【NLP相关】attention的代码实现
【NLP相关】attention的代码实现
Attention模型是现今机器学习领域中非常热门的模型之一,它可以用于自然语言处理、计算机视觉、语音识别等领域。本文将介绍Attention模型的代码实现。
1. attention机制的原理
首先,我们需要了解Attention模型的基本概念。Attention是一种机制,它可以用于选择和加权输入序列的不同部分,从而使得模型更加关注那些对输出结果更加重要的部分。在自然语言处理任务中,输入序列通常是由一些词语组成的,而输出序列通常是一个标签或者一句话。Attention模型可以帮助我们更好地理解输入序列中的每一个词语对输出序列的影响。关于attention的详细介绍,可以参见我的另一篇博客:深入理解attention机制(产生、发展、原理、应用和代码实现)
2. attention机制的代码实现
(1)基于PyTorch实现
接下来,我们将介绍如何使用PyTorch实现一个基本的Attention模型。我们假设输入序列是一个由nnn个词语组成的序列,输出序列是一个由mmm个标签组成的序列。首先,我们需要定义一个包含两个线性变换的网络层,分别用于将输入序列和输出序列的维度映射到一个相同的维度空间。代码如下所示:
class AttentionLayer(nn.Module):def __init__(self, input_size, output_size):super(AttentionLayer, self).__init__()self.input_proj = nn.Linear(input_size, output_size, bias=False)self.output_proj = nn.Linear(output_size, output_size, bias=False)
在定义完网络层之后,我们需要实现Attention的计算过程。在本文中,我们将使用加性Attention的计算方式。具体来说,我们需要计算每一个输入词语与输出标签之间的相似度,然后将相似度进行归一化处理,最终得到一个由nnn个归一化的权重组成的向量。代码如下所示:
def forward(self, inputs, outputs):inputs = self.input_proj(inputs) # (batch_size, n, input_size) -> (batch_size, n, output_size)outputs = self.output_proj(outputs) # (batch_size, m, output_size) -> (batch_size, m, output_size)scores = torch.bmm(inputs, outputs.transpose(1, 2)) # (batch_size, n, output_size) * (batch_size, output_size, m) -> (batch_size, n, m)weights = F.softmax(scores, dim=1) # (batch_size, n, m)return weights
在代码中,我们首先将输入序列和输出序列分别进行线性变换,并计算它们之间的相似度。然后,我们使用softmax函数将相似度进行归一化处理,从而得到一个n×mn \times mn×m的归一化权重矩阵。
最后,我们可以将Attention计算的结果与输入序列相乘,得到一个由mmm个加权输入向量组成的向量。代码如下所示:
class AttentionLayer(nn.Module):def __init__(self, input_size, output_size):super(AttentionLayer, self).__init__()self.input_proj = nn.Linear(input_size, output_size, bias=False)self.output_proj = nn.Linear(output_size, output_size, bias=False)def forward(self, inputs, outputs):inputs = self.input_proj(inputs) # (batch_size, n, input_size) -> (batch_size, n, output_size)outputs = self.output_proj(outputs) # (batch_size, m, output_size) -> (batch_size, m, output_size)scores = torch.bmm(inputs, outputs.transpose(1, 2)) # (batch_size, n, output_size) * (batch_size, output_size, m) -> (batch_size, n, m)weights = F.softmax(scores, dim=1) # (batch_size, n, m)context = torch.bmm(weights.transpose(1, 2), inputs) # (batch_size, m, n) * (batch_size, n, output_size) -> (batch_size, m, output_size)return context
在代码中,我们将归一化权重矩阵和输入序列进行矩阵乘法运算,得到一个由mmm个加权输入向量组成的向量。这个向量就是Attention模型的输出结果。
至此,我们已经完成了Attention模型的代码实现。当然,这只是一个基本的Attention模型,它还可以通过增加更多的层来提升性能,比如Multi-Head Attention等。同时,在使用Attention模型时还需要考虑到一些细节问题,比如输入序列的长度不一定相同、输出序列的长度也不一定相同等。因此,Attention模型的具体实现方式还需要根据具体的任务来进行设计和调整。
(2)TensorFlow实现
在TensorFlow中,我们可以使用tf.keras.layers.Attention层来实现Attention机制。下面,我们将使用一个示例来演示如何在TensorFlow中使用Attention机制。
首先,我们需要导入必要的库和数据集。在这个示例中,我们将使用IMDB电影评论情感分类数据集,这是一个二元分类任务,我们需要将评论分为积极或消极两种情感。
