C++中的容器
1.1 线性容器
1)std::array
看到这个容器的时候肯定会出现这样的问题:
为什么要引入 std::array 而不是直接使用 std::vector?
已经有了传统数组,为什么要用 std::array?
先回答第一个问题,与 std::vector 不同,std::array 对象的大小是固定的,如果容器大小是固定的,那么可以优先考虑使用 std::array 容器。 另外由于 std::vector 是自动扩容的,当存入大量的数据后,并且对容器进行了删除操作, 容器并不会自动归还被删除元素相应的内存,这时候就需要手动运行 shrink_to_fit() 释放这部分内存。
std::vector<int> v;
std::cout << "size:" << v.size() << std::endl; // 输出 0
std::cout << "capacity:" << v.capacity() << std::endl; // 输出 0
// 如下可看出 std::vector 的存储是自动管理的,按需自动扩张
// 但是如果空间不足,需要重新分配更多内存,而重分配内存通常是性能上有开销的操作
v.push_back(1);
v.push_back(2);
v.push_back(3);
std::cout << "size:" << v.size() << std::endl; // 输出 3
std::cout << "capacity:" << v.capacity() << std::endl; // 输出 4
// 这里的自动扩张逻辑与 Golang 的 slice 很像
v.push_back(4);
v.push_back(5);
std::cout << "size:" << v.size() << std::endl; // 输出 5
std::cout << "capacity:" << v.capacity() << std::endl; // 输出 8
// 如下可看出容器虽然清空了元素,但是被清空元素的内存并没有归还
v.clear();
std::cout << "size:" << v.size() << std::endl; // 输出 0
std::cout << "capacity:" << v.capacity() << std::endl; // 输出 8
// 额外内存可通过 shrink_to_fit() 调用返回给系统
v.shrink_to_fit();
std::cout << "size:" << v.size() << std::endl; // 输出 0
std::cout << "capacity:" << v.capacity() << std::endl; // 输出 0而第二个问题就更加简单,使用 std::array 能够让代码变得更加“现代化”,而且封装了一些操作函数,比如获取数组大小以及检查是否非空,同时还能够友好的使用标准库中的容器算法,比如 std::sort。
使用 std::array 很简单,只需指定其类型和大小即可:
#include <iostream>
#include <array>
#include <algorithm> // std::sortusing namespace std;// int *arr_p = arr;
//当我们开始用上了 std::array 时,难免会遇到要将其兼容 C 风格的接口,这里有三种做法:
void foo(int *p, int len) {return;
}int main() {// 数组大小参数必须是常量表达式constexpr int len = 4;std::array<int, len> arr = {1, 3, 2, 4};cout << "arr is empty[1] or not empty[0] ? " << arr.empty() << endl; // 检查容器是否为空cout << "arr's size is: " << arr.size() << endl; // 返回容纳的元素数// 迭代器支持cout << "The original arr is: " << endl;for (auto &i : arr) {cout << i <<" ";}// 用 lambda 表达式排序std::sort(arr.begin(), arr.end(), [](int a, int b) {return b < a;});// 非法,不同于 C 风格数组,std::array 不会自动退化成 T*// std::array<int, 4> arr = {1,2,3,4};// C 风格接口传参// foo(arr, arr.size()); // 非法, 无法隐式转换foo(&arr[0], arr.size());foo(arr.data(), arr.size());// 使用 `std::sort`std::sort(arr.begin(), arr.end());cout << "\n";cout << "The sorted arr is: " << endl;for (auto &i : arr) {cout << i << " ";}}2)std::forward_list
std::forward_list 是一个列表容器,使用方法和 std::list 基本类似,因此我们就不花费篇幅进行介绍了。
需要知道的是,和 std::list 的双向链表的实现不同,std::forward_list 使用单向链表进行实现, 提供了 O(1) 复杂度的元素插入,不支持快速随机访问(这也是链表的特点), 也是标准库容器中唯一一个不提供 size() 方法的容器。当不需要双向迭代时,具有比 std::list 更高的空间利用率。
1.2 无序容器
我们已经熟知了传统 C++ 中的有序容器 std::map/std::set,这些元素内部通过红黑树进行实现, 插入和搜索的平均复杂度均为 O(log(size))。在插入元素时候,会根据 < 操作符比较元素大小并判断元素是否相同, 并选择合适的位置插入到容器中。当对这个容器中的元素进行遍历时,输出结果会按照 < 操作符的顺序来逐个遍历。
而无序容器中的元素是不进行排序的,内部通过 Hash 表实现,插入和搜索元素的平均复杂度为 O(constant), 在不关心容器内部元素顺序时,能够获得显著的性能提升。
C++11 引入了的两组无序容器分别是:std::unordered_map/std::unordered_multimap 和 std::unordered_set/std::unordered_multiset。
它们的用法和原有的 std::map/std::multimap/std::set/set::multiset 基本类似, 由于这些容器我们已经很熟悉了,便不一一举例,我们直接来比较一下std::map和std::unordered_map:
#include <iostream>
#include <string>
#include <unordered_map>
#include <map>
