将Q算法和D算法结合应用到llm解码上之人在回路
将Q算法和D算法结合应用到llm解码上之人在回路
- 参考地址
- 代码
- 解释
参考地址
https://dongfangyou.blog.csdn.net/article/details/136466609
代码
import numpy as np
from tqdm import tqdmfrom sample import net, char2id_dict, get_real_p# 假设的词汇表
VOCABULARY = list(char2id_dict.keys())# 初始化Q表
q_table = {}
for word1 in VOCABULARY:for word2 in VOCABULARY:q_table[(word1, word2)] = 0# Q学习参数
alpha = 0.1 # 学习率
gamma = 0.6 # 折扣因子# 用户反馈函数
def get_user_feedback(generated_text):# 这个函数应该根据用户的实际反馈来更新Q表# 在这个简化示例中,我们随机生成反馈# print(f"Generated Text: {generated_text}")print("Please give your feedback (1 for positive, -1 for negative, 0 for neutral):")feedback = int(input())# feedback = np.random.choice([-1, 0, 1]) # 负面、中性、正面反馈return feedback# Q学习更新函数
def q_learning_update(q_table, state, action, reward, next_state):current_q = q_table.get((state, action), None)if current_q is None:current_q = 0q_table[(state, action)]=0max_future_q = max([q_table.get((next_state, a), 0) for a in VOCABULARY])new_q = (1 - alpha) * current_q + alpha * (reward + gamma * max_future_q)q_table[(state, action)] = new_qreturn q_table# LLM解码器
class LanguageModel:def __init__(self):# 假设的生成概率分布passdef generate_text(self, start_word, q_table):text = [start_word]current_word = start_wordwhile len(text) < 10: # 生成10个词汇的文本next_word = self.choose_next_word(current_word, q_table)text.append(next_word)current_word += next_wordreturn ' '.join(text)def choose_next_word(self, current_word, q_table):if np.random.rand() < 0.1: # 10%的概率随机选择return np.random.choice(VOCABULARY)else:# 根据Q表和模型概率选择下一个词汇q_values = []voc_probs=get_real_p(current_word, net, char2id_dict)for word in tqdm(VOCABULARY):v=q_table.get((current_word, word), 0) + voc_probs[char2id_dict[word]]q=wordq_values.append((v, q))return max(q_values)[1]# D*算法的重新规划函数
def d_star_lite_replan(q_table, generated_text, user_feedback):# 根据用户反馈更新Q表words = generated_text.split()for i in range(len(words) - 1):state = words[i]action = words[i + 1]reward = user_feedbacknext_state = words[i + 2] if i + 2 < len(words) else Noneq_table = q_learning_update(q_table, state, action, reward, next_state)return q_table# 训练循环
model = LanguageModel()
for episode in range(100):generated_text = model.generate_text('当时明月在', q_table)print(f"Episode {episode}: {generated_text}")# 获取用户反馈reward = get_user_feedback(generated_text)# 使用D*算法重新规划解码策略q_table = d_star_lite_replan(q_table, generated_text, reward)# 最终生成的文本
final_text = model.generate_text('当时明月在', q_table)
print(f"Final Text: {final_text}")解释
上述代码是一个简化的Q学习算法和D*算法的示例,用于生成文本。
首先,代码定义了一个词汇表VOCABULARY,以及一个初始Q表q_table,以及学习率alpha和折扣因子gamma。
接下来,代码定义了两个函数get_user_feedback和q_learning_update。get_user_feedback函数用于获取用户对生成的文本的反馈,可以选择负面、中性或正面反馈,或者根据实际情况自定义反馈。q_learning_update函数用于更新Q表,根据当前状态、动作、奖励和下一个状态来更新Q值。
然后,代码定义了一个LanguageModel类,其中包含生成文本和选择下一个词汇的函数。在生成文本的过程中,根据当前词汇和Q表来选择下一个词汇。其中,有10%的概率随机选择,90%的概率根据Q表和模型概率选择。
接下来,代码定义了一个d_star_lite_replan函数,用于根据用户反馈重新规划解码策略。根据生成的文本和用户反馈,更新Q表。
最后,代码使用循环进行训练。在每个循环中,生成文本并获取用户反馈,根据用户反馈重新规划解码策略。训练结束后,生成最终的文本。
需要注意的是,代码中的LanguageModel类和相关函数只是用于示例,实际应用中需要根据具体需求进行修改和优化。此外,代码中的模型生成概率分布和词汇表是假设的,实际应用中需要根据实际情况进行定义。
相关文章:

