ChatGPT引领的AI面试攻略系列:cuda和tensorRT
系列文章目录
- cuda和tensorRT(本文)
- AI全栈工程师
文章目录
- 系列文章目录
- 一、前言
- 二、面试题
- 1. CUDA编程基础
- 2. CUDA编程进阶
- 3. 性能优化
- 4. TensorRT基础
- 5. TensorRT进阶
- 6. 实际应用与案例分析
- 7. 编程与代码实践
- 8. 高级话题与趋势
一、前言
随着人工智能技术的飞速发展,该领域的就业机会也随之增多。无论是刚刚踏入这一领域的新手,还是经验丰富的专业人士,都可能面临着各种面试挑战。为了帮助广大求职者更好地准备人工智能相关的面试,本系列博客旨在提供一系列精选的面试题目及其详尽的解析。
值得一提的是,这些面试题及其解答是通过最新的人工智能模型——ChatGPT生成的。ChatGPT作为一款领先的自然语言处理工具,不仅能够理解和生成人类般的文本,还能够提供深度学习和人工智能领域的专业知识。通过利用这一技术,我们能够高效地收集和总结出一系列覆盖广泛的面试题,这些题目既包括基础知识点,也涵盖了最新的技术趋势和高级议题。
本系列博客的目的不仅是为读者提供实际的面试题目和答案,更重要的是通过这些内容,帮助读者深入理解各个概念,掌握问题解决的方法和思路。无论是面对基础题还是高难度题目,读者都能够找到解题的灵感和策略。
需要指出的是,尽管ChatGPT提供了强大的支持,但对于面试准备来说,真正的理解和实践经验才是关键。因此,我们鼓励读者不仅要阅读和理解这些面试题及其解答,更要积极地将所学知识应用于实际的项目和问题解决中。此外,面对技术的快速变化,持续学习和适应新技术也是每位人工智能领域专业人士必须具备的能力。
希望本系列博客能成为您人工智能领域面试准备的有力助手,不仅帮助您成功应对面试,更能促进您在人工智能领域的长期发展和成长。
二、面试题
1. CUDA编程基础
-
解释CUDA编程模型的基本概念。
CUDA(Compute Unified Device Architecture)是一个由NVIDIA开发的并行计算平台和编程模型,允许开发者使用NVIDIA GPU进行通用计算。CUDA编程模型提供了一种通过使用核函数(在GPU上并行执行的函数)来执行数以千计的并行线程的方法,从而使得能够高效地利用GPU的大规模并行计算能力。 -
描述GPU的内存层次结构。
GPU的内存层次结构由几个主要部分组成:- 全局内存(Global Memory):所有线程都可以访问的大容量存储空间,但访问延迟最高。
- 共享内存(Shared Memory):在同一个线程块(Block)内的线程间共享的低延迟内存。
- 寄存器(Registers):每个线程独有的最快速的存储空间。
- 常量和纹理内存(Constant and Texture Memory):缓存,用于存储频繁访问的数据,可以提高某些类型数据的访问效率。
-
如何在CUDA中管理内存(分配、释放、数据传输)?
在CUDA中,内存管理涉及在GPU设备的全局内存中分配和释放内存,以及在主机(CPU)和设备(GPU)之间传输数据:- 分配内存:使用cudaMalloc()函数在GPU上分配内存。
- 释放内存:使用cudaFree()函数释放之前分配的内存。
- 数据传输:使用cudaMemcpy()函数在主机和设备之间复制数据。
-
什么是核函数(Kernel)?如何定义和调用?
核函数是在CUDA中执行的特殊函数,可以在GPU上并行执行多个线程。核函数通过__global__修饰符定义,并且只能从主机代码调用。
__global__ void kernelName(参数列表) {// 核函数代码
}
调用核函数时,需要指定执行配置,包括线程块的数量和每个线程块中的线程数量:
kernelName<<<numBlocks, threadsPerBlock>>>(参数);
- 解释CUDA线程的层次结构。
CUDA的线程组织为三级层次结构:- 线程(Thread):执行核函数的最小单元。
- 线程块(Block):一组可以协作的线程,共享同一块共享内存。
- 网格(Grid):整个核函数的线程块集合。
- 如何计算线程索引和使用它来访问数据?
在CUDA核函数中,每个线程通过其唯一的索引来访问数据元素。对于一维数据,线程索引可以通过threadIdx.x + blockIdx.x * blockDim.x计算得到。对于二维或三维数据,也可以使用threadIdx.y、threadIdx.z、blockIdx.y、blockIdx.z等进行相应计算。 - 什么是warp?它与性能优化有何关联?
Warp是CUDA中执行指令的基本单位,由32个线程组成。一个warp中的所有线程同时执行相同的指令。Warp与性能优化关联密切,因为避免线程之间的分歧可以最大化利用GPU的计算资源。 - 解释共享内存和全局内存的区别。
- 共享内存是在同一个线程块内的线程间共享的,访问速度快,但容量有限。
- 全局内存对所有线程都可见,容量大,但访问速度慢,且可能导致访问延迟。
- 如何处理CUDA程序中的错误?
CUDA API函数和核函数调用后,可以通过检查CUDA的错误代码来处理错误,例如使用cudaGetLastError()和cudaError_t类型。 - CUDA中的同步机制是什么?
CUDA提供了同步机制,如__syncthreads(),用于线程块内的线程同步。这确保了线程块内的所有线程都达到同一执行点,才能继续执行后续操作。这对于共享资源的一致访问和更新是必要的。
2. CUDA编程进阶
- 描述CUDA流(Stream)的概念和用途。
