NLP Seq2Seq模型
🍨 本文为[🔗365天深度学习训练营学习记录博客🍦 参考文章:365天深度学习训练营🍖 原作者:[K同学啊 | 接辅导、项目定制]\n🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/mingtian-fkmxf/zxwb45)Seq2Seq模型是一种深度学习模型,用于处理序列到序列的任务,它由两个主要部分组成:编码器(Encoder)和解码器(Decoder)。
-
编码器(Encoder): 编码器负责将输入序列(例如源语言句子)编码成一个固定长度的向量,通常称为上下文向量或编码器的隐藏状态。编码器可以是循环神经网络(RNN)、长短期记忆网络(LSTM)或者变种如门控循环单元(GRU)等。编码器的目标是捕捉输入序列中的语义信息,并将其编码成一个固定维度的向量表示。
-
解码器(Decoder): 解码器接收编码器生成的上下文向量,并根据它来生成输出序列(例如目标语言句子)。解码器也可以是RNN、LSTM、GRU等。在训练阶段,解码器一次生成一个词或一个标记,并且其隐藏状态从一个时间步传递到下一个时间步。解码器的目标是根据上下文向量生成与输入序列对应的输出序列。
在训练阶段,Seq2Seq模型的目标是最大化目标序列的条件概率给定输入序列。为了实现这一点,通常使用了一种称为教师强制(Teacher Forcing)的技术,即将目标序列中的真实标记作为解码器的输入。但是,在推理阶段(即模型用于生成新的序列时),解码器则根据先前生成的标记生成下一个标记,直到生成一个特殊的终止标记或达到最大长度为止。
下面演示了如何使用PyTorch实现一个简单的Seq2Seq模型,用于将一个序列翻译成另一个序列。这里我们将使用一个虚构的数据集来进行简单的法语到英语翻译。
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn.utils.rnn import pad_sequence
from torch.utils.data import DataLoader, Dataset# 定义数据集
class SimpleDataset(Dataset):def __init__(self, data):self.data = datadef __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]# 定义Encoder
class Encoder(nn.Module):def __init__(self, input_dim, emb_dim, hidden_dim):super(Encoder, self).__init__()self.embedding = nn.Embedding(input_dim, emb_dim)self.rnn = nn.GRU(emb_dim, hidden_dim)def forward(self, src):embedded = self.embedding(src)outputs, hidden = self.rnn(embedded)return outputs, hidden# 定义Decoder
class Decoder(nn.Module):def __init__(self, output_dim, emb_dim, hidden_dim):super(Decoder, self).__init__()self.embedding = nn.Embedding(output_dim, emb_dim)self.rnn = nn.GRU(emb_dim, hidden_dim)self.fc_out = nn.Linear(hidden_dim, output_dim)def forward(self, input, hidden):input = input.unsqueeze(0)embedded = self.embedding(input)output, hidden = self.rnn(embedded, hidden)prediction = self.fc_out(output.squeeze(0))return prediction, hidden# 定义Seq2Seq模型
class Seq2Seq(nn.Module):def __init__(self, encoder, decoder, device):super(Seq2Seq, self).__init__()self.encoder = encoderself.decoder = decoderself.device = devicedef forward(self, src, trg, teacher_forcing_ratio=0.5):batch_size = trg.shape[1]trg_len = trg.shape[0]trg_vocab_size = self.decoder.fc_out.out_featuresoutputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)encoder_outputs, hidden = self.encoder(src)input = trg[0,:]for t in range(1, trg_len):output, hidden = self.decoder(input, hidden)outputs[t] = outputteacher_force = np.random.rand() < teacher_forcing_ratiotop1 = output.argmax(1) input = trg[t] if teacher_force else top1return outputs# 设置参数
