大数据经典面试例题
程序员的金三银四求职宝典
随着春天的脚步渐近,对于许多程序员来说,一年中最繁忙、最重要的面试季节也随之而来。金三银四,即三月和四月,被广大程序员视为求职的黄金时期。在这两个月里,各大公司纷纷开放招聘,求职者们则通过一轮又一轮的面试,力争心仪的职位。而如何在这关键的时期脱颖而出,成为每个求职者关注的焦点。
接下来给各位即将进行面试的求职者一些经典的大数据面试例题
1.请简述你对大数据的特点的理解
大数据特点总的来说就五个字: 大多值快信
数据体量大, 种类,来源多样化, 价值密度低, 速度快, 数据的质量高(准确性,可信赖度)
2.请简述你对分布式 和 集群的理解
分布式: 多台机器做不同的事情, 然后组成1个整体.
集群: 多台机器做相同的事情.
3.请简述你对HDFS架构的理解
namenode:主节点
1.管理整个HDFS集群
2.维护和管理元数据
SecondaryNameNode:辅助节点
辅助namenode管理元数据的
datanode:从节点
1.维护和管理源文件
2.负责数据的读,写操作
3.定时向namenode报活
4.请简述HDFS特点
HDFS文件系统可存储超大文件,时效性稍差。
HDFS具有硬件故障检测和自动快速恢复功能。
HDFS为数据存储提供很强的扩展能力。
HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改。
HDFS可在普通廉价的机器上运行。
5.请简述你对Yarn架构的理解
ResourceManager:主节点
1.负责任务的接收
2.负责资源的调度和分配
nodemanager:从节点
负责接收并执行ResourceManager分配过来的计算任务
6.请简述namenode是如何管理datanode的
心跳机制:
1.datanode会定时3秒向namenode发送心跳包,告知namenode我还活着
2.如果超过一定时间630秒,namenode没有收到datanode的心跳包,就会认为它宕机了,此时就会将该datanode的块信息交由给其他活跃的datanode来存储
3.所有的datanode会定时6小时,向namenode汇报一次自己完整的块信息,让namenode校验更新
负载均衡:
namenode会保证所有的datanode的资源使用率尽量保持一致
副本机制:
可以提高容错率,默认的副本数是3
如果当前副本总数>默认的副本数,namenode会自动删除某个副本
如果当前副本总数<默认的副本数,namenode会自动增加该副本
如果当前活跃的机器总数<默认的副本数,就会强制进入到安全模式,在安全模式下只能读不能写
7.请简述你对Hive架构的理解
Hive的客户端
SQL解析器: 解析SQL语法的, 就将其转成MR任务
元数据管理服务: 维护和管理元数据的, 且要能存储元数据
8.数据库 和 数据仓库 之间的区别是什么
OLTP: 数据库
面向事务,采集数据,操作的是在线数据(实时),增删改查,数据量相对较小,对数据的安全性(事务性),时效性要求相对较高
OLAP: 数据仓库
面向主题,分析数据,操作的是离线数据(历史),查, 数据量相对较大,对数据的安全性(事务性),时效性要求相对较低
9.分区表和分桶表的区别是什么
不同点:
1.作用不同
分区 = 分文件夹
分桶 = 分文件
2.字段要求不同
分区字段必须是表中没有的字段
分桶字段必须是表中已有的字段
3.本质不同
分区 = 避免全表扫描,降低扫描次数,提高查询效率,分文件夹也便于维护管理
分桶 = 减少join次数,提高查询效率,另一个角度是:方便我们进行数据采样
相同点
殊途同归,最终目的都是为了提高查询效率
10.内部表和外部表的区别是什么
1. 建表格式不同.
内部表: 直接创建即可, 默认就是内部表.
外部表: 建表是需要加 external关键字.
2. 权限不同, 是否会删除源文件.
内部表: 也叫受管理表, 删除内部表时, 不仅会删除元数据(Hive中查不到了), 还会删除源文件(HDFS也查不到了)
外部表: 只会删除元数据(Hive中查不到了), 不会删除源文件(HDFS中还在)
11.请简述你对Hive调优的理解?
1. 改硬件.
2. 开启或者增大某些设置(配置). 负载均衡, 严格模式(禁用低效SQL), 动态分区数...
3. 关闭或者减小某些设置(配置). 严格模式(动态分区), 推测执行...
4. 减少IO传输. Input(输入)/Output(输出), 列存储orc, 压缩协议snappy, join优化