int main() {// 两组结构按同样的顺序初始化std::unordered_map<int, std::string> u = {{1, "1"},{3, "3"},{2, "2"}};std::map<int, std::string> v = {{1, "1"},{3, "3"},{2, "2"}};// 分别对两组结构进行遍历std::cout << "std::unordered_map" << std::endl;for( const auto & n : u)std::cout << "Key:[" << n.first << "] Value:[" << n.second << "]\n";std::cout << std::endl;std::cout << "std::map" << std::endl;for( const auto & n : v)std::cout << "Key:[" << n.first << "] Value:[" << n.second << "]\n";
}最终的输出结果为:
std::unordered_map
Key:[2] Value:[2]
Key:[3] Value:[3]
Key:[1] Value:[1]
std::map
Key:[1] Value:[1]
Key:[2] Value:[2]
Key:[3] Value:[3]1.3 元组
了解过 Python 的程序员应该知道元组的概念,纵观传统 C++ 中的容器,除了 std::pair 外, 似乎没有现成的结构能够用来存放不同类型的数据(通常我们会自己定义结构)。 但 std::pair 的缺陷是显而易见的,只能保存两个元素。
1.3.1元组基本操作
关于元组的使用有三个核心的函数:
std::make_tuple: 构造元组
std::get: 获得元组某个位置的值
std::tie: 元组拆包
#include <tuple>
#include <iostream>
auto get_student(int id)
{// 返回类型被推断为 std::tuple<double, char, std::string>if (id == 0)return std::make_tuple(3.8, 'A', "张三");if (id == 1)return std::make_tuple(2.9, 'C', "李四");if (id == 2)return std::make_tuple(1.7, 'D', "王五");return std::make_tuple(0.0, 'D', "null");// 如果只写 0 会出现推断错误, 编译失败
}
int main()
{auto student = get_student(0);std::cout << "ID: 0, "<< "GPA: " << std::get<0>(student) << ", "<< "成绩: " << std::get<1>(student) << ", "<< "姓名: " << std::get<2>(student) << '\n';double gpa;char grade;std::string name;// 元组进行拆包std::tie(gpa, grade, name) = get_student(1);std::cout << "ID: 1, "<< "GPA: " << gpa << ", "<< "成绩: " << grade << ", "<< "姓名: " << name << '\n';
}std::get 除了使用常量获取元组对象外,C++14 增加了使用类型来获取元组中的对象:
std::tuple<std::string, double, double, int> t("123", 4.5, 6.7, 8);
std::cout << std::get<std::string>(t) << std::endl;
std::cout << std::get<double>(t) << std::endl; // 非法, 引发编译期错误
std::cout << std::get<3>(t) << std::endl;1.3.2运行期索引
如果你仔细思考一下可能就会发现上面代码的问题,std::get<> 依赖一个编译期的常量,所以下面的方式是不合法的:
int index = 1;
std::get<index>(t);那么要怎么处理?答案是,使用 std::variant<>(C++ 17 引入),提供给 variant<> 的类型模板参数 可以让一个 variant<> 从而容纳提供的几种类型的变量(在其他语言,例如 Python/JavaScript 等,表现为动态类型):
#include <variant>
template <size_t n, typename... T>
constexpr std::variant<T...> _tuple_index(const std::tuple<T...>& tpl, size_t i) {if constexpr (n >= sizeof...(T))throw std::out_of_range("越界.");if (i == n)return std::variant<T...>{ std::in_place_index<n>, std::get<n>(tpl) };return _tuple_index<(n < sizeof...(T)-1 ? n+1 : 0)>(tpl, i);
}
template <typename... T>
constexpr std::variant<T...> tuple_index(const std::tuple<T...>& tpl, size_t i) {return _tuple_index<0>(tpl, i);
}
template <typename T0, typename ... Ts>
std::ostream & operator<< (std::ostream & s, std::variant<T0, Ts...> const & v) { std::visit([&](auto && x){ s << x;}, v); return s;
}这样我们就能:
int i = 1;
std::cout << tuple_index(t, i) << std::endl;1.3.3元组合并与遍历
还有一个常见的需求就是合并两个元组,这可以通过 std::tuple_cat 来实现:
auto new_tuple = std::tuple_cat(get_student(1), std::move(t));马上就能够发现,应该如何快速遍历一个元组?但是我们刚才介绍了如何在运行期通过非常数索引一个 tuple 那么遍历就变得简单了, 首先我们需要知道一个元组的长度,可以:
template <typename T>
auto tuple_len(T &tpl) {return std::tuple_size<T>::value;
}
这样就能够对元组进行迭代了:
// 迭代
for(int i = 0; i != tuple_len(new_tuple); ++i)// 运行期索引std::cout << tuple_index(new_tuple, i) << std::endl;1.4总结
本章简单介绍了现代 C++ 中新增的容器,它们的用法和传统 C++ 中已有的容器类似,相对简单,可以根据实际场景丰富的选择需要使用的容器,从而获得更好的性能。
std::tuple 虽然有效,但是标准库提供的功能有限,没办法满足运行期索引和迭代的需求,好在我们还有其他的方法可以自行实现。
相关文章:

