【python】遵守 robots.txt 规则的数据爬虫程序

程序1
编写一个遵守 robots.txt 规则的数据爬虫程序涉及到多个步骤,包括请求网页、解析 robots.txt 文件、扫描网页内容、存储数据以及处理异常。由于编程语言众多,且每种语言编写爬虫程序的方式可能有所不同,以下将使用 Python 语言举例,提供一个简化的流程。
注意:以下代码只是一个示例,并不是一个完备的、可直接运行的程序。此外,实际应用中还需要处理网络错误、限速遵循礼貌原则,以及可能的存储问题等等。
import requests
from urllib.robotparser import RobotFileParser
from bs4 import BeautifulSoup# 初始化robots.txt解析器
def init_robot_parser(url):rp = RobotFileParser()rp.set_url(url + "/robots.txt")rp.read()return rp# 爬取页面
def crawl_page(url, user_agent='MyBot'):rp = init_robot_parser(url)if rp.can_fetch(user_agent, url):headers = {'User-Agent': user_agent}response = requests.get(url, headers=headers)if response.status_code == 200:return response.textelse:print(f"爬取被禁止在: {url}")return None# 解析页面,提取数据
def extract_data(html):soup = BeautifulSoup(html, 'html.parser')# 这里根据实际需要定制提取数据的代码# 例子: 提取所有的a标签for link in soup.find_all('a'):href = link.get('href')print(href)# 应该将提取的数据存储到数据库或文件系统等# 主函数
def main():url = 'http://example.com' # 目标网站user_agent = 'MyBot' # 爬虫名称html = crawl_page(url, user_agent)if html:extract_data(html)if __name__ == "__main__":main()
程序2
编写遵守`robots.txt`规则的数据爬虫需要遵循几个关键步骤。以下是一个遵守`robots.txt`规则的Python数据爬虫的示例:
1. 解析`robots.txt`:使用`urllib.robotparser`模块来解析目标网站的`robots.txt`文件,并确定哪些页面是可爬取的。
2. 请求数据:使用如`requests`的库发起网络请求,获取网页内容。
3. 分析内容:利用如`BeautifulSoup`的库分析网页内容,提取所需数据。
4. 遵循爬虫规则:确保在爬取时尊重`robots.txt`文件中的`Crawl-delay`指令,并且不爬取`Disallow`中指定的页面。
下面是精简版的代码实现:
import requests
from urllib.robotparser import RobotFileParser
from time import sleep
from bs4 import BeautifulSoupclass MySpider:def __init__(self, base_url):self.base_url = base_urlself.robots_url = base_url + "/robots.txt"self.robot_parser = RobotFileParser()def fetch_robots_txt(self):response = requests.get(self.robots_url)# 假定robots.txt存在,若不存在需要额外处理self.robot_parser.parse(response.text.splitlines())def crawl(self, path):url = self.base_url + path# 检查是否允许爬取if self.robot_parser.can_fetch("*", url):crawl_delay = self.robot_parser.crawl_delay("*")if crawl_delay:sleep(crawl_delay) # 根据 Crawl-delay 设置等待response = requests.get(url)if response.status_code == 200:return response.textelse:print(f"被禁止爬取:{url}")return Nonedef parse(self, html):# 使用 BeautifulSoup 或其它工具解析 htmlsoup = BeautifulSoup(html, 'html.parser')# 这里进行具体的解析任务# ...base_url = "https://example.com" # 假设这是您要爬取的网站的根URL
spider = MySpider(base_url)# 获取并解析robots.txt
spider.fetch_robots_txt()# 爬取网站中的特定路径
path_to_crawl = "/some-page" # 你要爬取的页面路径
html_content = spider.crawl(path_to_crawl)if html_content:# 解析获取的网页内容spider.parse(html_content)注意,上述代码是一个基础示例。在实际应用中,还需要考虑一些其他因素:
- 异常处理:网络请求和内容解析时可能会出现异常。
- 日志记录:记录爬虫的行为,方便追踪问题和调试。
- 遵守法律法规:不同国家和地区对网络爬虫有不同的法律要求,在编写和运行爬虫之前,应当了解并遵守当地的法律。
- 更复杂的URL规则和爬取策略:需要更精细化地处理 URL 规则,并设计合理的爬取策略来避免服务器的压力。

