seq2seq翻译实战-Pytorch复现
🍨 本文为[🔗365天深度学习训练营学习记录博客 🍦 参考文章:365天深度学习训练营 🍖 原作者:[K同学啊 | 接辅导、项目定制]\n🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/mingtian-fkmxf/zxwb45)一、前期准备
from __future__ import unicode_literals, print_function, division
from io import open
import unicodedata
import string
import re
import randomimport torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as Fdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
1.1 搭建语言类
定义了两个常量 SOS_token 和 EOS_token,其分别代表序列的开始和结束。 Lang 类,用于方便对语料库进行操作:
●word2index 是一个字典,将单词映射到索引
●word2count 是一个字典,记录单词出现的次数
●index2word 是一个字典,将索引映射到单词
●n_words 是单词的数量,初始值为 2,因为序列开始和结束的单词已经被添加
SOS_token = 0
EOS_token = 1# 语言类,方便对语料库进行操作
class Lang:def __init__(self, name):self.name = nameself.word2index = {}self.word2count = {}self.index2word = {0: "SOS", 1: "EOS"}self.n_words = 2 # Count SOS and EOSdef addSentence(self, sentence):for word in sentence.split(' '):self.addWord(word)def addWord(self, word):if word not in self.word2index:self.word2index[word] = self.n_wordsself.word2count[word] = 1self.index2word[self.n_words] = wordself.n_words += 1else:self.word2count[word] += 11.2 文本处理函数
def unicodeToAscii(s):return ''.join(c for c in unicodedata.normalize('NFD', s)if unicodedata.category(c) != 'Mn')# 小写化,剔除标点与非字母符号
def normalizeString(s):s = unicodeToAscii(s.lower().strip())s = re.sub(r"([.!?])", r" \1", s)s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)return s1.3 文件读取函数
def readLangs(lang1, lang2, reverse=False):print("Reading lines...")# 以行为单位读取文件lines = open('%s-%s.txt' % (lang1, lang2), encoding='utf-8'). \read().strip().split('\n')# 将每一行放入一个列表中# 一个列表中有两个元素,A语言文本与B语言文本pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]# 创建Lang实例,并确认是否反转语言顺序if reverse:pairs = [list(reversed(p)) for p in pairs]input_lang = Lang(lang2)output_lang = Lang(lang1)else:input_lang = Lang(lang1)output_lang = Lang(lang2)return input_lang, output_lang, pairsMAX_LENGTH = 10 # 定义语料最长长度eng_prefixes = ("i am ", "i m ","he is", "he s ","she is", "she s ","you are", "you re ","we are", "we re ","they are", "they re "
)def filterPair(p):return len(p[0].split(' ')) < MAX_LENGTH and \len(p[1].split(' ')) < MAX_LENGTH and p[1].startswith(eng_prefixes)def filterPairs(pairs):# 选取仅仅包含 eng_prefixes 开头的语料return [pair for pair in pairs if filterPair(pair)]def prepareData(lang1, lang2, reverse=False):# 读取文件中的数据input_lang, output_lang, pairs = readLangs(lang1, lang2, reverse)print("Read %s sentence pairs" % len(pairs))# 按条件选取语料pairs = filterPairs(pairs[:])print("Trimmed to %s sentence pairs" % len(pairs))print("Counting words...")# 将语料保存至相应的语言类for pair in pairs:input_lang.addSentence(pair[0])output_lang.addSentence(pair[1])# 打印语言类的信息print("Counted words:")print(input_lang.name, input_lang.n_words)print(output_lang.name, output_lang.n_words)return input_lang, output_lang, pairsinput_lang, output_lang, pairs = prepareData('eng', 'fra', True)
print(random.choice(pairs))常量 MAX_LENGTH,表示语料中句子的最大长度。
元组 eng_prefixes,包含一些英语句子的前缀。这些前缀用于筛选语料,只选择以这些前缀开头的句子
filterPair 函数用于过滤语料对。它的返回值是一个布尔值,表示是否保留该语料对。这里的条件是:两个句子的长度都不超过 MAX_LENGTH,并且输出语句(第二个句子)以 eng_prefixes 中的某个前缀开头
filterPairs 函数接受一个语料对列表,然后调用 filterPair 函数过滤掉不符合条件的语料对,返回一个新的语料对列表。
prepareData 函数是主要的数据准备函数。它调用了之前定义的 readLangs 函数来读取语言对,然后使用 filterPairs 函数按条件过滤语料对。接着,它打印读取的句子对数、过滤后的句子对数,并统计语料中的词汇量。最后,它将语料保存到相应的语言类中,并返回这些语言类对象以及过滤后的语料对。

