组基轨迹建模 GBTM的介绍与实现(Stata 或 R)
基本介绍
组基轨迹建模(Group-Based Trajectory Modeling,GBTM)(旧名称:Semiparametric mixture model)
历史:由DANIELS.NAGIN提出,发表文献《Analyzing Developmental Trajectories:A Semiparametric,Group-Based Approach》
GBTM能够将一群人的轨迹分类并生成数个具有代表性的运动轨迹模型,然后对每个轨迹模型进行分析,以了解人们的运动特征、生理水平和风险等级等。GBTM的核心思想是将人群分成几组,每组中的人员都具有类似的运动规律,这些规律被用于描述和预测他们未来的运动轨迹,从而为个人和群体的健康管理提供更科学的依据。
- 主要用于分析纵向数据,探索总体中的异质性
- 原理:假定总体存在异质性,即总体中存在若干个不同发展轨迹或模式的潜在亚组
- 目的:探索总体中包含有多少个发展趋势不同的亚组,并确定各亚组的发展轨迹
- 轨迹的等级与形状由模型的回归参数决定,模型的回归参数通过最大似然比估计
组轨迹建模流程
组轨迹模型的建立是需要不断建立、反馈、修正的过程。
1.拟合1~6组轨迹模型,每个轨迹分别拟合线性、平方和立方
2.通过模型计算模型参数估计,剔除无意义的估计项,重新拟合。
3.通过比较不同模型间的拟合评价指标和专业可解释性选择合适的轨迹。
4.评价模型内充分性。
实现方法
1. 基于Stata 【traj包】
安装包命令
new install traj, force数值格式: 目标变量的纵向指标+采集时间
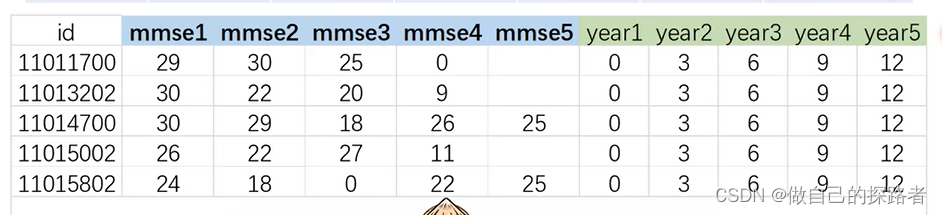
导入数据
import delimited ".\data.csv", clearGBTM分析
# GBTM分析
# s1 到 s5 和 t1 到 t5 是变量名,s1到s5作为重复测量的自变量,t1到t5作为时间变量
traj,var(s1-s5)indep(t1-t5)model(cnorm) min(0) max(30)order (3 3 2)
traj: 表示进行轨迹分析。var(s1-s5): 指定要进行轨迹分析的变量,这里使用s1到s5作为变量。indep(t1-t5): 指定作为独立变量的时间变量,这里使用t1到t5作为时间变量。model(cnorm): 指定模型类型为连续型的正态模型。min(0) max(30): 指定轨迹分析的时间范围为0到30。order(3 3 2): 指定轨迹分析中的多项式次数,这里选择三次多项式。
# 绘图
traj plot,x title(YearsSince Baseline) y title(MMSEscore)cix label(0(3) 12) ylabel
(0(5)30)
traj: 表示进行轨迹分析。var(s1-s5): 指定要进行轨迹分析的变量,这里使用s1到s5作为变量。indep(t1-t5): 指定作为独立变量的时间变量,这里使用t1到t5作为时间变量。model(cnorm): 指定模型类型为连续型的正态模型。min(0) max(30): 指定轨迹分析的时间范围为0到30。order(3 3 2): 指定轨迹分析中的多项式次数,这里选择三次多项式,多次重复拟合

