NLP - 依存句法分析、句子歧义
1. 语言结构的两种观点
- Constituency = phrase struct grammar = context-free grammars(CFGs)
- Dependency structure
对于context-free grammars(CFGs)
短语结构(Constituency):短语结构语法是一种描述语言结构的方法,它将句子划分为短语(phrase)的组合。根据短语结构语法的观点,句子由短语构成,而这些短语又由更小的短语或单词组成。
- w o r d s − > p h r a s e s − > b i g g e r p h r a s e s words -> phrases -> bigger phrases words−>phrases−>biggerphrases
上下文无关文法(CFGs):上下文无关文法是一种形式化的语法模型,用于描述一类语言的结构(嵌套短语)。它基于一组规则,其中每个规则指定了一个非终结符(可以被进一步展开的符号)如何被替换为终结符(不可再展开的符号)或其他非终结符。
- 举例: 举例: 举例:
E x p r − > E x p r + E x p r Expr -> Expr + Expr Expr−>Expr+Expr
E x p r − > E x p r ∗ E x p r Expr -> Expr * Expr Expr−>Expr∗Expr
E x p r − > ( E x p r ) Expr -> (Expr) Expr−>(Expr)
E x p r − > n u m Expr -> num Expr−>num


Det 指的是 Determiner, 在语言学中的含义为 限定词
P 指的是 Preposition,在语言学中的含义为 介词
…
NP 指的是 Noun Phrase, 在语言学中的含义为 名词短语
VP 指的是 Verb Phrase, 在语言学中的含义为 动词短语
PP 指的是 Prepositional Phrase, 在语言学中的含义为 介词短语
举例:

总结:
在自然语言中,将句子处理为constituency grammar,constituency grammar的标准形式是context-free grammars。还有其他的方法,比如说tree adjoining grammars等。
但是在计算机语言中,另一种dependency structure看待方式最常见。
对于Dependency structure
依存结构(Dependency Structure) 是一种描述语言结构的语法表示方法,它关注词与词之间的依存关系。
它不是使用各种类型的短语,而是直接通过单词与其他的单词关系表示句子的结构,显示哪些单词依赖于(修饰或是其参数)哪些其他单词。
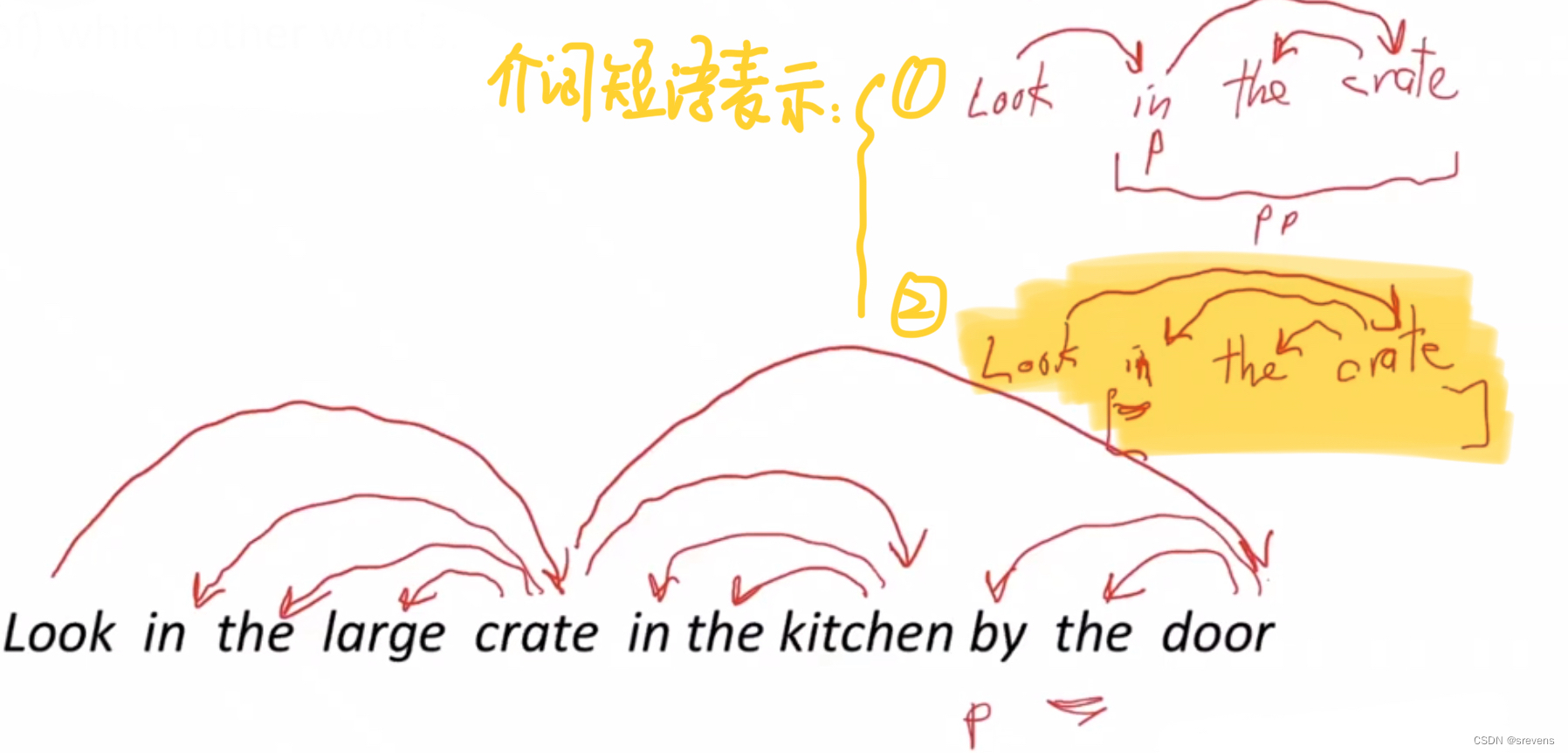
look 是整个句子的根,look 依赖于 crate (或者说 crate 是 look 的依赖)
o in, the, large 都是 crate 的依赖
o in the kitchen 是 crate 的修饰
o in, the 都是 kitchen 的依赖
o by the door 是 crate 的依赖
为什么我们需要句子结构?
为了能够正确的解释语言。因为一个句子常常出现一下错误:
介词短语依附歧义

San Jose cops kill man with knife
- 警察用刀杀了那个男子
- cops 是 kill 的 subject (subject 指 主语)
man 是 kill 的 object (object 指 宾语)
knife 是 kill 的 modifier (modifier 指 修饰符)
- cops 是 kill 的 subject (subject 指 主语)
- 警察杀了那个有刀的男子
- knife 是 man 的 modifier (名词修饰符,简称为 nmod)
中文一般不会出现这种问题,因为中文的介词短语通常位于动词的前面。
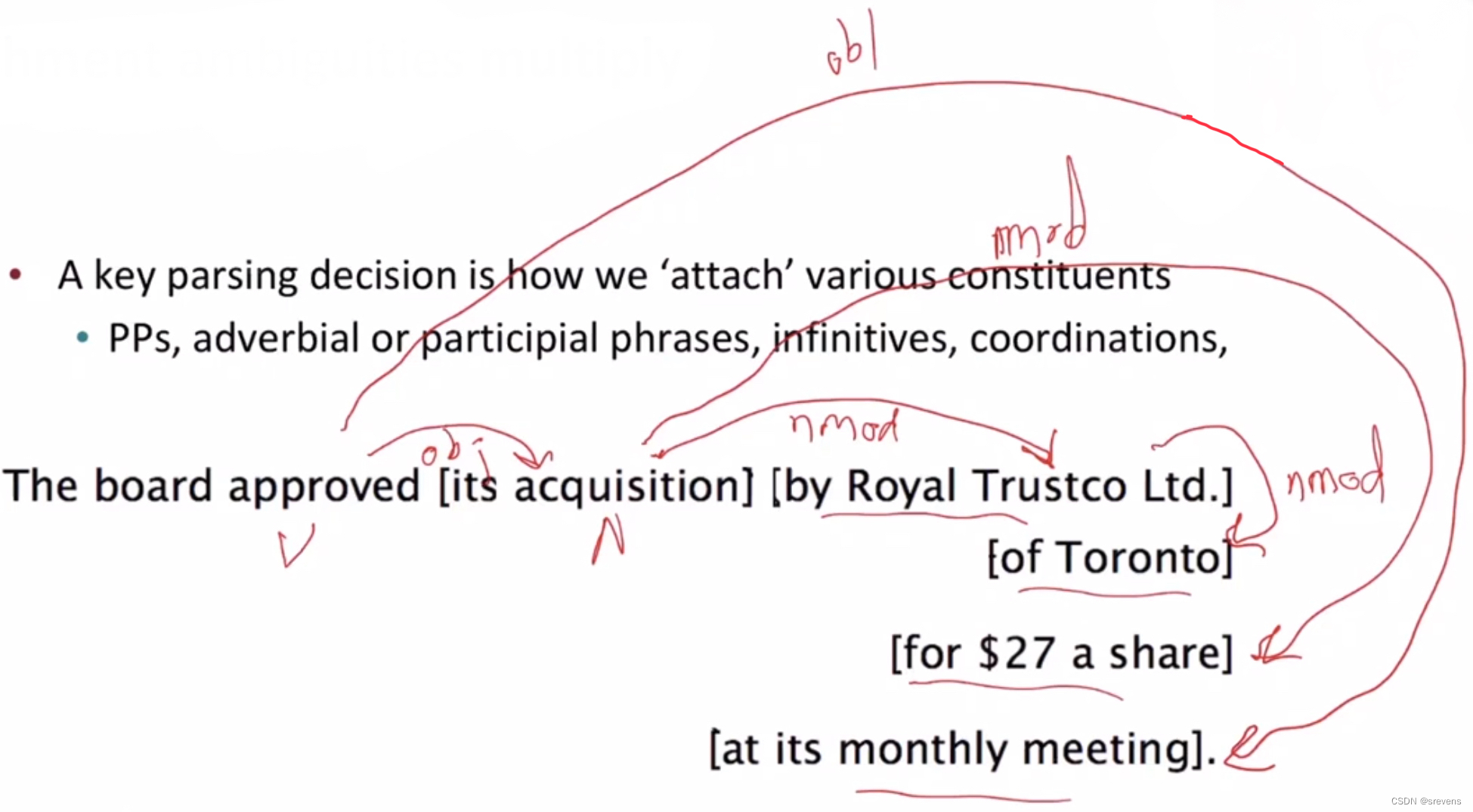
board 是 approved 的 主语,acquisition 是 approved 的谓语
上述句子中有四个介词短语:
by Royal Trustco Ltd. 是修饰 acquisition 的,即董事会批准了这家公司的收购
of Toronto 可以修饰 approved, acquisition, Royal Trustco Ltd. 之一,经过分析可以得知是修饰 Royal Trustco Ltd. 即表示这家公司的位置
for $27 a share 修饰 acquisition
at its monthly meeting 修饰 approved , 即表示批准的时间地点
面对这样复杂的句子结构,我们需要考虑指数级的可能结构,这个序列被称为 Catalan numbers
Catalan numbers : C n = ( 2 n ) ! / [ ( n + 1 ) ! n ! ] :C_n=(2n)!/[(n+1)!n!] :Cn=(2n)!/[(n+1)!n!]
协调范围模糊