将Q算法和D算法结合应用到llm解码上之人在回路
将Q算法和D算法结合应用到llm解码上之人在回路 参考地址代码解释 参考地址 https://dongfangyou.blog.csdn.net/article/details/136466609 代码 import numpy as np from tqdm import tqdmfrom sample import net, char2id_dict, get_real_p# 假设的词汇表 VOCABULARY lis…...
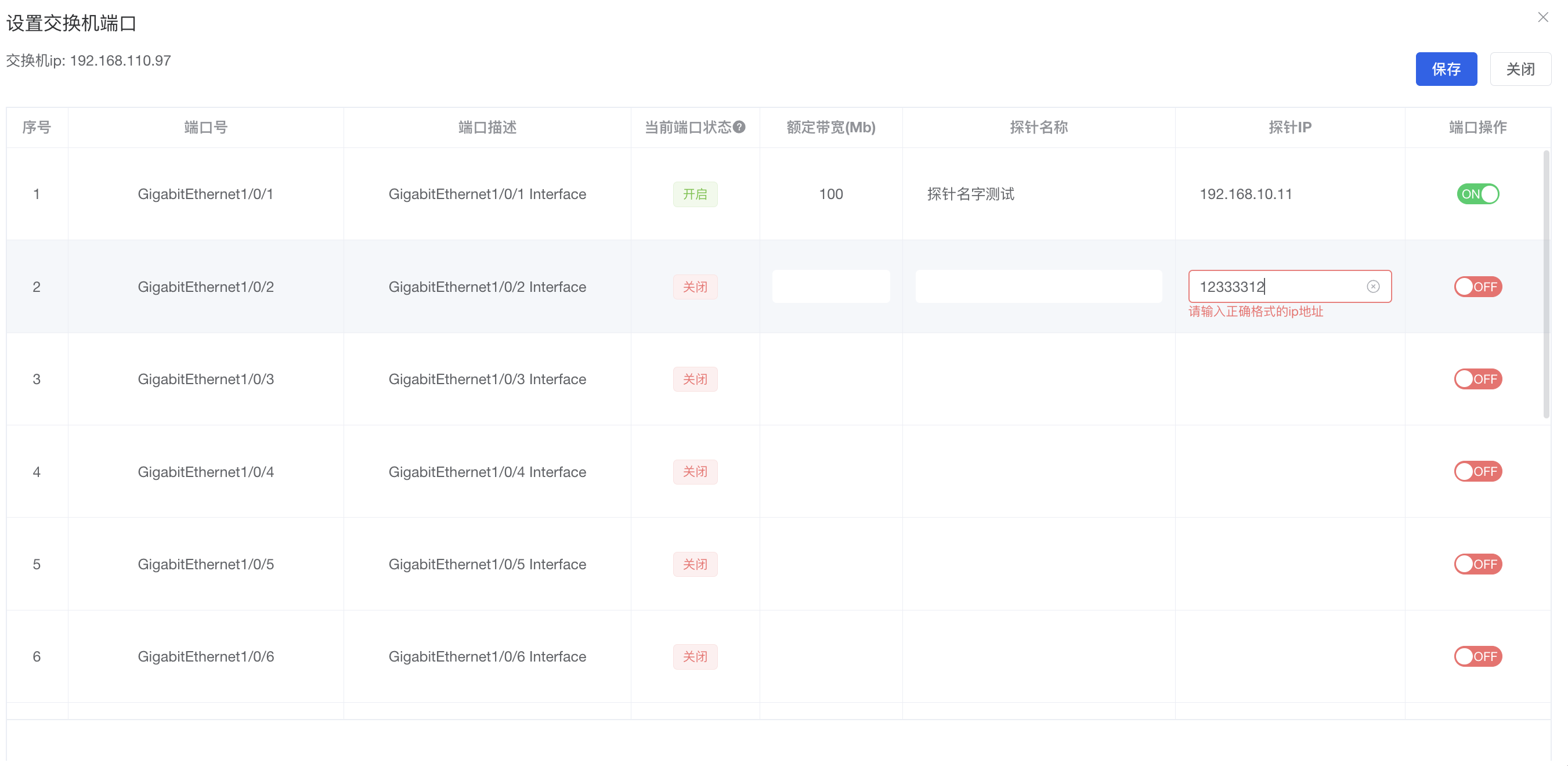
el-table-column嵌套el-form-item不能进行校验问题解决
项目为vue3elementPlus开发的项目 业务要求:table表格展示数据,其中有一行是ip地址可展示可修改,此处要求增加自定义校验规则 先看一下效果: 此处先描述一下,问题出在了哪里,我将el-table的data,使用一个…...

