推荐系统经典模型YouTubeDNN代码
文章目录
- 前言
- 数据预处理部分
- 模型训练预测部分
- 总结与问答
前言
- 上一篇讲到过YouTubeDNN论文部分内容,但是没有代码部分。最近网上教学视频里看到一段关于YouTubeDNN召回算法的代码,现在我分享一下给大家参考看一下,并附上一些我对代码的理解。
数据预处理部分
- 首先我们需要对数据集进行预处理,数据集格式如下图所示
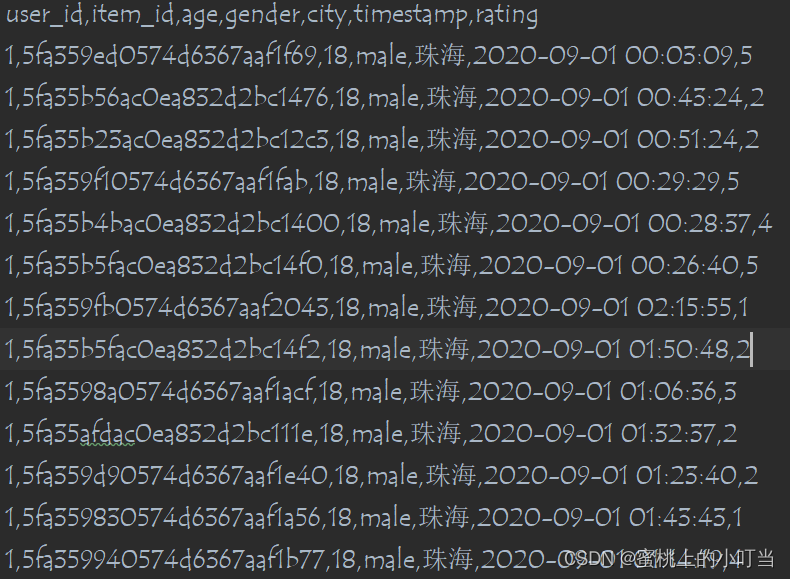
- 根据YouTubeDNN论文,输入的数据是用户的信息、视频的ID序列、用户搜索的特征和一些地理信息等其他信息。到了基于文章内容的信息流产品中,就变成了用户 ID、年龄、性别、城市、阅读的时间戳再加上视频的ID。我们把这些内容可以组合成YouTubeDNN需要的内容,最后处理成需要的Embedding。
from tqdm import tqdm
import numpy as np
import random
from tensorflow.python.keras.preprocessing.sequence import pad_sequencesdef gen_data_set(data, negsample=0):# 根据timestamp排序数据,并替换data.sort_values("timestamp", inplace=True)#根据item_id进行去重item_ids = data['item_id'].unique()# 构建训练与测试listtrain_set = list()test_set = list()for reviewrID, hist in tqdm(data.groupby('user_id')):# 正样本列表pos_list = hist['item_id'].tolist()rating_list = hist['rating'].tolist()if negsample > 0:# 候选集中去掉用户看过的item项目candidate_set = list(set(item_ids) - set(pos_list))# 随机选择负采样样本neg_list = np.random.choice(candidate_set, size=len(pos_list) * negsample, replace=True)for i in range(1, len(pos_list)):if i != len(pos_list) - 1:# 训练集和测试集划分train_set.append((reviewrID, hist[::-1], pos_list[i], 1, len(hist[:: -1]), rating_list[i]))for negi in range(negsample):train_set.append((reviewrID, hist[::-1], neg_list[i * negsample + negi], 0, len(hist[::-1])))else:test_set.append((reviewrID, hist[::-1], pos_list[i], 1, len(hist[::-1]), rating_list[i]))# 打乱数据集random.shuffle(train_set)random.shuffle(test_set)return train_set, test_setdef gen_model_input(train_set, user_profile, seq_max_len):# 用户idtrain_uid = np.array([line[0] for line in train_set])# 历史交互序列train_seq = [line[1] for line in train_set]# 物品idtrain_iid = np.array([line[2] for line in train_set])# 正负样本标签train_label = np.array([line[3] for line in train_set])# 历史交互序列长度train_hist_len = np.array([line[4] for line in train_set])train_seq_pad = pad_sequences(train_seq, maxlen=seq_max_len, padding='post', truncating='post', value=0 )train_model_input = {"user_id": train_uid, "item_id": train_iid, "hist_item_id": train_seq_pad, "hist_len": train_hist_len}for key in {"gender", "age", "city"}:train_model_input[key] = user_profile.loc[train_model_input['user_id']][key].valuesreturn train_model_input, train_label
- 代码解释:
- **gen_data_set() **主要作用是接收数据集(data)和一个负采样(negsample)参数,返回一个训练集列表(trainset)和一个测试集列表(testset)。具体流程是先通过timetamp列对数据进行排序,根据item_id进行去重;然后根据user_id分组形成正负样本(正样本为购买过的,负样本为没有购买过的),对于negsample大于0,我们就要进行负采样,也就是随机选择一些没有购买过的商品为负样本,然后将它们保存到训练集中;最后,将正负样本数据以及其他信息(如历史交互序列、用户 ID 和历史交互序列的长度)保存到训练集列表和测试集列表中。
- gen_model_input() 主要作用就是接收一个训练集列表、用户画像信息和序列最大长度参数,返回训练模型的输入和标签。首先将训练集列表拆分成 5 个列表(train_uid train_seq train_iid train_label train_hist_len);然后使用pad_sequences() 函数对历史交互序列进行填充处理,将其变成长度相同的序列。最后,将用户画像信息(gender age city)加入到训练模型的关键字中,返回训练模型的输入和标签。
- pad_sequences():pad_sequences()这个函数是来自于TensorFlow中数据预处理的一种方法,主要就是数据预填充。在TensorFlow2.8版本之前可以通过
