YOLOV8介绍
原文链接:
1、 详解YOLOv8网络结构/环境搭建/数据集获取/训练/推理/验证/导出
2、Yolov8的详解与实战
3、YOLOV8模型训练+部署(实战)()有具体部署和训练实现代码YOLOV8模型训练+部署(实战)()
4、官方平台介绍Ultralytics Inc.
5、YOLOv8改进有效系列目录 | 包含卷积、主干、检测头、注意力机制、Neck上百种创新机制(有非常好的参考和启示价值)
6、源码github地址: GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite
1、导读
YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的基于YOLOV5进行更新的 下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务,鉴于Yolov5的良好表现,Yolov8在还没有开源时就收到了用户的广泛关注。其主要结构如下图所示:

2、YOLOv8相对于Yolov5的核心改动
从YOLOv8的网络结构可以看出,其延用了YOLOv5的网络结构思想,网络还是分为三个部分: 基于CSP(紧凑和分离)的主干网络(backbone),特征增强网络(neck),检测头(head) 三个部分。
改进总结:
- Backbone的改进:YOLOV5中的C3模块被替换成了C2f模块,实现了进一步的轻量化。同时保持了CSP的思想,保留了YOLOv5等架构中使用的SPPF(空间金字塔池化)模块。
- 特征增强网络(neck): YOLOv8使用PA-FPN(路径聚合网络-特征金字塔网络)的思想,具体实施过程中将YOLOV5中的PA-FPN上采样阶段的卷积去除了,并且将其中的C3模块替换为了C2f模块。
- 检测头(head) :区别于YOLOV5的耦合头,YOLOV8使用了Decoupled-Head,使得网络的训练和推理更加高效。
- 其它更新部分:
- Anchor-Free的思想:抛弃了Anchor-Base,采用了Anchor-Free的思想。
- 损失函数的改进:分类使用BCEloss,回归使用DFL Loss+CIOU Loss。
- 样本匹配方式的改进:采用了Task-Aligned Assigner匹配方式。
这些改进使得YOLOv8在保持了YOLOv5网络结构的优点的同时,进行了更加精细的调整和优化,提高了模型在不同场景下的性能。
yolov8是个模型簇,从小到大包括:yolov8n、yolov8s、yolov8m、yolov8l、yolov8x等。模型参数、运行速度、参数量等详见下表:

对比yolov5,如下表:

mAP和参数量都上升了不少。
3、YOLOv8的网络结构详解
- Backbone:它采用了一系列卷积和反卷积层来提取特征,同时也使用了残差连接和瓶颈结构来减小网络的大小和提高性能。该部分采用了C2f模块作为基本构成单元,与YOLOv5的C3模块相比,C2f模块具有更少的参数量和更优秀的特征提取能力。
- Neck:它采用了多尺度特征融合技术,将来自Backbone的不同阶段的特征图进行融合,以增强特征表示能力。具体来说,YOLOv8的Neck部分包括一个SPPF模块、一个PAA模块和两个PAN模块。
- Head:它负责最终的目标检测和分类任务,包括一个检测头和一个分类头。检测头包含一系列卷积层和反卷积层,用于生成检测结果;分类头则采用全局平均池化来对每个特征图进行分类。
3.1 Backbone
由最上面的YOLOv8网络结构图我们可以看出在其中的Backbone部分,由5个卷积模块和4个C2f模块和一个SPPF模块组成。

(其中浅蓝色为卷积模块,黄色为C2f模块深蓝色为SPPF模块 )
如果上图看的不够直观,我们来看一下YOLOv8的文件中的yaml文件,看一下它backbone部分的结构组成部分,会更加直观。
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9上面的部分就是YOLOv8的yaml文件的Backbone部分,可以看到其由5个Conv模块,四个C2f模块以及一个SPPF模块组成,下面我们来根据每个模块的组成来进行讲解。
3.1.1 卷积模块(Conv)
在其中卷积模块的结构主要为下图

