Java面试题之mysql
Mysql
- 1. MySQL的索引原理是什么?什么是索引?以及索引的优缺点?
- 2. 解释一下B+树和B树的区别及各自定义?
- 3. MyISAM索引和Innodb索引的区别?
- 4. 什么是聚簇索引?辅助索引?
- 5.非聚簇索引一定会回表查询么?
- 6. 什么是回表操作?
- 7. 什么是索引覆盖?
- 8.什么是短索引?
- 9.索引的数据结构有哪几种?
- 10. MySQL的索引的创建原则?MySQL不适合建立索引的情况?
- 11. 使用索引一定能提高查询性能么?
- 12. MySQL的主键索引?联合索引?唯一索引?
- 13. MySQL的索引下推是啥意思?
- 14. MySQL索引的最左前缀原则是什么?
- 15. MySQL的索引的rows很大会引起什么问题?
- 16. MySQL的解决慢查询的方法?explain方法怎么用的?
- 17. MySQL的Sql优化方法有什么?
- 18. MySQL的left join、right join、inner join、join的区别?
- 19. MySQL的小表驱动大表是什么意思?
- 20. binlog和redo log的具体解释?
- 22. binlog和redo log区别?
- 23. MySQL的exists和in的区别是什么?
- 24.drop、delete、truncate的区别?
- 25.UNION 和UNION All的区别?
- 26. MySQL的数据库的连接池都有什么?你用过什么?
- 27. 数据库的三大范式是什么?
- 28. 使用自增主键和UUID的区别?
- 29. 字段为什么要求定义为not null?
- 30. 什么是数据库事务?以及事务的四大特性?
- 31. MySQL的脏读?幻读?不可重复读?
- 32. MySQL的隔离机制?
- 33. 隔离级别和锁的关系?
- 34. MySQL的锁都有什么?表、页、行级锁?共享锁?排它锁?
- 35. MySQL中Innodb和MyISAM中使用什么锁?
- 36. MySQL中Innodb行级锁怎么实现的?
- 37. MySQL的死锁及其解决的方法?
- 38.乐观锁和悲观锁定义及实现?
- 39.超键?外键?候选键?主键?
- 40. SQL的生命周期的步骤?
- 41. 大表数据查询,怎么优化?
- 42. 关心过业务系统里sql的耗时么?统计过慢查询么?对慢查询都怎么优化?
- 43. 大批量删除数据的方法?
- 44. 大表优化,数据量大,CRUD慢,该如何优化?
- 45. MySQL的分库分表你们是怎么做的?用了什么中间件?
- 46. MySQL的主从复制的工作原理?
- 47. MySQL的读写分离是什么?以及解决方案?
- 48.MySQL有一个连接断了,我怎样保证获取不到这个连接?
- 49. MySQL的搜索引擎之间的区别与特点?怎么选择合适的引擎?
- 50. MySQL的更新语句的执行流程?
- 51. 什么情况会导致锁表?
- 52. 为什么插入MySQL会变慢?
持续更新中~
1. MySQL的索引原理是什么?什么是索引?以及索引的优缺点?
索引是一种数据结构,使用索引可以快速访问数据库表中的特定信息。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。索引是一个文件,是要占用物理空间的
优点:
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
- 可以大大加快数据的检索速度,提高查询性能。
- 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
- 在使用分组和排序子句进行数据检索时,索引可以显著减少查询中分组和排序的时间。
- 通过使用索引,可以在查询的过程中使用优化隐藏器,提高系统的性能。
缺点:
- 创建索引和维护索引需要耗费时间,这种时间随着数据量的增加而增加。
- 索引需要占用物理空间,除了数据表占用的数据空间之外,每一个索引还需要占用一定的物理空间。
- 当对表中的数据进行增加、删除和修改时,索引也需要动态维护,这可能会降低数据的维护速度。
索引的基本原理:
- 把创建了索引的列的内容进行排序;
- 对排序结果生成倒排表;
- 在倒排表内容上拼上数据地址链;
- 在查询的时候,先拿到倒排内容,再取出数据地址链,从而拿到具体数据;
2. 解释一下B+树和B树的区别及各自定义?
叶子节点:没有子节点的节点;
非叶子节点:度不为0的节点,又称分支节点;
根节点:顶端的节点称为根节点;
一个节点下面最多两个节点;
度:结点拥有的子树数;
平衡二叉树(AVL树):满足二叉树特性基础,每个节点树高度差不超过1;
二叉查找树:左子节点小于当前节点的键值,右子节点大于当前节点的键值
为什么选择B+树实现索引:
B+树的内部节点只存放键,不存值,因此,一次读取,可以在内存中获取更多的键。一般来说索引本身也很大,不可能全部存储内存中,因此索引往往以索引文件形式存到磁盘上,索引查找就要产生I/O消耗,所以选择一个数据结构的优劣就是I/O查找复杂度,B+树叶子节点存有全部数据,叶子节点用链表链接连接,也是顺序存储的,读值得时候会提前读进内存,减少I/O次数,查询排序都快,磁盘分block块存储的,一次读取若干block块,B+树不存数据,所以,B+树单次IO信息量大于B树,B+树IO次数就少于B树,所以用B+树;
B树:
- B树适合随机检索;
- B树不稳定,最好是根节点就查到了,最坏查到叶子节点;
- B树的每个节点都带有数据;
B+树:
- B+树所有的叶子节点包含了全部的数据;
- B+树所有非叶子节点可以看成是索引节点,没有数据,只存键;
- B+树每个叶子节点都带有指向下一个叶子节点的指针,形成有序链表;
- B+树必须查询到叶子节点;
3. MyISAM索引和Innodb索引的区别?
- Innodb是聚簇索引,MyISAM是非聚簇索引;
- Innodb的主键索引的叶子节点存储着行数据,因此主键索引非常高效;
- MyISAM索引的叶子节点存储的事行数据地址,需要再一次寻址才能得到数据;
- Innodb非主键索引的叶子节点存储的是主键和其他带索引的列数据,因此查询时做到覆盖索引会非常高效。
4. 什么是聚簇索引?辅助索引?
聚簇索引:将数据存储和索引放到了一块,找到了索引就找到了数据(在一棵树上);
非聚簇索引:索引结构的叶子节点指向了数据的对应位置上(不在一棵树上)。
辅助索引:(也称为非主键索引或二级索引)
- 辅助索引通常只存在于非聚集索引上,在InnoDB存储引擎中,辅助索引的叶子节点包含的不是数据行的完整信息,而是对应数据行的主键值。这是因为InnoDB的数据是按照主键的顺序存储的,也就是说,主键索引(也称为聚簇索引)决定了数据的物理存储顺序。
- 当执行一个查询时,如果使用辅助索引来查找数据,InnoDB首先会查找辅助索引来找到相应的主键值,然后使用这个主键值去查找聚簇索引(即主键索引),最终定位到实际的数据行。这个过程需要两步,因此被称为“二次查找”。
- 辅助索引不会存在于聚簇索引上。在InnoDB存储引擎中,聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。聚簇索引的叶子节点存放着一整行的数据,而辅助索引(非聚簇索引)的叶子节点存储的是主键值,而不是数据的物理位置。辅助索引是在聚簇索引之上创建的,用于提高查询性能。由于辅助索引的存在不影响数据在聚簇索引中的组织,所以一张表可以有多个辅助索引。
总之,辅助索引和聚簇索引是两种不同的索引类型,它们在InnoDB存储引擎中有不同的结构和用途。辅助索引用于提高查询性能,而聚簇索引则决定了数据的物理存储顺序
5.非聚簇索引一定会回表查询么?
不一定,如果涉及到的查询语句所查询的字段是否全部命中了索引,如果全部命中了,就不必再回表查询。
6. 什么是回表操作?
通过索引查询找到主键的键值,在通过主键值查全表,就叫回表查询。
7. 什么是索引覆盖?
如果要查询的字段都建立过索引,那么索引会直接在索引表中查询而不会访问原始数据(否则只要有一个字段没有建立索引就会全表扫描),这就叫做索引覆盖。
因此我们需要尽可能在select后只写必要查询的字段,以增加索引覆盖的几率。
8.什么是短索引?
短索引(Short Index)是一种优化索引的方法,用于减少索引占用的存储空间和提高查询性能。在MySQL数据库中,短索引是指对字符串类型的列进行索引时,不使用整个字符串的长度,而是选择字符串的前N个字符来创建索引。这样可以减少索引的存储空间,并且由于索引长度变短,查询速度也可能会得到提高。
短索引的使用场景通常是在字符串类型的列中,这些列的数据值很长,但是前缀部分就足够区分不同的数据值。通过只索引字符串的前N个字符,可以避免对整个字符串进行索引,从而减少索引的存储空间。同时,由于查询时通常只需要匹配字符串的前缀部分,短索引也可以提高查询性能。
需要注意的是,短索引虽然可以减少存储空间和提高查询性能,但也会降低索引的选择性。索引的选择性是指不重复的索引值(基数)与数据表中的记录总数的比值。选择性越高,索引的过滤效果越好,查询性能也会更高。因此,在选择使用短索引时,需要权衡存储空间和查询性能与索引选择性的关系,选择最合适的索引策略。
9.索引的数据结构有哪几种?
哈希索引:底层的数据结构就是哈希表,只能用于对等比较,例如‘=’,是一次定位数据,所以检索效率高于b树索引。
B树索引:是mysql默认的算法,因为不仅可以用在=、>、<、<=、>=和between这些比较操作符上,还可以用于like操作符,只要查询不以通配符开头就可,比如‘jack%’可以,‘%jack’就不可以。
10. MySQL的索引的创建原则?MySQL不适合建立索引的情况?
- 数据少的情况不适合建立索引;
- 经常insert不适合建立索引;
- 数据重复且平分,比如只有A、B两个值不适合建立索引;
- 非空字段上建立索引;
- 查询频繁的字段才适合建立索引;
- 尽量的扩展索引,而不是新建索引;
- 定义为text、image、bit的数据类型不要建立索引;
11. 使用索引一定能提高查询性能么?
不一定,索引是需要空间来存储的,也需要定期维护,而且每当有记录被修改、删除和增加的时候索引本身也会被修改。
12. MySQL的主键索引?联合索引?唯一索引?
主键索引:数据列不可以重复,不允许null值;
唯一索引:数据列不可以重复,允许为null值,一个表允许多个唯一索引存在;
联合索引:(复合索引)
- 可以使用多个字段建立一个索引,在联合索引中,如果想要命中索引,需要按照建立索引时的字段顺序挨个使用,否则无法命中索引。
- mysql使用索引的时候需要索引有序,假设现在建立了‘name,age,school’的联合索引,name索引的排序为:先按照name排序,再按age,school进行排序。
- 注意事项:在建立联合索引时候,一般情况下,将需求查询频繁或者字段选择性搞的列放在前面。
13. MySQL的索引下推是啥意思?
是5.6之后提出的一个新特性,(Index Condition Pushdown,简称ICP),用于优化数据查询;
- 假设,我们设置了一个联合索引name、age,语句是“name like “张%” and age = 20 and school = ‘大学’ ”;
- 在5.6之前,只会走name的索引,name右边的都不看,拿到了主键值,再去回表操作,如果name条件找到了1000个,那就要回1000次表;
- 在5.6之后,在取出索引同时会根据where条件直接过滤掉不满足条件记录的,减少回表次数,这就是索引下推,name like ‘张%’ age = 20,查出来之后,再对school进行回表判断就好了。
- 使用ICP会把age的判断下推给存储引擎;
- 不使用ICP会把age的判断给server进行;
需要注意的是,索引下推是否使用,以及在哪些场景下使用,取决于优化器的选择。优化器会根据查询的具体情况和数据分布等因素,判断使用索引下推是否可以提高查询效率。因此,在某些场景下,即使存在索引下推的条件,优化器也可能选择不使用索引下推。
14. MySQL索引的最左前缀原则是什么?
- 最左匹配原则的原理:利用索引前提是索引里的key有序,abcd联合索引a是全局有序,b是针对a来说局部有序,以此类推;
- 在创建联合索引时,根据业务需求,where子句中使用最频繁的一列放在最左边;
- 遇到范围查询(>,<,between,like等)就会停止匹配,比如a=1 and b=2 and c>3 and d=4,如果建立的是abcd的索引顺序,d是用不到索引的,abc的顺序可以任意调整;
- =和in是可以乱序的,a=1 and b=2 and c=3,建立abc的索引顺序可以任意顺序,mysql的查询优化器会帮忙优化成索引可以识别的形式。
15. MySQL的索引的rows很大会引起什么问题?
当面试官提到“索引的rows很大会怎么样”时,他们可能想考察你对索引性能、数据库优化和查询效率的理解。
“当索引的rows很大时,这意味着索引可能变得不那么高效,因为它需要更多的时间和资源来查找数据。具体来说,大索引可能导致以下问题:
- 性能下降:随着索引大小的增加,查找特定值所需的时间可能会增加,从而导致查询性能下降。
- 空间成本:大索引会占用更多的磁盘空间,这可能会增加存储成本,并可能影响其他数据库操作的性能。
- 维护开销:大索引在进行插入、更新或删除操作时需要更多的维护,这可能会影响到系统的整体性能。
为了应对这些问题,我们可以采取以下策略:
- 优化索引设计:只为必要的列创建索引,避免过度索引。同时,选择适当的索引类型和数据类型。
- 定期维护:通过重建或优化索引来减少其大小,并保持其性能。
- 监控和调整:定期监控索引的使用情况和性能,根据需要进行调整。
16. MySQL的解决慢查询的方法?explain方法怎么用的?
EXPLAIN 命令是 MySQL 中用于查看查询优化器如何执行 SQL 查询的主要方法。通过 EXPLAIN,我们可以获得查询执行计划中的很多信息,从而分析 SQL 语句的执行情况,找出可能的性能瓶颈,并进行相应的优化。
要使用 EXPLAIN,只需在 SQL 查询的 SELECT 语句前加上 EXPLAIN 关键字。例如:
EXPLAIN SELECT * FROM student_info WHERE student_id='A01234567';
执行了包含 EXPLAIN 的查询后,你会得到一个包含多列的输出结果。这些列的含义如下:
- id:查询的序列号,用于区分查询中的各个部分。
- select_type:查询的类型,用于区分普通查询、联合查询、子查询等复杂查询。
- type:访问类型,显示使用了何种类型的索引或全表扫描。其值从最好到最差依次为:
Systemconst(主键索引或者唯一索引)eq_ref(在join查询中用primary key or unique not null索引关联)ref(使用非唯一索引查找数据)range(索引范围查找)index(遍历索引)ALL(全表扫描)fulltext(使用全文索引)
- table:查询的数据表。
- possible_keys:可能应用到的索引,但不一定被查询实际使用。
- key:实际使用的索引。
- ref:显示索引的哪一列被用于查找。
