从预训练到通用智能(AGI)的观察和思考

1.预训练词向量
预训练词向量(Pre-trained Word Embeddings)是指通过无监督学习方法预先训练好的词与向量之间的映射关系。这些向量通常具有高维稠密特征,能够捕捉词语间的语义和语法相似性。最著名的预训练词向量包括Google的Word2Vec(包括CBOW和Skip-Gram两种模型)、GloVe(Global Vectors for Word Representation)以及后来的FastText等。
预训练词向量的主要优点在于它们可以从大量的未标记文本数据中学习到词汇的通用表示,这种表示可以被应用于各种下游自然语言处理任务,如情感分析、命名实体识别、机器翻译等,作为初始化词嵌入层使用,从而显著提高模型性能,减少对标注数据的依赖。
更近一步,随着深度学习的发展,诸如BERT(Bidirectional Encoder Representations from Transformers)、ELMo(Embeddings from Language Models)和GPT(Generative Pre-training Transformer)等模型引入了更复杂的预训练技术,不仅能学习词级别的表示,还能学习到更高级别的句法和语义特征,这些预训练模型在经过微调后同样能在众多NLP任务上取得优秀效果。

2.预训练
预训练技术在自然语言处理(NLP)领域确实经历了持续而显著的发展。以下是一些近期的关键进展:
-
更大的模型规模:
GPT-3(2020年发布)代表了模型大小上的巨大飞跃,它拥有超过1750亿个参数,并展示了前所未有的零样本和少样本学习能力。 -
更高效的预训练方法:
MoE(Mixture of Experts)架构被用于如Google的Switch Transformer和DeepMind的Pathways语言模型中,这种架构允许模型在计算资源有限的情况下扩大规模。 -
多模态预训练模型:
继续拓展单模态模型之外,ViT(Vision Transformer)和DALL-E等模型开始处理图像和文本之间的联合预训练,实现了跨模态的理解和生成能力,比如OpenAI的CLIP、ALIGN和Imagen等。 -
持续学习和无监督训练:
如Aristo和通义千问这样的模型通过持续学习不断吸收新知识和数据,提高模型的性能和实时性。 -
预训练任务创新:
如BERT后续的改进模型如RoBERTa通过优化预训练策略取得了更好的效果,同时出现了更多针对特定任务设计的预训练任务,如SpanBERT对跨度标记进行了优化,ALBERT通过跨层参数共享减小模型大小。 -
跨语言预训练:
XLM、mBERT和XLM-R等模型致力于解决多语言环境下NLP问题,通过大规模多语言数据进行预训练,实现对多种语言的理解和处理。 -
自监督学习的新范式:
自我对话式的预训练方式(如Reformer、DeBERTa)以及自我监督信号的设计(如对比学习)有所提升,例如Facebook AI的Data2Vec采用了统一的自监督学习框架。 -
模型压缩与轻量化:
对于BERT等大型模型,研究者们还致力于将其模型大小缩小,同时保持较高的性能,例如DistilBERT、TinyBERT等模型,以便在计算资源有限的环境中部署。 -
可持续性和效率:
近期研究也开始关注模型的能耗和环境影响,探索更加节能高效的训练方法和模型架构。
以上列举了一些方向性的趋势和亮点,具体的最新进展和技术细节可能随着时间和研究推进有所不同,请结合最新的学术文献和技术报道获取更详尽的信息。
