模型优化_XGBOOST学习曲线及改进,泛化误差
代码
from xgboost import XGBRegressor as XGBR
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.linear_model import LinearRegression as LR
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split,cross_val_score as CV,KFold
from sklearn.metrics import mean_squared_error as MSE
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from time import time
import datetime#加载数据
data=load_boston()
X=data.data
y=data.target#划分数据集
Xtrain,Xtest,ytrain,ytest=train_test_split(X,y,test_size=0.3,random_state=420)#定位模型,进行fit
reg=XGBR(n_estimators=100).fit(Xtrain,ytrain)#进行预测
reg.predict(Xtest)
reg.score(Xtest,ytest)#返回的是R平方
MSE(ytest,reg.predict(Xtest))
reg.feature_importances_
#查看SKLEARN中所有的模型评估指标
import sklearn
sorted(sklearn.metrics.SCORERS.keys())# ======================================
#交叉验证,与线性回归随机森林进行结果比对
reg=XGBR(n_estimators=100)from sklearn.model_selection import train_test_split,cross_val_score
cross_val_score(reg,Xtrain,ytrain,cv=5).mean()##交叉验证既可以解决数据集的数据量不够大问题,也可以解决参数调优的问题。
#这块主要有三种方式:简单交叉验证(HoldOut检验)、k折交叉验证(k-fold交叉验证)
cross_val_score(reg,Xtrain,ytrain,cv=5,scoring="neg_mean_squared_error").mean()#绘制学习曲线
def plot_learning_curve(estimator,title,X,y,ax=None,#选择子图ylim=None,#设置纵坐标的取值范围cv=None,#交叉验证n_jobs=None):from sklearn.model_selection import learning_curvetrain_sizes,train_scores,test_scores=learning_curve(estimator,X,y,shuffle=True,cv=cv,random_state=420,n_jobs=n_jobs)if ax==None:ax=plt.gca()else:ax=plt.figure()ax.set_title(title)if ylim is not None:ax.set_ylim(*ylim)ax.set_xlabel("Traing example")ax.set_ylabel("Score")ax.grid()#绘制网格ax.plot(train_sizes,np.mean(train_scores,axis=1),"o-",color="r",label="traing score")ax.plot(train_sizes,np.mean(test_scores,axis=1),"o-",color="g",label="test.py score")ax.legend(loc="best")return ax#学习曲线的绘制
cv=KFold(n_splits=5,shuffle=True,random_state=42)
plot_learning_curve(XGBR(n_estimators=100,random_state=420),"XGB",Xtrain,ytrain,ax=None,cv=cv)
#绘制学习曲线,查看n_estimators对模型的影响
#绘制学习曲线,查看n_estimators对模型的影响
axis=range(10,50,1)
rs=[]
for i in axis:reg=XGBR(n_estimators=i)cv1=cross_val_score(reg,Xtrain,ytrain,cv=5).mean()rs.append(cv1)
print(axis[rs.index(max(rs))],max(rs))
plt.figure(figsize=(20,5))
plt.plot(axis,rs,c='red',label="XGB")
plt.legend()
plt.show()

