基于Mahout实现K-Means聚类
需求分析
需要对数据集进行预处理,选择合适的特征进行聚类分析,确定聚类的数量和初始中心点,调用Mahout提供的K-Means算法进行聚类计算,评估聚类结果的准确性和稳定性。同时,需要对Mahout的使用和参数调优进行深入学习和实践,以保证聚类结果的有效性和可靠性。
系统实现
1.对实验整体的理解:
本次实验,我们的目的是理解聚类的原理,并且掌握常见聚类的算法,以及掌握使用Mahout实现K-Means聚类分析算法的过程。
2.实验整体流程分析:
- 创建项目,导入开发依赖包
- 编写工具类
- 编写聚类分析的代码
- 将聚类结果输出
- 评估聚类的效果
3.准备工作:
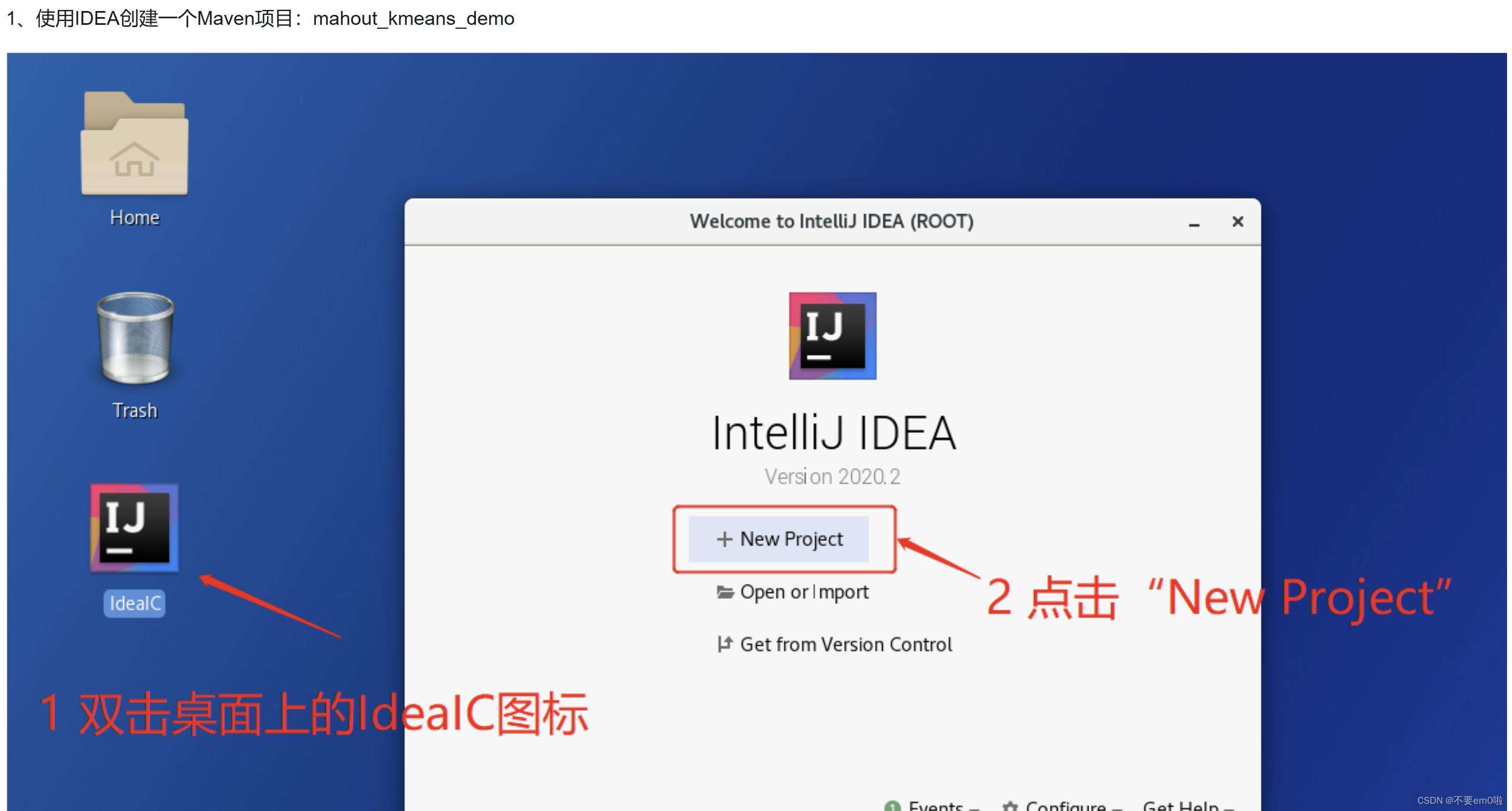
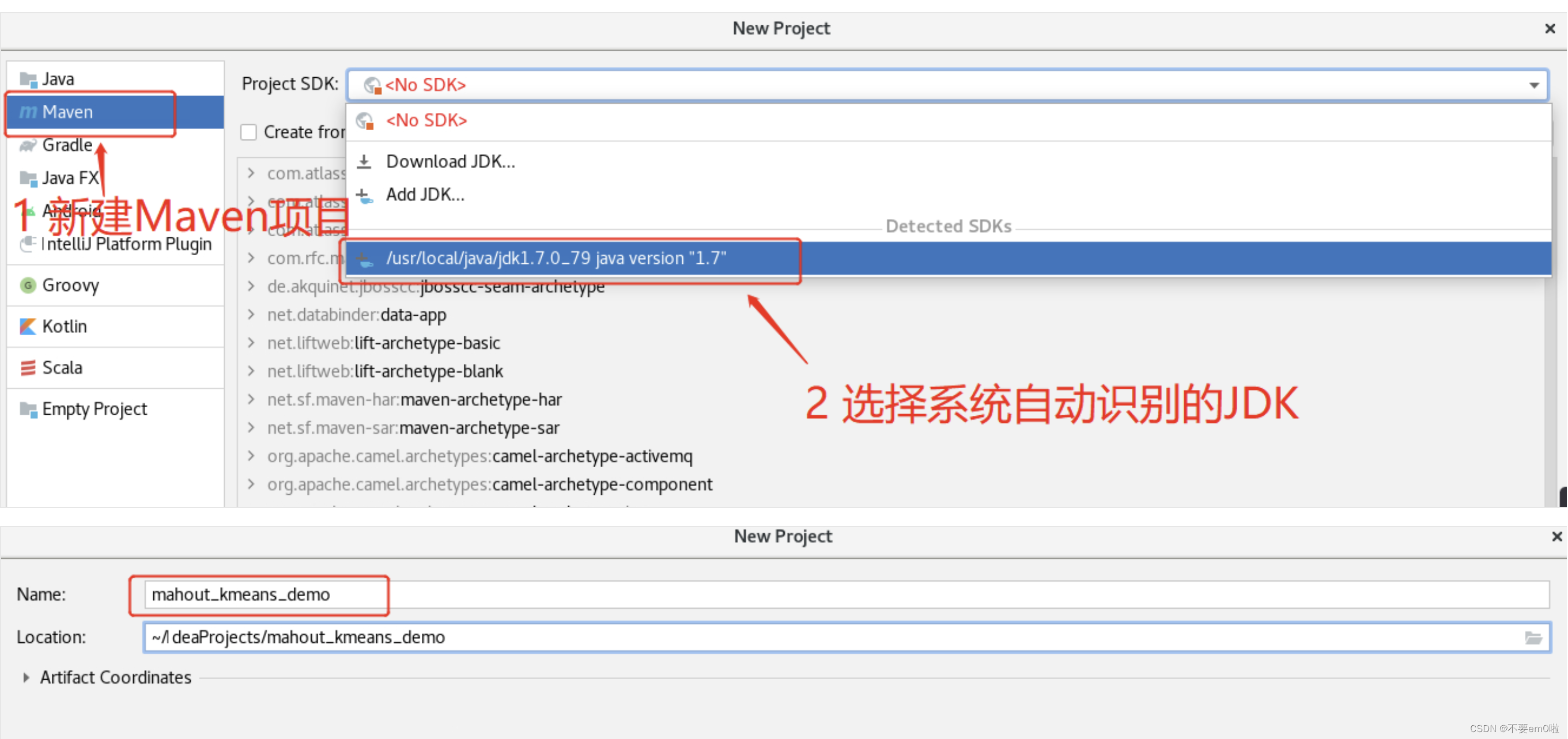
- 使用IDEA创建一个Maven项目:mahout_kmeans_demo
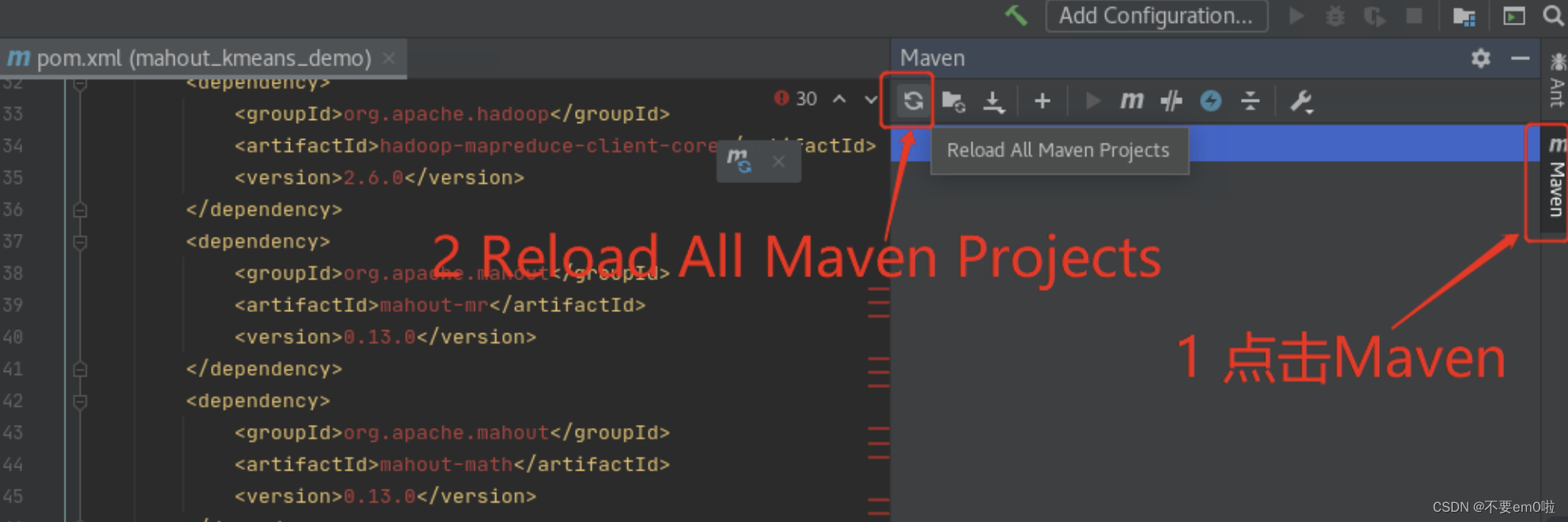
- 修改pom.xml文件,导入开发MapReduce所需的Jar包
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.6.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.6.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.6.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-common</artifactId><version>2.6.