RL笔记:基于策略迭代求CliffWaking-v0最优解(python实现)
目录
1. 概要
2. 实现
3. 运行结果
1. 概要
CliffWalking-v0是gym库中的一个例子[1],是从Sutton-RLbook-2020的Example6.6改编而来。不过本文不是关于gym中的CliffWalking-v0如何玩的,而是关于基于策略迭代求该问题最优解的实现例。

CliffWalking-v0的游戏环境是一个4*12的网格(如上图【1】所示)。游戏规则如下:
Agent从左下角出发,在每个网格中,可以采取{UP,DOWN,RIGHT,LEFT}中任意一个动作。但是,如果采取动作后会越出边界的话,就退回原地。到达右下角的网格的话,一局游戏结束。
最下面一排网格中除了左下角(出发网格)和右下角(目标网格)以外,是所谓的悬崖网格,如果采取行动后掉入悬崖网格,会得到-100点的奖励(或者说惩罚),并且会被直接扔回出发点。其它情况下,每次行动有-1点的奖励(或者说惩罚)。Agent必需最小化到达目标网格的开销(最大化奖励,或者说最小化惩罚)。
这个游戏非常简单,不用计算,直觉就可以知道,最优策略是:在出发点向上走一格;然后在第3行一路右行;到达最右侧后向下移动一格后即到达目标网格。总的奖励是-13点。
以下给出基于策略迭代算法来求解这个问题的最优策略,看看能不能得出以上直觉上的最优策略。
2. 实现
CliffWalking-v0游戏的环境设定类似于GridWorld,所以这里采用了类似于GridWorld的状态表示方法。环境类对象创建时,用一个二维数组表示网格环境中各cell的类型,“1”表示Terminate cell;“-1”表示Cliff cells;“0”表示其它cells。如下所示:
grid = [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]grid[3][11] = 1 # Terminate cellfor k in range(1,11):grid[3][11] = -1 # Cliff cells环境的转移状态函数P(s’,r|s,a)用Environment::transit_func()实现,如下所示:
def transit_func(self, state, action):"""Prob(s',r|s,a) stored in one dict[(s',reward)]."""transition_probs = {}if not self.can_action_at(state):# Already on the terminal cell.return transition_probsopposite_direction = Action(action.value * -1)for a in self.actions:prob = 0if a == action:prob = self.move_probelif a != opposite_direction:prob = (1 - self.move_prob) / 2next_state = self._move(state, a)if next_state.row == (self.row_length - 1) and 0 < next_state.column < (self.column_length - 1):reward = -100next_state = State(self.row_length - 1, 0) # Return to start grid when falls into cliff grid.else:reward = -1if (next_state,reward) not in transition_probs:transition_probs[(next_state,reward)] = probelse:transition_probs[(next_state,reward)] += probreturn transition_probsdef can_action_at(self, state):'''Assuming:grid[i][j] = 1: Terminate gridgrid[i][j] =-1: Cliff gridsgrid[i][j] = 0: Other grids'''if self.grid[state.row][state.column] == 0:return Trueelse:return Falsedef _move(self, state, action):"""Predict the next state upon the combination of {state, action}{state, action} --> next_stateCalled in transit_func()"""if not self.can_action_at(state):raise Exception("Can't move from here!")next_state = state.clone()# Execute an action (move).if action == Action.UP:next_state.row -= 1elif action == Action.DOWN:next_state.row += 1elif action == Action.LEFT:next_state.column -= 1elif action == Action.RIGHT:next_state.column += 1# Check whether a state is out of the grid.if not (0 <= next_state.row < self.row_length):next_state = stateif not (0 <= next_state.column < self.column_length):next_state = state# Entering into cliff grids is related to the correspong penalty and # reset to start grid, hence will be handled upper layer.return next_statePlanner类实现一个规划基类,进一步PolicyIterationPlanner类作为Planner子类实现了基于策略迭代的规划器,其中核心就是PolicyIterationPlanner:: policy_evaluation() 和 PolicyIterationPlanner::plan()。策略迭代算法在上一篇(RL笔记:动态规划(2): 策略迭代)中已经介绍,此处不再赘述。
PolicyIterationPlanner:: policy_evaluation()实现的是策略评估,如下所示:
def policy_evaluation(self, gamma, threshold):V = {}for s in self.env.states:# Initialize each state's expected reward.V[s] = 0while True:delta = 0for s in V:expected_rewards = []for a in self.policy[s]:action_prob = self.policy[s][a]r = 0for prob, next_state, reward in self.transitions_at(s, a):r += action_prob * prob * \(reward + gamma * V[next_state])expected_rewards.append(r)value = sum(expected_rewards)delta = max(delta, abs(value - V[s]))V[s] = valueif delta < threshold:breakreturn VPolicyIterationPlanner::plan()则实现了完整的策略迭代算法(策略评估部分调用了policy_evaluation())代码如下所示:
def plan(self, gamma=0.9, threshold=0.0001):"""Implement the policy iteration algorithmgamma : discount factorthreshold: delta for policy evaluation convergency judge."""self.initialize()states = self.env.statesactions = self.env.actionsdef take_max_action(action_value_dict):return max(action_value_dict, key=action_value_dict.get)while True:update_stable = True# Estimate expected rewards under current policy.V = self.policy_evaluation(gamma, threshold)self.log.append(self.dict_to_grid(V))for s in states:# Get an action following to the current policy.policy_action = take_max_action(self.policy[s])# Compare with other actions.action_rewards = {}for a in actions:r = 0for prob, next_state, reward in self.transitions_at(s, a):r += prob * (reward + gamma * V[next_state])action_rewards[a] = rbest_action = take_max_action(action_rewards)if policy_action != best_action:update_stable = False# Update policy (set best_action prob=1, otherwise=0 (greedy))for a in self.policy[s]:prob = 1 if a == best_action else 0self.policy[s][a] = prob# Turn dictionary to gridself.V_grid = self.dict_to_grid(V)self.iters = self.iters + 1print('PolicyIteration: iters = {0}'.format(self.iters))self.print_value_grid()print('******************************')if update_stable:# If policy isn't updated, stop iterationbreak3. 运行结果
运行结果如下(右下角可以忽视,因为到达右下角后游戏结束了,不会再有进一步的行动了):