import tensorflow as tf
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Input, Dense, Embedding, Flatten, LSTM, Bidirectional, Attention
from tensorflow.keras.models import Model
import numpy as np# 加载IMDB数据集
max_features = 20000
maxlen = 200
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
x_train = pad_sequences(x_train, padding='post', maxlen=maxlen)
x_test = pad_sequences(x_test, padding='post', maxlen=maxlen)
接下来,我们将使用Keras函数式API构建一个双向LSTM模型,并在其中加入Attention层。
# 构建模型
input_layer = Input(shape=(maxlen,))
embedding_layer = Embedding(max_features, 128)(input_layer)
lstm_layer = Bidirectional(LSTM(64, return_sequences=True))(embedding_layer)
attention_layer = Attention()([lstm_layer, lstm_layer])
flatten_layer = Flatten()(attention_layer)
output_layer = Dense(1, activation='sigmoid')(flatten_layer)
model = Model(inputs=input_layer, outputs=output_layer)# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
在这个模型中,我们首先使用Embedding层将输入序列转换为向量表示,然后将其输入到一个双向LSTM层中。接下来,我们使用Attention层将LSTM层的输出与自身进行注意力计算,得到每个时间步的权重。最后,我们将加权后的输出进行展平,并通过一个全连接层得到二元分类的输出。
最后,我们可以训练和评估这个模型。
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=5, validation_data=(x_test, y_test))# 评估模型
loss, accuracy = model.evaluate(x_test, y_test, verbose=0)
print('Test accuracy:', accuracy)
3. attention模型的应用
(1)机器翻译
机器翻译是自然语言处理领域的一个重要任务,而Attention模型在机器翻译中的应用尤为广泛。在传统的机器翻译模型中,通常使用固定长度的向量来表示输入序列,并将其输入到一个循环神经网络(RNN)中进行处理。但是,这种方法存在一个问题,就是当输入序列很长时,模型会出现信息丢失的情况,无法捕捉到关键的上下文信息。为了解决这个问题,Attention模型被引入到了机器翻译中。在Attention模型中,我们不仅考虑到输入序列中每个词的信息,还将每个词的权重也作为输入,使得模型可以更加关注到重要的词汇信息。通过这种方式,Attention模型可以更加准确地进行翻译,并且在处理长文本时也可以避免信息丢失的问题。
(2)文本分类
在文本分类中,Attention模型可以帮助我们更好地捕捉到文本中的关键信息。传统的文本分类模型通常使用固定长度的向量来表示输入文本,并将其输入到一个全连接层中进行分类。但是,这种方法也存在信息丢失的问题,无法捕捉到文本中的重要信息。为了解决这个问题,Attention模型被引入到了文本分类中。在Attention模型中,我们将每个词的向量表示作为输入,并使用注意力机制来确定每个词的重要程度。通过这种方式,Attention模型可以更加准确地分类文本,并且在处理长文本时也可以避免信息丢失的问题。
(3)图像标注
在图像标注中,Attention模型可以帮助我们更好地理解图像中的内容,并生成更加准确的图像描述。传统的图像标注模型通常使用固定长度的向量来表示图像,并将其输入到一个循环神经网络中进行处理。但是,这种方法也存在信息丢失的问题,无法捕捉到图像中的重要信息。为了解决这个问题,Attention模型被引入到了图像标注中。在Attention模型中,我们将每个图像区域的向量表示作为输入,并使用注意力机制来确定每个区域的重要程度。通过这种方式,Attention模型可以更加准确地理解图像中的内容,并生成更加准确的图像描述。此外,Attention模型还可以帮助我们在图像标注中实现多模态输入,即将图像和文本结合起来进行标注,从而提高标注的准确性。
(4)文本生成
在文本生成任务中,Attention模型可以帮助我们更好地生成连贯、准确的文本。传统的文本生成模型通常使用循环神经网络来生成文本,但是在生成过程中,模型可能会出现重复、模糊等问题。为了解决这个问题,Attention模型被引入到了文本生成中。在Attention模型中,我们不仅使用循环神经网络来生成文本,还将每个词的向量表示作为输入,并使用注意力机制来确定每个词的生成概率。通过这种方式,Attention模型可以更加准确地生成文本,并且避免出现重复、模糊等问题。
相关文章:
【NLP相关】attention的代码实现
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...
凌恩生物资讯
凌恩生物转录组项目包含范围广,项目经验丰富,人均10年以上项目经验,其中全长转录组测序研究基因结构已经成为发文章的趋势,研究物种包括高粱、玉米、拟南芥、鸡、人和小鼠、毛竹、棉花等。凌恩生物提供专业的全长转录组测序及分析…...
)
Leetcode 148. 排序链表(二路归并)
题目: 给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。 解法一: 递归解法,自顶向下 链表版二路归并排序(升序,递归版),稳定排序 时间复杂度…...