程序3
创建一个遵守 robots.txt 规则的数据爬虫的示例程序相当复杂,因为它需要考虑多个方面,包括解析 robots.txt 规则、避开禁止访问的路径、遵守爬取时间间隔(Crawl-delay)等。
以下是一个简化的 Python 程序,展示了如何使用 urllib.robotparser 库读取和解析 robots.txt 文件,以及如何使用 requests 库实现基本的网页爬取功能。注意,此示例仅作为演示之用,并不是一个完整功能的爬虫。
首先,安装 requests 库,如果 Python 环境尚未安装它的话:
pip install requests接下来是示例程序:
import requests
from urllib.robotparser import RobotFileParser
from urllib.parse import urlparseclass SimpleCrawler:def __init__(self, base_url):self.base_url = base_urlself.robot_parser = RobotFileParser()self.crawl_delay = 0self.parse_robots_txt()def parse_robots_txt(self):robot_url = urlparse(self.base_url)robot_url = f"{robot_url.scheme}://{robot_url.netloc}/robots.txt"self.robot_parser.set_url(robot_url)self.robot_parser.read()self.crawl_delay = self.robot_parser.crawl_delay("*")def can_fetch(self, url):return self.robot_parser.can_fetch("*", url)def fetch_page(self, url):if self.can_fetch(url):response = requests.get(url)if response.status_code == 200:return response.textelse:print(f"Access denied by robots.txt: {url}")return None# 注意此方法可能不遵守 Crawl-delay,视乎 `requests` 的具体实现和网络条件。def fetch_pages(self, urls):for url in urls:page_content = self.fetch_page(url)if page_content:print(f"Fetched URL: {url[:60]}...") # 打印URL的前60个字符else:print(f"Failed to fetch URL: {url[:60]}...")# 遵守robots.txt的Crawl-delay设置等待相应时间if self.crawl_delay:time.sleep(self.crawl_delay)# 使用示例
if __name__ == "__main__":# 确保这个 URL 是你有权限爬取的base_url = "http://example.com"crawler = SimpleCrawler(base_url)url_list = ["http://example.com/page1","http://example.com/page2",# 添加更多你希望爬取的页面]crawler.fetch_pages(url_list)此代码定义了一个 SimpleCrawler 类,初始化时给它一个基础 URL。它将尝试读取此网站的 robots.txt,并解析其中的规则。`can_fetch` 方法用来判断是否允许抓取指定的 URL。`fetch_page` 方法负责实际的抓取工作,并遵守 robots.txt 中的 Disallow 规则。`fetch_pages` 方法是一个遍历 URL 列表并依次抓取每个页面的高层次封装。
请注意,在使用此代码时,应确保:
1. 遵守目标网站的 robots.txt 规则。
2. 尊重 Crawl-delay 提示,此代码示例仅在遍历 URL 列表时等待指定时间,而不是在连续请求之间等待。
3. 在实际部署到爬虫程序之前,需要进行全面的测试和额外的错误处理工作。
以上只是一个基础示例,真实环境中的爬虫还需要考虑 IP 被封禁、各种 HTTP 状态码处理、异常处理、日志记录、爬取速率控制等更多复杂情况。此外,为了完整遵守 robots.txt,爬虫还需要处理 Sitemap 和 Allow 指令,以及 User-agent 和 Crawl-delay 对不同爬虫的特定规则。
相关文章:
【python】遵守 robots.txt 规则的数据爬虫程序
程序1 编写一个遵守 robots.txt 规则的数据爬虫程序涉及到多个步骤,包括请求网页、解析 robots.txt 文件、扫描网页内容、存储数据以及处理异常。由于编程语言众多,且每种语言编写爬虫程序的方式可能有所不同,以下将使用 Python 语言举例&am…...

