突破编程_C++_STL教程( list 的高级特性)
1 std::list 的排序
1.1 基础类型以及 std::string 类型的排序
std::list的排序可以通过调用其成员函数sort()来实现。sort()函数使用默认的比较操作符(<)对std::list中的元素进行排序。这意味着,如果元素类型定义了<操作符,std::list将使用它来比较元素。
例如,如果有一个std::list<int>,则可以这样排序它:
#include <list>
#include <algorithm> int main()
{std::list<int> myList = { 4, 2, 5, 1, 3 };myList.sort();// myList现在包含{1, 2, 3, 4, 5} return 0;
}
如果 list 里面的元素类型没有定义<操作符,或者需要使用自定义的比较函数,则可以通过传递一个比较函数或对象给sort()函数来实现。这个比较函数或对象应该接受两个参数(即需要比较的两个元素)并返回一个布尔值,指示第一个参数是否应该在排序后出现在第二个参数之前。
例如有一个std::list<std::string>,并且需要按照字符串的长度来排序它,可以这样做:
#include <list>
#include <algorithm>
#include <string> bool compareByStringLength(const std::string& a, const std::string& b) {return a.size() < b.size();
}int main()
{std::list<std::string> myList = { "apple", "banana", "cherry", "date" };myList.sort(compareByStringLength);// myList现在按照字符串长度排序,可能包含{"date", "apple", "cherry", "banana"} return 0;
}
上面代码中定义了一个名为 compareByStringLength 的比较函数,它比较两个字符串的长度。然后将这个函数作为参数传递给 sort() 函数,以按照字符串长度对 std::list 进行排序。
1.2 自定义类型的排序
如果需要对 std::list 中的自定义类型进行排序,则需要提供一个自定义的比较函数或比较对象,该函数或对象定义了如何比较两个自定义类型的对象。这个比较函数或对象应该接受两个参数并返回一个布尔值,用于确定第一个参数是否应该在排序后出现在第二个参数之前。
下面是一个例子,展示了如何对 std::list 中的自定义类型进行排序:
#include <list>
#include <string>
#include <iostream>
#include <algorithm> // 自定义类型
struct Person {std::string name;int age;// 构造函数 Person(const std::string& name, int age) : name(name), age(age) {}// 为了方便输出,重载<<操作符 friend std::ostream& operator<<(std::ostream& os, const Person& person) {os << "Name: " << person.name << ", Age: " << person.age;return os;}
};// 自定义比较函数,用于排序Person对象
bool comparePersonByAge(const Person& a, const Person& b) {return a.age < b.age; // 按年龄升序排序
}int main()
{// 创建一个包含Person对象的std::list std::list<Person> people = {{"Alice", 25},{"Bob", 20},{"Charlie", 30},{"David", 25}};// 使用自定义比较函数对people进行排序 people.sort(comparePersonByAge);// 输出排序后的结果 for (const auto& person : people) {std::cout << person << std::endl;}return 0;
}
上面代码的输出为:
Name: Bob, Age: 20
Name: Alice, Age: 25
Name: David, Age: 25
Name: Charlie, Age: 30
上面代码中定义了一个 Person 结构体,它包含 name 和 age 两个成员。然后创建了一个 comparePersonByAge 函数,它接受两个 Person 对象并比较它们的年龄。这个函数将用于 std::list 的 sort 成员函数来按照年龄对 Person 对象进行排序。
最后,在main函数中,创建了一个 std::list<Person>并初始化了几个 Person 对象。然后调用 sort 成员函数并传递 comparePersonByAge 函数作为比较对象,从而对 people 列表进行排序。
注意:如果需要按照降序排序,可以在comparePersonByAge函数中将比较操作从<改为>。此外,如果自定义类型定义了<操作符,也可以直接使用默认的排序而不需要提供自定义比较函数。
2 std::list 的主要应用场景
以下是一些std::list的主要应用场景:
(1)频繁插入和删除操作: std::list 允许在序列中的任意位置进行常数时间的插入和删除操作。这使得它非常适合需要频繁添加或移除元素的场景,如日志记录、任务队列、事件处理等。
(2)双向迭代: std::list 支持双向迭代,这意味着可以轻松地遍历列表,向前或向后移动。这种特性在处理需要前后关联的数据时非常有用,如文本编辑器中的撤销与重做操作。
(3)保持元素顺序: std::list 通过链表结构保持元素的插入顺序。这对于需要维护元素原始顺序的场景(如数据库查询结果、事件历史记录等)非常有用。
(4)动态数据结构: 当数据结构的大小经常变化时,std::list 是一个很好的选择。与基于数组的容器(如 std::vector)相比,std::list 在插入和删除元素时不需要移动大量数据,因此性能更高。
(5)内存管理: 在某些情况下,可能希望更好地控制内存使用。std::list 允许管理每个元素的内存分配,这在处理大量数据或需要精确控制内存使用的场景中非常有用。
(6)与线程安全容器结合使用: std::list 可以与其他线程安全容器(如 std::list<std::unique_ptr<T>>)结合使用,以在多线程环境中安全地管理资源。
2.1 std::list 应用于任务队列
std::list 在任务队列的应用场景中特别有用,特别是当需要频繁地在队列的任意位置插入和删除任务时。由于 std::list 的双向链表结构,它支持在常数时间内完成这些操作,这使得它成为处理动态任务队列的理想选择。
下面是一个简单的示例,展示了如何使用 std::list 来实现一个任务队列:
#include <iostream>
#include <list>
#include <thread>
#include <chrono>
#include <mutex>
#include <condition_variable> // 任务类型定义
struct Task {Task() {}Task(int id, std::function<void()> work) : id(id), work(work) {}int id;std::function<void()> work;
};// 任务队列类
class TaskQueue
{
public:// 向队列中添加任务 void pushTask(Task task) {std::lock_guard<std::mutex> lock(mtx);tasks.push_back(task);condVar.notify_one(); // 通知等待的线程有新任务到来 }// 从队列中取出任务并执行 bool popTask(Task& task) {std::unique_lock<std::mutex> lock(mtx);condVar.wait(lock, [this] { return !tasks.empty(); }); // 等待直到有任务到来 task = tasks.front();tasks.pop_front(); // 移除并返回队列前端的任务 return true;}// 检查队列是否为空 bool isEmpty() {std::lock_guard<std::mutex> lock(mtx);return tasks.empty();}
private:std::list<Task> tasks;std::mutex mtx;std::condition_variable condVar;};// 模拟任务执行的函数
void simulateWork(int taskId) {std::cout << "Executing task " << taskId << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1)); // 模拟耗时任务
}int main()
{TaskQueue taskQueue;// 启动生产者线程,向队列中添加任务 std::thread producer([&taskQueue]() {for (int i = 0; i < 10; ++i) {taskQueue.pushTask(Task(i, std::bind(simulateWork, i)));std::this_thread::sleep_for(std::chrono::milliseconds(500)); // 模拟任务生成间隔 }});// 启动消费者线程,从队列中取出并执行任务 std::thread consumer([&taskQueue]() {Task task;while (taskQueue.popTask(task)) {task.work(); // 执行任务 }});// 等待生产者和消费者线程完成 producer.join();consumer.join();return 0;
}
上面代码的输出为:
Executing task 0
