[项目设计] 从零实现的高并发内存池(三)
🌈 博客个人主页:Chris在Coding
🎥 本文所属专栏:[高并发内存池]
❤️ 前置学习专栏:[Linux学习]
⏰ 我们仍在旅途

目录
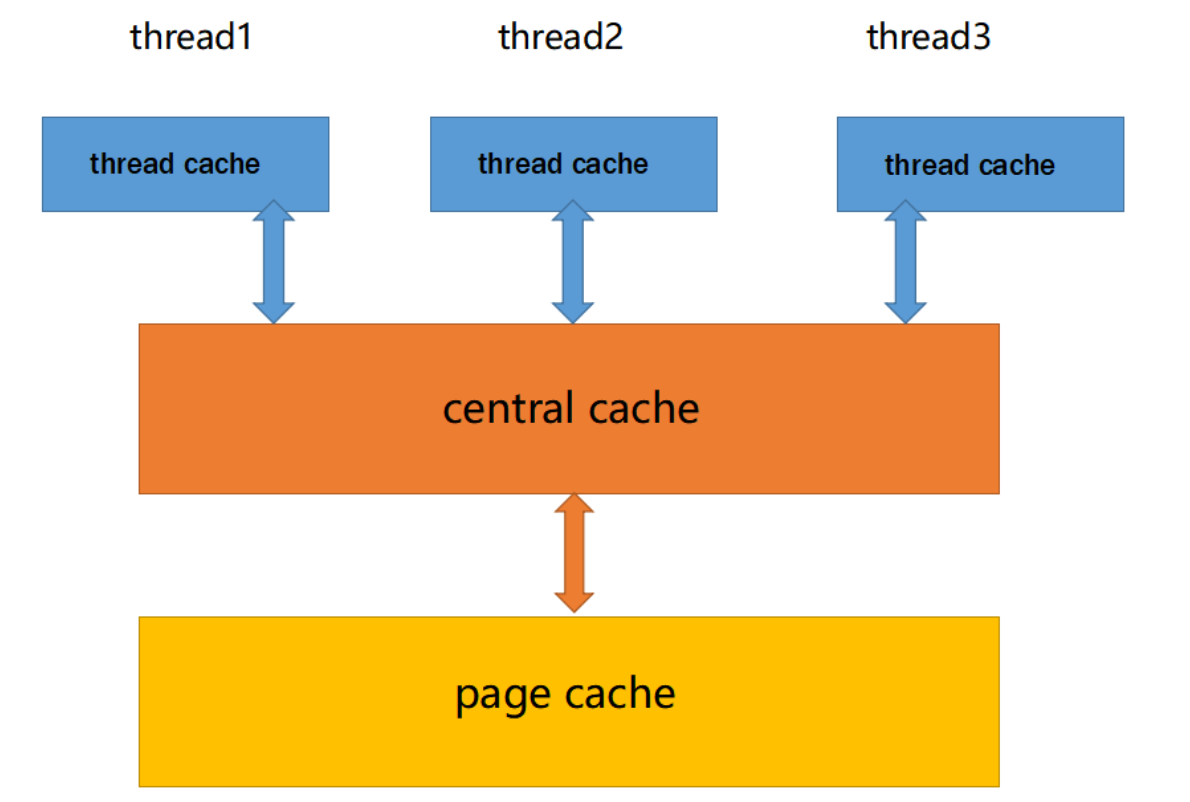
4.CentralCache实现
4.1 CentralCache整体架构
4.2 围绕Span的相关设计
页号
Span
Spanlist
4.3 向CentralCache申请内存
CentralCache.h
FetchFromCentralCache
FetchRangeObj
5.PageCache实现
5.1 PageCache整体架构
5.2 向CentralCache申请内存
PageCache.h
GetOneSpan
NewSpan
申请过程联调单元测试
4.CentralCache实现
4.1 CentralCache整体架构