INPUT_DIM = 10
OUTPUT_DIM = 10
ENC_EMB_DIM = 32
DEC_EMB_DIM = 32
HID_DIM = 64
N_LAYERS = 1
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5# 实例化模型
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
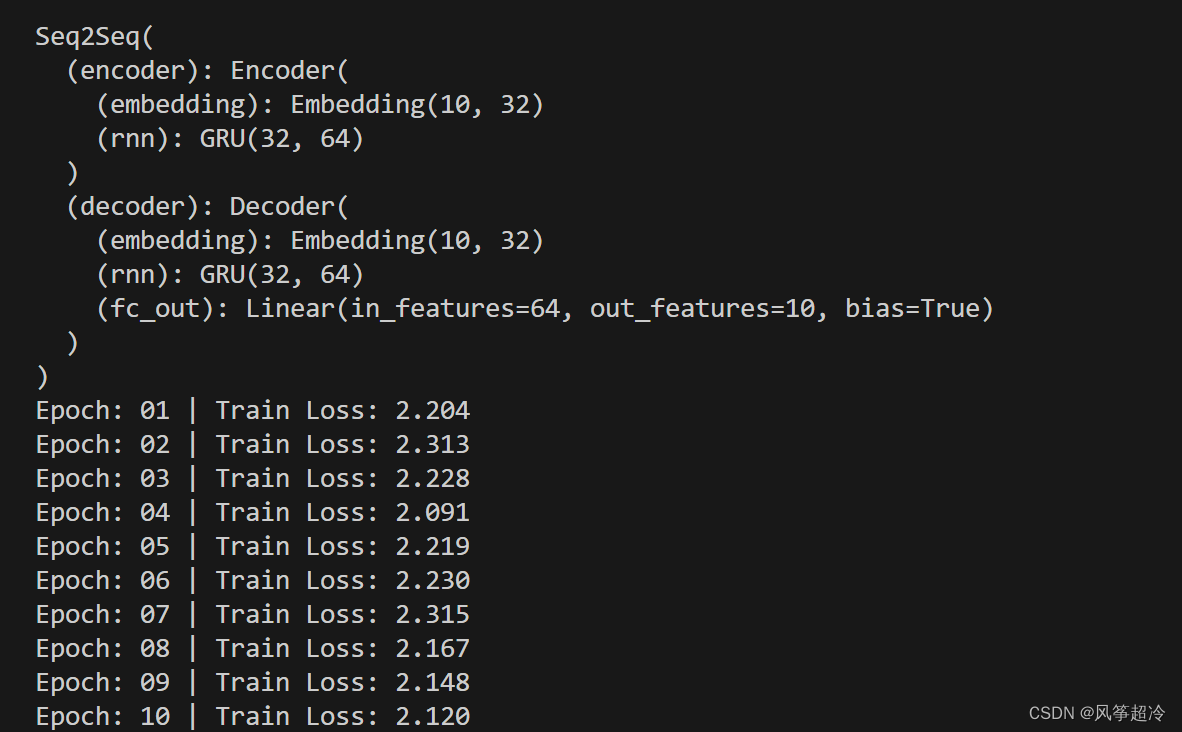
model = Seq2Seq(enc, dec, device).to(device)# 打印模型结构
print(model)# 定义训练函数
def train(model, iterator, optimizer, criterion, clip):model.train()epoch_loss = 0for i, batch in enumerate(iterator):src, trg = batchsrc = src.to(device)trg = trg.to(device)optimizer.zero_grad()output = model(src, trg)output_dim = output.shape[-1]output = output[1:].view(-1, output_dim)trg = trg[1:].view(-1)loss = criterion(output, trg)loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), clip)optimizer.step()epoch_loss += loss.item()return epoch_loss / len(iterator)# 定义测试函数
def evaluate(model, iterator, criterion):model.eval()epoch_loss = 0with torch.no_grad():for i, batch in enumerate(iterator):src, trg = batchsrc = src.to(device)trg = trg.to(device)output = model(src, trg, 0) # 关闭teacher forcingoutput_dim = output.shape[-1]output = output[1:].view(-1, output_dim)trg = trg[1:].view(-1)loss = criterion(output, trg)epoch_loss += loss.item()return epoch_loss / len(iterator)# 示例数据
train_data = [(torch.tensor([1, 2, 3]), torch.tensor([3, 2, 1])),(torch.tensor([4, 5, 6]), torch.tensor([6, 5, 4])),(torch.tensor([7, 8, 9]), torch.tensor([9, 8, 7]))]# 超参数
BATCH_SIZE = 3
N_EPOCHS = 10
LEARNING_RATE = 0.001
CLIP = 1# 数据集与迭代器
train_dataset = SimpleDataset(train_data)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)# 定义损失函数与优化器
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
criterion = nn.CrossEntropyLoss()# 训练模型
for epoch in range(N_EPOCHS):train_loss = train(model, train_loader, optimizer, criterion, CLIP)print(f'Epoch: {epoch+1:02} | Train Loss: {train_loss:.3f}')
相关文章:
NLP Seq2Seq模型
🍨 本文为[🔗365天深度学习训练营学习记录博客🍦 参考文章:365天深度学习训练营🍖 原作者:[K同学啊 | 接辅导、项目定制]\n🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/mi…...
如何在 Linux 上使用 dmesg 命令
文章目录 1. Overview2.ring buffer怎样工作?3.dmesg命令4.移除sudo需求5. 强制彩色输出6.使用人性化的时间戳7.使用dmesg的人性化可读时间戳8.观察实时event9.检索最后10条消息10.搜索特定术语11.使用Log Levels12.使用Facility Categories13.Combining Facility a…...

