关于MediaEval数据集的Dataset构建(Text部分-使用PLM BERT)
import random
import numpy as np
import pandas as pd
import torch
from transformers import BertModel,BertTokenizer
from tqdm.auto import tqdm
from torch.utils.data import Dataset
import re
"""参考Game-On论文"""
"""util.py"""
def set_seed(seed_value=42):random.seed(seed_value)np.random.seed(seed_value)# 用于设置生成随机数的种子torch.manual_seed(seed_value)torch.cuda.manual_seed_all(seed_value)
"""util.py""""""文本预处理-textGraph.py"""
# 文本DataSet类def text_preprocessing(text):"""- Remove entity mentions (eg. '@united')- Correct errors (eg. '&' to '&')@param text (str): a string to be processed.@return text (Str): the processed string."""# Remove '@name'text = re.sub(r'(@.*?)[\s]', ' ', text)# Replace '&' with '&'text = re.sub(r'&', '&', text)# Remove trailing whitespacetext = re.sub(r'\s+', ' ', text).strip()# removes linkstext = re.sub(r'(?P<url>https?://[^\s]+)', r'', text)# remove @usernamestext = re.sub(r"\@(\w+)", "", text)# remove # from #tagstext = text.replace('#', '')return textclass TextDataset(Dataset):def __init__(self,df,tokenizer):# 包含推文的主文件框架self.df = df.reset_index(drop=True)# 使用的分词器self.tokenizer = tokenizerdef __len__(self):return len(self.df)def __getitem__(self, idx):if torch.is_tensor(idx):idx = idx.tolist()# 帖子的文本内容text = self.df['tweetText'][idx]# 作为唯一标识符的id ‘tweetId'unique_id = self.df['tweetId'][idx]# 创建一个空的列表来存储输出结果input_ids = []attention_mask = []# 使用tokenizer分词器encoded_sent = self.tokenizer.encode_plus(text = text_preprocessing(text), # 这里使用的是预处理的句子,而不是直接对原句子使用tokenizeradd_special_tokens=True, # 添加[CLS]以及[SEP]等特殊词元max_length=512, # 最大截断长度padding='max_length', # padding的最大长度return_attention_mask=True, # 返回attention_masktruncation=True #)# 获取编码效果input_ids = encoded_sent.get('input_ids')# 获取attention_mask结果attention_mask = encoded_sent.get('attention_mask')# 将列表转换成张量input_ids = torch.tensor(input_ids)attention_mask =torch.tensor(attention_mask)return {'input_ids':input_ids,'attention_mask':attention_mask,'unique_id':unique_id}def store_data(bert,device,df,dataset,store_dir):lengths = []bert.eval()for idx in tqdm(range(len(df))):sample = dataset.__getitem__(idx)print('原始sample[input_ids]和sample[attention_mask]的维度:',sample['input_ids'].shape,sample['attention_mask'].shape)# 升维input_ids,attention_mask = sample['input_ids'].unsqueeze(0),sample['attention_mask'].unsqueeze(0)input_ids = input_ids.to(device)attention_mask = attention_mask.to(device)# 得到唯一标识属性unique_id = sample['unique_id']# 计算token的个数num_tokens = attention_mask.sum().detach().cpu().item()"""不生成新的计算图,而是只做权重更新"""with torch.no_grad():out = bert(input_ids=input_ids,attention_mask=attention_mask)# last_hidden_state.shape是(batch_size,sequence_length,hidden_size)out_tokens = out.last_hidden_state[:,1:num_tokens,:].detach().cpu().squeeze(0).numpy() # token向量# 保存token级别表示filename = f'{emed_dir}{unique_id}.npy'try:np.save(filename, out_tokens)print(f"文件{filename}保存成功")except FileNotFoundError:# 文件不存在,创建新文件并保存np.save(filename, out_tokens)print(f"文件{filename}创建成功并保存成功")lengths.append(num_tokens)## Save semantic/ whole text representation# 保存语义 也就是整个文本的表示out_cls = out.last_hidden_state[:,0,:].unsqueeze(0).detach().cpu().squeeze(0).numpy() ## cls vectorfilename = f'{emed_dir}{unique_id}_full_text.npy'# 尝试保存.npy文件,如果文件不存在则自动创建try:np.save(filename, out_cls)print(f"文件{filename}保存成功")except FileNotFoundError:# 文件不存在,创建新文件并保存np.save(filename, out_cls)print(f"文件{filename}创建成功并保存成功")return lengthsif __name__=='__main__':device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 根目录root_dir = "./dataset/image-verification-corpus-master/image-verification-corpus-master/mediaeval2015/"emed_dir = './Embedding_File'# 文件路径train_csv_name = "tweetsTrain.csv"test_csv_name = "tweetsTest.csv"# 加载PLM和分词器tokenizer = BertTokenizer.from_pretrained('./bert/')bert = BertModel.from_pretrained('./bert/', return_dict=True)bert = bert.to(device)# 用于存储每个推文的Embeddingstore_dir ="Embed_Post/"# 创建训练数据集的Embedding表示df_train = pd.read_csv(f'{root_dir}{train_csv_name}')df_train = df_train.dropna().reset_index(drop=True)# 训练数据集的编码结果train_dataset = TextDataset(df_train,tokenizer)lengths = store_data(bert, device, df_train, train_dataset, store_dir)## Create graph data for testing set# 为测试集创建Embedding表示df_test = pd.read_csv(f'{root_dir}{test_csv_name}')df_test = df_test.dropna().reset_index(drop=True)test_dataset = TextDataset(df_test, tokenizer)lengths = store_data(bert, device, df_test, test_dataset, store_dir)"""文本预处理-textGraph.py"""相关文章:
)
关于MediaEval数据集的Dataset构建(Text部分-使用PLM BERT)
import random import numpy as np import pandas as pd import torch from transformers import BertModel,BertTokenizer from tqdm.auto import tqdm from torch.utils.data import Dataset import re """参考Game-On论文""" ""&qu…...

