Go 简单设计和实现可扩展、高性能的泛型本地缓存
相信大家对于缓存这个词都不陌生,但凡追求高性能的业务场景,一般都会使用缓存,它可以提高数据的检索速度,减少数据库的压力。缓存大体分为两类:本地缓存和分布式缓存(如 Redis)。本地缓存适用于单机环境下,而分布式缓存适用于分布式环境下。在实际的业务场景中,这两种缓存方式常常被结合使用,以利用各自的优势,实现高性能的数据读取。本文将会探讨如何极简设计并实现一个可扩展、高性能的本地缓存。
设计总览
在设计一个本地缓存时,我们需要考虑以下几个关键方面:
- 并发安全 确保缓存的读写在多个
goroutine环境下是安全的。通常使用sync.Mutex或sync.RWMutex来避免竞态条件和数据不一致的问题。 - 淘汰策略 专注于当缓存空间有限时如何选择移除哪些数据。常见的淘汰策略包括 最近最少使用(
LRU)、最不经常使用(LFU)、先进先出(FIFO)等。 - 内存管理 合理管理内存的使用。例如通过限制缓存大小或实现内存淘汰机制,避免内存泄露和过度消耗。
- ······
除了上面列出的三项,在必要的情况下,我们可能还需要考虑其他方面,例如监控和日志、容错和恢复等。

