SparkStreaming在实时处理的两个场景示例
简介
Spark Streaming是Apache Spark生态系统中的一个组件,用于实时流式数据处理。它提供了类似于Spark的API,使开发者可以使用相似的编程模型来处理实时数据流。
Spark Streaming的工作原理是将连续的数据流划分成小的批次,并将每个批次作为RDD(弹性分布式数据集)来处理。这样,开发者可以使用Spark的各种高级功能,如map、reduce、join等,来进行实时数据处理。Spark Streaming还提供了内置的窗口操作、状态管理、容错处理等功能,使得开发者能够轻松处理实时数据的复杂逻辑。
Spark Streaming支持多种数据源,包括Kafka、Flume、HDFS、S3等,因此可以轻松地集成到各种数据管道中。它还能够与Spark的批处理和SQL引擎进行无缝集成,从而实现流式处理与批处理的混合使用。

本文以 TCP、kafka场景讲解spark streaming的使用
消息队列下的信息铺抓
类似消息队列的有redis、kafka等核心组件。
本文以kafka为例,向kafka中实时抓取数据,
pom.xml中添加以下依赖
<dependencies><!-- Spark Core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.2.0</version></dependency><!-- Spark Streaming --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.2.0</version></dependency><!-- Spark SQL --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.2.0</version></dependency><!-- Kafka --><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.8.0</version></dependency><!-- Spark Streaming Kafka Connector --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.2.0</version></dependency><!-- PostgreSQL JDBC --><dependency><groupId>org.postgresql</groupId><artifactId>postgresql</artifactId><version>42.2.24</version></dependency>
</dependencies>创建项目编写以下代码实现功能
package org.example;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.*;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import org.apache.kafka.common.serialization.StringDeserializer;import java.util.*;public class SparkStreamingKafka {public static void main(String[] args) throws InterruptedException {// 创建 Spark 配置SparkConf sparkConf = new SparkConf().setAppName("spark_kafka").setMaster("local[*]").setExecutorEnv("setLogLevel", "ERROR");//设置日志等级为ERROR,避免日志增长导致的磁盘膨胀// 创建 Spark Streaming 上下文JavaStreamingContext streamingContext = new JavaStreamingContext(sparkConf, new Duration(2000)); // 间隔两秒扑捉一次// 创建 Spark SQL 会话SparkSession sparkSession = SparkSession.builder().config(sparkConf).getOrCreate();// 设置 Kafka 相关参数Map<String, Object> kafkaParams = new HashMap<>();kafkaParams.put("bootstrap.servers", "10.0.0.105:9092,10.0.0.106:9092,10.0.0.107:9092");kafkaParams.put("key.deserializer", StringDeserializer.class);kafkaParams.put("value.deserializer", StringDeserializer.class);kafkaParams.put("auto.offset.reset", "earliest");// auto.offset.reset可指定参数有// latest:从分区的最新偏移量开始读取消息。// earliest:从分区的最早偏移量开始读取消息。// none:如果没有有效的偏移量,则抛出异常。kafkaParams.put("enable.auto.commit", true); //采用自动提交offset 的模式kafkaParams.put("auto.commit.interval.ms",2000);//每隔离两秒提交一次commited-offsetkafkaParams.put("group.id", "spark_kafka"); //消费组名称// 创建 Kafka streamCollection<String> topics = Collections.singletonList("spark_kafka"); // Kafka 主题名称JavaDStream<ConsumerRecord<String, String>> kafkaStream = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent(),ConsumerStrategies.Subscribe(topics, kafkaParams) //订阅kafka);//定义数据结构StructType schema = new StructType().add("key", DataTypes.LongType).add("value", DataTypes.StringType);kafkaStream.foreachRDD((VoidFunction<JavaRDD<ConsumerRecord<String, String>>>) rdd -> {// 转换为 DataFrameDataset<Row> df = sparkSession.createDataFrame(rdd.map(record -> {return RowFactory.create(record.offset(), record.value()); //将偏移量和value聚合}), schema);// 写入到 PostgreSQLdf.write()//选择写入数据库的模式.mode(SaveMode.Append)//采用追加的写入模式//协议.format("jdbc")//option 参数.option("url", "jdbc:postgresql://localhost:5432/postgres") // PostgreSQL 连接 URL//确定表名.option("dbtable", "public.spark_kafka")//指定表名.option("user", "postgres") // PostgreSQL 用户名.option("password", "postgres") // PostgreSQL 密码.save();});// 启动 Spark StreamingstreamingContext.start();// 等待 Spark Streaming 应用程序终止streamingContext.awaitTermination();}
