BeautifulSoup+xpath+re+css简单复习+新的scrapy的学习
1.BeautifulSoup soup = BeautifulSoup(html,'html.parser')all_ico=soup.find(class_="DivTable")
2.xpath
trs = resp.xpath("//tbody[@id='cpdata']/tr")
hong = tr.xpath("./td[@class='chartball01' or @class='chartball20']/text()").extract()
这个意思是找到 tbody[@id='cpdata'] 这个东西 ,然后在里面找到[@class='chartball01]这个东西,然后extract()提取信息内容
3.re
img_name = re.findall('alt="(.*?)"',response)
这个意思是找到(.*?)这个里面的东西,在response,这个response是text
4.css
element3 = element2.find_element(By.CSS_SELECTOR,'a[target="_blank"]').click()
用css找到标签为a的target="_blank"这个东西,然后点击
如果是标签啥都不加,class用@,ID用#
下面是今天学习scrapy的成果:
先是复习创建一个scrapy(都是在命令里面)
1.scrapy startproject +名字(软件包的名字)
2.cd+名字-打开它
3.scrapy genspider +名字(爬虫的名字)+区域地址
4.scrapy crawl +名字(爬虫的名字)
在setting里面修改


今天不在命令里面跑了
在名字(软件包的名字)下建立一个 python文件

然后运行就OK
下面还有在管道里面的存储方法(存储为csv形式)
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass Caipiao2Pipeline:def open_spider(self,spider):#开启文件#打开self.f = open("data2.csv",mode='a',encoding="utf-8") #self====>在这个class中定义一个对象def close_spider(self,spider):#关闭文件self.f.close()def process_item(self, item, spider):print("====>",item)self.f.write(f"{item['qi']}")self.f.write(',')self.f.write(f"{item['hong']}")self.f.write(',')self.f.write(f"{item['lan']}")self.f.write("\n")# with open("data.csv",mode='a',encoding="utf-8") as f:# f.write(f"{item['qi']}")# f.write(',')# f.write(f"{item['hong']}")# f.write(',')# f.write(f"{item['lan']}")# f.write("\n")return item
第一种是传统的 with open
第二种是,开始运行,之后在管道里会运行一个方法, open_spider 在这里面打开文件
下面所有代码和成果
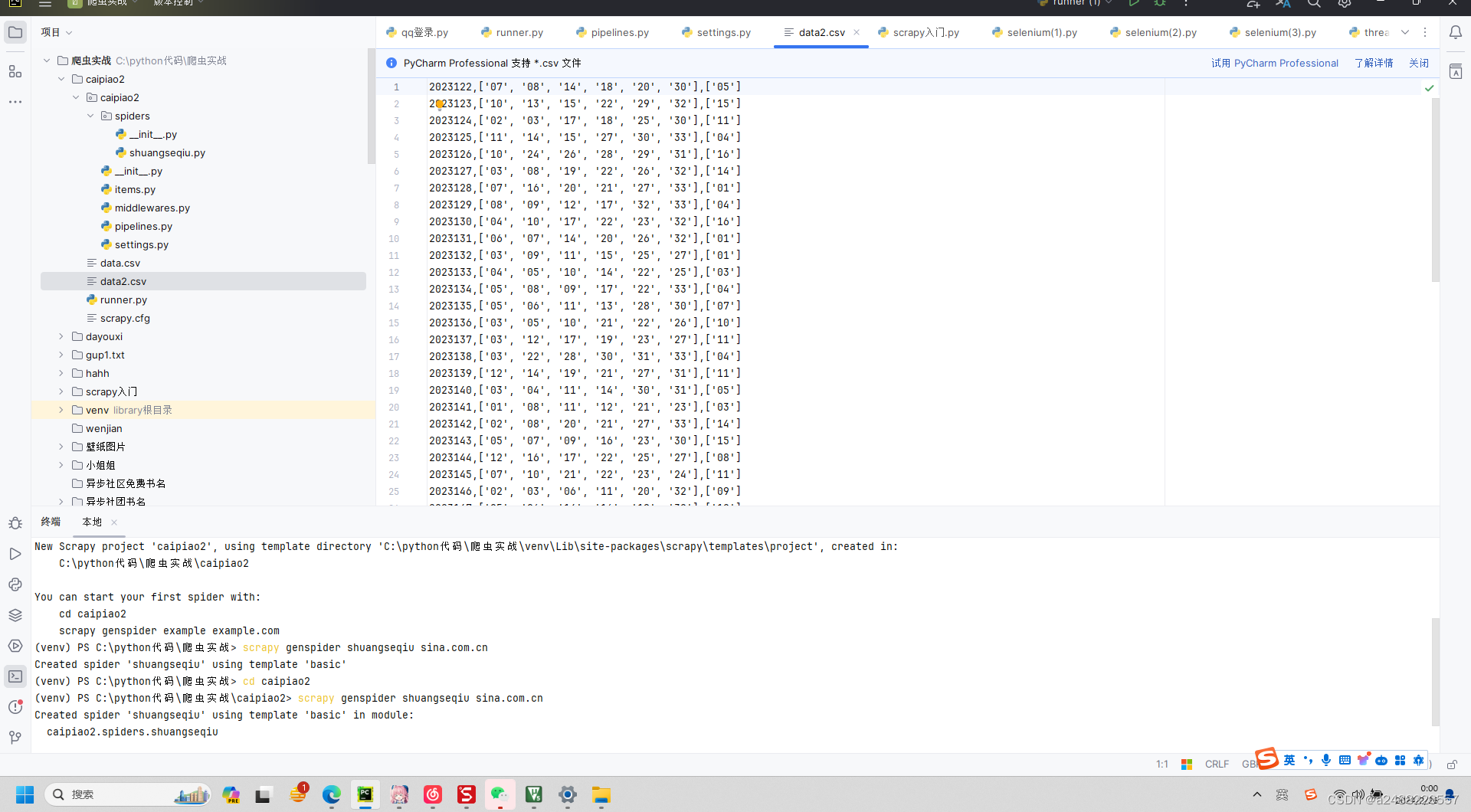