哈希桶结构: Central Cache 和 Thread Cache 都采用了哈希桶的结构。这意味着内存块根据其大小被分配到不同的桶中。每个桶都可以独立地管理一定大小范围内的内存块。
锁机制: 由于 Central Cache 是多个线程共享的,所以在访问 Central Cache 时需要考虑线程安全性。一种常见的做法是使用桶锁,即为每个桶分配一个锁。这样在多个线程同时访问同一个桶时,只有该桶的锁会被竞争,而其他桶的访问不受影响,从而降低了锁的竞争程度。
Span 结构: Central Cache 中的每个桶中存储的是 Span,而不是单个内存块。Span之间以双向链表的形式链接。Span 是以页为单位的大块内存,它们会被切分为更小的内存块以便分配给线程使用。每个 Span 中还包含一个空闲链表,其中存储了切分后的内存块。这种设计能够提高内存分配的效率,减少内存碎片化。
Spanlist: Spanlist 采用双向链表结构组织维护Span内存块,这样可以在 O(1) 的时间内进行Span的分配和释放操作。通过简单地修改指针,就可以将内存块从 Span 的空闲链表中取出或者放回,这样保证了内存分配和释放的高效性。
Spanlists与 freelists遵循同一对齐映射规则: 在 Central Cache 中,Spanlists 是存储 Spanlist(Span 的双向链表)的数组,而 freelists 则是存储空闲内存块链表的数组。 它们的下标对应关系设计得非常巧妙,即 freelists 的下标与 Spanlists 中的每个桶对应。这样就能够确保每个桶中的 Span 在 freelists 中有相应的位置,从而方便线程在需要时快速定位到合适的内存块。
内存块的切分: 每个 Span 中的内存块是根据其所在的哈希桶的大小要求进行切分的,以对应下标相同的freelist。这样可以确保每个哈希桶中存储的内存块大小是符合预期的,方便线程在需要时从 Central Cache 中获取适当大小的内存块。
4.2 围绕Span的相关设计
页号
前面讲到Span 是以页为单位的大块内存,在讲到定长内存池时我们也提过页的大小一般是8K,既然Span是以页为单位,那么我们可以将整个内存从零开始划分成不同的页并编号的形式统一管理。
这里,我们可以给不同的页编上不同的ID(也就是页号)用于区分
可是页号要用什么类型来表示呢?
- 在32位平台下,进程地址空间的大小是 。
- 在64位平台下,进程地址空间的大小是 。
- 页的大小通常是8KB。
- 在32位平台下,进程地址空间可以被分成个页。
- 在64位平台下,进程地址空间可以被分成 个页。
而size_t类型能表示的数值范围为: 0到-1 ,因此我们不能单纯用size_t来实现,这里需要借助条件编译的方式在Common.h中实现不同平台下的页号类型。
#ifdef _WIN64
typedef unsigned long long PAGEID;
#elif _WIN32
typedef size_t PAGEID;
#endif(在32位下,_WIN32有定义,_WIN64没有定义;而在64位下,_WIN32和_WIN64都有定义)
Span
struct Span
{PAGEID _pageId = 0;size_t _n = 0;Span* _next = nullptr;Span* _prv = nullptr;size_t _used = 0;void* _freeList = nullptr;
};
- _pageId:记录大块内存起始页的页号,便于后续在Page Cache中进行内存合并。
- _n:记录该Span管理的页的数量,这个数量并不是固定的,可能会根据各种因素进行调整。
- _next和_prev:双链表结构,用于将Span组织成链表,方便进行插入和删除操作。
- _used:记录被分配给thread cache的内存块数量,当所有内存块被还回时,_used变为0,表示该Span可被归还给Page Cache。
- _freeList:切好的小块内存的空闲链表,用于存储被切分出来的内存块,以便于后续分配给请求线程。
Spanlist
通过我们之前CentralCache的整体架构,我们知道CentralCache的每个哈希桶里面存储的都是一个双链表结构,对于该双链表结构我们直接定义为Spanlist对其进行封装。其逻辑就是基础的带头双向循环链表,这里不多赘述。需要注意的是我们在这里需要定义好我们的桶锁,因为CentralCache可能会同时有多个线程访问,通过桶锁(也就是只在每个Spanlist加锁)的方式,我们不仅满足了线程安全,同时也降低了锁的竞争激烈程度。
class SpanList //带头双向循环链表
{
public:SpanList(){_head = new Span;_head->_next = _head;_head->_prv = _head;}bool empty(){return _head->_next == _head;}Span* begin(){return _head->_next;}Span* end(){return _head;}void push_front(Span* span){insert(_head->_next, span);}Span* pop_front(){return erase(_head->_next);}void insert(Span* pos, Span* span){//插在pos前面span->_next = pos;span->_prv = pos->_prv;pos->_prv->_next = span;pos->_prv = span;}Span* erase(Span* pos){pos->_next->_prv = pos->_prv;pos->_prv->_next = pos->_next;return pos;}std::mutex _mtx; // 桶锁
private:Span* _head;
};
4.3 向CentralCache申请内存
CentralCache.h
每个线程都有一个属于自己的thread cache,我们是用TLS来实现每个线程无锁的访问属于自己的thread cache的。而central cache和page cache在整个进程中只有一个,我们直接将其设置为单例模式。
#pragma once
#include"Common.h"
class CentralCache
{
public:static CentralCache& GetInstance(){return _SingleInstance;}// ...
private:CentralCache(){}CentralCache(const CentralCache&) = delete;static CentralCache _SingleInstance;SpanList _spanlists[NFREELISTS];
};为了保证CentralCache类只能创建一个对象,我们将central cache的构造函数和拷贝构造函数设置为私有。CentralCache类当中还需要有一个CentralCache类型的静态的成员变量,当程序运行起来后我们就立马创建该对象,在此后的程序中就只有这一个单例了。
CentralCache CentralCache::_SingleInstance;FetchFromCentralCache
