慢sql优化记录1
慢sql为:
select count(*) from t_wf_process p left join t_wf_core_dofile dofile on p.wf_instance_uid = dofile.instanceid join zwkj_department d on p.userdeptid = d.department_guid ,t_wf_core_item i,wf_node n where (p.IS_DUPLICATE != 'true' or p.IS_DUPLICATE is null) and p.is_show = 1 and (p.is_back is null or (p.is_back != '2' and p.is_back != '4')) and i.id = p.wf_item_uid and p.wf_node_uid=n.wfn_id and p.user_uid = $1 and p.is_over= 'OVER' and p.finsh_time in (select max(p2.finsh_time) from t_wf_process p2 where p2.process_title is not null and (p2.is_back is null or (p2.is_back != '2' and p2.is_back != '4')) and p2.user_uid = $2 and p2.is_over = 'OVER' and p2.is_show = 1 and p2.finsh_time is not null group by p2.wf_instance_uid) and decode((select count(1) from t_wf_core_end_instanceid t where p.wf_instance_uid = t.instanceId), 0, 0, 1) = 1 order by p.apply_time desc;
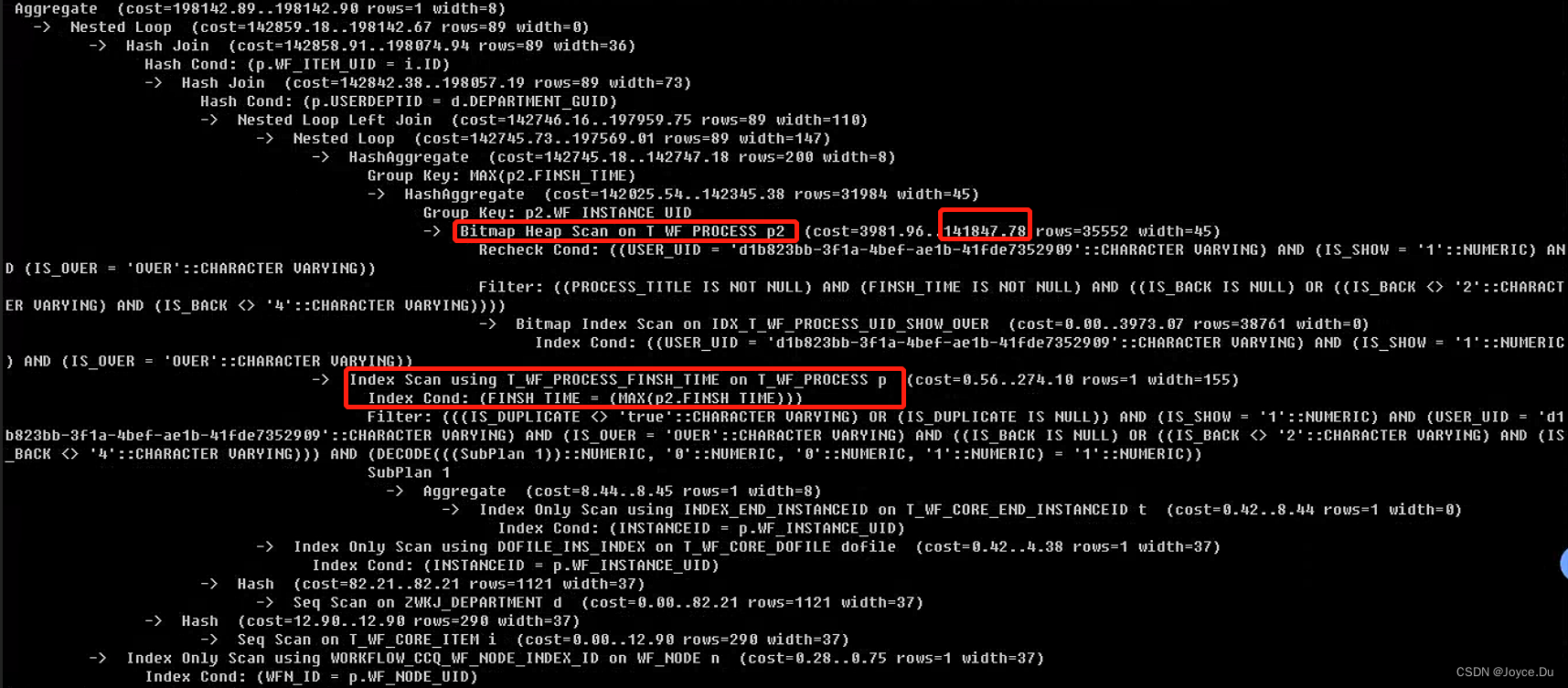
优化1:可以看出子查询和负查询都用了同样的查询条件来过滤大表t_wf_process(约600w记录,15G),这样不可避免会多次访问大表,可以采用CTE临时表的方式减少对大表的访问(finish_time子查询有is not null过滤,父查询因为限制了finish_time在子查询中,所以也可以有这个过滤条件)
