【OpenCV】车牌自动识别算法的设计与实现
写目录
- 一. 🦁 设计任务说明
- 1.1 主要设计内容
- 1.1.1 设计并实现车牌自动识别算法,基本功能要求
- 1.1.2 参考资料
- 1.1.3 参考界面布局
- 1.2 开发该系统软件环境及使用的技术说明
- 1.3 开发计划
- 二. 🦁 系统设计
- 2.1 功能分析
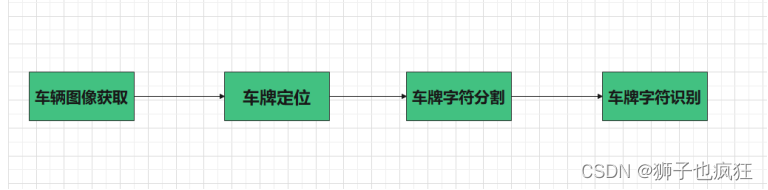
- 2.1.1 车辆图像获取
- 2.1.2 车牌定位
- 2.1.3 车牌字符分割
- 2.1.4 车牌字符识别
- 2.2 部分功能代码实现
- 2.3 概要设计
- 2.4 详细设计
- 2.4.1 读取图像
- 2.4.2 降噪
- 2.4.3 二值化
- 2.4.4 将图像边缘连接为一个整体
- 2.4.5 查找车牌(矩形区域)
- 2.4.6 图形修正
- 2.4.7 颜色识别
- 2.4.8 车牌部分二值化
- 2.4.9 字符分割(投影法)
- 2.4.10 匹配模板
- 三. 🦁 程序运行结果
- 四. 🦁 算法性能
- 五. 🦁 总结

一. 🦁 设计任务说明
1.1 主要设计内容
1.1.1 设计并实现车牌自动识别算法,基本功能要求
Ⅰ. 对给定的包含有汽车车牌的照片进行处理,利用图像分割算法将目标从背景中分离出来。
Ⅱ. 对目标图像进行合适的处理,然后利用Tesseract库实现车牌号码的识别,将结果输出。
Ⅲ. 要求提供比较友好的用户接口,可以对新的图片导入到系统中进行处理,并将结果返回给用户。
Ⅳ. 要求处理过程的自动化,即输入图像,自动输出车牌信息,无需人去干预。
1.1.2 参考资料
Ⅰ. OpenCV官方参考文档
Ⅱ. Github网站
Ⅲ. 文字识别可以用Tesseract库实现,也可以用其他方式实现
1.1.3 参考界面布局