这个是爬虫函数
import scrapyclass ShuangseqiuSpider(scrapy.Spider):name = "shuangseqiu"allowed_domains = ["sina.com.cn"]start_urls = ["https://view.lottery.sina.com.cn/lotto/pc_zst/index?lottoType=ssq&actionType=chzs&type=50&dpc=1"]def parse(self, resp,**kwargs):#提取trs = resp.xpath("//tbody[@id='cpdata']/tr")for tr in trs: #每一行qi = tr.xpath("./td[1]/text()").extract_first()hong = tr.xpath("./td[@class='chartball01' or @class='chartball20']/text()").extract()lan = tr.xpath("./td[@class='chartball02']/text()").extract()#存储yield {"qi":qi,"hong":hong,"lan":lan}这个是管道函数
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass Caipiao2Pipeline:def open_spider(self,spider):#开启文件#打开self.f = open("data2.csv",mode='a',encoding="utf-8") #self====>在这个class中定义一个对象def close_spider(self,spider):#关闭文件self.f.close()def process_item(self, item, spider):print("====>",item)self.f.write(f"{item['qi']}")self.f.write(',')self.f.write(f"{item['hong']}")self.f.write(',')self.f.write(f"{item['lan']}")self.f.write("\n")# with open("data.csv",mode='a',encoding="utf-8") as f:# f.write(f"{item['qi']}")# f.write(',')# f.write(f"{item['hong']}")# f.write(',')# f.write(f"{item['lan']}")# f.write("\n")return item
这个是启动函数:
from scrapy.cmdline import executeif __name__ =="__main__":execute("scrapy crawl shuangseqiu".split())相关文章:
BeautifulSoup+xpath+re+css简单复习+新的scrapy的学习
1.BeautifulSoupsoup BeautifulSoup(html,html.parser)all_icosoup.find(class_"DivTable") 2.xpath trs resp.xpath("//tbody[idcpdata]/tr") hong tr.xpath("./td[classchartball01 or classchartball20]/text()").extract() 这个意思是找…...