形容词修饰语歧义

例句:Students get first hand job experience
- first hand 表示 第一手的,直接的,即学生获得了直接的工作经验
- first 是 hand 的形容词修饰语(amod)- first 修饰 experience, hand 修饰 job 😏😏😏😏
动词短语依存歧义

例句:Mutilated body washes up on Rio beach to be used for Olympic beach volleyball.
- to be used for Olympic beach volleyball 是 动词短语(VP)
- 修饰的是 body 还是 beach ?
依存路径识别语义关系
.
.
2. 依存语法和依存结构
依存语法 假设 句法结构包括词汇项之间的关系,通常是二元不对称关系,称为依赖关系,用箭头表示。
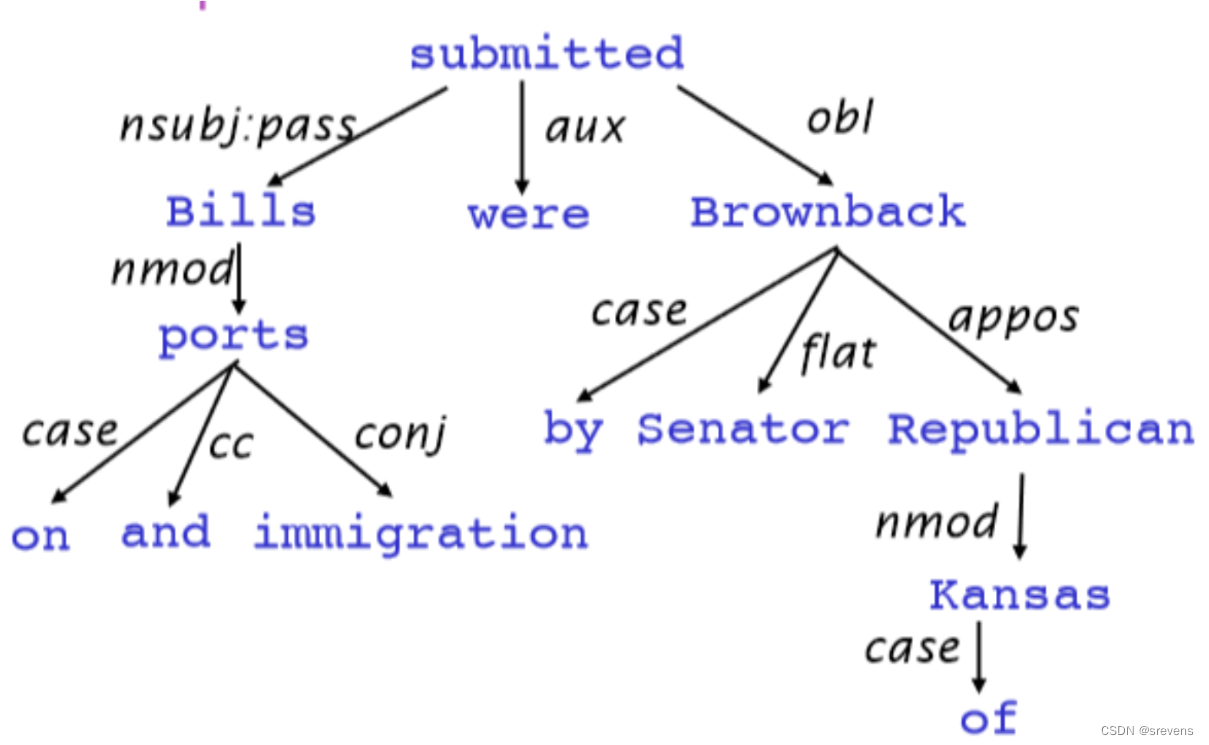
箭头通常标记为语法关系的名称(主题、介词对象、apposition等)。
依赖关系的获取一般参考 通用依赖(universal dependency)。
箭头连接 头部(上级) 和 依赖(下属)
- A -> 依赖于 A 的事情
通常,依赖关系形成一棵树(单头、无环、连接图)

我们通常添加一个 假ROOT 指向整个句子的root ,因此句子里的每个词都可以依赖于句子中的另一个词 或 句子的假ROOT。
后面构建解析时,会用到。
自然语言处理并开始构建依存语法
构建通用依赖关系(Universal Dependencies):
我们想要拥有一个统一的、并行的依赖描述,可用于任何人类语言。
- 以前 手工编写语法(grammar) 然后训练得到可以解析句子的解析器
- 用一条规则捕捉很多东西真的很有效率,但是事实证明这在实践中不是一个好主意
- 只是为一个特定的解析器编写语法,可重用性差
- 语法规则符号越来越复杂,并且没有共享和重用人类所做的工作
- 句子结构上的 treebanks 支持结构更有效
带注释数据的兴起
Treebank是一个包含大量句子的语料库,每个句子都进行了句法分析,并标注了依存关系。这些标注的句法结构提供了从句子中提取依存关系的基础数据。
通过使用Treebank,研究人员可以分析不同语言中的句法结构,并从中提取共性和普遍性的依存关系模式。他们可以识别出常见的依存关系类型、确定词语之间的依存关系,以及捕捉不同语言中的语法规律。
- 从一开始,构建 treebank 似乎比构建语法慢得多,也没有那么有用
- 但是 treebank 给我们提供了许多东西
-
- 具有高度可重用性
- 许多解析器、词性标记器等可以构建在它之上
- 能够获得更多关于句子的统计信息,如频率和分布信息
- 是一种评估系统的方法,为特定句子选择正确的解析器(评估解析器准确度)
- 具有高度可重用性
通过treebank可以获得通用依赖关系,一旦有了依赖关系,我们如何构建解析器?
为了构建一个准确的依赖项解析器,除了已经有了依赖关系的标注数据外,还需要其他信息来源,这是因为:
- 数据稀疏性: Treeband 依赖关系标注数据可能是有限的,特别是对于某些特定语言或领域而言。在这种情况下,单纯依靠标注数据可能无法涵盖所有语言结构的变化和复杂性。额外的信息来源可以帮助解析器学习更全面、更准确的依赖关系。
- 上下文信息: 依赖项解析需要考虑句子中的上下文信息,而单独的依赖关系标注数据往往只提供了局部的依赖关系信息。通过引入其他信息来源,例如语法规则、语言模型或词汇语境等,可以帮助解析器更好地理解句子的整体结构和上下文关系。
- 错误修正和噪声处理: 标注数据可能存在错误或噪声,这可能导致依赖项解析器学习到不正确的依赖关系。通过利用其他信息来源,可以帮助检测和修正标注数据中的错误,提高解析器的准确性。
- 泛化能力: 依赖项解析器的目标是能够适应新的、未标注的句子,而不仅仅是标注数据中的例子。额外的信息来源可以提供更广泛的语言知识和特征,帮助解析器泛化到新的句子并进行准确的解析。
|||
V
依赖项解析的信息来源是什么?
- Bilexical affinities(两个单词间的密切关系)
- [discussion → \to → issues] 是可能的
- Dependency distance(依赖距离)
- 依赖项主要是邻近词
- Intervening material(介于中间的物质)
- 依赖很少跨越介于中间的动词或标点符号
- Valency of heads(中心词的价位)
- 一个中心词通常在哪一侧有多少依赖项?

|||
V
有了这些依赖项解析的信息,我们怎么使用这些信息来构建解析器?
通过为每个单词选择它所依赖的其他单词(包括根)来解析一个句子
- 通常有一些限制
- 只有一个单词是依赖于根的
- 不存在循环 A → B , B → A A\to B,B\to A A→B,B→A
- 这使得依赖项成为树
- 箭头是否可以交叉?
- 箭头(依赖关系)通常是不允许交叉的,这被称为投射性(projectivity)
- 在 非投射性(non-projective) 依赖结构中,箭头可以交叉(下面这个例子)