记录Paint部分常用的方法
Paint部分常用的方法1、实例化之后Paint的基本配置2、shader 和 ShadowLayer3、pathEffect4、maskFilter5、colorFilter6、xfermode1、实例化之后Paint的基本配置 Paint.Align Align指定drawText如何将其文本相对于[x,y]坐标进行对齐。默认为LEFTPaint.Cap Cap指定了笔画线和路…...
ArrayList集合底层原理
ArrayList集合底层原理ArrayList集合底层原理1.介绍2.底层实现3.构造方法3.1集合的属性4.扩容机制5.其他方法6.总结ArrayList集合底层原理 1.介绍 ArrayList是List接口的可变数组的实现。实现了所有可选列表操作,并允许包括 null 在 内的所有元素。 每个 Array…...

内网部署swagger快解析映射方案发布让外网访问
计算机业内人士对于swagger并不陌生, 不少人选择用swagger做为API接口文档管理。Swagger 是一个规范和完整的框架,用于生成、描述、调用和可视化 RESTful 风格的 Web 服务。总体目标是使客户端和文件系统作为服务器以同样的速度来更新文件的方法&#x…...
全网最全整理,自动化测试10种场景处理(超详细)解决方案都在这......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 自动化工作流程 自动…...

【c++】指针的学习
指针是C中非常重要的概念,理解指针的使用可以使程序更高效,并且可以处理更加复杂的数据结构。 指针是一个变量,它存储了另一个变量的地址。通过指针访问这个变量可以提高程序的效率,尤其是在处理大型数据结构时。 在C中࿰…...

华为OD机试题,用 Java 解【水仙花数】问题
华为Od必看系列 华为OD机试 全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典使用说明 参加华为od机试,一定要注意不…...