二、Seq2Seq 模型
2.1 编码器(Encoder)
class EncoderRNN(nn.Module):def __init__(self, input_size, hidden_size):super(EncoderRNN, self).__init__()self.hidden_size = hidden_sizeself.embedding = nn.Embedding(input_size, hidden_size)self.gru = nn.GRU(hidden_size, hidden_size)def forward(self, input, hidden):embedded = self.embedding(input).view(1, 1, -1)output = embeddedoutput, hidden = self.gru(output, hidden)return output, hiddendef initHidden(self):return torch.zeros(1, 1, self.hidden_size, device=device)2.2 解码器(Decoder)
class DecoderRNN(nn.Module):def __init__(self, hidden_size, output_size):super(DecoderRNN, self).__init__()self.hidden_size = hidden_sizeself.embedding = nn.Embedding(output_size, hidden_size)self.gru = nn.GRU(hidden_size, hidden_size)self.out = nn.Linear(hidden_size, output_size)self.softmax = nn.LogSoftmax(dim=1)def forward(self, input, hidden):output = self.embedding(input).view(1, 1, -1)output = F.relu(output)output, hidden = self.gru(output, hidden)output = self.softmax(self.out(output[0]))return output, hiddendef initHidden(self):return torch.zeros(1, 1, self.hidden_size, device=device)三、训练
3.1 数据预处理
def indexesFromSentence(lang, sentence):return [lang.word2index[word] for word in sentence.split(' ')]# 将数字化的文本,转化为tensor数据
def tensorFromSentence(lang, sentence):indexes = indexesFromSentence(lang, sentence)indexes.append(EOS_token)return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)# 输入pair文本,输出预处理好的数据
def tensorsFromPair(pair):input_tensor = tensorFromSentence(input_lang, pair[0])target_tensor = tensorFromSentence(output_lang, pair[1])return (input_tensor, target_tensor)3.2 训练函数
使用use_teacher_forcing 的目的是在训练过程中平衡解码器的预测能力和稳定性。以下是对两种策略的解释:
1. Teacher Forcing:在每个时间步(di循环中),解码器的输入都是目标序列中的真实标签。这样做的好处是,解码器可以直接获得正确的输入信息,加快训练速度,并且在训练早期提供更准确的梯度信号,帮助解码器更好地学习。然而,过度依赖目标序列可能会导致模型过于敏感,一旦目标序列中出现错误,可能会在解码器中产生累积的误差。
2. Without Teacher Forcing:在每个时间步,解码器的输入是前一个时间步的预测输出。这样做的好处是,解码器需要依靠自身的预测能力来生成下一个输入,从而更好地适应真实应用场景中可能出现的输入变化。这种策略可以提高模型的稳定性,但可能会导致训练过程更加困难,特别是在初始阶段。一般来说,Teacher Forcing策略在训练过程中可以帮助模型快速收敛,而Without Teacher Forcing策略则更接近真实应用中的生成场景。通常会使用一定比例的Teacher Forcing,在训练过程中逐渐减小这个比例,以便模型逐渐过渡到更自主的生成模式。
综上所述,通过使用use_teacher_forcing 来选择不同的策略,可以在训练解码器时平衡模型的预测能力和稳定性,同时也提供了更灵活的生成模式选择。
teacher_forcing_ratio = 0.5def train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=MAX_LENGTH):# 编码器初始化encoder_hidden = encoder.initHidden()# grad属性归零encoder_optimizer.zero_grad()decoder_optimizer.zero_grad()input_length = input_tensor.size(0)target_length = target_tensor.size(0)# 用于创建一个指定大小的全零张量(tensor),用作默认编码器输出encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)loss = 0# 将处理好的语料送入编码器for ei in range(input_length):encoder_output, encoder_hidden = encoder(input_tensor[ei], encoder_hidden)encoder_outputs[ei] = encoder_output[0, 0]# 解码器默认输出decoder_input = torch.tensor([[SOS_token]], device=device)decoder_hidden = encoder_hiddenuse_teacher_forcing = True if random.random() < teacher_forcing_ratio else False# 将编码器处理好的输出送入解码器if