Java中使用Jsoup实现网页内容爬取与Html内容解析并使用EasyExcel实现导出为Excel文件
场景
Pythont通过request以及BeautifulSoup爬取几千条情话:
Pythont通过request以及BeautifulSoup爬取几千条情话_爬取情话-CSDN博客
Node-RED中使用html节点爬取HTML网页资料之爬取Node-RED的最新版本:
Node-RED中使用html节点爬取HTML网页资料之爬取Node-RED的最新版本_node-red html-CSDN博客
Jsoup
Jsoup是一种Java 的HTML(html也是XML文档)解析器,可直接解析某个URL地址、HTML文本内容。
它提供了一套易于操作的API,可通过DOM,CSS以及类似于jQuery选择器的操作方法来取出和操作数据。
使用jsoup就可以解析HTML。
Jsoup使用的是DOM解析方式,把整个HTML文档(XML文档)加载到内存中形成一棵DOM树,得到文档的Document对象。
HTML里的标签,会转换成Element对象。
官网地址:
jsoup: Java HTML parser, built for HTML editing, cleaning, scraping, and XSS safety
EasyExcel
Java解析、生成Excel比较有名的框架有Apache poi、jxl。但他们都存在一个严重的问题就是非常的耗内存,
poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,
比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。
easyexcel重写了poi对07版Excel的解析,一个3M的excel用POI sax解析依然需要100M左右内存,
改用easyexcel可以降低到几M,并且再大的excel也不会出现内存溢出;03版依赖POI的sax模式,
在上层做了模型转换的封装,让使用者更加简单方便。
官网地址:
关于Easyexcel | Easy Excel
注:
博客:
https://blog.csdn.net/badao_liumang_qizhi
实现
1、引入依赖
<!--Jsoup 是一个用于解析HTML和XML文档的Java库--><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.3</version></dependency><!--EasyExcel是一个基于Java的、快速、简洁、解决大文件内存溢出的Excel处理工具--><dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>3.0.5</version></dependency>2、找到需要爬取的网页内容
比如以下面为例
2023财富世界500强企业榜单 2023全球500强企业 世界500强排名一览表→买购网
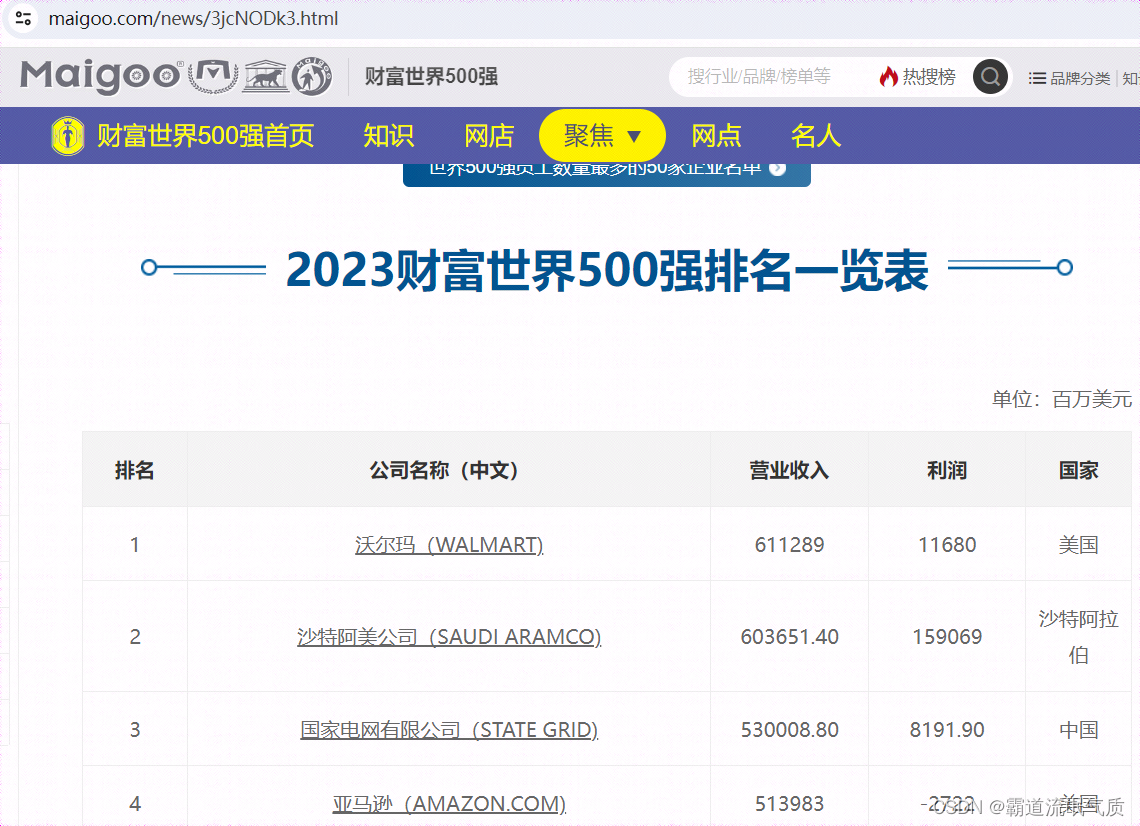
这里要获取500强排名数据,因为单次刷新网页只能返回100条数据,所以只解析前100条。获取更多数据可根据其分页请求规则分别进行爬取。
打开F12找到要爬取的数据的dom结构
这里要获取到id为t_container的div元素大的第22个子元素(索引为21)的table元素的tr元素的td数据。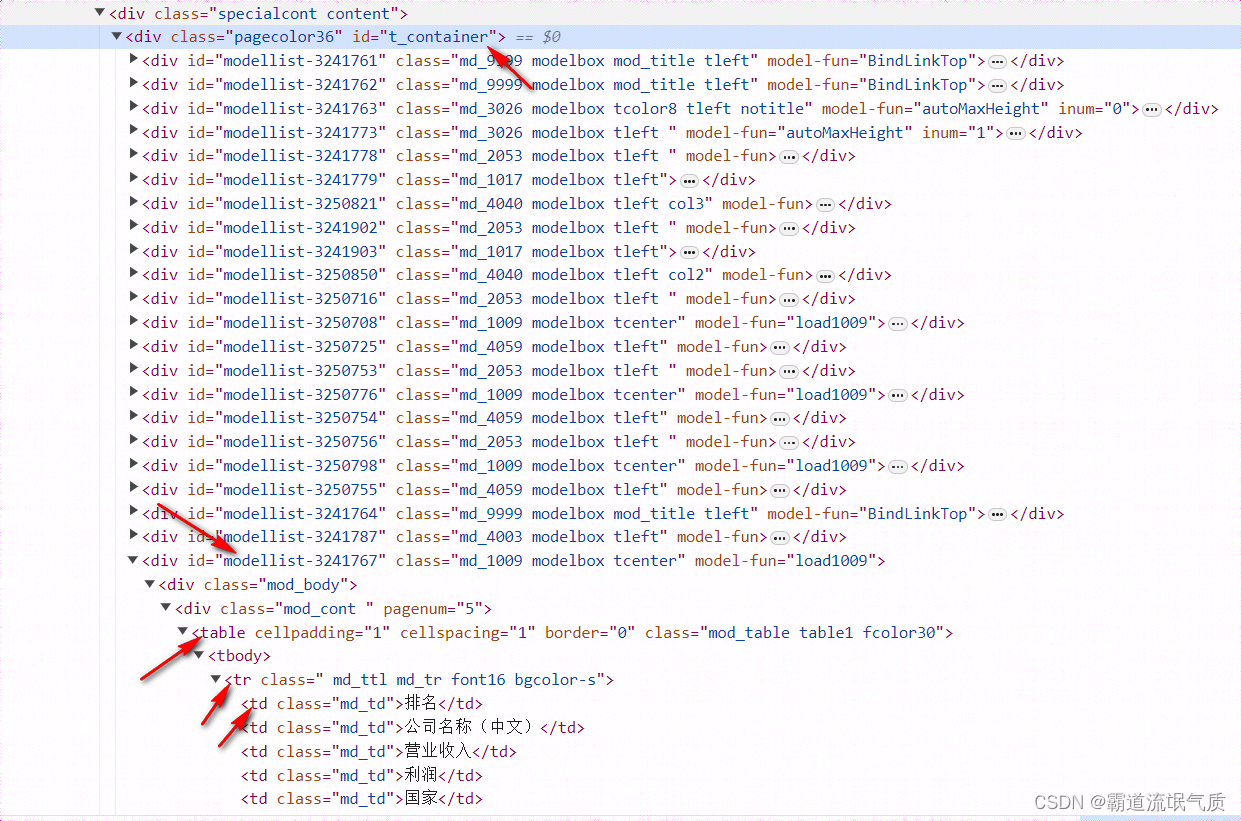
3、编写测试代码,连接并解析html元素
String url = "https://www.maigoo.com/news/3jcNODk3.html";try {//读取url,得到DocumentDocument document = Jsoup.connect(url).ignoreContentType(true).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3").timeout(30000).header("referer","https://www.maigoo.com").get();Elements select = document.select("#t_container > div:eq(21) table tr");} catch (IOException e) {e.printStackTrace();}注意这里使用选择器的语法:
#t_container 代表id为t_container
>代表找父元素下的子元素
div:eq(21) 代表第22个元素
table tr 代表table 标签下tr标签
更多select选择器用法
Use CSS selectors to find elements: jsoup Java HTML parser
Selector overview
tagname: find elements by tag, e.g.div#id: find elements by ID, e.g.#logo.class: find elements by class name, e.g..masthead[attribute]: elements with attribute, e.g.[href][^attrPrefix]: elements with an attribute name prefix, e.g.[^data-]finds elements with HTML5 dataset attributes[attr=value]: elements with attribute value, e.g.[width=500](also quotable, like[data-name='launch sequence'])[attr^=value],[attr$=value],[attr*=value]: elements with attributes that start with, end with, or contain the value, e.g.[href*=/path/][attr~=regex]: elements with attribute values that match the regular expression; e.g.img[src~=(?i)\.(png|jpe?g)]*: all elements, e.g.*ns|tag: find elements by tag in a namespace prefix, e.g.fb|namefinds<fb:name>elements*|tag: final elements by tag in any namespace prefix, e.g.*|namefinds<fb:name>and<name>elements
Selector combinations
el#id: elements with ID, e.g.div#logoel.class: elements with class, e.g.div.mastheadel[attr]: elements with attribute, e.g.a[href]- Any combination, e.g.
a[href].highlight ancestor child: child elements that descend from ancestor, e.g..body pfindspelements anywhere under a block with class "body"parent > child: child elements that descend directly from parent, e.g.div.content > pfindspelements; andbody > *finds the direct children of the body tagsiblingA + siblingB: finds sibling B element immediately preceded by sibling A, e.g.div.head + divsiblingA ~ siblingX: finds sibling X element preceded by sibling A, e.g.h1 ~ pel, el, el: group multiple selectors, find unique elements that match any of the selectors; e.g.div.masthead, div.logo