【Linux】-- 基本指令
目录 用户管理 adduser passwd userdel pwd ls指令 -l -a -d -F -r -t -R -1 which alias ll ls -n cd cd - cd ~ touch -d stat mkdir -p rmdir rm -r -f man cp 编辑 -r -f mv cat -n tac more less -N head tail | 管道 dat…...
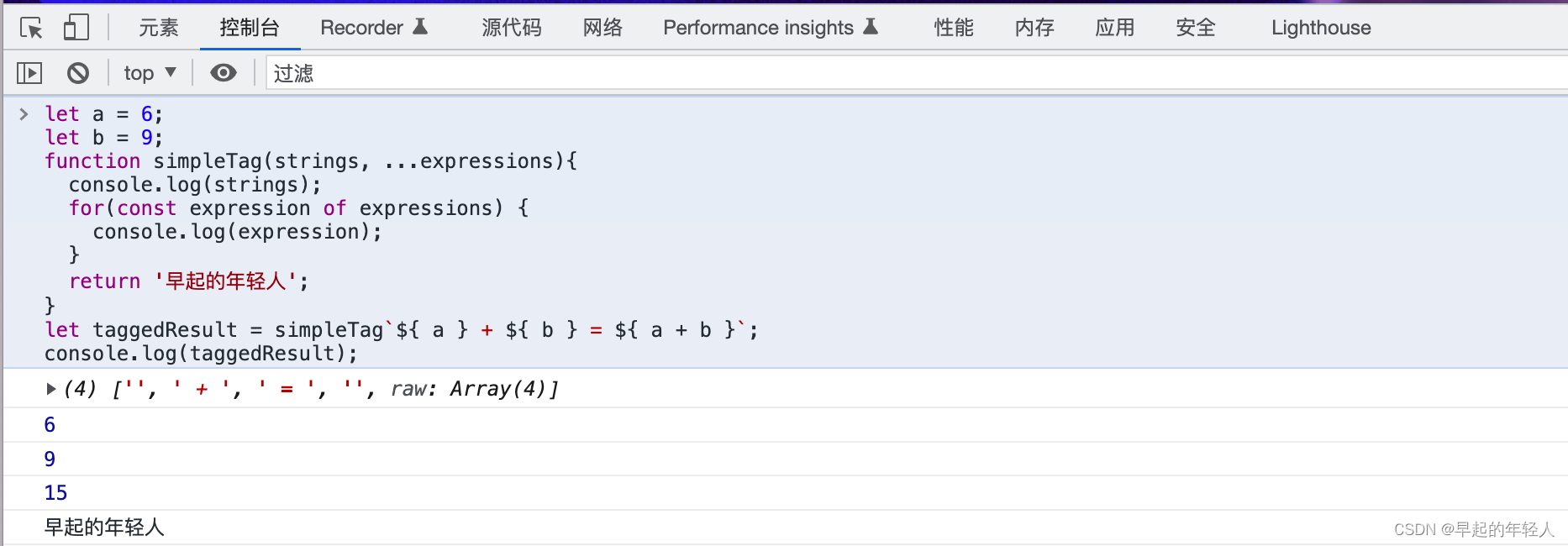
JavaScript 中的 String 类型 模板字面量定义字符串
ECMAScript 6新增了使用模板字面量定义字符串的能力。与使用单引号或双引号不同,模板字面量保留换行字符,可以跨行定义字符串: let str1 早起的年轻人\n喜欢经常跳步;let str2 早起的年轻人喜欢经常跳步;console.log(str1);// 早起的年轻人…...
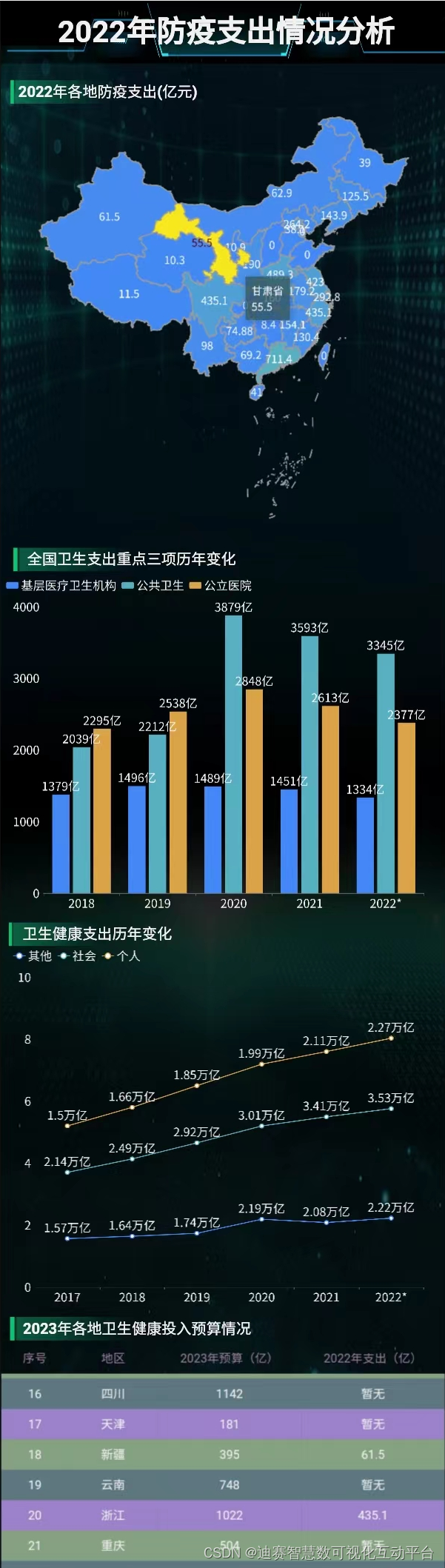
我国防疫数据报告,2022年广东花费711亿,北京人均支出第一
哈喽大家好,2023年已经过去一段时间了,随着防疫策略的调整,小伙伴们是不是开始到处旅行购物了呢?当然了,对于自身的健康情况小伙伴们还是要多多关注,不要松懈。随着春节过后有序复工复产,各地纷…...