QML学习之Text
文本显示是界面开发中的重要内容,在Qt Quick模块中提供了 Text 项来进行文本的显示,其中可以使用 font 属性组对文本字体进行设置: font.bold:是否加粗,取值为true或false font.capitalization:大写策略&a…...
)
轮转数组(元素位置对调、数据的左旋、右旋)
189. 轮转数组 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮转 1 步: [7,1,2,3,4,5,6] 向右轮转 2 步: [6,7,1,2,3,4,5] 向右轮转 3 步: …...

喜迎乔迁,开启新章 ▏易我科技新办公区乔迁庆典隆重举行
2024年1月18日,易我科技新办公区乔迁庆典在热烈而喜庆的氛围中隆重举行。新办公区的投入使用,标志着易我科技将以崭新姿态迈向新的发展阶段。 ▲ 易我科技新办公区 随着公司业务的不断发展和壮大,为了更好地适应公司发展的需要,…...
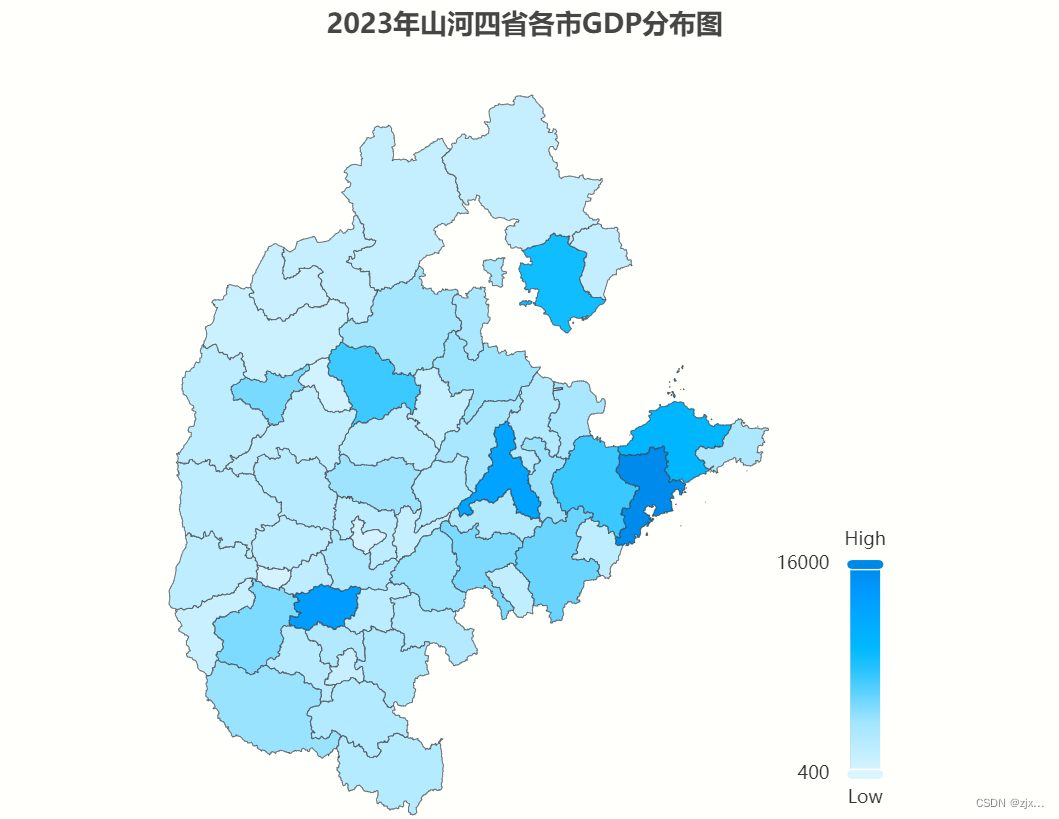
多个地区地图可视化
1. 配置Json文件 1.1 获得每个省份的json数据 打开 阿里云数据可视化平台 主页。 在搜索框中输入所需省份。 将json文件下载到本地。 1.2 将各省份的json数据进行融合 打开 geojson.io 主页 点击 open,上传刚刚下载的 json 文件,对多个省份不断…...
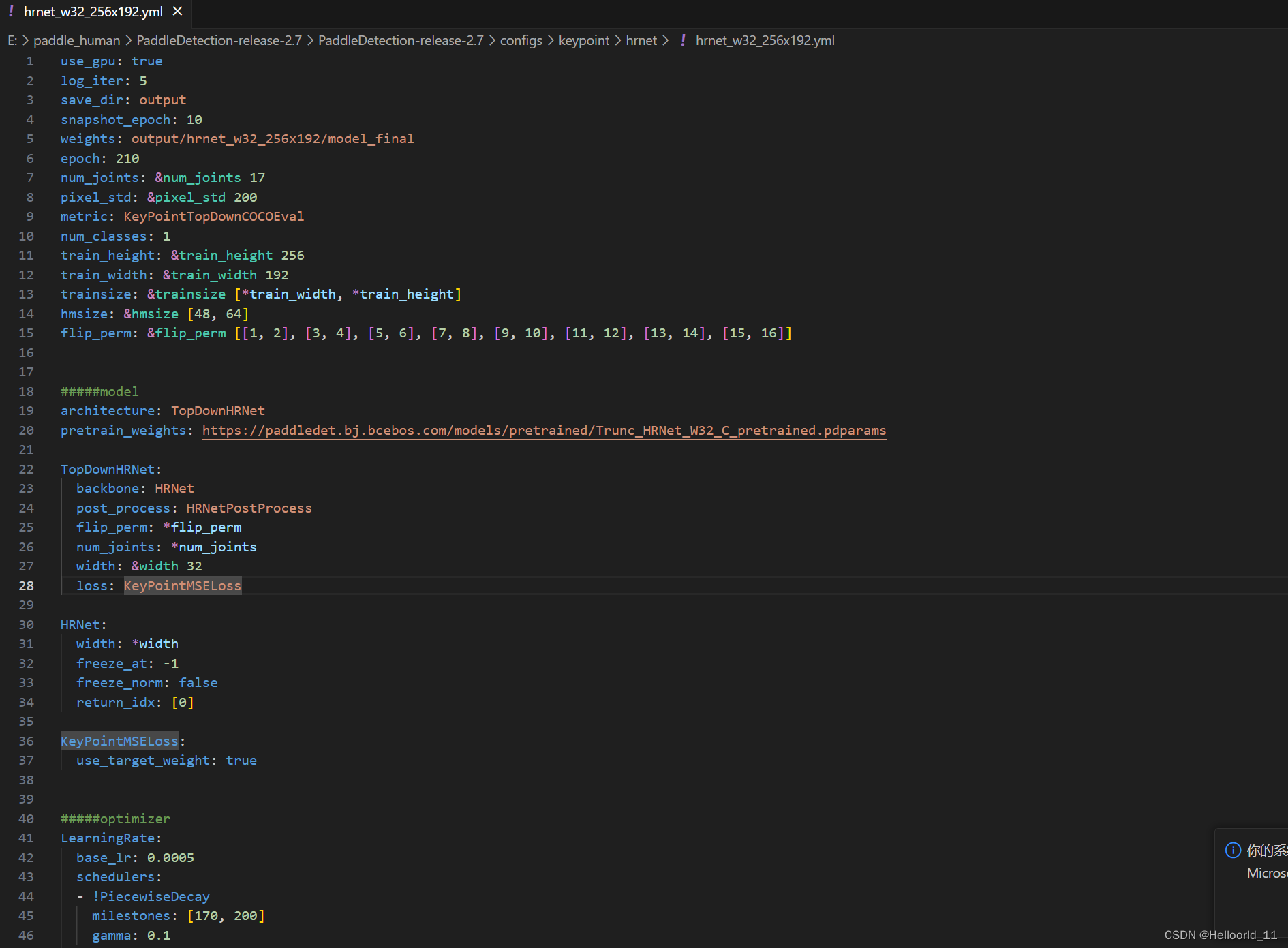
学习使用paddle来构造hrnet网络模型
1、首先阅读了hrnet的网络结构分析,了解到了网络构造如下: 参考博文姿态估计之2D人体姿态估计 - (HRNet)Deep High-Resolution Representation Learning for Human Pose Estimation(多家综合)-CSDN博客 最…...

