批量爬取网站图片脚本
不分文件夹
import requests
from bs4 import BeautifulSoup
import os
from concurrent.futures import ThreadPoolExecutordef download_image(img_url):# 检查图片后缀是否为.jpg或.jpegif img_url.lower().endswith(('.jpg', '.jpeg')):try:img_response = requests.get(img_url, stream=True)img_size = int(img_response.headers.get('content-length', 0))if img_size > 50 * 1024: # 大于50KBfilename = os.path.join(images_dir, img_url.split('/')[-1])with open(filename, 'wb') as f:for chunk in img_response.iter_content(1024):f.write(chunk)print(f"Downloaded {img_url}")except Exception as e:print(f"Error downloading {img_url}: {e}")else:print(f"Skipped {img_url} due to file extension")def download_images_from_page(url):page_response = requests.get(url)page_soup = BeautifulSoup(page_response.content, 'html.parser')images = page_soup.find_all('img')with ThreadPoolExecutor(max_workers=5) as executor: # 可以调整max_workers来改变线程数for img in images:img_url = img['src']executor.submit(download_image, img_url)def main(base_url, start_path):global images_dirimages_dir = 'images'if not os.path.exists(images_dir):os.makedirs(images_dir)start_url = f"{base_url}/{start_path}"response = requests.get(start_url)soup = BeautifulSoup(response.content, 'html.parser')links = soup.find_all('h3')for link in links:a_tag = link.find('a', href=True)if a_tag:full_url = f"{base_url}/{a_tag['href']}"download_images_from_page(full_url)# 示例中使用的基本URL和开始路径
base_url = 'http://xxxxxxx'
start_path = 'thread6.php?fid=15'if __name__ == "__main__":main(base_url, start_path)按文件夹分类
import requests
from bs4 import BeautifulSoup
import os
from concurrent.futures import ProcessPoolExecutor
import redef sanitize_folder_name(name):"""清理文件夹名称,移除或替换不合法的文件系统字符。"""return re.sub(r'[\\/*?:"<>|]', '_', name)def download_image(data):img_url, filename_prefix = dataif img_url.lower().endswith(('.jpg', '.jpeg')):try:img_response = requests.get(img_url, stream=True)img_size = int(img_response.headers.get('content-length', 0))if img_size > 20 * 1024: # 大于20KBfilename = f"{filename_prefix}.jpg"with open(filename, 'wb') as f:for chunk in img_response.iter_content(1024):f.write(chunk)print(f"Downloaded {filename}")except Exception as e:print(f"Error downloading {img_url}: {e}")else:print(f"Skipped {img_url} due to file extension")def download_images_from_page(url, base_dir):page_response = requests.get(url)page_soup = BeautifulSoup(page_response.content, 'html.parser')images = page_soup.find_all('img')img_data = []for i, img in enumerate(images):img_url = img['src']filename_prefix = os.path.join(base_dir, f"{i:04d}")img_data.append((img_url, filename_prefix))with ProcessPoolExecutor(max_workers=4) as executor: # 调整max_workers来改变进程数executor.map(download_image, img_data)def main(base_url, start_path):global images_dirimages_dir = 'images'if not os.path.exists(images_dir):os.makedirs(images_dir)start_url = f"{base_url}/{start_path}"response = requests.get(start_url)soup = BeautifulSoup(response.content, 'html.parser')links = soup.find_all('h3')for link_index, link in enumerate(links):a_tag = link.find('a', href=True)if a_tag:folder_name = sanitize_folder_name(a_tag.text.strip())full_url = f"{base_url}/{a_tag['href']}"page_dir = os.path.join(images_dir, folder_name)if not os.path.exists(page_dir):os.makedirs(page_dir)download_images_from_page(full_url, page_dir)# 示例中使用的基本URL和开始路径
base_url = 'http://xxx/pw'
start_path = 'thread1022.php?fid=15&page=3'if __name__ == "__main__":main(base_url, start_path)相关文章:

批量爬取网站图片脚本
不分文件夹 import requests from bs4 import BeautifulSoup import os from concurrent.futures import ThreadPoolExecutordef download_image(img_url):# 检查图片后缀是否为.jpg或.jpegif img_url.lower().endswith((.jpg, .jpeg)):try:img_response requests.get(img_ur…...

scrapy 爬虫:多线程爬取去微博热搜排行榜数据信息,进入详情页面拿取第一条微博信息,保存到本地text文件、保存到excel
如果想要保存到excel中可以看我的这个爬虫 使用Scrapy 框架开启多进程爬取贝壳网数据保存到excel文件中,包括分页数据、详情页数据,新手保护期快来看!!仅供学习参考,别乱搞_爬取贝壳成交数据c端用户登录-CSDN博客 最终…...

网络、UDP编程
1.网络协议模型: OSI协议模型 应用层 实际发送的数据 表示层 发送的数据是否加密 会话层 是否建立会话连接 传输层 数据传输的方式(数据报、流式) 网络层 …...
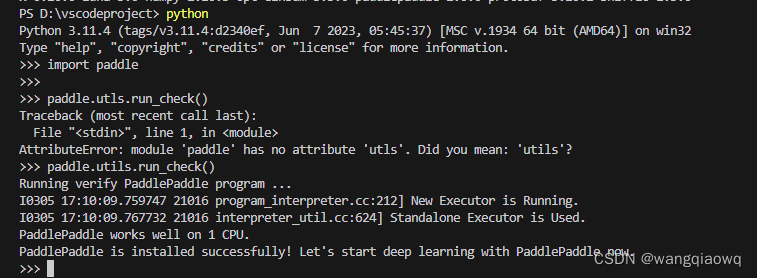
VSCode安装与使用
1、下载地址:Documentation for Visual Studio Code 在 VS Code 中使用 Python - 知乎 (zhihu.com) 自动补全和智能感知检测、调试和单元测试在Python环境(包括虚拟环境和 conda 环境)之间轻松切换 在 VS Code 中安装插件非常的简单,只需要打开 VS Code…...

进程和线程的区别与联系
进程和线程是计算机系统中两个重要的概念,它们在操作系统中扮演着不同的角色,并有着不同的特点和用途。以下是详细信息: 进程。进程是操作系统中资源分配的基本单位,它包括程序、数据和进程控制块。每个进程都有自己的地址空间&a…...

6、Redis-KV设计、全局命令和安全性
目录 一、value设计 二、Key设计 三、全局命令——针对所有key 四、安全性 一、value设计 ①是否需要排序?需要:Zset ②需要缓存的数据是单个值还是多个值? 单个值:简单值---String;对象值---Hash多个值&#x…...

python之海龟绘图
海龟绘图(turtle)是一个Python内置的绘图库,也被称为“Turtle Graphics”或简称“Turtles”。它采用了一种有趣的绘图方式,模拟一只小海龟在屏幕上爬行,而小海龟爬行的路径就形成了绘制的图形。这种绘图方式最初源自20…...

Java实战:Spring Boot 实现异步记录复杂日志
日志记录是软件开发中非常重要的一环,它可以帮助我们快速定位问题、监控程序运行状态等。在 Spring Boot 应用中,异步记录日志是一种常见的需求。本文将详细介绍如何在 Spring Boot 中实现异步记录复杂日志,包括异步日志的基本原理、实现方式…...