投射性(projectivity)
投射性(projectivity):当单词按线性顺序排列时,没有交叉的依赖弧,所有的弧都在单词的上方
- 用CFG树表示的依赖关系必须是投影的
- 通过将每个类别的一个子类别作为头来形成依赖关系
- 依赖理论通常允许 非投射(non-projective)结构 来解释移位的成分
- 如果没有这些非投射依赖关系,就不可能很容易获得某些结构的语义
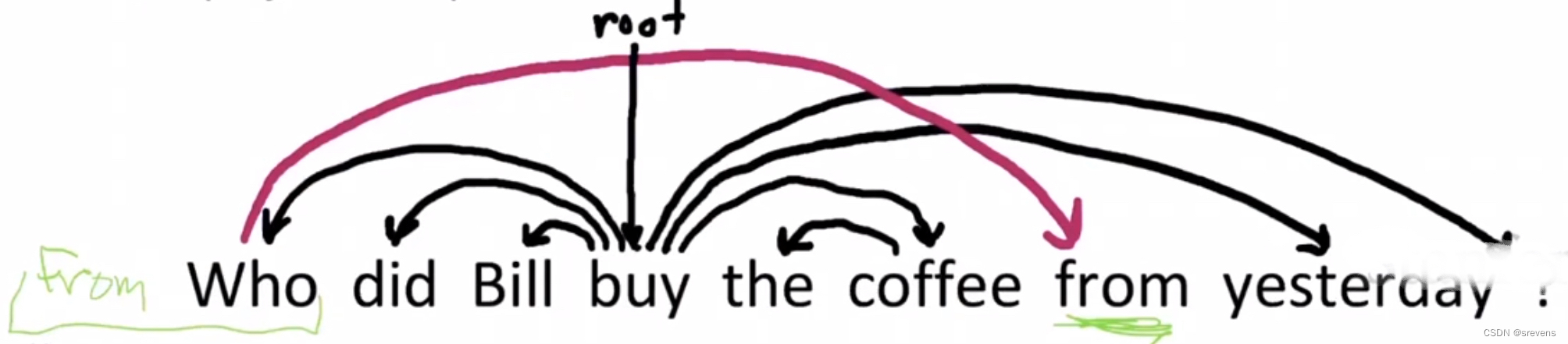
- 如果没有这些非投射依赖关系,就不可能很容易获得某些结构的语义
.
3. 依存句法分析方法
如何构建解析器?
- Dynamic programming
- Eisner(1996)提出了一种复杂度为 O ( n 3 ) O(n^3) O(n3) 的聪明算法
- 它生成头部位于末尾而不是中间的解析项
- Graph algorithms
- 为一个句子创建一个最小生成树
- McDonald et al:s (2005) MSTParser 使用ML分类器独立地对依赖项进行评分(他使用MIRA进行在线学习,但它也可以是其他东西)
- Constraint Satisfaction
- 去掉不满足硬约束的边
- Karlsson(1990), etc.
- “Transition-based parsing” or"deterministic dependency parsing"
- 良好的机器学习分类器
- MaltParser(Nivreet al. 2008)指导下的依存贪婪选择。已证明非常有效。
Greedy transition-based parsing[Nivre 2003]
基于贪婪转换的解析 的一种简单形式:
- 解析器执行一系列自底向上的操作
- 大致类似于shift-reduce解析器中的"shift"或"reduce",但"reduce"操作专门用于创建头在左或右的依赖项
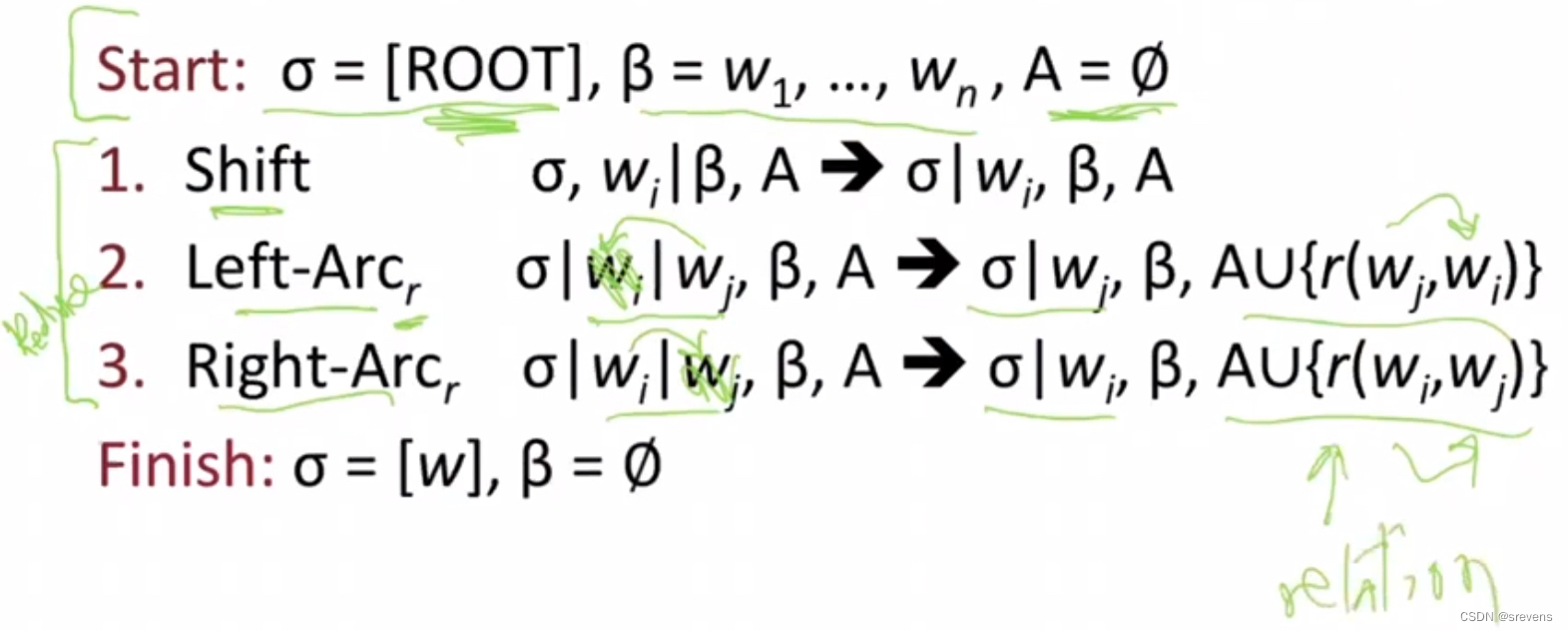
- 解析器如下:
- 栈 σ 写在右上方
- 以 ROOT 符号开始,由若干 w i w_i wi 组成
- 缓存 β \beta β 写在左上方
- 以输入序列开始,由若干 w i w_i wi 组成
- A A A 是一个依存弧的集合 ,
- 一开始为空。每条边的形式是 ( w i , r , w j ) (w_i,r,w_j) (wi,r,wj) , 其中 r r r 描述了节点的依存关系
- 一组操作
- 栈 σ 写在右上方
- 最终目标是 σ = [ w ] , β = ϕ A 包含了所有的依存弧 \sigma= [w],\ \beta= \phi\\\ A 包含了所有的依存弧 σ=[w], β=ϕ A包含了所有的依存弧
伪代码
状态转变示意图
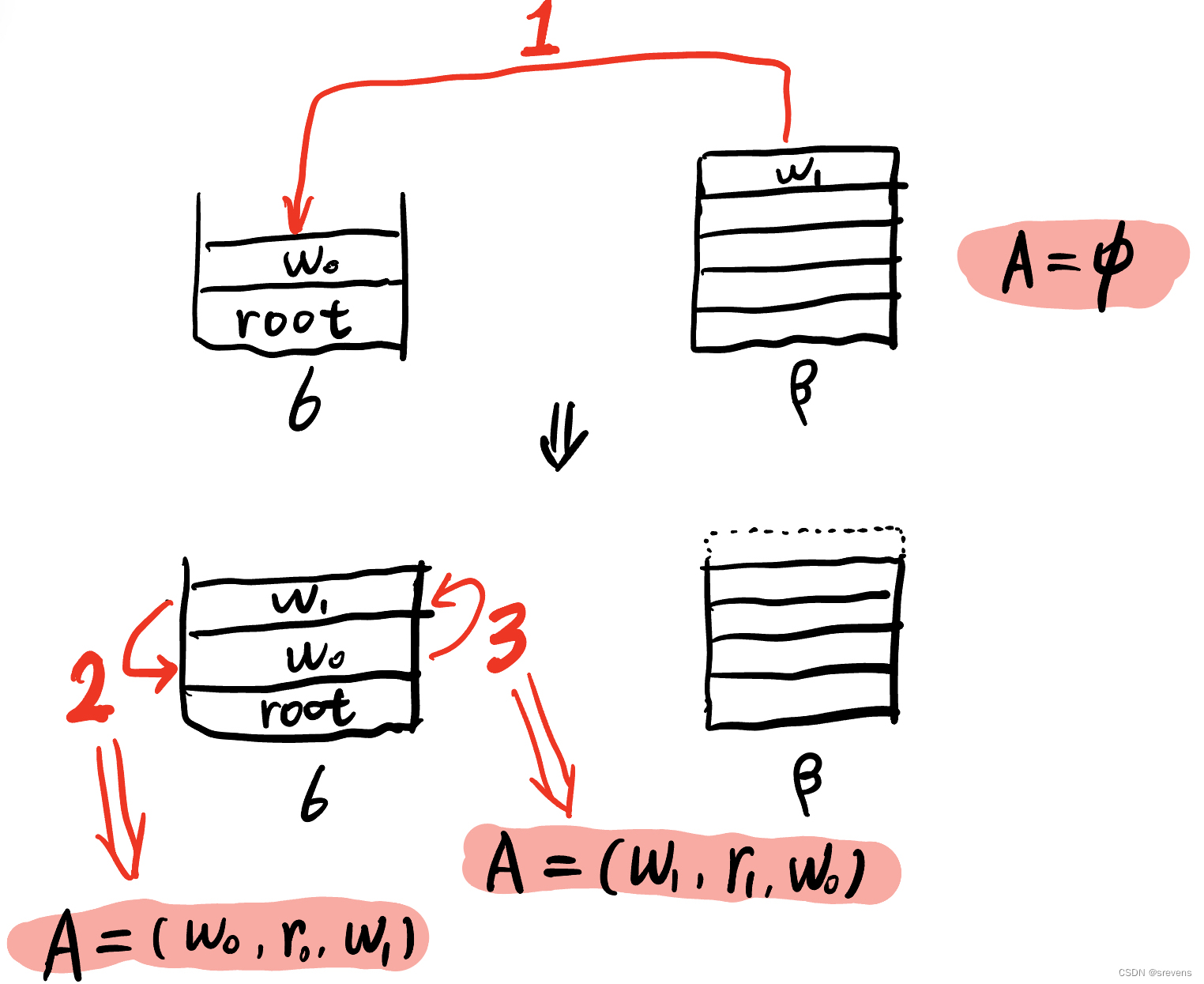
state之间的转变有三类:
· SHIFT:将buffer中的第一个词移出并放到stack上。
· LEFT-ARC:将 ( w j , r , w i ) (w_j,r,w_i) (wj,r,wi) 加入边的集合 A, 其中 w i w_i wi 是stack上的次顶层的词, w j w_j wj 是stack上的最顶层的词。
