为什么ChatGPT预训练能非常好地捕捉语言的普遍特征和模式
ChatGPT能够非常好地捕捉语言的普遍特征和模式,主要得益于以下几个方面的原因:
-
大规模语料库:ChatGPT的预训练是在大规模文本语料库上进行的,这些语料库涵盖了来自互联网、书籍、文章、对话记录等多种来源的丰富数据。这种大规模的语料库包含了广泛的语言样式、话题和领域,使得模型能够接触到丰富多样的语言信息。
-
无监督学习:ChatGPT采用了无监督学习的方式进行预训练,即模型在预训练过程中并不需要标注的任务目标。这意味着模型可以自主学习语言的普遍特征和模式,而不受特定任务或标注数据的限制。
-
自注意力机制:ChatGPT中采用了Transformer模型的自注意力机制,使得模型能够同时考虑到输入序列中所有位置的信息,并根据位置之间的关联性动态调整注意力权重。这种机制使得模型能够更好地捕捉到文本中的长距离依赖关系和上下文信息,从而更好地理解语言的结构和语义。
-
大规模参数:ChatGPT采用了较大规模的模型参数进行预训练,这使得模型具有更强的表示能力和学习能力。大规模参数模型能够更好地拟合复杂的语言数据分布,从而更好地捕捉语言的普遍特征和模式。
-
多任务学习:在预训练过程中,ChatGPT通过同时进行多个预测任务(如下一个单词预测、遮蔽语言模型等)来学习语言表示。这种多任务学习的方式使得模型能够学习到多种不同层次、不同粒度的语言特征,从而更全面地捕捉语言的普遍特征和模式。
综上所述,ChatGPT通过在大规模语料库上进行无监督学习,在模型结构和训练方式上的优势,使得模型能够充分地学习到语言的普遍特征和模式,从而在各种自然语言处理任务中取得优异的性能表现。
1.多任务学习
在ChatGPT的预训练过程中,采用了多任务学习的方式,即同时进行多个预测任务,以提高模型对语言的理解和表示能力。这种多任务学习的方式确实有助于模型更全面地捕捉语言的普遍特征和模式,以下是关于多任务学习在ChatGPT中的一些细节:
-
下一个单词预测任务:
ChatGPT首先进行了下一个单词预测任务,即给定一个文本序列中的前文,模型需要预测下一个单词是什么。这个任务可以帮助模型学习到语言的局部结构和语法规则。 -
遮蔽语言模型任务:
ChatGPT还采用了遮蔽语言模型任务,即在输入文本中随机遮蔽一些单词,然后让模型预测这些被遮挡的单词。这个任务可以帮助模型学习到上下文之间的关联性和语义信息。 -
位置编码任务:
ChatGPT还可能包含了对位置编码的学习任务,即模型需要学习如何将位置信息嵌入到输入文本中,以便更好地理解文本中单词之间的顺序关系。 -
其他辅助任务:
除了上述任务外,ChatGPT还可能包含其他辅助任务,如预测句子的连续性、句子分类等,以进一步丰富模型的语言表示。
通过同时进行多个预测任务,ChatGPT可以学习到多种不同层次、不同粒度的语言特征。例如,下一个单词预测任务有助于模型学习到局部的语言结构和语法规则,而遮蔽语言模型任务则有助于模型学习到上下文之间的长距离依赖关系和语义信息。这样的多任务学习方式使得ChatGPT能够更全面地捕捉语言的普遍特征和模式,从而提高了模型的预测能力和泛化能力。
原因
多任务学习的方式能够更全面地捕捉语言的普遍特征和模式的原因主要有以下几点:
-
任务之间的互补性:
不同的任务通常会关注于语言的不同方面,例如语法、语义、连续性等。通过同时进行多个任务学习,模型可以从不同的角度去理解语言,从而更全面地学习到语言的各个方面的特征和模式。 -
丰富的训练信号:
多任务学习可以为模型提供更丰富的训练信号。每个任务都提供了一种特定的监督信号,帮助模型更好地学习到数据中的模式和规律。通过同时考虑多个任务的训练信号,模型可以获得更多的信息,并更好地捕捉到数据的潜在结构。 -
迁移学习和泛化能力:
多任务学习可以提高模型的泛化能力。当模型在多个任务上学习到了共享的特征表示时,这些表示可以被有效地迁移到新的任务中,从而提高了模型在新任务上的性能。 -
减少过拟合:
多任务学习可以帮助模型学习到更加泛化的特征表示,减少了模型对于特定任务的过拟合风险。通过在多个任务上共同学习,模型能够更好地捕捉到数据中的通用特征,从而提高了模型的泛化能力,减少了在特定任务上的过拟合现象。
综上所述,多任务学习的方式能够通过任务之间的互补性、丰富的训练信号、迁移学习和泛化能力以及减少过拟合等方面的优势,使得模型更全面地捕捉语言的普遍特征和模式。
方法
在ChatGPT中,使用多任务学习的方法主要是通过在预训练阶段引入多个不同的预测任务,让模型同时学习多种语言表示。具体步骤如下:
-
定义多个预测任务:
ChatGPT预训练阶段通常包括多个预测任务,这些任务旨在帮助模型学习到多种语言特征和模式。常见的任务包括下一个单词预测、遮蔽语言模型、连续性预测等。 -
构建损失函数:
对于每个预测任务,定义相应的损失函数。损失函数通常根据任务类型而定,如交叉熵损失用于分类任务,均方误差用于回归任务等。 -
模型训练:
在预训练阶段,通过最小化多个预测任务的损失函数来训练模型。这样模型就可以同时学习多种语言表示,使得模型能够更全面地捕捉语言的普遍特征和模式。
具体的多任务学习过程如下所示:
-
输入文本序列:
输入一个文本序列,该序列可能是一个句子或一个段落。 -
多任务预测:
对于每个预测任务,对输入文本序列进行处理,并根据任务的要求生成相应的预测结果。例如,对于下一个单词预测任务,模型可能会尝试预测输入文本序列中的下一个单词是什么。 -
计算损失:
根据每个预测任务的预测结果和真实标签,计算相应的损失值。对于每个任务,使用相应的损失函数计算损失值。 -
损失组合:
将所有预测任务的损失值组合起来,形成最终的总损失函数。 -
反向传播和参数更新:
通过反向传播算法,计算总损失函数对模型参数的梯度,并根据梯度更新模型参数。这样模型就可以逐步优化自己,使得在多个预测任务上都取得较好的预测效果。