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>2.6.0</version></dependency><dependency><groupId>org.apache.mahout</groupId><artifactId>mahout-mr</artifactId><version>0.13.0</version></dependency><dependency><groupId>org.apache.mahout</groupId><artifactId>mahout-math</artifactId><version>0.13.0</version></dependency><dependency><groupId>org.apache.mahout</groupId><artifactId>mahout-hdfs</artifactId><version>0.13.0</version></dependency><dependency><groupId>org.apache.mahout</groupId><artifactId>mahout-integration</artifactId><version>0.13.0</version></dependency><dependency><groupId>org.apache.mahout</groupId><artifactId>mahout-examples</artifactId><version>0.13.0</version></dependency>
</dependencies>下载相关依赖包
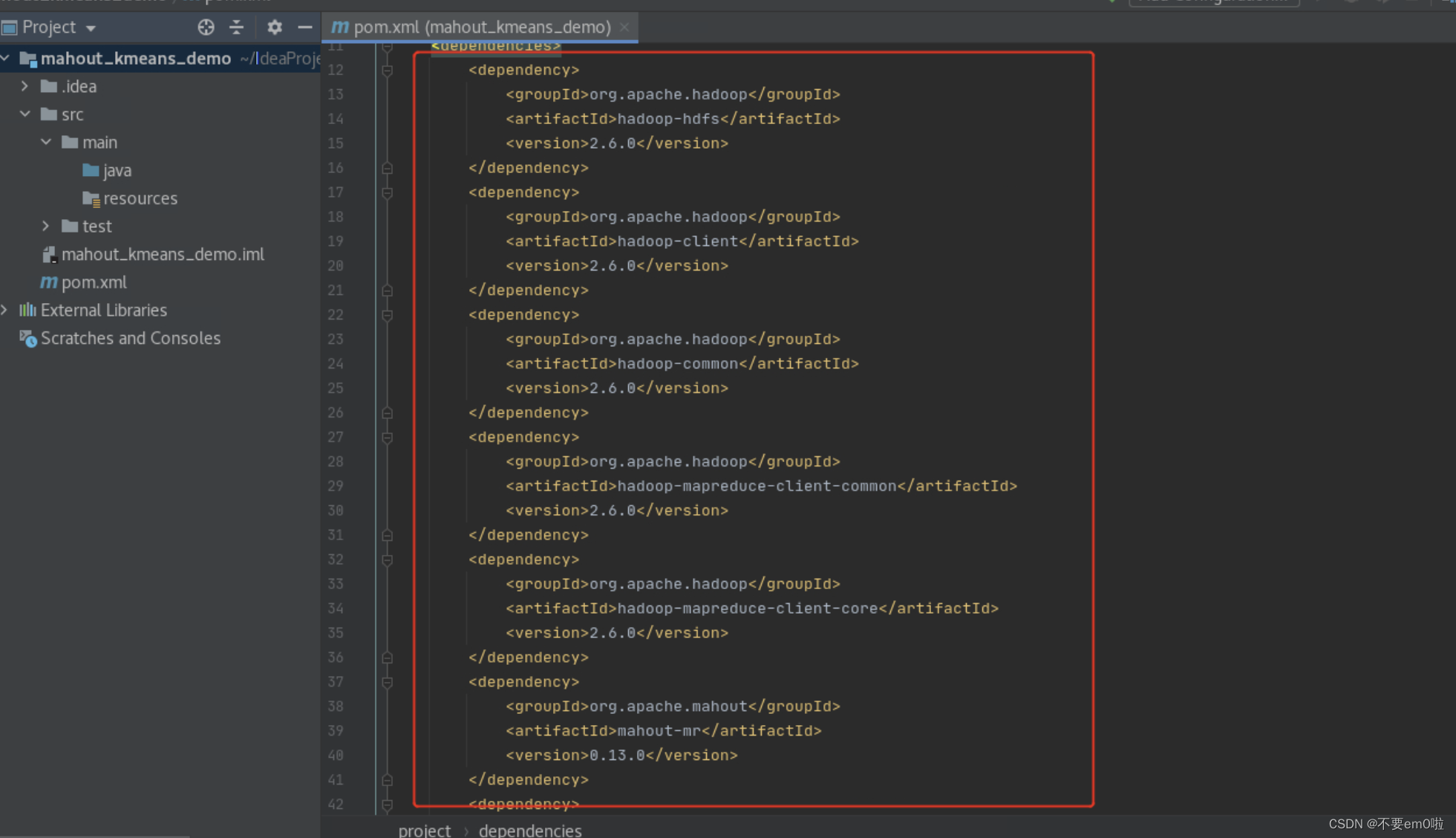
等待pom.xml文件不再出现错误即可
- 准备实验数据并下载