WPF的DataGrid设置标题头
要设置DataGrid标题头的分割线、背景色和前景色等属性,您可以使用DataGrid的样式和模板来自定义标题头的外观。下面是详细解释以及示例代码: 分割线设置: 您可以使用DataGrid.ColumnHeaderStyle样式中的BorderThickness和BorderBrush属性来设…...
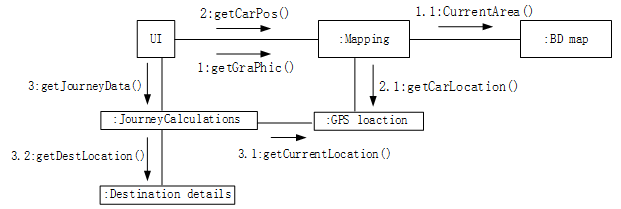
【软考】UML中的图之通信图
目录 1. 说明2. 图示3. 特性4. 例题4.1 例题1 1. 说明 1.通信图强调收发消息的对象的结构组织2.早期版本叫做协作图3.通信图强调参加交互的对象和组织4.首先将参加交互的对象作为图的顶点,然后把连接这些对象的链表示为图的弧,最后用对象发送和接收的消…...

为什么ChatGPT预训练能非常好地捕捉语言的普遍特征和模式
ChatGPT能够非常好地捕捉语言的普遍特征和模式,主要得益于以下几个方面的原因: 大规模语料库:ChatGPT的预训练是在大规模文本语料库上进行的,这些语料库涵盖了来自互联网、书籍、文章、对话记录等多种来源的丰富数据。这种大规模的…...
如何安装ProtoBuf环境
1 🍑下载 ProtoBuf🍑 下载 ProtoBuf 前⼀定要安装依赖库:autoconf automake libtool curl make g unzip 如未安装,安装命令如下: Ubuntu ⽤⼾选择: sudo apt-get install autoconf automake libtool cur…...
C语言 vs Rust应该学习哪个?
C语言 vs Rust应该学习哪个? 在开始前我有一些资料,是我根据网友给的问题精心整理了一份「C语言的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家!!&am…...
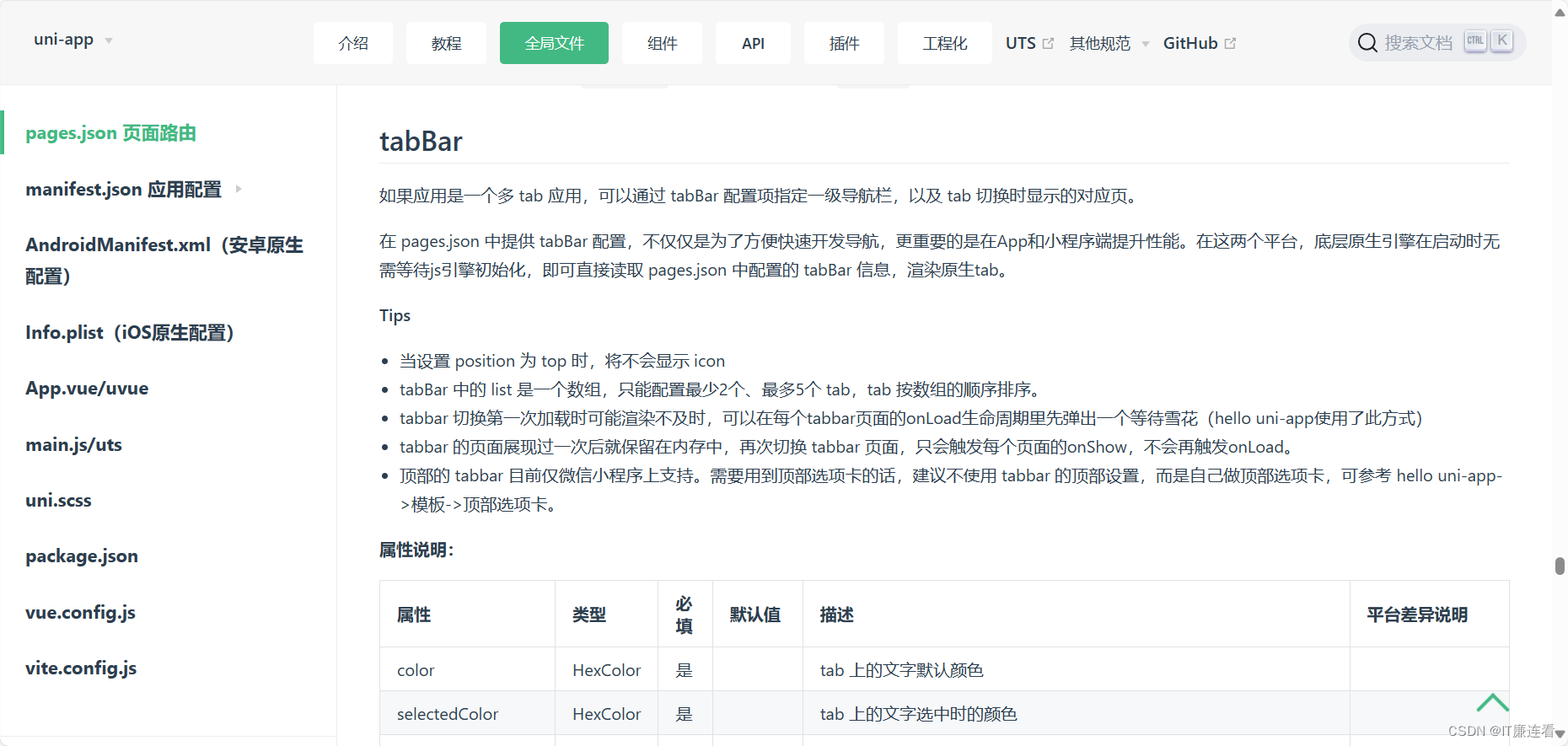
IT廉连看——Uniapp——配置文件pages
IT廉连看——Uniapp——配置文件pages [IT廉连看] 本堂课主要为大家介绍pages.json这个配置文件 一、打开官网查看pages.json可以配置哪些属性。 下面边写边讲解 新建一个home页面理解一下这句话。 以下一些页面的通用配置 通用设置里我们可以对导航栏和状态栏进行一些设…...

