获取mac地 …...

内部控制提纲
当然,以下是一个更详细的关于内部控制的论文提纲: 一、引言 1.1 内部控制的定义与重要性 解释内部控制的基本概念和它在企业管理中的作用阐述内部控制对企业风险管理和运营效率的影响 1.2 内部控制的目标与原则 列出内部控制的主要目标,…...
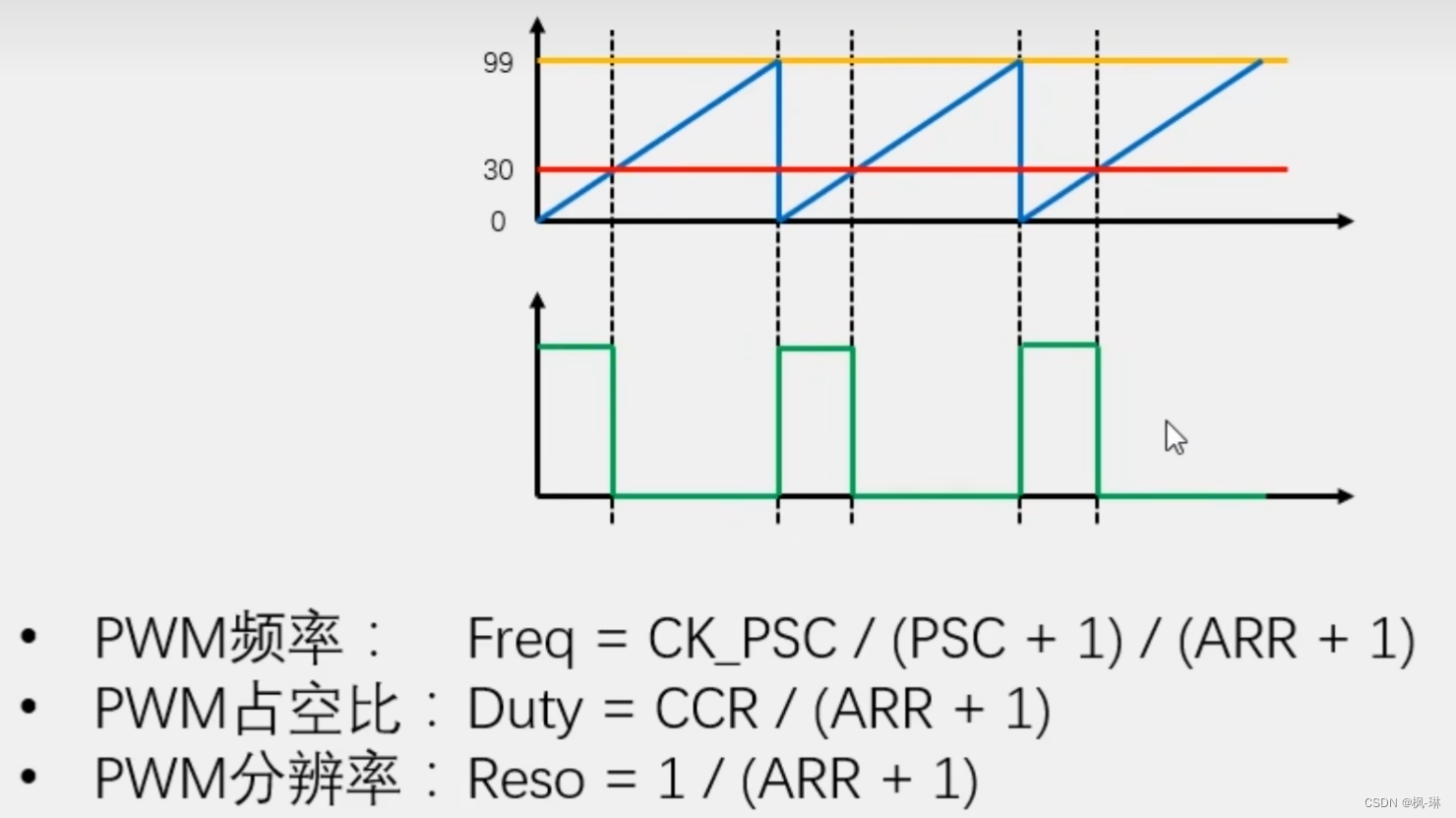
江科大stm32 定时器 TIM输出比较--学习笔记
这几天遇到输出比较相关的问题,于是来学习下TIM输出比较部分知识点! 输出比较简介 CNT是计数器的值,CCR寄存器是捕获/ 比较寄存器 简单的讲,输出比较就是用来输出PWM波形。 PWM简介 占空比:高电平占一个周期的比例。…...