- rows:根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数。
此外,还有其他一些列,如 Extra,用于显示额外的信息,如是否使用了文件排序、临时表等。
在查看 EXPLAIN 的输出时,你需要注意以下几点:
- 确保查询使用了正确的索引。如果
key列显示为NULL,那么可能需要考虑添加或优化索引。 - 注意
type列的值。如果值为ALL,表示进行了全表扫描,这通常意味着性能较差,可能需要优化查询或添加索引。 rows列的值也很重要。如果它的值很大,那么查询可能需要优化,以减少需要检查的行数。
通过分析 EXPLAIN 的输出,你可以更好地理解查询的执行过程,并找出可能的性能瓶颈。这对于优化复杂的 SQL 查询和提高数据库性能非常有帮助。
17. MySQL的Sql优化方法有什么?
- 对查询进行优化,应尽量避免全表扫描,首先应考虑在where及order by涉及的列上建立索引;
- 尽量避免在where字句中使用!=,<,>,null,or,in,not in,like,字段表达式,函数;
- 查询的select 不要用*,用啥字段写啥字段。
18. MySQL的left join、right join、inner join、join的区别?
INNER JOIN(或 JOIN):
- 返回两个表中匹配的行。
- 只有当左表和右表中的连接字段都有匹配的值时,行才会出现在结果集中。
- 如果左表或右表中的某行没有匹配项,那么该行不会出现在结果集中。
- 这是一种“等值连接”,因为它只返回在两个表中具有相同连接字段值的行。
LEFT JOIN(或 LEFT OUTER JOIN):
- 返回左表中的所有行,以及右表中匹配的行。
- 如果左表中的某行在右表中没有匹配项,那么结果集中该行的右表部分将包含NULL值。
- 这意味着,无论右表是否有匹配项,左表中的所有行都会出现在结果集中。
RIGHT JOIN(或 RIGHT OUTER JOIN):
- 与LEFT JOIN相反,它返回右表中的所有行,以及左表中匹配的行。
- 如果右表中的某行在左表中没有匹配项,那么结果集中该行的左表部分将包含NULL值。
- 这意味着,无论左表是否有匹配项,右表中的所有行都会出现在结果集中。
总的来说,选择哪种连接类型取决于你想要从查询中获取什么样的数据。如果你只想获取两个表中都有的数据,那么使用INNER JOIN。如果你想从一个表中获取所有数据,即使它在另一个表中没有匹配项,那么使用LEFT JOIN或RIGHT JOIN,具体取决于你想保留哪个表的所有数据。
19. MySQL的小表驱动大表是什么意思?
小表驱动大表是一种数据库查询优化策略,其核心思想是在进行表连接操作时,优先遍历数据量较小的表(小表),然后使用该小表中的数据去大表中查找匹配的行。这种策略通过减少需要检查的行数来优化查询性能。它在处理大量数据时非常有用,可以帮助提高查询的效率和性能。
这种策略之所以有效,是因为它减少了需要在大表中进行的查找次数。如果先遍历大表,再去小表中查找匹配的行,可能会导致大量的无效查找,因为大表中的很多行可能在小表中没有对应的匹配行。而通过小表驱动大表的方式,我们可以确保每次在大表中进行的查找都是基于小表中的实际数据,从而提高了查询效率。
为了实现小表驱动大表的策略,通常需要确保小表上的连接字段(如上述例子中的用户ID)有合适的索引,以便快速查找匹配的行。此外,在某些情况下,可能还需要手动调整SQL查询语句的顺序或使用特定的查询提示来告诉数据库优化器采用这种策略。
20. binlog和redo log的具体解释?
Binlog(二进制日志):
Binlog记录的是逻辑操作,它捕捉的是MySQL上层(即Server层)执行的实际SQL语句。例如,如果你执行了一个UPDATE语句来修改某个表中的记录,Binlog会记录这个UPDATE语句的完整内容,而不是记录实际在数据页上所做的物理更改。
这种记录方式有几个好处:
- 可读性强:Binlog的内容对于人类来说相对容易理解,因为它记录的是我们实际执行的SQL语句。
- 支持复制:在主从复制场景中,Master节点的Binlog会被发送到Slave节点,Slave节点通过执行这些Binlog中的SQL语句来保持与Master的数据同步。
- 支持点时间恢复:如果你知道某个特定的时间点,你可以使用Binlog来恢复到那个时间点的数据状态。
Redo Log(重做日志):
Redo Log是InnoDB存储引擎层面的日志,它记录的是数据页的物理更改。当事务发生时,InnoDB不会立即修改实际的数据页,而是先将这些更改记录到Redo Log中。这意味着,即使系统突然崩溃,已提交的事务的更改仍然可以通过Redo Log来恢复。
Redo Log记录的是“在某个数据页上做了什么修改”,而不是具体的SQL语句。例如,如果你执行了一个UPDATE语句,Redo Log不会记录这个UPDATE语句,而是记录这个操作实际在数据页上所做的更改,如更改了哪些字节的值。
这种记录方式的好处是:
- 持久性:确保即使在系统崩溃的情况下,已提交的事务的更改也不会丢失。
- 快速恢复:在系统重启后,InnoDB可以通过扫描Redo Log来快速应用未提交到数据页的事务更改,从而快速恢复到崩溃前的状态。
总结一下,Binlog和Redo Log的主要区别在于它们记录的内容和目的。Binlog记录的是逻辑操作(即SQL语句),主要用于复制和数据恢复;而Redo Log记录的是物理更改(即数据页上的更改),主要用于确保事务的持久性和在系统崩溃时的快速恢复。
22. binlog和redo log区别?
Binlog(二进制日志)和Redo Log(重做日志)是MySQL数据库中两种不同类型的日志,它们在数据库的操作和恢复过程中起着不同的作用。以下是它们之间的主要区别:
产生位置:Binlog是在MySQL的Server层产生的,而Redo Log是在InnoDB存储引擎层产生的。这意味着,MySQL数据库中的任何存储引擎对于数据库的更改都会产生Binlog。
日志内容:Binlog是逻辑日志,它记录的是SQL语句的原始逻辑,比如“给ID=2这一行的c字段加1”。而Redo Log是物理日志,记录的是数据页上的修改,即“在某个数据页上做了什么修改”。
记录时间:Binlog记录的是事务提交完毕之后的DML和DDL SQL语句。而Redo Log记录的是事务发起之后的DML和DDL SQL语句。
文件使用方式:Binlog不是循环使用的,当文件写满或者实例重启之后,会生成新的Binlog文件。而Redo Log是循环使用的,当最后一个文件写满之后,会重新写第一个文件。
作用:Binlog的主要作用是用于主从复制和数据恢复。而Redo Log的主要作用是确保事务的持久性,即在系统崩溃或故障时,能够利用Redo Log来恢复数据。
23. MySQL的exists和in的区别是什么?
- 如果查询的两个表大小差不多,in和exists差别不大;
- 如果两个表一个是大表一个是小表,子查询表大的用的是exists,反之用in;
- not in 和not exists;如果查询语句用了not in,那么内外表都进行全表扫描,没有用到索引;not exists的子查询能用上表的索引,所以,not exists比not in 快;
为什么某种情况下exists比in快:
当使用 IN 时,子查询需要返回所有满足条件的值,然后主查询针对这些值进行过滤。如果子查询返回的结果集很大,这可能会导致主查询的性能下降。 当使用EXISTS 时,只要子查询找到至少一个满足条件的行,它就会停止执行。这种“短路”行为使得 EXISTS 在某些情况下比 IN 更高效。
24.drop、delete、truncate的区别?
delete:表结构还在,删除部分数据,可回滚;
truncate:表结构还在,删除全部数据,不可回滚;
drop:表结构和数据都被删除,索引和权限也会被删除,不可回滚;
25.UNION 和UNION All的区别?
- union all 不会合并重复记录行;
- union效率高于union all;
26. MySQL的数据库的连接池都有什么?你用过什么?
MySQL数据库的连接池是一种技术,用于管理数据库连接的创建、使用和释放,以提高应用程序的性能和可伸缩性。通过连接池,应用程序可以重用已经创建的数据库连接,而不是每次需要与数据库交互时都创建新的连接。这样可以减少连接和断开连接的开销,提高应用程序的响应速度。
在MySQL中,常用的连接池实现有以下几种:
MySQL Connector/J连接池:这是MySQL官方提供的Java数据库连接(JDBC)驱动程序的连接池实现。它提供了对连接池的配置选项,如初始连接数、最大连接数、最小连接数等。许多Java应用程序使用MySQL Connector/J来连接MySQL数据库,并利用其连接池功能。
C3P0连接池:C3P0是一个开源的Java连接池库,支持多种数据库,包括MySQL。它提供了丰富的配置选项和性能监控功能,被广泛用于企业级应用程序中。
HikariCP连接池:HikariCP是另一个流行的Java连接池库,以其高性能和低延迟而著称。它提供了简洁的配置和强大的功能,如自动配置、连接超时、连接测试等。HikariCP在许多性能要求高的应用程序中被广泛使用。
DBCP连接池:DBCP(Database Connection Pooling)是Apache Commons项目的一部分,是一个开源的Java连接池库。它支持多种数据库,包括MySQL,并提供了连接池的基本功能,如连接管理、配置和监控。
连接池代理:除了上述提到的连接池实现,还有一些连接池代理工具,如ProxySQL。ProxySQL是一个开源的MySQL代理,它可以实现连接池、查询缓存、读写分离等功能。通过将应用程序连接到ProxySQL,可以间接地使用MySQL连接池。
在实际使用中,我根据自己的需求和项目特点,曾经使用过MySQL Connector/J连接池和HikariCP连接池。MySQL Connector/J连接池简单易用,适合简单的应用程序和快速原型开发。而HikariCP连接池则更适合于对性能有较高要求的生产环境,它能够提供更快的连接速度和更好的性能表现。
27. 数据库的三大范式是什么?
- 第一范式:每个列都不可以再拆分;
- 第二范式:在第一范式基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分;
- 第三范式:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
28. 使用自增主键和UUID的区别?
推荐使用自增主键Id,因为Innodb的主键索引是聚簇索引,主键索引的B+树叶子节点上存储了主键索引和全部数据(顺序存储),如果是自增的,就可以向后排列即可,但是如果是UUID,新来的Id与原来的大小不确定,就会造成数据移动,产生很多内存碎片,不连接,造成性能下降;
使用自增主键也有缺点,合并表时,会有主键冲突;
29. 字段为什么要求定义为not null?
null值会占用更多的字节,且会在程序中造成很多与预期不符的情况。
30. 什么是数据库事务?以及事务的四大特性?
事务是一个不可分割的数据库操作序列,也是数据库并发控制的基本单位,其执行的结果,必须使数据库从一种一致状态变到另一种一致性状态。事务是逻辑上的一组操作,要么都执行,要么都不执行。
- 原子性:事务是最小的执行单位,不允许分割;
- 一致性:执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
- 隔离性:并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
- 持久性:一个事务被提交之后,他对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
31. MySQL的脏读?幻读?不可重复读?
- 脏读(Drity Read):事务A读取事务B更新的数据,事务B回滚A读到的就是脏数据;
- 幻读(Phantom Read):在一个事务的两次查询中数据不一致,一个事务第一次查询,查了几列数据,另一个事物此时插入了新的数据,先前的事务在接下来的查询中会发现多了几列数据,就叫幻读;
- 不可重复读(Non-repeatable Read):在一个事物的两次查询数据不一致,这可能是两次查询过程中插入了一个事务更新或者删除的原有的数据;
32. MySQL的隔离机制?
SQL的四个隔离级别是为了解决事务并发执行时可能出现的问题,如脏读、不可重复读和幻读。这四个隔离级别分别是:
读未提交(Read Uncommitted):
- 这是最低的隔离级别。在这个级别下,一个事务可以读取另一个未提交事务的数据。因此,它可能读取到“脏”数据(即其他事务尚未提交的数据)。
- 可能出现的问题:脏读、不可重复读、幻读。
读已提交(Read Committed):
- 这是大多数数据库系统的默认隔离级别(例如Oracle、SQL Server)。在这个级别下,一个事务只能读取另一个已经提交的事务的数据。
- 可以避免脏读,因为读取的数据都是已经提交的。但是,仍然可能出现不可重复读和幻读。
可重复读(Repeatable Read):
- 这是MySQL的默认隔离级别。在这个级别下,一个事务在整个过程中可以多次读取同一数据,并且每次读取的数据都是相同的(即其他事务不能修改该数据)。
- 可以避免脏读和不可重复读,但是仍然可能出现幻读。
串行化(Serializable):
- 这是最高的隔离级别。在这个级别下,事务是完全串行执行的,即一次只能有一个事务执行。
- 避免了脏读、不可重复读和幻读,但性能开销最大,因为事务必须等待其他事务完成才能执行。
事务隔离机制的实现基于锁机制和并发调度,其中并发调度用的是MVVC(多版本并发控制),通过保存修改的旧版本信息来支持并发一致性读和回滚等特性。
33. 隔离级别和锁的关系?
读取未提交(Read Uncommitted):读取数据不需要加共享锁,这样就不会跟被修改的数据上的排它锁冲突;
读取已提交(Read Committed):读操作需要加共享锁,但是在语句执行完以后释放共享锁;
可重复读(Repeatable Read):读操作需要加共享锁,但是在事务提交之前并不释放共享锁,也就是必须等待事务执行完毕以后才释放共享锁;
串行化(Serializable):限制性最强的隔离级别,因为该级别锁定整个范围的键,并一直持有锁,直到事务完成。
34. MySQL的锁都有什么?表、页、行级锁?共享锁?排它锁?
隔离级别越低,事务请求的锁越少
在没有索引的情况下,Innodb只能使用表锁
在关系型数据库中,可以按照锁的颗粒度把数据库分为行级锁,表级锁和页级锁;
- 行级锁:是最细粒度的一种锁,对行进行加锁,加锁力度最小,但是开销也最大,会出现死锁,并发程度最高;行级锁又分为共享锁和排它锁;
- 表级锁:最大力粒度的一种锁,实现简单,加锁快,资源消耗较少,锁冲突出现最高,并发度最低;表级锁又分为表共享读锁(共享锁)和表独占写锁(排他锁);
- 页级锁:一次锁定相邻的一组记录,介于表级锁和行级锁之间,会出现死锁,并发度一般。
锁的类别上可分为:
- 共享锁:又叫做读锁,当用户要进行数据读取时,对数据加上共享锁,可以同时加多个;
