【机器学习】在Python中进行K-Means聚类和层次聚类
Python中聚类算法API的使用指南
聚类分析是数据分析中一种常见的无监督学习方法,通过将相似的对象分组在一起,我们能够识别出数据集中的自然分群。本文将介绍如何使用Python中的聚类算法接口,KMeans和层次聚类方法。
K-Means 聚类
K-Means是一种广泛使用的聚类算法,它的目标是将数据点分成K个组,使得组内的点彼此相似,而组间的点不相似。下面是如何使用K-Means聚类分析的步骤:
步骤一:导入必要的库
首先,需要导入KMeans类,它在sklearn.cluster模块中。
from sklearn.cluster import KMeans
步骤二:加载数据
我们使用pandas库来加载数据。确保数据文件的路径是正确的。
import pandas as pddf = pd.read_excel(CLUS_FILE_PATH, index_col=0)
步骤三:应用K-Means聚类
创建一个KMeans实例,并通过.fit()方法应用于数据。
kmeans = KMeans(n_clusters=3, random_state=0).fit(df)
步骤四:保存聚类结果
将聚类标签添加到原始数据框中,并保存到Excel文件。
df['Cluster'] = kmeans.labels_
df.to_excel('kmeans聚类分析结果.xlsx')
层次聚类
层次聚类是另一种常见的聚类方法,它通过构建一个多层次的嵌套分群树来组织数据,这个树被称为树状图(Dendrogram)。相对于K-Means,层次聚类不需要指定k值就可以完成聚类,但是要分类出标签的话,我们需要指定一个距离,如果两个样本超出这个距离则不属于同一类。
步骤一:导入库
导入进行层次聚类和绘制树状图所需的库。
from scipy.cluster.hierarchy import dendrogram, linkage, fcluster
from scipy.spatial.distance import pdist
步骤二:加载数据并计算距离矩阵
同样地,我们先加载数据,然后计算距离矩阵,使用欧式距离。
df = pd.read_excel(CLUS_FILE_PATH, index_col=0)
distance_matrix = pdist(df, metric='euclidean')
步骤三:执行层次聚类
使用linkage函数进行层次聚类,这里采用了’ward’方法。
Z = linkage(distance_matrix, method='ward')
步骤四:确定聚类数并保存结果
通过选择一个最大距离阈值来确定聚类数,并把聚类结果保存到Excel。
clusters = fcluster(Z, max_d=50, criterion='distance')
df['Cluster'] = clusters
df.to_excel('层次聚类分析结果.xlsx')
步骤五:绘制树状图并保存
最后,利用dendrogram函数绘制树状图,并保存为图片。
plt.figure(figsize=(10, 50))
dendrogram(Z, orientation='left', labels=df.index, leaf_rotation=0, leaf_font_size=10)
plt.title('层次聚类的树状图')
plt.ylabel('中药名称')
plt.xlabel('距离')
plt.tight_layout()
plt.savefig('层次聚类树状图.png')
plt.show()
层次聚类的树状图
我们可以看到,各个中药被层次聚类组织成了一颗一颗嵌套的树,这些树描述了不同中药之间的距离关系。