话接上回,当线程申请某一大小的内存时,如果ThreadCache中对应的空闲链表不为空,那么直接取出一个内存块进行返回即可,但如果此时该空闲链表为空,那么这时ThreadCache就需要向调用FetchFromCentralCache函数来向CentralCache申请内存了。
这个时候我们可以结合本章讲到的CentralCache的整体架构来大致分析 FetchFromCentralCache的调用流程。由于我们是将CentralCache的Span链表与ThreadCache的空闲链表下标一 一对应,我们可以直接传入index。而根据所传入的index下标,CentralCache就可以找到对应的Spanlist链表,从中取得一个Span块,再拿取里面已经切分好的内存块
void* ThreadCache::FetchFromCentralCache(size_t index, size_t align_size)
{size_t batch_num = std::min(_freelists[index].MaxSize(), SizeTable::BatchSizeLimit(align_size));if (_freelists[index].MaxSize() == batch_num){_freelists[index].MaxSize()++;}void* start = nullptr;void* end = nullptr;size_t actual_num = CentralCache::GetInstance().FetchRangeObj(start, end, batch_num, align_size);assert(actual_num > 0);if (actual_num == 1){assert(start == end);return start;}else{_freelists[index].push_range(*(void**)start, end);return start;}return nullptr;
}慢开始算法反馈调节
void* ThreadCache::FetchFromCentralCache(size_t index, size_t align_size)
{size_t batch_num = min(_freelists[index].MaxSize(), SizeTable::BatchSizeLimit(align_size));if (_freelists[index].MaxSize() == batch_num){_freelists[index].MaxSize()++;}// ...
}我们在SizeTable中加入对该大小的内存块单次申请个数的上限计算函数BatchSizeLimit()
class SizeTable
{
public:// ...static size_t BatchSizeLimit(size_t size){size_t maxnum = MAXSIZE / size;if (maxnum < 2){maxnum = 2;}else if (maxnum > 512){maxnum = 512;}return maxnum;}// ...
};我们在FreeList中加入该空闲链表内存块单次申请个数的上限函数
class FreeList
{
public:// ...size_t& MaxSize(){return _MaxSize;}// ...
private:// ...size_t _MaxSize = 1;// ...
};- 通过慢开始算法最开始不会一次向CentralCache一次批量要太多,因为一次性要太多了可能用不完,造成空间资源浪费
- 随着向CentralCache申请内存的次数增加,该空闲链表每次可申请内存块的最大值_MaxSize就会随之增大,相应的每次申请到的batch_num就会不断增长,直到上限
- align_size越大,一次向central cache要的batch_num就越小,可以避免过多内存被浪费。
- align_size越小,一次向central cache要的batch_num就越大,可以减少频繁申请内存的次数,提高资源利用率。
push_range()
这里我们假设FetchRangeObj()为我们申请回了一串内存块链表,这里我们只需要返回一个内存块返回供外部调用,而多余的则需要插回到我们发起申请的空闲链表中,于是我们继续在FreeList中加入push_range()来满足
class FreeList
{
public:// ...void push_range(void* start,void* end){*(void**)end = _FreeList;_FreeList = start;}// ...
};FetchRangeObj
size_t actual_num = CentralCache::GetInstance().FetchRangeObj(start, end, batch_num, align_size);这里我们要从central cache获取n个指定大小的对象,这些对象肯定都是从central cache对应哈希桶的某个span中取出来的,因此取出来的这n个对象是链接在一起的,我们只需要得到这段链表的头和尾即可,这里可以采用输出型参数进行获取。
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batch_num, size_t align_size)
{size_t index = SizeTable::Index(align_size);_spanlists[index]._mtx.lock();Span* span = GetOneSpan(_spanlists[index], align_size);size_t actual_num = 1;start = span->_freeList;end = start;while (*(void**)end != nullptr && actual_num < batch_num){end = *(void**)end;++actual_num;}span->_freeList = *(void**)end;*(void**)end = nullptr;span->_used += actual_num;_spanlists[index]._mtx.unlock();return actual_num;}- 首先,根据 align_size 计算出对应的 index,用于确定在 _spanlists 数组中的位置。
- 获取到对应 _spanlists[index] 的互斥锁,确保在多线程环境下的安全访问。
- 调用 GetOneSpan 函数(后面实现)从 _spanlists[index] 中获取一个 Span 对象,用于管理内存块。
- 通过遍历 Span 对象的自由链表,获取 batch_num 个内存块的范围。
- 将获取到的内存块范围的起始地址和结束地址分别保存在 start 和 end 中,并同时更新 actual_num 记录实际获取的内存块数量。
- 更新 Span 对象的相关信息,包括更新 freeList 指针、增加 used 计数等。
- 释放对 _spanlists[index] 的互斥锁,确保其他线程能够访问该 _spanlists[index]。
- 返回实际获取的内存块数量 actual_num。
5.PageCache实现
5.1 PageCache整体架构

