Linux 进程间通信
目录
管道
匿名管道(pipe)
有名管道(fifo)
小结
共享内存
消息队列
信号量
System V IPC的结构设计
Posix与System V的关系
管道
匿名管道(pipe)
我们知道,在Linux中通过fork创建的子进程,在父进程没有将标准io流重定向的情况下,子进程用cout或printf等函数默认是向屏幕打印数据的。那么这是为什么呢?其原因在于,每一个进程都有它的文件描述符表以及页表等内核数据结构,而子进程在创建时,是会拷贝父进程的这些内核数据结构中的内容的,这其中就包括了文件描述符表以及页表的映射等信息,所以子进程文件描述符表中的内容起初是和父进程的一样的。
也就是说进程就可以利用这一特性,通过父子进程向同一个文件中读写数据,以实现父子间进程的通信。而匿名管道其实就是利用这一原理实现的进程间通信的一个特性。所以匿名管道仅限于具有“血缘关系”的两个进程之间进行通信,这里的“血缘关系”指的就是父子进程或兄弟进程等关系。
而匿名管道的本质就是通过在内存中创建一个临时的管道文件,这个管道文件的缓冲区不经过磁盘等外设,只在内存中进行交互,所以其实管道的底层就是文件。所以匿名管道的生命周期是随进程的,进程退出了,管道也就关闭了,对应的临时文件也就被删除了。其中,Linux下的管道指令"|"就是利用的匿名管道的原理,先创建管道,再创建进程,进而实现通信。
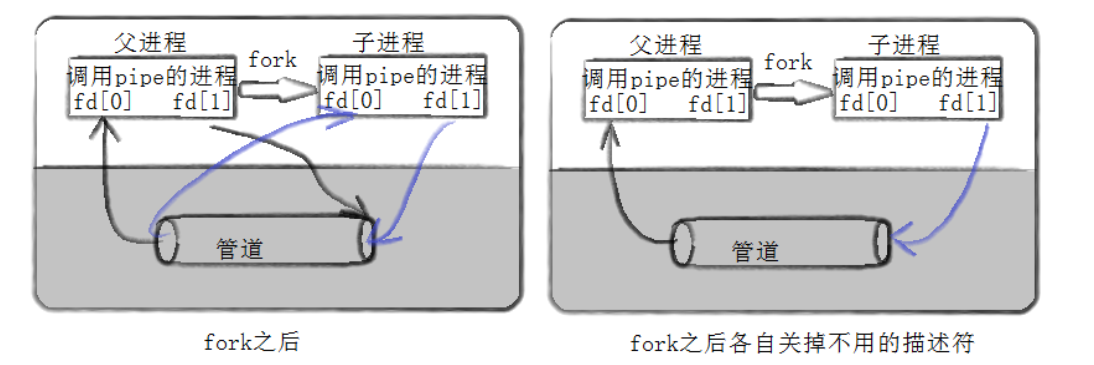
而通常我们使用匿名管道的过程原理为,父进程先分别以读写的方式打开一个文件,这样文件的读权限和写权限就分到了两个文件描述符中,即读端和写端。接着创建子进程,然后将父进程的读端关闭,子进程的写端关闭,这样父进程就作为写端,只能向管道中写数据,子进程作为读端,只能向进程中读数据。于是便形成了的利用匿名管道的进程间通信。不光是父子进程,其实我们也可以创建两个子进程,然后一个子进程做写端,一个子进程做读端,让两子进程之间进行通信。
Linux下匿名管道对应的系统调用为pipe:
#include <unistd.h>int pipe(int pipefd[2]);接口说明:
- pipe接口,用于创建一个管道。
- pipefd为输出型参数,pipefd[0]表示管道的读端,pipefd[1]是写端。创建管道成功返回0,失败返回-1并设置errno变量。

至于匿名管道的读写端为什么要分开,这是因为如果将管道文件只用一个文件描述符来控制读写,就会使得读写段的文件偏移量是一样的,就需要不断调整文件的偏移量,导致使用成本的增加。
有名管道(fifo)
由于匿名管道只适用于具有亲缘关系的进程之间通信,所以匿名管道是有一定局限性的,进而就有了有名管道。有名管道又叫命名管道,可以让没有亲缘关系的进程之间也可以利用管道实现通信。
有名管道的原理和匿名管道的原理类似,匿名管道是先创建一个具有读写权限的管道文件,然后读端进程关闭写端,写端进程关闭读端。而有名管道不需要这么麻烦,直接在内存中创建一个管道文件,然后让读端以只读的形式打开,写端以只写的形式打开即可。
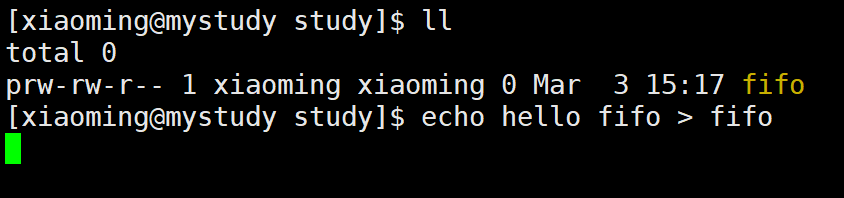
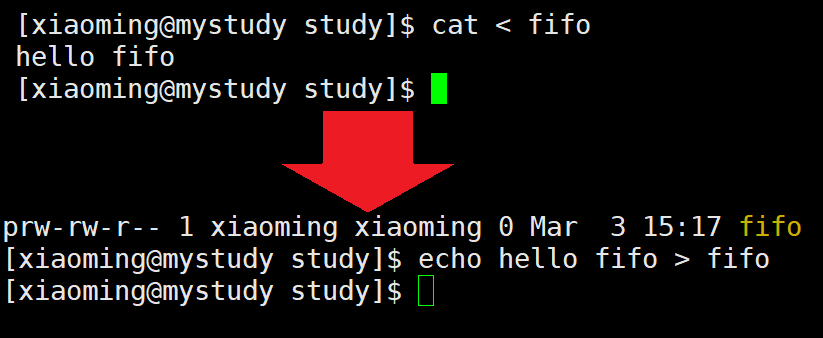
对应的系统指令为mkfifo,用法与mkdir基本一致,就是创建一个管道文件。要注意,管道文件只在内存中与进程之间进行交互,且不会向磁盘中刷新数据,所以其大小一直为0。