}在执行代码前,向创建名为spark_kafka的topic
kafka-topics.sh --create --topic spark_kafka --bootstrap-server 10.0.0.105:9092,10.0.0.106:9092,10.0.0.107:9092向spark_kafka 主题进行随机推数
kafka-producer-perf-test.sh --topic spark_kafka --thrghput 10 --num-records 10000 --record-size 100000 --producer-props bootstrap.servers=10.0.0.105:9092,10.0.0.106:9092,10.0.0.107:9092运行过程中消费的offset会一直被提交到每一个分区
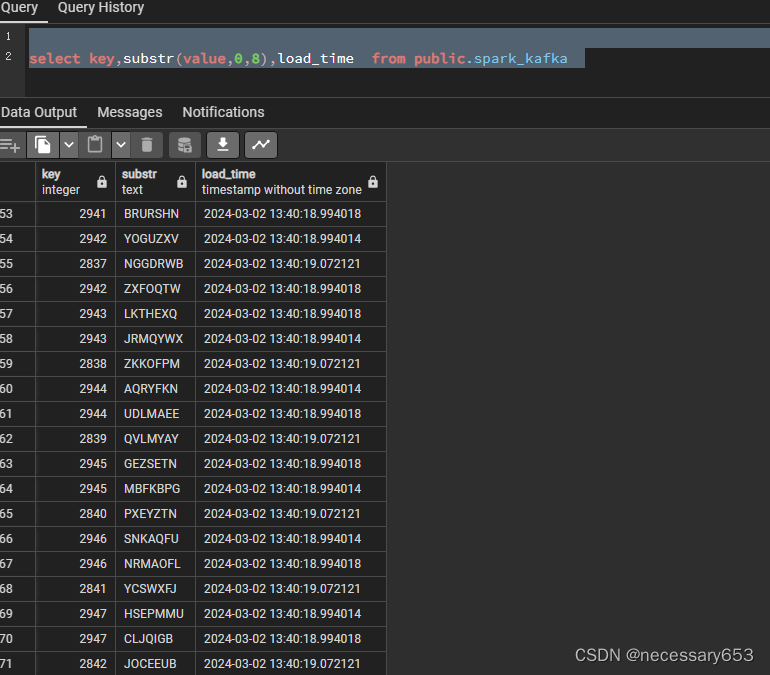
此时在数据库中查看,数据已经实时落地到库中
TCP
TCP环境下,实时监控日志的输出,可用于监控设备状态、环境变化等。当监测到异常情况时,可以实时发出警报。
package org.example;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.*;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import org.apache.kafka.common.serialization.StringDeserializer;import java.util.*;public class SparkStreamingKafka {public static void main(String[] args) throws InterruptedException {// 创建 Spark 配置SparkConf sparkConf = new SparkConf().setAppName("spark_kafka") // 设置应用程序名称.setMaster("local[*]") // 设置 Spark master 为本地模式,[*]表示使用所有可用核心// 设置日志等级为ERROR,避免日志增长导致的磁盘膨胀.setExecutorEnv("setLogLevel", "ERROR");// 创建 Spark Streaming 上下文JavaStreamingContext streamingContext = new JavaStreamingContext(sparkConf, new Duration(2000)); // 间隔两秒扑捉一次// 创建 Spark SQL 会话SparkSession sparkSession = SparkSession.builder().config(sparkConf).getOrCreate();// 设置 Kafka 相关参数Map<String, Object> kafkaParams = new HashMap<>();kafkaParams.put("bootstrap.servers", "10.0.0.105:9092,10.0.0.106:9092,10.0.0.107:9092"); // Kafka 服务器地址kafkaParams.put("key.deserializer", StringDeserializer.class); // key 反序列化器类kafkaParams.put("value.deserializer", StringDeserializer.class); // value 反序列化器类kafkaParams.put("auto.offset.reset", "earliest"); // 从最早的偏移量开始消费消息kafkaParams.put("enable.auto.commit", true); // 采用自动提交 offset 的模式kafkaParams.put("auto.commit.interval.ms", 2000); // 每隔两秒提交一次 committed-offsetkafkaParams.put("group.id", "spark_kafka"); // 消费组名称// 创建 Kafka streamCollection<String> topics = Collections.singletonList("spark_kafka"); // Kafka 主题名称JavaDStream<ConsumerRecord<String, String>> kafkaStream = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent(),ConsumerStrategies.Subscribe(topics, kafkaParams) // 订阅 Kafka);// 定义数据结构StructType schema = new StructType().add("key", DataTypes.LongType).add("value", DataTypes.StringType);kafkaStream.foreachRDD((VoidFunction<JavaRDD<ConsumerRecord<String, String>>>) rdd -> {// 转换为 DataFrameDataset<Row> df = sparkSession.createDataFrame(rdd.map(record -> {return RowFactory.create(record.offset(), record.value()); // 将偏移量和 value 聚合}), schema);// 写入到 PostgreSQLdf.write()// 选择写入数据库的模式.mode(SaveMode.Append) // 采用追加的写入模式// 协议.format("jdbc")// option 参数.option("url", "jdbc:postgresql://localhost:5432/postgres") // PostgreSQL 连接 URL// 确定表名.option("dbtable", "public.spark_kafka") // 指定表名.option("user", "postgres") // PostgreSQL 用户名.option("password", "postgres") // PostgreSQL 密码.save();});// 启动 Spark StreamingstreamingContext.start();// 等待 Spark Streaming 应用程序终止streamingContext.awaitTermination();}
}在10.0.0.108 打开9999端口键入数值 ,使其被spark接收到并进行运算
nc -lk 9999开启端口可以键入数值 此时会在IDEA的控制台显示其计算值

