Python读取hbase数据库
1. hbase连接
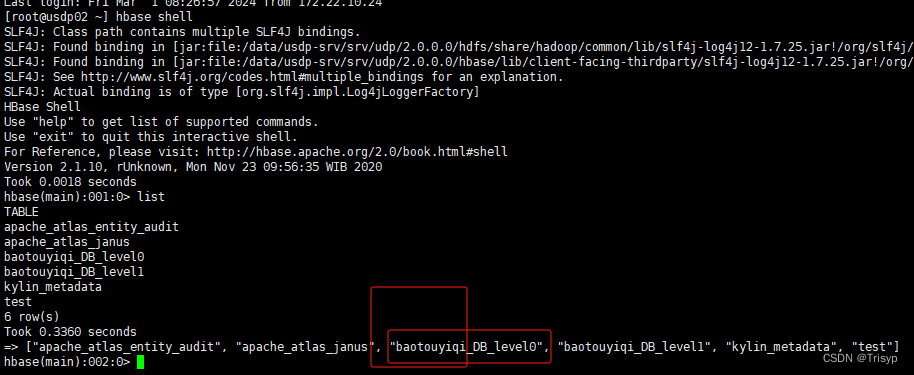
首先用hbase shell 命令来进入到hbase数据库,然后用list命令来查看hbase下所有表,以其中表“DB_level0”为例,可以看到库名“baotouyiqi”是拼接的,python代码访问时先连接:
def hbase_connection(hbase_master, hbase_port, table_prefix=None):connection = happybase.Connection(host=hbase_master, port=hbase_port, table_prefix=table_prefix)return connection
connection = hbase_connection(hbase_master, hbase_port, table_prefix) # 在连接的时候创建项目空间
table = connection.table(tablename) # 获取表连接备注:完整代码在最后,想运行的直接滑倒最后复制即可
2. 按条件读取hbase数据
然后按照条件来查询表中想要的数据集,这里只列举两个条件:时间区间和指定列。同样,我们在shell下用scan命令来查看表中的数据结构:
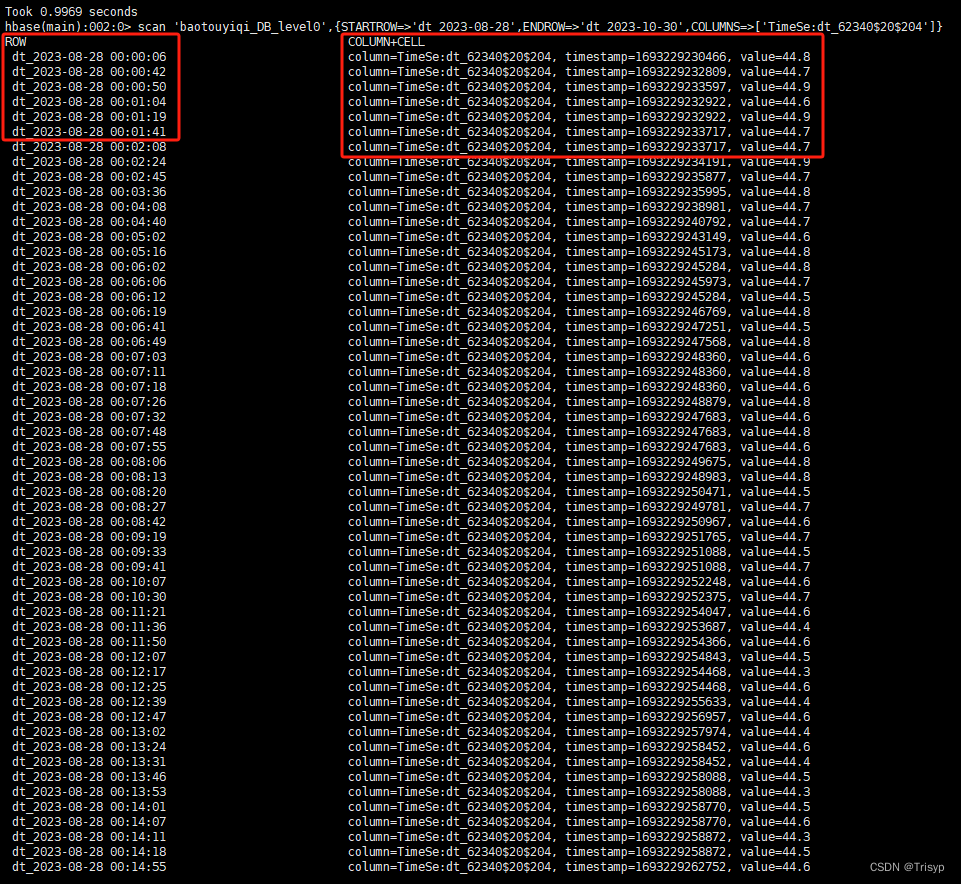
可以看到第一列是ROW,第二列是COLUMN+CELL,python代码取数据方法差不多:
date_prex_start = bytes('dt_' + starttime, encoding='utf-8') # row_start
date_prex_end = bytes('dt_' + endtime, encoding='utf-8') # row_stop
# 通过设置row key的前缀row_prefix参数来进行局部扫描
outdata = dict(table.scan(row_start=date_prex_start, row_stop=date_prex_end,columns=[onecolumn]))
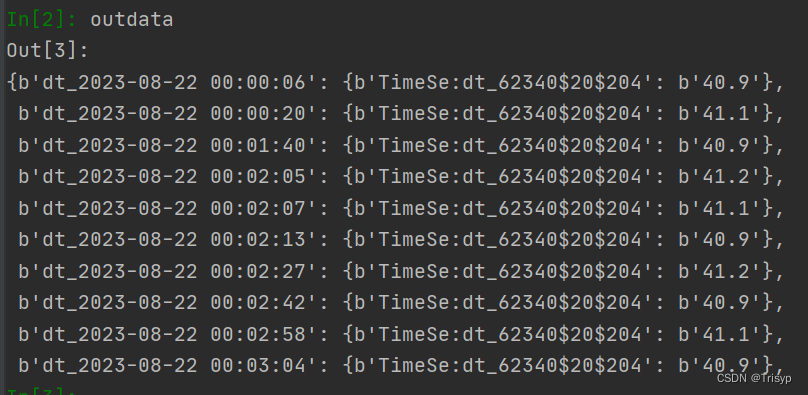
得到的结果如下,是个字典格式:
3. 按格式输出hbase数据结果
我们希望输出的结果是dataframe的,而且第一列是time,第二列是value,所以就做个简单格式处理:
timesep = list(map(lambda x: x.decode('utf-8').replace('dt_', ''), outdata.keys()))
tempdata = list(outdata.values())
valuelist = list(map(lambda x: float(list(x.values())[0]), tempdata))
if len(timesep) > 0:db_data2 = pd.DataFrame({'时间': timesep, onecolumn: valuelist})db_data2.loc[:, '时间2'] = [i[:16] for i in db_data2['时间']]db_data2 = db_data2.drop_duplicates(subset=['时间2'], keep='last') # 一分钟内多次数值取一个即可
else:db_data2 = pd.DataFrame()
if len(db_data2) < 1:return pd.DataFrame()
db_data2.loc[:, '时间戳'] = [time.mktime(time.strptime(i, "%Y-%m-%d %H:%M:%S")) for i in db_data2['时间']]
db_data2 = db_data2.sort_values(by=['时间戳'], ascending=False) # 将最新的数值放最前面
db_data3 = db_data2.drop(columns=['时间2', '时间戳'])
db_data3.columns = ['time', 'value']
4. 完整代码(code)
import happybase
import time
import pandas as pd
