hive真实表空间大小统计
1. 问题
如果是采用hdfs上传加载的表、或者是flume直接写hdfs的表空间通常看hive的属性是不准确的。
2. 思路
为了使结果更精确,我们直接使用linux下命令统计hive仓库目录下的每个表对应的文件夹目录占用空间的大小。
3. 解决方法
这里建立三层表结构
ods: 原始数据采集
ods.ods_hive_tablelist
ods.ods_hive_tablespace
dw:清洗整合
dw.dw_hive_metadata
mdl: 统计
mdl.mdl_hive_metadata_stat
3.1 ODS层数据采集
在ods层建立文件路径列表和每个路径占用空间大小。
create table ods.ods_hive_tablelist(
path string comment '表路径',
update_time string comment '更新时间'
) comment 'hive表更新时间'
partitioned by (pk_day string)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile;create table ods.ods_hive_tablespace(
path string comment '表路径',
size string comment '表占用大小(byte)',
blocksize string comment '副本占用大小(byte)'
) comment 'hive表空间占用统计'
partitioned by (pk_day string)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile;
这里的数据采集使用shell命令格式,我是使用pySpark里面直接执行的。
tableList = os.popen("""hdfs dfs -ls /user/hive/warehouse/*.db |awk '{print $8","$6" "$7}'""")
tablespaceList = os.popen("""hadoop fs -du /user/hive/warehouse/*.db|awk '{print $3","$1","$2}'""")new_tableList = []
for table in tableList:arr = table.replace('\n','').split(",")new_tableList.append((arr[0],arr[1]))new_tablespaceList = []
for tablespace in tablespaceList:arr = tablespace.replace('\n','').split(",")new_tablespaceList.append((arr[0],arr[1],arr[2]))#----ods----
current_dt = date.today().strftime("%Y-%m-%d")
print(current_dt)
spark.createDataFrame(new_tableList,['path','update_time']).registerTempTable('tablelist')
spark.createDataFrame(new_tablespaceList,['path','size','blocksize']).registerTempTable('tablespacelist')