本文将会讲解图中所给出的四个部分的设计:
Cache[K comparable, V any]:基于策略模式的灵活、可扩展和并发安全的缓存结构体设计。ICache[K comparable, V any]:缓存 API 接口,用于定义缓存API规范。SimpleCache[K comparable, V any]:基于简单map实现的缓存实例。LRUCache[K comparable, V any]:基于LRU淘汰算法实现的缓存实例。
ICache 接口
首先,定义一个 ICache 接口:
go
复制代码
// https://github.com/chenmingyong0423/go-generics-cache/blob/master/cache.go type ICache[K comparable, V any] interface { Set(ctx context.Context, key K, value V) error Get(ctx context.Context, key K) (V, error) Delete(ctx context.Context, key K) error Keys() []K }
该接口作为多种本地缓存实现的 API 标准,确保不同本地缓存的实现都有相同的基本操作。
Cache 适配器
go
复制代码
// https://github.com/chenmingyong0423/go-generics-cache/blob/master/cache.go type Cache[K comparable, V any] struct { cache ICache[K, *Item[V]] mutex sync.RWMutex janitor *janitor }
上述代码定义的 CacheK[comparable, V any] 结构体是一个基于泛型的缓存适配器实现,它不直接实现本地缓存的逻辑。Cache 结构体有三个字段:
1、cache ICache[K, *Item[V]]:
这是一个接口字段,用于抽象化底层的本地缓存操作。该接口定义了缓存的基本行为,如设置、获取和删除键值对。通过引入这个接口,Cache 结构体遵循了 依赖倒置原则 和 策略模式,使得可以根据具体需求灵活选择不同的缓存实现策略。
*Item[V] 是值的类型,这里使用了指针,指向一个 Item 结构,Item 结构体包含了实际的值和过期时间。
2、mutex sync.RWMutex:
读写互斥锁,用于避免并发读写时数据不一致性的问题。
3、janitor *janitor:
一个用于处理后台任务的结构体,例如定时清理过期数据,单独提出一个结构体是为了解耦。
Item 的设计
go
复制代码
// https://github.com/chenmingyong0423/go-generics-cache/blob/master/cache.go type ItemOption func(*itemOptions) type itemOptions struct { expiration time.Time } func WithExpiration(exp time.Duration) ItemOption { return func(o *itemOptions) { o.expiration = time.Now().Add(exp) } } type Item[V any] struct { value V expiration time.Time } func newItem[V any](value V, opts ...ItemOption) *Item[V] { var item = &itemOptions{} for _, opt := range opts { opt(item) } return &Item[V]{ value: value, expiration: item.expiration, } } func (i *Item[V]) Expired() bool { return !i.expiration.IsZero() && i.expiration.Before(time.Now()) }
Item 结构体作为本地缓存适配器 Cache 的 value 值的类型,它有两个字段和一个方法,分别是:
value:用于本地缓存对应key的value值。expiration:表示缓存值的过期时间。Expired:判断元素是否过期的方法。
为了方便创建并初始化 Item 元素,代码中实现了一个 newItem 函数,该函数除了接受 value 值以外,还接受一个或多个 ItemOption 类型的参数。这些参数是可选的,允许我们在创建 Item 实例时设置额外的属性。例如,可以通过 WithExpiration 函数选项来指定过期时间。
Item 这种设计方式使得元素支持 多种过期机制(固定时间过期和永久不过期的机制),同时提高了代码扩展性和灵活性。如果我们后续需要为 value 添加额外的属性,只需要往 Item 结构体新增字段即可,并且 newItem 方法,引入了函数选项模式,即使后面新增字段,这些字段可以作为可选参数初始化。例如支持 滑动过期时间。所有的新增操作都不会影响已有代码。
构造 Cache 的函数
go
复制代码
// https://github.com/chenmingyong0423/go-generics-cache/blob/master/cache.go // NewSimpleCache - 创建一个新的简单缓存。 // interval time.Duration - 清理过期缓存项的时间间隔。在这个间隔内,缓存将自动检查并清理过期项。 func NewSimpleCache[K comparable, V any](ctx context.Context, size int, interval time.Duration) *Cache[K, V] { cache := &Cache[K, V]{ cache: simple.NewCache[K, *Item[V]](size), janitor: newJanitor(ctx, interval), } cache.janitor.run(cache.DeleteExpired) return cache } // NewLruCache - 创建一个新的LRU缓存。 // interval time.Duration - 清理过期缓存项的时间间隔。在这个间隔内,缓存将自动检查并清理过期项。 func NewLruCache[K comparable, V any](ctx context.Context, cap int, interval time.Duration) *Cache[K, V] { cache := &Cache[K, V]{ cache: lru.NewCache[K, *Item[V]](cap), janitor: newJanitor(ctx, interval), } cache.janitor.run(cache.DeleteExpired) return cache }
上述代码段包含了两个构造函数,分别用于创建两种不同类型的本地缓存。以下是对这两个函数的详细说明:
1、NewSimpleCache 函数
这个函数用于创建一个简单缓存的实例。它接受以下参数:
ctx context.Context:上下文,用于管理缓存的生命周期和相关操作。size int:缓存的大小,可能表示缓存可以存储的最大项数。interval time.Duration:用于清理过期缓存项的时间间隔。在这个时间间隔内,缓存将自动检查并清理过期的项。
函数的实现逻辑如下:
- 创建一个
Cache[K, V]类型的实例。 - 使用
simple.NewCache[K, *Item[V]](size)创建一个简单缓存的底层实现,并将其赋值给Cache实例的cache字段。 - 使用
newJanitor(ctx, interval)创建一个清理过期项的janitor,并将其赋值给Cache实例的janitor字段。 - 通过
cache.janitor.run(cache.DeleteExpired)启动janitor,以定期运行DeleteExpired方法清理过期项。 - 返回创建的
Cache实例。
2、 NewLruCache 函数
这个函数用于创建一个基于最近最少使用(LRU)策略的缓存实例。它的参数与 NewSimpleCache 相同:
ctx context.Context:上下文,用于管理缓存的生命周期和相关操作。cap int:缓存的容量,指示缓存可以存储的最大项数。interval time.Duration:用于清理过期缓存项的时间间隔。
函数的实现逻辑类似于 NewSimpleCache,但它使用 lru.NewCache[K, *Item[V]](cap) 来创建一个基于 LRU 策略的底层缓存实现。
这两个函数提供了不同策略的本地缓存实现,分别适用于不同的应用场景。简单缓存可能适用于基本的缓存需求,而基于 LRU 的缓存更适合于需要淘汰老旧数据以节省空间的场景。通过这样的设计,使用者可以根据具体需求选择最适合的缓存策略。
下一个大章节的内容将详细介绍 simple 和 lru 这两种本地缓存的实现细节。
janitor 的设计
go
复制代码
// https://github.com/chenmingyong0423/go-generics-cache/blob/master/cache.go type janitor struct { ctx context.Context interval time.Duration done chan struct{} once sync.Once } func (j *janitor) stop() { j.once.Do(func() { close(j.done) }) } func (j *janitor) run(cleanup func(ctx context.Context)) { go func() { ticker := time.NewTicker(j.interval) defer ticker.Stop() for { select { case <-ticker.C: cleanup(j.ctx) case <-j.ctx.Done(): j.stop() case <-j.done: cleanup(j.ctx) return } } }() }
janitor 可以认为是一个处理后台任务的结构体,其作用是定时清理 本地缓存 的过期数据。
下面是对 janitor 结构体的字段和方法的具体解释:
ctx:context上下文,作用是控制run方法中的协程何时停止执行,也就是控制后台任务的停止执行。interval:时间间隔,指定清理操作的执行频率。done:一个通道(channel),用于发出停止信号。当通道被关闭时,意味着run方法中的写成停止执行,结束后台任务。once:一个sync.Once的实例,确保关闭done通道只执行一次。stop方法:用于停止janitor的运行,它利用sync.Once来确保关闭done通道的操作只执行一次,避免多次关闭通道导致的panic。关闭done通道将导致run方法中的协程停止执行。run方法:该方法接受一个 clean 清理函数,里面包含用户自定义的清理逻辑。run方法启动一个协程。在协程里,首先创建了一个定时器,用于控制任务的执行间隔时间;接着启动一个for循环,它使用select语句来监听多个通道:- 当
ticker.C通道接收到信号时(即每隔j.interval时间),调用cleanup函数执行清理操作。 - 当
j.ctx.Done()通道接收到信号时(即上下文被取消或超时),调用j.stop()方法来停止janitor。 - 当
j.done通道被关闭时(通过调用stop方法),执行最后一次清理操作然后退出协程。
- 当
方法详解
Get 方法
go
复制代码
// https://github.com/chenmingyong0423/go-generics-cache/blob/master/cache.go func (c *Cache[K, V]) Get(ctx context.Context, key K) (v V, err error) { c.mutex.RLock() defer c.mutex.RUnlock() item, err := c.cache.Get(ctx, key) if err != nil { return } if item.Expired() { return v, cacheError.ErrNoKey } return item.value, nil }
该方法的作用是通过指定的 key 获取对应的 value,核心逻辑:
- 加读锁:通过添加读锁,避免在读取数据时有更新或删除操作,导致数据不一致的问题。
- 判断元素是否过期:通过
Expired方法判断元素是否过期,成立则返回一个明确的错误error。 - 返回结果:返回所匹配到的
value值。
Set
go
复制代码
// https://github.com/chenmingyong0423/go-generics-cache/blob/master/cache.go func (c *Cache[K, V]) Set(ctx context.Context, key K, value V, opts ...ItemOption) (err error) { c.mutex.Lock() defer c.mutex.Unlock() item := newItem[V](value, opts...) return c.cache.Set(ctx, key, item) }
该方法用于将键值对 key-value 保存到本地缓存中。Set 方法除了接收 key 和 value 作为必要参数,还接受一个或多个 ItemOption 类型的参数作为可选配置。
核心逻辑:
- 加写锁:为了保证在写入数据时的协程安全性,
Set方法首先加上写锁。这样做可以防止在写操作进行时发生读操作,避免可能导致的数据不一致问题。 - 创建并初始化 Item:利用
newItem[V]函数创建一个Item实例,其中value是必传参数。此外,根据不同的使用场景,可以通过传递ItemOption类型的参数来初始化Item的可选配置,如设置过期时间等。 - 设置键值对:最后,通过
c.cache.Set调用底层的实现的方法将键值对保存到本地缓存中。 - 返回结果:返回
nil或可能的错误(如果写入过程中发生错误)。
SetNX
go
复制代码
