爬虫入门到精通_基础篇5(PyQuery库_PyQuery说明,初始化,基本CSS选择器,查找元素,遍历,获取信息,DOM操作)
1 PyQuery说明:
- PyQuery是python中一个强大而又灵活的网页解析库,如果你觉得正则写起来太麻烦,又觉得BeautifulSoup语法太难记,如果你熟悉jQuery的语法那么,PyQuery就是你绝佳的选择。
安装
pip3 install pyquery
2 初始化
介绍三种初始化PyQuery的方法。
1.字符串初始化
html = '''
<div><ul><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div>
'''
from pyquery import PyQuery as pq # 习惯写法,用字母pq来代替PyQuery类doc = pq(html) # 声明PyQuery对象doc,传入html这个参数(字符串)
print(doc('li')) # 用css选择器来实现,如果要选id前面加#,如果选class,前面加.,如果选标签名,什么也不加

2. URL初始化
from pyquery import PyQuery as pq
doc=pq(url='http://www.baidu.com')#直接请求传入的url
print(doc('head'))
选择出了head标签
3.文件初始化
demo.html为本地文件
from pyquery import PyQuery as pq
doc=pq(filename='demo.html')#指定文件名,该文件在运行目录下
print(doc('head'))
3 基本CSS选择器
html = '''
<div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div>
'''
from pyquery import PyQuery as pqdoc = pq(html)
print(doc('#container .list li'))
# 会查找id为container class为list,标签为li的对象,只是层级关系,后者并非一定是前者的子对象
# 注意用空格隔开

4 查找元素
查找子元素
html = '''
<div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div>
'''from pyquery import PyQuery as pqdoc = pq(html)
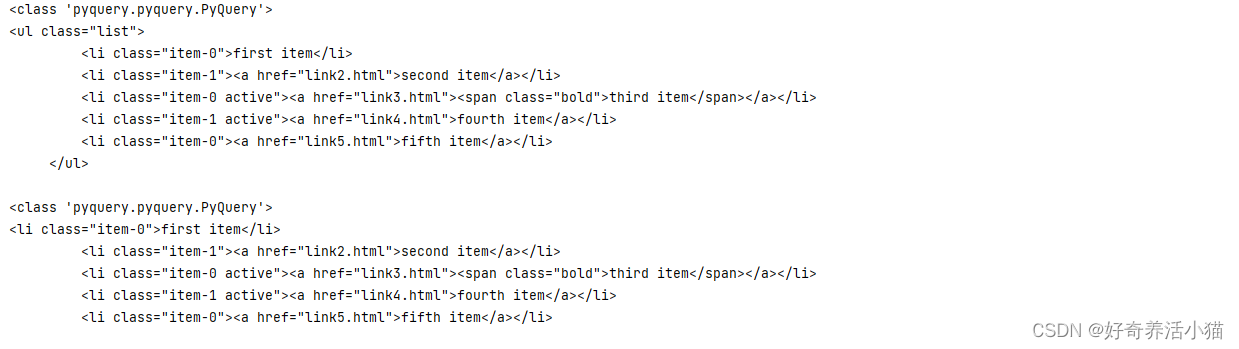
items = doc('.list') # 拿到items,里面选择了list类
print(type(items))
print(items)
lis = items.find('li') # 利用find方法,查找items里面的li标签,得到的lis也可以继续调用find方法往下查找,层层剥离
print(type(lis))
print(lis)
也可以用**.children()**查找直接子元素:
html = '''
<div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div>
'''from pyquery import PyQuery as pqdoc = pq(html)
items = doc('.list')
lis = items.children()
print(type(lis))
print(lis)
lis = items.children('.active')
print(lis)

查找父元素
html = '''
<div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div>
'''
from pyquery import PyQuery as pqdoc = pq(html)
items = doc('.list')
container = items.parent() # .parent()查找对象的父元素
print(type(container))
print(container)