相关文章:
SparkStreaming在实时处理的两个场景示例
简介 Spark Streaming是Apache Spark生态系统中的一个组件,用于实时流式数据处理。它提供了类似于Spark的API,使开发者可以使用相似的编程模型来处理实时数据流。 Spark Streaming的工作原理是将连续的数据流划分成小的批次,并将每个批次作…...

02点亮一个LED
书接上回 上回讲到创建一个示例工程 今天讲如何实现LED的点亮 点亮一个led 所需代码 参考来源网络 延时函数参考: Delay.c #include "stm32f10x.h"/*** brief 微秒级延时* param xus 延时时长,范围:0~233015* retval 无*/ vo…...

【代码分享】
//插入排序 void lnsertionSort(int a[], int n) { int end 0; int tmp 0; int i 0; for (i 0;i < n - 1; i) { end i; tmp a[end 1]; while (end > 0) { if (a[end] > tmp) { a[end 1] a[end]; end–; } else { break; } } a[end 1] tmp; } } //希尔排序…...

windows 使用ffmpeg .a静态库:读取Wav音频并保存PCM
ffmpeg读取Wav音频并保存PCM(源代码保存成 c 文件): // test_ffmpeg.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。 ////#include <iostream>#include <libavcodec/avcodec.h> #include <libavform…...