Pseudo selectors
:has(selector): find elements that contain elements matching the selector; e.g.div:has(p):is(selector): find elements that match any of the selectors in the selector list; e.g.:is(h1, h2, h3, h4, h5, h6)finds any heading element:not(selector): find elements that do not match the selector; e.g.div:not(.logo):contains(text): find elements that contain the given text. The search is case-insensitive; e.g.p:contains(jsoup):containsOwn(text): find elements that directly contain the given text:matches(regex): find elements whose text matches the specified regular expression; e.g.div:matches((?i)login):matchesOwn(regex): find elements whose own text matches the specified regular expression:lt(n): find elements whose sibling index (i.e. its position in the DOM tree relative to its parent) is less thann; e.g.td:lt(3):gt(n): find elements whose sibling index is greater thann; e.g.div p:gt(2):eq(n): find elements whose sibling index is equal ton; e.g.form input:eq(1)- Note that the above indexed pseudo-selectors are 0-based, that is, the first element is at index 0, the second at 1, etc
除使用select选择器之外还可使用XPath选择器用法
Use XPath selectors to find elements and nodes: jsoup Java HTML parser
4、解析dom数据并赋值到对象添加到list
新建实体对象,并添加excel注解
import com.alibaba.excel.annotation.ExcelProperty;
import lombok.Builder;
import lombok.Data;import java.io.Serializable;@Data
@Builder
public class WealthEntity implements Serializable {private static final long serialVersionUID = -1760099890427975758L;@ExcelProperty(value = "排名",index = 0)private Integer index;@ExcelProperty(value = "公司名称",index = 1)private String companyName;@ExcelProperty(value = "收入",index = 2)private String income;@ExcelProperty(value = "利润",index = 3)private String profit;}进行dom解析和添加到list