use_teacher_forcing:# Teacher forcing: Feed the target as the next inputfor di in range(target_length):decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)loss += criterion(decoder_output, target_tensor[di])decoder_input = target_tensor[di] # Teacher forcingelse:# Without teacher forcing: use its own predictions as the next inputfor di in range(target_length):decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)topv, topi = decoder_output.topk(1)decoder_input = topi.squeeze().detach() # detach from history as inputloss += criterion(decoder_output, target_tensor[di])if decoder_input.item() == EOS_token:breakloss.backward()encoder_optimizer.step()decoder_optimizer.step()return loss.item() / target_lengthimport time
import mathdef asMinutes(s):m = math.floor(s / 60)s -= m * 60return '%dm %ds' % (m, s)def timeSince(since, percent):now = time.time()s = now - sincees = s / (percent)rs = es - sreturn '%s (- %s)' % (asMinutes(s), asMinutes(rs))def trainIters(encoder,decoder,n_iters,print_every=1000,plot_every=100,learning_rate=0.01):start = time.time()plot_losses = []print_loss_total = 0 # Reset every print_everyplot_loss_total = 0 # Reset every plot_everyencoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate)decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate)# 在 pairs 中随机选取 n_iters 条数据用作训练集training_pairs = [tensorsFromPair(random.choice(pairs)) for i in range(n_iters)]criterion = nn.NLLLoss()for iter in range(1, n_iters + 1):training_pair = training_pairs[iter - 1]input_tensor = training_pair[0]target_tensor = training_pair[1]loss = train(input_tensor, target_tensor, encoder,decoder, encoder_optimizer, decoder_optimizer, criterion)print_loss_total += lossplot_loss_total += lossif iter % print_every == 0:print_loss_avg = print_loss_total / print_everyprint_loss_total = 0print('%s (%d %d%%) %.4f' % (timeSince(start, iter / n_iters),iter, iter / n_iters * 100, print_loss_avg))if iter % plot_every == 0:plot_loss_avg = plot_loss_total / plot_everyplot_losses.append(plot_loss_avg)plot_loss_total = 0return plot_losses四、训练与评估
hidden_size = 256
encoder1 = EncoderRNN(input_lang.n_words, hidden_size).to(device)
attn_decoder1 = DecoderRNN(hidden_size, output_lang.n_words).to(device)plot_losses = trainIters(encoder1, attn_decoder1, 100000, print_every=5000) 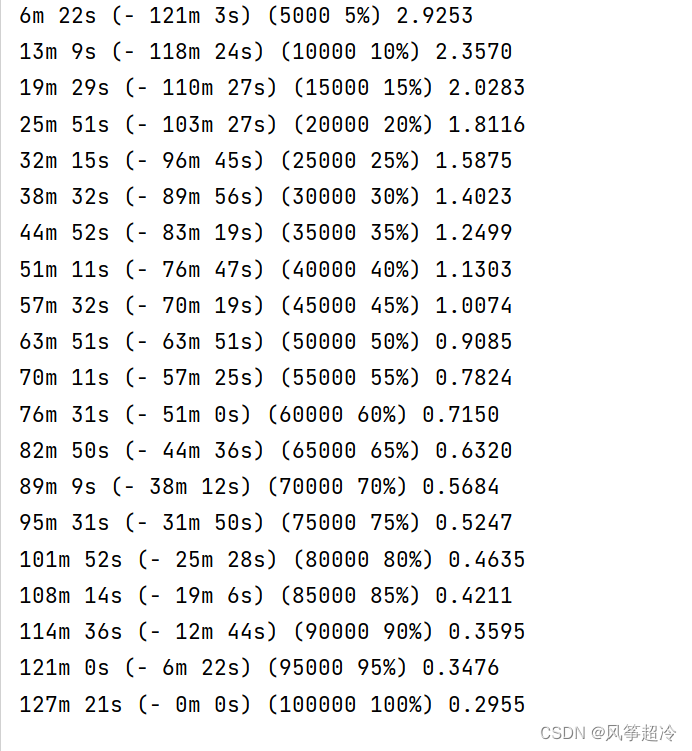
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息
# plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率epochs_range = range(len(plot_losses))plt.figure(figsize=(8, 3))plt.subplot(1, 1, 1)
plt.plot(epochs_range, plot_losses, label='Training Loss')
plt.legend(loc='upper right')
plt.title('Training Loss')
plt.show()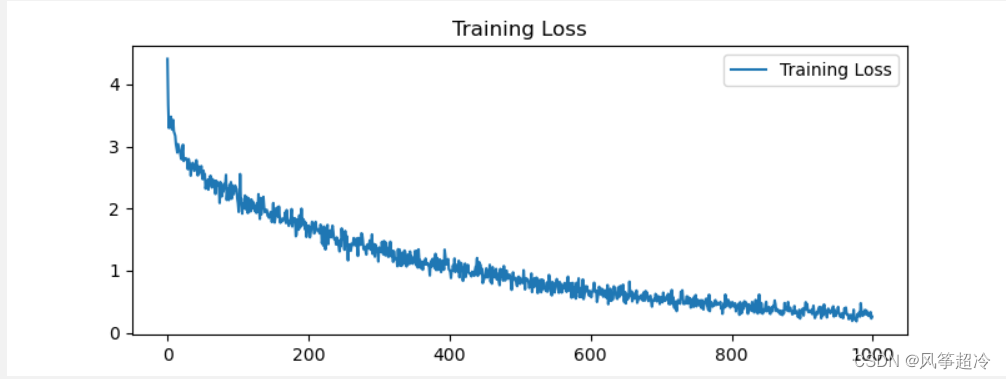
相关文章:
seq2seq翻译实战-Pytorch复现
🍨 本文为[🔗365天深度学习训练营学习记录博客 🍦 参考文章:365天深度学习训练营 🍖 原作者:[K同学啊 | 接辅导、项目定制]\n🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/…...
软考69-上午题-【面向对象技术2-UML】-关系
一、关系 UML中有4种关系: 依赖;关联;泛化;实现。 1-1、依赖 行为(参数),参数就是被依赖的事物,即:独立事物。 当独立事物发生变化时,依赖事务行为的语义也…...