Docker部署ZooKeeper
在分布式系统中,ZooKeeper是一个关键的组件,用于协调和管理多个节点之间的状态。本文将详细介绍如何使用Docker安装和部署ZooKeeper,包括非集群部署和集群部署两种情况。 非集群部署 前期准备 在开始之前,请确保你已经安装了Docker,并且拥有sudo权限。 关闭防火墙和SEL…...
在PyCharm中使用Git
安装Git CMD检查Git版本 打开cmd,输入git version,检查当前下载版本 配置git的user信息 在cmd中输入 git config --global user.name "用户名"git config --global user.email "用户邮箱"输入:git config --list&…...
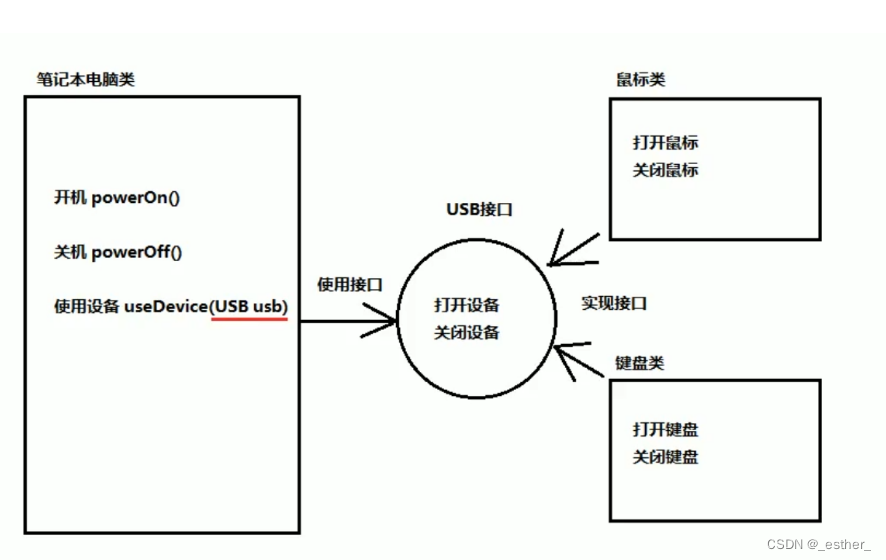
【JavaSE】 P165 ~ P194 抽象方法,抽象类,接口,接口内容,多接口实现和父类继承,多态,向上转型,向下转型
目录 抽象抽象的概念抽象方法和抽象类的格式抽象方法和抽象类的使用抽象方法和抽象类的注意事项● 练习1. 写一个父类图形类,其中有方法,功能计算面积为抽象方法。2. 抽象类继承。判断对错,没错的分析运行结果3. 发红包,群内用户类作为父类,有…...

LeetCode: 数组中的第K个最大元素
问题描述 在未排序的数组中找到第k个最大的元素。请注意,你需要找的是数组排序后的第k个最大的元素,而不是第k个不同的元素。 解题思路 解决这个问题有多种方法,下面是几种常见的解题策略: 排序后选择: 将数组排序,…...