使用爬虫去获取四六级成绩
使用爬虫去获取四六级成绩 今天出成绩,没过,二战六级依然惨死,那么我就写一个简单的爬虫,其实也可以封装成一个接口的,然后直接输入姓名 身份证好 以及四六级即可获取成绩,我就是简单的玩了一下哈…...

洛谷P1256 显示图像
广搜练手题 题目链接 思路 打印每个数与其最近的 1 1 1的曼哈顿距离,显然广搜,存储每一个 1 1 1,针对每一个 1 1 1开始广搜,逐层更新,每轮后更新的为两轮之中的最小曼哈顿距离 ACcode #include<bits/stdc.h>…...
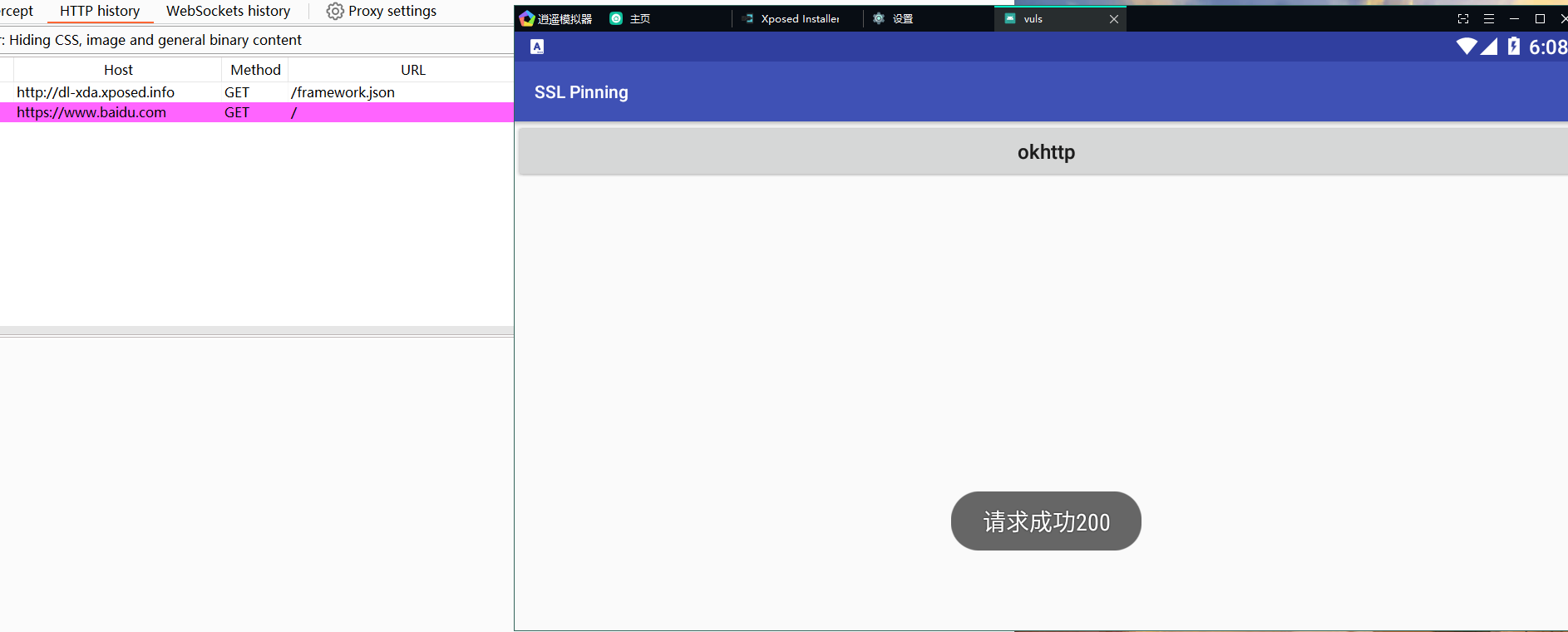
模拟器抓HTTP/S的包时如何绕过单向证书校验(XP框架)
模拟器抓HTTP/S的包时如何绕过单向证书校验(XP框架) 逍遥模拟器无法激活XP框架来绕过单向的证书校验,如下图: 解决办法: 安装JustMePlush.apk安装Just Trust Me.apk安装RE管理器.apk安装Xposedinstaller_逍遥64位…...