order参数的设定【重要】
确定亚组数及其轨迹需要多次重复拟合,才能获得最佳轨迹数目及形状。一般先从较少亚组数开始拟合,每一亚组先从高阶开始,若高阶参数无统计学意义则去除继续拟合低阶参数
多次尝试寻找最佳参数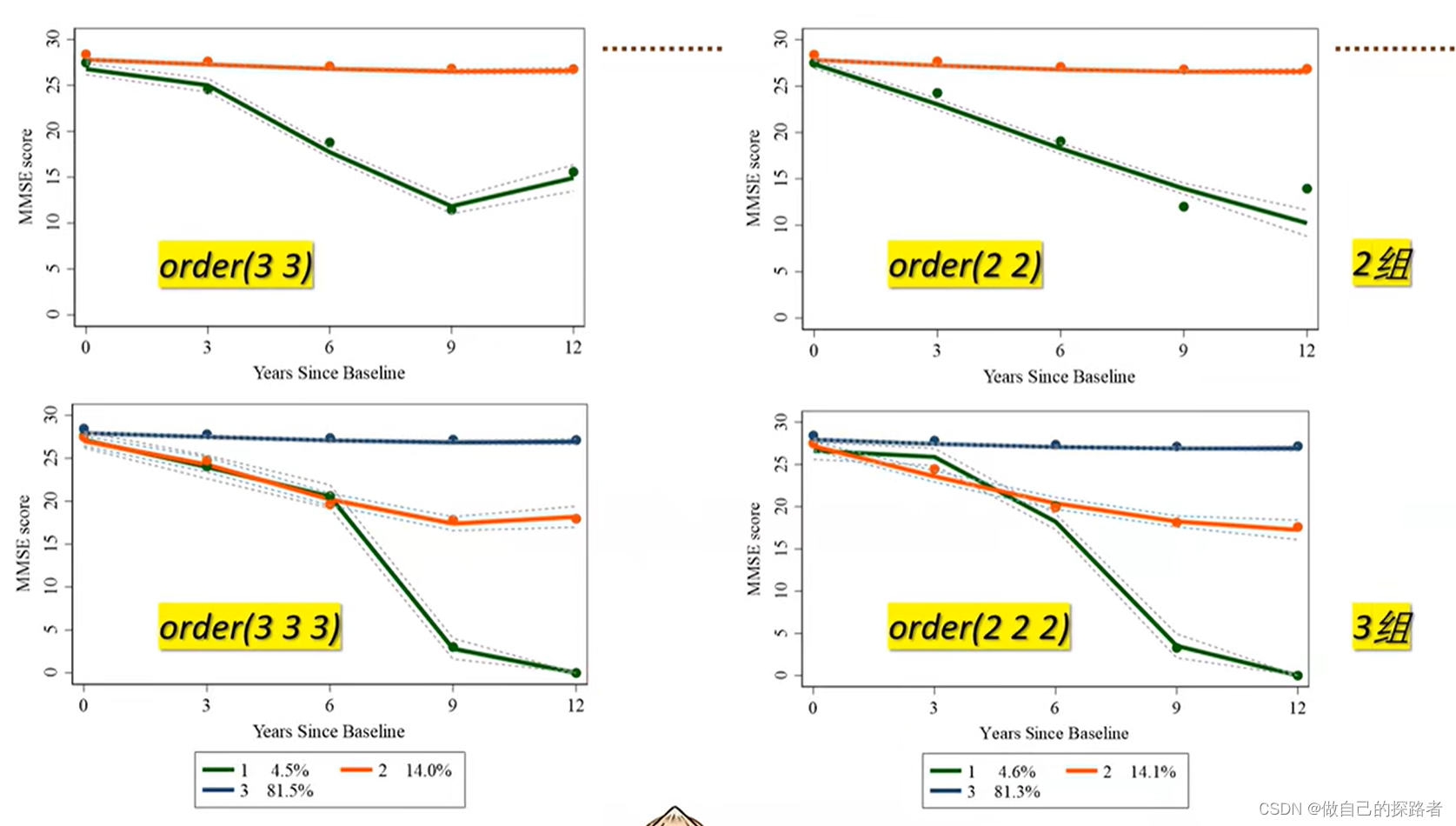 参考指标: 查看Maximum Likelihood Estimates Model:Censored Normal(c norm) 的输出表格
参考指标: 查看Maximum Likelihood Estimates Model:Censored Normal(c norm) 的输出表格
通过查看Prob > |T| 【即P值】,一般需要选取该分组的最高阶具有统计学意义。
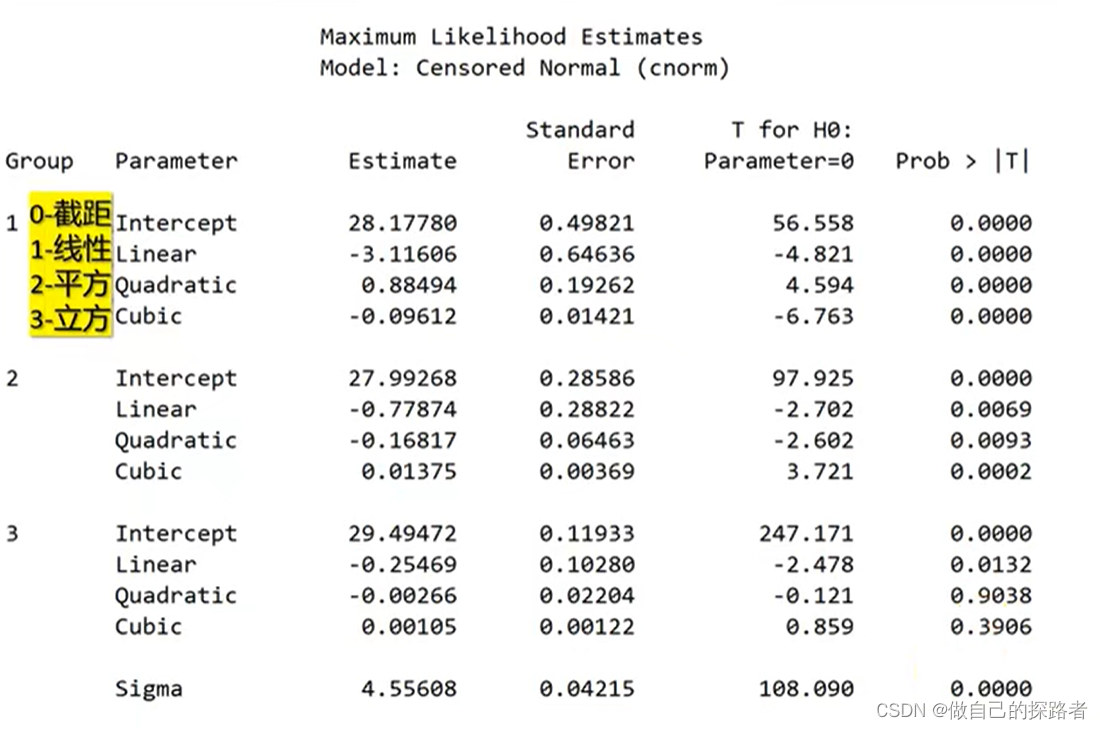
最佳分组数量如何确定?
贝叶斯信息标准(Bayesianinformationcriterion,BIC)
- BIC值绝对值越小--趋0, 表示模型拟合程度越好
- 查看方式:查看Maximum Likelihood Estimates Model:Censored Normal(c norm) 的输出表格的最下方
平均验后分组概率(average posterioror ob ability,AvePP)
- 判定每一个体被归属为特定轨迹的概率,越接近1越好
- 反映每一个体被分到相应亚组的后验概率
- >0.7时,作为模型可以接受的标准
- 查看方式:需要命令实现
list_traj_Group-_traj_ProbG1
2. 基于R 【trajeR包】
TrajeR 支持几种数据分布
- 删失(或常规)正态分布 【Censored (or regular) Normal distribution】代码中简称为CNORM ;
- 零膨胀泊松分布 【Zero Inflated Poisson distribution】;
- 泊松分布【Poisson 】;
- 伯努利分布【Bernouilli 】;
- Beta分布(只包括可能性) ;
- 非线性回归 【Non linear regression】
每个亚组的运动轨迹采用多项式建模,也可以采用非线性模型。
包的主要函数
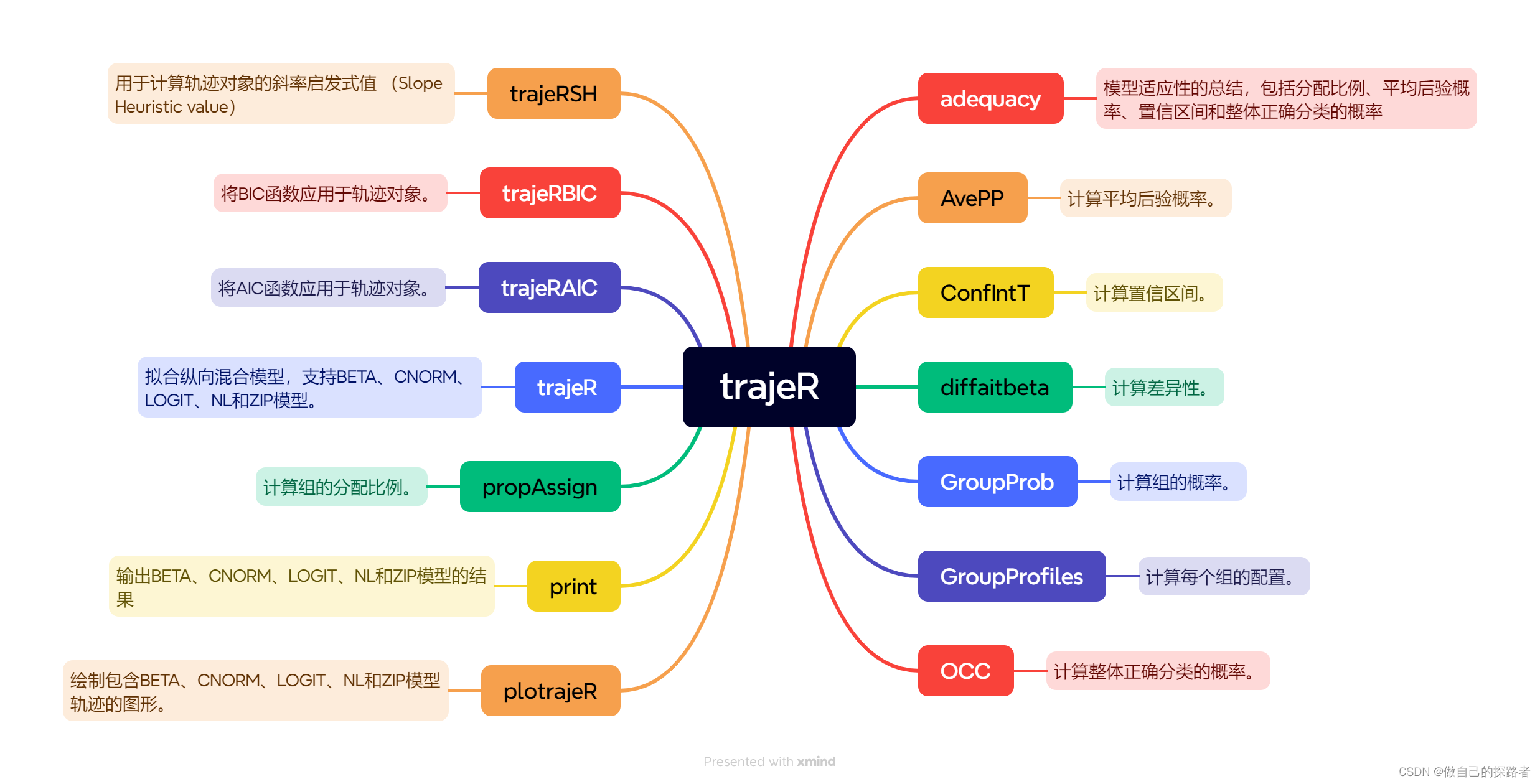
安装与加载
## install dev version of trajeR from github
devtools::install_github("gitedric/trajeR")## load trajeR package
library(trajeR)trajeR() 最重要的函数
trajeR(Y,A,Risk = NULL,TCOV = NULL,degre = NULL,degre.nu = 0,degre.phi = 0,Model,Method = "L",ssigma = FALSE,ymax = max(Y, na.rm = TRUE) + 1,ymin = min(Y, na.rm = TRUE) - 1,hessian = TRUE,itermax = 100,paraminit = NULL,ProbIRLS = TRUE,refgr = 1,fct = NULL,diffct = NULL,nbvar = NULL,ng.nl = NULL,nls.lmiter = 50
)参数
Y: 模型中自变量的矩阵。
A:模型中时间变量的矩阵。
Risk:一个可选的矩阵,修改属于群的概率。默认情况下,它的值是一个矩阵,其中一列的值为1
TCOV:一个可选的矩阵,包含影响轨迹本身的时间协变量。默认值为 NULL。
degre:整数向量,每个多项式中最高次幂的指数,即order参数的设定。degre的个数表示设定的组别数量,degre中第 i 个数字分别代表 第 i 组的最高次幂的指数degre.nu:整数向量。 ZIP 模型中所有泊松部分的度。
degre.phi:整数向量。 BETA 模型中 β 参数的度。
Model: 指定模型,该值为 LOGIT :混合模型的 LOGIT;截尾正态混合模型的 CNORM 或零膨胀泊松混合模型的 ZIP。
Method:指定用于查找模型参数的方法。最大似然估计法则为 L,内含拟牛顿法的期望最大化方法的值为 EM,迭代加权最小二乘法的期望最大化方法的值为 EMIWRLS。