tablelistdf = spark.sql('''(select path,update_time,current_date() as pk_day from tablelist where path != '') ''')
tablelistdf.show(10)tablelistdf.repartition(2).write.insertInto('ods.ods_hive_tablelist',True)tablespacelistdf = spark.sql('''(select path,size,blocksize,current_date() as pk_day from tablespacelist where path != '')''')
tablespacelistdf.show(10)
tablespacelistdf.repartition(2).write.insertInto('ods.ods_hive_tablespace',True)
经过简单的清洗后,落表。
ods.ods_hive_tablelist表的显示如下:
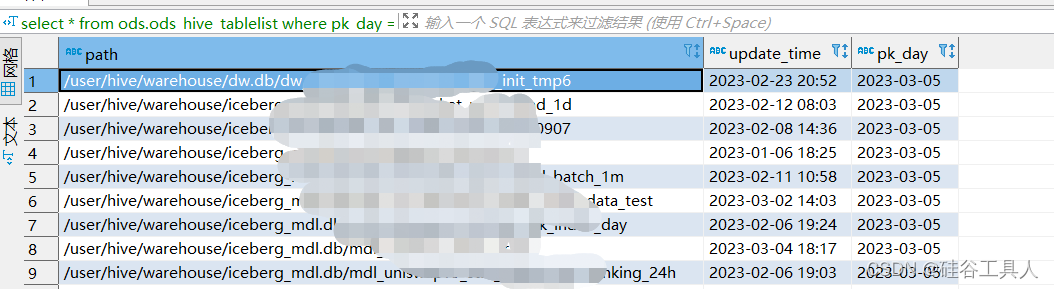
在ods.ods_hive_tablespace中显示的如下
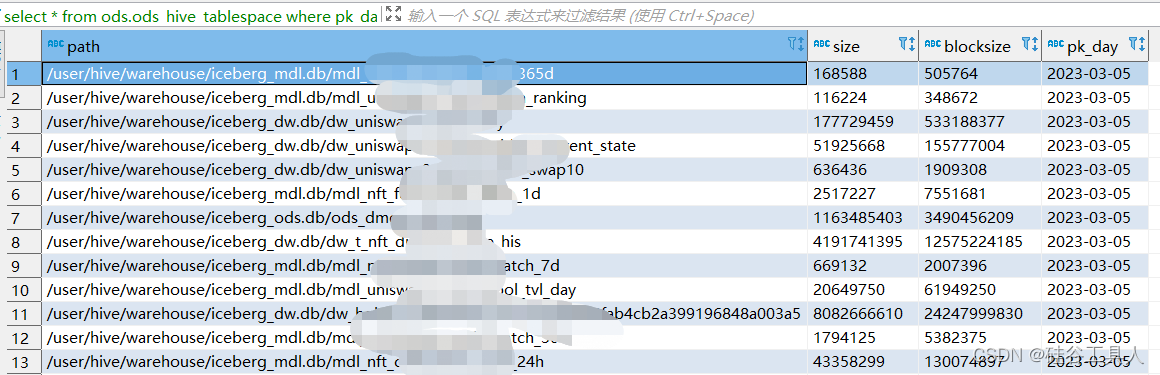
3.2 清洗整合入仓
接下来在dw层进行整合,对应的表结构如下:
create table dw.dw_hive_metadata(
dbname string comment '数据库名',
tblname string comment '表名',
path string comment '表路径',
update_date string comment '更新日期',
update_time string comment '更新时间',
mb double comment '表占用大小(MB)',
gb double comment '表占用大小(GB)',
size double comment '表占用大小(byte)',
blocksize double comment '副本占用大小(byte)',
blocksize_gb double comment '副本占用大小(gb)'
) comment 'hive表元数据统计'
partitioned by (pk_day string)
stored as textfile;
这里整合ods层的两张表关联,就可以拼接出每个表占用的空间大小:
#----dw----
dwdf = spark.sql('''(
selectsplit(a.path,'/')[4] as dbname,split(a.path,'/')[5] as tblname,a.path,substr(a.update_time,1,10) as update_date,a.update_time,nvl(round(b.size/1000/1000,2),0) as mb,nvl(round(b.size/1000/1000/1000,2),0) as gb,nvl(round(b.size,2),0) as size,nvl(round(b.blockSize,2),0) as blocksize,nvl(round(b.blockSize/1000/1000/1000,2),0) as blocksize_gb,a.pk_day
from(select * from ods.ods_hive_tablelist where pk_day = current_date()) aleft join(select * from ods.ods_hive_tablespace where pk_day = current_date()) b