我们可以通过重定向对管道文件进行读写数据,需要注意的是,通过重定向对管道文件写入数据时就会导致终端阻塞,直到管道内的数据被读出。
对应的,创建有名管道的函数也叫做mkfifo:
#include <sys/types.h>
#include <sys/stat.h>int mkfifo(const char *pathname, mode_t mode);函数说明:
- mkfifo,用于创建一个fifo(有名管道)文件。
- pathname 参数:是要创建的文件,默认是在当前目录下。
- mode 参数:是对应管道文件的权限说明(rwx等)。
- 返回值:成功返回0,失败返回-1。
用法示例:
mkfifo("./temp", 0664);管道文件在使用时像普通文件一样使用即可,open打开,read和write进行读写,打开文件时注意权限控制即可。
特别的,在使用open打开命名管道时可以适当添加 O_NONBLOCK 打开方式:
- 以读权限打开FIFO时
- 不加 O_NONBLOCK:阻塞直到有相应进程为写而打开该FIFO
- 添加 O_NONBLOCK:立刻返回成功
- 以写权限打开FIFO时
- 不加 O_NONBLOCK:阻塞直到有相应进程为读而打开该FIFO
- 添加 O_NONBLOCK:立刻返回失败,错误码为ENXIO
小结
- 管道的本质就是文件,进程退出之后管道会被关闭。即管道的生命周期是随进程的。
- 匿名管道只适用于具有血缘关系的进程之间进行通信,而有名管道则没有这个限制。
- 匿名管道由pipe接口创建并打开。命名管道由mkfifo函数创建,用open打开。
- fifo(命名管道)与pipe(匿名管道)之间唯一的区别在它们创建与打开的方式不同,一但这些工作完成之后,它们具有相同的语义。
- 管道只能单向通信,即只能一端写另一端读。
- 管道是面向字节流的,也就是说没有C语言中以'\0'结尾等语言规则。
- 如果读写端正常,管道为空,则读端就会阻塞。
- 如果读写端正常,管道被写满,写端就会阻塞。
- 如果所有管道写端对应的文件描述符被关闭,则read返回0。
- 如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出。
- 管道的大小上限为 PIPE_BUF,PIPE_BUF保存在 limits.h 头文件中。所以如果管道内的数据量小于 PIPE_BUF 的情况下,写端写入多少数据,读端就可以一次性读入多少数据。所以当要写入的数据量不大于PIPE_BUF时,Linux能保证管读写的原子性。对应的,当要写入的数据量大于PIPE_BUF时,Linux将不再保证读写的原子性。
共享内存
概念阐述
可以看出,管道这种进程通信方式虽然使用简单,但是效率比较低,不适合进程间频繁地交换数据,并且管道只能传输无格式的字节流。所以操作系统还为我们提供了其它进程间通信的方式。
共享内存,顾名思义就是允许不相干的进程共享同一块物理内存,这个物理内存就称为共享内存。也就是说如果某个进程对共享内存的数据做了修改,那么其它进程访问到的内存数据也会随之发生变化。所以共享内存在使用时存在一定的安全问题。
接下来我们来深入理解下共享内存的原理。首先,每个进程都有属于自己的进程控制块(PCB)和逻辑地址空间(Addr Space),并且都有一个与之对应的页表,负责将进程的逻辑地址(虚拟地址)与物理地址进行映射,通过内存管理单元(MMU)进行管理。两个不同进程的逻辑地址通过页表映射到物理空间的同一区域,它们所共同指向的这块区域就是共享内存,原理图如下。