Python爬虫实战:从API获取数据
引言 在现代软件开发中,API已经成为获取数据的主要方式之一。API允许不同的软件应用程序相互通信,共享数据和功能。在本文中,我们将学习如何使用Python从API获取数据,并探讨其在实际应用中的价值。 目录 引言 二、API基础知识 …...
音频转换器哪个好?3款电脑软件+3款手机应用
在当今的数字时代,音频转换已成为许多用户日常的需求。为了帮助您找到最佳的音频转换工具,我们将介绍3款电脑软件和3款手机应用。这些工具都各有特点,能够满足不同用户的需求。 1.电脑软件篇 1.1金舟音频大师 金舟音频大师是一款多功能的音…...

惯性导航 | 运动学---运动模型
惯性导航 | 运动学---运动模型 IMU系统的运动学 IMU系统的运动学 惯性测量单元(IMU)已经非常普及了。我们在绝大多数电子设备中都能找到IMU:车辆、手机、手表、头盔,甚至足球当中都内置了IMU。它们的体积很小,安装在设…...
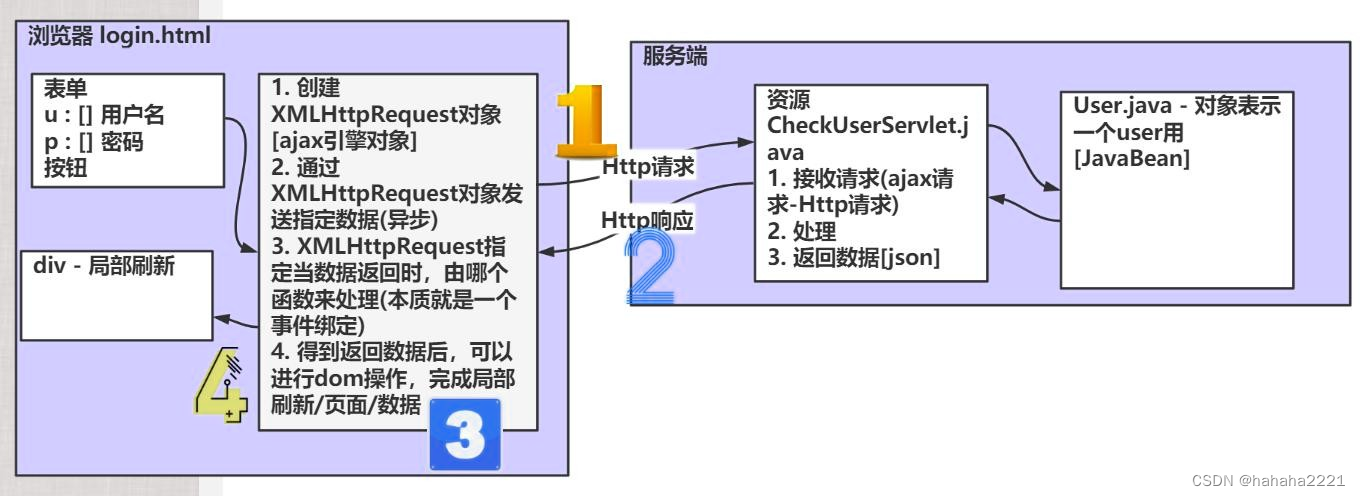
Java Web(十一)--JSON Ajax
JSON JSon在线文档: JSON 简介 JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式。轻量级指的是跟xml做比较。数据交换指的是客户端和服务器之间业务数据的传递格式。 它基于 ECMAScript (W3C制定的JS规范)的一个子集,采…...
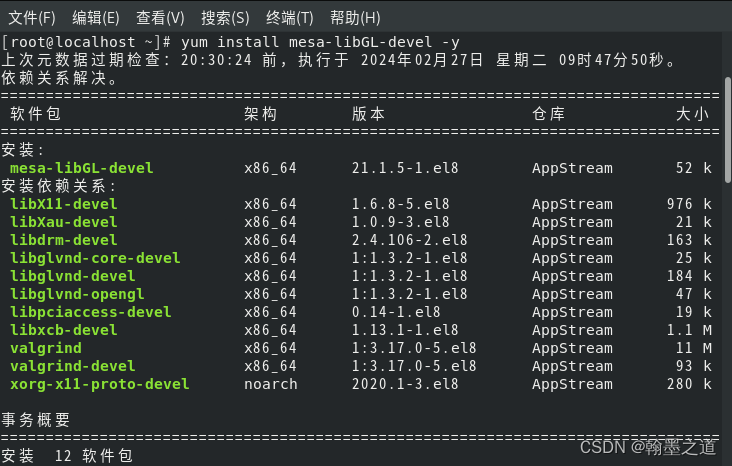
GL/gl.h: No such file or directory(CentOS8 QT5.12.12)
1.问题描述 新建的QT工程,出现如下问题: GL/gl.h: No such file or directory 2.原因分析 centos系统里面缺少opengl库 3.解决方法 运行命令: yum install mesa-libGL -devel -y...