AUTOSAR E2E P01配置避坑指南:Counter、DataID模式与CRC算法那些容易搞错的细节
AUTOSAR E2E P01配置实战精要:从CRC算法到状态机调优的工程化解决方案 在汽车电子系统开发中,AUTOSAR E2E保护机制如同通信系统的"免疫系统",默默守护着关键安全数据的传输完整性。作为功能安全工程师,我们常常在项目SO…...

安知鱼主题音乐播放器集成教程:打造个性化音乐空间
安知鱼主题音乐播放器集成教程:打造个性化音乐空间 【免费下载链接】hexo-theme-anzhiyu 安知鱼主题,这是一个简洁美丽的hexo主题。 项目地址: https://gitcode.com/gh_mirrors/he/hexo-theme-anzhiyu 安知鱼主题是一款简洁美丽的Hexo主题&#x…...

【2026奇点大会权威解码】:AGI临界突破的5大技术信号与虚拟世界融合时间表
第一章:2026奇点智能技术大会:AGI与虚拟世界 2026奇点智能技术大会(https://ml-summit.org) AGI驱动的虚拟世界范式跃迁 本届大会首次展示可交互、自演化的通用人工智能体(AGI Agent)在大规模虚拟世界中的实时协同能力。这些智能…...

苍穹外卖|DAY6-Redis和店铺营业状态设置模块
目录 九、Redis 1. Redis入门 1.1 Redis下载与安装 1.2 Redis服务启动与停止 1.3 Redis图形化工具 2. Redis数据类型 3. Redis常用命令 3.1 字符串操作命令 3.2 哈希操作命令 3.3 列表操作命令 3.4 集合操作命令 3.5 有序集合操作命令 3.6 通用命令 4. 在Java中操…...

用Verilog在FPGA上实现一个多功能数字钟:从模块划分到上板调试的完整流程
基于FPGA的多功能数字钟工程实践:从模块化设计到硬件调试全解析 在嵌入式系统开发领域,FPGA因其并行处理能力和硬件可重构特性,成为数字系统设计的理想平台。本文将深入探讨如何利用Verilog HDL在FPGA上实现一个具备计时、闹钟、日期显示和秒…...
)
告别MyBatis的‘?‘占位符:用p6spy 3.9.1在Spring Boot里打印可直接执行的SQL(附自定义日志格式)
告别MyBatis的?占位符:用p6spy 3.9.1在Spring Boot里打印可直接执行的SQL(附自定义日志格式) 调试SQL语句是Java开发中的日常操作,但MyBatis和JPA等ORM框架输出的预编译SQL总带着恼人的?占位符。每次排查问题时,开发…...

突破限制,自由掌控:WindowResizer让每个窗口都按你的想法调整
突破限制,自由掌控:WindowResizer让每个窗口都按你的想法调整 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 你是否遇到过这样的情况:某些应用…...
)
基于双积分滑模控制的双有源桥DAB单移相DC-DC变换器仿真研究(Simulink仿真实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

UEFI Setup界面开发避坑指南:grayoutif、suppressif条件控制与varstore变量存储的实战解析
UEFI Setup界面开发避坑指南:条件控制与变量存储的实战解析 在UEFI固件开发中,Setup界面作为用户与系统交互的重要桥梁,其开发质量直接影响用户体验和系统稳定性。本文将深入探讨如何避免UEFI Setup界面开发中的常见陷阱,特别是条…...

Day03:ReAct架构概述:从_军师_到_将军_的进化
文章目录一、ReAct架构概述:从"军师"到"将军"的进化一、ReAct 架构概述:从 "军师" 到 "将军" 的进化二、ReAct 的工作模式:让 AI 像人类一样思考和行动2.1 核心循环机制:Thought-Action-…...