亚马逊自养号测评:如何安全搭建环境,有效规避风险
要在亚马逊上进行自养号测评,构建一个真实的国外环境至关重要。这包括模拟国外的服务器、IP地址、浏览器环境,甚至支付方式,以创建一个完整的国际操作环境。这样的环境能让我们自由注册、养号并下单,确保所有操作均符合国际规范。…...
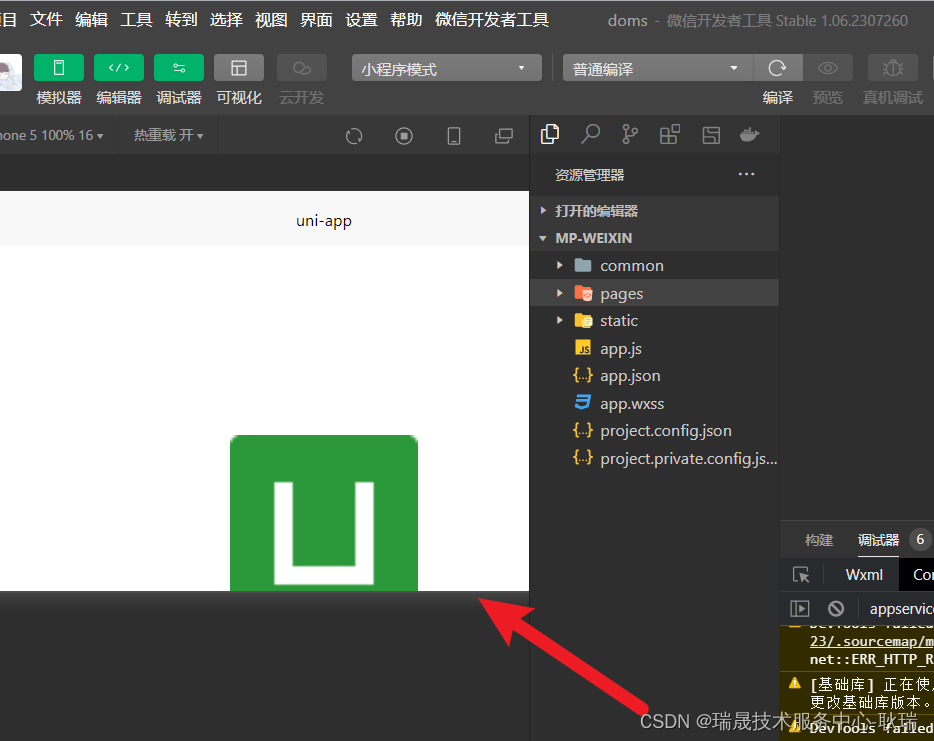
uniApp 调整小程序 单个/全部界面横屏展示效果
我们打开uni项目 小程序端运行 默认是竖着的一个效果 我们打开项目的 pages.json 给需要横屏的界面 的 style 属性 加上 "mp-weixin": {"pageOrientation": "landscape" }界面就横屏了 如果是要所有界面都横屏的话 就直接在pages.json 的 gl…...
匿名内部类)
【java】18:内部类(2)匿名内部类
(1)本质是类(2)内部类(3)该类没有名字(4)同时还是一个对象 说明:匿名内部类是定义在外部类的局部位置,比如方法中,并且没有类名 1.匿名内部类的…...

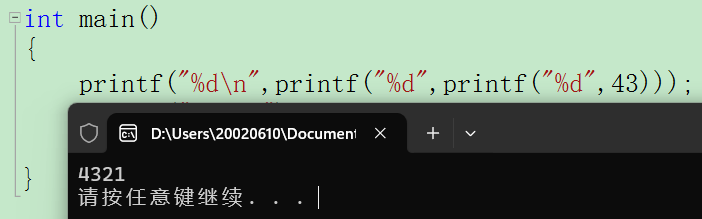
c语言之字符串的输入和输出
c语言在输出字符串时,用格式符‘%s",代码比较简洁 如果说数组长度大于字符串长度,也只输出\0前的内容 字符串默认后面有\0. 如果字符串有多个\0,会默认在第一个\0结束 #include<stdio.h> int main() {int i;char a…...