// https://github.com/chenmingyong0423/go-generics-cache/blob/master/cache.go func (c *Cache[K, V]) SetNX(ctx context.Context, key K, value V, opts ...ItemOption) (b bool, err error) { c.mutex.Lock() defer c.mutex.Unlock() _, err = c.cache.Get(ctx, key) if err != nil { if errors.Is(err, cacheError.ErrNoKey) { item := newItem[V](value, opts...) return true, c.cache.Set(ctx, key, item) } return false, err } return false, nil }
该方法和 Set 方法功能相似,但它与 Set 方法的主要区别在于它不会覆盖已存在的键值对。
核心逻辑:
- 加写锁:为了保证在写入数据时的协程安全性,
SetNX方法首先加上写锁。这样做可以防止在写操作进行时发生读操作,避免可能导致的数据不一致问题。 - 检查键是否存在:首先尝试获取指定的
key。如果键不存在(识别为cacheError.ErrNoKey错误),则继续执行;如果获取过程中发生其他错误,方法将返回错误。 - 条件性写入:如果指定的键不存在于缓存中,
SetNX会利用newItem[V]函数创建一个新的Item实例,并将其与key一起保存到缓存中。在这个过程中,它也接受可选的ItemOption参数,允许对缓存项进行进一步的配置,例如设置过期时间。 - 返回结果:如果键已存在,方法返回
false和nil错误,表示没有新的键值对被添加。如果键不存在且成功设置了新的键值对,方法返回true和可能发生的错误error(如果写入过程中发生错误)。
Delete
go
复制代码
// https://github.com/chenmingyong0423/go-generics-cache/blob/master/cache.go func (c *Cache[K, V]) Delete(ctx context.Context, key K) (err error) { c.mutex.Lock() defer c.mutex.Unlock() return c.cache.Delete(ctx, key) }
该方法用于从本地缓存中删除指定的键值对。
核心逻辑:
- 加写锁:首先,
Delete方法获取一个写锁。这是为了保证在删除操作进行时,缓存的状态不会被其他的读或写操作所干扰,从而确保操作的协程安全性。 - 调用底层删除方法:在锁定状态下,该方法通过调用
c.cache.Delete(ctx, key)来执行实际的删除操作。这一步骤涉及到对底层缓存数据结构的操作,以确保指定的键key被移除。 - 返回结果:方法最后返回执行结果,
nil或可能发送的错误error。
Keys
go
复制代码
// https://github.com/chenmingyong0423/go-generics-cache/blob/master/cache.go func (c *Cache[K, V]) Keys() []K { return c.cache.Keys() }
该方法用于获取本地缓存中所有的键,并以切片的形式返回这些键。返回的键的顺序取决于底层本地缓存实现的具体细节。
DeleteExpired
go
复制代码
// https://github.com/chenmingyong0423/go-generics-cache/blob/master/cache.go func (c *Cache[K, V]) DeleteExpired(ctx context.Context) { c.mutex.RLock() keys := c.Keys() c.mutex.RUnlock() i := 0 for _, key := range keys { if i > 10000 { return } c.mutex.Lock() if item, err := c.cache.Get(ctx, key); err == nil && item.Expired() { _ = c.cache.Delete(ctx, key) } c.mutex.Unlock() i++ } }
该方法用于删除本地缓存中已过期的项。核心逻辑:
- 加读锁:方法首先加上读锁(
c.mutex.RLock()),以安全地访问共享资源。 - 获取所有键:然后,它调用
c.Keys()方法来获取缓存中所有的键,并将这些键存储在keys切片中。 - 释放读锁:获取完所有键后,方法释放读锁(
c.mutex.RUnlock())。 - 迭代检查和删除:接下来,方法遍历
keys切片中的每个键。在遍历过程中,它实现了以下步骤:- 限制检查次数:设置一个计数器
i,如果检查的项数超过 10000,方法将提前结束。 - 加写锁:对于每个键,方法加上写锁(
c.mutex.Lock())以安全地执行写操作。 - 检查并删除过期项:方法尝试获取每个键对应的项。如果获取成功且该项已过期(
item.Expired()返回true),则调用c.cache.Delete(ctx, key)来删除该键值对。 - 释放写锁:完成检查和可能的删除操作后,方法释放写锁(
c.mutex.Unlock())。
- 限制检查次数:设置一个计数器
- 计数器递增:每检查一个键,计数器
i递增。这用于控制方法检查的最大项数,避免可能的性能问题。
这里做了一个优化:引入了一个计数器,当 i 超过 10000 时,则停止操作。这样做的好处:
- 减少锁占用时间,防止性能下降:在有大量键值对的情况下,遍历和检查所有项会频繁获取写锁,对整个缓存系统的性能产生负面影响。尤其是在高并发的环境中。限制检查数量有助于减少锁的占用时间。
计数器 i 的最大值应根据具体场景进行调整,因为不同的应用环境和性能要求会影响到合适的最大值选择。
本地缓存的具体实现
simple cache
go
复制代码
// https://github.com/chenmingyong0423/go-generics-cache/blob/master/simple/simple_cache.go type Cache[K comparable, V any] struct { cache map[K]V } func NewCache[K comparable, V any](size int) *Cache[K, V] { return &Cache[K, V]{ cache: make(map[K]V, size), } } func (c *Cache[K, V]) Set(_ context.Context, key K, value V) error { c.cache[key] = value return nil } func (c *Cache[K, V]) Get(_ context.Context, key K) (V, error) { var ( value V ok bool ) if value, ok = c.cache[key]; !ok { return value, cacheError.ErrNoKey } return value, nil } func (c *Cache[K, V]) Delete(_ context.Context, key K) error { if _, ok := c.cache[key]; ok { delete(c.cache, key) return nil } return cacheError.ErrNoKey } func (c *Cache[K, V]) Keys() []K { keys := make([]K, 0) for key := range c.cache { keys = append(keys, key) } return keys }