sigma:默认情况下,它的值为 FALSE。对于 CNORM 模型,指出我们是否需要对所有正态分布函数使用相同的 σ。
ymax:对于 CNORM 模型,指示数据的最大值。它只关注有删失数据的模型。默认情况下,它的值是数据加1的最大值。
ymin:对于 CNORM 模型,指示数据的最小值。它只关注有删失数据的模型。默认情况下,它的值是数据的最大值减1。
hessian:指出我们是否要计算hessian 矩阵。默认是FALSE。如果使用的方法是似然的,hessian 是通过反转信息的费舍尔矩阵计算。为了避免数值奇异矩阵,我们利用 MASS 包中的 ginv 函数求出伪逆矩阵。如果方法是 EM 或 EMIWRLS,则采用路易斯法计算hessian 。
itermax:表示优化函数或 EM 算法的最大迭代次数。
paraminit:初始参数向量。在默认情况下,trajeR 根据范围或标准差计算初始值。
ProbIRLS:指出了预测器概率搜索中的起诉方法。如果 TRUE (默认)我们使用 IRLS 方法,如果 FALSE 我们使用优化方法。
refgr:引用组的数目。默认为1。
fct:非线性模型中函数 f 的定义
diffct:非线性模型中函数 f 的微分
nbvar:非线性模型中变量的个数。
ng.nl:非线性模型的亚组数
nls.l miter:非线性模型的组数
输出结果
beta:参数 β 的向量delta:时间协变量theta:用时间协变量sd:参数的标准差的向量。tab:一个包含所有参数和标准差的矩阵Likelihood:由参数得到的似然的实数ng,:由参数得到的似然的实数model:由参数得到的似然的实数method:所用方法的字符串。
# 代码示例
solL = trajeR(data[,1:5], data[,6:10], ng = 3, degre=c(2,2,2), Model="CNORM", Method = "L", ssigma = FALSE, hessian = TRUE)拟合模型
#读取数据
data = read.csv(system.file("extdata", "CNORM2gr.csv", package = "trajeR"))
data = as.matrix(data)
# 拟合模型:拟合2个组,第一个组的最高次方为平方,第2个组的最高次方也为平方。
sol = trajeR(Y = data[, 2:6], A = data[, 7:11], degre = c(2,2), Model = "CNORM", Method = "EM")# 结果输出
print(sol)# 绘图 【如下】
plotrajeR(sol)# 结果输出
> print(sol)
Call TrajeR with 2 groups and a 2,2 degrees of polynomial shape of trajectory.
Model : Censored Normal
Method : Expectation-maximization group Parameter Estimate Std. Error T for H0: Prob>|T| param.=0
--------------------------------------------------------------------1 Intercept 11.04411 2.45556 4.49759 1e-05 Linear -9.31101 1.88182 -4.94787 0 Quadratic 0.94224 0.30679 3.07128 0.00237 2 Intercept -6.00923 2.61924 -2.29426 0.02261 Linear 6.98117 1.99415 3.50082 0.00055 Quadratic -1.14198 0.32309 -3.5345 0.00049
--------------------------------------------------------------------1 sigma1 4.96653 0.37773 13.14835 0 2 sigma2 6.60139 0.38434 17.17574 0
