python | 列表,元组,字符串,集合,字典
列表:
- 可以容纳任意数目不同类型的元素(支持我们学过的任意数据类型)
- 元素之间有先后顺序
- 用中括号包裹,每个元素用逗号隔开
例如:
students = ['林黛玉','薛宝钗','贾元春','贾探春','史湘云','妙玉','贾迎春','贾惜春','王熙凤','贾巧姐','李纨','秦可卿'
]列表可容纳任意个元素,当然也包括 0 个元素。这样的列表我们称为 空列表,只用一对中括号 [] 表示即可,中间不加逗号。
反向索引的数字和我们日常生活中的倒数数字是一样的,用 -1 表示倒数第一个,用 -2 表示倒数第二个。
正向索引 和 反向索引 (比如:students[-1])都是通过位置,查找对应值的方法
快速获取列表索引值的方法:使用
列表.index(元素内容)的形式
列表元素的修改:
通过 列表[索引] = 新值 的格式
# 第二个名字,索引为 1
students[1] = '贾宝玉'列表元素的添加:
在列表末尾添加一个元素:append() 方法会在列表末尾新增一个元素,同时列表长度加一
students.append('贾宝玉')在列表中间某个位置插入一个元素:insert() 方法
students.insert(9, '贾琏')列表元素的删除:
用列表的 pop() 方法,pop() 的功能是:返回列表指定位置的元素,并删除这个元素。 pop() 可以传入一个参数,表示要删除的元素的索引,如果不传入,就默认为最后一个元素的索引。
students.pop()可以使用更加便捷的 del 语句来操作列表,格式为:del 列表[索引]。
del students[0]通过 列表.remove(值) 的方式,我们可以在列表中找到 第一个 指定的值,然后将它删除。
students.remove('王熙凤')列表的分片:
列表分片用一对以冒号分隔的索引位置表示,格式为 列表[起始索引:结束索引]。比如要获取 students 中第三到第五个元素,也就是索引为 2,3,4 的元素,就要写成 students[2:5]。
on_duty = ['贾琏', '王熙凤', '林黛玉', '贾宝玉', '李纨', '薛宝钗', '妙玉']# 打印周一周二值日的人
print(on_duty[:2])# 打印周三到周五值日的人
print(on_duty[2:5])# 打印周末值日的人
print(on_duty[-2:])截取前三个元素,就写成
list[:3];而截取最后四个元素,就写成list[-4:];截取中间部分list[a:b],分片长度就是 b - a。
列表常用方法:
统计元素出现的次数:count() 方法可以统计元素在列表中出现的次数
students = ['林黛玉', '贾宝玉', '薛宝钗', '贾宝玉']
print(students.count('贾宝玉'))
# 输出:2排序:sort() 是一个很强大的方法,可以对列表内的元素进行排序。
str_list = ["lin", "jia", "xue"]
str_list.sort()
print(str_list)
# 输出:['jia', 'lin', 'xue']num_list = [4, 2, 1, 9]
num_list.sort()
print(num_list)
# 输出:[1, 2, 4, 9]
- 字符串列表的排序按照每个元素首字母的顺序来排序,比如 j 在 l 前面,l 在 x 前面,可以简单地按照 26 个字母顺序表即可;
- 数值列表的排序是按照数值大小从小到大进行排序,比如 1 比 2 小,所以 1 在 2 前面。
反转、复制和清空:reverse()、copy()、clear() 方法
# reverse() 方法:将列表顺序反转
students = ["林黛玉", "贾宝玉", "薛宝钗"]
students.reverse()
print(students)
# 输出:['薛宝钗', '贾宝玉', '林黛玉']# copy() 方法:复制一个同样的列表
students1 = ["林黛玉", "贾宝玉", "薛宝钗"]
students2 = students1.copy()
print(students2)
# 输出:['林黛玉', '贾宝玉', '薛宝钗']# clear() 方法:清空列表
students = ["林黛玉", "贾宝玉", "薛宝钗"]
students.clear()
print(students)
# 输出:[]列表的基本运算:
成员运算符 in:用来判断一个元素是否在一个列表中,格式为 元素 in 列表。这是一个布尔表达式,如果元素在列表中,结果为布尔值 True,反之为 False。
students = ['林黛玉','薛宝钗','贾元春','妙玉','贾惜春','王熙凤','秦可卿','贾宝玉'
]
miaoyu_in = '妙玉' in students
print(miaoyu_in)
# 输出:Truexiangyun_in = '史湘云' in students
print(xiangyun_in)
# 输出:False加法和乘法:
# 列表的加法
students = ['林黛玉', '薛宝钗', '贾元春', '贾探春', '史湘云', '妙玉', '贾迎春', '贾惜春', '王熙凤', '贾琏', '贾巧姐', '李纨', '秦可卿', '贾宝玉']parents = ['贾敬', '贾政', '王夫人', '贾赦', '邢夫人']meeting = students + parents# 打印 meeting 的结果,以及最终人数
print(meeting)
print('与会人数为', len(meeting), '人')
# 输出:
# ['林黛玉', '薛宝钗', '贾元春', '贾探春', '史湘云', '妙玉', '贾迎春', '贾惜春', '王熙凤', '贾琏', '贾巧姐', '李纨', '秦可卿', '贾宝玉', '贾敬', '贾政', '王夫人', '贾赦', '邢夫人']
# 与会人数为 19 人#列表的乘法
lag_behind = ['贾探春', '秦可卿', '贾惜春', '贾琏']
# 用乘法快速生成轮班表
recite_list = lag_behind * 5print(recite_list)
# 输出:['贾探春', '秦可卿', '贾惜春', '贾琏', '贾探春', '秦可卿', '贾惜春', '贾琏', '贾探春', '秦可卿', '贾惜春', '贾琏', '贾探春', '秦可卿', '贾惜春', '贾琏', '贾探春', '秦可卿', '贾惜春', '贾琏']列表的扩展操作:
zip() 函数:它的作用是将两个长度相同的列表合并起来,相同位置的元素会被一一组对,变成一个元组。结果返回一个组合好的打包对象,需要我们再用 list() 函数转换回列表。