在其中主要结构为一个2D的卷积一个BatchNorm2d和一个SiLU激活函数,整个卷积模块的作用为:
- 下采样:每个卷积模块中的卷积层都采用步长为2的卷积核进行下采样操作,以减小特征图的尺寸并增加通道数。
- 非线性表示:每个卷积层之后都添加了Batch Normalization(批标准化)层和ReLU激活函数,以增强模型的非线性表示能力。
在其中Batch Normalization(批标准化)是深度学习中常用的一种技术,用于加速神经网络的训练。Batch Normalization通过对每个小批量数据进行标准化,使得神经网络在训练过程中更加稳定,可以使用更高的学习率,并且减少了对初始化权重的依赖。Batch Normalization的基本思想是:对每个小批量数据进行标准化,使得每个特征的均值为0,方差为1,然后再通过一个可学习的缩放因子和平移因子来调整数据的分布,从而使得神经网络更容易训练。
3.1.2 C2f 模块
在YOLOv8的网络结构中C2f模块算是YOLOv8的一个较大的改变,与YOLOv5的C3模块相比,C2f模块具有更少的参数量和更优秀的特征提取能力。下图为C2f的内部网络结构图。
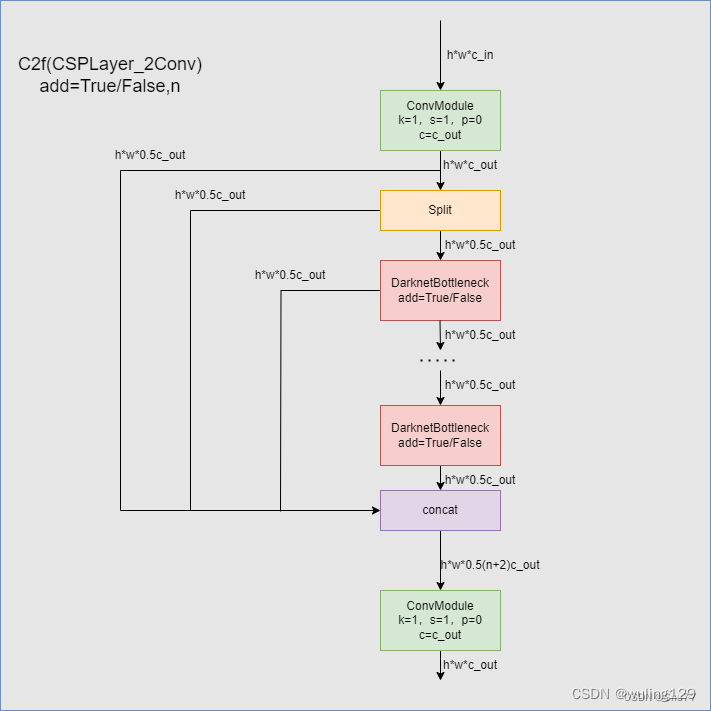
在C2f模块中我们可以看到输入首先经过一个k=1,s=1,p=0,c=c_out的卷积模块进行了处理,然后经过一个split处理(在这里split和后面的concat的组成其实就是所谓的残差模块处理)经过数量为n的DarknetBottleneck模块处理以后将残差模块和主干模块的结果进行Concat拼接在经过一个卷积模块处理进行输出。
在其中提到的残差连接(residual connections)是一种用于构建深层神经网络的技术。它的核心思想是通过跳过层级连接来传递残差或误差。
在传统的神经网络中,信息流通过一层层的网络层,每一层都通过非线性激活函数进行转换和提取特征。然而,随着神经网络的加深,可能会出现"梯度消失"或"梯度爆炸"的问题,导致网络收敛困难或性能下降。
残差连接通过引入跨层级的连接,将输入的原始信息直接传递到后续层级,以解决梯度消失和爆炸问题。具体而言,它将网络的输入与中间层的输出相加,形成了一个"捷径"或"跳跃连接",从而允许梯度更容易地传播。
数学上,假设我们有一个输入x,通过多个网络层进行处理后得到预测值H(x)。那么残差连接的表达式为: F(x) = H(x) + x 。其中,F(x)为残差块的输出,H(x)为经过一系列网络层处理后得到的特征表示,x为输入直接连接到残差块中的跳跃连接。
通过残差连接,网络可以更容易地学习残差或误差,从而使网络更深层次的特征表达更准确。这对于训练深层神经网络非常有用,可以提高网络的性能和收敛速度。
在C2f模块中用到的DarknetBottleneck模块其中使用多个3x3卷积核进行卷积操作,提取特征信息。同时其具有add是否进行残差链接的选项。
其实整个C2f模块就是一个改良版本的Darknet
- 首先,使用1x1卷积核将输入通道数减少到原来的1/2,以减少计算量和内存消耗。
- 然后,使用多个3x3卷积核进行卷积操作,提取特征信息。
- 接着,使用残差链接,将输入直接加到输出中,从而形成了一条跨层连接。
- 接着,再次使用1x1卷积核恢复特征图的通道数。
3.1.3 SPPF模块
YOLOv8的SPPF模块相对于YOLOv5的SPPF模块并没有任何的改变。
在传统的卷积神经网络中,通常使用全连接层来将卷积和池化层提取的特征映射到固定长度的向量上,以便进行分类或检测。然而,全连接层需要固定大小的输入(例如640*640(YOLOV5)、32*32(LenNet)、224*224(ImageNet)),这使得网络无法处理尺寸不同的输入图像。因此,SPP-Net引入了空间金字塔池化(SPP,Spatial Pyramid Pooling)模块,用于解决输入图像尺寸不同的问题,并且可以在不同尺寸的输入图像上实现准确的分类和检测。
在SPP-Net中,输入图像首先通过一个卷积神经网络进行特征提取。然后,在SPP层中进行池化操作,将卷积层的输出特征图(Feature Map)分成不同尺度的网格,对于每个网格,都对其内部进行池化操作,池化输出的结果拼接成一个固定长度的特征向量。这个特征向量可以用于后续的分类任务,下面的图是介绍从一张输入图上提取提特征图然后产生固定长度的特征向量然后输入到全连接层中进行分类的流程图。

下面将通过一个简单的例子来说明SPP-Net是如何解决选择性搜索问题的是如何将不同大小的特征图转换为固定长度的特征向量的。假设我们有一个输入图像大小为300✖300像素,由于我们希望网络能够处理不同大小的输入图像,因此我们先对输入图像进行卷积操作,得到一个特征图大小为15✖ 15✖ 1024其中分别表示一个特征图的宽度、高度和每个位置上的特征向量的维数。具体来说,在这个例子中,15✖ 15表示特征图的宽度和高度,1024表示每个位置上的特征向量的维数。然后,我们使用SPP层对特征图进行池化操作,将其分成1✖1、2✖2和4✖4三个尺度的网格,并对每个网格内部进行池化操作。最后,对于每个尺度,将池化输出的结果拼接成一个固定长度的特征向量。假设我们选择的池化操作是最大池化,每个网格内部的池化操作输出的结果是一个特征向量,我们将这些特征向量拼接起来,得到一个长度为1024✖(1+4+9)=15360的特征向量。这个特征向量可以作为分类器的输入,用于分类任务。
下面这个图诠释了上面的例子,方框内的部分即SPP部分,其分成1✖1、2✖2和4✖4三个尺度的网格进行特征向量的提取然后进行拼接固定长度的特征向量并将其输入到全连接层中用于分类任务,需要注意的是SPP通常在一个网络结构的最后一层,输出结果直接输入给检测头进行检测,或者输入给Neck部分进行特征向量的拼接操作以将不同尺度下的特征向量进行拼接提高检测和分类效率。

SPP-Net的优点包括:
- 对任意大小的输入图像进行处理,具有较好的泛化能力和适用性;
- 可以用于多种计算机视觉任务,包括图像分类、物体检测、场景分类等;
- 可以减少网络训练和测试时间,提高网络的效率;
- 在多个数据集和比赛中取得了不错的表现,证明了其有效性和通用性。
3.2 Neck
YOLOv8的Neck部分是该模型中的一个关键组件,它在特征提取和融合方面起着重要作用。 YOLOv8的Neck部分依然采用PAN-FPN的思想,下图的a,b,c为一个Neck部分的流程示意图。