from tensorflow.python.keras.preprocessing.sequence import pad_sequences调用,后期版本则是在keras.utils里,这里建议使用低版本tesorflow2,具体版本信息请参考链接。
模型训练预测部分
- 进入模型训练阶段,我们需要先了解一下,代码里我们所使用的一些包和函数介绍
- sklearn.preprocessing.LabelEncoder:对数据进行特征编码
- deepctr.feature_column.SparseFeat, VarLenSparseFeat:用户构建用户和物品特征输入。
- deepmatch:用于构建和训练推荐模型
- faiss:高效向量相似性搜索库
- models.recall.preprocess.gen_data_set, gen_model_input:数据预处理部分(自建)
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from models.recall.preprocess import gen_data_set, gen_model_input
from deepctr.feature_column import SparseFeat, VarLenSparseFeat
from tensorflow.python.keras import backend as K
from tensorflow.python.keras.models import Model
import tensorflow as tf
from deepmatch.models import *
from deepmatch.utils import recall_N
from deepmatch.utils import sampledsoftmaxloss
import numpy as np
from tqdm import tqdm
import faissclass YouTubeModel(object):def __init__(self, embedding_dim=32):self.SEQ_LEN = 50self.embedding_dim = embedding_dimself.user_feature_columns = Noneself.item_feature_columns = Nonedef training_set_construct(self):# 数据加载data = pd.read_csv('../../data/read_history.csv')# 负采样个数negsample = 0# 特征编码features = ["user_id", "item_id", "gender", "age", "city"]features_max_idx={}for feature in features:lbe = LabelEncoder()data[feature] = lbe.fit_transform(data[feature]) + 1features_max_idx[feature] = data[feature].max() + 1# 抽取用户、物品特征(并去重)user_info = data[["user_id", "gender", "age", "city"]].drop_duplicates('user_id')item_info = data[["item_id"]].drop_duplicates('item_id')# 构建输入数据train_set, test_set = gen_data_set(data, negsample)# 转化模型输入train_model_input, train_label = gen_model_input(train_set, user_info, self.SEQ_LEN)test_model_input, test_label = gen_model_input(test_set, user_info, self.SEQ_LEN)# 用户端特征输入self.user_feature_columns = [SparseFeat('user_id', features_max_idx['user_id'], 16),SparseFeat('gender', features_max_idx['gender'], 16),SparseFeat('age', features_max_idx['age'], 16),SparseFeat('city', features_max_idx['city'], 16),VarLenSparseFeat(SparseFeat('hist_item_id', features_max_idx['item_id'],self.embedding_dim, embedding_name='item_id'),self.SEQ_LEN, 'mean', 'hist_len')]# 物品端特征输入self.item_feature_columns = [SparseFeat('item_id', features_max_idx['item_id'], self.embedding_dim)]return train_model_input, train_label, test_model_input, test_label, train_set, test_set, user_info, item_infodef training_model(self, train_model_input, train_label):K.set_learning_phase(True)if tf.