泛化误差:用来衡量模型在未知数据集上的准确率
#绘制学习曲线,查看n_estimators对模型的影响
axis=range(10,50,1)
rs=[]#偏差,衡量的是准确率
var=[]#方差,衡量的是稳定性
ge=[]#泛化误差的可控部门
for i in axis:reg=XGBR(n_estimators=i)cv1=cross_val_score(reg,Xtrain,ytrain,cv=5)rs.append(cv1.mean())#记录偏差,返回的R平方就是偏差部门,衡量的是准确率var.append(cv1.var())ge.append((1-cv1.mean())**2+cv1.var())
print(axis[rs.index(max(rs))],max(rs),var[rs.index(max(rs))])
print(axis[var.index(min(var))],rs[var.index(min(var))],min(var))
print(axis[ge.index(min(ge))],rs[ge.index(min(ge))],var[ge.index(min(ge))],min(ge))
plt.figure(figsize=(20,5))
plt.plot(axis,rs,c='red',label="XGB")
plt.legend()
plt.show()
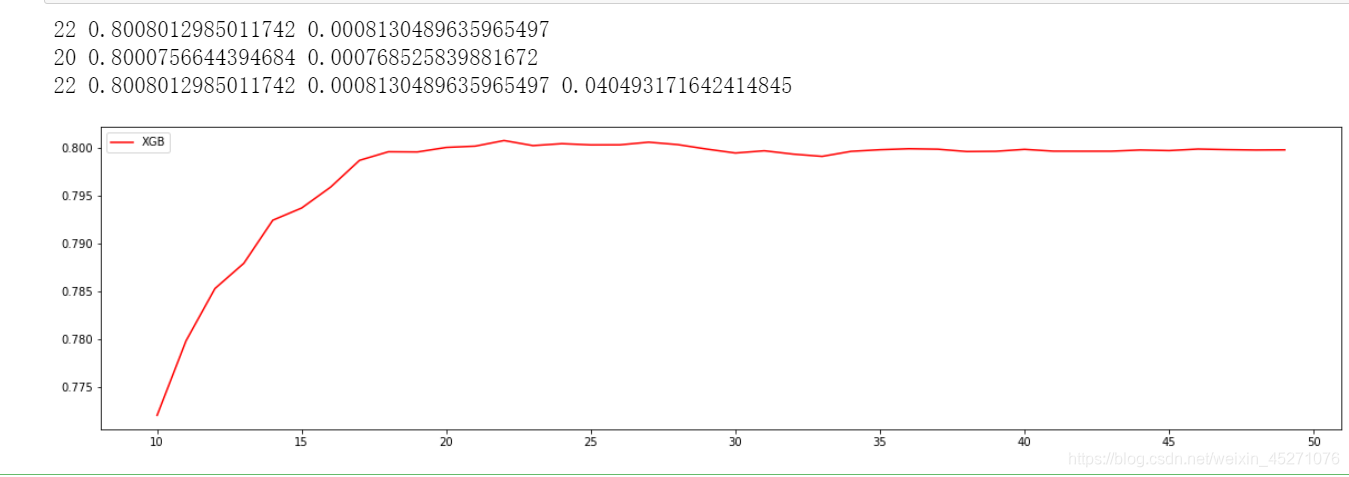
#绘制学习曲线,查看n_estimators对模型的影响
#绘制学习曲线,查看n_estimators对模型的影响
axis=range(10,30,1)
rs=[]#偏差,衡量的是准确率
var=[]#方差,衡量的是稳定性
ge=[]#泛化误差的可控部门
for i in axis:reg=XGBR(n_estimators=i)cv1=cross_val_score(reg,Xtrain,ytrain,cv=5)rs.append(cv1.mean())#记录偏差,返回的R平方就是偏差部门,衡量的是准确率var.append(cv1.var())ge.append((1-cv1.mean())**2+cv1.var())
print(axis[rs.index(max(rs))],max(rs),var[rs.index(max(rs))])
print(axis[var.index(min(var))],rs[var.index(min(var))],min(var))
print(axis[ge.index(min(ge))],rs[ge.index(min(ge))],var[ge.index(min(ge))],min(ge))
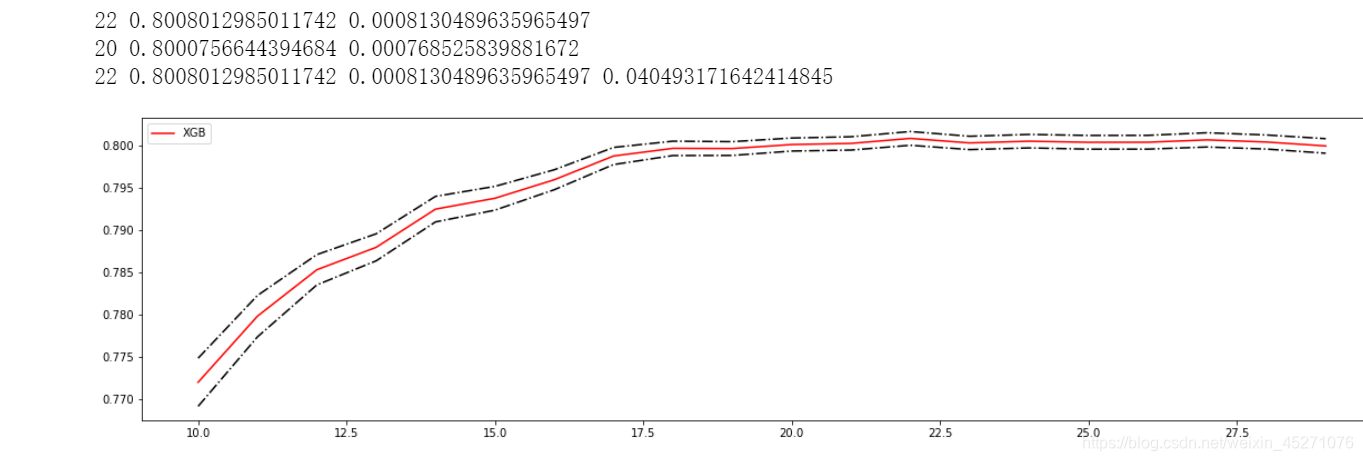
#添加方差线条
rs=np.array(rs)
var=np.array(var)#源代码这里*0.01
plt.figure(figsize=(20,5))
plt.plot(axis,rs,c='red',label="XGB")
plt.plot(axis,rs+var,c="black",linestyle="-.")
plt.plot(axis,rs-var,c="black",linestyle="-.")
plt.legend()
plt.show()
#看看泛化误差的可控部分如何
plt.figure(figsize=(20,5))
plt.plot(axis,ge,c='red',label="XGB")
plt.legend()
plt.show()
从这个过程中观察n_estimators参数对模型的影响,我们可以得出以下结论:
首先,XGB中的树的数量决定了模型的学习能力,树的数量越多,模型的学习能力越强。只要XGB中树的数量足够
了,即便只有很少的数据, 模型也能够学到训练数据100%的信息,所以XGB也是天生过拟合的模型。但在这种情况
下,模型会变得非常不稳定。
第二,XGB中树的数量很少的时候,对模型的影响较大,当树的数量已经很多的时候,对模型的影响比较小,只能有
微弱的变化。当数据本身就处于过拟合的时候,再使用过多的树能达到的效果甚微,反而浪费计算资源。当唯一指标
或者准确率给出的n_estimators看起来不太可靠的时候,我们可以改造学习曲线来帮助我们。
第三,树的数量提升对模型的影响有极限,最开始,模型的表现会随着XGB的树的数量一起提升,但到达某个点之
后,树的数量越多,模型的效果会逐步下降,这也说明了暴力增加n_estimators不一定有效果。
这些都和随机森林中的参数n_estimators表现出一致的状态。在随机森林中我们总是先调整n_estimators,当
n_estimators的极限已达到,我们才考虑其他参数,但XGB中的状况明显更加复杂,当数据集不太寻常的时候会更加
复杂。这是我们要给出的第一个超参数,因此还是建议优先调整n_estimators,一般都不会建议一个太大的数目,
300以下为佳。
参考:
XGBOOST学习曲线及改进,泛化误差-CSDN博客
相关文章:
模型优化_XGBOOST学习曲线及改进,泛化误差
代码 from xgboost import XGBRegressor as XGBR from sklearn.ensemble import RandomForestRegressor as RFR from sklearn.linear_model import LinearRegression as LR from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split,c…...