Executing task 1
Executing task 2
Executing task 3
Executing task 4
Executing task 5
Executing task 6
Executing task 7
Executing task 8
Executing task 9
上面代码中定义了一个 Task 结构体来表示任务,它包含一个标识符和一个工作函数。TaskQueue 类提供了 pushTask 方法来向队列中添加任务,以及 popTask 方法来从队列中取出并执行任务。TaskQueue 还使用了一个互斥锁和一个条件变量来确保线程安全,并允许消费者在任务可用时被唤醒。
simulateWork 函数模拟了任务的执行过程,它只是打印任务 ID 并休眠一秒钟来模拟耗时任务。在 main 函数中,创建了一个生产者线程来生成任务,并将其添加到任务队列中,同时还创建了一个消费者线程来从队列中取出任务并执行。
2.2 std::list 应用于文本编辑器中的撤销与重做操作
在文本编辑器的撤销与重做操作中,使用 std::list 的双向迭代特性可以使得在向前和向后遍历编辑历史时都非常高效。下面是一个示例,该示例演示了如何使用 std::list 来管理编辑历史,并支持撤销和重做操作,同时体现了双向迭代在处理这种需要前后关联的数据时的优势。
#include <iostream>
#include <list>
#include <string> // 文本编辑器类
class TextEditor
{
public:// 构造函数 TextEditor() : currentPos(history.end()) {}// 输入文本 void inputText(const std::string& text) {// 添加新文本到历史记录 history.push_back(text);// 更新当前位置迭代器 currentPos = std::prev(history.end());}// 撤销操作 void undo() {if (currentPos != history.begin()) {// 如果不是第一次编辑,则向前移动迭代器 --currentPos;}}// 重做操作 void redo() {if (std::next(currentPos) != history.end()) {// 如果还有后续的历史记录,则向后移动迭代器 ++currentPos;}}// 获取当前文本 std::string getCurrentText() const {if (currentPos != history.end()) {return *currentPos;}return "";}// 显示编辑历史 void showHistory() const {for (const auto& text : history) {std::cout << text << std::endl;}}private:std::list<std::string> history; // 存储编辑历史的列表 std::list<std::string>::iterator currentPos; // 当前编辑位置的迭代器
};int main() {TextEditor editor;// 用户输入一些文本 editor.inputText("Initial text.");editor.inputText("Edited text.");editor.inputText("Edited again.");// 显示编辑历史 editor.showHistory();// 执行撤销操作 editor.undo();std::cout << "After undo: " << editor.getCurrentText() << std::endl;// 执行重做操作 editor.redo();std::cout << "After redo: " << editor.getCurrentText() << std::endl;// 再次显示编辑历史来验证状态 editor.showHistory();return 0;
}
上面代码的输出为:
Initial text.
Edited text.
Edited again.
After undo: Edited text.
After redo: Edited again.
Initial text.
Edited text.
Edited again.
在上面代码中,TextEditor 类使用 std::list 来维护编辑历史。每次调用 inputText 方法时,它都会清除当前位置之后的所有历史记录,并将新文本添加到历史列表的末尾。撤销操作通过向前移动迭代器并删除当前元素来实现,而重做操作则通过向后移动迭代器来实现。由于 std::list 支持双向迭代,因此这些操作都是常数时间复杂度的,非常高效。
3 std::list 的扩展与自定义
在大多数情况下,不需要对 std::list 做扩展与自定义,因为它已经提供了非常完整的功能集。然而,如果需要更高级的功能或定制行为,则可以考虑以下几种方法:
(1)继承自 std::list:
可以通过继承 std::list 并添加自定义成员函数来扩展其功能。然而,这通常不是推荐的做法,因为继承标准库组件可能导致未定义的行为或意外的副作用。标准库组件通常设计为不可继承的,并且它们的内部实现可能会在不同版本的编译器或标准库中发生变化。
(2)使用适配器模式:
适配器模式允许将一个类的接口转换为另一个类的接口,而不需要修改原始类。可以创建一个适配器类,它封装了一个 std::list 实例,并提供了自定义的接口。这样,可以在不修改 std::list 本身的情况下添加新功能。
(3)自定义迭代器:
std::list 允许使用自定义迭代器。开发人员可以创建自己的迭代器类,该类提供对 std::list 元素的访问,并在迭代过程中添加自定义逻辑。然后,可以将这些自定义迭代器传递给 std::list 的成员函数,以在遍历元素时应用自定义行为。
(4)使用代理类:
代理类是一个设计模式,它允许一个类代表另一个类的功能,并在调用功能时添加额外的逻辑。你可以创建一个代理类,它封装了一个 std::list 实例,并提供与 std::list 相同的接口。在代理类的实现中,可以在调用 std::list 的方法之前或之后添加自定义逻辑:
(5)自定义分配器:
std::list 使用分配器来管理内存。可以通过提供一个自定义的分配器来定制 std::list 的内存分配行为。自定义分配器可以允许你控制内存的分配策略,例如使用内存池、共享内存或其他高级内存管理技术。
4 实现一个简单的 std::list 容器
如下是一个一个简化的 std::list 容器的实现,仅包含基本的构造函数、析构函数、插入和遍历功能:
#include <iostream> template <typename T>
class MyList
{
public:struct Node {T data;Node* next;Node* prev;Node(const T& value) : data(value), next(nullptr), prev(nullptr) {}};MyList() : head(nullptr), tail(nullptr) {}~MyList() {clear();}void push_back(const T& value) {Node* newNode = new Node(value);if (head == nullptr) {head = newNode;tail = newNode;}else {tail->next = newNode;newNode->prev = tail;tail = newNode;}}void push_front(const T& value) {Node* newNode = new Node(value);if (head == nullptr) {head = newNode;tail = newNode;}else {newNode->next = head;head->prev = newNode;head = newNode;}}void clear() {Node* current = head;while (current != nullptr) {Node* next = current->next;delete current;current = next;}head = nullptr;tail = nullptr;}void display() const {Node* current = head;while (current != nullptr) {std::cout << current->data << " ";current = current->next;}std::cout << std::endl;}private:Node* head;Node* tail;
};int main()
{MyList<int> myList;myList.push_back(10);myList.push_back(20);myList.push_front(5);myList.display();myList.clear();return 0;
}
上面代码的输出为:
5 10 20
这个简化的 MyList 类包含了一个内部的Node结构,用于存储数据以及指向下一个和上一个节点的指针。MyList 类提供了 push_back 和 push_front 方法用于在列表的末尾和开头插入元素,clear 方法用于删除所有元素,以及 display 方法用于遍历并打印列表中的所有元素。
相关文章:
)
突破编程_C++_STL教程( list 的高级特性)
1 std::list 的排序 1.1 基础类型以及 std::string 类型的排序 std::list的排序可以通过调用其成员函数sort()来实现。sort()函数使用默认的比较操作符(<)对std::list中的元素进行排序。这意味着,如果元素类型定义了<操作符ÿ…...
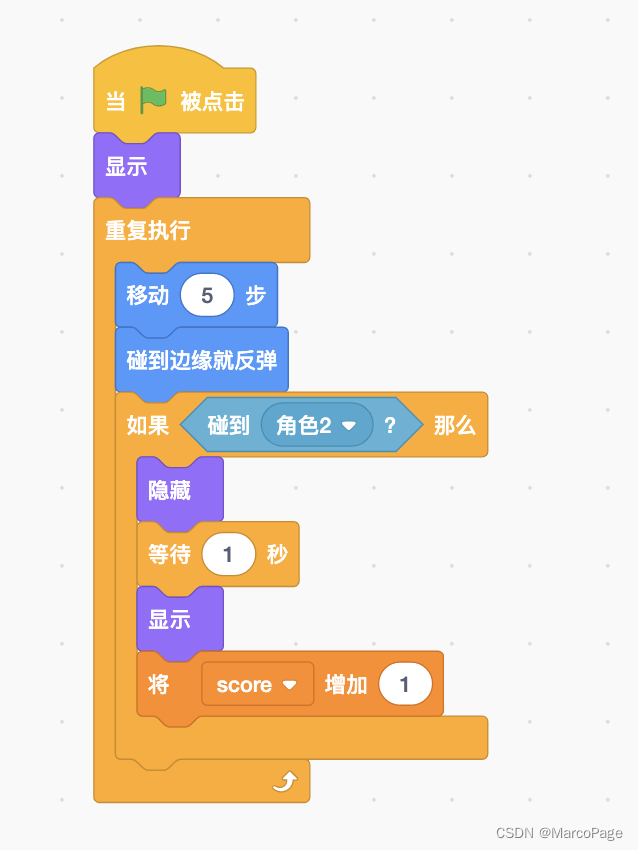
Scratch 第十六课-弹珠台游戏
第十六课-弹珠台游戏 大家好,今天我们一起做一款弹珠台scratch游戏,我们也可以叫它弹球游戏!这款游戏在刚出来的时候非常火爆。小朋友们要认真学习下! 这节课的学习目标 物体碰撞如何处理转向问题。复习键盘对角色的控制方式。…...