__version__ >= '2.0.0':tf.compat.v1.disable_eager_execution()# 定义模型model = YoutubeDNN(self.user_feature_columns, self.item_feature_columns, num_sampled=100,user_dnn_hidden_units=(128, 64, self.embedding_dim))# 使用adam优化,损失函数使用softmax+cross_entropymodel.compile(optimizer="adam", loss=sampledsoftmaxloss)# 训练并保存训练过程中的数据model.fit(train_model_input, train_label, batch_size=512, epochs=20, verbose=1, validation_split=0.0,)return model# 提取用户和物品的embedding layerdef extract_embedding_layer(self, model, test_model_input, item_info):all_item_model_input = {"item_id": item_info['item_id'].values, }# 获取用户、item的embedding_layeruser_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)item_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)user_embs = user_embedding_model.predict(test_model_input, batch_size=2 ** 12)item_embs = item_embedding_model.predict(all_item_model_input, batch_size=2 ** 12)print(user_embs.shape)print(item_embs.shape)return user_embs, item_embs# 计算召回率和命中率def eval(self, user_embs, item_embs, test_model_input, item_info, test_set):test_true_label = {line[0]: line[2] for line in test_set}index = faiss.IndexFlatIP(self.embedding_dim)index.add(item_embs)D, I = index.search(np.ascontiguousarray(user_embs), 50)s = []hit = 0# 统计预测结果for i, uid in tqdm(enumerate(test_model_input['user_id'])):try:pred = [item_info['item_id'].value[x] for x in I[i]]recall_score = recall_N(test_true_label[uid], pred, N=50)s.append(recall_score)if test_true_label[uid] in pred:hit += 1except:print(i)# 计算召回率和命中率recall = np.mean(s)hit_rate = hit / len(test_model_input['user_id'])return recall, hit_ratedef scheduler(self):# 构建训练集、测试集train_model_input, train_label, test_model_input, test_label, \train_set, test_set, user_info, item_info = self.training_set_construct()self.training_model(train_model_input, train_label)# 获取用户、item的layeruser_embs, item_embs = self.extract_embedding_layer(model, test_model_input, item_info)# 评估模型recall, hit_rate = self.eval(user_embs, item_embs, test_model_input, item_info, test_set)print(recall, hit_rate)if __name__ == '__main__':model = YouTubeModel()model.scheduler()
- 代码解释:
- training_set_construct:加载数据集,特征编码,数据集预处理,使用deepctr库中的SparseFeat(离散), VarLenSparseFeat(变长)实现用户物品的特征输入。
- training_model:YoutubeDNN构建训练模型,compile编译训练模型,fit模型训练。
- extract_embedding_layer:提取用户和物品的Embedding Layer。
- eval:评估模型计算召回率和命中率,使用faiss中的faiss.IndexFlatIP(余弦距离搜索并非余弦相似度),统计预测结果,计算召回率为recall_score的平均值;命中率则是集中次数hit与test_model_input的总数。
- scheduler:串联整个召回代码的函数,负责调用。
总结与问答
- 代码中提到的离散特征和变长特征该如何选择?
- 答:首先我们要理解一下什么事离散特征,什么是变长特征?
- 离散特征:是指具有有限取值或离散类别的特征,例如性别、国家、城市等(用户画像信息)。对于离散特征,可以使用embedding来将其映射到低维连续向量空间中。这使得模型能够学习离散特征之间的相关性和交互关系。通常情况下,离散特征需要经过编码(例如one-hot multi-hot)并与其他特征一起输入到模型中。
- 变长特征:是指具有可变长度的特征,例如用户的历史行为序列或商品的标签列表。对于变长特征,可以使用循环神经网络(RNN)或Transformer等模型来建模。这些模型可以处理可变长度的序列,并捕捉序列中的时序关系和上下文信息。
- 所以对于多特征输入,通常需要混合使用。
相关文章:
推荐系统经典模型YouTubeDNN代码
文章目录 前言数据预处理部分模型训练预测部分总结与问答 前言 上一篇讲到过YouTubeDNN论文部分内容,但是没有代码部分。最近网上教学视频里看到一段关于YouTubeDNN召回算法的代码,现在我分享一下给大家参考看一下,并附上一些我对代码的理解…...
spring boot 使用RSA非对称加密,前后端传递参数加解密)
学习加密(三)spring boot 使用RSA非对称加密,前后端传递参数加解密
1.前面一篇是AES对称加密写了一个demo,为了后面的两者结合使用,今天去了解学习了下RSA非对称加密. 2.这是百度百科对(对称加密丶非对称加密)的解释: (1)对称加密算法在加密和解密时使用的是同一个秘钥。 (2)非对称加密算法需要两个密钥来进行加密和解密,这两个秘钥…...