leetcode200. 岛屿数量
leetcode200. 岛屿数量 题目 思路 遍历每一个网格,若网格为1,岛屿数量1,利用一个深度优先搜索函数将岛屿置零,注意判断数组边界 代码 class Solution:def numIslands(self, grid: List[List[str]]) -> int:self.grid grid…...

MySQL--索引类型详解
索引的类型 主键索引: PRIMARY KEY,当一张表的某个列是主键的时候,该列就是主键索引,一张表只允许有一个主键索引,主键所在的列不能为空。 创建主键索引的SQL语法: # 给user表中的id字段创建名为id_ind…...

R语言中ggplot2图例位置、颜色、背景、标题
目录 1、不显示图例 2、自定义图例位置 3、修改图例背景颜色、外框颜色、大小 4、修改图例大小 5、图例设置背景、线框为空 6、自定义设置多个图例的标题 7、设置多个图例的之间的间隔 8、取消不需要的图例显示 1、不显示图例 theme(legend.position "none"…...

波卡 Alpha 计划启动,呼唤先锋创新者重新定义 Web3 开发
原文:https://polkadot.network/blog/the-polkadot-alpha-program-a-new-era-for-decentralized-building-collaboration/ 编译:OneBlock 区块链领域不断发展,随之而来的是发展和创新机会的增加。而最新里程碑是令人振奋的 Polkadot Alpha …...

公网IP与私有IP及远程互联
1.公网有私有IP及NAT 公网IP是全球唯一的IP,通过公网IP,接入互联网的设备是可以访问你的设备。但是IPV4资源有限,一般ISP(Internet Service Provider)并不会为用户提供公网IP。所以家里的计算机在公司是没法直接使用windows远程桌面直接访问…...