with t1 as (select wf_instance_uid,userdeptid,IS_DUPLICATE,wf_item_uid , wf_node_uid,finsh_time,apply_time,process_title from t_wf_process where user_uid = $1 and is_show = 1 AND (is_back IS NULL OR (is_back != '2' AND is_back != '4')) AND is_over = 'OVER' and finsh_time IS NOT NULL)
优化2: decode((select count(1) from t_wf_core_end_instanceid t where p.wf_instance_uid = t.instanceId), 0, 0, 1) = 1
这种decode包含两表的关联,较耗cpu,可以改成exists方式(简单的表达式具有最优的性能)
exists (select 1 from t_wf_core_end_instanceid t where p.wf_instance_uid = t.instanceId)
优化3:条件里p.finsh_time in (select max(p2.finsh_time) from t_wf_process p2 where p2.process_title is not null ...)这里还有子查询,可以使用any(array())代替p.finsh_time =any(array (select max(p2.finsh_time) from t_wf_process p2 where p2.process_title is not null ...))
优化4:同时还可以给t_wf_process的user_uid、is_show、is_back、is_over、finish_time加上联合索引
create index idx_process_multiple on t_wf_process(user_uid,is_show,is_back,is_over,finsh_time);
优化
with t1 as (select wf_instance_uid,userdeptid,IS_DUPLICATE,wf_item_uid , wf_node_uid,finsh_time,apply_time,process_title from t_wf_processwhere user_uid = $1 and is_show = 1 AND (is_back IS NULL OR (is_back != '2' AND is_back != '4')) AND is_over = 'OVER' and finsh_time IS NOT NULL) SELECT count (*) FROM t1 p LEFT JOIN t_wf_core_dofile dofile ON p.wf_instance_uid = dofile.instanceid JOIN zwkj_department d ON p.userdeptid = d.department_guid, t_wf_core_item i, wf_node n WHERE (p.IS_DUPLICATE != 'true' OR p.IS_DUPLICATE IS NULL) AND i.id = p.wf_item_uid AND p.wf_node_uid = n.wfn_id AND p.finsh_time = any(array( SELECT max (p2.finsh_time) FROM t1 p2 WHERE p2.process_title IS NOT NULL GROUP BY p2.wf_instance_uid) ) and exists (select 1 from t_wf_core_end_instanceid t where p.wf_instance_uid = t.instanceId) ;
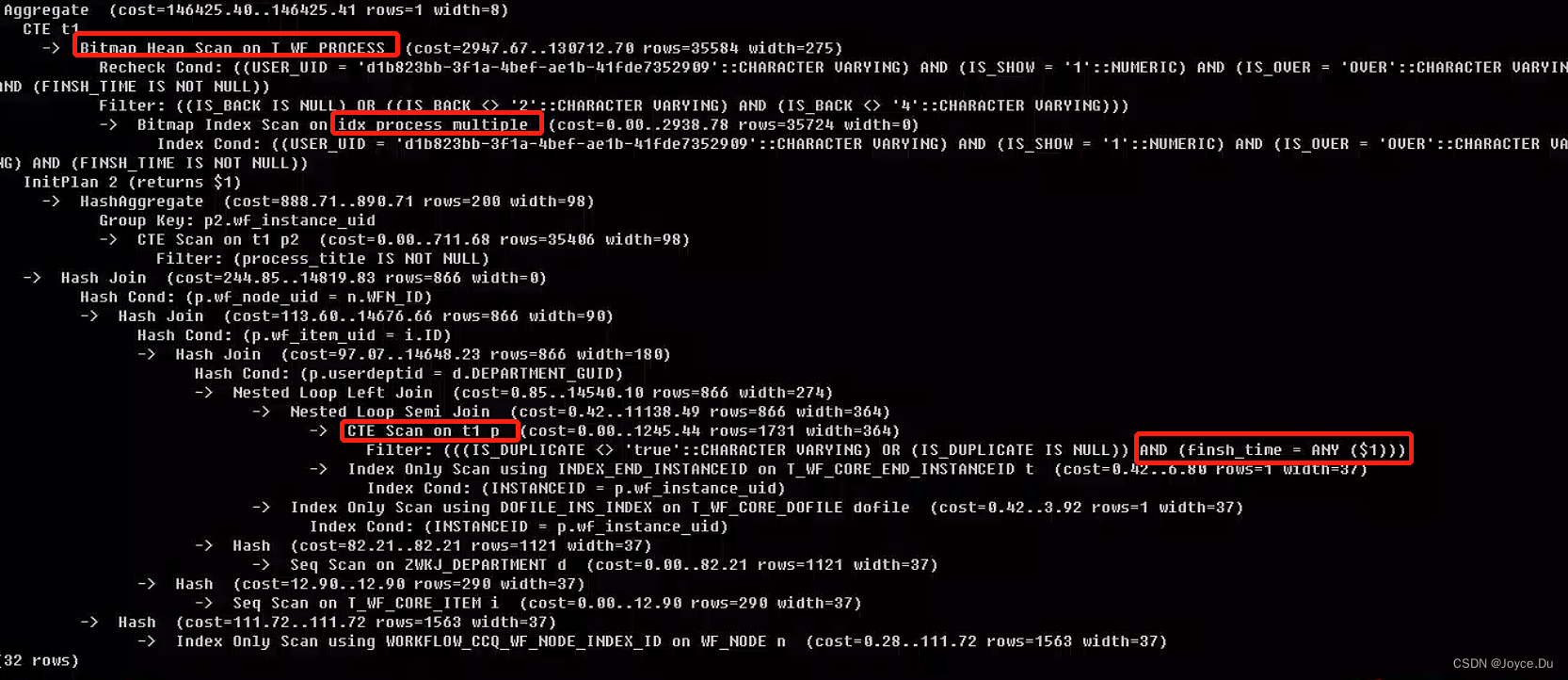
之前的索引看看使用情况要不要删除
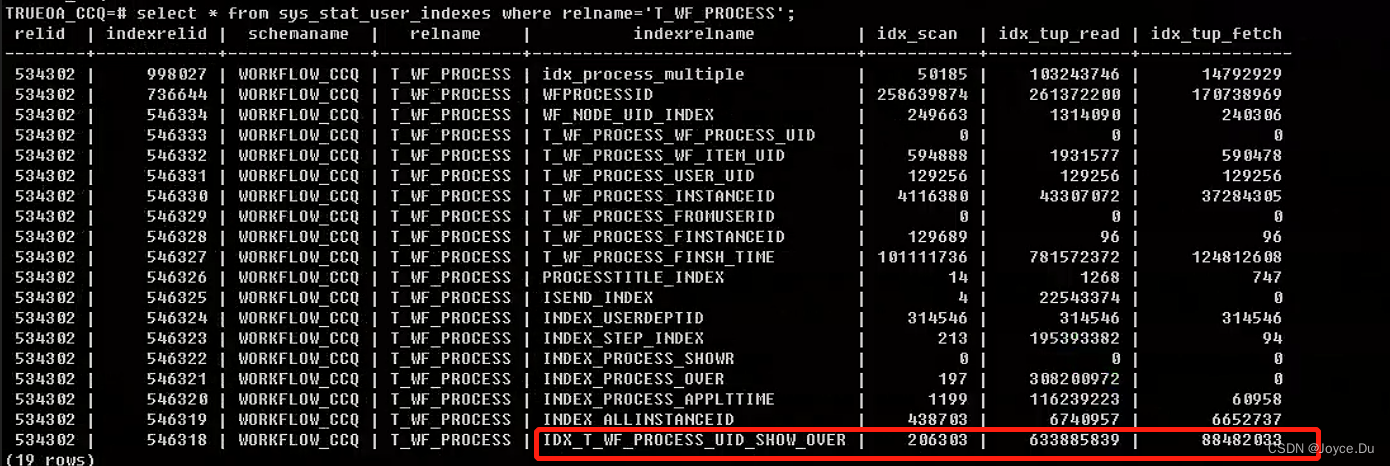
优化前的执行计划cost较大,但执行时间较少
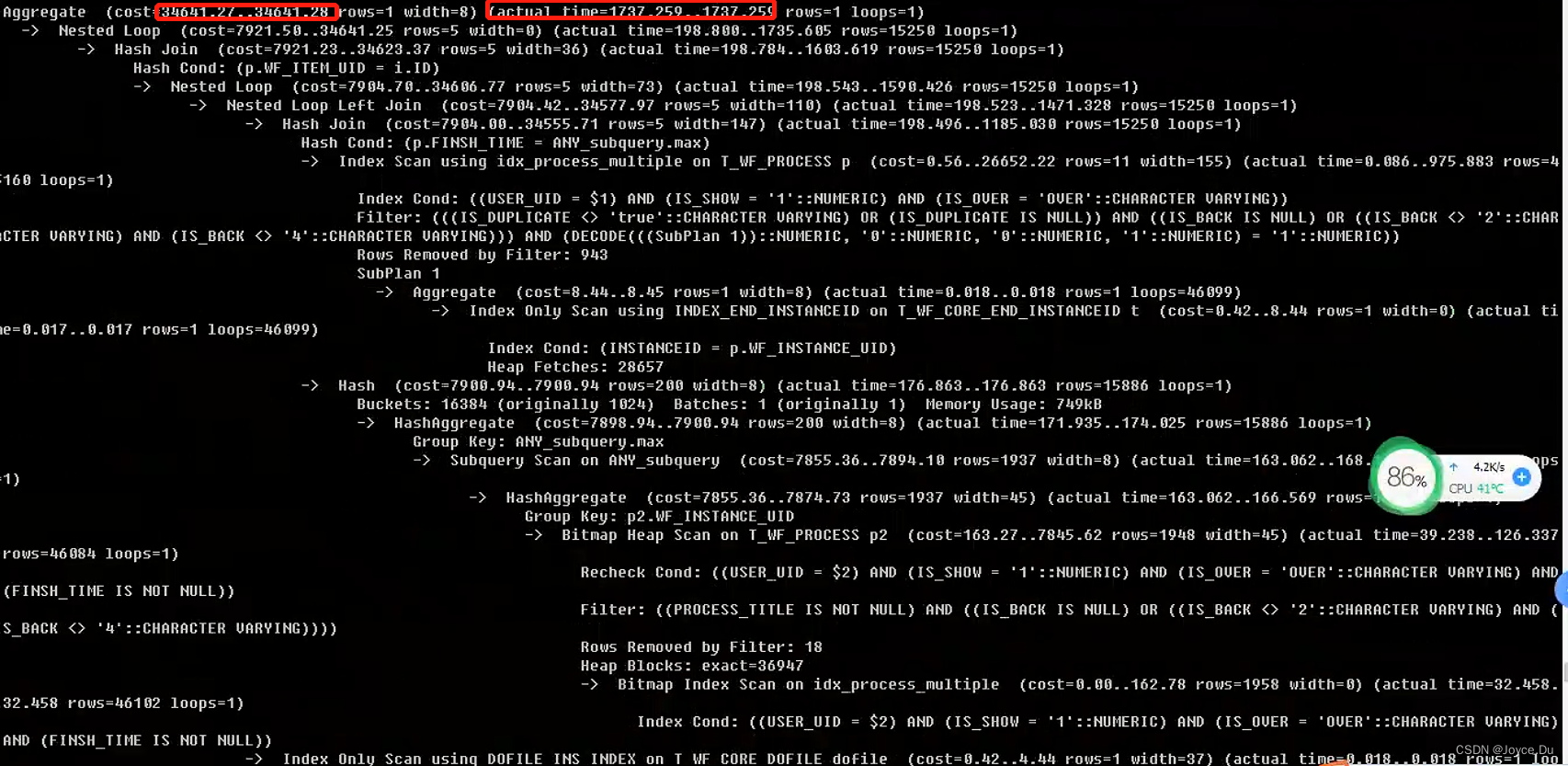
优化后的执行计划cost很小,执行时间很长,主要耗时在cte表的访问