上面的步骤展示了如何使用Python进行K-Means聚类和层次聚类分析。聚类是一个强大的工具,可以帮助我们发现数据中的模式和结构。通过实践这些步骤,你会对聚类分析有更深的了解。
利用PCA降维以可视化聚类结果
绘图函数(可直接复制,然后按下文调用)
def plot_clus_2D(clustered_data, class_col, method):n_clusters = clustered_data[class_col].nunique()# 执行PCA降维,降至2维pca = PCA(n_components=2)data_reduced = pca.fit_transform(clustered_data.drop(columns=[class_col]))# 创建一个新的DataFrame来保存降维后的数据和聚类标签data_2D = pd.DataFrame(data_reduced, columns=['PC1', 'PC2'])data_2D[class_col] = clustered_data[class_col].values# 设置绘图参数fig, ax = plt.subplots(figsize=(10, 8))# 为每个聚类设置不同的颜色colors = ['red', 'green', 'blue'] # 你可以根据需要的聚类数修改颜色if n_clusters > 3: # 如果聚类数超过3,扩展颜色列表import matplotlib.colors as mcolorscolors = list(mcolors.TABLEAU_COLORS.values())[:n_clusters]# 绘制每个聚类的散点图for i in range(n_clusters):# 从聚类数据中提取当前聚类的数据cluster_data = data_2D[data_2D[class_col] == i]# 绘制散点图ax.scatter(cluster_data['PC1'], cluster_data['PC2'],color=colors[i], label=f'Cluster {i}', alpha=0.5)# 添加图例和标题ax.legend()ax.set_title(f'{method} 聚类结果 - PCA降维可视化(2D)')ax.set_xlabel('Principal