数据结构之七大排序
𝙉𝙞𝙘𝙚!!👏🏻‧✧̣̥̇‧✦👏🏻‧✧̣̥̇‧✦ 👏🏻‧✧̣̥̇:Solitary_walk
⸝⋆ ━━━┓
- 个性标签 - :来于“云”的“羽球人”。 Talk is cheap. Show me the code
┗━━━━━━━ ➴ ⷯ本人座右铭 : 欲达高峰,必忍其痛;欲戴王冠,必承其重。
👑💎💎👑💎💎👑
💎💎💎自💎💎💎
💎💎💎信💎💎💎
👑💎💎 💎💎👑 希望在看完我的此篇博客后可以对你有帮助哟👑👑💎💎💎👑👑 此外,希望各位大佬们在看完后,可以互相支持,蟹蟹!
👑👑👑💎👑👑👑
思维导图:
1直接插入排序
1.1插入排序的思想
把待排序的数据依次与当前已经有序的数据进行比较,直到待排的数据全部排完得到一组新的有序的数据
生活中的玩扑克牌就是插入排序的一种体现

动图的过程:
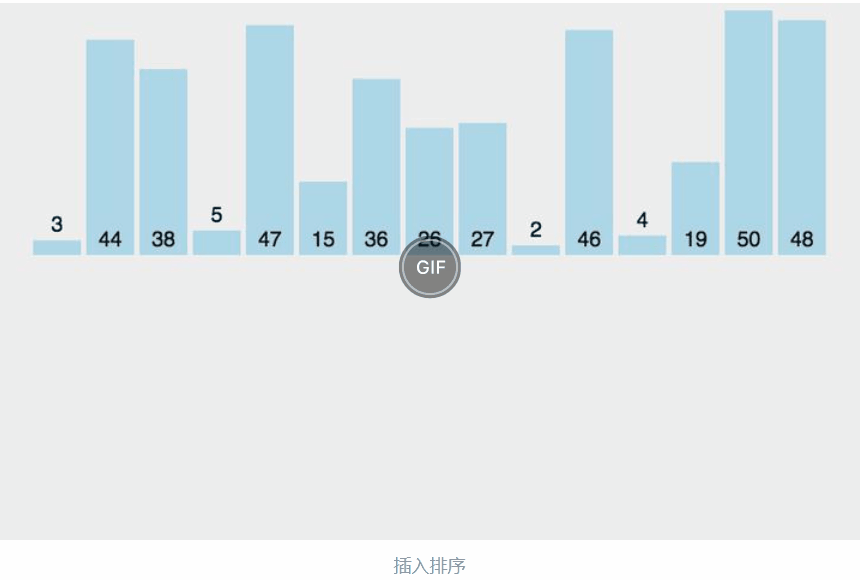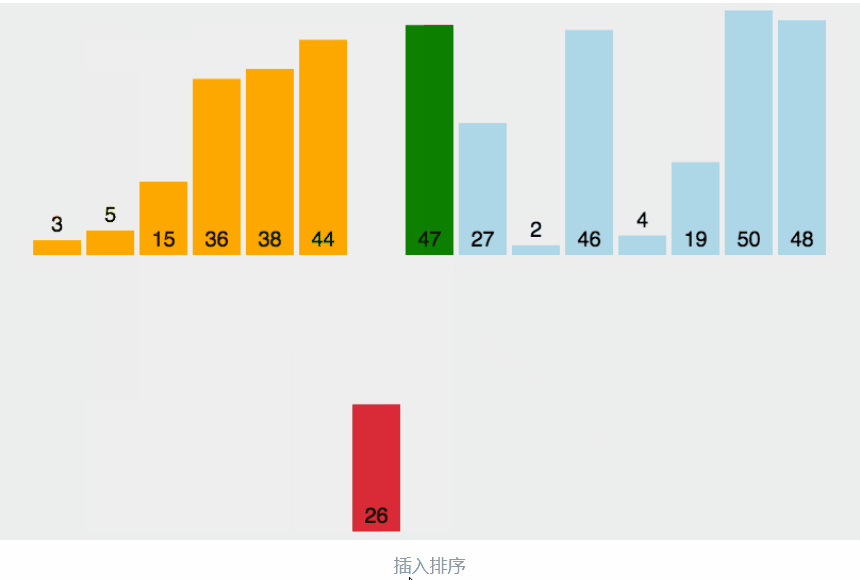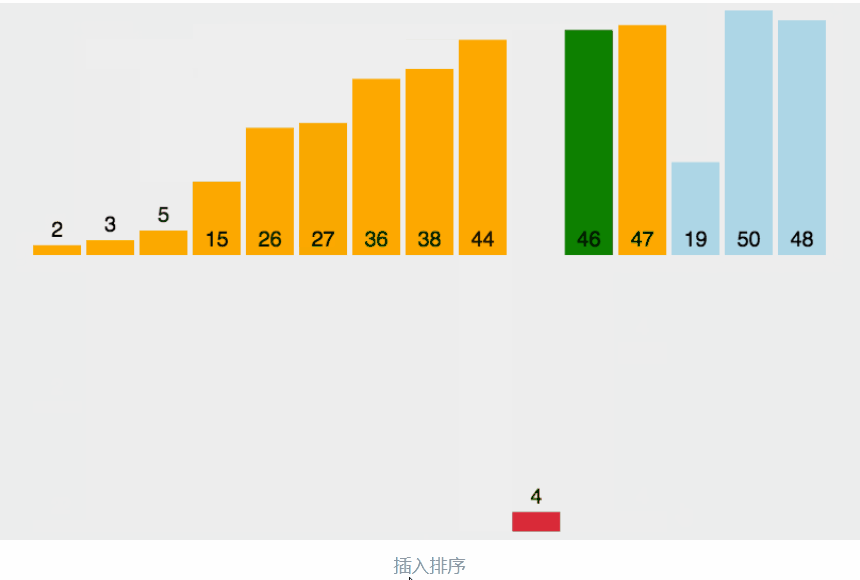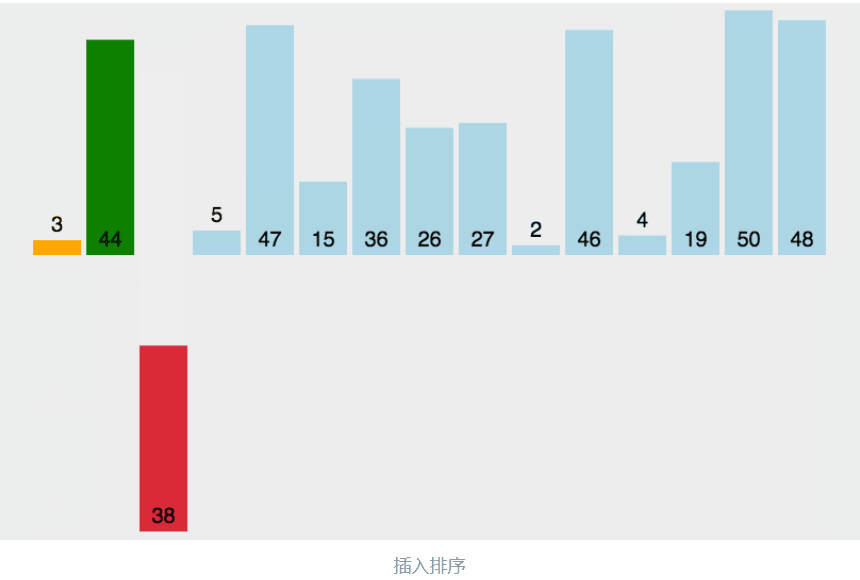
分析:
1.2代码的实现
void Insert_sort(int* a, int num)
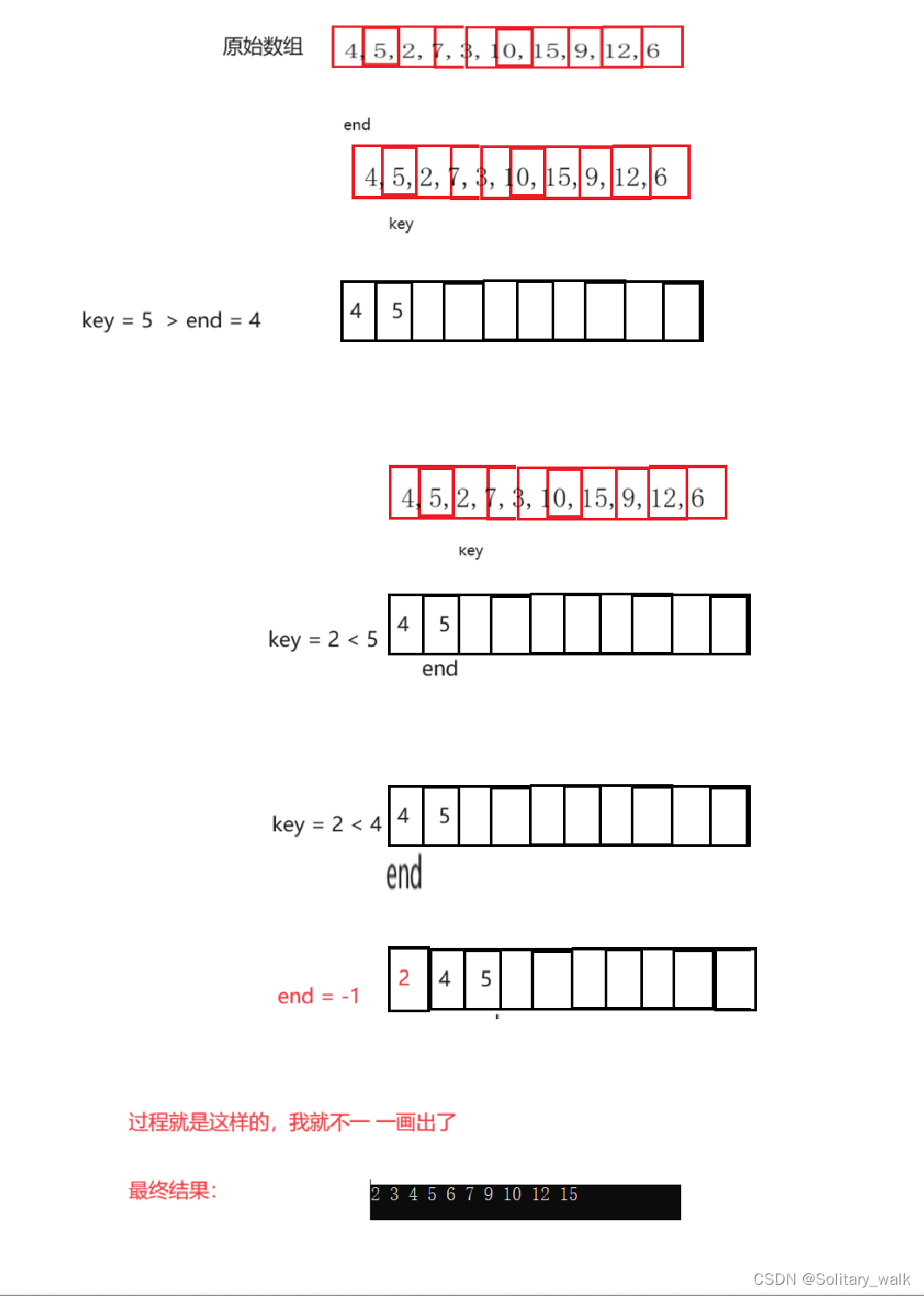
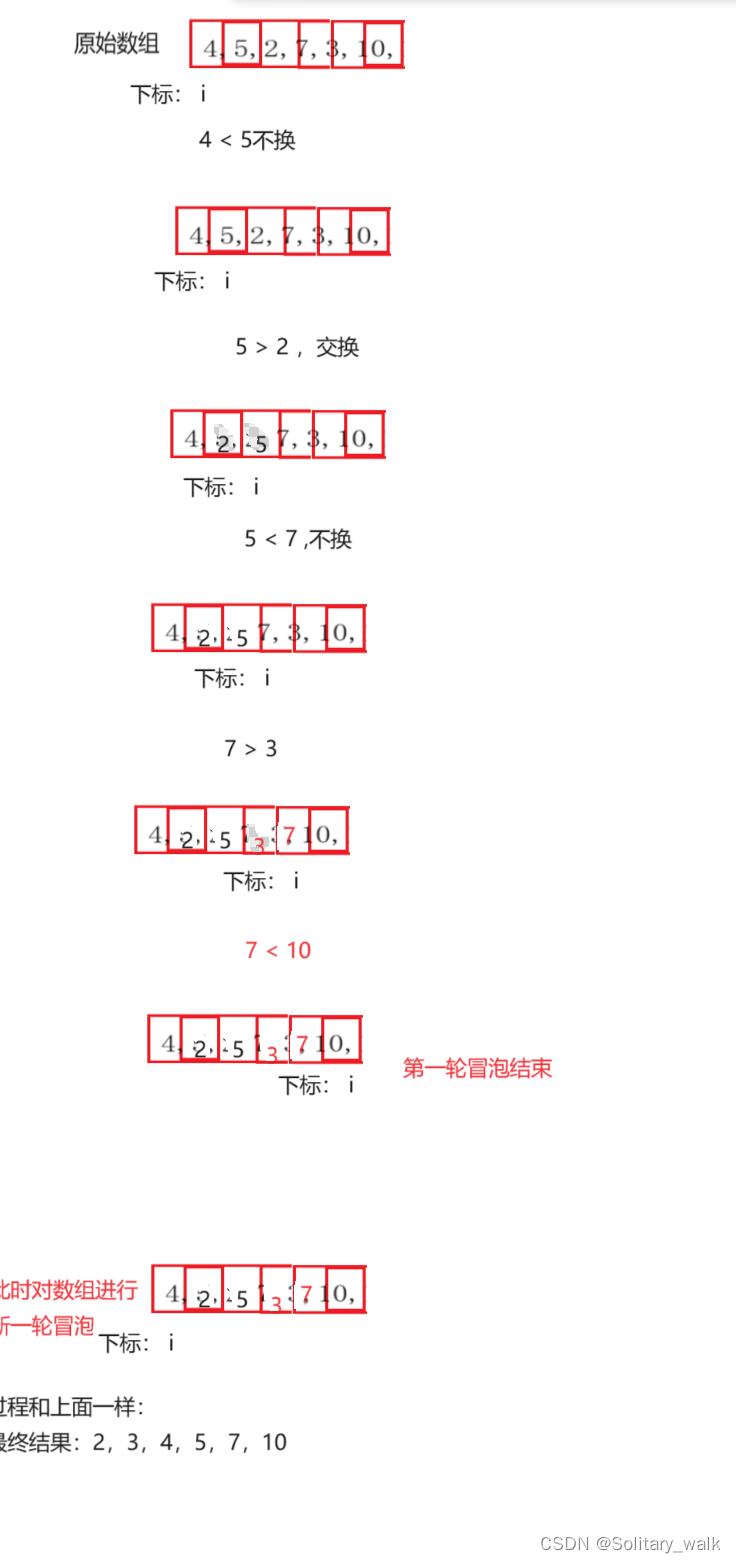
{for (int i = 1; i < num; i++) //i= 1默认只有一个数的时候有序{//升序排int end = i - 1;int key = a[i];while (end >= 0){if (key < a[end]){//后挪数据a[end + 1] = a[end];end--;}else //key >= a[end]break;}a[end + 1] = key;//break出来或者是end= -1都可以把key解决掉}}1.3插入排序对应的时间复杂度以及空间复杂度的分析
时间复杂度
最好的情况下:原数组本身就是升序的,在对数组进行升序排列,(N-1)个数一共比较(N-1)次,此时不需要进行数据的挪动,所以时间复杂度是 O(N)
最坏情况:原数组本身就是逆序的,当你想进行升序排列的话,(N-1)个数一共需要进行O(N^2)级别次,每比较一次就进行一次数据挪动,所以对应时间复杂度 O(N^2)
2希尔排序(缩小增量法)
希尔排序是对直接插入排序的优化。
2.1希尔排序的思想
先选定一个整数,把待排序文件中所有记录分成多个组,所有距离为gap(取决于数组大小)分在同一组内,并对每一组内的记录进行排序,重复上述分组和排序的工作。当 gap=1时,所有记录在一组内已经是有序。
总的来说就是先对原数组进行预排序,让数组接近有序,在进行一次直接排序即可有序
插入排序可以视为特殊的希尔排序。
分析:
接下来就是对数组进行预排序:注意是在原数组的空间进行排序的,预排序的关键就是如何确定 gap的值以及下标边界的范围
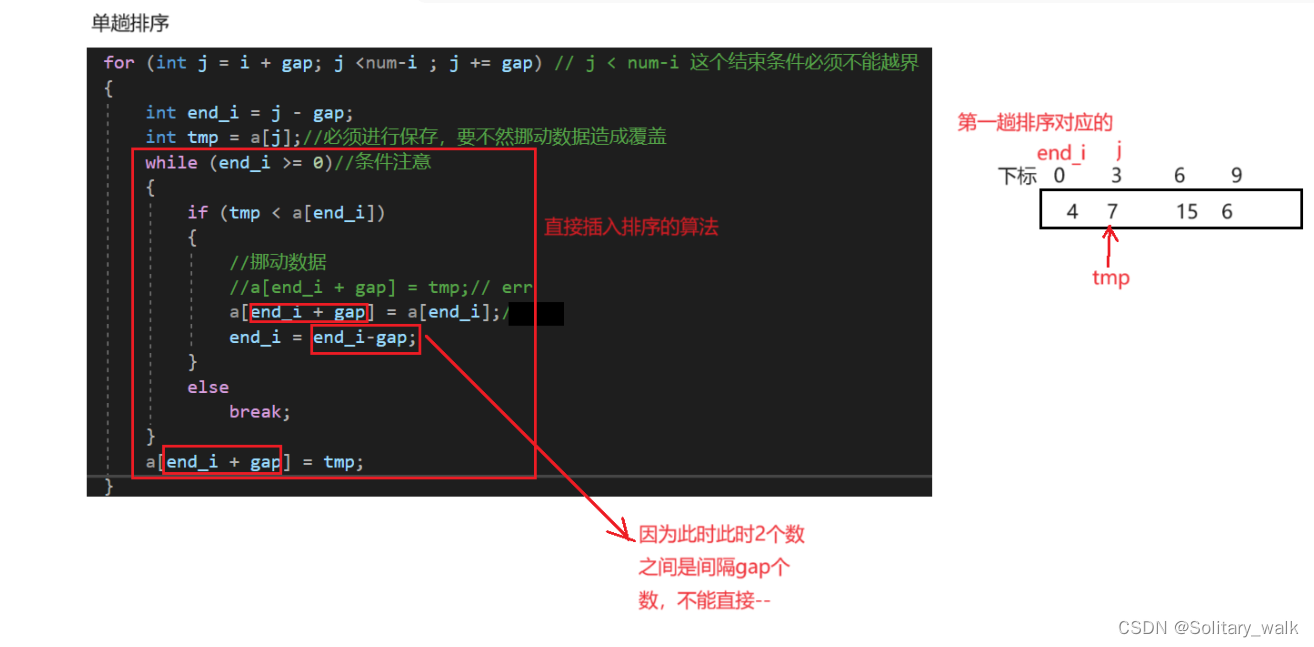
单趟排序用直接插入排序来进行。
进行第一趟的排序:
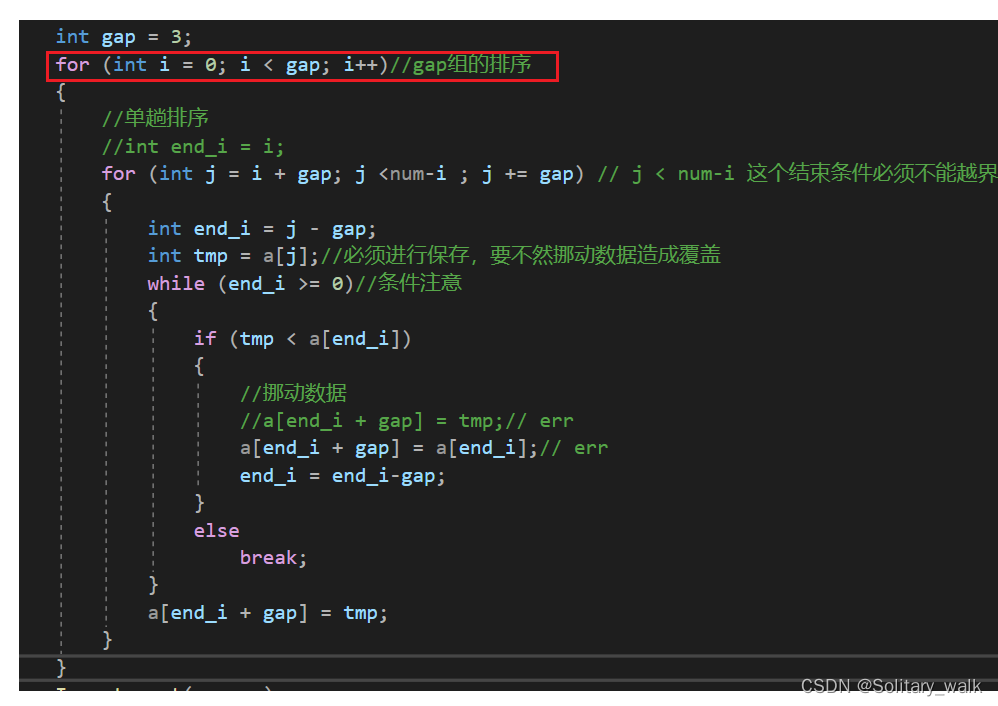
不止一趟的排序:再来一个for循环搞定多趟的排序
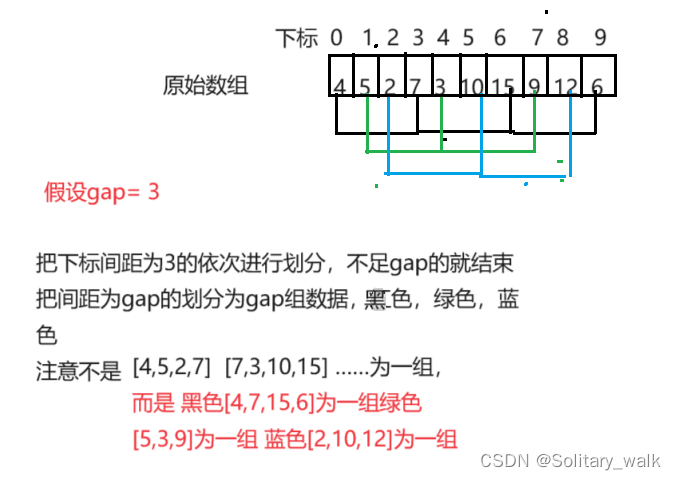
gap具体的取值由数组的东西而决定,一般对于gap的取值有2个方法可行,但是需要注意条件的判断以及必须保证 gap = 1的时候也能进行排序, gap = N / 2 或者是 gap =( N / 3) + 1,注意gap取不同的值对应结束的条件不同