面向对象编程入门:掌握C++类的基础(2/3):深入理解C++中的类成员函数
在C编程中,类是构建程序的基石,而理解类的默认成员函数对于高效使用C至关重要。本文将深入探讨这六个默认成员函数及其他相关概念,提供给读者一个全面的视角。 类的6个默认成员函数: 如果一个类中什么成员都没有,简称为…...

javaWeb学习04
AOP核心概念: 连接点: JoinPoint, 可以被AOP控制的方法 通知: Advice 指哪些重复的逻辑,也就是共性功能(最终体现为一个方法) 切入点: PointCut, 匹配连接点的条件,通知仅会在切入点方法执行时被应用 目标对象: Target, 通知所应用的对象 通知类…...
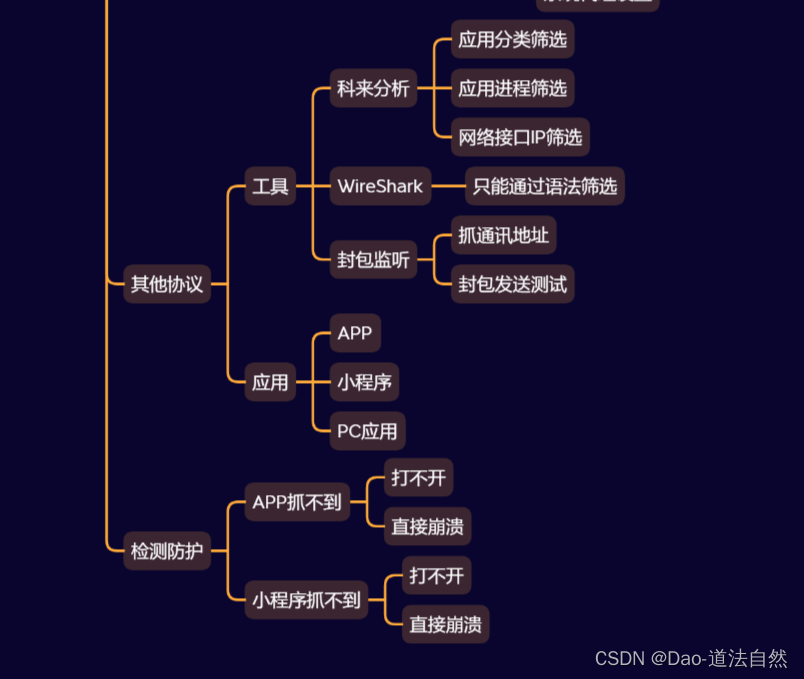
Day07:基础入门-抓包技术全局协议封包监听网卡模式APP小程序PC应用
目录 非HTTP/HTTPS协议抓包工具 WireShark 科来网络分析系统 WPE封包 思维导图 章节知识点: 应用架构:Web/APP/云应用/三方服务/负载均衡等 安全产品:CDN/WAF/IDS/IPS/蜜罐/防火墙/杀毒等 渗透命令:文件上传下载/端口服务/Sh…...