整个Neck部分的步骤如下:将特征提取网络(Backbone)的输出P3,P4,P5输入进PAN-FPN网络结构,使得多个尺度的特征图进行融合;将P5经过上采样与P4进行融合得到F1,将F1经过C2f层和一次上采样与P3进行融合得到T1,将T1经过一次卷积层与F1经过融合得到F2,将F2经过一次C2f层得到T2,将T2经过一次卷积层与P5融合得到F3,将F3经过一次C2f层得到T3,最终得到T1、T2、T3就是整个Neck的产物;
上述过程可以描述为下图,在图片上做了一些标准方便理解。

上述的过程可以在代码部分看到,我们同样看YOLOv8的yaml文件,能够更直观的看到这个步骤,大家可以看代码同时对应图片来进行分析:
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
Neck部分的整体功能的详细分析如下:
- 1. Neck的作用:
- Neck部分在YOLOv8模型中负责对来自Backbone的特征进行进一步处理和融合,以提高目标检测的准确性和鲁棒性。它通过引入不同的结构和技术,将多尺度的特征图进行融合,以便更好地捕捉不同尺度目标的信息。
- 2. 特征金字塔网络(Feature Pyramid Network, FPN):
- YOLOv8的Neck部分通常采用特征金字塔网络结构,用于处理来自Backbone的多尺度特征图。FPN通过在不同层级上建立特征金字塔,使得模型能够在不同尺度上进行目标检测。它通过上采样和下采样操作,将低层级的细节特征与高层级的语义特征进行融合,以获取更全面和丰富的特征表示。
- 3. 特征融合(Feature Fusion):
- Neck部分还包括特征融合的操作,用于将来自不同层级的特征进行融合。这种特征融合有助于提高模型对目标的检测准确性,尤其是对于不同尺度的目标。
- 4. 上采样和下采样:
- Neck部分通常会使用上采样和下采样操作,以调整特征图的尺度和分辨率。上采样操作可以将低分辨率的特征图放大到与高分辨率特征图相同的尺寸,以保留更多的细节信息。而下采样操作则可以将高分辨率的特征图降低尺寸,以减少计算量和内存消耗。
YOLOv8的Neck部分通过特征金字塔网络和特征融合等操作,有效地提取和融合多尺度的特征,从而提高了目标检测的性能和鲁棒性。这使得模型能够更好地适应不同尺度和大小的目标,并在复杂场景下取得更准确的检测结果。
PAN-FPN(具有特征金字塔网络的路径聚合网络)是一种用于计算机视觉中对象检测的神经网络架构。它将特征金字塔网络(FPN)与路径聚合网络(PAN)相结合,以提高目标检测的准确性和效率。
FPN 用于从不同比例的图像中提取特征,而 PAN 用于跨网络的不同层聚合这些特征。这允许网络检测不同大小和分辨率的对象,并处理具有多个对象的复杂场景。
3.3 Head
如果Backbone和Neck部分可以理解为准备工作,那么Head部分就是收获的部分,经过前面的准备工作我们得到了Neck部分的输出T1、T2、T3分别代表不同层级的特征图,Head部分就是对这三个特征图进行处理以产生模型的的输出结果的一个过程。
YOLOv8的Head部分我们先来看一下它的网络结构。

可以看到在YOLOv8的Head部分,体现了最核心的改动—>解耦头(Decoupled-Head),顾名思义就是将原先的一个检测头分解成两个部分。
在Head部分的三个解耦头分别对应着Neck部分的特征图输出T1、T2、T3。、
解耦头的工作流程是:
将网络得到的特征图T1,T2,T3分别输入解耦头头进行预测,检测头的结构如下图所示其中包含4个3×3卷积与2个1×1卷积,同时在检测头的回归分支中添加WIOU损失函数如图4所示,回归头部需要计算预测框与真实框之间的位置偏移量,然后将偏移量送入回归头部进行损失计算,然后输出一个四维向量,分别表示目标框的左上角坐标x、y和右下角坐标x、y。分类头部针对于每个Anchor Free提取的候选框对其进行RoI Pooling和卷积操作得到一个分类器输出张量每个位置上的值表示该候选框属于每个类别的概率,在最后通过极大值抑制方式筛选出最终的检测结果