去掉cte表再试下:
select count(*) from t_wf_process p left join t_wf_core_dofile dofile on p.wf_instance_uid = dofile.instanceid join zwkj_department d on p.userdeptid = d.department_guid ,t_wf_core_item i,wf_node n where (p.IS_DUPLICATE != 'true' or p.IS_DUPLICATE is null) and p.is_show = 1 and (p.is_back is null or (p.is_back != '2' and p.is_back != '4')) and i.id = p.wf_item_uid and p.wf_node_uid=n.wfn_id and p.user_uid = $1 and p.is_over= 'OVER' and p.finsh_time = any(array(select max(p2.finsh_time) from t_wf_process p2 where p2.process_title is not null and (p2.is_back is null or (p2.is_back != '2' and p2.is_back != '4')) and p2.user_uid = $2 and p2.is_over = 'OVER' and p2.is_show = 1 and p2.finsh_time is not null group by p2.wf_instance_uid) ) and exists (select 1 from t_wf_core_end_instanceid t where p.wf_instance_uid = t.instanceId);
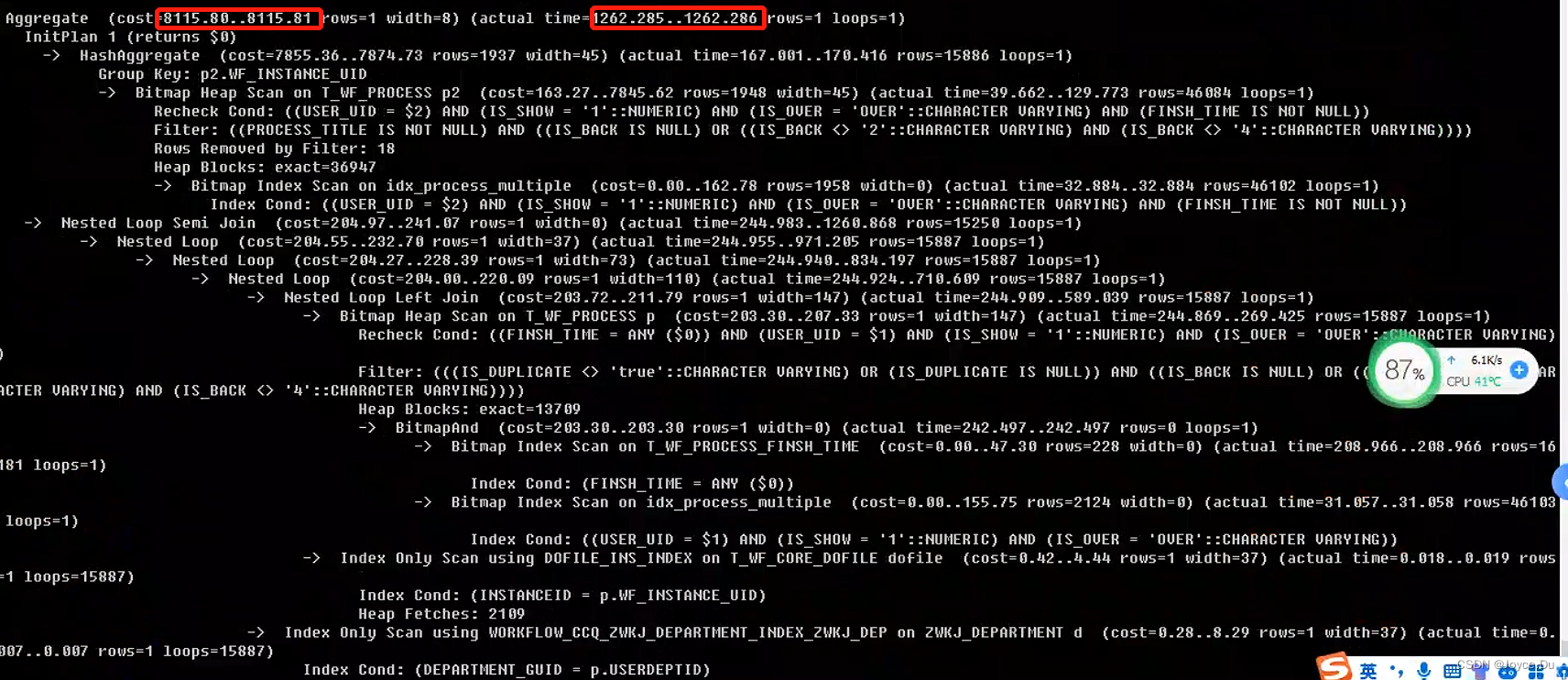
这时候cost和执行时间都较优,可以选择优化2、3、4,优化子查询和加索引的方法
相关文章:
慢sql优化记录1
慢sql为: select count(*) from t_wf_process p left join t_wf_core_dofile dofile on p.wf_instance_uid dofile.instanceid join zwkj_department d on p.userdeptid d.department_guid ,t_wf_core_item i,wf_node n where (p.IS_DUPLICATE ! true or p.IS_DU…...