1.2 开发该系统软件环境及使用的技术说明
PyQt5:5.11.3
opencv-python:4.2
1.3 开发计划

二. 🦁 系统设计
2.1 功能分析
2.1.1 车辆图像获取
车辆图像获取是车牌识别的第一步,也是很重要的一步,车辆图像的好坏对后面的工作有很大的影响。如果车辆图像的质量太差,连人眼都没法分辨,那么肯定不会被机器所识别出来。车辆图像都是在实际现场拍摄出来的,实际环境情况比较复杂,图像受天气和光线等环境影响较大,在恶劣的工作条件下系统性能将显著下降。
现有的车辆图像获取方式主要有两种:
一种是由彩色摄像机和图像采集卡组成,其工作过程是:当车辆检测器(如地感线圈、红外线等)检测到车辆进入拍摄范围时,向主机发送启动信号,主机通过采集卡采集一幅车辆图像,为了提高系统对天气、环境、光线等的适应性,摄像机一般采用自动对焦和自动光圈的一体化机,同时光照不足时还可以自动补光照明,保证拍摄图片的质量;另一种是由数码照相机构成,其工作过程是:当车辆检测器检测到车辆进入拍摄范围时,直接给数码照相机发送一个信号,数码相机自动拍摄一幅车辆图像,再传到主机上,数码相机的一些技术参数可以通过与数码相机相连的主机进行设置,光照不足时也需要自动开启补光照明,保证拍摄图片的质量。
2.1.2 车牌定位
车牌定位的主要工作是从摄入的汽车图像中找到汽车牌照所在位置,并把车牌从该区域中准确地分割出来,供字符分割使用。因此,牌照区域的确定是影响系统性能的重要因素之一,牌照的定位与否直接影响到字符分割和字符识别的准确率。目前车牌定位的方法很多,但总的来说可以分为以下4类:
- (1)基于颜色的分割方法,这种方法主要利用颜色空间的信息,实现车牌分割,包括彩色边缘算法、颜色距离和相似度算法等;
- (2)基于纹理的分割方法,这种方法主要利用车牌区域水平方向的纹理特征进行分割,包括小波纹理、水平梯度差分纹理等;
- (3)基于边缘检测的分割方法;
- (4)基于数学形态法的分割方法。
2.1.3 车牌字符分割
要识别车牌字符,前提是先进行车牌字符的正确分割与提取。字符分割的任务是把多列或多行字符图像中的每个字符从整个图像中切割出来成为单个字符。车牌字符的正确分割对字符的识别是很关键的。传统的字符分割算法可以归纳为以下三类:直接分割法、基于识别基础上的分割法、自适应分割线类聚法。
- 直接分割法简单,但它的局限是分割点的确定需要较高的准确性;
- 基于识别基础上的分割法是把识别和分割结合起来,但是需要识别的高准确性,它根据分类和识别的耦合程度又有不同的划分;
- 自适应分割线聚类法是要建立一个分类器,用它来判断图像的每一列是否是分割线,它是根据训练样本来进行自适应学习的神经网络分类器,但对于粘连字符训练困难。也有直接把字符组成的单词当作一个整体来识别的,诸如运用马尔科夫数学模型等方法进行处理,这些算法主要应用于印刷体文本识别。
2.1.4 车牌字符识别
与一般印刷体字符识别相比,车牌字符识别尤其自身的特点,它是文字识别技术与车牌图像自身因素协调兼顾的综合技术,目前,车牌字符识别算法主要是基于模板匹配、特征匹配或神经网络的方法。我国的车牌字符包括50多个汉字,25个大写英文字母,10个数字,总共也就80多个字符,鉴于车牌识别系统的特殊性,如果照搬普通汉字识别的方法,对文字细化后再提取其结构或统计特征,非但得不到意想的结果,反而会降低识别率。
2.2 部分功能代码实现
def __imreadex(self, filename):return cv2.imdecode(np.fromfile(filename, dtype=np.uint8), cv2.IMREAD_COLOR)def __point_limit(self, point):if point[0] < 0:point[0] = 0if point[1] < 0:point[1] = 0def __find_waves(self, threshold, histogram):up_point = -1 # 上升点is_peak = Falseif histogram[0] > threshold:up_point = 0is_peak = Truewave_peaks = []for i, x in enumerate(histogram):if is_peak and x < threshold:if i - up_point > 2:is_peak = Falsewave_peaks.append((up_point, i))elif not is_peak and x >= threshold:is_peak = Trueup_point = iif is_peak and up_point != -1 and i - up_point > 4:wave_peaks.append((up_point, i))return wave_peaksdef __seperate_card(self, img, waves):part_cards = []for wave in waves:part_cards.append(img[:, wave[0]:wave[1]])return part_cardsdef __accurate_place(self, card_img_hsv, limit1, limit2, color):row_num, col_num = card_img_hsv.shape[:2]xl = col_numxr = 0yh = 0yl = row_num# col_num_limit = self.cfg["col_num_limit"]row_num_limit = self.cfg["row_num_limit"]col_num_limit = col_num * 0.8 if color != "green" else col_num * 0.5 # 绿色有渐变for i in range(row_num):count = 0for j in range(col_num):H = card_img_hsv.item(i, j, 0)S = card_img_hsv.item(i, j, 1)V = card_img_hsv.item(i, j, 2)if limit1 < H <= limit2 and 34 < S and 46 < V:count += 1if count > col_num_limit:if yl > i:yl = iif yh < i:yh = ifor j in range(col_num):count = 0for i in range(row_num):H = card_img_hsv.item(i, j, 0)S = card_img_hsv.item(i, j, 1)V = card_img_hsv.item(i, j, 2)if limit1 < H <= limit2 and 34 < S and 46 < V:count += 1if count > row_num - row_num_limit:if xl > j:xl = jif xr < j:xr = jreturn xl, xr, yh, yldef __preTreatment(self, car_pic):if type(car_pic) == type(""):img = self.