Spark实战-基于Spark日志清洗与数据统计以及Zeppelin使用
Saprk-日志实战
一、用户行为日志
1.概念
用户每次访问网站时所有的行为日志(访问、浏览、搜索、点击)用户行为轨迹,流量日志
2.原因
分析日志:网站页面访问量网站的粘性推荐
3.生产渠道
(1)Nginx(2)Ajax
4.日志内容

日志数据内容:1.访问的系统属性:操作系统、浏览器等2.访问特征:点击URL,跳转页面(referer)、页面停留时间3.访问信息:seesion_id、访问id信息(地市\运营商)注意:Nginx配置,可以获取指定信息
5.意义
(1)网站的眼睛投放广告收益
(2)网站的神经网站布局(影响用户体验)
(3)网站的大脑
二、离线数据处理
1.处理流程
1)数据采集
Flume:产生的Web日志,写入到HDFS2)数据清洗Spark\Hive\MapReduce--》HDFS(Hive/Spark SQL表)3)数据处理按照业务逻辑进行统计分析Spark\Hive\MapReduce--》HDFS(Hive/Spark SQL表)4)处理结果入库RDBMS(MySQL)\NoSQL(HBase、Redis)5)数据可视化展示通过图形化展示:饼图、柱状图、地图、折线图Echarts、HUE、Zeppelin

三、项目需求
code/video
需求一:统计imooc主站最受欢迎的课程/手记Top N访问次数需求二:按地市统计imooc主站最受欢迎的Top N课程a.根据IP地址获取出城市信息b.窗口函数在Spark SQL中的使用需求三:按流量统计imooc主站最受欢迎的Top N课程
四、日志内容
需要字段:访问时间、访问URL、访问过程耗费流量、访问IP地址日志处理:一般的日志处理方式,我们是需要进行分区的,按照日志中的访问时间进行相应的分区,比如: d, h,m5(每5分钟一个分区)输入:访问时间、访问URL、耗费的流量、访问IP地址信息
输出:URL、cmsType(video/article)、cmsId(编号)、流量、ip、城市信息、访问时间、天
Maven打包
mvn install:install-file -Dfile=D:\ipdatabase-master\ipdatabase-master\target\ipdatabase-1.0-SNAPSHOT.jar -DgroupId=com.ggstar2 -DartifactId=ipdatabase -Dversion=1.0 -Dpackaging=jar
五、数据清洗
1.原始日志解析
package com.saddam.spark.MuKe.ImoocProjectimport org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession/*** 第一步清洗:抽取出所需要指定列数据** 添加断点,可以查看各个字段*/
object SparkStatFormatJob {def main(args: Array[String]): Unit = {val spark=SparkSession.builder().appName("SparkStatFormatJob").master("local[2]").getOrCreate()val logRDD = spark.sparkContext.textFile("D:\\Spark\\DataSets\\access.20161111.log")// logRDD.take(10).foreach(println)val result = logRDD.map(line => {val split = line.split(" ")val ip = split(0)/*** 原始日志的第三个和第四个字段拼接起来就是完整的时间字段:* [10/Nov/2016:00:01:02 +0800]==>yyyy-MM-dd HH*///TODO 使用时间解析工具类val time = split(3) + " " + split(4)//"http://www.imooc.com/code/1852" 引号需要放空val url = split(11).replaceAll("\"", "")val traffic = split(9)//使用元组// (ip,DateUtils.parse(time),url,traffic)DateUtils.parse(time) + "\t" + url + "\t" + traffic + "\t" + ip}).take(20).foreach(println)// result.saveAsTextFile("D:\\Spark\\OutPut\\log_local_2")
/*
(10.100.0.1,[10/Nov/2016:00:01:02 +0800])
(117.35.88.11,[10/Nov/2016:00:01:02 +0800])
(182.106.215.93,[10/Nov/2016:00:01:02 +0800])
(10.100.0.1,[10/Nov/2016:00:01:02 +0800])*/spark.stop()
}
}
2.日期工具类
package com.saddam.spark.MuKe.ImoocProjectimport java.util.{Date, Locale}
import org.apache.commons.lang3.time.FastDateFormat/*** 日期时间解析工具类*/
object DateUtils {// 输入文件日期时间格式//[10/Nov/2016:00:01:02 +0800]val YYYYMMDDHHMM_TIME_FOEMAT= FastDateFormat.getInstance("dd/MMM/yyyy:HH:mm:ss Z",Locale.ENGLISH)//目标日期格式//2016-11-10 00:01:02val TARGET_FORMAT=FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")/***解析时间* @param time* @return*/def parse(time:String)={TARGET_FORMAT.format(new Date(getTime(time)))}/*** 获取输入日志时间:long类型** time:[10/Nov/2016:00:01:02 +0800]* @param time* @return*/def getTime(time:String)= {try {YYYYMMDDHHMM_TIME_FOEMAT.parse(time.substring(time.indexOf("[") + 1, time.lastIndexOf("]"))).getTime} catch {case e: Exception => {0l}}}def main(args: Array[String]): Unit = {println(parse("[10/Nov/2016:00:01:02 +0800]"))}
}