Elements select = document.select("#t_container > div:eq(21) table tr");List<WealthEntity> list = new ArrayList<>();for (int i = 1; i < select.size(); i++) {Element tr = select.get(i);Elements tds = tr.select("td");Integer index = Integer.valueOf(tds.get(0).text());String companyName = tds.get(1).text();String income = tds.get(2).text();String profit = tds.get(3).text();WealthEntity wealthEntity = WealthEntity.builder().index(index).companyName(companyName).income(income).profit(profit).build();list.add(wealthEntity);}5、导出为excel
String fileName = "D:/2023财富世界100强.xlsx";EasyExcel.write(fileName,WealthEntity.class).sheet("100强").doWrite(list);6、完整示例代码
String url = "https://www.maigoo.com/news/3jcNODk3.html";try {//读取url,得到DocumentDocument document = Jsoup.connect(url).ignoreContentType(true).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3").timeout(30000).header("referer","https://www.maigoo.com").get();Elements select = document.select("#t_container > div:eq(21) table tr");List<WealthEntity> list = new ArrayList<>();for (int i = 1; i < select.size(); i++) {Element tr = select.get(i);Elements tds = tr.select("td");Integer index = Integer.valueOf(tds.get(0).text());String companyName = tds.get(1).text();String income = tds.get(2).text();String profit = tds.get(3).text();WealthEntity wealthEntity = WealthEntity.builder().index(index).companyName(companyName).income(income).profit(profit).build();list.add(wealthEntity);}String fileName = "D:/2023财富世界100强.xlsx";EasyExcel.write(fileName,WealthEntity.class).sheet("100强").doWrite(list);} catch (IOException e) {e.printStackTrace();}7、运行结果
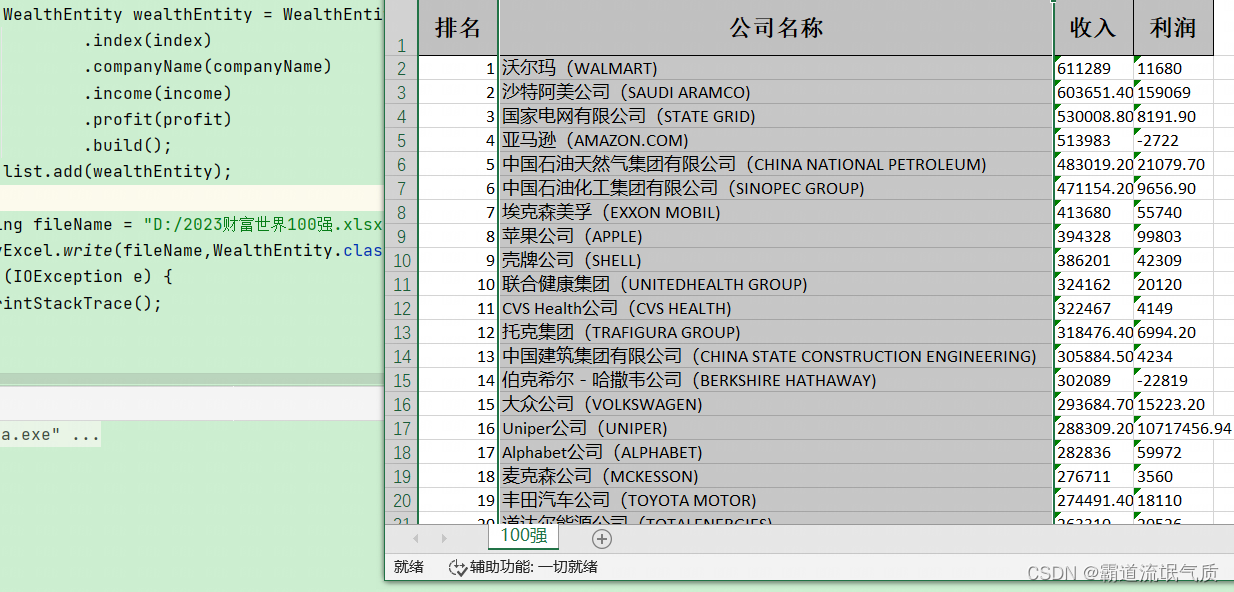
相关文章:
Java中使用Jsoup实现网页内容爬取与Html内容解析并使用EasyExcel实现导出为Excel文件
场景 Pythont通过request以及BeautifulSoup爬取几千条情话: Pythont通过request以及BeautifulSoup爬取几千条情话_爬取情话-CSDN博客 Node-RED中使用html节点爬取HTML网页资料之爬取Node-RED的最新版本: Node-RED中使用html节点爬取HTML网页资料之爬…...