Redis 多线程操作同一个Key如何保证一致性?
单线程模型:Redis 是单线程模型的,它通过一个事件循环来处理所有客户端请求,这意味着 Redis 在任何时刻只会处理一个请求,从而避免了并发访问同一个 Key 的问题。这种设计保证了数据的一致性。 乐观锁(Watchÿ…...

单链表合并
【问题描述】 建立两个升序排列的单链表,表中元素的数据类型是整数,将建立的两个链表合并为 一个新的升序的单链表,并输出显示已合并好的有序的单链表 。 【输入形式】分别输入两组数据,两组数据以回车分隔;每组数据…...

【如何像网吧一样弄个游戏菜单在家里】
GGmenu 个人家庭版游戏、应用管理 桌面图标管理器...

CSS~~
CSS是一门语言,用于控制网页表现 CSS(Cascading Style Sheet):层叠样式表 W3C标准:网页主要由三部分组成 结构:HTML 表现: CSS 行为:JavaScript 1,CSS的导入方式 (1)内联样式 在标签内部使用style属性,属性值是cs…...

Docker技术概论(1):Docker与虚拟化技术比较
Docker技术概论(1) Docker与虚拟化技术比较 - 文章信息 - Author: 李俊才 (jcLee95) Visit me at: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 291148484163.com. Shenzhen ChinaAddress of this article:https:…...
alibabacloud学习笔记07(小滴课堂)
讲解Sentinel自定义异常降级-新旧版本差异 讲解新版Sentinel自定义异常数据开发实战 如果我们都使用原生的报错,我们就无法得到具体的报错信息。 所以我们要自定义异常返回的数据提示: 实现BlockExceptionHandler并且重写handle方法: 使用F…...
Ansible-Playbook
目录 1、概念介绍 roles 角色 playbook 核心元素 ansible-playbook 命令 playbook 简单案例 2、Ansible 变量 自定义变量 facts 变量 Palybook 部署 LAMP ansible 端安装 LAMP playbook 系统环境脚本 构建 httpd 任务 构建 mariadb 任务 构建 php 任务 编写整个任务…...