【JS 算法题: 将 json 转换为字符串】
题目简介 其实就是手撕 JSON.stringfy()。 算法实现 输入 原则上来说,输入的是一个 json 对象。但需要考虑到异常情况,即输入了其它类型的数据,比如:12, true, ‘abc’, [‘red’, ‘green’], null, undefined 等。 输出 …...
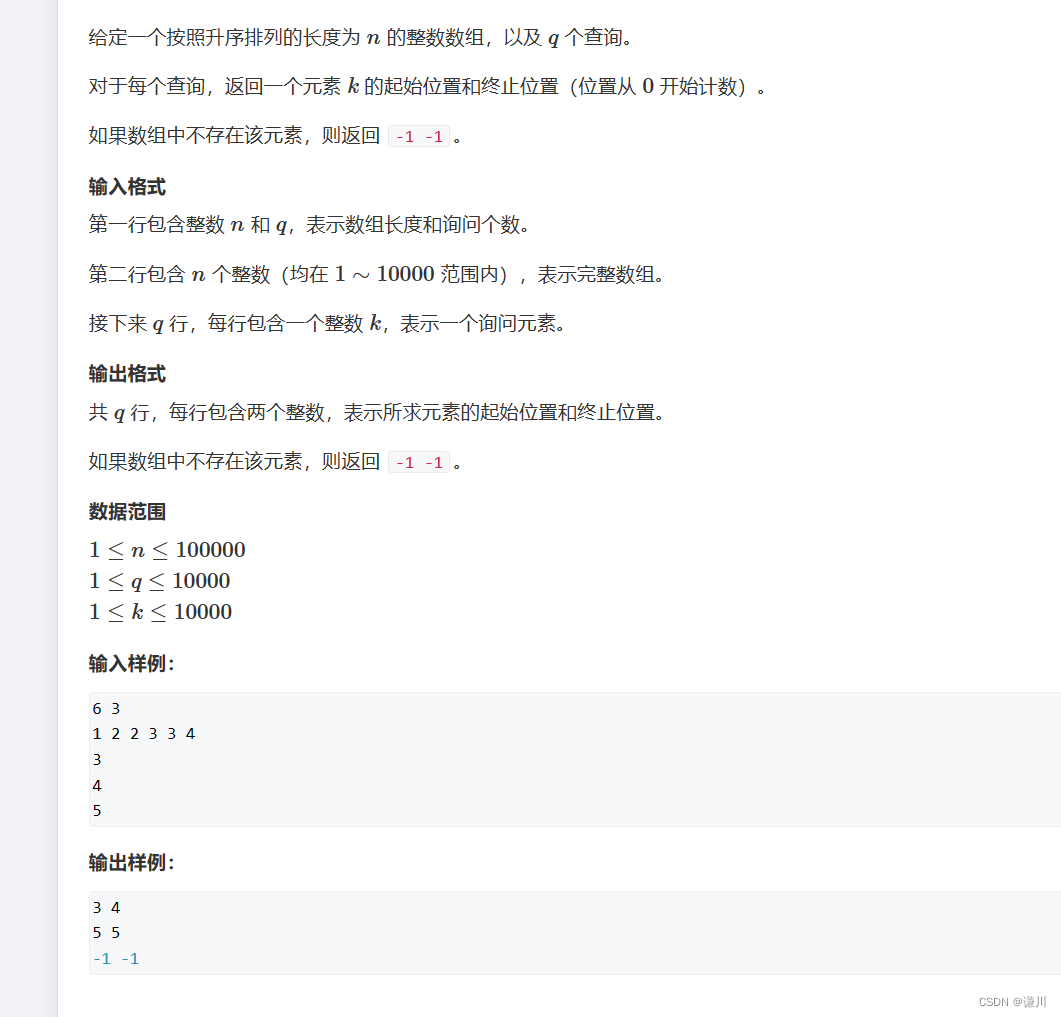
数的范围 刷题笔记
思路 寻找第一个大于等于目标的 数 因为该数组是升序的 所以 我们可以采用二分的方式 逼近答案 定义一个左指针和一个右指针 当左右指针重合时 就是我们要找的答案 当我们寻找第一个大于等于x的数时 a[mid]>x,答案在mid处 或者在mid的左边 因此让rmid继续逼近 如果…...