· RIGHT-ARC:将 ( w i , r , w j ) (w_i,r,w_j) (wi,r,wj) 加入边的集合 A, 其中 w i w_i wi 是stack上的次顶层的词, w j w_j wj 是stack上的最顶层的词。
我们不断的进行上述三类操作,直到从初始态达到最终态。
我们在每个状态下该如何选择状态转换呢?
||| (当然还有其他的转变方案)
V
基于 Arc 标准转换的解析器
基于贪婪转换的解析是基于Arc标准转换的一种具体实现方法。
“I ate fish” 例子分析
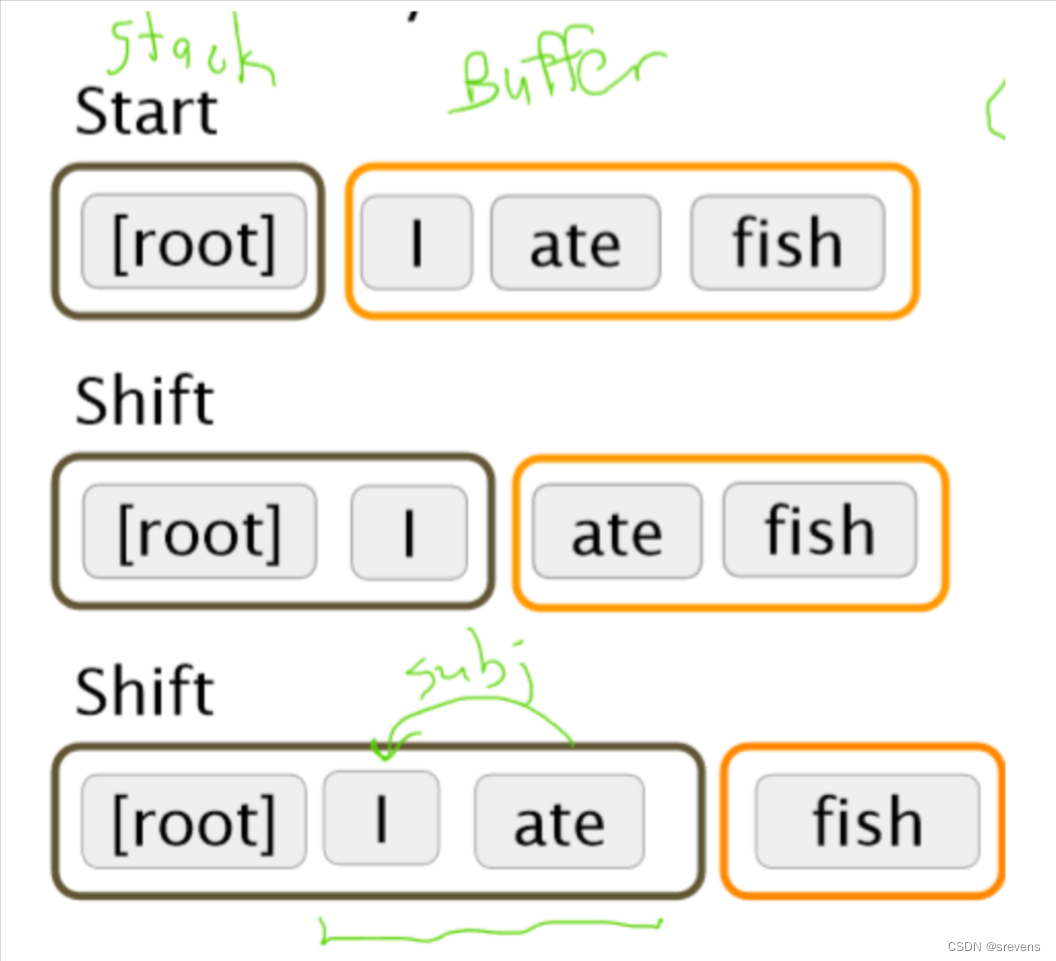
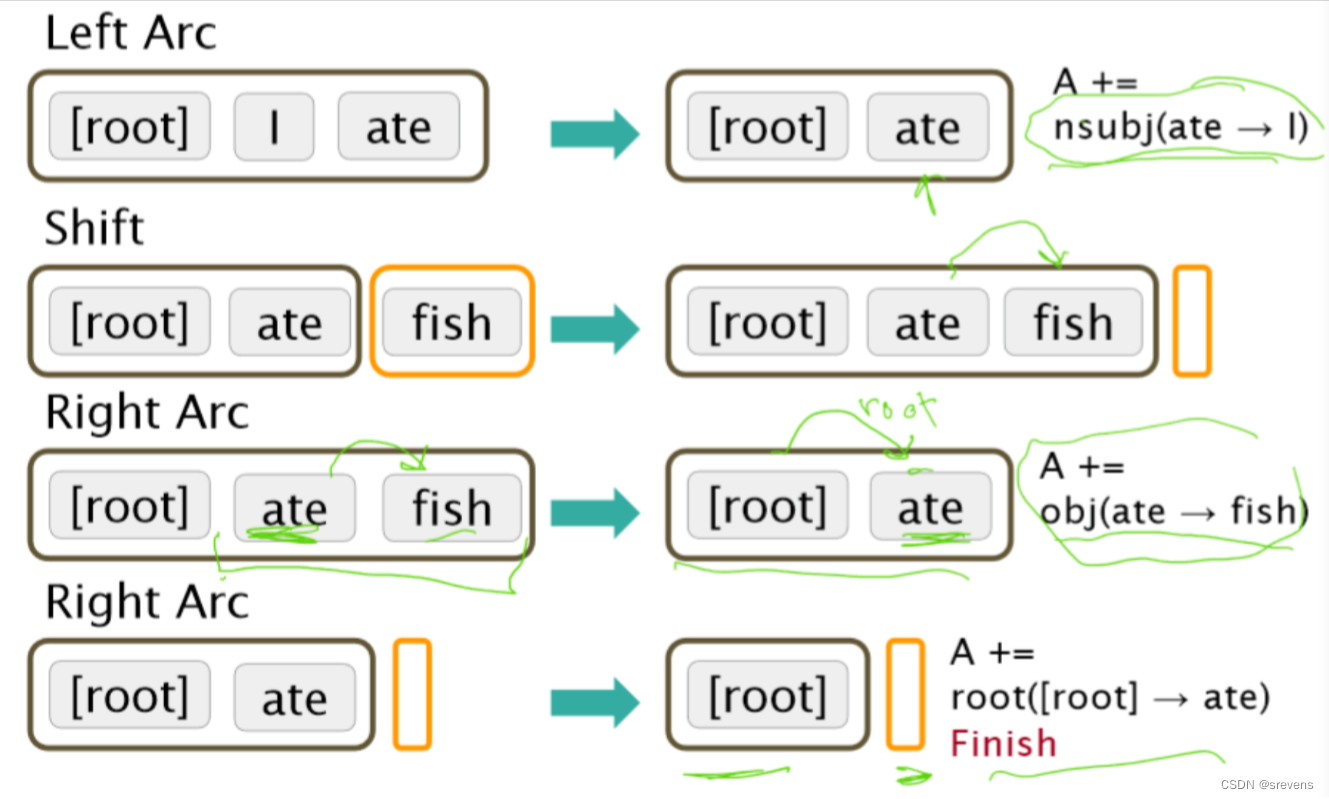
我们如何选择下一步行动 / 怎么判断我们选择的下一步对不对?
用机器学习!
MaltParser[Nivreand Hall 2005]
MaltParser是一个支持Greedy transition-based parsing的工具,它提供了基于Arc标准的转移系统解析算法的实现。
- 每个转换动作都由一个有区别分类器(例如softmax classifier) 对每个合法的转换进行预测
- 最多三种无类型的选择
- 左弧(Left-Arc)、右弧(Right-Arc)和规约(Reduce)
- 当带有类型时,对于每个可能的依存关系类型,都可以进行左弧和右弧的转换操作,以及规约操作。
- 所以最多 ∣ R ∣ × 2 + 1 |R|\times2+1 ∣R∣×2+1 种,其中 ∣ R ∣ |R| ∣R∣是可能的依存关系类型数目
- 特征可以包括栈顶单词、PQS(部分队列状态);缓冲区中的第一个单词、POS(词性)等等。
- 特征在预测转换动作时起着重要的作用。它们提供当前句子状态的信息,帮助分类器做出正确的转换动作预测。
- 最多三种无类型的选择
- 在最简单的形式中是没有搜索的
- 在解析过程中不使用搜索策略,而是根据分类器的预测结果直接执行转换操作。 这种形式不考虑多个可能的解析路径,而是仅根据当前状态和分类器的预测进行决策。虽然这种形式简单直接,但由于每个步骤只考虑局部最优解,可能会牺牲一些准确性,准确性可能不如使用搜索策略的更复杂方法。
- 但是,如果你愿意,你可以有效地执行一个 Beam search 束搜索(虽然速度较慢,但效果更好):
- 在解析过程中,在每个时间步骤中保留k个最好的解析结果。
- 这样做的目的是探索多个可能的解析路径,并在解析过程中保留一些备选的选择。通过保留多个解析前缀,可以增加解析的覆盖范围,提高解析准确性。
- 该模型的精度略低于依赖解析的最高水平,但它提供了非常快的线性时间解析,性能非常好。
依存解析评估:(标记)依存准确度
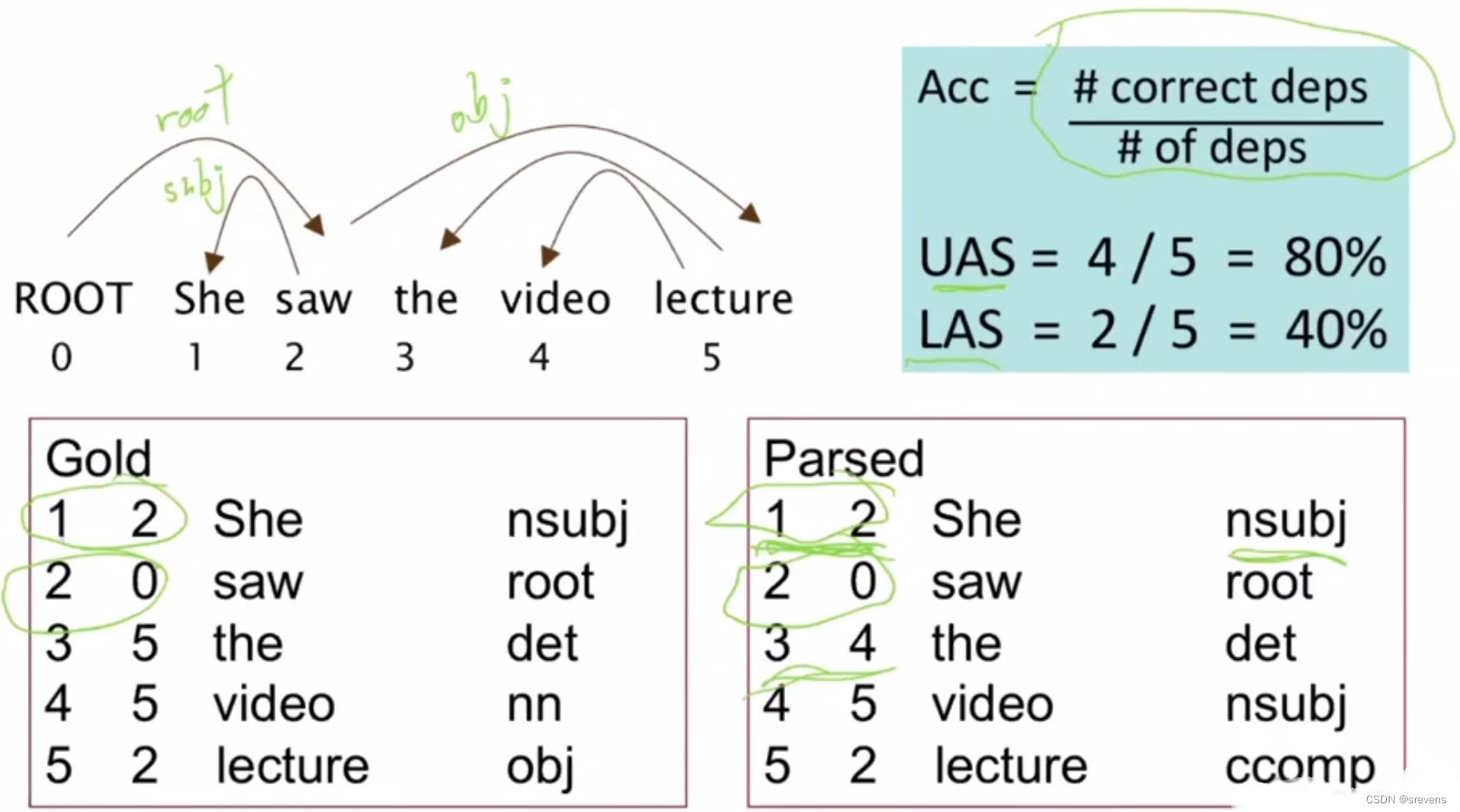
其中,UAS (unlabeled attachment score)指 无标记依存正确率,LAS (labeled attachment score)指 有标记侬存正确率。
怎么构建机器学习分类器?
先要 特征表示:
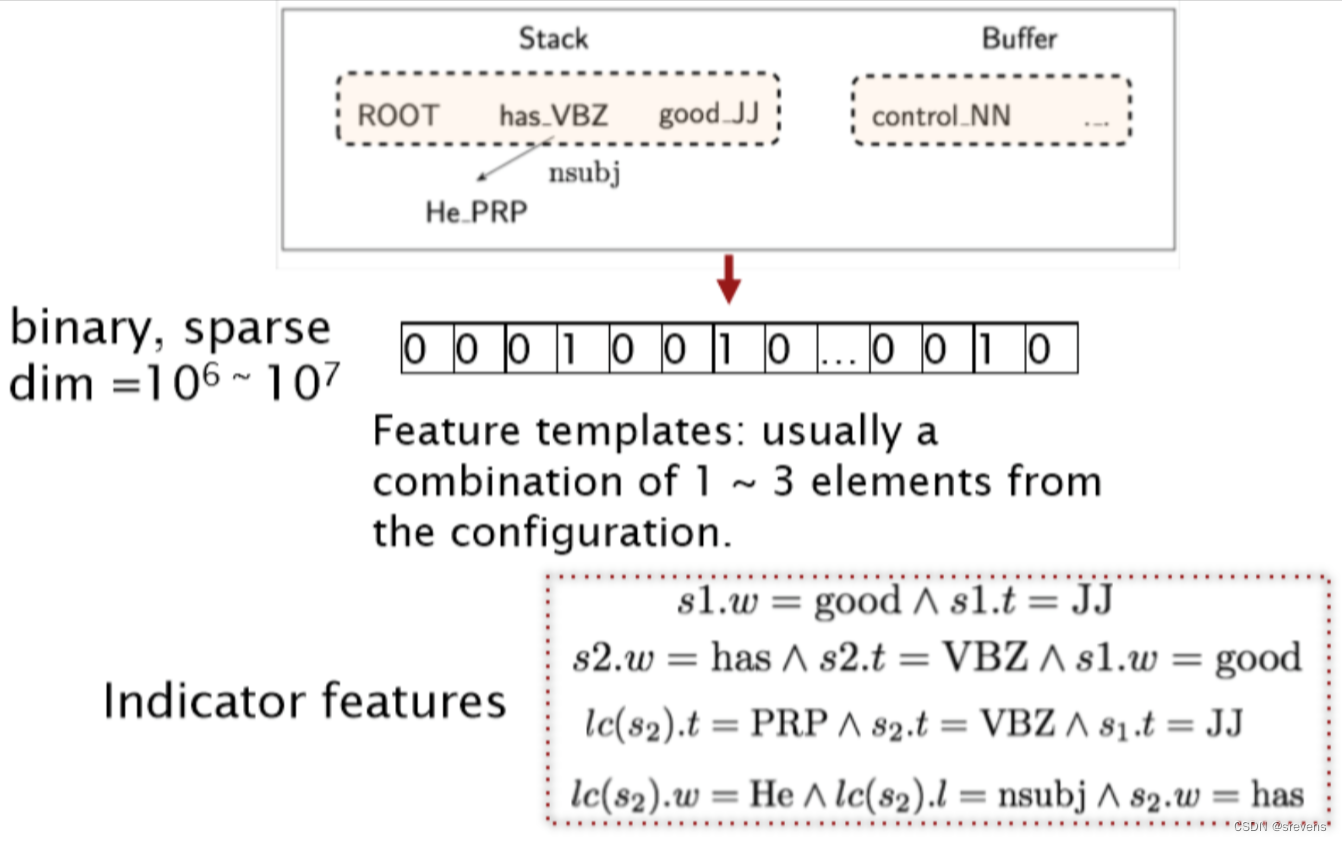
在传统的特征表示方法中,特征向量通常是非常长的二元稀疏向量(大多数元素取值为0),其维度范围在 1 0 6 10^6 106到 1 0 7 10^7 107之间。
特征模板 是一种用于构建特征向量的模板或规则。
- 它们通常由1到3个元素组成,每个元素代表一个特定的语言学或结构属性。