由此可见,以上实现的确得出了跟直感相同的最优策略。
完整代码参见:reinforcement-learning/CliffWalking-v0.py
本强化学习之学习笔记系列总目录参见:强化学习笔记总目录
[1] Cliff Walking - Gym Documentation (gymlibrary.dev)
相关文章:
RL笔记:基于策略迭代求CliffWaking-v0最优解(python实现)
目录 1. 概要 2. 实现 3. 运行结果 1. 概要 CliffWalking-v0是gym库中的一个例子[1],是从Sutton-RLbook-2020的Example6.6改编而来。不过本文不是关于gym中的CliffWalking-v0如何玩的,而是关于基于策略迭代求该问题最优解的实现例。 CliffWalking-v0的…...

350. 两个数组的交集 II
两个数组的交集 II 给你两个整数数组 nums1 和 nums2 ,请你以数组形式返回两数组的交集。返回结果中每个元素出现的次数,应与元素在两个数组中都出现的次数一致(如果出现次数不一致,则考虑取较小值)。可以不考虑输出结…...
Android仿微信选择图片
效果展示首先先添加用到的权限<uses-permission android:name"android.permission.INTERNET" /><!--获取手机存储卡权限--><uses-permission android:name"android.permission.READ_EXTERNAL_STORAGE"/><uses-permission android:nam…...

python+嵌入式——串口通信篇(收发解包)
目录前言安装pyserialpyserial大致概括整体流程硬件连接例子(简单版)详细使用serial初始化参数发包收包收包检查包并解包python struct模块结语前言 这几年,自己也做了一些嵌入式机器人。在整个开发的过程中,调通信通常会花费一段比较长的时间ÿ…...
剖析G1 垃圾回收器
简单回顾 在Java当中,程序员在编写代码的时候只需要创建对象,从来不需要考虑将对象进行释放,这是因为Java中对象的垃圾回收全部由JVM替你完成了(所有的岁月静好都不过是有人替你负重前行)。 而JVM的垃圾回收由垃圾回收器来负责,在…...
如何打造一款专属于自己的高逼格电脑桌面
作为一名电脑重度使用者,你是否拥有一款属于你自己的高逼格电脑桌面呢?你是不是也像大多数同学一样,会把所有的内容全部都堆积到电脑桌面,不仅找东西困难,由于桌面内容太多还会导致C盘空间不足,影响电脑的反…...

【C++】string的使用及其模拟实现
文章目录1. STL的介绍1.1 STL的六大组件1.2 STL的版本1.3 STL的缺陷2. string的使用2.1 为什么要学习string类?2.2 常见构造2.3 Iterator迭代器2.4 Capacity2.5 Modifiers2.6 String operations3. string的模拟实现3.1 构造函数3.2 拷贝构造函数3.3 赋值运算符重载和…...