from pathlib import Pathos_file_name = Path(__file__).namedef hbase_connection(hbase_master, hbase_port, table_prefix=None):connection = happybase.Connection(host=hbase_master, port=hbase_port, table_prefix=table_prefix)return connectiondef get_data_by_tum(hbase_master, hbase_port, table_prefix, tablename, columnslist, starttime, endtime):columnsid = '$'.join(columnslist)onecolumn = 'TimeSe:dt_' + columnsid # columnconnection = hbase_connection(hbase_master, hbase_port, table_prefix) # 在连接的时候创建项目空间table = connection.table(tablename) # 获取表连接date_prex_start = bytes('dt_' + starttime, encoding='utf-8') # row_startdate_prex_end = bytes('dt_' + endtime, encoding='utf-8') # row_stop# 通过设置row key的前缀row_prefix参数来进行局部扫描outdata = dict(table.scan(row_start=date_prex_start, row_stop=date_prex_end,columns=[onecolumn]))timesep = list(map(lambda x: x.decode('utf-8').replace('dt_', ''), outdata.keys()))tempdata = list(outdata.values())valuelist = list(map(lambda x: float(list(x.values())[0]), tempdata))if len(timesep) > 0:db_data2 = pd.DataFrame({'时间': timesep, onecolumn: valuelist})db_data2.loc[:, '时间2'] = [i[:16] for i in db_data2['时间']]db_data2 = db_data2.drop_duplicates(subset=['时间2'], keep='last') # 一分钟内多次数值取一个即可else:db_data2 = pd.DataFrame()if len(db_data2) < 1:return pd.DataFrame()db_data2.loc[:, '时间戳'] = [time.mktime(time.strptime(i, "%Y-%m-%d %H:%M:%S")) for i in db_data2['时间']]db_data2 = db_data2.sort_values(by=['时间戳'], ascending=False) # 将最新的数值放最前面db_data3 = db_data2.drop(columns=['时间2', '时间戳'])db_data3.columns = ['time', 'value']return db_data3if __name__ == '__main__':begin_time = '2023-08-22 00:00:00'end_time = '2023-08-23 00:00:00'hbase_master = "142.21.8.22"hbase_port = 9097table_prefix = "baotouyiqi"table_name = "DB_level0"onedata = ["62340", "20", "204"]dataget = get_data_by_tum(hbase_master, hbase_port, table_prefix, table_name,onedata, begin_time, end_time)print(dataget)
相关文章:
Python读取hbase数据库
1. hbase连接 首先用hbase shell 命令来进入到hbase数据库,然后用list命令来查看hbase下所有表,以其中表“DB_level0”为例,可以看到库名“baotouyiqi”是拼接的,python代码访问时先连接: def hbase_connection(hbase…...