Java8 - LocalDateTime时间日期类使用详解
🏷️个人主页:牵着猫散步的鼠鼠 🏷️系列专栏:Java全栈-专栏 🏷️个人学习笔记,若有缺误,欢迎评论区指正 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默&…...

3D城市模型可视化:开启智慧都市探索之旅
随着科技的飞速发展,我们对城市的认知已经不再局限于平面的地图和照片。今天,让我们领略一种全新的城市体验——3D城市模型可视化。这项技术将带领我们走进一个立体、生动的城市世界,感受前所未有的智慧都市魅力。 3D城市模型通过先进的计算机…...

某查查首页瀑布流headers加密
目标网站: 某查查 对目标网站分析发现 红框内的参数和值都是加密的,是根据算法算出来的,故进行逆向分析。 由于没有固定参数名,只能通过搜索headers,在搜索的位置上打上断点,重新请求。 断点在此处断住&a…...

Microsoft Visio 文本框上标或下标
Microsoft Visio 文本框上标或下标 1. 文本框公式2. 选中需要成为上标或下标的部分,开始 - > 段落 -> 字体 -> 常规 -> 位置 -> 上标 / 下标3. 文本框公式4. 快捷键References 1. 文本框公式 2. 选中需要成为上标或下标的部分,开始…...
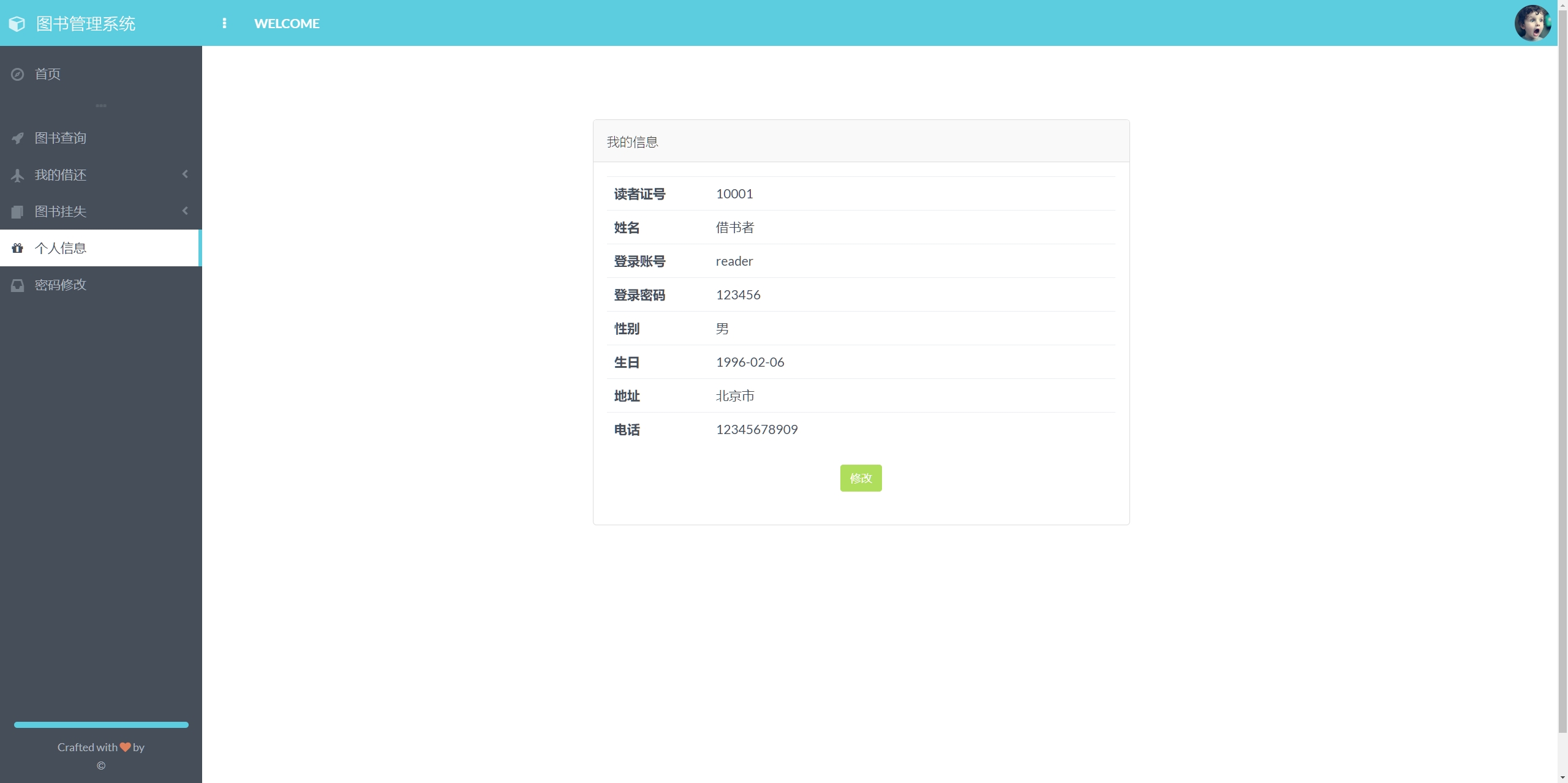