智慧文旅|AI数字人导览:让旅游体验不再局限于传统
AI数字人导览作为一种创新的展示方式,已经逐渐成为了VR全景领域的一大亮点,不仅可以很好的嵌入在VR全景中,更是能够随时随地为观众提供一种声情并茂的讲解介绍,结合VR场景的沉浸式体验,让观众仿佛置身于真实场景之中&a…...

spring boot 集成 mysql ,mybatisplus多数据源
1、需要的依赖,版本自行控制 <dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId> </dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java<…...
CLion中常用快捷键(仍适用其他编译软件)
基本编辑操作: 复制:Ctrl C粘贴:Ctrl V剪切:Ctrl X撤销:Ctrl Z重做:Ctrl Shift Z (不小心撤销了 需要返回之前的操作 相当于下一步)全选:Ctrl A 导航࿱…...
考研复习c语言初阶(1)
本人准备考研,现在开始每天更新408的内容,目标这个月结束C语言和数据结构,每天更新~ 一.再次认识c语言 C语言是一门通用计算机编程语言,广泛应用于底层开发。C语言的设计目标是提供一种能以简易 的方式编译、处理低级存储器、产生…...
HTML—常用标签
常用标签: 标题标签:<h1></h1>......<h6></h6>段落标签:<p></p>换行标签:<br/>列表:无序列表<ul><li></li></ul> 有序列表<ol>&…...