- 排它锁:又叫做写锁,当用户进行写入数据时,对数据上排它锁,排它锁只可以加一个,他和其他排它锁,共享锁都互斥。
35. MySQL中Innodb和MyISAM中使用什么锁?
- MyISAM采用表级锁;
- Innodb支持行级锁和表级锁,默认是行级锁;
36. MySQL中Innodb行级锁怎么实现的?
InnoDB的行锁是通过给索引的索引项加锁来实现的。
InnoDB按照辅助索引进行数据操作时,辅助索引和主键索引都将锁定指定的索引项。通过索引进行数据检索时,InnoDB才使用行级锁,否则InnoDB将使用表锁。
需要注意的是,即使查询条件中使用了索引字段,是否使用索引来检索数据是由MySQL通过判断不同执行计划的代价来决定的。例如,对于一些很小的表,MySQL可能会认为全表扫描效率更高,从而不使用索引,这种情况下InnoDB将使用表锁,而不是行锁。
InnoDB的行锁机制(算法)包括RecordLock、CapLock和Next-key Lock三种锁。
- RecordLock:锁定单个行记录的锁,它支持RC和RR隔离级别。
- CapLock:间隙锁,锁定索引记录间隙,确保索引记录的间隙不变,它仅在RR隔离级别下支持。
- Next-key Lock:是记录锁和间隙锁的组合,同时锁住数据,并且锁住数据前后范围,它在RR隔离级别下被使用。当SQL操作含有唯一索引时,InnoDB会对Next-Key Lock进行优化,降级为RecordLock,仅锁住索引本身而非范围。
37. MySQL的死锁及其解决的方法?
死锁:是指两个或者多个事务在同一个资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
解决办法:
- 如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会;
- 在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生的概率;
- 对于非常容易产生死锁的业务部分,可以尝试升级锁颗粒度,通过表级锁减少死锁产生的概率;
38.乐观锁和悲观锁定义及实现?
乐观锁:假设不会发生冲突,只在提交时检查是否违反数据完整性,在修改数据时把事务锁起来,通过version的方式来进行锁定,实现方式一般会用版本号控制和CAS算法。适用于读场景多的情况。
悲观锁:假设会发生冲突,在查询时就把事务锁起来,实现方式:使用数据库中的锁机制。适用于写场景多的情况。
39.超键?外键?候选键?主键?
超键(Super Key):在关系中能唯一标识元组的属性集称为关系模式的超键。一个属性可以作为一个超键,多个属性组合在一起也可以作为一个超键。超键包含候选键和主键。
候选键(Candidate Key):是最小超键,即没有冗余元素的超键。
主键(Primary Key):数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合。一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null)。主键是选中的一个候选键,具有唯一性。
外键(Foreign Key):在一个表中存在的另一个表的主键称此表的外键。外键主要是用来描述两个表的关系。
40. SQL的生命周期的步骤?
建立连接:应用服务器与数据库服务器之间建立连接。这通常涉及TCP/IP连接和GLP协议。
接收SQL请求:数据库服务器接收到客户端发送的SQL请求。
解析SQL:数据库进程解析SQL语句,生成执行计划。在这个过程中,数据库会检查SQL语句的语法,引用的对象,以及调用优化器来确定查询计划。
执行SQL:根据解析和优化后的执行计划,数据库执行SQL语句。这可能包括从磁盘读取数据、对数据进行逻辑处理、排序、分组、过滤等操作。
返回结果:数据库将执行结果发送回客户端。结果可能是一个数据集、一个错误消息、一个影响行数等信息。
关闭连接:在完成所有操作后,数据库服务器关闭与客户端的连接,释放相关资源。
41. 大表数据查询,怎么优化?
- 使用索引:
- 确保查询条件中的列有索引,特别是WHERE、JOIN和ORDER BY子句中用到的列。
- 避免在索引列上使用函数或计算,这可能导致索引失效。
- 使用覆盖索引(Covering Index)来减少数据查找时需要读取的数据量。
- 定期监控索引的使用情况,避免维护过多的无效索引。
- 查询优化:
- 减少返回的数据量,只选择需要的列,避免SELECT *。
- 使用LIMIT语句限制返回的行数。
- 避免在查询中使用子查询,特别是在大数据集上,可以考虑使用JOIN来代替。
- 使用预编译的SQL语句(如Prepared Statements)来避免SQL注入并减少解析时间。
- 表分区:
- 对于非常大的表,可以考虑使用表分区将数据分散到不同的物理区域,提高查询性能。
- 根据查询模式和业务需求选择合适的分区键。
- 数据库设计:
- 规范化数据库设计,避免数据冗余,但也要考虑到查询性能,有时候适当的反规范化可以提高查询速度。
- 使用合适的数据类型,避免不必要的数据类型转换。
- 硬件和配置优化:
- 提高I/O性能,如使用SSD、增加内存等。
- 调整数据库配置参数,如缓冲区大小、连接池大小等。
- 考虑使用多核处理器并行处理查询。
- 使用缓存:
- 利用查询缓存来存储频繁执行的查询结果,减少数据库访问。
- 使用应用级别的缓存(如Redis、Memcached)来缓存热点数据。
- 分批处理:
- 对于非常大的数据集,考虑分批处理数据,而不是一次性处理所有数据。
- 使用分页查询(如LIMIT和OFFSET)来分批获取数据。
- 异步处理:
- 对于非实时要求的查询,可以考虑使用异步处理,如后台任务或消息队列。
- 监控和诊断:
- 使用数据库监控工具来识别性能瓶颈。
- 分析查询执行计划(EXPLAIN)来找出性能问题。
- 外部工具和服务:
- 使用数据库代理(如ProxySQL)来分发和缓存查询。
- 考虑使用数据仓库或分布式数据库系统来处理大数据量。
- 考虑查询逻辑:
- 避免在查询中使用NOT IN、<> 或 != 操作符,因为它们通常不会使用索引。
- 使用UNION ALL 代替UNION,除非需要去除重复行。
- 避免在WHERE子句中使用OR来连接条件,这可能导致全表扫描。
42. 关心过业务系统里sql的耗时么?统计过慢查询么?对慢查询都怎么优化?
是的,我统计过慢查询。在项目中,我通常会定期分析数据库的慢查询日志来识别性能问题。通过慢查询日志,我可以找到执行时间较长的查询语句,并对其进行优化。
通过配置项:slow_query_log = on是开启慢查询,设置临界值:long_query_time = 2,查看:show VARIABLES like ‘long_query_time’,会在datadir下产生一个xxx-slow.log的文件,一旦超过我们设置的临界时间就会记录到该文件里。
43. 大批量删除数据的方法?
- 如果数据量大,先删除索引再删除数据,删完数据再重新建索引;
- 如果涉及到外键关联,可以先关闭外键约束,执行删除操作,然后再重新启用外键约束;可以使用SET FOREIGN_KEY_CHECKS=0;来关闭外键约束,执行删除操作后,再使用SET FOREIGN_KEY_CHECKS=1;重新启用外键约束;
- TRUNCATE TABLE 命令会删除表中的所有数据,但不会删除表本身。这是一个非常快速的操作,因为它不记录个别行的删除操作。
44. 大表优化,数据量大,CRUD慢,该如何优化?
- 限定数据范围:比如查询历史订单的时候,可以控制在一个月范围内;
- 读写分离:主库负责写,从库负责读;
- 缓存:使用缓存;
- 可以通过分库分表的方式进行优化,主要有垂直分表和水评分表。
45. MySQL的分库分表你们是怎么做的?用了什么中间件?
当面试官问到关于MySQL的分库分表以及使用的中间件时,你可以按照以下方式回答:
分库分表的做法:
水平拆分(Sharding):
- 将同一个表中的记录分散到多个结构相同的表中,通常基于某个字段的值进行拆分,如用户ID的范围、哈希值等。
- 这样可以将单个表的数据量减小,提高查询性能,并且可以通过增加更多的数据库服务器来分散读写压力。
垂直拆分:
- 将一个表中的列分散到多个不同的表中,每个表只包含部分列。
- 这种方式通常用于将大表拆分为多个小表,以减少单个表的复杂度和提高查询性能。
使用的中间件:
在分库分表的架构中,中间件起到了关键的作用,它们帮助管理和路由数据库请求。以下是一些常见的MySQL分库分表中间件:
ShardingSphere(原名Sharding-JDBC):
- 这是一个开源的分布式数据库解决方案套件,提供了数据分片、读写分离、分布式事务和数据库治理等功能。
- ShardingSphere可以作为JDBC驱动的一个轻量级框架,也可以结合Spring Boot等框架使用。
MyCAT:
- 是一个开源的、支持MySQL协议的分布式数据库系统,主要解决了单一MySQL数据库在大量数据、高并发场景下的性能瓶颈问题。
- MyCAT提供了全局的表结构,对上层应用来说无需关心底层数据的分布和分片细节。
Vitess:
- 由YouTube开发并开源的数据库分片解决方案,支持MySQL和PostgreSQL。
- Vitess提供了自动化的分片、故障转移、备份和恢复等功能。
DRDS(分布式关系型数据库服务):
- 阿里云提供的一种数据库服务,它支持MySQL协议,并为用户提供了透明的分库分表解决方案。
- DRDS可以帮助用户快速构建高并发、高可用、可扩展的分布式数据库系统。
46. MySQL的主从复制的工作原理?
- master数据写入更新binlog;
- master创建一个dump线程,向slave推送binlog;
- slave连接到master,创建一个IO线程接收binlog,并记录到relay log中继日志中;
- slave再开启一个sql线程,读取relay log事件并在slave执行,完成同步;
- slave记录自己binlog;
47. MySQL的读写分离是什么?以及解决方案?
读写分离:
- 将数据库的读操作和写操作分离到不同的数据库服务器上,以提高系统的并发处理能力。
- 写操作通常发生在主数据库上,而读操作可以发生在多个从数据库上。
MySQL的读写分离的解决方案有多种,以下是一些常见的方法:
- 基于应用层的解决方案:
程序修改MySQL操作类:直接在应用程序中区分读操作和写操作,将读请求发送到从库(Slave),写请求发送到主库(Master)。这种方式的优点是直接和数据库通信,简单快捷,可以实现随机方式的负载均衡和权限独立分配。但缺点是需要应用程序自己维护更新和增减服务器。
使用开源框架:例如MyBatis Plus、Sharding-JDBC等,这些框架提供了读写分离的功能,可以方便地在应用程序中实现读写分离。 - 基于代理层的解决方案:
使用MySQL代理:如mysql-proxy、Amoeba、MaxScale等。这些代理可以拦截应用程序对MySQL的请求,根据请求类型将其转发到相应的主库或从库。代理层的优点是对于应用程序来说是完全透明的,不需要修改应用程序代码。但缺点是可能存在单点失效的问题,需要通过部署多个代理实例来解决。
使用数据库中间件:如MyCAT、ShardingSphere-Proxy等。这些中间件也提供了读写分离的功能,并且提供了更多的功能,如数据分片、负载均衡等。使用中间件的优点是可以实现更高级别的数据库管理和优化,但缺点是需要部署和维护额外的中间件服务。
48.MySQL有一个连接断了,我怎样保证获取不到这个连接?
当面试官问到关于如何处理MySQL中的一个断开的连接,并如何确保不再获取到这个连接时,他们可能想考察你对数据库连接管理和错误处理的理解。这可能涉及到多个方面,包括连接池管理、错误捕获和处理、以及可能的重试策略。
以下是你可能给出的回答:
- 连接池管理:
- 使用连接池(如HikariCP, C3P0, DBCP等)来管理数据库连接。连接池会维护一个活动的连接集合,当应用程序需要数据库连接时,它会从池中获取一个连接。
- 当连接断开或无效时,连接池通常会检测到这种情况,并将其从池中移除。这样,应用程序就不会再尝试使用这个无效的连接。
- 错误捕获和处理:
- 在执行数据库操作时,使用try-catch语句来捕获可能抛出的异常。
- 当捕获到与连接断开相关的异常(如
java.sql.SQLException)时,可以关闭当前连接,并尝试从连接池中获取一个新的连接。
- 重试策略:
- 当检测到连接断开时,可以实施一个重试策略,尝试重新连接数据库。
- 可以设置最大重试次数和重试间隔,以防止无限循环或过多的重试导致资源浪费。
- 监控和日志:
- 监控数据库连接的状态和性能,以便及时发现并解决问题。
- 记录详细的日志,包括连接断开的原因、时间、以及采取的解决措施,以便后续分析和优化。
示例回答:
“当MySQL中的一个连接断开时,我会首先确保我的应用程序使用了一个可靠的连接池来管理数据库连接。这样,当连接断开或无效时,连接池可以自动将其从池中移除。在执行数据库操作时,我会使用try-catch语句来捕获可能的异常。如果捕获到与连接断开相关的异常,我会关闭当前连接,并从连接池中获取一个新的连接。此外,我还会实施一个重试策略,当检测到连接断开时,尝试重新连接数据库。为了确保问题的及时发现和解决,我还会监控数据库连接的状态和性能,并记录详细的日志。”
49. MySQL的搜索引擎之间的区别与特点?怎么选择合适的引擎?
- Innodb:(5.5之后默认引擎)提供了对数据库ACID事务的支持,并且还提供了行级锁和外键的约束,它的设计的目标就是处理大数据容量的数据库系统;
- MyIASM:(5.5之前默认引擎)不支持行级锁和外键,也不提供事务的支持;
- MEMORY:所有数据都在内存中,数据处理的速度快,但是安全性不高;
Innodb和MyIASM的区别:
| MyISAM | Innodb | |
|---|---|---|
| 存储空间 | 可被压缩,存储空间较小 | 需要更多的内存和存储,他会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引 |
| 文件格式 | 数据和索引是分开存储的,数据.MYD,索引.MYI | 数据和索引是集中存储的,.ibd |
| 可移植性、备份及恢复 | 文件的形式存储,跨平台数据转移更方便,在备份和恢复时可以单独对某个表进行操作 | 拷贝数据文件,备份binlog,或者用mysqldump |
| 外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 锁支持 | 表级锁 | 行级锁、表级锁、锁的力度更小并发能力更高 |
| select | 更优 | |
| insert、update、delete | 更优 | |
| select count(*) | 更快,内部维护了一个计数器,可以直接调取 | |
| 索引的实现方式 | B+树索引,MyISAM是堆表 | B+树索引,是索引组织表 |
| 哈希索引 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
50. MySQL的更新语句的执行流程?
51. 什么情况会导致锁表?
52. 为什么插入MySQL会变慢?
相关文章:

Java面试题之mysql
Mysql 1. MySQL的索引原理是什么?什么是索引?以及索引的优缺点?2. 解释一下B树和B树的区别及各自定义?3. MyISAM索引和Innodb索引的区别?4. 什么是聚簇索引?辅助索引?5.非聚簇索引一定会回表查询么?6. 什…...

抖音直播封禁申诉话术怎么讲?抖音直播封号怎么申请解封?
一.抖音直播封禁申诉话术怎么讲? 1. 了解封禁原因:首先,您需要清楚自己为何被封禁。抖音通常会在封禁时给出原因,如违规内容、恶意行为等。了解原因有助于您针对性地构建申诉话术。 2. 表达诚挚歉意:在申诉话术中,首…...
使用Jenkins部署前端Vue项目和后端Java服务
Jenkins安装相关插件,供后续使用(Dashboard - Manage Jenkins - Plugins) Maven Integration plugin https://plugins.jenkins.io/maven-plugin CloudBees Docker Build and Publish pluginhttps://plugins.jenkins.io/docker-build-publish…...

刷题——显示屏
目录 题目描述 输入格式 输出格式 输入输出样例 说明/提示 解 题目描述 液晶屏上,每个阿拉伯数字都是可以显示成 35 的点阵的(其中 X 表示亮点,. 表示暗点)。现在给出数字位数(不超过 100100)和一串数…...