LeetCode41题:缺失的第一个正数(python3)
这道题写的时候完全没有思路,看了很久的题解,才总结出来。 class Solution:def firstMissingPositive(self, nums: List[int]) -> int:nums_set set(nums)n len(nums)for i in range(1, n 1):if i not in nums_set:return ireturn n 1...

C# DataTable 对象操作
实现DataTable按字段进行分类、按列数据汇总、序列化对象数组、所有字段转小写、动态对象数组、数据分页 分类DataTableClassfiy实体: /// <summary>/// 单个分类表/// </summary>public class DataTableClassfiy{/// <summary>/// 分类名称/// &…...

web运行时安全
1.输入验证 对传递的数据的格式、长度、类型(前端和后端都要)进行校验。 对黑白名单校验:比如前端传递了一个用户名,可以搜索该用户是否在白名单或者黑名单列表。 针对黑名单校验,比如: // 手机号验证…...
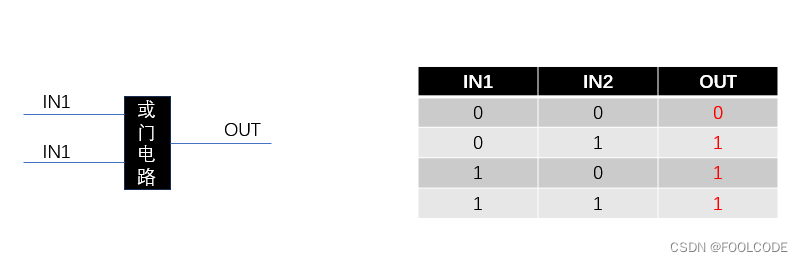
FPGA 与 数字电路的关系 - 这篇文章 将 持续 更新 :)