我们再从YOLOv8的yaml文件来看Head部分的作用

可以看到检测头部分的输出为15,18,21分别对应着Neck部分的三个输出特征图。
到此YOLOv8的网络结构部分讲解就已经完成,下面我们来看如何利用YOLOv8进行训练操作。
四、环境搭建
在配置好环境之后,在之后模型获取完成之后,我们可以进行配置的安装我们可以在命令行下输入如下命令进行环境的配置。
pip install -r requirements.txt
输入如上命令之后我们就可以看到命令行在安装模型所需的库了。
五、数据集获取
在我们开始训练之前,我们需要一份数据集,如何获取一个YOLOv8的数据集大家可以看原作者的的另一篇博客: 从YOLO官方指定的数据集网站Roboflow下载数据模型训练
超详细教程YoloV8官方推荐免费数据集网站Roboflow一键导出Voc、COCO、Yolo、Csv等格式
在上面随便下载了一个 数据集用它导出yolov8的数据集,以及自动给转换成txt的格式yaml文件也已经配置好了,我们直接用就可以。
六、模型获取
到这里假设你已经搭建好了环境和有了数据集,那么我们就可以进行模型的下载,因为yolov8目前还存在BUG并不稳定随时都有可能进行更新,所以不推荐大家通过其它的途径下载,最好通过下面的方式进行下载。
我们可以直接在终端命令下
(PS:这里需要注意的是我们需要在你总项目文件目录下输入这个命令,因为他会下载到当前目录下)
pip install ultralytics
如果大家去github上直接下载zip文件到本地可能会遇到报错如下,识别不了yolo命令,所以推荐大家用这种方式下载,
七、模型训练
我们来看一下主要的ultralytics目录结构,
我门打开cfg目录下的default.yaml文件可以配置模型的参数,
在其中和模型训练有关的参数及其解释如下:
| 参数名 | 输入类型 | ||
|---|---|---|---|
| 0 | task | str | YOLO模型的任务选择,选择你是要进行检测、分类等操作 |
| 1 | mode | str | YOLO模式的选择,选择要进行训练、推理、输出、验证等操作 |
| 2 | model | str/optional | 模型的文件,可以是官方的预训练模型,也可以是训练自己模型的yaml文件 |
| 3 | data | str/optional | 模型的地址,可以是文件的地址,也可以是配置好地址的yaml文件 |
| 4 | epochs | int | 训练的轮次,将你的数据输入到模型里进行训练的次数 |
| 5 | patience | int | 早停机制,当你的模型精度没有改进了就提前停止训练 |
| 6 | batch | int | 我们输入的数据集会分解为多个子集,一次向模型里输入多少个子集 |
| 7 | imgsz | int/list | 输入的图片的大小,可以是整数就代表图片尺寸为int*int,或者list分别代表宽和高[w,h] |
| 8 | save | bool | 是否保存模型以及预测结果 |
| 9 | save_period | int | 在训练过程中多少次保存一次模型文件,就是生成的pt文件 |
| 10 | cache | bool | 参数cache用于控制是否启用缓存机制。 |
| 11 | device | int/str/list/optional | GPU设备的选择:cuda device=0 or device=0,1,2,3 or device=cpu |
| 12 | workers | int | 工作的线程,Windows系统一定要设置为0否则很可能会引起线程报错 |
| 13 | name | str/optional | 模型保存的名字,结果会保存到'project/name' 目录下 |
| 14 | exist_ok | bool | 如果模型存在的时候是否进行覆盖操作 |
| 15 | prepetrained | bool | 参数pretrained用于控制是否使用预训练模型。 |
| 16 | optimizer | str | 优化器的选择choices=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto] |
| 17 | verbose | bool | 用于控制在执行过程中是否输出详细的信息和日志。 |
| 18 | seed | int | 随机数种子,模型中涉及到随机的时候,根据随机数种子进行生成 |
| 19 | deterministic | bool | 用于控制是否启用确定性模式,在确定性模式下,算法的执行将变得可重复,即相同的输入将产生相同的输出 |
| 20 | single_cls | bool | 是否是单标签训练 |
| 21 | rect | bool | 当 rect 设置为 True 时,表示启用矩形训练或验证。矩形训练或验证是一种数据处理技术,其中在训练或验证过程中,输入数据会被调整为具有相同宽高比的矩形形状。 |
| 22 | cos_lr | bool | 控制是否使用余弦学习率调度器 |
| 23 | close_mosaic | int | 控制在最后几个 epochs 中是否禁用马赛克数据增强 |
| 24 | resume | bool | 用于从先前的训练检查点(checkpoint)中恢复模型的训练。 |
| 25 | amp | bool | 用于控制是否进行自动混合精度 |
| 26 | fraction | float | 用于指定训练数据集的一部分进行训练的比例。默认值为 1.0 |
| 27 | profile | bool | 用于控制是否在训练过程中启用 ONNX 和 TensorRT 的性能分析 |
| 28 | freeze | int/list/optinal | 用于指定在训练过程中冻结前 n 层或指定层索引的列表,以防止它们的权重更新。这对于迁移学习或特定层的微调很有用。 |
7.1 训练的三种方式
7.1.1 方式一
我们可以通过命令直接进行训练在其中指定参数,但是这样的方式,我们每个参数都要在其中打出来。命令如下:
yolo task=detect mode=train model=yolov8n.pt data=data.yaml batch=16 epochs=100 imgsz=640 workers=0 device=0需要注意的是如果你是Windows系统的电脑其中的Workers最好设置成0否则容易报线程的错误。
7.1.2 方式二(推荐)
通过指定cfg直接进行训练,我们配置好ultralytics/cfg/default.yaml这个文件之后,可以直接执行这个文件进行训练,这样就不用在命令行输入其它的参数了。
yolo cfg=ultralytics/cfg/default.yaml7.1.3 方式三
我们可以通过创建py文件来进行训练,这样的好处就是不用在终端上打命令,这也能省去一些工作量,我们在根目录下创建一个名字为run.py的文件,在其中输入代码
from ultralytics import YOLO
model = YOLO("权重的地址")
data = "文件的地址"
model.train(data=data, epochs=100, batch=16)无论通过上述的哪一种方式在控制台输出如下图片的内容就代表着开始训练成功了!
八、模型验证/测试
| 参数名 | 类型 | 参数讲解 | |
|---|---|---|---|
| 1 | val | bool | 用于控制是否在训练过程中进行验证/测试。 |
| 2 | split | str | 用于指定用于验证/测试的数据集划分。可以选择 'val'、'test' 或 'train' 中的一个作为验证/测试数据集 |
| 3 | save_json | bool | 用于控制是否将结果保存为 JSON 文件 |
| 4 | save_hybird | bool | 用于控制是否保存标签和附加预测结果的混合版本 |
| 5 | conf | float/optional | 用于设置检测时的目标置信度阈值 |
| 6 | iou | float | 用于设置非极大值抑制(NMS)的交并比(IoU)阈值。 |
| 7 | max_det | int | 用于设置每张图像的最大检测数。 |
| 8 | half | bool | 用于控制是否使用半精度(FP16)进行推断。 |
| 9 | dnn | bool | ,用于控制是否使用 OpenCV DNN 进行 ONNX 推断。 |
| 10 | plots | bool | 用于控制在训练/验证过程中是否保存绘图结果。 |
验证我们划分的验证集/测试集的情况,也就是评估我们训练出来的best.pt模型好与坏
yolo task=detect mode=val model=best.pt data=data.yaml device=0九、模型推理
我们训练好自己的模型之后,都会生成一个模型文件,保存在你设置的目录下,当我们再次想要实验该模型的效果之后就可以调用该模型进行推理了,我们也可以用官方的预训练权重来进行推理。
推理的方式和训练一样我们这里就选一种来进行举例其它的两种方式都是一样的操作只是需要改一下其中的一些参数即可:
参数讲解
| 参数名 | 类型 | 参数讲解 | |
|---|---|---|---|
| 0 | source | str/optinal | 用于指定图像或视频的目录 |
| 1 | show | bool | 用于控制是否在可能的情况下显示结果 |
| 2 | save_txt | bool | 用于控制是否将结果保存为 .txt 文件 |
| 3 | save_conf | bool | 用于控制是否在保存结果时包含置信度分数 |
| 4 | save_crop | bool | 用于控制是否将带有结果的裁剪图像保存下来 |
| 5 | show_labels | bool | 用于控制在绘图结果中是否显示目标标签 |
| 6 | show_conf | bool | 用于控制在绘图结果中是否显示目标置信度分数 |
| 7 | vid_stride | int/optional | 用于设置视频的帧率步长 |
| 8 | stream_buffer | bool | 用于控制是否缓冲所有流式帧(True)或返回最新的帧(False) |
| 9 | line_width | int/list[int]/optional | 用于设置边界框的线宽度,如果缺失则自动设置 |
| 10 | visualize | bool | 用于控制是否可视化模型的特征 |
| 11 | augment | bool | 用于控制是否对预测源应用图像增强 |
| 12 | agnostic_nms | bool | 用于控制是否使用无关类别的非极大值抑制(NMS) |
| 13 | classes | int/list[int]/optional | 用于按类别筛选结果 |
| 14 | retina_masks | bool | 用于控制是否使用高分辨率分割掩码 |
| 15 | boxes | bool | 用于控制是否在分割预测中显示边界框。 |
这里需要需要注意的是我们用模型进行推理的时候可以选择照片也可以选择一个视频的格式都可以。支持的视频格式有
MP4(.mp4):这是一种常见的视频文件格式,通常具有较高的压缩率和良好的视频质量
AVI(.avi):这是一种较旧但仍广泛使用的视频文件格式。它通常具有较大的文件大小
MOV(.mov):这是一种常见的视频文件格式,通常与苹果设备和QuickTime播放器相关
MKV(.mkv):这是一种开放的多媒体容器格式,可以容纳多个视频、音频和字幕轨道
FLV(.flv):这是一种用于在线视频传输的流式视频文件格式
十、模型输出
当我们进行部署的时候可以进行文件导出,然后在进行部署。
YOLOv8支持的输出格式有如下:
1. ONNX(Open Neural Network Exchange):ONNX 是一个开放的深度学习模型表示和转换的标准。它允许在不同的深度学习框架之间共享模型,并支持跨平台部署。导出为 ONNX 格式的模型可以在支持 ONNX 的推理引擎中进行部署和推理。
2. TensorFlow SavedModel:TensorFlow SavedModel 是 TensorFlow 框架的标准模型保存格式。它包含了模型的网络结构和参数,可以方便地在 TensorFlow 的推理环境中加载和使用。
3. PyTorch JIT(Just-In-Time):PyTorch JIT 是 PyTorch 的即时编译器,可以将 PyTorch 模型导出为优化的 Torch 脚本或 Torch 脚本模型。这种格式可以在没有 PyTorch 环境的情况下进行推理,并且具有更高的性能。
4. Caffe Model:Caffe 是一个流行的深度学习框架,它使用自己的模型表示格式。导出为 Caffe 模型的文件可以在 Caffe 框架中进行部署和推理。
5. TFLite(TensorFlow Lite):TFLite 是 TensorFlow 的移动和嵌入式设备推理框架,支持在资源受限的设备上进行高效推理。模型可以导出为 TFLite 格式,以便在移动设备或嵌入式系统中进行部署。
6. Core ML(Core Machine Learning):Core ML 是苹果的机器学习框架,用于在 iOS 和 macOS 上进行推理。模型可以导出为 Core ML 格式,以便在苹果设备上进行部署。
这些格式都提供了不同的优势和适用场景。选择合适的导出格式应该考虑到目标平台和部署环境的要求,以及所使用的深度学习框架的支持情况。
模型输出的参数有如下
| 参数名 | 类型 | 参数解释 | |
|---|---|---|---|
| 0 | format | str | 导出模型的格式 |
| 1 | keras | bool | 表示是否使用Keras |
| 2 | optimize | bool | 用于在导出TorchScript模型时进行优化,以便在移动设备上获得更好的性能 |
| 3 | int8 | bool | 用于在导出CoreML或TensorFlow模型时进行INT8量化 |
| 4 | dynamic | bool | 用于在导出CoreML或TensorFlow模型时进行INT8量化 |
| 5 | simplify | bool | 用于在导出ONNX模型时进行模型简化 |
| 6 | opset | int/optional | 用于指定导出ONNX模型时的opset版本 |
| 7 | workspace | int | 用于指定TensorRT模型的工作空间大小,以GB为单位 |
| 8 | nms | bool | 用于在导出CoreML模型时添加非极大值抑制(NMS) |
命令行命令如下:
yolo task=detect mode=export model=best.pt format=onnx 到此为止本文的讲解就结束了,希望对大家对于YOLOv8模型理解有帮助,
相关文章:
YOLOV8介绍
原文链接: 1、 详解YOLOv8网络结构/环境搭建/数据集获取/训练/推理/验证/导出 2、Yolov8的详解与实战 3、YOLOV8模型训练部署(实战)()有具体部署和训练实现代码YOLOV8模型训练部署(实战)&…...
【ElfBoard】基于 Linux 的智能家居小项目
大家好,我是 Hello阿尔法,这段时间参与了保定飞凌嵌入式技术有限公司举办的 ElfBoard 共创社招募活动,并有幸成为了一名共创官,官方寄来了一块 ELF 1 开发板,开箱看这里 ELF 1 开箱初体验。 作为共创官,我…...
自动化测试介绍、selenium用法(自动化测试框架+爬虫可用)
文章目录 一、自动化测试1、什么是自动化测试?2、手工测试 vs 自动化测试3、自动化测试常见误区4、自动化测试的优劣5、自动化测试分层6、什么项目适合自动化测试 二、Selenuim1、小例子2、用法3、页面操作获取输入内容模拟点击清空文本元素拖拽frame切换窗口切换/标…...