六、项目需求
需求一
统计imooc主站最受欢迎的课程/手记TopN访问次数按照需求完成统计信息并将统计结果入库--使用DataFrame API完成统计分析--使用SQL API完成统计分析
package com.saddam.spark.MuKeimport java.sql.{Connection, DriverManager, PreparedStatement}import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._import scala.collection.mutable.ListBufferobject PopularVideoVisits {def main(args: Array[String]): Unit = {val spark=SparkSession.builder().appName("TopNStatJob").config("spark.sql.sources.partitionColumnTypeInference.enable", "false").master("local[2]").getOrCreate()val accessDF=spark.read.format("parquet").load("D:\\Spark\\DataSets\\clean_city")accessDF.printSchema()accessDF.show(false)/*
+----------------------------------+-------+-----+-------+---------------+----+-------------------+--------+
|url |cmsType|cmsId|traffic|ip |city|time |day |
+----------------------------------+-------+-----+-------+---------------+----+-------------------+--------+
|http://www.imooc.com/video/4500 |video |4500 |304 |218.75.35.226 |鏈煡 |2017-05-11 14:09:14|20170511|
|http://www.imooc.com/video/14623 |video |14623|69 |202.96.134.133 |鏈煡 |2017-05-11 15:25:05|20170511|
|http://www.imooc.com/article/17894|article|17894|115 |202.96.134.133 |鏈煡 |2017-05-11 07:50:01|20170511|*///代码重构val day="20170511"videoAccessTopNStat(spark,accessDF,day)//MySQL工具类测试println(MySQLUtils.getConnection())/*** 按照流量进行统计*/def videoAccessTopNStat(spark:SparkSession,accessDF:DataFrame,day:String)={//隐式转换import spark.implicits._//TODO 统计方式一:DataFrame方式统计videoval videoAccessTopNDF= accessDF.filter($"day"===day && $"cmsType"==="video").groupBy("day","cmsId").agg(count("cmsId").as("times"))videoAccessTopNDF.printSchema()videoAccessTopNDF.show(false)//TODO 统计方式二:SQL方式统计articleaccessDF.createOrReplaceTempView("temp")val videoAccessTopNSQL = spark.sql("select " +"day,cmsId,count(1) as times " +"from temp " +"where day='20170511' and cmsType='article' " +"group by day,cmsId " +"order by times desc")videoAccessTopNSQL.show(false)/*** TODO 将最受欢迎的TopN课程统计结果写入MySQL**/try{videoAccessTopNSQL.foreachPartition(partitionOfRecords=>{val list =new ListBuffer[DayVideoAccessStat]partitionOfRecords.foreach(info=>{val day=info.getAs[Integer]("day").toStringval cmsId=info.getAs[Long]("cmsId")val times=info.getAs[Long]("times")list.append(DayVideoAccessStat(day,cmsId,times))})StatDAO.insertDayVideoAccessTopN(list)})}catch {case e:Exception=>e.printStackTrace()}}spark.stop()}/*** 课程访问次数实体类*/case class DayVideoAccessStat(day:String,cmsId:Long,times:Long)/*** TODO MySQL操作工具类*/object MySQLUtils{def getConnection()={DriverManager.getConnection("jdbc:mysql://121.37.2x.xx:3306/imooc_project?user=root&password=xxxxxx&useSSL=false")}/*** 释放数据库连接等资源* @param connection* @param pstmt*/def release(connection: Connection, pstmt: PreparedStatement): Unit = {try {if (pstmt != null) {pstmt.close()}} catch {case e: Exception => e.printStackTrace()} finally {if (connection != null) {connection.close()}}}}/*** TODO DAO数据库接口*/object StatDAO{/*** 批量保存DayVideoAccessStat到数据库* insertDayVideoAccessTopN:每天访问视频的*/def insertDayVideoAccessTopN(list: ListBuffer[DayVideoAccessStat]): Unit = {var connection:Connection = nullvar pstmt:PreparedStatement = nulltry {connection =MySQLUtils.getConnection()connection.setAutoCommit(false) //设置手动提交val sql = "insert into day_video_access_topn_stat2(day,cms_id,times) values (?,?,?)"pstmt = connection.prepareStatement(sql)for (ele <- list) {pstmt.setString(1, ele.day)pstmt.setLong(2, ele.cmsId)pstmt.setLong(3, ele.times)pstmt.addBatch()}pstmt.executeBatch() // 执行批量处理connection.commit() //手工提交} catch {case e: Exception => e.printStackTrace()} finally {MySQLUtils.release(connection, pstmt)}}}}
需求二
按地市统计imooc主站最受欢迎的Top N课程
package com.saddam.spark.MuKeimport java.sql.{Connection, DriverManager, PreparedStatement}import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._import scala.collection.mutable.ListBufferobject PopularCiytVideoVisits {def main(args: Array[String]): Unit = {val spark=SparkSession.builder().appName("TopNStatJob").config("spark.sql.sources.partitionColumnTypeInference.enable", "false").master("local[2]").getOrCreate()val accessDF=spark.read.format("parquet").load("D:\\Spark\\DataSets\\clean_city")accessDF.printSchema()accessDF.show(false)//代码重构val day="20170511"//TODO 按照地市进行统计TopN课程cityAccessTopNStat(spark,accessDF,day)/*** 按照地市进行统计TopN课程* @param spark* @param accessDf*/def cityAccessTopNStat(spark: SparkSession,accessDF:DataFrame,day:String)={import spark.implicits._val cityAccessTopNDF=accessDF.filter($"day"===day&&$"cmsType"==="video").groupBy("day","city","cmsId").agg(count("cmsId").as("times")).orderBy($"times".desc)cityAccessTopNDF.printSchema()cityAccessTopNDF.show(false)//Windows函数在Spark SQL的使用val top3DF=cityAccessTopNDF.select(cityAccessTopNDF("day"),cityAccessTopNDF("city"),cityAccessTopNDF("cmsId"),cityAccessTopNDF("times"),row_number().over(Window.partitionBy(cityAccessTopNDF("city")).orderBy(cityAccessTopNDF("times").desc)).as("times_rank")).filter("times_rank <=3") //.show(false) //Top3/*** 将地市进行统计TopN课程统计结果写入MySQL**/try{top3DF.foreachPartition(partitionOfRecords=>{val list =new ListBuffer[DayCityVideoAccessStat]partitionOfRecords.foreach(info=>{val day=info.getAs[Integer]("day").toStringval cmsId=info.getAs[Long]("cmsId")val city=info.getAs[String]("city")val times=info.getAs[Long]("times")val timesRank=info.getAs[Int]("times_rank")list.append(DayCityVideoAccessStat(day,cmsId,city,times,timesRank))})StatDAO.insertDayCityVideoAccessTopN(list)})}catch {case e:Exception=>e.printStackTrace()}}spark.stop()} /*** 实体类*/case class DayCityVideoAccessStat(day:String, cmsId:Long, city:String,times:Long,timesRank:Int)/*** TODO MySQL操作工具类*/object MySQLUtils{def getConnection()={DriverManager.getConnection("jdbc:mysql://121.37.2x.xx:3306/imooc_project?user=root&password=xxxxxx&useSSL=false")}/*** 释放数据库连接等资源* @param connection* @param pstmt*/def release(connection: Connection, pstmt: PreparedStatement): Unit = {try {if (pstmt != null) {pstmt.close()}} catch {case e: Exception => e.printStackTrace()} finally {if (connection != null) {connection.close()}}}}/*** TODO DAO数据库接口*/object StatDAO{/*** 批量保存DayCityVideoAccessStat到数据库*/def insertDayCityVideoAccessTopN(list: ListBuffer[DayCityVideoAccessStat]): Unit = {var connection: Connection = nullvar pstmt: PreparedStatement = nulltry {connection = MySQLUtils.getConnection()connection.setAutoCommit(false) //设置手动提交val sql = "insert into day_video_city_access_topn_stat(day,cms_id,city,times,times_rank) values (?,?,?,?,?) "pstmt = connection.prepareStatement(sql)for (ele <- list) {pstmt.setString(1, ele.day)pstmt.setLong(2, ele.cmsId)pstmt.setString(3, ele.city)pstmt.setLong(4, ele.times)pstmt.setInt(5, ele.timesRank)pstmt.addBatch()}pstmt.executeBatch() // 执行批量处理connection.commit() //手工提交} catch {case e: Exception => e.printStackTrace()} finally {MySQLUtils.release(connection, pstmt)}}}
}
需求三
按流量统计imooc主站最受欢迎的Top N课程
package com.saddam.spark.MuKeimport java.sql.{Connection, DriverManager, PreparedStatement}import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._import scala.collection.mutable.ListBufferobject VideoTrafficVisits {def main(args: Array[String]): Unit = {val spark=SparkSession.builder().appName("TopNStatJob").config("spark.sql.sources.partitionColumnTypeInference.enable", "false").master("local[2]").getOrCreate()val accessDF=spark.read.format("parquet").load("D:\\Spark\\DataSets\\clean_city")accessDF.printSchema()accessDF.show(false)//代码重构val day="20170511"//TODO 按照流量进行统计videoTrafficsTopNStat(spark,accessDF,day)/*** 按照流量进行统计*/def videoTrafficsTopNStat(spark: SparkSession, accessDF:DataFrame,day:String): Unit = {import spark.implicits._val cityAccessTopNDF = accessDF.filter($"day" === day && $"cmsType" === "video").groupBy("day", "cmsId").agg(sum("traffic").as("traffics")).orderBy($"traffics".desc)//.show(false)/*** 将流量进行统计TopN课程统计结果写入MySQL**/try{cityAccessTopNDF.foreachPartition(partitionOfRecords=>{val list =new ListBuffer[DayVideoTrafficsStat]partitionOfRecords.foreach(info=>{val day=info.getAs[Integer]("day").toStringval cmsId=info.getAs[Long]("cmsId")val traffics=info.getAs[Long]("traffics")list.append(DayVideoTrafficsStat(day,cmsId,traffics))})StatDAO.insertDayVideoTrafficsAccessTopN(list)})}catch {case e:Exception=>e.printStackTrace()}}spark.stop()}/*** 实体类*/case class DayVideoTrafficsStat(day:String,cmsId:Long,traffics:Long)/*** TODO MySQL操作工具类*/object MySQLUtils{def getConnection()={DriverManager.getConnection("jdbc:mysql://121.37.2x.2xx1:3306/imooc_project?user=root&password=xxxxxx&useSSL=false")}/*** 释放数据库连接等资源* @param connection* @param pstmt*/def release(connection: Connection, pstmt: PreparedStatement): Unit = {try {if (pstmt != null) {pstmt.close()}} catch {case e: Exception => e.printStackTrace()} finally {if (connection != null) {connection.close()}}}}/*** TODO DAO数据库接口*/object StatDAO{/*** 批量保存DayVideoTrafficsStat到数据库*/def insertDayVideoTrafficsAccessTopN(list: ListBuffer[DayVideoTrafficsStat]): Unit = {var connection: Connection = nullvar pstmt: PreparedStatement = nulltry {connection = MySQLUtils.getConnection()connection.setAutoCommit(false) //设置手动提交val sql = "insert into day_video_traffics_topn_stat(day,cms_id,traffics) values (?,?,?) "pstmt = connection.prepareStatement(sql)for (ele <- list) {pstmt.setString(1, ele.day)pstmt.setLong(2, ele.cmsId)pstmt.setLong(3, ele.traffics)pstmt.addBatch()}pstmt.executeBatch() // 执行批量处理connection.commit() //手工提交} catch {case e: Exception => e.printStackTrace()} finally {MySQLUtils.release(connection, pstmt)}}}
}
删除已有数据
/*** 删除指定日期的数据*/def deleteData(day: String): Unit = {val tables = Array("day_video_access_topn_stat","day_video_city_access_topn_stat","day_video_traffics_topn_stat")var connection:Connection = nullvar pstmt:PreparedStatement = nulltry{connection = MySQLUtils.getConnection()for(table <- tables) {// delete from table ....val deleteSQL = s"delete from $table where day = ?"pstmt = connection.prepareStatement(deleteSQL)pstmt.setString(1, day)pstmt.executeUpdate()}}catch {case e:Exception => e.printStackTrace()} finally {MySQLUtils.release(connection, pstmt)}}
七、Zeppelin
官网
https://zeppelin.apache.org/
1.解压缩
[root@hadoop src]# tar zxvf zeppelin-0.7.1-bin-all
2.改名
[root@hadoop src]# mv zeppelin-0.7.1-bin-all zeppelin
3.启动
[root@hadoop bin]# ./zeppelin-daemon.sh start
4.Web界面
http://121.37.2xx.xx:8080
5.修改JDBC驱动