祖先节点
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''
from pyquery import PyQuery as pqdoc = pq(html)
items = doc('.list')
# parents = items.parents()#.parents()查找所有的祖先节点
parent = items.parents('.wrap') # 可以传入参数,再次进行筛选
print(parent)

兄弟元素
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''from pyquery import PyQuery as pqdoc = pq(html)
li = doc('.list .item-0.active') # 空格表示下一层,没有空格表示并列
print(li.siblings()) # .siblings()兄弟元素,即同级别的元素,不包括自己

还可以从结果里再次进行筛选:
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''from pyquery import PyQuery as pqdoc = pq(html)
li = doc('.list .item-0.active') # 空格表示下一层,没有空格表示并列
print(li.siblings('.active'))
5 遍历
如果查找的结果有多个元素,并且你想对每一个都进行操作,那么就要用到遍历了。遍历的关键就是items。
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''
from pyquery import PyQuery as pqdoc = pq(html)
lis = doc('li').items() # .items会是一个生成器,可以用来遍历
print(type(lis))
for li in lis:print(li)

6 获取信息
获取属性
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''
from pyquery import PyQuery as pqdoc = pq(html)
a = doc('.item-0.active a') # 选出同时具备这item-0,active两个信息的标签 空格表示这个标签内层的标签
print(a)
print(a.attr('href')) # a标签的href属性的内容,也就是一个超链接
print(a.attr.href) # 另一种写法

获取文本
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''
from pyquery import PyQuery as pqdoc = pq(html)
a = doc('.item-0.active a') # 选出同时具备这item-0,active两个信息的标签 空格表示这个标签内层的标签
print(a)
print(a.text()) # 获取该标签中的内容

获取HTML
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')#选中一个li标签
print(li)
print(li.html())#获得该标签中的html内容

7 DOM操作
对节点进行一些操作。这部分有许多的API,这里举一些例子。
addClass、removeClass
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''
from pyquery import PyQuery as pqdoc = pq(html)
li = doc('.item-0.active')
print(li)
li.removeClass('active') # 删除active这个class属性
print(li)
li.addClass('active') # 增加
print(li)

attr、css
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''
from pyquery import PyQuery as pqdoc = pq(html)
li = doc('.item-0.active')
print(li)
li.attr('name', 'link') # 如果不存在,就会向标签中添加一个内容为link的name属性,如果存在,那就改变之
print(li)
li.css('font-size', '14px') # 增加一个css
print(li)

remove
看下面的一段html,我们想要单独获得“Hello World”内容,但是和他并列的还有另外的内容,如果我们直接选中wrap标签然后.text,那么会获取两段内容。这时候可以先用remove方法把不需要的并列内容删除掉。
html = '''
<div class="wrap">Hello, World<p>This is a paragraph.</p></div>
'''
from pyquery import PyQuery as pqdoc = pq(html)
wrap = doc('.wrap')
print(wrap.text())wrap.find('p').remove() # 找到p标签然后删除
print(wrap.text())

其他DOM方法
其他DOM方法
伪类选择器
根据自身需要(顺序之类的),选择指定的标签。
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
'''
from pyquery import PyQuery as pqdoc = pq(html)
li = doc('li:first-child') # 选择li标签中的第一个
print(li)
li = doc('li:last-child')
print(li)
li = doc('li:nth-child(2)') # 获取第2个li标签
print(li)
li = doc('li:gt(2)') # 获取索引2个以后的li标签。注意!索引是从0开始的
print(li)
li = doc('li:nth-child(2n)') # 获取第偶数个的li标签
print(li)
li = doc('li:contains(second)') # 查找包含"second"文本的li标签

更多CSS选择器
更多CSS选择器
相关文章:
爬虫入门到精通_基础篇5(PyQuery库_PyQuery说明,初始化,基本CSS选择器,查找元素,遍历,获取信息,DOM操作)
1 PyQuery说明: PyQuery是python中一个强大而又灵活的网页解析库,如果你觉得正则写起来太麻烦,又觉得BeautifulSoup语法太难记,如果你熟悉jQuery的语法那么,PyQuery就是你绝佳的选择。 安装 pip3 install pyquery2 …...