__imreadex(car_pic)else:img = car_picpic_hight, pic_width = img.shape[:2]if pic_width > self.MAX_WIDTH:resize_rate = self.MAX_WIDTH / pic_widthimg = cv2.resize(img, (self.MAX_WIDTH, int(pic_hight * resize_rate)),interpolation=cv2.INTER_AREA)
#确定车牌颜色
colors = []
for card_index, card_img in enumerate(card_imgs):green = yellow = blue = black = white = 0try:card_img_hsv = cv2.cvtColor(card_img, cv2.COLOR_BGR2HSV)except:card_img_hsv = Noneif card_img_hsv is None:continuerow_num, col_num = card_img_hsv.shape[:2]card_img_count = row_num * col_numfor i in range(row_num):for j in range(col_num):H = card_img_hsv.item(i, j, 0)S = card_img_hsv.item(i, j, 1)V = card_img_hsv.item(i, j, 2)if 11 < H <= 34 and S > 34: yellow += 1elif 35 < H <= 99 and S > 34: green += 1elif 99 < H <= 124 and S > 34: blue += 1if 0 < H < 180 and 0 < S < 255 and 0 < V < 46:black += 1elif 0 < H < 180 and 0 < S < 43 and 221 < V < 225:white += 1color = "no"limit1 = limit2 = 0if yellow * 2 >= card_img_count:color = "yellow"limit1 = 11limit2 = 34 elif green * 2 >= card_img_count:color = "green"limit1 = 35limit2 = 99elif blue * 2 >= card_img_count:color = "blue"limit1 = 100limit2 = 124 elif black + white >= card_img_count * 0.7:color = "bw"# print(color)colors.append(color)if limit1 == 0:continuexl, xr, yh, yl = self.__accurate_place(card_img_hsv, limit1, limit2, color)if yl == yh and xl == xr:continueneed_accurate = Falseif yl >= yh:yl = 0yh = row_numneed_accurate = Trueif xl >= xr:xl = 0xr = col_numneed_accurate = Truecard_imgs[card_index] = card_img[yl:yh, xl:xr] \if color != "green" or yl < (yh - yl) // 4 else card_img[yl - (yh - yl) // 4:yh, xl:xr]if need_accurate: card_img = card_imgs[card_index]card_img_hsv = cv2.cvtColor(card_img, cv2.COLOR_BGR2HSV)xl, xr, yh, yl = self.__accurate_place(card_img_hsv, limit1, limit2, color)if yl == yh and xl == xr:continueif yl >= yh:yl = 0yh = row_numif xl >= xr:xl = 0xr = col_numcard_imgs[card_index] = card_img[yl:yh, xl:xr] \if color != "green" or yl < (yh - yl) // 4 else card_img[yl - (yh - yl) // 4:yh, xl:xr]return card_imgs, colors
2.3 概要设计
2.4 详细设计
2.4.1 读取图像
使用cv2.imdecode()函数将图片文件转换成流数据,赋值到内存缓存中,便于后续图像操作。使用cv2.resize()函数对读取的图像进行缩放,以免图像过大导致识别耗时过长。
2.4.2 降噪
使用cv2.GaussianBlur()进行高斯去噪。使用cv2.morphologyEx()函数进行开运算,再使用cv2.addWeighted()函数将运算结果与原图像做一次融合,从而去掉孤立的小点,毛刺等噪声。
高斯去噪 :
if blur > 0: img = cv2.GaussianBlur(img, (blur, blur), 0)
oldimg = img
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# cv2.imshow('GaussianBlur', img)
kernel = np.ones((20, 20), np.uint8)
img_opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel) # 开运算
img_opening = cv2.addWeighted(img, 1, img_opening, -1, 0); # 与上一次开运算结果融合
# cv2.imshow('img_opening', img_opening)