通过elementUI学习vue
<template><el-radio v-model"radio" label"1">备选项</el-radio><el-radio v-model"radio" label"2">备选项</el-radio> </template><script>export default {data () {return {radio: 1}…...
音视频数字化(数字与模拟-电视)
上一篇文章【音视频数字化(数字与模拟-音频广播)】谈了音频的广播,这次我们聊电视系统,这是音频+视频的采集、传输、接收系统,相对比较复杂。 音频系统的广播是将声音转为电信号,再调制后发射出去,利用“共振”原理,收音机接收后解调,将音频信号还原再推动扬声器,我…...
)
CSS复合选择器(二)
CSS复合选择器(二) 伪类选择器一、动态伪类:二、结构伪类三、否定伪类:四、UI伪类:五、目标伪类(了解)六、语言伪类(了解) 伪类选择器 作用:选中特殊状态的元…...

Postgresql中VACUUM操作原理和应用
VACUUM操作在PostgreSQL中的底层原理涉及几个关键概念,包括MVCC(多版本并发控制)、事务ID包裹、以及垃圾回收机制。我们逐一解析这些概念,以及它们是如何与VACUUM操作相互作用的。 关键概念 1. MVCC(多版本并发控制&…...
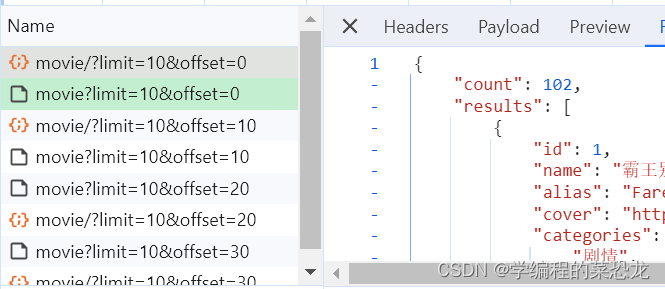
5.1 Ajax数据爬取之初介绍
目录 1. Ajax 数据介绍 2. Ajax 分析 2.1 Ajax 例子 2.2 Ajax 分析方法 (1)在网页页面右键,检查 (2)找到network,ctrl R刷新 (3)找 Ajax 数据包 (4)…...