![]()
哈希桶结构: PageCache 也采用哈希桶的结构,用于管理不同大小的内存页块。每个哈希桶对应一定数量的页数范围,例如一个哈希桶可能管理 1 页的内存块,另一个哈希桶可能管理 2 页的内存块,以此类推。
Span 管理: 类似于 CentralCache,PageCache 中的每个哈希桶也挂载着一系列的 Span 对象。这些 Span 对象用于管理连续的内存页块,记录了页块的起始地址和大小。
内存分配与释放: PageCache 负责管理大块内存页的分配和释放。当 CentralCache 需要大块内存页时,它会向 PageCache 发送请求。PageCache 根据请求的页数找到对应的哈希桶,从中获取一个 Span,并将该 Span 切分成适当数量的页块返回给 Central Cache。当页块被释放时,它们会被合并成更大的连续内存页块,以提高内存利用率。
内存大小与桶号映射: 与 CentralCache 不同,PageCache 的哈希桶映射规则采用直接定址法。例如,第 1 号哈希桶中挂载的都是 1 页的 Span,第 2 号哈希桶中挂载的都是 2 页的 Span,依此类推。这样设计的好处是能够简化哈希桶的访问,便于根据请求的页数快速定位到对应的哈希桶。
线程安全处理: 由于多个线程可能同时访问 PageCache 的不同哈希桶,为了保证数据的一致性和安全性,PageCache 使用一个大锁来保护整个 PageCache,确保在任何时候只有一个线程可以对 PageCache 进行访问。
5.2 向CentralCache申请内存
按照上述整体架构,PageCache中列表的个数是128个(这里为了满足数组下标直接对应,我们定义成129),以及页面位移 (页的大小 = 1<<PAGESHIFT)
static const int PAGESHIFT = 13;static const int NPAGES = 129;同时此时加上我们在实现定长内存池时封装的申请释放内存接口
#ifdef _WIN32
#include <windows.h>
#endif
inline static void* SystemAlloc(size_t kpage) {
#ifdef _WIN32void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#endifif (ptr == nullptr)throw std::bad_alloc();return ptr;
}
inline static void SystemFree(void* ptr)
{
#ifdef _WIN32VirtualFree(ptr, 0, MEM_RELEASE);
#endif
}PageCache.h
page cache在整个进程中也是只能存在一个的,因此我们也需要将其设置为单例模式。
#pragma once
#include"Common.h"
class PageCache
{
public:static PageCache& GetInstance(){return _SingleInstance;}std::mutex _pagemtx;
private:PageCache(){}PageCache(const PageCache&) = delete;static PageCache _SingleInstance;SpanList _Spanlists[NPAGES];
};当程序运行起来后我们就立马创建该对象,在此后的程序中就只有这一个单例了。
PageCache PageCache::_SingleInstance;GetOneSpan
Span* CentralCache::GetOneSpan(SpanList& list, size_t align_size)
{// 查看当前的spanlist中是否有还有未分配对象的spanSpan* it = list.begin();while (it != list.end()){if (it->_freeList != nullptr){return it;}else{it = it->_next;}}list._mtx.unlock();//没有一个现成能使用的span对象,多申请几个spanPageCache::GetInstance()._pagemtx.lock();Span* span = PageCache::GetInstance().NewSpan(SizeTable::PageSizeLimit(align_size));PageCache::GetInstance()._pagemtx.unlock();//把span切好后挂到自己的_freelist上void* start = (void*)(span->_pageId << PAGESHIFT);size_t bytes = span->_n << PAGESHIFT;void* end = (char*)start + bytes;span->_freeList = start;void* cur = start;void* tail = (char*)start + align_size;while (tail < end){*(void**)cur = tail;cur = tail;tail = (char*)tail + align_size;}*(void**)cur = nullptr;list._mtx.lock();list.push_front(span);return span;
}
遍历 SpanList: CentralCache 首先查看指定的 SpanList 中是否有未分配对象的 Span。它会遍历 SpanList,逐个检查每个 Span,如果找到了有空闲对象的 Span,就立即返回该 Span。
申请新的 Span: 如果 SpanList 中没有可用的 Span,CentralCache 就需要向 PageCache 申请新的 Span。它会通过调用 PageCache 的 NewSpan 方法来申请一个新的 Span。在申请 Span 之前,它会先锁住 PageCache,以确保并发情况下的线程安全。
切分 Span: 申请到新的 Span 后,CentralCache 需要将该 Span 切分成适当大小的内存块,以供后续分配给线程。它会将 Span 切分成多个对象,每个对象的大小由参数 align_size 决定。