闫震海:腾讯音乐空间音频技术的发展和应用 | 演讲嘉宾公布
一、3D 音频 3D 音频分论坛将于3月27日同期举办! 3D音频技术不仅能够提供更加真实、沉浸的虚拟世界体验,跨越时空的限制,探索未知的世界。同时,提供更加丰富、立体的情感表达和交流方式,让人类能够更加深入地理解彼此&…...

Java基础 - 6 - 面向对象(二)
Java基础 - 6 - 面向对象(一)-CSDN博客 二. 面向对象高级 2.1 static static叫做静态,可以修饰成员变量、成员方法 2.1.1 static修饰成员变量 成员变量按照有无static修饰,分为两种:类变量、实例变量(对象…...
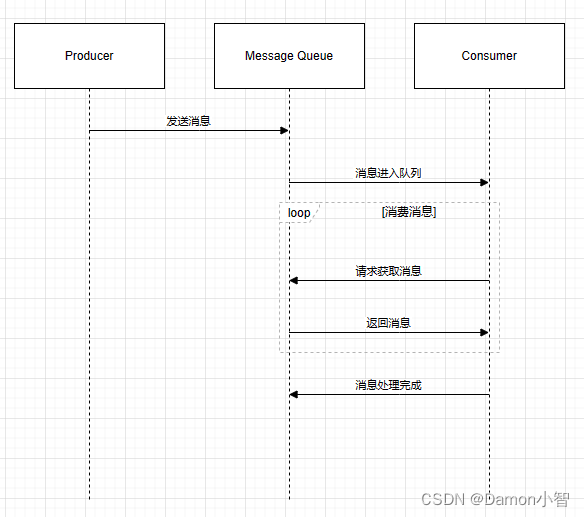
SpringCloud-MQ消息队列
一、消息队列介绍 MQ (MessageQueue) ,中文是消息队列,字面来看就是存放消息的队列。也就是事件驱动架构中的Broker。消息队列是一种基于生产者-消费者模型的通信方式,通过在消息队列中存放和传递消息,实现了不同组件、服务或系统…...
代码随想录算法训练营第三十八天|509. 斐波那契数、70. 爬楼梯、746. 使用最小花费爬楼梯
509. 斐波那契数 刷题https://leetcode.cn/problems/fibonacci-number/description/文章讲解https://programmercarl.com/0509.%E6%96%90%E6%B3%A2%E9%82%A3%E5%A5%91%E6%95%B0.html#%E7%AE%97%E6%B3%95%E5%85%AC%E5%BC%80%E8%AF%BE视频讲解https://www.bilibili.com/video/BV…...