近期预训练技术的发展主要集中在以下几个方面:
-
更大规模的模型: 随着计算能力的增强和数据集的扩大,研究人员不断尝试训练更大规模的模型。比如,2023年出发布的GPT-4模型,相比之前的版本有着更多的参数和更强的表征能力。
-
多模态预训练: 不仅仅局限于文本数据,研究人员开始探索多模态数据的预训练。这意味着模型可以同时处理文本、图像、音频等不同类型的数据,并学习它们之间的关联。例如,OpenAI发布的CLIP模型就可以处理图像和文本之间的语义关联。
-
领域自适应: 预训练模型在特定领域的性能往往不如在通用领域的表现好。因此,研究人员致力于开发领域自适应的预训练技术,使得模型可以更好地适应特定领域的数据和任务。例如,医疗领域的BERT模型(如BioBERT)针对医疗文本进行了预训练,取得了良好的效果。
-
知识增强: 为了提升模型的知识表示能力,研究人员开始探索如何利用外部知识源(如百科知识、知识图谱等)来增强预训练模型。这些方法可以帮助模型更好地理解和推理文本中的知识。例如,一些模型在预训练过程中结合了知识图谱的信息。
这些进展使得预训练模型在各种自然语言处理任务中取得了更好的性能,并为其在其他领域的应用提供了更广阔的可能性。
3.大规模预训练模型
大规模预训练模型是通用人工智能发展历程中的一个重要里程碑。让我们来看一下这个发展历程的主要阶段:
-
传统机器学习方法:早期的人工智能系统主要基于规则和专家知识构建,这些系统的性能受限于手工设计的特征和规则。
-
深度学习的崛起:随着计算能力的提升和数据量的增加,深度学习开始在各种任务上展现出色的性能。这些深度学习模型以神经网络为基础,通过大量数据进行端到端的训练,自动学习特征和模式。
-
大规模预训练模型的出现:随着数据和计算资源的不断增长,研究人员开始尝试训练更大规模的神经网络模型。这些模型在大规模的文本数据上进行预训练,例如BERT、GPT等。这种预训练模型通过阅读大量文本数据,学习了丰富的语言表示,可以被微调用于各种下游任务,如问答、文本生成等。
-
通用人工智能的追求:大规模预训练模型的成功启示了通用人工智能的可能性。研究人员开始探索如何进一步发展这些模型,使其能够在多个领域和任务上展现出更加普适的能力。这可能涉及更大规模的模型、更多样化的数据以及更强大的学习和推理能力。
-
挑战与前景:尽管大规模预训练模型取得了巨大成功,但通用人工智能仍然面临诸多挑战,如数据偏见、模型可解释性、迁移学习等。未来,通用人工智能的发展将需要跨学科的合作,结合深度学习、认知科学、哲学等多个领域的知识,以解决这些挑战并实现更高水平的人工智能。
4.通用智能
1.我们离通用智能还有多远?
尽管预训练技术和深度学习方法在最近几年里取得了巨大的进步,但是从专业领域的共识来看,我们离真正的通用智能模型仍有不小的距离。通用智能是指AI系统能够像人类一样灵活地应对各种未知环境和任务,具有自我意识、自主学习、创新思考、情感理解以及跨领域适应能力等特点。
目前,虽然诸如GPT-4、通义千问等先进模型在特定应用场景下表现出惊人的通用性,能够在很大程度上理解和生成高质量的语言内容,甚至解决一些复杂的任务,但它们仍然是受限制的专用系统,在泛化能力、推理能力、持续学习以及对真实世界的交互理解等方面还存在局限。
具体来说:
-
泛化能力:现有模型在未经历过的领域或任务上仍可能表现不佳,无法如同人类那样举一反三、触类旁通。
-
情境理解与因果推理:模型在处理抽象概念、逻辑推理以及理解复杂情境中的因果关系时,往往不如人类精准。
-
伦理与道德判断:模型尚缺乏内在的价值观和道德约束,对于决策可能带来的社会影响和伦理后果缺乏判断。