挂载到 SpanList: 切分完毕后,CentralCache 将该 Span 添加到对应的 SpanList 中,并将其挂载到链表的头部,以确保在下次申请时能够快速访问到该 Span。
返回 Span: 最后,CentralCache 返回新申请或已有的 Span 给调用方,以供线程分配使用。
总的来说,CentralCache 申请一个 Span 的过程包括查找现有 SpanList、申请新的 Span、切分 Span、挂载到 SpanList,并最终返回 Span。这个过程确保了线程在需要内存时能够及时获得所需的 Span 对象。
PageSizeLimit()
class FreeList
{
public:// ...static size_t PageSizeLimit(size_t align_size){size_t batch = BatchSizeLimit(align_size);size_t npage = batch * align_size;npage >>= PAGESHIFT;if (npage == 0)npage = 1;return npage;}// ...
};就像ThreadCache一次向CentralCache申请对象的个数上限,现在我们是根据对象的大小计算出CentralCache一次应该向PageCache申请几页的内存块。
我们用单次内存块申请的最大值乘以内存块的大小,再转化为页数去向堆申请内存。也就是说,CentralCache向PageCache申请内存时,要求申请到的内存尽量能够满足ThreadCache向CentralCache申请时的上限。
NewSpan
Span* PageCache::NewSpan(size_t k)
{if (!_Spanlists[k].empty()){Span* kspan = _Spanlists[k].pop_front();return kspan;}for (size_t n = k + 1; n < NPAGES; n++){if (!_Spanlists[n].empty()){Span* nspan = _Spanlists[n].pop_front();Span* kspan = new Span;kspan->_pageId = nspan->_pageId;kspan->_n = k;nspan->_pageId += k;nspan->_n -= k;_Spanlists[nspan->_n].push_front(nspan);return kspan;}}Span* maxspan = new Span;void* ptr = SystemAlloc(NPAGES - 1);maxspan->_pageId = (PAGEID)ptr >> PAGESHIFT;maxspan->_n = NPAGES - 1;_Spanlists[maxspan->_n].push_front(maxspan);return NewSpan(k);
}
首先,Page Cache 会尝试在对应的第 k 号桶中查找是否有可用的 span。如果有,则直接取出一个 span 返回给 Central Cache。
如果第 k 号桶中没有可用的 span,Page Cache 将继续在后面的桶中寻找。这时,Page Cache 不会立即向堆申请一个 k 页的 span,而是尝试找到一个大一点的 span,并根据需要将其切分成所需大小的 span。
当 Page Cache 在第 n+k 号桶中找到一个大小为 (n+k) 页的 span 时,它会将其切分成一个 n 页的 span 和一个 k 页的 span。然后,将 n 页的 span 挂到第 n 号桶中,而将 k 页的 span 返回给 Central Cache。
如果 Page Cache 在后续的桶中都找不到足够大的 span,那么就只能向堆申请一个较大的内存块,通常是 128 页大小的内存块。然后,Page Cache 将这个 128 页的 span 切分成一个 n 页的 span 和一个 (128-n) 页的 span,将 n 页的 span 返回给 Central Cache,而将 (128-n) 页的 span 挂到对应的桶中。
最后为了尽量避免出现重复的代码,我们最好不要再编写对应的切分代码。我们可以先将申请到的128页的span挂到page cache对应的哈希桶中,然后再递归调用该函数就行了,此时在往后找span时就一定会在第128号桶中找到该span,然后进行切分。
总的来说,Page Cache 会尽量以较大的内存块为单位进行分配,以便提高内存的连续性和管理效率。当需要获取较小的 span 时,Page Cache 会根据需要将大的 span 切分成合适大小的 span,而不是直接向堆申请小块大小的内存,以避免内存碎片化和管理复杂度的增加。
申请过程联调单元测试
当我们在C++代码中同时包含了algorithm头文件和Windows.h头文件时,可能会遇到名称冲突的问题。这是因为在Windows.h中定义了一个名为min的宏,与algorithm头文件中的min函数模板产生了冲突。由于编译器会优先匹配宏定义,因此当我们尝试调用std::min时,编译器会误认为我们想要调用Windows.h中的min宏,从而导致编译错误。这就是没有用命名空间进行封装的坏处,这时我们只能选择将std::去掉,让编译器调用Windows.h当中的min。
void TestAlloc()
{for (size_t i = 0; i < 1024; ++i){void* p1 = ConcurrentAlloc(6);cout << p1 << endl;}void* p2 = ConcurrentAlloc(8);cout << p2 << endl;
}int main()
{//TLSTest();TestAlloc();return 0;
}这里我们删掉之前ConcurrentAlloc.h中用于测试ThreadCache的代码
// cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;这里我们选择一步一步调试观察程序的运行是否符合我们的预期
1)首先,在第一次的申请我们的_freelist都是空的会继续向CentralCache申请内存