[python] 代码工具箱
在 Python 3 的开发过程中,有一些小而实用的工具包可以帮助减轻开发负担,提升工作效率。这些工具包通常专注于解决特定问题或提供特定功能,使代码更简洁和可维护。以下是一些常用的工具包,可以简化开发过程: backoff&a…...
Linux——网络基础
计算机网络背景 网络发展 独立模式: 计算机之间相互独立 在早期的时候,计算机之间是相互独立的,此时如果多个计算机要协同完成某种业务,那么就只能等一台计算机处理完后再将数据传递给下一台计算机,然后下一台计算机再进行相应…...

Vue:双token无感刷新
文章目录 初次授权与发放Token:Access Token的作用:Refresh Token的作用:无感刷新:安全机制:后端创建nest项目AppController 添加login、refresh、getinfo接口创建user.dto.tsAppController添加模拟数据 前端Hbuilder创…...

实现一个作用域插槽的场景
vue项目中,插槽slot有三种分别是:默认插槽、具名插槽、作用域插槽。默认插槽和具名插槽在平时的开发中用的比较多,作用域插槽用的相对较少,以前我对作用域插槽不是很理解,现在理解了一下。下面通过代码来实现一个作用域…...

Qt QPainter的使用方法
重点: 1.QPainter在QWidget窗口的paintEvent中使用。 2.QPainter通常涉及到设置画笔、设置画刷、绘图(QPen、QBrush、drawxx)三个流程。 class Widget : public QWidget {Q_OBJECTprotected:void paintEvent(QPaintEvent *event) Q_DEC…...

低代码:数智化助力新农业发展
随着科技的飞速发展和数字化转型的深入推进,低代码开发平台正逐渐成为软件开发的热门话题。尤其在农业领域,低代码技术为传统农业注入了新的活力,助力新农业实现高效、智能的发展。 低代码开发平台的概念与特点 随着科技的飞速发展࿰…...

3d模型怎么镜像?3d模型镜像的步骤---模大狮模型网
在3D建模软件中,对3D模型进行镜像操作通常是指沿着某个轴线(如X、Y、Z轴)进行镜像翻转,使模型在该轴线的一侧产生对称的镜像效果。以下是在常见的3D建模软件中对3D模型进行镜像的一般步骤: 3d模型镜像步骤: 选择模型:…...
笔记本hp6930p安装Android-x86补记
在上一篇日记中(笔记本hp6930p安装Android-x86避坑日记-CSDN博客)提到hp6930p安装Android-x86-9.0,无法正常启动,本文对此再做尝试,原因是:Android-x86-9.0不支持无线网卡,需要在BIOS中关闭WLAN…...

为什么MySQL中多表联查效率低,连接查询实现的原理是什么?
MySQL中多表联查效率低的原因主要涉及到以下几个方面: 数据量大: 当多个表通过连接查询时,如果这些表的数据量很大,那么查询就需要处理更多的数据,这自然会降低查询效率。 连接操作复杂性: 连接查询需要对参与连接的每个表中的数…...

从下一代车规MCU厘清存储器的发展(2)
目录 1.概述 2.MCU大厂的选择 2.1 瑞萨自研STT-MRAM 2.2 ST专注PCM 2.3 英飞凌和台积电联手RRAM 2.4 NXP如何计划eNVM 3.小结 1.概述 上篇文章,我们简述了当前主流的存储器技术,现在我们来讲讲各大MCU大厂的技术选择 2.MCU大厂的选择 瑞萨日…...
)
Redis(理论版)
Redis 1.Redis是什么 Redis其实就是一个数据库,它是一个文档型数据库(非关系型数据库),而mysql是一个关系型数据库。它是一个开源的、基于内存的高性能键值存储数据库,支持多种数据结构,广泛用于缓存、消息队列、应用…...
【NR 定位】3GPP NR Positioning 5G定位标准解读(四)
目录 前言 6 Signalling protocols and interfaces 6.1 支持定位操作的网络接口 6.1.1 通用LCS控制平面架构 6.1.2 NR-Uu接口 6.1.3 LTE-Uu接口 6.1.4 NG-C接口 6.1.5 NL1接口 6.1.6 F1接口 6.1.7 NR PC5接口 6.2 终端协议 6.2.1 LTE定位协议(LPP&#x…...