“色狼”用英语怎么说?柯桥日常英语,成人英语口语学习
最近有粉丝问我"色狼"英文翻译是啥 首先声明不是"colour wolf"哈 关于“色狼”的英文表达有很多 快和C姐一起来看看吧! 1.pervert 这个单词的意思是变态、色狼 是对性变态者最直观的描述 He is such a pervert! I saw him lo…...
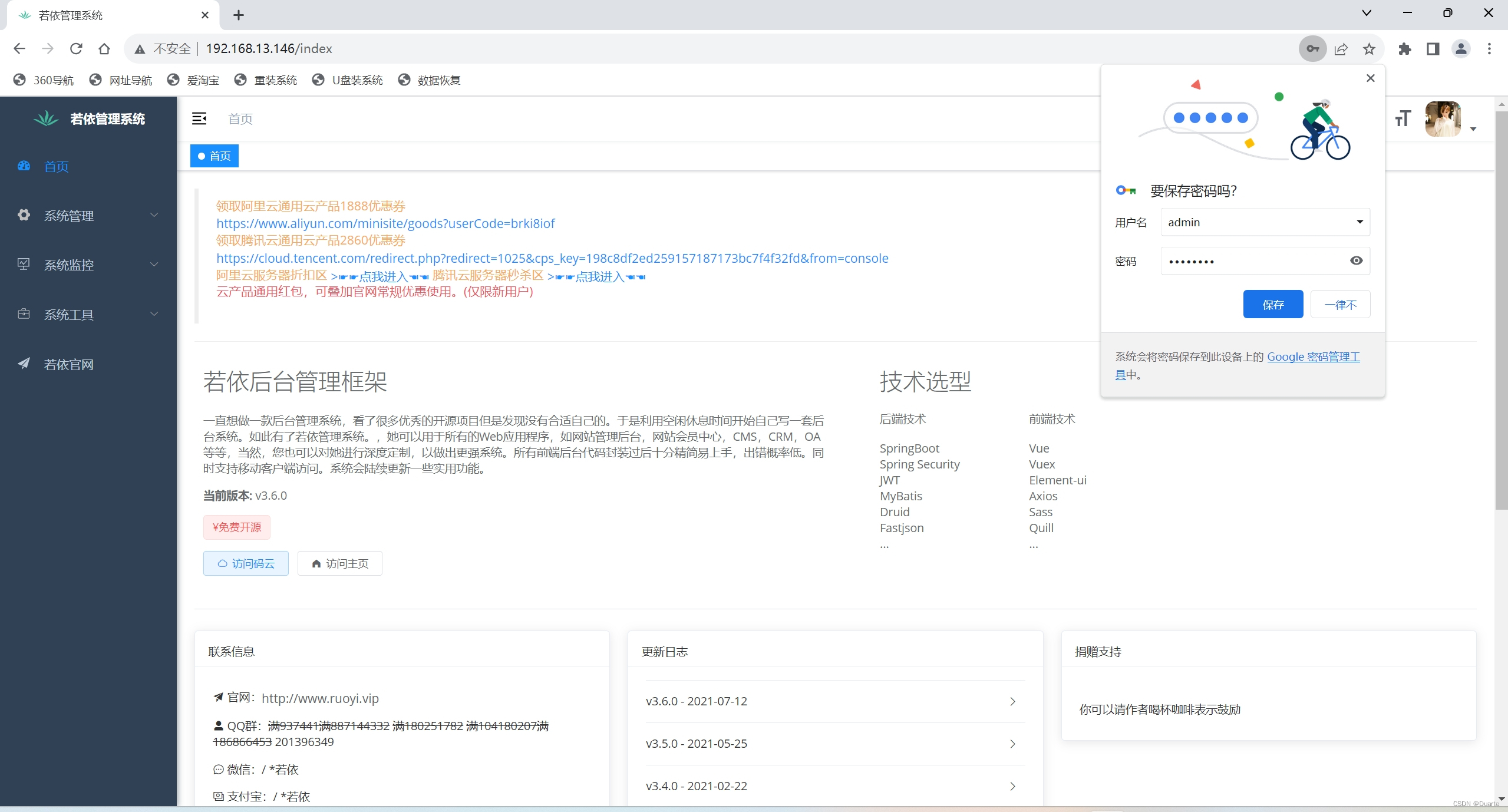
Docker前后端项目部署
目录 一、搭建项目部署的局域网 二、redis安装 三、MySQL安装 四、若依后端项目搭建 4.1 使用Dockerfile自定义镜像 五、若依前端项目搭建 一、介绍前后端项目 一张图带你看懂ruoyi的前后端项目部署 得出结论:需要4台服务器,都处于同一个局域网中…...