先说几个逻辑:(强调一下在这篇文章 输入路数 只有 1个或2个,输出只有1个,N个输入M个输出以后再说) 看下面的几个图: 图一( 忘了 这是 啥门,不是门吧 :)也就…...
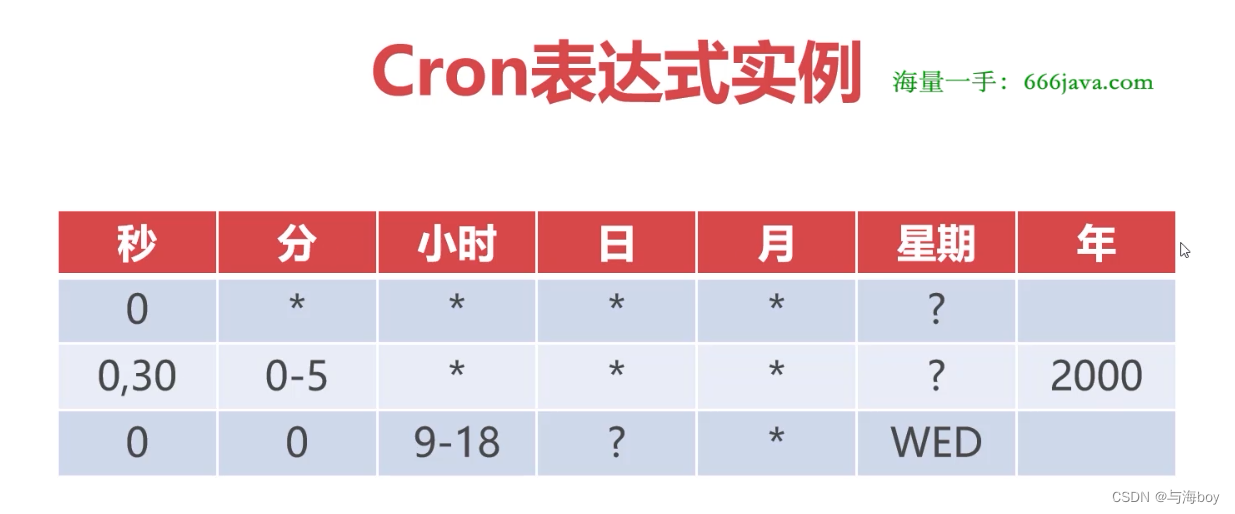
18 SpringMVC实战
18 SpringMVC实战 1. 课程介绍2. Spring Task定时任务1. 课程介绍 2. Spring Task定时任务 package com.imooc.reader.task...
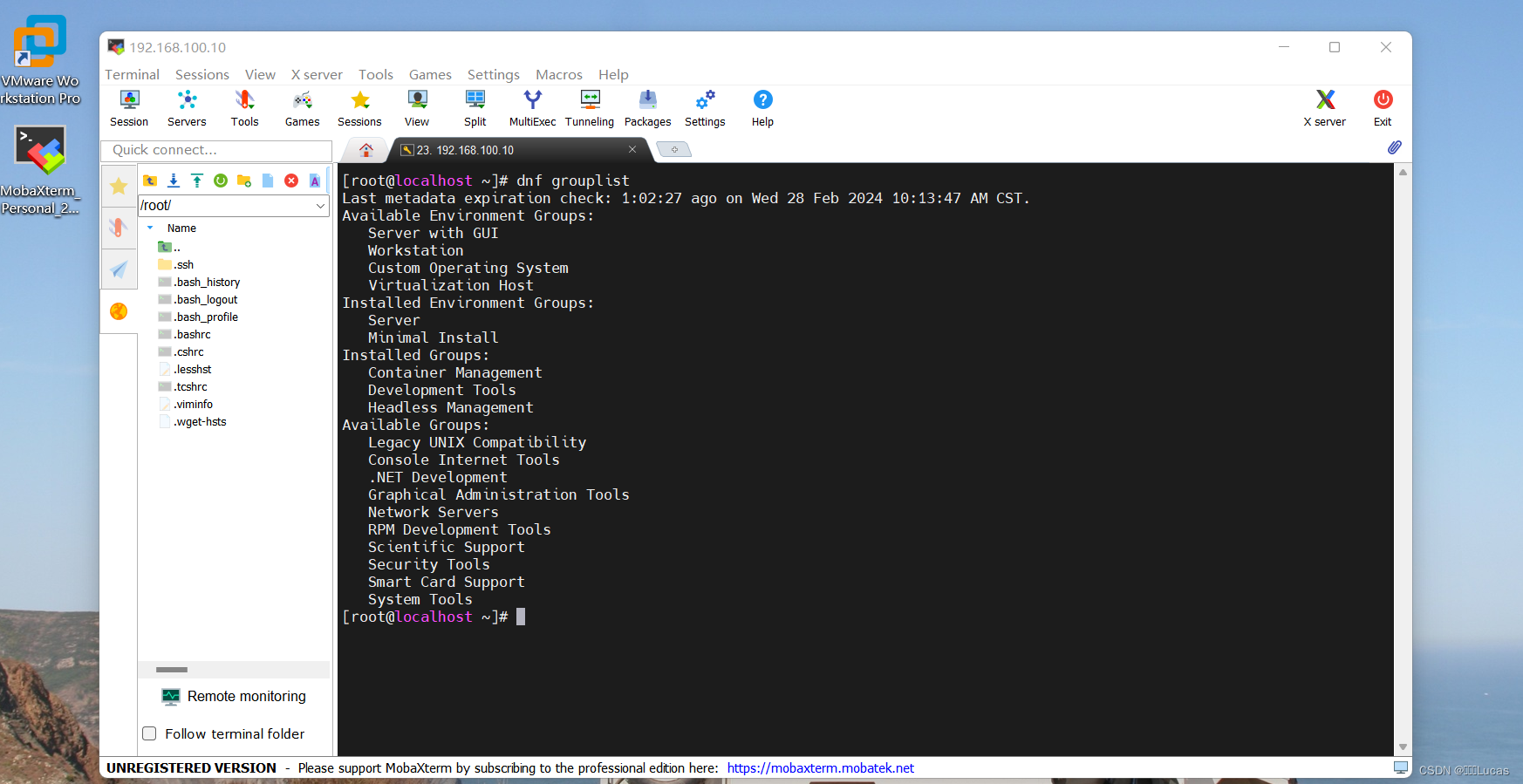
Rocky Linux 运维工具 dnf
一、dnf的简介 dnf是用于在基于RPM包管理系统的包管理工具。用户可以通过 yum来搜索、安装、更新和删除软件包,自动处理依赖关系,它是yum的继任者,旨在提供更快速、更现代化的软件包管理体验。。 二、dnf 的参数说明 序号参数描述1in…...
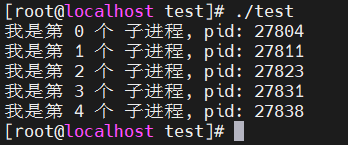
浅谈 Linux fork 函数
文章目录 前言fork 基本概念代码演示示例1:体会 fork 函数返回值的作用示例2:创建多进程,加深对 fork 函数的理解 前言 本篇介绍 fork 函数。 fork 基本概念 pid_t fork(void) fork 的英文含义是"分叉",在这里就是 …...