- 启动Hadoop集群。
终端输入start-all.sh
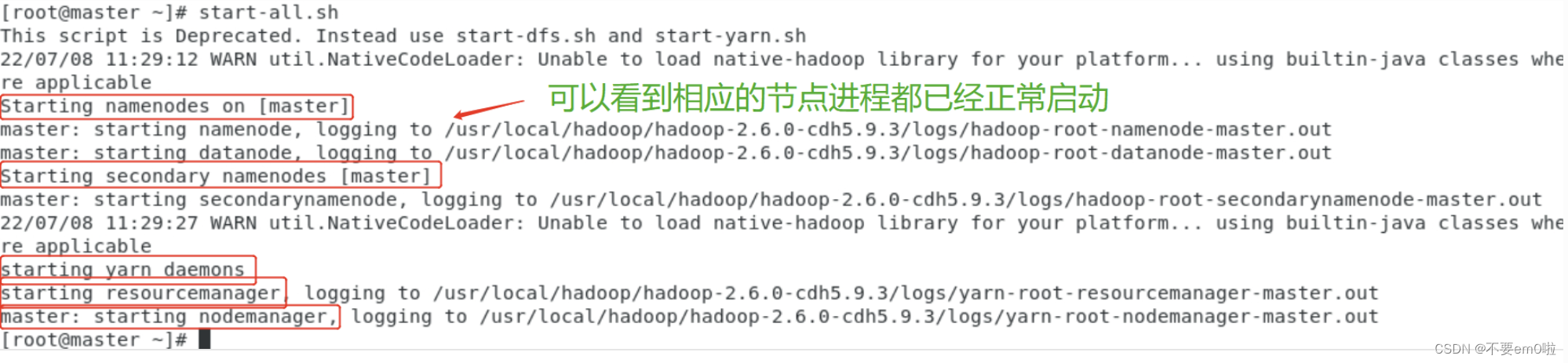
可以使用jps命令查看集群启动情况。