--------------------------------------------------------------------1 pi1 0.38688 0.0697 5.55096 0 2 pi2 0.61312 0.0697 8.79716 0
--------------------------------------------------------------------
Likelihood : -830.0071 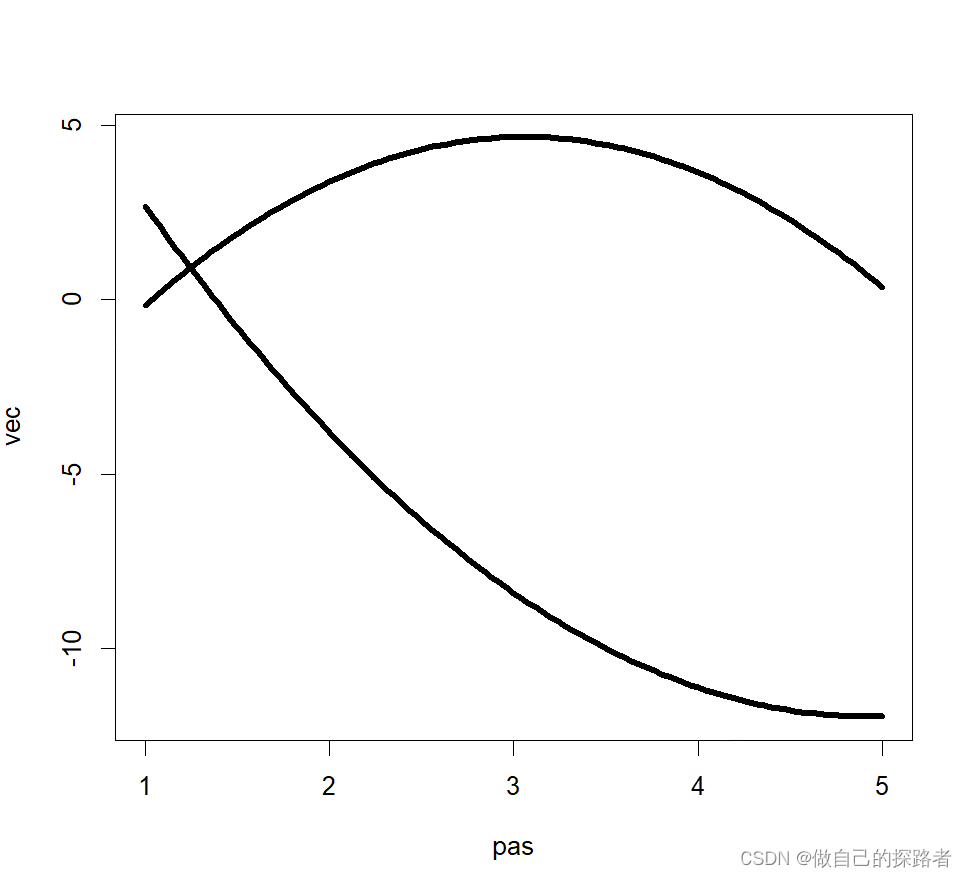
模型评估
用于评估模型的充分性(Adequacy of the model)。adequacy() 函数可以计算五种方法的总结结果,包括:分配比例(assignment proportion)、平均后验概率(average posterior probability)、置信区间(confidence interval)、正确分类的几率(odds of Correct Classification)。
adequacy(sol, Y = data[, 2:6], A = data[, 7:11])# 结果输出
# 1 2
# Prob. est. 0.4436785 0.5563215
# CI inf. 0.2230186 0.4482696
# CI sup. 0.5462226 0.7746488
# Prop. 0.3800000 0.6200000
# AvePP 0.9837616 0.9789556
# OCC 96.0110285 29.3529000
分组概率情况
# 每个个体分别分配到每个组的概率
GroupProb(sol, Y=data[, 2:6], A=data[, 7:11])
head(GroupProb(sol, Y=data[, 2:6], A=data[, 7:11]))
# Gr1 Gr2
# [1,] 2.205715e-09 0.9999999978
# [2,] 9.985604e-01 0.0014396289
# [3,] 1.121664e-09 0.9999999989
# [4,] 9.510136e-03 0.9904898637
# [5,] 9.996207e-01 0.0003792992
# [6,] 4.502507e-06 0.9999954975# 计算每个亚组的个体的比例
propAssign(sol, Y = data[, 2:6], A = data[, 7:11])
# 1 2
# [1,] 0.38 0.62批量建模参考
data = read.csv(system.file("extdata", "CNORM2gr.csv", package = "trajeR"))
data = as.matrix(data)
degre = list(c(2,2), c(1,1), c(1,2), c(2,1), c(0,0), c(0,1), c(1,0), c(0,0), c(0,2), c(2,0))
sol = list()
for (i in 1:10){sol[[i]] = trajeR(Y = data[, 2:6], A = data[, 7:11], degre = degre[[i]], Model = "CNORM", Method = "EM")}
资料来源
GitHub - gitedric/trajeR: Group Based Modeling Trajectory
trajeR: Fitting longitudinal mixture models in trajeR: Group Based Modeling Trajectory
纵向数据分析之组轨迹模型(GBTM)_哔哩哔哩_bilibili
如何利用重复测量的数值变量,评估其发展轨迹/变化趋势——基于Stata软件的组基轨迹建模Group-Based Trajectory Modeling方法介绍_哔哩哔哩_bilibili
相关文章:
组基轨迹建模 GBTM的介绍与实现(Stata 或 R)
基本介绍 组基轨迹建模(Group-Based Trajectory Modeling,GBTM)(旧名称:Semiparametric mixture model) 历史:由DANIELS.NAGIN提出,发表文献《Analyzing Developmental Trajectori…...