- 特征模板定义了如何从输入数据中提取特征,并将其表示为特征向量的形式。
指示器特征(indicator features) 是特征模板中的一种类型,它用于表示某些属性或条件的存在与否。
- 例如:缓冲区的第一个词是否是名词?
- 指示器特征是二元的,只能取0或1的值。
- 对于每个特征,如果属性存在,则特征向量中对应的位置设置为1;
- 如果属性不存在,则设置为0。
举个例子,假设我们正在进行垃圾邮件分类任务。
- 我们可以定义一个特征模板,其中包含三个元素:(1) 是否包含词语"buy",(2) 是否包含词语"money",(3) 是否包含词语"discount"。对于每个元素,我们可以使用指示器特征来表示其存在与否。
- 假设我们有一封邮件内容为:“Get a 50% discount on your next purchase!”。对于我们定义的特征模板,邮件中包含了"discount"这个词,因此对应的指示器特征值为1;而"buy"和"money"这两个词不在邮件中,所以对应的指示器特征值为0。特征向量可以表示为 [0, 0, 1]
通过使用这种特征表示方法,我们可以将输入数据转换为高维的稀疏特征向量,其中每个元素代表一个特定的属性或条件的存在与否。这样的特征向量可以用于训练机器学习分类器,并帮助分类器学习样本之间的模式和关系。
处理非投影性(non-projectivity)
- 弧标准算法通常只构建投影依赖树,即仅考虑形成投影结构的依存关系。
非投影性指的是句子中存在无法形成投影结构的依存关系。 - 处理方法:
- 在非投影弧上宣布失败:这意味着当存在无法形成投影结构的弧时,系统会放弃尝试构建该弧,从而确保最终的依存树是投影的。
- 只使用依赖形式的投影表示:一些语言的依存结构允许使用依赖形式来表示投影结构。在这种情况下,只使用依赖形式的结构来构建依存树,而非投影弧被忽略。
- 使用投影依赖项解析算法的后处理器:可以使用投影依赖项解析算法的后处理器来识别和解析非投影链接。这些后处理器可以通过修改依存树或添加额外的转换来处理非投影弧。
- 添加额外的转换:可以通过添加额外的转换来模拟非投影结构。例如,可以添加一个额外的交换转换或冒泡排序转换,以处理非投影弧。
- 转移到不受投影性限制的解析机制:另一种策略是将解析机制转移到不需要或不考虑投影性约束的方法上。例如,可以使用基于图的MSTParser(最小生成树解析器),它以图的形式表示句子结构,不受投影性限制。
相关文章:
NLP - 依存句法分析、句子歧义
1. 语言结构的两种观点 Constituency phrase struct grammar context-free grammars(CFGs)Dependency structure 对于context-free grammars(CFGs) 短语结构(Constituency):短语结构语法是一种描述语言结构的方法,它将句子划…...
vue实现图片上传至oss,返回url插入数据库,最后在前端页面上回显图片
vue前端上传图像 上传图片 使用上传图片的upload组件 <el-form-item label"设备图像"><el-upload//设置class样式class"avatar-uploader"//绑定上传路径:action"uploadUrl"//携带token值:headers"tokenInfo":show-file-lis…...

