【深度学习模型】6_3 语言模型数据集
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图
6.3 语言模型数据集(周杰伦专辑歌词)
本节将介绍如何预处理一个语言模型数据集,并将其转换成字符级循环神经网络所需要的输入格式。为此,我们收集了周杰伦从第一张专辑《Jay》到第十张专辑《跨时代》中的歌词,并在后面几节里应用循环神经网络来训练一个语言模型。当模型训练好后,我们就可以用这个模型来创作歌词。
6.3.1 读取数据集
首先读取这个数据集,看看前40个字符是什么样的。
import torch
import random
import zipfilewith zipfile.ZipFile('../../data/jaychou_lyrics.txt.zip') as zin:with zin.open('jaychou_lyrics.txt') as f:corpus_chars = f.read().decode('utf-8')
corpus_chars[:40]
输出:
'想要有直升机\n想要和你飞到宇宙去\n想要和你融化在一起\n融化在宇宙里\n我每天每天每'
这个数据集有6万多个字符。为了打印方便,我们把换行符替换成空格,然后仅使用前1万个字符来训练模型。
corpus_chars = corpus_chars.replace('\n', ' ').replace('\r', ' ')
corpus_chars = corpus_chars[0:10000]
6.3.2 建立字符索引
我们将每个字符映射成一个从0开始的连续整数,又称索引,来方便之后的数据处理。为了得到索引,我们将数据集里所有不同字符取出来,然后将其逐一映射到索引来构造词典。接着,打印vocab_size,即词典中不同字符的个数,又称词典大小。
idx_to_char = list(set(corpus_chars))
char_to_idx = dict([(char, i) for i, char in enumerate(idx_to_char)])
vocab_size = len(char_to_idx)
vocab_size # 1027
之后,将训练数据集中每个字符转化为索引,并打印前20个字符及其对应的索引。
corpus_indices = [char_to_idx[char] for char in corpus_chars]
sample = corpus_indices[:20]
print('chars:', ''.join([idx_to_char[idx] for idx in sample]))
print('indices:', sample)
输出:
chars: 想要有直升机 想要和你飞到宇宙去 想要和
indices: [250, 164, 576, 421, 674, 653, 357, 250, 164, 850, 217, 910, 1012, 261, 275, 366, 357, 250, 164, 850]
我们将以上代码封装在d2lzh_pytorch包里的load_data_jay_lyrics函数中,以方便后面章节调用。调用该函数后会依次得到corpus_indices、char_to_idx、idx_to_char和vocab_size这4个变量。
6.3.3 时序数据的采样
在训练中我们需要每次随机读取小批量样本和标签。与之前章节的实验数据不同的是,时序数据的一个样本通常包含连续的字符。假设时间步数为5,样本序列为5个字符,即“想”“要”“有”“直”“升”。该样本的标签序列为这些字符分别在训练集中的下一个字符,即“要”“有”“直”“升”“机”。我们有两种方式对时序数据进行采样,分别是随机采样和相邻采样。
6.3.3.1 随机采样
下面的代码每次从数据里随机采样一个小批量。其中批量大小batch_size指每个小批量的样本数,num_steps为每个样本所包含的时间步数。
在随机采样中,每个样本是原始序列上任意截取的一段序列。相邻的两个随机小批量在原始序列上的位置不一定相毗邻。因此,我们无法用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态。在训练模型时,每次随机采样前都需要重新初始化隐藏状态。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def data_iter_random(corpus_indices, batch_size, num_steps, device=None):# 减1是因为输出的索引x是相应输入的索引y加1num_examples = (len(corpus_indices) - 1) // num_stepsepoch_size = num_examples // batch_sizeexample_indices = list(range(num_examples))random.shuffle(example_indices)# 返回从pos开始的长为num_steps的序列def _data(pos):return corpus_indices[pos: pos + num_steps]if device is None:device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')for i in range(epoch_size):# 每次读取batch_size个随机样本i = i * batch_sizebatch_indices = example_indices[i: i + batch_size]X = [_data(j * num_steps) for j in batch_indices]Y = [_data(j * num_steps + 1) for j in batch_indices]yield torch.tensor(X, dtype=torch.float32, device=device), torch.tensor(Y, dtype=torch.float32, device=device)