midterm_rank = ['妙玉','薛宝钗','贾元春','王熙凤','林黛玉','贾巧姐','史湘云','贾迎春','贾宝玉','李纨','贾探春','秦可卿','贾惜春','贾琏'
]scores = [100, 92, 77, 85, 81, 90, 100, 86, 79, 93, 91, 96, 75, 84]# 将 scores 元素从低到高排列
scores.sort()# 倒转 scores 中的排列顺序
scores.reverse()print(scores)
# 输出:[100, 100, 96, 93, 92, 91, 90, 86, 85, 84, 81, 79, 77, 75]# 用 zip() 将两个列表合并
zipped = zip(midterm_rank, scores)# 将结果转换回列表后,赋值给 zipped_rank
zipped_rank = list(zipped)# 来看看结果
print(zipped_rank)
# 输出:[('妙玉', 100), ('薛宝钗', 100), ('贾元春', 96), ('王熙凤', 93), ('林黛玉', 92), ('贾巧姐', 91), ('史湘云', 90), ('贾迎春', 86), ('贾宝玉', 85), ('李纨', 84), ('贾探春', 81), ('秦可卿', 79), ('贾惜春', 77), ('贾琏', 75)]enumerate() 函数:“enumerate”单词本身意思是“枚举、数数”。所以对应的函数功能,就是一个一个地将列表中的元素数出来。它返回的是一个枚举对象,也需要我们用 list() 函数转换回列表。
# 枚举原排名表后,再转回列表的形式
rank_with_id = list(enumerate(midterm_rank))print(rank_with_id)
# 输出:[(0, '妙玉'), (1, '薛宝钗'), (2, '贾元春'), (3, '王熙凤'), (4, '林黛玉'), (5, '贾巧姐'), (6, '史湘云'), (7, '贾迎春'), (8, '贾宝玉'), (9, '李纨'), (10, '贾探春'), (11, '秦可卿'), (12, '贾惜春'), (13, '贾琏')]# enumerate()中这次有两个参数,一个为排名列表,一个为起始数字。
rank_with_ID = list(enumerate(midterm_rank, 1))print(rank_with_ID)
# 输出:[(1, '妙玉'), (2, '薛宝钗'), (3, '贾元春'), (4, '王熙凤'), (5, '林黛玉'), (6, '贾巧姐'), (7, '史湘云'), (8, '贾迎春'), (9, '贾宝玉'), (10, '李纨'), (11, '贾探春'), (12, '秦可卿'), (13, '贾惜春'), (14, '贾琏')]元组:
元组和列表非常相似。不同之处在于,外观上:列表是被方括号包裹起来的,而元组是被 圆括号 包裹起来的。本质上:列表里的元素可修改,元组里的元素是 不可以“增删改” 的。
还有一个微妙的地方要注意,就是只有一个元素的元组,在格式上与列表是不同的。仅一个元素 x 的列表写成 [x], 但仅一个元素的元组要在括号内多写个逗号:(x,)。
对于仅一个元素的元组,我们要特意加个逗号来声明:这是个元组。
single = (1,)
print(type(single))
# 输出:<class 'tuple'>元组不能用于增加、修改或删除语句。
由于查询与分片操作并不会改变数据,所以我们说的两种列表元素的查询方式以及分片操作,在元组中是可用的。列表运算符,元组也都支持,用
in查询元素是否在元组内;用+将两个元组叠加生成新元组;用*生成元素重复循环多次的新元组。
如果真的有特殊需求,需要修改元组中的元素:可以先用 list() 函数把元组转换成列表,相当于给数据“解锁”,将元素修改完毕后,再用 tuple() 函数转换回元组,相当于“重新上锁”。
students = ('林黛玉', '贾宝玉', '薛宝钗')# 用 list() 函数给数据“解锁”,生成一个相同元素的新列表
students_list = list(students)# 在新列表中修改元素
students_list[0] = '妙玉'# 两次给数据“上锁”
students = tuple(students_list)print(students)
# 输出:('妙玉', '贾宝玉', '薛宝钗')字符串:
Python 中的字符串是使用一对英文单引号(')或英文双引号(")包裹的任意文本。无论是用单引号还是用双引号,它俩的效果都是一样的,但需要保持前后引号的统一。
使用一对三引号(''' 或 """)来包裹多行字符串,三引号包裹的字符串和普通的字符串使用上没有区别,只是三引号支持多行字符串而已。
字符串拼接:
可以使用+或者*
str1 = '烦死了'
str2 = str1 + str1 + str1
print(str2)
# 输出:烦死了烦死了烦死了str11 = '烦死了'
str22 = str11 * 3 # 相当于 str11 + str11 + str11
print(str22)
# 输出:烦死了烦死了烦死了字符串格式化输出:
用+ 来拼接字符串:
def print_intro(name, age, city):intro = '我叫' + name + ',今年 ' + str(age) + ' 岁,来自' + city + '。'print(intro)print_intro('贝壳', 18, '世界各地')
# 输出:我叫贝壳,今年 18 岁,来自世界各地。提示:字符串类型和数字类型不能直接相加,需要用 str() 函数进行类型转换。
用字符串的格式化输出实现同样的功能:
def print_intro(name, age, city):intro = '我叫%s,今年 %d 岁,来自%s。' % (name, age, city)print(intro)print_intro('贝壳', 18, '世界各地')
# 输出:我叫贝壳,今年 18 岁,来自世界各地。提示:如果不太确定应该用什么占位符,%s 是万能的,它会把任何数据类型转换为字符串。
字符串索引:
str = 'Hello World'
print(str[6]) # 输出:W
print(str[-5]) # 输出:W字符串分片:
str = 'Hello World'