golang 装饰器模式详解
前言 我一直以来对golang的装饰器模式情有独衷,不是因为它酷,而是它带给我了太多的好处。首先我不想说太多的概念,熟记这些概念对我的编程来说一点用处没有。我只知道它给我带来了好处,下面谈谈我的理解。 这种模式可以很轻松地…...

刷题笔记day27-回溯算法2
216. 组合总和 III 这个思路还是,三部曲: 终止条件处理单层节点回溯节点 题中说的是,1到9的数,不能有重复。 k个数,和为n。 那么只要 len(path) k 的时候,判断 n 为0,就可以入切片了。 fun…...

前端架构: 脚手架命令行交互核心实现之inquirer和readline的应用教程
命令行交互核心实现 核心目标:实现命令行行交互,如List命令行的交互呢比命令行的渲难度要更大,因为它涉及的技术点会会更多它涉及以下技术点 键盘输入的一个监听 (这里通过 readline来实现)计算命令行窗口的尺寸清屏光标的移动输出流的静默 …...
【C++初阶】内存管理
目录 一.C语言中的动态内存管理方式 二.C中的内存管理方式 1.new/delete操作内置类型 2.new和delete操作自定义类型 3.浅识抛异常 (内存申请失败) 4.new和delete操作自定义类型 三.new和delete的实现原理 1.内置类型 2.自定义类型 一.C语…...