2.4.3 二值化
使用cv2.threshold()函数进行二值化处理,再使用cv2.Canny()函数找到各区域边缘。
ret, img_thresh = cv2.threshold(img_opening, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU) # 二值化
img_edge = cv2.Canny(img_thresh, 100, 200)
# cv2.imshow('img_edge', img_edge)

2.4.4 将图像边缘连接为一个整体
使用**cv2.morphologyEx()和cv2.morphologyEx()**两个函数分别进行一次开运算(先腐蚀运算,再膨胀运算)和一个闭运算(先膨胀运算,再腐蚀运算),去掉较小区域,同时填平小孔,弥合小裂缝。将车牌位置凸显出来。
kernel = np.ones((self.cfg["morphologyr"], self.cfg["morphologyc"]), np.uint8)
img_edge1 = cv2.morphologyEx(img_edge, cv2.MORPH_CLOSE, kernel) # 闭运算
img_edge2 = cv2.morphologyEx(img_edge1, cv2.MORPH_OPEN, kernel) # 开运算
# cv2.imshow('img_edge2', img_edge2)

2.4.5 查找车牌(矩形区域)
查找图像边缘整体形成的矩形区域,可能有很多,车牌就在其中一个矩形区域中,逐个排除不是车牌的矩形区域。车牌形成的矩形区域长宽比在2到5.5之间,因此使用cv2.minAreaRect()函数框选矩形区域计算长宽比,长宽比在2到5.5之间的可能是车牌,其余的矩形排除。最后使用cv2.drawContours()函数将可能是车牌的区域在原图中框选出来。

2.4.6 图形修正
矩形区域可能是倾斜的矩形,需要矫正,以便使用颜色定位,从而进一步确认是否是车牌。类似下两图(仅列举出两个,可能有很多)。
在这里插入图片描述 在这里插入图片描述