2.2代码的实现
void Shell_sort(int* a, int num)
{/*1:预排序:让他内部接近有序2:整个直接排序*///int gap = 3;int gap = num;//for (int i = 0; i < gap; i++)//gap组的排序while (gap >= 1){gap /= 2; //一定可以保证gap = 1的时候进行排序for (int i = 0; i < gap; i++) //多趟排序{//单趟排序//int end_i = i;for (int j = i + gap; j < num - i; j += gap) // j < num-i 这个结束条件必须不能越界{int end_i = j - gap;int tmp = a[j];//必须进行保存,要不然挪动数据造成覆盖while (end_i >= 0)//条件注意{if (tmp < a[end_i]){//挪动数据//a[end_i + gap] = tmp;// erra[end_i + gap] = a[end_i];// errend_i = end_i - gap;}elsebreak;}a[end_i + gap] = tmp;}}}//Insert_sort(a, num);
}2.3希尔排序对应的时间复杂度以及空间复杂度的分析
空间复杂度是O(1)并不需要额外的空间
对于时间复杂度的分析其实是有争议的,并没有一个具体的,但在 O(N *logN)~O(N^2)
3选择排序
3.1选择排序的思想
如果有N个元素需要排序,默认第一个元素为有序的,那么首先从N-1个元素中找到最小的那个元素与第0位置上的元素交换(重复以上过程)然后再从剩下的N-2个元素中找到最小的元素与下标为的1元素交换,之后再从剩下的N-2个元素中找到最小的元素与倒数第2位置上的元素交换,.......直到所有元素都排序好。
分析:
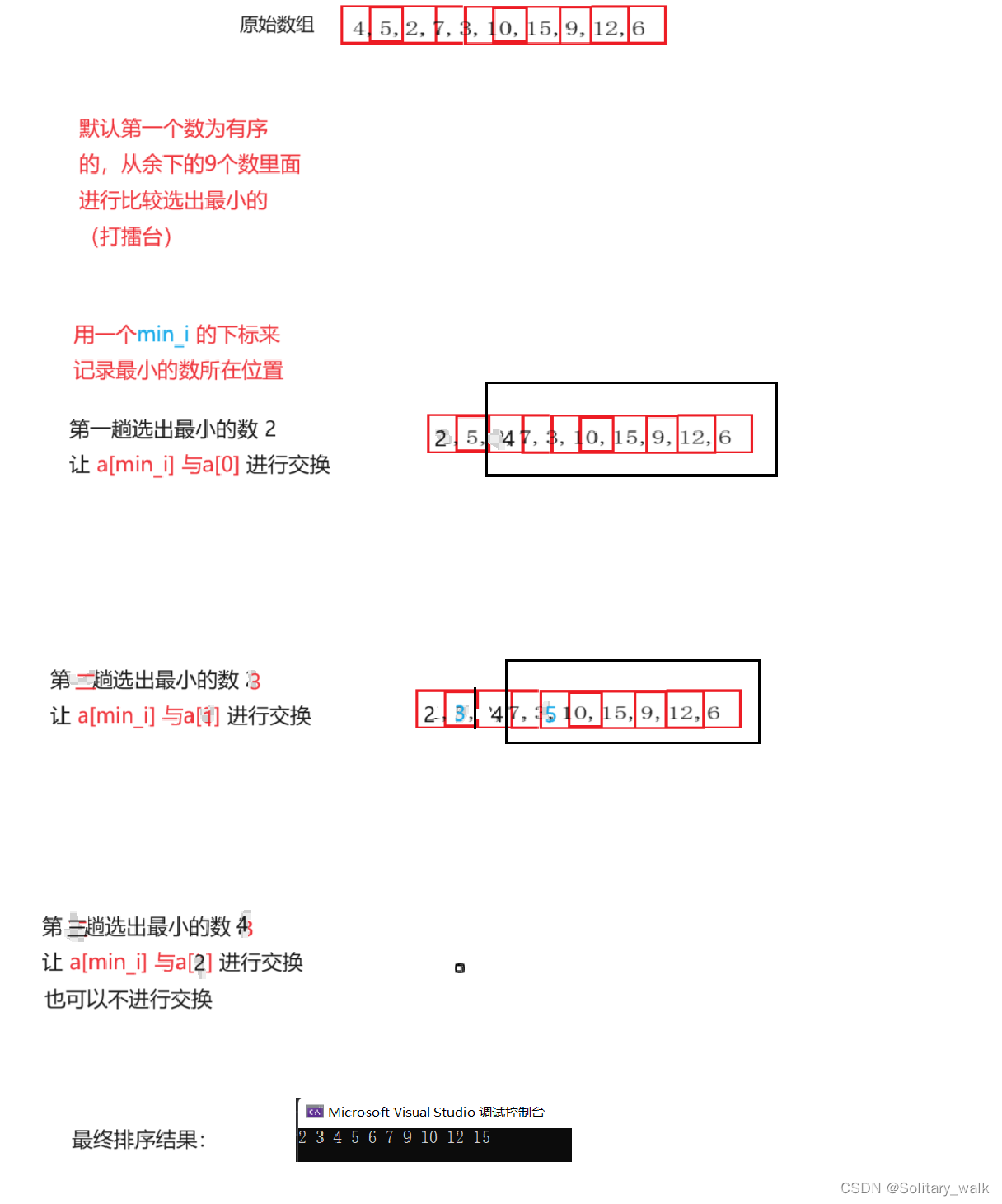
3.2代码的实现
void Select_sort(int* a, int num)
{for (int j = 0; j < num; j++){int min_i = j;int i = j + 1;//单趟排序for (i; i < num; i++){//升序排if (a[i] < a[min_i])min_i = i;}Swap(&a[j], &a[min_i]);}
}这个代码很好理解,其实他还是有可以优化的空间
优化版本:每一趟排序把最大的数和最小的数同时选出
void Select_sort(int* a, int num)
{//进行优化 每一趟排序找出当前数组里最小和最大的数因为一个升序的数组最小的数一定在第一个位置(相对而言)最大的数一定在最后一个位置(相对而言)int begin = 0;int end = num - 1;while (begin < end){//假设每趟排序中第一个数最大,最小,注意第一个数不一定下标为0int min_i = begin;int max_i = begin;for (int i = begin+1; i <= end ; i++){if (a[i] > a[max_i])max_i = i;if (a[i] < a[min_i])min_i = i;}Swap(&a[min_i], &a[begin]);//注意可能begin对应的数为最大,当与最小的数交换后,最大的数来到min_i对应的位置if (begin == max_i) //注意是下标max_i = min_i;//if (max_i != end) //当end位置就是最大的数就不用交换Swap(&a[max_i], &a[end]);begin++;end--;}
}3.3选择排序对应的时间复杂度以及空间复杂度的分析
时间复杂度:

空间复杂度:O(1)这个算法并没有开辟额外的空间
4堆排序
对于堆排序而言,可以采用向上调整来进行排序,也可以采用向下调整来进行排序,只不过二者的效率是不同的
4.1堆排序的思想
排升序也好,降序也罢,让堆顶元素与堆尾元素进行交换,然后在对余下的的非堆尾的所有元素进行建堆,具体建大堆还是建小堆取决于,自己是想升序排还是降序排
4.1.1向上调整进行堆排序
预备知识介绍:
堆只有大堆和小堆之分:大堆:根节点大于或者等于所有的节点;小堆:根节点小于或者是等于所有节点的
堆是一棵完全二叉树
数组里面的数据可以视为一个完全二叉树
父节点与孩子节点之间的关系(下标) 左孩子的下标:child = 2* paren_i +1 右孩子的下标:child_rignt = 左孩子下标+1 = 2* paren_i +2 注:parent_i 双亲节点的下标
4.1.1.1堆排序之前建大堆还是建小堆
在进行堆排序之前(默认排升序),需要先建一个大堆:建大堆可以保证最大元素与堆尾元素交换后,当前最大元素一定是在堆尾的(只是相对而言),或者说建大堆后,堆顶与队尾元素交换后,可以视为把堆顶元素尾插到堆尾,这样就能保证数组是以升序排列。同理,若是降序排的话,需要建小堆
4.1.1.2 向上建堆分析
建大堆:
从最后一个节点开始向上建堆,要是当前位置 child大于双亲parent 所对应的值,就进行交换,接下来就是进行更新 child= parent: child 来到双亲所对应位置, parenrt = (child -1) / 2
在执行这个逻辑: child大于双亲parent 所对应的值,就进行交换
分析见下:
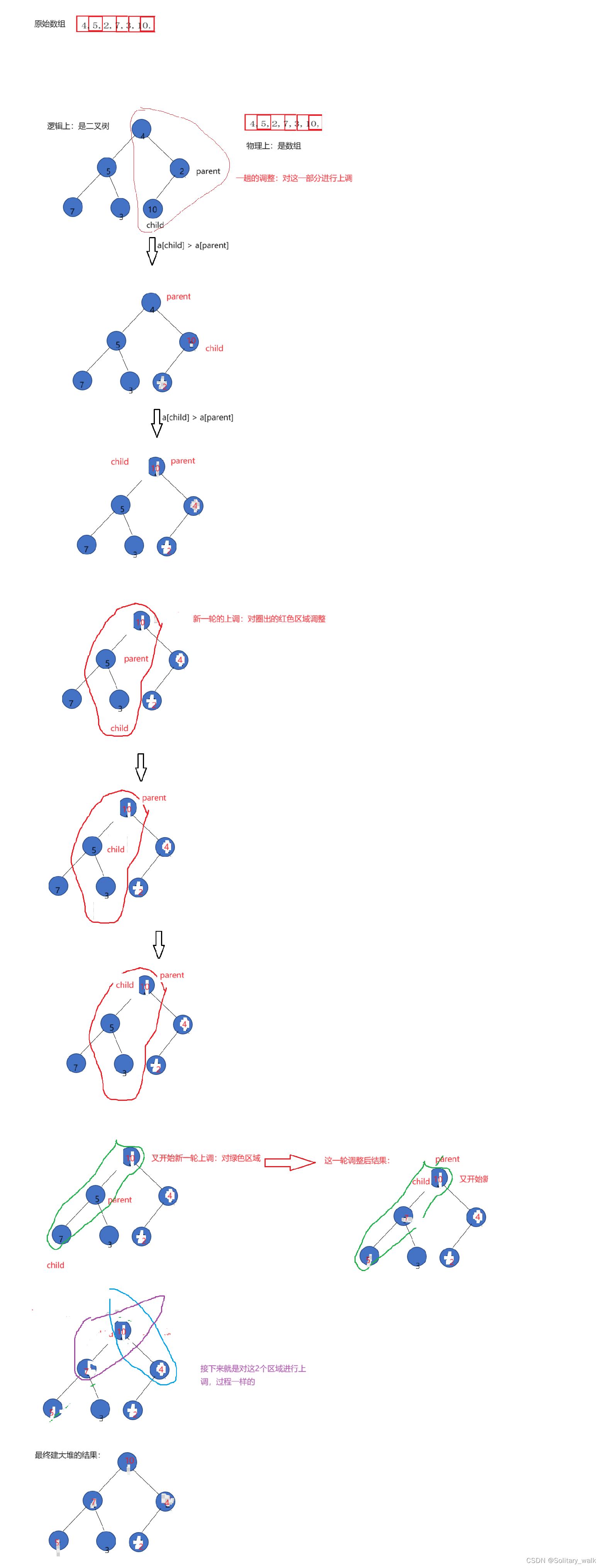
堆顶元素与堆尾元素交换后,对除堆尾的所有元素进行上调重新建大堆,选出当前最大的元素以此头插到堆尾元素的前面
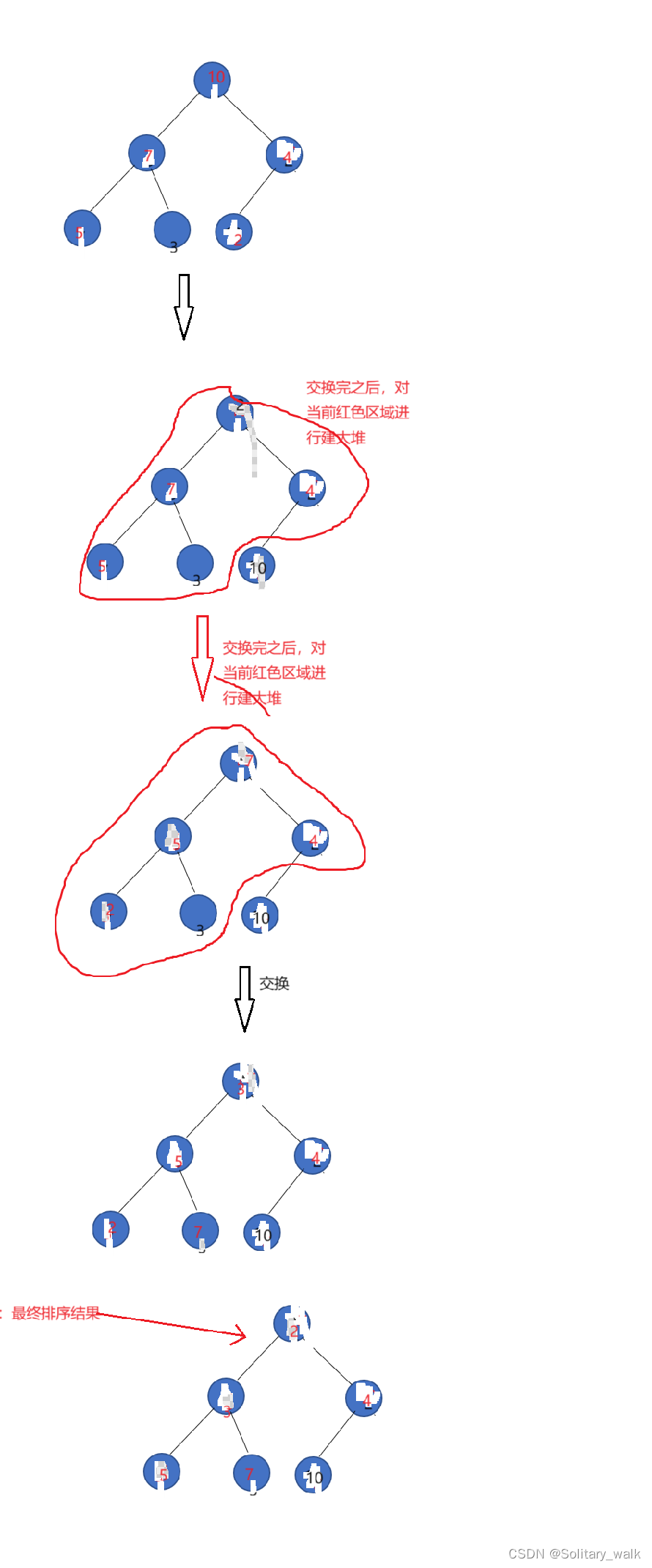
4.1.2向下调整进行堆排序
get 到了上调算法,那么咱也就轻松拿捏下调算法了,二者大同小异
还是老问题,先对当前数据进行下调建大堆,再利用堆顶与堆尾元素交换,依次进行下调
若是从4这个节点开始进行下调的话,他的左右子树都不符合堆的要求。很显然不能从4这个节点调整。只能倒着往前进行下调:从第一个非叶节点开始进行下调
分析见下:
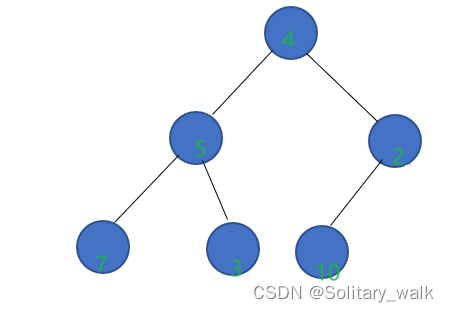
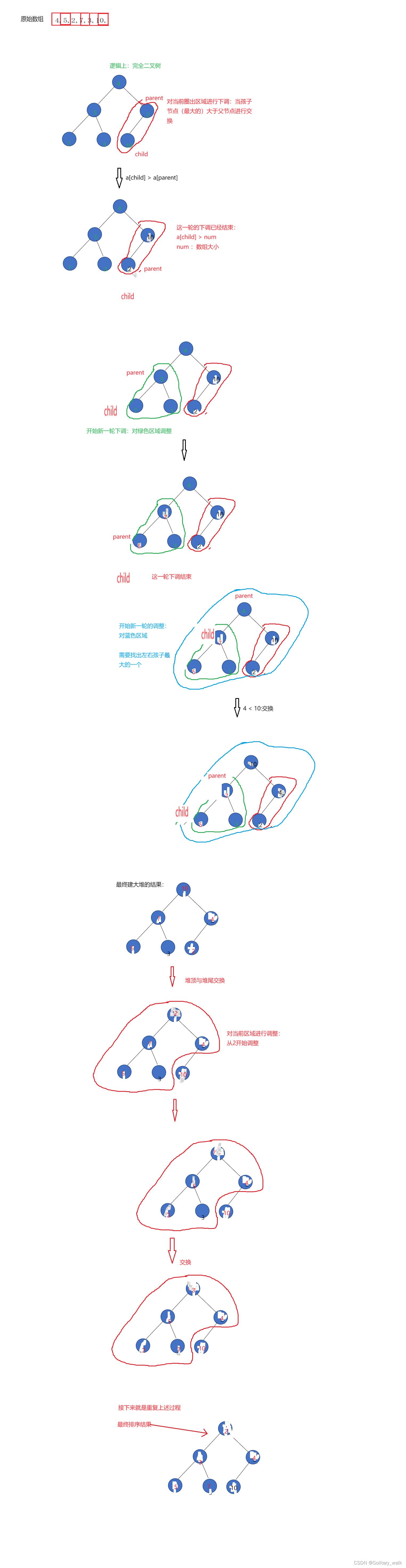
4.2代码的实现
上调代码:
void Adjust_up(int*a,int child) //问题1;第二个参数传孩子节点位置而不是双亲节点下标
{int parent = (child - 1) / 2;while (child >= 0) //问题2 : 结束条件必须是 chind >= 0而不能parent>= 0 最终parent的值永远是0 ,会出现死循环{if (a[child] > a[parent]){Swap(&a[child], &a[parent]);//依次上调进行更新child = parent;parent = (child - 1) / 2;}elsebreak;}
}
void Heap_sort(int* a, int num)
{//升序:建大堆 => 排序:堆顶元素依次与堆尾元素交换 最终结果: 第一小,第二小,…… 倒数次次大,倒数第二大,最大int pos = num - 1;for (pos; pos > 0; pos--){Adjust_up(a, pos);}//排序:上调pos = num - 1;while (pos >= 0){Swap(&a[0], &a[pos]);//堆顶元素依次放到堆尾// 问题4 //对于下的n-1 (n-2)(n-3)重新建大堆 不是建一次就OK的for (int i = pos - 1; i > 0; i--){Adjust_up(a, i);}pos--;}
}下调代码
void Adjudt_down(int* a, int parent, int num)