OpenCV-Python学习(22)—— OpenCV 视频读取与保存处理(cv.VideoCapture、cv.VideoWriter)
1. 学习目标 学习 OpenCV 的视频的编码格式 cv.VideoWriter_fourcc;学会使用 OpenCV 的视频读取函数 cv.VideoCapture;学会使用 OpenCV 的视频保存函数 cv.VideoWriter。 2. cv.VideoWriter_fourcc()常见的编码参数 2.1 参数说明 参数说明cv.VideoWr…...

2023-03-05力扣每日一题
链接: https://leetcode.cn/problems/triples-with-bitwise-and-equal-to-zero/ 题意: 模拟一个摩天轮,四个舱,每个舱最多四人,给一个数组,表示摩天轮每切换一次座舱会来多少人排队(人不会走…...

真正的IT技术男是什么样的?
我们经常会听到很多对IT男士的调侃称呼,“屌丝”、“宅男”,会逗的大家捧腹大笑。但是,大家要不要以为称呼IT男是“屌丝”、“宅男”,就当真以为他们是这样了。今天,青鸟学姐就带大家一起来了解一下,真正的…...
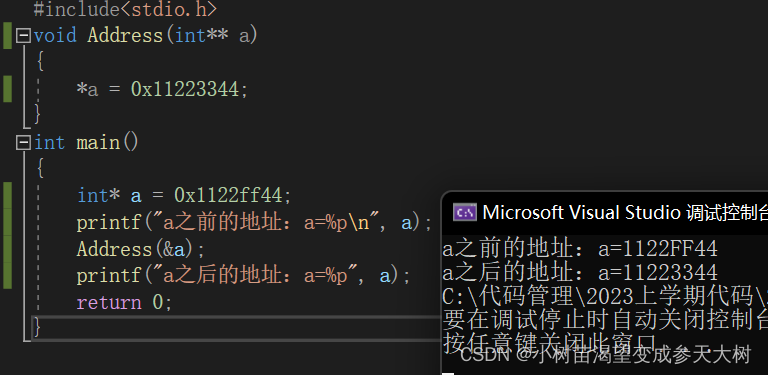
在函数中,用指针接收就可以改变相应的内容吗??
作者:小树苗渴望变成参天大树 作者宣言:认真写好每一篇博客 作者gitee:gitee 如 果 你 喜 欢 作 者 的 文 章 ,就 给 作 者 点 点 关 注 吧! 我们在不管指针那篇博客,还是在函数那篇博客中,我都给大家讲解过…...

Java+ElasticSearch+Pytorch实现以图搜图
以图搜图,涉及两大功能:1、提取图像特征向量。2、相似向量检索。第一个功能我通过编写pytorch模型并在java端借助djl调用实现,第二个功能通过elasticsearch7.6.2的dense_vector、cosineSimilarity实现。一、准备模型创建demo.py,输…...

【C语言学习笔记】:指针
指针的概念 指针是一个特殊的变量,它里面存储的数值被解释成为内存里的一个地址。要搞清一个指针需要搞清指针的四方面的内容:指针的类型,指针所指向的类型,指针的值或者叫指针所指向的内存区,还有指针本身所占据的内…...
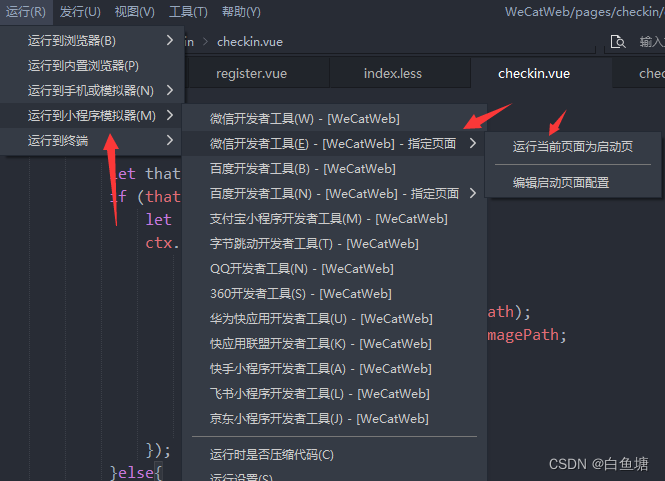
微信小程序搭建流程
一、申请微信开发者账号虽然开发微信小程序可以使用工具提供的测试号,但是测试号提供的功能极为有限,而且使用测试号开发的微信小程序不能上架发布。因此说我们想要开发一个可以上架的微信小程序,首先必须要申请微信开发者账号。大家尽可放心…...