com.mysql.jdbc.Driverxxxxxxjdbc:mysql://121.37.2x.xx:3306/imooc_project?root#mysql驱动
/usr/local/src/mysql-connector-java-5.1.27-bin.jar

6.创建note

7.查询表
%jdbcshow tables;

8.图形展示
%jdbcselect cms_id,times from day_video_access_topn_stat;

八、Spark on Yarn
Spark运行模式
1)Local:开发时使用
2)Standalone:Spark自带的,若一个集群是standalone,则需要在多台机器上同时部署Spark
3)YARN:建议生产上使用该模式,统一使用yarn进行整个集群作业(MR、Spark)的资源调度
4)Mesos不管使用那种模式,Spark应用程序代码是一模一样的,只需要在提交的时候指定--master指定
1.概述
Spark支持可插拔的集群管理模式对于yarn而言,Spark Application仅仅只是一个客户端而已
2.client模式
Driver运行在Client端(提交Spark作业的机器)
Client会和请求到的Container进行通信来完成作业的调度和执行,Client是不能退出的
日志信息在控制台输出,便于我们测试

3.cluster模式
Driver运行在ApplicationMaster中
Client提交完作业就可以关掉,因为作业已在Yarn上运行了
日志在终端输出,看控制台不到的,因为日志在Driver端,只能通过yarn logs -applicationId