{int child = 2 * parent + 1;//假设左孩最小while (child < num){if (child + 1 < num && a[child] < a[child + 1]) //可能右孩子最大,前提是右孩子必须存在{child += 1;}if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = 2 * parent + 1;}elsebreak;}
}
void Heap_sort(int* a, int num)
{//升序:建大堆 => 排序:堆顶元素依次与堆尾元素交换 最终结果: 第一小,第二小,…… 倒数次次大,倒数第二大,最大//下调来进行的int pos = num;//建大堆while (pos >= 0){Adjudt_down(a, (pos - 1 - 1) / 2, pos);//pos-1 最后一个节点下标 (pos - 1 - 1) / 2 最后一个节点的双亲位置pos--;}//排序pos = num -1;//最后一个数位置while (pos >0){Swap(&a[0], &a[pos]);/* for (int i = pos - 1; i >= 0; i--){Adjudt_down(a, (i-1)/2,pos);}*/Adjudt_down(a,0,pos );pos--;}}4.3堆排序对应的时间复杂度以及空间复杂度的分析
空间复杂度:O(1),并没有额外空间的消耗
利用向上调整来进行排序的时间复杂度: O(N * log N)
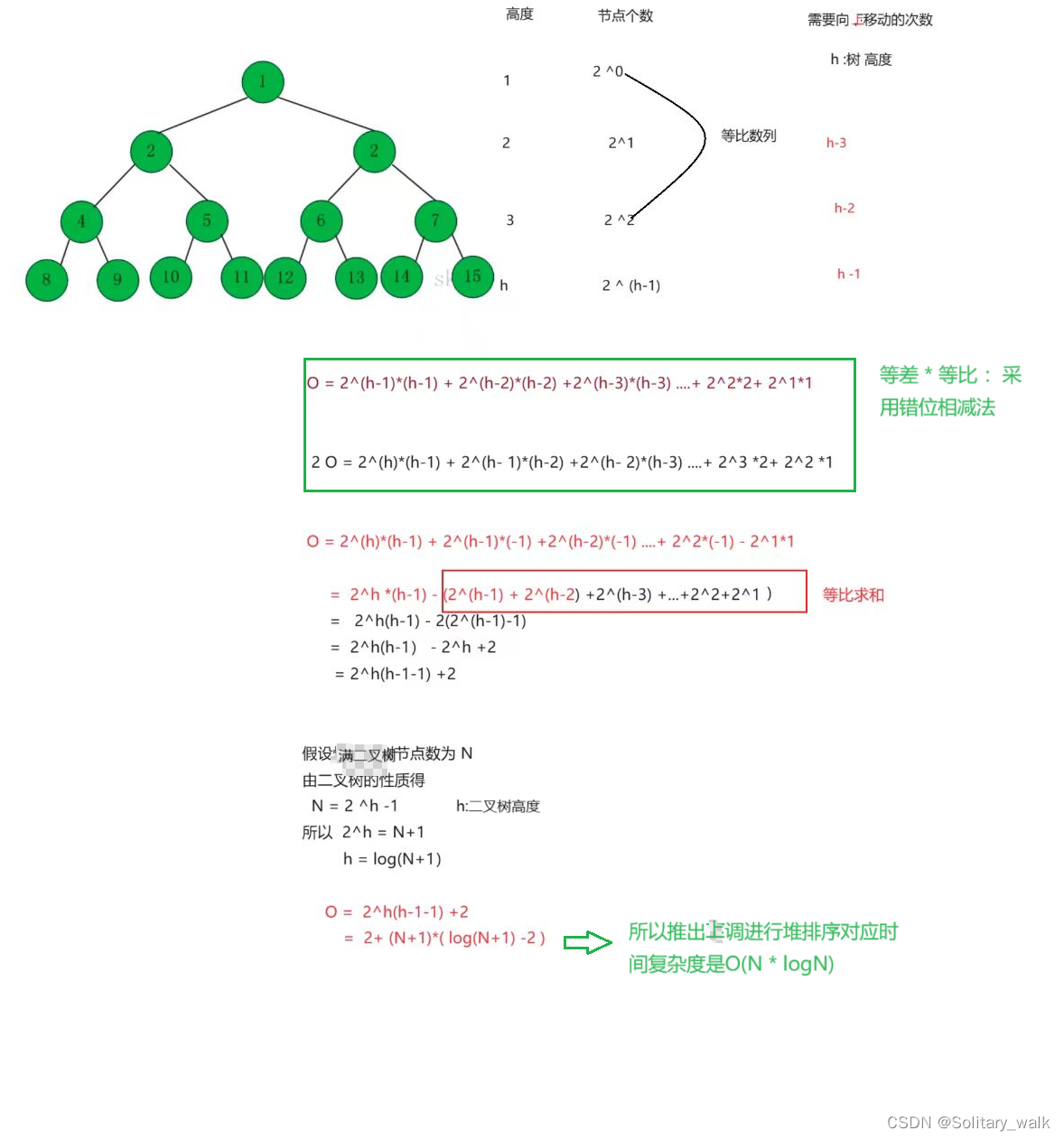
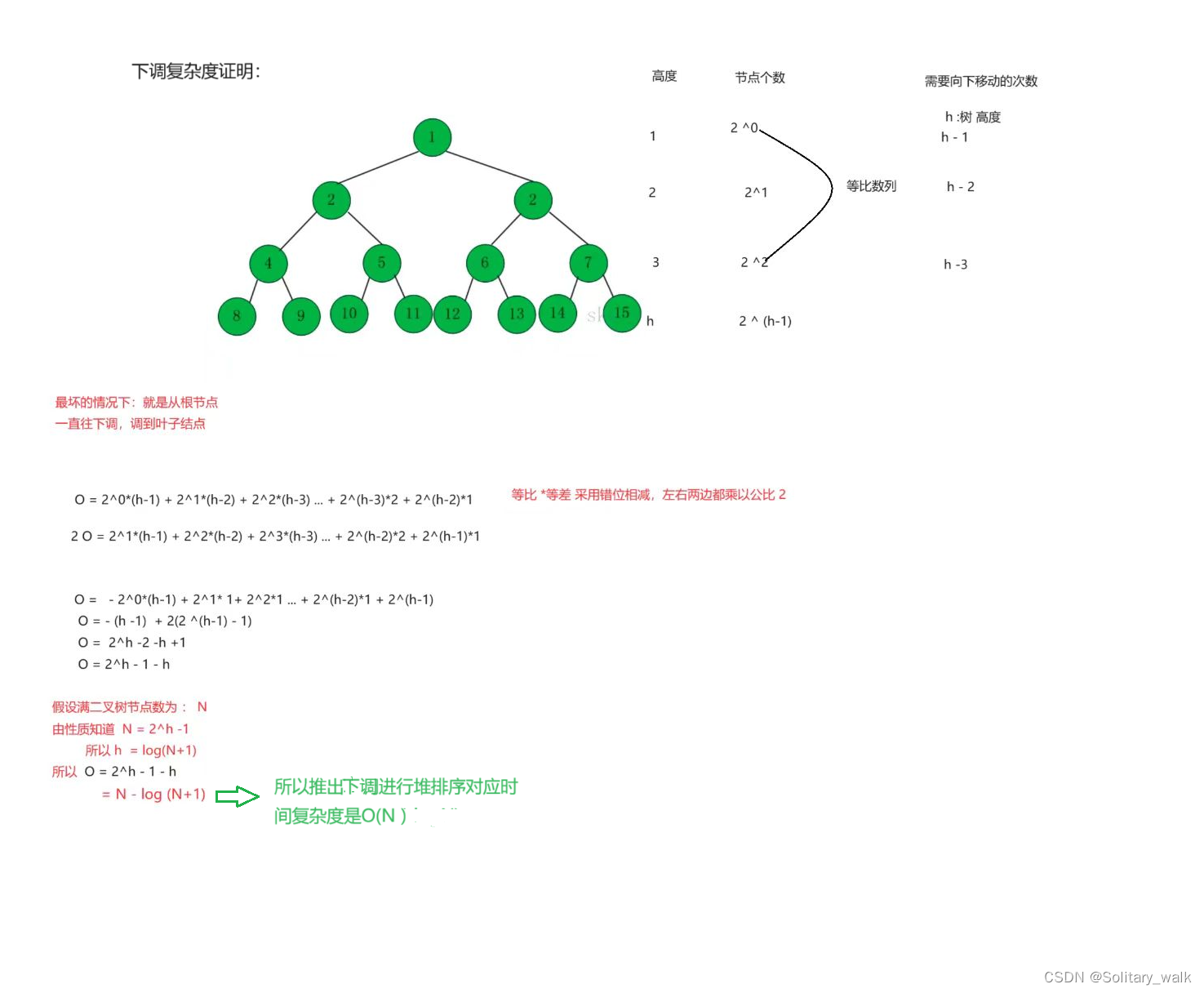
利用向下调整来进行排序的时间复杂 O(N)
5冒泡排序
5.1冒泡排序的思想
相邻两哥元素进行比较,若是满足条件,进行两两相邻元素进行交换
动图示范:
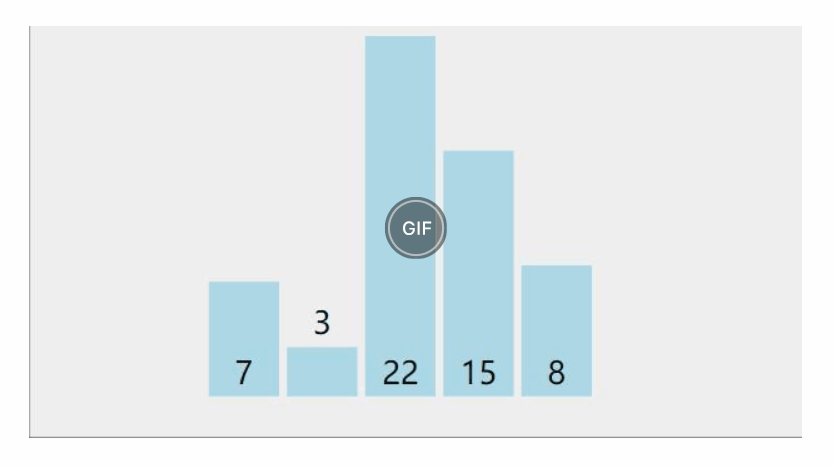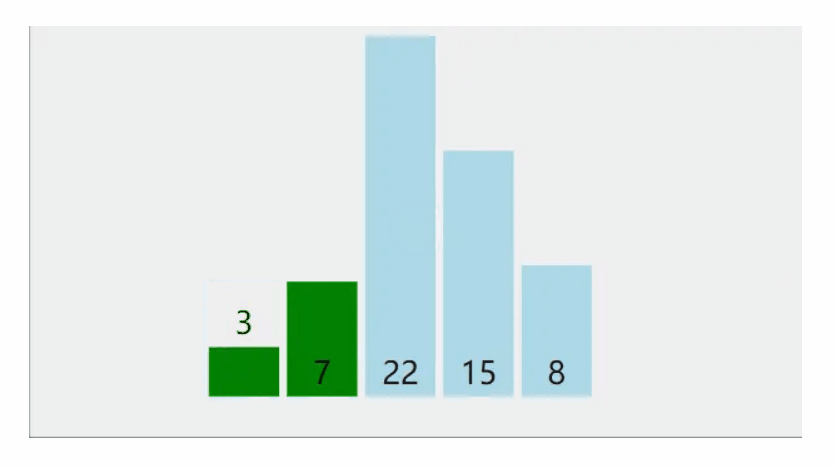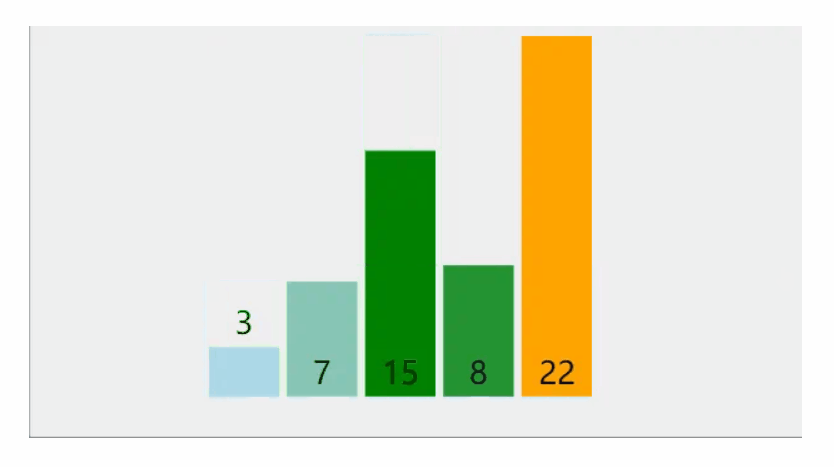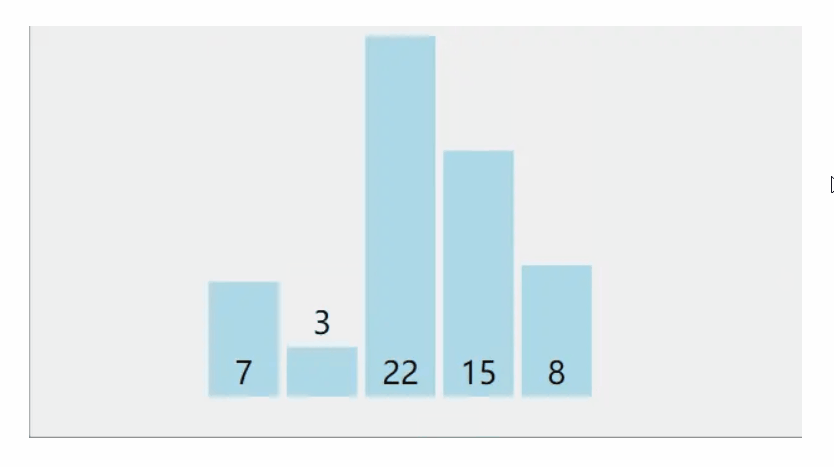
单趟排序
5.2代码的实现
void Bubble_sort(int* a, int num)
{int flag = 0;//默认数组有序for (int i = 0; i < num; i++){for (int j = 0; j < num-1-i; j++){if (a[j] > a[j + 1])//升序排{Swap(&a[j], &a[j + 1]);flag = 1;}}if (flag == 0)break;//数组本身就有序}
}5.3冒泡排序对应的时间复杂度以及空间复杂度的分析
时间复杂度:O(N^2)
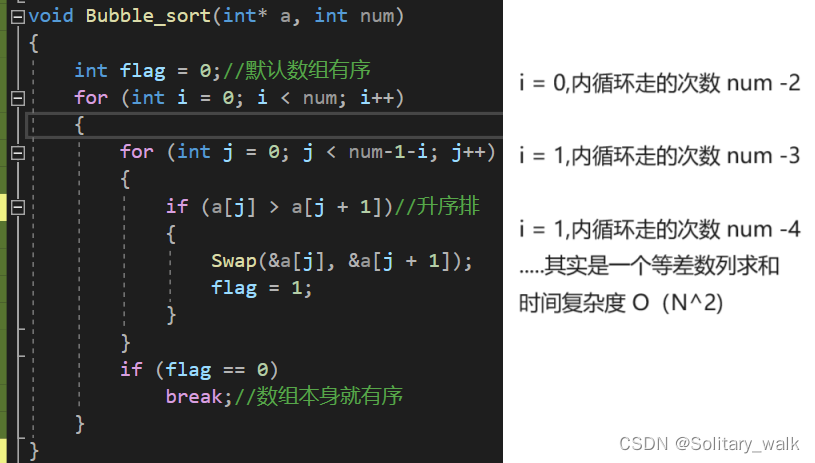
空间复杂度:O(1)
6快排
6.1快排的思想
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列
6.1.1Hoare法的快排实现
先选出一个元素作为基准,遍历原数组,把小于基准数的放到左边,大于基准数的放到右边
具体实现见下:默认一个数作为基准(只是相对而言,因为需要层层递归),定义2个变量 left ,right,其中left找大于基准数,right找小于基准数的,找到后 让left 与right 对应位置的数交换,再继续找知道left right相遇,此时与 基准数进行交换,并记录当前left的位置,作为下一次的查找范围
注意一些细节:在left找大,right找小,谁先走取决于基准数是在左边还是在右边
基准数(key_i)在左边,right先走进行找小,要是基准数(key_i)在右边,left先走进行找大
当key_i与left,right重合的时候也可以不进行交换
递归结束条件: begin >= end : begin = end 只有一个数,本身就是有序的不用进行排序, begin >end:说明区间不存在