12.SecondaryNameNode是如何辅助namenode管理元数据的
1. SecondaryNameNode会间隔60s(秒), 询问一次namenode, edits文件是否满足了阈值(1个小时, 或者100W次)
2. 如果满足条件, 就通知namenode创建新的Edits文件, 继续往里写入元数据信息.
3. 根据http协议, 从namenode上把要合并的edits文件 和 fsimage文件拉取到本地进行合并.
4. 将合并后的新的FSImage文件推送给namenode, 用来替换之前旧的FsImage文件.
细节: 旧的FSImage文件并不会被立即删除, 而是达到一定的阈值后, 才会被删除.
5. 对于Edits文件和FSImage文件的合并操作, 是由SecondaryNameNode独立完成的, 全程namenode不参与.
6. 实际开发中, namenode 和 SecondaryNameNode会被部署到不同的服务器上, 配置几乎一致, 只不过SecondaryNameNode的内存要稍大一些.
7. 在紧急情况下, SecondaryNameNode可以用来恢复namenode的元数据
13.HDFS的读数据流程
1. Client(客户端)请求namenode, 上传文件.
2. namenode接收到客户端请求后, 会校验权限, 并告知客户端是否可以上传.
校验: 客户端是否有写的权限, 及文件是否存在.
3. 如果可以上传, 客户端会按照128MB(默认)对文件进行切块.
4. Client(客户端)再次请求namenode, 第1个Block块的上传位置.
5. namenode会根据副本机制, 负载均衡, 机架感知原理及网络拓扑图, 返回给客户端存储该Block块的DataNode列表.
例如: node1, node2, node3
6. Client(客户端)会先连接就近的datanode机器, 然后依次和其他的datanode进行连接, 形成: 传输管道(Pipeline)
7. 采用数据报包(DataPacket)的形式传输数据, 每个包的大小不超过: 64KB, 并建立: 反向应答机制(ACK机制)
8. 具体的上传动作: node1 -> node2 -> node3, ACK反向应答机制: node3 => node2 => node1
9. 重复上述的步骤, 直至第1个Block块上传完毕.
10. 返回第4步, 客户端(Client)重新请求第2个Block的上传位置, 重复上述动作, 直至所有的Block块传输完毕
14.HDFS的写数据流程
1. Client(客户端)请求namenode, 读取文件.
2. namenode校验该客户端是否有读权限, 及该文件是否存在, 校验成功后, 会返回给客户端该文件的块信息.
3. Client(客户端)会连接上述的机器(节点), 并行的从中读取块的数据.
4. Client(客户端)读取完毕后, 会循环namenode获取剩下所有的(或者部分的块信息), 并行读取, 直至所有数据读取完毕.
5. Client(客户端)根据Block块编号, 把多个Block块数据合并成最终文件即可.
15.简述MR执行流程
1. MR任务分为MapTask任务 和 ReduceTask任务两部分, 其中: MapTask任务负责: 分, ReduceTask任务负责: 合.
1个切片(默认128MB) = 1个MapTask任务 = 1个分好区, 排好序, 规好约的磁盘文件.
1个分区 = 1个ReduceTask任务 = 1个结果文件.
2. 先切片, 每个切片对应1个MapTask任务, 任务内部会逐行读取数据, 交由MapTask任务来处理.
3. MapTask对数据进行分区,排序,规约处理后, 会将数据放到1个 环形缓冲区中(默认大小: 100MB, 溢写比: 0.8), 达到80MB就会触发溢写线程.
4. 溢写线程会将环形缓冲区中的结果写到磁盘的小文件中, 当MapTask任务结束的时候, 会对所有的小文件(10个/次)合并, 形成1个大的磁盘文件.
1个切片(默认128MB) = 1个MapTask任务 = 1个分好区, 排好序, 规好约的磁盘文件.
5. ReduceTask任务会开启拷贝线程, 从上述的各个结果文件中, 拉取属于自己分区的数据, 进行: 分组, 统计, 聚合.
6. ReduceTask将处理后的结果, 写到 结果文件中.
1个分区 = 1个ReduceTask任务 = 1个结果文件.
相关文章:

大数据经典面试例题
程序员的金三银四求职宝典 随着春天的脚步渐近,对于许多程序员来说,一年中最繁忙、最重要的面试季节也随之而来。金三银四,即三月和四月,被广大程序员视为求职的黄金时期。在这两个月里,各大公司纷纷开放招聘…...

软考56-上午题-【数据库】-数据库设计步骤2
一、回顾:数据库设计的步骤 1、用户需求分析:手机用户需求,确定系统边界; 2、概念设计(概念结构设计):是抽象概念模型,较理想的是采用E-R方法。 3、逻辑设计:E-R图——…...
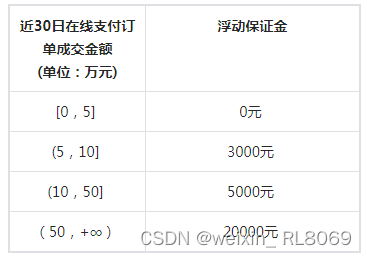
抖店入驻费用是多少?新手入驻都有哪些要求?2024费用明细!
我是电商珠珠 我做电商做了将近五年,做抖店做了三年多,期间还带着学员一起做店。 今天,就来给大家详细的讲一下在抖音开店,需要多少费用,最低需要投入多少。 1、营业执照200元左右 就拿个体店举例,在入…...

2024东南大学553复试真题及笔记
2023年真题知识点 引用指针 题目为 传递一个指针的引用做修改,输出指针指向的结果,但是指针被修改,结果就不一样了。 static 静态变量 类里面的静态成员变量,很简单的题目 for循环 看循环的内容输出字符串 try try catch捕…...
)
编程笔记 html5cssjs 096 JavaScript 前端开发(完结)
编程笔记 html5&css&js 096 JavaScript 前端开发 (完结) 一、前端开发二、范围三、价值四、在软件开发中地位总结 前端开发在软件开发生态系统中扮演着至关重要的角色。随着Web技术和移动互联网的发展,前端不再是简单的页面展示&…...
案例介绍:信息抽取技术在汽车销售与分销策略中的应用与实践
一、引言 在当今竞争激烈的汽车制造业中,成功的销售策略、市场营销和分销网络的构建是确保品牌立足市场的关键。作为一名经验丰富的项目经理,我曾领导一个专注于汽车销售和分销的项目,该项目深入挖掘市场数据,运用先进的信息抽取…...

几种常用的企业加密文件传输方式,最后一种更佳!
随着远程工作和云计算服务的广泛采用,企业必须实施有效的策略来保障敏感信息在传输过程中的安全性。本文将探讨企业在文件加密传输方面的几种常用策略,并重点介绍最后一种方式是如何利用其创新技术为企业提供数据传输的安全保障。 文件加密传输策略 企业…...

【全志D1-H 哪吒开发板】Debian系统安装调教和点灯指南
全志D1-H开发板【哪吒】使用Deabian系统入门 特别说明: 因为涉及到操作较多,博文可能会导致格式丢失 其中内容,会根据后续使用做优化调整 目录: 参考资料固件烧录启动调教点灯问题 〇、参考资料 官方资料 开发板-D1开发板【…...