-
自主性与创造力:通用智能应当具有自主设定目标、规划行动路径和创造性解决问题的能力,目前的AI系统大多是在给定框架内运行。
-
情感与社交智能:理解并恰当反应人类情绪和社会互动仍是难题,模型在这方面尚未达到与人同等水平。
综上所述,尽管AI研究界正在不断取得突破,但我们仍在追求通用智能的道路上继续探索和努力。专家预测的时间点各不相同,但普遍认为这是一个长期且充满挑战的目标,需要跨学科的合作与更多的理论与技术创新。
2. 通用智能发展现状
通用人工智能的发展现状是一个备受关注的话题。虽然目前尚未实现真正意义上的通用人工智能,但在人工智能领域已经取得了一些重要进展:
-
深度学习和神经网络技术的突破:深度学习模型和神经网络技术的发展为通用人工智能的实现提供了重要基础。通过大规模数据的训练和复杂模型的构建,计算机可以执行更加复杂的任务,这使得通用人工智能的实现变得更加可行。
-
强化学习的进步:强化学习是一种让机器通过试错来学习的方法,已经在实现通用人工智能的研究中发挥了重要作用。研究人员通过强化学习算法让计算机学会了在不同环境下做出决策和行动,这是通用人工智能的重要组成部分。
-
多模态学习:多模态学习是指让计算机能够同时理解和处理多种不同类型的数据,如图像、文字、语音等。这一领域的研究为实现通用人工智能提供了重要的技术支持,使得计算机能够更全面地理解和表达信息。
-
迁移学习和元学习:迁移学习和元学习是让计算机能够从一个任务中学到的知识迁移到另一个任务中的方法。这种能力是通用人工智能的重要组成部分,因为它使得计算机能够更加灵活地适应新的任务和环境。
虽然通用人工智能的实现还存在诸多挑战,如推理能力、常识理解、自我意识等,但随着技术的不断进步和研究的深入,人们对于实现通用人工智能的信心与希望依然持续。
3.实现通用人工智能面临的挑战
实现通用人工智能是一项复杂而艰巨的任务,离实现这个目标还有相当长的路要走。尽管大规模预训练模型的出现标志着人工智能领域的重要进步,但要实现真正的通用人工智能,仍然存在一些关键挑战和障碍需要克服:
-
理解和推理能力:当前的预训练模型在处理语言和感知任务上表现出色,但它们的理解和推理能力仍然有限。通用人工智能需要能够理解语境、推理逻辑,并从中推导出新的结论。
-
跨模态和跨领域的学习能力:通用人工智能需要能够处理多种类型的数据,包括文本、图像、声音等,而不仅仅局限于单一类型的数据。此外,它还应该能够在不同领域的任务上进行学习和推理。
-
长期记忆和持续学习:通用人工智能需要具备长期的记忆能力,能够在长时间内积累知识和经验,并且能够不断地从新的数据和经验中学习。
-
社交和情感智能:通用人工智能不仅需要具备认知能力,还需要能够理解和处理情感,以及与人类进行有效的社交互动。
-
道德和伦理问题:随着通用人工智能的发展,我们需要认真思考和解决与之相关的道德和伦理问题,包括隐私保护、公平性、责任与透明度等。
虽然我们在通用人工智能的道路上取得了一些进步,但要实现真正意义上的通用人工智能,仍然需要在这些方面进行深入研究和技术突破。这需要跨学科的合作,包括计算机科学、认知科学、神经科学等领域的专家共同努力。
相关文章:
从预训练到通用智能(AGI)的观察和思考
1.预训练词向量 预训练词向量(Pre-trained Word Embeddings)是指通过无监督学习方法预先训练好的词与向量之间的映射关系。这些向量通常具有高维稠密特征,能够捕捉词语间的语义和语法相似性。最著名的预训练词向量包括Google的Word2Vec&#…...