Java项目:29 基于SpringBoot+thymeleaf实现的图书管理系统
作者主页:源码空间codegym 简介:Java领域优质创作者、Java项目、学习资料、技术互助 文中获取源码 项目介绍 基于SpringBootthymeleaf实现的图书管理系统分为管理员、读者两个登录角色,一共是8个功能模块 管理员权限 图书管理:…...
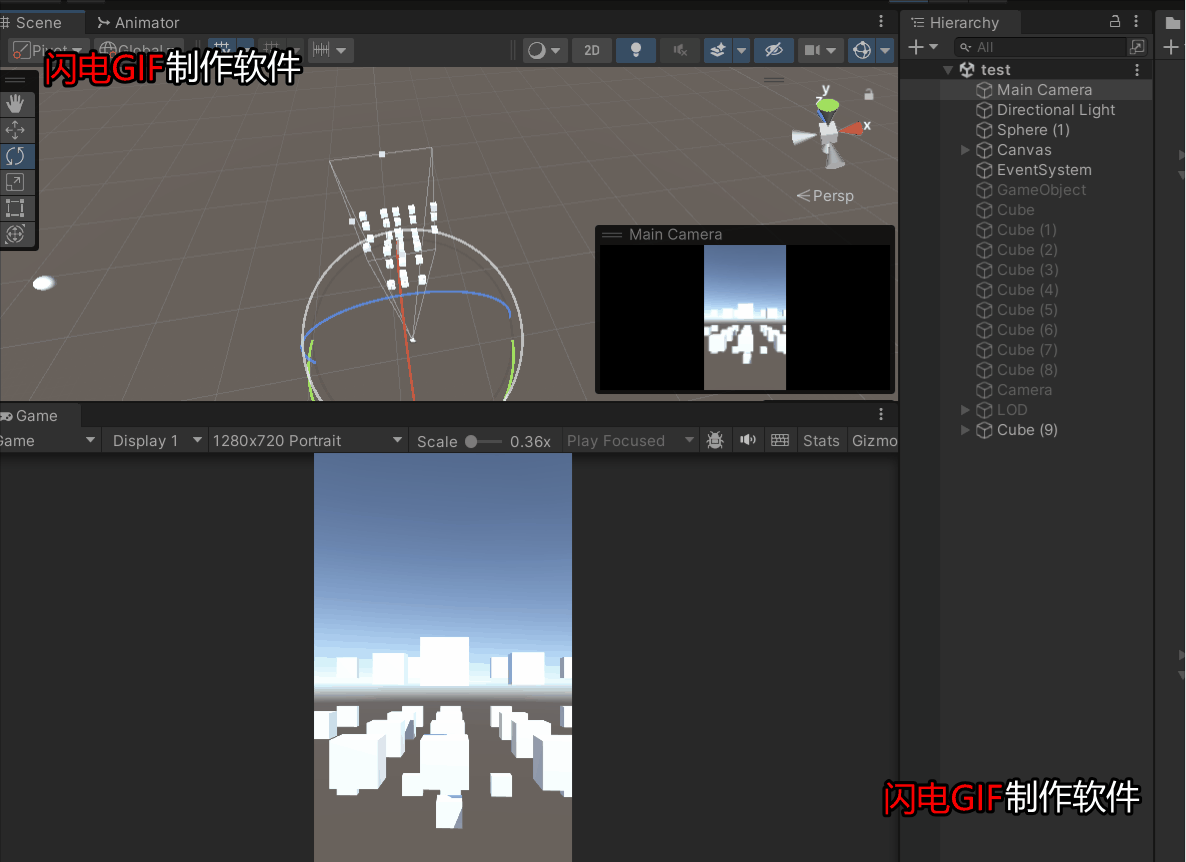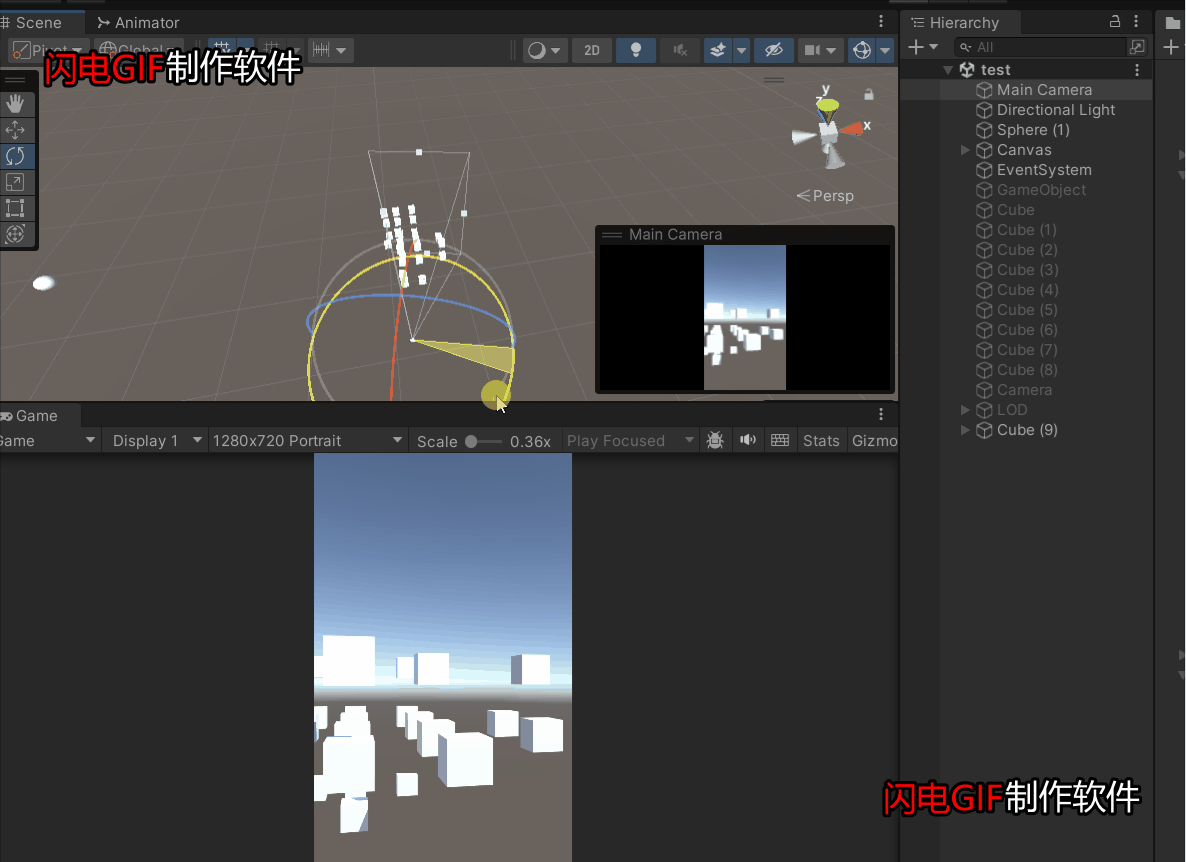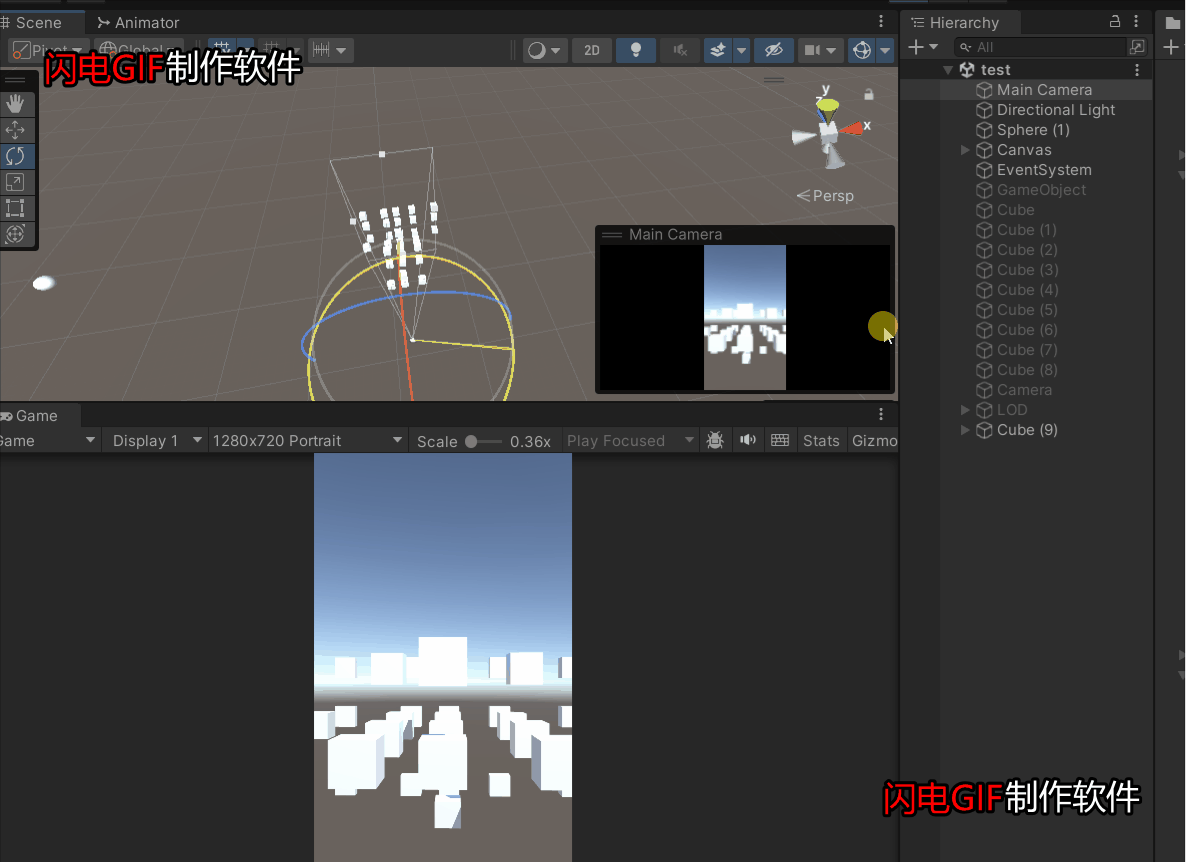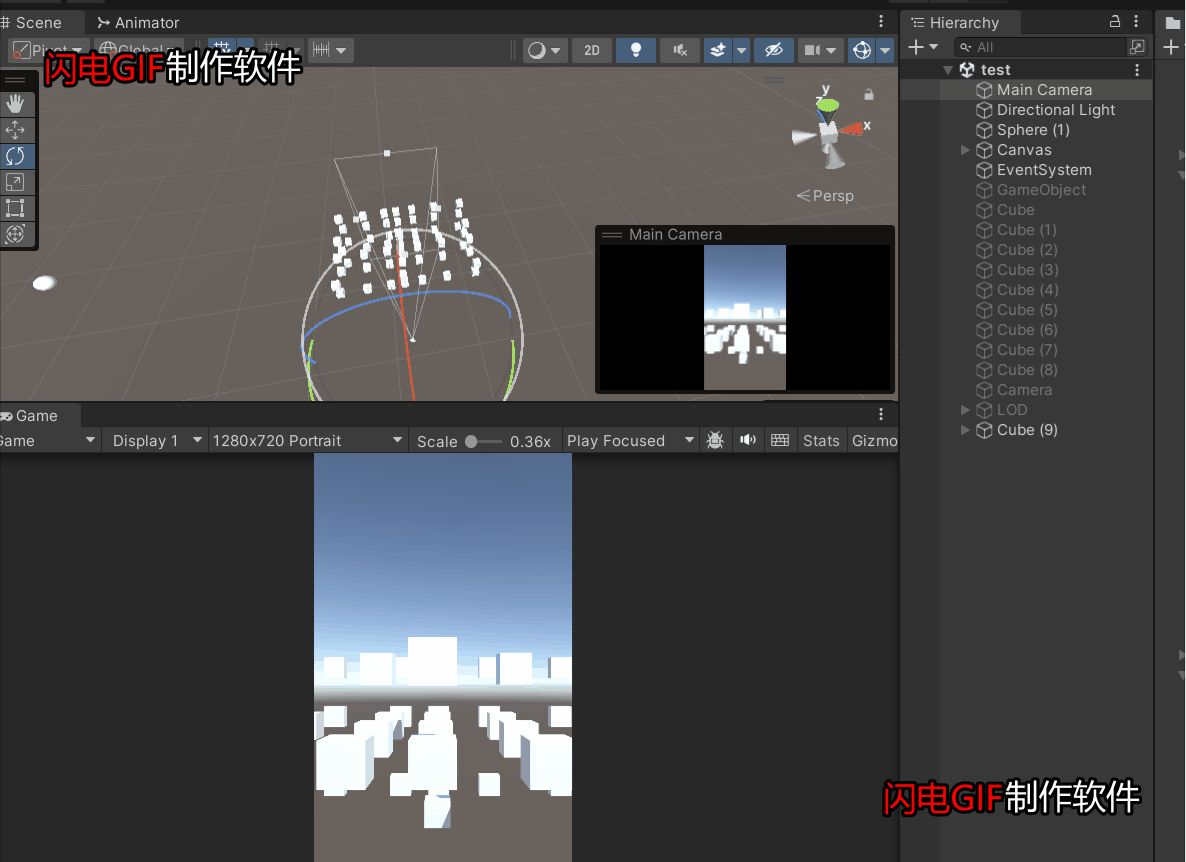
Unity游戏项目中的优化之摄像机视锥体剔除优化
在项目中一个完成的游戏场景一般都会有成千上百的物体,假如都去让GPU全部渲染一遍,那带来的消耗其实是挺大的,很多不在摄像机范围内的物体其实没有必要去渲染,尽管GPU自带剔除,但是如果从CPU阶段就提交给GPU指令——哪…...
)
超1000本计算机经典书籍分享(均可免费下载)
今天给大家推荐两个开源项目,均可百度网盘下载: 1 https://gitee.com/ForthEspada/CS-Books 超过1000本的计算机经典书籍、个人笔记资料以及作者在各平台发表文章中所涉及的资源等。 书籍资源包括C/C、Java、Python、Go语言、数据结构与算法、操作系统…...