on a.path = b.path and a.pk_day = b.pk_day
where a.path is not null
and a.path != ''
)''')
我们可以看到这个明细数据展示如下:
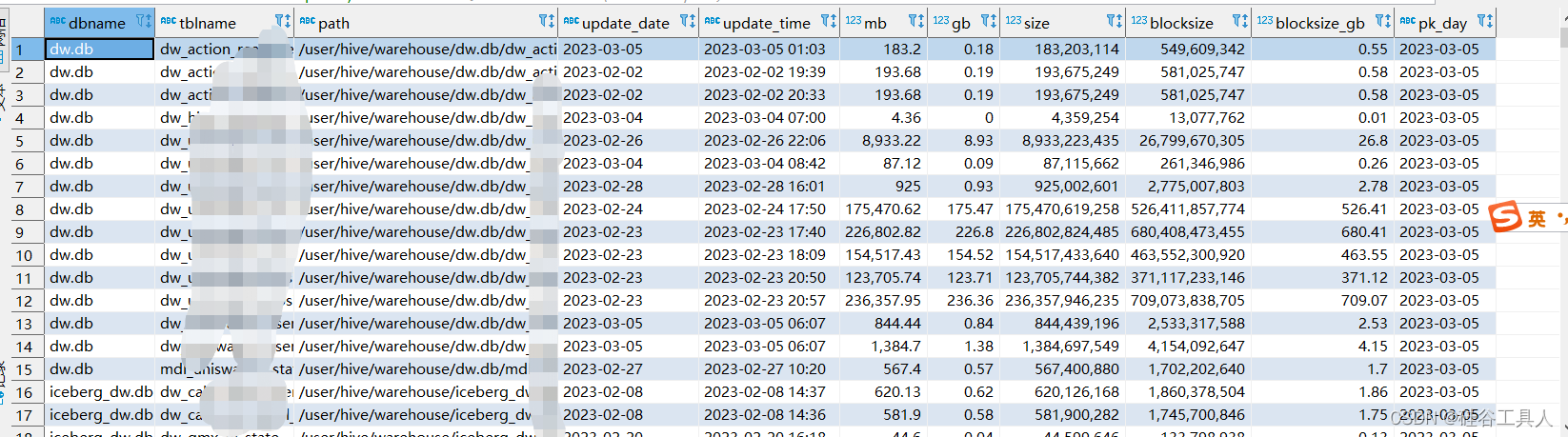
3.3 统计分析
这里可以根据需要自己增加统计逻辑,我这里按照db层级统计每天的增量大小。
统计层表结构如下:
create table mdl.mdl_hive_metadata_stat(
dbname string comment '数据库名',
tblcount int comment '表个数',
dbspace double comment '数据库空间(GB)',
dbspace_incr double comment '数据库空间日增量(GB)',
blockspace_incr double comment '服务器空间日增量(GB)'
) comment 'hive元数据db统计'
partitioned by (pk_day string)
stored as textfile;
实现方式:
#----mdl----
spark.sql('''(select pk_day,dbname,count(tblname) as tblCount,round(sum(gb),2) as dbspace,round(sum(blocksize_gb),2) as blockSpacefrom dw.dw_hive_metadatawhere pk_day>= date_sub(current_date(),7)group by pk_day,dbname)''').createTempView('tmp_a')spark.sql('''(selectpk_day,dbname,tblCount,dbspace,blockSpace,lag(dbspace,1,0) over(partition by dbname order by pk_day) as lagSpace,lag(blockSpace,1,0) over(partition by dbname order by pk_day) as lagBlockSpacefrom tmp_a
)''').createTempView('tmp_b')mdldf = spark.sql('''(
select dbname,tblCount,dbspace,
round((dbspace-lagSpace),2) as dbspace_incr,
round((blockSpace-lagBlockSpace),2) as blockspace_incr,
pk_day
from tmp_b where pk_day = current_date()
)''')
mdldf.show(10)
mdldf.repartition(1).write.insertInto('mdl.mdl_hive_metadata_stat',True)
最后看看,统计层的内容如下:
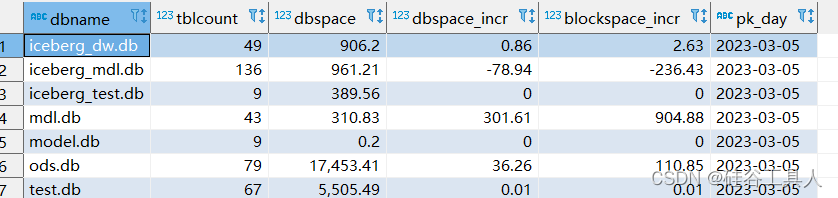
相关文章:
hive真实表空间大小统计
1. 问题 如果是采用hdfs上传加载的表、或者是flume直接写hdfs的表空间通常看hive的属性是不准确的。 2. 思路 为了使结果更精确,我们直接使用linux下命令统计hive仓库目录下的每个表对应的文件夹目录占用空间的大小。 3. 解决方法 这里建立三层表结构 ods: 原始…...