4.两种模式对比
Driver运行位置ApplicationMaster的职责运行输出日志的位置
5.案例
设置HADOOP_CONF_DIR=?
Client模式
./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master yarn \--executor-memory 1G \--num-executors 1 \/usr/local/src/spark/examples/jars/spark-examples_2.11-2.1.1.jar \4
Pi is roughly 3.1411378528446323
22/02/28 18:52:26 INFO server.ServerConnector: Stopped Spark@1b0a7baf{HTTP/1.1}{0.0.0.0:4040}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@8a589a2{/stages/stage/kill,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@192f2f27{/jobs/job/kill,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@1bdf8190{/api,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@4f8969b0{/,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@6fefce9e{/static,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@74cec793{/executors/threadDump/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@f9b7332{/executors/threadDump,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@18e7143f{/executors/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@209775a9{/executors,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@5db4c359{/environment/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@2c177f9e{/environment,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@33617539{/storage/rdd/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@47874b25{/storage/rdd,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@290b1b2e{/storage/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@1fc0053e{/storage,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@77307458{/stages/pool/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@389adf1d{/stages/pool,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@7bf9b098{/stages/stage/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@72e34f77{/stages/stage,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@6e9319f{/stages/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@6fa590ba{/stages,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@2416a51{/jobs/job/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@293bb8a5{/jobs/job,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@37ebc9d8{/jobs/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@5217f3d0{/jobs,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.184.135:4040
22/02/28 18:52:26 INFO cluster.YarnClientSchedulerBackend: Interrupting monitor thread
22/02/28 18:52:26 INFO cluster.YarnClientSchedulerBackend: Shutting down all executors
22/02/28 18:52:26 INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Asking each executor to shut down
22/02/28 18:52:26 INFO cluster.SchedulerExtensionServices: Stopping SchedulerExtensionServices
(serviceOption=None,services=List(),started=false)
22/02/28 18:52:26 INFO cluster.YarnClientSchedulerBackend: Stopped
22/02/28 18:52:26 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
22/02/28 18:52:26 INFO memory.MemoryStore: MemoryStore cleared
22/02/28 18:52:26 INFO storage.BlockManager: BlockManager stopped
22/02/28 18:52:26 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
22/02/28 18:52:26 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
22/02/28 18:52:26 INFO spark.SparkContext: Successfully stopped SparkContext
22/02/28 18:52:26 INFO util.ShutdownHookManager: Shutdown hook called
22/02/28 18:52:26 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-a95834c0-d38b-457b-89b2-fed00d5bef56Cluster模式
./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master yarn-cluster \--executor-memory 1G \--num-executors 1 \/usr/local/src/spark/examples/jars/spark-examples_2.11-2.1.1.jar \4Pi is roughly 3.1411378528446323
22/02/28 18:52:26 INFO server.ServerConnector: Stopped Spark@1b0a7baf{HTTP/1.1}{0.0.0.0:4040}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@8a589a2{/stages/stage/kill,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@192f2f27{/jobs/job/kill,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@1bdf8190{/api,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@4f8969b0{/,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@6fefce9e{/static,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@74cec793{/executors/threadDump/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@f9b7332{/executors/threadDump,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@18e7143f{/executors/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@209775a9{/executors,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@5db4c359{/environment/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@2c177f9e{/environment,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@33617539{/storage/rdd/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@47874b25{/storage/rdd,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@290b1b2e{/storage/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@1fc0053e{/storage,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@77307458{/stages/pool/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@389adf1d{/stages/pool,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@7bf9b098{/stages/stage/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@72e34f77{/stages/stage,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@6e9319f{/stages/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@6fa590ba{/stages,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@2416a51{/jobs/job/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@293bb8a5{/jobs/job,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@37ebc9d8{/jobs/json,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@5217f3d0{/jobs,null,UNAVAILABLE,@Spark}
22/02/28 18:52:26 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.184.135:4040
22/02/28 18:52:26 INFO cluster.YarnClientSchedulerBackend: Interrupting monitor thread
22/02/28 18:52:26 INFO cluster.YarnClientSchedulerBackend: Shutting down all executors
22/02/28 18:52:26 INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Asking each executor to shut down
22/02/28 18:52:26 INFO cluster.SchedulerExtensionServices: Stopping SchedulerExtensionServices
(serviceOption=None,services=List(),started=false)
22/02/28 18:52:26 INFO cluster.YarnClientSchedulerBackend: Stopped
22/02/28 18:52:26 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
22/02/28 18:52:26 INFO memory.MemoryStore: MemoryStore cleared
22/02/28 18:52:26 INFO storage.BlockManager: BlockManager stopped
22/02/28 18:52:26 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
22/02/28 18:52:26 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
22/02/28 18:52:26 INFO spark.SparkContext: Successfully stopped SparkContext
22/02/28 18:52:26 INFO util.ShutdownHookManager: Shutdown hook called
22/02/28 18:52:26 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-a95834c0-d38b-457b-89b2-fed00d5bef56
[root@hadoop01 spark]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster --executor-memory 1G --num-executors 1 /usr/local/src/spark/examples/jars/spark-examples_2.11-2.1.1.jar 4
Warning: Master yarn-cluster is deprecated since 2.0. Please use master "yarn" with specified deploy mode instead.
22/02/28 18:54:32 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/02/28 18:54:32 WARN util.Utils: Your hostname, hadoop01.localdomain resolves to a loopback address: 127.0.0.1; using 192.168.184.135 instead (on interface ens33)
22/02/28 18:54:32 WARN util.Utils: Set SPARK_LOCAL_IP if you need to bind to another address
22/02/28 18:54:32 INFO client.RMProxy: Connecting to ResourceManager at hadoop01/192.168.184.135:8032
22/02/28 18:54:32 INFO yarn.Client: Requesting a new application from cluster with 1 NodeManagers
22/02/28 18:54:33 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
22/02/28 18:54:33 INFO yarn.Client: Will allocate AM container, with 1408 MB memory including 384 MB overhead
22/02/28 18:54:33 INFO yarn.Client: Setting up container launch context for our AM
22/02/28 18:54:33 INFO yarn.Client: Setting up the launch environment for our AM container
22/02/28 18:54:33 INFO yarn.Client: Preparing resources for our AM container
22/02/28 18:54:33 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
22/02/28 18:54:35 INFO yarn.Client: Uploading resource file:/tmp/spark-c7e3fb91-c7d0-4f59-86ba-705a9f256144/__spark_libs__3085975169933820625.zip -> hdfs://hadoop01:9000/user/root/.sparkStaging/application_1646041633964_0004/__spark_libs__3085975169933820625.zip
22/02/28 18:54:35 INFO yarn.Client: Uploading resource file:/usr/local/src/spark/examples/jars/spark-examples_2.11-2.1.1.jar -> hdfs://hadoop01:9000/user/root/.sparkStaging/application_1646041633964_0004/spark-examples_2.11-2.1.1.jar
22/02/28 18:54:35 INFO yarn.Client: Uploading resource file:/tmp/spark-c7e3fb91-c7d0-4f59-86ba-705a9f256144/__spark_conf__2818552262823480245.zip -> hdfs://hadoop01:9000/user/root/.sparkStaging/application_1646041633964_0004/__spark_conf__.zip
22/02/28 18:54:35 INFO spark.SecurityManager: Changing view acls to: root
22/02/28 18:54:35 INFO spark.SecurityManager: Changing modify acls to: root
22/02/28 18:54:35 INFO spark.SecurityManager: Changing view acls groups to:
22/02/28 18:54:35 INFO spark.SecurityManager: Changing modify acls groups to:
22/02/28 18:54:35 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
22/02/28 18:54:35 INFO yarn.Client: Submitting application application_1646041633964_0004 to ResourceManager
22/02/28 18:54:35 INFO impl.YarnClientImpl: Submitted application application_1646041633964_0004
22/02/28 18:54:36 INFO yarn.Client: Application report for application_1646041633964_0004 (state: ACCEPTED)
22/02/28 18:54:36 INFO yarn.Client:client token: N/Adiagnostics: N/AApplicationMaster host: N/AApplicationMaster RPC port: -1queue: defaultstart time: 1646045675928final status: UNDEFINEDtracking URL: http://hadoop01:8088/proxy/application_1646041633964_0004/user: root
22/02/28 18:54:37 INFO yarn.Client: Application report for application_1646041633964_0004 (state: ACCEPTED)
22/02/28 18:54:38 INFO yarn.Client: Application report for application_1646041633964_0004 (state: ACCEPTED)
22/02/28 18:54:39 INFO yarn.Client: Application report for application_1646041633964_0004 (state: RUNNING)
22/02/28 18:54:39 INFO yarn.Client:client token: N/Adiagnostics: N/AApplicationMaster host: 192.168.184.135ApplicationMaster RPC port: 0queue: defaultstart time: 1646045675928final status: UNDEFINEDtracking URL: http://hadoop01:8088/proxy/application_1646041633964_0004/user: root
22/02/28 18:54:40 INFO yarn.Client: Application report for application_1646041633964_0004 (state: RUNNING)
22/02/28 18:54:41 INFO yarn.Client: Application report for application_1646041633964_0004 (state: RUNNING)
22/02/28 18:54:42 INFO yarn.Client: Application report for application_1646041633964_0004 (state: RUNNING)
22/02/28 18:54:43 INFO yarn.Client: Application report for application_1646041633964_0004 (state: FINISHED)
22/02/28 18:54:43 INFO yarn.Client:client token: N/Adiagnostics: N/AApplicationMaster host: 192.168.184.135ApplicationMaster RPC port: 0queue: defaultstart time: 1646045675928final status: SUCCEEDEDtracking URL: http://hadoop01:8088/proxy/application_1646041633964_0004/user: root
22/02/28 18:54:43 INFO util.ShutdownHookManager: Shutdown hook called
22/02/28 18:54:43 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-c7e3fb91-c7d0-4f59-86ba-705a9f256144
6.检测ID
[root@hadoop01 spark]# yarn logs -applicationId application_1646041633964_000322/02/28 18:59:05 INFO client.RMProxy: Connecting to ResourceManager at hadoop01/192.168.184.135:8032
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hive/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
/tmp/logs/root/logs/application_1646041633964_0003 does not exist.
Log aggregation has not completed or is not enabled.#未指定参数,看不到,未作聚合日志配置,需要通过webUI页面
7.WebUI查看结果
http://hadoop01:8042/node/containerlogs/container_1646041633964_0004_01_000001/root