2)之后在向CentralCache申请Span时也由于初始时为空,继而调用Newspan()向PageCache申请

3)在Newspan中,在for循环外打上断点,再跳转到断点处

4)此时跳转成功,说明PageCache初始时为空,此时申请128页的大Span,符合预期

5)这里我们可以查看申请得到Span的内存地址和Span转化后的_pageId

- ptr = 0x000001f579620000
- _pageId = 262916880

通过计算我们可以验证_pageId左移PAGESHIFT实际上就可以得到对应的Span的地址
具体原因也是我们之前提到的我们调用的VirtualAlloc接口返回的内存地址实际上是会按照页为单位对齐的,所以我们在封装的时候就是以页为单位去申请内存,所以自然就可以做到这样的转化
6)然后,我们取消前一个断点,再向for循环内部的if内部打上断点
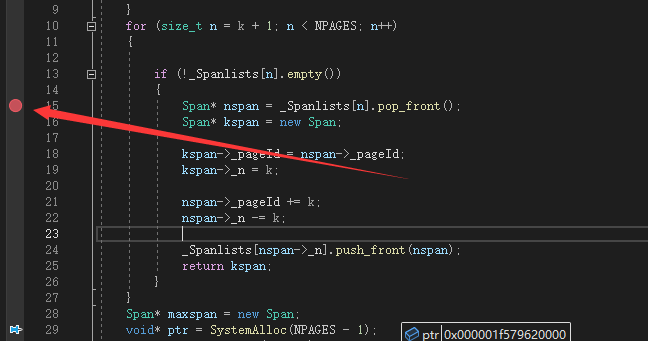
7)程序不仅成功进入断点而且把原先的128页的大Span拆分成了1页(返还给CentralCache)和127页(挂在Spanlist上)
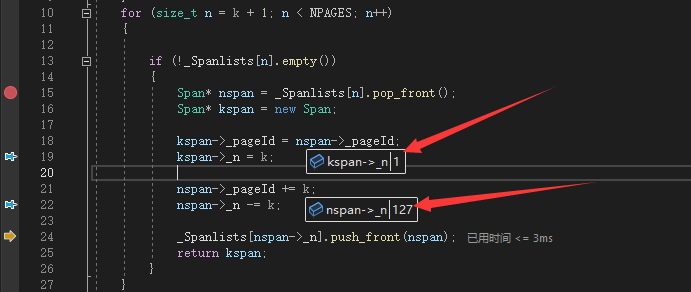
8)之后我们回到FetchFromCentralCache(),在判断取得一个内存块处打上断点,并且跳转成功,符合预期

9) 随后申请第一个内存块成功结束,成功打印出第一个结果

10) 接着,我们在for循环后打上断点,直接跳转观察1024此申请后的程序运行

这里我们做一下预估:1024次申请6字节,实际上由于内存对齐可以当作申请了1024次8字节,
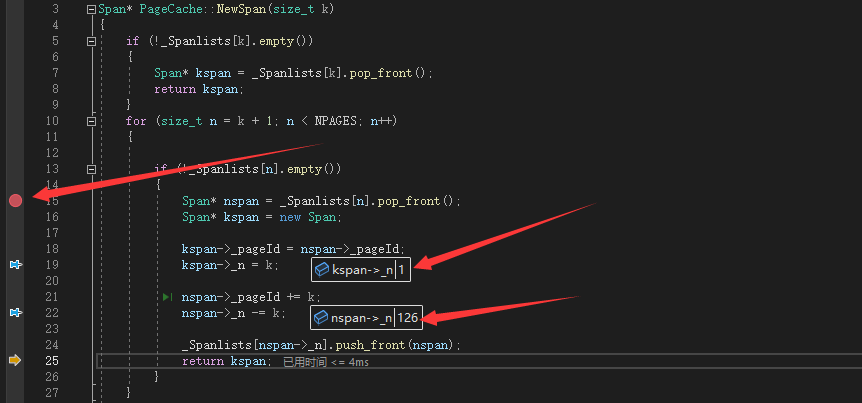
一共就申请了8*1024 = 8192 = 8KB 也就是恰好一页的内存 , 从前面得知我们第一次向PageCache申请的恰好是放有一页的Span内存块,经过前面1024次申请的消耗完,本次申请将会在继续向PageCache申请新的Span
11) 这里再一次成功跳转到NewSpan的if内部,此时我们将上一次剩下的127页Span又一次拆分成了1页的Span返还再将126页挂回,符合预期

相关文章:
[项目设计] 从零实现的高并发内存池(三)
🌈 博客个人主页:Chris在Coding 🎥 本文所属专栏:[高并发内存池] ❤️ 前置学习专栏:[Linux学习] ⏰ 我们仍在旅途 目录 4.CentralCache实现 4.1 CentralCache整体架构 4.2 围绕Span的相关设计…...