用冒泡排序模拟C语言中的内置快排函数qsort!
目录 编辑 1.回调函数的介绍 2. 回调函数实现转移表 3. 冒泡排序的实现 4. qsort的介绍和使用 5. qsort的模拟实现 6. 完结散花 悟已往之不谏,知来者犹可追 创作不易,宝子们!如果这篇文章对你们有帮助的话,别忘了给个免…...

智慧公厕:打造智慧城市环境卫生新标杆
随着科技的不断发展和城市化进程的加速推进,智慧城市建设已经成为各地政府和企业关注的焦点。而作为智慧城市环境卫生管理的基础设施,智慧公厕的建设和发展也备受重视,被誉为智慧城市的新标杆。本文以智慧公厕源头厂家广州中期科技有限公司&a…...

【学习版】Microsoft Office 2021安装破解教程
本文转载自知乎:https://zhuanlan.zhihu.com/p/655653158 由本人二次整理修改 用到的软件为:Office Tool Plus,下载链接:Office Tool Plus 官方网站 - 一键部署 Office (landian.vip) 下载页面:(随机找个站…...
基于java Springboot实现课程评分系统设计和实现
基于java Springboot实现课程评分系统设计和实现 博主介绍:多年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀作者、专注于Java技术领域 作者主页 央顺技术团队 Java毕设项目精品实战案例《1000套》 欢迎点赞 收藏 ⭐留言 文末获取源…...

git操作基本指令
1.查看用户名 git config user.name 2.查看密码 git config user.password 3.查看邮箱 git config user.email 4.修改用户名 git config --global user.name "xxx(新用户名)" 5.修改密码 git config --global user.password "xxx(新密码)" 6.修改…...

YOLO算法
YOLO介绍 YOLO,全称为You Only Look Once: Unified, Real-Time Object Detection,是一种实时目标检测算法。目标检测是计算机视觉领域的一个重要任务,它不仅需要识别图像中的物体类别,还需要确定它们的位置。与分类任务只关注对…...

【Android】更改手机主题导致app数据丢失问题
情景:在使用app过程中更改系统主题(比如从浅色主题改为深色主题),这时activity销毁重建了(即走了onPause、onStop、onSaveInstanceState、onDestroy、onCreate、onRestoreInstanceState、onStart、onResume的生命周期&…...

Dell R730 2U服务器实践3:安装英伟达上代专业AI训练Nvidia P4计算卡
Dell R730是一款非常流行的服务器,2U的机箱可以放入两张显卡,这次先用一张英伟达上代专业级AI训练卡:P4卡做实验,本文记录安装过程。 简洁步骤: 打开机箱将P4显卡插在4号槽位关闭机箱安装驱动 详细步骤: 对…...

Nacos环境搭建 -- 服务注册与发现
为什么需要服务治理 在未引入服务治理模块之前,服务之间的通信是服务间直接发起并调用来实现的。只要知道了对应服务的服务名称、IP地址、端口号,就能够发起服务通信。比如A服务的IP地址为192.168.1.100:9000,B服务直接向该IP地址发起请求就…...