C++学习笔记:set和map
set和map set什么是setset的使用 关联式容器键值对 map什么是mapmap的使用map的插入方式常用功能map[] 的灵活使用 set 什么是set set是STL中一个底层为二叉搜索树来实现的容器 若要使用set需要包含头文件 #include<set>set中的元素具有唯一性(因此可以用set去重)若用…...

990-28产品经理:Different types of IT risk 不同类型的IT风险
Your IT systems and the information that you hold on them face a wide range of risks. If your business relies on technology for key operations and activities, you need to be aware of the range and nature of those threats. 您的IT系统和您在其中持有的信息面临…...

wpa_supplicant与用户态程序的交互分析
1 wpa_supplicant与用户态程序wpa_cli的交互过程 1.1 交互接口类型 wpa_supplicant与用户态程序交互的主要接口包括以下几种: 1)命令行界面:通过命令行工具 wpa_cli 可以与 wpa_supplicant 进行交互。wpa_cli 允许用户执行各种 wpa_suppli…...
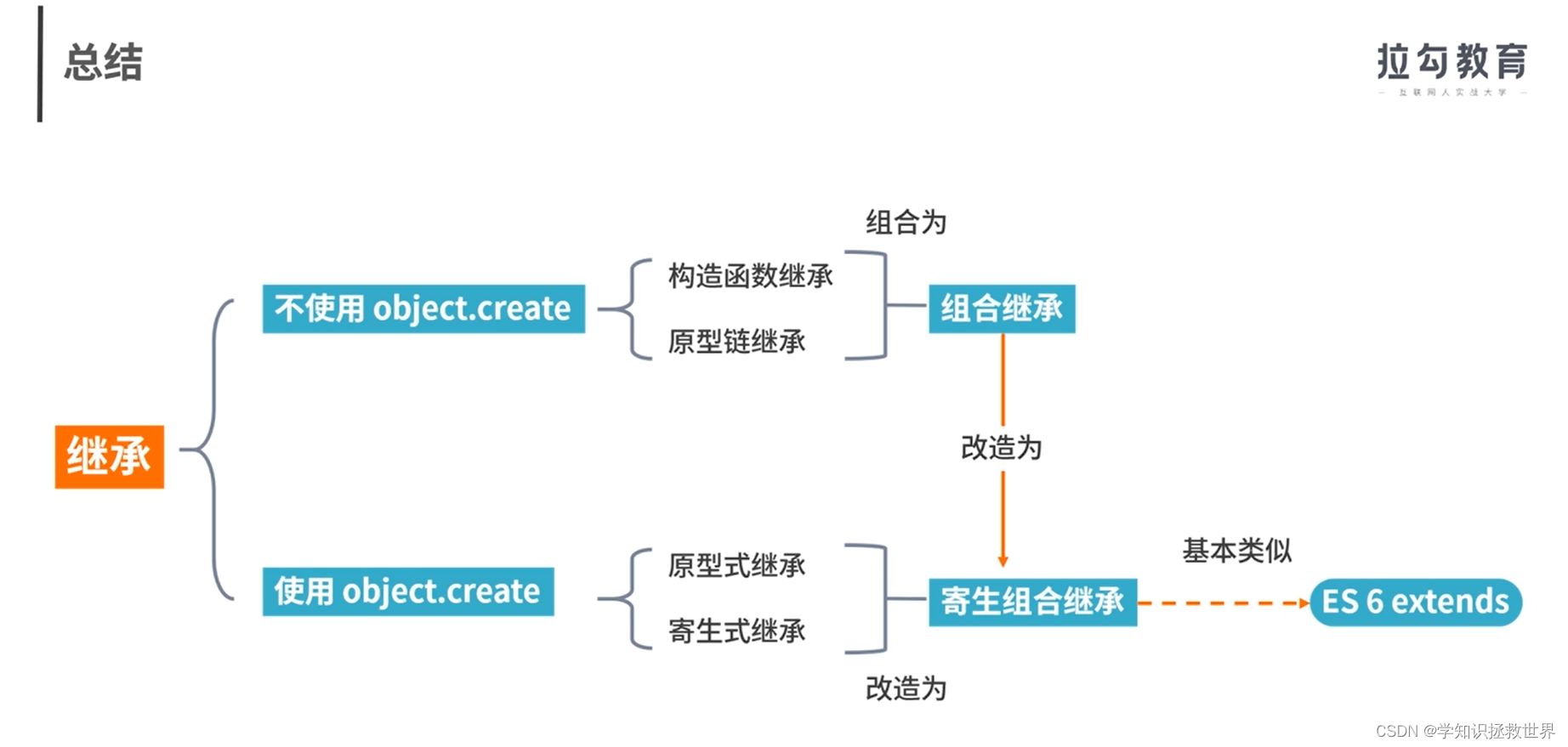
JavaScript继承 寄生组合式继承 extends
JavaScript继承 1、JS 的继承到底有多少种实现方式呢? 2、ES6 的 extends 关键字是用哪种继承方式实现的呢? 继承种类 原型链继承 function Parent1() {this.name parentlthis.play [1, 2, 3] }function Child1() {this.type child2 }Child1.prototype new Parent1(…...

Nginx 和Tomcat比较
Nginx和Tomcat是两种不同的技术,它们在应用场景、性能、动态处理能力等方面有所区别: 应用场景 Nginx通常用作静态内容服务器或代理服务器,可以将外部请求转发给其他应用服务器,如Tomcat、Django等。而Tomcat则主要用作应用服…...
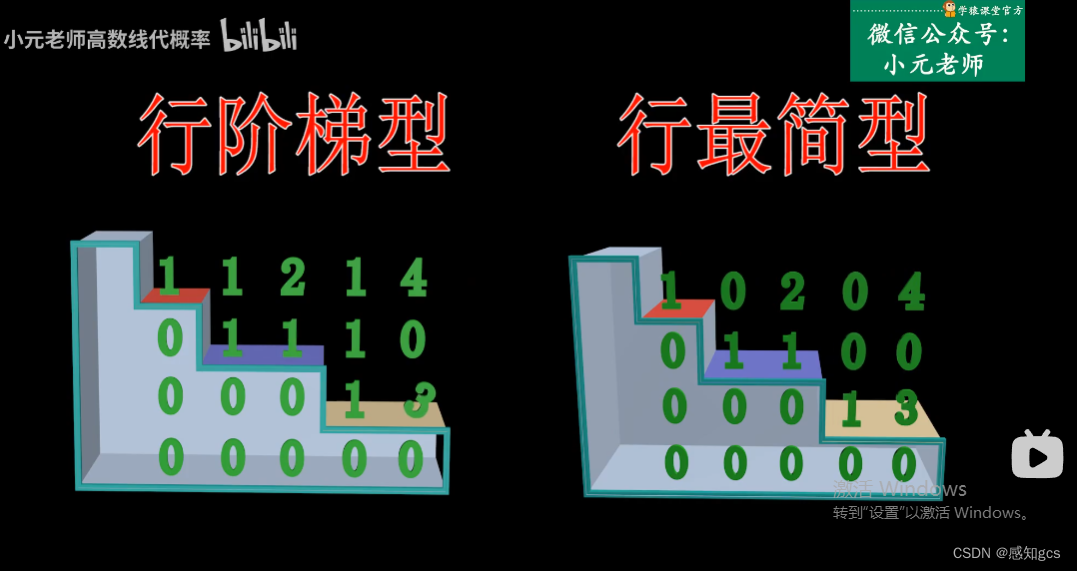
p18 线性代数,行阶梯型矩阵
行阶梯型矩阵 行最简型矩阵...