C++中的容器
1.1 线性容器1)std::array看到这个容器的时候肯定会出现这样的问题:为什么要引入 std::array 而不是直接使用 std::vector?已经有了传统数组,为什么要用 std::array?先回答第一个问题,与 std::vector 不同,…...
2023备战金三银四,Python自动化软件测试面试宝典合集(五)
接上篇八、抓包与网络协议8.1 抓包工具怎么用 我原来的公司对于抓包这块,在 App 的测试用得比较多。我们会使用 fiddler 抓取数据检查结果,定位问题,测试安全,制造弱网环境;如:抓取数据通过查看请求数据,请…...

SpringDI自动装配BeanSpring注解配置和Java配置类
依赖注入 上篇博客已经提到了DI注入方式的构造器注入,下面采用set方式进行注入 基于set方法注入 public class User {private String name;private Address address;private String[] books;private List<String> hobbys;private Map<String,String>…...
2月面经:真可惜...拿了小米的offer,字节却惨挂在三面
我是2月份参加字节跳动和华为的面试的,虽然我只拿下了小米的offer,但是我自己也满足了,想把经验分享出来,进而帮助更多跟我一样想进大厂的同行朋友们,希望大家可以拿到理想offer。 自我介绍 我是16年从南京工业大学毕…...

磐云PY-B8 网页注入
文章目录1.使用渗透机场景windows7中火狐浏览器访问服务器场景中的get.php,根据页面回显获取Flag并提交;2.使用渗透机场景windows7中火狐浏览器访问服务器场景中的post.php,根据页面回显获取Flag并提交;3.使用渗透机场景windows7中…...