Component 1')ax.set_ylabel('Principal Component 2')# 显示图表save_path = os.path.join(IMAGE_FOLDER, f'{method} 聚类结果 - PCA降维可视化(2D).png')plt.savefig(save_path)plt.show()def plot_clus_3D(clustered_data, class_col, method):""":param clustered_data: 带有聚类结果标签的数据集:param class_col: 代表聚类结果的列名:param n_clusters: 有多少个:param method::return:"""n_clusters = clustered_data[class_col].nunique()# 执行PCA降维,降至3维pca = PCA(n_components=3)data_reduced = pca.fit_transform(clustered_data.drop(columns=[class_col]))# 创建一个新的DataFrame来保存降维后的数据和聚类标签data_3D = pd.DataFrame(data_reduced, columns=['PC1', 'PC2', 'PC3'])data_3D[class_col] = clustered_data[class_col].values# 设置绘图参数fig = plt.figure(figsize=(10, 8))ax = fig.add_subplot(111, projection='3d')# 为每个聚类设置不同的颜色colors = ['red', 'green', 'blue'] # 根据需要的聚类数修改颜色if n_clusters > 3: # 如果聚类数超过3,扩展颜色列表import matplotlib.colors as mcolorscolors = list(mcolors.TABLEAU_COLORS.values())[:n_clusters]# 绘制每个聚类的散点图for i in range(n_clusters):# 从聚类数据中提取当前聚类的数据cluster_data = data_3D[data_3D[class_col] == i]# 绘制散点图ax.scatter(cluster_data['PC1'], cluster_data['PC2'], cluster_data['PC3'],color=colors[i], label=f'Cluster {i}', alpha=0.5)# 添加图例和标题ax.legend()ax.set_title(f'{method} 聚类结果 - PCA降维可视化(3D)')ax.set_xlabel('Principal Component 1')ax.set_ylabel('Principal Component 2')ax.set_zlabel('Principal Component 3')# 显示图表save_path = os.path.join(IMAGE_FOLDER, f'{method}_聚类结果_PCA降维可视化(3D).png')plt.savefig(save_path)plt.show()示例调用
clus_data = pd.read_excel('kmeans聚类分析结果.xlsx', index_col=0)
plot_clus_2D(clustered_data=clus_data, class_col='Cluster', method='K-means')
plot_clus_3D(clustered_data=clus_data, class_col='Cluster', method='K-means')clus_data = pd.read_excel('层次聚类分析结果.xlsx', index_col=0)
plot_clus_2D(clustered_data=clus_data, class_col='Cluster', method='层次聚类')
plot_clus_3D(clustered_data=clus_data, class_col='Cluster', method='层次聚类')2D可视化
K-Means聚类结果
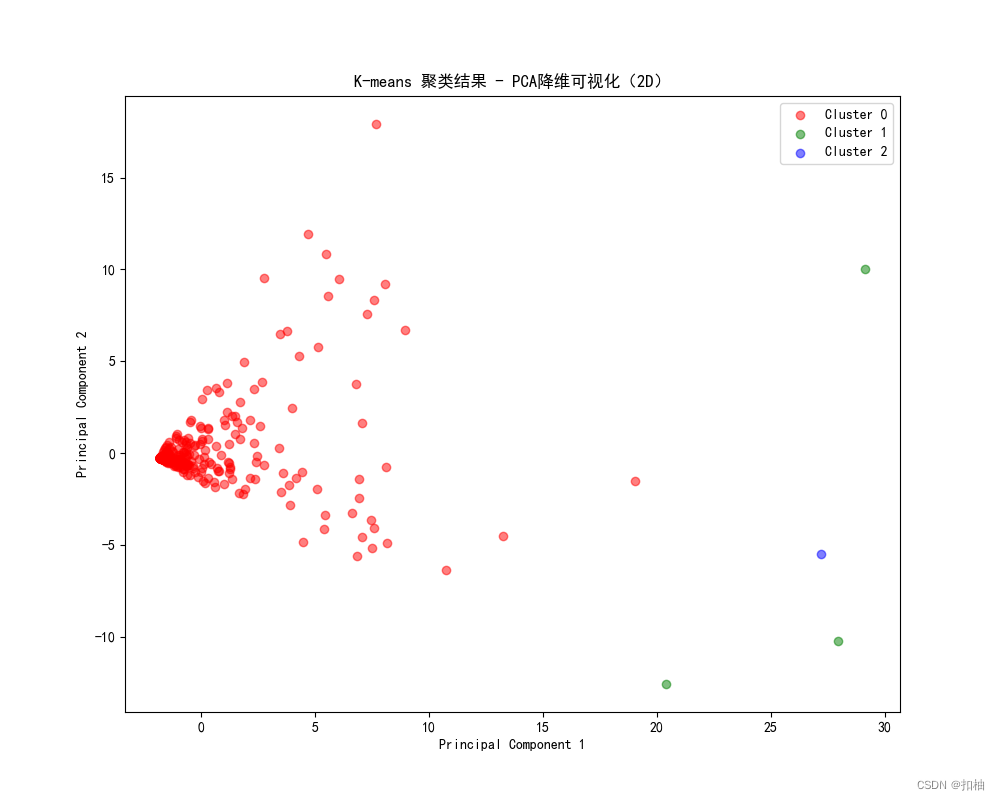
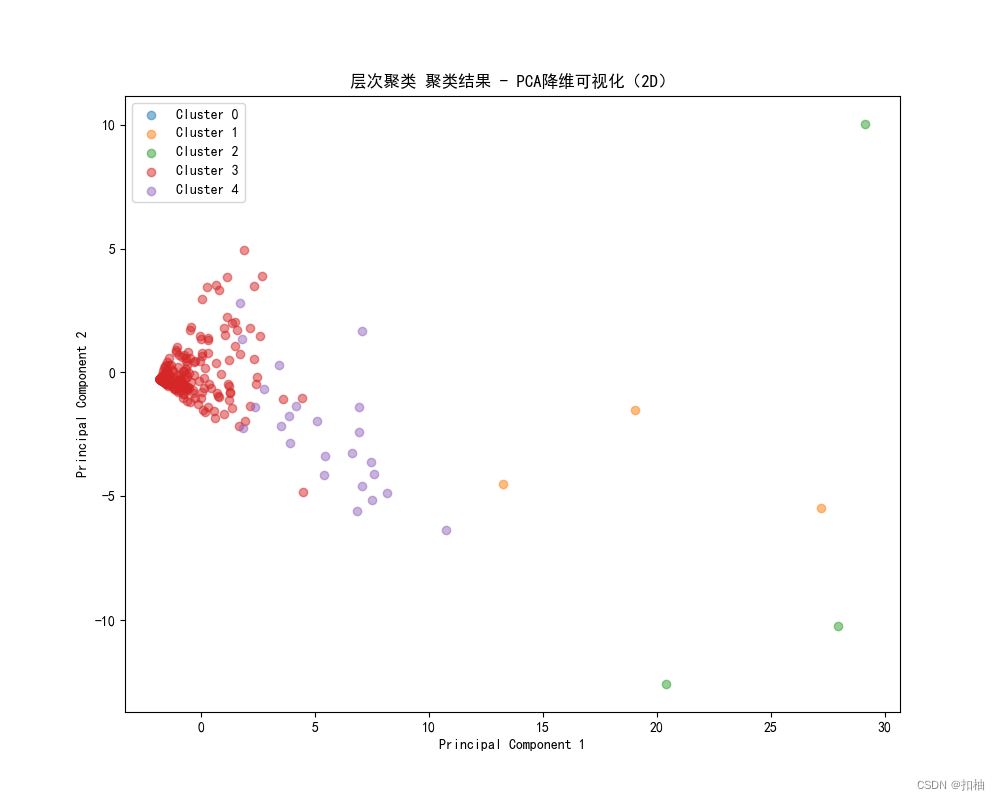
层次聚类结果
3D可视化
K-Means聚类结果
