从0开始学习NEON(1)
1、前言
在上个博客中对NEON有了基础的了解,本文将针对一个图像下采样的例子对NEON进行学习。
学习链接:CPU优化技术 - NEON 开发进阶
上文链接:https://blog.csdn.net/weixin_42108183/article/details/136412104
2、第一个例子
现在有一张图片,需要对UV通道的数据进行下采样,对于同种类型的数据,相邻的4个元素求和并求均值。示意图如下图所示:

假定图像数据的宽为16的整数倍,如果使用c++代码,可以写出下面的代码:
void DownscaleUv(uint8_t *src, uint8_t *dst, int32_t src_stride, int32_t dst_width, int32_t dst_height, int32_t dst_stride)
{//遍历每一行的数据for (int32_t j = 0; j < dst_height; j++){ // 偶数行起始位置,uint8_t *src_ptr0 = src + src_stride * j * 2;// 奇数行起始位置uint8_t *src_ptr1 = src_ptr0 + src_stride;// 存储起始位置uint8_t *dst_ptr = dst + dst_stride * j;// 没一次循环计算没for (int32_t i = 0; i < dst_width; i += 2){// U通道 (u1 + u2 + u3 + u4) / 4dst_ptr[i] = (src_ptr0[i * 2] + src_ptr0[i * 2 + 2] +src_ptr1[i * 2] + src_ptr1[i * 2 + 2]) / 4;// V通道 (v1 + v2 + v3 + v4) / 4dst_ptr[i + 1] = (src_ptr0[i * 2 + 1] + src_ptr0[i * 2 + 3] +src_ptr1[i * 2 + 1] + src_ptr1[i * 2 + 3]) / 4;}}
}
通过学习向量化编程,我们可知,数据的计算可以利用单指令多数据的方式进行加速,例如上面的例子中的内层循环,下面就使用NEON来试试吧。
3、第2个例子
为了进行向量化加速,首先需要将UV数据分离,将UV数据分离的操作在NEON中很容易进行, 使用vld2交织加载或者储存即可。对于每一行的数据,交织加载的示意图如下。

交织加载的基本原理是按照间隔挑选数据。交织加载的例子如下所示:
void DownscaleUvNeon()
{vector<uint8_t> data; // UVUVUVUVUV...for(int i=0;i<32;i++){data.push_back(i);}// uint8_t *src_ptr0 = (uint8_t *)data.data(); // load 第一行的数据uint8x16x2_t src;src = vld2q_u8(src_ptr0); // 交织读取 16 * 2 的数据,需要两个q寄存器。auto a = src_odd.val[0]; // 一行的U数据vector<uint8_t> show_data(16);vst1q_u8 (show_data.data(),a); // 将U数据顺序储存到内存中// 打印for(auto n : show_data){cout << static_cast<int>(n) << endl; // 0,2,4,6,...}
}
4、第3个例子
对于下UV数据采样来说,在偶数行进行上面的交织加载,再在奇数行上进行同样的操作。奇数行和偶数行相应的数据进行相加再求平均,即可得到最后的结果。代码实现如下:
#include <arm_neon.h>
void DownscaleUvNeon(uint8_t *src, uint8_t *dst, int32_t src_width, int32_t src_stride, int32_t dst_width, int32_t dst_height, int32_t dst_stride)
{//用于加载偶数行的源数据,2组每组16个u8类型数据,(16 * 8) * 2 = 128 * 128, 因此需要两个q寄存器。 uint8x16x2_t v8_src0;//用于加载奇数行的源数据uint8x16x2_t v8_src1;//目的数据变量,需要一个Q寄存器uint8x8x2_t v8_dst;//目前只处理16整数倍部分的结果int32_t dst_width_align = dst_width & (-16); // dst_width & (-16),最大能够整除16的数。//向量化剩余的部分需要单独处理int32_t remain = dst_width & 15;int32_t i = 0;//外层高度循环,逐行处理for (int32_t j = 0; j < dst_height; j++){//偶数行源数据地址uint8_t *src_ptr0 = src + src_stride * j * 2;//奇数行源数据地址uint8_t *src_ptr1 = src_ptr0 + src_stride;//目的数据指针uint8_t *dst_ptr = dst + dst_stride * j;//内层循环,一次16个u8结果输出for (i = 0; i < dst_width_align; i += 16){//提取数据,进行UV分离v8_src0 = vld2q_u8(src_ptr0); src_ptr0 += 32; // 偶数行进入下一个stridev8_src1 = vld2q_u8(src_ptr1);src_ptr1 += 32; // 奇数行行进入下一个stride//水平两个数据相加uint16x8_t v16_u_sum0 = vpaddlq_u8(v8_src0.val[0]);uint16x8_t v16_v_sum0 = vpaddlq_u8(v8_src0.val[1]);uint16x8_t v16_u_sum1 = vpaddlq_u8(v8_src1.val[0]);uint16x8_t v16_v_sum1 = vpaddlq_u8(v8_src1.val[1]);//上下两个数据相加,之后求均值v8_dst.val[0] = vshrn_n_u16(vaddq_u16(v16_u_sum0, v16_u_sum1), 2);v8_dst.val[1] = vshrn_n_u16(vaddq_u16(v16_v_sum0, v16_v_sum1), 2);//UV通道结果交织存储vst2_u8(dst_ptr, v8_dst);dst_ptr += 16;}//process leftovers......}
}
5、第4个例子
当图像的宽度不是16的整数倍,需要考虑结尾数据处理,按照链接里面的例子,可以分为以下几种。
1、 padding
也就是将数据补齐到想要的长度,如下图所示,比如我这里需要操作 uint8x8_t的数据,但是我的数据长度只有5,可以将数据的长度填充至8。