创建共享内存
#include <sys/ipc.h>
#include <sys/shm.h>int shmget(key_t key, size_t size, int shmflg);接口说明:
- shmget,用于获取(创建)一个System V的共享内存段。shmget创建的共享内存就和堆区申请的内存用法一样,直接使用即可。
- key 参数:key值用于标识一块共享内存块,相当于共享内存的独特密钥。它是多少不重要,关键在于它必须在内核中具有唯一性,这样才能保证共享内存之间不冲突。
- size 参数:想要获取的共享内存大小。一个新的共享内存段,其大小等于四舍五入到 PAGE_SIZE 的倍数的大小。所以size的大小最好设置为 PAGE_SIZE的整数倍,以免内存浪费,PAGE_SIZE 就在shmget的头文件中。例如当 PAGE_SIZE 为16,而我们设置的size为4095时,由于4096是16的整数倍,所以共享内存的实际大小其实是4096字节,但只给我们4095字节的使用权限。
- shmflg 参数:获取共享内存的方法,最常用的两个值为 IPC_CREAT 和 IPC_EXCL。其中IPC_CREAT 表示创建一个共享内存,如果不存在就直接创建,存在就直接获取并返回。IPC_CREAT | IPC_EXCL 表示创建一个共享内存,如果不存在就直接创建,存在就出错返回,程序就直接崩掉了,这两个选项组合使用,就能确保我们申请的共享内存一定是一个新的。其中 IPC_EXCL 不单独使用。其中,在创建共享内存时还需要像文件一样为其指明权限,例如0666权限等。
- 返回值:返回一个shmid,即当前共享内存的id。要注意区分shmid和key值的区别,shmid是一个共享内存的标识性id,我们在使用某一块共享内存时,通常用shmid来表示,而key只是用来创建共享内存的一个键值,shmid在每次进程启动时都有可能不一样,而key值不论何时都必须保持唯一不变。可以类比文件部分的内容,shimd相当于文件描述符,而key则相当于是inode。
用法示例:
shmget(_key, _size, IPC_CREAT | 0664);形成key值
我们直到,shmget的key值必须保持唯一,但如果共享内存多了的话,让我们人为规定则很难保证共享内存的唯一性。所以我们可以让计算机来帮我们设置key值。其中在Linux下就有一个ftok函数用专门用于生成对应的key值。
#include <sys/types.h>
#include <sys/ipc.h>key_t ftok(const char *pathname, int proj_id);函数说明:
- ftok函数,将路径名和项目标识符转换为System V IPC的密钥。
- pathname 参数:文件的路径。正是因为在树状文件结构的模式下,每一个文件的路径都是独一无二的,所以可以根据这个独特的路径来形成具有唯一性的key值。
- proj_id 参数:参数标识符,通常是我们在设计项目时人为规定的。
- 返回值:独一无二的key值。
关联共享内存
#include <sys/types.h>
#include <sys/shm.h>void *shmat(int shmid, const void *shmaddr, int shmflg);接口说明:
- shmat,用于将共享内存和进程之间进行关联。简单来说,只有共享内存和进程之间关联之后,进程才可以使用共享内存。
- shmid 参数:shmid就是共享内存对应的shmid,即shmget接口的返回值。
- shmaddr 参数:shmaddr 就是我们想让当前的共享内存挂接到共享区的哪个位置,但是一般让系统决定挂接到哪里,所以设置为 nullptr 即可,那么最终挂接到的虚拟地址会以返回值的形式返回给我们。
- shmflg 参数:shmflg就是关于挂载的权限,通常我们只需要按照共享内存默认的权限设置为0即可。
- 返回值:就是共享内存的起始地址。
取消关联
#include <sys/types.h>
#include <sys/shm.h>int shmdt(const void *shmaddr);接口说明:
- shmdt,对一块共享内存取消关联。
- shmaddr 参数:共享内存的起始地址,就是shmaddr接口的返回值。
删除共享内存
共享内存与管道不同,管道的生命周期是随进程的,而共享内存的生命周期是随操作系统的。也就是说,即使进程退出,共享内存也不会自动销毁。即共享内存是需要我们手动销毁的。
而我们可以用ipcs指令查看操作系统内所有的IPC资源,用ipcrm指令用于删除指定的IPC资源。其参数为-m表示共享内存,-q表示消息队列。例如 ipcs -m 是查看所有的共享内存资源,ipcrm -m 2 是删除shmid为2的共享内存。
同时,我们也可以利用系统接口来控制IPC资源,即shmctl接口。
#include <sys/ipc.h>
#include <sys/shm.h>int shmctl(int shmid, int cmd, struct shmid_ds *buf);参数说明:
- shmid:共享内存的shmid。
- cmd:表明我们要进行的操作,其中 IPC_RMID 表示是删除共享内存资源。
- buf:buf是一个输出型参数,其类型struct shmid_ds是一个内部的结构体,内有共享内存资源的一些信息,有些场景下需要获取共享内存资源的某些信息会用到。在删除对应共享内存资源的时候设为nullptr即可。
消息队列
概念阐述
消息队列顾名思义就是一个传递消息的队列,消息队列的本质就是存放在内存中的消息的链表,而消息本质上是用户自定义的数据结构。如果进程从消息队列中读取了某个消息,这个消息就会被从消息队列中删除。与共享内存不同的是,共享内存是进程之间直接共享一块内存,将资源直接暴漏出来的。而消息队列是将信息都统一发送到一个队列中,然后按照先进先出的顺序进行读取。
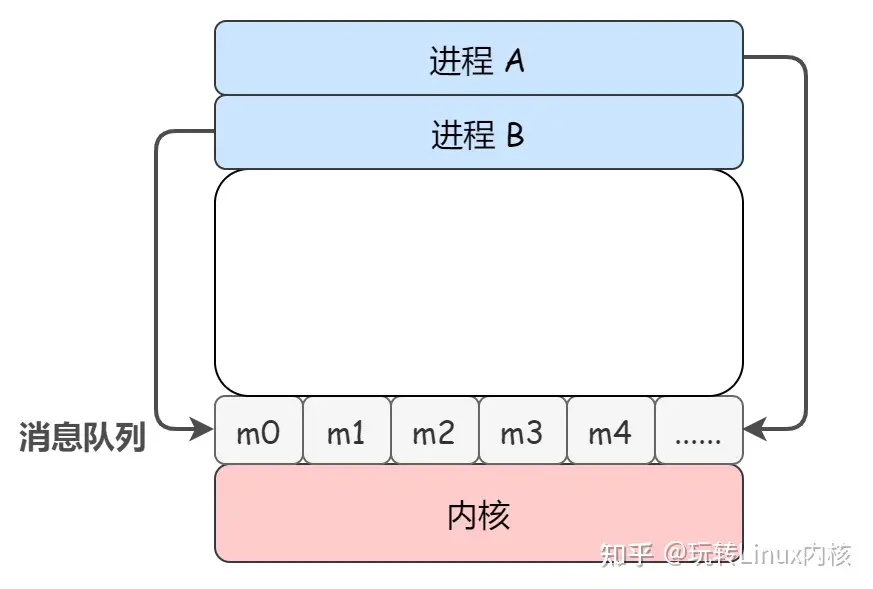
消息队列的使用和共享内存类似,只需要注意消息队列是逐条发送,逐条接收的即可。所以我们这里就简单介绍对应的系统调用即可。
获取消息队列
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>int msgget(key_t key, int msgflg);msgget和shmget用法类似,key值一般也是通过ftok函数来设置的,msgflg参数用法就等同与shmget的参数。返回值为int型的msqid,可以类比shmid。用法示例如下:
int msgid = msgget(_key, 0666|IPC_CREAT|IPC_EXCL);
收发消息
与共享内存不同的是,消息队列收发消息并不是直接收发的,而是需要通过封装一个结构体作为载体来收发消息的,这个结构体的构造如下:
struct msgbuf
{long mtype;char mtext[1];
}
mtype指的是消息的类型,必须大于0,要保证不同进程发送的数据的mtype是不同的,这样才能区分不同的类型,使mtype起到“类型”的作用。mtext[1]指的是队列中的数据,这里并不是说只能为1大小的数组,而是指的数据的统称,其可以为数组、变量、结构体对象,也可以是多个变量、数组、结构体对象等。但由于其底层是C语言,所以并不支持C++的class对象。正是因为又来mtype,所以当多个进程同时操作一个队列时,我们就可以区分哪些数据是哪一个进程发送的了。
接下来我们先来看收发数据的接口:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp,int msgflg);msgsnd接口的功能为发送数据,msgrcv接口的功能为接收数据。
参数说明如下:
- msqid 就是消息队列的msqid编号,即msgget的返回值。
- msgp 为struct msgbuf结构体对象的地址。
- msgsz 为收发信息的大小。
- msgflg 表示消息发送的方式,通常不需要特殊设置,设为0即可。
- 而 msgrcv 接口比 msgsnd 接口多了一个msgtyp参数,这个参数表示获取消息的类型。若为0,则获取队列中的第一个数据,无视类型。若大于0则表示获取指定类型的队列中的第一个消息。
用法示例:(只摘录了关键部分的代码)
// msg_buf 结构体
struct msg_buf
{long msgtype;char str[SIZE];
};// 写端
int main()
{msg_buf *msg = new msg_buf();key_t key = ftok(PATH, PROJ_ID);// if(key == -1) ...int msgid = msgget(key, IPC_CREAT | 0664);// if(msgid == -1) ...int num = 0;while (1){memset(msg, 0, sizeof(msg_buf));cin >> msg->str;msg->msgtype = getpid();int snd = msgsnd(msgid, msg, sizeof(msg->str), 0);// if(snd == -1) ...cout << msgid << " send over - " << num++ << endl;}
}// 读端
int main()
{key_t key = ftok(PATH, PROJ_ID);// if(key == -1) ...int msgid = msgget(key, IPC_CREAT | 0664);// if(msgid == -1) ...msg_buf *msg = new msg_buf();// if(snd == -1) ...while (1){ssize_t rcv = msgrcv(msgid, msg, sizeof(msg->str), msg->msgtype, 0);// if(rcv == -1) ...cout << msgid << " " << "get read: " << msg->str << endl;}
}信号量
概念阐述
- 临界资源:我们一般把共享的,任何时刻只允许一个执行流访问的资源,称为临界资源,这种临界资源一般都是内存空间。
- 临界区:每个进程中访问临界资源的那段程序称为临界区。每次只准许一个进程进入临界区,进入后不允许其他进程进入。
- 互斥:任何时刻只允许一个执行流访问共享资源就叫做互斥。
- 同步:让进程能够按照某个特定顺序访问共享资源就叫做同步。
- 信号量:信号量的本质是一个计数器,用来描述临界资源中数量的多少。
信号量的理解
内容参考:一文搞懂六大进程通信机制原理(全网最详细) - 知乎 (zhihu.com)
前面我们了解了共享内存的概念,如果多个进程同时修改同一个共享内存,那么先来的进程所写的内容就会被后来的覆盖。而且多个进程是可以并发执行的,但由于系统的资源有限,进程的执行不是一贯到底的, 而是以不可预知的速度异步性地向前推进,这就有可能会导致进程可能会出现预期之外的执行顺序,进而导致结果错误。
而我们可以通过保证共享资源在任何时刻只有一个进程在访问(互斥),或者让进程能够按照某个特定顺序访问共享资源(同步)来解决上述问题。进程的同步与互斥其实是一种对进程通信的保护机制,并不是用来传输进程之间真正通信的内容的,但是由于它们会传输信号量,所以也被纳入进程通信的范畴,称为低级通信。
我们通常使用信号量及其PV操作来实现同步与互斥,进而可以对诸如共享内存等临界资源有一个很好的管控。共享内存是一种临界资源。我们一般把共享的,或者任何时刻只允许一个执行流访问的资源,称为临界资源,临界资源一般都是内存空间的资源。
那么信号量与PV操作究竟是怎么一回事呢?事实上,信号量的本质其实就是一个变量 ,用以表示系统中某给临界资源的数量。例如某一块共享内存只允许2个进程同时访问,那么对应的信号量就为2。用户进程可以通过使用操作系统提供的一对原语来对信号量进行操作,从而很方便的实现进程互斥或同步。这一对原语就是 PV 操作:
- P 操作:将信号量值减 1,表示申请占用一个资源。如果结果小于 0,表示已经没有可用资源,则执行 P 操作的进程被阻塞。如果结果大于等于 0,表示现有的资源足够使用,则执行 P 操作的进程继续执行。例如,当信号量的值为 2 的时候,表示有 2 个资源可以使用,当信号量的值为 -2 的时候,表示有两个进程正在等待使用这个资源。
- V 操作:将信号量值加 1,表示释放一个资源,即使用完资源后归还资源。若加完后信号量的值小于等于 0,表示有某些进程正在等待该资源,由于我们已经释放出一个资源了,因此需要唤醒一个等待使用该资源(就绪态)的进程。
P 操作和 V 操作必须成对出现。缺少 P 操作就不能保证对共享内存的互斥访问,缺少 V 操作就会导致共享内存永远得不到释放、处于等待态的进程永远得不到唤醒。