# 下面两个效果一样
print(str[6:]) # 输出:World
print(str[-5:]) # 输出:World
- 分片是半闭半开区间,即包含前面索引位置的元素,不包含后面索引位置的元素。比如:string[m:n] 获取的是字符串 string 中索引为 m 到 n-1 之间的元素(包括 m 和 n-1);
- 分片中前后索引的值是可以省略的,前索引省略默认为 0,后索引省略默认为序列长度。
字符串不可变性:
但字符串一旦创建后是不可改变的,这个属性和元组类似,通过索引来改变字符串中元素就会报错:
name = '张艺兴'
name[0] = '贾'
print(name)
# 报错:TypeError: 'str' does not support item assignment on line 2字符串的相关方法:
upper():用于将字符串中的小写字母转为大写字母。
'abcd'.upper() # 'ABCD'lower():用于将字符串中的大写字母转为小写字母。
'ABCD'.lower() # 'abcd'capitalize():用于将字符串的第一个字母变成大写,其他字母变小写。首字符如果是非字母则不变,其他字母变小写。
'ABCD'.capitalize() # 'Abcd'
'aBcD'.capitalize() # 'Abcd'
'1abcd'.capitalize() # '1abcd'
'1aBcD'.capitalize() # '1abcd'title():用于返回“标题化”的字符串——即所有单词的首字母转为大写,其余字母均为小写。注意:非字母后的第一个字母将转为大写字母。
'this is an example string'.title() # This Is An Example String
'5g is coming'.title() # 5G Is Comingswapcase():用于对字符串的大小写字母进行互相转换。
'abcd'.swapcase() # 'ABCD'
'aBcD'.swapcase() # 'AbCd'分割、组合与移除方法:
split():
用于通过指定分隔符对字符串进行分割。split() 方法有两个可选参数,第一个参数为分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。第二个参数为最大分割次数,默认为 -1,即不限次数。
'好 运 连 连'.split() # ['好', '运', '连', '连']
'好 运 连 连'.split(' ') # ['好', '运', '连', '连']
'好-运-连-连'.split('-') # ['好', '运', '连', '连']
'好运连连'.split('运连') # ['好', '连']
'好 运 连 连'.split(' ', 1) # ['好', '运 连 连']join():
用于将序列中的元素以指定的字符连接生成一个新的字符串。join() 方法接收一个序列(列表、元组、字符串等)作为参数,前面的字符串用于连接符。
# 列表
''.join(['好', '运', '连', '连']) # 好运连连
'-'.join(['好', '运', '连', '连']) # 好-运-连-连# 元组
'-'.join(('好', '运', '连', '连')) # 好-运-连-连# 字符串
'-'.join('好运连连') # 好-运-连-连strip():
用于移除字符串开头和结尾指定的字符(默认为空字符)或字符序列。当传入一个字符串时,会将传入字符串中每个字符依次移除。
'好运连连 '.strip() #'好运连连'
'~~好运连连~~'.strip('~') #'好运连连'
'~~好运~~连连~~'.strip('~') #'好运~~连连'
'_~_好运连连_~~'.strip('~_') #'好运连连'定位与替换方法:
count():
用于统计字符串中某个字符串出现的次数。第一个参数为要统计次数的字符串,后两个可选参数为在字符串搜索的开始与结束索引。
'aabbcccd'.count('a') # 2
'aabbcccd'.count('ab') # 1
'aabbcccd'.count('e') # 0'aabbcccd'.count('a', 2, 6) # 0
# 等同于 'bbcc'.count('a')'aabbcccd'.count('c', 2, 6) # 2
# 等同于 'bbcc'.count('c')find():
用于检测字符串中是否包含子字符串,如果包含子字符串返回第一次出现的索引值,否则返回 -1。第一个参数为要查找的子字符串,后两个可选参数为在字符串搜索的开始与结束索引。
'abc'.find('b') # 1
'abcabc'.find('b') # 1
'abcabc'.find('d') # -1
'abcbcdabc'.find('bcd') # 3
'abcabc'.find('b', 1, 2) # 1
'abcabc'.find('b', 2, 3) # -1replace():
用于将字符串中的指定字符串替换成别的字符串。第一个参数为被替换字符串,第二个参数为替换字符串,第三个可选参数为替换的最多次数,默认为无限次。
'abcd'.replace('b', 'e') # 'aecd'
'abbbcbd'.replace('b', 'e') # 'aeeeced'
'abbbcbd'.replace('bb', 'e') # 'aebcbd'
'abbbcbd'.replace('b', 'e', 2) # 'aeebcbd'格式化输出方法:
可以使用字符串的 format() 方法:
'我叫{},今年 {} 岁,来自{}'.format('贝壳', 18, '世界各地')
# 我叫贝壳,今年 18 岁,来自世界各地集合:
集合(set)是一个无序的不重复元素序列。
集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作。
可以使用大括号 { } 创建集合,元素之间用逗号 , 分隔, 或者也可以使用 set() 函数创建集合。
set1 = {1, 2, 3, 4} # 直接使用大括号创建集合
set2 = set() # 使用 set() 函数创建集合创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
添加元素:
s.add( x ):将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。
s.update( x ):x 可以有多个,用逗号分开。