simple cache 实现了 ICache 接口,它的设计较为简单,以 map 作为其核心数据结构,使得键值对的存储和检索操作简单高效。这种缓存实现适用于不需要复杂缓存策略的基本用例。
需要注意的是,在 Get 和 Delete 方法中,如果键不存在,则会返回一个明确的错误 cacheError.ErrNoKey,这有助于调用者区分 "缓存未命中" 与其他类型的错误。
lru cache
go
复制代码
// https://github.com/chenmingyong0423/go-generics-cache/blob/master/lru/lru_cache.go type entry[K comparable, V any] struct { key K value V } func NewCache[K comparable, V any](cap int) *Cache[K, V] { return &Cache[K, V]{ maxEntries: cap, cache: make(map[K]*list.Element, cap), linkedDoublyList: list.New(), } } type Cache[K comparable, V any] struct { maxEntries int cache map[K]*list.Element linkedDoublyList *list.List } func (c *Cache[K, V]) Set(_ context.Context, key K, value V) error { if e, ok := c.cache[key]; ok { // 元素存在 c.linkedDoublyList.MoveToFront(e) e.Value.(*entry[K, V]).value = value return nil } // 元素不存在 e := &entry[K, V]{ key: key, value: value, } c.cache[key] = c.linkedDoublyList.PushFront(e) if c.linkedDoublyList.Len() > c.maxEntries { // 删除最后一个元素 e := c.linkedDoublyList.Back() c.linkedDoublyList.Remove(e) delete(c.cache, e.Value.(*entry[K, V]).key) } return nil } func (c *Cache[K, V]) Get(_ context.Context, key K) (v V, err error) { if e, ok := c.cache[key]; ok { c.linkedDoublyList.MoveToFront(e) e := e.Value.(*entry[K, V]) return e.value, nil } return v, cacheError.ErrNoKey } func (c *Cache[K, V]) Delete(_ context.Context, key K) error { if e, ok := c.cache[key]; ok { c.linkedDoublyList.Remove(e) delete(c.cache, key) return nil } return cacheError.ErrNoKey } func (c *Cache[K, V]) Keys() []K { keys := make([]K, 0) // 根据添加顺序返回 for e := c.linkedDoublyList.Back(); e != nil; e = e.Prev() { keys = append(keys, e.Value.(*entry[K, V]).key) } return keys }
lru cache 实现了 ICache 接口。这里借助了哈希表(map)和双向链表(这里使用 container 包里的一个具体实现 List)来实现 最近最少使用 lru 本地缓存。
类型定义
entry[K comparable, V any]:这是一个私有的结构体,用于存储缓存中的键(key)和值(value)。Cache[K comparable, V any]:这是公开的缓存结构体,包含以下字段:maxEntries:缓存能够存储的最大条目数。cache:一个映射,将键映射到双向链表中的元素(list.Element)。linkedDoublyList:一个list.List类型的双向链表,用于维护键的使用顺序。
构造函数
NewCache[K comparable, V any](cap int):创建并返回一个新的Cache[K, V]实例。接受缓存容量cap作为参数,并初始化内部结构。
方法
Set(_ context.Context, key K, value V):向缓存中添加一个键值对。基于 最近最少使用 的原则,如果键已经存在,则更新其值并将其移至链表的前端。如果键不存在,则创建一个新的entry项并将其加入链表的前端。如果加入新项后缓存超过最大容量,则从链表尾部移除最少使用的项。Get(_ context.Context, key K):根据键从缓存中检索值。如果找到了键,则将对应的链表元素移至前端并返回其值。如果键不存在,则返回cacheError.ErrNoKey错误。Delete(_ context.Context, key K):从缓存中删除指定的键及其对应的值。如果键存在,则从链表和map中移除相应的元素。Keys():返回一个包含缓存中所有键的切片,按照从最近到最少使用的顺序排列。
小结
本文详细介绍了如何设计和实现一个极简的可扩展、高性能的泛型本地缓存。
核心在于引入了 Cache 适配器,它的关键字段 cache 是一个类型为 ICache 的接口。这个设计使得我们能够灵活地提供多种不同底层实现的本地缓存实例,例如 simple cache 和 lru cache。这样,Cache 适配器不仅支持多样化的缓存策略,还保留了通用的缓存操作接口,如 Get、Set、SetNX 和 Delete。
在具体实现方面, simple cache 较为简单,基于 map 的读写操作实现,而 lru cache 则更为复杂,它结合哈希表(map)和双向链表(使用 container 包里的 List,也可以自己实现一个双向链表)来实现 最近最少使用 lru 本地缓存。
相关文章:
Go 简单设计和实现可扩展、高性能的泛型本地缓存
相信大家对于缓存这个词都不陌生,但凡追求高性能的业务场景,一般都会使用缓存,它可以提高数据的检索速度,减少数据库的压力。缓存大体分为两类:本地缓存和分布式缓存(如 Redis)。本地缓存适用于…...