4.执行聚类过程:
- 编写工具类HdfsUtil,对HDFS的基本操作进行封装
package com;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.mapred.JobConf;import java.io.IOException;
import java.net.URI;public class HdfsUtil {private static final String HDFS = "hdfs://master:9000/";private String hdfsPath;private Configuration conf;public HdfsUtil(Configuration conf) {this(HDFS, conf);}public HdfsUtil(String hdfs, Configuration conf) {this.hdfsPath = hdfs;this.conf = conf;}public static JobConf config() {JobConf conf = new JobConf(HdfsUtil.class);conf.setJobName("HdfsDAO");return conf;}public void mkdirs(String folder) throws IOException {Path path = new Path(folder);FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);if (!fs.exists(path)) {fs.mkdirs(path);System.out.println("Create: " + folder);}fs.close();}public void rmr(String folder) throws IOException {Path path = new Path(folder);FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);fs.deleteOnExit(path);System.out.println("Delete: " + folder);fs.close();}public void ls(String folder) throws IOException {Path path = new Path(folder);FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);FileStatus[] list = fs.listStatus(path);System.out.println("ls: " + folder);System.out.println("==========================================================");for (FileStatus f : list) {System.out.printf("name: %s, folder: %s, size: %d\n", f.getPath(), f.isDir(), f.getLen());}System.out.println("==========================================================");fs.close();}public void createFile(String file, String content) throws IOException {FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);byte[] buff = content.getBytes();FSDataOutputStream os = null;try {os = fs.create(new Path(file));os.write(buff, 0, buff.length);System.out.println("Create: " + file);} finally {if (os != null)os.close();}fs.close();}public void copyFile(String local, String remote) throws IOException {FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);fs.copyFromLocalFile(new Path(local), new Path(remote));System.out.println("copy from: " + local + " to " + remote);fs.close();}public void download(String remote, String local) throws IOException {Path path = new Path(remote);FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);fs.copyToLocalFile(path, new Path(local));System.out.println("download: from" + remote + " to " + local);fs.close();}public void cat(String remoteFile) throws IOException {Path path = new Path(remoteFile);FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);FSDataInputStream fsdis = null;System.out.println("cat: " + remoteFile);try {fsdis = fs.open(path);IOUtils.copyBytes(fsdis, System.out, 4096, false);} finally {IOUtils.closeStream(fsdis);fs.close();}}
}- 编写KMeansMahout类,执行聚类过程
package com;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.mahout.clustering.Cluster;
import org.apache.mahout.clustering.canopy.CanopyDriver;
import org.apache.mahout.clustering.conversion.InputDriver;
import org.apache.mahout.clustering.kmeans.KMeansDriver;
import org.apache.mahout.common.HadoopUtil;
import org.apache.mahout.common.distance.EuclideanDistanceMeasure;
import org.apache.mahout.utils.clustering.ClusterDumper;public class KMeansMahout {private static final String HDFS = "hdfs://master:9000";public static void main(String[] args) throws Exception {String localFile = "/home/data/iris.dat";// mahout输出至HDFS的目录String outputPath = HDFS + "/user/hdfs/kmeans/output";// mahout的输入目录String inputPath = HDFS + "/user/hdfs/kmeans/input/";// canopy算法的t1和t2double t1 = 2;double t2 = 1;// 收敛阀值double convergenceDelta = 0.5;// 最大迭代次数int maxIterations = 10;Path output = new Path(outputPath);Path input = new Path(inputPath);Configuration conf = new Configuration();HdfsUtil hdfs = new HdfsUtil(HDFS, conf);hdfs.rmr(inputPath);hdfs.mkdirs(inputPath);hdfs.copyFile(localFile, inputPath);hdfs.ls(inputPath);// 每次执行聚类前,删除掉上一次的输出目录HadoopUtil.delete(conf, output);// 执行聚类run(conf, input, output, new EuclideanDistanceMeasure(), t1, t2, convergenceDelta, maxIterations);}private static void run(Configuration conf, Path input, Path output,EuclideanDistanceMeasure euclideanDistanceMeasure, double t1, double t2,double convergenceDelta, int maxIterations) throws Exception {Path directoryContainingConvertedInput = new Path(output, "data");System.out.println("Preparing Input");// 将输入文件序列化,并选取RandomAccessSparseVector作为保存向量的数据结构InputDriver.runJob(input, directoryContainingConvertedInput,"org.apache.mahout.math.RandomAccessSparseVector");System.out.println("Running Canopy to get initial clusters");// 保存canopy的目录Path canopyOutput = new Path(output, "canopies");// 执行Canopy聚类CanopyDriver.run(conf, directoryContainingConvertedInput, canopyOutput,euclideanDistanceMeasure, t1, t2, false, 0.0, false);System.out.println("Running KMeans");// 执行k-means聚类,并使用canopy目录KMeansDriver.run(conf, directoryContainingConvertedInput,new Path(canopyOutput, Cluster.INITIAL_CLUSTERS_DIR + "-final"),output, convergenceDelta, maxIterations, true, 0.0, false);System.out.println("run clusterdumper");// 将聚类的结果输出至HDFSClusterDumper clusterDumper = new ClusterDumper(new Path(output, "clusters-*-final"),new Path(output, "clusteredPoints"));clusterDumper.printClusters(null);}