WEB服务器-Tomcat(黑马学习笔记)
简介 服务器概述 服务器硬件 ● 指的也是计算机,只不过服务器要比我们日常使用的计算机大很多。 服务器,也称伺服器。是提供计算服务的设备。由于服务器需要响应服务请求,并进行处理,因此一般来说服务器应具备承担服务并且保障…...
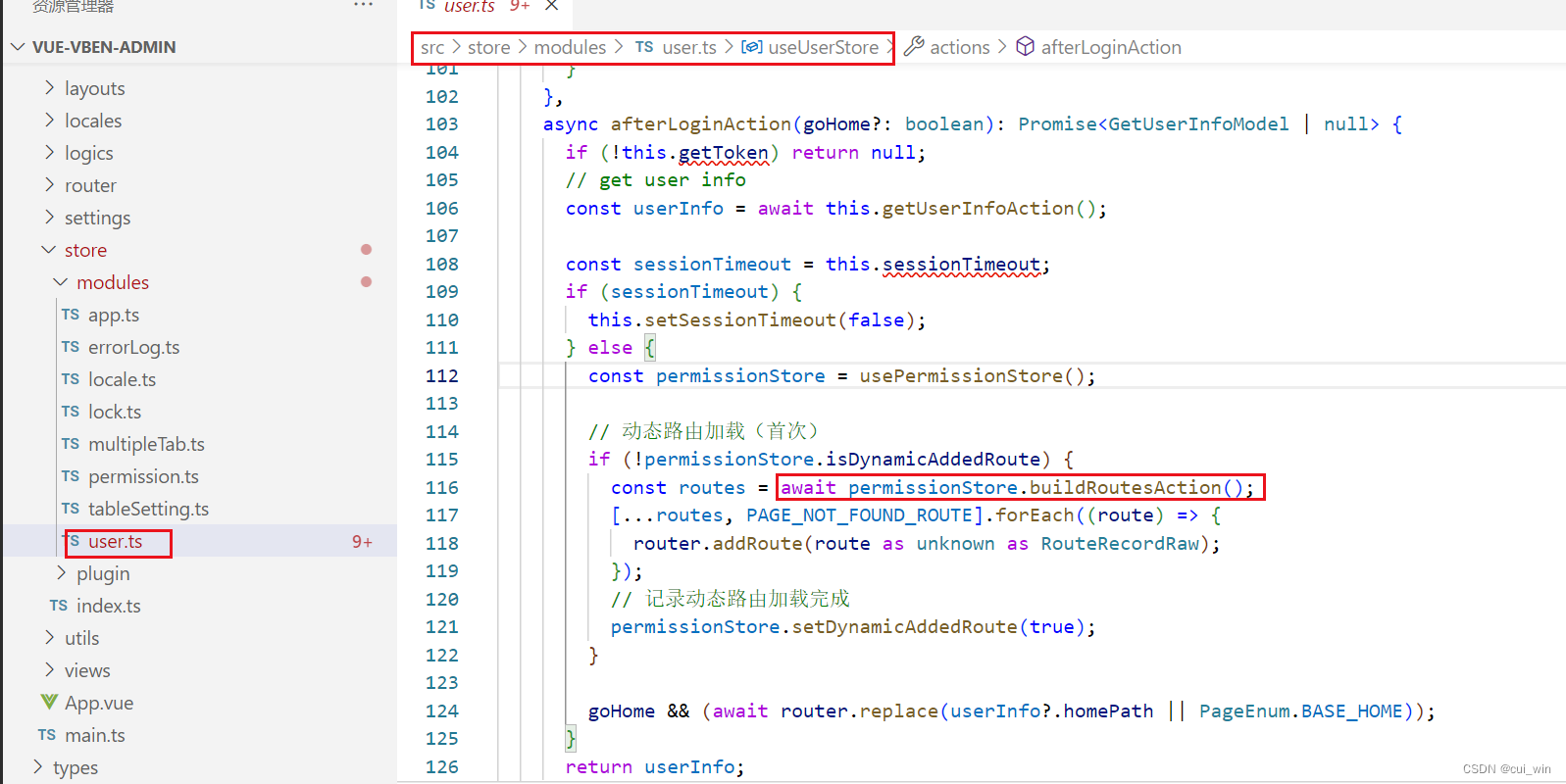
第五节:Vben Admin权限-前端控制方式
系列文章目录 第一节:Vben Admin介绍和初次运行 第二节:Vben Admin 登录逻辑梳理和对接后端准备 第三节:Vben Admin登录对接后端login接口 第四节:Vben Admin登录对接后端getUserInfo接口 第五节:Vben Admin权限-前端控制方式 文章目录 系列文章目录前言一、Vben Admin权…...
)
蓝桥杯备赛第二篇(背包问题)
1. 01 背包(采用状态压缩) public static void main(String[] args) {Scanner scanner new Scanner(System.in);int M scanner.nextInt();int N scanner.nextInt();int[] value new int[N 1];int[] weight new int[N 1];int[] dp new int[M 1];…...