让我们输入一个从0到29的连续整数的人工序列。设批量大小和时间步数分别为2和6。打印随机采样每次读取的小批量样本的输入X和标签Y。可见,相邻的两个随机小批量在原始序列上的位置不一定相毗邻。
my_seq = list(range(30))
for X, Y in data_iter_random(my_seq, batch_size=2, num_steps=6):print('X: ', X, '\nY:', Y, '\n')
输出:
X: tensor([[18., 19., 20., 21., 22., 23.],[12., 13., 14., 15., 16., 17.]])
Y: tensor([[19., 20., 21., 22., 23., 24.],[13., 14., 15., 16., 17., 18.]]) X: tensor([[ 0., 1., 2., 3., 4., 5.],[ 6., 7., 8., 9., 10., 11.]])
Y: tensor([[ 1., 2., 3., 4., 5., 6.],[ 7., 8., 9., 10., 11., 12.]])
6.3.3.2 相邻采样
除对原始序列做随机采样之外,我们还可以令相邻的两个随机小批量在原始序列上的位置相毗邻。这时候,我们就可以用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态,从而使下一个小批量的输出也取决于当前小批量的输入,并如此循环下去。这对实现循环神经网络造成了两方面影响:一方面,
在训练模型时,我们只需在每一个迭代周期开始时初始化隐藏状态;另一方面,当多个相邻小批量通过传递隐藏状态串联起来时,模型参数的梯度计算将依赖所有串联起来的小批量序列。同一迭代周期中,随着迭代次数的增加,梯度的计算开销会越来越大。
为了使模型参数的梯度计算只依赖一次迭代读取的小批量序列,我们可以在每次读取小批量前将隐藏状态从计算图中分离出来。我们将在下一节(循环神经网络的从零开始实现)的实现中了解这种处理方式。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def data_iter_consecutive(corpus_indices, batch_size, num_steps, device=None):if device is None:device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')corpus_indices = torch.tensor(corpus_indices, dtype=torch.float32, device=device)data_len = len(corpus_indices)batch_len = data_len // batch_sizeindices = corpus_indices[0: batch_size*batch_len].view(batch_size, batch_len)epoch_size = (batch_len - 1) // num_stepsfor i in range(epoch_size):i = i * num_stepsX = indices[:, i: i + num_steps]Y = indices[:, i + 1: i + num_steps + 1]yield X, Y
同样的设置下,打印相邻采样每次读取的小批量样本的输入X和标签Y。相邻的两个随机小批量在原始序列上的位置相毗邻。
for X, Y in data_iter_consecutive(my_seq, batch_size=2, num_steps=6):print('X: ', X, '\nY:', Y, '\n')
输出:
X: tensor([[ 0., 1., 2., 3., 4., 5.],[15., 16., 17., 18., 19., 20.]])
Y: tensor([[ 1., 2., 3., 4., 5., 6.],[16., 17., 18., 19., 20., 21.]]) X: tensor([[ 6., 7., 8., 9., 10., 11.],[21., 22., 23., 24., 25., 26.]])
Y: tensor([[ 7., 8., 9., 10., 11., 12.],[22., 23., 24., 25., 26., 27.]])
小结
- 时序数据采样方式包括随机采样和相邻采样。使用这两种方式的循环神经网络训练在实现上略有不同。
注:除代码外本节与原书此节基本相同,原书传送门
相关文章:

【深度学习模型】6_3 语言模型数据集
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图 6.3 语言模型数据集(周杰伦专辑歌词) 本节将介绍如何预处理一个语言模型数据集,并将其转换成字符级…...

技术选型思考:分库分表和分布式DB(TiDB/OceanBase) 的权衡与抉择
码到三十五 : 个人主页 心中有诗画,指尖舞代码,目光览世界,步履越千山,人间尽值得 ! 在当今数据爆炸的时代,数据库作为存储和管理数据的核心组件,其性能和扩展性成为了企业关注的重点。随着业…...

React改变数据【案例】
State传统方式 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>React Demo</title> <!--…...
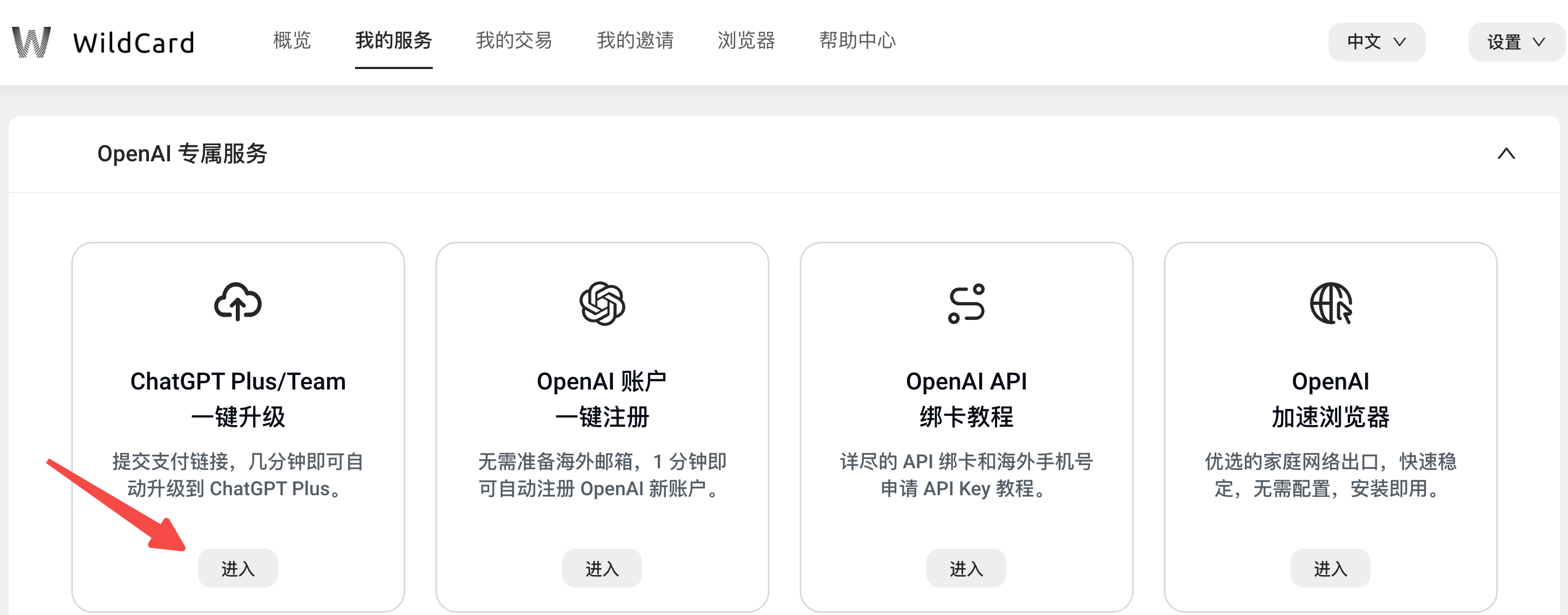
ChatGPT Plus 自动扣费失败,如何续订
ChatGPT Plus 自动扣费失败,如何续订 如果您的 ChatGPT Plus 订阅过期或扣费失败,本教程将指导您如何重新订阅。 本周更新 ChatGPT Plus 是一种每月20美元的订阅服务。扣费会自动进行,如果您的账户余额不足,OpenAI 将在一次扣费…...

Rust: Channel 代码示例
在 Rust 中,通道(Channel)通常使用 std::sync::mpsc(多生产者单消费者)或 tokio::sync::mpsc(在异步编程中,特别是使用 Tokio 运行时)来创建。下面是一个使用 std::sync::mpsc 的简单…...