}在KmeansMahout类上点击右键并执行程序
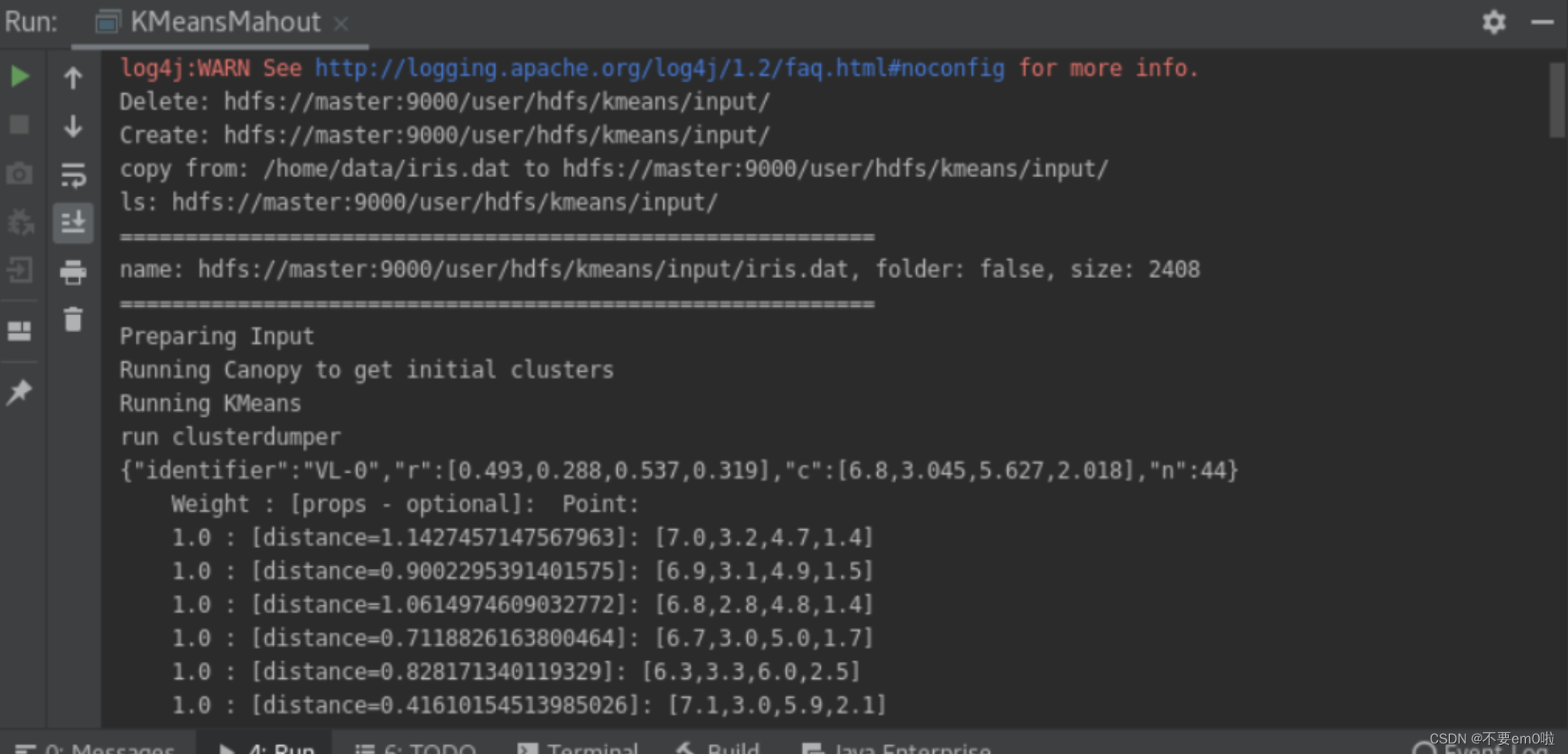
 执行结果在HDFS目录中
执行结果在HDFS目录中
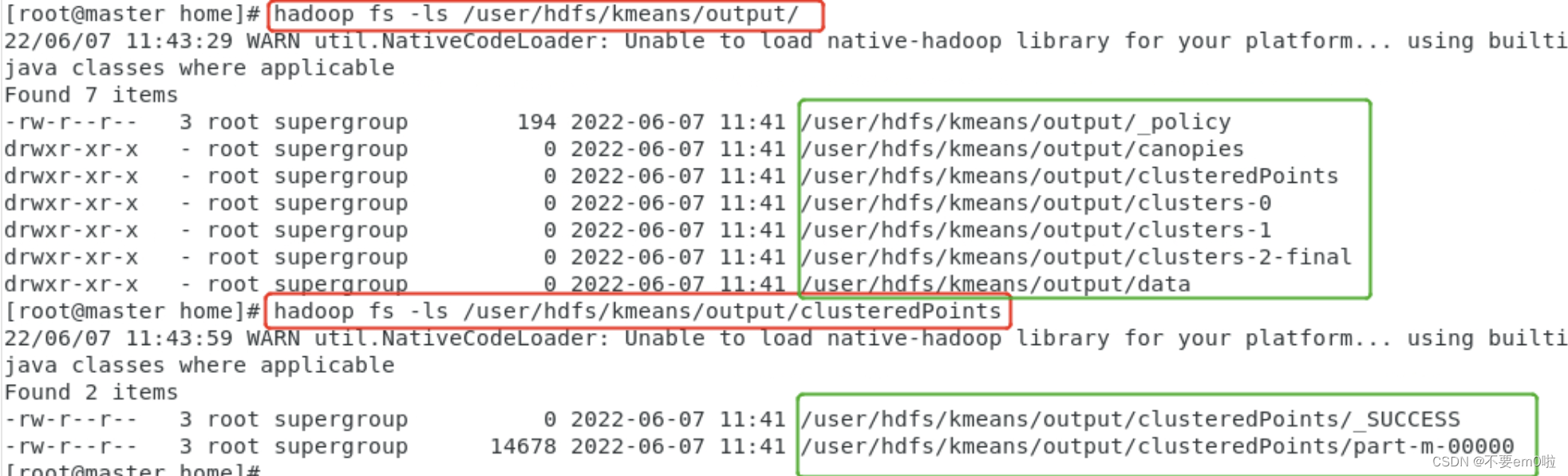
5.解析聚类结果:
- 从Mahout的输出目录下提取出所要的信息
- 编写ClusterOutput类,解析聚类后结果
package com;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.mahout.clustering.classify.WeightedPropertyVectorWritable;
import org.apache.mahout.math.Vector;import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;public class ClusterOutput {private static final String HDFS = "hdfs://master:9000";public static void main(String[] args) {try {// 需要被解析的mahout的输出文件String clusterOutputPath = "/user/hdfs/kmeans/output";// 解析后的聚类结果,将输出至本地磁盘String resultPath = "/home/data/result.txt";BufferedWriter bw;Configuration conf = new Configuration();conf.set("fs.default.name", HDFS);FileSystem fs = FileSystem.get(conf);SequenceFile.Reader reader = null;reader = new SequenceFile.Reader(fs, new Path(clusterOutputPath + "/clusteredPoints/part-m-00000"), conf);bw = new BufferedWriter(new FileWriter(new File(resultPath)));// key为聚簇中心IDIntWritable key = new IntWritable();WeightedPropertyVectorWritable value = new WeightedPropertyVectorWritable();while (reader.next(key, value)) {// 得到向量Vector vector = value.getVector();String vectorValue = "";// 将向量各个维度拼接成一行,用\t分隔for (int i = 0; i < vector.size(); i++) {if (i == vector.size() - 1) {vectorValue += vector.get(i);} else {vectorValue += vector.get(i) + "\t";}}bw.write(key.toString() + "\t" + vectorValue + "\n\n");}bw.flush();reader.close();} catch (Exception e) {e.printStackTrace();}}
}在ClusterOutput类上右键执行程序
 执行结果被保存在/home/data/result.txt文件中,打开终端执行以下命令
执行结果被保存在/home/data/result.txt文件中,打开终端执行以下命令
6.评估聚类效果:
- 编写InterClusterDistances类,计算平均簇间距离
package com;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Writable;
import org.apache.mahout.clustering.Cluster;
import org.apache.mahout.clustering.iterator.ClusterWritable;
import org.apache.mahout.common.distance.DistanceMeasure;
import org.apache.mahout.common.distance.EuclideanDistanceMeasure;import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
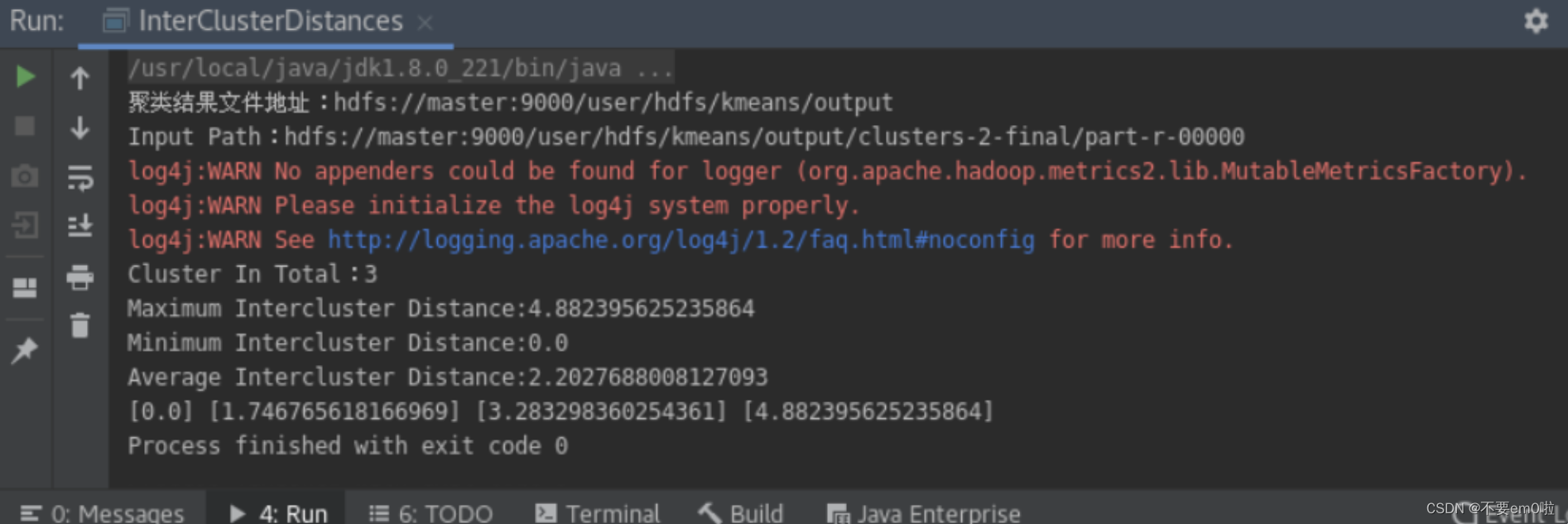
import java.util.Set;public class InterClusterDistances {private static final String HDFS = "hdfs://master:9000";public static void main(String[] args) throws Exception {String inputFile = HDFS + "/user/hdfs/kmeans/output";System.out.println("聚类结果文件地址:" + inputFile);Configuration conf = new Configuration();Path path = new Path(inputFile + "/clusters-2-final/part-r-00000");System.out.println("Input Path:" + path);FileSystem fs = FileSystem.get(path.toUri(), conf);List<Cluster> clusters = new ArrayList<Cluster>();SequenceFile.Reader reader = new SequenceFile.Reader(fs, path, conf);Writable key = (Writable) reader.getKeyClass().newInstance();ClusterWritable value = (ClusterWritable) reader.getValueClass().newInstance();while (reader.next(key, value)) {Cluster cluster = value.getValue();clusters.add(cluster);value = (ClusterWritable) reader.getValueClass().newInstance();}System.out.println("Cluster In Total:" + clusters.size());DistanceMeasure measure = new EuclideanDistanceMeasure();double max = 0;double min = Double.MAX_VALUE;double sum = 0;int count = 0;Set<Double> total = new HashSet<Double>();// 如果聚类的个数大于1才开始计算if (clusters.size() != 1 && clusters.size() != 0) {for (int i = 0; i < clusters.size(); i++) {for (int j = 0; j < clusters.size(); j++) {double d = measure.distance(clusters.get(i).getCenter(), clusters.get(j).getCenter());min = Math.min(d, min);max = Math.max(d, max);total.add(d);sum += d;count++;}}System.out.println("Maximum Intercluster Distance:" + max);System.out.println("Minimum Intercluster Distance:" + min);System.out.println("Average Intercluster Distance:" + sum / count);for (double d : total) {System.out.print("[" + d + "] ");}} else if (clusters.size() == 1) {System.out.println("只有一个类,无法判断聚类质量");} else if (clusters.size() == 0) {System.out.println("聚类失败");}}
}同样右键执行程序,得到下图结果
相关文章:
基于Mahout实现K-Means聚类
需求分析 需要对数据集进行预处理,选择合适的特征进行聚类分析,确定聚类的数量和初始中心点,调用Mahout提供的K-Means算法进行聚类计算,评估聚类结果的准确性和稳定性。同时,需要对Mahout的使用和参数调优进行深入学习…...
)
科技的成就(五十七)
535、Machine Learning "1959 年 7 月,塞缪尔首创 Machine Learning 一词。塞缪尔在“Some Studies in Machine Learning Using theGame of Checkers”一文中给 Machine Learning 下了个非正式定义:没有明确编程指令的情况下,能让计算机…...