leetcode—— 动态规划—— 零钱兑换
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。 计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。 你可以认为每种硬币的数量是无限的。 示…...
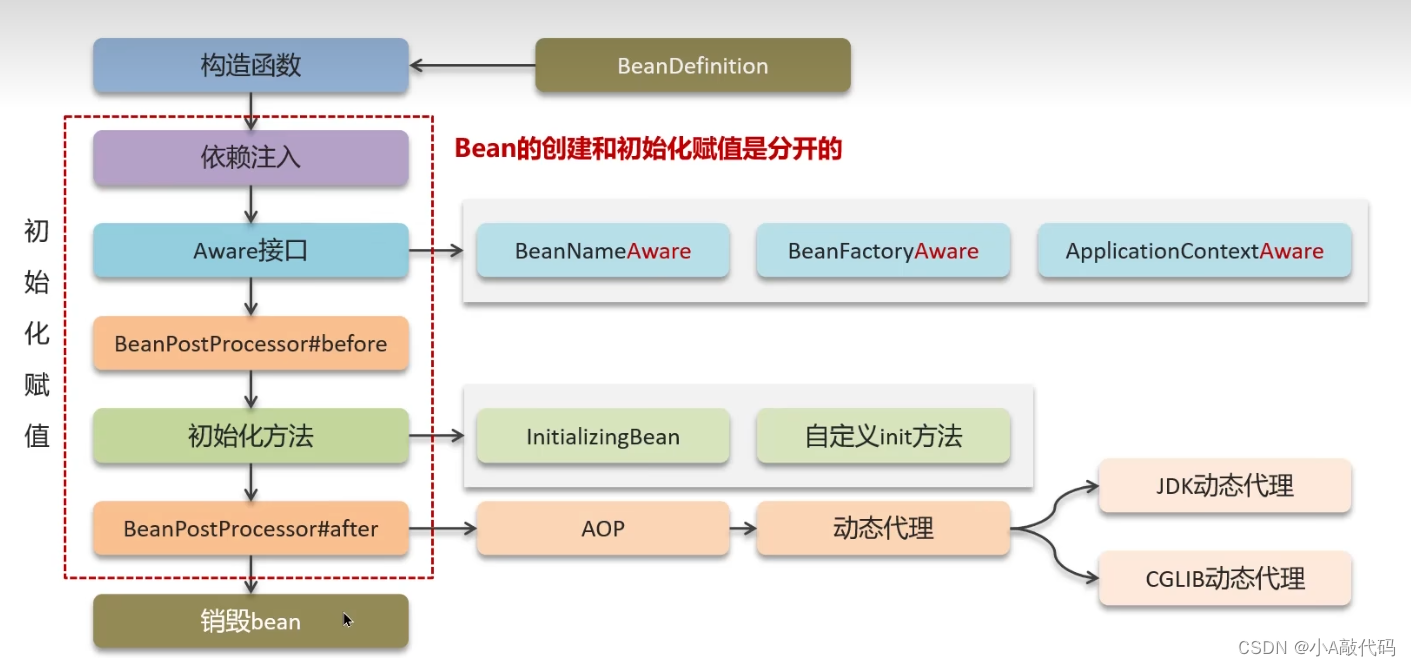
java面试题(spring框架篇)(黑马 )
树形图: 一、Spring框架种的单例bean是线程安全吗? Service Scope("singleton") public class UserServiceImpl implements UserService{ } singleton:bean在每个Spring IOC容器中只有一个实例 protype:一个bean的定义可以有多个…...

LeetCode27 移除元素
题目 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。元素的顺序可以改变。你不需要考虑数组中超出新长度后…...
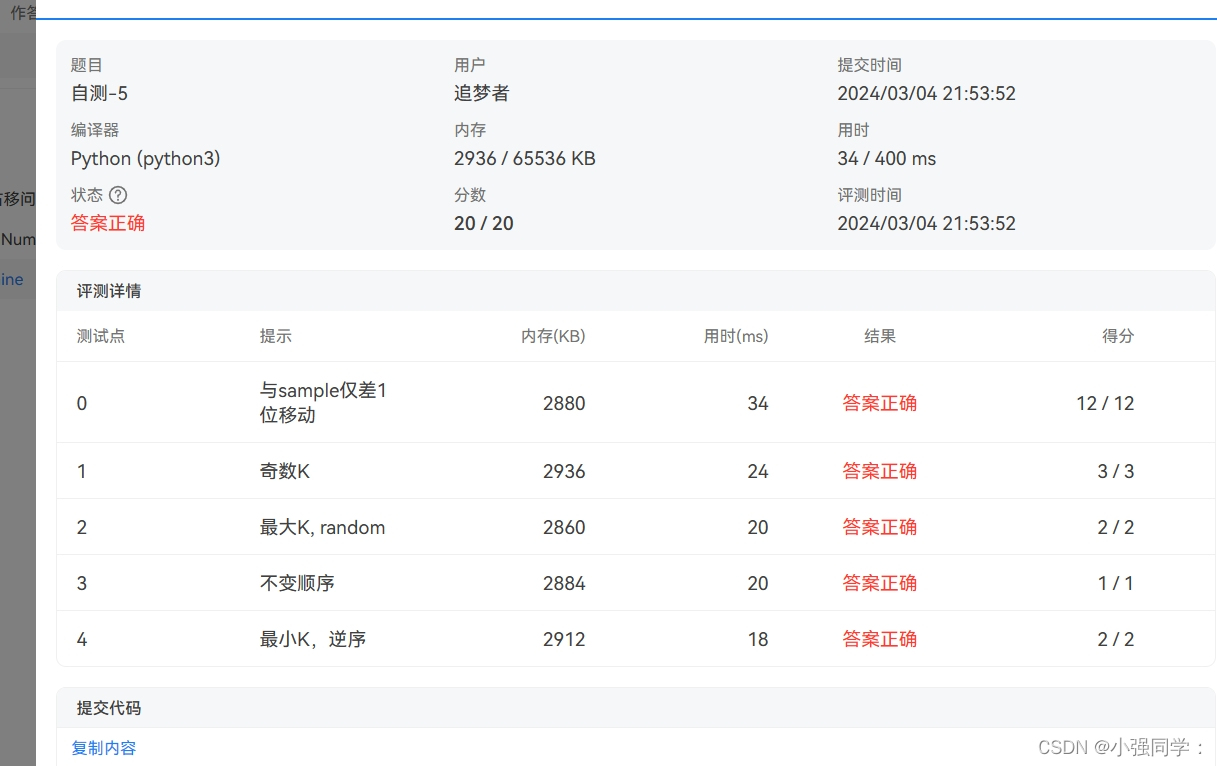
自测-5 Shuffling Machine(python版本)
文章预览: 题目翻译算法python代码oj反馈结果 题目 翻译 shuffle是用于随机化一副扑克牌的过程。由于标准的洗牌技术被认为是薄弱的,并且为了避免员工通过不适当的洗牌与赌徒合作的“内部工作”,许多赌场使用了自动洗牌机。你的任务是模拟一…...

你真的会设计测试用例吗?
前言 最近干的最多的事情就是设计测试用例、评审测试用例了,于是我不禁又想到了一个经典的问题:如何设计出优秀的测试用例? 可能有些童鞋看到这个问题会有些不以为然,这有什么好想的?干个测试谁还不会设计测试用例&a…...
外贸网站模板建站
测绘检测wordpress外贸主题 简洁实用的wordpress外贸主题,适合做测绘检测仪器设备的外贸公司使用。 https://www.jianzhanpress.com/?p5337 白马非马衣服WordPress外贸建站模板 白马非马服装行业wordpress外贸建站模板,适用于时间服装企业的官方网站…...