怀念在青鸟的日子
时间过的可真快,一转眼来到了2023年!我初中上完就没有在念,下了学门步入社会,那时的我一片迷茫,不知道该去干什 么,父母说要不去学挖掘机、理发、修车...我思考再三,一个都没有我喜欢的…...

学习记录---Python内置类型
文章目录字符串split()列表常见操作列表相减字典创建普通创建eval(s)添加或更新元素d[t] 1d.update({c: 3}){**d1, **d2} **字典解包装运算符删除元素 d.pop(c)属性d.items()d.keys()d.values()访问元素d[Name]d.get(score)遍历字典for key in dictfor key, values in dict.it…...
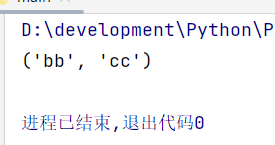
Python笔记 -- 列表
文章目录1、列表简介2、修改、添加、删除元素2.1、添加2.2、删除3、排序、倒序4、遍历列表5、创建数值列表6、列表切片7、列表复制8、元组1、列表简介 在Python中用方括号[]表示列表,用逗号隔开表示其元素 通过索引访问列表 names [aa,bb,cc,dd]print(names[0]) …...

谈谈UVM中的uvm_info打印
uvm_info宏的定义如下: define uvm_info(ID,MSG,VERBOSITY) \begin \if (uvm_report_enabled(VERBOSITY,UVM_INFO,ID)) \uvm_report_info (ID, MSG, VERBOSITY, uvm_file, uvm_line); \end 从这里可以看出uvm_info由两部分组成:uvm_report_enabled(VER…...
)
矩阵理论1 集合上的等价关系(equivalence relations on a set S)
定义 对于一个集合S, 如果集合E⊂SS\mathcal{E} \subset S\times SE⊂SS满足以下条件 自反性: 对于∀s∈S,都有(s,s)∈E\forall s\in S, 都有 (s, s) \in \mathcal{E}∀s∈S,都有(s,s)∈E对称性: (s,t)∈E⇔(t,s)∈E(s,t) \in \mathcal{E} \Leftrightarrow (t,s)\in \mathcal…...
【网络监控】Zabbix详细安装部署(最全)
文章目录Zabbix详细安装部署环境准备安装依赖组件访问初始化配置Zabbix详细安装部署 Zabbix 是一个高度集成的网络监控解决方案,可以提供企业级的开源分布式监控解决方案,由一个国外的团队持续维护更新,软件可以自由下载使用,运作…...

阿里云轻量服务器--Docker--Nacos安装(使用外部Mysql数据存储)
前言:docker 安装nacos 如果不设置外部的mysql 默认使用内嵌的内嵌derby为数据源,这个时候如果,重新部署nacos 则会造成原有数据丢失情况; 1 默认安装的nacos 启动后使用的是内嵌的存储: 2 使用外部mysql 作为存储&a…...
unity开发知识点小结01
unity对象生命周期函数 Awake():最早调用,所以可以实现单例模式 OnEnable():组件激活后调用,在Awake后调用一次 Stat():在Update()之前,OnEnable…...

软件系统[软件工程]
What’s the link? They all involve outdated (legacy) software technology. All have had huge socio-economical impact. Prompting national lockdowns. Spreadsheet workflow error led to thousands of preventable infections and deaths. Huge losses of citizen dat…...
电力系统稳定性的定义与分类
1电力系统稳定性的定义与分类 IEEE给出电力系统稳定性定义:电力系统稳定性是指电力系统这样的一种能力—对于给定的初始运行状态,经历物理扰动后,系统能够重新获得运行平衡点的状态,同时绝大多数系统变量有界,因此整个…...
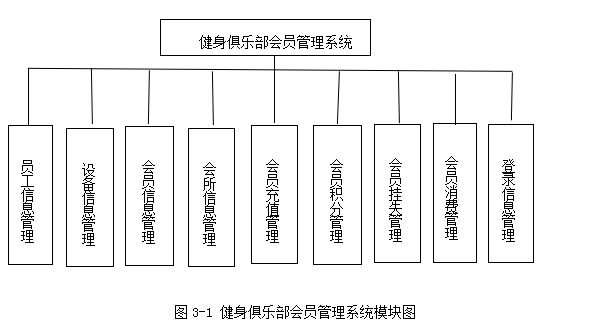
基于java的俱乐部会员管理系统
技术:Java、JSP等摘要:随着科学技术的飞速发展,科学技术在人们日常生活中的应用日益广泛,也给各行业带来发展的机遇,促使各个行业给人们提供更加优质的服务,有效提升各行业的管理水平。俱乐部通过使用一定的…...
线程池执行父子任务,导致线程死锁
前言, 一次线程池的不当使用,导致了现场出现了线程死锁,接口一直不返回。而且由于这是一个公共的线程池,其他使用了次线程池的业务也一直阻塞,系统出现了OOM,不过是幸好是线程同事测试出来的,没…...