set1={1,2,3,4}
set1.add(5)
print(set1) #{1, 2, 3, 4, 5}
set1.update({6,7})
print(set1) #{1, 2, 3, 4, 5, 6, 7}移除元素:
s.remove( x ):将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。
s.discard( x ):也是移除集合中的元素,且如果元素不存在,不会发生错误。
s.pop() :随机删除集合中的一个元素
set1={1,2,3,4}
set1.remove(3)
print(set1) #{1, 2, 4}
set1.discard(4)
print(set1) #{1, 2}
set1.pop()
print(set1) #{2}计算集合元素个数:
len(s):计算集合 s 元素个数。
set1={1,2,3,4}
print(len(set1)) #4清空集合:
s.clear():清空集合 s。
set1={1,2,3,4}
print(set1.clear()) #None字典:
字典 是由一对大括号({})包裹着的。和列表不同的是,字典的每个元素是 键值对
字典中的 键 需要是 唯一的,如果字典中有两个相同的 键,Python 只会保留后面那个。而 值 则没有限制,可以是任意类型的,也可以有相同的值。
scores = {'林黛玉': 95,'薛宝钗': 93,'贾宝玉': 78,'林黛玉': 78
}
print(scores)
# 输出:{'林黛玉': 78, '薛宝钗': 93, '贾宝玉': 78}字典的取值:
和列表类似,访问字典中的元素也使用方括号 []。不同的是,列表中括号内的是 索引,字典中括号内的是 键。
scores = {'林黛玉': 95,'薛宝钗': 93,'贾宝玉': 78
}
print(scores['林黛玉'])
# 输出:95字典元素的修改/添加/删除:
修改和添加都使用 字典名[键] = 值 的方式,如果 键 存在于字典中,就是修改,不存在就是添加。字典元素的删除和列表元素的删除一样也是使用 del 关键字进行删除。
scores = {'林黛玉': 95,'薛宝钗': 93,'贾宝玉': 78
}# 修改
scores['林黛玉'] = 90
print(scores)
# 输出:{'林黛玉': 90, '薛宝钗': 93, '贾宝玉': 78}# 添加
scores['袭人'] = 85
print(scores)
# 输出:{'林黛玉': 90, '薛宝钗': 93, '贾宝玉': 78, '袭人': 85}# 删除
del scores['林黛玉']
print(scores)
# 输出:{'薛宝钗': 93, '贾宝玉': 78, '袭人': 85}字典常用方法:
get():
将字典的键作为参数传入 get() 方法中,它就会帮我们查询字典中有没有这个键。如果存在的话,返回键对应的值;不存在的话,默认返回 None。
students = {'林黛玉': 95,'薛宝钗': 93,'贾宝玉': 78,'袭人': 85
}
print(students.get('林黛玉'))
# 输出:95
print(students.get('张艺兴'))
# 输出:Nonekeys():
keys() 方法则可以获取字典中所有的 键。
students = {'林黛玉': 95,'薛宝钗': 93,'贾宝玉': 78,'袭人': 85
}
names = students.keys()
print(names)
# 输出:dict_keys(['林黛玉', '薛宝钗', '贾宝玉', '袭人'])
print(type(names))
# 输出:<class 'dict_keys'>values():
与 keys() 方法相对应,我们可以通过 values() 方法获取字典中所有的 值。
students = {'林黛玉': 95,'薛宝钗': 93,'贾宝玉': 78,'袭人': 85
}
scores = students.values()
print(scores)
# 输出:dict_values([95, 93, 78, 85])
print(type(scores))
# 输出:<class 'dict_values'>
for score in scores:print(score)
# 输出:95 93 78 85items():
除了获取所有的键、值,我们也可以通过 items() 方法,一次性获取字典中所有的 键值对 ,其中每个键值对都是一个形如 (键, 值) 的元组。items() 方法返回的也是一个特殊类型,不可索引,可遍历。
students = {'林黛玉': 95,'薛宝钗': 93,'贾宝玉': 78,'袭人': 85
}
student = students.items()
print(student)
# 输出:dict_items([('林黛玉', 95), ('薛宝钗', 93), ('贾宝玉', 78), ('袭人', 85)])
print(type(items))
# 输出:<class 'dict_items'># 以 name, score 遍历 students 中键值对
for name, score in students.items():print('{}的分数是:{}'.format(name, score))# 输出:
# 林黛玉的分数是:95
# 薛宝钗的分数是:93
# 贾宝玉的分数是:78
# 袭人的分数是:85字典的嵌套:
列表中嵌套字典:
scores = [{'林黛玉': 95, '贾宝玉': 78},{'薛宝钗': 93, '袭人': 85}
]print(scores[0])
# 输出:{'林黛玉': 95, '贾宝玉': 78}print(scores[0]['林黛玉'])
# 输出:95字典中嵌套列表:
students = {'第一': ['林黛玉', '贾宝玉'],'第二': ['薛宝钗', '袭人']
}print(students['第一'])
# 输出:['林黛玉', '贾宝玉']
print(students['第一'][0])
# 输出:林黛玉字典中嵌套字典:
dictionary = {'apple': {'释义': '苹果', '词性': '名词'},'grape': {'释义': '葡萄', '词性': '名词'}
}print(dictionary['apple'])
# 输出:{'释义': '苹果', '词性': '名词'}
print(dictionary['apple']['释义'])
# 输出:苹果相关文章:

python | 列表,元组,字符串,集合,字典
列表: 可以容纳任意数目不同类型的元素(支持我们学过的任意数据类型)元素之间有先后顺序用中括号包裹,每个元素用逗号隔开 例如: students [林黛玉,薛宝钗,贾元春,贾探春,史湘云,妙玉,贾迎春,贾惜春,王熙凤,贾巧姐…...

稀疏图带负边的全源最短路Johnson算法
BellmanFord算法 Johnson算法解决的问题 带负权的稀疏图的全源最短路 算法流程 重新设置的每条边的权重都大于或等于0,跑完Djikstra后得到的全源最短路,记得要还原,即:f(u,v) d(u,v) - h[u] h[v] 例题...

oracle基础体系
一、 Oracle数据库服务器 数据库在各个行业都会有使用到;其实,我们平时无论是在与客户沟通或者交流中,所说的Oracle数据库是指Oracle数据库服务器(Oracle Server),它由Oracle实例(Oracle Instan…...

k8s运维问题整理
1.宕机或异常重启导致etcd启动失败 服务器非正常关机(意外掉电、强制拔电)后 etcd 数据损坏。 查看apiserver日志发现出现报错Error while dialing dial tcp 127.0.0.1:2379: connect: connection refused,2379是etcd的端口,那么a…...
设计模式分类和六大设计原则)
设计模式(一)设计模式分类和六大设计原则
0.设计模式的分类 GoF提出的设计模式总共有23种,根据目的准则分类分为三大类: 创建型模式,共五种:单例模式、工厂方法模式、抽象工厂模式、建造者模式、原型模式。 结构型模式,共七种:适配器模式、装饰模式…...

git的学习与使用(笔记最全)
什么是git Git是一种分布式版本控制系统,每个开发者都可以在自己的机器上拥有一个完整的仓库 特点 断网也可以工作:没网的情况下,不会影响工作。对于未提交到远程库的代码可以随时撤销。可以查看历史提交记录,以及文件内容的修改记…...

windows环境下Grafana+loki+promtail入门级部署日志系统,收集Springboot(Slf4j+logback)项目日志
🌹作者主页:青花锁 🌹简介:Java领域优质创作者🏆、Java微服务架构公号作者😄 🌹简历模板、学习资料、面试题库、技术互助 🌹文末获取联系方式 📝 往期热门专栏回顾 专栏…...