解决前端性能问题:如何优化大量数据渲染和复杂交互?
✨✨祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心!✨✨ 🎈🎈作者主页: 喔的嘛呀🎈🎈 目录 引言 一、分页加载数据 二、虚拟滚动 三、懒加载 四、数据缓存 五、减少重绘和回流 …...

【Vue3】深入理解Vue中的ref属性
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢…...

CentOS上安装与配置Nginx
CentOS上安装与配置Nginx Nginx是一款轻量级的Web服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,并在一个BSD-like协议下发行。以下是在CentOS系统上安装和配置Nginx的步骤。 🌟 前言 欢迎来到我的小天地,这…...
DataGrip 连接 Centos MySql失败
首先检查Mysql是否运行: systemctl status mysqld , 如果显示没有启动则需要启动mysql 检查防火墙是否打开,是否打开3306的端口 sudo firewall-cmd --list-all 如果下面3306没有打开则打开3306端口 publictarget: defaulticmp-block-inver…...
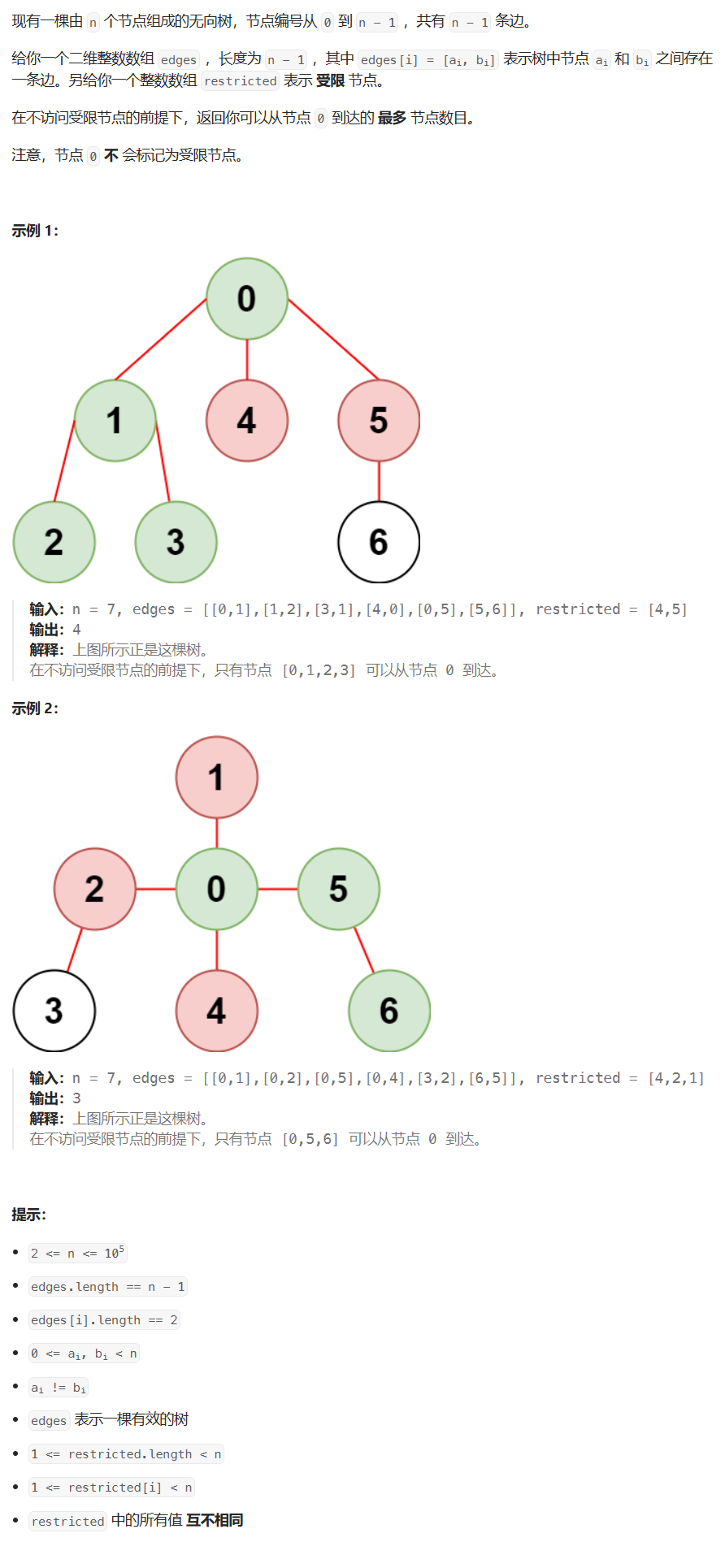
【图论】图的遍历 - 构建领接表(无向图)
文章目录 例题:受限条件下可到达节点的数目题目描述代码与注释模板抽象 例题:受限条件下可到达节点的数目 题目链接:2368. 受限条件下可到达节点的数目 题目描述 代码与注释 func reachableNodes(n int, edges [][]int, restricted []int)…...