通过这种多任务学习的方式,ChatGPT能够同时学习多种不同的语言特征和模式,使得模型更全面地捕捉语言的普遍特征,从而在各种自然语言处理任务中取得更好的性能表现。
难点和挑战
在ChatGPT中使用多任务学习确实面临一些难点和挑战,主要包括以下几个方面:
-
任务选择:选择合适的多任务学习任务是一项挑战。每个任务应该能够提供对语言不同方面的补充信息,同时还需要考虑任务之间的相关性以及它们对模型整体性能的影响。
-
损失函数设计:设计适合多任务学习的损失函数是一个挑战。不同任务可能需要不同类型的损失函数,而且这些损失函数的权重如何进行设置也需要认真考虑,以确保各任务对模型的贡献能够平衡。
-
模型结构设计:在ChatGPT中,需要设计适合多任务学习的模型结构。这可能包括添加额外的层或参数,以处理多个任务的输入和输出,同时确保模型具有足够的灵活性来适应不同任务的需求。
-
任务间的冲突和竞争:不同任务之间可能存在冲突和竞争的情况。例如,某些任务的优化目标可能会影响到其他任务的优化效果,需要仔细设计任务间的关系,以确保它们能够相互促进而不是相互干扰。
-
计算和资源需求:多任务学习可能会增加模型的计算和资源需求,因为需要同时处理多个任务的输入和输出。这可能会导致训练时间和资源成本的增加,需要在计算资源和性能之间做出权衡。
-
标注数据的需求:多任务学习通常需要更多的标注数据来支持不同任务的训练,这可能会增加数据收集和标注的成本和难度。
-
泛化能力和过拟合:多任务学习可能会影响模型的泛化能力和过拟合情况。如果任务之间存在较大差异,模型可能会过度拟合某些任务而忽略其他任务,因此需要通过合适的正则化方法来避免过拟合问题。
综上所述,使用多任务学习在ChatGPT中面临着任务选择、损失函数设计、模型结构设计、任务间的冲突和竞争、计算和资源需求、标注数据的需求、泛化能力和过拟合等方面的挑战,需要综合考虑这些因素来有效地利用多任务学习来提高模型的性能。
2.微调
在ChatGPT中,微调是指将预训练好的语言模型(如GPT)在特定的对话相关任务上进行有监督的调整,以适应任务的需求。下面详细介绍ChatGPT中微调的实现方法和策略,以及其中的亮点:
微调实现方法:
-
数据准备:
- 准备标注的对话数据,包括对话文本以及与之相关的标签或目标。
- 对数据进行预处理,如分词、去除停用词等。
-
模型结构调整:
- 将预训练的语言模型结构与任务相关的输出层结合起来,形成一个端到端的模型。
- 通常在预训练模型的输出后面添加一个全连接层,然后根据具体任务的需求设计输出层的结构,如分类任务需要添加一个softmax层。
-
损失函数定义:
- 根据任务的类型和目标,选择合适的损失函数,如交叉熵损失函数用于分类任务,均方误差用于回归任务等。
-
模型训练:
- 使用标注的对话数据对微调后的模型进行训练。
- 通常采用随机梯度下降(SGD)或其变种进行模型参数的更新,同时监控验证集上的性能并进行模型调优。
微调策略:
-
冻结部分参数:
通常情况下,会冻结预训练模型的大部分参数,只更新添加的输出层参数,以减少微调过程中的计算量和训练时间。 -
渐进解冻:
逐渐解冻预训练模型的一部分参数,允许其参与微调过程,以便更好地适应特定任务的数据特征。 -
多阶段微调:
将微调过程分为多个阶段,每个阶段针对特定的任务部分进行微调,以提高模型性能。 -
数据增强:
对标注数据进行增强,如添加噪声、随机扰动等,以增加模型的鲁棒性和泛化能力。
亮点:
-
迁移学习效果好:
由于ChatGPT是在大规模对话数据上进行预训练的,微调时可以利用这些丰富的对话数据来帮助模型更好地适应特定任务,从而在相对较少的标注数据上取得更好的效果。 -
模型结构简单有效:
ChatGPT的模型结构相对简单,只需要添加一个输出层即可完成微调,这使得微调的实现变得简单高效。 -
可解释性强:
由于ChatGPT是基于Transformer架构的,其注意力机制使得模型对于生成的输出具有一定的可解释性,能够根据输入的上下文来生成合理的回复。 -
适用性广泛:
ChatGPT可以用于多种对话相关的任务,如问答、对话生成、情感分析等,微调策略的灵活性使得模型可以适应不同的应用场景。
综上所述,ChatGPT中微调的实现方法和策略使得模型能够在特定任务上取得良好的性能表现,其简单有效的模型结构和丰富的预训练数据为微调提供了良好的基础,使得模型具有广泛的适用性和可解释性。
3.迁移学习效果好
迁移学习在ChatGPT中的效果良好主要有以下几个原因:
-
丰富的预训练数据:ChatGPT在大规模对话数据上进行了预训练,这些数据覆盖了各种语言风格、话题和对话场景。这种丰富的预训练数据使得模型能够学习到广泛的语言知识和对话模式,为在特定任务上进行微调提供了良好的基础。
-
通用语言表示:ChatGPT预训练的目标是尽可能好地捕捉语言的普遍特征和模式,而不是针对特定任务。这意味着预训练的模型学到的语言表示具有一定的通用性,可以适用于各种不同的任务和领域。
-
迁移学习:在微调过程中,ChatGPT通过微调预训练的参数来适应特定任务的需求。由于预训练模型已经在丰富的对话数据上学习到了丰富的语言表示,微调过程中可以利用这些学习到的知识和模式,从而在相对较少的标注数据上取得更好的效果。
-
泛化能力:ChatGPT通过预训练在大规模对话数据上,使得模型具有较强的泛化能力。即使在微调过程中遇到与预训练数据不同的对话场景或语言风格,模型也能够通过学习到的通用语言表示来适应新的任务。
-
特征提取器:ChatGPT可以看作是一个强大的特征提取器,它能够从原始文本中提取出丰富的语言特征。在微调过程中,这些特征能够为模型提供有用的信息,帮助模型更好地理解和解决特定任务。
综上所述,ChatGPT在大规模对话数据上进行预训练,使得模型具有丰富的语言表示和较强的泛化能力,在微调过程中能够充分利用预训练的知识和模式,从而在特定任务上取得更好的效果。
相关文章:

为什么ChatGPT预训练能非常好地捕捉语言的普遍特征和模式
ChatGPT能够非常好地捕捉语言的普遍特征和模式,主要得益于以下几个方面的原因: 大规模语料库:ChatGPT的预训练是在大规模文本语料库上进行的,这些语料库涵盖了来自互联网、书籍、文章、对话记录等多种来源的丰富数据。这种大规模的…...
如何安装ProtoBuf环境
1 🍑下载 ProtoBuf🍑 下载 ProtoBuf 前⼀定要安装依赖库:autoconf automake libtool curl make g unzip 如未安装,安装命令如下: Ubuntu ⽤⼾选择: sudo apt-get install autoconf automake libtool cur…...
C语言 vs Rust应该学习哪个?
C语言 vs Rust应该学习哪个? 在开始前我有一些资料,是我根据网友给的问题精心整理了一份「C语言的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家!!&am…...
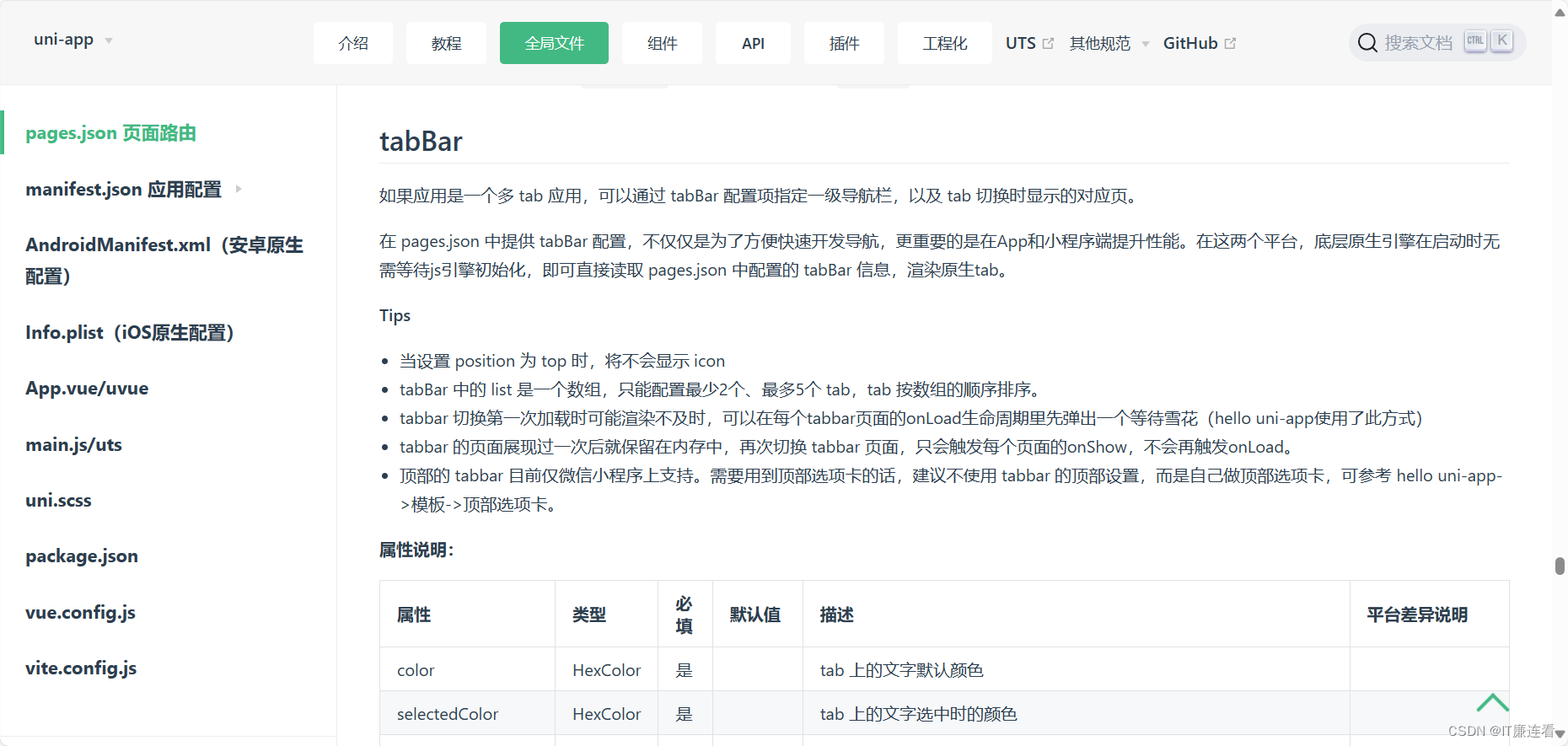
IT廉连看——Uniapp——配置文件pages
IT廉连看——Uniapp——配置文件pages [IT廉连看] 本堂课主要为大家介绍pages.json这个配置文件 一、打开官网查看pages.json可以配置哪些属性。 下面边写边讲解 新建一个home页面理解一下这句话。 以下一些页面的通用配置 通用设置里我们可以对导航栏和状态栏进行一些设…...