Midjourney绘图欣赏系列(七)
Midjourney介绍 Midjourney 是生成式人工智能的一个很好的例子,它根据文本提示创建图像。它与 Dall-E 和 Stable Diffusion 一起成为最流行的 AI 艺术创作工具之一。与竞争对手不同,Midjourney 是自筹资金且闭源的,因此确切了解其幕后内容尚不…...

深度学习应该如何入门?
深度学习是一门令人着迷的领域,但初学者可能会感到有些困惑。让我们从头开始,用通俗易懂的语言来探讨深度学习的基础知识。 1. 基础知识 深度学习需要一些数学和编程基础。首先,我们要掌握一些数学知识,如线性代数、微积分和概率…...

FreeRtos Queue(五)
本篇主要分析在中断中向队列里发消息xQueueGenericSendFromISR和在中断里从队列中读取消息xQueueReceiveFromISR。 前言: xQueueGenericSendFromISR 和 xQueueReceiveFromISR都是在中断里调用的而不是任务里调用的,所以队列满了或者是队列为空的时候自然就没有把当…...
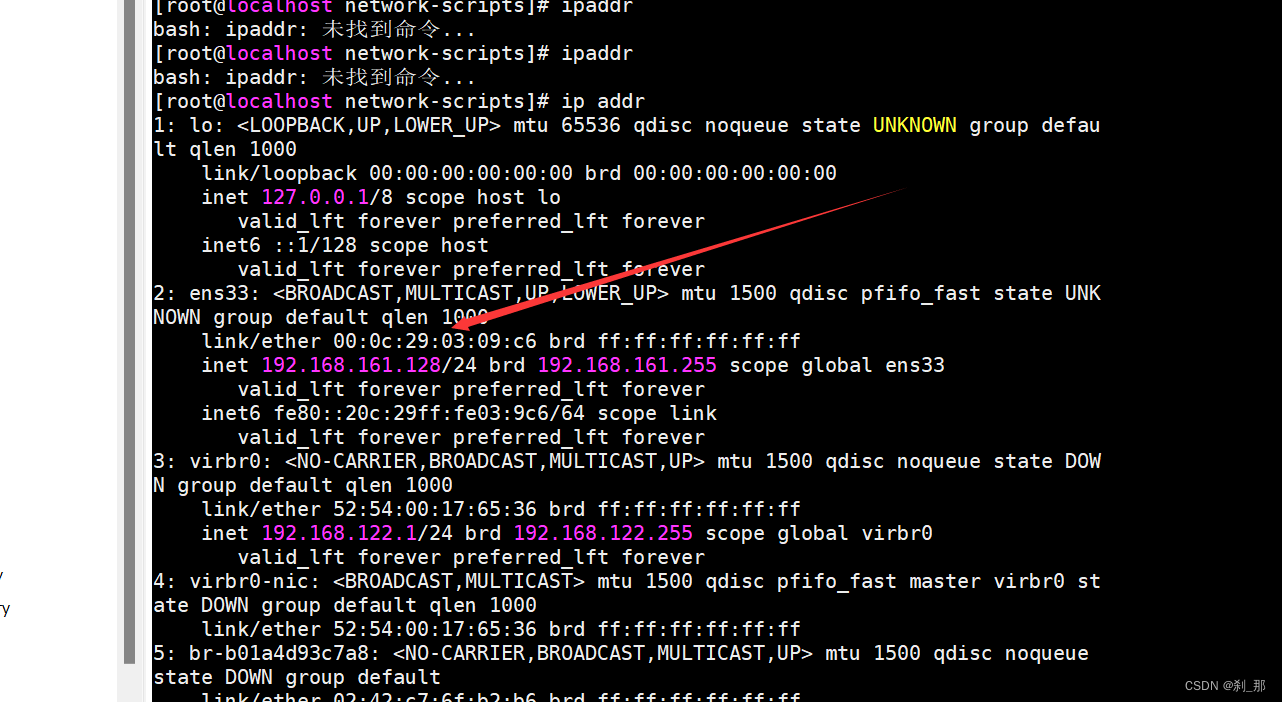
解决虚拟机静态网址设置后还是变动的的问题
源头就是我的虚拟机静态网址设置好了以后但是网址还是会变动 这是我虚拟机的配置 vi /etc/sysconfig/network-scripts/ifcfg-ens33 这是出现的问题 进入这里 cd /etc/sysconfig/network-scripts/ 然后我去把多余的ens33的文件都删了 然后还不行 后来按照这个图片进行了下 然后…...