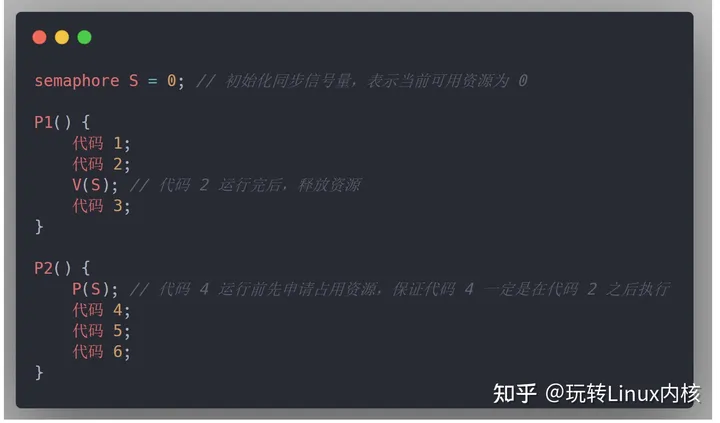
而进程同步,就是要各并发进程按要求有序地运行,示例如下:
以下两个进程 P1、P2 并发执行,由于存在异步性,因此二者交替推进的次序是不确定的。假设 P2 的 “代码4” 要基于 P1 的 “代码1” 和 “代码2” 的运行结果才能执行,那么我们就必须保证 “代码4” 一定是在 “代码2” 之后才会执行。
如果 P2 的 “代码4” 要基于 P1 的 “代码1” 和 “代码2” 的运行结果才能执行,那么我们就必须保证 “代码4” 一定是在 “代码2” 之后才会执行。
使用信号量和 PV 操作实现进程的同步也非常方便,分三步走:
- 定义一个同步信号量,并初始化为当前可用资源的数量
- 在优先级较高的操作的后面执行 V 操作,释放资源
- 在优先级较低的操作的前面执行 P 操作,申请占用资源
图例如下:


这也就解释了为什么当多个进程并发地往显示器打印数据时,显示器上的消息会出现错乱混乱或者和命令行混在一起的。这是因为显示器本质上是标准输出文件,也属于是共享资源,但我们并没有对这个标准输出文件加以保护,即没有对标准输出文件加锁,所以必然会导致上述的情况。
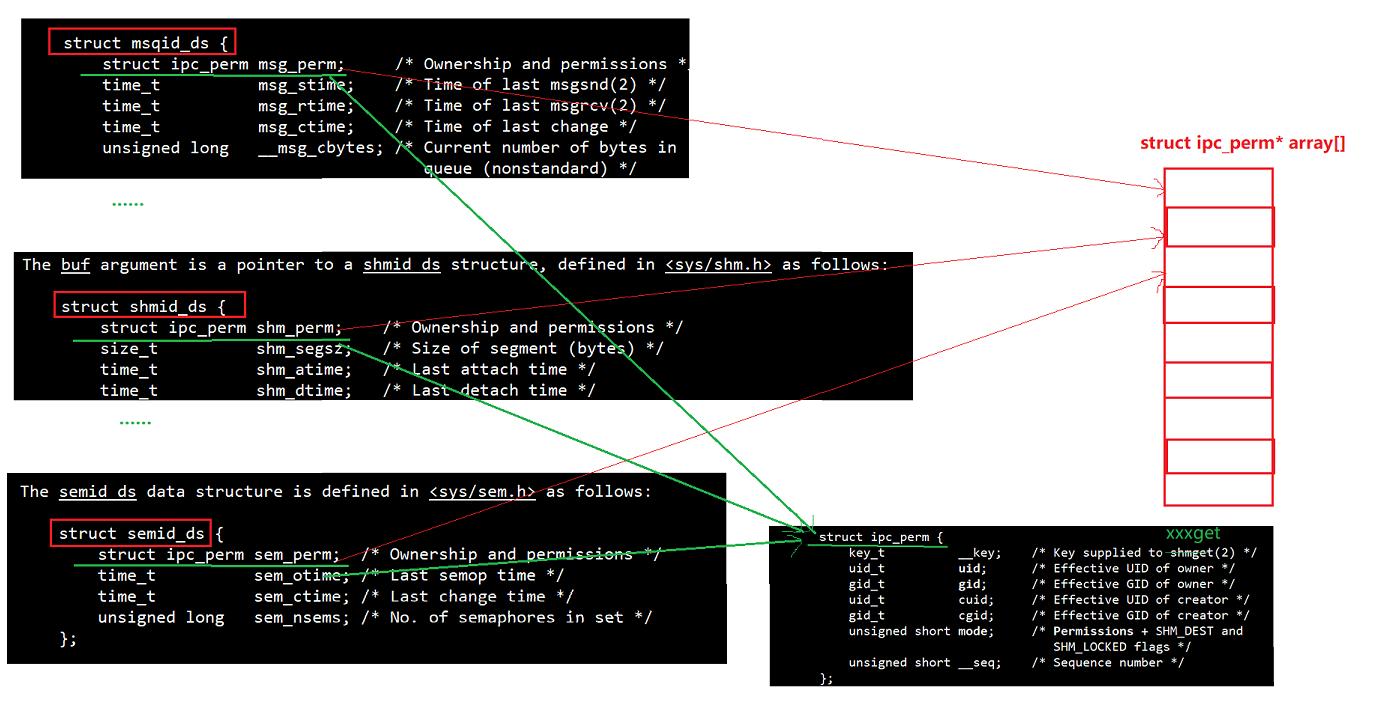
System V IPC的结构设计
操作系统是通过一个数组(struct ipc_perm* array[])来管理所有的System V IPC资源的,包括共享内存、消息队列、信号量等资源。这是因为这些 IPC 资源的结构体中的第一个字段是一个共同的ipc_perm结构体变量,其中包含了一些所有IPC资源公共的资源信息:
struct ipc_perm
{key_t __key; /* Key supplied to shmget(2) */uid_t uid; /* Effective UID of owner */gid_t gid; /* Effective GID of owner */uid_t cuid; /* Effective UID of creator */gid_t cgid; /* Effective GID of creator */unsigned short mode; /* Permissions + SHM_DEST andSHM_LOCKED flags */unsigned short __seq; /* Sequence number */
};每一种IPC资源的结构体,除了一个公共的ipc_perm结构体变量外,还有自己独特的一些属性信息。当某个进程需要访问某个 IPC 资源时,操作系统会在数组中从前往后,将用户提供的key值与数组中的每一个ipc_perm指针中的__key值进行对比。进而,进程可以通过这个数组找到对应资源的结构体指针,并根据 IPC 资源的类型进行合适的类型转换,以访问资源的其他属性,例如进行类似((struct shmid_ds*)address)->XXX的操作。而这个数组下标就是对应的 shmid 或者 msqid 或者 semid,可以类比文件描述符来理解。图例如下:
Posix与System V的关系
System V与Posix的渊源
上述介绍的共享内存、消息队列、信号量等内容,都是 System V 标准的进程通信方式,而在System V诞生之后,又有了一个Posix IPC的标准。而System V与Posix的渊源可以参考:
- 内容摘自:System V 与 POSIX_system v和posix 共享内存哪个好-CSDN博客
System V 以及POSIX 对信号量、共享内存、消息队列等进程之间共享方式提供了自己的解决方案。因此,在学习时难免存在疑惑,到底有什么区别,哪种方式更佳。经过网上搜索各种博客,做出简单的总结。
历史
UNIX两大贡献者贝尔实验室和BSD,在进程之间通信侧重不同,前者基于内核对进程之间的通信手段进行了改进,形成了“System V IPC”,而后者则是基于网络形成了套接字。而POSIX则是IEEE制定的标准,目的是为运行在不同操作系统上的软件提供统一的接口,实现者则是不同的操作系统内核开发人员。
效率
在信号量这种常用的同步互斥手段方面,POSIX在无竞争条件下是不会陷入内核的,而SYSTEM V则是无论何时都要陷入内核,因此性能稍差。
冗余
POSIX的sem_wait函数成功获取信号量后,进程如果意外终止,将无法释放信号量,而System V则提供了SEM_UNDO选项来解决这个问题。因此,相比而言,后者更加可靠。
应用
可能有小部分操作系统没有实现POSIX标准,System V更加广泛些,但是考虑到可移植性POSIX必然是一个趋势。在IPC,进程间的消息传递和同步上,似乎POSIX用得较普遍,而在共享内存方面,POSIX实现尚未完善,system V仍为主流。
多线程与多进程
在观察使用进程间通信手段后,会发现在多线程中使用的基本是POSIX标准提供的接口函数,而多进程则是基于System V。但是两者难道就不能交叉使用吗?多线程使用System V接口---不建议。线程相对于进程是轻量级的,例如调度的策略开销,如果使用System V这种每次调用都会陷入内核的接口,会丧失线程的轻量优势。所以,多线程之间的通信不使用System V的接口函数。
多进程使用POSIX
以mutex为例 ,POSIX的mutex如果要用于多进程,需要实现如下两点要求:(对于SEM信号量相对简单,因为提供了有名SEM的能够用于多进程,它是内核持续的,详见http://blog.csdn.net/firstlai/article/details/50706243)
mutex能为多个进程所见;
mutex本身不额外使用进程本地的内存,如堆内存。
对于第一条是很好满足的,只需要使mutex驻留在共享内存中,创建子进程之前初始化mutex即可;对于第二条GCC的pthread实现也满足,但是需要通过设置mutex的属性,mutex默认是PTHREAD_PROCESS_PRIVATE,即仅支持单进程。如果mutex驻留于共享内存,但pshared为PTHREAD_PROCESS_PRIVATE,此时多进程操作该mutex的行为是未定义的。因此需要设置为 PTHREAD_PROCESS_SHARED即可。
由于Posix IPC的相关接口一般是用于多线程,所以我们这里就不过多赘述了,仅展示相关的接口名称,具体如下:(内容摘自:Posix IPC-CSDN博客)
消息队列 信号量 共享内存<mqueue.h> <semaphore.h> <sys/mman.h>mq_open sem_open shm_openmq_close sem_close shm_unlinkmq_unlink sem_unlinksem_initsem_destroymq_getattr ftruncatemq_setattr fstatmq_send sem_wait mmapmq_receive sem_trywait munmapmq_notify sem_post sem_getvalue相关文章:
Linux 进程间通信
目录 管道 匿名管道(pipe) 有名管道(fifo) 小结 共享内存 消息队列 信号量 System V IPC的结构设计 Posix与System V的关系 管道 匿名管道(pipe) 我们知道,在Linux中通过fork创建的子…...
hippy 调试demo运行联调-mac环境准备篇
适用对于终端编译环境不熟悉的人看,仅mac端 hippy 调试文档官网地址 前提:请使用node16 联调预览效果图: 编译iOS Demo环境准备 未跑通,待补充 编译Android Demo环境准备 1、正常安装Android Studio 2、下载Android NDK&a…...