UE5常见问题处理笔记
一、C工程中的文件出现很多头文件找不到,比如:#include CoreMinimal.h文件提示找不到。 解决方法:在UE编辑器中选择菜单Tools -> Refresh Visual Studio Project。 二、莫名其妙的编译错误。 解决方法,找到工程根目录下的Bi…...
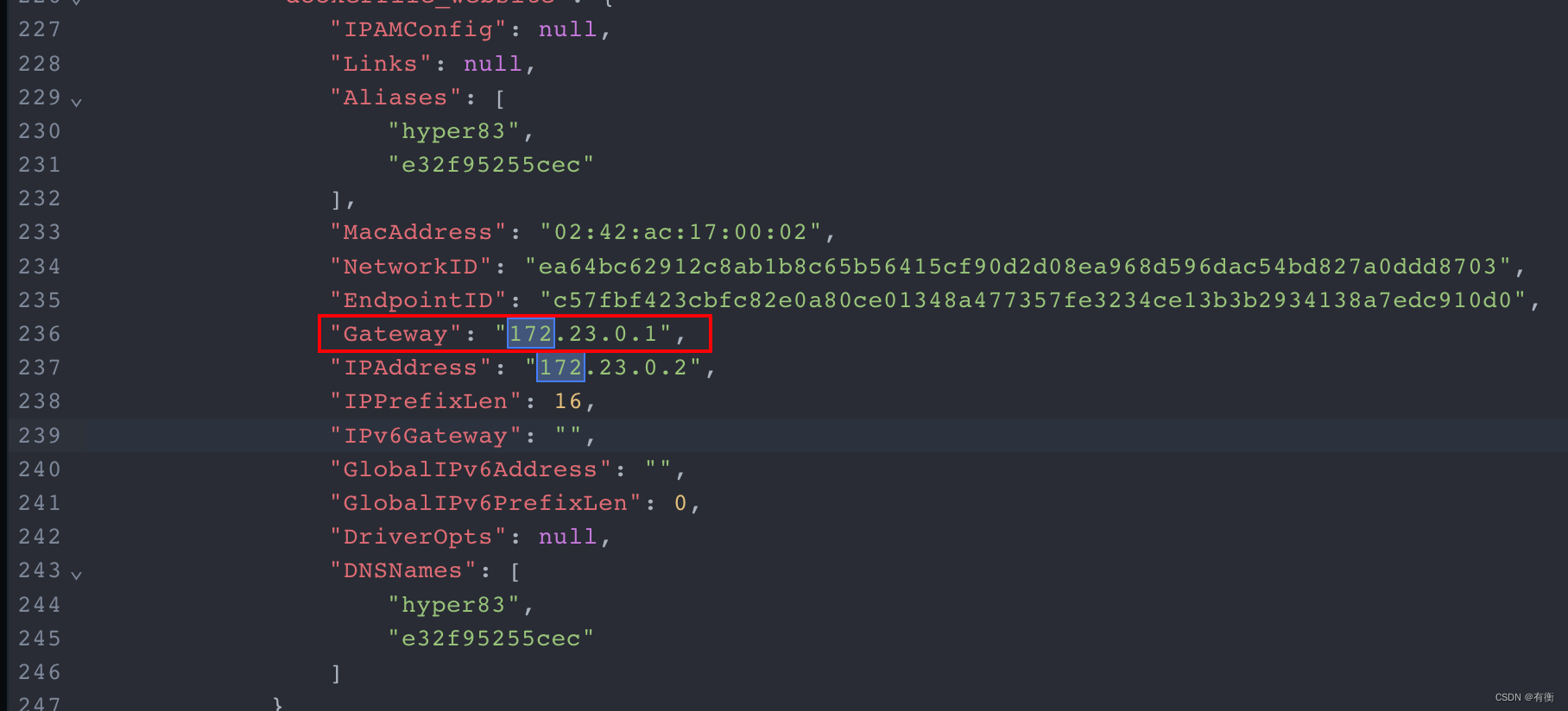
docker中hyperf项目配置虚拟域名
在学习hyperf框架时遇到一些问题,这里是直接用了docker环境 下载镜像运行容器 docker run --name