微信小程序引入Vant UI步骤
官方文档教程 1、通过 npm 安装 # 通过 npm 安装 npm i vant/weapp -S --production# 通过 yarn 安装 yarn add vant/weapp --production# 安装 0.x 版本 npm i vant-weapp -S --production2、修改 app.json 将 app.json 中的 “style”: “v2” 去除,小程序的新…...

【震撼发布】《致敬未来的攻城狮计划》| 文末赠书3本
《致敬未来的攻城狮计划》—— 文末有福利 摘要: 一个崭新的计划,寻找那群有志于向嵌入式发展的未来工程师! 文章目录1 活动计划初衷2 活动计划形式3 活动计划收获4 活动计划要求5 活动计划时间6 活动计划致谢7 活动计划特别说明8 温馨提示9 …...

8.装饰者模式
目录 简介 角色组成 实现步骤 1. 新建 Log.class,添加如下代码 2. 新建 Log4j.class,继承 Log.class,并实现 record() 方法 3. 新建 Decorator.class,继承 Log.class 4. 新建 Log4jDecorator.class,继承 Decorat…...
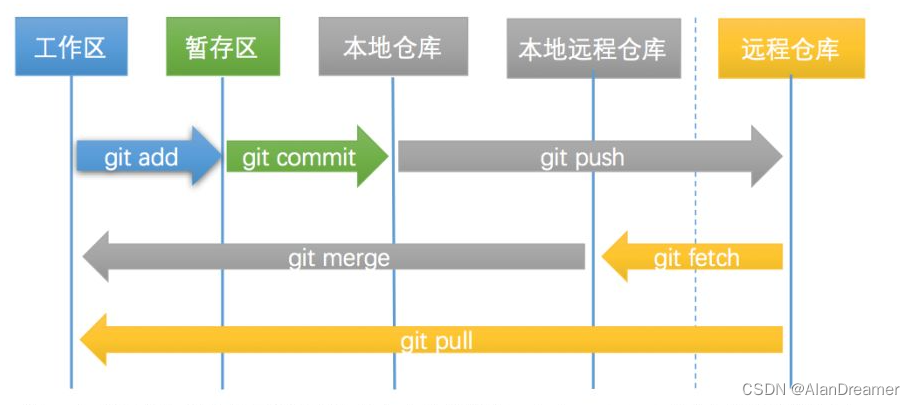
GIT基础常用命令-1 GIT基础篇
git基础常用命令-1 GIT基础篇1.git简介及配置1.1 git简介1.2 git配置config1.2.1 查看配置git config1.2.2 配置设置1.2.3 获取帮助git help2 GIT基础常用命令2.1 获取镜像仓库2.1.1 git init2.1.2 git clone2.2 本地仓库常用命令2.2.1 git status2.2.2 git add2.2.3 git diff2…...

华为OD机试题,用 Java 解【数列描述】问题
华为Od必看系列 华为OD机试 全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典使用说明 参加华为od机试,一定要注意不…...

2022掉队的“蔚小理”,按下了兔年加速键
配图来自Canva可画 进入2023年,各大车企又展开了新一轮的“竞速”。尽管1月份汽车整体销量出现了“阴跌”,但从各路车企发布的销量目标来看,车企对于2023依旧保持着较高的信心和预期。在一众车企中,以“蔚小理”为代表的新势力们…...
【NLP相关】attention的代码实现
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...
凌恩生物资讯
凌恩生物转录组项目包含范围广,项目经验丰富,人均10年以上项目经验,其中全长转录组测序研究基因结构已经成为发文章的趋势,研究物种包括高粱、玉米、拟南芥、鸡、人和小鼠、毛竹、棉花等。凌恩生物提供专业的全长转录组测序及分析…...
)
Leetcode 148. 排序链表(二路归并)
题目: 给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。 解法一: 递归解法,自顶向下 链表版二路归并排序(升序,递归版),稳定排序 时间复杂度…...