对简单工厂模式、工厂方法模式的思考
目录 1 背景1.1 题目描述1.2 输入描述1.3 输出描述1.4 输入示例1.5 输出示例 2 简单工厂模式3 工厂方法模式4 思考4.1 改进工厂方法模式 1 背景 题目源自:【设计模式专题之工厂方法模式】2.积木工厂 1.1 题目描述 小明家有两个工厂,一个用于生产圆形积木…...
【详识JAVA语言】面向对象程序三大特性之二:继承
继承 为什么需要继承 Java中使用类对现实世界中实体来进行描述,类经过实例化之后的产物对象,则可以用来表示现实中的实体,但是 现实世界错综复杂,事物之间可能会存在一些关联,那在设计程序是就需要考虑。 比如&…...

【剑指offer--C/C++】JZ3 数组中重复的数字
一、题目 二、本人思路及代码 这道题目它要求的时间空间利用率都是n,那么可以考虑创建一个长度为n的数组repeat初始化为0,下标代码出现的数字,下标对应的数组内容代表该下标数字出现的次数。然后遍历提供的数组,每出现一个数字&a…...
)
基于SpringBoot的在线拍卖系统设计与实现(源码)
项目源码:https://gitee.com/oklongmm/biye2 引言 随着互联网技术的发展,电子商务得以快速发展,其中之一的在线拍卖系统也逐渐得到了广泛的应用。但是,现有的在线拍卖系统在操作复杂性、安全性和稳定性方面存在一定的问题。为了…...