基于华为atlas的unet分割模型探索
Unet模型使用官方基于kaggle Carvana Image Masking Challenge数据集训练的模型。 模型输入为572*572*3,输出为572*572*2。分割目标分别为,0:背景,1:汽车。 Pytorch的pth模型转化onnx模型: import torchf…...

机器学习--循环神经网络(RNN)1
一、简介 循环神经网络(Recurrent Neural Network)是深度学习领域中一种非常经典的网络结构,在现实生活中有着广泛的应用。以槽填充(slot filling)为例,如下图所示,假设订票系统听到用户说&…...

基于java+springboot+vue实现的学生信息管理系统(文末源码+Lw+ppt)23-54
摘 要 人类现已进入21世纪,科技日新月异,经济、信息等方面都取得了长足的进步,特别是信息网络技术的飞速发展,对政治、经济、军事、文化等方面都产生了很大的影响。 利用计算机网络的便利,开发一套基于java的大学生…...
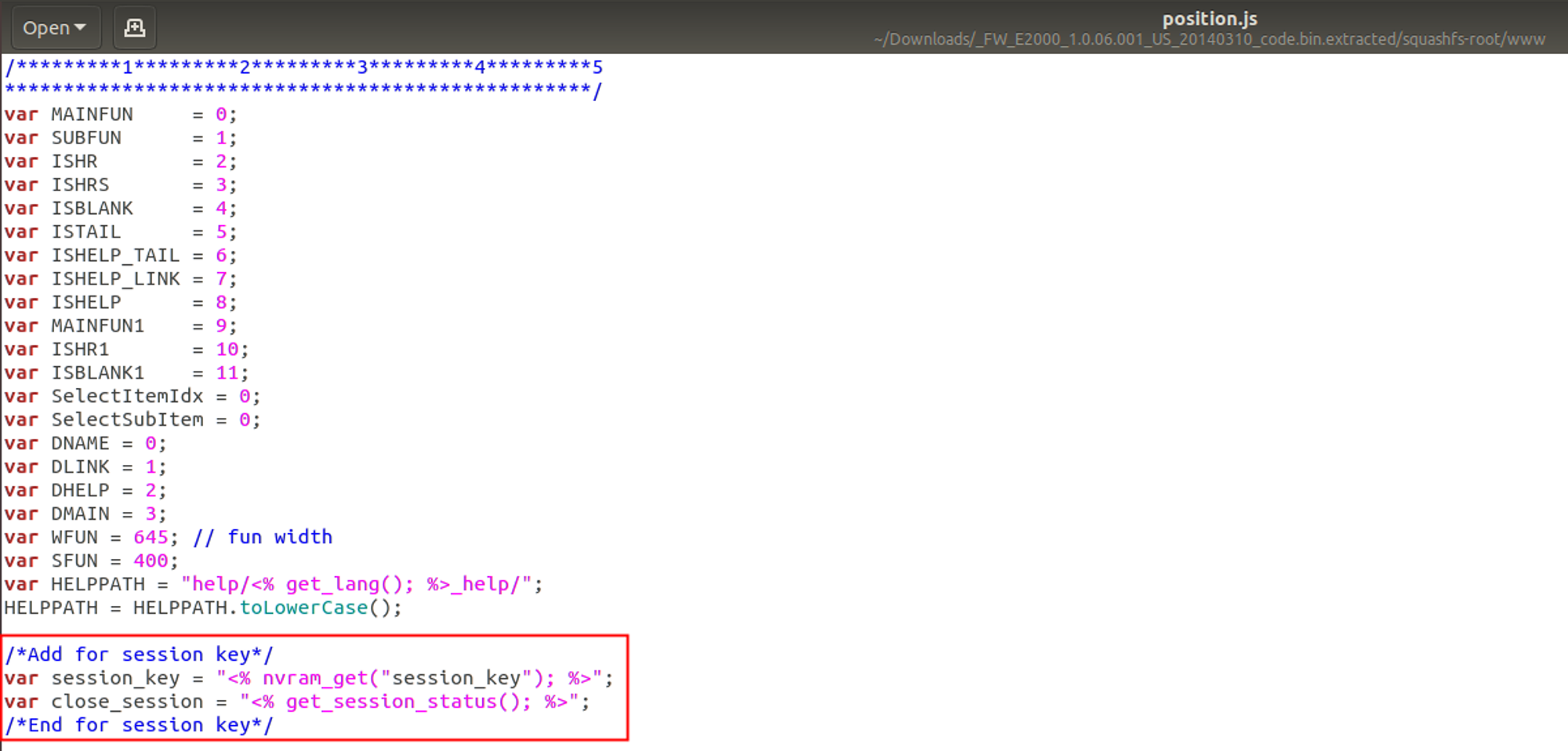
【漏洞复现】Linksys E2000 position.js 身份验证绕过漏洞(CVE-2024-27497)
0x01 产品简介 Linksys E2000是一款由思科(Cisco)品牌推出的无线路由器,它是一款支持2.4GHz和5GHz双频段的无线路由器,用户可以避开拥挤的2.4GHz频段,独自享受5GHz频段的高速无线生活。 0x02 漏洞概述 Linksys E200…...