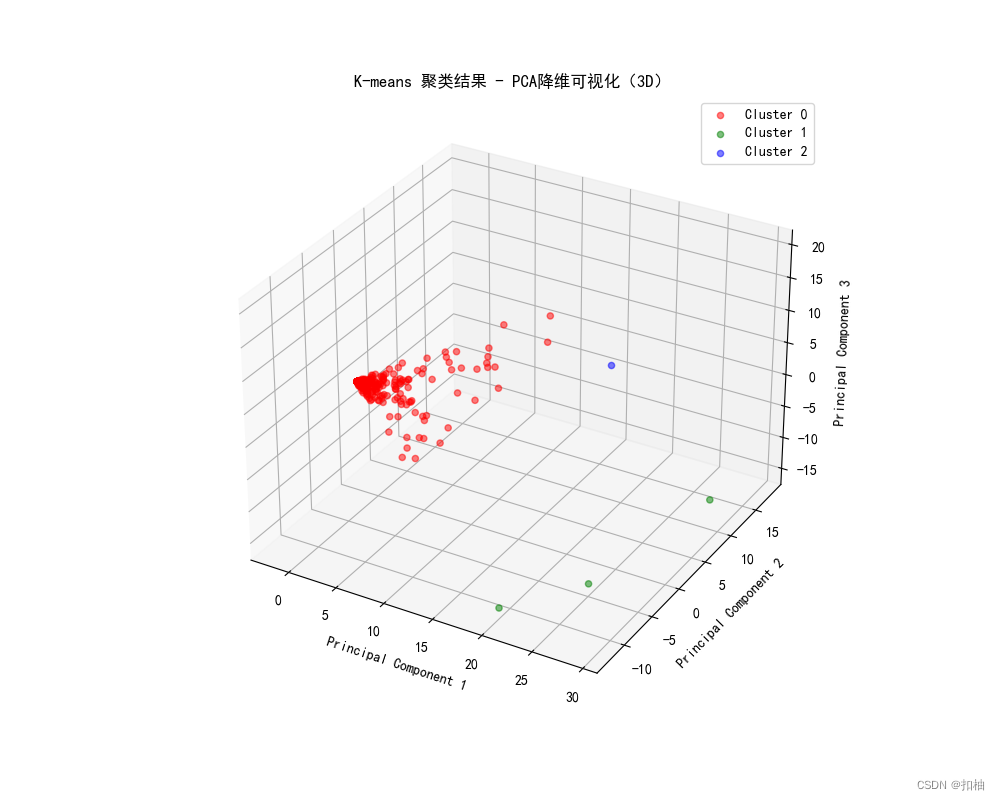
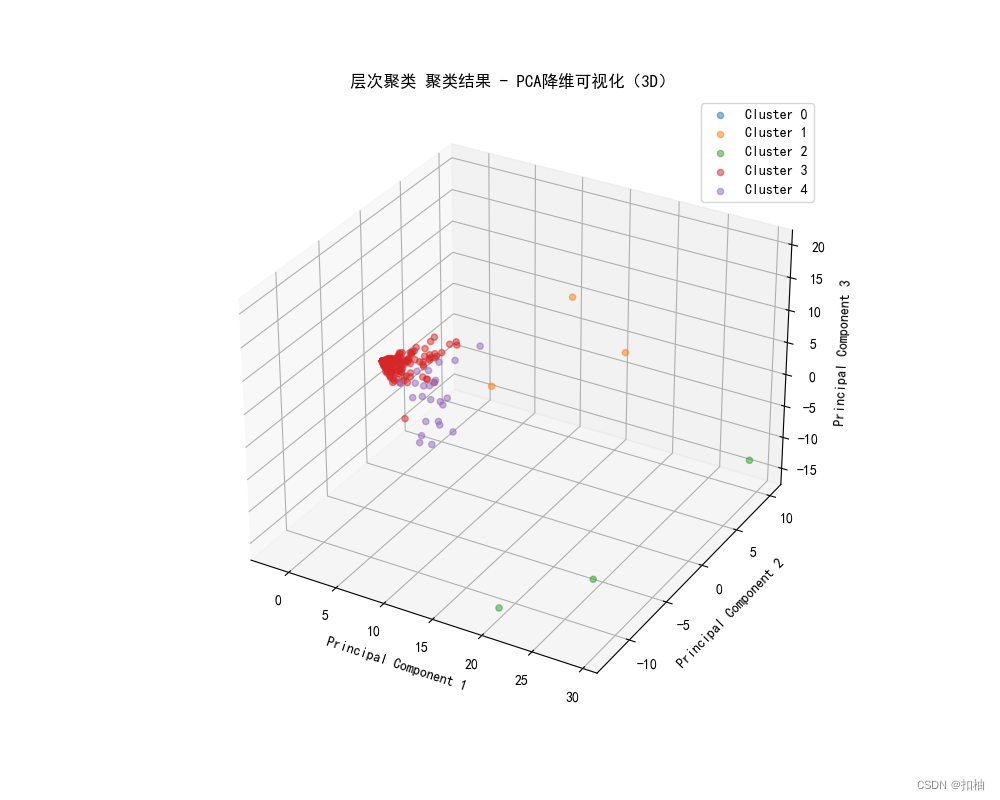
层次聚类结果
相关文章:
【机器学习】在Python中进行K-Means聚类和层次聚类
Python中聚类算法API的使用指南 聚类分析是数据分析中一种常见的无监督学习方法,通过将相似的对象分组在一起,我们能够识别出数据集中的自然分群。本文将介绍如何使用Python中的聚类算法接口,KMeans和层次聚类方法。 K-Means 聚类 K-Means…...
springboot254小区团购管理
小区团购管理设计与实现 摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计算机上安装小区团购管理软件来发挥其高效地信…...
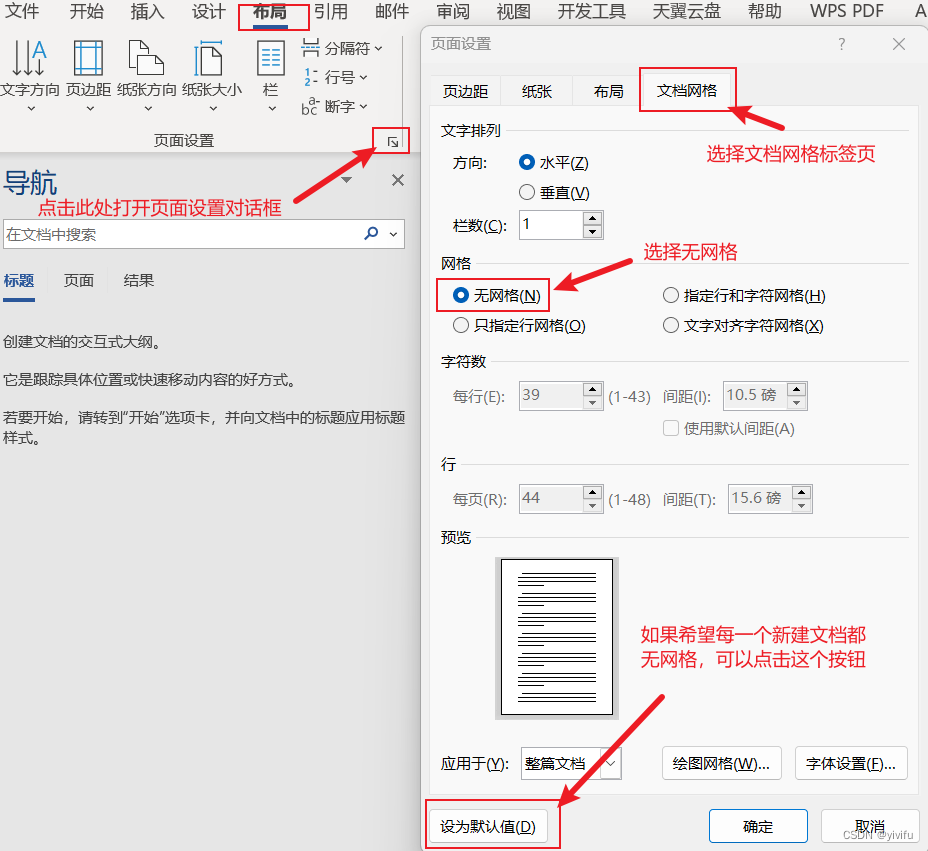
Word中的文档网格线与行距问题
在使用Word编辑文档时,经常会发生以下动图展示的这种情况: 上面的动图里,将文字大小放大到某个字号时,单倍行距的间距突然增加很多。造成这种情况的原因是文档中定义了网格线,并且设置了对齐到网格线。如果取消文档中…...
【简写Mybatis】03-Mapper xml的注册和使用
前言 在学习MyBatis源码文章中,斗胆想将其讲明白;故有此文章,如有问题,不吝指教! 注意: 学习源码一定一定不要太关注代码的编写,而是注意代码实现思想; 通过设问方式来体现代码中的…...
)
Vue源码系列讲解——指令篇【一】(自定义指令)
目录 1. 前言 2. 何时生效 3. 指令钩子函数 4. 如何生效 5. 总结 1. 前言 在Vue中,除了Vue本身为我们提供的一些内置指令之外,Vue还支持用户自定义指令。并且用户有两种定义指令的方式:一种是使用全局API——Vue.directive来定义全局指令…...
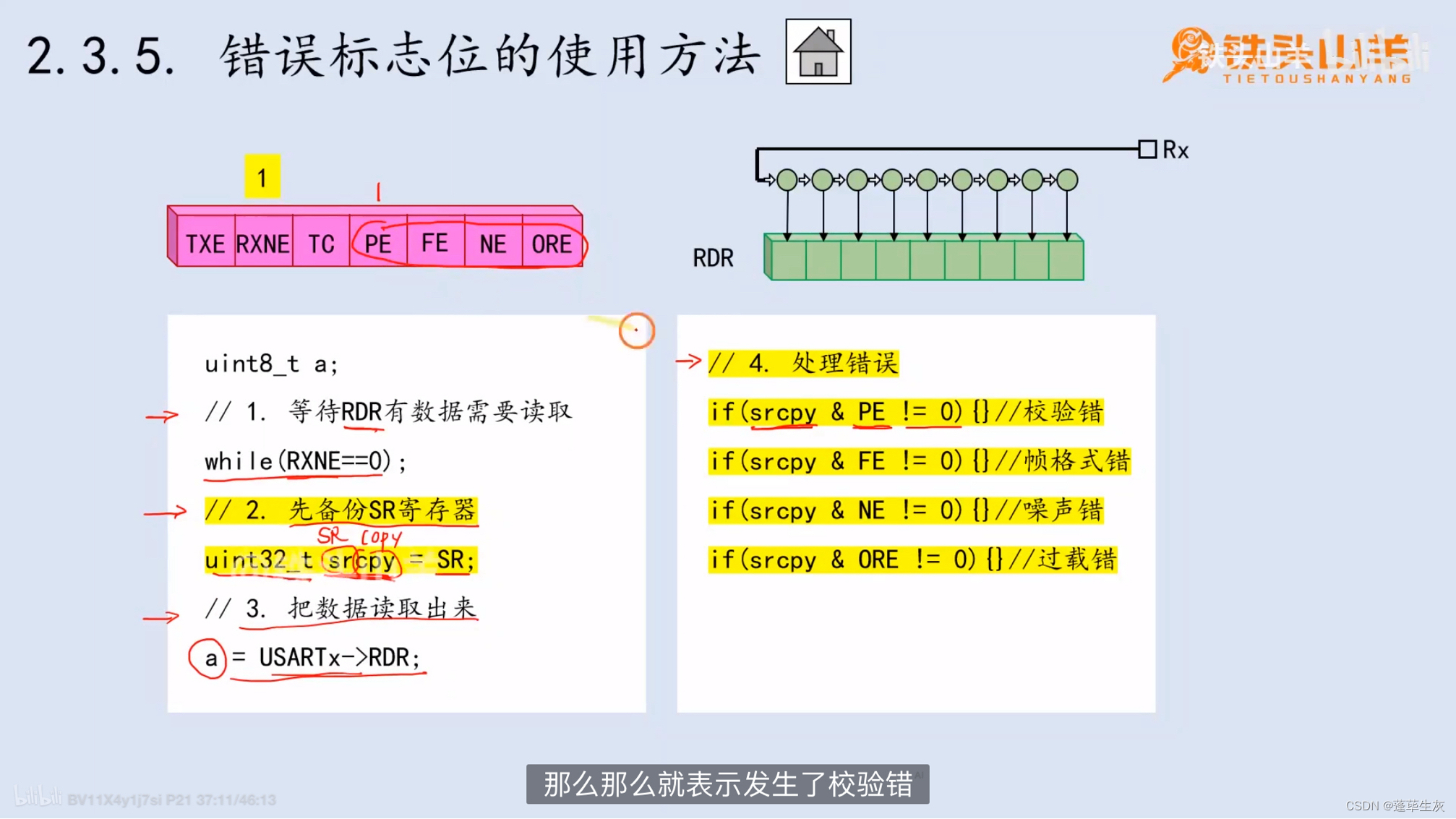
STM32(14)USART
USART:一种片上外设,用来实现串口通信,就是stm32内部的串口 USART简介 串并转换电路 串行通信和并行通信 串行:一根数据线,逐个比特位发送 为什么要串并转换 移位寄存器 USART的基本模型 通过查询SR(状态寄存器&…...