openCV xmake debug失效 release可以使用
在使用xmake构建一个项目时,添加openCV库,调用 imread函数时,debug函数失效, release可以使用,最后发现是xmake.lua写的有问题 option("OpenCV4.6.0")set_showmenu(true) set_default(true) set_category(&…...
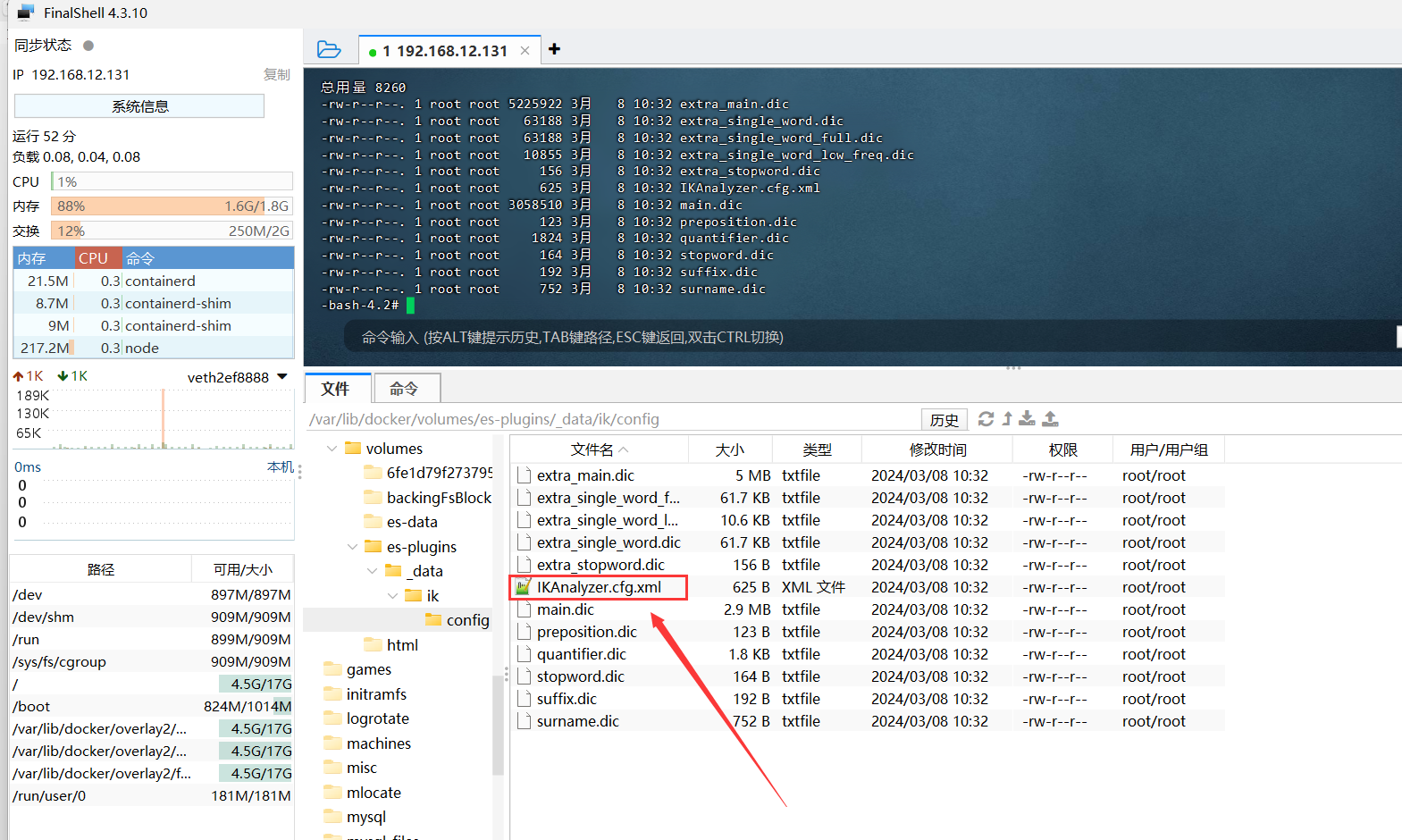
ES分布式搜索-IK分词器
ES分词器-IK 1、为什么使用分词器? es在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词。但默认的分词规则对中文处理并不友好。 我们在kibana的DevTools中测试: GET /_analyze {"analyzer": "…...