【golang】go module依赖的git tag被覆盖 如何处理 | 因测试产生大量的git tag 如何清除 最佳实践
一、场景 当我们把本地和远程git仓库的 tag全部删除,我们另外的项目依赖于这个被删除tag无法更新版本 如何处理? 如上图: 这里我创建了一个 v0.0.1 的tag,然后删除了这个tag,然后又创建了一个新的 v0.0.1的tag…...

Spring Cloud原理详解
Spring Cloud 是基于 Spring Boot 的微服务架构开发工具包,旨在帮助开发人员快速构建分布式系统中的一些常见模式,例如配置管理、服务发现、断路器、智能路由、微代理、控制总线、全局锁、领导选举、分布式会话和集群状态。Spring Cloud 是 Spring 生态系…...
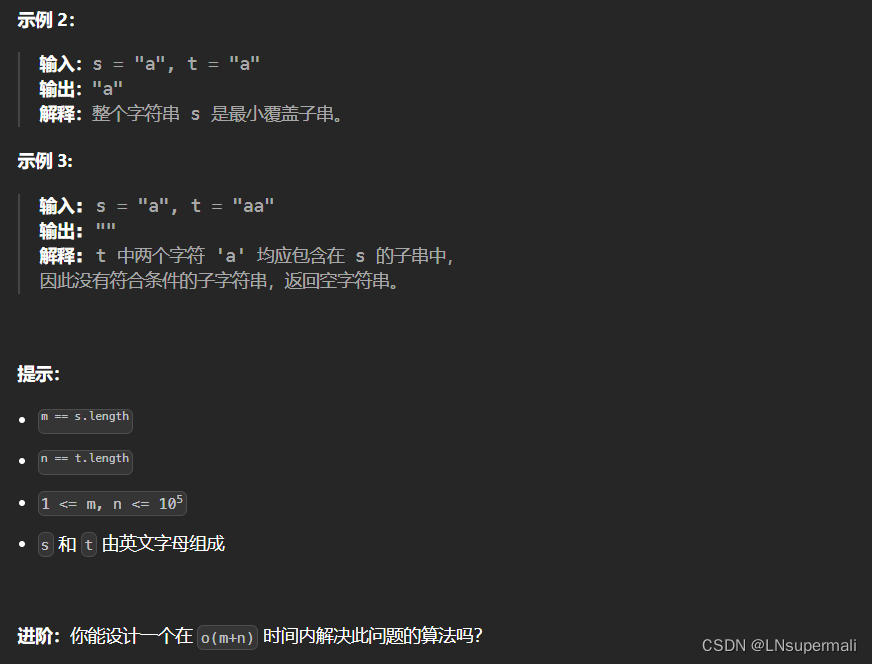
力扣76. 最小覆盖子串(滑动窗口)
Problem: 76. 最小覆盖子串 文章目录 题目描述思路复杂度Code 题目描述 思路 1.定义两个map集合need和window(以字符作为键,对应字符出现的个数作为值),将子串t存入need中; 2.定义左右指针left、right均指向0ÿ…...