记录Paint部分常用的方法
Paint部分常用的方法1、实例化之后Paint的基本配置2、shader 和 ShadowLayer3、pathEffect4、maskFilter5、colorFilter6、xfermode1、实例化之后Paint的基本配置 Paint.Align Align指定drawText如何将其文本相对于[x,y]坐标进行对齐。默认为LEFTPaint.Cap Cap指定了笔画线和路…...
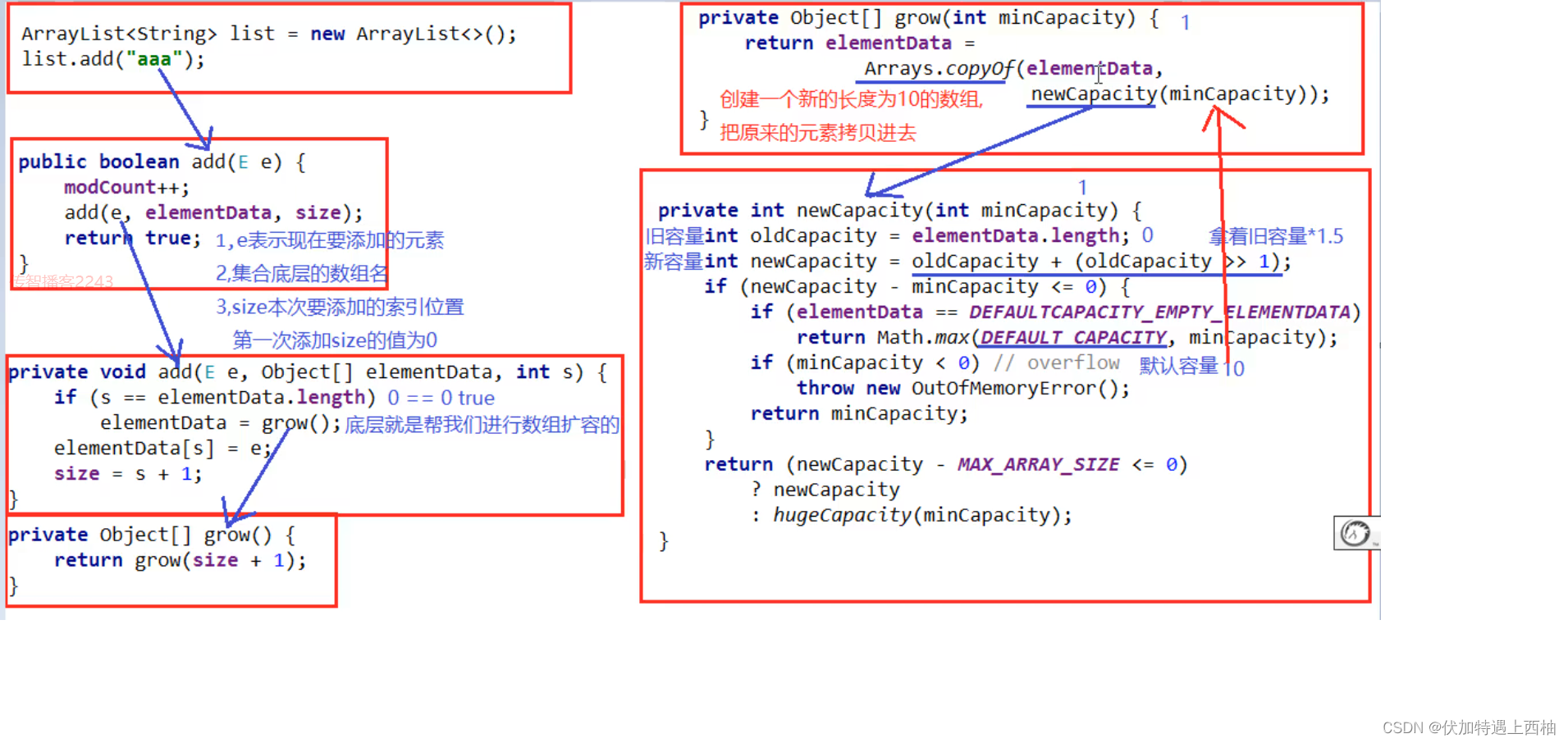
ArrayList集合底层原理
ArrayList集合底层原理ArrayList集合底层原理1.介绍2.底层实现3.构造方法3.1集合的属性4.扩容机制5.其他方法6.总结ArrayList集合底层原理 1.介绍 ArrayList是List接口的可变数组的实现。实现了所有可选列表操作,并允许包括 null 在 内的所有元素。 每个 Array…...