2.4.7 颜色识别
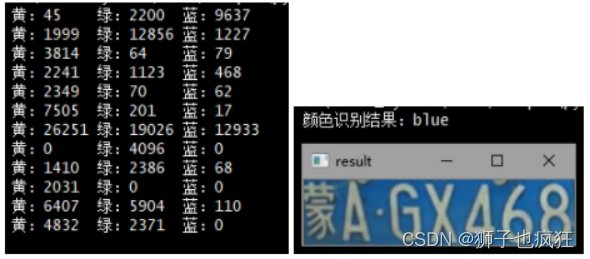
使用颜色定位,排除不是车牌的矩形,目前只识别车牌的颜色主要为蓝、绿、黄三种颜色车牌。根据矩形的颜色不同从而选出最可能是车牌的矩形。同时匹配出车牌的类型(颜色类型)。使用参数为cv2.COLOR_BGR2HSV的cv2.cvtColor()函数将原始的RGB图像转换成HSV图像,以便定位颜色。
基于HSV颜色模型可知色调H的取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。它们的补色是:黄色为60°,青色为180°,品红为300°;查阅相关资料确定出下表:
| 黄色 | 绿色 | 蓝色 | |
|---|---|---|---|
| H | 14-34 | 34-99 | 99-124 |
根据上表计算出每个矩形中各颜色的占有量,比较每个矩形三个颜色的占有量,即可确定最可能是车牌的矩形以及车牌颜色。
2.4.8 车牌部分二值化
利用参数为cv2.COLOR_BGR2GRAY的cv2.cvtColor()函数将定位到的车牌部分RGB图像转化为灰度图像,再利用cv2. threshold() 函数将灰度图像二值化。需要注意的是,黄、绿色车牌字符比背景暗、与蓝的车牌刚好相反,所以黄、绿车牌在二值化前需要利用cv2.bitwise_not( )函数取反向。
# 做一次锐化处理
kernel = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]], np.float32) # 锐化
card_img = cv2.filter2D(card_img, -1, kernel=kernel)
# cv2.imshow("custom_blur", card_img) # RGB转GARY
gray_img = cv2.cvtColor(card_img, cv2.COLOR_BGR2GRAY)
# cv2.imshow('gray_img', gray_img) # 黄、绿车牌字符比背景暗、与蓝车牌刚好相反,所以黄、绿车牌需要反向
if color == "green" or color == "yellow": gray_img = cv2.bitwise_not(gray_img)
# 二值化
ret, gray_img = cv2.threshold(gray_img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# cv2.imshow('gray_img', gray_img)
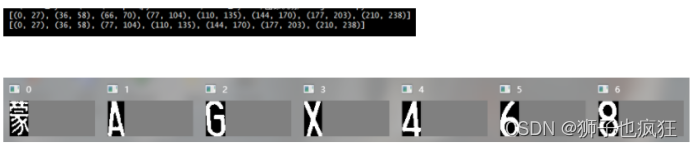
2.4.9 字符分割(投影法)
根据设定的阈值和图片直方图,找出波峰,利用找出的波峰,分隔图片。因为车牌中“ • ”也会产生一组波峰,因此将八组波峰中的第三组去除掉,即可得到每个字符的波峰,再根据每组波峰的宽度分割牌照图像得到每个字符的图像。
2.4.10 匹配模板
将分割后的每个图像逐个与已训练好的模板进行匹配,得到识别结果。
from _collections import OrderedDict
from flask import Flask, request, jsonify
from json_utils import jsonify
import numpy as np
import cv2
import time
from collections import OrderedDict
from Recognition import PlateRecognition# 实例化
app = Flask(__name__)
PR = PlateRecognition()# 设置编码-否则返回数据中文时候-乱码
app.config['JSON_AS_ASCII'] = False# route()方法用于设定路由;类似spring路由配置
@app.route('/', methods=['POST']) # 在线识别
def forecast():# 获取输入数据stat = time.time()file = request.files['image']img_bytes = file.read()image = np.asarray(bytearray(img_bytes), dtype="uint8")image = cv2.imdecode(image, cv2.IMREAD_COLOR)RES = PR.VLPR(image)if RES is not None:result = OrderedDict(Error=0,Errmsg='success',InputTime=RES['InputTime'],UseTime='{:.2f}'.format(time.time() - stat), # RES['UseTime'],Number=RES['Number'],From=RES['From'],Type=RES['Type'],List=RES['List'])else:result = OrderedDict(Error=1,Errmsg='unsuccess')return jsonify(result)if __name__ == '__main__':app.run()三. 🦁 程序运行结果
系统测试结果
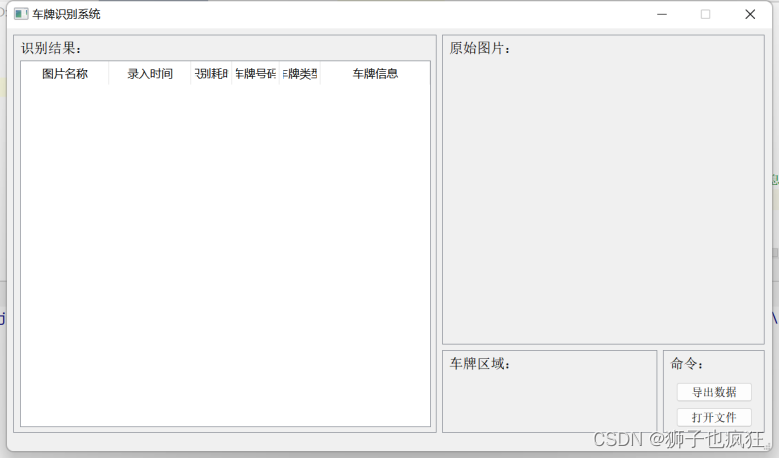
点击打开文件,在本地中选择要识别的车辆的照片
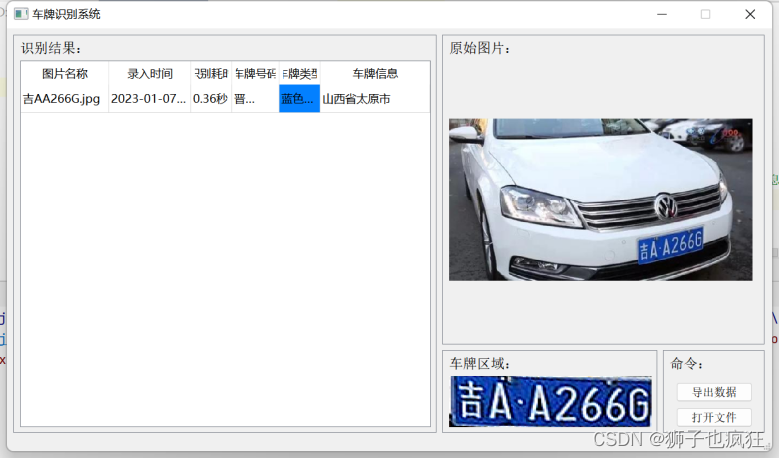
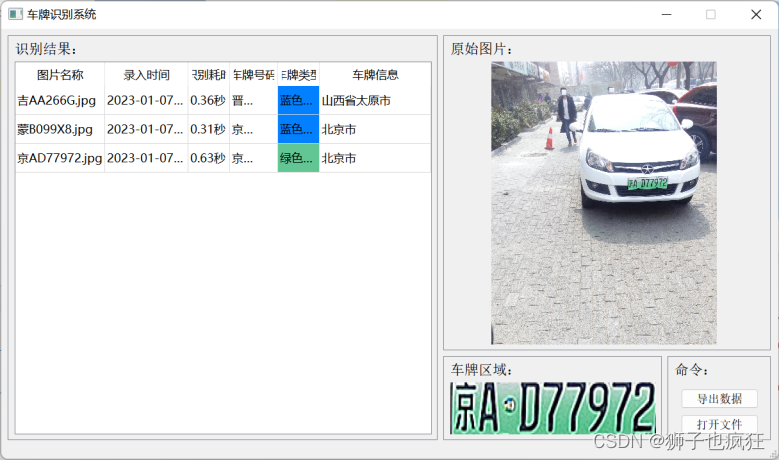
点击导出数据,得到所识别的车牌数据