作业 字符数组-统计和加密
字串中数字个数 描述 输入一行字符,统计出其中数字字符的个数。 输入 一行字符串,总长度不超过255。 输出 输出为1行,输出字符串里面数字字符的个数。 样例 #include <iostream> #include<string.h> using namespace std; int m…...
除F2题外补题报告)
Codeforces Round 719 (Div. 3)除F2题外补题报告
Codeforces Round 719 Div. 3 除F2题外补题报告 得分情况补题情况错题分析C题题目大意初次思路正解思路正解代码错误原因 D题题目大意初次思路正解思路正解代码错误原因 E题题目大意初次思路正解思路正解代码 F1题题目大意正解思路正解代码 G题题目大意正解思路正解代码 得分情…...

docker本地搭建spark yarn hive环境
docker本地搭建spark yarn hive环境 前言软件版本准备工作使用说明构建基础镜像spark on yarn模式构建on-yarn镜像启动on-yarn集群手动方式自动方式 spark on yarn with hive(derby server)模式构建on-yarn-hive镜像启动on-yarn-hive集群手动方式自动方式 常用示例spark执行sh脚…...

每日学习笔记:C++ 11的Tuple
#include <tuple> Tuple介绍(不定数的值组--可理解为pair的升级版) 定义 创建 取值 初始化 获取tuple元素个数、获取tuple某元素类型、将2个tuple类型串接为1个新tuple类型...