九、Spark项目运行到YARN
maven打包依赖

1.IDEA项目代码-词频统计
package com.bigdataimport org.apache.spark.sql.SparkSessionobject WordCountYARN {def main(args: Array[String]): Unit = {val spark=SparkSession.builder().getOrCreate()if(args.length!=2){println("Usage:WordCountYARN <inputPath><outputPath>")}val Array(inputPath,outputPath)=argsval rdd = spark.sparkContext.textFile(inputPath)val df = rdd.flatMap(x=>x.split("\t")).map(word=>(word,1)).reduceByKey((a,b)=>(a+b))df.saveAsTextFile(outputPath)spark.stop()}}
2.spark-submit
spark-submit \--class com.bigdata.WordCountYARN \--name WordCount \--master yarn \--executor-memory 1G \--num-executors 1 \/usr/local/src/spark/spark_jar/BYGJ.jar \hdfs://hadoop01:9000/wordcount.txt hdfs://hadoop01:9000/wc_output
3.查询结果
[root@hadoop01 spark_jar]# hadoop fs -cat /wc_output/part-*SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hive/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
(hive,5)
(spark,5)
(hadoop,2)
(hbase,3)-----------------------------------------
1.IDEA项目代码-日志清洗
package com.saddam.spark.MuKe.ImoocProject.LogCleanimport org.apache.spark.sql.{SaveMode, SparkSession}object SparkStatCleanJobYarn {def main(args: Array[String]): Unit = {val spark=SparkSession.builder().getOrCreate()if(args.length!=2){println("Usage:WordCountYARN <inputPath><outputPath>")}val Array(inputPath,outputPath)=argsval accessRDD = spark.sparkContext.textFile(inputPath)//TODO RDD->DFval accessDF=spark.createDataFrame(accessRDD.map(x=>AccessConvertUtil.parseLog(x)),AccessConvertUtil.struct)accessDF.coalesce(1).write.format("parquet").mode(SaveMode.Overwrite).partitionBy("day").save(outputPath)spark.stop()}
}
2.spark-submit
spark-submit \--class com.saddam.spark.MuKe.ImoocProject.LogClean.SparkStatCleanJobYarn \--name SparkStatCleanJobYarn \--master yarn \--executor-memory 1G \--num-executors 1 \--files /usr/local/src/spark/spark_jar/ipDatabase.csv,/usr/local/src/spark/spark_jar/ipRegion.xlsx \/usr/local/src/spark/spark_jar/Spark.jar \hdfs://hadoop01:9000/access.log hdfs://hadoop01:9000/log_output
3.查询结果
进入spark-shell
[root@hadoop01 datas]# spark-shell --master local[2] --jars /usr/local/src/mysql-connector-java-5.1.27-bin.jar
获取hdfs输出文件
/log_output/day=20170511/part-00000-36e30abb-3e42-4237-ad9f-a9f93258d4b2.snappy.parquet
读取文件
scala> spark.read.format("parquet").parquet("/log_output/day=20170511/part-00000-36e30abb-3e42-4237-ad9f-a9f93258d4b2.snappy.parquet").show(false)SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
+----------------------------------+-------+-----+-------+---------------+----+-------------------+
|url |cmsType|cmsId|traffic|ip |city|time |
+----------------------------------+-------+-----+-------+---------------+----+-------------------+
|http://www.imooc.com/video/4500 |video |4500 |304 |218.75.35.226 | |2017-05-11 14:09:14|
|http://www.imooc.com/video/14623 |video |14623|69 |202.96.134.133 | |2017-05-11 15:25:05|
|http://www.imooc.com/article/17894|article|17894|115 |202.96.134.133 | |2017-05-11 07:50:01|
|http://www.imooc.com/article/17896|article|17896|804 |218.75.35.226 | |2017-05-11 02:46:43|
|http://www.imooc.com/article/17893|article|17893|893 |222.129.235.182| |2017-05-11 09:30:25|
|http://www.imooc.com/article/17891|article|17891|407 |218.75.35.226 | |2017-05-11 08:07:35|
|http://www.imooc.com/article/17897|article|17897|78 |202.96.134.133 | |2017-05-11 19:08:13|
|http://www.imooc.com/article/17894|article|17894|658 |222.129.235.182| |2017-05-11 04:18:47|
|http://www.imooc.com/article/17893|article|17893|161 |58.32.19.255 | |2017-05-11 01:25:21|
|http://www.imooc.com/article/17895|article|17895|701 |218.22.9.56 | |2017-05-11 13:37:22|
|http://www.imooc.com/article/17892|article|17892|986 |218.75.35.226 | |2017-05-11 05:53:47|
|http://www.imooc.com/video/14540 |video |14540|987 |58.32.19.255 | |2017-05-11 18:44:56|
|http://www.imooc.com/article/17892|article|17892|610 |218.75.35.226 | |2017-05-11 17:48:51|
|http://www.imooc.com/article/17893|article|17893|0 |218.22.9.56 | |2017-05-11 16:20:03|
|http://www.imooc.com/article/17891|article|17891|262 |58.32.19.255 | |2017-05-11 00:38:01|
|http://www.imooc.com/video/4600 |video |4600 |465 |218.75.35.226 | |2017-05-11 17:38:16|
|http://www.imooc.com/video/4600 |video |4600 |833 |222.129.235.182| |2017-05-11 07:11:36|
|http://www.imooc.com/article/17895|article|17895|320 |222.129.235.182| |2017-05-11 19:25:04|
|http://www.imooc.com/article/17898|article|17898|460 |202.96.134.133 | |2017-05-11 15:14:28|
|http://www.imooc.com/article/17899|article|17899|389 |222.129.235.182| |2017-05-11 02:43:15|
+----------------------------------+-------+-----+-------+---------------+----+-------------------+
only showing top 20 rows十、项目性能调优
1.集群优化
存储格式的选择:https://www.infoq.cn/article/bigdata-store-choose/压缩格式的选择:默认:snapy
.config("spark.sql.parquet.compression.codec","gzip")修改
2.代码优化
选择高性能算子复用已有的数据
3.参数优化
并行度:spark.sql.shuffle.partitions 200 配置在为联接或聚合进行数据洗牌时使用的分区数。
spark-submit:--conf spark.sql.shuffle.partitions=500
IDEA:.config("","")分区字段类型推测:spark.sql.sources.partitionColumnTypeInference.enabled
spark-submit:--conf spark.sql.sources.partitionColumnTypeInference.enabled=false
IDEA:.config("","")
262 |58.32.19.255 | |2017-05-11 00:38:01|
|http://www.imooc.com/video/4600 |video |4600 |465 |218.75.35.226 | |2017-05-11 17:38:16|
|http://www.imooc.com/video/4600 |video |4600 |833 |222.129.235.182| |2017-05-11 07:11:36|
|http://www.imooc.com/article/17895|article|17895|320 |222.129.235.182| |2017-05-11 19:25:04|
|http://www.imooc.com/article/17898|article|17898|460 |202.96.134.133 | |2017-05-11 15:14:28|
|http://www.imooc.com/article/17899|article|17899|389 |222.129.235.182| |2017-05-11 02:43:15|
±---------------------------------±------±----±------±--------------±—±------------------+
only showing top 20 rows
## 十、项目性能调优### 1.集群优化~~~markdown
存储格式的选择:https://www.infoq.cn/article/bigdata-store-choose/压缩格式的选择:默认:snapy
.config("spark.sql.parquet.compression.codec","gzip")修改
2.代码优化
选择高性能算子复用已有的数据
3.参数优化
并行度:spark.sql.shuffle.partitions 200 配置在为联接或聚合进行数据洗牌时使用的分区数。
spark-submit:--conf spark.sql.shuffle.partitions=500
IDEA:.config("","")分区字段类型推测:spark.sql.sources.partitionColumnTypeInference.enabled
spark-submit:--conf spark.sql.sources.partitionColumnTypeInference.enabled=false
IDEA:.config("","")
相关文章:
Spark实战-基于Spark日志清洗与数据统计以及Zeppelin使用
Saprk-日志实战 一、用户行为日志 1.概念 用户每次访问网站时所有的行为日志(访问、浏览、搜索、点击)用户行为轨迹,流量日志2.原因 分析日志:网站页面访问量网站的粘性推荐3.生产渠道 (1)Nginx(2)Ajax4.日志内容 日志数据内容:1.访问的…...
Springboot中Redis的配置使用
新建 向pom.xml中添加依赖,这个可以不用标注版本号 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency> 配置yml文件(文件名不可以错…...
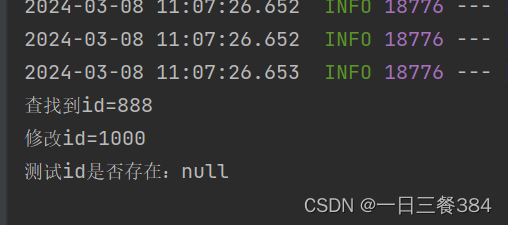
【node版本问题】运行项目报错 PostCSS received undefined instead of CSS string
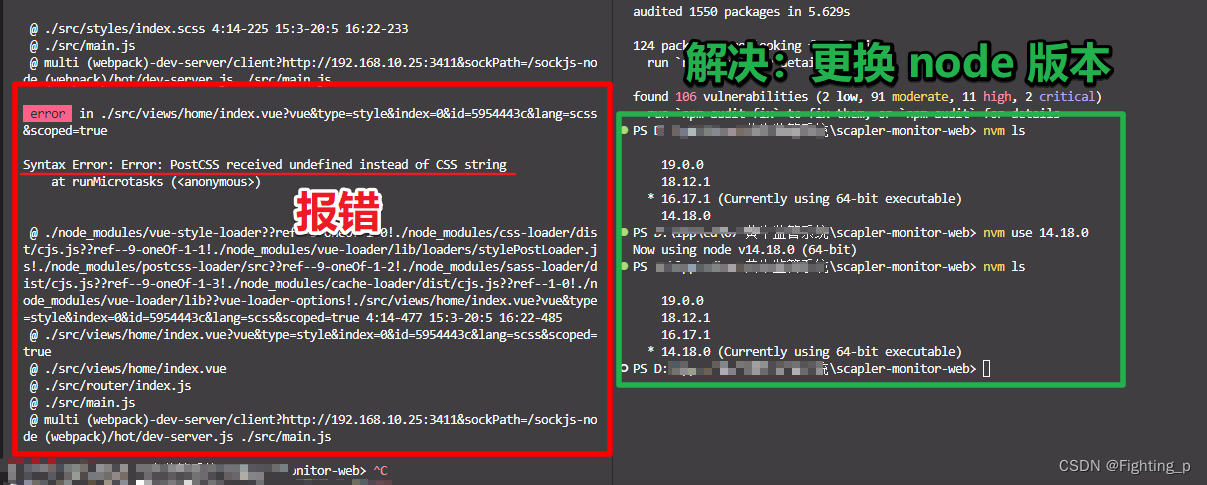
最近该项目没有做任何修改,今天运行突然跑不起来报错了 PostCSS received undefined instead of CSS string 【原因】突然想起来期间有换过 node 版本为 16.17.1 【解决】将 node 版本换回之前的 14.18.0 就可以了...