react-组件进阶
1.目标 能够实用props接收数据 能够实现父子组件之间的通讯 能够实现兄弟组件之间的通讯 能够给组件添加props校验 能够说出生命周期常用的钩子函数 能够知道高阶组件的作用 2.目录 组件通讯介绍 组件的props 组件通讯的三种方式 Context props深入 组件的生命周期 Render-p…...
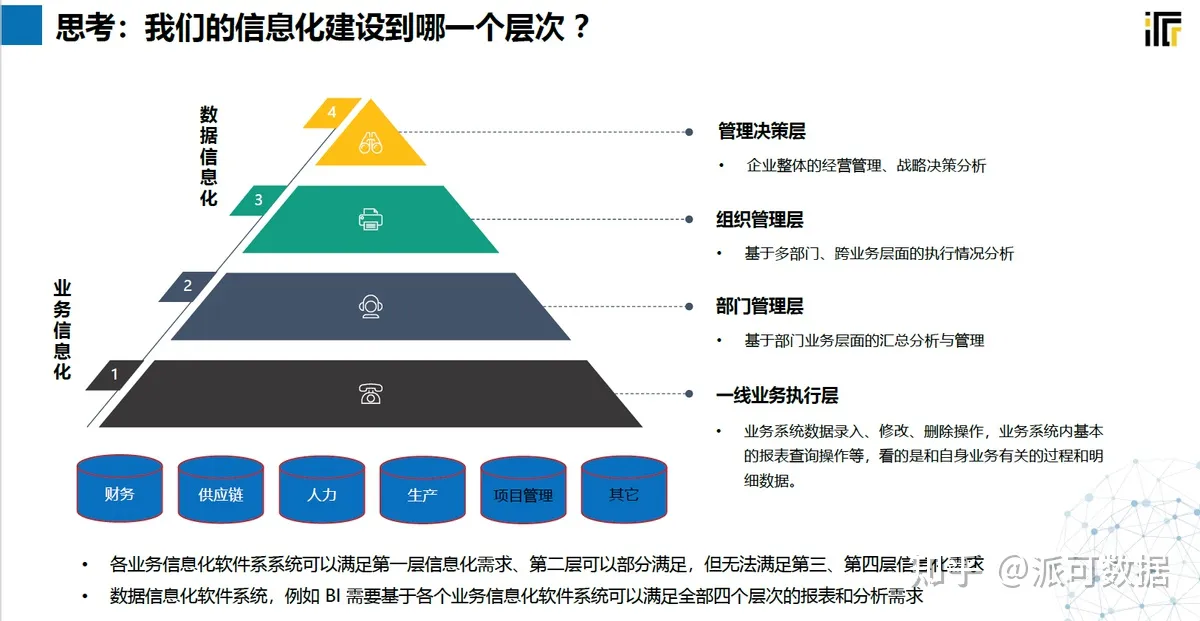
企业有了ERP,为什么还要上BI?
在我们以往和企业的沟通过程中,我们发现还是有相当多的一部分企业对于商业智能 BI 了解不多,或者对商业智能 BI 的理解仅停留在花花绿绿的可视化页面上,要么就是提出以下类似问题: 财务部门:BI 的财务分析指标也就是三…...