基于卷积神经网络的野外可食用植物分类系统
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :) 1. 项目简介 本文详细探讨了一基于深度学习的可食用植物图像识别系统。采用TensorFlow和Keras框架,利用卷积神经网络(CNN)进行模型训练和预测,并引入迁移学习模型…...
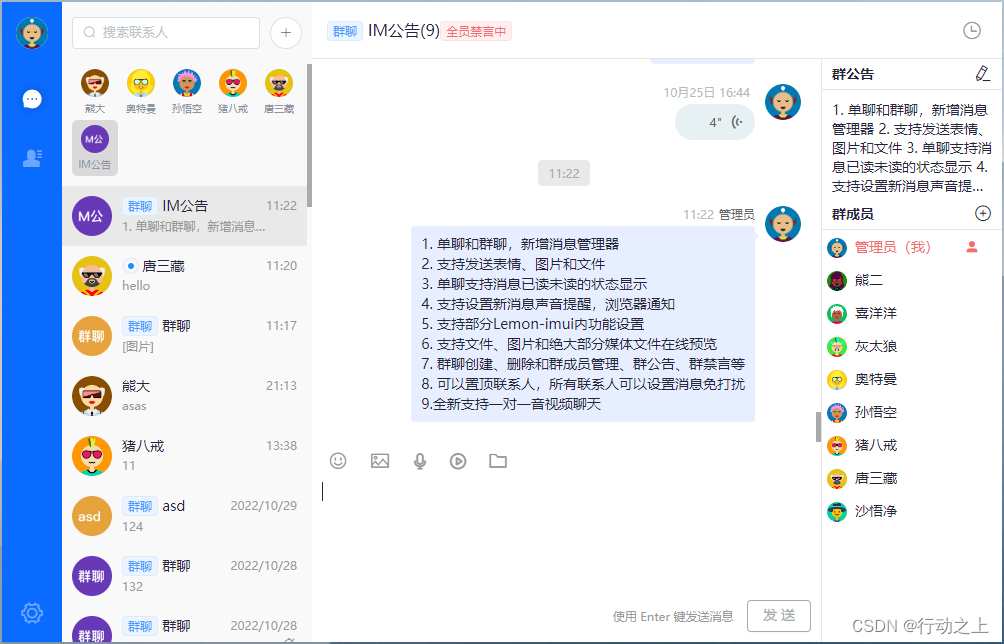
Raingad IM即时聊天/即时通讯网站源码,附带系统搭建教程
支持功能 支持单聊和群聊,支持发送表情、图片、语音、视频和文件消息单聊支持消息已读未读的状态显示,在线状态显示群聊创建、删除和群成员管理、群公告、群禁言等支持置顶联系人,消息免打扰;支持设置新消息声音提醒,…...
)
for语句的实际应用(3)
3145:【例24.3】 奇数求和 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 9847 通过数: 5442 【题目描述】 计算非负整数 m 到 n(包括 m 和 n)之间的所有奇数的和,其中,m 不大于 n,且 n 不大…...

c++ Windows获取软件安装列表信息
链接 #include <windows.h> #include <stdio.h> #include <iostream> #include <vector>using namespace std;#ifndef MSVCR #define _T #define _tcscpy strcpy #define _stprintf sprintf #define _tcscmp strcmp #endifclass SetupSoftInfo { publ…...

音视频学习笔记——c++多线程(一)
✊✊✊🌈大家好!本篇文章主要整理了部分多线程相关的内容重点😇。首先讲解了多进程和多线程并发的区别以及各自优缺点,之后讲解了Thead线程库的基本使用。 本专栏知识点是通过<零声教育>的音视频流媒体高级开发课程进行系统…...

消息队列常见问题
总的来讲,消息队列常见问题要么消息不能多,要么不能少,还有顺序性,以及积压处理的问题等。 1.消息不能多 也就是说,消息不能重复消费,随之带来的幂等性问题。 解决:一般结合业务场景…...

【leetcode热题】二叉树的前序遍历
难度: 中等通过率: 49.5%题目链接:. - 力扣(LeetCode) 题目描述 给定一个二叉树,返回它的 前序 遍历。 示例: 输入: [1,null,2,3] 1\2/3 输出: [1,2,3]进阶: 递归算法很简单,你可以通过迭代…...

Linux命令记不住?保姆级教程来了
在软件开发过程中,Linux操作系统因其稳定性、安全性和高效性而备受青睐。作为开发者,熟练掌握Linux常用命令,不仅可以提高工作效率,还能更好地管理服务器和进行代码部署。本文将介绍一些开发常用的Linux命令及其应用场景ÿ…...
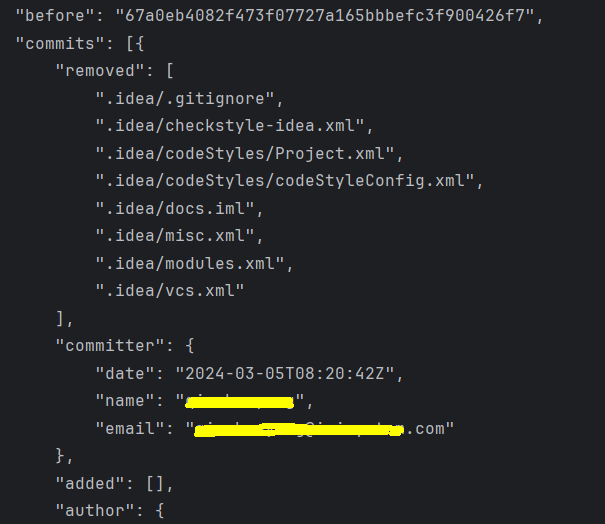
基于GitBucket的Hook构建ES检索PDF等文档全栈方案
背景 之前已简单使用ES及Kibana和在线转Base64工具实现了检索文档的demo,预期建设方案是使用触发器类型从公共的文档源拉取最新的文件,然后调用Java将文件转Base64后入ES建索引,再提供封装接口给前端做查询之用。 由于全部内容过长ÿ…...