四. 🦁 算法性能
每次处理时间小于1s
算法准确度为97%
五. 🦁 总结
设计过程中对于车牌部分的矩形的识别,出现识别错误区域的问题,通过查找网上的相关案例设定好判断条件以及和周围相同题目的同学请教其如何识别出车牌区域得以解决。通过此次综合项目练习,让我对以往的知识点的运用有了更进一步的实践和运用。
tips:
一个数字图像分析期末考核实验,如果您喜欢,可以一键三连哟!!!
【源码】后续会传上来,敬请期待吧!
相关文章:
【OpenCV】车牌自动识别算法的设计与实现
写目录一. 🦁 设计任务说明1.1 主要设计内容1.1.1 设计并实现车牌自动识别算法,基本功能要求1.1.2 参考资料1.1.3 参考界面布局1.2 开发该系统软件环境及使用的技术说明1.3 开发计划二. 🦁 系统设计2.1 功能分析2.1.1 车辆图像获取2.1.2 车牌…...

SpringBoot发送邮件
目录1. 获取授权码2. jar包引入3. 配置application4. 代码实现1. 获取授权码 以126邮箱为例,点开设置,选择POP3/SMTP/IMAP 开启POP3/SMTP服务,新增授权密码 扫码二维码,发送要求的短信内容到指定的号码即可,然后会返回…...
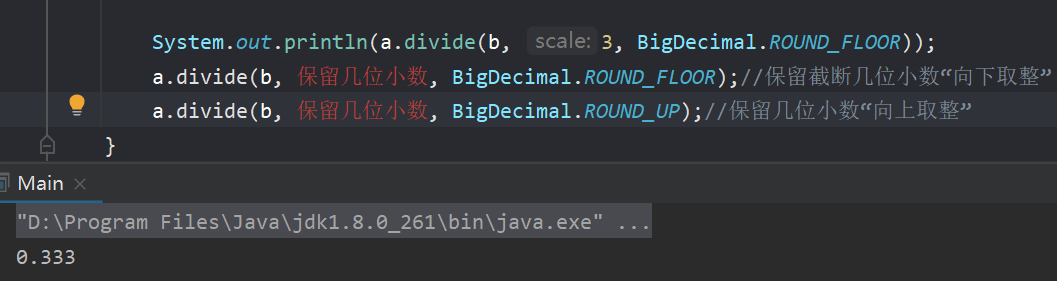
BigInteger类和BigDecimal类的简单介绍
文章目录📖前言:🎀BigInteger类和BigDecimal类的由来🎀BigDecimal类的优点🎀BigDecimal类容易引发的错误🏅处理方法📖前言: 本篇博客主要介绍BigInteger类和BigDecimal类的用途及常…...
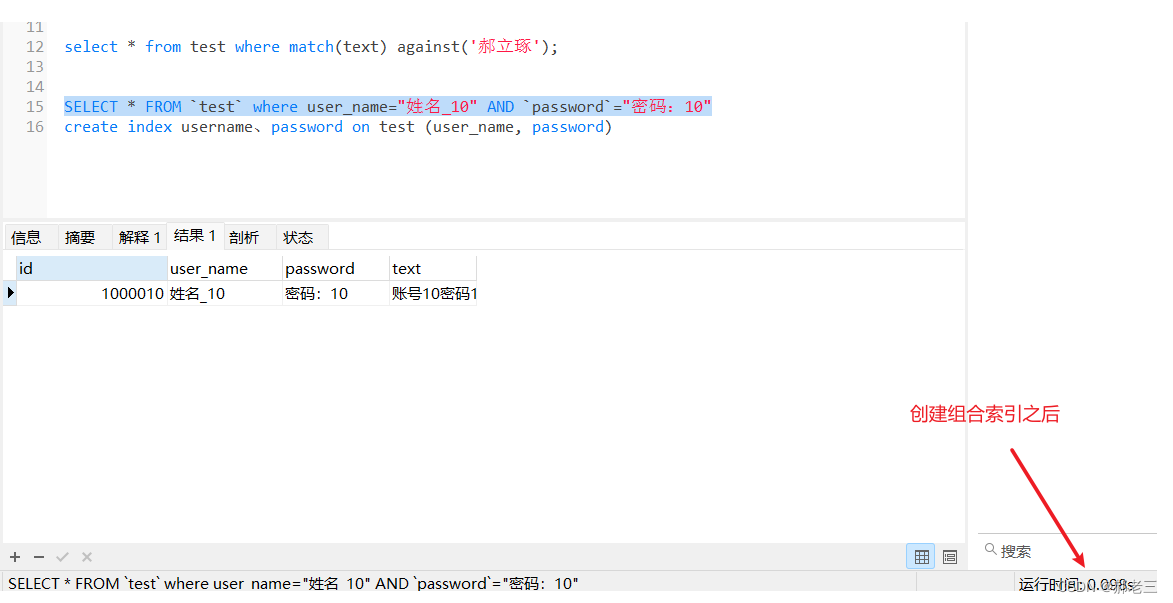
mysql五种索引类型---实操版本
背景 最近学习了Mysql的索引,索引对于Mysql的高效运行是非常重要的,正确的使用索引可以大大的提高MySql的检索速度。通过索引可以大大的提升查询的速度。不过也会带来一些问题。比如会降低更新表的速度(因为不但要把保存数据还要保存一下索引…...

【微信小程序】-- 页面导航 -- 编程式导航(二十三)
💌 所属专栏:【微信小程序开发教程】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! &…...

路由追踪工具 traceroute 使用技巧
路由追踪工具 traceroute 使用技巧路由追踪工作原理路由追踪实例1. 如何运行 traceroute2. 禁用 IP 地址和主机名映射3. 配置回复等待时间4. 配置每一跳的查询次数5. 配置 TTL 值我想知道一个数据包从出发地到目的地所遵循的路由,即所有转发实体(中间的路…...
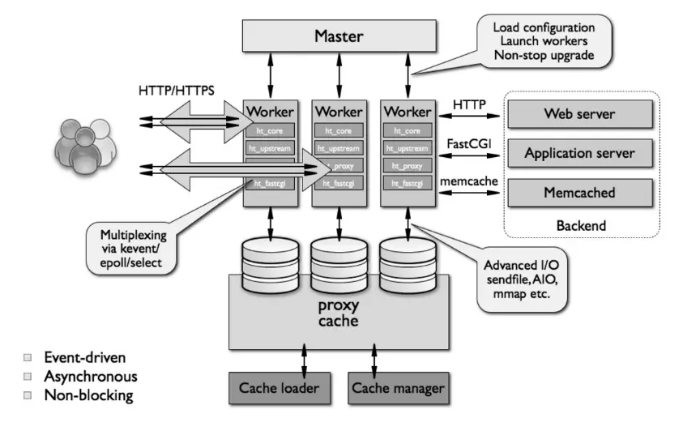
NGINX学习笔记 - 一篇了解NGINX的基本概念(一)
NGINX是什么? NGINX是一款由俄罗斯人伊戈尔赛索耶夫使用C语言开发的、支持热部署的、轻量级的WEB服务器/反向代理服务器/电子邮件代理服务器,因为占用内存较少,启动极快,高并发能力强,所以在互联网项目中广泛应用。可…...