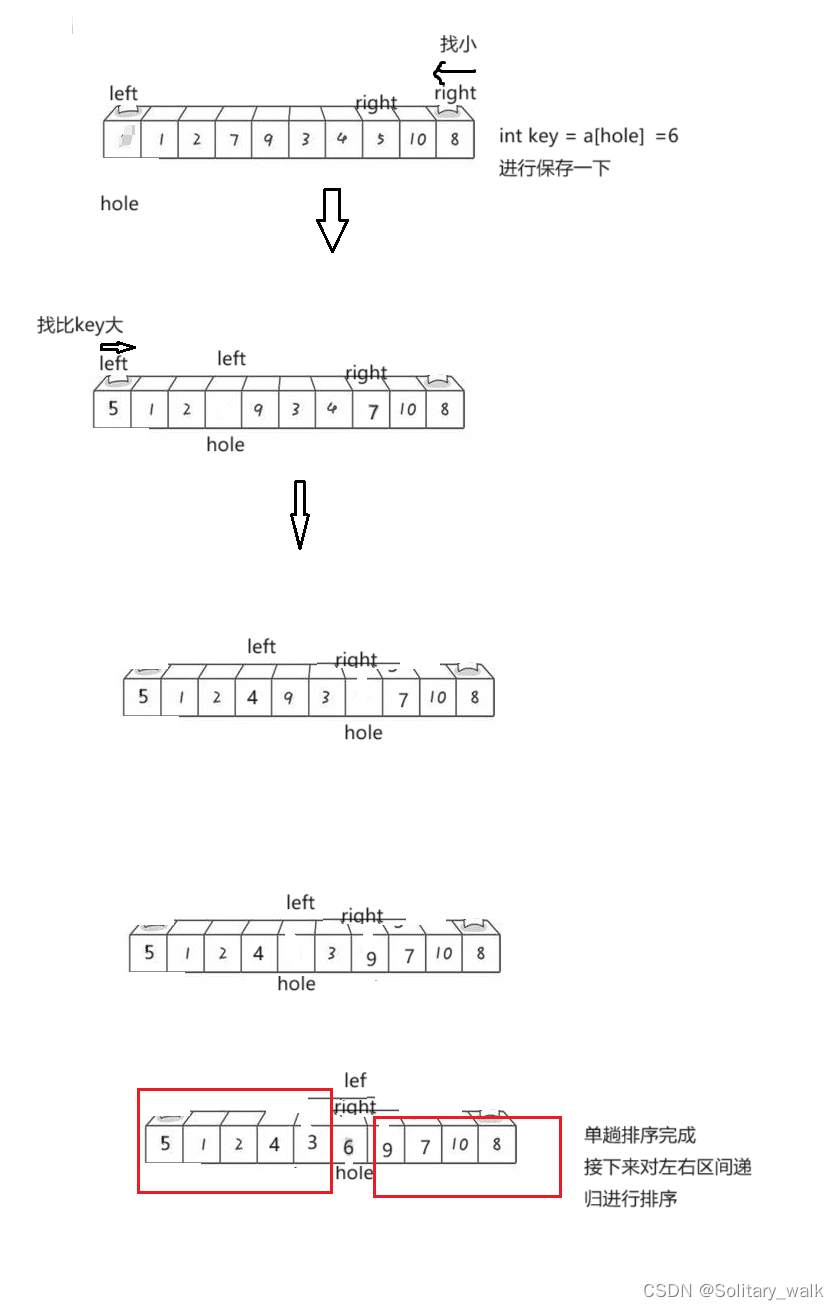
6.1.2挖坑法的快排实现
挖坑法和Horea法思想一样,只不过是另一种写法,不用注意left ,right先后走的顺序问题
假设第一个数为基准,同时也为坑所在位置(只是相对而言),依然是left找比 key大的,right找比key小的,因为left所在位置为坑,right先找找到与坑所在位置交换,让hole来到right所在位置,此时left找大,找到与hole所在位置交换,hole来到left坐在位置,最终left,right相遇(同时也是hole所在位置)让key 赋给hole所在位置单趟排序完成,接下来重复进行即可。
分析见下:
6.1.3前后指针法的快排实现