C语言:数组、字符串知识点整理:
数组:(长度的计算) 补充:数组长度sizeof(arr)/sizeof(arr[0]) 注意:!!!不适用于当arr 充当形参时(函数传参)!!! 因为函数…...
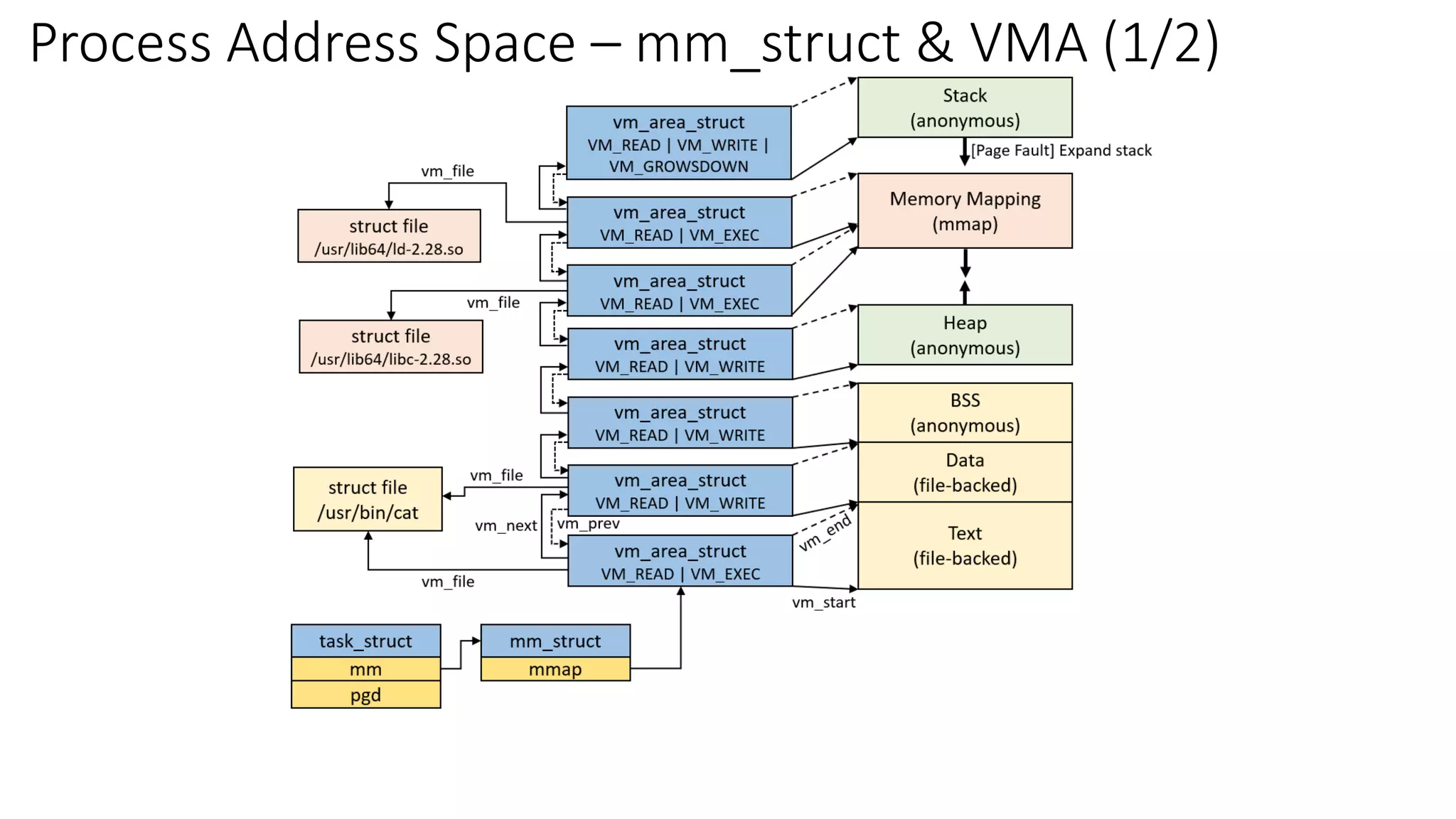
Linux mmap系统调用
文章目录 前言一、mmap()函数简介二、代码演示2.1 mmap使用场景2.2 私有匿名映射2.3 私有文件映射2.4 共享匿名映射2.5 共享文件映射 参考 前言 NAMEmmap, munmap - map or unmap files or devices into memorySYNOPSIS#include <sys/mman.h>void *mmap(void *addr, siz…...