Linux了解
简介 Linux是一种自由和开放源代码的类UNIX操作系统,由芬兰的Linus Torvalds于1991年首次发布。Linux最初是作为支持英特尔x86架构的个人电脑的一个自由操作系统,现在已经被移植到更多的计算机硬件平台,如手机、平板电脑、路由器、视频游戏控…...
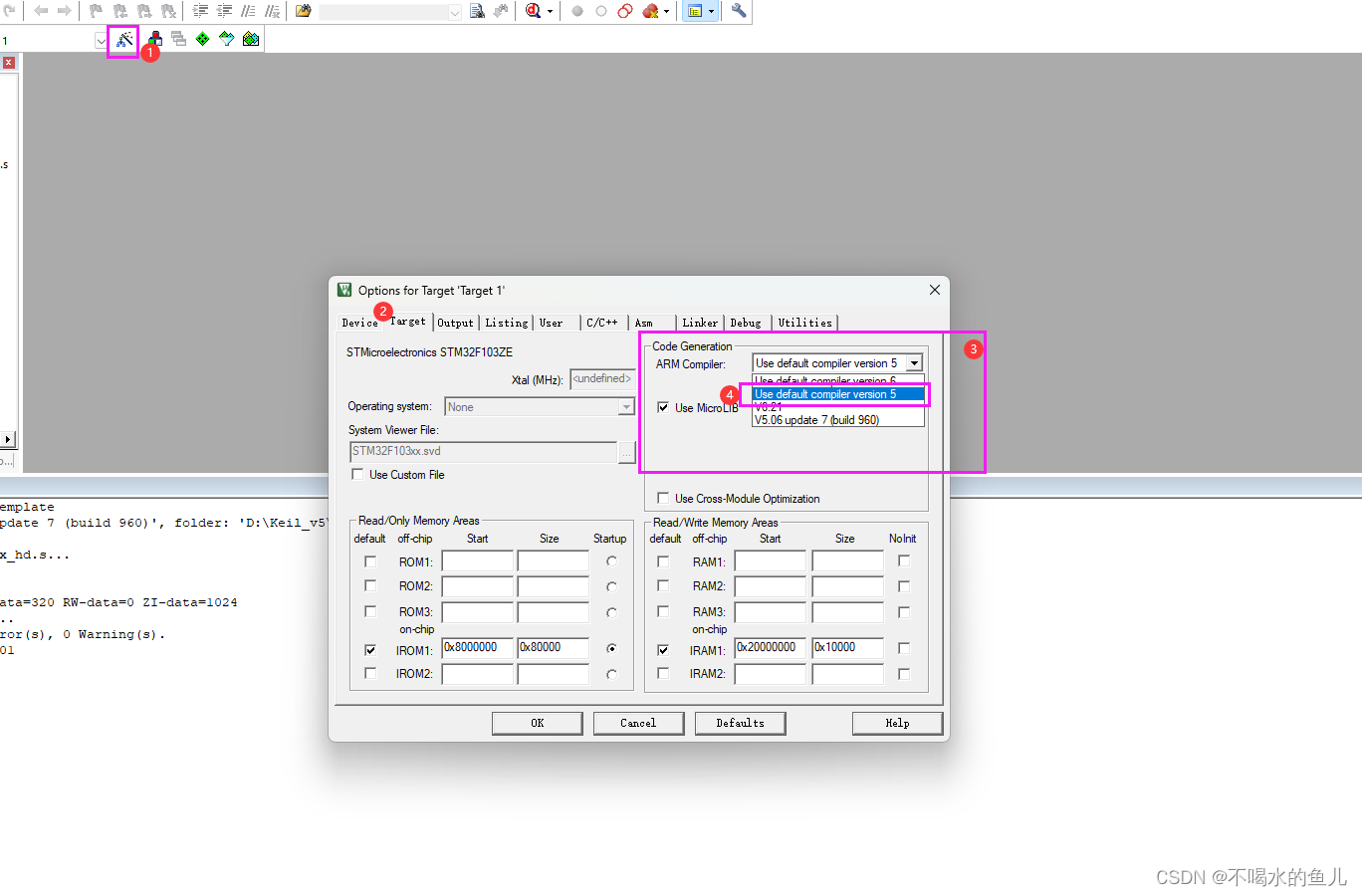
Keil新版本安装编译器ARMCompiler 5.06
0x00 缘起 我手头的项目在使用最新版本的编译器后,烧录后无法正常运行,故安装5.06,测试后发现程序运行正常,以下为编译器的安装步骤。 0x01 解决方法 1. 下载编译器安装文件,可以去ARM官网下载,也可以使用我…...