AI大模型提供商有哪些?
AI大模型提供商:引领人工智能创新浪潮 随着人工智能技术的迅猛发展,AI大模型成为了推动行业变革和创新的核心驱动力之一。作为AI领域的重要参与者,AI大模型提供商扮演着关键的角色。本文将围绕这一主题,介绍几家在AI大模型领域具…...
【Linux】部署单机项目(自动化启动)
目录 一.jdk安装 二.tomcat安装 三.MySQL安装 四.部署项目 一.jdk安装 1.上传jdk安装包 jdk-8u151-linux-x64.tar.gz 进入opt目录,将安装包拖进去 2.解压安装包 防止后面单个系列解压操作,我这边就直接将所有的要用的全部给解压,如下图注…...
MySQL:使用聚合函数查询
提醒: 设定下面的语句是在数据库名为 db_book里执行的。 创建t_grade表 USE db_book; CREATE TABLE t_grade(id INT,stuName VARCHAR(20),course VARCHAR(40),score INT );为t_grade表里添加多条数据 INSERT INTO t_grade(id,stuName,course,score)VALUES(1,测试0…...

【Linux C | 网络编程】套接字选项、getsockopt、setsockopt详解及C语言例子
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...
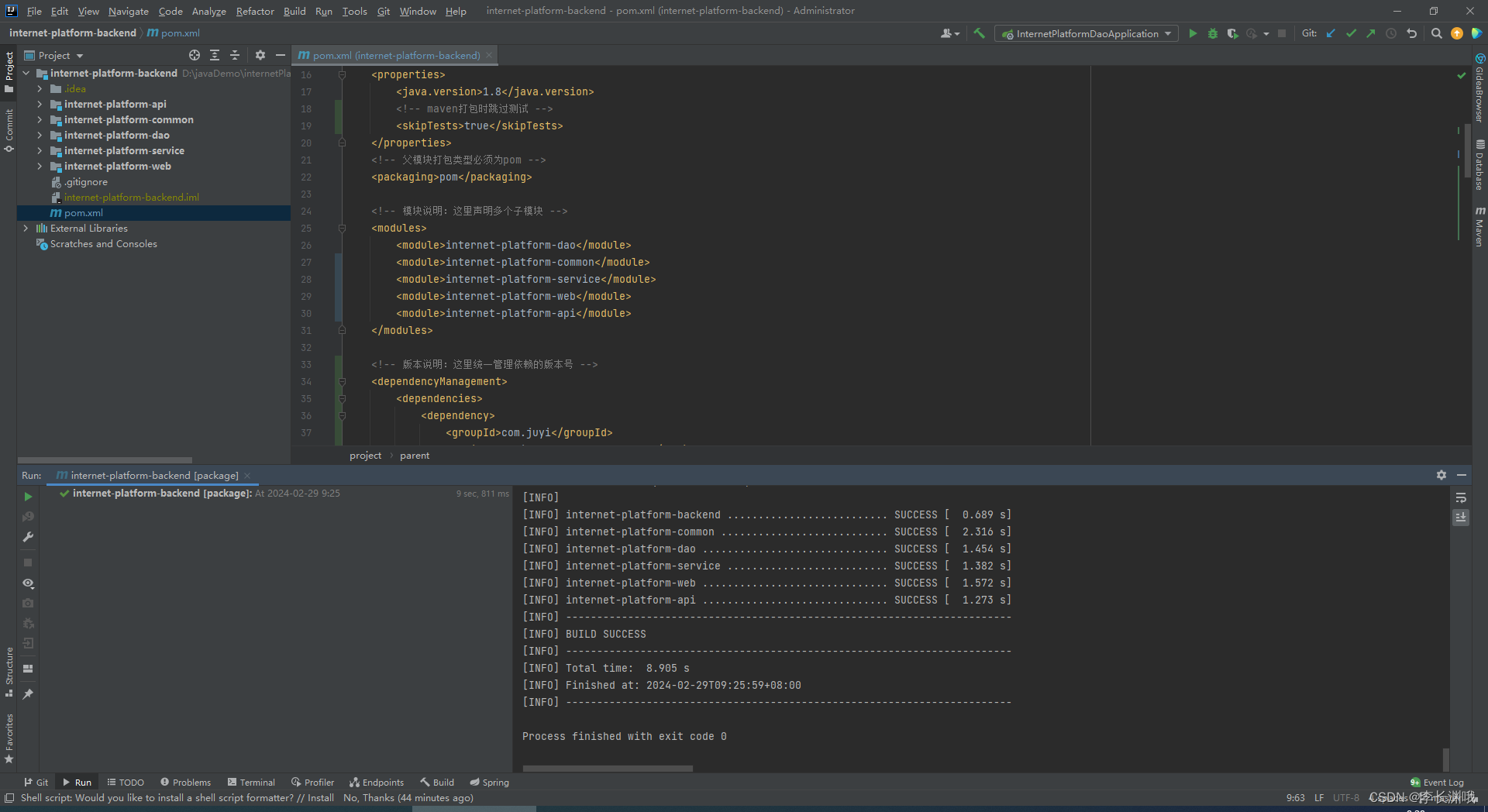
Springboot解决模块化架构搭建打包错误找不到父工程
Springboot解决模块化架构搭建打包错误找不到父工程 一、情况一找不到父工程依赖1、解决办法 二、情况二子工程相互依赖提示"程序包xxx不存在" 一、情况一找不到父工程依赖 报错信息 [ERROR] Failed to execute goal org.apache.maven.plugins:maven-deploy-plugin:…...