小白跟做江科大51单片机之DS1302可调时钟
原理部分 1.DS1302可调时钟介绍 单片机定时器主要占用CPU时间,掉电不能继续运行 图1 2.原理 图2 内部有寄存器,寄存的时候以时分秒寄存,以通信协议实现数据交互,就可以实现对数据进行访问和读写 3.主要寄存器定义 CE芯片使能…...
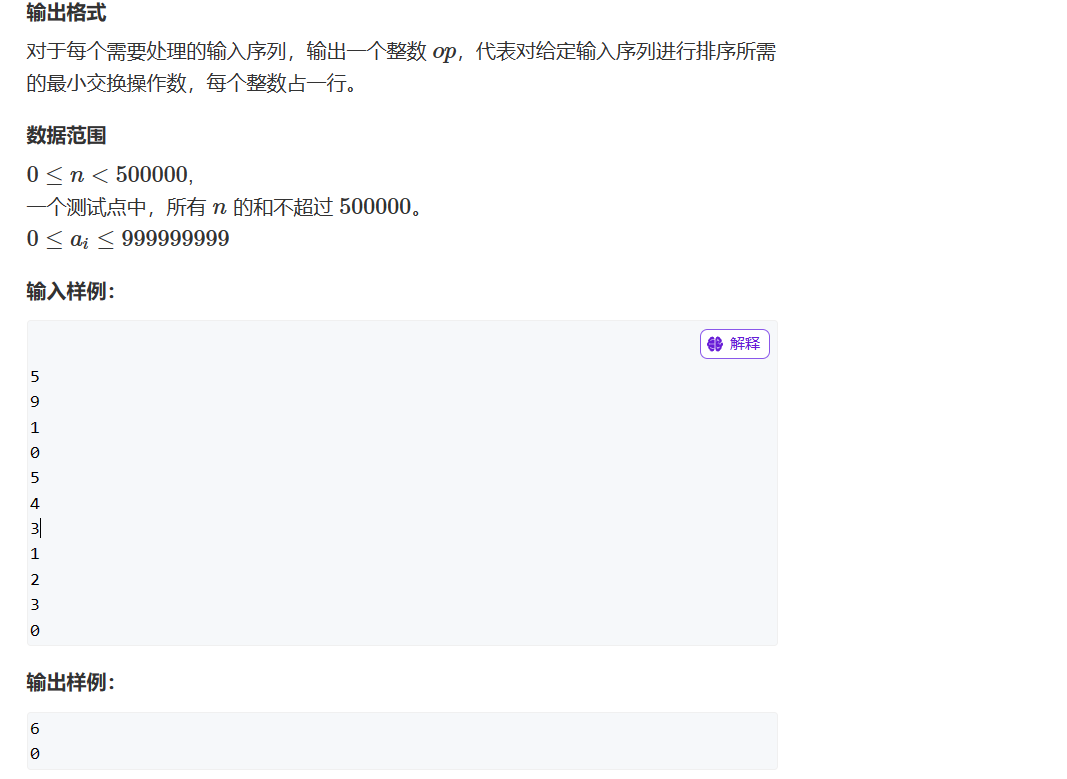
2024蓝桥杯每日一题(归并排序)
一、第一题:火柴排队 解题思路:归并排序 重点在于想清楚是对哪个数组进行归并排序求逆序对 【Python程序代码】 from math import * n int(input()) a list(map(int,input().split())) b list(map(int,input().split())) na,nb [],[] for …...
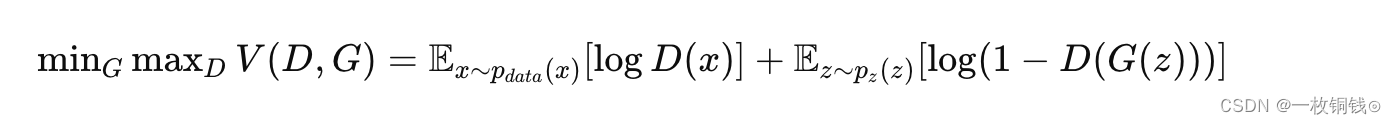
生成对抗网络 (GAN)
生成对抗网络(Generative Adversarial Networks,GAN)是由Ian Goodfellow等人在2014年提出的一种深度学习模型。GAN由两部分组成:一个生成器(Generator)和一个判别器(Discriminator)&…...