内网部署swagger快解析映射方案发布让外网访问
计算机业内人士对于swagger并不陌生, 不少人选择用swagger做为API接口文档管理。Swagger 是一个规范和完整的框架,用于生成、描述、调用和可视化 RESTful 风格的 Web 服务。总体目标是使客户端和文件系统作为服务器以同样的速度来更新文件的方法&#x…...
全网最全整理,自动化测试10种场景处理(超详细)解决方案都在这......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 自动化工作流程 自动…...

【c++】指针的学习
指针是C中非常重要的概念,理解指针的使用可以使程序更高效,并且可以处理更加复杂的数据结构。 指针是一个变量,它存储了另一个变量的地址。通过指针访问这个变量可以提高程序的效率,尤其是在处理大型数据结构时。 在C中࿰…...
华为OD机试题,用 Java 解【水仙花数】问题
华为Od必看系列 华为OD机试 全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典使用说明 参加华为od机试,一定要注意不…...

【Linux】-- 基本指令
目录 用户管理 adduser passwd userdel pwd ls指令 -l -a -d -F -r -t -R -1 which alias ll ls -n cd cd - cd ~ touch -d stat mkdir -p rmdir rm -r -f man cp 编辑 -r -f mv cat -n tac more less -N head tail | 管道 dat…...