hyperf -v /data/project:/data/project -p 9501:9501 -itd -w /data/project --privileged -u root --entrypoint /bin/sh 镜像ID配置docker-compose.yml version…...
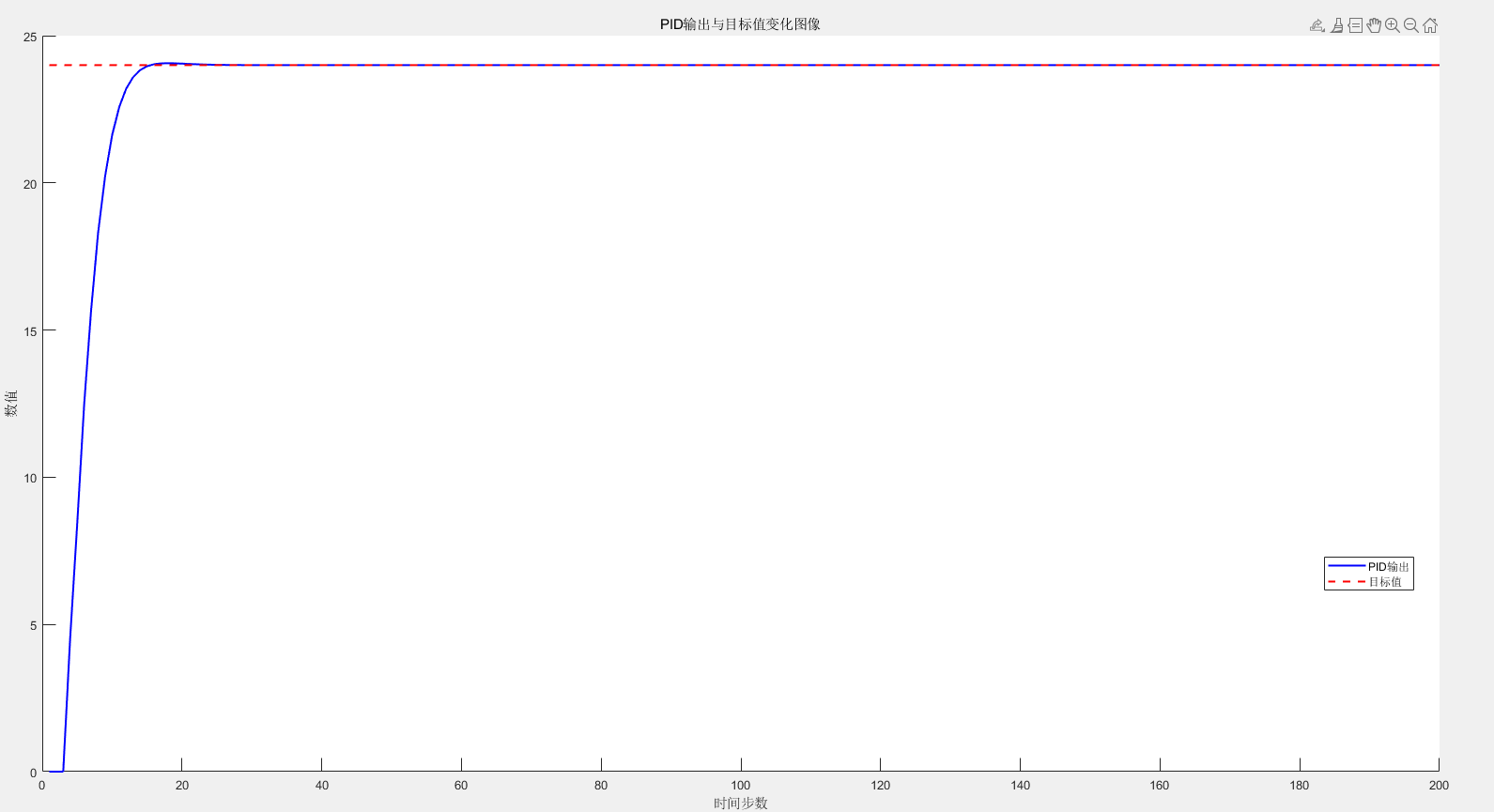
PID闭环控制算法的学习与简单使用
平台:matlab2021b,Vivado2018 应用场景和理解 一个早餐店,假如一天都有生意,生意有的时间很火爆,有时候又一般,老板又是个实在人,只知道在后厨蒸包子。由于包子蒸熟需要一定的时间,老…...