【基础训练 || Test-1】
总言 主要内容:一些习题。 文章目录 总言一、选择1、for循环、操作符(逗号表达式)2、格式化输出(转换说明符)3、for循环、操作符(逗号表达式、赋值和判等)4、if语句、操作符ÿ…...
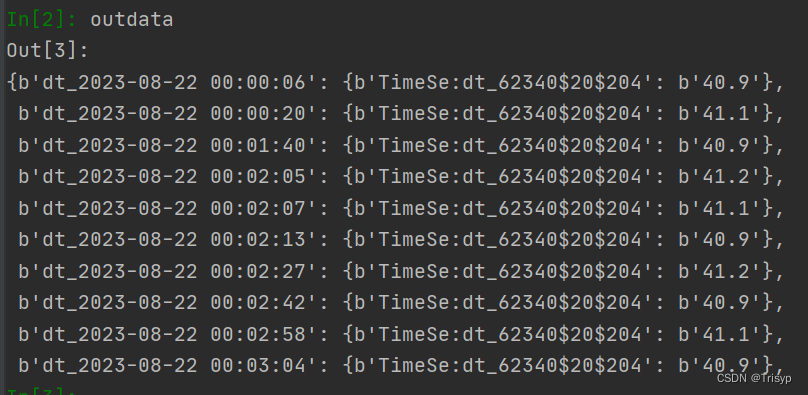
Python读取hbase数据库
1. hbase连接 首先用hbase shell 命令来进入到hbase数据库,然后用list命令来查看hbase下所有表,以其中表“DB_level0”为例,可以看到库名“baotouyiqi”是拼接的,python代码访问时先连接: def hbase_connection(hbase…...

LeetCode41题:缺失的第一个正数(python3)
这道题写的时候完全没有思路,看了很久的题解,才总结出来。 class Solution:def firstMissingPositive(self, nums: List[int]) -> int:nums_set set(nums)n len(nums)for i in range(1, n 1):if i not in nums_set:return ireturn n 1...

C# DataTable 对象操作
实现DataTable按字段进行分类、按列数据汇总、序列化对象数组、所有字段转小写、动态对象数组、数据分页 分类DataTableClassfiy实体: /// <summary>/// 单个分类表/// </summary>public class DataTableClassfiy{/// <summary>/// 分类名称/// &…...