卢森堡比利时土耳其媒体宣发稿助力跨境出海推广新闻营销
【本篇由言同数字科技有限公司原创】随着全球化进程的加速,越来越多的品牌开始考虑在海外市场扩展业务。对于品牌来说,跨境海外推广是必要的,因为它可以帮助品牌打开更大的市场、吸引更多的消费者、提高品牌知名度和形象,并在全球…...
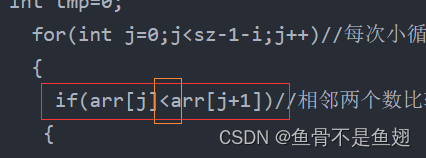
冒泡排序(C语言详解)
原理:从左到右一次比较,如果左侧数字比右侧数字大(小),则两数交换,否则比较下一 组数字,每一次大循环比较可以将乱序的最右侧数字改为最大(最小),…...
STC-ISP原厂代码研究之 V3.7d汇编版本
最近在研究STC的ISP程序,用来做一个上位机烧录软件,逆向了上位机软件,有些地方始终没看明白,因此尝试读取它的ISP代码,但是没有读取成功。应该是目前的芯片架构已经将引导代码放入在了单独的存储块中,而这存储块有硬件级的使能线,在面包板社区-宏晶STC单片机的ISP的BIN文…...
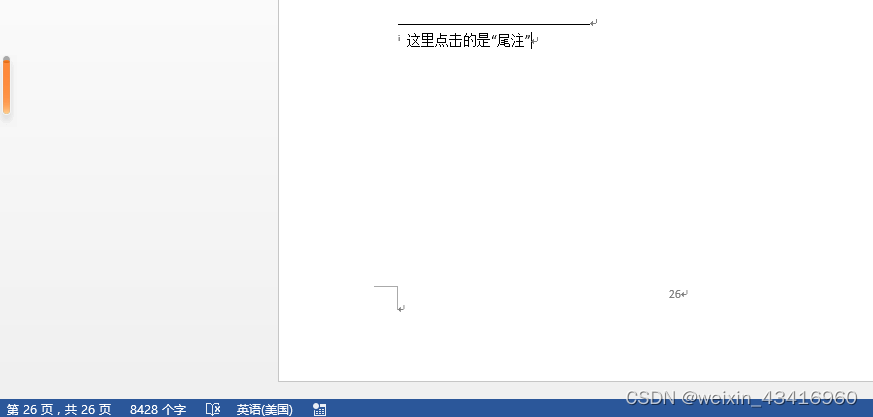
【word】引用文献如何标注右上角
一、在Word文档中引用文献并标注在右上角的具体步骤如下 1、将光标移动到需要添加文献标注的位置: 2、在文档上方的工具栏中选择“引用”选项: 3、点击“插入脚注”或“插入尾注”: ①如果选择的是脚注,则脚注区域会出现在本页的…...