2、Overlap
也就是重复利用其中的某些数据,在不填充其他数据的情况下进行,如下图所示,当需要利用uint8x4_t来对下面的数据进行计算时,可以先将04加载到寄存器上,再将36加载到寄存器上操作。

常用第二种方法对结尾数据进行处理,那么图像下采样的数据代码可以写成:
#include <arm_neon.h>void DownscaleUvNeon(uint8_t *src, uint8_t *dst, int32_t src_width, int32_t src_stride, int32_t dst_width, int32_t dst_height, int32_t dst_stride)
{uint8x16x2_t v8_src0;uint8x16x2_t v8_src1;uint8x8x2_t v8_dst;int32_t dst_width_align = dst_width & (-16); // 最大能够整除16的数。int32_t remain = dst_width & 15; // 需要剩余处理的数据长度int32_t i = 0;for (int32_t j = 0; j < dst_height; j++){uint8_t *src_ptr0 = src + src_stride * j * 2;uint8_t *src_ptr1 = src_ptr0 + src_stride;uint8_t *dst_ptr = dst + dst_stride * j;// 处理完宽度为16的整数倍数据了for (i = 0; i < dst_width_align; i += 16){v8_src0 = vld2q_u8(src_ptr0);src_ptr0 += 32;v8_src1 = vld2q_u8(src_ptr1);src_ptr1 += 32;uint16x8_t v16_u_sum0 = vpaddlq_u8(v8_src0.val[0]);uint16x8_t v16_v_sum0 = vpaddlq_u8(v8_src0.val[1]);uint16x8_t v16_u_sum1 = vpaddlq_u8(v8_src1.val[0]);uint16x8_t v16_v_sum1 = vpaddlq_u8(v8_src1.val[1]);v8_dst.val[0] = vshrn_n_u16(vaddq_u16(v16_u_sum0, v16_u_sum1), 2);v8_dst.val[1] = vshrn_n_u16(vaddq_u16(v16_v_sum0, v16_v_sum1), 2);vst2_u8(dst_ptr, v8_dst);dst_ptr += 16;}// process leftover// remain 剩余需要处理的数据长度if (remain > 0){// 从后往前回退一次向量计算需要的数据长度// 有部分数据是之前处理过的,这部分的数据在这里重复计算一次src_ptr0 = src + src_stride * (j * 2) + src_width - 32; src_ptr1 = src_ptr0 + src_stride;dst_ptr = dst + dst_stride * j + dst_width - 16;v8_src0 = vld2q_u8(src_ptr0);v8_src1 = vld2q_u8(src_ptr1);uint16x8_t v16_u_sum0 = vpaddlq_u8(v8_src0.val[0]);uint16x8_t v16_v_sum0 = vpaddlq_u8(v8_src0.val[1]);uint16x8_t v16_u_sum1 = vpaddlq_u8(v8_src1.val[0]);uint16x8_t v16_v_sum1 = vpaddlq_u8(v8_src1.val[1]);v8_dst.val[0] = vshrn_n_u16(vaddq_u16(v16_u_sum0, v16_u_sum1), 2);v8_dst.val[1] = vshrn_n_u16(vaddq_u16(v16_v_sum0, v16_v_sum1), 2);vst2_u8(dst_ptr, v8_dst);}}
}
3、 single
将剩余的元素单独处理,就是将剩余的元素利用NEON的只加载一个元素的功能,不推荐使用,因为这里又可能for循环多次。
4、将剩余的元素当作标量处理
也就是将剩下的元素直接使用c语言编程的方式进行计算。
void DownscaleUvNeonScalar(uint8_t *src, uint8_t *dst, int32_t src_width, int32_t src_stride, int32_t dst_width, int32_t dst_height, int32_t dst_stride)
{uint8x16x2_t v8_src0;uint8x16x2_t v8_src1;uint8x8x2_t v8_dst;int32_t dst_width_align = dst_width & (-16);int32_t remain = dst_width & 15;int32_t i = 0;for (int32_t j = 0; j < dst_height; j++){uint8_t *src_ptr0 = src + src_stride * j * 2;uint8_t *src_ptr1 = src_ptr0 + src_stride;uint8_t *dst_ptr = dst + dst_stride * j;for (i = 0; i < dst_width_align; i += 16) // 16 items output at one time{v8_src0 = vld2q_u8(src_ptr0);src_ptr0 += 32;v8_src1 = vld2q_u8(src_ptr1);src_ptr1 += 32;uint16x8_t v16_u_sum0 = vpaddlq_u8(v8_src0.val[0]);uint16x8_t v16_v_sum0 = vpaddlq_u8(v8_src0.val[1]);uint16x8_t v16_u_sum1 = vpaddlq_u8(v8_src1.val[0]);uint16x8_t v16_v_sum1 = vpaddlq_u8(v8_src1.val[1]);v8_dst.val[0] = vshrn_n_u16(vaddq_u16(v16_u_sum0, v16_u_sum1), 