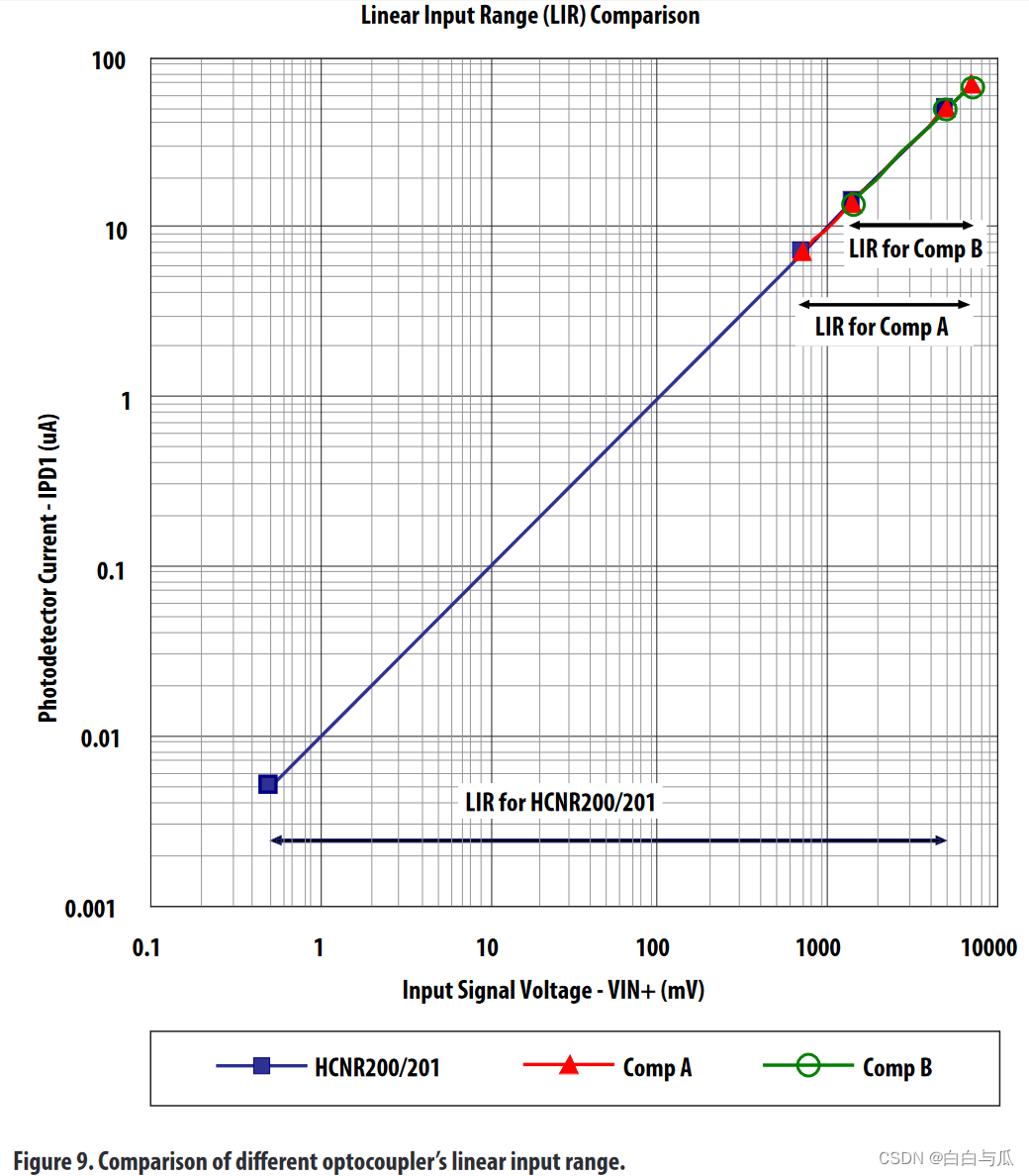
【无刷电机学习】光耦HCNR200基本原理及应用(资料摘抄)
【仅作自学记录,不出于任何商业目的。如有侵权,请联系删除,谢谢!】 本文摘抄翻译自: https://docs.broadcom.com/wcs-public/products/application-notes/application-note/331/6/av02-1333en-an_5394-16jul10.pdfhtt…...