CUDA流(Stream)是NVIDIA CUDA编程模型中的一个核心概念,用于实现设备端的异步并行执行。在CUDA编程中,流是一个任务队列,可以将一系列GPU操作(如kernel函数调用、内存复制等)放入不同的流中,让这些操作按照流的顺序进行执行,而不同流中的操作则可以并发执行。 - 如何利用CUDA动态并行?
CUDA动态并行允许GPU内核直接启动其他内核,无需通过CPU。这样可以减少CPU和GPU之间的数据交换,加速嵌套循环或递归算法的执行。 - 什么是原子操作?举例说明其应用。
原子操作是一种不可分割的操作,保证在并行编程中,同一时刻只有一个线程可以执行这个操作。在CUDA中,原子操作用于确保对共享数据的安全访问,例如,当多个线程需要更新同一个内存位置的值时,如累加操作atomicAdd。 - 解释统一虚拟内存(Unified Memory)。
统一虚拟内存(Unified Memory)是CUDA中的一种内存管理机制,它提供了一个统一的地址空间,使CPU和GPU可以共享数据而无需手动复制。这简化了编程模型并自动处理数据迁移,使开发者能够更容易地编写高效的CUDA程序。 - 如何优化内存访问模式以提高性能?
优化内存访问模式包括:- 合并内存访问:确保连续的线程访问连续的内存位置。
- 使用共享内存:利用快速的共享内存减少全局内存的访问。
- 避免内存访问冲突:如在访问共享内存时避免银行冲突。
- 循环展开:减少循环中的内存访问次数。
- 解释CUDA中的循环展开技术。
循环展开是一种优化技术,通过减少循环的迭代次数来减少循环控制的开销,同时增加每次迭代的工作量。在CUDA中,循环展开可以通过手动修改代码或使用编译器指令来实现,以提高内存访问效率和减少执行时间。 - 在CUDA中,如何实现并行算法的负载均衡?
并行算法的负载均衡可以通过以下方法实现:- 动态索引分配:使用原子操作动态分配任务,确保所有线程工作量均衡。
- 循环划分:将大循环分割成多个较小的块,以均匀分配给不同的线程。
- 使用多个内核和流:根据任务的不同部分和数据依赖性,将任务分配到多个内核和流中。
- 描述CUDA中使用的不同内存类型及其优化策略。
CUDA中的内存类型包括全局内存、共享内存、寄存器、常量内存和纹理内存。优化策略包括:- 全局内存:尽量合并内存访问,使用coalesced访问。
- 共享内存:利用以减少全局内存访问,注意避免银行冲突。
- 寄存器:有效利用寄存器以减少内存访问,但避免寄存器溢出。
- 常量和纹理内存:对于不变或重复访问的数据,使用常量和纹理内存以利用其缓存机制。
- 什么是银行冲突?如何避免?
银行冲突(Bank Conflict)是指当多个线程在同一时间内访问共享内存中的不同地址,但这些地址映射到同一个内存bank时发生的资源争用现象,导致访问被串行化,进而导致性能下降。避免银行冲突的方法包括调整数据结构布局,使得并行访问的线程访问不同的银行。 - 解释CUDA中的预取技术及其优势。
预取是一种性能优化技术,通过提前将数据从慢速内存(如全局内存)移动到快速内存(如寄存器或共享内存),以减少访问延迟。在CUDA中,可以手动编写代码来预取数据,或利用硬件的预取机制。预取的优势包括减少内存访问延迟和提高内存访问效率,从而提升整体性能。
3. 性能优化
-
如何使用NVIDIA Visual Profiler分析CUDA程序?
NVIDIA Visual Profiler (nvvp) 是一个图形化的性能分析工具,用于分析CUDA应用程序的性能。要使用NVIDIA Visual Profiler分析CUDA程序,请按照以下步骤操作:- 准备程序:确保CUDA程序已正确编译且能够运行。
- 启动Visual Profiler:可以通过命令行输入nvvp启动,或者从NVIDIA CUDA工具集中直接打开。
- 导入程序:在Visual Profiler中,选择“File”>“Import”>“Project”,然后导入你的CUDA二进制文件或项目。
- 配置分析选项:设置你想要收集的性能计数器和分析的特定范围。你可以选择特定的内核进行分析,或分析整个程序的执行。
- 开始分析:运行性能分析。Visual Profiler将执行你的CUDA程序,并收集有关执行的详细信息。
- 查看结果:分析完成后,Visual Profiler将显示一个性能报告,其中包含了执行时间、内存使用情况、占用率等关键性能指标。
- 性能优化:根据报告中的信息,识别程序的瓶颈,并进行相应的优化。Visual Profiler还可以提供优化建议。
-
描述几种常见的CUDA性能优化技巧
- 内存访问优化:通过合并内存访问来减少全局内存延迟,确保内存访问模式能够充分利用内存带宽。
- 使用共享内存:相比全局内存,共享内存具有更低的访问延迟。在可能的情况下,使用共享内存来存储频繁访问的数据。
- 最小化数据传输:尽量减少主机和设备之间的数据传输,特别是使用异步传输来重叠计算与数据传输。
- 循环展开:手动或使用编译器指令来展开循环,以减少循环开销并增加每个线程的工作量。
- 优化线程使用:根据算法和硬件的特点调整线程块的大小和形状,以提高并行度和占用率。
-
为什么要在CUDA程序中使用异步内存传输?
在CUDA程序中使用异步内存传输可以重叠内存传输和计算过程,从而提高程序的整体执行效率。异步传输允许CPU和GPU同时工作,而不是等待对方完成后再执行,这样可以显著减少程序的等待时间,特别是对于数据传输密集型的应用。 -
如何使用共享内存减少全局内存访问?
使用共享内存可以减少对全局内存的访问次数,方法包括:- 数据复用:当多个线程需要访问同一数据时,可以将数据加载到共享内存中,这样线程可以直接从共享内存中访问数据,而不是从全局内存中访问。
- 数据分块:将数据分为小块,每个线程块处理一个数据块,并将该块加载到共享内存中。这样可以减少全局内存的访问次数,并提高缓存的命中率。