P1331 海战
难度:普及- 题目背景 在峰会期间,武装部队得处于高度戒备。警察将监视每一条大街,军队将保卫建筑物,领空将布满了 F-2003 飞机。 此外,巡洋船只和舰队将被派去保护海岸线。不幸的是,因为种种原因&#x…...
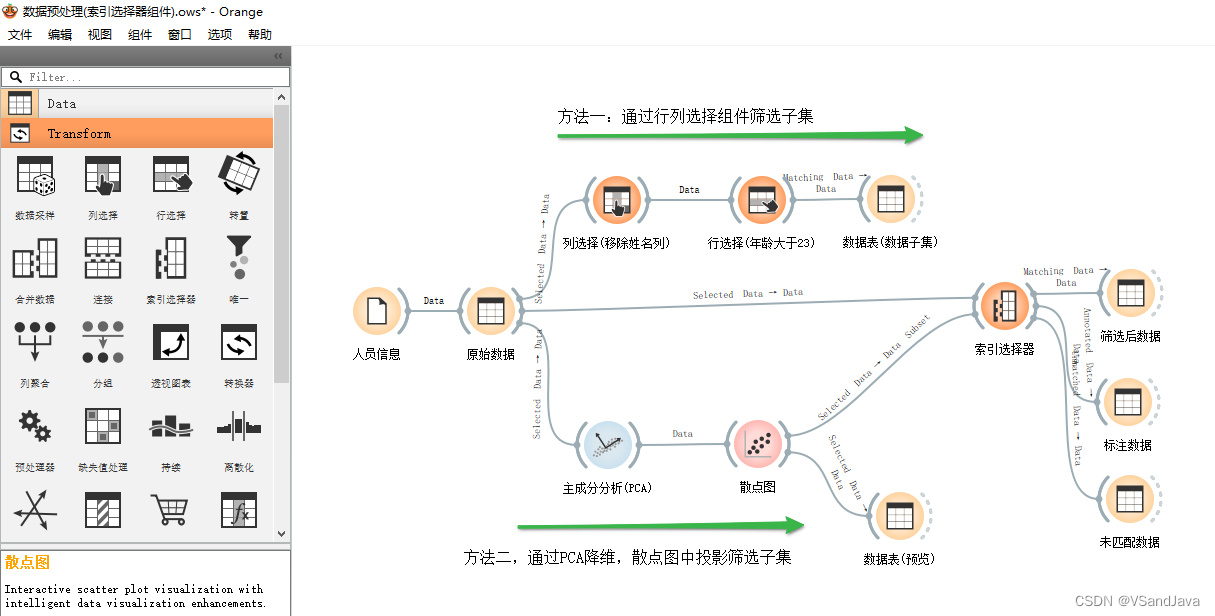
Orange3数据预处理(索引选择器组件)
组件描述 数据行即使在某些或全部原始变量被来自原始变量的计算变量替换时,也保持其身份。 此小部件获取两个数据表(“数据”和“数据子集”),它们可以追溯到同一来源。基于行身份而非实际数据,它会从“数据”中选择所…...
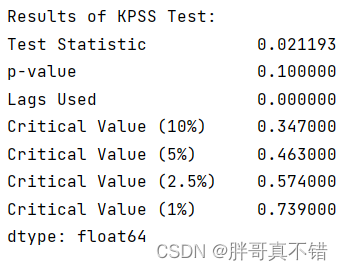
Python实现时间序列分析进行平稳性检验(ADF和KPSS)和差分去趋势(adfuller和kpss算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 时间序列分析中的平稳性检验是评估一个时间序列是否具有稳定的均值和方差。在经济学、金融学以及其他诸…...

代码随想录 Leetcode494. 目标和
题目: 代码(首刷看解析 2024年2月26日) 思路:根据题意,设两个背包,packageA存放前面是""的数字之和,packageB存放前面是“-”的数字之和 则sum packageA packageB; target packageA - packag…...
)
【5G NR】【一文读懂系列】移动通讯中使用的信道编解码技术-NR编解码LDPC和Polar概述(一)
目录 NR LDPC和Polar编码技术概述 LDPC(低密度奇偶校验码) LDPC 工作原理 LDPC 应用场景: LDPC 与其他编码技术相比的优势: Polar 极化码 Polar 工作原理 Polar 应用场景: Polar 与其他编码技术相比的优势&am…...

代码库管理工具Git介绍
阅读本文同时请参阅-----免费的Git图形界面工具sourceTree介绍 Git是一个分布式版本控制系统,它可以帮助开发者跟踪和管理代码历史。Git的命令行工具是使用Git的核心方式,虽然它可能看起来有些复杂,但是一旦掌握了基本命令,你…...

【长期更新】游戏开发中可能会用到的数学小工具
从一个向量生成一组正交基 https://graphics.pixar.com/library/OrthonormalB/paper.pdf...