Spring揭秘:BeanDefinitionRegistry应用场景及实现原理!
内容概要 BeanDefinitionRegistry接口提供了灵活且强大的Bean定义管理能力,通过该接口,开发者可以动态地注册、检索和移除Bean定义,使得Spring容器在应对复杂应用场景时更加游刃有余,增强了Spring容器的可扩展性和动态性…...
蓝桥杯(3.5)
789. 数的范围 import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner sc new Scanner(System.in);int n sc.nextInt();int q sc.nextInt();int[] res new int[n];for(int i0;i<n;i)res[i] sc.nextInt();while(q-- ! 0) {int…...
434G数据失窃!亚信安全发布《勒索家族和勒索事件监控报告》
最新态势快速感知 最新一周全球共监测到勒索事件90起,与上周相比数量有所增加。 lockbit3.0仍然是影响最严重的勒索家族;alphv和cactus恶意家族也是两个活动频繁的恶意家族,需要注意防范。 Change Healthcare - Optum - UnitedHealth遭受了…...
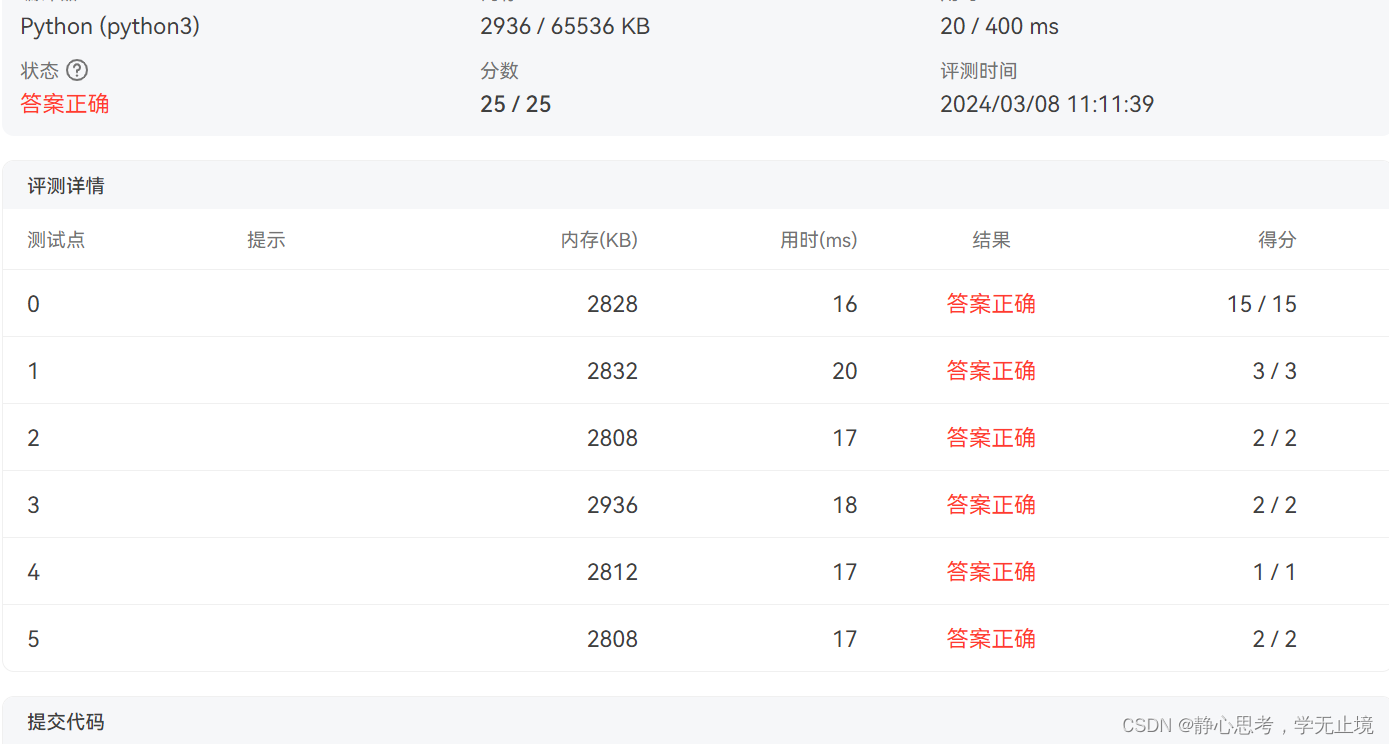
7-18 彩虹瓶(Python)
彩虹瓶的制作过程(并不)是这样的:先把一大批空瓶铺放在装填场地上,然后按照一定的顺序将每种颜色的小球均匀撒到这批瓶子里。 假设彩虹瓶里要按顺序装 N 种颜色的小球(不妨将顺序就编号为 1 到 N)。现在工…...
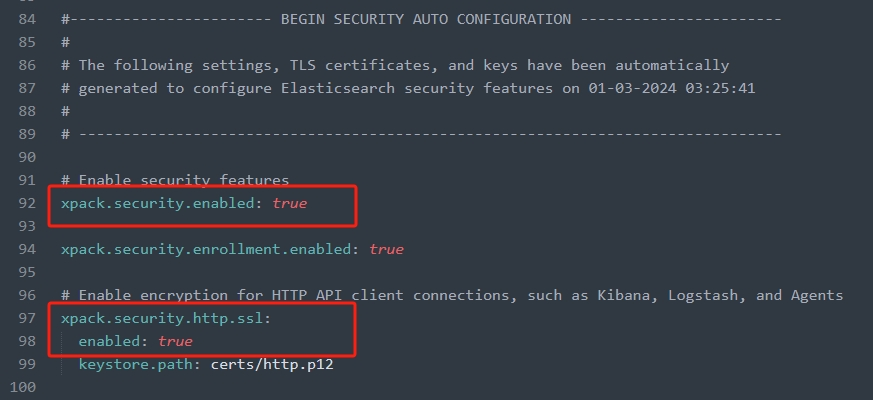
php使用ElasticSearch
ElasticSearch简介 Elasticsearch 是一个分布式的、开源的搜索分析引擎,支持各种数据类型,包括文本、数字、地理、结构化、非结构化。 Lucene与ElasticSearch Apache Lucene是一款高性能的、可扩展的信息检索(IR)工具库…...
wpf prism左侧抽屉式菜单
1.首先引入包MaterialDesignColors和MaterialDesignThemes 2.主页面布局 左侧菜单显示在窗体外,点击左上角菜单图标通过简单的动画呈现出来 3.左侧窗体外菜单 <Grid x:Name"GridMenu" Width"150" HorizontalAlignment"Left" Ma…...