XSS简介及xsslabs第一关
XSS被称为跨站脚本攻击(Cross-site scripting),由于和CSS(CascadingStyle Sheets)重名,所以改为XSS。 XSS主要速于javascript语言完成恶意的攻击行为,因为javascript可非常灵活的操作html、css和浏览器 XSS就是指通过利用网页开发时留下的漏…...
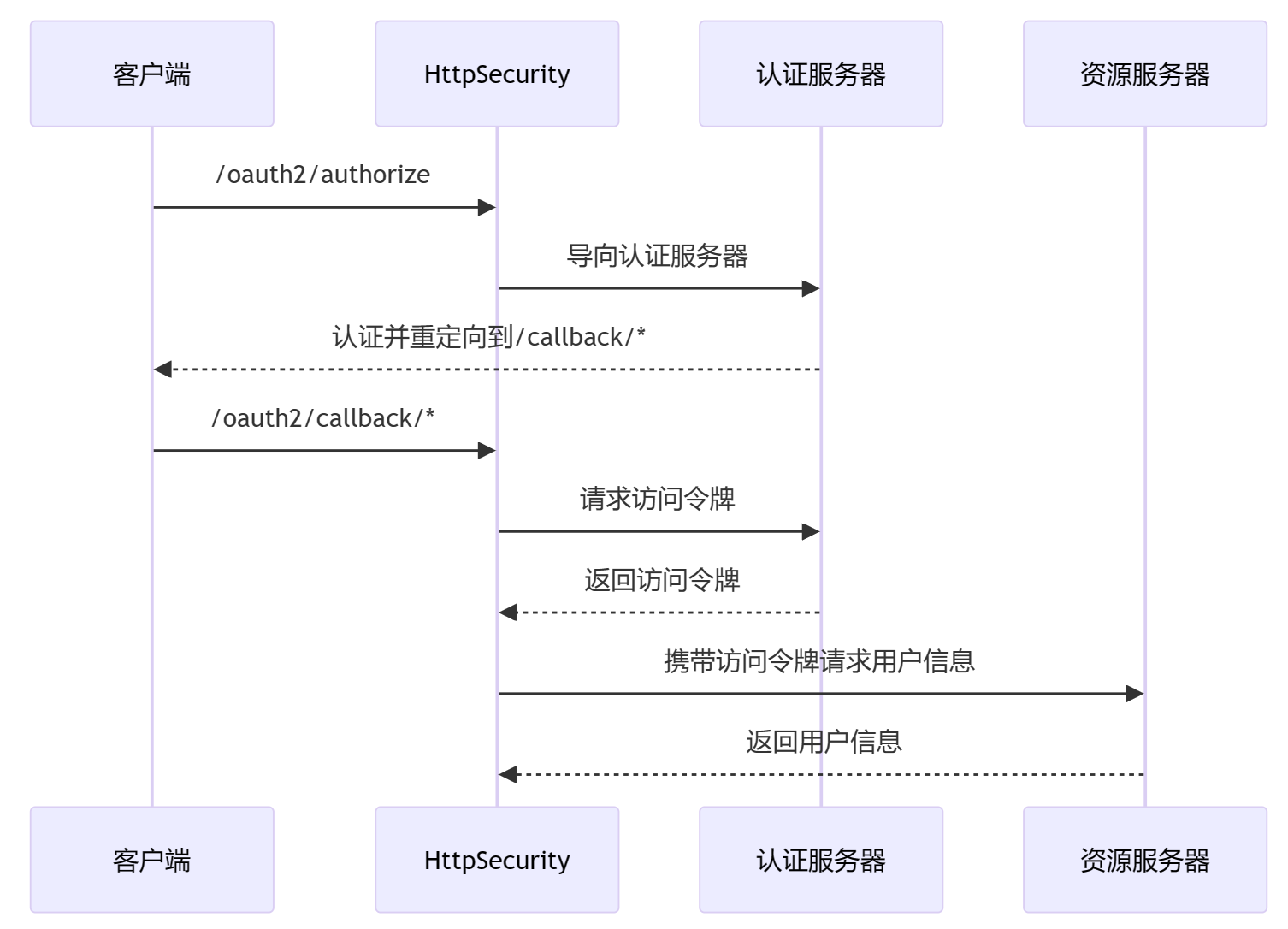
构建安全的REST API:OAuth2和JWT实践
引言 大家好,我是小黑,小黑在这里跟咱们聊聊,为什么REST API这么重要,同时,为何OAuth2和JWT在构建安全的REST API中扮演着不可或缺的角色。 想象一下,咱们每天都在使用的社交媒体、在线购物、银行服务等等…...