服务器上部署WEb服务方法
部署Web服务在服务器上是一个比较复杂的过程。这不仅仅涉及到配置环境、选择软件和设置端口,更有众多其它因素需要考虑。以下是在服务器上部署WEb服务的步骤: 1. 选择服务器:根据项目规模和预期访问量,选择合适的服务器类型和配置…...

设计模式:模版模式
模板模式(Template Pattern)是一种行为型设计模式,它定义了一个操作中的算法骨架,将一些步骤的具体实现延迟到子类中。模板模式使得子类可以在不改变算法结构的情况下重新定义算法的某些步骤。 在模板模式中,将算法的…...
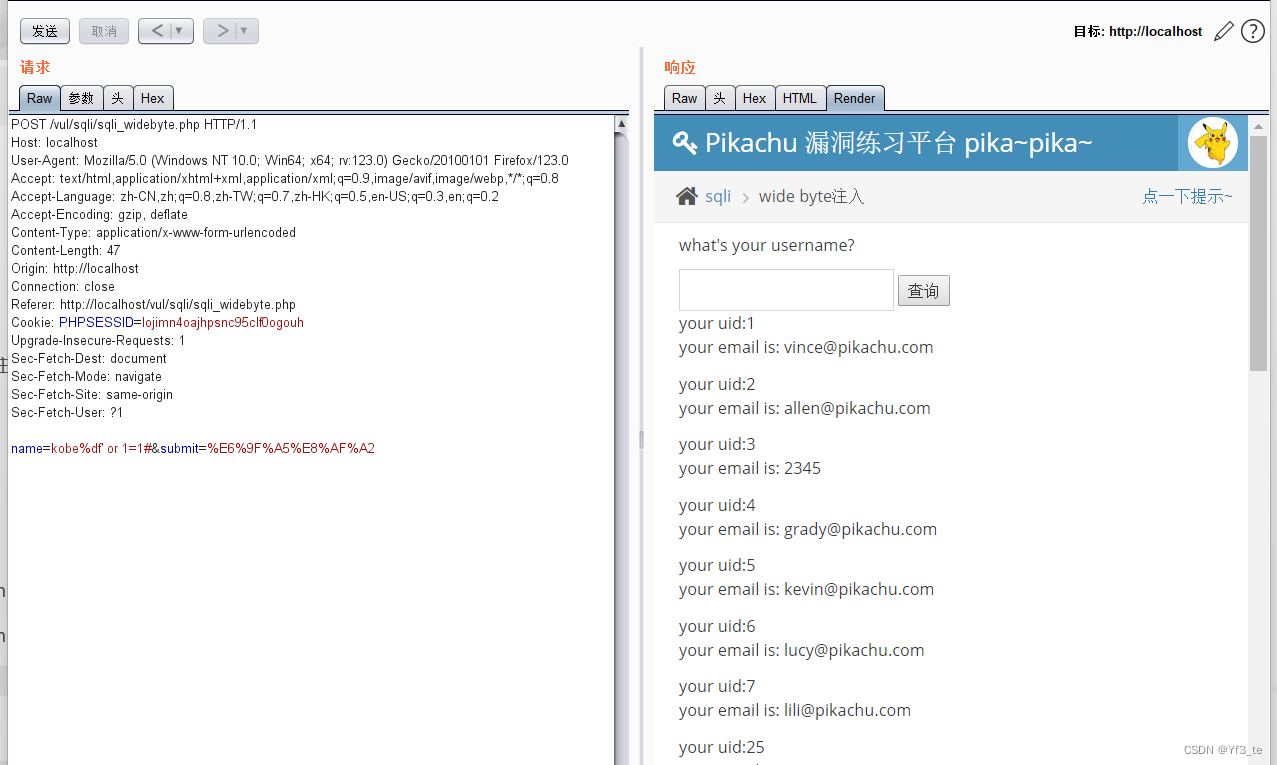
pikachu之特殊注入之搜索型注入、xx型注入、insert/update注入、delete注入、宽字节注入
一步一脚印!!! 补充:此处为什么不写http请求头注入,因为该注入类型只是换了注入点,语句其他根本没有什么变化 1.搜索型 先尝试输入常用payload: 1 or 11 #。 已经有回显 我们在查看提示 我们…...
docker构建hyperf环境
一,构建hyperf 镜像 官网git https://github.com/hyperf/hyperf-docker 使用dockerfile构建镜像 根据需要这里我使用8.1 swoole版本的镜像 在/home/hyperfdocker 目录中新建一个Dockerfile文件,将这个git上的Dockerfile内容复制粘贴进去 docker build…...