揭秘AI新纪元:近期人工智能发展的惊人突破与未来展望
近年来,人工智能(AI)领域的发展可谓是日新月异,其强大的潜力和广阔的应用前景引发了全球范围内的关注。本文将带您领略近期AI发展的风采,一探这个神奇领域的未来展望。 首先,让我们回顾一下近期AI领域的几…...

C语言基础练习——Day01
目录 选择题 编程题 打印从1到最大的n位数 计算日期到天数转换 选择题 1、执行下面程序,正确的输出是 int x5,y7; void swap(int x, int y) {int z;zx;xy;yz; } int main() { int x3,y8; swap(int x, int y);printf("%d,%d\n",x, y);return …...

用云手机进行舆情监测有什么作用?
在信息爆炸的时代,舆情监测成为企业和政府决策的重要工具。通过结合云手机技术,舆情监测系统在品牌形象维护、市场竞争、产品研发、政府管理以及市场营销等方面发挥着关键作用,为用户提供更智能、高效的舆情解决方案。 1. 品牌形象维护与危机…...

神经网络(neural network)
在这一章中我们将进入深度学习算法,学习一些神经网络相关的知识,这些是有更加强大的作用,更加广泛的用途。 神经元和大脑(neurons and the brain): 我们对于我们的编程的进步主要来自我们对于大脑的研究,根据我们对于大脑的研究…...
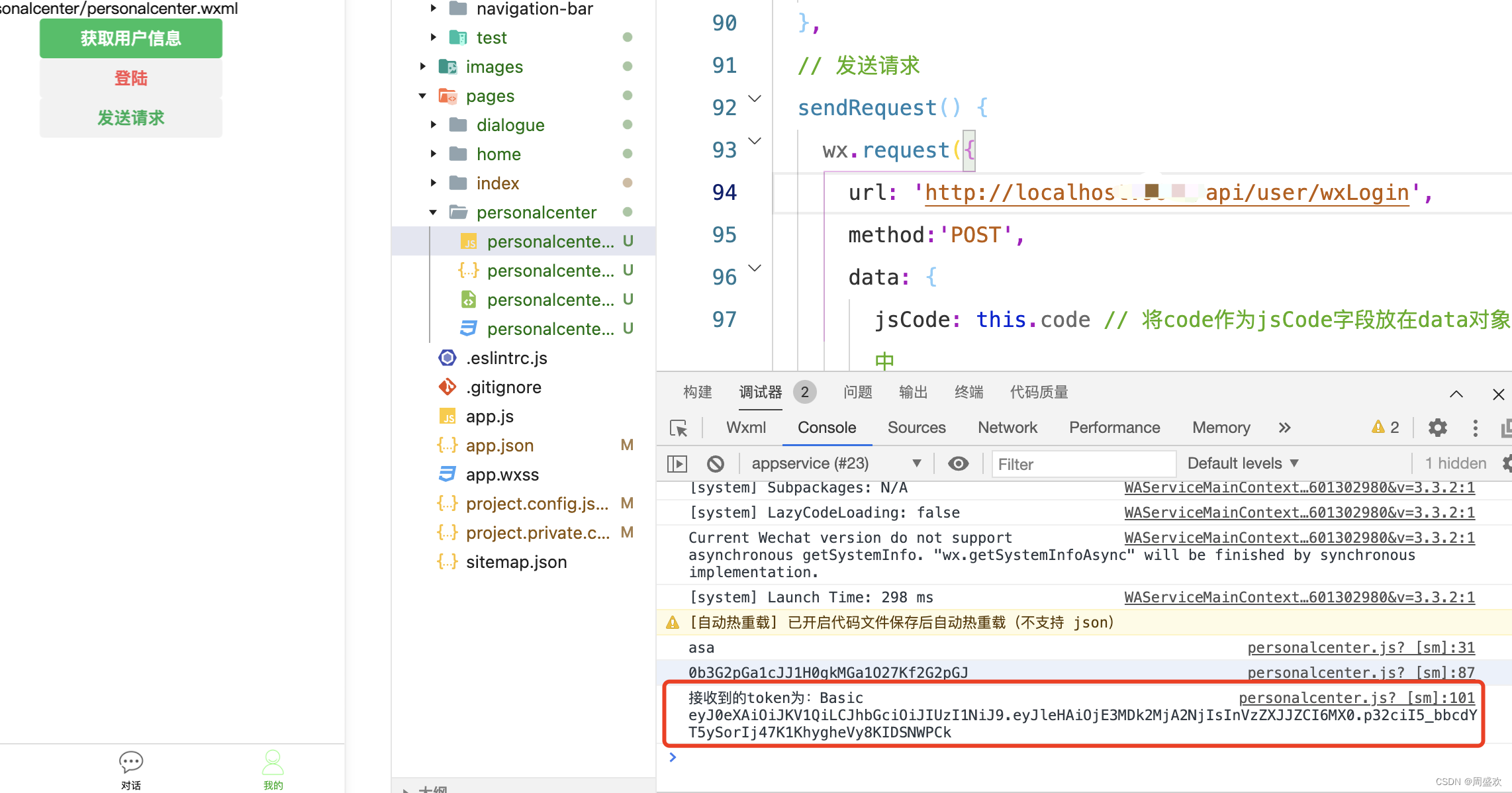
微信小程序用户登陆和获取用户信息功能实现
官方文档: https://developers.weixin.qq.com/miniprogram/dev/framework/open-ability/login.html 接口说明: https://developers.weixin.qq.com/miniprogram/dev/OpenApiDoc/user-login/code2Session.html 我们看官方这个图,梳理一下用户…...

2024年3月8日 晨会汇报
Good morning, colleagues! Before I dive into today’s work, I’d like to take a moment to share some updates over my work activities from yesterday and outline my agenda for today. Firstly, let me touch on the work activities from yesterday. Yesterday’…...