多点通信与域套接字:2024/3/4
作业1:广播 发送端: #include <myhead.h> int main(int argc, const char *argv[]) {//1.创建套接字int sfdsocket(AF_INET,SOCK_DGRAM,0);if(sfd-1){perror("socket error");return -1;}printf("sfd%d\n",sfd);//2.设置当前…...
52.2k star! 自己部署gpt4free, 免费使用各种GPT
GPT4Free是一个由开发者Xtekky在GitHub上发布的开源项目,它可以免费地使用GPT-3.5、GPT-4、llama、gemini-pro、bard、claude等多种大模型。截止到当前(2024.1.30)已经有52.2k star,可见其受欢迎程度。 github地址:https://github.com/xtekky…...
【HbuilderX】 uniapp实现 android申请权限 和 退出app返回桌面
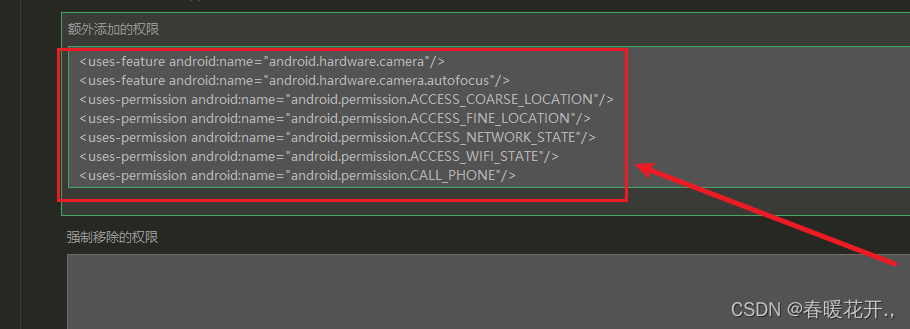
目录 android申请权限: 监听用户是否开启权限或关闭权限: 退出app返回桌面: android申请权限: 首先在 manifest.json 内添加你所需要用到权限 添加权限插件 permission.js 一次就好1/权限插件 - Gitee.comhttps://gitee.co…...
计算机网络之传输层 + 应用层
.1 CIDR地址块中还有三个特殊的地址块 a. 前缀 n 32 , 即32位IP地址都是前缀, 没有主机号, 这其实就是一个IP地址, 用于主机路由 b. 前缀 n 31 , 这个地址块中有两个IP地址, 主机号分别为0/1 , 这个地址块用于点对点链路 c. 前缀 n 0 , 用于默认路由使用二叉线索树查找转发…...
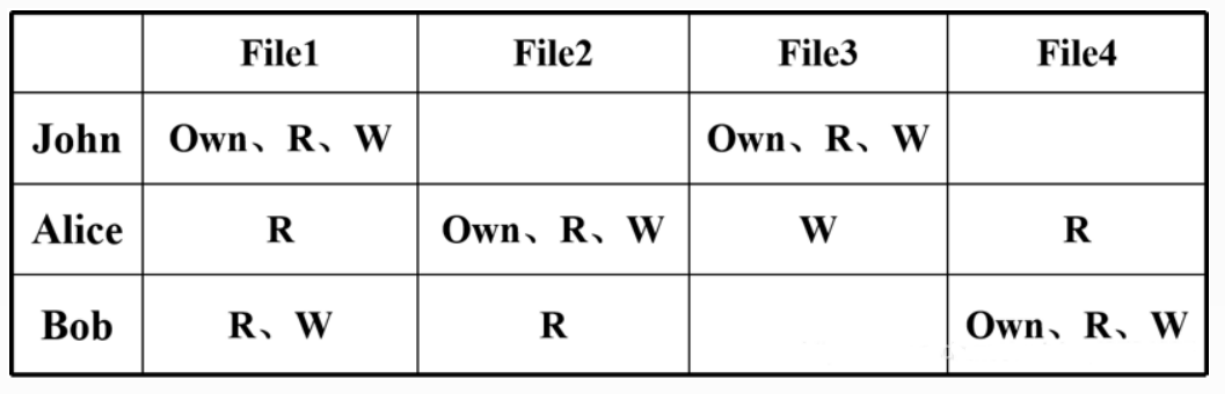
五、软考-系统架构设计师笔记-信息安全技术基础知识
信息安全技术基础知识 1、信息安全基础知识概述 信息安全的概念 信息安全包括 5 个基本要素: 机密性:确保信息不暴露给未授权的实体或进程。完整性:只有得到允许的人才能修改数据,并且能够判别出数据是否已被篡改。可用性:得到授权的实体在需要时可以…...
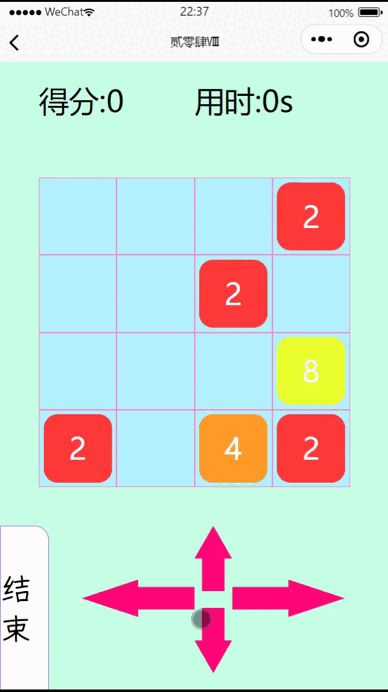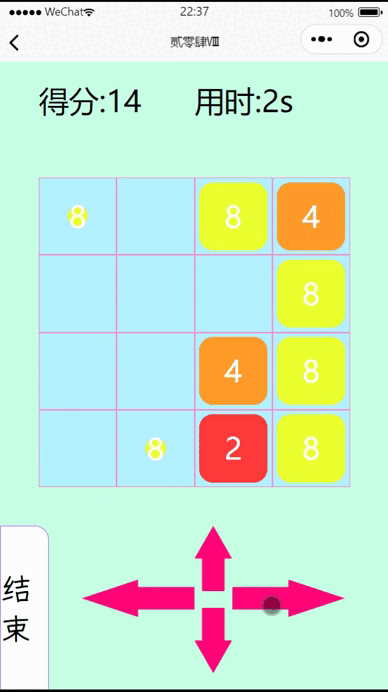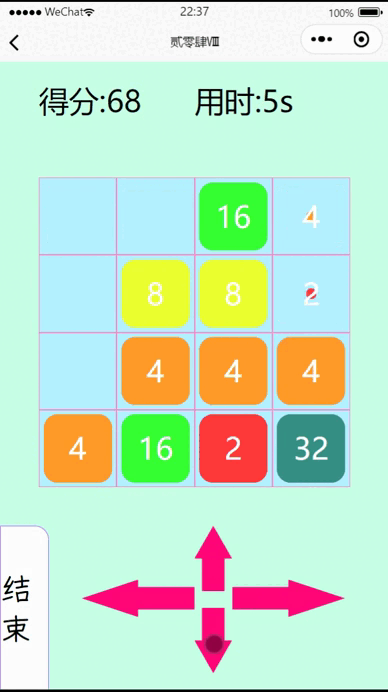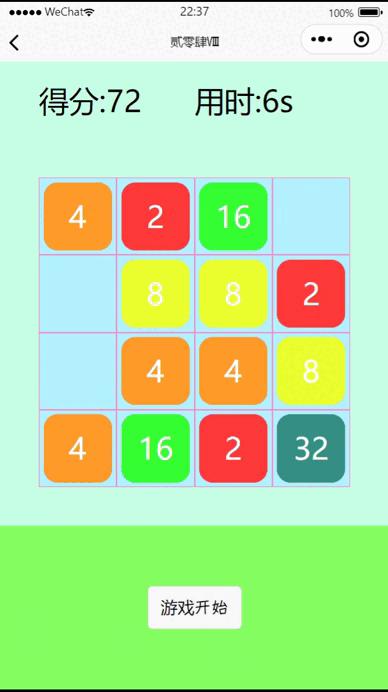
vue3+uniapp在微信小程序实现一个2048小游戏
一、效果展示 二、代码 <template><view class"page"><view class"top"><view class"score">得分:{{total}}</view><view class"time">用时:{{allTime}}s</view></view><view cl…...

Bittensor:去中心化AI网络的架构、挑战与激励模型优化
1. 项目概述:当AI遇上去中心化,Bittensor在解决什么核心问题?最近几年,AI模型的能力突飞猛进,但一个越来越明显的趋势是,顶尖的AI能力正快速向少数几家科技巨头集中。无论是训练所需的算力、高质量的数据集…...

3步快速上手SSDD:合成孔径雷达舰船检测终极指南
3步快速上手SSDD:合成孔径雷达舰船检测终极指南 【免费下载链接】Official-SSDD SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis 项目地址: https://gitcode.com/gh_mirrors/of/Official-SSDD SSDD(SAR S…...
)
手把手教你用Python+OpenBMI复现运动想象BCI实验(附完整代码与数据集)
Python实战:从OpenBMI到运动想象脑机接口的全流程复现指南在认知科学与脑机接口(BCI)研究领域,运动想象(Motor Imagery)实验一直是经典范式。传统上,这类实验多依赖Matlab生态完成,但随着Python在科学计算领域的崛起,越…...

生产环境最佳实践
生产环境最佳实践 前言 本文将介绍Spring Cloud Alibaba在生产环境中的最佳实践,包括配置优化、监控告警、高可用设计等方面。 一、高可用设计 1.1 服务端高可用 # Nacos集群配置 # 至少3个节点 # 推荐使用外部数据库spring:cloud:nacos:server-addr: nacos-1:8848,…...

Midjourney V6调色板设置失效的5大隐性原因:从--sref误用到色域压缩陷阱,一文终结色彩失真
更多请点击: https://codechina.net 第一章:Midjourney V6调色板设置失效的全局认知 Midjourney V6 引入了更严格的色彩语义解析机制,导致此前在 V5.x 中广泛使用的 --palette 参数(如 --palette vibrant 或 --palette muted&…...

岩土工程渗流问题之有限单元法--坝基渗流、围堰、土石坝自由面、黏土垫层防渗、污染土固化后渗控
第一天 有限元编程基础知识1.有限单元法基础简介(离散化、存储策略及方程解法、边界条件的处理)2.编程语言Fortran及编译工具Intel Visual Fortran(IVF)简介3.Fortran/Matlab/Julia等开源代码及程序库(geomlib/femlib)简介4.水工…...

为什么你的AI搜索总不准?2026年5款高精度免费工具底层架构拆解:向量引擎、重排序模块与Query理解差异全曝光
更多请点击: https://intelliparadigm.com 第一章:为什么你的AI搜索总不准?——2026年免费高精度AI搜索工具全景洞察 AI搜索不准,根源常被误判为“模型不够大”,实则多源于查询理解失焦、上下文截断、知识新鲜度缺失与…...
)
Gemini深度研究模式 vs Claude 3.5 Sonnet vs GPT-4o Research:12项学术任务横向评测(含原始数据表)
更多请点击: https://codechina.net 第一章:Gemini深度研究模式体验 Gemini 深度研究模式(Deep Research Mode)是 Google 推出的面向复杂信息探索任务的增强型交互能力,专为学术调研、技术尽调与跨源知识整合场景设计…...

TikTok客户端关键字符串追踪与ttencrypt协议解析
1. 这不是“破解”,而是协议层的工程化还原很多人看到“TikTok算法逆向”第一反应是:这得用IDA Pro硬啃SO文件、在ARM汇编里找特征码、对着混淆后的Java层反复脱壳——其实大错特错。我过去三年深度参与过5个主流短视频App的客户端通信分析项目ÿ…...
)
GD32F103RCT6串口调试避坑指南:从寄存器配置到DMA收发实战(附代码)
GD32F103RCT6串口调试避坑指南:从寄存器配置到DMA收发实战 第一次接触GD32的串口开发时,我对着电脑屏幕上乱码的数据抓耳挠腮——明明按照手册配置了115200波特率,为什么收到的全是"天书"?后来才发现是时钟树配置的问题…...