【外设篇】-显示器
显示屏是一种电光转换工具,现在市面上的显示器都是LCD(Liquid Crystal Display,液晶显示器) 显示器参数介绍 对比度 是指画面黑与白的比值,对比度越高能使色彩表现越丰富,对比度越高,显示器的…...
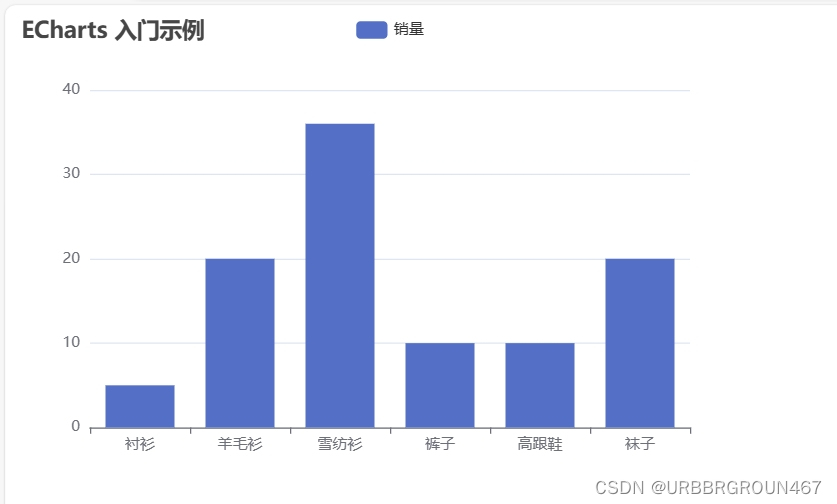
可视化图文报表
Apache Echarts介绍 Apache Echarts是一款基于Javascript的数据可视化图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表。 官网:Apache ECharts 入门案例: <!DOCTYPE html> <html>…...