动态IP代理技术在网络爬虫中的实际使用
目录 一、动态IP代理技术概述 二、动态IP代理技术的优势 三、动态IP代理技术的实际应用 四、注意事项 五、案例分析 六、结论 随着互联网的迅猛发展,网络爬虫成为了获取信息、分析数据的重要工具。然而,在进行大规模爬取时,爬虫常常面临…...

计算机网络:深入探索HTTP
引言: HTTP,全称超文本传输协议(Hypertext Transfer Protocol),是互联网上数据通信的基础。它定义了客户端(如浏览器)和服务器之间如何交互和传输数据。HTTP最初是为了支持Web浏览而设计的&…...
Netty(1)nio
一. NIO 基础 non-blocking io 非阻塞 IO 1. 三大组件 1.1 Channel & Buffer channel 有一点类似于 stream,它就是读写数据的双向通道,可以从 channel 将数据读入 buffer,也可以将 buffer 的数据写入 channel,而之前的 st…...
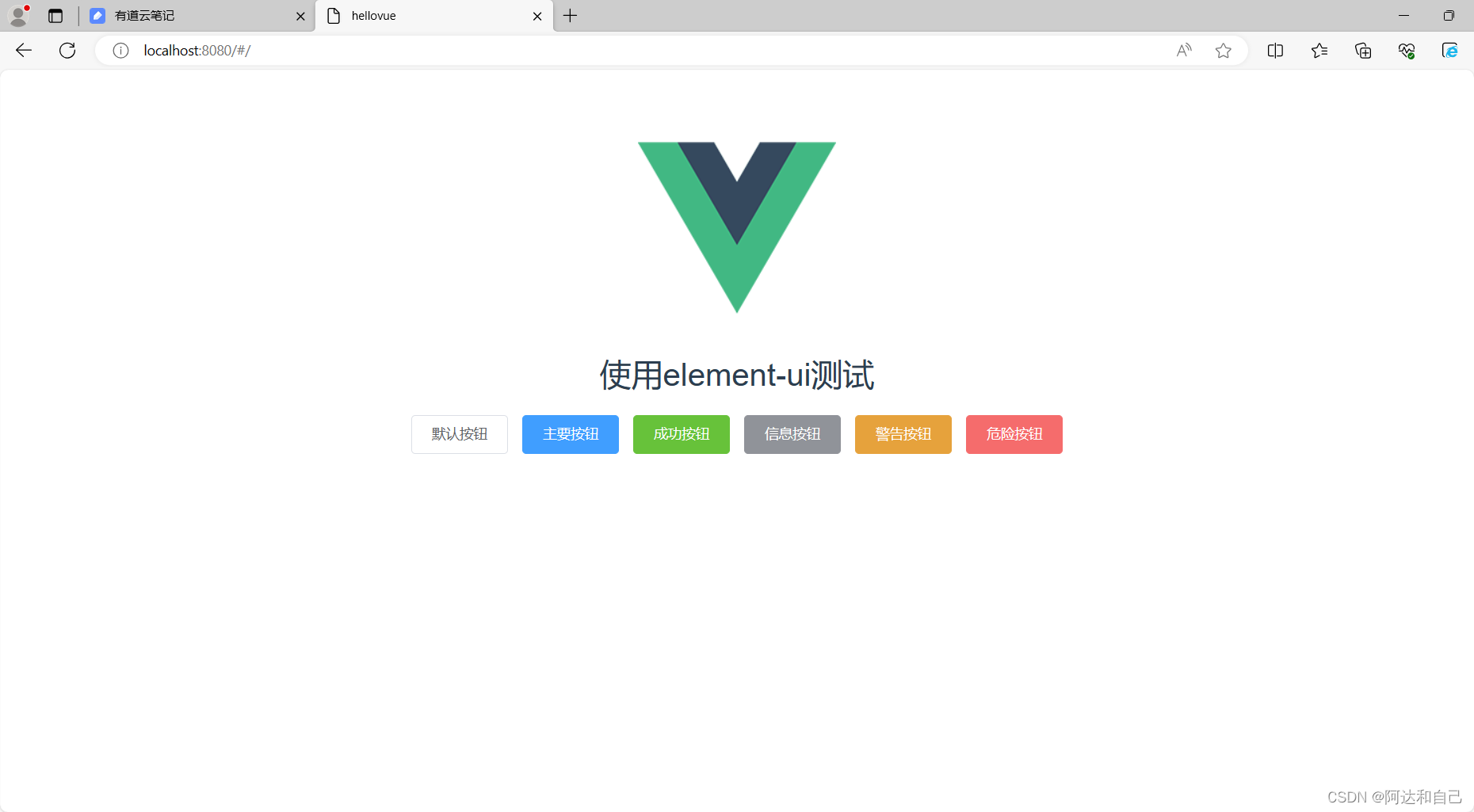
1.3 vue ui框架-element-ui框架
1 前言 ElementUI是一套基于VUE2.0的桌面端组件库,ElementUI提供了丰富的组件帮助开发人员快速构建功能强大、风格统一的页面。 ElementUI官网 https://element.eleme.io 2 安装 运行命令 cnpm i element-ui -S -S表示只在该项目下安装,不是全局安…...
)
关于MediaEval数据集的Dataset构建(Text部分-使用PLM BERT)
import random import numpy as np import pandas as pd import torch from transformers import BertModel,BertTokenizer from tqdm.auto import tqdm from torch.utils.data import Dataset import re """参考Game-On论文""" ""&qu…...