如何快速的搭建一个小程序
要快速搭建一个小程序,你可以按照以下步骤进行: 明确目标和需求:在开始搭建小程序之前,首先明确你的小程序的主要功能、目标用户以及希望实现的业务需求。这将帮助你更好地规划和设计小程序。选择小程序平台:根据你的…...

STM32自学☞AD多通道
涉及到的硬件有:光敏传感器,热敏传感器,红外对射传感器,电位器 通过adc将他们采集的模拟信号转换为数值 ad.c文件 #include "stm32f10x.h" #include "stm32f10x_adc.h" #include "ad.h" #inc…...

微服务之商城系统
一、商城系统建立之前的一些配置 1、nacos Nacos是一个功能丰富的开源平台,用于配置管理、服务发现和注册、健康检查等,帮助构建和管理分布式系统。 在linux上安装nacos容器的命令: docker run --name nacos-standalone -e MODEstandalone …...

安卓玩机工具推荐----高通芯片9008端口读写分区 备份分区 恢复分区 制作线刷包 工具操作解析
上期解析了下adb端口备份分区的有关操作 安卓玩机工具推荐----ADB状态读写分区 备份分区 恢复分区 查看分区号 工具操作解析 在以往的博文中对于高通芯片机型的分区读写已经分享了很多。相关类似博文 安卓备份分区----手动查询安卓系统分区信息 导出系统分区的一些基本操作 …...