【教程】Github环境配置新手指南(超详细)
写在前面: 如果文章对你有帮助,记得点赞关注加收藏一波,利于以后需要的时候复习,多谢支持! 文章目录 一、Github初始设置(一)登入Github(二)新建仓库 二、本地Git配置&am…...

突然发现一个很炸裂的平台!
平时小孟会开发很多的项目,很多项目不仅开发的功能比较齐全,而且效果比较炸裂。 今天给大家介绍一个我常用的平台,因含低代码平台,开发相当的快。 1,什么是低代码 低代码包括两种,一种低代码,…...

安卓开发面试题
安卓开发面试题 解释一下 Android 中的四大组件。 答:Android 中的四大组件是 Activity、Service、BroadcastReceiver 和 ContentProvider。其中,Activity 负责界面展示和与用户交互;Service 负责后台服务处理;BroadcastReceiver …...

es6面试题
ES6面试题 var、let、const区别 共同点:都是可以声明变量 区别: 1、var具有变量提升机制,let和const没有 2、var 声明的变量是函数作用域或全局作用域,而 const 和 let 声明的变量是块级作用域。 3、var可以多次声明同一个变量&a…...

Kafka MQ 生产者和消费者
Kafka MQ 生产者和消费者 Kafka 的客户端就是 Kafka 系统的用户,它们被分为两种基本类型:生产者和消费者。除 此之外,还有其他高级客户端 API——用于数据集成的 Kafka Connect API 和用于流式处理 的 Kafka Streams。这些高级客户端 API 使用生产者和消…...

tomcat优化与部署(三)------nignx优化与nginx +tomcat 部署
在目前流行的互联网架构中,Tomcat在目前的网络编程中是举足轻重的,由于Tomcat的运行依赖于JVM,从虚拟机的角度把Tomcat的调整分为外部环境调优 JVM 和 Tomcat 自身调优两部分 Tomcat 是一个流行的开源 Java 服务器,用于托管 Java …...

一个用libcurl多线程下载断言错误问题的排查
某数据下载程序,相同版本的代码,在64位系统中运行正常,但在32位系统中概率性出现断言错误。一旦出现,程序无法正常继续,即使重启亦不行。从年前会上领导提出要追到根,跟到底,到年后的今天&#…...
Docker的安装及MySQL的部署(CentOS版)
目录 1 前言 2 Docker安装步骤 2.1 卸载可能存在的旧版Docker 2.2 配置Docker的yum库 2.2.1 安装yum工具 2.2.2 配置Docker的yum源 2.3 安装Docker 2.4 启动和校验 2.5 配置镜像加速(使用阿里云) 2.5.1 进入控制台 2.5.2 进入容器镜像服务 2.5.3 获取指令并粘贴到…...

css 背景图片居中显示
background 简写 background: #ffffff url(https://profile-avatar.csdnimg.cn/b9abdd57de464582860bf8ade52373b6_misnice.jpg) center center / 100% no-repeat;效果如图:...