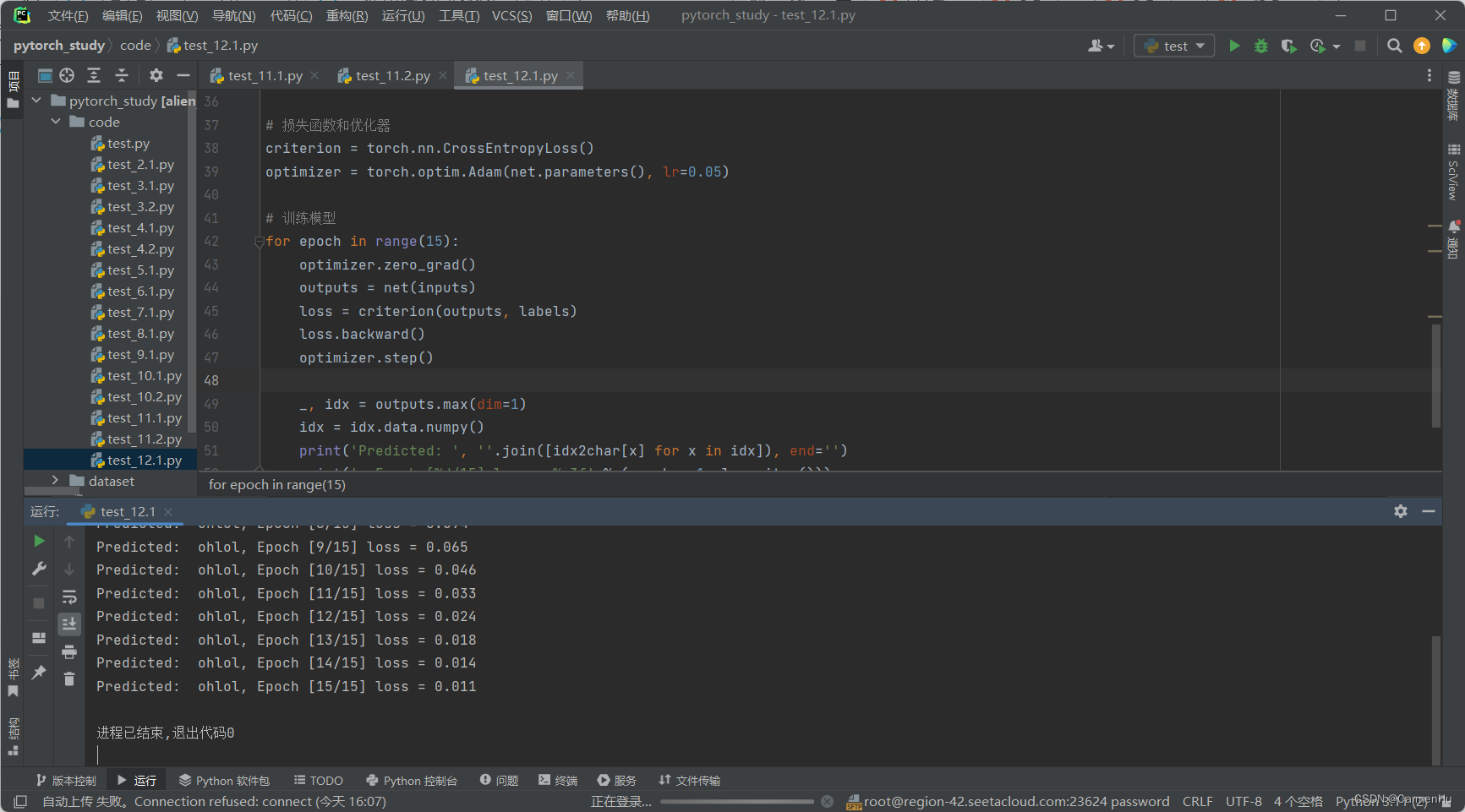
《PyTorch深度学习实践》第十二讲循环神经网络基础
一、RNN简介 1、RNN网络最大的特点就是可以处理序列特征,就是我们的一组动态特征。比如,我们可以通过将前三天每天的特征(是否下雨,是否有太阳等)输入到网络,从而来预测第四天的天气。 我们可以看RN…...
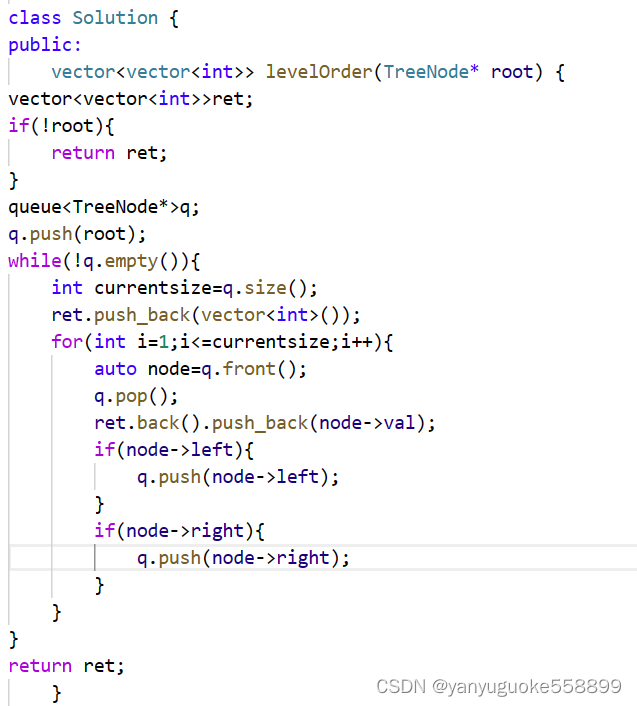
蓝桥杯算法题汇总
一.线性表:链式 例题:旋转链表 二.栈: 例题:行星碰撞问题 三.队列 三.数组和矩阵 例题: 四.哈希表 五.二叉树 主要方法是递归 主要考察点是遍历:前序,中序,后序遍历,层…...

【MySQL】学习多表查询和笛卡尔积 - 副本
](https://img-blog.csdnimg.cn/21dd41dce63a4f2da07b9d879ad0120b.png#pic_center) ??个人主页: ??热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 ??个人格言:“没有罗马,那就自己创造罗马~” #mermaid-svg-N8PeTKG6uLu4bJuM {font-family:“trebuchet ms”,…...