【postgresql 基础入门】带过滤条件的查询,where子句中的操作符介绍,案例展示,索引失效的大坑就在这里
查询数据-过滤数据 专栏内容: postgresql内核源码分析手写数据库toadb并发编程 开源贡献: toadb开源库 个人主页:我的主页 管理社区:开源数据库 座右铭:天行健,君子以自强不息;地势坤&#…...
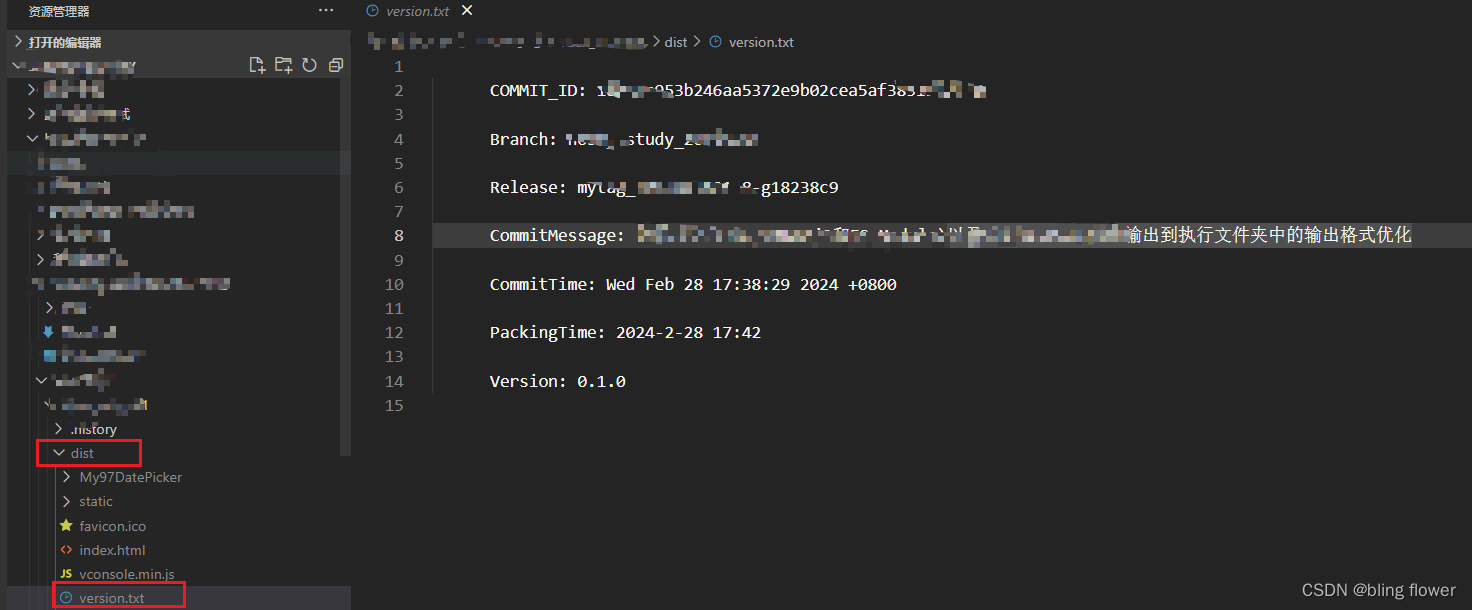
vue项目打包获取git commit信息并输出到打包后的指定文件夹中
需求背景: 前端项目经常打包,发包部署,为了方便测试及运维发现问题时与正确commit信息对比 实现方式: 使用Node.js的child_process模块来执行git命令 实现步骤: 1.在package.json的同级目录下新建一个version.js文件。…...