多传感器融合定位十-基于滤波的融合方法Ⅰ其二
多传感器融合定位十-基于滤波的融合方法Ⅰ其二3. 滤波器基本原理3.1 状态估计模型3.2 贝叶斯滤波3.3 卡尔曼滤波(KF)推导3.4 扩展卡尔曼滤波(EKF)推导3.5 迭代扩展卡尔曼滤波(IEKF)推导4. 基于滤波器的融合4.1 状态方程4.2 观测方程4.3 构建滤波器4.4 Kalman 滤波实际使用流程4…...
Java集合面试题:HashMap源码分析
文章目录一、HashMap源码二、HashMap数据结构模型图三、HashMap中如何确定元素位置四、关于equals与hashCode函数的重写五、阅读源码基本属性参考文章:史上最详细的 JDK 1.8 HashMap 源码解析参考文章:Hash详解参考文章:hashCode源码分析参考…...
,真题含思路)
华为OD机试 - 数组合并(Python),真题含思路
数组合并 题目 现在有多组整数数组, 需要将他们合并成一个新的数组。 合并规则, 从每个数组里按顺序取出固定长度的内容合并到新的数组中, 取完的内容会删除掉, 如果该行不足固定长度或者已经为空, 则直接取出剩余部分的内容放到新的数组中, 继续下一行。 如样例 1, 获得长度…...
Vue2创建移动端项目
一、Vscode Vscode 下载安装以及常用的插件 1、Vscode 下载 下载地址:Vscode 中文语言插件 搜索 chinese 主题 Atom 主题 文件图标主题 搜索 icon 源代码管理插件GitLens 搜索 GitLens Live Server _本地服务器 搜索 Live Server Prettier - Code formatt…...
PorterDuffXfermode与圆角图片
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl 圆角图片 在项目开发中,我们常用到这样的功能:显示圆角图片。 这个是咋做的呢?我们来瞅瞅其中一种实现方式 /*** param bitmap 原图* p…...

如何准备大学生电子设计竞赛
大学生电子设计竞赛难度中上,一般有好几个类型题目可以选择,参赛者可以根据自己团队的能力、优势去选择合适自己的题目,灵活自主空间较大。参赛的同学们可以在暑假好好学习相关内容,把往年的题目拿来练练手。这个比赛含金量还是有…...