Redis 8种基本数据类型及常用命令和数据类型的应用场景
小伙伴们好,欢迎关注,一起学习,无限进步 文章内容为学习的一些笔记及工作中遇到的一些问题 文章目录 Redis 五大数据类型keyStringListSetHashSorted Set 三种特殊类型Geospatial 地理位置HyperloglogBitmap Redis 五大数据类型 redis 官方网…...

JAVA内存模型与JVM内存结构
注意区分Java内存模型(Java Memory Model,简称JMM)与Jvm内存结构,前者与多线程相关,后者与JVM内部存储相关。本文会对两者进行简单介绍。 一、JAVA内存模型(JMM) 1. 概念 说来话长,由于在不同硬件厂商和…...

双导师的中国社科院与英国斯特灵大学创新与领导力博士
自1978年恢复高考之后,很长一段时间里我国的高校系统处于人才很匮乏的状态,那个时候很多高校招聘了大量硕士学历教师(其中很多人在留校后又读了在职博士),而且都是事业编制。那么接下来小编与中国社科院与英国斯特灵大…...

OpenXR 超详细的spec--API初始化介绍
3.API 初始化 3.1 Exported Functions 实现API loader的动态链接库(so/dll)必须export all core OpenXR API functions。然而application可以通过使用xrGetInstanceProcAddr()来获取指向extension函数的指针。 3.2 Function Pointers OpenXR所有函数的指针都可以通过函数xr…...
认识通讯协议——TCP/IP、UDP协议的区别,HTTP通讯协议的理解
目录 引出认识通讯协议1、TCP/IP协议,UDP协议的区别2、HTTP通讯协议的讲解 Redis冲冲冲——缓存三兄弟:缓存击穿、穿透、雪崩缓存击穿缓存穿透缓存雪崩 总结 引出 认识通讯协议——TCP/IP、UDP协议的区别,HTTP通讯协议的理解 认识通讯协议 …...

谈一谈工作中的前后端功能开发范围
在BS开发中,往往都是团队开发,分为前端和后端,往往经常会遇到此处功能是前端进行功能开发还是后端进行功能开发的讨论,本文以我自己的观点进行论述。 笔者的观点是: 功能实现的优先性:您强调,无…...

Kubernetes 学习总结(46)—— Pod 不停重启问题分析与解决
我们在做性能测试的时候,往往会发现我们的pod服务,频繁重启,通过kubectl get pods 命令,我们来逐步定位问题。 现象:running的pod,短时间内重启次数太多。 定位问题方法:查看pod日志 kubectl get event …...
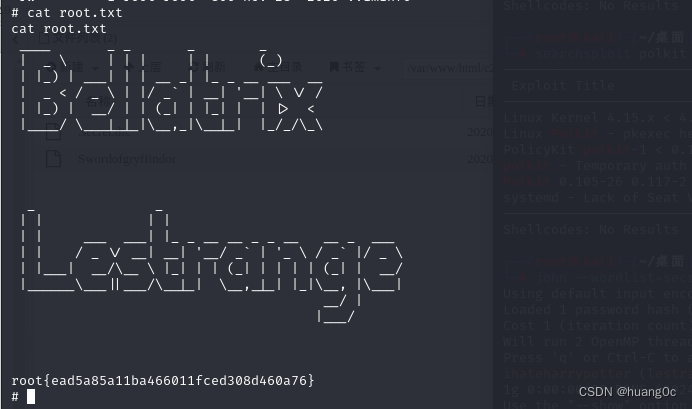
Vulnhub靶机:Bellatrix
一、介绍 运行环境:Virtualbox 攻击机:kali(10.0.2.4) 靶机:Bellatrix(10.0.2.9) 目标:获取靶机root权限和flag 靶机下载地址:https://www.vulnhub.com/entry/hogwa…...

深入探讨 AutoGPT:彻底改变游戏的自主 AI
原文地址:Deep Dive into AutoGPT: The Autonomous AI Revolutionizing the Game 2023 年 4 月 24 日 AutoGPT 是一个功能强大的工具,它通过 API 使用 GPT-4 和 GPT-3.5,通过将项目分解为子任务并在自动循环中使用互联网和其他工具来创建完…...