堆和堆排序
堆排序是一种与插入排序和并归排序十分不同的算法。 优先级队列 Priority Queue 优先级队列是类似于常规队列或堆栈数据结构的抽象数据类型(ADT)。优先级队列中的每个元素都有一个相关联的优先级key。在优先级队列中,高优先级的元素优先于…...
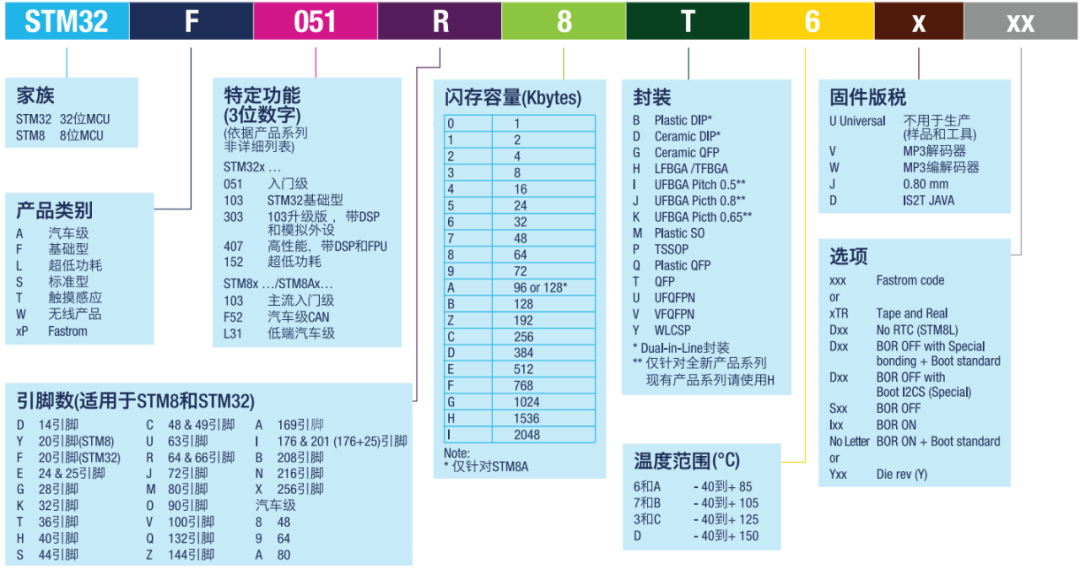
STM32 | 零基础 STM32 第一天
零基础 STM32 第一天 一、认知STM32 1、STM32概念 STM32:意法半导体基于ARM公司的Cortex-M内核开发的32位的高性能、低功耗单片机。 ST:意法半导体 M:基于ARM公司的Cortex-M内核的高性能、低功耗单片机 32:32位单片机 2、STM32开发的产品 STM32开发的产品&a…...
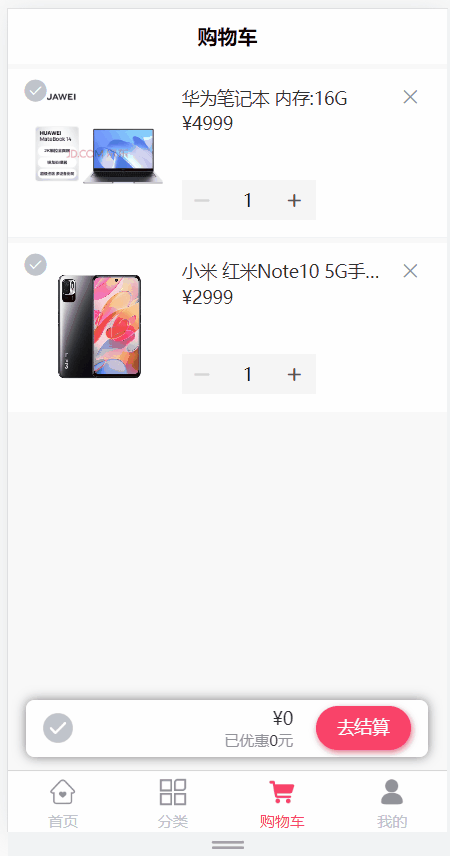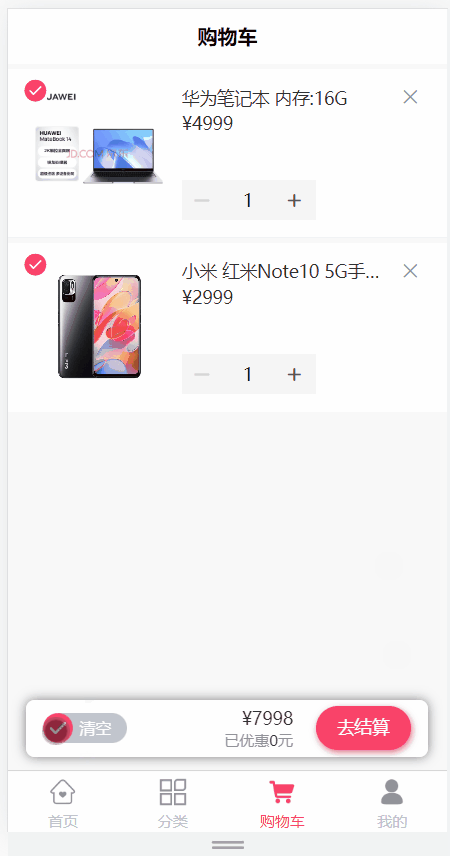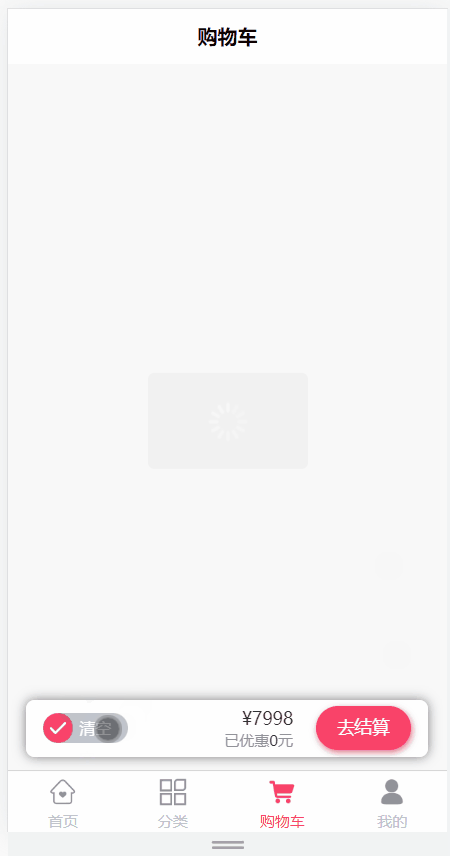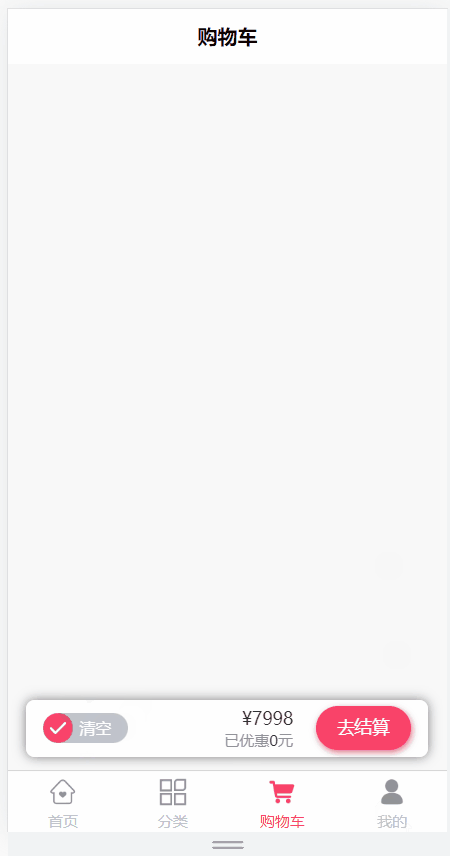
day16_购物车(添加购物车,购物车列表查询,删除购物车商品,更新选中商品状态,完成购物车商品的全选,清空购物车)
文章目录 购物车模块1 需求说明2 环境搭建3 添加购物车3.1 需求说明3.2 远程调用接口开发3.2.1 ProductController3.2.2 ProductService 3.3 openFeign接口定义3.3.1 环境搭建3.3.2 接口定义3.3.3 降级类定义 3.4 业务后端接口开发3.4.1 添加依赖3.4.2 修改启动类3.4.3 CartInf…...
基于Spring Boot的图书个性化推荐系统 ,计算机毕业设计(带源码+论文)
源码获取地址: 码呢-一个专注于技术分享的博客平台一个专注于技术分享的博客平台,大家以共同学习,乐于分享,拥抱开源的价值观进行学习交流http://www.xmbiao.cn/resource-details/1765769136268455938...
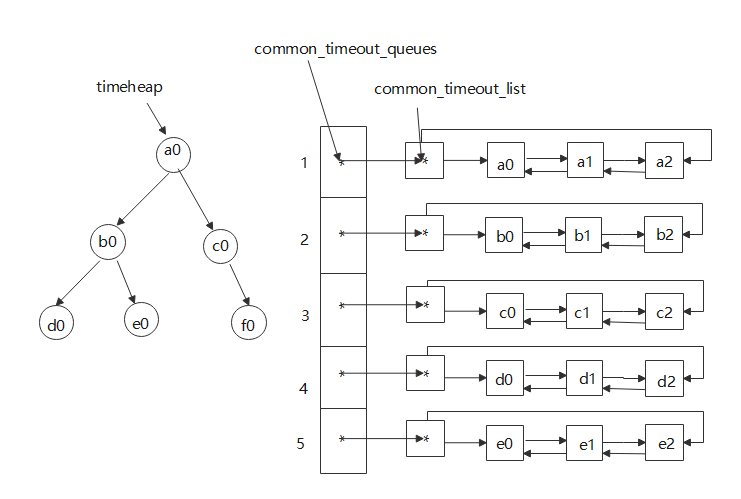
libevent源码解析:定时器事件(三)
文章目录 前言一、用例小根堆管理定时器事件小根堆和链表管理定时器事件区别 二、基本数据结构介绍结构体成员分析小根堆和链表common_timeout图示 三、源码分析小根堆管理定时器事件event_newevent_addevent_dispatch 链表common_timeout管理定时器事件event_base_init_common…...
3D资产管理
3D 资产管理是指组织、跟踪、优化和分发 3D 模型和资产以用于游戏、电影、AR/VR 体验等各种应用的过程。 3D资产管理也称为3D内容管理。 随着游戏、电影、建筑、工程等行业中 3D 内容的增长,实施有效的资产管理工作流程对于提高生产力、减少错误、简化工作流程以及使…...