6.2代码的实现
6.2.1Hoare法
int Part_sort1(int*a,int begin,int end) //Hoare 法
{int key_i = begin;//默认第一个数所在位置为基准int left = begin;int right = end;while (left < right){while (left < right){if (a[right] < a[key_i]) //找小break;right--;}while (left < right){if (a[left] > a[key_i]) //找大break;left++;}Swap(&a[left], &a[right]);}//left right一定相遇if(left != key_i)Swap(&a[key_i], &a[left]);return left;
}void Quick_sort(int* a,int begin, int end)//下标
{if (begin >= end)return;int meet_i = Part_sort3(a,begin,end);//此时数组分为3个区间 [begin,meet_i-1] meet_i [meet_i+1,end]Quick_sort(a, begin, meet_i-1 );Quick_sort(a, meet_i + 1,end);
}6.2.2 挖坑法
int Part_sort2(int* a, int begin, int end)
{int left = begin;int right = end;int key = a[begin];int hole = begin;while (left < right){while (left < right){if (a[right] < key){a[hole] = a[right];hole = right;break;}right--;}while (left < right){if (a[left] > key){a[hole] = a[left];hole = left;break;}left++;}}a[hole] = key;return left;
}
void Quick_sort(int* a,int begin, int end)//下标
{if (begin >= end)return;int meet_i = Part_sort3(a,begin,end);//此时数组分为3个区间 [begin,meet_i-1] meet_i [meet_i+1,end]Quick_sort(a, begin, meet_i-1 );Quick_sort(a, meet_i + 1,end);
}6.2.3前后指针
int Part_sort3(int* a, int left, int right)//前后指针
{int pre = left;int cur = left;int key = a[left];while (cur <= right){if (a[cur] >= key)cur++;else //cur < key{pre++;Swap(&a[pre], &a[cur]);cur++;}}Swap(&a[pre], &a[left]);//&key不可以return pre;
}void Quick_sort(int* a,int begin, int end)//下标
{if (begin >= end)return;int meet_i = Part_sort3(a,begin,end);//此时数组分为3个区间 [begin,meet_i-1] meet_i [meet_i+1,end]Quick_sort(a, begin, meet_i-1 );Quick_sort(a, meet_i + 1,end);
}
6.3快排对应的时间复杂度以及空间复杂度的分析
空间复杂度:O(1)
时间复杂度:O()
分析时间复杂度:
这三个方法实现的快排思想都是一样的,通过前期画图的理解,其实不难发现,快排的过程和二叉树往下递归的过程一样的
最坏的情况:O(N^2)当数组是降序的时候,这时候需要排成升序或者是数组本身就是升序需要排成降序的就是最坏的情况了,假设第一个数为基准,总的比较次数就是一个等差数列
最优的时间复杂度:O(N*logN)每一轮的排序都把区间差不多对半分(也就是基准数都来到中间位置)

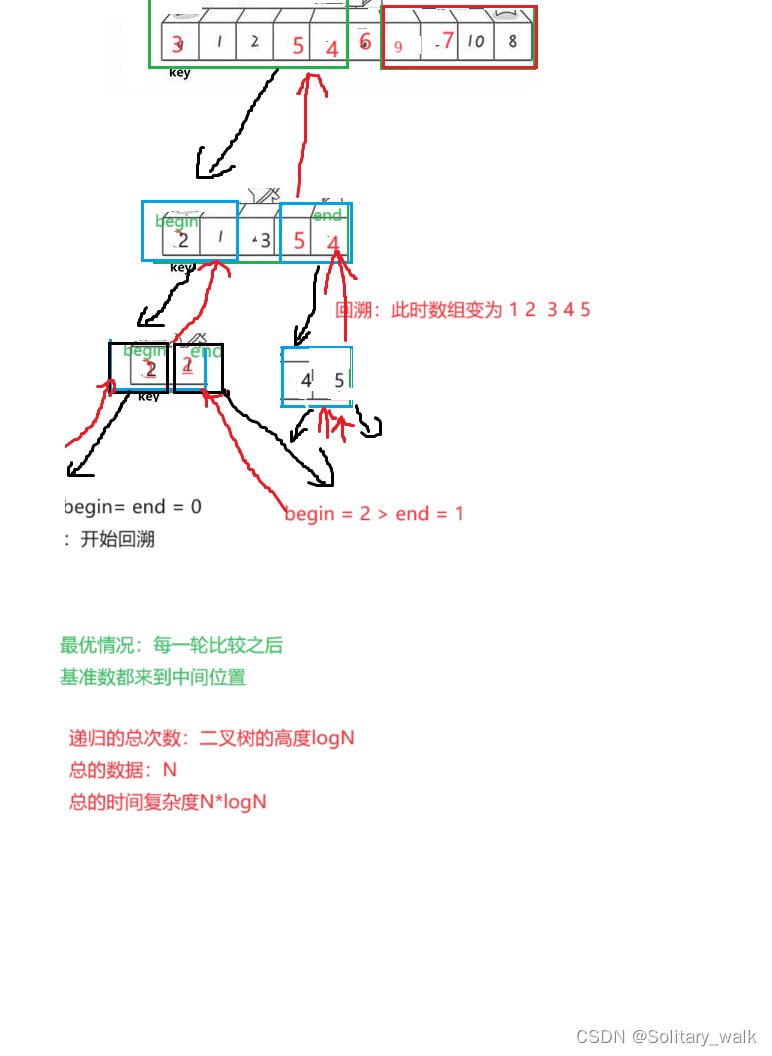
6.4快排的优化
很显然快排对随机数据的排序是很友好滴,当我们数据与要排序的方向相反的时候,那就很糟糕了,针对这个情况我们可以做些改进
三数取中:对left right mid(中间位置下标)取出一个不大不小的数
优化之后的代码:
int Get_mid(int* a, int left, int right)
{//三数取中 找不大不小的数所在位置int mid_i = (right + left) / 2;if (a[mid_i] > a[left]){if (a[left] > a[right])return left;else if (a[right] > a[mid_i]) //同时说明 left <= rightreturn mid_i;return right;}else// mid_i <= left{if (a[right] < a[mid_i])return mid_i;else if (a[right] > a[left]) //right>= mid_ireturn left;elsereturn right;}return mid_i;
}int Part_sort1(int*a,int begin,int end) //Hoare 法
{//三路划分优化:针对数组本身就有序int key_i = Get_mid(a, begin, end);Swap(&a[begin], &a[key_i]);//让中位数与下标0的数交换key_i = begin;//默认第一个数所在位置为基准int left = begin;int right = end;while (left < right){while (left < right){if (a[right] < a[key_i]) //找小break;right--;}while (left < right){if (a[left] > a[key_i]) //找大break;left++;}Swap(&a[left], &a[right]);}//left right一定相遇if (left != key_i)Swap(&a[key_i], &a[left]);return left;}7归并排序
7.1归并排序思想
为了方便理解这个思想先以一个题列来引入:合并2个有序数组,arr1,arr2:思想依次取小的尾插即可最终便可以实现整个数组有序。
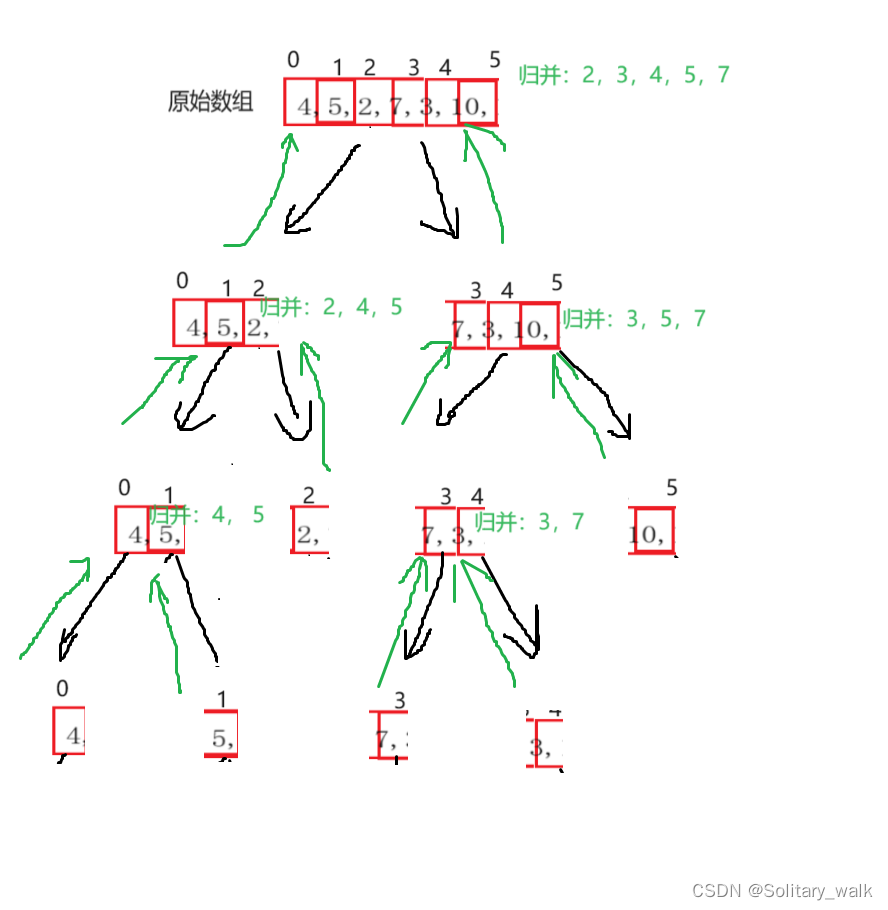
对于归并而言也是一样的:先把数组进行分解,最后在层层回溯进行归并
把数组对半分直至分成只有一个元素的时候,再进行归并
分析见下:
注意在进行归并的时候一定不能再原数组进行:造成数据的覆盖,所以查立就需要开辟一个数组大小同原数组大小一样
7.2代码实现
void _Merge_sort(int* a,int* tmp ,int begin,int end)
{if (begin >= end)return;int mid_i = (end + begin) / 2;//中位数下标//此时分成2个区间[begin,mid+i] [mid_i+1,end];//左区间递归_Merge_sort(a,tmp, begin, mid_i);//右区间递归_Merge_sort(a,tmp, mid_i + 1, end);//归并int left1 = begin;int right1 = mid_i;int left2 = mid_i + 1;int right2 = end;int i = begin;//注意这里不能设置为0 ,每次递归调用的时候要不都会在0 重新赋值while (left1 <= right1 && left2 <= right2){if (a[left1] < a[left2]){tmp[i++] = a[left1++];}else{tmp[i++] = a[left2++];}}while (left1 <= right1){tmp[i++] = a[left1++];}while (left2 <= right2){tmp[i++] = a[left2++];}memcpy(a+begin, tmp+begin, sizeof(int) * (end - begin + 1)); //注意这里不能是 a,tmp道理同上
}void Merge_sort(int* a, int num)
{int begin = 0, end = num -1;int* tmp = (int*)malloc(sizeof(int) * (end - begin + 1));if (tmp == NULL)return;memset(tmp, 0, sizeof(int) * (end - begin + 1));if (begin >= end)return;_Merge_sort(a, tmp, begin, end);
}
7.3时间复杂度以及空间复杂度分析
空间复杂度:O(N)需要为每次拷贝开辟额外空间
时间复杂度:O(N*logN)归并排序在进行递归调用的时候其实是一个二叉树往下递归的过程,外循环所指向次数就是二叉树的高度 logN,内循环是所执行次数N
7.4优化
当递归层次太深的时候,会造成栈顶溢出,因此就需要减少递归调用的次数
小区间优化
当递归到元素个数 少于10个的时候,这时候可以采用一些其他排序进行(效率高的),比如直接插入排序
为什么是少于10个呢?因为当递归到只有10个元素的时候这是就已经减少了80%以上的递归调用次数