去电脑维修店修电脑需要注意什么呢?装机之家晓龙
每当电脑出现故障时,你无疑会感到非常沮丧。 如果计算机已过了保修期,您将无法享受制造商的免费保修服务。 这意味着您必须自费找到一家电脑维修店。 去电脑维修店并不容易。 大家一定要知道,电脑维修非常困难,尤其是笔记本电脑维…...

国家妇女节放假是法定的假日
在这个充满活力和希望的春天,我们迎来了一个特殊的节日——国家妇女节。这是一个属于所有女性的节日,是一个庆祝女性成就、关爱女性权益的时刻。在这个特殊的日子里,我们不禁要问:国家妇女节放假是法定假日吗?让我们一…...

Pytorch线性回归实现(Pycharm实现)
步骤都在注释里写清楚了,可以自己调整循环的次数观察输出的w与b和loss的值 import torch#学习率,用来进行w和b的更新 learning_rate 0.01 #1. 准备数据 #这里使用y3x0.8.也就是w3,b0.8.创造一个500行1列的数据 xtorch.rand([500,1]) y_true…...

2024新疆专升本考试报名教程详解
2024新疆专升本报名时间已经开始了,想要参加考试报名的同学可以提前准备好报名照...
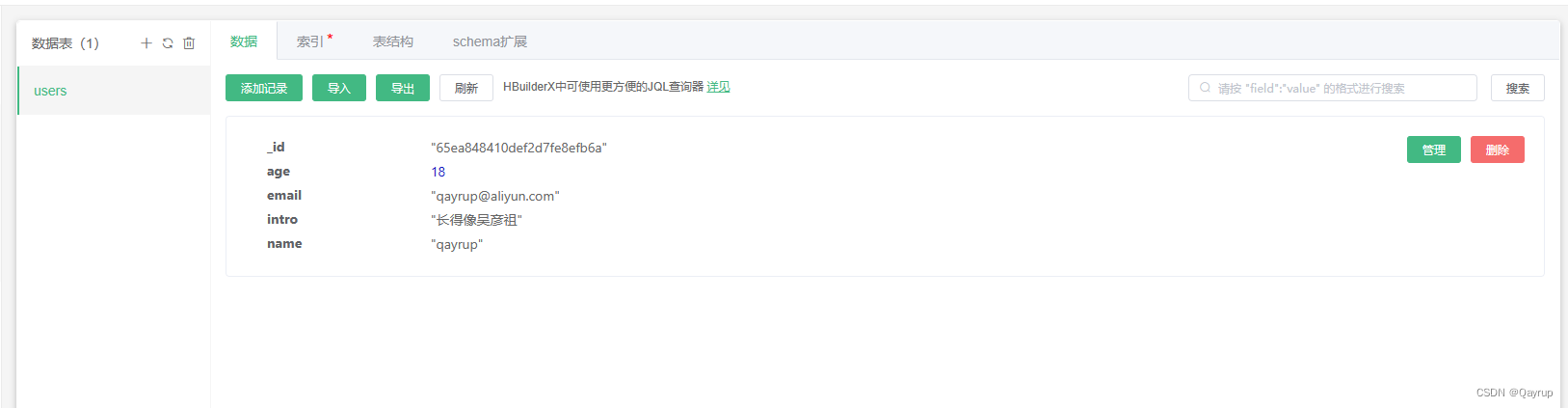
unicloud 云数据库概念及创建一个云数据库表并添加记录(数据)
云数据库概念 uniCloud提供了一个 JSON 格式的文档型数据库。顾名思义,数据库中的每条记录都是一个 JSON 格式的文档。 它是 nosql 非关系型数据库,如果您之前熟悉 sql 关系型数据库,那么两者概念对应关系如下表: 关系型JSON 文…...

抖音a_bogus逆向实战:手把手教你用Node.js补全缺失的window环境
抖音a_bogus逆向实战:Node.js环境补全指南 在JavaScript逆向工程领域,浏览器环境与服务端环境的差异一直是开发者面临的棘手问题。当我们尝试将抖音网页端的加密逻辑(如a_bogus生成算法)移植到Node.js环境时,经常会遇到…...

理解usearch的动态内存调整:实现高效向量搜索的终极指南
理解usearch的动态内存调整:实现高效向量搜索的终极指南 【免费下载链接】usearch Fast Open-Source Search & Clustering engine for Vectors & Arbitrary Objects in C, C, Python, JavaScript, Rust, Java, Objective-C, Swift, C#, GoLang, and Wolfr…...

迪文串口屏通信协议详解:从5AA5帧头到变量地址,一篇看懂HEX指令怎么发
迪文串口屏通信协议逆向解析:从帧头到数据域的HEX指令全解构 第一次拿到迪文串口屏的HEX指令时,那一串5A A5 11 82 0001 BFAA C6F4...让我完全摸不着头脑。为什么有的指令长度固定,有的却变化多端?地址字段和数据字段究竟如何划分…...

Wan2.2-I2V-A14B效果展示:水墨风、赛博朋克、胶片质感视频样例
Wan2.2-I2V-A14B效果展示:水墨风、赛博朋克、胶片质感视频样例 1. 惊艳的视频生成能力 Wan2.2-I2V-A14B文生视频模型展现了令人惊叹的创作能力,能够根据简单的文字描述生成高质量、风格多样的视频内容。这款专为RTX 4090D 24GB显存优化的私有部署镜像&…...
)
还在用老掉牙的HashTab?2024年最新文件哈希校验工具横向评测(附下载)
2024年文件哈希校验工具终极指南:告别过时方案,拥抱高效验证 还在为文件完整性验证发愁?每次下载重要软件都要反复核对哈希值却找不到趁手工具?作为从业十年的信息安全顾问,我见证了哈希校验工具从简陋到专业的演变。今…...

终极RPA档案解压指南:快速提取Ren‘Py游戏资源的完整教程
终极RPA档案解压指南:快速提取RenPy游戏资源的完整教程 【免费下载链接】unrpa A program to extract files from the RPA archive format. 项目地址: https://gitcode.com/gh_mirrors/un/unrpa 想要从RenPy视觉小说游戏中提取图片、音频和脚本资源吗&#x…...

ROS实战:UZH-FPV数据集下PL-EVIO与主流VIO算法的性能对比
1. UZH-FPV数据集与无人机视觉里程计的挑战 UZH-FPV数据集是苏黎世联邦理工学院发布的专门针对高速无人机场景的多模态数据集。这个数据集最大的特点在于它完整记录了无人机在高速机动飞行(最高速度超过10m/s)时的多传感器数据,包括双目事件相…...
)
RT-Thread PM组件实战:手把手教你为STM32L4移植低功耗驱动(含RTC时间补偿)
RT-Thread PM组件深度实战:STM32L4低功耗移植与RTC时间补偿全解析 1. 低功耗设计的工程挑战与解决方案 在电池供电的嵌入式设备开发中,我们常常面临一个核心矛盾:如何平衡系统性能与能耗。以智能水表为例,常规模式下MCU工作电流可…...
的图文多模态检索)
Nomic-Embed-Text-V2-MoE实战:基于卷积神经网络(CNN)的图文多模态检索
Nomic-Embed-Text-V2-MoE实战:基于卷积神经网络(CNN)的图文多模态检索 你有没有想过,让电脑像人一样,既能看懂图片,又能理解文字,还能把两者联系起来?比如,你拍一张商品…...

Jar Analyzer:提升Java开发效率的全方位JAR分析工具
Jar Analyzer:提升Java开发效率的全方位JAR分析工具 【免费下载链接】jar-analyzer Jar Analyzer - 一个 JAR 包 GUI 分析工具,方法调用关系搜索,方法调用链 DFS 算法分析,模拟 JVM 的污点分析验证 DFS 结果,字符串搜索…...