Claude 3家族惊艳亮相:AI领域掀起新浪潮,GPT-4面临强劲挑战
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法|MySQL| 💫个人格言:“没有罗马,那就自己创造罗马~” #mermaid-svg-agd7RSCGMblYxo85 {font-family:"trebuchet ms",verdana,arial,sans-serif;f…...

Linux Watchdog 机制是什么
当涉及到Linux操作系统的稳定性和可靠性时,Linux Watchdog机制是一个至关重要的议题。该机制旨在监控系统状态,确保在出现问题时采取适当的措施以维持系统的正常运行。本文将深入探讨Linux Watchdog机制的工作原理、应用范围以及如何配置和使用该机制来提…...

Linux权限问题
1.用户 Linux系统下分为两种用户 a.超级用户(root) b.普通用户 超级用户的命令提示符是“#”,普通用户的命令提示符是“$” 怎么切换用户呢? 命令 su 用户名 其中切换root可以为su 或者su root-----不用密码 普通用户切换…...

python基础练习题目
1. 根据身高体重,判断人的胖瘦 描述: 通过身高和体重,判断一个人的胖瘦。国际上一般采用BMI体重指数,计算公式为BMI 体重 / 身高2(保留小数点后1位),参考标准如下:…...

视频编码标准H.264/AVC,H.265/HEVC,VP8/VP9,AV1的基本原理、优缺点以及适用场景
视频编码标准是用于压缩数字视频数据的技术规范,以减少存储和传输所需的带宽。以下是关于H.264/AVC、H.265/HEVC、VP8/VP9和AV1这些标准的基本原理、优缺点以及适用场景的简要描述: H.264/AVC (Advanced Video Coding) 基本原理: H.264是一…...
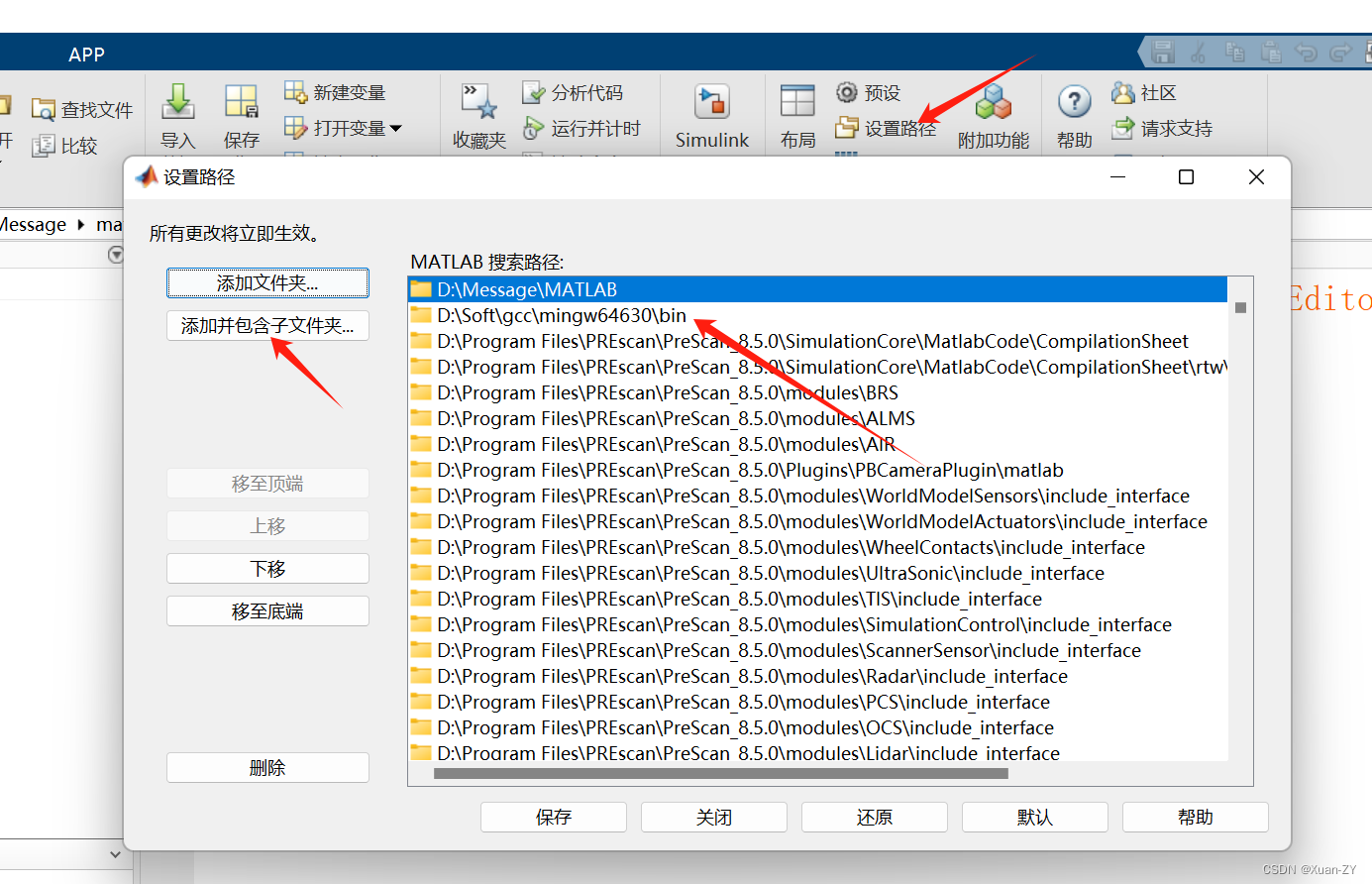
MATLAB2020a安装编译器mingw-64(6.3.0)
MATLAB2020a指定安装mingw-64(6.3.0)版本编译器 记录一下几个要点 mingw-64(6.3.0) 找到对应的mingw-64安装包 设置mingw的bin文件路径到环境变量 变量名:MW_MINGW64_LOC MATLAB设置路径...