深度学习的一个完整过程通常包括以下几个步骤
深度学习的一个完整过程通常包括以下几个步骤: 问题定义和数据收集: 定义清晰的问题,明确任务的类型(分类、回归、聚类等)以及预期的输出。收集和整理用于训练和评估模型的数据集。确保数据集的质量,进行预…...
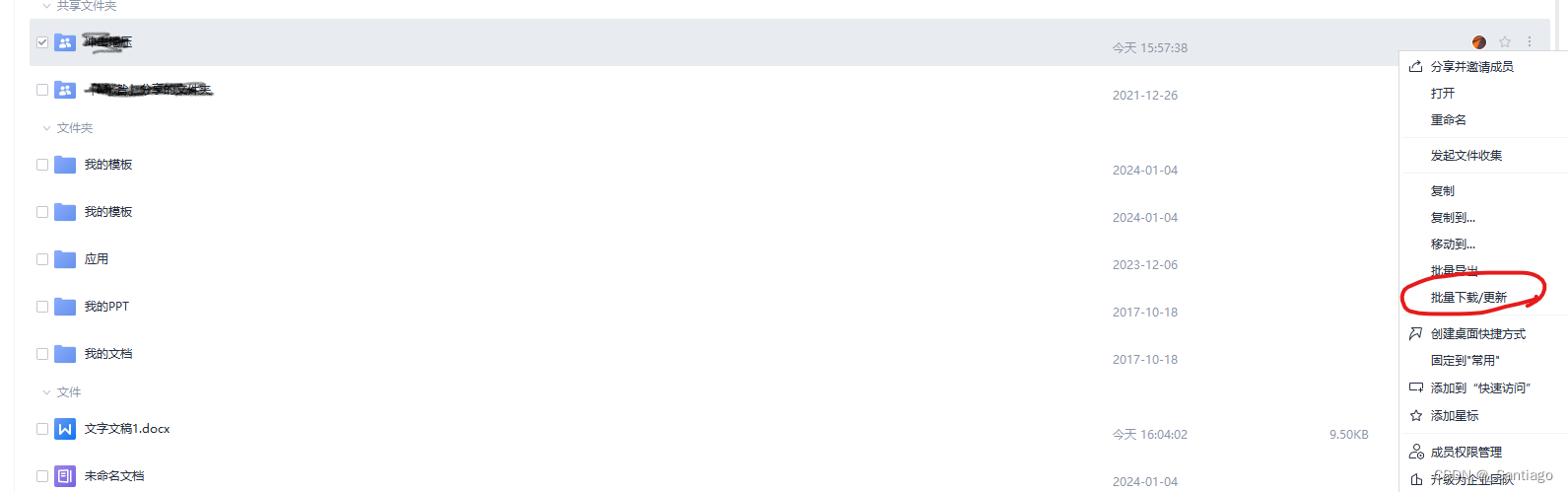
WPS如何共享文件和文件夹
1 WPS共享单个文件 用WPS打开要分享的文件,点击右上角的“分享”键,选择上传到云端。 之后点击“创建并分享”,即可分享该文档。 2 WPS创建共享文件夹 2.1 如何共享文件夹 首先打开WPS,点击左上角的首页。在首页栏中&#…...