MySQL 5.5、5.6、5.7的主从复制改进
主从复制面临的问题 MySQL一直以来的主从复制都是被诟病,原因是: 1、主从复制效率低 早期mysql的复制是通过将binlog语句异步推送到从库。从库启动一个IO线程将接收到的数据记录到relaylog中;另外启动一个SQL线程负责顺序执行relaylog中的语句实现对数据的拷贝。 这里的…...
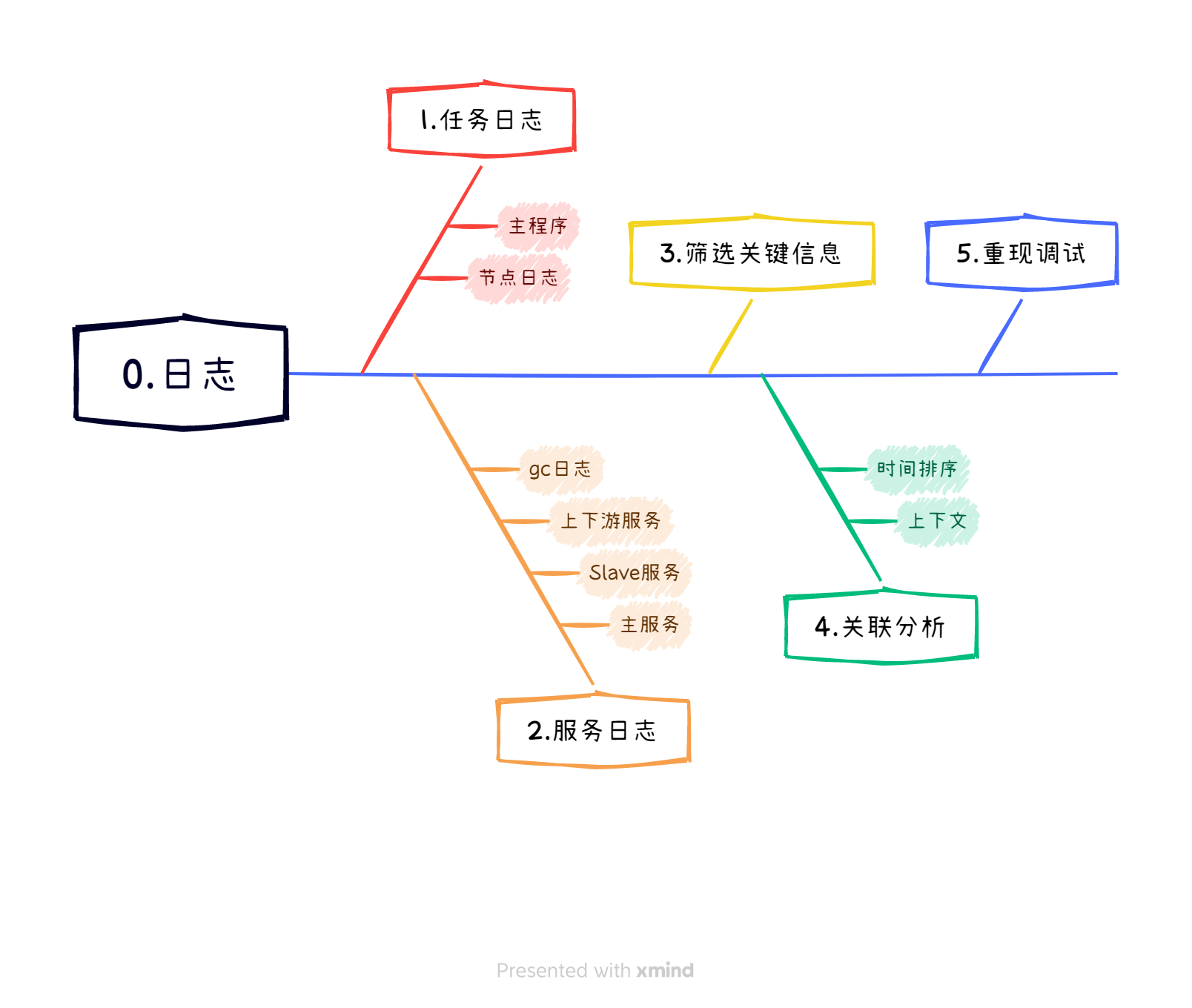
性能分析排查思路之日志(1)
本文是性能问题分析排查思路的展开内容之一,主要分为日志1期,机器4期、环境2期共7篇系列文章,本期是第一篇,讲日志的分析方法和经验。 系列文章传送门: 一图梳理性能问题分析排查思路-总体概述(0ÿ…...