Python网络请求高级篇:Requests库的深度运用
在Python网络请求中级篇中,我们了解了如何通过Requests库发送带参数的请求,处理Cookies,使用Session对象,以及设置请求头。在本文中,我们将进一步深入学习Requests库的高级功能,包括处理重定向,…...

AWS认证
AWS新增DEA-C01认证考试知识要点 原创 云计算狂魔 云计算狂魔 2024-03-04 23:58 北京 由于AWS将于3月12日正式启动DEA-C01认证考试,我们整理了相关考试知识要点,请各位考生了解。...
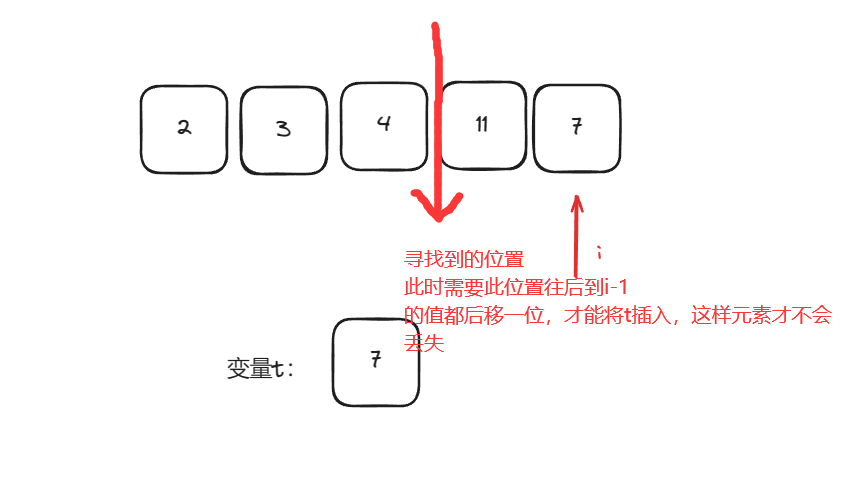
【排序】详解插入排序
一、思想 插入排序是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。具体步骤如下,将数组下标为0的元素视为已经排序的部分,从1开始遍历数组,在遍历的过程中当前元素从…...

Linux开发板移植rz、sz指令实现串口传输文件
一、开发环境 实现开发板和电脑通过串口来收发互传文件。 开发板:NUC980开发板 环境:Ubuntu 22.04.3 LTS 64-bit lrzsz的源码包:例如 lrzsz-0.12.20.tar.gz,下载地址https://ohse.de/uwe/software/lrzsz.html 二、移植步骤 在开发板上移植…...

Android抓包--不走代理的请求Proxy.NO_PROXY,过代理检测,burpsuite+Postern
网上很多不走代理检测的抓包都是charles + Postern 或 charles + Postern + burpsuite,本文使用burpsuite+Postern。 使用无代理 Proxy.NO_PROXY 访问网络接口原理 在Android开发中,大部分的App的网络请求都是基于charles 和 fiddler 来进行抓包的,对网络客户端使用无代理模…...

SQL教学: MySQL进阶操作详解--探索DML语句的高级用法
欢迎回到我们的SQL-DML语句教学系列。在之前的文章中,我们已经学习了如何使用DDL语句来定义和修改数据库的结构,以及如何使用DML语句进行基本的“增删改查”操作。今天,我们将进一步提升技能,探讨DML语句的高级用法,包…...
JavaScript命名标识符规范,JavaScript的for循环与双重for循环
一个合格的前端需要 戳这里领取完整开源项目:【一线大厂前端面试题解析核心总结学习笔记Web真实项目实战最新讲解视频】 哪些能力? 1、三大基础技能,js、css、html这三项技能是前端工程师能力中的基础,任何框架、工具、库都是基于…...
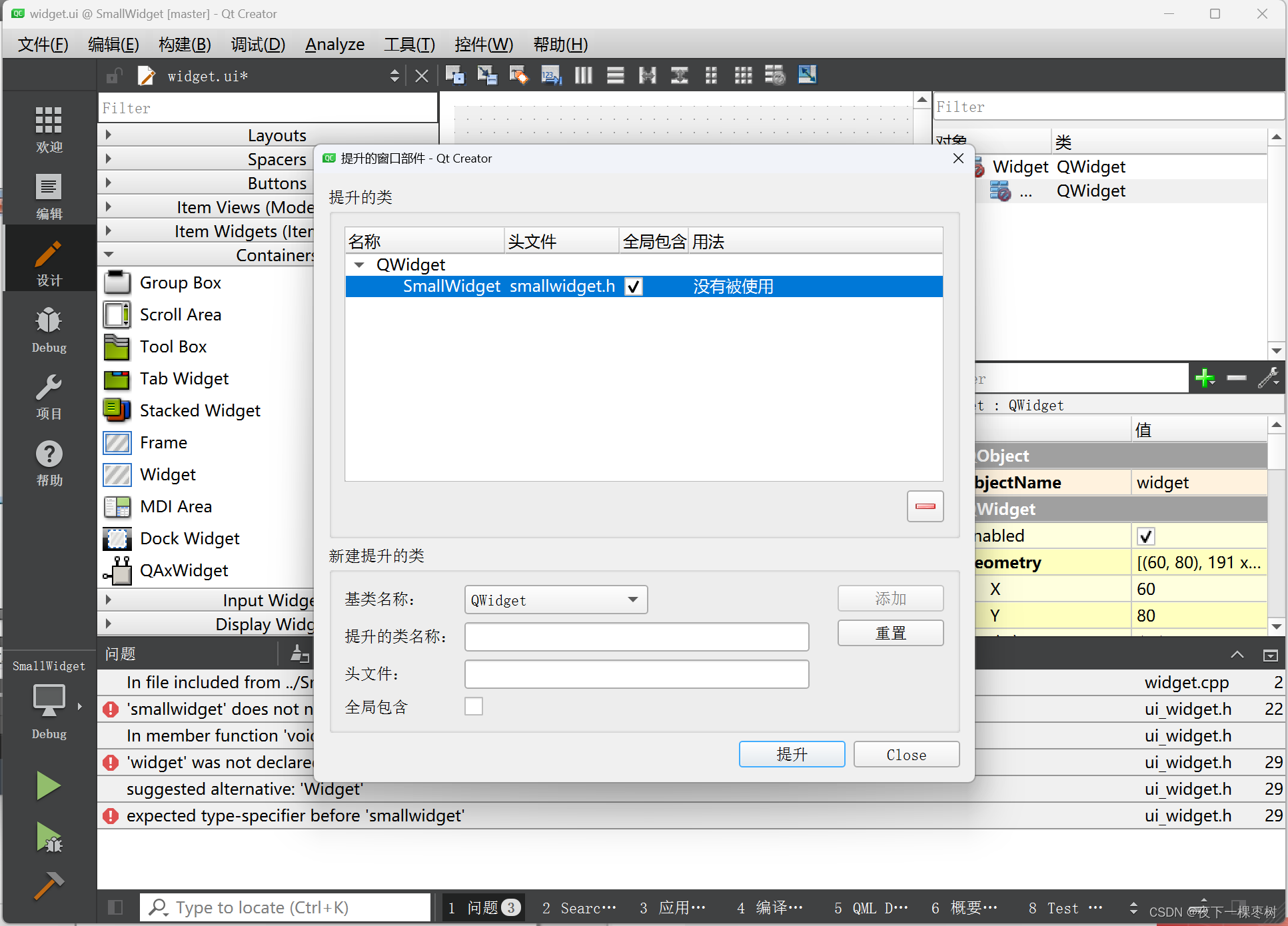
Qt/自定义控件的封装
新建文件,选择Qt设计师界面类 创建空界面 这是自己控件封装的文件,双击跳转到设计界面进行设计 跳转到其他的ui界面,创建一个widget 右键,选择提升为 在提升的类名称输入刚刚创建的类名,添加后选择提升,勾选…...