从0开始学习NEON(1)
1、前言 在上个博客中对NEON有了基础的了解,本文将针对一个图像下采样的例子对NEON进行学习。 学习链接:CPU优化技术 - NEON 开发进阶 上文链接:https://blog.csdn.net/weixin_42108183/article/details/136412104 2、第一个例子 现在有一张图片,需…...
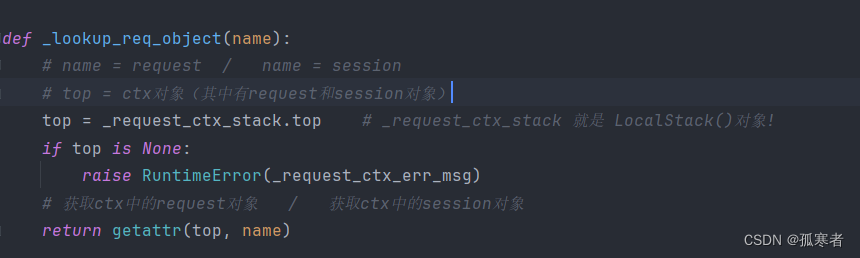
(二十三)Flask之高频面试点
目录: 每篇前言:Q1:为什么把request和session放在一起?Q2:Local对象的作用?Q3::LocalStack对象的作用?Q4:一个运行中的Flask应用程序分别包括几个Local/LocalStack&#…...
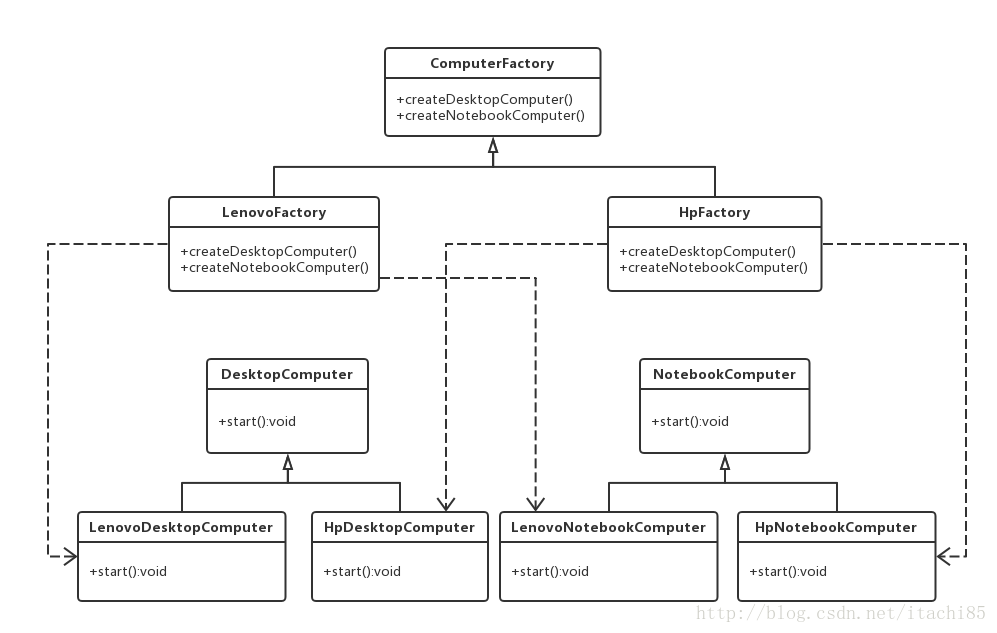
设计模式(十三)抽象工厂模式
请直接看原文:设计模式(十三)抽象工厂模式_抽象工厂模式告诉我们,要针对接口而不是实现进行设计。( )-CSDN博客 -------------------------------------------------------------------------------------------------------------------------------- …...