四种垃圾回收算法
1.标记清除算法 该算法先标记,后清除,将所有需要回收的算法进行标记,然后清除;这种算法的缺点是:效率比较低;标记清除后会出现大量不连续的内存碎片,这些碎片太多可能会使存储大对象会触发GC回…...
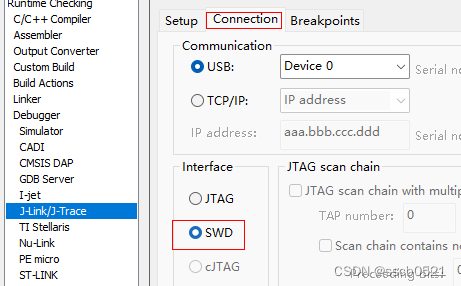
stm32f103zet6笔记1-led工程
1、选择串口调试 2、LED0连接到PB5,PB5设置为推挽输出。PE5同理。 3、生成成对的.c,.h文件。 4、debugger选择j-link。 5、connection选择SWD。 6、编写bsp_led.c,bsp_led.h文件。 7、下载调试,可以看到LED0 500ms闪烁一次,LED1 1000ms闪烁一…...

OpenDDS的Qos策略
目录 1、前言2、QoS策略2.1、LIVELINESS2.2、RELIABILITY2.3、HISTORY2.4、DURABILITY2.5、DURABILITY_SERVICE2.6 、RESOURCE_LIMITS2.7、PARTITION2.8、DEADLINE2.9、LIFESPAN2.10、USER_DATA2.11、TOPIC_DATA2.12、GROUP_DATA2.13、TRANSPORT_PRIORITY2.14、LATENCY_BUDGET2…...
)
string基本操作(C++)
增 1.1 “” str str ss;cout << str << endl; //234561提取字串 2.1 substr substr(pos): 提取从位置pos开始到末尾的子串。 #include <iostream> #include <string> using namespace std;int main(){string str "123456";//substr(pos…...
【网站项目】123网上书城系统
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...
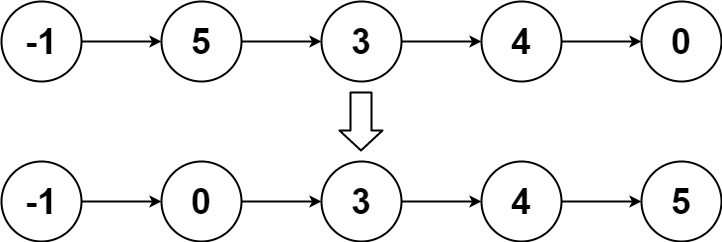
LeetCode148.排序链表
题目 给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。 示例 输入:head [4,2,1,3] 输出:[1,2,3,4] 输入:head [-1,5,3,4,0] 输出:[-1,0,3,4,5] 输入:head [] 输出:[] 思路…...

qt学习:网络调试助手客户端+服务端
目录 客户端 步骤 ui界面配置编辑 添加头函数,类成员数据,类成员函数 添加模块 构造函数 连接按钮 收到来自服务器的数据触发 发送按钮 断开按钮 向textEditRev文本编辑器中插入指定颜色的文本 服务端 步骤 ui界面配置 添加头函数&…...

C语言拾遗
函数的地址传递: 函数体内部想要修改函数体外部变量值的时候,使用地址传递 int set(int *pa) {//功能 } int main(void) {int a0;set(&a);//此时a的值经过set函数的修改,且传递到了main函数 } 函数体内想修改函数体外部指针的值的时候…...