全量知识系统问题及SmartChat给出的答复 之16 币圈生态链和行为模式
Q.42 币圈生态链和行为模式 我认为,上面和“币”有关的一系列概念和技术,按设计模式的划分 ,整体应该都属于行为模式,而且应该囊括行为模式的所有各个方面。 而行为又可以按照三种不同的导向(以目的或用途为导向、过…...
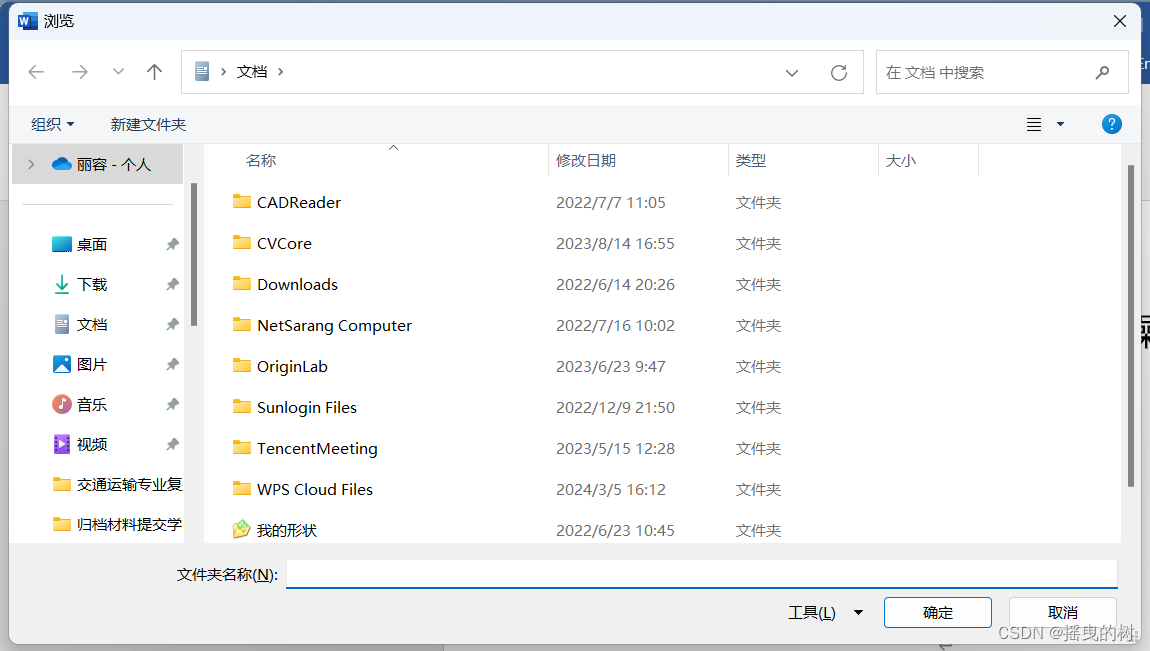
【MOMO_Tips】批量将word转换为PDF格式
批量将word转换为PDF格式 1.打开文件–>选项–>自定义功能区–>开发工具–>确定 2.点开开发工具,选择第一个visual basic 3.进入页面后找到插入–>模块,就可以看到这样的画面之后将下列vba代码复制粘贴到模块中 Sub ConvertWordsToPd…...
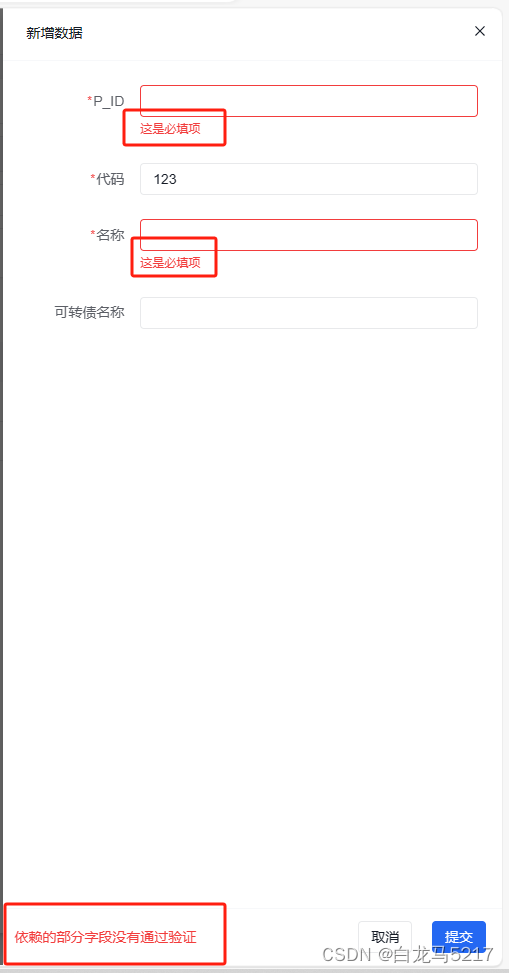
【JSON2WEB】08 Amis的事件和校验
【JSON2WEB】01 WEB管理信息系统架构设计 【JSON2WEB】02 JSON2WEB初步UI设计 【JSON2WEB】03 go的模板包html/template的使用 【JSON2WEB】04 amis低代码前端框架介绍 【JSON2WEB】05 前端开发三件套 HTML CSS JavaScript 速成 【JSON2WEB】06 JSON2WEB前端框架搭建 【J…...

抖店类目报白什么意思?什么类目需要报白?这次给你讲明白!
我是电商珠珠 不少新手在选择类目的时候,有些类目却无法选择,系统显示需要报白才可以。那什么是报白?怎么报白?今天我就一次性给你们讲清楚。 抖店类目报白什么意思? 根据官方的说法,报白就是针对一些比…...

<C++>【继承篇】
✨前言✨ 🎓作者:【 教主 】 📜文章推荐: ☕博主水平有限,如有错误,恳请斧正。 📌机会总是留给有准备的人,越努力,越幸运! 💦导航助手…...

size_t 和double相乘怎么转换size_t
在C中,size_t和double可以直接相乘,结果会自动转换为double类型。如果你想要得到的结果是size_t类型,你需要进行显式类型转换。但是要注意,double转size_t可能会丢失小数部分,只保留整数部分。 以下是一个例子&#x…...
打造丝滑下拉刷新(附Paging3联动实战))
告别传统SwipeRefreshLayout!用Compose的pullRefresh()打造丝滑下拉刷新(附Paging3联动实战)
用Compose的pullRefresh()重构Android下拉刷新体验:从基础封装到Paging3深度集成 下拉刷新作为移动端最基础的用户交互之一,在Jetpack Compose时代迎来了全新的设计范式。传统Android开发中,我们习惯使用SwipeRefreshLayout包裹RecyclerView的…...