【Java容器(jdk17)】ArrayList深入源码,就是这么简单
ArrayList深入源码一、ArrayList源码解析1. MIXIN 的混入2. 属性说明3. 构造方法4. 其他方法(核心)iterator 和 listIterator 方法add方法remove 方法sort方法其他二、ArrayList 为什么是线程不安全的?体现哪些方面呢?三、ArrayLi…...
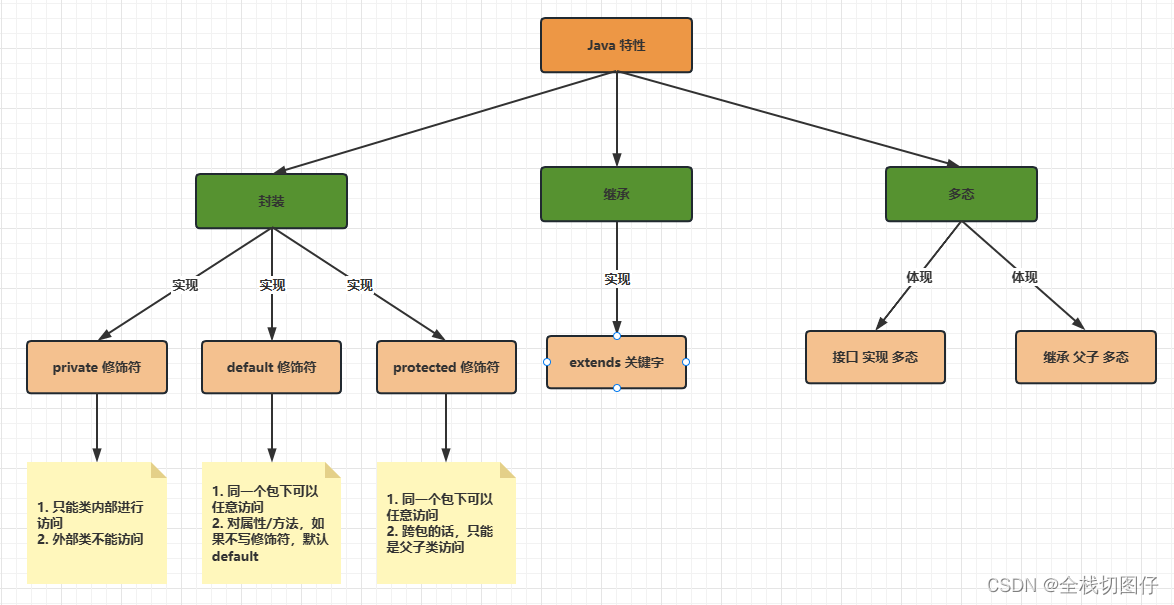
【Java 面试合集】简述下Java的三个特性 以及项目中的应用
简述下Java的特征 以及项目中的应用 1. 概述 上述截图中就是Java的三大特性,以及特性的实现方案。接下来就每个点展开来说说 2. 封装 满足:隐藏实现细节,公开使用方法 的都可以理解为是封装 而实现封装的有利手段就是权限修饰符了。可以根据…...
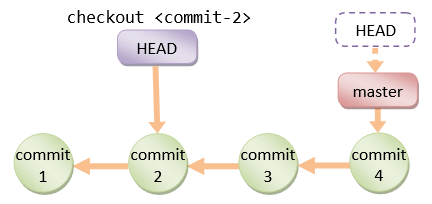
git基本概念图示【学习】
基本概念工作区(Working Directory)就是你在电脑里能看到的目录,比如名字为 gafish.github.com 的文件夹就是一个工作区本地版本库(Local Repository)工作区有一个隐藏目录 .git,这个不算工作区,…...

微前端qiankun架构 (基于vue2实现)使用教程
工具使用版本 node --> 16vue/cli --> 5 创建文件 创建文件夹qiankun-test。 使用vue脚手架创建主应用main和子应用dev 主应用 安装 qiankun: yarn add qiankun 或者 npm i qiankun -S 使用qiankun: 在 utils 内创建 微应用文件夹 microApp,在该文件夹…...

记录robosense RS-LIDAR-16使用过程3
一、wireshark抓包保存pcap文件并解析ubuntu18安装wireshark,参考下面csdn教程,官网教程我看的一脸蒙(可能英语太差)https://blog.csdn.net/weixin_46048542/article/details/121730448?spm1001.2101.3001.6650.2&utm_medium…...

【博学谷学习记录】大数据课程-学习第七周总结
Hadoop配置文件修改 Hadoop安装主要就是配置文件的修改,一般在主节点进行修改,完毕后scp下发给其他各个从节点机器 文件中设置的是Hadoop运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统中设置了JAVA_HOME,它也…...

154、【动态规划】leetcode ——494. 目标和:回溯法+动态规划(C++版本)
题目描述 原题链接:494. 目标和 解题思路 (1)回溯法 本题的特点是nums中每个元素只能使用一次,分别试探加上nums[index]和减去nums[index],然后递归的遍历下一个元素index 1。 class Solution { public:int res …...

MySQL-窗口函数
窗口函数概念常用窗口函数聚合窗口函数专用窗口函数语法OVER子句window_specwindow_name (命名窗口)partition_clause 分区order_clause 排序frame_clause 范围 (指定窗口大小)使用限制练习准备概念 窗口函数对一组查询执行类似于聚合的操作。然而&#…...