Vue中如何实现条件渲染?
在Vue中实现条件渲染非常简单且灵活,主要通过Vue的指令来实现。在Vue中,我们可以使用v-if和v-else指令来根据条件来渲染不同的内容。下面就让我们通过一个简单的示例来演示如何在Vue中实现条件渲染: <!DOCTYPE html> <html lang&qu…...
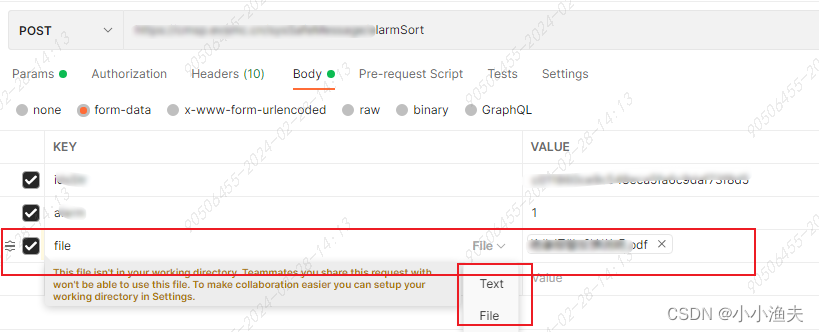
Postman上传文件的操作方法
前言 调用某个接口,测试上传文件功能。一时间不知如何上传文件,本文做个操作记录,期望与你有益。 步骤一、设置Headers key:Content-Type value:multipart/form-data 步骤二、设置Body 选择form-data key:file下拉框选择file类型value&…...

linux系统Jenkins工具介绍
Jenkins概念介绍 Jenkins概念Jenkins目的特性产品发布流程 Jenkins概念 Jenkins是一个功能强大的应用程序,允许持续集成和持续交付项目,无论用的是什么平台。这是一个免费的源代码,可以处理任何类型的构建或持续集成。集成Jenkins可以用于一些…...