Vue.js 深度解析:模板编译原理与过程
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...
Java多线程——如何保证原子性
目录 引出原子性保障原子性CAS 创建线程有几种方式?方式1:继承Thread创建线程方式2:通过Runnable方式3:通过Callable创建线程方式4:通过线程池概述ThreadPoolExecutor API代码实现源码分析工作原理:线程池的…...

stm32消息和邮箱使用
邮箱管里介绍 邮箱是C/OS-II中另一种通讯机制,它可以使一个任务或者中断服务子程序向另一个任务发送一个指针型的变量。该指针指向一个包含了特定“消息”的数据结构。为了在C/OS-II中使用邮箱,必须将OS_CFG.H中的OS_MBOX_EN常数置为1。使用邮箱之前,必须先建立该邮箱。该操…...

银行数字化转型导师坚鹏:银行数字化转型案例研究
银行数字化转型案例研究 课程背景: 数字化背景下,很多银行存在以下问题: 不清楚银行科技金融数智化案例? 不清楚银行供应链金融数智化案例? 不清楚银行普惠金融数智化案例? 不清楚银行跨境金融数智…...

142.乐理基础-音程的构唱练习
内容参考于:三分钟音乐社 上一个内容:141.乐理基础-男声女声音域、模唱、记谱与实际音高等若干问题说明-CSDN博客 本次内容最好去看视频: https://apphq3npvwg1926.h5.xiaoeknow.com/p/course/column/p_5fdc7b16e4b0231ba88d94f4?l_progra…...
【比较mybatis、lazy、sqltoy、mybatis-flex操作数据】操作批量新增、分页查询(二)
orm框架使用性能比较 环境: idea jdk17 spring boot 3.0.7 mysql 8.0比较mybatis、lazy、sqltoy、mybatis-flex操作数据 测试条件常规对象 orm 框架是否支持xml是否支持 Lambda对比版本mybatis☑️☑️3.5.4sqltoy☑️☑️5.2.98lazy✖️☑️1.2.4-JDK17-SNAPS…...
每日OJ题_链表②_力扣24. 两两交换链表中的节点
目录 力扣24. 两两交换链表中的节点 解析代码 力扣24. 两两交换链表中的节点 24. 两两交换链表中的节点 难度 中等 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即&…...
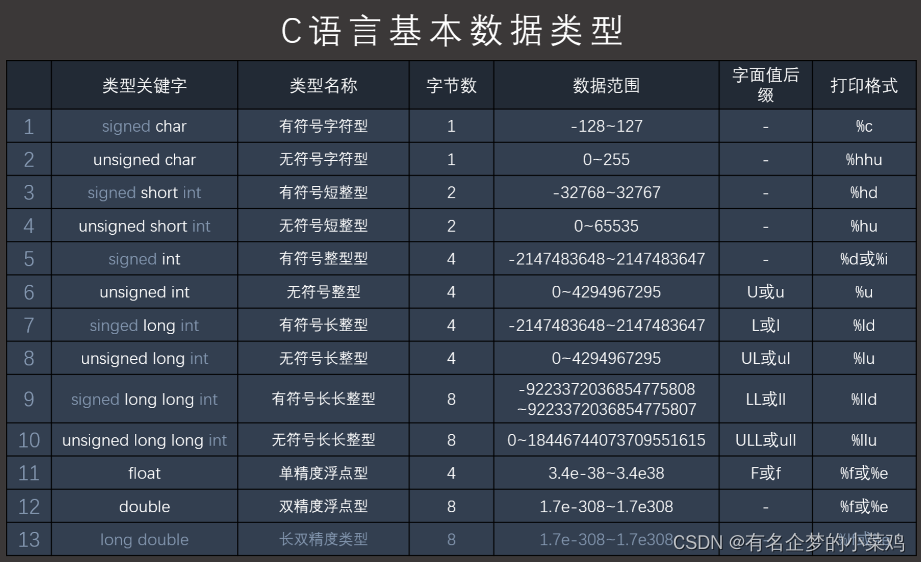
C语言数据类型详解及相关题——各种奇奇怪怪的偏难怪
文章目录 一、C语言基本数据类型溢出 二、存储原理符号位原码反码补码补码操作的例子 三、赋值中的类型转换常见返回类型——巨坑总结 一、C语言基本数据类型 溢出 因为数据范围(即存储单元的位的数量)的限制,可以表达的位数是有限的。 溢出…...

经典语义分割(二)医学图像分割模型UNet
经典语义分割(二)医学图像分割模型UNet 我们之前介绍了全卷积神经网络( FCN) ,FCN是基于深度学习的语义分割算法的开山之作。 今天我们介绍另一个语义分割的经典模型—UNet,它兼具轻量化与高性能,通常作为语义分割任务的基线测试模型&#x…...
三天学会阿里分布式事务框架Seata-seata事务日志mysql持久化配置
锋哥原创的分布式事务框架Seata视频教程: 实战阿里分布式事务框架Seata视频教程(无废话,通俗易懂版)_哔哩哔哩_bilibili实战阿里分布式事务框架Seata视频教程(无废话,通俗易懂版)共计10条视频&…...
C语言-简单实现单片机中的malloc示例
概述 在实际项目中,有些单片机资源紧缺,需要mallloc内存,库又没有自带malloc函数时,此时,就需要手动编写,在此做个笔录。(已在项目上使用),还可进入对齐管理机制。 直接…...