QGridLayout网格布局和QVBoxLayout垂直布局有着非常大的差别
QGridLayout网格布局:1.把这块控件划分成一个个的 单元格 2.把你的控件填充进入 单元格 3.这些有关限制大小的函数接口统统失效 setMaximumWidth() setMinimumWidth() setPolicySize()图示:我是用的网格布局,左边放QT…...
HCIA-HarmonyOS设备开发认证V2.0-习题2
目录 习题一习题二坚持就有收获 习题一 # 判断题## 1.PWM占空比指的是低电平时间占周期时间的百分比。(错误)正确(True)错误(False)解题: - PWM占空比指的是高电平时间占周期时间的百分比## 2.UART是通用异步收发传输器,是通用串行数据总线,…...
【npm】前端工程项目配置文件package.json详解
简言 详细介绍了package.json中每个字段的作用。 package.json 本文档将为您介绍 package.json 文件的所有要求。它必须是实际的 JSON,而不仅仅是 JavaScript 对象文字。 如果你要发布你的项目,这是一个特别重要的文件,其中name和version是…...

Python快速入门系列-2(Python的安装与环境设置)
第二章:Python的安装与环境设置 2.1 Python的下载与安装2.1.1 访问Python官网2.1.2 安装Python对于Windows用户对于macOS用户对于Linux用户 2.2 集成开发环境(IDE)的选择与设置2.2.1 PyCharm2.2.2 Visual Studio Code2.2.3 Jupyter Notebook2…...

Linux的环境安装以及项目部署
LInux软件安装 是在发行版是CentOS下安装 通常使用yum安装,可以在rpm上增加了自动解决依赖的功能 传输安装包方式安装JDK与tomcat 安装JDK ●安装包:将.gz文件通过Xftp传输到/opt目录下准备安装 ●解压:进入/opt目录,使用命令tar -zxvf 压缩包名称 (名称…...
ASUS华硕天选2锐龙版笔记本电脑FA506ICB/FA706IC原装出厂Windows11系统,预装OEM系统恢复安装开箱状态
链接:https://pan.baidu.com/s/122iHHEOtNUu4azhVPnxNuA?pwdsqk7 提取码:sqk7 适用型号: FA506IM、FA506IE、FA506IC、FA506IHR FA506IR、FA506IHRB、FA506ICB、FA506IEB FA706IM、FA706IE、FA706IC、FA706IHR FA706IR、FA706IHRB、F…...

登录校验认证
会话技术 会话:用户打开浏览器,访问web服务器的资源,会话建立,直到有一方断开连接,会话结束。在一次会话中可以包含多次请求和响应。 会话跟踪: 一种维护浏览器状态的方法,服务器需要识别多次请…...