Docker容器化解决方案
什么是Docker? Docker是一个构建在LXC之上,基于进程容器的轻量级VM解决方案,实现了一种应用程序级别的资源隔离及配额。Docker起源于PaaS提供商dotCloud 基于go语言开发,遵从Apache2.0开源协议。 Docker 自开源后受到广泛的关注和…...

Docker安装+基础命令
一、检测、配置安装环境 (1)查看linux版本,是否符合>centos 7 (2)查看网络是否通畅 (3)安装gcc,gcc-c编译器 (4)安装device-mapper-persistent-data和lvm2…...
构建高性能Linux Virtual Server(LVS)集群
目录 引言 一、集群的基本理论 (一)什么是集群 (二)集群的分类 (三)LB Cluster 负载均衡集群 1.按实现方式划分 2.按协议层划分 (四)HA 高可用集群实现 二、LVS简介 &…...

5分钟快速上手WuWa-Mod:解锁《鸣潮》游戏无限潜能的终极指南
5分钟快速上手WuWa-Mod:解锁《鸣潮》游戏无限潜能的终极指南 【免费下载链接】wuwa-mod Wuthering Waves pak mods 项目地址: https://gitcode.com/GitHub_Trending/wu/wuwa-mod 还在为《鸣潮》游戏中的技能冷却时间烦恼吗?想要体验无限体力、自动…...

用Rsoft DiffractionMOD给光伏减反膜‘算个命’:手把手教你仿真矩形光栅的反射谱
用Rsoft DiffractionMOD给光伏减反膜‘算个命’:手把手教你仿真矩形光栅的反射谱 在光伏组件研发中,减反射膜的性能直接影响着光电转换效率。传统试错法需要反复镀膜测试,成本高周期长。本文将演示如何通过Rsoft DiffractionMOD模块ÿ…...

从算法理想向工程现实的跨越:SLAM 核心架构、思维误区与 Nav2 实战避坑指南
前言:直面 SLAM 的“先有鸡还是先有蛋” 在机器人领域,SLAM(Simultaneous Localization and Mapping,同时定位与地图构建) 毫无疑问是最耀眼的明珠之一。简单来说,它的核心任务就是让一个机器人在未知环境中…...

终极解决方案:如何一次性安装所有Visual C++运行库合集
终极解决方案:如何一次性安装所有Visual C运行库合集 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 还在为Windows系统频繁弹出"缺少MSVCP140.…...

Diablo Edit2完全指南:暗黑破坏神2存档修改器终极使用教程
Diablo Edit2完全指南:暗黑破坏神2存档修改器终极使用教程 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾经在暗黑破坏神2中花费数小时刷装备却一无所获?或者想要…...

一键永久保存:B站缓存视频转换终极方案,让珍贵内容不再消失
一键永久保存:B站缓存视频转换终极方案,让珍贵内容不再消失 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾有过…...
)
WebSocket 库存实时监控实战(Java 服务端 + 前端)
目录 一、技术选型 二、搭建 Spring Boot 服务端 1. 创建项目 & 引入依赖 2. WebSocket 配置类 3. 库存实体类(库存 预警规则) 4. WebSocket 服务端核心代码 5. 提供接口:手动修改库存并推送 6. 启动类 三、前端页面࿰…...

暗黑3终极宏工具D3KeyHelper:5分钟配置你的自动战斗系统
暗黑3终极宏工具D3KeyHelper:5分钟配置你的自动战斗系统 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神…...
)
ESP8266透传总失败?手把手教你用Arduino IDE和串口助手搞定Blinker配网(避坑大全)
ESP8266透传配置终极指南:从AT指令到Blinker配网全解析 物联网开发者们,是否曾被ESP8266模块的透传配置折磨得焦头烂额?当你在深夜调试AT指令却只收到一堆乱码时,那种挫败感我深有体会。本文将带你彻底攻克这个物联网入门的第一道…...

量子计算中数据驱动的哈密顿修正方法研究
1. 量子门控中的哈密顿修正挑战在量子计算领域,超导transmon比特因其相对较长的相干时间和可扩展性,成为当前最有前景的量子处理器实现方案之一。然而,实际硬件中存在的器件间差异和串扰效应,使得基于理论模型的脉冲设计与真实硬件…...