MongoDB聚合运算符;$dateToParts
$dateToParts聚合运算符将日期表达式拆分成多个字段放在一个文档返回,属性有year、month、day、hour、minute、second和millisecond。如果iso8601属性设置为true,返回的各部分用ISO周日期返回,属性分别是:isoWeekYear、isoWeek、i…...

Spring MVC RequestMappingHandlerAdapter原理解析
在Spring MVC框架中,RequestMappingHandlerAdapter是一个核心的组件,负责将请求映射到具体的处理器方法上,并调用这些方法来处理请求。其中,invokeHandlerMethod方法是这个适配器中的一个关键方法,它负责实际调用处理器…...

反射整理学习
目录 1、反射介绍 2、反射API 2.1 获取类对应的字节码的对象(三种) 2.2 常用方法 3、反射的应用 3.1 创建 : 测试物料类 3.2 获取类对象 3.3 获取成员变量 3.4 通过字节码对象获取类的成员方法 3.5 通过字节码对象获取类的构造方法 4、创建对象…...

JavaScript 运算规则详解
在 JavaScript 中,运算规则是非常重要的基础知识,了解这些规则可以帮助我们正确地编写代码并避免一些常见的错误。本教程将详细介绍 JavaScript 中的各种运算规则,包括基本运算符、类型转换、运算优先级等内容。 1. 基本运算符 JavaScript …...

C++篇 语 句
到目前为止,我们只见过两种语句: return 语句和表达式语句。根据语句对执行顺 序的影响,C 语言其余语句大多属于以下 3 大类。 选择语句: if 语句和 switch 语句。循环语句: while 语句, do...while 语句和…...

简洁的在线观影开源项目
公众号:【可乐前端】,每天3分钟学习一个优秀的开源项目,分享web面试与实战知识。 每天3分钟开源 hi,这里是每天3分钟开源,很高兴又跟大家见面了,今天介绍的开源项目简介如下: 仓库名࿱…...

VB超级模块函数VB读写记事本-防止乱码支持UTF-8和GB2312编码
Private Sub Command1_Click() Writein “C:\Users\Administrator\Desktop\1.txt”, “文本文内容” End Sub Private Sub Form_Load() Text1 ReadANSI(“C:\Users\Administrator\Desktop\1.txt”) Text2 ReadUTF8(“C:\Users\Administrator\Desktop\1.txt”) End Sub 写入…...
XSS靶场-DOM型初级关卡
一、环境 XSS靶场 二、闯关 1、第一关 先看源码 使用DOM型,获取h2标签,使用innerHTML将内容插入到h2中 我们直接插入<script>标签试一下 明显插入到h2标签中了,为什么不显示呢?看一下官方文档 尽管插入进去了࿰…...
【嵌入式高级C语言】10:C语言文件
文章目录 1 文件的概述1.1 文件分类(存储介质)1.2 磁盘文件分类(存储方式)1.3 二进制文件和文本文件的区别 2 文件缓冲区3 文件指针4 文件的API4.1 打开文件4.2 关闭文件4.3 重新定位流4.3.1 fseek4.3.2 ftell4.3.3 rewind 4.4 字…...