PowerData 2024“数字经济-城市开源行”活动预告
2023,社区经过一年的发展,凝聚起了一批热爱社区、热爱开源的小伙伴。 2024,社区计划在全国十个城市举办"数字经济-城市开源行"活动,连接社区成员、传播数字技术、推广开源文化,吸引更多伙伴加入社区…...
QT多语言切换功能
一.目的 在做项目时,有时希望我们的程序可以在不同的国家使用,这样最好的方式是一套程序能适应于多国语言。 Qt提供了这样的功能,使得一套程序可以呈现出不同的语言界面。本文将介绍QT如何实现多语言,以中文和英文为例。 QT开发…...
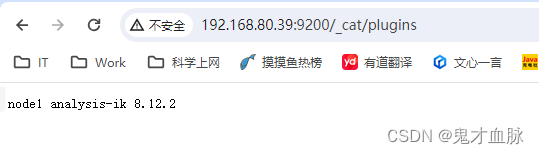
windows上elasticsearch的ik分词器的安装
下载 下载地址 在elasticsearch下的plugins文件夹下创建ik的文件夹 下载的ik压缩包解压到plugins/ik 重启elasticsearch 验证 http://ip:9200/_cat/plugins...

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的口罩识别系统(Python+PySide6界面+训练代码)
摘要:开发口罩识别系统对于提升公共卫生安全和疫情防控具有重要意义。本篇博客详细介绍了如何利用深度学习构建一个口罩识别系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并结合了YOLOv7、YOLOv6、YOLOv5的对比,给出…...

在Windows系统中启动Redis服务
前言 Redis是一个开源、高性能的键值对数据库,常用于缓存、消息队列等场景。本文将详细指导您如何在Windows系统上启动Redis服务。 第一步:确认Redis安装 确保您已经在Windows系统上成功安装了Redis。官方提供了预编译好的Windows版本,您可…...

k8s.gcr.io/pause:3.2镜像丢失解决
文章目录 前言错误信息临时解决推荐解决onetwo 前言 使用Kubernetes(k8s)时遇到了镜像拉取的问题,导致Pod沙盒创建失败。错误显示在尝试从k8s.gcr.io拉取pause:3.2镜像时遇到了超时问题,这通常是因为网络问题或者镜像仓库服务器的…...