戏说c第二十六篇: 测试完备性衡量(代码覆盖率)
前言 师弟:“师兄,我又被鄙视了。说我的系统太差,测试不过关。” 我:“怎么说?” 师弟:“每次发布版本给程夏,都被她发现一些bug,太丢人了。师兄,有什么方法来衡量测试的…...
C语言初阶—函数
函数:子程序,是一个大型程序中的某部分代码,由一个或多个语句块组成,它负责完成某项特定任务,而且相较于其他代码,具有相对独立性。一般会有输入参数并有返回值,提供对过程的封装和细节的隐藏&a…...
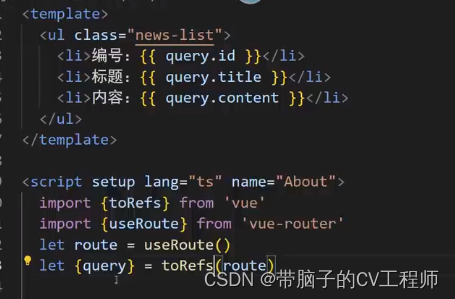
vue3的router
需求 路由组件一般放在,pages或views文件夹, 一般组件通常放在component文件夹 路由的2中写法 子路由 其实就是在News组件里面,再定义一个router-view组件 他的子组件,机会渲染在router-view区域 路由传参 <RouterLink :to"/news…...
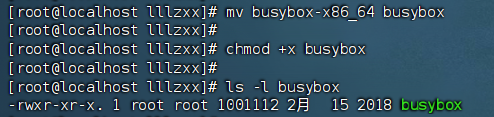
云时代【5】—— LXC 与 容器
云时代【5】—— LXC 与 容器 三、LXC(一)基本介绍(二)相关 Linux 指令实战:使用 LXC 操作容器 四、Docker(一)删除、安装、配置(二)镜像仓库1. 分类2. 相关指令…...
npm digital envelope routines::unsupported
问题描述:npm运行命令报错:digital envelope routines::unsupported 原因:node版本过高 解决方案:在运行命令之前加上 SET NODE_OPTIONS--openssl-legacy-provider && SET NODE_OPTIONS--openssl-legacy-provider &&a…...

深入理解Flutter中的StreamSubscription和StreamController
在Flutter中,StreamSubscription和StreamController是处理异步数据流的重要工具。它们提供了一种方便的方式来处理来自异步事件源的数据。本文将深入探讨它们的区别以及在实际应用中的使用场景。 StreamSubscription StreamSubscription代表了对数据流的订阅&…...
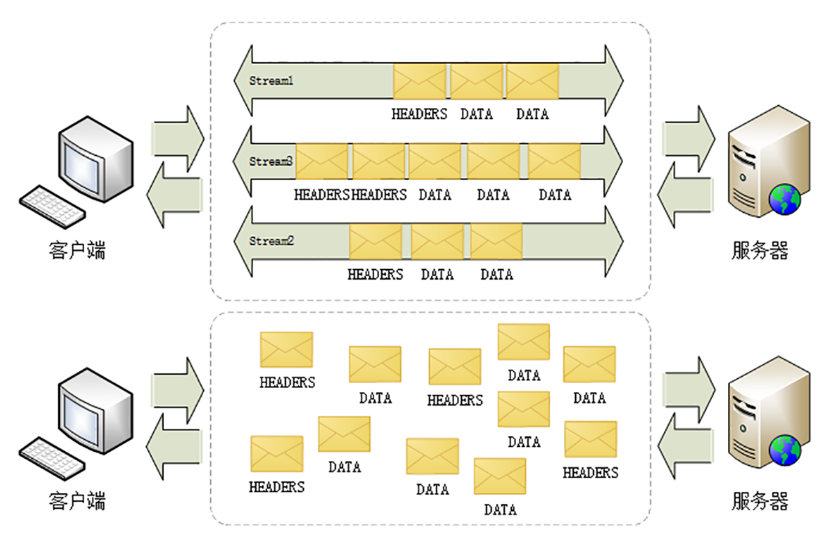
聊聊 HTTP 性能优化
作为用户的我们在 "上网冲浪" 的时候总是希望快一点,尤其是抢演唱会门票的时候,但是现实并非如此,有时候我们会遇到页面加载缓慢、响应延迟的情况。 而 HTTP 协议作为互联网世界的基础,从网站打开速度到移动应用的响应…...

六、防御保护---防火墙内容安全篇
攻击可能只是一个点,防御需要全方面进行 DPI --- 深度包检测技术 --- 主要针对完整的数据包(数据包分片,分段需要重组),之后对 数据包的内容进行识别。(应用层) 1,基于“特征字”的…...