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的活体人脸检测系统(Python+PySide6界面+训练代码)
摘要:本篇博客详细讲述了如何利用深度学习构建一个活体人脸检测系统,并且提供了完整的实现代码。该系统基于强大的YOLOv8算法,并进行了与前代算法YOLOv7、YOLOv6、YOLOv5的细致对比,展示了其在图像、视频、实时视频流和批量文件处…...
)
训练数据来源合法吗?(深度拆解Stable Code、CodeLlama等模型的著作权灰色地带)
第一章:智能代码生成与知识产权问题 2026奇点智能技术大会(https://ml-summit.org) 智能代码生成工具(如GitHub Copilot、Tabnine、CodeWhisperer)正深度融入开发工作流,但其训练数据多源于公开代码仓库(包括GPL、MIT…...

终极指南:vue-pure-admin CDN加速配置与优化技巧
终极指南:vue-pure-admin CDN加速配置与优化技巧 【免费下载链接】vue-pure-admin 全面ESMVue3ViteElement-PlusTypeScript编写的一款后台管理系统(兼容移动端) 项目地址: https://gitcode.com/GitHub_Trending/vu/vue-pure-admin vue…...

KMS_VL_ALL_AIO:终极Windows和Office激活解决方案完整指南
KMS_VL_ALL_AIO:终极Windows和Office激活解决方案完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活问题烦恼吗?KMS_VL_ALL_AIO是一款开源免…...

终极指南:如何用Win_ISO_Patching_Scripts快速制作集成最新补丁的Windows安装镜像
终极指南:如何用Win_ISO_Patching_Scripts快速制作集成最新补丁的Windows安装镜像 【免费下载链接】Win_ISO_Patching_Scripts Win_ISO_Patching_Scripts 项目地址: https://gitcode.com/gh_mirrors/wi/Win_ISO_Patching_Scripts 还在为手动集成Windows补丁而…...

企业级自动化测试架构设计:Chrome for Testing 实现30%测试效率提升的完整方案
企业级自动化测试架构设计:Chrome for Testing 实现30%测试效率提升的完整方案 【免费下载链接】chrome-for-testing 项目地址: https://gitcode.com/gh_mirrors/ch/chrome-for-testing Chrome for Testing 是Google专门为Web应用测试和自动化场景设计的Chr…...

Gemini 3 Flash:效率革命,如何重塑AI应用的“不可能三角”
1. 当AI遇上"不可能三角":传统方案的困局 在AI应用开发领域,开发者们长期被一个魔咒般的"不可能三角"所困扰——任何模型都难以同时兼顾响应速度、计算成本和推理精度这三个核心指标。就像手机摄影中的"夜景模式"总要面临…...

nhentai-cross跨平台漫画阅读器:终极免费解决方案
nhentai-cross跨平台漫画阅读器:终极免费解决方案 【免费下载链接】nhentai-cross A nhentai client 项目地址: https://gitcode.com/gh_mirrors/nh/nhentai-cross 还在为在不同设备上阅读漫画而烦恼吗?nhentai-cross跨平台漫画阅读器为你提供了…...

别再瞎选了!手把手教你为Zynq MPSOC项目选对AXI接口:ACP、HPC还是HP?
Zynq MPSoC三大AXI接口深度实战:从架构原理到选型决策 在Zynq MPSoC的软硬件协同设计中,AXI接口选型直接决定了系统性能天花板。当你在Vivado中看到ACP、HPC、HP这三个并排的AXI从接口时,是否曾困惑过它们真正的差异?本文将通过实…...

0基础搭建前后端分离项目:实现数据库账号密码登录
以下为具体实现方式:✅ 前后端分离✅ 前端:Vue2 Element UI✅ 后端:Java Spring Boot MySQL✅ 功能:注册 / 登录(基于数据库校验)✅ 使用 JWT(推荐做法)一、数据库设计࿰…...

从面试官视角看嵌入式C/C++:那些年我们踩过的坑与避开的雷
嵌入式C/C面试官的深度思考:技术考察背后的逻辑与实战智慧 在嵌入式开发领域,技术面试往往是一场无声的博弈。作为面试官,我们设计的每一个问题都像精心布置的棋盘,等待着候选人展示他们的思维路径。但这场博弈的目的不是难倒对方…...