2);v8_dst.val[1] = vshrn_n_u16(vaddq_u16(v16_v_sum0, v16_v_sum1), 2);vst2_u8(dst_ptr, v8_dst);dst_ptr += 16;}//process leftoversrc_ptr0 = src + src_stride * j * 2;src_ptr1 = src_ptr0 + src_stride;dst_ptr = dst + dst_stride * j;for (int32_t i = dst_width_align; i < dst_width; i += 2){dst_ptr[i] = (src_ptr0[i * 2] + src_ptr0[i * 2 + 2] +src_ptr1[i * 2] + src_ptr1[i * 2 + 2]) / 4;dst_ptr[i + 1] = (src_ptr0[i * 2 + 1] + src_ptr0[i * 2 + 3] +src_ptr1[i * 2 + 1] + src_ptr1[i * 2 + 3]) / 4;}}
}
6、总结
本次学习中通过一个下采样的例子学习的NEON编程过程中的优势以及将要面临的问题,主要是剩余数据处理的方式,后面将继续深入学习。
/ 4;
dst_ptr[i + 1] = (src_ptr0[i * 2 + 1] + src_ptr0[i * 2 + 3] +src_ptr1[i * 2 + 1] + src_ptr1[i * 2 + 3]) / 4;}
}
}
#### 6、总结本次学习中通过一个下采样的例子学习的NEON编程过程中的优势以及将要面临的问题,主要是剩余数据处理的方式,后面将继续深入学习。
相关文章:
从0开始学习NEON(1)
1、前言 在上个博客中对NEON有了基础的了解,本文将针对一个图像下采样的例子对NEON进行学习。 学习链接:CPU优化技术 - NEON 开发进阶 上文链接:https://blog.csdn.net/weixin_42108183/article/details/136412104 2、第一个例子 现在有一张图片,需…...
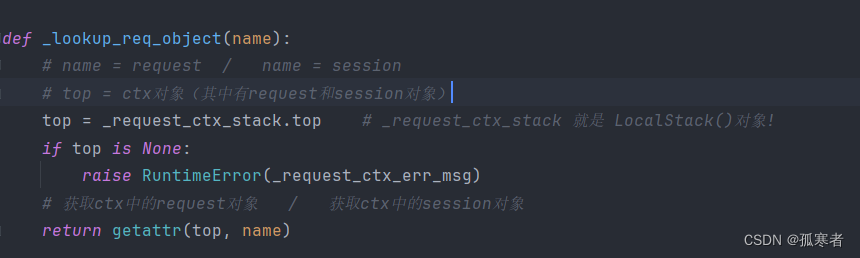
(二十三)Flask之高频面试点
目录: 每篇前言:Q1:为什么把request和session放在一起?Q2:Local对象的作用?Q3::LocalStack对象的作用?Q4:一个运行中的Flask应用程序分别包括几个Local/LocalStack&#…...
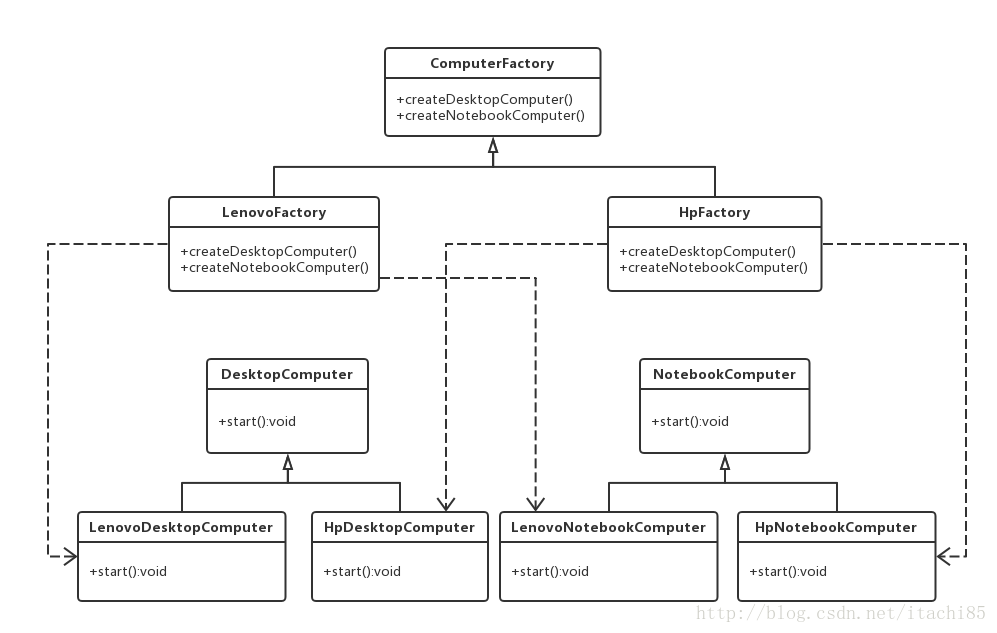
设计模式(十三)抽象工厂模式
请直接看原文:设计模式(十三)抽象工厂模式_抽象工厂模式告诉我们,要针对接口而不是实现进行设计。( )-CSDN博客 -------------------------------------------------------------------------------------------------------------------------------- …...