鸿蒙Harmony应用开发—ArkTS声明式开发(基础手势:Blank)
空白填充组件,在容器主轴方向上,空白填充组件具有自动填充容器空余部分的能力。仅当父组件为Row/Column/Flex时生效。 说明: 该组件从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 子组件…...
【手游联运平台搭建】游戏平台的作用
随着科技的不断发展,游戏行业也在不断壮大,而游戏平台作为连接玩家与游戏的桥梁,发挥着越来越重要的作用。游戏平台不仅为玩家提供了便捷的游戏体验,还为游戏开发者提供了广阔的市场和推广渠道。本文将从多个方面探讨游戏平台的作…...

手把手教会你 - StreamAPI基本用法
1. 简介 目前响应式编程的学习中很多时候都用到了Lambda表达式和StreamAPI,那么今天就在这里记录一下一些最基本的使用方法。 StreamAPI中引入了流的概念,其将集合看作一种流,流在管道中传输(动态的),可以…...

和为K的子数组
题目: 使用前缀和的方法可以解决这个问题,因为我们需要找到和为k的连续子数组的个数。通过计算前缀和,我们可以将问题转化为求解两个前缀和之差等于k的情况。 假设数组的前缀和数组为prefixSum,其中prefixSum[i]表示从数组起始位…...
Redis:java中redis的基本使用(springboot)
文章目录 springboot中使用redisspringboot 连接 redis三种方式导入依赖增删改查小练习 springboot中使用redis springboot 连接 redis三种方式 jedis (redis官方提供的)springboot自带的redisson (基于jedis优化的,性能最好,使…...