Spring-Cloud-Gateway的过滤器的执行顺序问题
过滤器的种类 Spring-Cloud-Gateway中提供了3种类型的过滤器,分别是:路由过滤器、Default过滤器和Global过滤器。 路由过滤器和Default过滤器 路由过滤器和Default过滤器本质上是同一种过滤器,只不过作用范围不一样,路由过滤器…...

Android性能优化的底层逻辑
前言性能优化仿佛成了每个程序员开发的必经之路,要想出人头地,与众不同,你还真需要下点功夫去研究Android的性能优化,比如说,从优化应用启动、UI加载、再到内存、CPU、GPU、IO、还有耗电等等,当你展开一个方…...
Gradle+SpringBoot多模块开发
关于使用Gradle结合SpringBoot进行多模块开发。 本来是打算使用buildSrc之类的,但是感觉好像好麻烦,使用这种方法就可以实现,没必要采用其他的。 我不怎么会表述,可能写的跟粑粑一样,哈哈哈哈 这是我的项目地址。 存在…...

Qt 之 emit、signals、slot的使用
本文福利,莬费领取Qt开发学习资料包、技术视频,内容包括(C语言基础,Qt编程入门,QT信号与槽机制,QT界面开发-图像绘制,QT网络,QT数据库编程,QT项目实战,QSS&am…...

每日学术速递3.6
Subjects: cs.CV 1.Multi-Source Soft Pseudo-Label Learning with Domain Similarity-based Weighting for Semantic Segmentation 标题:用于语义分割的基于域相似性加权的多源软伪标签学习 作者:Shigemichi Matsuzaki, Hiroaki Masuzawa, Jun Miura …...
)
C# 将对象转换成字节数组(二进制数据)
在将自定义对象或者数组等这样的数据存储到数据库时往往需要转换成二进制字节,尤其是在一些O/RM数据库框架中,下面是转换的函数,一个是将对象转换成二进制字节数组,另一个是将从数据库中读取的二进制流转换成程序中的对象。 这里…...

巾帼绽芬芳 一起向未来(下篇)
编者按:为了隆重纪念纪念“三八”国际妇女节113周年,快来与你全方位、多层次分享交流“三八”国际妇女节的前世今生。分上篇(节日简介、节日发展和节日意义)、中篇(节日活动宗旨和世界各国庆祝方式)和下篇&…...

代码还原小试牛刀(一):魔改的MD5
一、目标 2023年了,MD5已经是最基础的签名算法了,但如果你还只是对输入做了简单的MD5,肯定会被同行们嘲笑。加点盐(salt)是一种基本的提升,但在这个就业形势严峻的时代,仅仅加盐肯定不够了。 …...

6. 找大佬
1 题目描述 找大佬成绩20开启时间2021年09月24日 星期五 18:00折扣0.8折扣时间2021年11月15日 星期一 00:00允许迟交否关闭时间2021年11月23日 星期二 10:00 众所周知,每个专业里都会有一些大佬隐藏在人群里。软件工程专业也是如此。今天的你就像从人群中找到真正的…...

【CSS】标签显示模式 ① ( 标签显示模式 | 块级元素 )
文章目录一、标签显示模式 ( 块级元素 | 行内元素 )二、块级元素1、块级元素简介2、块级元素特点3、文字块级元素4、代码示例一、标签显示模式 ( 块级元素 | 行内元素 ) 标签显示模式 : 指的是 标签显示的方式 , 标签类型有很多 , 不同的情景使用不同类型的标签 ; 块级元素 : …...
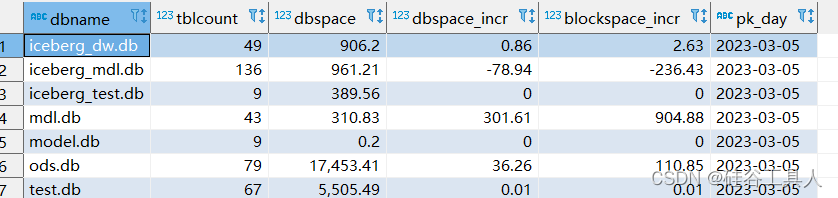
hive真实表空间大小统计
1. 问题 如果是采用hdfs上传加载的表、或者是flume直接写hdfs的表空间通常看hive的属性是不准确的。 2. 思路 为了使结果更精确,我们直接使用linux下命令统计hive仓库目录下的每个表对应的文件夹目录占用空间的大小。 3. 解决方法 这里建立三层表结构 ods: 原始…...