创建数据表
Oracle从入门到总裁:https://blog.csdn.net/weixin_67859959/article/details/135209645 如果要进行数据表的创建 create table 表名称 (列名称 类型 [DEFAULT 默认值 ] ,列名称 类型 [DEFAULT 默认值 ] ,列名称 类型 [DEFAULT 默认值 ] ,...列名称 类型 [DEFAULT 默认值 ] )…...

香瓜树莓派RP2350之USB虚拟串口驱动开发实战
1. 硬件准备与环境搭建 第一次接触树莓派RP2350开发板时,我被它小巧的体积和强大的功能惊艳到了。这块板子虽然只有信用卡大小,但内置双核ARM Cortex-M0处理器,主频高达133MHz,特别适合用来做嵌入式开发。要实现USB虚拟串口功能&…...

ComfyUI-Impact-Pack面部增强功能与ControlNet模型兼容性完全指南
ComfyUI-Impact-Pack面部增强功能与ControlNet模型兼容性完全指南 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址: https://…...

绿色极简:一款712KB的快捷回复工具深度解析
在信息交互频繁的当下,客服人员和社群运营者每天都要面对大量重复性咨询。 同样的问候语、同样的产品介绍、同样的售后说明,一天要输入几十甚至上百次。 这种低效的手工重复劳动,不仅消耗大量时间,更容易因疲劳导致错字或遗漏。…...

AndLua逆向实战:从混淆字节码到源码还原的完整解析
1. AndLua逆向工程入门:从加密原理到实战准备 第一次接触AndLua逆向时,我被那些看似乱码的加密字符串搞得一头雾水。后来才发现,这就像玩解谜游戏,只要掌握关键线索就能层层突破。AndLua作为Android平台上的Lua实现,其…...

FireRed-OCR Studio入门必看:@st.cache_resource缓存机制原理与实测提速
FireRed-OCR Studio入门必看:st.cache_resource缓存机制原理与实测提速 你是不是也遇到过这样的烦恼?每次打开一个AI工具,都要等上好几分钟,看着进度条一点点加载,心里那个急啊。特别是处理文档的时候,上传…...

Windows Cleaner:彻底解决C盘空间不足的终极指南
Windows Cleaner:彻底解决C盘空间不足的终极指南 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你的Windows电脑是不是经常出现C盘爆红的警告&#x…...

Mysql--基础知识点--102--redo log内容
下面以 InnoDB 存储引擎 的 redo log 为例,给出一个典型的 UPDATE 操作 产生的 redo log 内容示例。 环境准备 假设有一张表: CREATE TABLE t1 (id INT PRIMARY KEY, name VARCHAR(20)) ROW_FORMATCOMPACT;执行更新: BEGIN; UPDATE t1 SET na…...

作为普通散户,我用ToClaw炒股 20 天的真实体验:到底是盯盘神器还是智商税?
作为普通散户,我用ToClaw炒股 20 天的真实体验:到底是盯盘神器还是智商税? 先交代一下背景。我是2019年入市的普通散户,本金不多,就十几万在股市里折腾。干过追涨杀跌、听过大V荐股、研究过K线指标,亏亏赚赚…...

5个简单步骤,用免费工具Untrunc快速修复损坏的MP4视频文件
5个简单步骤,用免费工具Untrunc快速修复损坏的MP4视频文件 【免费下载链接】untrunc Restore a truncated mp4/mov. Improved version of ponchio/untrunc 项目地址: https://gitcode.com/gh_mirrors/un/untrunc 你是否曾遇到过珍贵的视频文件突然无法播放&a…...

Go-CQHTTP实战指南:如何构建高效稳定的QQ机器人解决方案
Go-CQHTTP实战指南:如何构建高效稳定的QQ机器人解决方案 【免费下载链接】go-cqhttp cqhttp的golang实现,轻量、原生跨平台. 项目地址: https://gitcode.com/gh_mirrors/go/go-cqhttp Go-CQHTTP是基于Mirai和MiraiGo项目的OneBot-v11标准协议Gola…...