将Q算法和D算法结合应用到llm解码上之人在回路
将Q算法和D算法结合应用到llm解码上之人在回路 参考地址代码解释 参考地址 https://dongfangyou.blog.csdn.net/article/details/136466609 代码 import numpy as np from tqdm import tqdmfrom sample import net, char2id_dict, get_real_p# 假设的词汇表 VOCABULARY lis…...
el-table-column嵌套el-form-item不能进行校验问题解决
项目为vue3elementPlus开发的项目 业务要求:table表格展示数据,其中有一行是ip地址可展示可修改,此处要求增加自定义校验规则 先看一下效果: 此处先描述一下,问题出在了哪里,我将el-table的data,使用一个…...

leetcode200. 岛屿数量
leetcode200. 岛屿数量 题目 思路 遍历每一个网格,若网格为1,岛屿数量1,利用一个深度优先搜索函数将岛屿置零,注意判断数组边界 代码 class Solution:def numIslands(self, grid: List[List[str]]) -> int:self.grid grid…...

MySQL--索引类型详解
索引的类型 主键索引: PRIMARY KEY,当一张表的某个列是主键的时候,该列就是主键索引,一张表只允许有一个主键索引,主键所在的列不能为空。 创建主键索引的SQL语法: # 给user表中的id字段创建名为id_ind…...

R语言中ggplot2图例位置、颜色、背景、标题
目录 1、不显示图例 2、自定义图例位置 3、修改图例背景颜色、外框颜色、大小 4、修改图例大小 5、图例设置背景、线框为空 6、自定义设置多个图例的标题 7、设置多个图例的之间的间隔 8、取消不需要的图例显示 1、不显示图例 theme(legend.position "none"…...

波卡 Alpha 计划启动,呼唤先锋创新者重新定义 Web3 开发
原文:https://polkadot.network/blog/the-polkadot-alpha-program-a-new-era-for-decentralized-building-collaboration/ 编译:OneBlock 区块链领域不断发展,随之而来的是发展和创新机会的增加。而最新里程碑是令人振奋的 Polkadot Alpha …...

公网IP与私有IP及远程互联
1.公网有私有IP及NAT 公网IP是全球唯一的IP,通过公网IP,接入互联网的设备是可以访问你的设备。但是IPV4资源有限,一般ISP(Internet Service Provider)并不会为用户提供公网IP。所以家里的计算机在公司是没法直接使用windows远程桌面直接访问…...

openCV xmake debug失效 release可以使用
在使用xmake构建一个项目时,添加openCV库,调用 imread函数时,debug函数失效, release可以使用,最后发现是xmake.lua写的有问题 option("OpenCV4.6.0")set_showmenu(true) set_default(true) set_category(&…...
ES分布式搜索-IK分词器
ES分词器-IK 1、为什么使用分词器? es在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词。但默认的分词规则对中文处理并不友好。 我们在kibana的DevTools中测试: GET /_analyze {"analyzer": "…...

基于卷积神经网络的野外可食用植物分类系统
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :) 1. 项目简介 本文详细探讨了一基于深度学习的可食用植物图像识别系统。采用TensorFlow和Keras框架,利用卷积神经网络(CNN)进行模型训练和预测,并引入迁移学习模型…...
Raingad IM即时聊天/即时通讯网站源码,附带系统搭建教程
支持功能 支持单聊和群聊,支持发送表情、图片、语音、视频和文件消息单聊支持消息已读未读的状态显示,在线状态显示群聊创建、删除和群成员管理、群公告、群禁言等支持置顶联系人,消息免打扰;支持设置新消息声音提醒,…...
)
for语句的实际应用(3)
3145:【例24.3】 奇数求和 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 9847 通过数: 5442 【题目描述】 计算非负整数 m 到 n(包括 m 和 n)之间的所有奇数的和,其中,m 不大于 n,且 n 不大…...

c++ Windows获取软件安装列表信息
链接 #include <windows.h> #include <stdio.h> #include <iostream> #include <vector>using namespace std;#ifndef MSVCR #define _T #define _tcscpy strcpy #define _stprintf sprintf #define _tcscmp strcmp #endifclass SetupSoftInfo { publ…...

音视频学习笔记——c++多线程(一)
✊✊✊🌈大家好!本篇文章主要整理了部分多线程相关的内容重点😇。首先讲解了多进程和多线程并发的区别以及各自优缺点,之后讲解了Thead线程库的基本使用。 本专栏知识点是通过<零声教育>的音视频流媒体高级开发课程进行系统…...

消息队列常见问题
总的来讲,消息队列常见问题要么消息不能多,要么不能少,还有顺序性,以及积压处理的问题等。 1.消息不能多 也就是说,消息不能重复消费,随之带来的幂等性问题。 解决:一般结合业务场景…...

【leetcode热题】二叉树的前序遍历
难度: 中等通过率: 49.5%题目链接:. - 力扣(LeetCode) 题目描述 给定一个二叉树,返回它的 前序 遍历。 示例: 输入: [1,null,2,3] 1\2/3 输出: [1,2,3]进阶: 递归算法很简单,你可以通过迭代…...