微型计算机技术
摘要:微型计算机是通用计算机的一个重要发展分支,自1981年美国IBM公司推出第一代商用微型计算机以来,微型计算机迅速进入社会各个领域,且技术不断更新、产品快速换代,已成为人们工作和生活中不可缺少的基本工具。 一、微型计算机技术发展历史 1.第一代微处理器(19…...
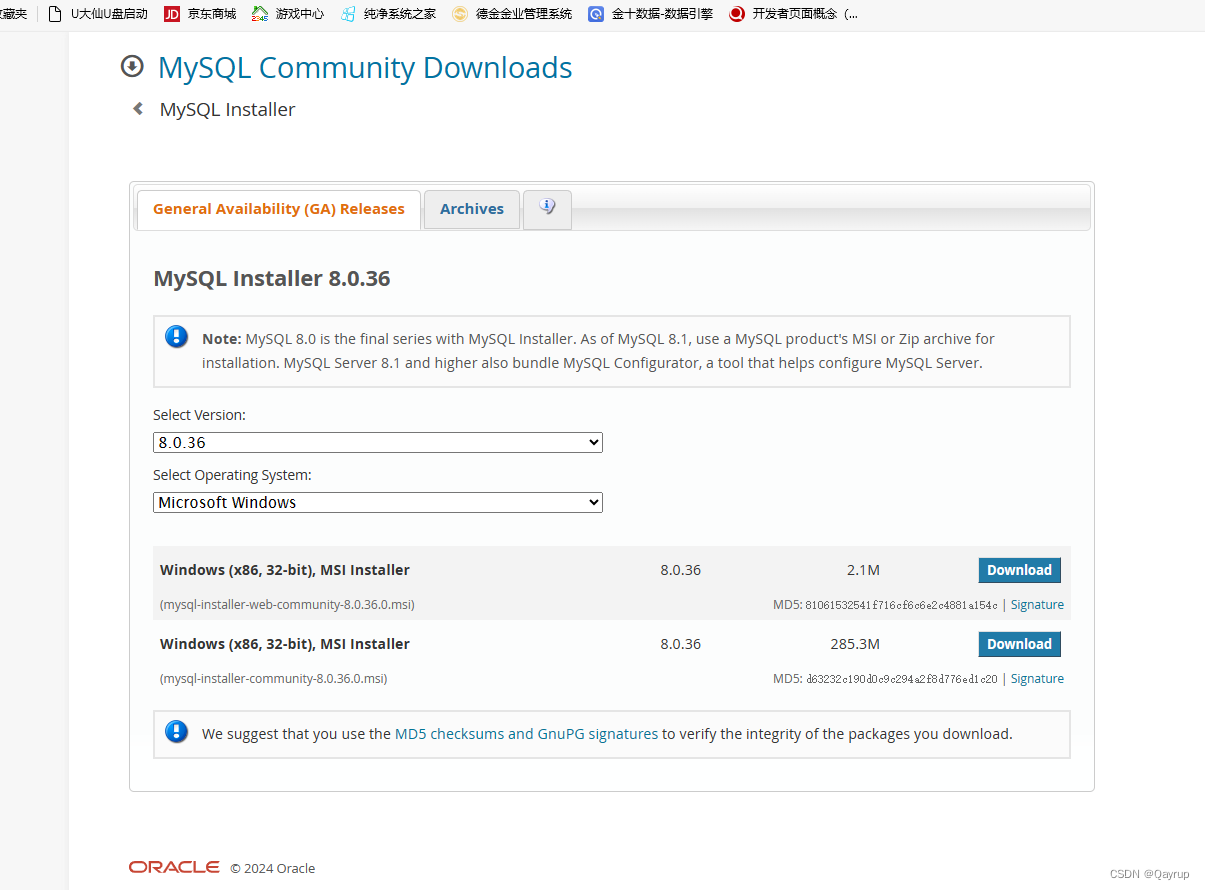
mysql下载教程
什么是mysql MySQL是一种开源的关系型数据库管理系统,由瑞典MySQL AB公司开发,现在由Oracle公司维护。MySQL支持多个操作系统,包括Linux、Windows、macOS等。它是一种客户端/服务器模式的数据库,提供高效、可靠、稳定的数据存储和…...
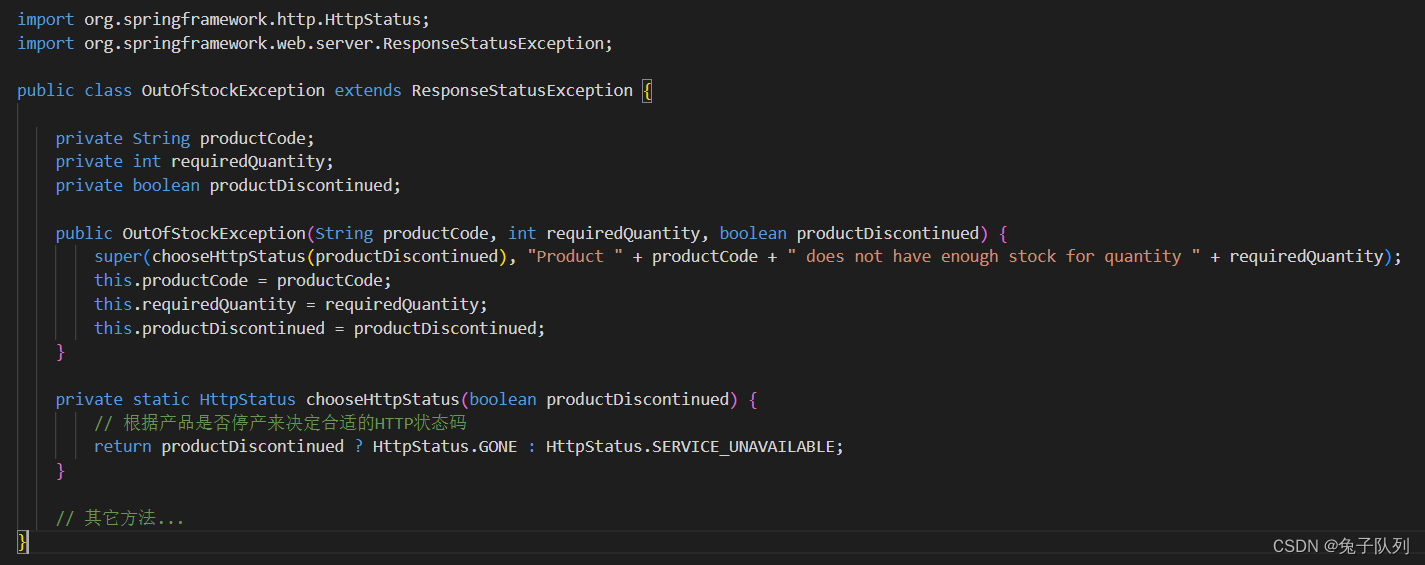
ResponseStatusException
目录 概述: 综合实例: 继承 ResponseStatusException-自定义异常类 继承 ResponseStatusException-自定义响应头信息 继承 ResponseStatusException-定制更多异常处理逻辑 继承 ResponseStatusException-根据异常发生的上下文动态改变 HTTP 状态码…...
第五十二回 戴宗二取公孙胜 李逵独劈罗真人-飞桨AI框架安装和使用示例
吴用说只有公孙胜可以破法术,于是宋江请戴宗和李逵去蓟州。两人听说公孙胜的师傅罗真人在九宫县二仙山讲经,于是到了二仙山,并在山下找到了公孙胜的家。 两人请公孙胜去帮助打高唐州,公孙胜说听师傅的。罗真人说出家人不管闲事&a…...