vue 移动端app预览和保存pdf踩坑
需求 使用Vue开发h5,嵌套到Android和IOS的Webview里,需要实现pdf预览和保存功能,预览pdf的功能,我这边使用了三个库,pdf5,pdf.js,vue.pdf,现在把这三个库在app端的坑分享一下。先说…...
Vueuse:打造高效的 Vue.js 开发利器
Vueuse:打造高效的 Vue.js 开发利器 Vueuse 是一个功能强大的 Vue.js 生态系统工具库,它提供了一系列的可重用的 Vue 组件和函数,帮助开发者更轻松地构建复杂的应用程序。本文将介绍 Vueuse 的主要特点和用法,以及它在 Vue.js 开发…...

mysql锁的创建方式
在 MySQL 中,锁是用来控制多个用户对同一数据的访问。主要有两种类型的锁:表级锁和行级锁。MySQL 的锁定机制主要是通过 SQL 语句来实现的,而不是通过特定的锁定命令。下面是一些常见的锁相关的 SQL 操作方式:表级锁 MySQL 中,表级锁是最基本的锁策略,它会锁定整个表。一…...
5.WEB渗透测试-前置基础知识-常用的dos命令
内容参考于: 易锦网校会员专享课 上一篇内容:4.WEB渗透测试-前置基础知识-快速搭建渗透环境(下)-CSDN博客 常用的100个CMD指令 1.gpedit.msc—–组策略 2. sndrec32——-录音机 3. Nslookup——-IP地址侦测器 ,是一个…...
解决:code ERESOLVE:ERESOLVE could not resolve 的报错问题
报错实例 报错原因 是我执行npm i xxx-xx的时候会出现这个错误 查了资料表示是node.js的问题 或者的依赖本身的问题 解决 1.在后面加上 --legacy-peer-deps 示例:npm i sass-loader7.3.1 --legacy-peer-deps 2,检查node版本,更改node版本 …...

Dockerfile(3) - WORKDIR 指令详解
WORKDIR 切换到镜像中的指定路径,设置工作目录在 WORKDIR 中需要使用绝对路径,如果镜像中对应的路径不存在,会自动创建此目录一般用 WORKDIR 来替代 切换目录进行操作的指令 RUN cd <path> && <do something> WORKDIR…...

2024万元投影仪怎么选?极米RS10 Ultra和当贝X5 Ultra实测横评
随着过去一年投影仪的不断进步,高端型号在2024年初的选择变得更加多样。除了激光外混光已然成为“金字塔顶端”的一种全新光源选择。目前主流的就是作为Dual Light 2.0新升级的极米RS10 Ultra,以及ALPD5.0超级全色激光代表当贝X5 Ultra。很多人也肯定想知…...