使用华为云云函数functiongraph
之前使用腾讯云serverless,但是突然开始收费了。所以改用functiongraph 首先登陆华为云。 目录 1.登录华为云 2.在控制台找到functiongraph并开通 3.添加依赖包: 3.1 制作依赖包 3.2引入依赖包 4.发送请求 4.1直接发送 4.1.1uri 4.1.2 请求头…...
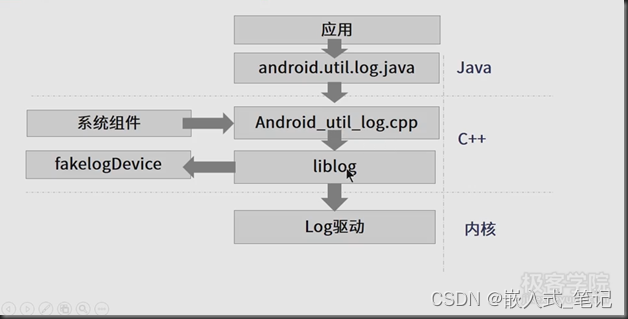
Android logcat系统
一 .logcat命令介绍 android log系统: logcat介绍 : logcat是android中的一个命令行工具,可以用于得到程序的log信息. 二.C/Clogcat访问接口 Android系统中的C/C日志接口是通过宏来使用的。在system/core/include/android/log.h定义了日志的级别: /…...

android 使用协程CoroutineScope 实现定时器
满足延迟执行、立即执行,每次任务间隔时长,总时长的任务 使用1 class TimeViewModel:Viewmodel(){//测试延迟5秒开始执行任务,然后每隔1秒执行1次,总执行时间60秒fun testTime(){var startTime System.currentTimeMillis()log(…...

【algorithm】算法基础课---排序算法(附笔记 | 建议收藏)
🚀write in front🚀 📝个人主页:认真写博客的夏目浅石. 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝 📣系列专栏:AcWing算法学习笔记 💬总结:希望你看完…...

UnityShader——09数学知识3
方阵 行与列数量相等的矩阵,n*n阶矩阵 对角矩阵 当对角线以外的矩阵内元素全为0,则称之为对角矩阵,对角矩阵的前提是必须是方阵 单位矩阵 对角线元素全为1,其余元素全为0,属于对角矩阵的一部分 矩阵和向量 把1 * n阶矩阵称…...

langchain学习笔记(九)
RunnableBranch: Dynamically route logic based on input | 🦜️🔗 Langchain 基于输入的动态路由逻辑,通过上一步的输出选择下一步操作,允许创建非确定性链。路由保证路由间的结构和连贯。 有以下两种方法执行路由 1、通过Ru…...
周处除三害在线资源最新电影1080p高清
打开下面这个链接就可以看到 周处除三害在线资源最新电影1080p高清 如果链接打不开,就复制下面的网址到浏览器打开 https://www.zhufaka.cn/liebiao/A09504AE3BF8BD06 用阿里云盘下载,下载完成之后,用迅雷播放 周处除三害在线资源最新电…...

STM32CubeIDE基础学习-新建STM32CubeIDE基础工程
STM32CubeIDE基础学习-新建STM32CubeIDE基础工程 前言 有开发过程序的朋友都清楚,后面开发是不需要再新建工程的,一般都是在初学时或者有特殊需要的时候才需要新建项目工程的。 后面开发都是可以在这种已有的工程上添加相关功能就行,只要前…...

R语言简介|你对R语言了解多少?
R语言是一种专门用于统计计算和图形展示的开源编程语言,它在数据科学领域有着广泛的应用。下面对R语言的环境、基础语法及注释进行解释: R语言环境 安装与配置 安装R语言通常可以从官方站点下载对应操作系统的安装包,如Windows、Linux、ma…...
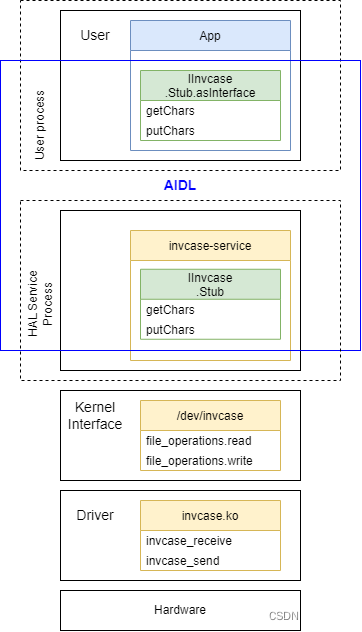
Android的硬件接口HAL
我一直觉得,现代计算机不是一门科学,起码快算不上一门理科科学。上上下下全是人造,左左右右全是生意,用管理学,经济学去学计算机,也许更看得懂很多问题。HAL就是一个典型例子。 传统Linux绕开了微软的霸权…...

【js】数组的常用方法
增加 push,unshift,splice,concat 前面三种修改原数组,concat不会修改原数组push 从后面添加数据,并返回新数组的长度unshift 从前面添加数据,并返回新数组的长度splice 可以接受三个参数,第一个参数开始位置,第二个参数是删除元素的数量,第三个参数是插入的数据concat 合并数…...
08. Nginx进阶-Nginx动静分离
简介 什么是动静分离? 通过中间件将动态请求和静态请求进行分离。分离资源,减少不必要的请求消耗,减少请求延时。 动静分离的好处 动静分离以后,即使动态服务不可用,静态资源仍不受影响。 动静分离示意图 动静分离…...