学习python时一些笔记
1、winr 命令提示符的快捷键 输入cmd进入终端 2、在终端运行桌面上的python文件 cd desktop(桌面) cd是进入该文件夹的意思。 cd .. 回到上一级 运行python时一定要找到文件的所在地 输入python进入,exit()退出%s字符串占位符%d数字占位符%f浮点数占位符input输…...
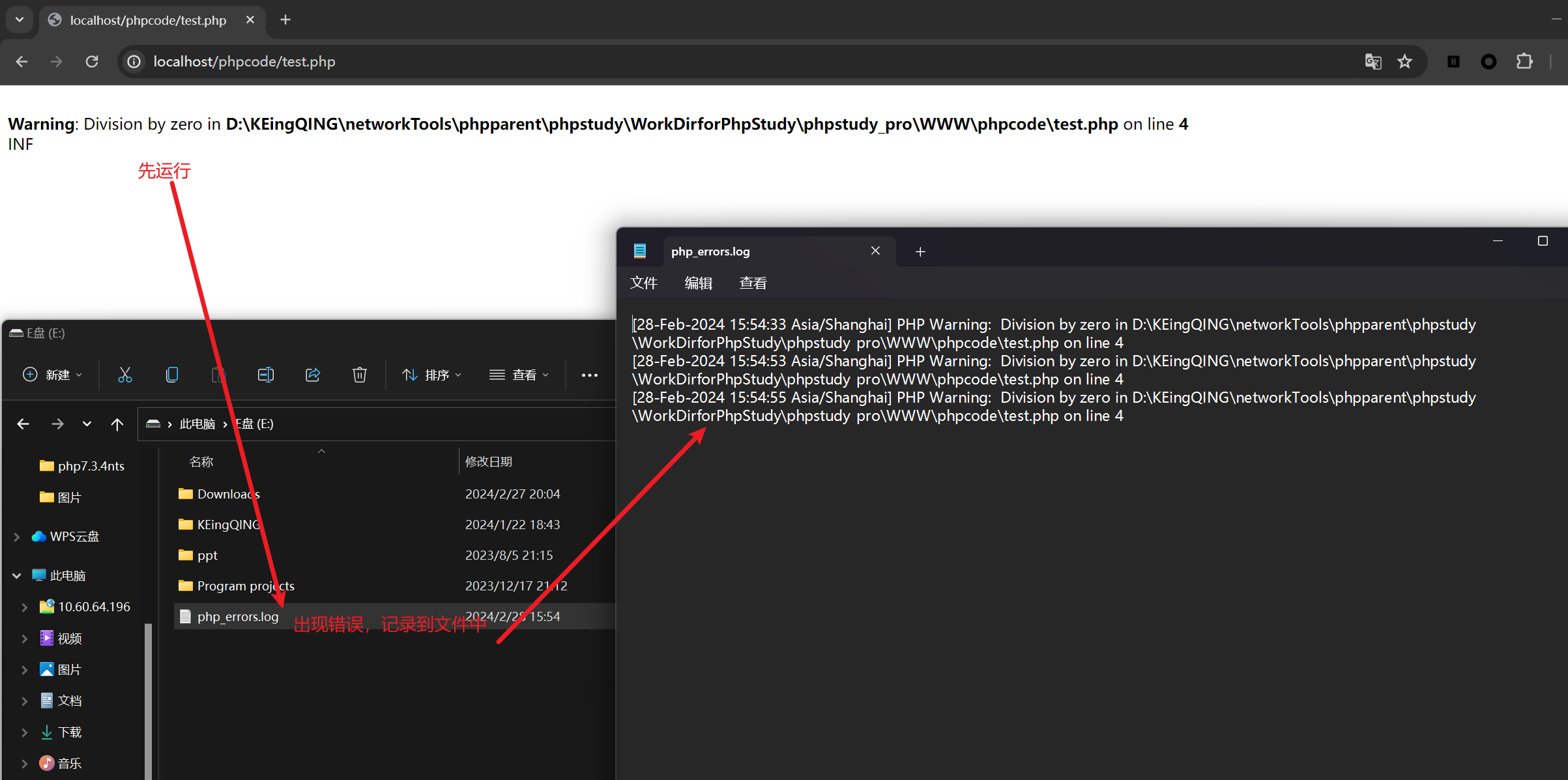
php基础学习之错误处理(其二)
在实际应用中,开发者当然不希望把自己开发的程序的错误暴露给用户,一方面会动摇客户对己方的信心,另一方面容易被攻击者抓住漏洞实施攻击,同时开发者本身需要及时收集错误,因此需要合理的设置错误显示与记录错误日志 一…...

云计算 2月28号 (linux的磁盘分区)
一 存储管理 主要知识点: 基本分区、逻辑卷LVM、EXT3/4/XFS文件系统、RAID 初识硬盘 机械 HDD 固态 SSD SSD的优势 SSD采用电子存储介质进行数据存储和读取的一种技术,拥有极高的存储性能,被认为是存储技术发展的未来新星。 与传统硬盘相比,…...
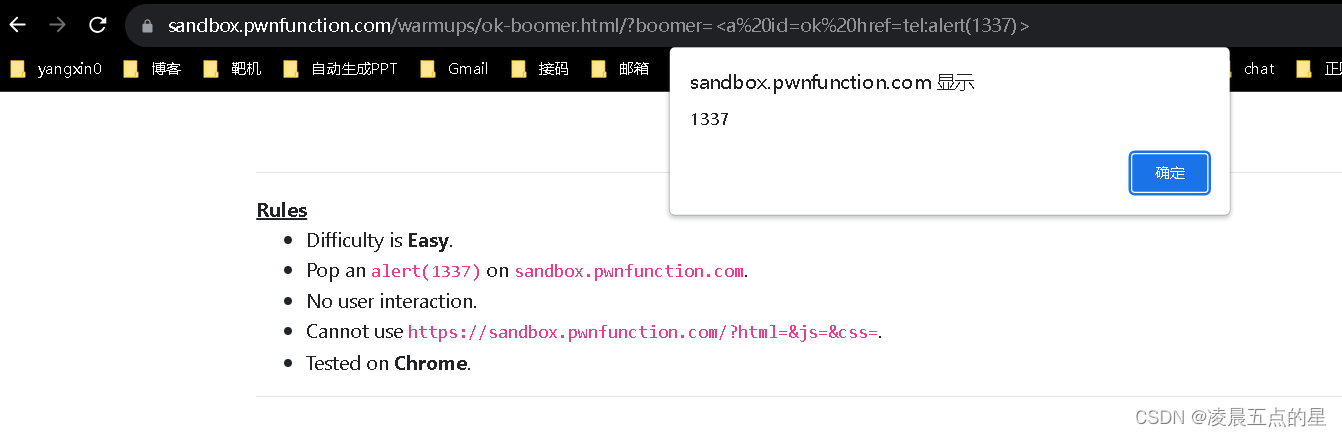
demo型xss初级靶场
一、环境 XSS Game - Ma Spaghet! | PwnFunction 二、开始闯关 第一关 看看代码 试一下直接写 明显进来了为什么不执行看看官方文档吧 你不执行那我就更改单标签去使用呗 ?somebody<img%20src1%20onerror"alert(1)"> 防御: innerText 第二关…...