【C++设计模式】学习笔记(1):面向对象设计原则
目录 简介面向对象设计原则(1)依赖倒置原则(DIP)(2)开放封闭原则(OCP)(3)单一职责原则(SRP)(4)Liskov替换原则(LSP)(5)接口隔离原则(ISP)(6)优先使用对象组合,而不是类继承(7)封装变化点(8)针对接口编程,而不是针对实现编程结语简介 Hello! 非常感谢您阅读海…...

终极iOS设备降级指南:使用Legacy-iOS-Kit让旧设备重获新生 [特殊字符]
终极iOS设备降级指南:使用Legacy-iOS-Kit让旧设备重获新生 🚀 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Le…...

GPU资源利用率监测与优化实战指南
1. GPU资源利用率监测基础解析在超算中心和AI训练集群中,GPU资源利用率(GPU_UTIL)是衡量计算效率的核心指标。这个看似简单的百分比背后,实际上反映了GPU内部多个执行单元的综合活跃状态。通过NVIDIA的DCGM(Data Cente…...

新手小白必看!AI大模型自学路线图,从入门到精通_自学AI大模型学习路线推荐
自学AI大模型学习路线推荐 今天,我想和大家分享一条自学AI大模型的学习路线,希望能帮助新手小白们更好地进入这个领域。 1. 打好基础:数学与编程 数学基础 线性代数:理解矩阵、向量、特征值、特征向量等概念。推荐课程:…...

重构计算机历史叙事:挖掘被遗忘的贡献者与构建包容性科技未来
1. 项目概述:为什么我们需要重写计算机历史如果你问一个对计算机历史稍有了解的人,让他列举几位先驱,大概率会听到冯诺依曼、艾伦图灵、比尔盖茨、史蒂夫乔布斯这些名字。这个名单很长,但有一个共同点:他们几乎都是白人…...

汽车软件化演进:从原生应用到手机集成的技术路径与实战解析
1. 从机械到智能:汽车软件化的十字路口十年前,当福特和通用汽车开始在硅谷和南加州大肆招聘软件工程师时,很多人可能还没意识到,这不仅仅是一次普通的“招兵买马”,而是一场深刻改变汽车工业基因的序曲。2014年那会儿&…...

应用安全从被动到主动:企业如何提升弹性与可靠性,降低安全债务?
ZDNET核心观点应用安全需董事会层面问责,企业文化影响“设计即安全”工作,运营模式将预防转化为行动。企业聚焦软件策略改变网络安全结果,挑战是在开发周期早期融入安全措施,构建捕捉漏洞和隐患的工具技术。本文将从被动到主动的转…...

AI智能体技能库架构设计与实现:从标准化到工程化实践
1. 项目概述:从零构建一个AI智能体技能库最近在GitHub上看到一个挺有意思的项目,叫leon2k2k2k/agent-skills。光看名字,你可能觉得这又是一个关于AI智能体(Agent)的普通代码仓库。但作为一个在AI应用开发领域摸爬滚打了…...

Narrative-craft:工程化叙事框架的设计、实现与集成指南
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“Narrative-craft”,作者是chengjialu8888。光看名字,你可能会觉得这又是一个讲“叙事”或者“故事创作”的抽象工具。但点进去仔细研究后,我发现它远不止于此。这…...

QFN测试插座技术解析与应用实践
1. QFN测试插座的技术挑战与解决方案在半导体测试领域,QFN封装器件的测试一直是个棘手问题。这种无引线四方扁平封装虽然节省空间、散热优异,但恰恰因为缺少传统引脚,使得测试接触变得异常困难。我经手过不少QFN测试项目,最头疼的…...

RAGday13-day15
Day13:RAG 常见问题 & 调优实战检索不到内容原因:分块太小、关键词太偏、没做混合检索解决:换递归 / 父子分块、加上 ES 混合检索、做 Query 改写搜到内容多但答不对原因:检索杂、没重排、没上下文压缩解决:加 Rer…...