CSAPP-程序的机器级表示
文章目录 概念扫盲思想理解经典好图安全事件 概念扫盲 1.汇编代码使用文本格式,相较于汇编的二进制可读性更好 2.程序内存包括:可执行的机器代码、操作系统需要的信息、管理过程调用和返回的运行时栈、用户分配的内存块 3.链接器为函数调用找到匹配的可…...
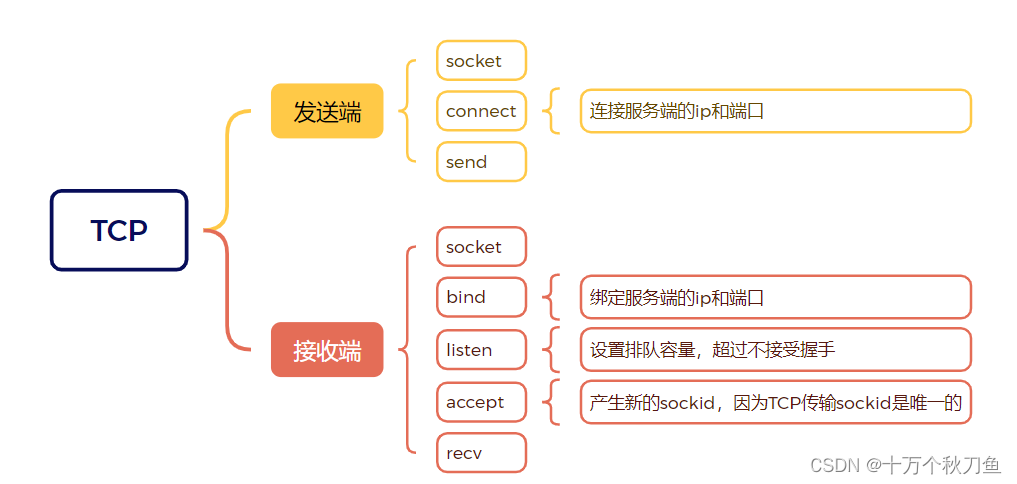
TCP传输收发
TCP通信: TCP发端: socket connect send recv close TCP收端: socket bind listen accept send recv close 1.connect int connect(int sockfd, const struct sockaddr *addr, socklen_t ad…...

OJ习题之——圆括号编码
圆括号编码 1.题目描述2.完整代码3.图例演示 1.题目描述 题目描述 令Ss1 s2 …sn是一个规则的圆括号字符串。S以2种不同形式编码: (1)用一个整数序列Pp1 p2 … pn编码,pi代表在S中第i个右圆括号的左圆括号数量。(记为…...
Android耗电分析之Battery Historian工具使用
Battery-Historian是谷歌推出的一款专门分析Bugreport的工具,是谷歌在2015年I/O大会上推出的一款检测运行在android5.0(Lollipop)及以后版本的设备上电池的相关信息和事件的工具,是一款对于分析手机状态,历史运行情况很好的可视化分析工具。 …...

终极指南:Windows平台APK安装器如何让安卓应用无缝运行
终极指南:Windows平台APK安装器如何让安卓应用无缝运行 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在Windows电脑上运行安卓应用曾经是一个技术难题&am…...

终极D2DX宽屏补丁:让经典暗黑破坏神2在现代PC上完美重生
终极D2DX宽屏补丁:让经典暗黑破坏神2在现代PC上完美重生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 你是否还…...

网盘下载新革命:九大平台一键直链,告别客户端束缚
网盘下载新革命:九大平台一键直链,告别客户端束缚 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

告别Python依赖!手把手教你用C++复现Librosa的Mel频谱和MFCC特征提取
高性能C音频特征提取实战:从Librosa原理到嵌入式部署优化 在语音识别和音频分析领域,Mel频谱和MFCC特征提取是基础但关键的技术环节。许多开发者习惯使用Python的Librosa库快速实现原型,但当需要部署到生产环境时,Python的解释器性…...

Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行
Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为macOS软件安装更新而烦恼吗?…...

Forge模组开发效率提升:Gradle插件自动化构建与热部署实践
1. 项目概述:一个为Forge模组开发者准备的“瑞士军刀”如果你是一名Minecraft Forge模组的开发者,或者你正打算踏入这个充满创造力的领域,那么你大概率经历过这样的场景:为了测试一个简单的功能改动,你需要反复地执行g…...

实战指南:用UABEA高效解析Unity资源结构的5个关键要点
实战指南:用UABEA高效解析Unity资源结构的5个关键要点 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 在Unity开发的世界里,资源管理往往是项目优化中最棘手的一环。你是否曾经…...

【ElevenLabs情绪模拟技术白皮书】:基于2,147小时情感语音标注数据集的11类基础情绪迁移模型验证报告
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术白皮书概述 ElevenLabs的情绪模拟技术并非简单调节音高或语速,而是基于多模态情感表征学习(Multimodal Affective Representation Learning, MARL&#x…...

基于MCP协议构建AI编程助手:unloop-mcp文件系统服务器实战指南
1. 项目概述:一个面向开发者的“解循环”MCP服务器最近在GitHub上看到一个挺有意思的项目,叫Escapepaleolithic247/unloop-mcp。光看这个名字,可能有点摸不着头脑,但如果你是一个经常和AI助手(比如Claude、Cursor等&am…...
:启动时快稍后慢,断断续续哥还在)
车载以太网之要火系列 - 第46篇:郭大侠学SOME/IP (offer Service):启动时快稍后慢,断断续续哥还在
写在开篇蓉儿继续挖坑上回说到,郭靖搞清楚了Offer Service的基本原理——服务端广播“我会啥,我在这”,TTL告诉客户端有效期。郭靖合上笔记本,突然皱起眉头:“蓉儿,我有个问题——如果每个ECU都每隔1.5秒发…...