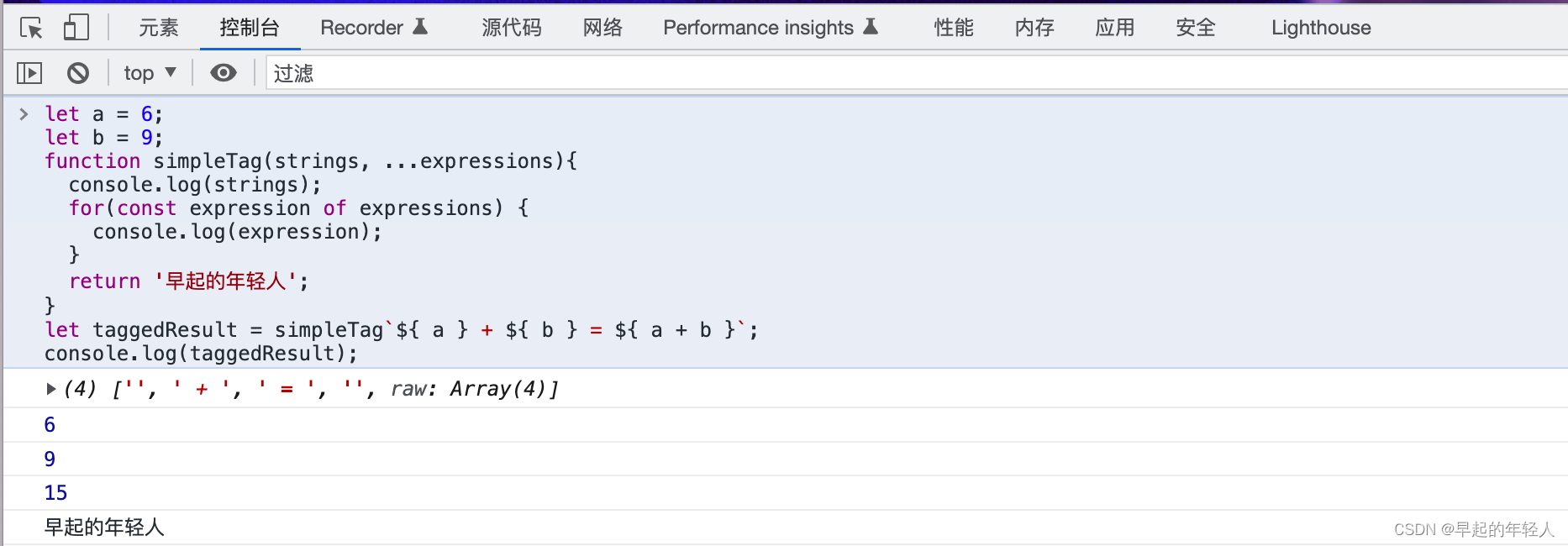
JavaScript 中的 String 类型 模板字面量定义字符串
ECMAScript 6新增了使用模板字面量定义字符串的能力。与使用单引号或双引号不同,模板字面量保留换行字符,可以跨行定义字符串: let str1 早起的年轻人\n喜欢经常跳步;let str2 早起的年轻人喜欢经常跳步;console.log(str1);// 早起的年轻人…...
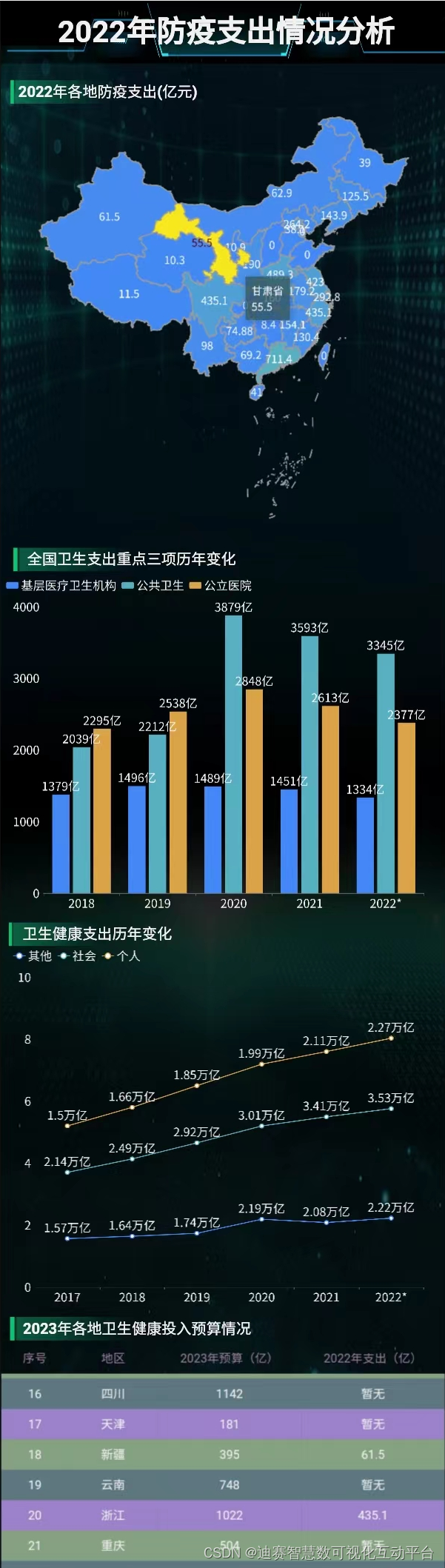
我国防疫数据报告,2022年广东花费711亿,北京人均支出第一
哈喽大家好,2023年已经过去一段时间了,随着防疫策略的调整,小伙伴们是不是开始到处旅行购物了呢?当然了,对于自身的健康情况小伙伴们还是要多多关注,不要松懈。随着春节过后有序复工复产,各地纷…...

OpenCV-Python学习(22)—— OpenCV 视频读取与保存处理(cv.VideoCapture、cv.VideoWriter)
1. 学习目标 学习 OpenCV 的视频的编码格式 cv.VideoWriter_fourcc;学会使用 OpenCV 的视频读取函数 cv.VideoCapture;学会使用 OpenCV 的视频保存函数 cv.VideoWriter。 2. cv.VideoWriter_fourcc()常见的编码参数 2.1 参数说明 参数说明cv.VideoWr…...