- 协作加载:线程块中的线程可以协作地将数据加载到共享内存中,这样可以通过合并内存访问来提高内存访问效率。
-
解释并行度和占用率对CUDA性能的影响
- 并行度是指同时执行的线程数。在CUDA中,高并行度意味着有更多的线程同时执行,可以更充分地利用GPU的计算资源。但是,并行度过高可能会导致资源争用,如共享内存和寄存器的限制。
- 占用率是指GPU上活跃的线程数与最大可能线程数的比例。高占用率通常意味着GPU资源被充分利用,但过高的占用率可能会导致资源竞争,降低每个线程的性能。找到适当的占用率是优化CUDA程序性能的关键。低占用率可能意味着GPU的一些计算单元处于空闲状态,没有被充分利用。
优化CUDA程序通常涉及到平衡并行度和占用率,以达到最佳的性能表现。
4. TensorRT基础
-
TensorRT是什么?它如何加速深度学习模型?
TensorRT是一个由NVIDIA提供的高性能深度学习推理(Inference)引擎,用于生产环境中部署深度学习模型。TensorRT可以对深度学习模型进行优化,通过以下方式加速模型的推理性能:- 层和张量融合:将多个层和操作融合成一个更高效的操作。
- 精度校准:使用低精度(如FP16或INT8)计算来加速推理,同时尽可能保持精度。
- 内核自动调优:为特定的硬件选择最优的算法和内核。
- 动态张量:支持动态输入尺寸,优化执行路径。
-
解释TensorRT的工作流程
TensorRT的工作流程通常包括以下几个步骤:- 模型转换:将训练好的深度学习模型(通常是ONNX, Caffe等格式)导入到TensorRT。
- 模型优化:TensorRT对模型进行层合并、精度校准、内核选择等优化操作。
- 编译:将优化后的模型编译成一个高效的推理引擎。
- 推理:在应用程序中加载TensorRT引擎,进行数据的输入、模型推理和获取推理结果。
-
如何使用TensorRT优化现有的深度学习模型?
优化现有深度学习模型的步骤包括:- 准备模型:确保模型以TensorRT支持的格式存储,如ONNX。
- 导入模型:使用TensorRT提供的API将模型导入到TensorRT环境中。
- 设置优化配置:根据模型和目标平台的需求,选择合适的优化选项,如精度校准、最大批量大小等。
- 构建推理引擎:执行优化和编译过程,生成优化后的推理引擎。
- 推理:使用优化后的引擎进行推理,观察性能和精度的变化。
-
什么是精度校准?在TensorRT中的作用是什么?
精度校准是一种技术,用于将模型从高精度(如FP32)转换为低精度(如FP16或INT8)计算,以加速模型推理。在TensorRT中,精度校准通过一个校准过程实现,该过程使用一小部分输入数据来估计最佳的量化参数,以最小化低精度计算对模型精度的影响。这使得在保持可接受精度的同时显著提高推理速度。 -
TensorRT支持哪些网络层和操作?
TensorRT支持广泛的网络层和操作,包括但不限于:- 常见的卷积层(Convolution)、全连接层(Fully Connected)、激活层(如ReLU)。
- 池化层(Pooling)、归一化层(Normalization)。
- 循环神经网络层(RNNs)、长短期记忆网络(LSTMs)。
- 自定义层,通过TensorRT的插件机制实现。
随着TensorRT版本的更新,支持的层和操作会不断增加,以满足不断发展的深度学习模型需求。
5. TensorRT进阶
-
如何在TensorRT中自定义层?
在TensorRT中,如果你的模型包含TensorRT原生不支持的层,可以通过自定义插件来实现这些层。自定义层的步骤通常包括:- 实现插件接口:继承IPluginV2接口(或其派生接口,如IPluginV2IOExt用于支持动态输入输出)并实现必要的方法,包括层的前向传播(enqueue)等。
- 注册插件:创建插件实例并在模型构建过程中注册。
- 使用插件:在模型定义中,使用注册的插件来替代不支持的层。
自定义插件让TensorRT可以支持几乎任何类型的层或操作,从而扩展了TensorRT的适用范围。
-
解释TensorRT中的序列化和反序列化
在TensorRT中,序列化是指将优化后的推理引擎转换为一个平台无关的字节流(通常是一个文件),这样可以在不需要重新进行优化的情况下重用。反序列化是序列化的逆过程,即将字节流转换回TensorRT推理引擎。这使得模型部署更加高效,因为模型的优化和编译过程只需要执行一次,优化后的模型可以在不同的系统上部署和执行。 -
TensorRT如何处理动态输入大小?
TensorRT通过动态形状(Dynamic Shapes)支持动态输入大小。在定义模型时,你可以指定输入的形状范围(最小、最优、最大形状),TensorRT在构建期间会考虑这个形状范围来优化模型。在执行推理时,可以根据实际输入数据的大小来选择合适的优化执行路径。这一特性对于处理变化的输入数据(如不同尺寸的图像)非常有用。 -
解释TensorRT的插件机制
TensorRT的插件机制允许用户扩展TensorRT的功能,通过自定义插件来支持新的层、操作或特殊的优化。插件可以是自定义的层实现,或者是对现有操作的特殊优化。使用插件机制时,需要实现特定的接口,并在模型构建过程中将这些插件注册到TensorRT引擎。这种机制使得TensorRT能够灵活地适应新的网络架构和算法,保持其在深度学习推理领域的前沿性能。 -
如何在TensorRT中实现多GPU推理?
在TensorRT中实现多GPU推理涉及到在每个GPU上分别加载和执行推理引擎。具体步骤如下:- 环境准备:确保系统中有多个NVIDIA GPU,并且已经安装了CUDA和TensorRT。