服务器上部署WEb服务方法
部署Web服务在服务器上是一个比较复杂的过程。这不仅仅涉及到配置环境、选择软件和设置端口,更有众多其它因素需要考虑。以下是在服务器上部署WEb服务的步骤: 1. 选择服务器:根据项目规模和预期访问量,选择合适的服务器类型和配置…...

设计模式:模版模式
模板模式(Template Pattern)是一种行为型设计模式,它定义了一个操作中的算法骨架,将一些步骤的具体实现延迟到子类中。模板模式使得子类可以在不改变算法结构的情况下重新定义算法的某些步骤。 在模板模式中,将算法的…...
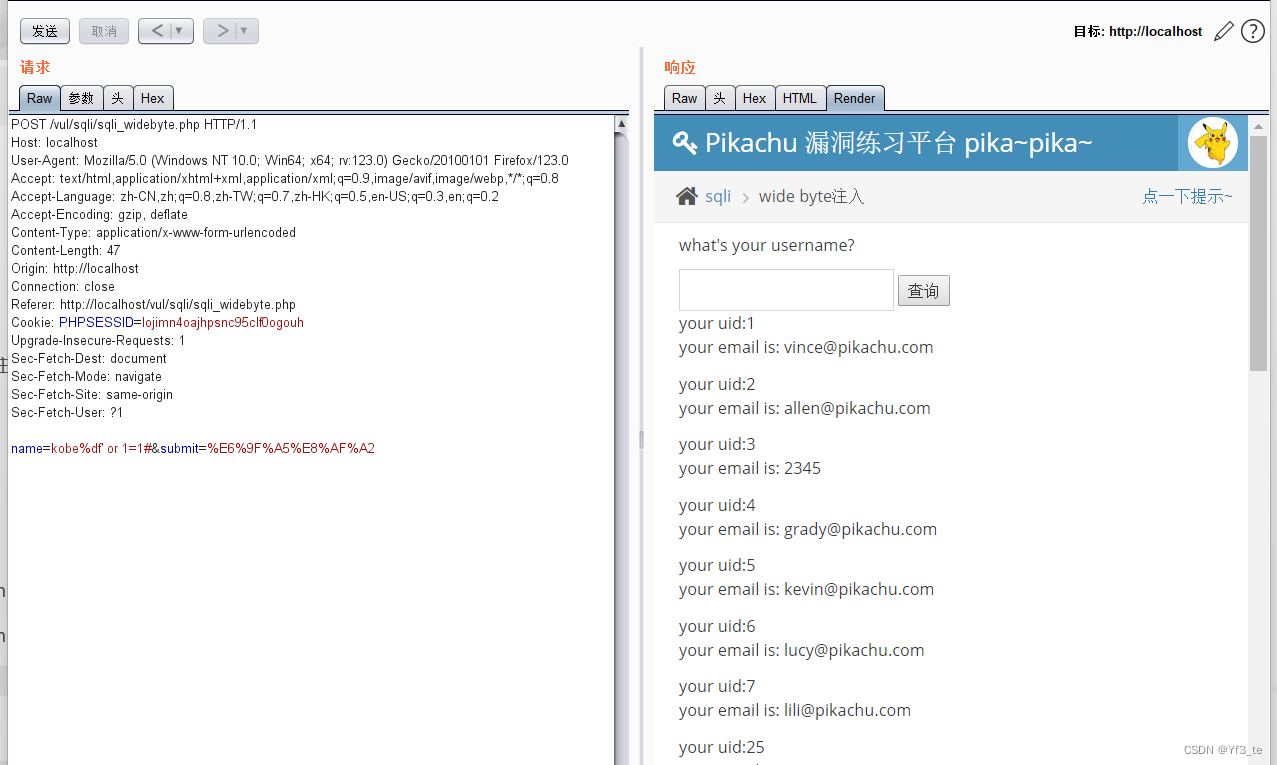
pikachu之特殊注入之搜索型注入、xx型注入、insert/update注入、delete注入、宽字节注入
一步一脚印!!! 补充:此处为什么不写http请求头注入,因为该注入类型只是换了注入点,语句其他根本没有什么变化 1.搜索型 先尝试输入常用payload: 1 or 11 #。 已经有回显 我们在查看提示 我们…...
docker构建hyperf环境
一,构建hyperf 镜像 官网git https://github.com/hyperf/hyperf-docker 使用dockerfile构建镜像 根据需要这里我使用8.1 swoole版本的镜像 在/home/hyperfdocker 目录中新建一个Dockerfile文件,将这个git上的Dockerfile内容复制粘贴进去 docker build…...