Python列表操作教程
Python列表操作教程 【免费下载链接】mx-bili-plugin 项目地址: https://gitcode.com/gh_mirrors/mx/mx-bili-plugin 基础概念 列表是Python中最常用的数据结构之一... 视频演示 关键代码示例 # 创建列表 my_list [1, 2, 3, 4, 5]# 列表切片操作 subset my_list[1…...

设计师必备!Sketch MeaXure:告别手动标注,5分钟搞定设计规范的终极方案
设计师必备!Sketch MeaXure:告别手动标注,5分钟搞定设计规范的终极方案 【免费下载链接】sketch-meaxure 项目地址: https://gitcode.com/gh_mirrors/sk/sketch-meaxure 还在为繁琐的设计标注而头疼吗?Sketch MeaXure插件…...
)
【Dify国产化部署实战指南】:信创环境适配、等保合规与性能压测全闭环(2024最新版)
第一章:Dify国产化部署测试概述Dify 是一款开源的低代码大语言模型应用开发平台,支持快速构建 AI 原生应用。在信创背景下,其国产化适配能力成为关键评估维度。本章聚焦于 Dify 在主流国产软硬件环境下的部署验证实践,涵盖操作系统…...

别再只盯着Kaggle了!这10个免费数据源网站,让你数据分析项目素材不重样
解锁数据分析新视野:10个鲜为人知的免费数据宝藏平台 当你在深夜对着电脑屏幕,反复加载着Kaggle上那个已经被无数人用过的泰坦尼克号数据集时,是否曾想过——数据分析的世界远不止于此?真正有价值的数据分析项目,往往始…...
)
用DAC0832和汇编语言生成波形:一个微机接口实验的保姆级复盘(附完整代码)
用DAC0832和汇编语言生成波形:从硬件连调到代码优化的全流程实战 记得第一次接触DAC0832芯片时,面对密密麻麻的引脚和晦涩的时序图,我完全不知道从何下手。直到在实验室熬了三个通宵,烧坏两块芯片后,才真正理解数模转换…...

ITK-SNAP医学图像分割:3步掌握专业级医学影像分析
ITK-SNAP医学图像分割:3步掌握专业级医学影像分析 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 想要在医学影像分析中实现精准分割却无从下手?ITK-SNAP这款开源工具…...

从数据碎片到数字记忆:WeChatMsg如何重构你的微信对话价值
从数据碎片到数字记忆:WeChatMsg如何重构你的微信对话价值 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/W…...

从SGL到XSimGCL:图对比推荐中的“简化”革命与性能跃迁
1. 图对比学习推荐算法的演进之路 推荐系统领域近年来最令人兴奋的突破之一,就是图对比学习技术的引入。作为一名长期跟踪推荐算法发展的从业者,我亲眼见证了从传统协同过滤到图神经网络的演进,再到如今对比学习带来的性能飞跃。这就像是从手…...

2026届学术党必备的十大降重复率平台推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于学术写作跟科研发表进程当中,重复率过高属于常见阻碍。降重网站当作辅助工具&a…...

QQ空间说说备份终极指南:5分钟免费导出所有历史记录
QQ空间说说备份终极指南:5分钟免费导出所有历史记录 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否担心QQ空间里那些珍贵的青春记忆会随着时间流逝而消失?…...