HTTP Cookie 你了解多少?
Cookie是什么? 先给大家举个例子,F12 打开浏览器的页面之后,我们能在 Response Headers 的字段里面看到一个header 叫做 Set-Cookie,如下所示 图中包含的 Set-Cookie 为 Set-Cookie:uuid_tt_dd10_20293537580-1709432565344-232…...

【QT+QGIS跨平台编译】之五十六:【QGIS_CORE跨平台编译】—【qgsmeshcalclexer.cpp生成】
文章目录 一、Flex二、生成来源三、构建过程一、Flex Flex (fast lexical analyser generator) 是 Lex 的另一个替代品。它经常和自由软件 Bison 语法分析器生成器 一起使用。Flex 最初由 Vern Paxson 于 1987 年用 C 语言写成。 “flex 是一个生成扫描器的工具,能够识别文本中…...

ar时间序列
AR时间序列模型(AutoRegressive Time Series Model)是一种用于分析和预测时间序列数据的统计模型。该模型假设未来的观测值与过去的观测值相关,且该相关性可以通过线性回归来描述。 AR模型的基本思想是将当前时刻的观测值表示为过去几个时刻的…...

Android 14 AAOS audio
文章目录 乘客音频投放到主音频区动态路由配置controlhal实现的具体流程control hal AudioGain的callbackAudioModuleChange变化的通知 乘客音频投放到主音频区 场景: 是将乘客区的Media 属性的数据通过主屏区的设备进行播放。具体而言 在副屏user11播放的音乐是输出…...

文心一言 VS 讯飞星火 VS chatgpt (207)-- 算法导论15.4 4题
四、说明如何只使用表 c 中 2*min(m,n) 个表项及O(1)的额外空间来计算LCS的长度。然后说明如何只用 min(m,n) 个表项及O(1)的额外空间完成相同的工作。要写代码的时候,请用go语言。 文心一言: 在只使用 2 * min(m, n) 个表项和 …...

【论文笔记】Attention Is All You Need
【论文笔记】Attention Is All You Need 文章目录 【论文笔记】Attention Is All You NeedAbstract1 Introduction2 Background补充知识:软注意力 soft attention 和硬注意力 hard attention?补充知识:加法注意力机制和点乘注意力机制Extende…...
(亲测可用)Adobe Photoshop 2024下载与安装
背景介绍:Adobe Photoshop 2024 是全球最受欢迎的图像编辑软件之一,2024年的版本带来了一系列令人印象深刻的功能: AI增强的自动选择和蒙版工具:现在,用户可以更轻松地选择和处理复杂的图像元素。更多的3D渲染功能&…...

uniapp聊天记录本地存储(详细易懂)
目录 目录 1、通过websocket拿取数据 2、获取聊天数据 3、聊天信息存储 、更新 4、读取聊天记录 5、发送信息,信息获取 6、最终效果 1.聊天信息的存储格式 2、样式效果 写聊天项目,使用到了本地存储。需要把聊天信息保存在本地,实时获…...