WPF常用mvvm开源框架介绍 vue的mvvm设计模式鼻祖
WPF(Windows Presentation Foundation)是一个用于构建桌面应用程序的.NET框架,它支持MVVM(Model-View-ViewModel)架构模式来分离UI逻辑和业务逻辑。以下是一些常用的WPF MVVM开源框架: Prism Prism是由微软…...

HTML <script>元素的10个属性
将javascrip插入HTML的主要方法是使用<script>元素,这个元素是网景公司(Netscape)创造出来的,script 元素所属类型因其用法而异。位于 head 元素中的 script 元素属于元数据元素,位于其他元素(如 bod…...
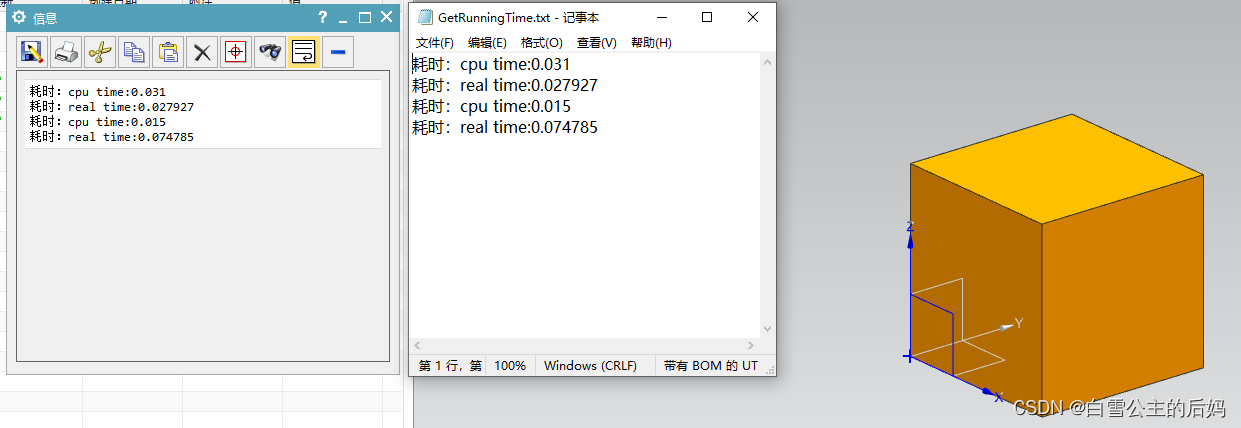
NX二次开发:ListingWindow窗口的应用
一、概述 在NX二次开发的学习中,浏览博客时发现看到[社恐猫]和[王牌飞行员_里海]这两篇博客中写道有关信息窗口内容的打印和将窗口内容保存为txt,个人人为在二次开发项目很有必要,因此做以下记录。 ListingWindow信息窗口发送信息四种位置类型 设置Listi…...