HTTP Cookie 你了解多少?
Cookie是什么? 先给大家举个例子,F12 打开浏览器的页面之后,我们能在 Response Headers 的字段里面看到一个header 叫做 Set-Cookie,如下所示 图中包含的 Set-Cookie 为 Set-Cookie:uuid_tt_dd10_20293537580-1709432565344-232…...

【QT+QGIS跨平台编译】之五十六:【QGIS_CORE跨平台编译】—【qgsmeshcalclexer.cpp生成】
文章目录 一、Flex二、生成来源三、构建过程一、Flex Flex (fast lexical analyser generator) 是 Lex 的另一个替代品。它经常和自由软件 Bison 语法分析器生成器 一起使用。Flex 最初由 Vern Paxson 于 1987 年用 C 语言写成。 “flex 是一个生成扫描器的工具,能够识别文本中…...

ar时间序列
AR时间序列模型(AutoRegressive Time Series Model)是一种用于分析和预测时间序列数据的统计模型。该模型假设未来的观测值与过去的观测值相关,且该相关性可以通过线性回归来描述。 AR模型的基本思想是将当前时刻的观测值表示为过去几个时刻的…...

Android 14 AAOS audio
文章目录 乘客音频投放到主音频区动态路由配置controlhal实现的具体流程control hal AudioGain的callbackAudioModuleChange变化的通知 乘客音频投放到主音频区 场景: 是将乘客区的Media 属性的数据通过主屏区的设备进行播放。具体而言 在副屏user11播放的音乐是输出…...

文心一言 VS 讯飞星火 VS chatgpt (207)-- 算法导论15.4 4题
四、说明如何只使用表 c 中 2*min(m,n) 个表项及O(1)的额外空间来计算LCS的长度。然后说明如何只用 min(m,n) 个表项及O(1)的额外空间完成相同的工作。要写代码的时候,请用go语言。 文心一言: 在只使用 2 * min(m, n) 个表项和 …...

【论文笔记】Attention Is All You Need
【论文笔记】Attention Is All You Need 文章目录 【论文笔记】Attention Is All You NeedAbstract1 Introduction2 Background补充知识:软注意力 soft attention 和硬注意力 hard attention?补充知识:加法注意力机制和点乘注意力机制Extende…...
(亲测可用)Adobe Photoshop 2024下载与安装
背景介绍:Adobe Photoshop 2024 是全球最受欢迎的图像编辑软件之一,2024年的版本带来了一系列令人印象深刻的功能: AI增强的自动选择和蒙版工具:现在,用户可以更轻松地选择和处理复杂的图像元素。更多的3D渲染功能&…...

uniapp聊天记录本地存储(详细易懂)
目录 目录 1、通过websocket拿取数据 2、获取聊天数据 3、聊天信息存储 、更新 4、读取聊天记录 5、发送信息,信息获取 6、最终效果 1.聊天信息的存储格式 2、样式效果 写聊天项目,使用到了本地存储。需要把聊天信息保存在本地,实时获…...