【推荐算法系列十八】:DSSM 召回算法
参考 推荐系统中 DSSM 双塔模型汇总(二更) DSSM 和 YouTubeDNN 都是比较经典的 U2I 模型。 U2I 召回 U2I 召回也就是 User-to-Item 召回,它基于用户的历史行为以及用户的一些个人信息,对系统中的候选物品进行筛选,挑…...
CNAN知识图谱辅助推荐系统
CNAN知识图谱辅助推荐系统 文章介绍了一个基于KG的推荐系统模型,代码也已开源,可以看出主要follow了KGNN-LS 。算法流程大致如下: 1. 算法介绍 算法除去attention机制外,主要的思想在于:user由交互过的item来表示、i…...

大数据经典面试例题
程序员的金三银四求职宝典 随着春天的脚步渐近,对于许多程序员来说,一年中最繁忙、最重要的面试季节也随之而来。金三银四,即三月和四月,被广大程序员视为求职的黄金时期。在这两个月里,各大公司纷纷开放招聘…...

软考56-上午题-【数据库】-数据库设计步骤2
一、回顾:数据库设计的步骤 1、用户需求分析:手机用户需求,确定系统边界; 2、概念设计(概念结构设计):是抽象概念模型,较理想的是采用E-R方法。 3、逻辑设计:E-R图——…...
抖店入驻费用是多少?新手入驻都有哪些要求?2024费用明细!
我是电商珠珠 我做电商做了将近五年,做抖店做了三年多,期间还带着学员一起做店。 今天,就来给大家详细的讲一下在抖音开店,需要多少费用,最低需要投入多少。 1、营业执照200元左右 就拿个体店举例,在入…...

2024东南大学553复试真题及笔记
2023年真题知识点 引用指针 题目为 传递一个指针的引用做修改,输出指针指向的结果,但是指针被修改,结果就不一样了。 static 静态变量 类里面的静态成员变量,很简单的题目 for循环 看循环的内容输出字符串 try try catch捕…...
)
编程笔记 html5cssjs 096 JavaScript 前端开发(完结)
编程笔记 html5&css&js 096 JavaScript 前端开发 (完结) 一、前端开发二、范围三、价值四、在软件开发中地位总结 前端开发在软件开发生态系统中扮演着至关重要的角色。随着Web技术和移动互联网的发展,前端不再是简单的页面展示&…...
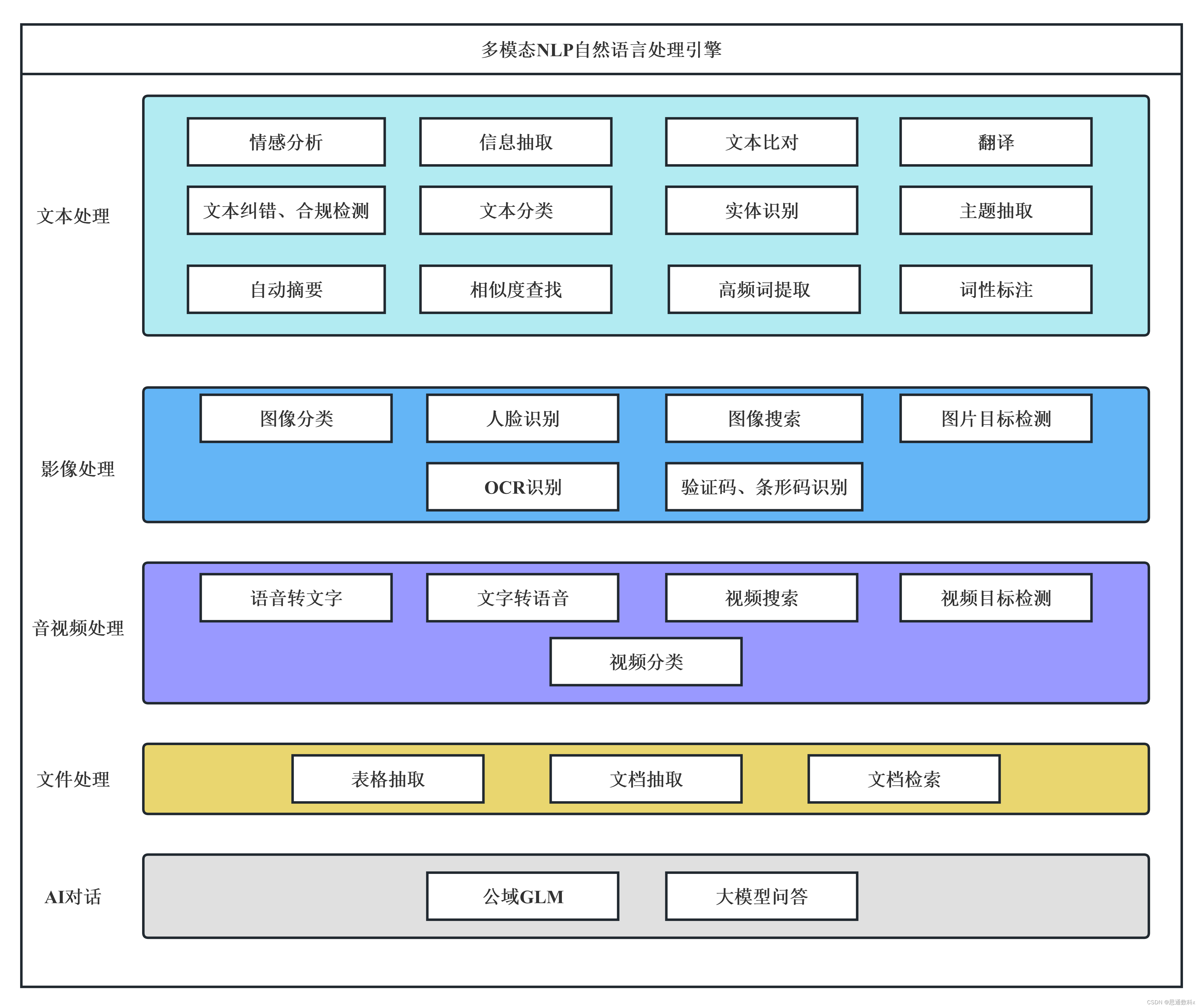
案例介绍:信息抽取技术在汽车销售与分销策略中的应用与实践
一、引言 在当今竞争激烈的汽车制造业中,成功的销售策略、市场营销和分销网络的构建是确保品牌立足市场的关键。作为一名经验丰富的项目经理,我曾领导一个专注于汽车销售和分销的项目,该项目深入挖掘市场数据,运用先进的信息抽取…...