QML学习之Text
文本显示是界面开发中的重要内容,在Qt Quick模块中提供了 Text 项来进行文本的显示,其中可以使用 font 属性组对文本字体进行设置: font.bold:是否加粗,取值为true或false font.capitalization:大写策略&a…...
)
轮转数组(元素位置对调、数据的左旋、右旋)
189. 轮转数组 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮转 1 步: [7,1,2,3,4,5,6] 向右轮转 2 步: [6,7,1,2,3,4,5] 向右轮转 3 步: …...

喜迎乔迁,开启新章 ▏易我科技新办公区乔迁庆典隆重举行
2024年1月18日,易我科技新办公区乔迁庆典在热烈而喜庆的氛围中隆重举行。新办公区的投入使用,标志着易我科技将以崭新姿态迈向新的发展阶段。 ▲ 易我科技新办公区 随着公司业务的不断发展和壮大,为了更好地适应公司发展的需要,…...
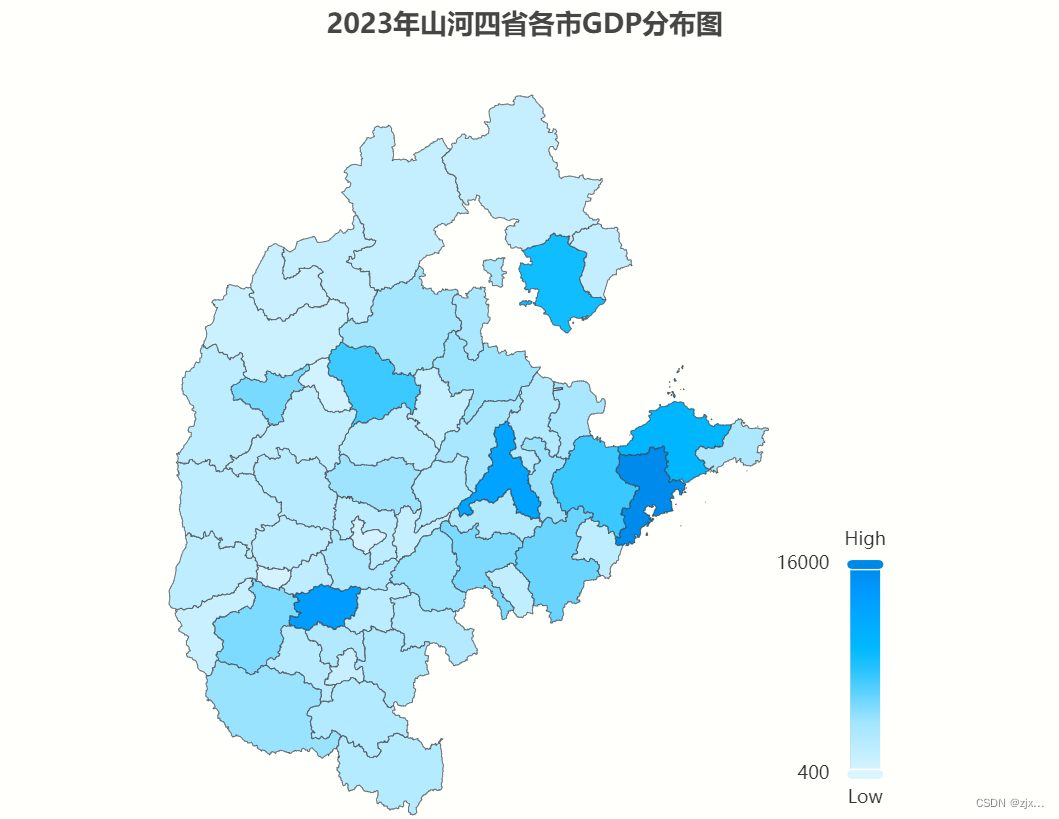
多个地区地图可视化
1. 配置Json文件 1.1 获得每个省份的json数据 打开 阿里云数据可视化平台 主页。 在搜索框中输入所需省份。 将json文件下载到本地。 1.2 将各省份的json数据进行融合 打开 geojson.io 主页 点击 open,上传刚刚下载的 json 文件,对多个省份不断…...
学习使用paddle来构造hrnet网络模型
1、首先阅读了hrnet的网络结构分析,了解到了网络构造如下: 参考博文姿态估计之2D人体姿态估计 - (HRNet)Deep High-Resolution Representation Learning for Human Pose Estimation(多家综合)-CSDN博客 最…...