全面整理!机器学习常用的回归预测模型
Datawhale干货 作者:曾浩龙,Datawhale意向成员 前言 回归预测建模的核心是学习输入 到输出 (其中 是连续值向量)的映射关系。条件期望 是 到 的回归函数。简单来说,就是将样本的特征矩阵映射到样本标签空间。 图…...

在vue中对keep-alive的理解,它是如何实现的,具体缓存的是什么?
对keep-alive的理解,它是如何实现的,具体缓存的是什么? (1)keep-alive有以下三个属性:注意:keep-alive 包裹动态组件时,会缓存不活动的组件实例。主要流程 (2)…...

章节一、认识three.js与开发环境学习笔记01;
一、如何学习WEB可视化3D技术与课程内容演示; 1、项目案例: 政府有大量的新基建的项目:如数字孪生、智慧城市、智慧园区、智慧工厂、智慧消防等等都涉及了3d的可视化技术; 2、如何系统的学号WEB 3D可视化技术? three…...
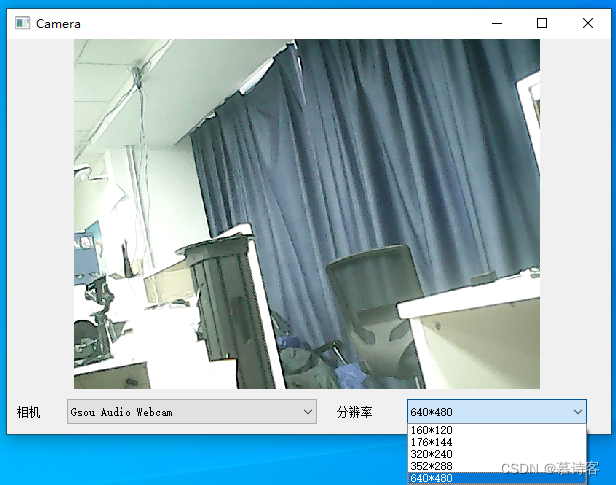
QT摄像头采集
主界面为显示框,两个下拉框,一个是所有相机,一个是相机支持的分辨率 系统根据UI界面自动生成的部分不再描述,以下为其他部分源码 widget.h #include <QWidget> #include <QMouseEvent> class QCamera; class QCamer…...

C语言第三十四弹---动态内存管理(下)
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】 动态内存管理 1、动态内存经典笔试题分析 1.1、题目1 1.2、题目2 1.3、题目3 1.4、题目4 2、柔性数组 2.1、柔性数组的特点 2.2、柔性数组的使用 2.3、…...
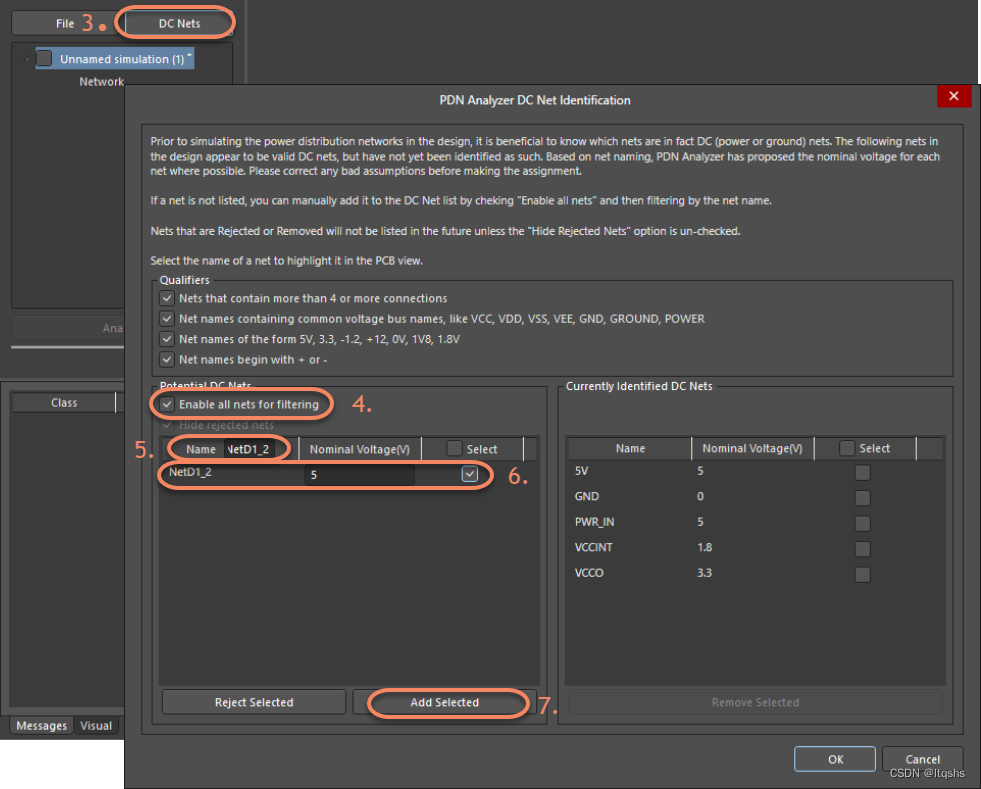
PDN分析及应用系列二-简单5V电源分配-Altium Designer仿真分析-AD
PDN分析及应用系列二 —— 案例1:简单5V电源分配 预模拟DC网络识别 当最初为PCB设计打开PDN分析仪时,它将尝试根据公共电源网络命名法从设计中识别所有直流电源网络。 正确的DC网络识别对于获得最准确的模拟结果非常重要。 在示例项目中已经识别出主DC网络以简化该过程。 …...

Vue开发实例(一)Vue环境搭建第一个项目
Vue环境搭建&第一个项目 一、环境搭建二、安装Vue脚手架三、创建Vue项目 一、环境搭建 下载方式从官网下载:http://nodejs.cn/download/ 建议下载v12.16.0版本以上的,因为版本低无法创建Vue的脚手架 检验是否安装成功 配置环境变量 新增NODE_HOME&…...