嵌入式 Linux进程间的通信--信号
目录 信号 信号的概述 信号类型 信号发送 1、kill 函数 2、raise函数 3、pause函数 信号处理 可以结合上一篇文章一起看: 嵌入式 Linux进程之间的通信_丘比特惩罚陆的博客-CSDN博客 信号 信号的概述 软中断信号(signal,又简称为…...

2026年冰袋吸水粉厂家大揭秘:选择指南与行业趋势题
随着冷链物流行业的快速发展,冰袋吸水粉作为冷链运输中不可或缺的保冷材料,其市场需求持续增长。然而,市场上冰袋吸水粉的质量参差不齐,如何选择一家值得信赖的厂家成为许多采购商关注的重点。本文将从行业背景、技术特点及市场趋…...

2025届毕业生推荐的AI学术平台推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在学术写作范畴之内,怎样迅速、精确地给论文确定一个既契合规范又能够切实有效吸…...

Midjourney玩具相机风格从翻车到封神:1个--v 6.1专属参数组合+2个隐藏式胶片颗粒注入指令+1套曝光补偿校准表
更多请点击: https://intelliparadigm.com 第一章:Midjourney玩具相机风格的视觉本质与审美悖论 失真即真实:玩具相机的光学哲学 玩具相机(Toy Camera)风格在 Midjourney 中并非简单模拟 Lomography 或 Holga 的物理…...

如何快速掌握NCBI基因组批量下载:面向生物信息学新手的完整实战指南
如何快速掌握NCBI基因组批量下载:面向生物信息学新手的完整实战指南 【免费下载链接】ncbi-genome-download Scripts to download genomes from the NCBI FTP servers 项目地址: https://gitcode.com/gh_mirrors/nc/ncbi-genome-download NCBI基因组数据批量…...

从真空袋到回流焊:一份给硬件创业团队的元器件储存与使用避坑指南
从真空袋到回流焊:硬件创业团队的元器件储存与使用避坑指南 当你拆开一包全新的芯片,是否曾想过这些看似坚固的小方块其实对环境湿度极其敏感?对于资源有限的硬件创业团队来说,正确处理MSL(湿度敏感等级)元…...

XSS-Game 实战解析:从Level1到Level18的攻防思维演进
1. XSS-Game入门:理解基础注入逻辑 第一次接触XSS-Game时,很多人会疑惑这到底是个什么游戏。简单来说,这是一个专门设计用来练习XSS(跨站脚本攻击)技术的在线靶场,包含18个难度递增的关卡。每个关卡都模拟了…...

SuperMap Objects开发避坑指南:从COM引用到内存释放的实战经验总结
SuperMap Objects开发避坑指南:从COM引用到内存释放的实战经验总结 在GIS二次开发领域,SuperMap Objects以其强大的空间数据处理能力备受开发者青睐。然而,当我们将这个COM组件集成到C# WinForms项目中时,往往会遇到一些官方文档…...

UE5《Electric Dreams》项目PCG技术解析 之 基于PCGSettings的模块化关卡构建
1. PCG技术为何成为UE5开发者的新宠 第一次在UE5.2中接触到PCG框架时,那种感觉就像从手动挡汽车换成了自动驾驶。以前用Houdini做程序化生成时,光是处理插件兼容性和资源导入问题就能耗掉大半天。现在原生集成的PCG框架直接把开发效率提升了至少三倍&…...

ME6206A 系列低压差线性稳压器
概述ME6206A 系列是高精度、低功耗、采用 CMOS 技 术制造的正电压稳压器。这些器件提供大电流,具有显 著的小电压差。 该系列与低 ESR 陶瓷电容器兼容,限流器的折返 电路也作为短路保护输出电流限制器和输出引脚。性能特点高精度输出电压:1%输…...

从协议到实践:国密TLCP协议深度解析与Nginx国密化改造实战
1. 国密TLCP协议的前世今生 第一次接触国密TLCP协议是在2018年参与某金融机构的安全改造项目。当时客户明确提出要使用国产密码算法,但在实际部署过程中发现,现有的国际标准SSL/TLS协议对国密算法支持非常有限。这就是TLCP协议诞生的背景 - 为了解决国产…...