【Java阿里云短信服务SDK实战】——企业级通知短信的配置、封装与业务集成
1. 阿里云短信服务基础配置 第一次接触阿里云短信服务时,我被它复杂的控制台界面弄得有点懵。不过实际操作下来发现,企业级短信通知的配置流程其实就像搭积木,只要按步骤来就能搞定。这里分享下我在工单系统中配置短信通知的真实经历。 首先要…...

Fofax进阶技巧:自定义Fx语法规则与实战应用
1. 认识Fofax与Fx语法 第一次接触Fofax时,我完全被它的效率震惊了。这个用Go语言编写的命令行工具,就像是给FoFa搜索引擎装上了涡轮增压器。你可能已经熟悉FoFa的基本查询,但Fofax带来的Fx语法才是真正的游戏规则改变者。简单来说,…...
)
【仅开放至Q3末】SITS2026改造原始日志脱敏包+Prompt工程checklist(含17个金融/政务场景特化模板)
第一章:SITS2026案例:大模型客服系统改造 2026奇点智能技术大会(https://ml-summit.org) 某大型金融集团原有客服系统基于规则引擎与传统NLU模块构建,响应准确率不足68%,平均首次解决时长(FTTR)达4.7分钟…...

学生党福利:如何利用学校License免费安装MATLAB RoadRunner并接入Carla
教育用户专属:MATLAB RoadRunner与Carla联动的完整指南 在高校实验室里,仿真工具链的搭建往往让许多同学头疼不已。作为自动驾驶、机器人仿真领域的黄金组合,MATLAB RoadRunner与Carla的配合使用能大幅提升研究效率。但专业软件高昂的授权费…...
)
Pycharm远程开发终极指南:AutoDL服务器+YOLOv5环境配置(含守护进程技巧)
PyCharm远程开发实战:AutoDL服务器YOLOv5环境配置与稳定训练方案 远程开发已成为深度学习工程师的必备技能,特别是当本地硬件资源不足时,云服务器提供了强大的计算支持。本文将手把手带你完成从零开始的完整工作流,涵盖环境配置、…...
)
hadoop+Spark+Java基于搜索日志的图文推荐系统设计(源码+文档+调试+可视化大屏)
前言本文介绍了一款使用spring boot开发的搜索日志的图文推荐,及其设计与实现过程。根据软件工程对软件系统开发定制的规则和标准,详细的介绍了系统的分析与设计过程,并且详细的概括了系统的开发与测试过程,将其与JAVA语言紧密结合…...

3步精通抖音批量下载:从零开始打造个人视频素材库
3步精通抖音批量下载:从零开始打造个人视频素材库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...
)
VSCode Markdown PDF 自定义字体与样式全攻略(告别默认僵硬格式)
1. 为什么需要自定义Markdown转PDF的样式? 每次用VSCode把Markdown文件导出为PDF时,总觉得哪里不对劲——默认的字体像是从90年代的打印机里直接蹦出来的,行间距挤得像早高峰地铁,代码块的背景色苍白得像是低血糖患者。这种"…...

避坑指南:uniapp的swiper组件为什么总出现空白间隙?
深度解析:uniapp中swiper组件空白间隙的成因与根治方案 在uniapp开发过程中,swiper组件作为实现滑动切换效果的利器,被广泛应用于轮播图、内容分页等场景。然而不少开发者都遇到过这样的困扰:明明内容已经完整填充,swi…...

3分钟快速上手!MaaYuan代号鸢如鸢自动化辅助工具终极指南
3分钟快速上手!MaaYuan代号鸢如鸢自动化辅助工具终极指南 【免费下载链接】MaaYuan 代号鸢 / 如鸢 一键长草小助手 项目地址: https://gitcode.com/gh_mirrors/ma/MaaYuan 还在为《代号鸢》和《如鸢》的日常任务重复操作而烦恼吗?MaaYuan作为一款…...