Android全屏黑边解决方案
在Android12以上的手机,设置全屏后屏幕底部有黑边或者白边,有的屏幕顶部有黑边。解决方案很简单,在使用的主题中添加对应的设置即可,如下: res/values/themes.xml <resources><style name"Base.Theme.La…...

【矩阵】【方向】【素数】3044 出现频率最高的素数
作者推荐 动态规划的时间复杂度优化 本文涉及知识点 素数 矩阵 方向 LeetCode 3044 出现频率最高的素数 给你一个大小为 m x n 、下标从 0 开始的二维矩阵 mat 。在每个单元格,你可以按以下方式生成数字: 最多有 8 条路径可以选择:东&am…...

什么是RPC?谈谈你对RPC的理解
RPC(Remote Procedure Call,远程过程调用)是一种计算机通信协议。它允许一台计算机(客户端)通过网络调用另一台计算机(服务器)上的程序,并等待该程序的结果返回。RPC抽象了网络通信的…...

C语言实现哈希查找之线性探测算法
C语言中实现一个简单的哈希表,并包括线性探测和二次探测再散列处理冲突的功能: 1. 定义哈希表结构 首先,定义一个哈希表的结构,包括存储空间、哈希表的大小等。 2. 实现哈希函数 选择一个合适的哈希函数来计算键值的哈希值。 …...

js:lodash template文件模板语法和应用
文档 https://www.lodashjs.com/docs/lodash.templatehttps://lodash.com/docs/4.17.15#template 语法 <% VALUE %> 用来做不转义插值;<%- VALUE %> 用来做 HTML 转义插值;<% expression %> 用来描述 JavaScript 流程控制。 示例 …...

在Windows系统上安装Docker和SteamCMD容器的详细指南有哪些?
在Windows系统上安装Docker和SteamCMD容器的详细指南有哪些? 安装Docker: 首先,需要在Windows操作系统上激活WSL2功能。这是因为Docker作为一个容器工具,依赖于已存在并运行的Linux内核环境。可以通过使用winget来安装Docker。具体…...

点击输入框,获取提示信息
HTML结构代码 <body><input><p>单击输入框获取焦点。</p><span>请输入你的电话号码?</span></body> Java script代码 <script type"text/JavaScript">let pdocument.getElementsByTagName(input)[0];console.lo…...

从JBase Basic到金融交易:解析Temenos T24核心系统的编程基石
1. 金融系统的隐形骨架:Temenos T24与JBase Basic的共生关系 第一次接触Temenos T24核心银行系统的开发者,往往会惊讶于其独特的编程架构。这个支撑全球数百家银行日常运作的系统,竟建立在名为JBase Basic的特定领域语言之上。这种设计绝非偶…...

终极网盘不限速指南:八大平台直链下载工具完整教程
终极网盘不限速指南:八大平台直链下载工具完整教程 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

[Python]获取文件属性
[Python]获取文件属性很多时候,我们需要获取一个文件的属性,比如创建日期,访问日期,修改日期,大小 ,只读还是隐藏等属性。用python是相当的方便。下面是我通过查资料得到的方法:文件属性的获取&…...

FreeRTOS下STM32 HAL库I2C通信避坑:别再傻等I2C_WaitOnFlagUntilTimeout了
FreeRTOS下STM32 HAL库I2C通信优化:从阻塞等待到高效任务调度 在嵌入式开发中,I2C总线因其简单的两线制接口和广泛的外设支持而备受青睐。然而,当我们将STM32的HAL库与FreeRTOS结合使用时,一个常见的性能陷阱正在悄然吞噬着系统的…...

AIVideo效果展示:多风格视频生成作品,实测惊艳
AIVideo效果展示:多风格视频生成作品,实测惊艳 1. 开篇:AI视频创作的新纪元 想象一下,你只需要输入一个简单的主题,就能在几分钟内获得一部包含专业分镜、精美画面、自然配音和精准字幕的完整视频。这不是科幻电影中…...

从零搭建多舵机控制系统:PCA9685驱动详解与Proteus虚拟调试
1. 为什么选择PCA9685驱动多舵机系统 第一次接触机械臂项目时,我被16个舵机同步控制的问题难住了。传统方案需要占用大量单片机PWM资源,布线复杂得像蜘蛛网。直到发现了PCA9685这颗神器芯片,才真正体会到什么叫"专业的事交给专业的芯片做…...

SQL中的键与约束
在SQL这里所说的约束是一种规则,它不是一个具体的代码或者指令。然后我们创建了键,然后给不同的键添加了不同的规则,用来实现约束。 约束的存在主要解决三大问题,确保数据库数据可靠: 防止无效数据:比如禁…...

Multibit技术解析:从低功耗设计到面积优化的实践指南
1. Multibit技术入门:为什么我们需要它? 第一次接触Multibit技术时,我和很多工程师一样充满疑问:为什么要在设计中引入这种看似复杂的结构?直到在实际项目中遇到面积和功耗的双重挑战,才真正体会到它的价值…...

Gazebo仿真中实现Velodyne 16线激光雷达与URDF机器人模型的高效集成
1. 为什么要在Gazebo中集成Velodyne激光雷达 在机器人仿真开发中,激光雷达是最常用的传感器之一。Velodyne 16线激光雷达因其性价比高、性能稳定,成为很多开发者的首选。但在Gazebo仿真环境中直接使用它,经常会遇到各种报错和显示问题。 我刚…...

YOLOv5-Lite架构设计:ShuffleNetV2、PPLcNet、RepVGG三大骨干网络详解
YOLOv5-Lite架构设计:ShuffleNetV2、PPLcNet、RepVGG三大骨干网络详解 【免费下载链接】YOLOv5-Lite 🍅🍅🍅YOLOv5-Lite: Evolved from yolov5 and the size of model is only 900kb (int8) and 1.7M (fp16). Reach 15 FPS on the…...