微信小程序引入Vant UI步骤
官方文档教程 1、通过 npm 安装 # 通过 npm 安装 npm i vant/weapp -S --production# 通过 yarn 安装 yarn add vant/weapp --production# 安装 0.x 版本 npm i vant-weapp -S --production2、修改 app.json 将 app.json 中的 “style”: “v2” 去除,小程序的新…...

【震撼发布】《致敬未来的攻城狮计划》| 文末赠书3本
《致敬未来的攻城狮计划》—— 文末有福利 摘要: 一个崭新的计划,寻找那群有志于向嵌入式发展的未来工程师! 文章目录1 活动计划初衷2 活动计划形式3 活动计划收获4 活动计划要求5 活动计划时间6 活动计划致谢7 活动计划特别说明8 温馨提示9 …...

基于STM32单片机人体健康检测血糖检测监测无线蓝牙APP设计S312
本系统由STM32F103C8T6单片机核心板、OLED屏、无线模块、血糖模拟检测、蜂鸣器报警、电源电路、按键电路组成。【1】液晶显示:OLED液晶显示心率值、心率上下限、血氧值、血氧阈值、血压值、血压阈值、血糖值、血糖上下限值以及心率血氧是否在采集测算中、当前数据是…...

RK3588 NPU部署YOLOv8全流程:从ONNX转换到板端C++/Python推理优化
1. 项目概述:为什么要在RK3588上部署YOLOv8?最近在边缘计算项目里,我遇到了一个典型的需求:客户需要在本地设备上实时分析摄像头画面,识别特定物体并分割出它们的轮廓,同时要求设备功耗低、体积小、成本可控…...
)
MATLAB调用C/C++库报错?手把手教你配置Visual Studio 2022编译器(含低版本MATLAB适配指南)
MATLAB调用C/C库报错?手把手教你配置Visual Studio 2022编译器(含低版本MATLAB适配指南) 当你在MATLAB中尝试调用C/C库时,突然弹出一个令人头疼的错误提示:"未找到支持的编译器或 SDK"。这种情况在工程开发和…...

你的参考文献规范吗?IEEE/Elsevier投稿前必查:LaTeX引用Early Access文章的正确姿势与避坑指南
IEEE/Elsevier投稿实战:LaTeX引用Early Access文献的终极解决方案 在学术出版的快节奏世界里,Early Access(提前在线发布)已成为主流期刊加速知识传播的重要方式。当你在深夜赶完论文最后一稿,突然发现参考文献列表里…...

为什么选择Lacinia?5大优势带你了解这个强大的GraphQL解决方案
为什么选择Lacinia?5大优势带你了解这个强大的GraphQL解决方案 【免费下载链接】lacinia GraphQL implementation in pure Clojure 项目地址: https://gitcode.com/gh_mirrors/la/lacinia 在当今API开发领域,GraphQL已经成为构建高效数据接口的重…...

AD21原理图设计避坑指南:搞定多通道编译时的‘多个网络名称’报错
AD21多通道设计实战:彻底解决"Multiple Net Names"报错难题 当你在AD21中精心设计了一个多通道电路,满心期待点击"编译"按钮时,Messages面板突然弹出的红色"Multiple Net Names"错误提示,就像交响乐…...

【独家首发】ElevenLabs尚未官方支持的希伯来文增强模式:基于phoneme-level微调的48小时快速部署方案
更多请点击: https://intelliparadigm.com 第一章:希伯来文语音合成的技术挑战与ElevenLabs生态定位 希伯来文是一种自右向左(RTL)书写的辅音音素文字,其语音合成面临多重语言学与工程学挑战:元音符号&…...

Python开发者三步完成Taotoken API密钥配置与调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者三步完成Taotoken API密钥配置与调用 对于希望快速接入大模型能力的Python开发者而言,Taotoken平台提供的…...

Kubernetes 安全加固清单:从 RBAC 到 etcd 加密的生产实践
在云原生时代,Kubernetes 已成为容器编排的事实标准,但默认配置下的 K8s 并不安全。一次错误的 RBAC 权限配置、一个暴露的 etcd 端口、或者一个特权模式的 Pod,都可能成为攻击者的入口。本文从认证授权、Pod 安全、网络隔离、数据加密四个维…...
)
STM32 I2C驱动AT24C02 EEPROM:手把手教你搞定页边界对齐与连续读写(附完整代码)
STM32 I2C驱动AT24C02 EEPROM:页边界对齐与连续读写实战指南 在嵌入式开发中,EEPROM因其非易失性存储特性成为参数保存的首选方案。而AT24C02作为经典的I2C接口EEPROM,其页写入机制却暗藏玄机——许多开发者第一次遭遇"写入数据丢失&quo…...