RPC--一起学习吧之架构
RPC(远程过程调用)是一种网络通信协议,它允许一台计算机(客户端)上的程序调用另一台计算机(服务器)上的程序,就像调用本地程序一样。RPC 可以使得网络中的不同进程能够相互调用&…...
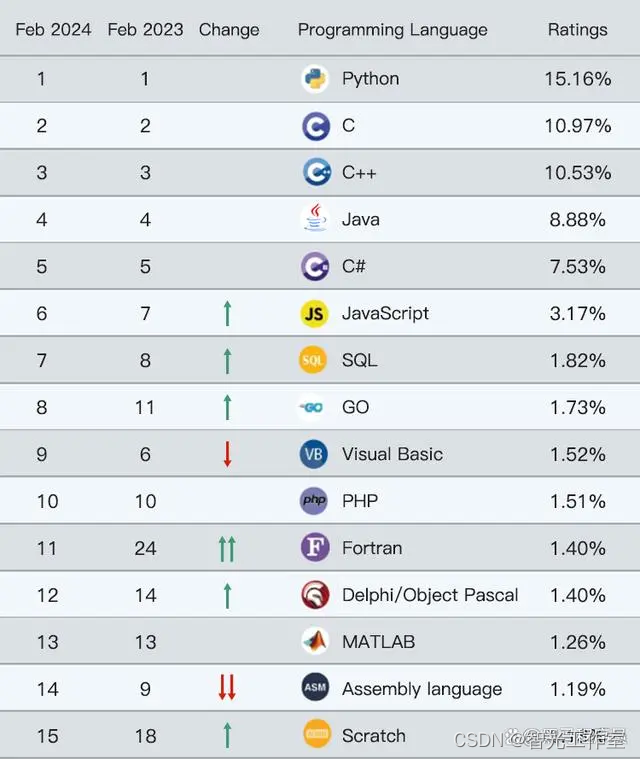
服务器后端是学习java还是php
没有绝对的"最好"语言,每种后端语言都有其适用的场景和特点。以下是几种常用的后端语言: 1. Java:Java是一种通用且强大的语言,广泛用于企业级应用和大型系统。它有很好的性能和可靠性,并且具有优秀的生态系…...

DCFL: for Oriented Tiny Object Detection
文章目录 AbstractIntroductionContributionRelated Work定向目标检测微小目标检测多尺度学习标签分配上下文信息特征增强MethodOverview动态先验Coarse Prior MatchingFiner Dynamic Posterior MatchingAblation StudyAnalysis不平衡问题的调解可视化速度Conclusionhh 源代码 …...

基于SpringBoot 的实验设备预约系统的设计及实现
摘 要 随着高校与科研院所实验教学规模扩大,传统人工预约实验设备效率低、易冲突、管理混乱,已无法满足师生需求。为提升设备利用率、规范预约流程、减少时间冲突与资源浪费,构建一套基于网络的实验设备预约系统十分必要。该系统可实现在线预…...

桌面图标变白纸别慌!手把手教你用右键属性+路径复制,5分钟找回所有软件图标
桌面图标异常修复指南:从白纸图标到完整恢复的实战解析 电脑桌面上那些熟悉的图标突然变成白纸,这种看似小问题却让人倍感困扰。不必惊慌,这通常是系统图标缓存更新不及时或软件关联异常导致的常见现象。本文将带你深入理解图标显示机制&…...

手算反向传播:从链式法则到梯度消失的物理直觉
1. 项目概述:这不是又一节“神经网络入门”,而是一次真正踩进反向传播泥潭的实操复盘“Intro to Neural Networks Part II — Brilliant.org”这个标题乍看平平无奇,像是在线教育平台里再普通不过的一节进阶课。但如果你真点开它,…...

如何将普通桌面实时转换为3D立体视频?nunif iw3-desktop完全指南
如何将普通桌面实时转换为3D立体视频?nunif iw3-desktop完全指南 【免费下载链接】nunif Misc; latest version of waifu2x; 2D video to stereo 3D video conversion 项目地址: https://gitcode.com/gh_mirrors/nu/nunif 你是否曾想过在VR头显中观看你的电脑…...

为什么这款文档转换工具能同时实现高效与精准?揭秘Marker的核心优势
为什么这款文档转换工具能同时实现高效与精准?揭秘Marker的核心优势 【免费下载链接】marker Convert PDF to markdown JSON quickly with high accuracy 项目地址: https://gitcode.com/GitHub_Trending/ma/marker 在当今信息爆炸的时代,处理PD…...

数采网关的应用与特点
摘要在工业自动化、智能制造和物联网(IoT)快速发展的背景下,数据采集网关(数采网关)作为连接现场设备与上层管理系统的关键枢纽,发挥着至关重要的作用。它能够实现工业设备数据的实时采集、协议转换、边缘计…...
)
强制启动 Cursor IDE 主程序(不带 Agent 模式)
🔧 终极解决:强制启动 Cursor IDE 主程序(不带 Agent 模式)方法 1:用「命令行」强制启动主程序(最稳)按 WinR 打开运行窗口,输入 cmd 回车,打开命令提示符输入下面这行命…...

离子原生QAOA算法:量子优化新突破
1. 离子原生QAOA算法概述量子近似优化算法(Quantum Approximate Optimization Algorithm, QAOA)是近年来量子计算领域最具前景的算法之一,特别适用于解决组合优化问题。该算法通过交替应用问题哈密顿量和混合哈密顿量,构建参数化量…...

IDM激活脚本完全指南:3种方法实现永久免费使用
IDM激活脚本完全指南:3种方法实现永久免费使用 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 还在为Internet Download Manager(IDM&…...

模型加速全景图:从“瘦身”到“飞驰”的知识图谱
文章目录知识图谱:模型加速的三大维度维度一:模型自身优化(让模型更“瘦”)维度二:计算过程优化(让计算更“顺”)维度三:硬件与系统优化(让硬件更“忙”)如何…...