WPF常用mvvm开源框架介绍 vue的mvvm设计模式鼻祖
WPF(Windows Presentation Foundation)是一个用于构建桌面应用程序的.NET框架,它支持MVVM(Model-View-ViewModel)架构模式来分离UI逻辑和业务逻辑。以下是一些常用的WPF MVVM开源框架: Prism Prism是由微软…...

HTML <script>元素的10个属性
将javascrip插入HTML的主要方法是使用<script>元素,这个元素是网景公司(Netscape)创造出来的,script 元素所属类型因其用法而异。位于 head 元素中的 script 元素属于元数据元素,位于其他元素(如 bod…...
NX二次开发:ListingWindow窗口的应用
一、概述 在NX二次开发的学习中,浏览博客时发现看到[社恐猫]和[王牌飞行员_里海]这两篇博客中写道有关信息窗口内容的打印和将窗口内容保存为txt,个人人为在二次开发项目很有必要,因此做以下记录。 ListingWindow信息窗口发送信息四种位置类型 设置Listi…...

设计模式-结构型模式-外观模式
外观模式(Facade),为子系统中的一组接口提供一个一致的界面,此模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。[DP] 首先,定义子系统的各个组件接口和具体实现类: // 子系统组件接…...
)
C++学习第四天(类与对象下)
1、构造函数的其他知识 构造函数体赋值 在创建对象时,编译器通过调用构造函数,给对象中各个成员变量一个合适的初始值 构造函数调用之后,对象中已经有了一个初始值,但是不能将其称为对对象中成员变量的初始化,构造函…...