Java Web之网页开发基础复习
tomcat之网页开发基础复习 **声明** :HTML标准规范 </!doctype> <html> : 根标签 <head>: 头部标签 内含<title><meta><link><style> <body>: 主体 <body></body> html标签 单标签: <标签名 \> 双标…...
华容道问题求解第一部分_详细设计(一)之棋子和游戏类_初始化部分
按:因为自控力和能力的原因,这个其实是在和代码同时进行的。 主要 类 说明 这一层是整个项目的基础,将对未来的算法的效率产生重要影响。为了和界面隔离,以及自身逻辑的清晰,下面的两个类是必须的,棋子类…...

【框架】Spring 框架重点解析
Spring 框架重点解析 1. Spring 框架中的单例 bean 是线程安全的吗? 不是线程安全的 Spring 框架中有一个 Scope 注解,默认的值是 singleton,即单例的;因为一般在 Spring 的 bean 对象都是无状态的(在生命周期中不被…...

【Appium 系列】第20节-测试项目结构设计 — 从脚本到工程
对应代码:配套代码/test/ 完整目录结构说明:本节讲解如何组织一个中大型 Appium 测试项目,从目录结构到文件职责,从脚本到工程的演进。这节讲什么测试项目从小到大会经历三个阶段:阶段 1:脚本阶段test_logi…...
)
不止于安装:在Ubuntu上为Arduino IDE 2.x手动添加冷门芯片支持(以LGT8F328P为例)
不止于安装:在Ubuntu上为Arduino IDE 2.x手动添加冷门芯片支持(以LGT8F328P为例) 当你在Ubuntu上完成Arduino IDE 2.x的基础安装后,真正的挑战才刚刚开始。对于那些非官方支持的开发板,如LGT8F328P,标准的库…...

sdk-manager-plugin源码剖析:学习Gradle插件架构的完美案例 [特殊字符]
sdk-manager-plugin源码剖析:学习Gradle插件架构的完美案例 🚀 【免费下载链接】sdk-manager-plugin DEPRECATED Gradle plugin which downloads and manages your Android SDK. 项目地址: https://gitcode.com/gh_mirrors/sd/sdk-manager-plugin …...

【电路板】基于matlab模拟电路板激光加工中的热分布【含Matlab源码 15559期】
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

二刷hot100-226.翻转二叉树
还是用层序遍历,内存循环在将左右节点入队后,置换左右节点:/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this…...

3步掌握React Easy Crop:从零到精通的图像裁剪完整指南
3步掌握React Easy Crop:从零到精通的图像裁剪完整指南 【免费下载链接】react-easy-crop A React component to crop images/videos with easy interactions 项目地址: https://gitcode.com/gh_mirrors/re/react-easy-crop 你是否在为React应用中的图片裁剪…...

瑞芯微RV1126边缘AI开发套件实战:从模型部署到工业应用
1. 项目概述与核心价值最近几年,边缘计算和人工智能的结合,正在从实验室和云端大规模地走向我们身边的真实场景。无论是工厂里实时检测产品瑕疵的摄像头,还是社区里识别异常行为的安防设备,都离不开一个核心:一个能放在…...

从测试分类到缺陷管理
目录 1.多维测试分类:覆盖测试全场景 1.1 按测试目标分类 1.2 按执行方式分类 1.3 按测试方法分类 1.4 按测试阶段分类 1.5 按实施组织分类 2. 测试用例设计 2.1 用例设计万能公式 2.2 六大核心设计方法 3. 测试核心流程与 bug 管理 3.1 软件测试生命…...

Cursor Free VIP终极指南:5步实现AI编程助手永久免费使用
Cursor Free VIP终极指南:5步实现AI编程助手永久免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your …...

3步实现Adobe全家桶完整激活:终极破解方案详解
3步实现Adobe全家桶完整激活:终极破解方案详解 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP是一款专业的Adobe软件激活工具,能…...