保姆级教程:在OBS Studio里开启H.264帧内刷新,解决录屏文件体积暴增问题
保姆级教程:在OBS Studio里开启H.264帧内刷新,解决录屏文件体积暴增问题 你是否遇到过这样的困扰:用OBS Studio录制静态界面(比如文档、代码编辑器)时,明明画面几乎没有变化,生成的视频文件却像…...

GitHub合规自动化:法律条款代码化与开源许可证检查实践
1. 项目概述:当法律条款遇上代码仓库最近在折腾一个挺有意思的项目,叫Clause-Logic/exoclaw-github。光看名字,你可能会有点懵——“Clause-Logic”听起来像是法律或合同条款的逻辑分析,“exoclaw”这个组合词有点科幻感ÿ…...

ISG系统三大电机结构深度解析:永磁同步、感应与开关磁阻电机对比
1. 项目概述:从“电机”到“ISG系统”的深度关联在混合动力与新能源车领域,ISG(Integrated Starter Generator,集成式启动发电一体机)系统是一个核心的动力单元。它不像传统汽车那样,启动电机和发电机是分开…...
Transit Map:让公共交通可视化变得简单有趣的工具
Transit Map:让公共交通可视化变得简单有趣的工具 【免费下载链接】transit-map The server and client used in transit map simulations like swisstrains.ch 项目地址: https://gitcode.com/gh_mirrors/tr/transit-map 还在为复杂的交通网络数据可视化而烦…...

【独家首发】ElevenLabs尚未官方支持的希伯来文增强模式:基于phoneme-level微调的48小时快速部署方案
更多请点击: https://intelliparadigm.com 第一章:希伯来文语音合成的技术挑战与ElevenLabs生态定位 希伯来文是一种自右向左(RTL)书写的辅音音素文字,其语音合成面临多重语言学与工程学挑战:元音符号&…...

从0到1搭建AI心理健康预警系统:我是如何用BERT+BiLSTM捕捉情绪拐点的
一、 痛点:为什么通用大模型干不了这活?首先声明,我们不是大模型黑。但在心理预警这个场景下,直接用GPT-4或者文心一言的API,有三个致命伤:成本炸裂: 每天几万条的学生/员工咨询日志ÿ…...

Android音视频应用开发中的性能与功耗优化策略
引言 随着移动设备的普及和5G网络的推进,Android音视频应用(如视频会议、直播平台)已成为日常生活和工作的重要组成部分。然而,这些应用往往面临性能瓶颈(如卡顿、延迟)和功耗过高(如电池快速耗尽)的问题。作为一名Android音视频应用开发工程师,掌握性能优化和功耗优…...

Coding爆发打破「AI泡沫论」,MiniMax能否卡位下一个Google?
【Coding爆发打破「AI泡沫论」】 Coding的爆发,彻底断绝了「AI泡沫论」,这已成为共识。阿里财报显示MaaS ARR超过80亿元,年底还有望再涨三倍以上,意味着只有投入没有回报的周期已过去,能开始盈利,大小玩家都…...

腾讯云轻量服务器镜像搬家到本地硬盘:一个被共享按钮“骗”了的故事
腾讯云轻量服务器镜像本地化实战:从共享陷阱到完整备份指南 第一次在腾讯云控制台点击"共享镜像"按钮时,我天真地以为数据已经安全地躺在我的本地硬盘里了。直到三天后需要紧急调用服务器环境时,才发现那个绿色的对勾图标不过是场…...

FreeRTOS任务通知:轻量级任务通信机制详解与实战应用
1. 项目概述:为什么你需要关注FreeRTOS任务通知?在嵌入式实时操作系统(RTOS)的开发中,任务间的通信与同步是核心课题。如果你用过FreeRTOS,肯定对队列、信号量、事件组这些通信机制不陌生。它们功能强大&am…...