Vue.js中的$nextTick
其实目前在我现有的开发经历中,我还没有实际运用过$nextTick,今天在看书时,学习到了这个东西,所以做个笔记记录一下。 一、$nextTick是什么? $nextTick 是 Vue提供的一个方法,用于在 DOM 更新之后执行回调…...
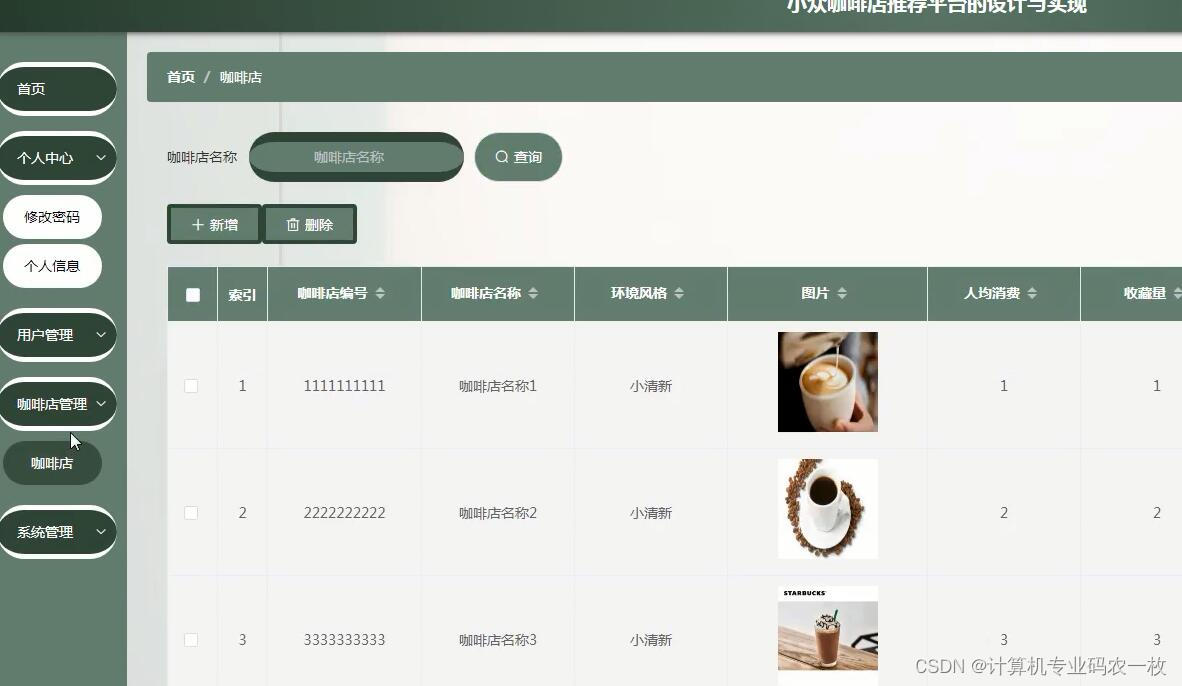
python+mysql咖啡店推荐系统django+vue
(1).研究的基本内容 系统的角色分为: 1.管理员 2.会员 3.非会员 角色不同,权限也不相同 技术栈 后端:python 前端:vue.jselementui 框架:django/flask Python版本:python3.7 数据库:mysql5.7…...
综合实验nginx+nfs+kpa
综合实验 实验目的: 静态资源和动态资源分别存放在远端存储NFS上,NFS上数据实现实时备份,用户通过负载访问后端的web服务。实现ngixn负载高可用,当keepalived master宕机,vip能自动跳转到备用节点 实验环境ÿ…...
springboot197基于springboot的毕业设计系统的开发
简介 【毕设源码推荐 javaweb 项目】基于springbootvue 的毕业设计系统的开发 适用于计算机类毕业设计,课程设计参考与学习用途。仅供学习参考, 不得用于商业或者非法用途,否则,一切后果请用户自负。 看运行截图看 第五章 第四章 …...

group by报错
# 报错:[42000][1055] Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column base.biz_org_rep.ID which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_modeonly_full_grou…...

3、云原生安全之falco的部署
文章目录 1、helm安装2、拉去镜像失败与解决3、安装faclo4、安装nfs服务器,配置k8s的持久卷4.1、创建nfs服务器,4.2、部署master节点(nsf服务的客户端)4.3、pv与pvc4.4、假设pv和pvc的配置文件出错了5、安装falcosidekick可视化(建议跳过,直接使用6)6、安装faclo与falco…...
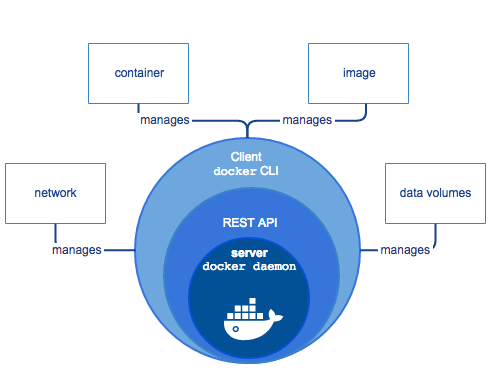
Docker架构概述
Docker是基于Go语言实现的开源容器项目,能够把开发的应用程序自动部署到容器的开源的应用容器引擎。Docker的构想是要实现"Build, Ship and Run Any App, Anywhere",即通过对应用的封装(Packaging)、分发(Distribution)、部署(Deployment)、运…...
安装 node 错误的配置环境变量之后使用 npm 报错
安装 node 错误的配置环境变量之后使用 npm 报错 node:internal/modules/cjs/loader:1147 throw err; ^ Error: Cannot find module ‘F:\ACodeTools\Node\node_modules\npm\bin\node_modules\npm\bin\npm-cli.js’ at Module._resolveFilename (node:internal/modules/cjs/loa…...