【python】遵守 robots.txt 规则的数据爬虫程序
程序1 编写一个遵守 robots.txt 规则的数据爬虫程序涉及到多个步骤,包括请求网页、解析 robots.txt 文件、扫描网页内容、存储数据以及处理异常。由于编程语言众多,且每种语言编写爬虫程序的方式可能有所不同,以下将使用 Python 语言举例&am…...

使用爬虫去获取四六级成绩
使用爬虫去获取四六级成绩 今天出成绩,没过,二战六级依然惨死,那么我就写一个简单的爬虫,其实也可以封装成一个接口的,然后直接输入姓名 身份证好 以及四六级即可获取成绩,我就是简单的玩了一下哈…...

洛谷P1256 显示图像
广搜练手题 题目链接 思路 打印每个数与其最近的 1 1 1的曼哈顿距离,显然广搜,存储每一个 1 1 1,针对每一个 1 1 1开始广搜,逐层更新,每轮后更新的为两轮之中的最小曼哈顿距离 ACcode #include<bits/stdc.h>…...
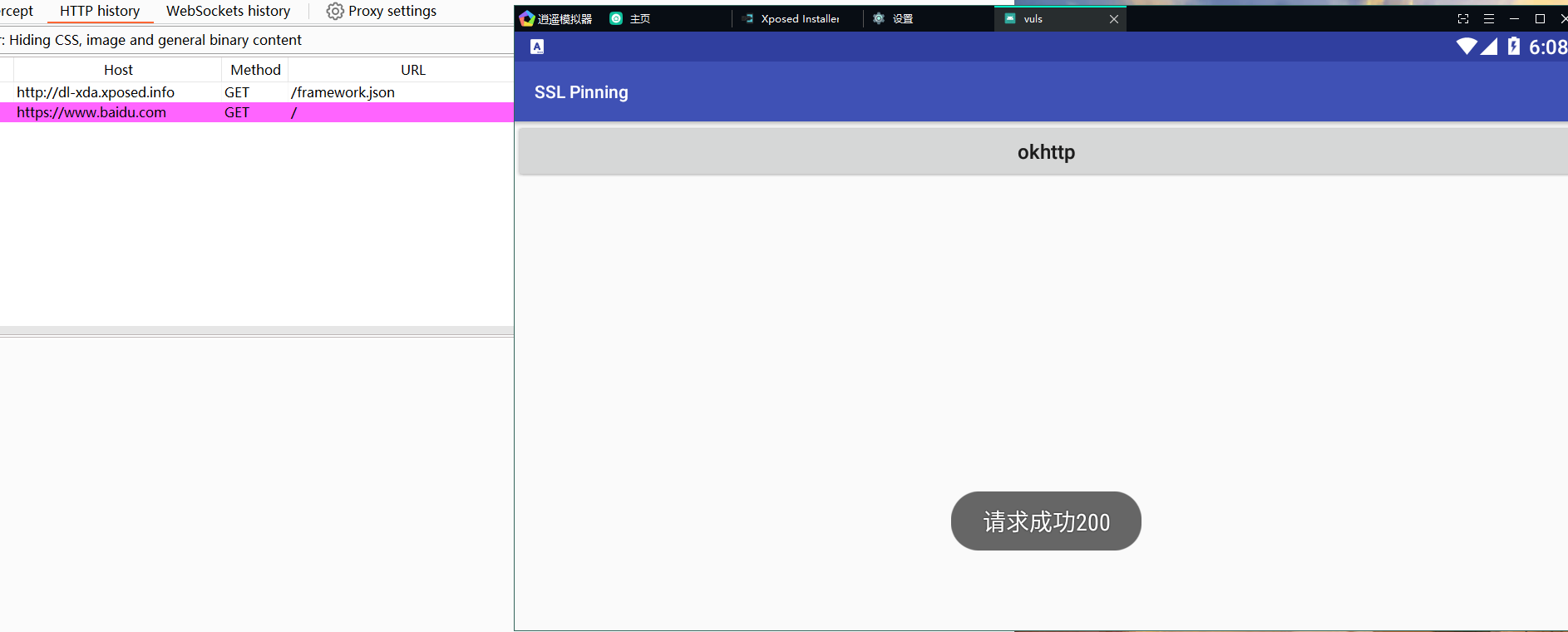
模拟器抓HTTP/S的包时如何绕过单向证书校验(XP框架)
模拟器抓HTTP/S的包时如何绕过单向证书校验(XP框架) 逍遥模拟器无法激活XP框架来绕过单向的证书校验,如下图: 解决办法: 安装JustMePlush.apk安装Just Trust Me.apk安装RE管理器.apk安装Xposedinstaller_逍遥64位…...