大唐杯学习笔记:Day4
1.1NR帧结构 5G NR中,依然采用一帧10ms,并将一帧分为10子帧,每个子帧为1ms。每个子帧包含几个时隙(slot),每个时隙由14个OFDM符号构成(在常规CP下)。 μ \mu μ Δ f 2 μ ∗ 15 [ K H Z ] \Delta f2^{\mu}*15[KHZ] Δf2μ∗15[KHZ]Cyclic prefix015Normal130Normal260Normal…...
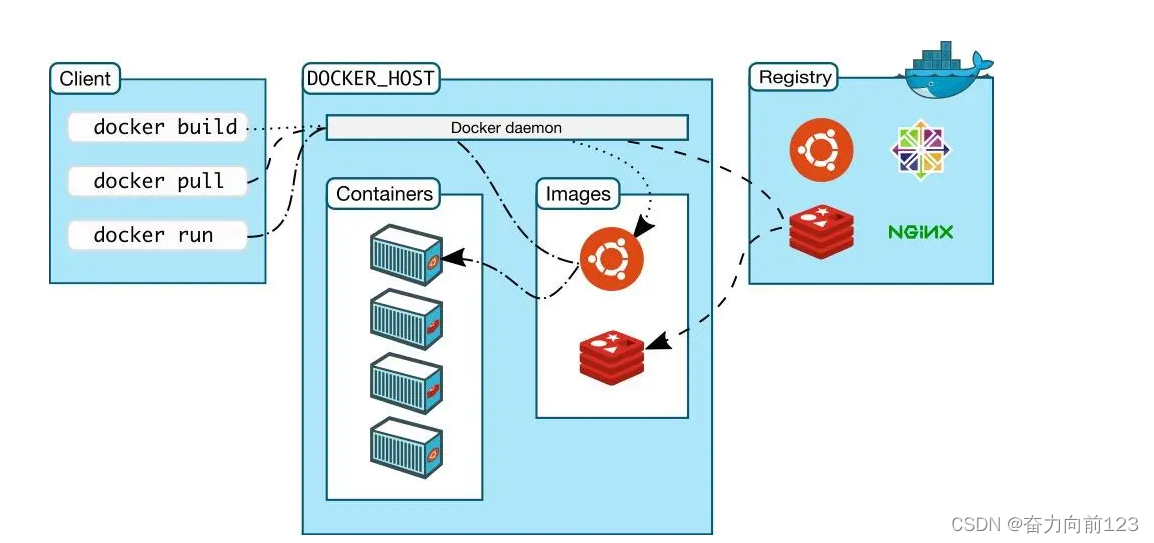
docker基线安全修复和容器逃逸修复
一、docker安全基线存在的问题和修复建议 1、将容器的根文件系统挂载为只读 修复建议: 添加“ --read-only”标志,以允许将容器的根文件系统挂载为只读。 可以将其与卷结合使用,以强制容器的过程仅写入要保留的位置。 可以使用命令&#x…...

ZooKeeper概述
ZooKeeper是一个开源的分布式协调服务,由Apache Software Foundation维护。它主要用于解决分布式应用中遇到的一些最常见问题,如命名服务、状态同步、配置管理和群集管理等。通过提供一套简单但强大的API,ZooKeeper使得从简单的锁服务到复杂的…...

【sgCollapseBtn】自定义组件:底部折叠/展开按钮
特性: 支持自定义折叠状态支持自定义标签名称 sgCollapseBtn源码 <template><div :class"$options.name" click"show !show" :placement"placement"><div class"collapse-btns"><div class"c…...

如何根据玩家数量和游戏需求选择最合适的服务器配置?
根据玩家数量和游戏需求选择最合适的服务器配置,首先需要考虑游戏的类型、玩家数量、预计的在线时间以及对内存和CPU性能的需求综合考虑。对于大型多人在线游戏,如MMORPG或MOBA等,由于需要更多的CPU核心数来支持更复杂的游戏逻辑和处理大量数…...

问题解决:各版本的vc_redist下载地址 缺少msvcr100.dll、msvcr120.dll、msvcr140.dll
Visual C Redistributable for Visual Studio各版本的官方链接。解决缺少msvcr100.dll、msvcr120.dll、msvcr140.dll的问题。 下面全部为官方链接: Microsoft Visual C Redistributable 2019 x86: https://aka.ms/vs/16/release/VC_redist.x86.exe x64: https://ak…...
182基于matlab的半监督极限学习机进行聚类
基于matlab的半监督极限学习机进行聚类,基于流形正则化将 ELM 扩展用于半监督,三聚类结果可视化输出。程序已调通,可直接运行。 182matlab ELM 半监督学习 聚类 模式识别 (xiaohongshu.com)...