web运行时安全
1.输入验证 对传递的数据的格式、长度、类型(前端和后端都要)进行校验。 对黑白名单校验:比如前端传递了一个用户名,可以搜索该用户是否在白名单或者黑名单列表。 针对黑名单校验,比如: // 手机号验证…...
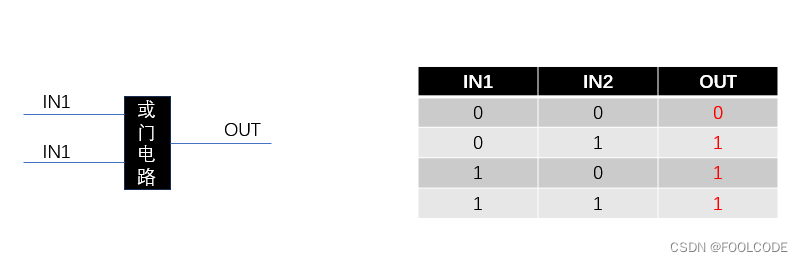
FPGA 与 数字电路的关系 - 这篇文章 将 持续 更新 :)
先说几个逻辑:(强调一下在这篇文章 输入路数 只有 1个或2个,输出只有1个,N个输入M个输出以后再说) 看下面的几个图: 图一( 忘了 这是 啥门,不是门吧 :)也就…...
18 SpringMVC实战
18 SpringMVC实战 1. 课程介绍2. Spring Task定时任务1. 课程介绍 2. Spring Task定时任务 package com.imooc.reader.task...
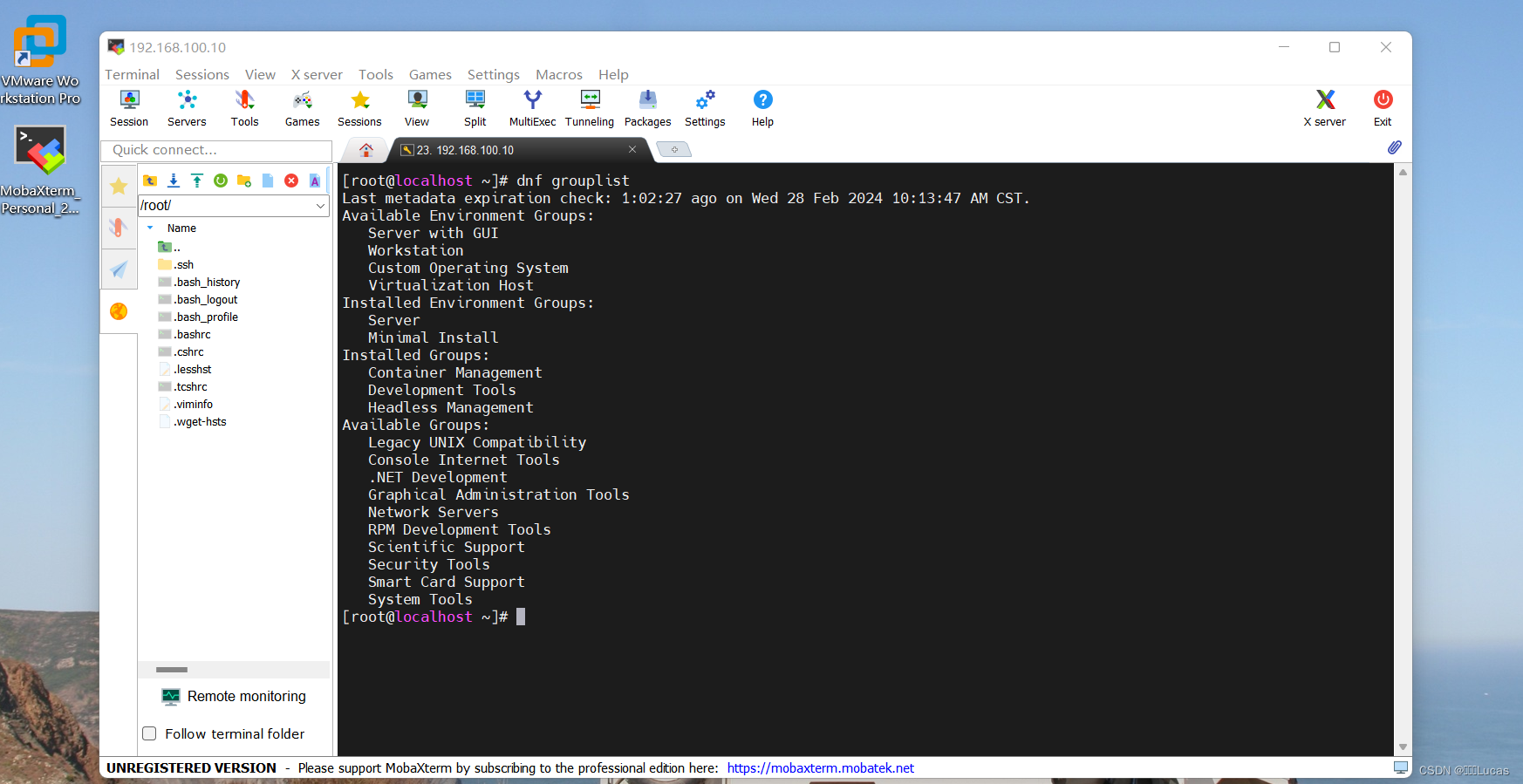
Rocky Linux 运维工具 dnf
一、dnf的简介 dnf是用于在基于RPM包管理系统的包管理工具。用户可以通过 yum来搜索、安装、更新和删除软件包,自动处理依赖关系,它是yum的继任者,旨在提供更快速、更现代化的软件包管理体验。。 二、dnf 的参数说明 序号参数描述1in…...