【AI Agent系列】【MetaGPT多智能体学习】0. 环境准备 - 升级MetaGPT 0.7.2版本及遇到的坑
之前跟着《MetaGPT智能体开发入门课程》学了一些MetaGPT的知识和实践,主要关注在MetaGPT入门和单智能体部分(系列文章附在文末,感兴趣的可以看下)。现在新的教程来了,新教程主要关注多智能体部分。 本系列文章跟随《M…...
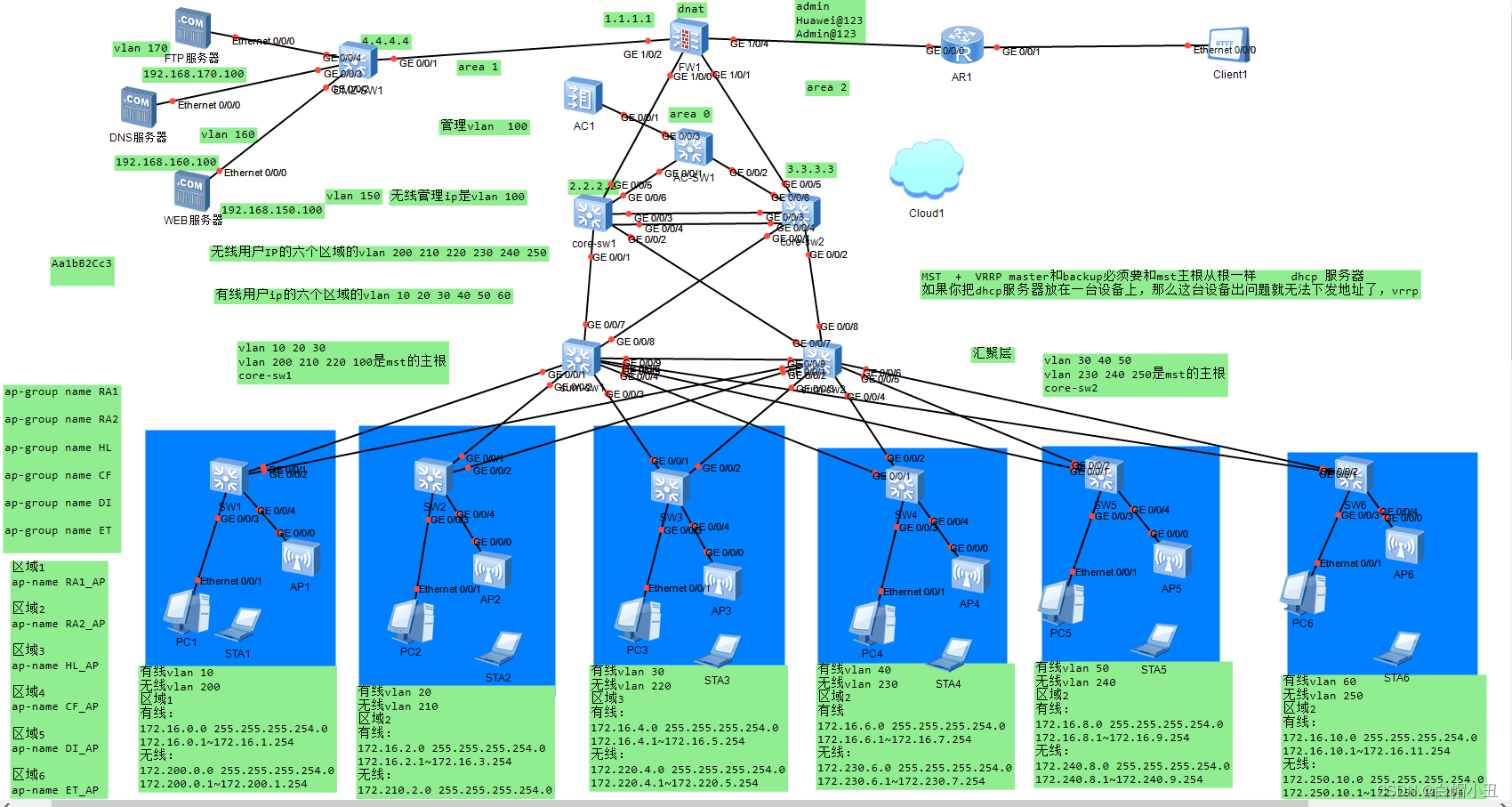
python自动化管理和zabbix监控网络设备(无线AC控制瘦ap配置部分)
目录 前言 拓扑 一、AC-SW1 二、Core-sw1 三、Core-sw2 四、汇聚层 五、AC1 六、SW1-6 七、DMZ区域 前言 具体原理和操作可以访问我的主页视频 白帽小丑的个人空间-白帽小丑个人主页-哔哩哔哩视频 拓扑 一、AC-SW1 sys sysname AC-SW1 vlan batch 100 200 210 220 2…...
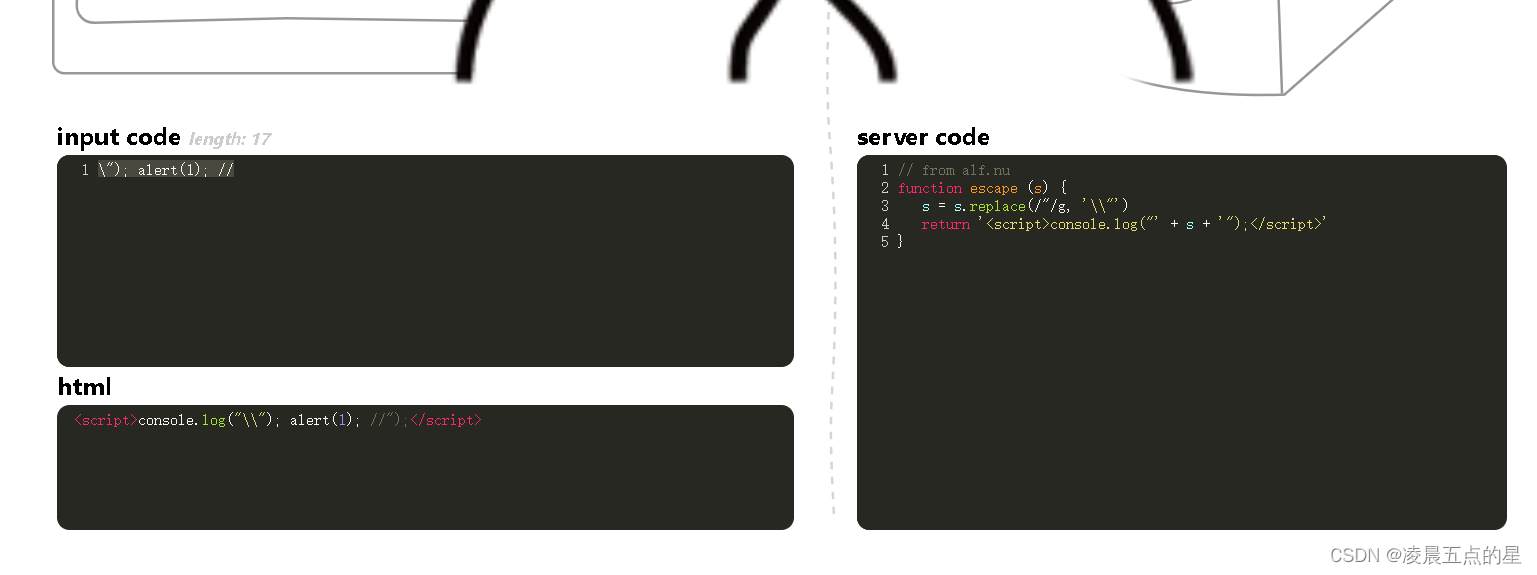
XSS中级漏洞(靶场)
目录 一、环境 二、正式开始闯关 0x01 0x02 0x03 0x04 0x05 0x06 0x07 0x08 0x0B 0x0C 0x0D 0x0E 0x0F 0x10 0x11 0x12 一、环境 在线环境(gethub上面的) alert(1) 二、正式开始闯关 0x01 源码: 思路:闭…...