设计模式-结构型模式-外观模式
外观模式(Facade),为子系统中的一组接口提供一个一致的界面,此模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。[DP] 首先,定义子系统的各个组件接口和具体实现类: // 子系统组件接…...
)
C++学习第四天(类与对象下)
1、构造函数的其他知识 构造函数体赋值 在创建对象时,编译器通过调用构造函数,给对象中各个成员变量一个合适的初始值 构造函数调用之后,对象中已经有了一个初始值,但是不能将其称为对对象中成员变量的初始化,构造函…...

【AI Agent系列】【MetaGPT多智能体学习】0. 环境准备 - 升级MetaGPT 0.7.2版本及遇到的坑
之前跟着《MetaGPT智能体开发入门课程》学了一些MetaGPT的知识和实践,主要关注在MetaGPT入门和单智能体部分(系列文章附在文末,感兴趣的可以看下)。现在新的教程来了,新教程主要关注多智能体部分。 本系列文章跟随《M…...
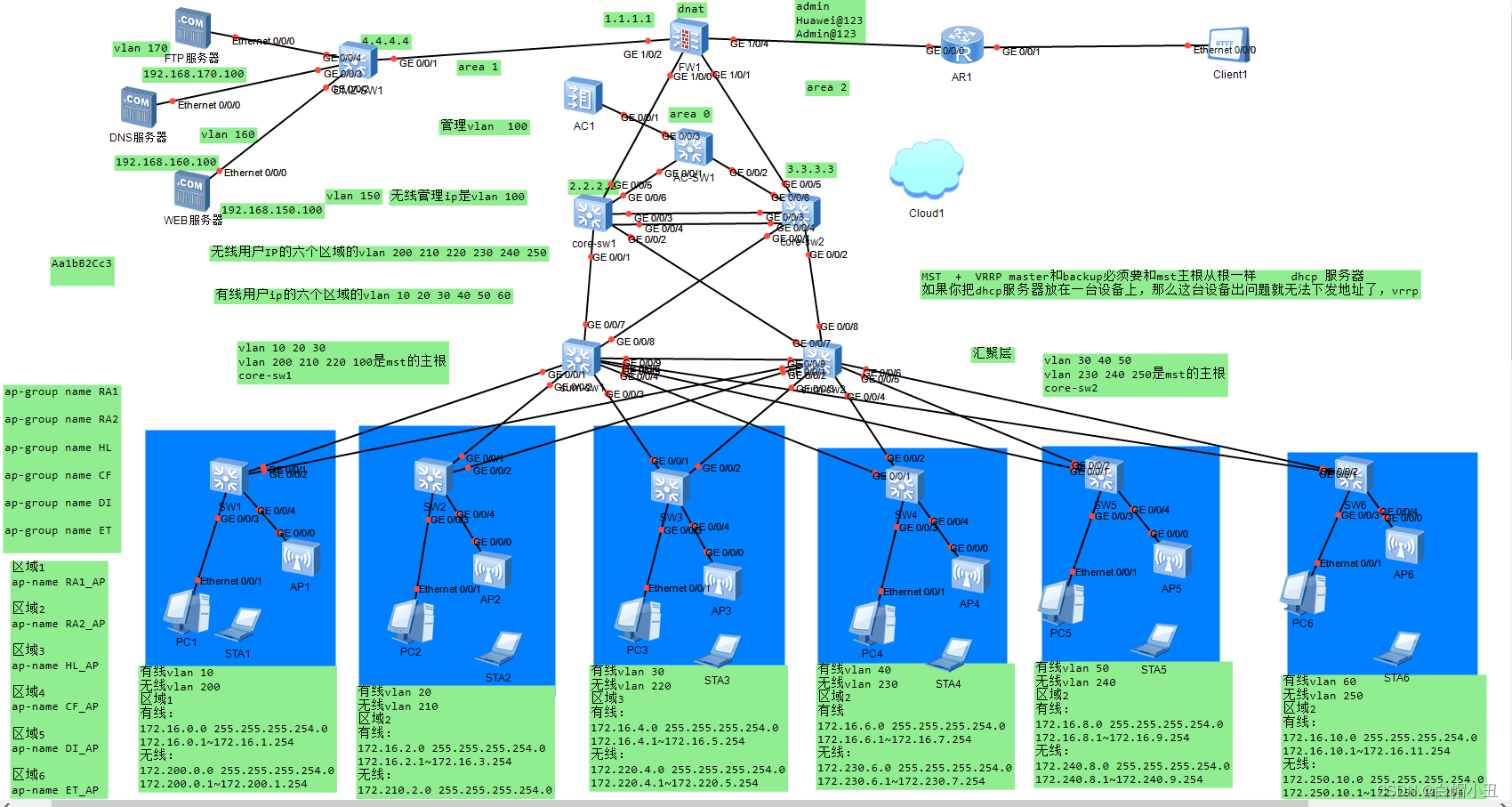
python自动化管理和zabbix监控网络设备(无线AC控制瘦ap配置部分)
目录 前言 拓扑 一、AC-SW1 二、Core-sw1 三、Core-sw2 四、汇聚层 五、AC1 六、SW1-6 七、DMZ区域 前言 具体原理和操作可以访问我的主页视频 白帽小丑的个人空间-白帽小丑个人主页-哔哩哔哩视频 拓扑 一、AC-SW1 sys sysname AC-SW1 vlan batch 100 200 210 220 2…...
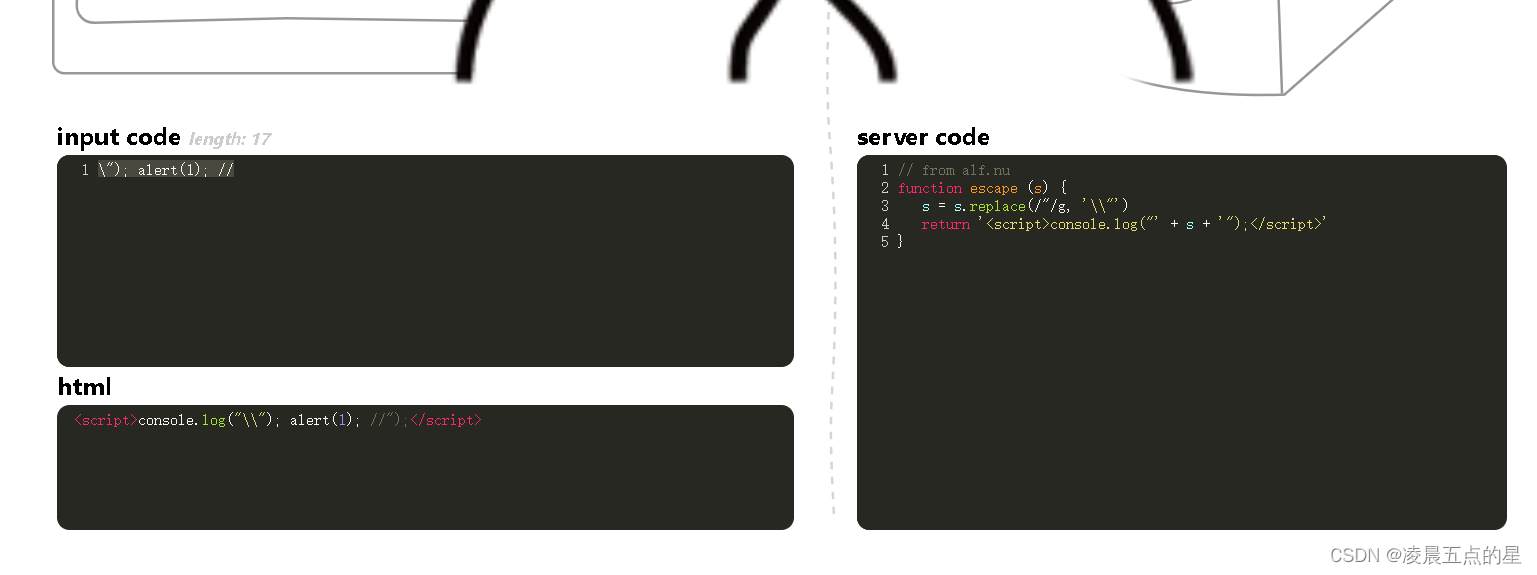
XSS中级漏洞(靶场)
目录 一、环境 二、正式开始闯关 0x01 0x02 0x03 0x04 0x05 0x06 0x07 0x08 0x0B 0x0C 0x0D 0x0E 0x0F 0x10 0x11 0x12 一、环境 在线环境(gethub上面的) alert(1) 二、正式开始闯关 0x01 源码: 思路:闭…...