破解“局部合格、整体偏差”困局:三维扫描如何实现精密机械零部件微米级精准检测?
汽车结构支撑件(如转向系统壳体、底盘集成支架)作为整车安全与操控性能的核心载体,承担着定位、承载、减振与部件集成的关键使命。其安装面平面度、关键孔位位置度与同轴度、复杂筋条轮廓度等精度指标,直接决定了转向系统的响应精…...
并优化代码)
别再为OpenMV串口传图卡顿发愁了!手把手教你选对硬件(STM32 SWD vs TTL)并优化代码
OpenMV串口传图性能优化实战:从硬件选型到代码调优 当你在实验室调试OpenMV串口传图项目时,是否经历过这样的场景:图像传输像老式拨号上网一样缓慢,帧率低得让人怀疑人生,调试界面卡成PPT?这背后往往隐藏着…...

GTA5线上小助手:5大核心功能让你的洛圣都冒险更轻松高效
GTA5线上小助手:5大核心功能让你的洛圣都冒险更轻松高效 【免费下载链接】GTA5OnlineTools GTA5线上小助手 项目地址: https://gitcode.com/gh_mirrors/gt/GTA5OnlineTools 还在为GTA5线上模式中繁琐的任务和漫长的游戏进程感到困扰吗?GTA5线上小…...

ansys网格的一阶和二阶什么区别?
一阶和二阶网格的核心区别在于单元内插值函数的阶次不同,导致精度与计算成本的差异。简单来说,一阶单元用直线描述变形,二阶单元用曲线描述,因此二阶更精确但更耗资源。 一阶网格(Linear Element) 节点分布:仅在单元角点设置节点,如六面体有8个节点(Solid185)。…...

如何快速掌握炉石传说游戏自动化:开源智能助手完整教程
如何快速掌握炉石传说游戏自动化:开源智能助手完整教程 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 你是否厌倦了每天重复的炉石传说日常…...

从隔壁实验室到网易食堂:一个非985研究生的Python爬虫实习转正全记录
从实验室到网易食堂:一位普通研究生的Python爬虫逆袭之路 记得第一次听说隔壁实验室的Lucky拿到网易实习offer时,我们整个实验室都沸腾了。不是因为网易有多难进——事实上每年都有名校生进入各大厂——而是因为Lucky和我们一样,来自一所普通…...

告别卡顿!用NoMachine在Win10上丝滑远程Ubuntu Gnome桌面的保姆级教程
告别卡顿!用NoMachine在Win10上丝滑远程Ubuntu Gnome桌面的保姆级教程 远程办公和跨平台协作已成为现代开发者的日常刚需。当你在咖啡馆用Windows笔记本调试云端Ubuntu服务器上的图形界面应用时,是否经历过VNC的模糊卡顿或RDP的兼容性问题?本…...
)
NotebookLM辅助文献综述全链路拆解(2024最新版:支持arXiv/DOI/中文知网多源解析)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM文献综述辅助的范式变革 NotebookLM 是 Google 推出的基于用户自有文档的 AI 助手,其核心能力在于对上传 PDF、TXT 等学术文献进行语义索引与上下文感知问答,彻底重构…...

[实践|鸿蒙] 从HAP到APP:DevEco Studio编译构建全流程实战解析
1. 鸿蒙应用构建基础:理解HAP与APP的关系 第一次接触鸿蒙应用开发时,我被HAP和APP这两个概念搞得有点懵。经过几个项目的实战,终于搞明白了它们的关系。简单来说,HAP(Harmony Ability Package)就像乐高积木…...