C语言数组案例编程
1. 编写一个程序实现:从键盘输入15个整数存入数组,然后统计其中正整数的个数。 【要求】采用函数编程 #include<stdio.h> void input(int a[],int n) {int i; for(i0;i<n;i)scanf("%d",&a[i]); }int positiveNum(int a[],int n…...
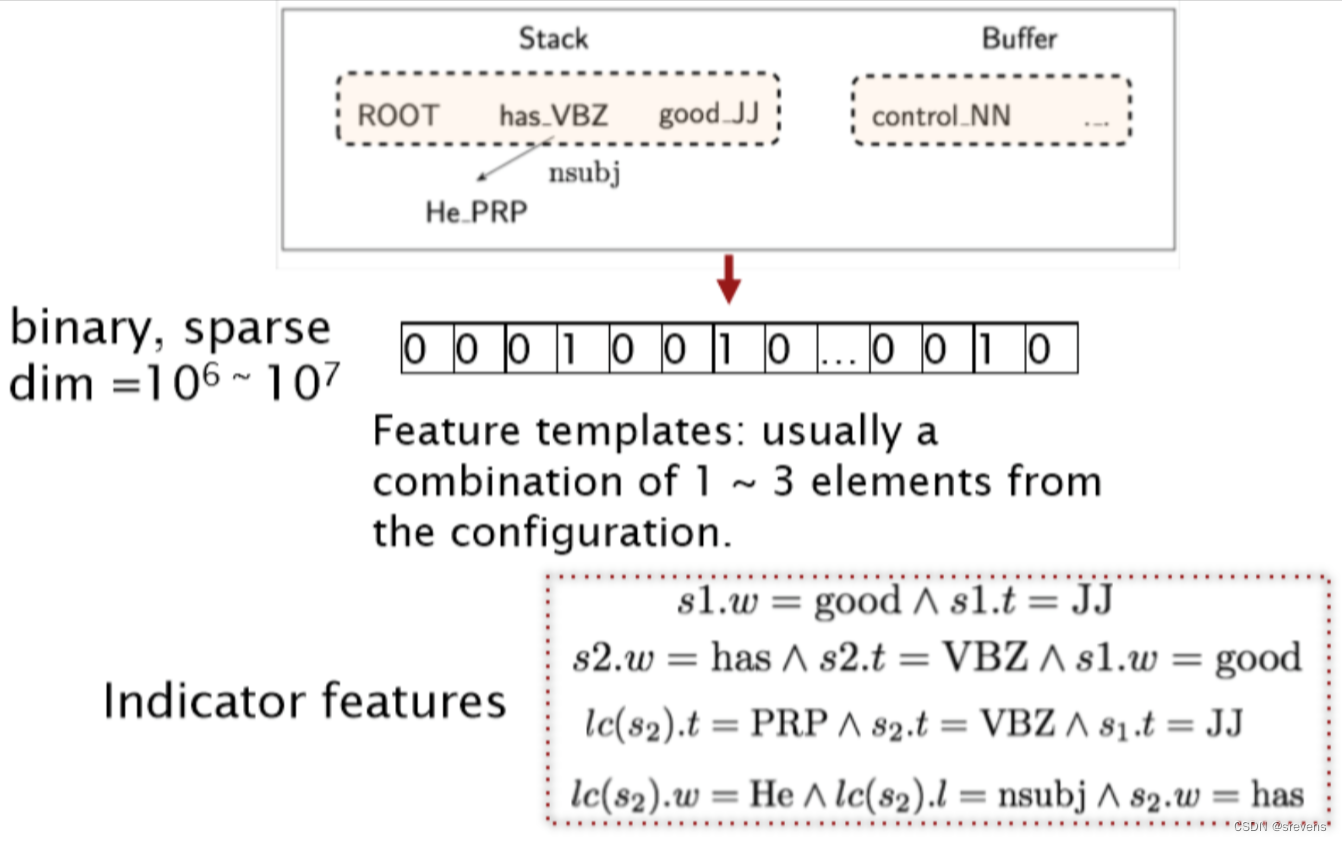
NLP - 依存句法分析、句子歧义
1. 语言结构的两种观点 Constituency phrase struct grammar context-free grammars(CFGs)Dependency structure 对于context-free grammars(CFGs) 短语结构(Constituency):短语结构语法是一种描述语言结构的方法,它将句子划…...
vue实现图片上传至oss,返回url插入数据库,最后在前端页面上回显图片
vue前端上传图像 上传图片 使用上传图片的upload组件 <el-form-item label"设备图像"><el-upload//设置class样式class"avatar-uploader"//绑定上传路径:action"uploadUrl"//携带token值:headers"tokenInfo":show-file-lis…...