etcd java 客户端jetcd库踩坑日志
问题 Q: EtcdException: Unable to resolve endpoints [http://0.0.0.0:2379/] A: 经过测试,endpoints最后的斜杠不能写,完整的endpoints是http://0.0.0.0:2379 Q: java.lang.NoSuchMethodError: io.netty.buffer.Po…...
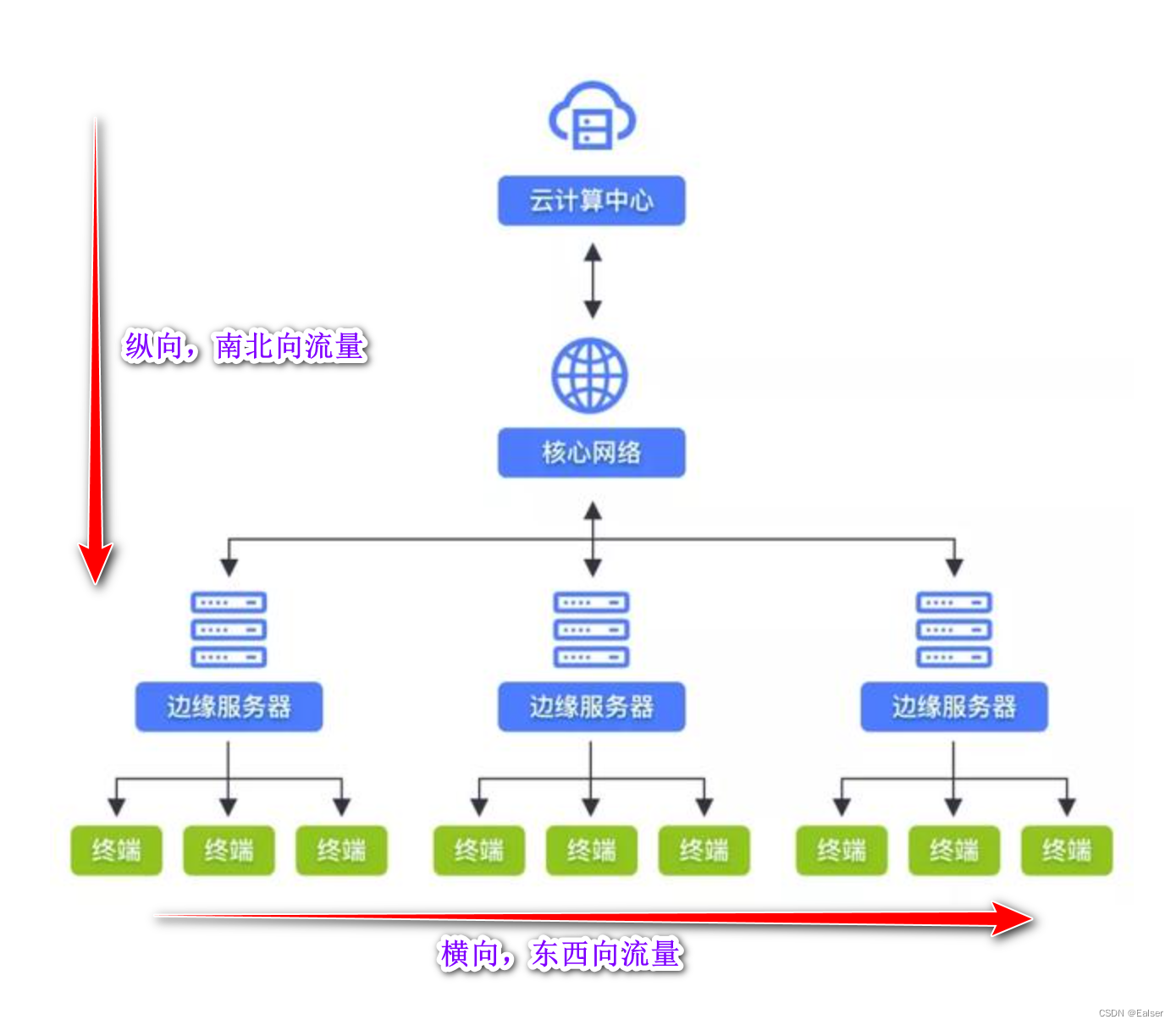
<网络安全>《61 微课堂<第1课 南北向流量是什么?>》
1 形象化解释 在网络安全中,经常听到南北向流量这个词。那究竟是什么意思呢? 这里的南北,就是地图上的东西南北,是方向。我们在画网络架构图时,往往是由上到下依次是web层、应用层、数据层,流量从web层到…...