WebCord安全特性深度解析:保护你的Discord隐私
WebCord安全特性深度解析:保护你的Discord隐私 【免费下载链接】WebCord A Discord and SpaceBar :electron:-based client implemented without Discord API. 项目地址: https://gitcode.com/gh_mirrors/we/WebCord WebCord是一款基于Electron的Discord客户…...

从SGL到XSimGCL:图对比推荐中的“简化”革命与性能跃迁
1. 图对比学习推荐算法的演进之路 推荐系统领域近年来最令人兴奋的突破之一,就是图对比学习技术的引入。作为一名长期跟踪推荐算法发展的从业者,我亲眼见证了从传统协同过滤到图神经网络的演进,再到如今对比学习带来的性能飞跃。这就像是从手…...

Zynq-7000 PS和PL双CAN实战:从时钟配置到波特率计算的保姆级调试笔记
Zynq-7000双CAN控制器开发实战:时钟配置与波特率计算全解析 在嵌入式系统开发中,CAN总线因其高可靠性和实时性被广泛应用于工业控制、汽车电子等领域。Xilinx Zynq-7000系列SoC因其独特的PS(Processing System)和PL(Pr…...

Audio Annotator:如何用免费开源工具3分钟完成专业音频标注?[特殊字符]
Audio Annotator:如何用免费开源工具3分钟完成专业音频标注?🚀 【免费下载链接】audio-annotator A JavaScript interface for annotating and labeling audio files. 项目地址: https://gitcode.com/gh_mirrors/au/audio-annotator 还…...
:覆盖17类常识任务、9大基准测试与3家头部实验室未公开数据对比)
AGI常识推理能力发展白皮书(2024权威评估版):覆盖17类常识任务、9大基准测试与3家头部实验室未公开数据对比
第一章:AGI常识推理能力发展概览 2026奇点智能技术大会(https://ml-summit.org) 常识推理是通用人工智能(AGI)实现类人认知的关键门槛,指模型在缺乏显式训练标注的前提下,调用隐含于人类经验中的物理规律、社会规范、…...

DouyinLiveRecorder智能文字提取:如何轻松获取40+平台直播关键信息
DouyinLiveRecorder智能文字提取:如何轻松获取40平台直播关键信息 【免费下载链接】DouyinLiveRecorder 可循环值守和多人录制的直播录制软件,支持抖音、TikTok、Youtube、快手、虎牙、斗鱼、B站、小红书、pandatv、sooplive、flextv、popkontv、twitcas…...

iOS 17-26越狱完整指南:安全解锁iPhone隐藏功能
iOS 17-26越狱完整指南:安全解锁iPhone隐藏功能 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项目地址: https…...

nli-distilroberta-base新手入门:句子关系判断的3个实用场景
nli-distilroberta-base新手入门:句子关系判断的3个实用场景 1. 认识nli-distilroberta-base nli-distilroberta-base是一个基于DistilRoBERTa模型的自然语言推理(NLI)服务,专门用于判断两个句子之间的关系。它可以帮助我们快速分析文本之间的逻辑关联…...

Qwen-Image-2512-SDNQ在VSCode中的开发环境配置全攻略
Qwen-Image-2512-SDNQ在VSCode中的开发环境配置全攻略 想在VSCode中快速搭建Qwen-Image-2512-SDNQ的开发环境?这篇教程将手把手带你完成从零开始的配置过程,让你在10分钟内就能开始AI图像生成的开发工作。 1. 环境准备与基础配置 在开始之前,…...

安立Anritsu MS9740B台式光谱分析仪概述
安立Anritsu MS9740B台式光谱分析仪概述安立MS9740B是一款高性能台式光谱分析仪,广泛应用于光通信、激光器测试、光纤传感等领域。其设计兼顾高精度与操作便捷性,支持波长范围覆盖600至1750 nm,分辨率带宽可达0.05 nm。主要技术参数波长范围&…...