- 模型优化:为每个目标GPU单独优化并构建TensorRT推理引擎。如果所有GPU都是相同的型号,可以只构建一次推理引擎然后在所有GPU上加载。
- 多线程或多进程:使用多线程或多进程来管理不同的GPU。每个线程或进程负责在一个GPU上加载和执行推理引擎。
- 数据管理:确保每个GPU接收到正确的输入数据,并从各自的GPU收集推理结果。
通过这种方式,可以有效地利用多GPU资源来提高推理的吞吐量。不过,需要注意的是,管理多GPU资源和同步可能会增加编程的复杂度。
6. 实际应用与案例分析
-
在CUDA中如何实现矩阵乘法的优化?
CUDA中实现矩阵乘法的优化可以通过以下几种策略:- 使用共享内存:将输入矩阵的子块加载到共享内存中,减少对全局内存的访问次数,因为共享内存比全局内存访问速度快得多。
- 块分割(Tiling):将矩阵分割成小块(tiles),每个线程块计算一个小块的结果,这样可以提高缓存利用率并减少内存访问延迟。
- 循环展开:手动展开计算循环,减少循环的开销。
- 使用warp内的线程协作:利用一个warp内的32个线程紧密协作,可以减少同步和通信的开销。
- 精细调整线程配置:根据具体的GPU架构调整线程块的大小和形状,以最大化占用率和性能。
-
描述一个使用TensorRT加速的深度学习模型的案例
一个典型的案例是使用TensorRT加速卷积神经网络(CNN)模型进行图像分类。假设有一个基于ResNet-50架构的模型,已经在ImageNet数据集上训练完成。通过以下步骤使用TensorRT加速:- 模型转换:将训练好的ResNet-50模型从其原始格式(如PyTorch的.pth或TensorFlow的.pb)转换为ONNX格式。
- 模型优化:使用TensorRT对ONNX模型进行优化,包括层融合、精度校准(FP32到FP16或INT8)以及选择最优的内核实现。
- 构建推理引擎:从优化后的模型构建TensorRT推理引擎。
- 执行推理:在实际应用中加载推理引擎,对输入图像进行处理并执行推理,得到分类结果。
使用TensorRT加速后,模型的推理时间显著减少,同时保持了较高的准确率,适合在边缘设备上进行高效的实时图像分类。
-
如何在CUDA中实现图像处理算法(如高斯模糊)?
在CUDA中实现高斯模糊可以遵循以下步骤:- 定义高斯核:根据高斯模糊的公式和所需的模糊程度(标准差σ),计算高斯核的权重。
- 全局内存中存储图像:将待处理的图像数据加载到GPU的全局内存中。
- 使用共享内存优化:为了减少全局内存访问,可以将每个线程块需要处理的图像区域加载到共享内存中。
- 并行计算:每个线程计算输出图像中的一个像素值,通过在输入图像上应用高斯核并对周围像素进行加权求和来实现。
- 处理边界:实现适当的边界检查,以确保不会访问无效的内存地址。
-
使用TensorRT处理变长输入数据的策略是什么?
处理变长输入数据的策略包括:- 动态形状:在TensorRT 7及更高版本中,可以为模型的输入定义动态形状范围,这允许模型在不同大小的输入上执行推理。
- 序列批处理:对于序列数据或变长数据,可以使用填充(padding)来标准化输入长度,并在批处理中处理多个序列,TensorRT可以优化这种批处理的执行。
-
如何在CUDA程序中实现与CPU的协同计算?
在CUDA程序中实现与CPU的协同计算通常涉及以下步骤:- 异步内存传输:使用cudaMemcpyAsync函数来异步地在CPU和GPU之间传输数据,以便CPU可以在GPU执行计算时并行地执行其他任务。
- 流(Streams):使用CUDA流来组织数据传输和计算,使得数据传输和计算可以重叠,同时在不同的流中并行执行任务。
- 事件(Events):使用CUDA事件来同步CPU和GPU的计算,确保在需要时CPU和GPU之间的数据一致性和计算的正确顺序。
通过这些方法,可以有效地利用GPU和CPU的计算资源,提高整体应用程序的性能。
7. 编程与代码实践
- 编写一个CUDA程序,实现向量加法。
下面是一个实现向量加法的简单CUDA程序示例。这个程序将两个向量相加,并将结果存储在第三个向量中。
#include <iostream>// CUDA Kernel for Vector Addition
__global__ void vectorAdd(const float *A, const float *B, float *C, int numElements) {int i = blockDim.x * blockIdx.x + threadIdx.x;if (i < numElements) {C[i] = A[i] + B[i];}
}int main() {int numElements = 50000; // Number of elements in each vectorsize_t size = numElements * sizeof(float);float *h_A = (float *)malloc(size);float *h_B = (float *)malloc(size);float *h_C = (float *)malloc(size);// Initialize input vectorsfor (int i = 0; i < numElements; ++i) {h_A[i] = rand() / (float)RAND_MAX;h_B[i] = rand() / (float)RAND_MAX;}float *d_A, *d_B, *d_C;cudaMalloc(&d_A, size);cudaMalloc(&d_B, size);cudaMalloc(&d_C, size);// Copy input