Linux命令记不住?保姆级教程来了
在软件开发过程中,Linux操作系统因其稳定性、安全性和高效性而备受青睐。作为开发者,熟练掌握Linux常用命令,不仅可以提高工作效率,还能更好地管理服务器和进行代码部署。本文将介绍一些开发常用的Linux命令及其应用场景ÿ…...
基于GitBucket的Hook构建ES检索PDF等文档全栈方案
背景 之前已简单使用ES及Kibana和在线转Base64工具实现了检索文档的demo,预期建设方案是使用触发器类型从公共的文档源拉取最新的文件,然后调用Java将文件转Base64后入ES建索引,再提供封装接口给前端做查询之用。 由于全部内容过长ÿ…...

C语言:数组、字符串知识点整理:
数组:(长度的计算) 补充:数组长度sizeof(arr)/sizeof(arr[0]) 注意:!!!不适用于当arr 充当形参时(函数传参)!!! 因为函数…...

134. Rancher 系统身份验证
它是 Rancher 身份验证代理的一部分: 牛模拟系统是Rancher实现身份验证的关键组成部分。 主体必须明确拥有“冒充”权限才能冒充其他用户。 Rancher 为 Kubernetes 新增的关键特性之一是集中式用户身份验证。该特性允许用户使用一套凭据对任何 Kubernetes 集群进行…...

Spring Boot项目启动慢?试试这个编译时注解@Indexed,让你的应用秒启动
Spring Boot启动性能优化:Indexed注解的深度实践指南 当你的Spring Boot应用膨胀到数百个组件时,每次启动等待的那几十秒是否让你焦躁不安?在微服务架构中,频繁的本地调试和快速迭代部署对启动速度的敏感度远超想象。传统解决方案…...

业务视角下的金融SRC快速挖掘思路
0x01 简介挖掘金融类漏洞的核心不仅仅是技术点本身,更需要深入理解业务链路、资金流转规则、风控策略与账户体系,从而在“设计缺陷”中找到突破点。本文总结梳理常见的金融逻辑漏洞类型及关键节点的可利用点,帮助安全人员深入理解这些场景&am…...

从气象云图到地形渲染:用Python Matplotlib的contourf函数实现数据可视化实战
从气象云图到地形渲染:用Python Matplotlib的contourf函数实现数据可视化实战 当气象学家需要展示台风路径上的温度分布,当地质工程师分析地震波传播的强度变化,或是当环境科学家研究污染物扩散范围时,他们面临的共同挑战是如何将…...

超越心跳包:5种防止SSH断连的奇技淫巧,从tmux到Mosh全攻略
超越心跳包:5种防止SSH断连的奇技淫巧,从tmux到Mosh全攻略 每次跨国视频会议卡成PPT时,我总想起那些年在哈萨克斯坦油田调试设备的经历——卫星网络延迟高达800ms,SSH连接平均存活时间不超过3分钟。传统的心跳包配置在这种极端环境…...

Liunx创建挂载步骤
1. 查看磁盘情况lsblk # 查看所有块设备 fdisk -l # 查看磁盘分区详情(需 root)2. 分区(以 /dev/sdb 为例)fdisk /dev/sdb进入交互界面后:n → 新建分区p → 主分区(或 e 扩展分区)回车接受默认…...

告别复杂建模!3D Face HRN人脸重建模型一键部署与使用全攻略
告别复杂建模!3D Face HRN人脸重建模型一键部署与使用全攻略 1. 从照片到3D模型:这个AI能做什么? 想象一下这样的场景:你手头只有一张普通的证件照,但需要在3D软件中快速创建一个逼真的人脸模型。传统方法可能需要数…...

强力浏览器扩展:如何用Markdown Viewer优雅预览本地与在线技术文档
强力浏览器扩展:如何用Markdown Viewer优雅预览本地与在线技术文档 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer 你是否曾经为无法直接在浏览器中查看Markdown文件而…...

Camera Shakify深度剖析:从真实拍摄到数字动画的抖动艺术
Camera Shakify深度剖析:从真实拍摄到数字动画的抖动艺术 【免费下载链接】camera_shakify 项目地址: https://gitcode.com/gh_mirrors/ca/camera_shakify 在Blender动画创作中,相机运动的真实性往往是区分业余作品与专业作品的关键分水岭。你是…...

Mapbox踩坑实录:图层叠加、图片更新、弹窗样式,这些坑我帮你填平了
Mapbox实战避坑指南:图层管理、动态图片与弹窗优化 第一次在项目中集成Mapbox时,那种兴奋感很快被各种意想不到的报错消磨殆尽。记得凌晨三点调试updateImage方法时,控制台不断抛出"Image dimensions must match"的错误——原来只是…...