【LeetCode】1768_交替合并字符串_C
题目描述 给你两个字符串 word1 和 word2 。请你从 word1 开始,通过交替添加字母来合并字符串。如果一个字符串比另一个字符串长,就将多出来的字母追加到合并后字符串的末尾。 返回 合并后的字符串 。 https://leetcode.cn/problems/merge-strings-al…...

C#解析JSON
https://blog.csdn.net/weixin_43046974/article/details/131449900 C#解析JSON 1. JSON定义2. JSON一般构成及解析方法3. 解析举例子 1. JSON对象解析,只包含一层对象{}2. 嵌套JSON对象解析,包含多层对象{}3. JSON数组解析1(数组循环遍历&…...

AI图像识别算法助力安全生产*提升风险监测效率---豌豆云
2024年开年来安全生产事故频发,工厂爆炸、工程坍陷等重大安全生产事故的发生再次为我们敲响了警钟。 安全生产是企业发展的生命线,而传统的安全监测手段存在盲区和延迟,难以及时发现和应对潜在风险。 AI图像识别算法通过利用先进的计算机视…...

ASP.NET Core 分层设计实践拒绝胖Controller
Controller 是 API 的入口,理论上应该只做三件事:接收请求、调用下层、返回响应。但在实际项目中,不少开发者会把用户校验、金额判断、业务限制条件直接写进 Controller Action,久而久之就成了所谓的"胖 Controller"。 这不只是代码整洁的问题。业务规则一旦耦合…...

动态阻抗匹配增益单元:破解脑电前端 “弱信号放大” 难题
通过上一篇文章的学习,相信大家对自研脑机接口模拟前端的整体框架有了一定的了解,其中动态阻抗匹配增益单元是解决 “微弱脑电信号无法稳定放大” 这一核心难题的关键。今天这篇文章,蔡哥就带大家来聊聊这项技术的设计背景、实现思路和实际效…...

8051单片机中断向量号计算与配置详解
1. C51中断向量号计算方法解析在8051单片机开发中,中断处理是最核心的功能之一。作为一名长期使用Keil C51工具链的嵌入式开发者,我经常遇到新手询问如何正确计算中断向量号的问题。这个看似简单的数字背后,其实隐藏着8051架构的设计哲学。1.…...

Keil A51汇编器INCDIR参数分隔符问题解析
1. 问题现象与背景解析 最近在使用Keil C51开发工具链中的A51汇编器时,遇到了一个看似简单却令人困惑的报错。当执行以下命令时: A51 ASAMPLE.A51 PRINT(ASAMPLE.LST) INCDIR(H1;H2)系统抛出了致命错误: A51 FATAL ERROR -LINE: C:…...

Joy-Con Toolkit:一站式解决Switch手柄所有问题的智能管理工具
Joy-Con Toolkit:一站式解决Switch手柄所有问题的智能管理工具 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit Joy-Con Toolkit是一款专为Nintendo Switch手柄设计的开源管理工具,为游戏玩…...

Super IO插件终极指南:Blender批量导入导出效率提升300%的完整实战方案
Super IO插件终极指南:Blender批量导入导出效率提升300%的完整实战方案 【免费下载链接】super_io blender addon for copy paste import / export 项目地址: https://gitcode.com/gh_mirrors/su/super_io 在3D创作工作流中,文件导入导出是每个设…...

零基础转行工业AI视觉全攻略|从入门学习、项目积累、求职就业到副业接单完整路径
摘要:当下传统自动化、机械、普通编程岗位普遍存在内卷严重、薪资天花板低、成长空间有限等问题。而工业AI视觉作为智能制造核心刚需赛道,具备岗位缺口大、薪资溢价高、技术生命周期长、可主业就业副业接单的核心优势,成为应届生、职场转行、…...

Java解析支付宝PKCS#8私钥失败的根源与解决方案
1. 这不是密钥格式错了,是Java对PKCS#8私钥的“认知偏差”在作祟 你刚把支付宝开放平台下载的 .pem 私钥文件丢进 Java 项目,调用 AlipayClient.execute() 就立刻报错:“RSA2签名遭遇异常,请检查私钥格式是否正确”。第一反应…...

从QPLL与CPLL选型到线速计算:一份给Xilinx GTY新手的时钟配置速查手册
从QPLL与CPLL选型到线速计算:一份给Xilinx GTY新手的时钟配置速查手册 第一次接触Xilinx UltraScale系列FPGA的GTY收发器时,最让人头疼的莫过于时钟配置。面对QPLL0、QPLL1和CPLL三种时钟源,以及N1、N2、M、D等分频参数,新手工程师…...

DECO项目架构解析:从源码理解装饰器并发模型的设计哲学
DECO项目架构解析:从源码理解装饰器并发模型的设计哲学 【免费下载链接】deco 项目地址: https://gitcode.com/gh_mirrors/de/deco DECO(Decorated Concurrency)是一个革命性的Python并行计算框架,它通过装饰器实现了简洁…...