【JS 算法题: 将 json 转换为字符串】
题目简介 其实就是手撕 JSON.stringfy()。 算法实现 输入 原则上来说,输入的是一个 json 对象。但需要考虑到异常情况,即输入了其它类型的数据,比如:12, true, ‘abc’, [‘red’, ‘green’], null, undefined 等。 输出 …...

Cursor Free VIP破解工具终极指南:5分钟实现AI编程助手永久免费使用
Cursor Free VIP破解工具终极指南:5分钟实现AI编程助手永久免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve rea…...
)
客制化键盘党必看:在Ubuntu 22.04上让F1-F12键失灵的HS75T/珂芝K75恢复正常(附一键脚本)
客制化键盘在Ubuntu下的F键修复指南:从原理到一键解决方案作为一名长期使用客制化机械键盘的Linux开发者,我深知那种当F5调试键突然失灵时的崩溃感。特别是当你刚入手一款颜值与手感俱佳的HS75T或珂芝K75,却发现在Ubuntu下连接蓝牙或2.4G接收…...

BooruDatasetTagManager:10倍提升AI训练数据标注效率的智能解决方案
BooruDatasetTagManager:10倍提升AI训练数据标注效率的智能解决方案 【免费下载链接】BooruDatasetTagManager 项目地址: https://gitcode.com/gh_mirrors/bo/BooruDatasetTagManager 面对数千张AI训练图像的繁琐标注工作,你是否感到力不从心&am…...

BetterGI原神自动化工具:5分钟快速上手指南,解放你的游戏时间
BetterGI原神自动化工具:5分钟快速上手指南,解放你的游戏时间 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄地 | 一条…...

用Python+SPSS搞定数学建模A题:从问卷数据清洗到慢性病影响因素分析全流程
PythonSPSS数学建模实战:慢性病影响因素分析与可视化全流程数学建模竞赛中,数据处理与分析能力往往决定了作品的深度与竞争力。面对慢性病影响因素分析这类典型的社会医学问题,如何高效完成从原始问卷到可视化报告的全流程?本文将…...
)
保姆级教程:Win10到Win11,VMware虚拟机无损迁移全流程(含GRUB修复)
从Win10到Win11:VMware虚拟机无损迁移与GRUB修复终极指南当你拿到崭新的Win11电脑,最头疼的莫过于如何将旧电脑上那些精心配置的VMware虚拟机环境完整迁移过来。特别是那些承载着重要开发环境或测试数据的Linux虚拟机,稍有不慎就可能面临系统…...

小样本下机器学习模型性能稳定性评估:分位数与置信区间实战
1. 项目概述与核心价值在机器学习项目的落地过程中,我们常常会面临一个灵魂拷问:这个模型到底有多“稳”?你辛辛苦苦调参、优化,在某个特定测试集上跑出了95%的准确率,但换个数据划分方式,或者重新初始化一…...

ICE-T框架:破解机器学习教学黑箱,培养计算与解释性思维
1. 项目概述:为什么我们需要一个全新的机器学习教学框架?在过去的几年里,我亲眼见证了“人工智能”和“机器学习”从一个高深莫测的学术词汇,迅速演变为中小学乃至大学课堂上的热门话题。作为一名长期关注教育技术落地的从业者&am…...

语音“下一首“控制车载音乐播放!
V1.0一个android apk,这个app可以监听手机的语音,然后我可以发语音来控制播放下一首歌曲,给语音指令,下一个,就会在酷狗音乐上播放下一首歌曲。节省点击的操作,因为在车上手去点击,影响开车。V1…...

AI正在重构工程师岗位:被替代的不是“人”,而是低维度能力
过去很多人认为,AI更适合写文案、做客服、生成图片,而真正复杂的工程领域——尤其是工业、制造、自动化系统——依然离不开工程师。 但最近一个劳动仲裁案例,让越来越多工程技术人员开始重新思考这个问题: 一位从事测绘工作15年的工程师,因为企业全面导入AI自动化测绘系…...