C++学习笔记:set和map
set和map set什么是setset的使用 关联式容器键值对 map什么是mapmap的使用map的插入方式常用功能map[] 的灵活使用 set 什么是set set是STL中一个底层为二叉搜索树来实现的容器 若要使用set需要包含头文件 #include<set>set中的元素具有唯一性(因此可以用set去重)若用…...

CH340串口调试进阶:手把手教你搭建RS422转TTL双机通信测试环境
CH340串口调试进阶:手把手教你搭建RS422转TTL双机通信测试环境 在工业自动化、物联网设备开发中,稳定可靠的串行通信是设备间数据交互的基石。当传输距离超过几米,或环境存在电磁干扰时,传统的TTL电平通信就会暴露出抗干扰能力弱、…...

河北邯郸职称评审的方式有哪几种?
1、以考代评以考代评就是指有些专业技术岗位可以通过参加考试而不是递交繁琐的材料来获得专业技术职务资格。只要顺利通过国家指定的科目考试,你就可以获得专业技术资格,省去了各种审核流程的烦恼。2、只评不考只评不考是目前zui常见、适用范围zui广的一…...

终极指南:如何用ESP32-A2DP库快速构建蓝牙音频设备
终极指南:如何用ESP32-A2DP库快速构建蓝牙音频设备 【免费下载链接】ESP32-A2DP A Simple ESP32 Bluetooth A2DP Library (to implement a Music Receiver or Sender) that supports Arduino, PlatformIO and Espressif IDF 项目地址: https://gitcode.com/gh_mir…...

电子书转有声书完整指南:一键实现1158种语言的AI语音合成
电子书转有声书完整指南:一键实现1158种语言的AI语音合成 【免费下载链接】ebook2audiobook Generate audiobooks from e-books, voice cloning & 1158 languages! 项目地址: https://gitcode.com/GitHub_Trending/eb/ebook2audiobook 你是否曾希望将心爱…...

Flink 2.2集成Flink CDC 3.6
1 、部署Flink CDC tar -zxf flink-cdc-3.6.0-2.2-bin.tar.gz -C /usr/bigtop/3.3.0/usr/libln -s /usr/bigtop/3.3.0/usr/lib/flink-cdc-3.6...

QuantConnect Lean引擎架构深度剖析:构建模块化量化交易系统的技术实现
QuantConnect Lean引擎架构深度剖析:构建模块化量化交易系统的技术实现 【免费下载链接】Lean Lean Algorithmic Trading Engine by QuantConnect (Python, C#) 项目地址: https://gitcode.com/GitHub_Trending/le/Lean QuantConnect Lean引擎是一个开源的量…...

昇腾CANN ops-blas:GEMM 在 NPU 上为什么可以快到极致
矩阵乘是所有深度学习计算的根。Attention、全连接、卷积展开——归根到底都是矩阵乘。ops-blas 是 CANN 里专门做高性能 GEMM(General Matrix Multiply)的算子库,核心目标是把昇腾 NPU 的 Cube 单元利用率拉到 90% 以上。 ops-blas 和 ops-n…...

5月21日-23日微相携多款产品亮相2026世界无人机大会暨UASE无人机展以先进无人机侦测反制技术产品赋能城市低空安全防护
微相亮相2026世界无人机大会暨UASE无人机展...

DOM 基础全面解析
系列文章目录 《JavaScript 基础与进阶笔记》(前期偏基础巩固与常见面试点,后续进入闭包、异步、工程化等进阶主题) 第 01 篇:数据类型与类型判断第 02 篇:变量声明与作用域第 03 篇:闭包与高阶函数第 04…...

DLSS Swapper:3分钟掌握游戏性能调优的终极秘诀
DLSS Swapper:3分钟掌握游戏性能调优的终极秘诀 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否厌倦了等待游戏开发商更新DLSS版本?是否曾因DLSS版本不兼容导致游戏崩溃而烦恼?…...