CW023A-H035 CW023A-R230铜合金硬度材质书
CW023A-H035 CW023A-R230铜合金硬度材质书C2100W-O、C2680TWS-OL、C2200W-1/2H、C2800TS-O 、C2800T-H、C2800T-1/2H、C2700TS-O、C4430T-O、C2700T-O、C2700T-H、C2700T-OL、C2800TS-1/2H、C2800T-OL、C2700-O、C2800TS-H、C2700-H、C2700T-1/2H、C2600TS-1/2H、C2700-1/2H、C…...
)
Ribbon负载均衡:提升应用性能与可靠性的秘密武器(一)
本系列文章简介: 本系列文章将深入探讨Ribbon负载均衡的工作原理、应用场景和实践经验,帮助大家更好地理解和应用这一强大的技术。通过合理配置和优化Ribbon负载均衡,您可以为您的应用带来更高的性能和可靠性,从而获得竞争优势并满…...
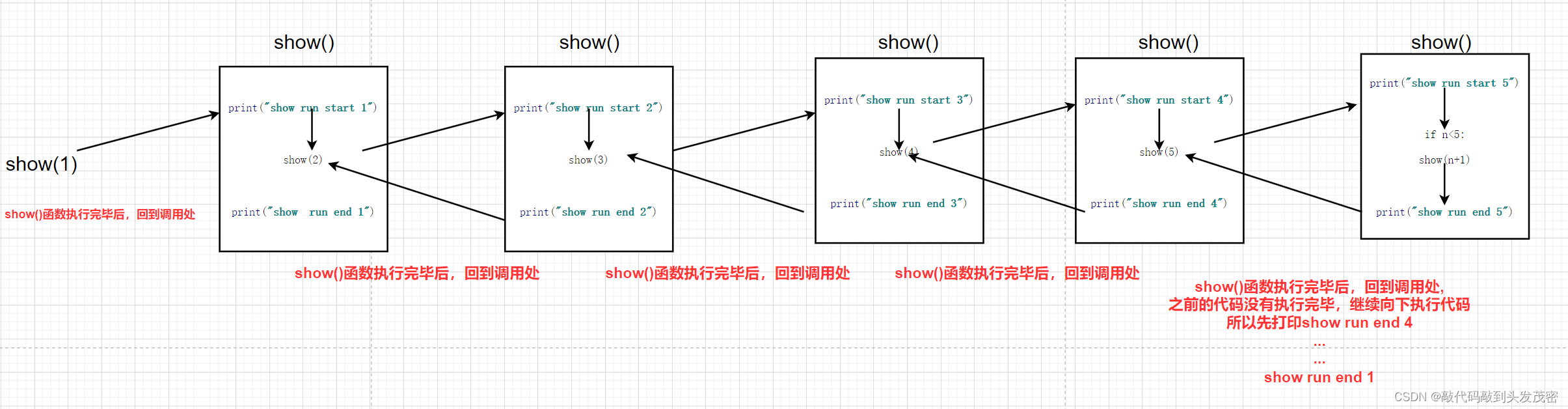
python递归算法
递归算法 一、嵌套调用的过程二、递归的基本原则1、递归的基本原则2、无限递归调用3、正常递归调用4、阶乘问题5、力扣:231. 2 的幂6、力扣面试题 08.05. 递归乘法7、力扣、326. 3 的幂8、力扣342. 4的幂 一、嵌套调用的过程 def show1():print("show 1 run s…...
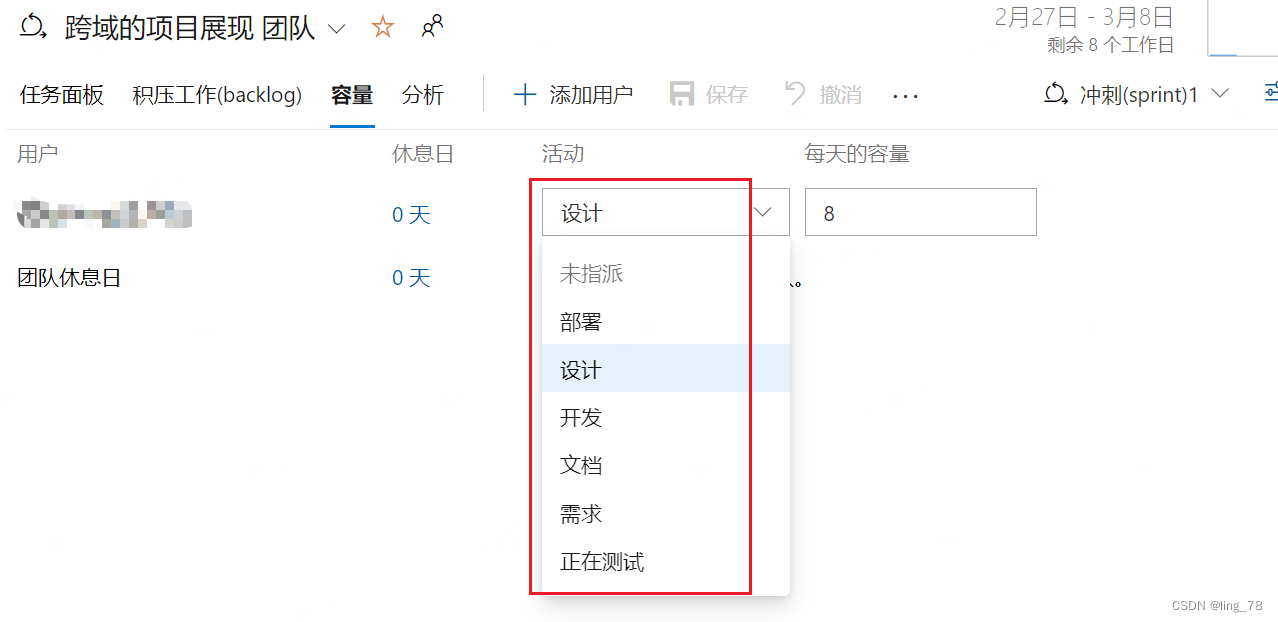
azure devops工具实践分析
对azure devops此工具的功能深挖,结合jira的使用经验的分析 1、在backlog的功能描述,可理解为需求项,这里包括了bug,从开发的角度修复bug也是个工作项,所以需求的范围是真正的需求(开发接收到的已经确认的…...
)
2024年2月19日-2月25日(全面进行+收集免费虚幻商城资源,20小时,合计2561小时,剩余7439小时)
试试周一到周五重点进行,周末抄写源码,周一晚上看书很快就在22:00睡着,早上可以看看视频教程,出租车上补觉。 执行如下: 周一: 8:01-9:20ue4 rpg(184…...