vectors from host to devicecudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);int threadsPerBlock = 256;int blocksPerGrid = (numElements + threadsPerBlock - 1) / threadsPerBlock;vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements);// Copy result vector from device to hostcudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);// Free device memorycudaFree(d_A);cudaFree(d_B);cudaFree(d_C);// Free host memoryfree(h_A);free(h_B);free(h_C);return 0;
}
确保在具有CUDA支持的环境中编译和运行此程序。
-
如何在CUDA核函数中使用条件语句,且不影响性能?
在CUDA核函数中使用条件语句时,要注意避免线程执行路径的分歧,尤其是同一warp内的线程。如果条件语句导致同一warp内的线程走向不同的执行路径,将会导致线程串行执行不同的路径,从而影响性能。为了减少性能损失:- 尽量保证同一warp内的线程执行相同的条件分支。
- 如果可能,使用计算代替条件分支,例如使用逻辑运算和算术运算来避免分支。
- 如果条件分支不可避免,尽量减少分支内的计算量。
-
使用TensorRT优化一个简单的卷积神经网络
优化卷积神经网络(CNN)的步骤大致如下:- 准备模型:首先,需要将CNN模型转换为TensorRT支持的格式,如ONNX。
- 创建TensorRT引擎:使用TensorRT的API读取模型文件,应用优化,并创建推理引擎。这可能涉及设置输入输出格式、选择精度(FP32, FP16, INT8)、进行层融合等优化操作。
- 序列化和部署:将优化后的推理引擎序列化到磁盘,然后在目标设备上反序列化,进行推理。
由于代码实现细节较多,具体实现请参考NVIDIA的TensorRT文档和示例。
-
在CUDA中,如何实现并行归约操作?
并行归约操作(如求和、最大值等)通常通过分层归约的方式实现,每个线程处理一部分数据,然后逐步合并结果。在实现时,可以使用共享内存来存储中间结果,并通过同步确保数据的一致性。归约过程中需要特别注意避免线程间的冲突和确保高效的内存访问模式。 -
解释如何在TensorRT中使用INT8量化
在TensorRT中使用INT8量化涉及以下步骤:- 精度校准:使用一部分训练数据或代表性数据集进行精度校准,确定最佳的量化参数。
- 模型转换:将模型的权重和激活从高精度(如FP32)转换为INT8格式,同时应用校准得到的量化参数。
- 构建和优化推理引擎:在指定INT8精度的情况下构建和优化推理引擎,TensorRT会自动应用INT8量化以加速模型推理。
使用INT8量化可以显著提高模型的推理速度和吞吐量,同时对于大多数任务,精度损失是可控的。
8. 高级话题与趋势
-
CUDA在异构计算中的角色
CUDA(Compute Unified Device Architecture)是NVIDIA推出的一种并行计算平台和编程模型,它使得开发者能够使用NVIDIA的GPU来进行通用计算——即GPGPU(通用计算图形处理单元)。在异构计算环境中,CUDA扮演着至关重要的角色,使得GPU不仅仅被视为图形渲染的工具,而是作为能够执行复杂计算任务的强大处理器。
主要贡献包括:- 加速计算密集型任务:CUDA极大地提高了处理高性能计算(HPC)、深度学习、科学计算等计算密集型任务的能力。通过将任务分解成可以并行处理的小块,CUDA使得成千上万的核心能够同时工作,从而加速计算过程。
- 提供高级编程模型:CUDA为开发者提供了一套相对易于理解和使用的编程工具和APIs,使得开发者可以更容易地将现有的CPU代码迁移到GPU,或者开发新的并行算法。
- 支持异构编程:在异构计算环境中,不同的任务可能更适合在CPU或GPU上执行。CUDA提供了灵活的编程模型和工具,使得开发者可以根据任务的特点,选择最适合的计算资源,实现CPU和GPU的协同工作,优化整体应用性能。
- 推动技术创新:CUDA加速了深度学习和人工智能的研究与应用,使得训练大型神经网络成为可能。此外,它还在科学研究、金融分析、图像处理等多个领域推动了技术创新。
-
TensorRT在边缘计算设备中的应用
TensorRT是一个由NVIDIA提供的高性能深度学习推理引擎,用于生产部署。在边缘计算设备中,TensorRT具有以下应用:- 实时推理:在边缘设备上实现快速的推理响应时间,适用于需要实时处理的应用,如自动驾驶车辆、机器人导航、实时监控等。
- 低功耗:优化的推理计算减少了边缘设备的能耗,这对于电池供电的设备尤为重要,如无人机、便携式医疗设备等。
- 减少带宽需求:通过在边缘设备上直接进行数据处理和推理,减少了将大量数据传输到云端的需求,这有助于应对带宽限制和减少延迟。
- 隐私和安全:处理敏感数据时,TensorRT可以在数据生成的地点(即边缘设备上)进行推理,减少数据泄露的风险。
- 支持多种网络和模型:TensorRT支持多种深度学习模型和网络架构,使其能够广泛应用于各种边缘设备上的AI应用,包括图像和视频分析、语音识别、自然语言处理等。
综上所述,TensorRT在边缘计算中的应用显著提高了边缘设备处理深度学习任务的能力,同时优化了性能、功耗和带宽使用,使得边缘智能成为可能。
相关文章:

ChatGPT引领的AI面试攻略系列:cuda和tensorRT
系列文章目录 cuda和tensorRT(本文)AI全栈工程师 文章目录 系列文章目录一、前言二、面试题1. CUDA编程基础2. CUDA编程进阶3. 性能优化4. TensorRT基础5. TensorRT进阶6. 实际应用与案例分析7. 编程与代码实践8. 高级话题与趋势 一、前言 随着人工智能…...

【战略前沿】人形机器人制造商Figure获得了OpenAI、Jeff Bezos、Nvidia和其他科技巨头的资助
原文:Humanoid robot-maker Figure gets funding from OpenAI, Jeff Bezos, Nvidia, and other tech giants 作者:ASSOCIATED PRESS ———————————————— Figure成立不到两年,还没有商业产品,但正在说服有影响力的…...

多块磁盘组磁盘离线导致VSAN存储崩溃的VSAN数据恢复案例
VSAN简介: VSAN是以vSphere内核为基础进行开发、可扩展的分布式存储架构。VSAN存储层由VSAN控制和管理,VSAN存储层是通过vSphere集群主机中闪存和硬盘的存储空间构建的,供vSphere集群使用的统一共享存储层。 VSAN存储是一个对象存储ÿ…...
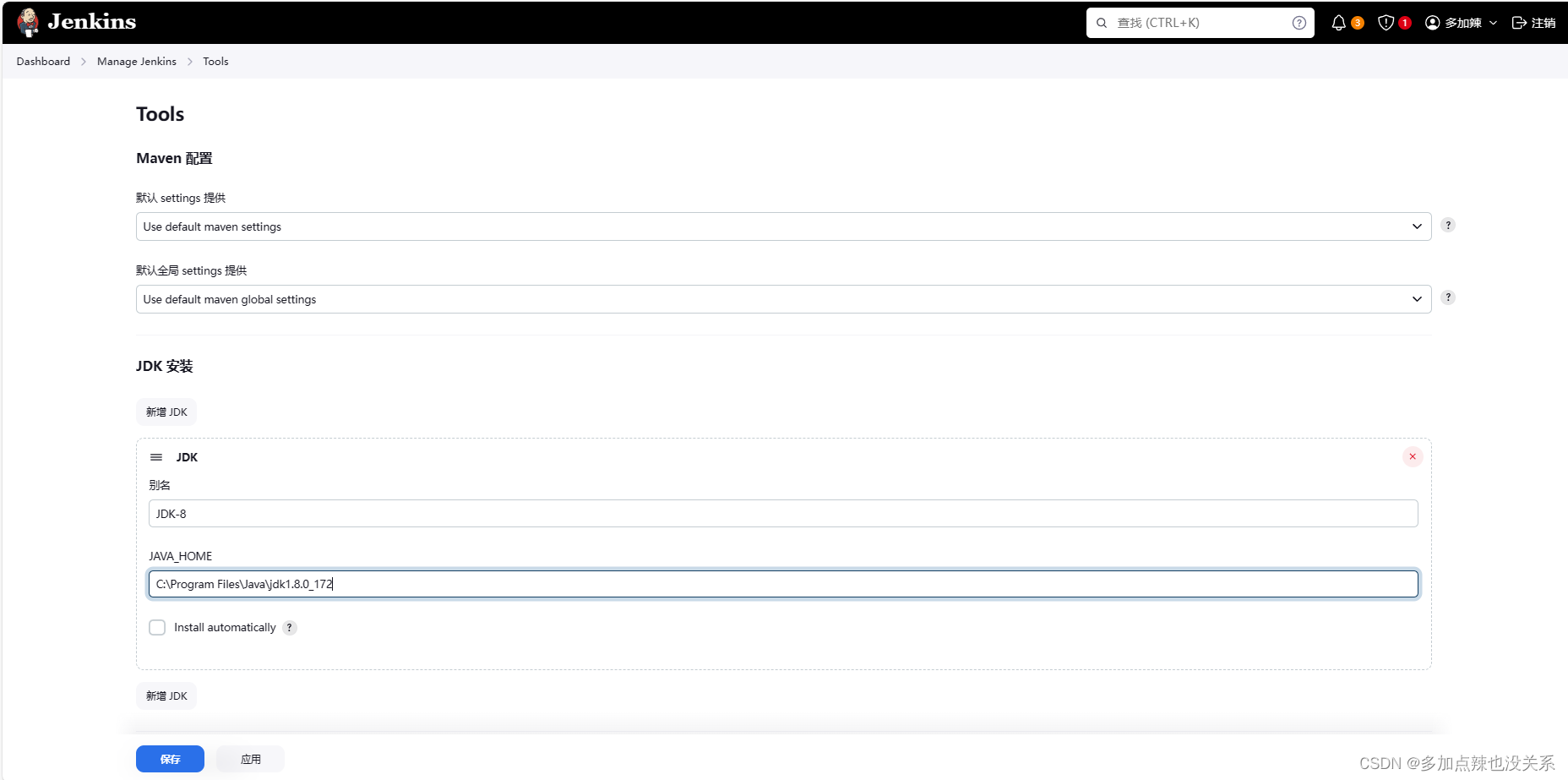
Jenkins 的安装(详细教程)
文章目录 一、简介二、安装前准备三、windows 安装与启动1. 方式一2. 方式二3. 方式三 四、创建管理员用户五、常用设置1. 配置镜像地址2. 更改工作目录3. 开启可注册用户4. 全局变量配置 一、简介 官网:https://www.jenkins.io 中文文档:https://www.j…...
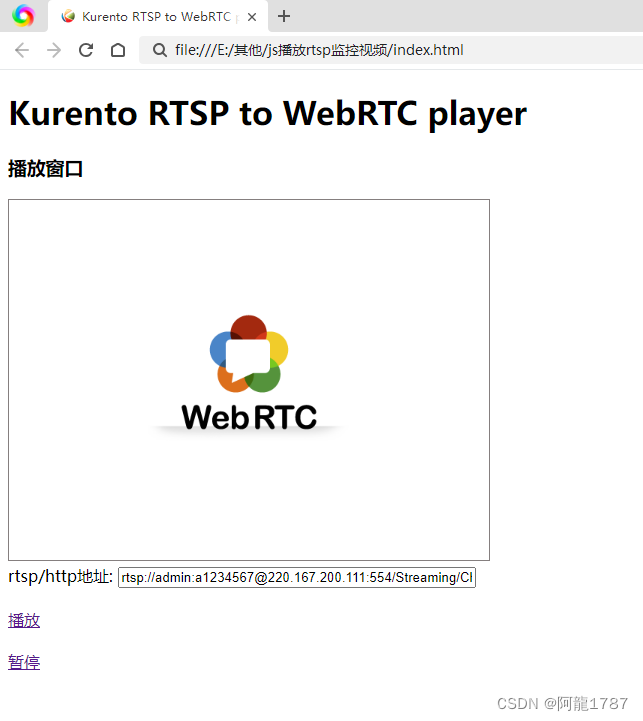
使用html网页播放多个视频的几种方法
前言 因为项目测试需要,我需要可以快速知道自己推流的多路视频流质量,于是我想到可以使用html网页来播放视频,实现效果极其简单,方法有好几种,以下是几种记录: 注意:测试过,VLC需要使…...