Matlab 最小二乘插值(曲线拟合)
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 在多项式插值时,当数据点个数较多时,插值会导致多项式曲线阶数过高,带来不稳定因素。因此我们可以通过固定幂基函数的最高次数 m(m < n),来对我们要拟合的曲线进行降阶。之前的函数形式就可以变为: 二、实现…...

如何快速掌握tsMuxer:视频无损封装的终极指南
如何快速掌握tsMuxer:视频无损封装的终极指南 【免费下载链接】tsMuxer tsMuxer is a transport stream muxer for remuxing/muxing elementary streams, EVO/VOB/MPG, MKV/MKA, MP4/MOV, TS, M2TS to TS to M2TS. Supported video codecs H.264/AVC, H.265/HEVC, V…...

NVIDIA显卡终极色彩校准指南:novideo_srgb让广色域显示器回归真实色彩
NVIDIA显卡终极色彩校准指南:novideo_srgb让广色域显示器回归真实色彩 【免费下载链接】novideo_srgb Calibrate monitors to sRGB or other color spaces on NVIDIA GPUs, based on EDID data or ICC profiles 项目地址: https://gitcode.com/gh_mirrors/no/novi…...

告别卡顿与黑边:D2DX让你的《暗黑破坏神2》在现代PC上完美重生
告别卡顿与黑边:D2DX让你的《暗黑破坏神2》在现代PC上完美重生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 你…...

FigmaCN:3分钟破解设计师的语言障碍,工作效率提升40%的秘密武器
FigmaCN:3分钟破解设计师的语言障碍,工作效率提升40%的秘密武器 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?每次…...

联想刃7000K BIOS高级配置优化指南:解锁隐藏参数设置与性能调优
联想刃7000K BIOS高级配置优化指南:解锁隐藏参数设置与性能调优 【免费下载链接】Lenovo-7000k-Unlock-BIOS Lenovo联想刃7000k2021-3060版解锁BIOS隐藏选项并提升为Admin权限 项目地址: https://gitcode.com/gh_mirrors/le/Lenovo-7000k-Unlock-BIOS 本文详…...

Armv8-R内存一致性模型解析与Cortex-R82实践
1. Cortex-R82/R82AE内存一致性解析:架构师视角的深度指南 在实时计算领域,内存一致性模型直接影响着多核系统的确定性和性能表现。作为Armv8-R架构的旗舰处理器,Cortex-R82/R82AE集群通过精细的内存属性控制机制,为汽车电子、工业…...

百度网盘直链解析:告别限速的Python神器实战指南
百度网盘直链解析:告别限速的Python神器实战指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾经面对百度网盘几十KB的下载速度感到绝望?当你…...

WeChatMsg:如何将微信聊天记录转化为永久数字资产
WeChatMsg:如何将微信聊天记录转化为永久数字资产 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChatMsg…...
”)
再论观点“C++是否应避免使用普通指针,而使用智能指针(包括shared,unique,weak)”
再论观点“C是否应避免使用普通指针,而使用智能指针(包括shared,unique,weak)” PS:笔者这次投稿的问题是:https://www.zhihu.com/question/319277442。老规矩,顺手投稿的问题&…...

大语言模型驱动的定性研究编码自动化:GATOS工作流实践指南
1. 项目概述:当大语言模型遇见定性研究编码如果你做过定性研究,比如分析几百份开放式问卷、访谈转录稿,或者处理海量的用户反馈,你肯定对“编码”这个环节又爱又恨。爱的是,它能将杂乱无章的文本转化为结构化的见解&am…...