Vue.js中的$nextTick
其实目前在我现有的开发经历中,我还没有实际运用过$nextTick,今天在看书时,学习到了这个东西,所以做个笔记记录一下。 一、$nextTick是什么? $nextTick 是 Vue提供的一个方法,用于在 DOM 更新之后执行回调…...

PCL2启动器微软账户登录皮肤显示问题的完整解决方案与实践指南
PCL2启动器微软账户登录皮肤显示问题的完整解决方案与实践指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL PCL2启动器作为一款功能强大的Minecraft第三方启动器&#…...

英雄联盟终极自动化工具:5分钟快速上手League Akari完整指南
英雄联盟终极自动化工具:5分钟快速上手League Akari完整指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为繁琐的游戏操作…...

如何快速掌握开源笔记工具:Xournal++ 终极使用指南
如何快速掌握开源笔记工具:Xournal 终极使用指南 【免费下载链接】xournalpp Xournal is a handwriting notetaking software with PDF annotation support. Written in C with GTK3, supporting Linux (e.g. Ubuntu, Debian, Arch, SUSE), macOS and Windows 10. S…...

Oracle误操作先别慌:Flashback、UNDO、回收站、Redo 与归档日志一次讲清楚 2026-05-24
1、背景说明本文整理 Oracle 生产环境中误操作恢复相关的核心知识点,包括:Flashback Database Flashback Query UNDO Recycle Bin FRA 快速恢复区 Redo Archived Redo Log 归档日志适用于 Oracle 单实例、RAC,以及 CDB/PDB 多租户环境。在 CD…...

AMD Ryzen硬件调试神器:5分钟掌握SMU Debug Tool核心技巧
AMD Ryzen硬件调试神器:5分钟掌握SMU Debug Tool核心技巧 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:/…...
)
从Python开发者视角,5分钟上手洛书编程语言(解释器1.7.0版)
从Python开发者视角,5分钟上手洛书编程语言(解释器1.7.0版)如果你已经熟悉Python,那么学习洛书编程语言会是一个有趣的体验。洛书作为一门支持中英文关键字的解释型语言,在设计哲学和语法细节上与Python有着诸多不同。…...

机器学习辅助第一性原理:高精度计算电化学氧化还原电位
1. 项目概述:当机器学习遇上第一性原理,破解电化学模拟的精度瓶颈在电化学、材料科学和计算化学的交叉领域,预测一个分子或离子在溶液中的氧化还原电位,就像试图在暴风雨中测量一滴雨滴的精确落点。这个数值,直接决定了…...

企业级MCP Server OAuth授权接入的七层防御实践
1. 这不是又一篇“OAuth流程图”——企业级MCP Server为什么必须自己实现授权接入你有没有遇到过这样的场景:公司新上线的内部运维平台(我们暂且叫它MCP,即Monitoring & Control Platform)需要对接钉钉、飞书或企业微信的组织…...

机器学习赋能非结构网格CFD:GNN、PINN与降阶建模实战
1. 项目概述:机器学习如何重塑非结构网格CFD 在计算流体力学(CFD)领域,非结构网格是处理复杂几何形状的“瑞士军刀”。与规则排列的结构化网格不同,非结构网格由不规则分布的节点和单元(如三角形、四面体&a…...

Arm嵌入式工具链全解析:从获取到优化
1. Arm嵌入式工具链概述Arm Toolchain for Embedded是Arm公司为嵌入式系统开发提供的一套完整工具链集合,包含编译器、调试器、链接器等核心组件。作为嵌入式开发领域的标准工具链,它支持从Cortex-M系列微控制器到Cortex-A系列应用处理器的全系列Arm架构…...