python 基础知识点(蓝桥杯python科目个人复习计划58)
今日复习内容:做题 例题1:仙境诅咒 问题描述: 在一片神秘的仙境中,有N位修仙者,他们各自在仙境中独立修炼,拥有他们独特的修炼之地和修炼之道,修炼者们彼此之间相互尊重,和平相处…...
【基于React实现共享单车管理系统】—React基础知识巩固(二)
【基于React实现共享单车管理系统】—React基础知识巩固(二) 一、React介绍 Facebook开源的一个JavaScript库React结合生态构成的一个MV*库 React的特点 Declarative(声明式编码)Component-Based(组件化编码&#…...

云桥通+跨境电商:SDWAN企业组网优化跨境网络案例
跨境电商企业在全球范围内展开业务,需构建稳定高效的网络架构以支持其电商平台运营。云桥通SDWAN企业组网技术为跨境电商提供网络连接和管理的优化,提升网络性能、可靠性和安全性。以下是一家跨境电商企业的SDWAN组网案例,详细介绍其实施情况…...

服务器有几种http强制跳转https设置方法
目前为站点安装SSL证书开启https加密访问已经是件很简单的事了,主要是免费SSL证书的普及,为大家提供了很好的基础。 Apache环境下如何http强制跳转https访问。Nginx环境下一般是通过修改“你的域名.conf”文件来实现的。 而Apache环境下通过修改.htacces…...
web坦克大战小游戏
H5小游戏源码、JS开发网页小游戏开源源码大合集。无需运行环境,解压后浏览器直接打开。有需要的订阅后,私信本人,发源码,含60+小游戏源码。如五子棋、象棋、植物大战僵尸、贪吃蛇、飞机大战、坦克大战、开心消消乐、扑鱼达人、扫雷、打地鼠、斗地主等等。 <!DOCTYPE htm…...
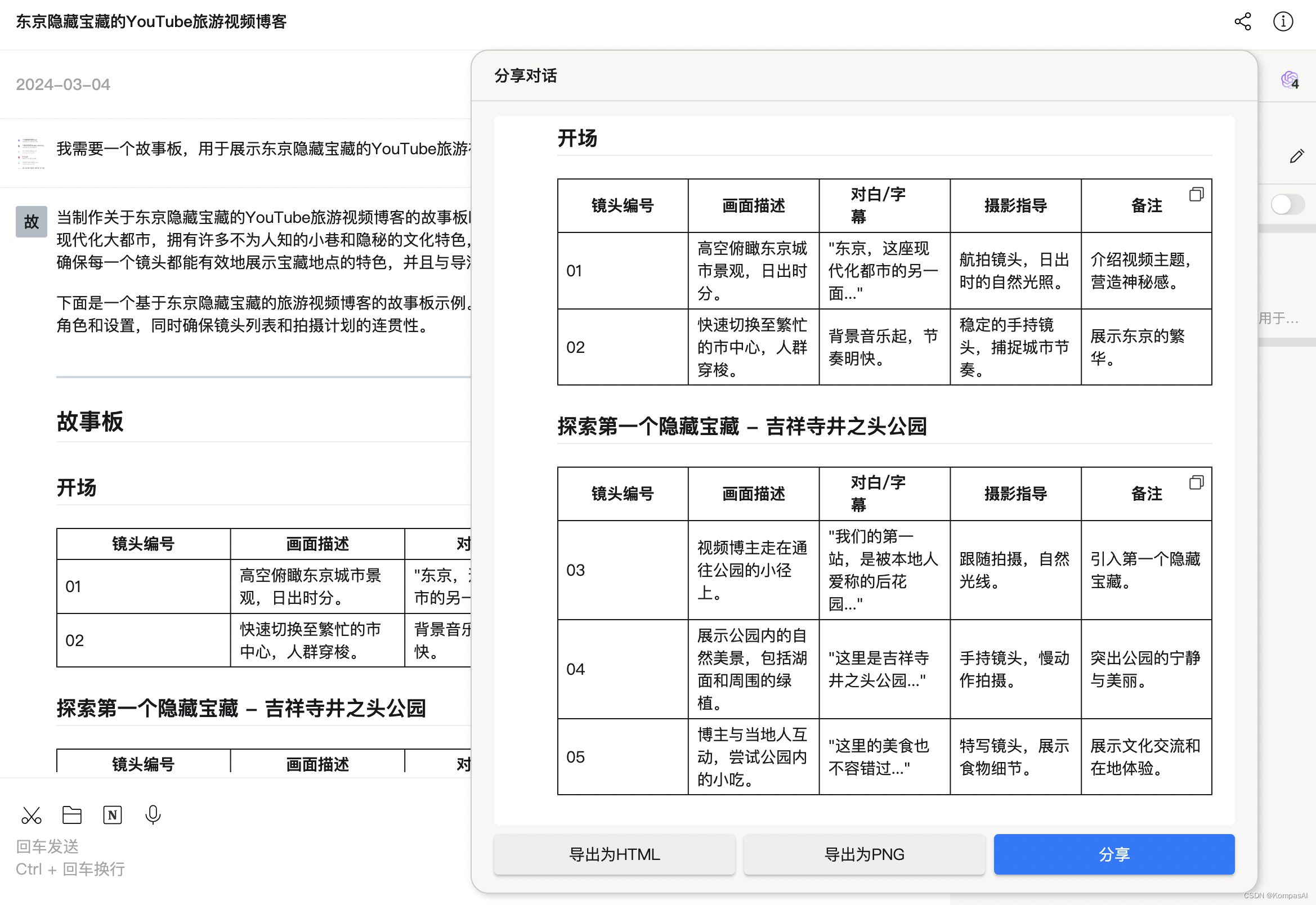
如何使用生成式人工智能探索视频博客的魅力?
视频博客,尤其是关于旅游的视频博客,为观众提供了一种全新的探索世界的方式。通过图像和声音的结合,观众可以身临其境地体验到旅行的乐趣和发现的喜悦。而对于内容创作者来说,旅游视频博客不仅能分享他们的旅行故事,还…...

gpt批量工具,gpt批量生成文章工具
GPT批量工具在今天的数字化时代扮演着越来越重要的角色,它们通过人工智能技术,可以自动批量生成各种类型的文章,为用户提供了便利和效率。本文将介绍5款不同的GPT批量工具,并介绍一款知名的147GPT生成工具,以及另外一款…...

Python知识汇总
重要链接: matplotlib库:matplotlib — Matplotlib 3.5.1 documentation DataFrame库:DataFrame — pandas 2.2.1 documentation (pydata.org) Python Matplotlib 实现散点图、曲线图、箱状图、柱状图示例:Python Matplotlib 实…...

WEB面试题
1.基础 Web 技术: 1.1 h5 行内元素和块级元素 行内元素不会独占一行,高度和宽度由内容决定,不能单独设置宽高, 不能设置上下的margin和padding,只能设置左右的margin和padding; …...

Android Studio 六大基本布局详解
Android应用开发中,布局是至关重要的一部分,而Android Studio作为主流的开发工具,提供了多种布局方式来灵活适应不同的界面需求。在本文中,我们将深入探讨Android Studio中的六大基本布局,旨在帮助开发者更好地理解和运…...

如何应对IT服务交付中的问题?
如何应对IT服务交付中的问题? 按需交付服务的挑战IT服务体系的复杂性恶性循环的形成学会洞察的重要性书籍简介参与方式 按需交付服务的挑战 一致性、可靠性、安全性、隐私性和成本效益的平衡:成功的按需交付服务需要满足这些要求,这需要服务…...