7.5非递归的实现
先一 一进行归并 ,再二 二进行归并,依次类推直至数组有序
这个看起来是容易理解但是写起来很容易有问题:频繁的越界 ,以及拷贝数据下标的选择
分析见下:
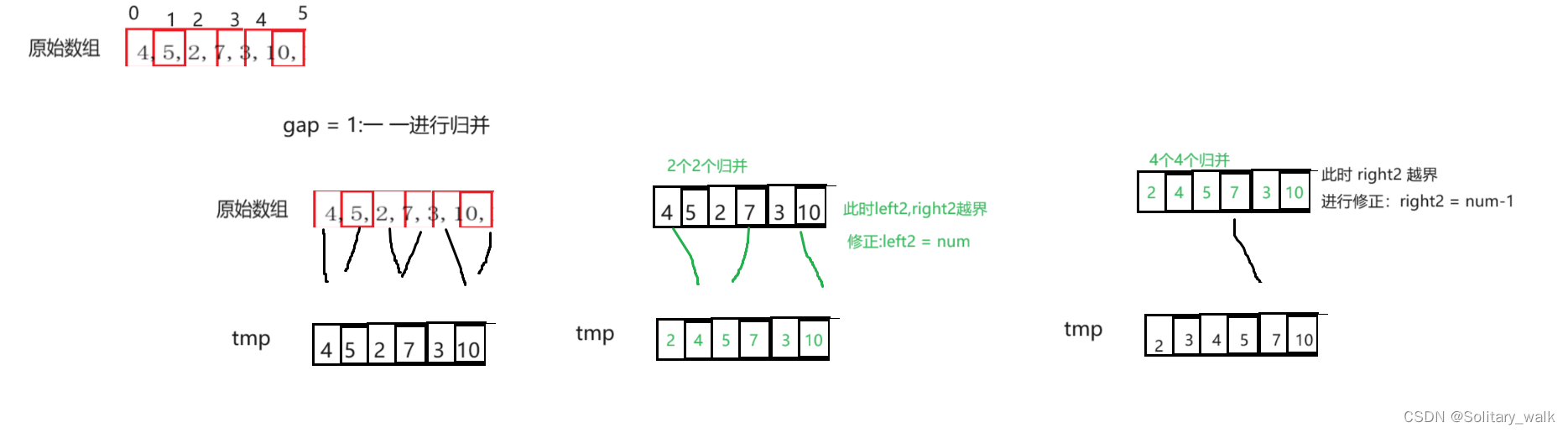
代码:
void Merge_sortNonR(int* a, int num)
{int* tmp = (int*)malloc(sizeof(int) * num);if (tmp == NULL)return;memset(tmp,0, sizeof(int) * num);//全部初始化0int gap = 1;//int i = 0;//记录tmp中下标位置while (gap < num) //需要取等{int i = 0;//记录tmp中下标位置for ( int j = 0; j < num ; j = j+2*gap) //单趟{int begin1 = j;int end1 = gap - 1 + begin1;int begin2 = gap + begin1;int end2 = gap - 1 + begin2;if (end1 >= num){end1 = num - 1;begin2 = num;end2 = num;}if (begin2 >= num){begin2 = num;end2 = num;}if ( end2 >= num){end2 = num - 1;}while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2])tmp[i++] = a[begin1++];elsetmp[i++] = a[begin2++];}while (begin1 <= end1 ){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}} memcpy(a, tmp, sizeof(int) * num);//memcpy(a, tmp, sizeof(int) *i);gap *= 2;}
}结语
以上就是要share 的内容,对于排序这部分知识也是不容忽视的。怎么说呢,你说他简单吧,但确实是不容易,说他难吧也不是多么难,就是自己把思想get 到,结合画图以及调试等相关的技巧慢慢的磨合吧,没有什么是一学就会的,尤其是在学习方面,希望大家看完此篇博客对相关排序的理解可以更上一层楼,各位大佬们支持一下呗,蟹蟹!
相关文章:
数据结构之七大排序
𝙉𝙞𝙘𝙚!!👏🏻‧✧̣̥̇‧✦👏🏻‧✧̣̥̇‧✦ 👏🏻‧✧̣̥̇:Solitary_walk ⸝⋆ ━━━┓ - 个性标签 - :来于“云”的“羽球人”。…...
【MySQL】数据库中常用的函数
目录 聚合函数COUNT()函数的多种用法COUNT(*)COUNT(主键)COUNT(1)COUNT(常量)COUNT(非主键)COUNT(distinct(字段)) COUNT()函数小结 字符函数length(str)函数:获取参数值的字节个数concat(str1,str2,...)函数:字符串拼接upper(str)、lower(str)函数:大小…...
)
嵌入式面试常见问题(四)
1.在基于Linux的网络套接字编程中,如果需要创建一个IPv4的网络套接字,应该在socket函数中指定domain参数为AF_INET 解析: socket()函数创建套接字 函数原型:int socket(int domain, int type, int protocol); domain:协议簇&…...
用Java在Spring Boot项目中,如何传递来传递一个对象(多个参数??
前言: 在前面我们已经了解到,Spring Boot项目中,可以传递一个参数,或者多个参数,但是,随着参数的增加,咱们总不能每增加一个参数,就重新写一段代码吧??这样显…...

如何利用ChatGPT搞科研?论文检索、写作、基金润色、数据分析、科研绘图(全球地图、植被图、箱型图、雷达图、玫瑰图、气泡图、森林图等)
以ChatGPT、LLaMA、Gemini、DALLE、Midjourney、Stable Diffusion、星火大模型、文心一言、千问为代表AI大语言模型带来了新一波人工智能浪潮,可以面向科研选题、思维导图、数据清洗、统计分析、高级编程、代码调试、算法学习、论文检索、写作、翻译、润色、文献辅助…...

一命通关二分搜索
二分法 简介 和双指针一样,二分法也是一种优化方法,或者说二分法就是双指针的一类。不过,二分法的思想比双指针诞生更早也更广泛,在我们日常生活里也无时不刻在使用二分的思想。 比如我们想回顾某些影片,但是只记得…...

串联所有单词的子串
题目链接 串联所有单词的子串 题目描述 注意点 words[i] 和 s 由小写英文字母组成1 < words.length < 5000可以以 任意顺序 返回答案words中所有字符串长度相同 解答思路 根据滑动窗口哈希表解决本题,哈希表存储words中所有的单词及单词的出现次数&#…...