几种常用的企业加密文件传输方式,最后一种更佳!
随着远程工作和云计算服务的广泛采用,企业必须实施有效的策略来保障敏感信息在传输过程中的安全性。本文将探讨企业在文件加密传输方面的几种常用策略,并重点介绍最后一种方式是如何利用其创新技术为企业提供数据传输的安全保障。 文件加密传输策略 企业…...
2期)
C语言学习笔记(自用)2期
一、数据类型和变量C语言提供了丰富的数据类型来描述生活中的数据这些各式各样的数据类型,是程序向电脑申请内存来存储变量的指令数据类型分为整数类型,字符类型,浮点类型类型就是相似数据有的共同特征,编译器只有知道了类型以后&…...

5步终极指南:如何永久免费使用Cursor Pro AI编程助手
5步终极指南:如何永久免费使用Cursor Pro AI编程助手 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tria…...

深入解析现代游戏修改框架的5大核心模块架构
深入解析现代游戏修改框架的5大核心模块架构 【免费下载链接】REFramework Mod loader, scripting platform, and VR support for all RE Engine games 项目地址: https://gitcode.com/GitHub_Trending/re/REFramework REFramework是一款专为RE引擎游戏设计的企业级游戏…...

DBSwitch迁移踩坑记:当PostgreSQL的TRUNCATE语法遇上openGauss,我这样改源码
DBSwitch迁移实战:从PostgreSQL到openGauss的TRUNCATE语法改造之旅 在异构数据库迁移领域,DBSwitch作为一款高效的工具,能够实现不同数据库之间的数据流转。然而,当我们将目光投向PostgreSQL与openGauss这两种看似同源却存在微妙差…...

深度解析Pycdc:C++实现的Python字节码反编译器架构设计与技术实现
深度解析Pycdc:C实现的Python字节码反编译器架构设计与技术实现 【免费下载链接】pycdc C python bytecode disassembler and decompiler 项目地址: https://gitcode.com/GitHub_Trending/py/pycdc Pycdc作为一款基于C开发的Python字节码反编译器,…...

通过curl命令快速测试Taotoken大模型聚合接口的连通性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型聚合接口的连通性 在接入大模型服务时,直接使用curl命令进行接口测试是一种高效且…...

网易2026年Q1财报:游戏增长背后,AI、跨端与全球化面临哪些挑战?
网易发布2026年Q1财报5月21日,网易发布2026年第一季度财报。大体上,网易呈现出基本面企稳、公司效率提升以释放利润的态势。财报显示,网易Q1净收入306亿元,同比增长6.1%,Non - GAAP归母净利润为107亿元。游戏及相关增值…...

普通人必学!巧用 AI 轻松提升日常办事效率
一、为什么现在必须学会用 AI?先说一个事实:2025 年以来,国内大模型赛道迎来了爆发式增长。DeepSeek 横空出世,以极高的性价比引发全行业关注;字节跳动的豆包、月之暗面的 Kimi、阿里的通义千问、百度的文心一言等产品…...

在Node.js服务中集成Taotoken实现智能问答与内容生成功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现智能问答与内容生成功能 对于Node.js后端开发者而言,为应用添加智能问答或内容生成能…...

揭秘K12课堂AI转型真相:3个被90%学校忽略的PlayAI部署陷阱及72小时应急修复指南
更多请点击: https://intelliparadigm.com 第一章:PlayAI教育领域应用案例 PlayAI 作为面向教育场景的轻量级AI交互平台,已在多个教学实践中展现出显著的适配性与可扩展性。其核心优势在于无需深度编程基础即可构建个性化学习路径、实时学情…...