C++设计模式_创建型模式_工厂方法模式
目录 C设计模式_创建型模式_工厂方法模式 一、简单工厂模式 1.1 简单工厂模式引入 1.2 简单工厂模式 1.3 简单工厂模式利弊分析 1.4 简单工厂模式的UML图 二、工厂方法模式 2.1 工厂模式和简单工厂模式比较 2.2 工厂模式代码实现 2.3 工厂模式UML 三、抽象工厂模式 3.1 战斗场景…...
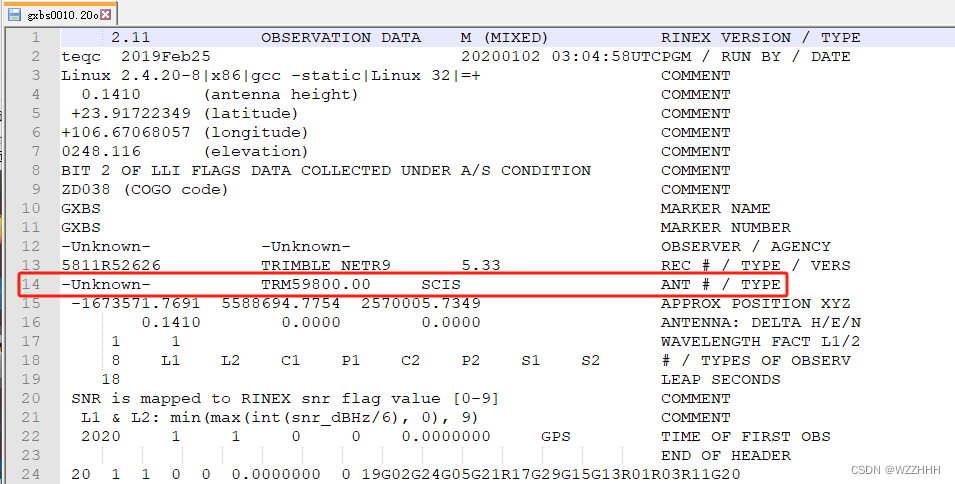
matlab批量替换txt文本文件的特定行的内容
1.下图所示,我想要替换第14行。 2.运行代码后,第14行已经更改为需要的内容。 clc,clear; %%----------------------需要更改的地方------------------------------------ % 设置要操作的文本文件路径,替换为你自己的文件路径 path D:\paper_…...
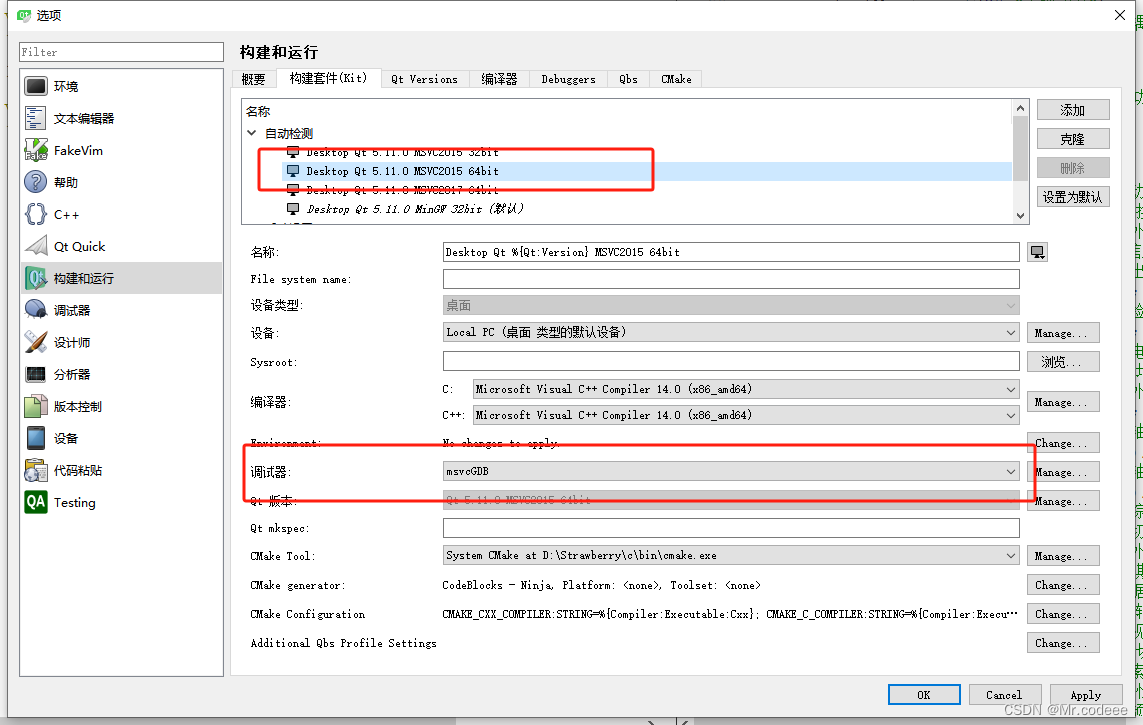
Qt Creator配置MSVC编译环境、调试环境
在windows上开发,一般使用Qt Creator自带mingw编译器,编译和调试都很方便,安装Qt时勾选后,自动配置完毕。 但是有时候我们需要使用MSVC的编译器,这个时候我们没法直接使用,需要配置环境才能使用࿰…...
)
Linux系统运维命令:终止监听在 TCP端口80上的所有进程(使用lsof,grep,awk组合命令, 终止监听在 TCP某个端口上的所有进程)
目 录 一、需求 二、解决方法 1、解决思路 2、命令 三、实例演示和命令解释 1、实例演示 (1)查看目前有哪些在TCP端口80监听的进程 (2)、使用命令 (3)、查看效果 2、命令解…...
)
开源模型应用落地-业务优化篇(七)
一、背景 在本篇学习中,我们要介绍消息中间件,它可以帮助我们将核心和辅助流程分开,让它们互相独立。同时,还要关注在使用消息中间件时需要注意的地方。并且将这种思想应用到其他实际场景中。 二、术语 2.1、消息中间件 消息中间件是一种在分布式系统中用于处理消息传递的…...