Ubuntu制作本地安装源
Ubuntu制作本地安装源 应用场景离线安装包的制作(可联网电脑)更新源安装软件 生成依赖关系在另外一台Ubuntu上离线安装安装 使用deb http方式安装安装nginx更新ubuntu数据库,并安装应用 应用场景 当我们需要在多台电脑安装同一个软件,并且软…...
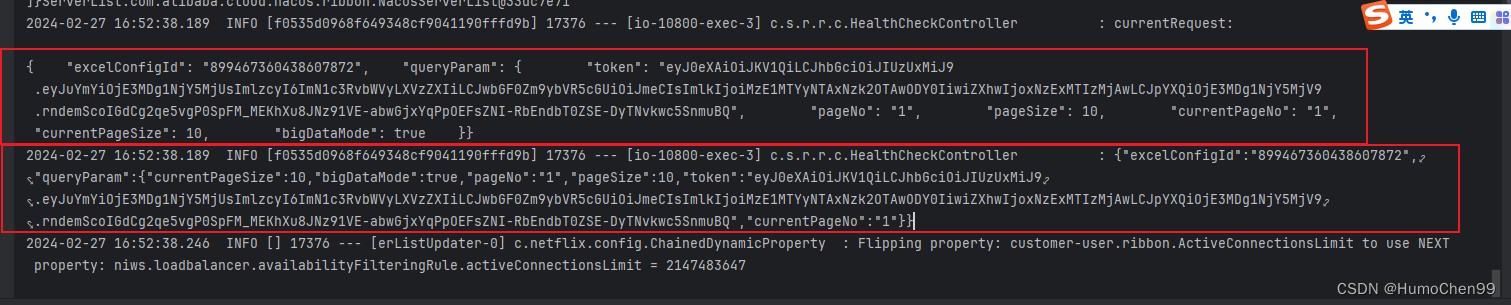
java springmvc/springboot 项目通过HttpServletRequest对象获取请求体body工具类
请求 测试接口 获取到的 获取到打印出的json字符串里有空格这些,在json解析的时候正常解析为json对象了。 工具类代码 import lombok.extern.slf4j.Slf4j; import org.springframework.web.context.request.RequestContextHolder; import org.springframework.we…...

新手怎么使用github?
GitHub新手使用指南,涵盖了从注册、创建仓库、版本控制基本操作到SSH密钥配置等关键步骤: 第一步:注册与登录 访问GitHub官方网站:https://github.com。点击页面右上角的"sign up"按钮开始注册账号。输入有效的电子邮…...

CSS_实现三角形和聊天气泡框
如何用css画出一个三角形 1、第一步 写一个正常的盒子模型,先给个正方形的div,便于观察,给div设置宽高和背景颜色 <body><div class"box"></div> </body> <style>.box {width: 100px;height: 100px…...