如何在Windows上直接安装APK文件:APK-Installer终极指南
如何在Windows上直接安装APK文件:APK-Installer终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了笨重的安卓模拟器?想要在W…...

基于vue的食品企业供应链管理信息系统[vue]-计算机毕业设计源码+LW文档
摘要:本文聚焦于食品企业供应链管理的信息化需求,阐述了一个基于Vue框架的食品企业供应链管理信息系统的设计与实现过程。该系统整合了仓库管理、商品查询、供应商管理、用户管理、采购管理、生产管理、销售管理及物流管理等多方面功能。通过Vue及相关技…...

全网最细!OpenClaw 工具系统深度解析:从原子能力到企业级安全,AI 智能体的“万能手脚“完全指南
一、前言:OpenClaw 工具——AI 智能体从"聊天"到"干活"的核心分水岭 当 AI 大模型(GPT/Claude/Gemini)解决了"思考与理解"的问题后,真正决定智能体价值的,是它能否落地执行、操作现实与…...

深度解析Unity IL2CPP逆向工程:Cpp2IL架构设计与技术实现
深度解析Unity IL2CPP逆向工程:Cpp2IL架构设计与技术实现 【免费下载链接】Cpp2IL Work-in-progress tool to reverse unitys IL2CPP toolchain. 项目地址: https://gitcode.com/gh_mirrors/cp/Cpp2IL Cpp2IL作为专注于Unity IL2CPP逆向工程的开源工具&#…...

Ostrakon-VL像素终端部署:飞桨PaddlePaddle后端兼容方案
Ostrakon-VL像素终端部署:飞桨PaddlePaddle后端兼容方案 1. 项目背景与特点 1.1 像素特工终端概述 Ostrakon-VL像素终端是一款专为零售与餐饮行业设计的智能扫描工具,基于Ostrakon-VL-8B多模态大模型开发。与传统工业级UI不同,该终端采用8…...

Gotestsum核心功能解析:从基础输出到JUnit XML集成
Gotestsum核心功能解析:从基础输出到JUnit XML集成 【免费下载链接】gotestsum go test runner with output optimized for humans, JUnit XML for CI integration, and a summary of the test results. 项目地址: https://gitcode.com/gh_mirrors/go/gotestsum …...

Qwen3-4B-Instruct应用案例:智能写作助手如何提升工作效率
Qwen3-4B-Instruct应用案例:智能写作助手如何提升工作效率 1. 智能写作助手带来的效率革命 在信息爆炸的时代,文字工作者每天面临着巨大的创作压力。无论是撰写商业文案、技术文档还是创意内容,传统的人工写作方式往往效率低下且质量不稳定…...

基础篇六 Nuxt4 状态管理:useState 的正确用法
文章目录 一、useState 基础二、跨组件共享三、封装成 Composable四、用户状态管理五、购物车状态六、持久化存储七、SSR 注意事项八、useState vs Pinia总结 个人网站 组件间共享数据是前端开发的常见需求。Vue 2 时代我们用 Vuex,Vue 3 有了 Pinia,但 …...

终极指南:如何用mPDF快速实现PHP到PDF的高效转换
终极指南:如何用mPDF快速实现PHP到PDF的高效转换 【免费下载链接】mpdf PHP library generating PDF files from UTF-8 encoded HTML 项目地址: https://gitcode.com/gh_mirrors/mp/mpdf 还在为PHP项目中生成PDF文件而烦恼吗?mPDF这个免费开源的P…...

uni-app中H5页面通过web-view跳转小程序的完整解决方案
1. 为什么H5页面跳转小程序会报错? 最近在做一个uni-app项目时,遇到了一个典型问题:在H5页面中通过web-view跳转小程序时,控制台报错"wx.miniProgram is undefined"或者"navigateTo is undefined"。这个问题困…...