外包干了2年,技术退步明显
先说一下自己的情况,研究生,19年进入广州某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测试…...
计算机网络面经-HTTPS加密过程
前言 在上篇文章HTTPS详解一中,我已经为大家介绍了 HTTPS 的详细原理和通信流程,但总感觉少了点什么,应该是少了对安全层的针对性介绍,那么这篇文章就算是对HTTPS 详解一的补充吧。还记得这张图吧。 HTTPS 和 HTTP的区别 显然&am…...

2024年最佳硬盘!为台式电脑、NAS等产品量身定做的顶级机械硬盘
机械硬盘(HDD)可能看起来像是古老的技术,但它们仍然在许多地方提供“足够好”的性能,并且它们很容易以同等的价格提供最多的存储空间。 尽管最好的SSD将为你的操作系统和引导驱动器提供最好的体验,并提供比HDD更好的应…...
)
串的匹配算法——BF算法(朴素查找算法)
串的模式匹配:在主串str的pos位置查找子串sub,找到返回下标,没有找到返回-1。 1.BF算法思想 相等则继续比较,不相等则回退;回退是i退到刚才位置的下一个(i-j1);j退到0;利用子串是否…...
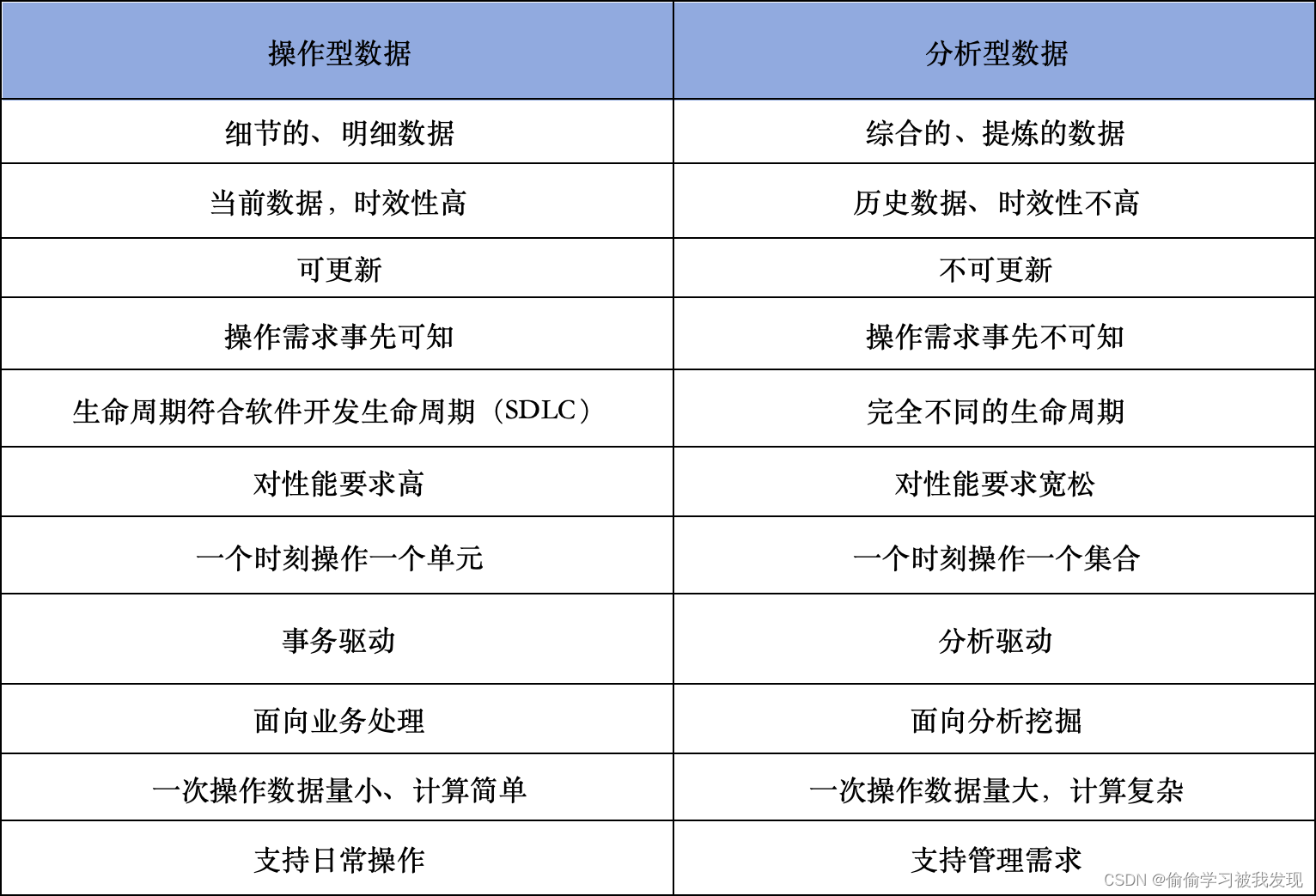
数据处理分类、数据仓库产生原因
个人看书学习心得及日常复习思考记录,个人随笔。 数据处理分类 操作型数据处理(基础) 操作型数据处理主要完成数据的收集、整理、存储、查询和增删改操作等,主要由一般工作人员和基层管理人员完成。 联机事务处理系统ÿ…...