Redis 多线程操作同一个Key如何保证一致性?
单线程模型:Redis 是单线程模型的,它通过一个事件循环来处理所有客户端请求,这意味着 Redis 在任何时刻只会处理一个请求,从而避免了并发访问同一个 Key 的问题。这种设计保证了数据的一致性。 乐观锁(Watchÿ…...

单链表合并
【问题描述】 建立两个升序排列的单链表,表中元素的数据类型是整数,将建立的两个链表合并为 一个新的升序的单链表,并输出显示已合并好的有序的单链表 。 【输入形式】分别输入两组数据,两组数据以回车分隔;每组数据…...

【如何像网吧一样弄个游戏菜单在家里】
GGmenu 个人家庭版游戏、应用管理 桌面图标管理器...

CSS~~
CSS是一门语言,用于控制网页表现 CSS(Cascading Style Sheet):层叠样式表 W3C标准:网页主要由三部分组成 结构:HTML 表现: CSS 行为:JavaScript 1,CSS的导入方式 (1)内联样式 在标签内部使用style属性,属性值是cs…...

Docker技术概论(1):Docker与虚拟化技术比较
Docker技术概论(1) Docker与虚拟化技术比较 - 文章信息 - Author: 李俊才 (jcLee95) Visit me at: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 291148484163.com. Shenzhen ChinaAddress of this article:https:…...
alibabacloud学习笔记07(小滴课堂)
讲解Sentinel自定义异常降级-新旧版本差异 讲解新版Sentinel自定义异常数据开发实战 如果我们都使用原生的报错,我们就无法得到具体的报错信息。 所以我们要自定义异常返回的数据提示: 实现BlockExceptionHandler并且重写handle方法: 使用F…...
Ansible-Playbook
目录 1、概念介绍 roles 角色 playbook 核心元素 ansible-playbook 命令 playbook 简单案例 2、Ansible 变量 自定义变量 facts 变量 Palybook 部署 LAMP ansible 端安装 LAMP playbook 系统环境脚本 构建 httpd 任务 构建 mariadb 任务 构建 php 任务 编写整个任务…...

UE5常见问题处理笔记
一、C工程中的文件出现很多头文件找不到,比如:#include CoreMinimal.h文件提示找不到。 解决方法:在UE编辑器中选择菜单Tools -> Refresh Visual Studio Project。 二、莫名其妙的编译错误。 解决方法,找到工程根目录下的Bi…...

Windows网络音频革命:Scream虚拟声卡完整指南
Windows网络音频革命:Scream虚拟声卡完整指南 【免费下载链接】scream Virtual network sound card for Microsoft Windows 项目地址: https://gitcode.com/gh_mirrors/sc/scream 还在为有线音频的束缚而烦恼吗?想象一下,将你的Window…...

RISC-V MCU移植RTOS实战:以鸿蒙OS LiteOS-M与CH32V307为例
1. 项目概述与核心思路 最近在折腾一块沁恒微电子的CH32V307开发板,这是一颗基于RISC-V架构的MCU,性能不错,外设也丰富。手头正好有个任务,需要把华为的鸿蒙OS LiteOS-M内核给移植上去。这活儿听起来挺唬人,但实际拆解…...

ATK-UART2ETH模块实战:5分钟搞定串口设备联网,告别老旧PLC的通讯烦恼
ATK-UART2ETH模块实战:5分钟搞定串口设备联网,告别老旧PLC的通讯烦恼 在工业自动化领域,老旧设备改造一直是个令人头疼的问题。想象一下这样的场景:车间里那台服役十年的西门子S7-200 PLC还在兢兢业业地工作,但它唯一…...

如何用Python快速接入Taotoken调用多模型API完成开发任务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何用Python快速接入Taotoken调用多模型API完成开发任务 对于开发者而言,快速验证想法、构建原型是开发流程中的关键环…...

手写LoRA:从矩阵低秩分解到PyTorch参数化实现
1. 项目概述:为什么今天你必须真正搞懂 LoRA,而不是只看个热闹我带过三届校招算法工程师,也帮五家中小企业的技术团队落地过大模型应用。每次聊到模型微调,总有人一上来就问:“老师,我这台3090能不能跑Llam…...

终极Python金融数据接口:3步掌握免费高效的A股数据获取方案
终极Python金融数据接口:3步掌握免费高效的A股数据获取方案 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析和量化交易领域,获取准确、及时且成本可控的市场…...

Burp Suite安装避坑指南:Java环境、代理配置与HTTPS解密全解析
1. 为什么Burp Suite的安装,比你想象中更值得花20分钟认真对待 很多人点开“Burp Suite安装教程”,心里想的是:“不就是下载个JAR包,双击运行吗?5分钟搞定。”我试过——在三台不同配置的Windows机器上,用…...

Python:4 == 4.0 结果为True的原因
特殊情况:在 Python 中,整数和浮点数进行比较时,如果数值相等,则结果为 True。即 4 4.0 的结果是 True。如果两个对象代表相同的概念或数值,即使类型不同(如 int 和 float),也可能返…...

2026年最新亲测3款亲子教育免费AI工具,再也不用为辅导作业头大了
作为一个天天跟音频、视频打交道的IT技术博主,同时也是一位二年级小学生的家长,我这两年踩过的“教育工具坑”真不少。孩子上课注意力不集中、回家记不住重点、家长会信息记不全、辅导作业时自己讲得口干舌燥孩子却一脸懵……这些场景,估计有…...

深圳不锈钢五金冲压件
在深圳,不锈钢五金冲压件的市场需求巨大,广泛应用于智能家居、无人机、医疗器械、安防设备等众多领域。然而,面对众多的供应商,如何挑选到合适的合作伙伴成为了许多企业的难题。今天,我们就来对比测评几家深圳的不锈钢…...