[Python] 缓存实用工具
cachetools 是一个 Python 库,提供了用于缓存的实用工具,包括各种缓存算法和数据结构,如 LRU(最近最少使用)缓存、TTL(时间到期)缓存等。使用 cachetools 可以轻松地在 Python 应用程序中实现缓…...
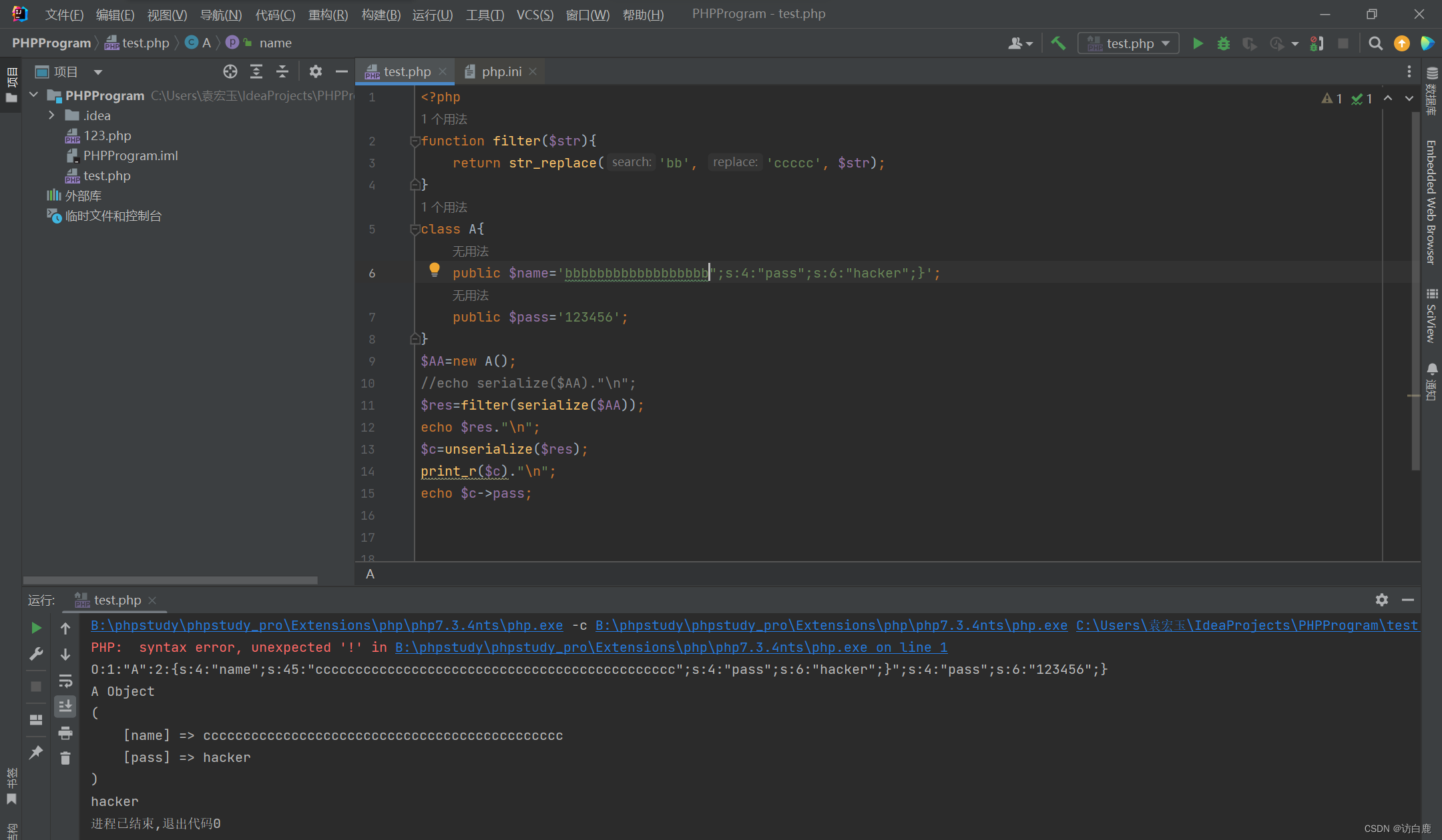
php反序列化字符逃逸
php反序列化和序列化 PHP序列化:serialize() 序列化是将变量或对象转换成字符串的过程,用于存储或传递 PHP 的值的过程中,同时不丢失其类型和结构。“序列化”是一种把对象的状态转化成字节流的机制 类似于这样的结构: O:4:&quo…...
的单例模式)
延迟加载(Lazy Initialization)的单例模式
延迟加载(Lazy Initialization)的单例模式是一种在对象第一次被请求时才创建单例实例的设计模式。这种方法可以减少程序启动时的负载和启动时间,特别是当单例对象的创建开销较大或者在启动时不一定需要该对象时。 下面是实现延迟加载单例模式…...

C++三级专项 流感传染
时间限制:1000 内存限制:65536 有一批易感人群住在网格状的宿舍区内,宿舍区为n*n的矩阵,每个格点为一个房间,房间里可能住人,也可能空着。在第一天,有些房间里的人得了流感,以后每…...

解决VMware安装macOS后分辨率锁死的烦恼:手把手教你安装VMware Tools并自定义显示设置
突破VMware中macOS显示限制:从工具安装到完美适配的全流程指南 当你在VMware中成功安装macOS系统后,可能会立刻遇到一个令人沮丧的问题——屏幕分辨率被锁定在低分辨率状态,窗口无法自由缩放,操作体验大打折扣。这种显示限制不仅…...

别再用土办法改论文了!书匠策AI官网www.shujiangce.com才是2025届毕业生的“通关密码“
你有没有经历过这种崩溃瞬间? 凌晨两点,你对着电脑屏幕,查重率39%,AIGC疑似率67%。导师发来一条消息:"这篇不像你写的,重写。" 那一刻,你是不是特别想问一句:我到底该怎…...

书匠策AI到底有多懂毕业生?一个论文小白的“开挂“实录,看完你也想试!
嗨,各位正在为毕业论文头秃的宝子们!👋 我是你们的论文科普搭子,今天不讲枯燥的写作技巧,直接给大家安利一个我最近发现的"宝藏神器"——书匠策AI( 官网直达:www.shujiangce.com&…...

CANN/pypto Tensor索引功能
pypto.Tensor索引功能说明 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto Tensor索引是Tensor的核心操作之一,用于从Tensor中筛选、…...

B-Parameter小模型:精度、速度与成本的帕累托最优
1. 小模型正在悄悄改写游戏规则:为什么10B参数的模型能干翻100B巨兽?最近在几个技术团队做模型选型咨询,几乎每场讨论都会有人抛出这个问题:“我们业务场景明明很垂直,推理延迟要求严苛,GPU显存还卡在24G&a…...

DINOv3特征工程实战:构建可解释、可增量、可部署的CV数据科学工作流
1. 项目概述:这不是又一个ViT教程,而是一份面向实战的数据科学家操作手册“DINOv3 Playbook”这个标题里藏着三个关键信号:DINOv3是Meta最新发布的视觉自监督模型,Playbook不是论文摘要,也不是API文档,而是…...
Flink SQL 核心重难点(窗口函数、水印))
【FlinkSQL笔记】(三)Flink SQL 核心重难点(窗口函数、水印)
一、窗口函数 流式数据无限无边界,例如想要统计每5分钟、每1小时的数据,必须用窗口函数,这是Flink SQL和普通SQL最大的区别之一。 1、 滚动窗口 TUMBLE(最常用) 特点:无重叠、无间隔、固定时长,…...

合同系统功能详解:相对方管理
上一期,我们讲解了合同系统的业务功用。本期开始,我们将逐一对合同系统的核心功能进行拆解,结合实际业务场景展开详细讲解。今天,我们重点介绍合同系统中的相对方管理功能。 在实际业务落地过程中,不同企业的经营业态…...

沥青生产导向的常减压过程模拟及排产计划优化【附仿真】
✨ 长期致力于沥青生产、多目标优化、遗传算法、排产、换热网络综合、粒子群算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)原油实沸点切割与沥青…...

1987年6月27日下午13-15点出生性格、运势和命运
1987年6月17日,下午15点到17点之间,正值盛夏时节,阳光炽烈而漫长。这一天出生的孩子,是中国改革开放后“黄金十年”中诞生的又一批弄潮儿。他们的成长轨迹,与全球化浪潮的涌入、市场经济的深化以及互联网的萌芽几乎同步…...