Kubernetes 几大概念的作用
更详细的组件通信流程 Kubernetes 主要由以下几个核心组件组成: 1. etcd 保存了整个集群的状态; 2. API Server 提供了资源操作的唯一入口,并提供认证,授权,访问控制,API 注册和发现等机制; …...

别再只调学习率了!YOLOv11训练技巧全解析:从数据增强到损失函数优化
别再只调学习率了!YOLOv11训练技巧全解析:从数据增强到损失函数优化 在目标检测领域,YOLO系列模型一直以其速度和精度的平衡著称。但很多开发者在训练YOLOv11时,往往把注意力局限在学习率调整上,忽略了训练流程中其他关…...
)
2026奇点大会闭门圆桌实录:AGI训练能耗 vs 气候收益的黄金平衡点(附12国算力调度协议原始签字页扫描件)
第一章:2026奇点智能技术大会:AGI与气候变化 2026奇点智能技术大会(https://ml-summit.org) 本届大会首次将通用人工智能(AGI)系统级能力与全球气候建模、减碳路径优化及极端天气预测深度耦合,标志着AI从工具性辅助迈…...
与RSSI校准)
AD9361实战笔记:手把手教你配置Tx功率监控(TPM)与RSSI校准
AD9361实战笔记:手把手教你配置Tx功率监控(TPM)与RSSI校准 在射频系统设计中,精确的功率监控和信号强度测量是确保通信质量的关键环节。AD9361作为一款高度集成的射频收发器,其内置的发射功率监控(TPM&…...

工业控制系统安全:PLC编程与协议分析入门
工业控制系统安全:PLC编程与协议分析入门 随着工业4.0和智能制造的快速发展,工业控制系统(ICS)的安全性日益受到关注。作为工业自动化核心的可编程逻辑控制器(PLC),其编程与通信协议的安全性直…...

Redis桌面管理器终极指南:告别命令行,用Another Redis Desktop Manager轻松管理数据库
Redis桌面管理器终极指南:告别命令行,用Another Redis Desktop Manager轻松管理数据库 【免费下载链接】AnotherRedisDesktopManager 🚀🚀🚀A faster, better and more stable Redis desktop manager [GUI client], co…...
)
STM32 IAP升级避坑指南:Ymodem协议实战中那些容易忽略的细节(附代码)
STM32 IAP升级避坑指南:Ymodem协议实战中那些容易忽略的细节(附代码) 在嵌入式开发领域,IAP(In-Application Programming)技术为产品固件升级提供了极大便利,而Ymodem协议因其高效可靠的特点成为…...

掌控系统散热:FanControl智能风扇控制完全指南
掌控系统散热:FanControl智能风扇控制完全指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanCon…...

告别点击跳转烦恼:给Zotero+Word/WPS添加文献引用超链接的两种方法
科研写作效率革命:Zotero文献引用超链接的终极解决方案 每次修改论文时,最让人抓狂的莫过于在几十页的文档中来回翻找参考文献。明明Zotero已经帮我们自动生成了完美的引用格式,却还要手动在正文和参考文献列表之间来回切换——这种低效的操作…...

手把手教你用CVX和Mosek求解器搞定指数锥规划:从entr函数到投资组合优化实战
从理论到实践:基于CVX与Mosek的指数锥优化全流程解析 在金融工程与机器学习领域,许多核心问题最终都归结为包含指数、对数或熵函数的凸优化问题。传统求解器在处理这类问题时往往面临效率瓶颈,而指数锥(Exponential Coneÿ…...

深入理解ESP32 BLE扫描:从扫描间隔、窗口到白名单,如何优化你的设备发现策略?
ESP32 BLE扫描性能优化实战:从参数调优到智能过滤策略 在物联网设备爆炸式增长的今天,BLE(低功耗蓝牙)技术已成为连接智能设备的首选方案之一。作为开发者,我们经常面临一个核心挑战:如何在资源受限的嵌入式…...