【会议征稿通知】第四届经济发展与商业文化国际学术会议(ICEDBC2024)
第四届经济发展与商业文化国际学术会议(ICEDBC2024) The 4th International Conference on Economic Development and Business Culture (ICEDBC 2024) 第四届经济发展与商业文化国际学术会议(ICEDBC2024)将于2024年6月21-23日在…...
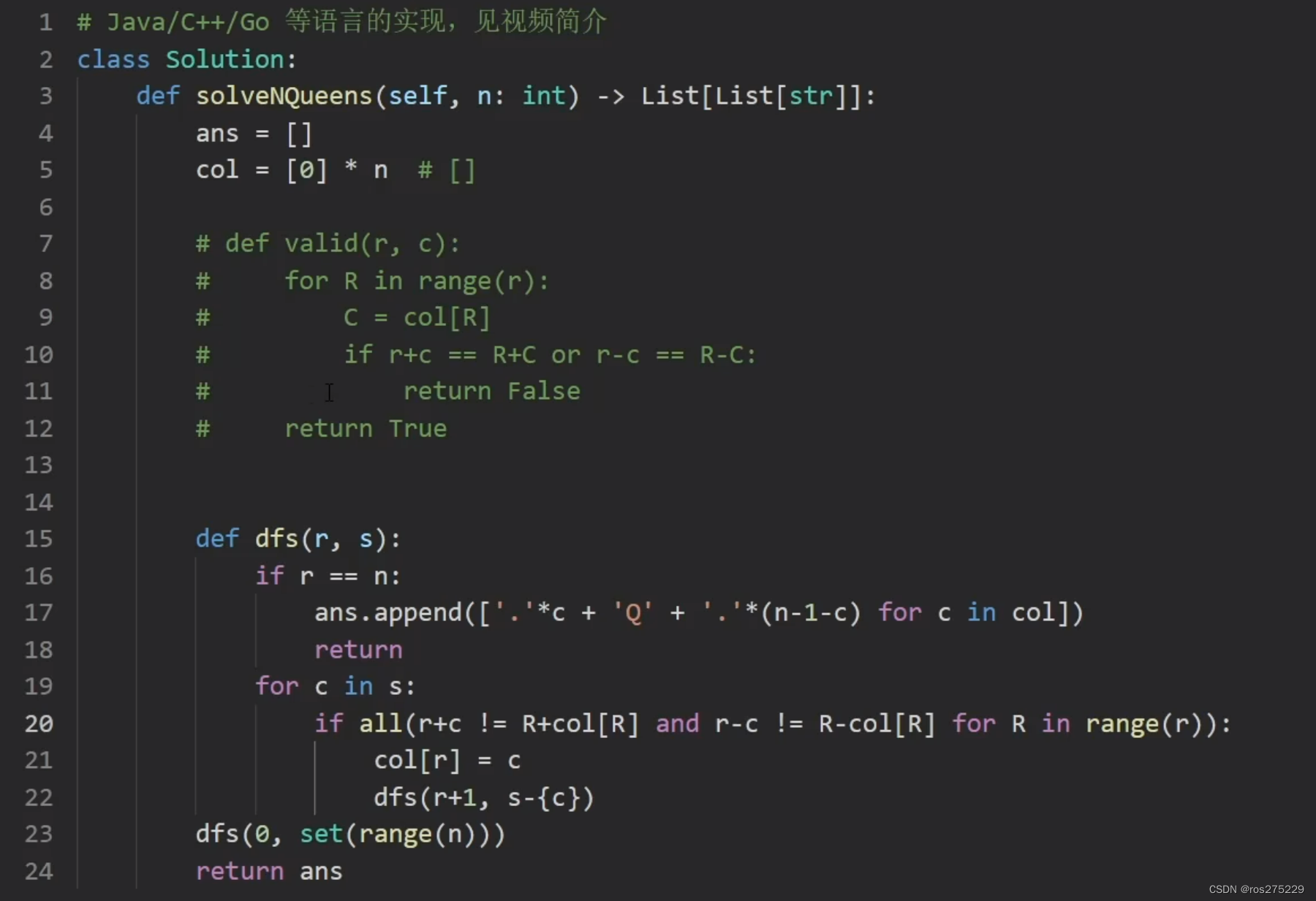
回溯算法套路③排列型回溯+N皇后【基础算法精讲 16】
46 . 全排列 链接 : . - 力扣(LeetCode) 思路 : 那么怎么确定选了那个数呢? 这里设置一个used表示i选没选过 ; class Solution { public:vector<vector<int>> ans;vector<int> path;void backtrack(vector<int>nums,vect…...

MyBatis-Plus 框架中的自定义元对象处理器
目录 一、代码展示二、代码解读 一、代码展示 package com.minster.yanapi.handler;import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler; import org.apache.ibatis.reflection.MetaObject; import org.springframework.stereotype.Component;import java.util…...
)
Node.js_基础知识(fs模块 - 文件操作)
写入 文件操作 流式写入:fs.createWriteStream(path[, options]) 可以减少打开关闭文件的次数适用于:大文件写入、频繁写入参数说明: path:文件路径文件夹操作: 调用mkdir方法:fs.mkdir(./a/b/c, err => {}) 递归创建文件夹:加参数recursive fs.mkdir(./a/b/c, {recu…...

基于C#开发OPC DA客户端——搭建KEPServerEX服务
简介 OPC DA (OLE for Process Control Data Access) 是一种工业自动化领域中的通信协议标准,它定义了应用程序如何访问由OPC服务器提供的过程控制数据。OPC DA标准允许软件应用程序(客户端)从OPC服务器读取实时数据或向服务器写入数据&…...
)
让你的函数,返回你需要的“两个值” (函数传址、结构体作为参数传参)
总结:1.结构体完成你的目标 2.指针传参 方法2. void get_a_b(int* a, int* b) { *a 13; *b 14; //通过解引用,找到并修改 } int main() { int a 0; int b 0; get_a_b(&a, &b); //传地址 prin…...

快速上手:在 Android 设备上运行 Pipy
Pipy 作为一个高性能、低资源消耗的可编程代理,通过支持多种计算架构和操作系统,Pipy 确保了它的通用性和灵活性,能够适应不同的部署环境,包括但不限于云环境、边缘计算以及物联网场景。它能够在 X86、ARM64、海光、龙芯、RISC-V …...

【操作系统学习笔记】文件管理1.3
【操作系统学习笔记】文件管理1.3 参考书籍: 王道考研 视频地址: Bilibili I/O 控制方式 程序直接控制方式中断驱动方式DMA 方式通道控制方式 程序直接控制方式 关键词: 轮询 完成一次读/写操作的流程 CPU 向控制器发出读指令。于是设备启动,并且状态寄存器设…...
基于springboot+vue的酒店管理系统
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、阿里云专家博主、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战,欢迎高校老师\讲师\同行交流合作 主要内容:毕业设计(Javaweb项目|小程序|Pyt…...

Linux 相关命令
文章目录 目录相关操作vim 编辑器命令行模式插入模式底行模式 目录相关操作 查看当前目录下的文件 ls创建目录 mkdir 目录名进入文件,首先确认位于文件的目录 vi 文件名 vim 编辑器 命令行模式 控制光标的移动,字符或行的删除,移动复制某区域…...
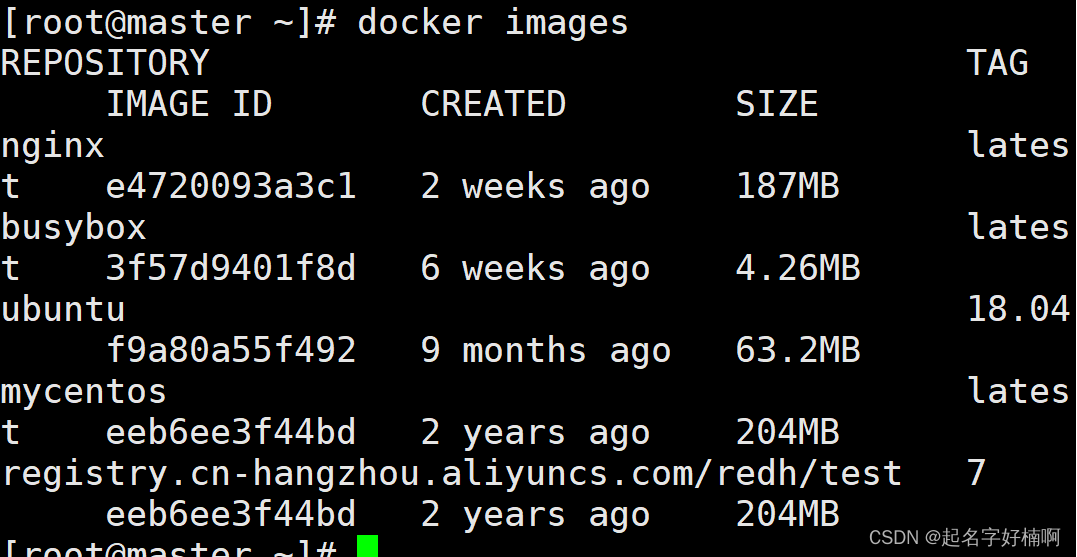
阿里云搭建私有docker仓库(学习)
搭建私有云仓库 首先登录后直接在页面搜索栏中搜索“容器镜像服务” 进入后直接选择个人版(可以免费使用) 选择镜像仓库后创建一个镜像仓库 在创建仓库之前我们先创建一个命名空间 然后可以再创建我们的仓库,可以与我们的github账号进行关联…...
)
MySQL数据库基本操作(一)
数据库的基本概念 1. 数据库的英文单词: DataBase 简称 : DB 2. 什么数据库?* 用于存储和管理数据的仓库。 3. 数据库的特点:1. 持久化存储数据的。其实数据库就是一个文件系统2. 方便存储和管理数据3. 使用了统一的方式操作数…...

【暗月安全】2021年渗透测试全套培训视频
参与培训需要遵守国家法律法规,相关知识只做技术研究,请勿用于违法用途,造成任何后果自负与本人无关。 中华人民共和国网络安全法(2017 年 6 月 1 日起施行) 第二十二条 任何个人和组织不得从事入侵他人网络、干扰他…...
)
Linux 进程从入门到实战(一)
.个人主页:晓风飞专栏:数据结构|Linux|C语言路漫漫其修远兮,吾将上下而求索文章目录进程为什么要存在内存??操作系统进程什么是进程?PCB(进程控制块)操作系统如何管理进程࿱…...

量子转导技术:微波与光学量子系统的桥梁
1. 量子转导技术概述量子转导技术是连接微波与光学量子系统的关键桥梁,其核心功能是实现不同频段量子信息的高保真转换。作为一名长期从事量子器件研发的工程师,我见证了这项技术从实验室走向实际应用的完整历程。简单来说,它就像量子世界的&…...
全线工程塑料产品与技术服务)
宏裕塑胶代理沙伯基础创新SABIC(原GE塑料)全线工程塑料产品与技术服务
宏裕塑胶依托源头直采模式,整合沙伯基础创新 SABIC(原 GE 塑料)等国际一线品牌工程塑料原料,为制造业企业提供高性价比、稳定可控的供应链解决方案,助力客户降本增效,适用于汽车零配件、精密电子、注塑生产…...

观察使用 Taotoken Token Plan 套餐后的月度成本变化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察使用 Taotoken Token Plan 套餐后的月度成本变化 对于个人开发者或小型团队而言,大模型 API 的调用成本是项目预算…...

Taotoken官方折扣活动如何切实降低模型调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken官方折扣活动如何切实降低模型调用成本 1. 成本感知:从按需付费到计划性支出 对于个人开发者或中小型团队而言…...
如何免费解决BT下载速度慢问题?终极trackerslist配置指南
如何免费解决BT下载速度慢问题?终极trackerslist配置指南 【免费下载链接】trackerslist Updated list of public BitTorrent trackers 项目地址: https://gitcode.com/GitHub_Trending/tr/trackerslist 你是否曾为BT下载的龟速而烦恼?种子明明显…...

端到端关键词识别技术范式:WeKWS在边缘计算场景下的架构创新与实践
端到端关键词识别技术范式:WeKWS在边缘计算场景下的架构创新与实践 【免费下载链接】wekws Production First and Production Ready End-to-End Keyword Spotting Toolkit 项目地址: https://gitcode.com/gh_mirrors/we/wekws 在物联网设备普及的今天&#x…...

AMD Ryzen终极调试工具:硬件级性能调优完全指南
AMD Ryzen终极调试工具:硬件级性能调优完全指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.…...

如何快速掌握uesave:Unreal引擎存档编辑的完整指南
如何快速掌握uesave:Unreal引擎存档编辑的完整指南 【免费下载链接】uesave Rust library and CLI to read and write Unreal Engine save files 项目地址: https://gitcode.com/gh_mirrors/ue/uesave uesave是一款专门用于处理Unreal引擎游戏存档文件的开源…...

从装饰器原理到实战:手把手教你用TypeScript为NestJS方法实现一个‘网络代理’
从装饰器原理到实战:手把手教你用TypeScript为NestJS方法实现一个‘网络代理’ 在Node.js生态中,装饰器(Decorator)作为一种元编程工具,正逐渐从实验性特性转变为现代框架的核心支柱。NestJS正是这一趋势的典型代表—…...