Ubuntu系统新硬盘挂载
Ubuntu系统新硬盘挂载 服务器通常会面临存储不足的问题,大部分服务器都是ubuntu系统,该篇博客浅浅记载一下在ubuntu系统上挂载新硬盘的步骤。本篇博文仅仅记载简单挂载一块新的硬盘,而没有对硬盘进行分区啥的。如果需要更加完善的教程&#…...
)
山东大学2022-2023学期实时绘制期末考试真题(回忆版)
山东大学2022年到2023年实时绘制期末考试 (一共9到小题,每题10分或12分,包含多个小问,上午考完下午回忆写的,大体就这些,复习时还是应该全面一点。) AABB包围盒构建过程;中间节点和叶…...

社交媒体 SEO 优化应该注意哪些
社交媒体 SEO 优化的核心要点 在当今数字化时代,社交媒体已经成为品牌营销和用户互动的重要平台。单靠社交媒体上的粉丝数量不能保证品牌的成功。为了在众多用户中脱颖而出,社交媒体 SEO 优化显得尤为重要。社交媒体 SEO 优化应该注意哪些关键点呢&…...

用快马AI快速构建web终端原型:复刻xshell免费版核心体验
最近在尝试复刻xshell免费版的核心体验,想做一个轻量级的web终端原型。作为一个经常需要远程连接服务器的开发者,xshell的简洁高效一直让我印象深刻。这次我用InsCode(快马)平台快速实现了这个想法,整个过程特别顺畅,分享下我的实…...

S-UI配置文件加密终极指南:保护敏感信息的最佳实践 [特殊字符]
S-UI配置文件加密终极指南:保护敏感信息的最佳实践 🔒 S-UI是一款基于SagerNet/Sing-Box构建的高级Web面板,提供多协议支持和流量管理功能。在使用过程中,配置文件包含大量敏感信息,如API密钥、用户数据和服务器配置&…...
Pixel Language Portal实战教程:使用WebSockets实现低延迟流式翻译响应
Pixel Language Portal实战教程:使用WebSockets实现低延迟流式翻译响应 1. 引言:当翻译遇上像素冒险 想象你正在玩一款16-bit像素风RPG游戏,每次对话选择都会触发实时翻译效果,文字像能量块一样在屏幕上流动。这正是Pixel Langu…...

使用cv_unet_image-colorization增强电商商品图像的实践
使用cv_unet_image-colorization增强电商商品图像的实践 电商平台中,商品图像的质量直接影响消费者的购买决策。本文将分享如何利用cv_unet_image-colorization模型,为老商品图上色、提升低质图像质量,从而显著改善商品展示效果。 1. 电商图像…...

暗黑破坏神2存档编辑器:5分钟解决20年存档管理难题的终极免费方案
暗黑破坏神2存档编辑器:5分钟解决20年存档管理难题的终极免费方案 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 你是否曾在《暗黑破坏神2》中花费数百小时培养角色,却因存档损坏而前功尽弃?…...

如何快速实现STL转STEP:面向3D设计新手的完整指南
如何快速实现STL转STEP:面向3D设计新手的完整指南 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 你是否遇到过这样的困境:精心设计的3D打印模型完成后,想要…...

【无标题】MySQL数据库基础实例教程单元2 学习笔记
2.1 关系数据库设计 2.1.1 数据的加工 数据设计本质上是对现实世界信息的逐步抽象和加工,过程分为三个阶段。首先是现实世界,包含客观存在的事物、业务需求和事物之间的联系。然后进入信息世界,把现实事物抽象为概念模型,方便理解…...

JL杰理AC696N系列开发GPIO使用指南:模式、配置与特殊IO
引言GPIO是嵌入式开发最基础也最容易出问题的部分。拉高拉低看起来简单,但驱动能力不够、上下拉没配对、特殊引脚没处理,经常导致外设工作不正常或者功耗异常。JL杰理AC696N的GPIO功能挺全的,有普通、强、超强三种驱动能力,还支持…...