【力扣100】 118.杨辉三角
添加链接描述 思路: 递推公式是[n,x][n-1,x-1][n-1,x] class Solution:def generate(self, numRows: int) -> List[List[int]]:if numRows1:return [[1]]if numRows2:return [[1],[1,1]]res[[1],[1,1]]for i in range(2,numRows): # i代表的是层数的下标&…...
好物周刊#44:现代终端工具
https://github.com/cunyu1943 村雨遥的好物周刊,记录每周看到的有价值的信息,主要针对计算机领域,每周五发布。 一、项目 1. Github-Hosts 通过修改 Hosts 解决国内 Github 经常抽风访问不到,每日更新。 2. 餐饮点餐商城 针对…...

每日五道java面试题之springMVC篇(一)
目录: 第一题. 什么是Spring MVC?简单介绍下你对Spring MVC的理解?第二题. Spring MVC的优点第三题. Spring MVC的主要组件?第四题. 什么是DispatcherServlet?第五题. 什么是Spring MVC框架的控制器? 第一题. 什么是S…...

3分钟学会Charticulator:零代码制作专业数据图表的终极指南
3分钟学会Charticulator:零代码制作专业数据图表的终极指南 【免费下载链接】charticulator Interactive Layout-Aware Construction of Bespoke Charts 项目地址: https://gitcode.com/gh_mirrors/ch/charticulator 还在为制作专业图表而头疼吗?…...

音乐歌词获取终极指南:如何3分钟搞定全网歌曲歌词的完整方案
音乐歌词获取终极指南:如何3分钟搞定全网歌曲歌词的完整方案 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 你是否曾经为了找到一首心爱歌曲的完整歌词而花费…...

在 Claude Code 中配置 Taotoken 以解决封号与 Token 不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Claude Code 中配置 Taotoken 以解决封号与 Token 不足问题 对于依赖 Claude Code 进行编程辅助的开发者而言,服务中…...

别再写一堆CASE WHEN了!PostgreSQL里COALESCE和NULLIF这两个函数,帮你把SQL写得又短又稳
告别冗长SQL:用PostgreSQL的COALESCE和NULLIF重构条件逻辑 在数据处理的世界里,SQL就像是我们与数据库对话的语言。但你是否经常遇到这样的情况:为了处理各种空值和边界条件,你的SQL查询变成了一个由无数CASE WHEN语句组成的庞然大…...

XHS-Downloader终极指南:如何高效批量下载小红书内容
XHS-Downloader终极指南:如何高效批量下载小红书内容 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&…...
前,这5个NDR和约束设置没做好,后期时序肯定崩)
ICC II时钟树综合(CTS)前,这5个NDR和约束设置没做好,后期时序肯定崩
ICC II时钟树综合前的5个致命陷阱:NDR与约束设置实战指南 时钟树综合(CTS)是数字后端设计中最关键的阶段之一,而90%的后期时序问题往往源于CTS前的配置疏漏。本文将深入剖析五个最容易被忽视却影响深远的设置环节,结合…...

机器学习40讲-总结课:机器学习的模型体系
用17讲的篇幅,我和你分享了目前机器学习中的大多数主流模型。可是除开了解了各自的原理,这些模型背后的共性规律在哪里,这些规律又将如何指导对于新模型的理解呢?这就是今天这篇总结的主题。 要想在纷繁复杂的模型万花筒中梳理出一条清晰的脉络,还是要回到最原始的出发点…...

【多智能体】多智能体多视角三维空间定位的神经动力学方法【含Matlab源码 15447期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab武动乾坤博客之家💞…...

基于深度学习的hCaptcha验证码本地化破解方案与实践指南
1. 项目概述:当验证码不再是“拦路虎”在自动化脚本、数据采集或者日常的批量操作中,验证码(CAPTCHA)就像一道横亘在程序与目标网站之间的自动门。它本意是区分人类和机器,保护网站安全,但对于有正当自动化…...

崩坏星穹铁道终极自动化指南:三月七小助手完整使用教程
崩坏星穹铁道终极自动化指南:三月七小助手完整使用教程 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 还在为《崩坏:星穹铁道》中繁琐的日常…...