3个关键步骤:如何用XXMI启动器统一管理多款热门游戏模组
3个关键步骤:如何用XXMI启动器统一管理多款热门游戏模组 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher 你是否曾经为不同游戏的模组管理感到头疼?每个游…...

Trae中Qwen3-Coder-Plus模型实战:提升代码可测试性的智能重构策略
1. 认识Qwen3-Coder-Plus与代码可测试性 第一次接触Qwen3-Coder-Plus时,我正为一个Java服务类缺乏单元测试而头疼。这个阿里开源的代码大模型,能在Trae环境中直接对现有代码进行智能重构。最让我惊讶的是,它不仅能生成符合规范的代码…...

如何快速掌握抗体序列分析:ANARCI完整入门指南
如何快速掌握抗体序列分析:ANARCI完整入门指南 【免费下载链接】ANARCI Antibody Numbering and Antigen Receptor ClassIfication 项目地址: https://gitcode.com/gh_mirrors/an/ANARCI 抗体序列编号是抗体研究和药物开发中的关键环节,而ANARCI&…...

终极指南:如何用BOTW存档编辑器轻松修改《塞尔达传说:旷野之息》游戏数据
终极指南:如何用BOTW存档编辑器轻松修改《塞尔达传说:旷野之息》游戏数据 【免费下载链接】BOTW-Save-Editor-GUI A Work in Progress Save Editor for BOTW 项目地址: https://gitcode.com/gh_mirrors/bo/BOTW-Save-Editor-GUI 在海拉鲁大陆的冒…...

终极指南:3步掌握IwaraDownloadTool高效视频批量下载
终极指南:3步掌握IwaraDownloadTool高效视频批量下载 【免费下载链接】IwaraDownloadTool Iwara 下载工具 | Iwara Downloader 项目地址: https://gitcode.com/gh_mirrors/iw/IwaraDownloadTool 你是否曾为Iwara平台上的精彩视频无法离线保存而烦恼ÿ…...

DeepSeek-OCR-WEBUI助力文档数字化:批量处理图片转文字
DeepSeek-OCR-WEBUI助力文档数字化:批量处理图片转文字 1. 产品概述与核心价值 1.1 什么是DeepSeek-OCR-WEBUI DeepSeek-OCR-WEBUI是一款基于深度学习的光学字符识别工具,专门为需要将大量图片、PDF等非结构化文档转换为可编辑文本的用户设计。它通过…...

专业级ModBus主站工具:QModMaster的工业通信架构深度解析
专业级ModBus主站工具:QModMaster的工业通信架构深度解析 【免费下载链接】qModbusMaster Fork of QModMaster (https://sourceforge.net/p/qmodmaster/code/ci/default/tree/) 项目地址: https://gitcode.com/gh_mirrors/qm/qModbusMaster 在工业自动化领域…...

LiuJuan20260223Zimage与MySQL数据库交互:安装配置与数据管理
LiuJuan20260223Zimage与MySQL数据库交互:安装配置与数据管理 为AI模型数据提供稳定可靠的数据存储方案 1. 前言:为什么需要数据库支持 在实际的AI应用开发中,我们经常遇到一个痛点:模型生成的数据如何持久化保存?比如…...

原神抽卡数据分析神器:告别手动记录,轻松掌握抽卡规律
原神抽卡数据分析神器:告别手动记录,轻松掌握抽卡规律 【免费下载链接】genshin-wish-export Easily export the Genshin Impact wish record. 项目地址: https://gitcode.com/GitHub_Trending/ge/genshin-wish-export 还在为原神抽卡记录无法导出…...

大模型---RLHF
目录 1.RLHF的定义 2.LLM的RLHF 3.奖励模型 4.RLHF的主要问题与局限 5.“非显式RL”方法 (1)DPO (2)RRHF 后续有更深入学习,再继续补充: 1.RLHF的定义 RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)的核心思想就是先让人告诉模型…...