将SpringBoot项目改造成solon项目
solon项目介绍 官网 Java “生态型”应用开发框架:更快、更小、更简单。 启动快 5 ~ 10 倍;并发高 2~ 3 倍; 内存省 1/3 ~ 1/2;打包缩到 1/2 ~ 1/10;同时支持 java8, java11, java17, java21&a…...
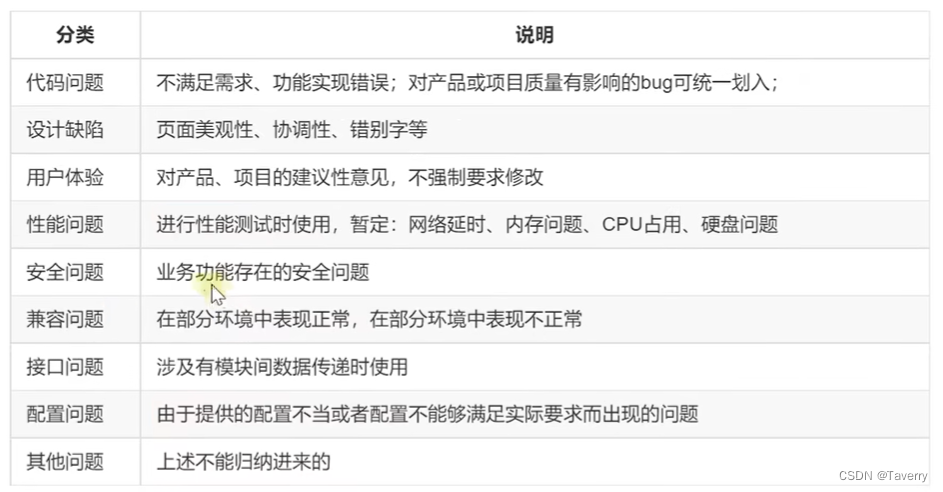
更详细的软件测试理论基础:流程,开发、测试模型,测试分类,测试用例及其设计方法,缺陷
文章目录 一、测试流程二、开发模型1、 瀑布模型2、增量模型3、快速模型4、其他 三、测试模型1、V模型2、W模型 四、测试分类五、测试用例 test case六、测试用例设计方法1、等价类划分法2、边界值分析法3、因果图法4、判定表法5、正交法6、场景法7、流程分析法8、错误推测法方…...

融合链上数据与市场情绪的以太坊Gas价格预测模型实践
1. 项目概述:当链上数据遇见市场情绪在以太坊生态里混迹多年的开发者或交易员,大概都经历过这样的深夜:盯着钱包里一笔迟迟无法确认的交易,看着Gas价格像过山车一样飙升,心里盘算着是咬牙追加Gas费,还是取消…...

2026财务分析师新人如何快速提升能力:从“账房先生”到“战略参谋”的跃迁之路
2026年的财务领域,规则已经彻底改写。传统的“记账、算账、报账”正在被RPA和AI快速替代,企业真正渴求的,不再是只会做账的“会计”,而是能够深入业务、洞察数据、驱动决策的财务分析师。这不仅是职业进阶的必然要求,更…...
)
告别刻录光盘!用Rufus 4.5快速搞定Win10 U盘安装盘(保姆级图文指南)
用Rufus 4.5打造Win10 U盘安装盘的终极指南在数字时代,光驱已经逐渐退出历史舞台,但系统安装的需求依然存在。传统的光盘安装方式不仅速度慢,而且对硬件有要求。相比之下,U盘安装系统更加高效便捷。本文将详细介绍如何使用Rufus 4…...

3个关键维度重新定义工作价值:科学量化你的职业选择
3个关键维度重新定义工作价值:科学量化你的职业选择 【免费下载链接】worth-calculator Calculating the actual value of your job beyond just salary 项目地址: https://gitcode.com/gh_mirrors/wo/worth-calculator 你是否曾在深夜加班时思考,…...

AI Agent的节能与绿色计算:优化计算资源消耗的算法与策略
AI Agent节能与绿色计算实战:从算法优化到工程落地的全栈减碳指南 摘要/引言 你有没有算过,调用一次GPT-4生成1000字的回答,消耗的电量相当于一个普通家庭LED灯亮3个小时?据国际能源署2024年发布的报告,全球数据中心的年碳排放已经达到12亿吨,占全球总碳排放的2.1%,和…...

从COCO person_keypoints到YOLO格式:一份完整的姿态估计数据集转换脚本与避坑指南
从COCO到YOLO格式:姿态估计数据集转换实战手册在计算机视觉领域,姿态估计任务正从学术研究快速走向工业应用。许多开发者希望利用YOLO系列模型(如YOLOv8-Pose)进行训练,却常常在数据预处理阶段遇到障碍。本文将提供一套…...

人形机器人场景数据采集实战:从方案设计到质量验收
人形机器人场景数据采集实战:从方案设计到质量验收 摘要:人形机器人场景数据采集与传统工业数据采集有本质区别——场景复杂、交互多样、数据量巨大。本文基于多个落地项目经验,从采集方案设计、设备选型、场景编排、质量验收四个环节&#x…...

统信UOS 20.1060专业版美化全攻略:从桌面到开机GRUB,一张图搞定所有壁纸
统信UOS 20.1060专业版视觉定制指南:全系统美学统一方案当你第一次启动全新安装的统信UOS专业版时,那个默认的蓝色渐变桌面或许会让你感到一丝失望——它专业、稳重,但缺乏个性。作为一名追求效率与美感并存的技术爱好者,我一直在…...

第一次的博客
我是???计划考研由于是跨考,计划从0开始,先打c语言基础,再学习数据结构每天二~三小时暂无...

多重检验策略:提升NPLM信号无关搜索的鲁棒性与均匀性
1. 项目概述在粒子物理实验数据分析中,我们常常面临一个核心困境:我们不知道新物理信号会以何种形式出现。传统的“模型依赖”搜索,比如针对特定质量的希格斯玻色子或暗物质候选粒子,需要预先定义一个精确的理论模型。然而&#x…...