java环境搭建
要搭建 Java 环境,你需要进行以下步骤: 1. 下载和安装 JDK(Java Development Kit):访问 Oracle 官方网站(https://www.oracle.com/java/technologies/javase-jdk14-downloads.html),…...
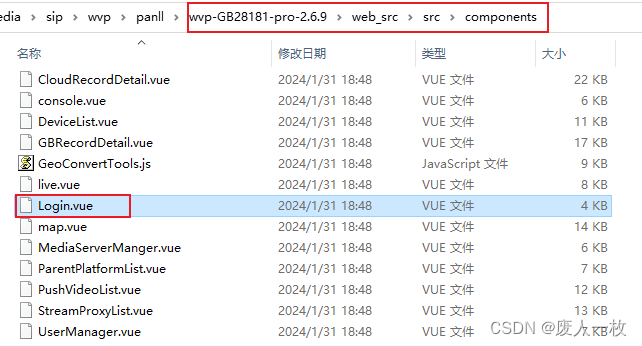
【GB28181】wvp-GB28181-pro快速修改登录页面名称(前端)
引言 作为一个非前端开发人员,自己摸索起来比较费劲,也浪费了很多时间 本文快速帮助开发者修改为自己名称的一个国标平台 文章目录 一、 预期效果展示二、 源码修改-前端三、 验证修改效果一、 预期效果展示 二、 源码修改-前端 需要修改的文件位置: 项目工程下web_src目录…...
【lv15 day1 设备号申请和注销】
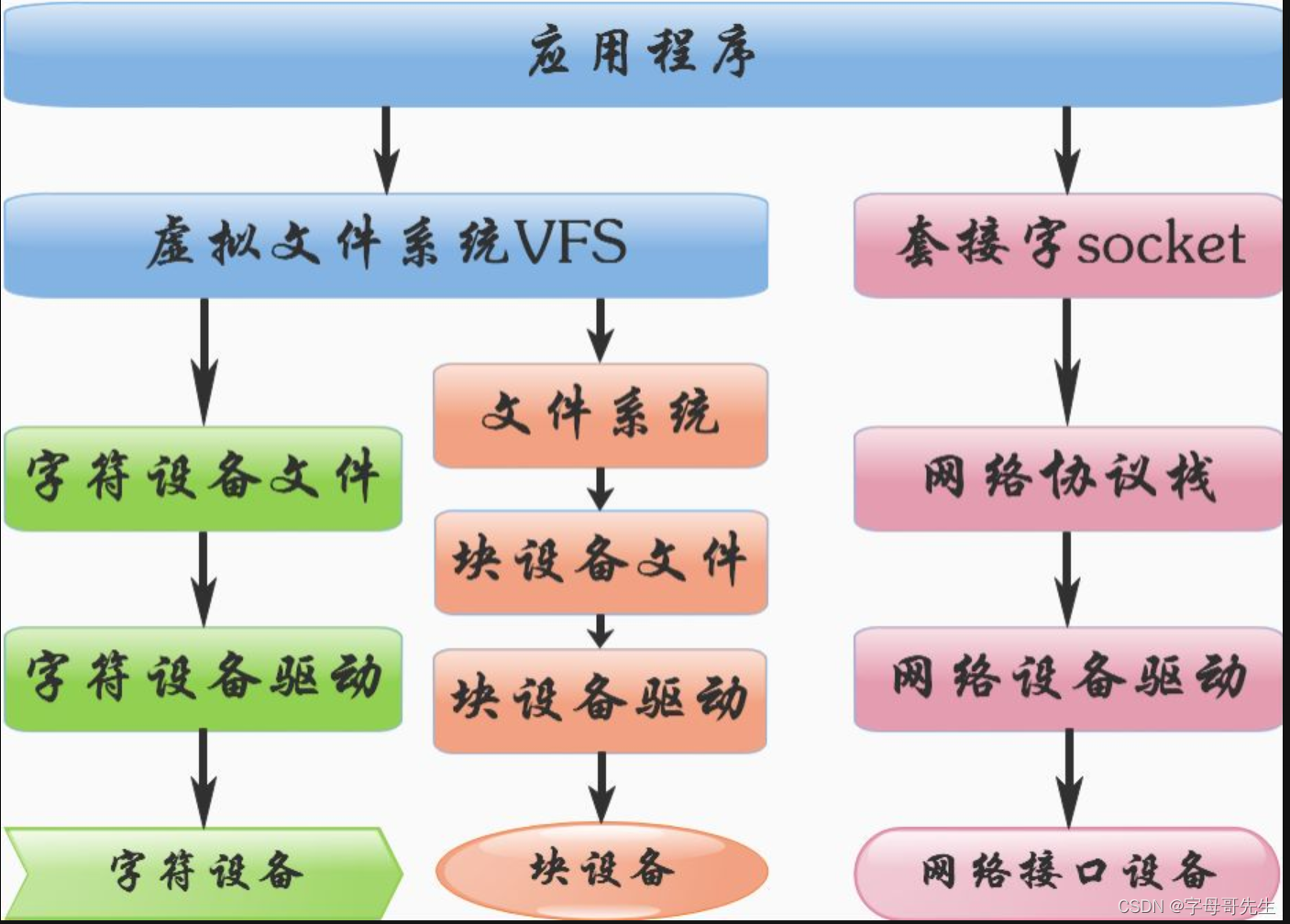
一、Linux内核对设备的分类 linux的文件种类: -:普通文件 d:目录文件 p:管道文件 s:本地socket文件 l:链接文件 c:字符设备 b:块设备Linux内核按驱动程序实现模型框架的不同&#…...

JVM对象创建与内存分配机制
JVM对象创建与内存分配机制 JVM对象创建与内存分配机制 JVM对象创建与内存分配机制对象的创建过程内存分配对象栈上分配对象逃逸分析标量替换 对象在Eden区分配大对象直接进入老年代长期存活的对象将进入老年代对象年龄动态判断老年代空间分配担保机制 对象头与指针压缩对象头利…...

自抗扰控制三阶LADRC在三相LCL逆变器模型中的应用:图一至图三的详细展示及参考文献
自抗扰控制三阶LADRC控制三相LCL逆变器模型 图一:d轴参考电流在0.15从40变到80的并网电压电流波形 图二:三阶LADRC结构控制LCL三阶模型 图三:整体结构图 参考文献:基于抗扰控制三相LCL逆变器控制策略研究 光伏并网逆变器最头疼的就是LCL滤波器引发的震荡问题。这玩意儿参数敏感…...

从caching_sha2_password到mysql_native_password:Navicat连接MySQL 8.0的两种主流方案解析
1. MySQL 8.0身份验证插件变更的背景 最近不少朋友在用Navicat连接MySQL 8.0时遇到了"plugin caching_sha2_password could not be loaded"的错误提示,这其实是MySQL 8.0引入的一个重大安全变更。作为长期使用MySQL的老用户,我第一次遇到这个问…...

软件冲刺待办列表管理化的任务管理
在快节奏的软件开发中,高效的任务管理是团队成功的关键。软件冲刺待办列表管理化的任务管理,正是为了解决这一痛点而生。它将敏捷开发中的冲刺(Sprint)与待办列表(Backlog)相结合,帮助团队清晰规…...

告别纸上谈兵:在Multisim里玩转74系列芯片,做个能计分能倒计时的抢答器仿真
从理论到实践:用Multisim打造智能抢答器系统 在数字电路的学习过程中,许多初学者都会遇到一个共同的困境——虽然能够理解74系列芯片的数据手册和逻辑功能表,但当真正需要将这些芯片组合成一个完整系统时,却不知从何下手。本文将…...

ComfyUI Impact Pack 安装后报错排查指南:从依赖缺失到解决方案
1. 遇到ComfyUI Impact Pack报错怎么办? 最近有不少朋友反馈,明明已经安装了ComfyUI Impact Pack插件,但运行时还是会出现"节点未找到"的报错提示。这种情况我遇到过好几次,刚开始也是一头雾水,后来慢慢摸索…...

用FPGA实现一个USB转串口工具:从协议理解到Verilog实战
用FPGA实现一个USB转串口工具:从协议理解到Verilog实战 在嵌入式开发领域,USB转串口工具就像工程师的"瑞士军刀"——从单片机调试到工业设备通信都离不开它。市面上虽然有成品的USB转TTL模块,但自己动手用FPGA实现一个,…...
)
告别复杂配置!在Ubuntu 20.04/22.04上快速部署Astra Pro摄像头(含PCL点云实时显示)
在Ubuntu 20.04/22.04上极简部署Astra Pro深度相机的完整指南 深度相机在机器人、三维重建和计算机视觉领域扮演着越来越重要的角色。Astra Pro作为一款性价比极高的深度感知设备,其部署过程却常常让开发者头疼。本文将彻底改变这一现状——通过自动化脚本和现代包管…...

2026 年 5 大编程网站深度对比:零基础到就业,谁才是自学首选?
引言:自学编程的崛起与平台的抉择 在数字浪潮的推动下,编程自学已成为许多人迈向IT行业的首选路径。据《2025年在线教育趋势报告》显示,全球有超过60%的编程学习者倾向于通过线上平台进行自学。然而,从“零基础”到“成功就业”的…...

Tinder联合World推身份验证:前往验证球验证,可获五次免费推广及“已验证人类徽章”
Tinder携手World ID:面部扫描验证解锁免费推广Tinder用户通过前往World公司的身份验证球进行面部扫描,证明自己是真实人类后,可在应用程序中获得五次免费推广机会。这一服务源于去年World在日本的试点项目,如今正拓展至包括日本和…...

从蓝牙到UWB:手把手拆解CCC R3标准如何实现车辆‘厘米级’安全定位
从蓝牙到UWB:手把手拆解CCC R3标准如何实现车辆‘厘米级’安全定位 当你的手机靠近车门时,车辆自动解锁;坐进驾驶舱的瞬间,引擎悄然启动——这种科幻电影般的体验,正通过CCC R3标准中的UWB定位技术走进现实。与传统方…...