Day12-【Java SE进阶】JDK8新特性:Lambda表达式、方法引用、常见算法、正则表达式、异常
一、JDK8新特性 1.Lambda表达式 Lambda表达式是JDK 8开始新增的一种语法形式;作用:用于简化名内部类的代码写法。 注意:Lambda表达式并不是说能简化全部匿名内部类的写法,只能简化函数式接口的匿名内部类。 有且仅有一个抽象方法的接口。注意:将来我们见到的大部…...

go mod中如何解决 xxx/yyy/lib@v1.1.0: unrecognized import path
需要检查的几个地方 这个错误通常出现在 Go 模块系统无法找到指定版本的模块时。有几种可能的原因和解决方法: 模块未被发布或标记: 确保 xxx/yyy/lib 模块的版本 v1.1.0 已经被正确地发布或标记。你可以在对应的 GitLab 仓库中查看是否存在 v1.1.0 标签…...

d2dx:让经典暗黑破坏神2在现代PC上焕发新生的终极方案
d2dx:让经典暗黑破坏神2在现代PC上焕发新生的终极方案 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 你是否还记…...

QtAwesome:为Python桌面应用添加专业图标库的终极指南
QtAwesome:为Python桌面应用添加专业图标库的终极指南 【免费下载链接】qtawesome Iconic fonts in PyQt and PySide applications 项目地址: https://gitcode.com/gh_mirrors/qta/qtawesome 你是否厌倦了为PyQt或PySide应用寻找合适的图标资源?Q…...

SpringCloud微服务进阶-Nacos更加全能的注册中心劫
插件化架构 v3 版本最大的变化是引入了模块化插件系统。此前版本中集成在核心包里的原生功能,现在被拆分成独立的插件。 每个插件都是一个独立的 Composer 包,包含 Swift 和 Kotlin 代码、权限清单以及原生依赖。开发者只需安装实际用到的插件࿰…...

成本管理化技术中的成本估算成本控制成本优化
成本管理化技术中的成本估算、成本控制与成本优化 在现代企业管理中,成本管理化技术是提升企业竞争力的关键手段。成本估算、成本控制与成本优化作为其核心环节,直接影响企业的盈利能力和可持续发展。无论是制造业、服务业还是互联网行业,精…...

WVP-PRO流媒体服务器实战:如何优雅地自动清理无人观看的国标/代理流?
WVP-PRO流媒体服务器资源优化:无人观看流自动清理实战指南 在视频监控和流媒体服务运维中,服务器资源的高效利用是保证系统稳定运行的关键。想象一下,当你的平台同时承载数百路摄像头直播和点播回放时,那些已经无人观看却仍在消耗…...

OpCore-Simplify革命性指南:5步智能配置黑苹果的完整方案
OpCore-Simplify革命性指南:5步智能配置黑苹果的完整方案 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的OpenCore配置而头疼…...

3分钟上手Nebula Console:图数据库管理的终极命令行工具指南 [特殊字符]
3分钟上手Nebula Console:图数据库管理的终极命令行工具指南 🚀 【免费下载链接】nebula-console Command line interface for the Nebula Graph service 项目地址: https://gitcode.com/gh_mirrors/ne/nebula-console Nebula Console是NebulaGra…...

免费APK直装神器:告别模拟器,3分钟在Windows上畅玩安卓应用
免费APK直装神器:告别模拟器,3分钟在Windows上畅玩安卓应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为安卓模拟器卡顿、臃肿而烦恼吗…...

SolidWorks2020多版本共存攻略:如何在同一台电脑上安装多个版本
SolidWorks多版本共存实战指南:从安装到优化的完整方案 对于机械设计师、工程师和学生而言,有时需要在同一台计算机上运行多个版本的SolidWorks。可能是为了兼容不同客户的项目文件,或是测试新版本功能的同时保留稳定版本。本文将深入探讨如何…...
BallonTranslator:免费开源的一键漫画翻译神器
BallonTranslator:免费开源的一键漫画翻译神器 【免费下载链接】BallonsTranslator 深度学习辅助漫画翻译工具, 支持一键机翻和简单的图像/文本编辑 | Yet another computer-aided comic/manga translation tool powered by deeplearning 项目地址: https://gitco…...