2026,AI Agent 真的开始上班了——从 MCP 协议到生产部署,一份踩坑实录
爆款标题备选2026 年,我司来了一个 AI 同事——Agent 落地实录MCP 协议 LangChain Dify:把 AI Agent 塞进生产环境的正确姿势BBC 报道了三个中国人的 AI 恐惧,但我想说点不一样的AI Agent 从 Demo 到生产,中间隔着一个 MCP 协议…...

LDAP查询服务延时查询及问题排查处理
文章目录一、使用服务器管理器管理本地和远程服务器二、LDAP查询用时三、LDAP查询高延迟排查步骤推荐阅读一、使用服务器管理器管理本地和远程服务器 默认情况下,服务器管理器包含在 Windows Server 中,无需单独安装。 在以下步骤中,将使用服…...

【Java入门|集合全解析:List、Set与Map详解】
Java集合Java集合分为单列集合和双列集合,也就是 Collection 和 Map 。顾名思义, Collection 一个位置上仅存放一个元素; Map 一个位置上有两个元素(分为键和值)。 Map 和 Collection 下又分别衍生出多种集合种类&…...

别再为EDFA仿真报错发愁了!手把手教你用OptiSystem搞定‘Initial Delay’和‘Iterations’设置
光通信仿真实战:EDFA参数调优与收敛问题深度解析 第一次打开OptiSystem完成EDFA仿真时,看到红色报错提示框弹出那种手足无措的感觉,相信很多工程师都记忆犹新。不同于简单的单向光路设计,掺铒光纤放大器(EDFAÿ…...

UVM寄存器模型简化实践:提升芯片验证效率的封装与自动化方案
1. 项目概述:为什么我们需要简化UVM寄存器模型?如果你在芯片验证领域摸爬滚打过几年,尤其是深度参与过SoC或复杂IP的验证,那么对UVM寄存器模型(UVM Register Model)一定是又爱又恨。爱的是,它提…...

Vibe Coding 灾难的爆发
AI 编程工具确实正在颠覆软件行业,但几乎比我所见过的任何事物都更属于那个"如果没有丰富的前期经验,你不应该在家尝试"的类别: Reddit 上 vibe coding 灾难故事堆积如山。除非你介入并为 AI 建立结构,否则它就会推送垃…...

魔,法变,声器,低延迟高保真设计,让语音聊天与直播互动更具趣味性与辨识度
获取连接: 魔法变声器https://pan.quark.cn/s/77bfbefc8233 魔,法变,声器是一款专为移动端语音交互设计的实时音频处理工具。 它针对游戏开黑与社交场景进行了低延迟优化,能在不占用过多系统资源的前提下,将原始人声精准转换为目标音色&…...

实习前自我培训-Day3学习
Day3学习–MySQL 企业开发使用方式 使用命令mysql -hip地址 -P端口号 -uroot -p来连接远程的数据库 数据模型关系型数据库:建立在关系模型基础上,由多张相互连接的二维表组成的数据库特点:使用表存储数据,格式同意,便于…...

当 SpringBoot 请求踏上“七层之旅”:OSI 模型与你的每一行代码
你在 Controller 里写了一个 GetMapping,浏览器敲下回车,数据就回来了。 可你有没有想过,这短短几十毫秒里,你的数据经历了多少次“变装”和“安检”? 从 HTTP 报文到 TCP 段,再到 IP 包、以太网帧——每一…...

pixi-editor
npm: zouchengxin/pixi-editor 在线地址:pixi-editor.pages.dev 还在为PixiJS缺少可视化编辑器而烦恼?试试 zouchengxin/pixi-editor! 基于 PixiJS 构建的无限画布组件,支持画布平移、缩放,以及元素的拖动、旋转、缩…...