深度解析BepInEx插件依赖管理架构与冲突解决机制实现
深度解析BepInEx插件依赖管理架构与冲突解决机制实现 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx作为Unity Mono、IL2CPP和.NET框架游戏的核心插件与模组框架ÿ…...

C语言编程实战题库:从入门到精通的必备练习
1. 为什么C语言需要实战题库? 我第一次接触C语言是在大学计算机系的入门课上。当时老师讲完基础语法后,直接让我们写一个简单的计算器程序。结果全班80%的同学对着空白的编辑器发呆,完全不知道从何下手。这个经历让我深刻认识到:光…...

推荐系统架构设计思路
推荐系统架构设计思路 在信息爆炸的时代,推荐系统已成为互联网平台提升用户体验的核心技术之一。无论是电商、社交媒体还是内容平台,推荐系统都能通过分析用户行为数据,精准推送个性化内容,从而提高用户粘性和商业价值。本文将介…...

网盘直链下载助手:告别限速困扰的完整解决方案
网盘直链下载助手:告别限速困扰的完整解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / …...

【读书笔记】《人间信》
《人间信》麦家一、这是一本什么样的书? 《人间信》是麦家的最新长篇小说。用麦家自己的话说,这是"一本从心底里喊出来的书"——压抑了几十年、深到看不见底的话,终于被大声喊了出来。 著名作家王蒙对此书的评价是:&quo…...

3分钟解锁QQ音乐加密格式:终极QMC解密转换完整指南
3分钟解锁QQ音乐加密格式:终极QMC解密转换完整指南 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾经下载了QQ音乐的歌曲,却发现只能在特定…...

5步终极方案:用MediaCreationTool.bat轻松绕过Windows 11硬件限制
5步终极方案:用MediaCreationTool.bat轻松绕过Windows 11硬件限制 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.ba…...

LFM2.5-1.2B-Thinking-GGUF轻量化优势展示:与更大参数模型的效率对比
LFM2.5-1.2B-Thinking-GGUF轻量化优势展示:与更大参数模型的效率对比 1. 小模型的大能量 在AI领域,大参数模型往往被视为性能的代名词。但今天我们要展示的LFM2.5-1.2B-Thinking-GGUF模型,将彻底改变这一认知。这个仅有12亿参数的"小个…...

SharpKeys:Windows键盘重映射终极指南,轻松打造个性化输入体验
SharpKeys:Windows键盘重映射终极指南,轻松打造个性化输入体验 【免费下载链接】sharpkeys SharpKeys is a utility that manages a Registry key that allows Windows to remap one key to any other key. 项目地址: https://gitcode.com/gh_mirrors/…...
)
手把手教你用Skyline引擎实现丝滑的小程序交互动画(附左滑删除完整代码)
手把手教你用Skyline引擎实现丝滑的小程序交互动画(附左滑删除完整代码) 在移动应用开发中,流畅的动画效果是提升用户体验的关键因素。微信小程序的Skyline引擎为开发者提供了突破性的性能提升,特别适合实现复杂的手势交互和动画效…...