VPX基于全国产飞腾FT-2000+/64核+复旦微FPGA的计算刀片
6U VPX计算板 产品简介 产品特点 飞腾计算平台,国产化率100% VPX-MPU6902是一款基于飞腾FT-2000/64核的计算刀片,主频2.2GHz,负责业务数据流的管控和调度。搭配自带独立显示芯片的飞腾X100芯片,可用于于各类终端及服务器类应用场…...

ifcplusplus 示例 函数中英文 对照分析
有需求,需要分析 ifc c渲染,分析完,有 230个函数,才能完成一个加载,3d加载真的是大工程! 函数中英文对照表,方便 日后开发,整理思路顺畅!!!&#…...
)
天一个数据分析题(一百七十三)
聚类算法的主要应用场景是用户分群,聚类是一种无监督方法,以下哪个不是衡量聚类效果好坏的评估方法()。 A. 轮廓系数 B. 平方根标准误差 C. ARI(调整的兰德系数) D. 相关系数 题目来源于CDA模拟题库 点击此处获取答案...

抖音批量下载器终极指南:免费获取高清无水印视频的完整教程
抖音批量下载器终极指南:免费获取高清无水印视频的完整教程 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...

从单张RGB-D图像到3D点云:用Open3D五分钟重建你的桌面场景
从单张RGB-D图像到3D点云:用Open3D五分钟重建你的桌面场景 当iPhone的LiDAR扫描仪捕捉到桌面上咖啡杯的轮廓时,那些跳动的深度数据点背后,隐藏着一个完整的3D世界。本文将以一杯咖啡的深度图像为起点,带你体验从二维像素到三维点云…...

Windows资源管理器的视觉翻译官:让HEIC缩略图重获新生
Windows资源管理器的视觉翻译官:让HEIC缩略图重获新生 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 想象一下&…...

Unity新手避坑指南:用OnMouseOver做悬停UI,为什么你的提示框总‘鬼畜’抖动?
Unity悬停UI优化实战:告别抖动提示框的5个关键策略 当你在Unity中实现鼠标悬停提示功能时,是否遇到过提示框像"打地鼠"一样疯狂抖动的尴尬场景?这种看似简单的交互效果背后,隐藏着Unity事件系统、坐标转换和渲染管线的复…...

告别数据线?实测用手机Termux+网络串口给ESP32无线OTA升级
手机Termux网络串口实现ESP32无线OTA升级全攻略 想象一下这样的场景:你正坐在咖啡馆里,突然灵感迸发想修改ESP32设备的固件。传统方式需要翻出数据线、连接电脑、打开开发环境...但现在,只需掏出手机就能完成从代码修改到固件烧录的全流程。这…...

深入RTKLIB数据流核心:手把手教你用C语言模拟一个简易的str2str
从零构建GNSS数据流引擎:C语言实现轻量级str2str核心框架 在GNSS数据处理领域,RTKLIB的str2str工具如同一位不知疲倦的交通指挥员,日夜不停地调度着各类数据流。但当我们剥开其成熟的外壳,会发现核心数据流转发逻辑竟可以用不到50…...

MinerU智能文档服务部署避坑指南:常见问题解决与性能优化技巧
MinerU智能文档服务部署避坑指南:常见问题解决与性能优化技巧 1. 部署前的关键准备 1.1 硬件环境选择 MinerU智能文档服务对硬件要求极为友好,但在实际部署中仍需注意以下细节: CPU选择:优先选择支持AVX2指令集的处理器&#…...

3分钟解锁Axure RP中文界面:从英文障碍到设计自由
3分钟解锁Axure RP中文界面:从英文障碍到设计自由 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 还在被Axure RP的英…...
)
OpenClaw 飞书机器人对接全教程|Windows 端可视化配置 + 避坑指南(2026 最新)
前言 OpenClaw(小龙虾 AI)打通飞书通讯链路后,可在飞书单聊 / 群聊中直接下达指令,实现本地 AI 自动化办公,无需切换窗口。Windows 端部署已支持可视化配置 零命令行,无需手动敲代码,全程鼠标…...

从‘强组合定理’到‘Moments Accountant’:搞懂差分隐私深度学习中那点‘隐私预算’是怎么省下来的
从‘强组合定理’到‘Moments Accountant’:差分隐私深度学习的隐私预算优化之道 在深度学习模型训练过程中,数据隐私保护已成为不可忽视的核心议题。差分隐私(Differential Privacy)作为当前最受认可的隐私保护框架,通…...